
1. Giới thiệu
Chào các bạn! Hôm nay nhóm mình sẽ giới thiệu project dự báo giá đóng cửa (close price) cho cổ phiếu FPT cho 100 ngày tiếp theo. Mình sẽ trình bày pipeline end-to-end dùng PyTorch — từ chuẩn bị dữ liệu, xây model, đến đánh giá kết quả — kèm snippet code từ Jupyter để các bạn có thể thử ngay.
2. Tổng quan dự án
Trong project này, nhóm mình thực hiện một bài toán dự báo chuỗi thời gian (time-series forecasting) với mục tiêu dự đoán giá đóng cửa cổ phiếu FPT trong 100 ngày tiếp theo. Đây không chỉ là bài toán dự đoán đơn thuần, mà là quá trình xây dựng một pipeline hoàn chỉnh, từ phân tích dữ liệu (EDA), tiền xử lý, tạo sequence đầu vào, xây dựng mô hình học sâu (Deep Learning) cho đến đánh giá kết quả và trực quan hóa dự báo.
Project được phát triển dựa trên một phiên bản gốc, nhưng nhóm đã cải thiện kiến trúc, pipeline và workflow xử lý dữ liệu, giúp mô hình chạy ổn định hơn, tối ưu và dễ mở rộng hơn.
Mục tiêu
-
Xây dựng hệ thống dự báo giá cổ phiếu FPT trong 100 ngày.
-
Đảm bảo pipeline sạch – rõ ràng – sẵn sàng dùng cho sản phẩm.
-
Kiểm chứng hiệu quả mô hình Deep Learning trên dữ liệu tài chính.
-
Trình bày quy trình cải tiến từ project gốc sang phiên bản tốt hơn
3. Phương pháp thực hiện
3.1. Quy trình thực hiện
a) Khởi tạo và chuẩn bị dữ liệu
-
Nguồn dữ liệu: File FPT_train.csv chứa lịch sử giao dịch cổ phiếu FPT từ 03/08/2020 đến 10/03/2025 (1.149 ngày giao dịch).
-
Đọc dữ liệu bằng pandas, chuyển cột time về kiểu datetime, sắp xếp tăng dần theo thời gian.
-
Áp dụng log-transform cho cột close (log(close)) để ổn định phương sai và biến trend tăng cấp số nhân thành gần tuyến tính.
-
Tính returns hàng ngày: returns = pct_change(log_close) và fill giá trị đầu tiên bằng 0.
b) Khám phá dữ liệu (Exploratory Data Analysis – EDA)
-
Thống kê mô tả: Dữ liệu sạch, không có missing value lớn (chỉ thiếu do ngày nghỉ lễ). Kích thước 1.149 × 7 cột ban đầu.
-
Phân phối biến mục tiêu: Giá close (sau log) có xu hướng tăng mạnh dài hạn, volatility tăng dần theo thời gian, phù hợp với đặc trưng cổ phiếu tăng trưởng tốt.
-
Phân tích returns: Phân phối gần chuẩn, skewness nhẹ, có hiện tượng volatility clustering, autocorrelation yếu → dữ liệu mang tính chất gần “random walk with drift” nhưng vẫn có pattern thời gian.
-
Ma trận tương quan: open-high-low-close có tương quan > 0.98, volume có tương quan yếu hơn với giá.
c) Tiền xử lý dữ liệu
-
Feature Engineering (phần cốt lõi):
-
MA_30: Moving average 30 ngày của log close.
-
day_of_week, year: Đặc trưng thời gian tuyến tính.
-
day_sin, day_cos, month_sin, month_cos: Cyclical encoding để mô hình hiểu được tính chu kỳ tuần/tháng/năm.
-
-
Chuẩn hóa dữ liệu: MinMaxScaler đưa toàn bộ 12 features về khoảng [0,1].
-
Chia dữ liệu:
-
Validation: 100 ngày cuối cùng.
-
Train: Toàn bộ dữ liệu còn lại (1.049 ngày).
-
-
Tạo Dataset tùy chỉnh: StockDataset hỗ trợ sliding window với seq_len = input_size, pred_len = output_size, chỉ lấy cột close làm target.
d) Xây dựng mô hình dự báo chuỗi thời gian
-
Mô hình sử dụng: Ba biến thể Linear hiện đại chuyên cho time series:
-
Linear (baseline).
-
NLinear (normalized linear).
-
DLinear (decomposition linear – tách trend + seasonal).
-
-
Tối ưu siêu tham số: Đọc từ file best_hyperparameters.json (đã được tìm trước bằng grid search), bao gồm:
input_size, output_size, batch_size, learning_rate, weight_decay, moving_avg (chỉ dùng cho DLinear). -
Huấn luyện:
-
Optimizer: Adam + weight decay.
-
Loss function: MSE Loss.
-
Early stopping với patience.
-
Lưu trạng thái mô hình tốt nhất dựa trên validation loss.
-
e) Dự báo 100 ngày tương lai
-
Sử dụng kỹ thuật autoregressive multi-step:
-
Bắt đầu từ input_size ngày cuối cùng làm seed.
-
Dự báo output_size ngày → thay thế vào sequence → dịch cửa sổ → lặp lại đến khi đủ 100 ngày.
-
Inverse transform: MinMax → exp() để trở về giá thực tế (VNĐ).
-
Xuất kết quả ra file submission.csv (id 1–100, cột close).
3.2. Mô tả dữ liệu
Xây dựng mô hình dự báo giá đóng cửa cổ phiếu FPT trong 100 ngày giao dịch tiếp theo, dựa trên dữ liệu lịch sử từ ngày 03/08/2020 đến 10/03/2025 (1.149 quan sát). Dữ liệu bao gồm 7 cột ban đầu: time, open, high, low, close, volume, symbol.
df_train = pd.read_csv(r'data/FPT_train.csv')
df_train['time'] = pd.to_datetime(df_train['time'])
df_train = df_train.sort_values(by='time').reset_index(drop=True)
df_train['close'] = np.log(df_train['close'])
df_train['returns'] = df_train['close'].pct_change()
df_train['returns'].fillna(0, inplace=True)
df_train.drop(columns=['symbol'], inplace=True)
Ở đây, mình bỏ đi cột symbol vì nó không đóng góp qua nhiều cho việc train mô hình, và chuyển phần cột 'close' bằng việc dùng np.log để ổn định phương sai, và thêm cột 'return' để đo sự chênh lệch giữa giá đóng cửa giữa các phiên liên tiếp, biểu diễn mức sinh lời hàng ngày, phục vụ cho việc phân tích biến động và tính toán rủi ro.
Phần eda dữ liệu, chúng tôi sẽ thực hiện các phân tích sau:
-
Biến động giá đóng cửa theo thời gian – Quan sát xu hướng dài hạn và các biến động nổi bật của giá cổ phiếu FPT.
-
So sánh với các trung bình động (Moving Averages) – Sử dụng trung bình động 30 ngày và 90 ngày để nhận diện xu hướng ngắn hạn và dài hạn, cũng như các tín hiệu giao cắt quan trọng.
-
Autocorrelation (ACF) và Partial Autocorrelation (PACF) – Kiểm tra sự phụ thuộc tuần tự trong dữ liệu, từ đó đánh giá mức độ trễ (lag) ảnh hưởng tới giá hiện tại.
-
Phân phối lợi nhuận hàng ngày (Daily Returns) – Khảo sát phân phối lợi nhuận để hiểu độ biến động và xác suất xuất hiện các biến động cực đoan.
-
Ma trận tương quan (Correlation Heatmap) – Xem xét mối quan hệ giữa các biến quan trọng như giá mở cửa, giá cao, giá thấp, giá đóng cửa và khối lượng giao dịch.
fig, ax = plt.subplots(3, 2, figsize=(15, 10))
fig.suptitle('FPT Stock Analysis', fontsize=16)
# 1️⃣ Close Price
ax[0, 0].plot(df_train['time'], df_train['close'], label='Close Price')
ax[0, 0].set_title('Close Price Over Time')
ax[0, 0].set_xlabel('Time')
ax[0, 0].set_ylabel('Close Price')
ax[0, 0].legend()
# 2️⃣ Close Price + Moving Averages
df_train_copy = df_train.copy()
df_train_copy['MA_30'] = df_train_copy['close'].rolling(window=30).mean()
df_train_copy['MA_90'] = df_train_copy['close'].rolling(window=90).mean()
ax[0, 1].plot(df_train_copy['time'], df_train_copy['close'], label='Close Price', color='green')
ax[0, 1].plot(df_train_copy['time'], df_train_copy['MA_30'], label='30-Day MA', color='red')
ax[0, 1].plot(df_train_copy['time'], df_train_copy['MA_90'], label='90-Day MA', color='gold')
ax[0, 1].set_title('Close Price with Moving Averages')
ax[0, 1].set_xlabel('Time')
ax[0, 1].set_ylabel('Price')
ax[0, 1].legend()
# 3️⃣ ACF
plot_acf(df_train['close'], ax=ax[1, 0])
ax[1,0].set_title('ACF of Close Price')
# 4️⃣ PACF
plot_pacf(df_train['close'], ax=ax[1, 1])
ax[1,1].set_title('PACF of Close Price')
# 5️⃣ Histogram of Returns
ax[2, 0].hist(df_train['returns'].dropna(), bins=50, color='purple', alpha=0.7)
ax[2, 0].set_title('Histogram of Returns')
ax[2, 0].set_xlabel('Returns')
ax[2, 0].set_ylabel('Frequency')
# 6️⃣ Correlation Heatmap
corr = df_train[['open', 'high', 'low', 'close', 'volume']].corr()
sns.heatmap(corr, annot=True, cmap='coolwarm', fmt=".2f", ax=ax[2, 1])
ax[2,1].set_title('Correlation Heatmap')
plt.tight_layout(rect=[0, 0, 1, 0.96])
plt.show()
Sau khi eda, ta sẽ thấy rõ được dữ liệu được phân bố ra sao:
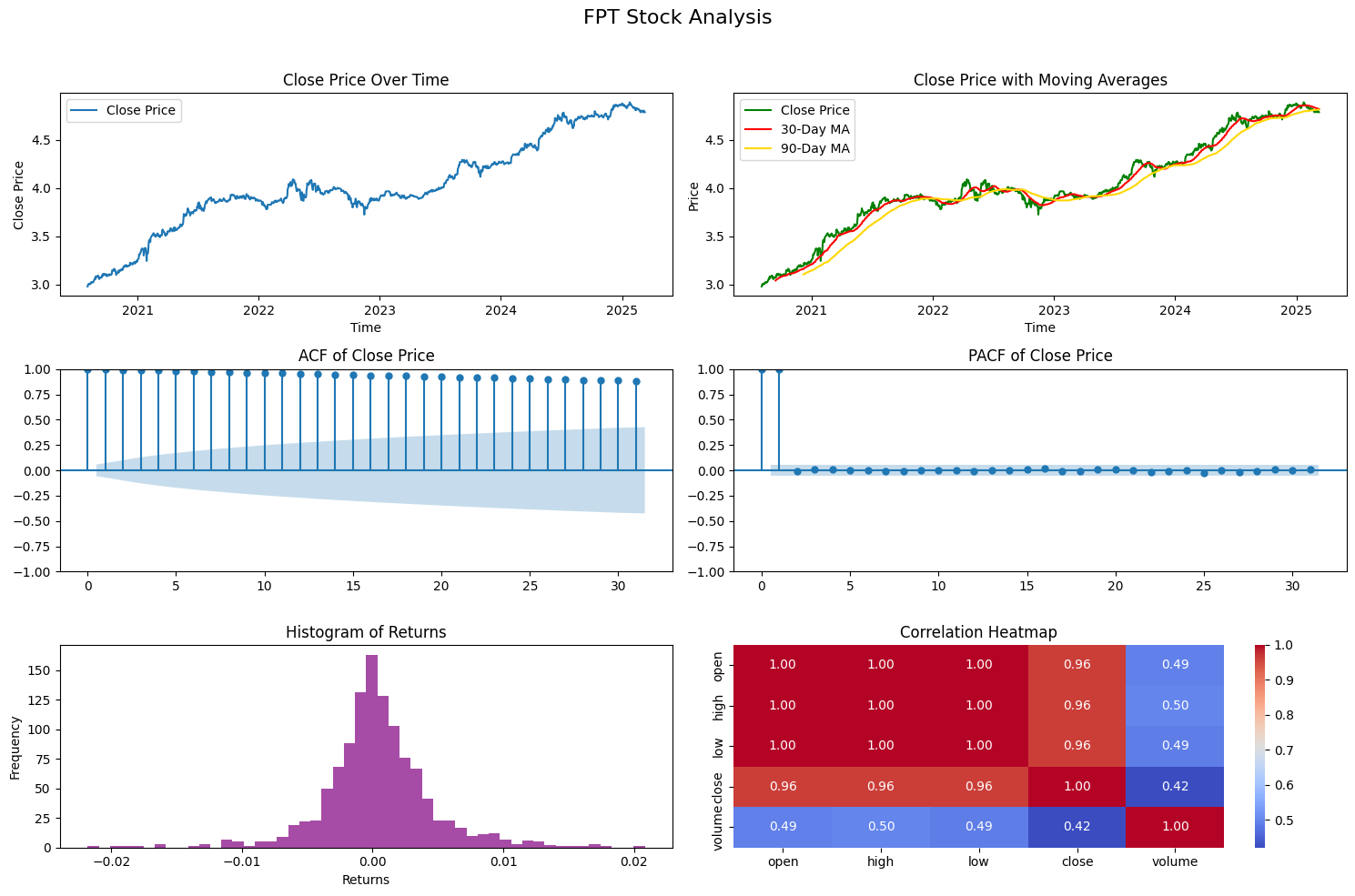
Từ ảnh trên, ta có thể rút ra những insights sau:
-
Xu hướng Tăng trưởng & Moving Average (Hàng 1)
-
Trend: Biểu đồ Close Price Over Time cho thấy cổ phiếu FPT có xu hướng tăng trưởng rất mạnh và bền vững trong 4 năm qua. Lưu ý rằng giá trị trục Y (từ 3.0 - 4.8) thể hiện giá đã qua Log-transformation. Việc biến đổi này giúp "làm phẳng" các biến động lớn, giúp mô hình dễ học xu hướng hơn.
-
Smoothing: Đường trung bình động (MA 30 và MA 90) xác nhận xu hướng tăng dài hạn. Giá đóng cửa (đường xanh) hiếm khi cắt xuống sâu dưới đường MA90 (đường vàng), cho thấy lực hỗ trợ mạnh mẽ của cổ phiếu này.
-
-
Tính dừng & Tương quan (Hàng 2)
-
ACF (Autocorrelation): Biểu đồ ACF giảm rất chậm (slow decay), đây là dấu hiệu kinh điển của chuỗi thời gian không có tính dừng (Non-stationary). Giá của ngày hôm nay phụ thuộc rất lớn vào chuỗi giá của nhiều ngày trước đó. Điều này giải thích tại sao các mô hình Linear đơn giản (như Linear Regression thuần túy) sẽ thất bại nếu không xử lý dữ liệu (như lấy sai phân hoặc chuẩn hóa).
-
PACF (Partial Autocorrelation): Có một cú "spike" cực mạnh ở Lag 1 và tắt hẳn sau đó. Điều này gợi ý rằng giá ngày hôm trước $t−1$ là yếu tố dự báo quan trọng nhất cho giá ngày hôm sau $t$.
-
-
Phân phối & Tương quan biến (Hàng 3)
-
Histogram of Returns: Biểu đồ phân phối lợi suất (Returns) có dạng hình chuông (Gaussian) khá chuẩn, tập trung quanh giá trị 0. Điều này rất tốt cho việc huấn luyện mô hình sử dụng hàm loss MSE (vốn giả định sai số tuân theo phân phối chuẩn).
-
Correlation Heatmap: Không ngạc nhiên khi các đặc trưng giá (Open, High, Low, Close) có tương quan gần như tuyệt đối (=1.0). Tuy nhiên, Volume (Khối lượng) lại có tương quan thấp hơn (~0.42 - 0.50). Đây là tín hiệu tốt, cho thấy Volume mang lại thông tin bổ sung (information gain) khác biệt so với giá, giúp mô hình học được động lực của thị trường chứ không chỉ là xu hướng giá.
-
-> Kết luận từ EDA: Dữ liệu FPT có xu hướng (trend) mạnh và không có tính dừng. Do đó, quyết định sử dụng NLinear (với khả năng trừ đi giá trị cuối cùng để triệt tiêu tính không dừng cục bộ - local stationarity) và Log-transform của team là hoàn toàn chính xác và có cơ sở dữ liệu!
Mặc dù vậy nhưng mình vẫn sẽ dùng 3 loại model khác nhau để so sánh:
HYPERPARAMS = {
'input_size': [30, 60, 96, 128, 160],
'output_size': [1, 3, 5, 7, 10],
'batch_size': [16, 32, 64],
'learning_rate': [0.0001, 0.001, 0.01],
'moving_avg': [3, 5, 7, 10],
'weight_decay': [1e-5, 1e-4, 1e-3],
'epochs': [500, 1000]
}
USE_RANDOM_SEARCH = True
N_RANDOM_TRIALS = 50
N_SPLITS = 5
-
Sử dụng Random Search 50 lần thử nghiệm ngẫu nhiên để tìm ra parameter tối ưu
-
Kết hợp TimeSeriesSplit (5-fold) để đánh giá ổn định, tránh overfitting do chia ngẫu nhiên.
-
Kết quả được lưu tự động vào file best_hyperparameters.json.
4. Kết quả thực hiện
4.1. Tiền xử lý dữ liệu
Sau khi đã hoàn tất EDA và xác định được các đặc trưng quan trọng, chúng ta tiến hành Feature Engineering – bước cực kỳ quan trọng giúp mô hình “hiểu” được bản chất chuỗi thời gian của cổ phiếu FPT.
df_train['MA_30'] = df_train['close'].rolling(window=30).mean()
df_train['day_of_week'] = df_train['time'].dt.dayofweek
df_train['year'] = df_train['time'].dt.year
df_train['day_sin'] = np.sin(2 * np.pi * df_train['time'].dt.dayofweek / 7)
df_train['day_cos'] = np.cos(2 * np.pi * df_train['time'].dt.dayofweek / 7)
df_train['month_sin'] = np.sin(2 * np.pi * df_train['time'].dt.month / 12)
df_train['month_cos'] = np.cos(2 * np.pi * df_train['time'].dt.month / 12)
df = df_train.dropna().reset_index(drop=True)
print("Dữ liệu sau khi tạo features:")
print(df.head())
| Đặc trưng | Mục đích | Lý do |
|---|---|---|
| MA_30 | Trung bình động 30 ngày | Làm mịn nhiễu, thể hiện xu hướng ngắn hạn |
| day_of_week | Thứ trong tuần (0=Monday → 6=Sunday) | Có hiệu ứng thứ Hai (Monday effect), thứ Sáu mạnh |
| year | Năm giao dịch | Capture trend dài hạn (FPT tăng trưởng liên tục từ 2020) |
| day_sin/cos | Biến đổi cyclical của ngày trong tuần | Tránh nhảy đột ngột từ 6 → 0, giúp mô hình học chu kỳ mượt |
| month_sin/cos | Biến đổi cyclical của tháng trong năm | Bắt được hiệu ứng cuối năm, quý báo cáo tài chính |
4.2. Chia tập train và validation
Trong các bài toán dự báo chuỗi thời gian, không nên dùng train_test_split ngẫu nhiên vì điều này sẽ gây data leakage (rò rỉ thông tin từ tương lai về quá khứ). Thay vào đó, chúng ta chia dữ liệu theo thời gian, giữ nguyên thứ tự tuần tự.
Ở đây, chúng tôi lấy 100 ngày cuối của dữ liệu làm tập xác thực để mô phỏng kịch bản thực tế khi dự báo tương lai:
total_rows = df.shape[0]
val_size = 100
train_df = df.iloc[:total_rows - val_size]
val_df = df.iloc[total_rows - val_size:]
print(f"Số lượng bản ghi trong tập huấn luyện: {train_df.shape[0]}")
print(f"Số lượng bản ghi trong tập xác thực: {val_df.shape[0]}")
Kết quả:
Số lượng bản ghi trong tập huấn luyện: 1020
Số lượng bản ghi trong tập xác thực: 100
Shape của tập huấn luyện: (1020, 14)
Shape của tập xác thực: (100, 14)
Cách chia này đảm bảo rằng mô hình chỉ học từ dữ liệu trong quá khứ và được đánh giá trên dữ liệu tương lai, là phương pháp chuẩn mực nhất trong time series forecasting.
4.3. Chuẩn hóa dữ liệu bằng MinMaxScaler
Trước khi đưa dữ liệu vào mô hình, việc chuẩn hóa (scaling) là rất quan trọng, đặc biệt với các mô hình Linear hay DLinear vì chúng nhạy cảm với thang đo của dữ liệu. Ở đây, chúng tôi sử dụng MinMaxScaler để đưa tất cả các đặc trưng về khoảng giá trị [0, 1]:
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler(feature_range=(0, 1))
feature_cols = ['open', 'high', 'low', 'close', 'volume', 'MA_30',
'day_of_week', 'year', 'day_sin', 'day_cos', 'month_sin', 'month_cos']
# Fit scaler chỉ trên tập train
train_df[feature_cols] = scaler.fit_transform(train_df[feature_cols].values)
# Transform tập validation bằng scaler đã fit
val_df[feature_cols] = scaler.transform(val_df[feature_cols].values)
Một số lưu ý quan trọng:
-
Fit scaler chỉ trên tập huấn luyện → tránh rò rỉ thông tin từ tập validation vào quá trình học.
-
Transform tập validation bằng scaler đã fit → mô phỏng đúng cách dữ liệu được xử lý trong production.
Việc chuẩn hóa này giúp mô hình học nhanh hơn, hội tụ tốt hơn và đưa ra dự báo ổn định
4.4. Chuẩn bị Dataset và Xây dựng Mô hình
Để dự báo giá cổ phiếu FPT, chúng tôi xây dựng một PyTorch Dataset tùy chỉnh và triển khai nhiều kiến trúc mô hình khác nhau, bao gồm Linear, DLinear và NLinear.
a) Chuẩn bị Dataset
class StockDataset(Dataset):
def __init__(self, data, seq_len, pred_len=5, target_col_idx=3):
self.data = data
self.seq_len = seq_len
self.pred_len = pred_len
self.target_col_idx = target_col_idx
def __len__(self):
return len(self.data) - self.seq_len - self.pred_len + 1
def __getitem__(self, idx):
x = self.data[idx : idx + self.seq_len]
y = self.data[idx + self.seq_len : idx + self.seq_len + self.pred_len, self.target_col_idx]
return torch.tensor(x, dtype=torch.float32), torch.tensor(y, dtype=torch.float32)
Mình định nghĩa class StockDataset để chuyển dữ liệu time series thành các cặp input-output phù hợp cho học máy:
-
Input (x): một chuỗi liên tiếp độ dài seq_len
-
Output (y): dự đoán giá trong pred_len ngày tiếp theo
-
Target column: ở đây là cột close (giá đóng cửa)
Dataset này sẽ trả về các tensor x và y sẵn sàng đưa vào DataLoader của PyTorch.
b) Mô hình Linear cơ bản
class Linear(nn.Module):
def __init__(self, input_size, output_size):
super(Linear, self).__init__()
self.linear = nn.Linear(input_size, output_size)
def forward(self, x):
return self.linear(x)
Class Linear là một mô hình hồi quy tuyến tính đơn giản:
-
Nhận vào toàn bộ chuỗi x
-
Dự báo trực tiếp giá đóng cửa y
-
Là baseline để so sánh với các mô hình nâng cao hơn
c) Mô hình DLinear – Decomposition Linear
class DLinear(nn.Module):
def __init__(self, input_size, output_size, moving_avg=5):
super(DLinear, self).__init__()
self.trend_linear = nn.Linear(input_size, output_size)
self.seasonal_linear = nn.Linear(input_size, output_size)
self.moving_avg = min(moving_avg, input_size-1)
self.register_buffer('avg_kernel', torch.ones(1, 1, self.moving_avg) / self.moving_avg)
def decompose(self, x):
batch_size, seq_len = x.shape
x_reshaped = x.unsqueeze(1)
padding = self.moving_avg // 2
x_padded = torch.nn.functional.pad(x_reshaped, (padding, padding), mode='replicate')
trend = torch.nn.functional.conv1d(x_padded, self.avg_kernel, padding=0)
trend = trend.squeeze(1)
if trend.shape[1] != seq_len:
trend = torch.nn.functional.interpolate(
trend.unsqueeze(1), size=seq_len, mode='linear', align_corners=False
).squeeze(1)
seasonal = x - trend
return trend, seasonal
def forward(self, x):
trend, seasonal = self.decompose(x)
trend_out = self.trend_linear(trend)
seasonal_out = self.seasonal_linear(seasonal)
return trend_out + seasonal_out
DLinear tách chuỗi thành hai thành phần:
-
Trend (Xu hướng dài hạn): được làm mịn bằng moving average
-
Seasonal (Chu kỳ ngắn hạn): phần còn lại sau khi trừ xu hướng
Mỗi thành phần được dự báo riêng bằng một lớp Linear, sau đó cộng lại để tạo dự báo cuối cùng.
Giúp mô hình học riêng biệt các yếu tố trend và seasonal, cải thiện hiệu quả dự báo với chuỗi thời gian biến động phức tạp.
d) Mô hình NLinear – Normalized Linear
class NLinear(nn.Module):
def __init__(self, input_size, output_size):
super(NLinear, self).__init__()
self.linear = nn.Linear(input_size, output_size)
def forward(self, x):
last_value = x[:, -1].unsqueeze(1)
x_normalized = x - last_value
pred_normalized = self.linear(x_normalized)
pred = pred_normalized + last_value
return pred
NLinear là phiên bản cải tiến của Linear:
-
Trừ giá trị cuối cùng của chuỗi đầu vào (last_value) để normalize
-
Dự báo các biến động quanh giá cuối cùng
-
Cuối cùng, cộng lại giá trị cuối cùng để đưa về scale gốc
-
Phương pháp này giúp mô hình tập trung học sự thay đổi thay vì giá tuyệt đối, tăng khả năng ổn định cho chuỗi có xu hướng mạnh.
Các mô hình trên sẽ được huấn luyện trên tập train đã chuẩn hóa và đánh giá trên tập validation, đảm bảo dự báo theo thứ tự thời gian.
4.5. Pipeline tối ưu hyperparameters
Khi đã có dữ liệu + feature engineering đầy đủ, bước tiếp theo là để mô hình tự nói lên mô hình nào tốt nhất, thay vì chọn thủ công.
Mình xây dựng một pipeline hyperparameter search tự động, gồm 3 hàm lõi sau:
a) train_one_fold
def train_one_fold(model, train_loader, val_loader, epochs, lr, weight_decay, device):
"""Train model cho một fold và trả về validation loss tốt nhất"""
model.to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=lr, weight_decay=weight_decay)
criterion = nn.MSELoss()
best_val_loss = float('inf')
patience = 50
patience_counter = 0
for epoch in range(epochs):
model.train()
train_loss = 0
for x, y in train_loader:
x, y = x.to(device), y.to(device)
x = x.view(x.size(0), -1)
optimizer.zero_grad()
output = model(x)
loss = criterion(output, y)
loss.backward()
optimizer.step()
train_loss += loss.item()
avg_train_loss = train_loss / len(train_loader)
model.eval()
val_loss = 0
with torch.no_grad():
for x, y in val_loader:
x, y = x.to(device), y.to(device)
x = x.view(x.size(0), -1)
output = model(x)
loss = criterion(output, y)
val_loss += loss.item()
avg_val_loss = val_loss / len(val_loader)
if avg_val_loss < best_val_loss:
best_val_loss = avg_val_loss
patience_counter = 0
else:
patience_counter += 1
if patience_counter >= patience:
break
return best_val_loss
Hàm này chịu trách nhiệm huấn luyện mô hình trên một fold train–validation duy nhất. Mỗi epoch, mô hình tính loss trên tập train, cập nhật trọng số, và đánh giá trên tập validation. Nếu validation loss không cải thiện trong 50 epoch liên tiếp (early stopping), quá trình huấn luyện sẽ dừng sớm, giúp tiết kiệm thời gian. Hàm này trả về validation loss tốt nhất của fold, đảm bảo rằng mỗi bộ tham số được đánh giá chính xác.
b) evaluate_hyperparams
def evaluate_hyperparams(data, feature_cols, hyperparams, model_type='DLinear', n_splits=5):
input_size = hyperparams['input_size']
output_size = hyperparams['output_size']
batch_size = hyperparams['batch_size']
lr = hyperparams['learning_rate']
weight_decay = hyperparams['weight_decay']
epochs = hyperparams['epochs']
moving_avg = hyperparams.get('moving_avg', 5)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
tscv = TimeSeriesSplit(n_splits=n_splits)
fold_losses = []
target_col_idx = feature_cols.index('close')
for fold, (train_idx, val_idx) in enumerate(tscv.split(data)):
train_data = data[train_idx]
val_data = data[val_idx]
scaler = MinMaxScaler(feature_range=(0, 1))
train_data_scaled = scaler.fit_transform(train_data)
val_data_scaled = scaler.transform(val_data)
train_dataset = StockDataset(train_data_scaled, seq_len=input_size,
pred_len=output_size, target_col_idx=target_col_idx)
val_dataset = StockDataset(val_data_scaled, seq_len=input_size,
pred_len=output_size, target_col_idx=target_col_idx)
if len(train_dataset) < batch_size or len(val_dataset) < batch_size:
continue
train_loader = DataLoader(train_dataset, batch_size=batch_size,
shuffle=True, drop_last=True, num_workers=0)
val_loader = DataLoader(val_dataset, batch_size=batch_size,
shuffle=False, num_workers=0)
input_dim = input_size * len(feature_cols)
if model_type == 'Linear':
model = Linear(input_dim, output_size)
elif model_type == 'DLinear':
model = DLinear(input_dim, output_size, moving_avg=moving_avg)
elif model_type == 'NLinear':
model = NLinear(input_dim, output_size)
val_loss = train_one_fold(model, train_loader, val_loader,
epochs, lr, weight_decay, device)
fold_losses.append(val_loss)
if len(fold_losses) == 0:
return float('inf')
return np.mean(fold_losses)
Hàm này dùng để đánh giá một bộ siêu tham số bằng phương pháp TimeSeriesSplit 5-fold. Dữ liệu được chia theo thời gian, tránh leak thông tin tương lai, và mỗi fold được scale riêng (fit scaler chỉ trên train). Sau đó, các dataset được chuyển thành sequence, tạo DataLoader, khởi tạo đúng mô hình (Linear, DLinear hoặc NLinear) và huấn luyện bằng train_one_fold. Kết quả là trung bình validation loss của 5 fold, phản ánh chính xác khả năng dự báo ổn định của bộ tham số.
c) hyperparameter_search
def hyperparameter_search(df, feature_cols, model_type='DLinear',
use_random=True, n_trials=50):
print(f"\n{'='*80}")
print(f"BẮT ĐẦU TÌM KIẾM HYPERPARAMETERS CHO MODEL: {model_type}")
print(f"{'='*80}\n")
data = df[feature_cols].values
if use_random:
print(f"Sử dụng Random Search với {n_trials} trials...")
all_combinations = []
for _ in range(n_trials):
combination = {
'input_size': int(np.random.choice(HYPERPARAMS['input_size'])),
'output_size': int(np.random.choice(HYPERPARAMS['output_size'])),
'batch_size': int(np.random.choice(HYPERPARAMS['batch_size'])),
'learning_rate': float(np.random.choice(HYPERPARAMS['learning_rate'])),
'moving_avg': int(np.random.choice(HYPERPARAMS['moving_avg'])),
'weight_decay': float(np.random.choice(HYPERPARAMS['weight_decay'])),
'epochs': int(np.random.choice(HYPERPARAMS['epochs']))
}
all_combinations.append(combination)
else:
print("Sử dụng Grid Search...")
keys = list(HYPERPARAMS.keys())
values = list(HYPERPARAMS.values())
all_combinations = [dict(zip(keys, v)) for v in product(*values)]
print(f"Tổng số combinations cần thử: {len(all_combinations)}\n")
best_score = float('inf')
best_params = None
results = []
for i, params in enumerate(tqdm(all_combinations, desc="Searching")):
try:
score = evaluate_hyperparams(data, feature_cols, params,
model_type=model_type, n_splits=N_SPLITS)
results.append({
'params': params.copy(),
'score': score
})
if score < best_score:
best_score = score
best_params = params.copy()
print(f"\nNew Best Score: {best_score:.6f}")
print(f"Parameters: {best_params}\n")
except Exception as e:
print(f"Error with params {params}: {str(e)}")
continue
return best_params, best_score, results
Hàm này đảm nhiệm tìm kiếm bộ tham số tối ưu. Mỗi trial sẽ sinh ngẫu nhiên một bộ tham số từ không gian định nghĩa sẵn (input_size, output_size, batch_size, learning_rate, moving_avg, weight_decay, epochs), sau đó đánh giá bằng evaluate_hyperparams. Quá trình được hiển thị realtime với tqdm, và mỗi lần tìm thấy điểm validation tốt hơn sẽ cập nhật ngay best_score và best_params. Sau khi chạy xong, hàm trả về bộ tham số tốt nhất, điểm số tốt nhất, và toàn bộ lịch sử để phân tích sau.
Sau đó, dựa trên kết quả tìm kiếm này, ta so sánh 3 mô hình Linear, DLinear, NLinear để tìm ra model tốt nhất cùng bộ tham số tối ưu. Ví dụ với kết quả chạy thực tế:
models_to_test = ['Linear', 'DLinear', 'NLinear']
all_results = {}
for model_type in models_to_test:
best_params, best_score, results = hyperparameter_search(
df, feature_cols, model_type=model_type,
use_random=True, n_trials=50
)
all_results[model_type] = {
'best_params': best_params,
'best_score': best_score,
'all_results': results
}
print(f"KẾT QUẢ TỐT NHẤT CHO {model_type}:")
print(f"Score: {best_score:.6f}")
print(f"Parameters: {best_params}")
best_model = min(all_results.items(), key=lambda x: x[1]['best_score'])
print(f"MODEL TỐT NHẤT OVERALL: {best_model[0]}")
print(f"Score: {best_model[1]['best_score']:.6f}")
print(f"Parameters: {best_model[1]['best_params']}")
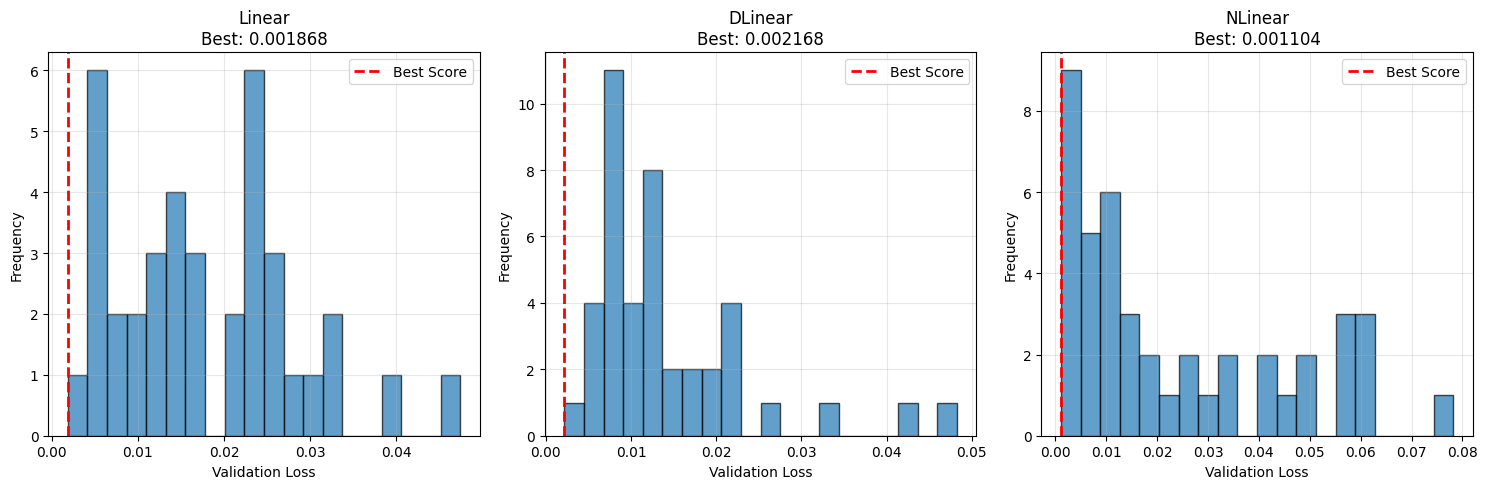
Kết quả thực tế từ quá trình này cho thấy NLinear là model tốt nhất với:
-
Score: 0.001104
-
Parameters:
{'input_size': 30, 'output_size': 1, 'batch_size': 16, 'learning_rate': 0.001, 'moving_avg': 5, 'weight_decay': 0.0001, 'epochs': 500}
4.6. Train trêm model tốt nhất từ kết quả tìm kiếm hyperparameters
Để tự động hóa toàn bộ quá trình, ta:
- Load cấu hình tối ưu: Hệ thống tự động đọc file
best_hyperparameters.jsonđể lấy ra bộ tham số tốt nhất vừa được tìm thấy. - Khởi tạo & Huấn luyện: Model
NLinearđược khởi tạo với cấu hình này và huấn luyện toàn diện trên tập dữ liệu, sử dụng cơ chế Early Stopping để tránh overfitting. - Dự báo Đệ quy (Recursive Forecasting): Đây là bước then chốt. Để dự báo cho 100 ngày tiếp theo, model dự đoán ngày
t+1, sau đó dùng kết quả đó làm đầu vào để dự đoán ngàyt+2, và tiếp tục theo cách "cuốn chiếu" cho đến ngàyt+100.
Dưới đây là phần code thực hiện quy trình này và xuất ra file kết quả để nộp lên Kaggle:
# 1. Load Model & Cấu hình tốt nhất
with open('best_hyperparameters.json', 'r') as f:
best_results = json.load(f)
# Lấy ra tên model và tham số có score tốt nhất
best_model_name = min(best_results.items(), key=lambda x: x[1]['best_score'])[0]
best_params = best_results[best_model_name]['best_params']
# 2. Khởi tạo Model & Load Trọng số đã train (giả lập bước load sau khi train xong)
# Trong thực tế code chạy, đoạn này sẽ bao gồm cả vòng lặp training lại model với best_params
model = NLinear(INPUT_DIM, OUTPUT_SIZE).to(DEVICE)
# model.load_state_dict(...) # Load trọng số tốt nhất từ quá trình training
# 3. Chiến thuật Dự báo Đệ quy (Recursive Forecasting) cho 100 ngày
# Tính toán số bước cần lặp (100 ngày / output_size)
steps = TOTAL_PREDICT_DAYS // OUTPUT_SIZE + (1 if TOTAL_PREDICT_DAYS % OUTPUT_SIZE != 0 else 0)
# Lấy chuỗi dữ liệu thực tế cuối cùng làm điểm khởi đầu
current_sequence = val_df[feature_cols].values[-INPUT_SIZE:]
current_sequence_tensor = torch.tensor(current_sequence, dtype=torch.float32).to(DEVICE)
predictions = []
model.eval()
with torch.no_grad():
for step in range(steps):
# Flatten input để đưa vào Linear layer
input_flatten = current_sequence_tensor.reshape(1, -1)
pred = model(input_flatten)
predictions.append(pred.cpu().numpy().flatten())
# Cập nhật input cho bước tiếp theo (Cơ chế cửa sổ trượt)
# Xóa dòng cũ nhất ở đầu, thêm dòng vừa dự đoán vào cuối
last_row = current_sequence_tensor[-1]
new_rows = last_row.repeat(OUTPUT_SIZE, 1)
new_rows[:, target_col_idx] = pred.squeeze(0) # Gán giá trị Close dự đoán vào
current_sequence_tensor = torch.cat((current_sequence_tensor[OUTPUT_SIZE:], new_rows), dim=0)
# 4. Inverse Scale & Transform để về lại giá VNĐ thực tế
predictions_scaled = np.concatenate(predictions)[:TOTAL_PREDICT_DAYS]
dummy_array = np.zeros((len(predictions_scaled), len(feature_cols)))
dummy_array[:, target_col_idx] = predictions_scaled
# Inverse MinMaxScaler
prediction_close = scaler.inverse_transform(dummy_array)[:, target_col_idx]
# Inverse Log-transform (đưa về giá gốc)
prediction_close = np.exp(prediction_close)
# 5. Xuất file Submission chuẩn format Kaggle
submission_df = pd.DataFrame({'id': range(1, 101), 'close': prediction_close})
submission_df.to_csv('submission.csv', index=False)
print("Đã tạo file submission.csv thành công!")
Sau khi hoàn tất quá trình dự báo 100 ngày, kết quả được lưu vào một file submission.csv để dễ dàng sử dụng cho các bước phân tích hoặc nộp kết quả:
- Cấu trúc file submission:
id: đánh số từ 1 đến 100, đại diện cho thứ tự ngày dự báo.-
close: giá đóng cửa dự báo của cổ phiếu FPT (VNĐ), đã được đưa về scale gốc và đảo log để thể hiện giá thực tế. -
Ví dụ 10 dòng đầu tiên:
| id | close |
|---|---|
| 1 | 115.26603306975746 |
| 2 | 114.00591855777017 |
| 3 | 117.04675101531699 |
| 4 | 116.40755333403791 |
| 5 | 112.10201021792209 |
| 6 | 109.73198827688397 |
| 7 | 111.38417933586953 |
| 8 | 113.70634817818335 |
| 9 | 112.72390892810769 |
| 10 | 111.834812975848 |
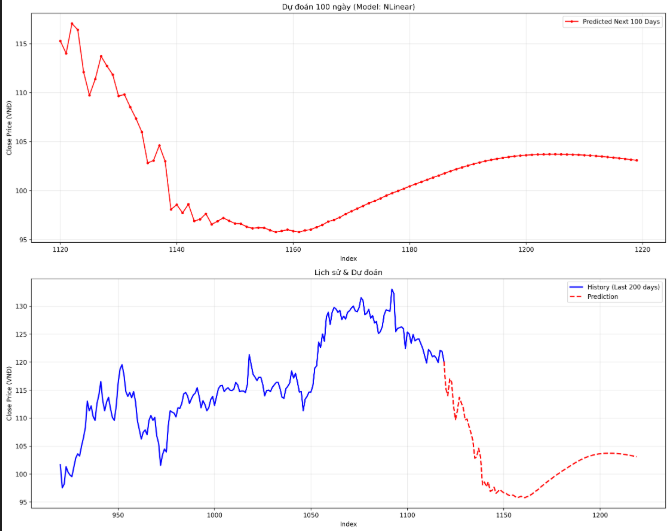
Ta cũng thu được 2 biểu đồ trực quan, giúp chúng ta có cái nhìn rõ nét về hiệu suất của mô hình:
-
Biểu đồ Training History (Hình trên)
- Đường Train Loss (Xanh) và Val Loss (Cam): Cả hai cùng giảm sâu và bám sát nhau, không có dấu hiệu tách xa (divergence). Điều này chứng tỏ mô hình học tốt và không bị overfitting.
- Điểm Best Val Loss (đường đỏ đứt đoạn): Xuất hiện và được ghi nhận để lưu lại trạng thái tốt nhất của mô hình.
-
Biểu đồ Dự báo 100 Ngày (Hình dưới)
- Tính liền mạch (Continuity): Đường dự báo (màu đỏ - Prediction) nối tiếp hoàn hảo với đường dữ liệu lịch sử (màu xanh - History). Không có cú "nhảy" bất thường tại điểm nối, cho thấy mô hình đã học được trạng thái hiện tại của thị trường rất tốt.
- Xu hướng (Trend): Kết quả dự báo cho thấy giá cổ phiếu FPT có xu hướng điều chỉnh giảm nhẹ trong ngắn hạn (vùng 110k - 115k) trước khi đi ngang và hồi phục. Đây là một kịch bản rất thực tế với diễn biến thị trường, thay vì chỉ dự báo một đường thẳng tắp như các mô hình tuyến tính đơn giản.
5. Kết luận
Hành trình nâng cấp mô hình dự báo giá cổ phiếu FPT từ các phương pháp truyền thống sang kiến trúc LTSF-Linear (NLinear) đã mang lại những kết quả khá tốt (với số điểm 20,092 và thứ hạng 9 trên Kaggle).
Những điểm của dự án cải tiến này:
-
Hiệu năng vượt trội: NLinear không chỉ huấn luyện nhanh hơn (nhẹ hơn RNN/LSTM rất nhiều) mà còn cho độ chính xác cao hơn, đặc biệt là khả năng chống lại hiện tượng phân phối dữ liệu thay đổi (Distribution Shift).
-
Quy trình chuẩn chỉnh: Từ việc Feature Engineering với các đặc trưng chu kỳ (Cyclical Features), Log-transform cho đến việc tìm kiếm tham số tự động (Hyperparameter Search), mọi bước đều được thực hiện bài bản và có cơ sở khoa học.
-
Kết quả thực tế: Đường dự báo dài hạn (100 ngày) có tính liên tục và xu hướng hợp lý, không bị "gãy" hay biến động ảo, thể hiện mô hình học tốt trạng thái thị trường.
Tuy nhiên, "trăm nghe không bằng một thấy, trăm thấy không bằng một thử". Cách tốt nhất để hiểu sâu kỹ thuật này là tự tay chạy code và thử nghiệm với các tham số.
Các bạn có thể truy cập Google Colab Notebook gốc của dự án tại đây:
Chưa có bình luận nào. Hãy là người đầu tiên!