
Bài viết thuộc nhóm Conquer048
1. Giới thiệu tổng quan
Trong kỷ nguyên Trí tuệ nhân tạo, bài toán Scene Text Recognition (STR) – nhận diện chữ trong môi trường tự nhiên – đã vượt xa khả năng của các hệ thống OCR truyền thống. Trước các thách thức như biến dạng góc nhìn, nhiễu nền phức tạp và đa dạng phông chữ, các phương pháp hiện đại đã chuyển dịch sang kiến trúc Hybrid, kết hợp nhiều mô hình chuyên biệt trong một pipeline thống nhất.
Sự kết hợp giữa YOLO, ConvNeXt và Transformer Decoder hình thành một hệ thống OCR mạnh mẽ, tối ưu hóa toàn bộ chuỗi xử lý: từ định vị vùng chữ, trích xuất đặc trưng thị giác cho đến giải mã và sinh chuỗi ký tự.
2. Giới thiệu lý thuyết các thành phần
2.1. Text Detection với YOLO (You Only Look Once)
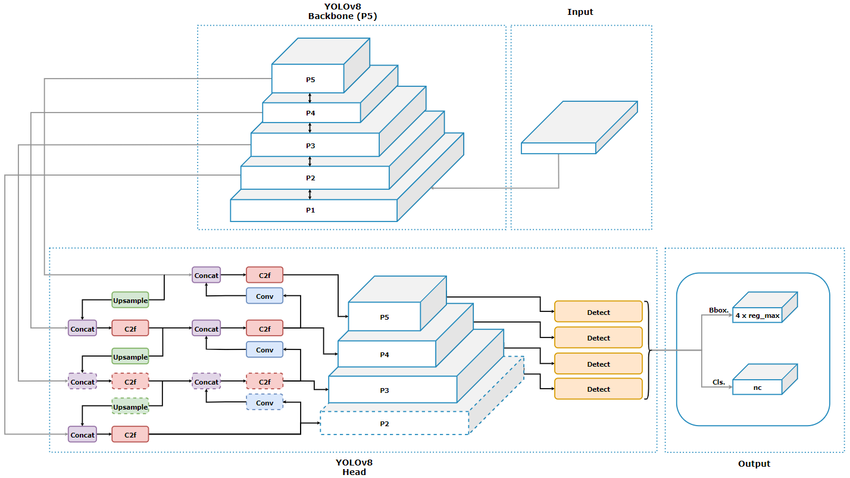
YOLO đóng vai trò là giai đoạn phát hiện (Detection Stage), chịu trách nhiệm xác định vị trí các vùng chứa văn bản trong khung hình phức tạp.
- Cơ chế: Thay vì quét trượt từng vùng nhỏ, YOLO dự đoán trực tiếp các tham số $x, y, w, h$ cùng với điểm tin cậy (confidence score) của các bounding boxes chứa văn bản.
- Ưu điểm: Tốc độ xử lý cao, phù hợp thời gian thực và khả năng phát hiện đa quy mô (multi-scale), giúp nhận diện hiệu quả cả các dòng chữ nhỏ hoặc ở xa.

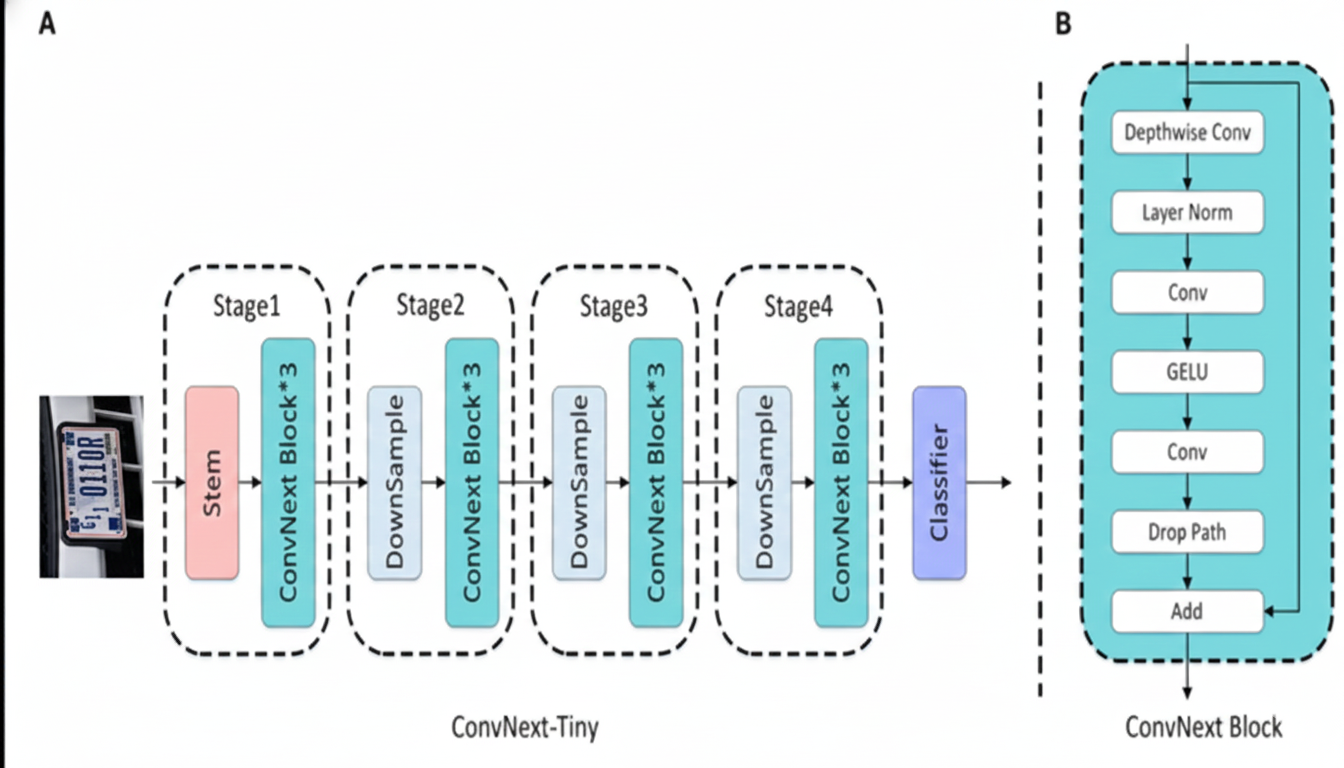
2.2. Feature Extraction với ConvNeXt
Sau khi YOLO cắt được các vùng ảnh chứa văn bản, các vùng này được đưa vào ConvNeXt để trích xuất đặc trưng.
- Đặc điểm: ConvNeXt là mạng CNN được thiết kế lại theo tư duy hiện đại, sử dụng Depthwise Convolution và Large Kernel ($7 \times 7$), giúp mở rộng trường thụ cảm và nắm bắt tốt cấu trúc hình học của ký tự.
- Vai trò: ConvNeXt đóng vai trò Visual Encoder, chuyển đổi ảnh đầu vào thành các feature maps giàu thông tin về nét vẽ, hình dáng và bố cục ký tự.
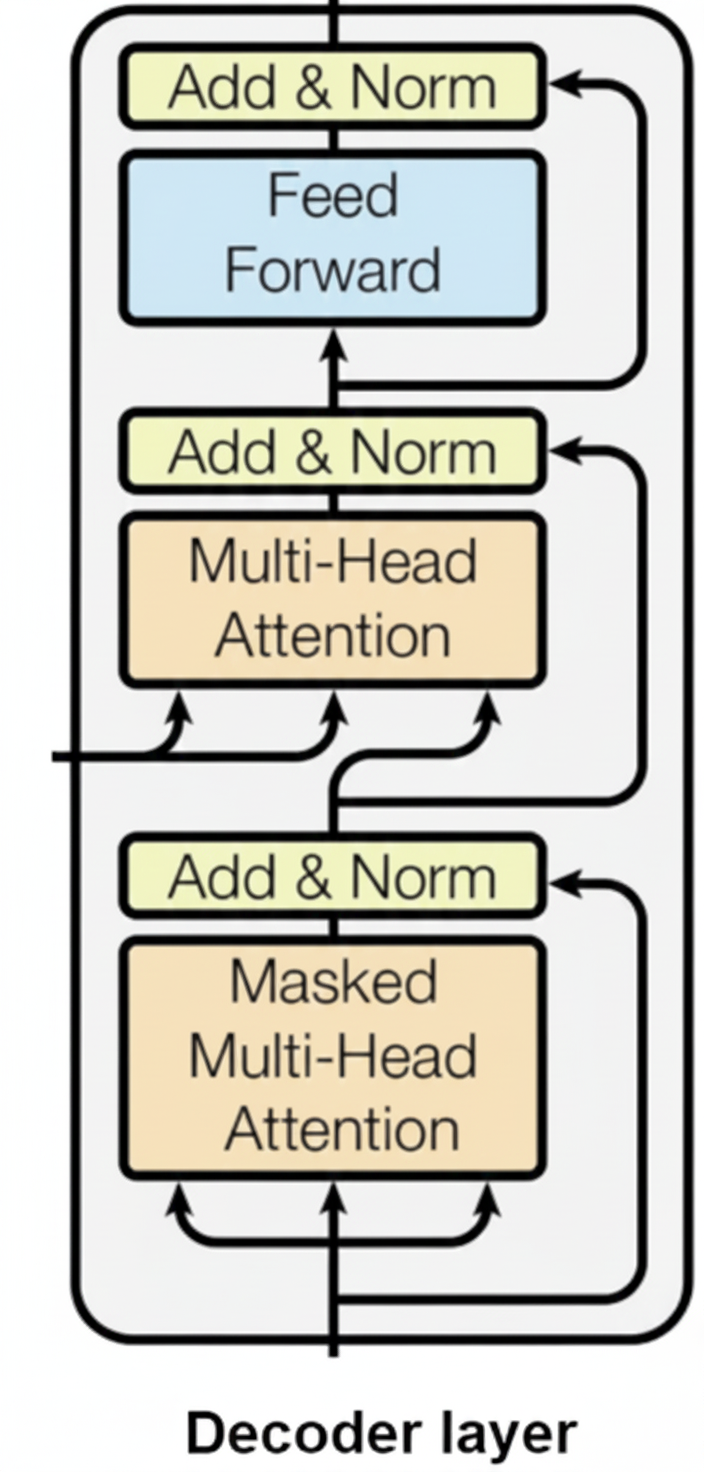
2.3. Sequence Recognition với Transformer Decoder
Đây là thành phần cốt lõi của quá trình nhận diện, nơi các đặc trưng thị giác được giải mã (decode) thành chuỗi văn bản có ý nghĩa.
- Cơ chế Decoder Attention: Transformer Decoder sử dụng:
- Self-Attention để mô hình hóa quan hệ ngữ cảnh giữa các ký tự đã sinh.
- Cross-Attention để liên kết chuỗi ký tự với các đặc trưng hình ảnh do ConvNeXt cung cấp.
- Positional Encoding: Bổ sung thông tin thứ tự và vị trí tương đối trong chuỗi, giúp Decoder duy trì cấu trúc không gian–tuần tự của văn bản trong quá trình sinh ký tự.
3. Quy trình Triển khai (Implementation Flow)
Một hệ thống OCR Hybrid điển hình được triển khai theo ba bước chính:
Bước 1: Detection Stage (YOLO)
Huấn luyện YOLO trên tập dữ liệu có nhãn là các khung bao quanh văn bản. Đầu ra của bước này là các image crops chứa từng dòng hoặc khối chữ.
- Lưu ý: Nên áp dụng Perspective Transform để hiệu chỉnh các vùng văn bản bị nghiêng, đưa chúng về dạng gần nằm ngang trước khi nhận diện.
from ultralytics import YOLO
import cv2
# 1. Load mô hình YOLOv8n đã pre-train (hoặc path tới file .pt của bạn)
# Thông thường bạn cần fine-tune trên tập dữ liệu Text Detection
model_det = YOLO('yolov8n.pt')
def detect_text(image_path):
results = model_det(image_path)
crops = []
for result in results:
boxes = result.boxes.xyxy.cpu().numpy() # Lấy tọa độ bounding box
img = result.orig_img
for box in boxes:
x1, y1, x2, y2 = map(int, box)
# Cắt vùng ảnh chứa chữ
crop = img[y1:y2, x1:x2]
crops.append(crop)
return crops # Trả về danh sách các image crops để đưa vào giai đoạn 2
Bước 2: Encoding Stage (ConvNeXt)
Các đoạn ảnh văn bản được đưa qua backbone ConvNeXt.
Đầu vào: Ảnh kích thước $H \times W \times 3$.
Đầu ra: Feature map có kích thước $C \times H' \times W'$, đại diện cho chuỗi đặc trưng thị giác.
Bước 3: Decoding Stage (Transformer Decoder)
Feature map được làm phẳng (flatten) và chuyển thành chuỗi visual tokens, sau đó đưa vào Transformer Decoder.
- Decoder sử dụng cơ chế Autoregressive Decoding hoặc Parallel Decoding để dự đoán xác suất từng ký tự trong bộ từ điển (alphabet), cho đến khi gặp token kết thúc
<EOS>.
import torch
import torch.nn as nn
from torchvision.models import convnext_tiny, ConvNeXt_Tiny_Weights
class HybridOCR(nn.Module):
def __init__(self, num_classes, d_model=512, nhead=8, num_decoder_layers=6):
super(HybridOCR, self).__init__()
# --- PHASE 2: CONVNEXT TINY (Visual Encoder) ---
# Load backbone và loại bỏ lớp head phân loại gốc
backbone = convnext_tiny(weights=ConvNeXt_Tiny_Weights.DEFAULT)
self.feature_extractor = nn.Sequential(*list(backbone.children())[:-2])
# Lớp chiếu (Projection) để map số channel của ConvNeXt (768) về d_model (512)
self.proj = nn.Linear(768, d_model)
# --- PHASE 3: TRANSFORMER DECODER ---
# Embedding cho ký tự đầu vào của Decoder
self.char_embedding = nn.Embedding(num_classes, d_model)
# Positional Encoding (để Decoder hiểu thứ tự ký tự)
self.pos_encoder = nn.Parameter(torch.randn(1, 100, d_model)) # Giả định max sequence 100
decoder_layer = nn.TransformerDecoderLayer(d_model=d_model, nhead=nhead, batch_first=True)
self.transformer_decoder = nn.TransformerDecoder(decoder_layer, num_layers=num_decoder_layers)
# Head cuối cùng để dự đoán ký tự
self.fc_out = nn.Linear(d_model, num_classes)
def forward(self, x, tgt):
# 1. Trích xuất đặc trưng (ConvNeXt)
# Input x: (Batch, 3, H, W)
features = self.feature_extractor(x) # Output: (Batch, 768, H', W')
# 2. Flatten feature map thành chuỗi (Sequence of visual tokens)
features = features.flatten(2).permute(0, 2, 1) # (Batch, Seq_Len, 768)
features = self.proj(features) # (Batch, Seq_Len, d_model)
# 3. Decoding
tgt_emb = self.char_embedding(tgt) + self.pos_encoder[:, :tgt.size(1), :]
# Cross-attention xảy ra ở đây giữa tgt_emb và features (memory)
output = self.transformer_decoder(tgt=tgt_emb, memory=features)
logits = self.fc_out(output)
return logits
# Khởi tạo mô hình
# num_classes = số ký tự trong bảng chữ cái + <SOS>, <EOS>, <PAD>
model_rec = HybridOCR(num_classes=100)
4. Trực quan hóa kết quả.
Để minh họa trực quan quy trình hoạt động của hệ thống Hybrid OCR, chúng ta sẽ quan sát quá trình xử lý trên một mẫu biển số xe thực tế. Dữ liệu được sử dụng trong ví dụ này được lấy từ cuộc thi ICPR 2026 LRLPR (Low-Resolution License Plate Recognition) – một thử thách chuyên biệt về nhận diện biển số xe từ hình ảnh chất lượng thấp, thường gặp trong các hệ thống giám sát giao thông thực tế.
Quá trình này mô phỏng lại hai giai đoạn then chốt của pipeline:
4.1. Giai đoạn Detection (YOLO) trên dữ liệu LR từ ICPR 2026
Mô hình YOLO sẽ quét toàn bộ khung hình ảnh có độ phân giải thấp (LR) từ dataset ICPR 2026 và khoanh vùng đối tượng biển số xe bằng một Bounding Box.
Input: Ảnh gốc độ phân giải thấp (LR) từ một track bất kỳ trong tập dữ liệu ICPR 2026.
Output: Tọa độ vùng chứa chữ (được đánh dấu bằng khung xanh lá cây) sau khi YOLO đã phát hiện.
Ví dụ minh họa:

Phân tích: Ngay cả với ảnh LR, YOLO vẫn thể hiện khả năng định vị chính xác vùng biển số, đặt nền móng cho giai đoạn nhận diện tiếp theo.
4.2. Giai đoạn Recognition (ConvNeXt + Transformer) và kết quả OCR
Sau khi vùng biển số đã được cắt ra từ ảnh LR (và có thể được làm nét thêm thông qua các kỹ thuật tiền xử lý hoặc Super-Resolution nếu có), đoạn ảnh này sẽ được đưa vào ConvNeXt để trích xuất đặc trưng, và sau đó Transformer Decoder sẽ giải mã chuỗi ký tự.
Input: Vùng ảnh biển số đã được cắt từ output của YOLO (ảnh LR, có thể đã được làm nét).
Output: Chuỗi ký tự biển số xe và điểm tin cậy (confidence score) theo định dạng của cuộc thi ICPR 2026.
Ví dụ minh họa:

Kết quả OCR: BAQ3G62
Confidence: 0.97
Định dạng output: track_001, BAQ3G62; 0.97
Phân tích tổng thể: Nhờ sự kết hợp mạnh mẽ của ConvNeXt trong việc trích xuất các đặc trưng hình ảnh ngay cả từ dữ liệu LR, cùng với khả năng mô hình hóa chuỗi hiệu quả của Transformer Decoder, hệ thống của chúng ta có thể nhận diện chính xác biển số BAQ3G62 với độ tin cậy rất cao (0.97), thể hiện hiệu quả trên dữ liệu LR đầy thách thức của ICPR 2026.
5. Những lưu ý quan trọng khi thực hiện
5.1. Vấn đề Độ phân giải (Resolution)
Kích thước vùng chữ do YOLO phát hiện có thể rất đa dạng, trong khi ConvNeXt yêu cầu đầu vào chuẩn hóa.
Lưu ý: Resize ảnh quá mức dễ làm biến dạng ký tự. Nên sử dụng Letterboxing (padding) để bảo toàn tỷ lệ khung hình (aspect ratio).
5.2. Hàm mất mát (Loss Function)
Trong kiến trúc Transformer Decoder, thay vì sử dụng CTC Loss truyền thống (thường dùng cho RNN), hệ thống ưu tiên sử dụng Cross-Entropy kết hợp với kỹ thuật Label Smoothing.
Kỹ thuật này giúp mô hình không trở nên quá "tự tin" vào một nhãn duy nhất, từ đó giảm thiểu overfitting và tăng khả năng hội tụ trên các tập dữ liệu nhiễu.
-
Cơ chế: Thay vì sử dụng nhãn dạng "hard label" (xác suất bằng 1 cho ký tự đúng và 0 cho các ký tự còn lại), Label Smoothing phân bổ một lượng nhỏ xác suất $\epsilon$ cho toàn bộ các ký tự khác trong bộ từ điển $|V|$.
-
Công thức phân phối mục tiêu:
Xác suất mục tiêu mới $q(i)$ cho ký tự thứ $i$ được tính như sau:
$$q(i) = \begin{cases} 1 - \epsilon & \text{nếu } i = y \\ \frac{\epsilon}{|V| - 1} & \text{nếu } i \neq y \end{cases}$$
- Hàm mất mát Label Smoothing Cross-Entropy:
$$\mathcal{L}_{LS} = -\sum_{i=1}^{|V|} q(i) \log(p_i)$$
Trong đó:
* $y$: Nhãn thực tế (ground truth).
* $p_i$: Xác suất dự báo của mô hình cho ký tự thứ $i$ sau lớp Softmax.
* $\epsilon$: Hệ số làm mượt (thường chọn $0.1$).
Tại sao lại quan trọng? Trong Scene Text Recognition, các ký tự thường có ngoại hình tương đồng (ví dụ: số
0và chữO, số1và chữl). Label Smoothing giúp mô hình học được các đặc trưng "mềm" hơn, giúp hệ thống hoạt động ổn định hơn khi gặp phải các phông chữ lạ hoặc bị biến dạng nhẹ.
5.3. Chiến lược huấn luyện và Dữ liệu tổng hợp (Synthetic Data)
Transformer Decoder là một thành phần cực kỳ "đói" dữ liệu. Nếu chỉ huấn luyện trên các tập dữ liệu thực tế (thường có quy mô nhỏ), mô hình rất dễ bị hiện tượng học vẹt (overfitting).
- Quy trình huấn luyện đa tầng:
- Giai đoạn Pre-train: Huấn luyện trên các bộ dữ liệu tổng hợp khổng lồ như MJSynth (VGG Dataset) hoặc SynthText. Việc này giúp ConvNeXt học cách trích xuất nét vẽ và Decoder học được quy luật phối hợp ký tự cơ bản.
- Giai đoạn Fine-tune: Tinh chỉnh mô hình trên dữ liệu thực tế với tốc độ học (learning rate) thấp để thích nghi với các biến dạng thực tế như ánh sáng yếu, nhòe chuyển động hoặc bụi bẩn.
- Data Augmentation đặc thù: Ngoài các phép xoay/lật, cần áp dụng Perspective Distortion (biến dạng phối cảnh) để giả lập góc nhìn nghiêng và Gaussian Noise để mô phỏng nhiễu cảm biến ảnh.
Cảnh báo về Language Modeling: Vì Transformer Decoder hoạt động như một mô hình ngôn ngữ (Language Model), nó có xu hướng tự động "sửa lỗi" dựa trên xác suất chuỗi. Điều này đôi khi khiến mô hình dự đoán theo quán tính thay vì nhìn vào hình ảnh (ví dụ: dự đoán chữ "Apple" dù ảnh thực tế là "App1e"). Cần cân bằng tập dữ liệu để tránh thiên kiến này.
5.4. Tối ưu hóa suy luận (Inference Optimization)
Việc kết hợp YOLO, ConvNeXt và Transformer tạo ra một hệ thống có tham số lớn. Để triển khai hiệu quả trong thực tế, cần tập trung vào các kỹ thuật giải mã và tối ưu hóa đồ thị tính toán.
-
Thuật toán giải mã (Decoding Strategy):
- Greedy Search: Chọn ký tự có xác suất cao nhất tại mỗi bước. Ưu điểm là tốc độ nhanh nhất nhưng dễ mắc lỗi dây chuyền nếu một ký tự ở giữa bị đoán sai.
- Beam Search: Duy trì một nhóm $k$ ứng viên tiềm năng nhất tại mỗi bước giải mã. Kỹ thuật này giúp sửa lỗi hiệu quả bằng cách xem xét tổng thể xác suất của cả chuỗi văn bản, đổi lại chi phí tính toán sẽ cao hơn.
-
Graph Optimization: * Chuyển đổi toàn bộ pipeline sang định dạng ONNX hoặc TensorRT. Việc này giúp gộp các lớp tính toán (layer fusion) và tối ưu hóa việc phân bổ bộ nhớ, giúp giảm đáng kể độ trễ (latency) khi chạy thực tế.
- Áp dụng Dynamic Shape cho đầu vào của YOLO để linh hoạt xử lý các kích thước ảnh khác nhau mà không cần resize gây biến dạng chữ.
6.Kết luận
Sự kết hợp giữa YOLO, ConvNeXt và Transformer Decoder thể hiện rõ tư duy thiết kế hệ thống OCR hiện đại: mỗi thành phần đảm nhiệm đúng vai trò của mình. Kiến trúc này không chỉ đạt độ chính xác cao mà còn có khả năng mở rộng, là nền tảng vững chắc cho các ứng dụng từ số hóa tài liệu đến phân tích văn bản trong video thời gian thực.
7.Tài liệu tham khảo (References)
Tài liệu được tham khảo từ AIO 2025
Redmon, J., et al. You Only Look Once: Unified, Real-Time Object Detection..
Liu, Z., et al. (2022). A ConvNet for the 2020s. (Bài báo gốc giới thiệu về ConvNeXt, cách hiện đại hóa CNN để cạnh tranh với Vision Transformers).
Vaswani, A., et al. (2017). Attention Is All You Need. (Nghiên cứu đột phá về kiến trúc Transformer và cơ chế Self-Attention).
Baoguang Shi, et al. An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition. (Nền tảng về việc kết hợp CNN và chuỗi ký tự trong OCR).
Bautista, D., & Atienza, R. (2022). Scene Text Recognition with Permuted Autoregressive Sequence Models (PARSeq). (Một trong những phương pháp SOTA sử dụng Transformer cho nhận diện chữ).
Li, H., et al. Show, Attend and Read: A Simple and Strong Baseline for Irregular Text Recognition. (Sử dụng cơ chế 2D-Attention để xử lý văn bản bị biến dạng).
MJSynth (VGG Synthetic Text Dataset) và SynthText: Hai bộ dữ liệu tổng hợp quan trọng nhất để pre-train các mô hình STR.
Ultralytics YOLOv8/v10 Documentation: Tài liệu hướng dẫn triển khai các phiên bản YOLO mới nhất cho bài toán Detection.
Bài viết rất dễ hiểu và đúng cái mình đang tìm 👍 Cảm ơn tác giả đã chia sẻ, đọc xong học được khá nhiều.