
1. Bối cảnh ra đời của Transformer: Khi mô hình tuần tự chạm trần giới hạn
Trước năm 2017, hầu hết các bài toán xử lý dữ liệu dạng chuỗi (sequence data) – như xử lý ngôn ngữ tự nhiên (NLP), dịch máy, nhận dạng giọng nói – đều dựa trên một nhóm kiến trúc quen thuộc: RNN (Recurrent Neural Network) và các biến thể cải tiến như LSTM hay GRU.
Đặc điểm chung của các mô hình này là xử lý dữ liệu theo trình tự thời gian:
token sau chỉ được xử lý sau khi token trước đó đã hoàn thành. Điều này khiến chúng phù hợp một cách tự nhiên với ngôn ngữ – vốn được con người đọc từ trái sang phải.
Tuy nhiên, chính cách tiếp cận “tuần tự” này lại tạo ra hàng loạt giới hạn mang tính cấu trúc:
-
Không thể song song hóa
Do mỗi bước phụ thuộc vào bước trước, việc huấn luyện RNN/LSTM gần như không tận dụng được sức mạnh của GPU/TPU hiện đại → thời gian training tăng theo độ dài chuỗi. -
Vanishing / Exploding Gradient
Khi chuỗi quá dài, gradient truyền ngược qua nhiều bước thời gian dễ bị tiêu biến hoặc bùng nổ, khiến mô hình học kém ổn định. -
Học kém các quan hệ xa (Long-range dependency)
Dù LSTM/GRU được thiết kế để “ghi nhớ dài hạn”, trên thực tế khả năng liên kết các token cách xa nhau vẫn rất hạn chế.
Ví dụ kinh điển thường được trích dẫn:
“The animal didn’t cross the street because it was tired.”
Để hiểu đúng câu này, mô hình phải biết rằng “it” ám chỉ “animal”, dù giữa chúng là cả một mệnh đề dài. Với RNN/LSTM, thông tin này phải được “truyền tay” qua nhiều bước → rất dễ bị suy hao.
👉 Nói cách khác: trước năm 2017, cộng đồng AI đã có các mô hình “đọc tuần tự tốt”, nhưng chưa có mô hình nào vừa hiểu ngữ cảnh toàn cục, vừa scale hiệu quả trên phần cứng hiện đại.
2. Transformer là gì? Cuộc thay đổi tư duy từ “đọc tuần tự” sang “nhìn toàn cục”
Transformer ra đời như một sự đảo ngược hoàn toàn cách tư duy truyền thống về xử lý chuỗi.
Thay vì hỏi:
“Token này nên được xử lý sau token nào?”
Transformer đặt câu hỏi khác:
“Token này liên quan đến những token nào, và mức độ liên quan là bao nhiêu?”
Về bản chất, Transformer là một kiến trúc neural network xử lý dữ liệu chuỗi không dựa vào recurrence (lặp theo thời gian), mà dựa hoàn toàn vào Attention mechanism.
Ý tưởng cốt lõi có thể tóm gọn như sau:
- Mô hình nhìn toàn bộ chuỗi cùng một lúc
- Mỗi token có thể tương tác trực tiếp với mọi token khác
- Mức độ tương tác được học thông qua Attention score
Thay vì “truyền thông tin dần dần” như RNN, Transformer cho phép:
- Token ở đầu câu truy cập trực tiếp token ở cuối câu
- Không cần nhớ thông tin qua nhiều bước trung gian
- Dễ dàng song song hóa khi huấn luyện
Chính triết lý này được khái quát trong tiêu đề bài báo gốc:
Attention Is All You Need (2017)
Thông điệp ở đây không chỉ là một kỹ thuật mới, mà là một tuyên bố mang tính nền tảng:
Nếu mô hình biết cách tập trung (attention) đúng chỗ, thì recurrence không còn cần thiết nữa.
Transformer vì thế không chỉ là “một mô hình mới”, mà là một khung tư duy mới cho toàn bộ ngành NLP và sau này là AI nói chung – từ BERT, GPT, cho đến các mô hình đa phương thức hiện đại.
3. Kiến trúc tổng thể của Transformer: Encoder – Decoder và sự phân vai rõ ràng
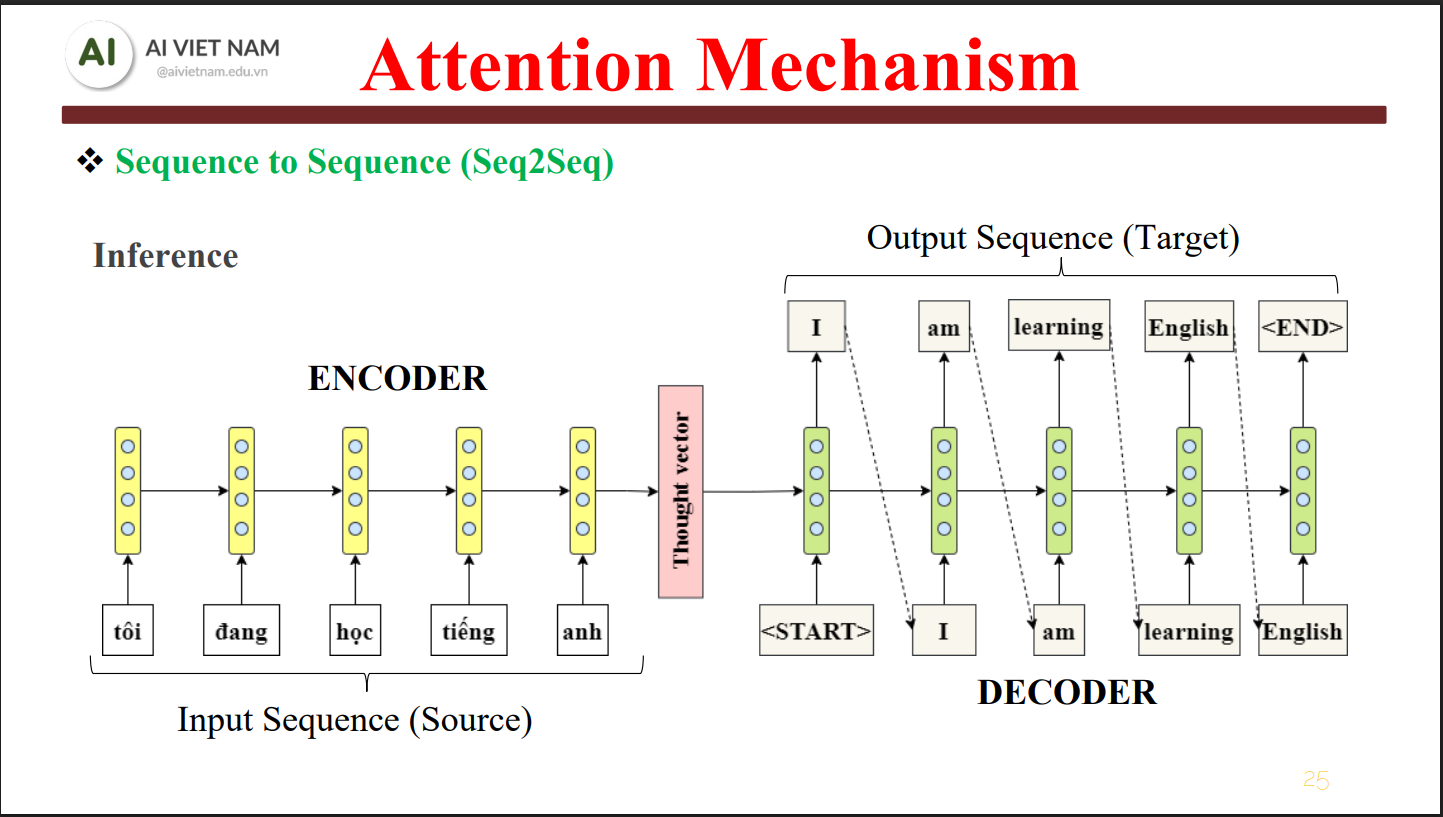
Encoder – Decoder và sự phân vai rõ ràng
Ở mức kiến trúc tổng thể, Transformer được xây dựng dựa trên hai khối chính: Encoder và Decoder.
Cách chia này không mới hoàn toàn (đã xuất hiện từ Seq2Seq), nhưng Transformer đã tái định nghĩa hoàn toàn cách hai khối này hoạt động, đặc biệt là cách chúng trao đổi thông tin thông qua Attention.
3.1. Encoder – Bộ máy hiểu ngữ nghĩa của chuỗi đầu vào
Encoder nhận vào một chuỗi token (input sequence) và biến nó thành một tập các vector biểu diễn giàu ngữ nghĩa.
Vai trò cốt lõi của Encoder là:
- Hiểu ý nghĩa từng token
- Hiểu ngữ cảnh của token đó trong toàn bộ câu
- Mã hóa cả quan hệ gần và quan hệ xa giữa các token
Về mặt cấu trúc, Encoder không phải là một khối đơn lẻ mà là stack của nhiều layer giống nhau (thường là 6, 12, 24 layer tùy mô hình). Mỗi layer Encoder gồm hai thành phần chính:
-
Multi-Head Self-Attention
→ Cho phép mỗi token “nhìn” tất cả token khác trong chuỗi để quyết định mức độ liên quan. -
Feed-Forward Network (FFN)
→ Một mạng fully-connected áp dụng độc lập lên từng token, giúp tăng khả năng biểu diễn phi tuyến.
Quan trọng nhất:
👉 Encoder không sinh chuỗi mới, mà chỉ tạo ra biểu diễn trung gian (latent representation) – thứ mà Decoder (hoặc task downstream) sẽ sử dụng.
3.2. Decoder – Cỗ máy sinh chuỗi có kiểm soát
Nếu Encoder là “người hiểu”, thì Decoder là “người viết”.
Decoder nhận vào:
- Biểu diễn từ Encoder (nếu có)
- Các token đã sinh trước đó
Và nhiệm vụ của nó là:
- Sinh ra token tiếp theo trong chuỗi output
- Đảm bảo tính nhân quả (autoregressive) trong quá trình sinh
Một layer Decoder gồm ba khối chính:
-
Masked Multi-Head Self-Attention
Chỉ cho phép token tại vị trí t nhìn các token ≤ t
Ngăn mô hình “nhìn trước tương lai”
Đây là yếu tố sống còn để huấn luyện các mô hình sinh văn bản -
Encoder–Decoder Attention (Cross-Attention)
Decoder học cách tập trung vào các phần quan trọng trong output của Encoder
Rất quan trọng trong các bài toán như dịch máy, tóm tắt -
Feed-Forward Network
3.3. Vì sao có mô hình chỉ dùng Encoder hoặc chỉ dùng Decoder?
Sự linh hoạt của Transformer cho phép tách rời hoặc kết hợp hai khối này, dẫn đến các họ mô hình phổ biến:
-
Chỉ Encoder
→ Phù hợp với các bài toán hiểu (understanding) như:
Classification
Information Retrieval
Semantic Search
Ví dụ: BERT -
Chỉ Decoder
→ Phù hợp với các bài toán sinh (generation):
Text generation
Chatbot
Code generation
Ví dụ: GPT -
Encoder – Decoder đầy đủ
→ Phù hợp với các bài toán chuyển đổi chuỗi:
Machine Translation
Summarization
Ví dụ: T5
👉 Cốt lõi nằm ở chỗ: Transformer không bị ràng buộc bởi một dạng task duy nhất, mà là một kiến trúc nền (foundation architecture).
4. Tokenization & Embedding: Cách Transformer “hiểu” văn bản dưới dạng số
Trước khi Attention hay Transformer có thể hoạt động, văn bản cần được chuyển đổi sang dạng số học.
Quá trình này gồm hai bước liên tiếp nhưng khác bản chất:
- Tokenization – chia văn bản thành các đơn vị xử lý
- Embedding – ánh xạ mỗi token thành vector trong không gian liên tục
4.1. Tokenization – Phân rã ngôn ngữ thành đơn vị có thể học
Máy tính không hiểu từ, câu hay ý nghĩa; nó chỉ xử lý chuỗi ký hiệu rời rạc.
Tokenization là bước biến văn bản thô thành chuỗi token mà mô hình có thể xử lý.
Có ba chiến lược tokenization phổ biến:
4.1.1. Word-level Tokenization
- Mỗi từ được coi là một token
Vấn đề:
- Vocabulary rất lớn
- Không xử lý tốt từ mới (out-of-vocabulary)
4.1.2. Subword-level Tokenization (phổ biến nhất)
- Tách từ thành các đơn vị nhỏ hơn
- Các thuật toán tiêu biểu:
- BPE (Byte Pair Encoding)
- WordPiece
- Unigram Language Model
Ví dụ:
"Transformer is powerful"
→ ["Transform", "er", "is", "power", "ful"]
Ưu điểm:
- Giảm kích thước vocabulary
- Xử lý tốt từ hiếm, từ mới, từ ghép
4.1.3. Byte-level Tokenization
- Làm việc trực tiếp trên byte
- Không cần vocabulary từ vựng truyền thống
- Phù hợp với mô hình lớn và đa ngôn ngữ
👉 Điểm mấu chốt:
Tokenization không chỉ là bước tiền xử lý, mà ảnh hưởng trực tiếp đến khả năng biểu diễn và hiệu suất của mô hình Transformer.
4.2. Embedding – Khi token trở thành vector ngữ nghĩa
Sau khi token hóa, mỗi token ban đầu chỉ là một ID rời rạc.
Để mô hình có thể học và suy luận, các token này cần được ánh xạ vào một không gian vector liên tục.
Mỗi token i được biểu diễn bởi một vector:
$$ \mathbf{x}_i \in \mathbb{R}^{d_{\text{model}}} $$
Trong đó:
- $\mathbf{x}_i$: embedding của token thứ i
- $d_{\text{model}}$: chiều không gian embedding (model dimension)
Giá trị thường gặp của $d_{\text{model}}$:
- 512 – Transformer gốc (Attention Is All You Need)
- 768 – BERT-base
- 1024, 2048 hoặc lớn hơn – các mô hình lớn (large-scale models)
Về bản chất, Embedding:
- Là một bảng tra (lookup table) ánh xạ từ token ID → vector
- Được học cùng với toàn bộ mô hình thông qua backpropagation
- Các token có ngữ nghĩa gần nhau sẽ có vector gần nhau trong không gian embedding
Điểm quan trọng cần lưu ý
👉 Embedding không chứa thông tin vị trí (position)
→ Đây chính là lý do Transformer cần Positional Encoding,
một thành phần sẽ được trình bày ngay sau đó.
5. Positional Encoding – Cách Transformer học được thứ tự trong chuỗi (thành phần sống còn)
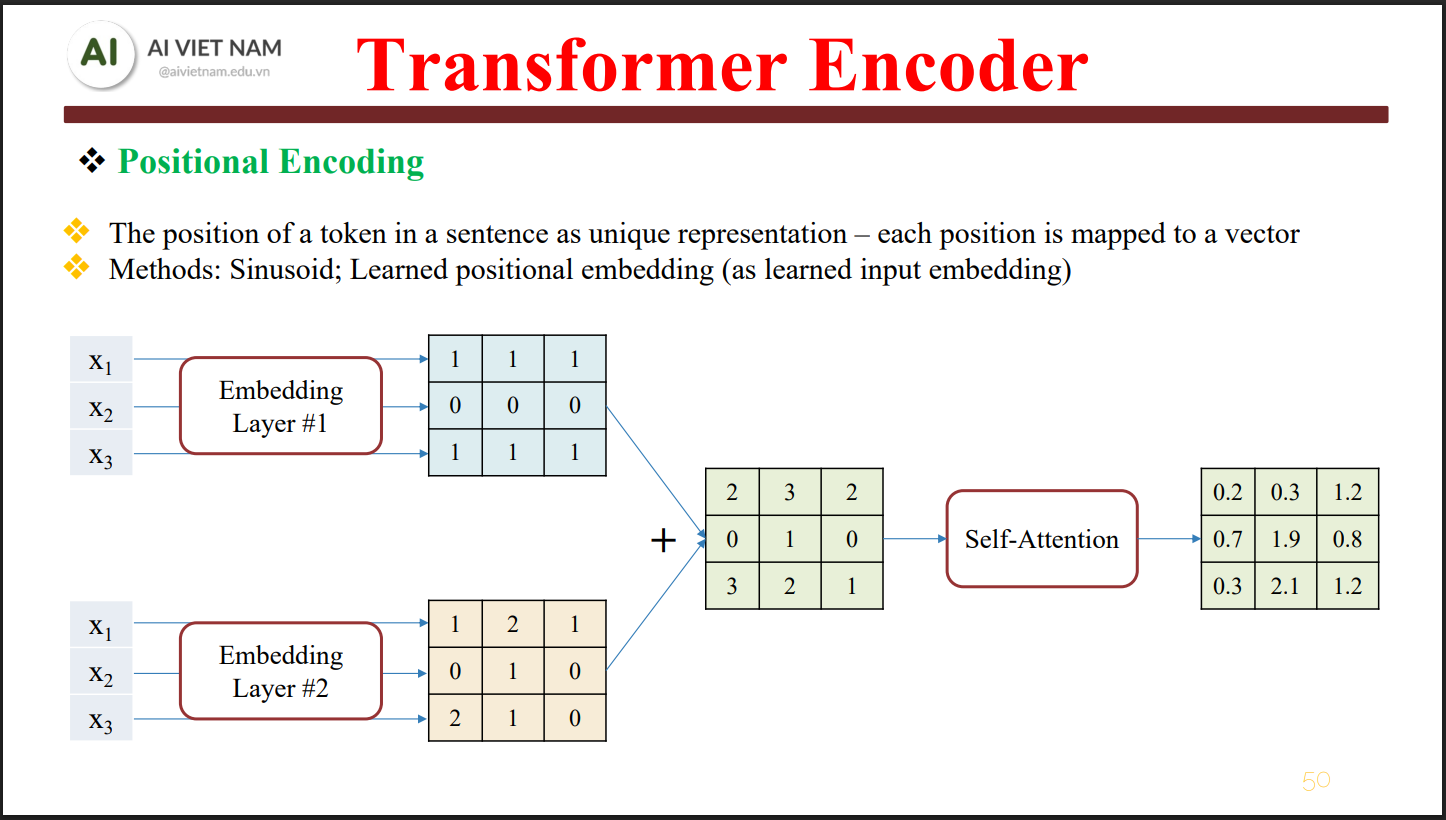
Cách Transformer học được thứ tự trong chuỗi
Một trong những điểm độc đáo nhưng cũng dễ gây nhầm lẫn nhất của Transformer là:
👉 Transformer hoàn toàn không có khái niệm thứ tự (order) một cách tự nhiên.
Khác với RNN / LSTM – nơi token được xử lý lần lượt theo thời gian,
Transformer xử lý toàn bộ chuỗi song song.
Điều này mang lại lợi thế lớn về:
- Tốc độ
- Khả năng scale
- Khai thác song song phần cứng (GPU / TPU)
Nhưng đồng thời tạo ra một vấn đề nghiêm trọng:
Nếu không bổ sung thông tin vị trí, Transformer không thể phân biệt:
“I eat rice”
“Rice eat I”
Về mặt Attention thuần túy, hai câu trên chỉ là cùng một tập token,
thứ tự hoàn toàn không tồn tại.
👉 Positional Encoding ra đời để giải quyết đúng vấn đề này:
bổ sung thông tin vị trí của token trong chuỗi vào embedding đầu vào.
5.1. Vì sao Embedding thuần là chưa đủ?
Như đã trình bày ở phần trước:
- Token embedding biểu diễn ý nghĩa ngữ nghĩa
- Nhưng không chứa thông tin vị trí
- Hai token giống nhau ở vị trí khác nhau → embedding giống hệt nhau
Ví dụ:
“The cat sat on the mat”
Từ “the” ở đầu câu và “the” trước “mat”
→ cùng một vector embedding
Nếu không có thông tin vị trí:
- Attention không biết token nào đứng trước
- Không học được cấu trúc cú pháp
- Không thể hiểu quan hệ tuần tự
👉 Do đó, Transformer cần một cơ chế để “gắn tọa độ” cho token trong câu.
5.2. Ý tưởng cốt lõi của Positional Encoding
Thay vì thay đổi kiến trúc Attention, nhóm tác giả Transformer chọn cách:
Cộng thêm một vector vị trí vào embedding token
Quy trình rất đơn giản về mặt hình thức:
Mỗi token sau khi thêm thông tin vị trí sẽ có embedding cuối cùng:
$$ \mathbf{z}_i = \mathbf{x}_i + \mathbf{PE}_i $$
Trong đó:
- $\mathbf{x}_i$: token embedding của token thứ i
- $\mathbf{PE}_i$: positional encoding tại vị trí i
- $\mathbf{z}_i$: embedding cuối cùng đưa vào Encoder / Decoder
👉 Embedding cuối cùng vừa mang ý nghĩa ngữ nghĩa, vừa mang thông tin vị trí
5.3. Positional Encoding dạng sin–cos (bản gốc của Transformer)
Trong bài báo Attention Is All You Need, tác giả sử dụng hàm sin và cos
để mã hóa vị trí, thay vì học embedding vị trí như tham số tự do.
Công thức Positional Encoding (sin – cos)
$$ \text{PE}_{(pos,\,2i)} = \sin\!\left(\frac{pos}{10000^{\frac{2i}{d_{\text{model}}}}}\right) $$
$$ \text{PE}_{(pos,\,2i+1)} = \cos\!\left(\frac{pos}{10000^{\frac{2i}{d_{\text{model}}}}}\right) $$
Trong đó:
- $pos$: vị trí token trong chuỗi $(0, 1, 2, \dots)$
- $i$: chỉ số chiều trong vector embedding
- $d_{\text{model}}$: số chiều embedding (512, 768, 1024, …)
👉 Chiều chẵn dùng sin
👉 Chiều lẻ dùng cos
Cách hiểu trực giác
- Mỗi cặp (sin, cos) có tần số khác nhau
- Token ở các vị trí khác nhau → vector vị trí khác nhau
- Nhưng vẫn có cấu trúc liên tục và tuần hoàn
5.4. Vì sao lại dùng sin–cos mà không học embedding vị trí?
Đây là một quyết định thiết kế quan trọng. Có 3 lý do chính.
5.4.1. Tổng quát hóa cho chuỗi dài hơn lúc train
Sin–cos cho phép mô hình:
- Áp dụng cho chuỗi dài hơn dữ liệu huấn luyện
- Không bị giới hạn bởi số lượng embedding vị trí cố định
5.4.2. Mô hình suy ra được vị trí tương đối
Nhờ tính chất toán học:
$$ \sin(a + b), \quad \cos(a + b) $$
→ Attention có thể học quan hệ khoảng cách giữa hai token,
không chỉ vị trí tuyệt đối.
👉 Điều này rất quan trọng cho bài toán ngôn ngữ.
5.4.3. Không cần thêm tham số học
- Không tăng số lượng parameter
- Giảm nguy cơ overfitting theo vị trí
- Ổn định hơn khi huấn luyện
5.5. Positional Encoding ảnh hưởng thế nào đến Attention?
Khi embedding đầu vào đã chứa thông tin vị trí:
$$ \mathbf{z}_i = \mathbf{x}_i + \mathbf{PE}_i $$
Trong Self-Attention:
- Query, Key, Value đều mang thông tin thứ tự
- Attention score phản ánh ngữ nghĩa + vị trí
👉 Đây là lý do Transformer có thể:
- Hiểu cấu trúc câu
- Hiểu quan hệ trước – sau
- Dù không có recurrence hay convolution
5.6. Các biến thể Positional Encoding hiện đại (mở rộng)
Ngoài sin–cos, thực tế còn nhiều biến thể:
-
Learned Positional Embedding
(BERT gốc) -
Relative Positional Encoding
(Transformer-XL, T5) -
Rotary Positional Embedding (RoPE)
(GPT-NeoX, LLaMA)
6. Self-Attention – Trái tim thực sự của Transformer
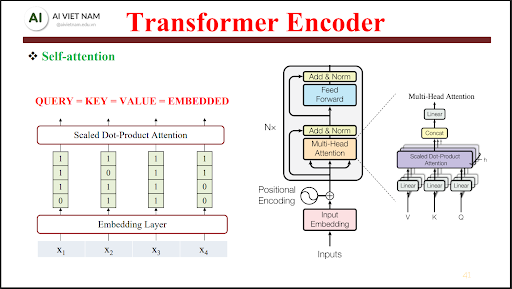
Self-Attention – Trái tim thực sự của Transformer
Nếu phải chọn một thành phần duy nhất làm nên sức mạnh của Transformer,
thì đó chính là Self-Attention.
Không phải Encoder,
không phải Decoder,
cũng không phải số lượng tham số —
mà là khả năng cho mỗi token tự quyết định:
Nó nên chú ý đến token nào khác trong chuỗi, và mức độ chú ý là bao nhiêu?
6.1. Trực giác cốt lõi của Self-Attention
Khi xử lý một token, Transformer không đọc từ trái sang phải như RNN.
Thay vào đó, nó đặt câu hỏi:
“Để hiểu tôi, tôi cần quan tâm đến những token nào khác, và mức độ quan tâm là bao nhiêu?”
Ví dụ câu:
“The animal didn’t cross the street because it was tired.”
Khi xử lý token “it”, mô hình cần:
- Bỏ qua “street”
- Chú ý mạnh vào “animal”
Self-Attention cho phép điều này xảy ra trong một bước duy nhất,
không cần truyền thông tin qua nhiều timestep.
👉 Đây chính là cách Transformer học được long-range dependency
một cách tự nhiên và hiệu quả.
6.2. Query – Key – Value: Cách token “đối thoại” với nhau
Về mặt toán học, mỗi token embedding $\mathbf{x}$
được chiếu tuyến tính thành ba vector khác nhau.
Sau khi có embedding đầu vào $X$, Transformer tạo ra ba không gian biểu diễn:
$$ Q = X W_Q,\quad K = X W_K,\quad V = X W_V $$
Trong đó:
- Query (Q): Tôi đang tìm thông tin gì?
- Key (K): Tôi có thông tin gì để người khác tìm?
- Value (V): Nội dung thực sự tôi sẽ cung cấp
Các ma trận trọng số học được:
$$ W_Q,\; W_K,\; W_V \in \mathbb{R}^{d_{\text{model}} \times d_k} $$
Ý nghĩa:
- $d_{\text{model}}$: số chiều embedding đầu vào
- $d_k$: số chiều của Query / Key
(thường $d_k = d_{\text{model}} / h$, với $h$ là số head)
👉 Cùng một token embedding $X$,
nhưng khi nhân với các ma trận khác nhau,
nó sẽ đóng ba vai trò khác nhau trong Self-Attention.
6.3. Công thức Attention – Trọng số hóa thông tin
Cơ chế Scaled Dot-Product Attention được định nghĩa như sau:
$$ \text{Attention}(Q, K, V) = \text{softmax}\!\left(\frac{QK^\top}{\sqrt{d_k}}\right) V $$
Giải thích từng thành phần
-
$QK^\top$
→ Đo mức độ liên quan giữa các token
(dot product giữa Query và Key) -
$\sqrt{d_k}$
→ Chuẩn hóa để tránh giá trị dot product quá lớn
→ Giúp softmax không bị bão hòa
→ Ổn định gradient khi huấn luyện -
$\text{softmax}(\cdot)$
→ Chuyển điểm liên quan thành trọng số attention
→ Tổng các trọng số bằng 1 -
Nhân với $V$
→ Trộn thông tin từ các token khác
→ Theo mức độ quan trọng đã được attention xác định
👉 Kết quả cuối cùng là một biểu diễn mới cho mỗi token,
được tạo ra bằng cách tổng hợp có trọng số thông tin
từ toàn bộ chuỗi.
7. Multi-Head Attention – Một góc nhìn là không đủ
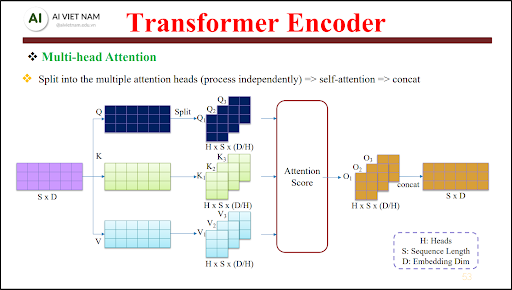
Multi-Head Attention – Một góc nhìn là không đủ
Một câu hỏi tự nhiên đặt ra:
“Một Attention head có đủ để hiểu ngôn ngữ không?”
Câu trả lời: Không.
7.1. Vì sao cần nhiều Attention Head?
Ngôn ngữ tồn tại nhiều loại quan hệ khác nhau:
- Ngữ pháp (subject – verb)
- Ngữ nghĩa
- Phụ thuộc xa (long-range dependency)
- Tham chiếu (coreference)
👉 Một head chỉ có thể học tốt một kiểu quan hệ chi phối.
Vì vậy, Transformer sử dụng $h$ attention head song song,
mỗi head nhìn câu theo một “lăng kính” khác nhau.
7.2. Công thức Multi-Head Attention
Trong Multi-Head Attention, mỗi head thực hiện Self-Attention độc lập:
$$ \text{head}_i = \text{Attention}(Q_i, K_i, V_i) $$
Sau đó, các head được ghép lại và chiếu tuyến tính để tạo đầu ra cuối cùng:
$$ \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \dots, \text{head}_h)\, W_O $$
Trong đó:
- $h$: số lượng head
- $W_O$: ma trận chiếu đầu ra, kết hợp thông tin từ tất cả các head
Kết quả đạt được
- Mô hình nhìn cùng một câu dưới nhiều “lăng kính” khác nhau
- Mỗi head học một kiểu quan hệ riêng:
- cú pháp
- ngữ nghĩa
- quan hệ xa – gần
- Giúp Transformer hiểu sâu cả cấu trúc lẫn ý nghĩa của câu
👉 Đây là lý do một head là không đủ,
và Multi-Head Attention trở thành thành phần không thể thiếu của Transformer.
8. Feed Forward Network (FFN) – Xử lý phi tuyến từng token
Sau lớp Self-Attention, mỗi token tiếp tục đi qua một
Feed-Forward Network (FFN) độc lập:
$$ \text{FFN}(x) = \max\!\left(0,\; x W_1 + b_1\right) W_2 + b_2 $$
Trong đó:
- $W_1 \in \mathbb{R}^{d_{\text{model}} \times d_{\text{ff}}}$
- $W_2 \in \mathbb{R}^{d_{\text{ff}} \times d_{\text{model}}}$
- $d_{\text{ff}}$ thường rất lớn, ví dụ 2048
(lớn hơn nhiều so với $d_{\text{model}}$)
Vai trò của FFN
- Tăng khả năng biểu diễn phi tuyến cho từng token
- Không trộn thông tin giữa các token
- Chỉ làm giàu biểu diễn riêng lẻ cho từng token
👉 Có thể hiểu FFN như một MLP nhỏ,
được áp dụng giống hệt nhau cho mọi vị trí trong chuỗi.
9. Residual Connection & Layer Normalization – Điều kiện để Transformer “rất sâu”
Mỗi sublayer trong Transformer
(Self-Attention hoặc FFN)
đều được bọc bởi Residual Connection + Layer Normalization:
$$ \text{LayerNorm}\big(x + \text{Sublayer}(x)\big) $$
Tác dụng chính
- Giữ gradient ổn định khi huấn luyện
- Travòi mất thông tin ban đầu nhờ đường truyền residual
- Cho phép huấn luyện mô hình rất sâu
(hàng chục đến hàng trăm layer)
👉 Không có residual + layer normalization
→ Transformer không thể scale lớn và rất khó train ổn định.
10. Encoder Layer hoàn chỉnh – Một khối chuẩn
Một Encoder layer trong Transformer gồm các thành phần sau (theo đúng thứ tự):
- Multi-Head Self-Attention
- Add & Layer Normalization
- Feed Forward Network (FFN)
- Add & Layer Normalization
Các Encoder layer này được lặp lại $N$ lần:
- $N = 6$ trong paper gốc Attention Is All You Need
- $N = 12, 24, 48$ hoặc 96+ trong các mô hình hiện đại
👉 Mỗi layer không chia sẻ tham số, nhưng có cấu trúc giống hệt nhau.
👉 Điều này giúp Transformer xây dựng biểu diễn ngày càng trừu tượng qua từng tầng.
11. Decoder & Masked Attention – Sinh ngôn ngữ có kiểm soát
Decoder khác Encoder ở hai điểm cốt lõi:
11.1. Masked Self-Attention
- Không cho token nhìn thấy các token ở tương lai
- Đảm bảo mô hình chỉ dựa vào thông tin quá khứ
👉 Điều này giúp Transformer hoạt động theo cơ chế autoregressive
→ sinh từng token một, giống như quá trình viết của con người.
11.2. Encoder–Decoder Attention
- Decoder chú ý vào output của Encoder
- Cho phép mô hình:
- căn chỉnh câu nguồn – câu đích
- học ánh xạ giữa hai chuỗi khác nhau
👉 Thành phần này rất quan trọng cho các bài toán:
- Dịch máy
- Tóm tắt văn bản
- Question Answering có ngữ cảnh
Kết luận ngắn gọn:
👉 Decoder giúp Transformer viết từng token một cách hợp lý và có kiểm soát.
12. Vì sao Transformer vượt trội so với RNN / LSTM?
| Tiêu chí | RNN / LSTM | Transformer |
|---|---|---|
| Xử lý song song | ❌ | ✅ |
| Long context | Kém | Tốt |
| Khả năng scale | Khó | Rất tốt |
| Phù hợp LLM | ❌ | ✅ |
👉 Điểm mấu chốt:
Transformer loại bỏ hoàn toàn ràng buộc thời gian tuần tự,
cho phép mô hình học quan hệ dài hạn hiệu quả hơn nhiều.
13. Các biến thể Transformer tiêu biểu
Một số kiến trúc nổi bật dựa trên Transformer:
-
BERT
→ Encoder hai chiều
→ Mạnh về hiểu ngữ nghĩa -
GPT
→ Decoder autoregressive
→ Mạnh về sinh nội dung -
T5
→ Encoder–Decoder
→ Mọi bài toán đều quy về text-to-text -
Vision Transformer (ViT)
→ Image → Patch → Token
→ Áp dụng Transformer cho thị giác -
Multimodal Transformer
→ Kết hợp Text + Image + Audio
→ Nền tảng cho các mô hình AI đa phương thức hiện đại
14. Kết luận – Transformer dưới góc nhìn tổng hợp
Sau khi bóc tách từng thành phần, có thể thấy Transformer không mạnh nhờ một chi tiết riêng lẻ, mà nhờ sự kết hợp chặt chẽ giữa Attention, Positional Encoding, Multi-Head cơ chế và kiến trúc Encoder–Decoder có thể mở rộng. Self-Attention cho phép mô hình nắm bắt quan hệ giữa các token ở mọi khoảng cách trong chuỗi, Positional Encoding bổ sung thông tin thứ tự mà kiến trúc song song vốn thiếu, trong khi Feed Forward Network, Residual Connection và Layer Normalization đảm bảo khả năng học phi tuyến ổn định ở độ sâu lớn. Tất cả các thành phần này phối hợp với nhau để tạo nên một kiến trúc vừa linh hoạt, vừa có khả năng scale mạnh.
Điểm mấu chốt khiến Transformer vượt trội so với RNN/LSTM không nằm ở việc “phức tạp hơn”, mà ở chỗ nó tách rời hoàn toàn việc hiểu quan hệ ngữ nghĩa khỏi ràng buộc thời gian. Nhờ đó, Transformer vừa giải quyết được bài toán long-range dependency, vừa tận dụng tối đa tính song song của phần cứng hiện đại. Đây là lý do các mô hình dựa trên Transformer có thể mở rộng lên hàng chục hoặc hàng trăm layer, xử lý ngữ cảnh dài, và huấn luyện trên tập dữ liệu cực lớn mà các kiến trúc cũ không thể theo kịp.
Tuy Transformer vẫn tồn tại những hạn chế rõ ràng, đặc biệt là chi phí tính toán bậc hai theo độ dài chuỗi, nhưng chính các hạn chế này đã thúc đẩy sự ra đời của hàng loạt cải tiến như Sparse Attention, Longformer hay Flash Attention. Điều đó cho thấy Transformer không phải một “điểm kết thúc”, mà là một nền móng kiến trúc để cộng đồng tiếp tục tối ưu và mở rộng.
Tóm lại, Transformer đã xác lập một chuẩn mới cho cách xây dựng mô hình xử lý chuỗi trong AI hiện đại. Hiểu rõ Transformer không chỉ giúp nắm vững các mô hình như BERT, GPT hay T5, mà còn giúp người học hình dung được cách AI hiện đại biểu diễn, liên kết và suy luận thông tin. Ở mức độ nền tảng, đây là một trong những kiến thức cốt lõi nhất nếu muốn đi sâu vào LLM, GenAI và các hệ thống AI quy mô lớn ngày nay.
Đọc bài viết này rối cả não mà chưa hiểu :D, cảm ơn tác giả