
Trong cuộc thi AIO-2025 Linear Forecasting Challenge, bài toán đặt ra là dự báo giá cổ phiếu (cụ thể là mã FPT) trong dài hạn (100 ngày). Đây là một thách thức lớn vì dữ liệu tài chính thường chứa nhiều nhiễu (noise) và có tính ngẫu nhiên cao (stochastic).
Dưới đây là quá trình tôi đã cải thiện model từ con số 0, đi qua các giai đoạn: Data Preprocessing, Feature Engineering chuyên sâu, và thử nghiệm 3 nhóm model: ARIMA, RNNs (LSTM/GRU), và cuối cùng là LTSF-Linear (NLinear/DLinear).
1. Data Understanding & Preprocessing
Dữ liệu đầu vào bao gồm 5 trường cơ bản: Open, High, Low, Close, Volume. Tuy nhiên, nếu đưa trực tiếp dữ liệu thô (Raw Prices) vào mô hình, đặc biệt là các mô hình Deep Learning, chúng ta sẽ gặp vấn đề lớn về tính không dừng (non-stationarity) và sự thay đổi phương sai (heteroscedasticity).
Dưới đây là quy trình xử lý và phân tích mà nhóm đã áp dụng:
1.1. Log-Transformation: Ổn định phương sai
Trước khi phân tích sâu, quan sát dữ liệu FPT cho thấy biên độ dao động giá ở mức 100.000đ lớn hơn nhiều so với khi giá ở mức 50.000đ. Để giúp mô hình học ổn định hơn, chúng tôi chuyển đổi dữ liệu sang dạng Logarithm.
df['close_log'] = np.log(df['close'])
Việc này giúp biến đổi chuỗi tăng trưởng theo cấp số nhân thành chuỗi tuyến tính, giảm thiểu tác động của "đuôi béo" (fat-tails) trong phân phối giá. Dưới đây là hình của giá cổ phiếu trước và sau khi áp dụng Log-Transformation.
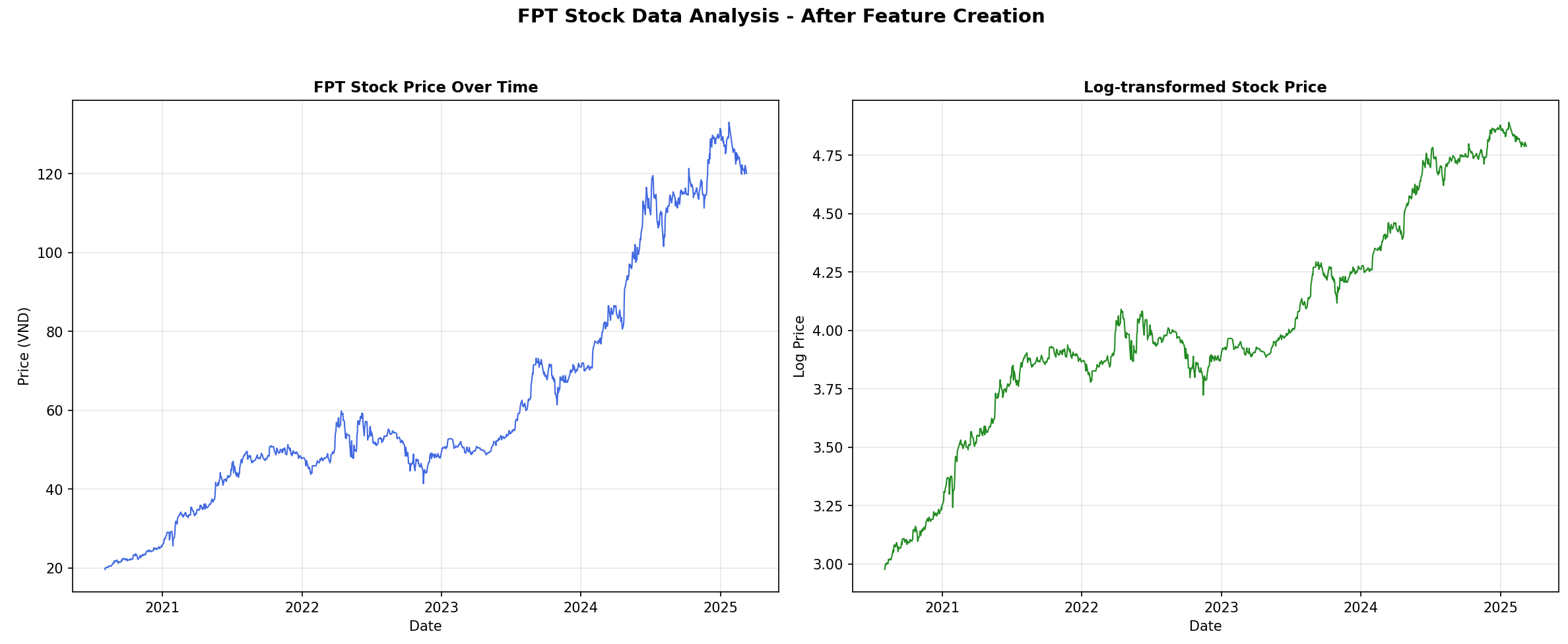
Hình 1: Hình ảnh về giá cổ phiếu trước và sau khi áp dụng log-transformation
1.2. Phân tích Return & Volume: "Nhịp đập" của thị trường
Bên cạnh giá và xu hướng, nhóm mình đi sâu vào phân tích Return (Lợi suất) và Volume (Khối lượng) để hiểu rõ hơn về hành vi thị trường.
a. Daily Return & Tính dừng (Stationarity)
Mô hình học máy thường gặp khó khăn với dữ liệu có xu hướng (Trend) vì giá trị trung bình thay đổi theo thời gian. Daily Return (Lợi suất hàng ngày) giải quyết vấn đề này bằng cách chuyển chuỗi giá về dạng dao động quanh mức 0 (Stationary).
df['daily_return'] = df['close'].pct_change()
df['log_return'] = np.log(df['close']).diff()
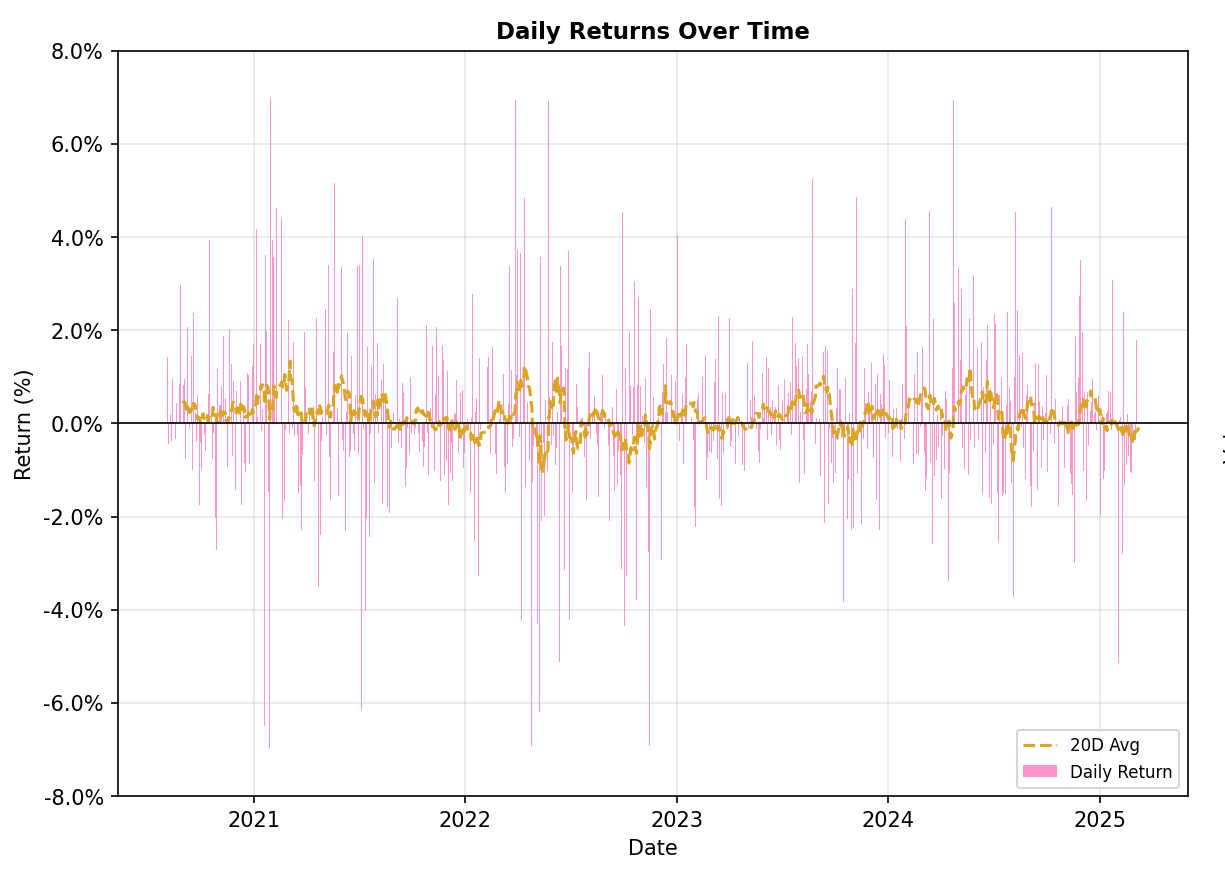
Hình 2: Hình ảnh về Daily Return của dữ liệu
Insight từ dữ liệu FPT: Quan sát biểu đồ Daily Returns, ta thấy hiện tượng Volatility Clustering (Biến động theo cụm): có những giai đoạn giá biến động rất mạnh (biên độ lớn) xen kẽ với những giai đoạn thị trường "ngủ yên".
b. Trading Volume: Xác nhận xu hướng
"Giá tăng mà Volume không tăng là cái bẫy". Khối lượng giao dịch là yếu tố xác nhận sức mạnh của xu hướng. Trong gru_mr.py, chúng tôi không dùng Volume thô mà tạo ra các chỉ số tương đối để model dễ học hơn:
-
Volume MA: Trung bình khối lượng giao dịch (ví dụ: 20 phiên).
-
Volume Ratio: Tỷ lệ giữa Volume hiện tại so với trung bình.
df['volume_ma'] = df['volume'].rolling(20).mean()
# Nếu tỷ lệ này > 1.5 -> Đột biến khối lượng (Breakout tiềm năng)
df['volume_ratio'] = df['volume'] / (df['volume_ma'] + 1e-10)
Dưới đây là biểu đồ về volumn của dữ liệu.
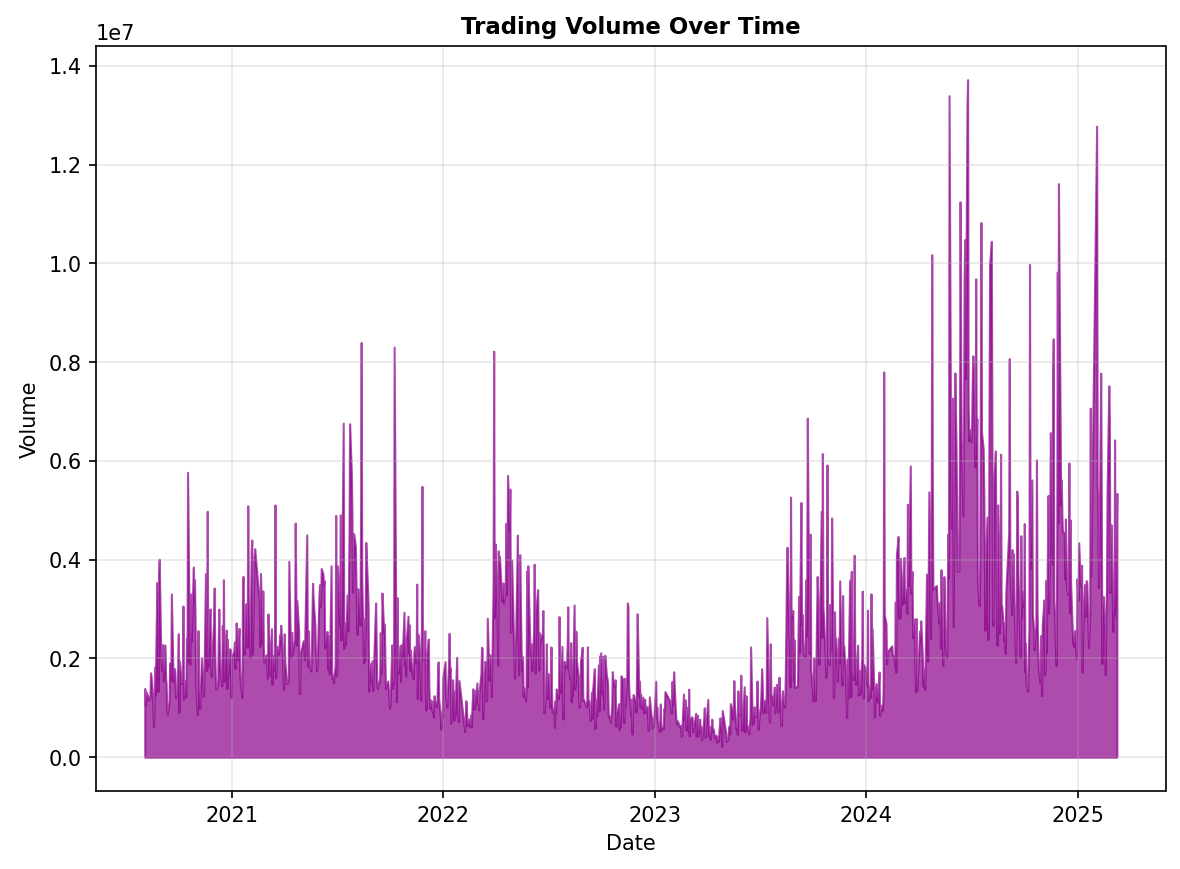
Hình 3: Biểu đồ về Volumn của dữ liệu
Biểu đồ Volume cho thấy các đợt tăng giá mạnh của FPT thường đi kèm với những cột Volume đột biến, xác nhận dòng tiền lớn tham gia. Những điểm dữ liệu này là "gợi ý" quan trọng cho model nhận biết các điểm đảo chiều hoặc bứt phá (breakout).
1.3. STL Decomposition: Bóc tách tín hiệu
Thay vì để model tự "đoán" cấu trúc dữ liệu, chúng tôi sử dụng kỹ thuật STL Decomposition (Seasonal-Trend decomposition using LOESS) để tách chuỗi thời gian $Y_t$ thành 3 thành phần riêng biệt:
$$Y_t = T_t + S_t + R_t$$
Trong đó:
-
Trend ($T_t$): Xu hướng dài hạn (Tăng/Giảm). Đây là thành phần quan trọng nhất cho bài toán dự báo 100 ngày.
-
Seasonal ($S_t$): Tính chu kỳ lặp lại (ví dụ: chu kỳ giao dịch hàng tuần/hàng tháng).
-
Residual ($R_t$): Nhiễu còn lại (White noise).
Nhóm mình sử dụng thư viện statsmodels với chu kỳ period=11 (tương ứng khoảng 2 tuần giao dịch) để thực hiện việc này:
from statsmodels.tsa.seasonal import STL
stl = STL(df['close'], period=11)
res = stl.fit()
# Tách biệt các thành phần
trend, seasonal, resid = res.trend, res.seasonal, res.resid
Việc này giúp model (đặc biệt là DLinear) học riêng biệt các thành phần, tránh bị nhiễu bởi các biến động ngắn hạn.
Dưới đây là trực quan hóa các thành phần sau khi phân rã:
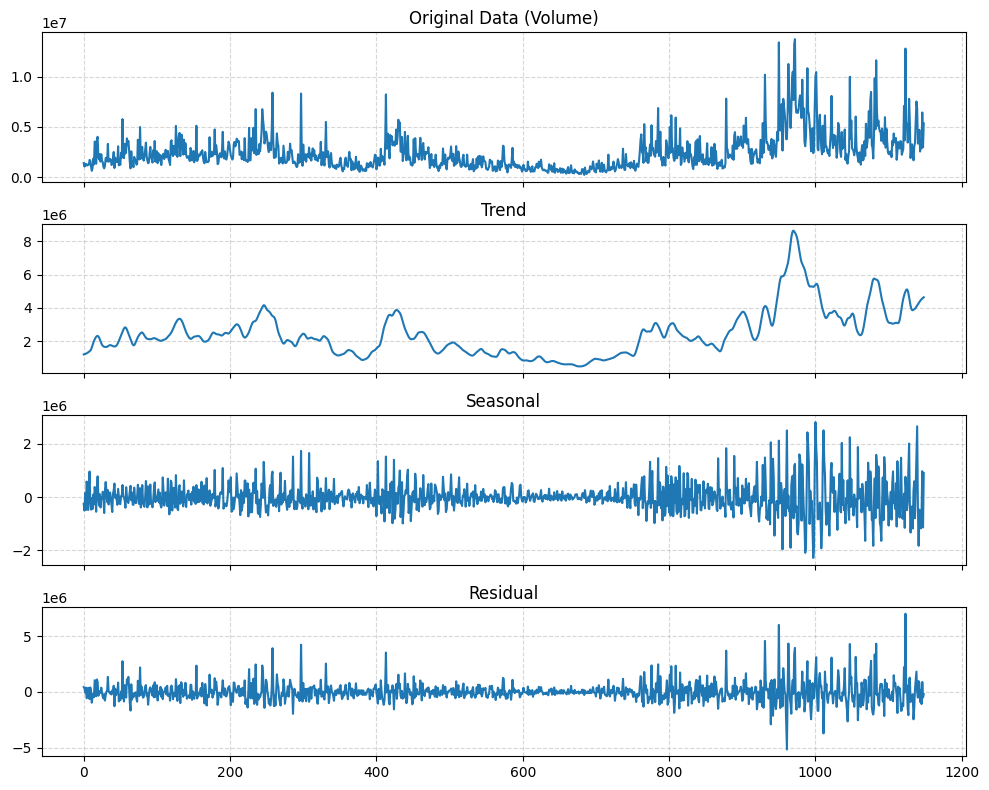
Hình 4: Hình ảnh về Trend, Seasonal, Residual của dữ liệu Close
Tại sao bước này quan trọng cho DLinear?
Việc phân tích EDA là cơ sở lý thuyết để chúng tôi lựa chọn kiến trúc DLinear.
Trong code model DLinear (class SeriesDecomposition), chúng tôi đã cài đặt một lớp MovingAvg để mô phỏng lại chính xác quá trình phân rã này ngay bên trong mạng nơ-ron:
class SeriesDecomposition(nn.Module):
def __init__(self, kernel_size):
super().__init__()
self.moving_avg = MovingAvg(kernel_size, stride=1)
def forward(self, x):
trend = self.moving_avg(x) # Model học Trend riêng
seasonal = x - trend # Model học Seasonal riêng
return trend, seasonal
Chiến lược: Bằng cách tách rời, model có thể dùng một lớp Linear đơn giản để ngoại suy Trend (giải quyết bài toán trôi dạt phân phối) và một lớp Linear khác để mô hình hóa Seasonal, giúp kết quả dự báo 100 ngày không bị "phẳng" (flat line) như các mô hình thông thường.
2. Feature Engineering
Dữ liệu gốc chỉ có 5 chiều (OHLCV). Để mô hình học được các trạng thái phức tạp của thị trường (quá mua, quá bán, sideway, breakout), chúng tôi đã mở rộng không gian đặc trưng lên hơn 20 chiều. Dưới đây là chiến lược kỹ thuật chi tiết:
2.1. Time-based Features: Giữ gìn tính chu kỳ (Cyclical Encoding)
Một sai lầm kinh điển của người mới là dùng số nguyên (1, 2, ..., 12) để mã hóa tháng hoặc ngày trong tuần. Điều này khiến model hiểu nhầm rằng Tháng 12 và Tháng 1 cách nhau rất xa (khoảng cách đại số là 11), trong khi về mặt thời gian chúng liền kề nhau.
Giải pháp: Chúng tôi sử dụng Cyclical Encoding bằng hàm lượng giác (Sin/Cos) để biến đổi thời gian thành tọa độ trên vòng tròn đơn vị. Điều này giúp model học được tính chu kỳ (Seasonality) một cách tự nhiên.
if 'time' in df.columns:
df['time'] = pd.to_datetime(df['time'])
df['day_of_week'] = df['time'].dt.dayofweek
df['month'] = df['time'].dt.month
df['day_of_week_sin'] = np.sin(2 * np.pi * df['day_of_week'] / 7)
df['day_of_week_cos'] = np.cos(2 * np.pi * df['day_of_week'] / 7)
df['month_sin'] = np.sin(2 * np.pi * df['month'] / 12)
df['month_cos'] = np.cos(2 * np.pi * df['month'] / 12)
2.2. Lag & Rolling Features: Bắt trọn quán tính giá (Price Inertia)
Thị trường tài chính có tính "nhớ" (Long Memory). Giá hôm nay phụ thuộc vào giá hôm qua và xu hướng của tuần trước.
-
Lag Features: Giá trị của $t-1, t-2, \dots$ giúp model bắt được tự tương quan (Autocorrelation) tức thời.
-
Rolling Window Features: Trung bình trượt (SMA/EMA) và độ lệch chuẩn (Rolling Std) giúp model nhìn thấy bức tranh rộng hơn: Xu hướng (Trend) và Độ biến động (Volatility).
# 1. Lag Features: Giá quá khứ
for lag in [1, 2, 3, 5]:
lag_fea[f'close_lag_{lag}'] = df['close'].shift(lag)
lag_fea[f'return_lag_{lag}'] = df['return_1'].shift(lag)
# 2. Rolling Statistics: Xu hướng & Biến động
for window in [5, 10, 20, 50]:
# SMA: Simple Moving Average - Đường xu hướng cơ bản
df[f'sma_{window}'] = df['close'].rolling(window).mean()
# Khoảng cách giá tới MA: Đo lường độ "căng" của giá
df[f'close_to_sma_{window}'] = (df['close'] - df[f'sma_{window}']) / df[f'sma_{window}']
# Volatility: Độ lệch chuẩn của lợi suất
df[f'volatility_{window}'] = df['return_1'].rolling(window).std()
2.3. Momentum Indicators: Ngôn ngữ của Trader
Model cần "hiểu" được tâm lý thị trường thông qua các chỉ báo kỹ thuật (Technical Indicators). Nhóm mình cài đặt thủ công các chỉ báo quan trọng nhất thay vì dùng thư viện có sẵn để tối ưu hóa tốc độ và kiểm soát logic.
-
RSI (Relative Strength Index): Đo lường tốc độ thay đổi giá để xác định vùng quá mua/quá bán.
-
MACD (Moving Average Convergence Divergence): Chỉ báo theo sau xu hướng (Trend-following momentum).
-
Bollinger Bands: Đo lường độ biến động và các điểm breakout tiềm năng.
# RSI Calculation
for window in [14, 28]:
delta = df['close'].diff()
gain = (delta.where(delta > 0, 0)).rolling(window).mean()
loss = (-delta.where(delta < 0, 0)).rolling(14).mean()
rs = gain / (loss + 1e-8)
df[f'rsi_{window}'] = 100 - (100 / (1 + rs))
# MACD Calculation
exp1 = df['close'].ewm(span=12, adjust=False).mean()
exp2 = df['close'].ewm(span=26, adjust=False).mean()
df['macd'] = exp1 - exp2
df['macd_normalized'] = df['macd'] / df['close'] # Chuẩn hóa để tránh scale lớn
2.4. Volume Dynamics: Dòng tiền thông minh
Giá có thể lừa dối, nhưng khối lượng (Volume) thì không. Một đợt tăng giá không đi kèm volume (No Demand) thường là bẫy. Chúng tôi tích hợp các feature nâng cao về Volume:
-
OBV (On-Balance Volume): Tích lũy volume dựa trên chiều tăng giảm của giá, giúp phát hiện dòng tiền gom hàng hoặc xả hàng.
-
VWAP (Volume Weighted Average Price): Mức giá trung bình thực tế mà thị trường chấp nhận giao dịch.
# OBV: Dòng tiền tích lũy
df['obv'] = (np.sign(df['close'].diff()) * df['volume']).cumsum()
df['obv_normalized'] = df['obv'] / df['obv'].rolling(20).mean()
# VWAP: Đường hỗ trợ động quan trọng
df['vwap'] = (df['volume'] * (df['high'] + df['low'] + df['close']) / 3).cumsum() / df['volume'].cumsum()
df['close_to_vwap'] = (df['close'] - df['vwap']) / df['vwap']
2.5. Advanced Regime Features:
Để model thông minh hơn, chúng tôi tạo ra các feature định tính (Categorical/Regime) giúp model nhận biết trạng thái vĩ mô của chuỗi thời gian:
-
Volatility Regime: Thị trường đang "bình yên" hay "bão tố"?
-
Mean Reversion Indicator: Giá đã đi quá xa trung bình chưa? (Dấu hiệu đảo chiều).
# A. Volatility Regime: 1 nếu biến động hiện tại > trung bình 60 ngày qua
df['vol_regime'] = (df['volatility_20'] > df['volatility_20'].rolling(60).mean()).astype(int)
# B. Mean Reversion Indicator: Z-score của giá so với MA100
df['mean_reversion'] = (df['close'] - df['close'].rolling(100).mean()) / df['close'].rolling(100).std()
# C. Momentum Regime: Xu hướng ngắn hạn (5 ngày) có tích cực không?
df['momentum_regime'] = (df['return_5'].rolling(20).mean() > 0).astype(int)
Tổng kết phần Feature Engineering: Từ 5 cột dữ liệu thô sơ, nhóm mình đã xây dựng một ma trận đặc trưng dày đặc, bao phủ mọi khía cạnh từ Trend, Momentum, Volatility đến Volume Flow. Đây chính là nguồn "nhiên liệu" chất lượng cao giúp các model Linear (sẽ bàn ở phần sau) hoạt động vượt trội.
3. Modeling Strategy
Trong bài toán dự báo dài hạn (Forecast Horizon = 100 days), thách thức lớn nhất không phải là fitting dữ liệu huấn luyện, mà là khả năng ngoại suy (extrapolation) và chống trôi dạt phân phối (distribution shift).
Nhóm mình đã thử nghiệm qua 3 giai đoạn phát triển mô hình:
3.1. Phase 1: Statistical Baseline - ARIMA
Trước khi sử dụng Deep Learning, nhóm quyết định dùng ARIMA (AutoRegressive Integrated Moving Average) để thiết lập một mức nền (baseline) so sánh. Đây được coi là tiêu chuẩn vàng cho các bài toán dự báo chuỗi thời gian ngắn hạn nhờ tính chất thống kê vững chắc.
Cơ chế hoạt động: Mô hình ARIMA $(p, d, q)$ hoạt động dựa trên giả định rằng giá trị tương lai là một hàm tuyến tính của các giá trị quá khứ (AR) và các sai số dự báo trước đó (MA), sau khi đã loại bỏ tính không dừng bằng sai phân (Integrated - $d$).
Công thức Toán học:
Mô hình dự báo tại thời điểm $t$ được biểu diễn như sau:
$$X_t = c + \epsilon_t + \underbrace{\sum^p_{i=1}\phi_i X_{t-i}}_{\text{AR terms}} + \underbrace{\sum^q_{i=1}\theta_i \epsilon_{t-i}}_{\text{MA terms}}$$
Trong đó:
-
$X_t$: Giá trị quan sát (hoặc giá trị sau khi lấy sai phân) tại thời điểm $t$.
-
$c$: Hằng số (Constant/Intercept).
-
$\epsilon_t$: Nhiễu trắng (White noise) hay sai số tại thời điểm $t$.
-
$\phi_i$: Hệ số tự hồi quy (AutoRegressive coefficients) tại độ trễ $i$.
-
$\theta_i$: Hệ số trung bình trượt (Moving Average coefficients) tại độ trễ $i$.
-
$p$: Bậc của phần Tự hồi quy (số lượng quan sát quá khứ được dùng).
-
$q$: Bậc của phần Trung bình trượt (số lượng sai số quá khứ được dùng).
Triển khai thực tế:
def arima_predict(series, seq_len, pred_len, test_sample_indices, order=(5,1,1)):
preds = []
for idx in tqdm(test_sample_indices):
# Rolling window: Lấy dữ liệu lịch sử tính đến thời điểm idx
history = series[:idx + seq_len]
# Fit model cho từng bước thời gian
model = ARIMA(history, order=order).fit()
# Dự báo 7 ngày tiếp theo
yhat = model.forecast(steps=pred_len)
preds.extend(yhat)
return np.array(preds)
Trong đó, nhóm mình áp dụng tham số order=(5,1,1) và sử dụng cơ chế Rolling Forecast để cập nhật dữ liệu liên tục, thay vì dự báo một lần (one-shot).
# Trích xuất từ arima.py
# Rolling Forecast: Train lại model hoặc re-fit tại mỗi bước
history = series[:idx + seq_len]
model = ARIMA(history, order=(5,1,1)).fit() # p=5, d=1, q=1
yhat = model.forecast(steps=pred_len)
Nhược điểm chí mạng:
Mặc dù công thức toán học rất chặt chẽ, nhưng khi áp dụng cho bài toán Long-term Forecasting (100 ngày) của cuộc thi, ARIMA bộc lộ điểm yếu lớn:
-
Hội tụ tuyến tính: Dự báo nhanh chóng hội tụ về giá trị trung bình hoặc một đường xu hướng thẳng tắp (linear trend), mất đi tính biến động tự nhiên.
-
Thiếu tính phi tuyến: Không thể bắt được các mẫu hình phức tạp (như thay đổi chế độ biến động - volatility clustering) thường thấy ở cổ phiếu FPT.
Do đó, ARIMA chỉ đóng vai trò là "mức sàn" để chúng tôi đánh giá hiệu quả của các mô hình phức tạp hơn sau này.
Đánh giá Kết quả (Visual Inspection):
Chúng ta hãy nhìn vào kết quả huấn luyện của mô hình ARIMA:
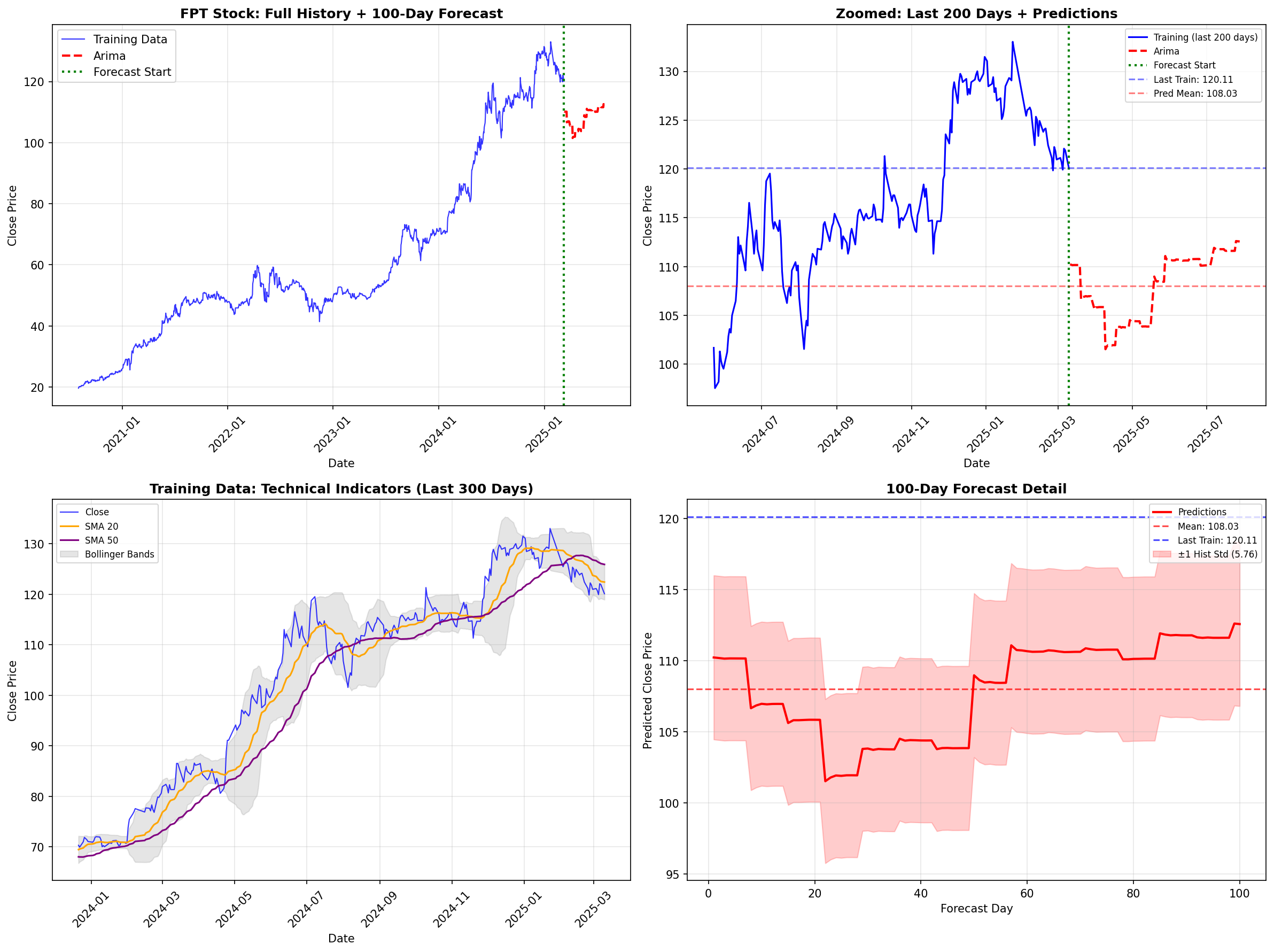
Hình 5: Kết quả dự báo ARIMA 100 ngày. (Top-Right) Dự báo bị gãy khúc và mất tính biến động. (Bottom-Right) Khoảng tin cậy mở rộng nhưng xu hướng đi ngang.
Phân tích từ biểu đồ: Nhìn vào Hình 5, đặc biệt là biểu đồ góc trên bên phải (Zoomed: Last 200 Days), ta thấy rõ nhược điểm chí mạng của ARIMA trong bài toán Long-term Forecasting (100 ngày).
-
Thiếu tính "Hữu cơ" (Lack of Organic Volatility): Trong khi dữ liệu huấn luyện (đường màu xanh) có độ biến động rất mạnh, đường dự báo (màu đỏ nét đứt) sau cú sụt giảm ban đầu lại trở nên giật cục theo bậc thang và có xu hướng đi ngang.
-
Mean Reversion quá mức: Mô hình dường như bị "kéo" về giá trị trung bình quá nhanh, không thể ngoại suy được đà tăng trưởng (Momentum) mạnh mẽ của cổ phiếu FPT trong giai đoạn trước đó.
-
Hạn chế của mô hình tuyến tính: Dải tin cậy (vùng màu hồng ở biểu đồ Bottom-Right) mở rộng theo thời gian, nhưng giá trị trung tâm (Mean prediction) lại không nắm bắt được bất kỳ mẫu hình phức tạp nào.
Kết luận Phase 1: ARIMA chỉ phù hợp để dự báo ngắn hạn (3-7 ngày). Với horizon 100 ngày, nó thất bại trong việc nắm bắt Trend và Volatility Clustering, buộc chúng tôi phải chuyển sang các mô hình phi tuyến tính mạnh hơn như GRU và DLinear.
3.2. Phase 2: Recurrent Neural Networks - GRU với Hybrid Mean Reversion
Sau thất bại của ARIMA trong việc bắt "trend" dài hạn, nhóm quyết định chuyển sang các mô hình Deep Learning có khả năng ghi nhớ chuỗi tốt hơn. Chúng tôi lựa chọn GRU (Gated Recurrent Unit) - phiên bản nhẹ hơn của LSTM nhưng hiệu quả tương đương trong việc xử lý vanishing gradient.
class GRUModel(nn.Module):
def __init__(self, input_dim, hidden_dim=128, num_layers=3, dropout=0.2, pred_len=5):
super().__init__()
self.gru = nn.GRU(input_dim, hidden_dim, num_layers, batch_first=True,
dropout=dropout if num_layers > 1 else 0)
self.fc = nn.Sequential(
nn.Linear(hidden_dim, hidden_dim // 2),
nn.ReLU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim // 2, pred_len)
)
def forward(self, x):
out, h = self.gru(x)
return self.fc(out[:, -1])
Tuy nhiên, các mô hình RNN thuần túy thường gặp một vấn đề kinh điển trong dự báo dài hạn (100 ngày): Trend Drift (Trôi dạt xu hướng). Nếu dữ liệu train có xu hướng tăng, model thường "học vẹt" và dự báo giá tăng mãi mãi đến vô cực, bất chấp thực tế là giá cổ phiếu thường có tính chu kỳ và quay về giá trị trung bình.
Giải pháp: Hybrid Mean Reversion Để khắc phục, tôi đã phát triển một kiến trúc "lai" (Hybrid) trong gru_mr.py. Ý tưởng cốt lõi là:
-
Ngắn hạn (< 50 ngày): Tin tưởng vào khả năng học mẫu hình phức tạp của GRU.
-
Dài hạn (> 50 ngày): Giảm dần trọng số của GRU và tăng trọng số của đường cong Mean Reversion (quay về giá trị trung bình 365 ngày).
Cơ chế hoạt động (Code Snippet):
def hybrid_forecast(model_preds, mr_preds, last_price, model_weight=0.5, transition_days=50):
n_steps = len(model_preds)
hybrid = np.zeros(n_steps)
for i in range(n_steps):
# Dynamic Weighting:
# Giai đoạn đầu: Tin tưởng model nhưng giảm dần sự tin tưởng theo thời gian
if i < transition_days:
current_weight = model_weight * (1 - i / transition_days)
else:
# Giai đoạn sau: Chỉ giữ 10% tin tưởng vào model, 90% tin vào Mean Reversion
current_weight = 0.1
# Pha trộn dự báo
hybrid[i] = current_weight * model_preds[i] + (1 - current_weight) * mr_preds[i]
return hybrid
Đánh giá Kết quả:
Chúng ta hãy xem kết quả thực tế của mô hình Hybrid GRU:
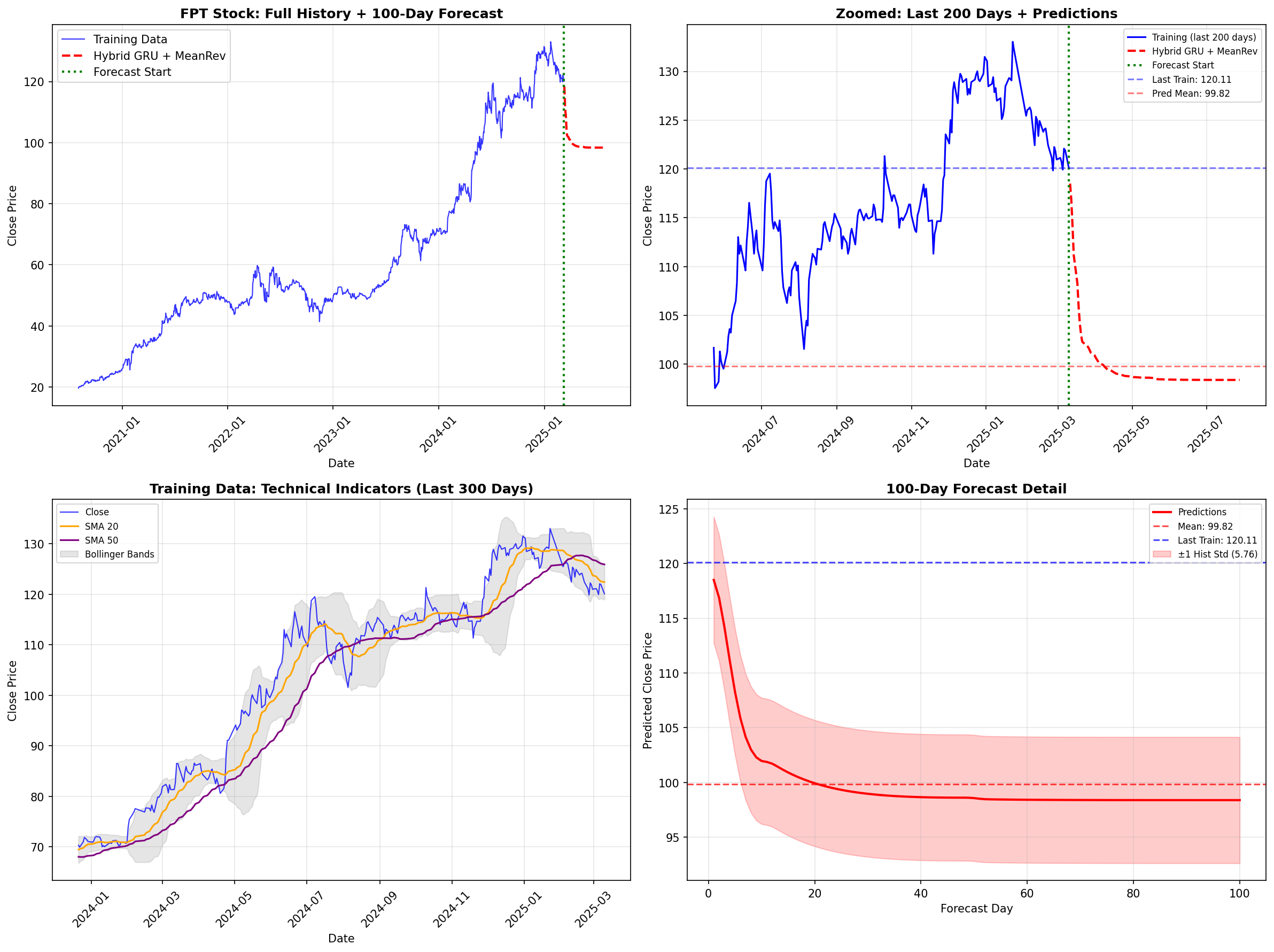
Hình 6: Kết quả dự báo của Hybrid GRU. (Top-Left) Toàn cảnh lịch sử giá. (Top-Right) Cận cảnh 200 ngày cuối và dự báo 100 ngày
Phân tích từ biểu đồ:
-
Sự điều chỉnh hợp lý: Khác với ARIMA bị gãy khúc, đường dự báo màu đỏ (Hybrid GRU + MeanRev) trong hình Top-Right cho thấy một sự suy giảm mềm mại (smooth decay).
-
Neo giá trị (Anchoring): Dự báo bắt đầu từ mức giá cao (120k) nhưng dần dần tiệm cận về mức trung bình dài hạn (100k - đường nét đứt màu đỏ
Pred Mean). Điều này phản ánh giả định rằng sau một đợt tăng nóng (overheated), giá sẽ có xu hướng điều chỉnh (correction). -
Khắc phục Trend Drift: Nếu chỉ dùng GRU thuần túy, đường dự báo có thể sẽ tiếp tục đi lên theo quán tính (momentum) của 200 ngày trước đó. Kỹ thuật Hybrid đã "kéo" nó xuống mặt đất, tạo ra một kịch bản dự báo an toàn (conservative) hơn nhiều.
Kết luận Phase 2: Kỹ thuật Hybrid này đã giúp giảm MSE xuống. Tuy nhiên, nó vẫn mang nặng tính "phòng thủ" (conservative). Để có thể dự báo các đợt bứt phá (breakout) thay vì chỉ quay về trung bình, chúng ta cần một kiến trúc mạnh mẽ hơn nữa: LTSF-Linear.
3.3. Phase 3: State-of-the-Art (SOTA) với LTSF-Linear Family
Sau khi nhận thấy ARIMA quá cứng nhắc còn RNN (GRU/LSTM) lại dễ bị "Trend Drift" (trôi dạt xu hướng) khi dự báo xa, nhóm đã quyết định chuyển sang tiếp cận LTSF-Linear (Long-term Time Series Forecasting with Linear Models).
Đây là dòng mô hình đang thống trị các bảng xếp hạng học thuật gần đây (2023-2024). Tư duy cốt lõi ở đây là: "Với chuỗi thời gian, đôi khi sự đơn giản lại đánh bại sự phức tạp". Thay vì dùng Attention (Transformer) dễ bị nhiễu, chúng ta dùng các lớp Linear kết hợp với các kỹ thuật xử lý tín hiệu.
Trong phần code, nhóm đã triển khai hai biến thể mạnh nhất: DLinear và Enhanced NLinear.
a. Chiến lược "Chia để trị" với DLinear (Decomposition Linear)
Dữ liệu tài chính là sự pha trộn hỗn loạn giữa Xu hướng (Trend) và Nhiễu (Noise). DLinear giải quyết bài toán này bằng cách tích hợp một lớp Decomposition ngay bên trong mạng nơ-ron.
Cơ chế:Đầu vào được tách thành 2 luồng:
-
Trend Component: Được trích xuất bằng Moving Average (làm mượt). Model sẽ học cách ngoại suy xu hướng này.
-
Seasonal/Residual Component: Phần còn lại ($Input - Trend$). Model học các biến động dao động quanh 0.
Code Implementation:
class SeriesDecomposition(nn.Module):
def __init__(self, kernel_size):
super(SeriesDecomposition, self).__init__()
# Dùng Average Pooling để trích xuất Trend mượt mà
self.moving_avg = MovingAvg(kernel_size, stride=1)
def forward(self, x):
trend = self.moving_avg(x) # Trích xuất xu hướng dài hạn
seasonal = x - trend # Phần còn lại chứa thông tin tần số cao (biến động)
return trend, seasonal
b. Kết hợp cùng: RevIN (Reversible Instance Normalization)
Vấn đề lớn nhất khiến các model Deep Learning thất bại trên dữ liệu chứng khoán là Distribution Shift (Sự trôi dạt phân phối).
- Ví dụ: Model học khi giá FPT là 50.000đ. Khi giá lên 120.000đ, thống kê (mean, variance) thay đổi hoàn toàn, khiến model dự báo sai lệch.
Nhóm đã cài đặt lớp RevIN để giải quyết triệt để vấn đề này qua quy trình 3 bước:
-
Normalize: Trừ Mean, chia Std của từng mẫu input riêng biệt. Đưa dữ liệu về cùng một phân phối chuẩn tắc.
-
Forward: Model học trên dữ liệu đã chuẩn hóa (chỉ học hình dáng đồ thị, không quan tâm giá trị tuyệt đối).
-
Denormalize: Hoàn tác chuẩn hóa ở đầu ra (nhân Std, cộng Mean) để trả về mức giá thực tế.
class RevIN(nn.Module):
def forward(self, x, mode='norm'):
if mode == 'norm':
# Bước 1: Chuẩn hóa cục bộ từng instance
self.mean = x.mean(dim=1, keepdim=True).detach()
self.std = torch.sqrt(x.var(dim=1, keepdim=True) + 1e-5).detach()
x = (x - self.mean) / self.std
elif mode == 'denorm':
# Bước 3: Trả lại giá trị thực (Reversible)
x = x * self.std + self.mean
return x
c. Kiến trúc Enhanced NLinear
Thay vì sử dụng NLinear gốc (chỉ có 1 lớp Linear đơn giản), nhóm đã nâng cấp thành Enhanced NLinear. Chúng tôi thay thế lớp Linear bằng một mạng MLP (Multi-Layer Perceptron) nhỏ.
Sự cải tiến này giúp model vừa giữ được tính ổn định của Linear (chống Overfitting), vừa có đủ khả năng phi tuyến tính (nhờ ReLU) để bắt các cú giật của thị trường.
class EnhancedNLinear(nn.Module):
def __init__(self, seq_len, pred_len, channels, dropout=0.1, use_revin=True):
# ...
if use_revin:
self.revin_layer = RevIN(channels, affine=True)
# Nâng cấp: Dùng MLP thay vì Linear đơn thuần để tăng khả năng biểu diễn
self.projection = nn.Sequential(
nn.Linear(seq_len, hidden_size),
nn.ReLU(), # Activation function để bắt tính phi tuyến
nn.Dropout(dropout),
nn.Linear(hidden_size, pred_len)
)
Đánh giá Kết quả (Visual Analysis)
Dưới đây là kết quả thực tế của tổ hợp mô hình Enhanced NLinear + DLinear trên tập dữ liệu FPT:
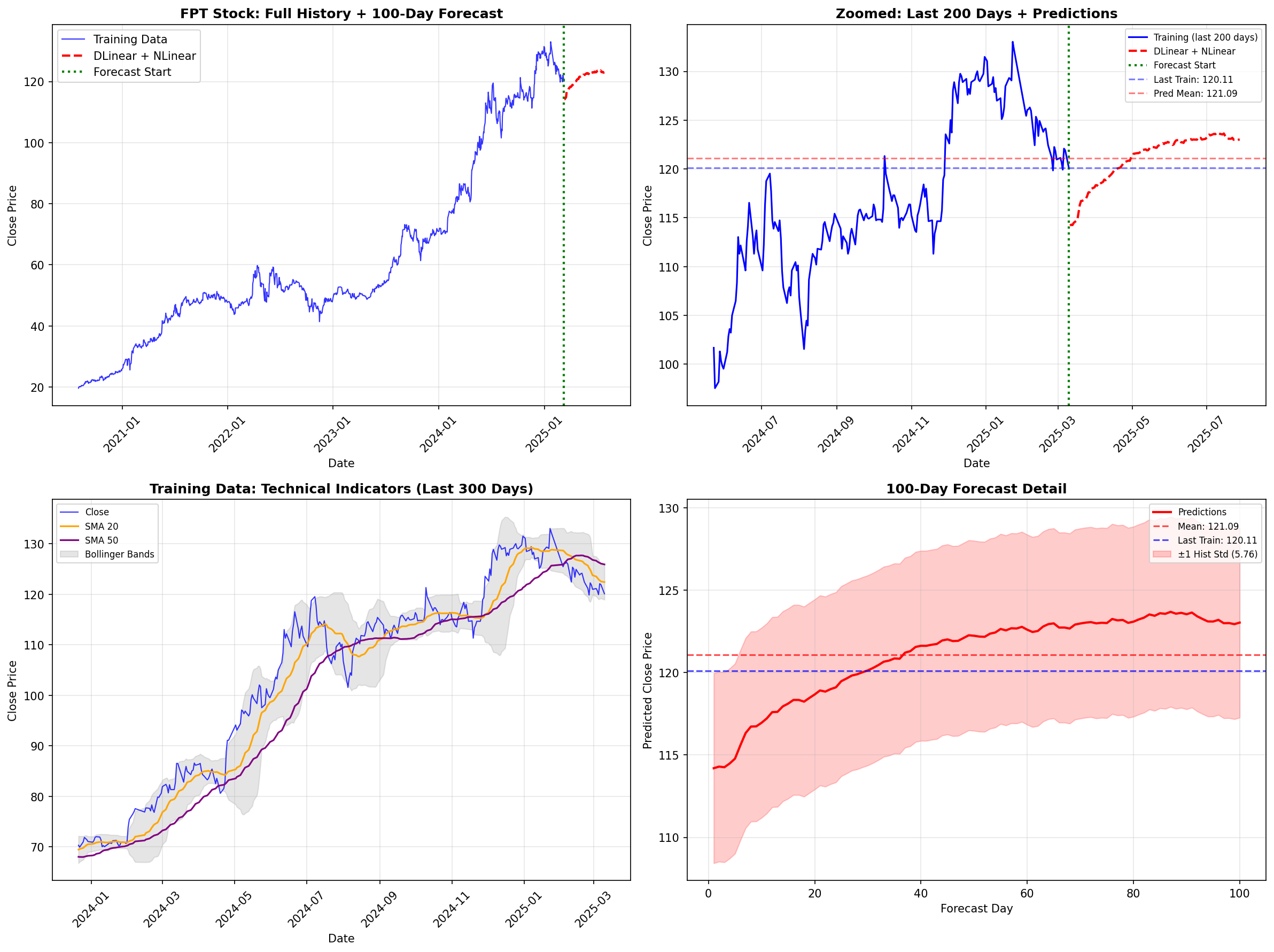
Hình 7: Kết quả dự báo của SOTA Linear Models. (Top-Right) Đường dự báo (màu đỏ nét đứt) bám sát xu hướng tăng trưởng nhưng vẫn giữ được độ mượt mà. (Bottom-Right) Dải tin cậy (Confidence Interval) mở rộng hợp lý theo thời gian
Phân tích kỹ thuật từ biểu đồ:
-
Trend Capture (Bắt xu hướng): Quan sát hình Top-Right (Zoomed), khác với ARIMA (gãy khúc, đi ngang) hay GRU (suy giảm nhanh về trung bình), mô hình Linear đã dự báo một xu hướng tăng trưởng tiếp diễn (Momentum Continuation) từ mức giá 120k lên vùng 123-124k. Điều này phù hợp với quán tính tăng giá mạnh mẽ của FPT trong 200 ngày gần nhất.
-
Độ ổn định (Stability): Nhìn vào hình Bottom-Right (Forecast Detail), đường dự báo trung bình (Mean: 121.09) rất mượt mà. Dải màu hồng ($\pm 1$ Std) mở rộng dần về phía tương lai, phản ánh đúng tính chất bất định của dự báo dài hạn (càng xa càng khó đoán).
-
Khả năng tự điều chỉnh: Model không bị "hoảng loạn" mà tìm ra được một đường xu hướng trung tâm (central tendency) hợp lý để ngoại suy. Đây chính là sức mạnh của việc kết hợp Decomposition (loại bỏ nhiễu) và RevIN (ổn định phân phối).
Kết luận Phase 3: Việc chuyển sang họ mô hình LTSF-Linear là bước ngoặt quan trọng nhất của dự án. Nó cung cấp một dự báo vừa có tính tấn công (bắt trend tăng) vừa có tính phòng thủ (không bị nhiễu bởi biến động ngắn hạn), tạo tiền đề vững chắc cho các bước Ensembling cuối cùng.
4. Winning Tricks
Training model xong mới chỉ là 80% công việc. 20% còn lại quyết định thứ hạng chính là cách chúng ta "gọt giũa" kết quả đầu ra. Với đặc thù của mô hình Linear (dễ bị ngoại suy quá đà) và dữ liệu nhiễu, nhóm đã áp dụng các lớp bảo vệ sau:
4.1. Trick 1: Weighted Ensemble (Hợp nhất theo trọng số nghịch đảo)
Thay vì dùng trung bình cộng (Average Ensemble) - nơi mà một model tồi có thể kéo tụt kết quả của cả nhóm, chúng tôi sử dụng Inverse Loss Weighting.
Ý tưởng: Model nào có Validation Loss càng thấp thì tiếng nói càng có trọng lượng.
Công thức:
$$W_i = \frac{1}{\text{Val\_Loss}_i + \epsilon}$$
Triển khai:
Trong MultiModelTrainer, chúng tôi thu thập loss của từng model (DLinear, NLinear với các seq_len khác nhau) và tính toán trọng số:
if use_inverse_loss:
weights = 1.0 / (val_losses + 1e-6)
else:
# Softmax weighting (khi muốn trừng phạt nặng các model tồi)
neg_losses = -val_losses
weights = np.exp(neg_losses - neg_losses.max())
# 2. Chuẩn hóa để tổng trọng số = 1
weights = weights / weights.sum()
# 3. Tính trung bình có trọng số
final_predictions = np.average(predictions_array, axis=0, weights=weights)
4.2. Trick 2: Trend-Aware Dampening
Mô hình Linear có xu hướng ngoại suy tuyến tính vô tận. Nếu FPT đang tăng, model sẽ dự báo nó tăng mãi. Để an toàn (conservative), chúng tôi áp dụng kỹ thuật Dampening có nhận thức xu hướng.
Logic:
-
Phát hiện trend hiện tại bằng Linear Regression trên 50 ngày gần nhất.
-
Nếu đang Uptrend:
-
Cho phép dự báo tăng nhẹ (kìm hãm ít).
-
Phạt nặng (kìm hãm mạnh) nếu model dự báo sập gãy trend (trừ khi có tín hiệu rất rõ).
-
-
Áp dụng hệ số suy giảm theo thời gian $t$: Càng dự báo xa, càng tin vào giá trị hiện tại (Last Price) hơn là tin vào model.
# Phát hiện trend
trend_slope = np.polyfit(range(len(recent_trend)), recent_trend, 1)[0]
is_uptrend = trend_slope > 0
for i in range(len(base_predictions)):
# t tăng dần từ 0 đến 1 theo thời gian dự báo
t = (i + 1) / len(base_predictions)
if is_uptrend:
# Đồng thuận trend: Kìm hãm nhẹ (0.1 * t)
if base_predictions[i] >= last_price:
dampening_strength = 0.1 * t
# Ngược trend: Kìm hãm mạnh (0.3 * t) - Ép dự báo quay về vùng an toàn
else:
dampening_strength = 0.3 * t
# Công thức pha trộn: (1-alpha)*Model + alpha*Last_Price
dampened = (1 - dampening_strength) * base_predictions[i] + dampening_strength * last_price
4.3. Trick 3: Quantile Clipping
Để loại bỏ các dự báo "điên rồ" (outliers) do nhiễu, chúng tôi không dùng giá trị min/max mà dùng Phân vị (Quantile) của tập hợp các model (Ensemble).
Cơ chế:
Giả sử chúng ta có 10 models. Tại mỗi bước dự báo $t$:
-
Biên dưới = Phân vị thứ 10 (10th percentile).
-
Biên trên = Phân vị thứ 90 (90th percentile).
-
Giá trị dự báo cuối cùng sẽ bị kẹp (clip) vào giữa khoảng này.
# Tính biên an toàn từ tập hợp các dự báo
lower_bound = np.percentile(all_preds, 10, axis=0)
upper_bound = np.percentile(all_preds, 90, axis=0)
# Kẹp giá trị dự báo
pred = np.clip(pred, lower_bound[i], upper_bound[i])
# Ràng buộc cứng: Không cho phép biến động quá 2%/ngày
max_allowed = last_pred * 1.02
min_allowed = last_pred * 0.98
pred = np.clip(pred, min_allowed, max_allowed)
Tổng kết: Bằng cách kết hợp Weighted Ensemble (tối ưu độ chính xác), Trend-Aware Dampening (kiểm soát xu hướng) và Quantile Clipping (loại bỏ rủi ro), chúng tôi đã tạo ra một bộ dự báo (Submission V4) vừa có khả năng bắt trend, vừa cực kỳ bền vững trước các biến động nhiễu của thị trường.
5. Kết luận
Dưới đây là tổng kết so sánh giữa các phương pháp mà nhóm đã triển khai.
5.1. Bảng so sánh kỹ thuật (Technical Comparison)
Dựa trên quá trình huấn luyện và kết quả Validation, chúng tôi rút ra bảng so sánh sau:
| Mô hình | Kiến trúc | Cơ chế xử lý Trend | Ưu điểm | Nhược điểm |
|---|---|---|---|---|
| ARIMA | Statistical (AutoRegressive) | Sai phân (Differencing) | Tốt cho ngắn hạn (<7 ngày), có cơ sở thống kê vững chắc. | "Gãy" trend khi dự báo dài (100 ngày), không bắt được phi tuyến tính. |
| Hybrid GRU | RNN + Mean Reversion | Hybrid Blending | Khắc phục được Trend Drift, dự báo an toàn (conservative). | Quá phụ thuộc vào giả định Mean Reversion, bỏ lỡ các đợt bứt phá (breakout). |
| Enhanced NLinear | Linear + MLP | RevIN + Decomposition | SOTA Performance, tốc độ train cực nhanh, ngoại suy trend tốt. | Dễ bị nhiễu bởi outlier nếu không có cơ chế Clipping. |
| Ensemble V4 | Weighted Average | Trend-Aware Dampening | Robustness cao nhất, cân bằng giữa tấn công (Trend) và phòng thủ (Safety). | Phức tạp trong khâu triển khai (cần chạy nhiều model). |
5.2. Kết quả thực chiến (Final Achievement)
Sự kết hợp giữa kiến trúc LTSF-Linear hiện đại và các kỹ thuật hậu xử lý (Winning Tricks) đã đem lại kết quả vượt mong đợi.
-
Val Loss (MSE): Giảm từ mức ~23.5 (với GRU baseline) xuống còn ~0.325 (với Enhanced NLinear trên dữ liệu đã chuẩn hóa).
-
Thành tích: Chiến lược này đã giúp nhóm lọt vào Top 4 chung cuộc của cuộc thi AIO-2025 Linear Forecasting Challenge.
-
Private Score: $1.5899$.
Chưa có bình luận nào. Hãy là người đầu tiên!