
Phần 1: Từ RNN/LSTM đến Transformer
1. Bài toán cốt lõi: “mã hoá chuỗi”
Trong text classification, thứ ta cần không chỉ là “mỗi từ là một vector”, mà là:
- Mỗi token sau khi mã hoá phải mang ngữ cảnh (contextualized)
- Ta cần một vector đại diện toàn câu để đưa vào classifier
$$X = (x_1, x_2, ..., x_L) \to H = (h_1, h_2, ..., h_L)$$
trong đó $h_i$ không còn là embedding tĩnh mà đã chứa thông tin liên quan đến các token khác trong câu.
2. RNN: cách tiếp cận tuần tự và trực giác “đọc từng chữ”
2.1. RNN làm gì?
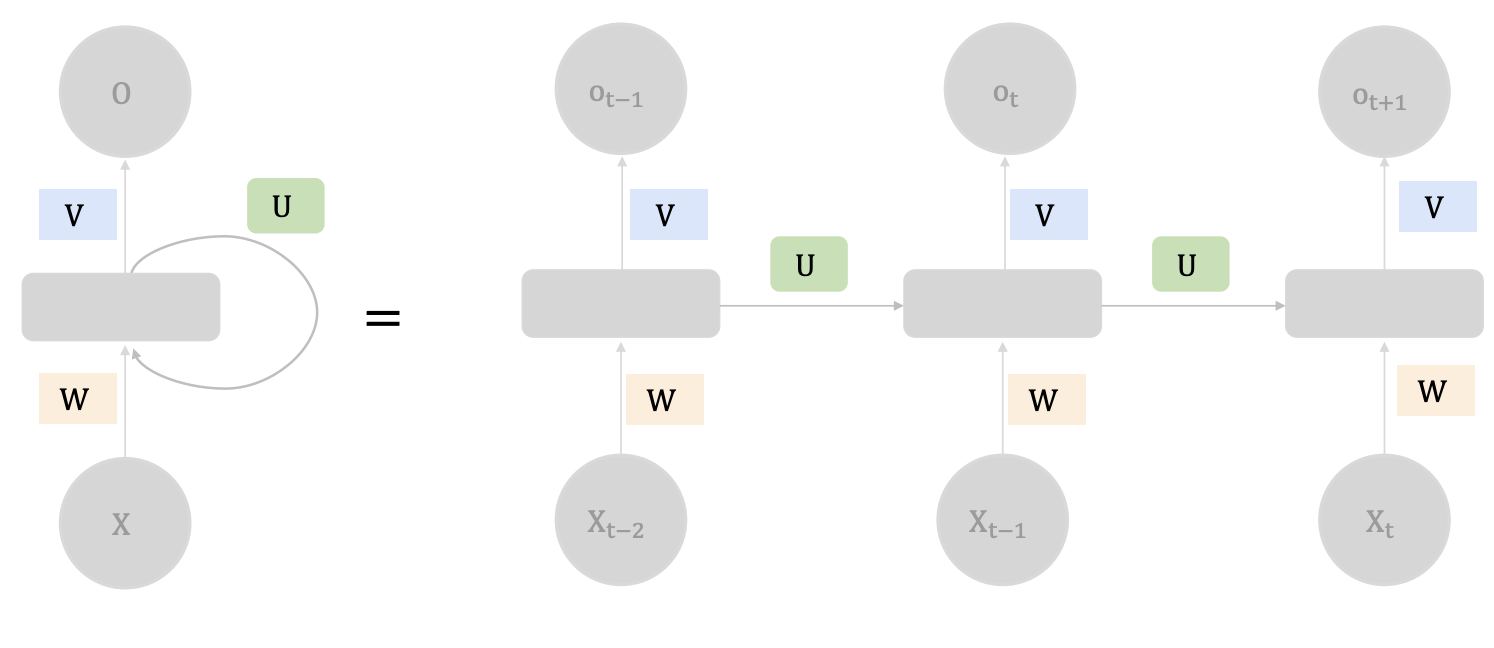
Hình 1: Cấu trúc của RNN (Nguồn: AI Vietnam)
RNN là mô hình hoá chuỗi bằng cách cập nhật hidden state theo thời gian
$$h_t = f(W_xx_t + W_hh_{t-1} + b)$$
- $x_t$: embedding tại thời điểm t
- $h_{t-1}$: ký ức từ các bước trước
- $h_t$: trạng thái mới sau khi đọc token t
Trực giác: RNN giống như khi chúng ta đọc văn bản từ trái sang phải, mỗi lần thêm một từ thì cập nhật hiểu biết dần một câu, từ kế tiếp được dự đoán dựa vào các từ gần trước đó.
2.2. Vì sao RNN từng là lựa chọn mặc định cho MLP?
Vì nó có hai điểm phù hợp với dữ liệu ngôn ngữ:
- Tự nhiên có thứ tự (order-aware) do cập nhật theo thời gian.
- Xử lý được chuỗi dài ngắn khác nhau mà không cần cố định L ngay từ đầu, có thể thêm từ vào bất cứ lúc nào.
3. Nhưng RNN/LSTM/GRU “đụng trần” ở đâu?
3.1. Nút thắt 1: Tính toán tuần tự, khó song song hoá
RNN bắt buộc tính $h_t$ xong mới tính được $h_{t+1}$. Nghĩa là:
- Với sequence length L, ta có L bước phụ thuộc nối tiếp.
- GPU mạnh ở song song, nhưng RNN buộc phải xếp hàng.
=> Khi dữ liệu lớn (nhiều câu, câu dài), chi phí thời gian huấn luyện tăng vì không tận dùng được parallelism tốt.
3.2. Nút thắt 2: Long-range dependencies và đường truyền gradient quá dài
Muốn token ở cuối câu "biết" token ở đầu câu, thông tin phải đi qua chuỗi cập nhật:
$$x_1 \to h_1 \to h_2 \to ... \to h_L$$
- $x_1$: input tại thời điểm $t$
- $h_t$: hidden state của RNN tại thời điểm $t$
Khoảng cách hiệu dụng giữa hai token xa nhau là O(L) bước. Đây là nguyên nhân sâu xa khiến RNN khó nắm bắt mối quan hệ dài hạn, tín hiệu mờ dần, gradient dễ bị vanishing/exploding.
3.3. Nút thắt 3: “Information bottleneck” trong một vector trạng thái
RNN cố gắng nén toàn bộ quá khứ vào $h_t$. Khi câu phức tạp hoặc dài thì:
- $h_t$ phải vừa nhớ thực thể, vừa nhớ ngữ pháp, vừa nhớ sentiment cue.
- Việc nhét quá nhiều vào một vector cố định trở thành bottleneck.
4. LSTM/GRU: cải tiến rất tốt, nhưng vẫn chưa giải quyết triệt để
4.1. LSTM/GRU khắc phục gì?
LSTM đưa vào cơ chế cổng (gating) và cell state $c_t$ để giữ thông tin dài hạn tốt hơn. LSTM tạo đường đi dễ thở hơn cho gradient, cho phép mô hình chọn cái gì cần nhớ, cái gì để quên. Điều này giúp RNN tiến bộ rõ rệt trên nhiều bài toán.
4.2. Nhưng LSTM vẫn bị giới hạn gì?
- Vẫn tuần tự, khó song song hoá.
- Khoảng cách giữa token xa vẫn dài, dù nhớ tốt hơn nhưng vẫn phải truyền qua nhiều bước
- Trong thực tế, khi scale lên dữ liệu lớn, mô hình encoder kiểu attention thường vượt trội hơn.
=> Thay vì truyền tin qua thời gian, chúng ta nối trực tiếp mọi token với nhau
5. Tiêu chí của một encoder tốt hơn: “mỗi token nhìn được toàn bộ chuỗi”
Desire property cho encoder: Biểu diễn mới của token $i$ nên được tạo bằng cách trộn thông tin từ mọi token $j$, với trọng số phản ảnh mức độ liên quan theo ngữ cảnh.
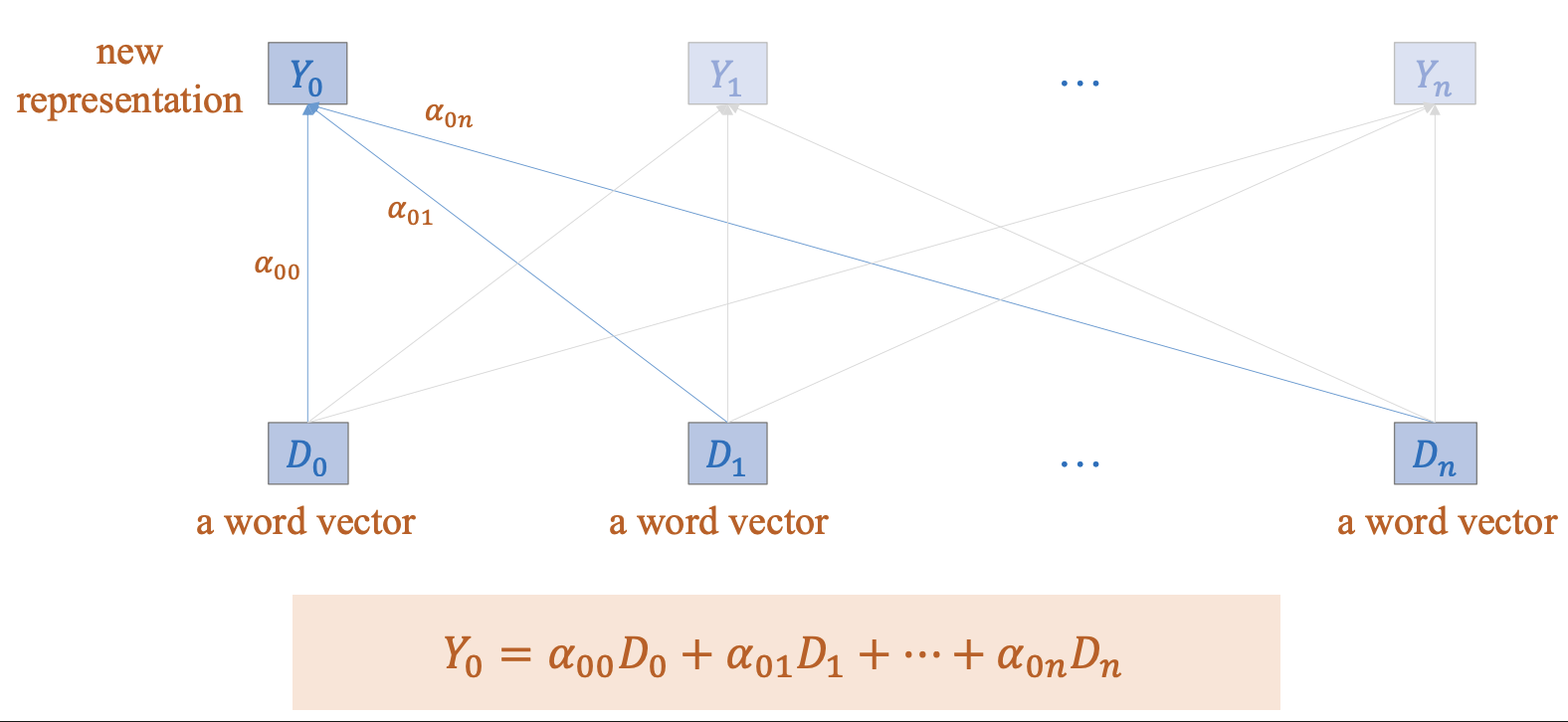
Hình 2: Biểu diễn mới của encoder (Nguồn: AI Vietnam)
Công thức:
$$y_i = \sum_{j=1}^{L}\alpha_{ij}D_j,\ \sum_{j=1}^{L}\alpha_{ij} = 1$$
- $i$: chỉ số của token đang được cập nhật
- $j$: chỉ số của token được tham chiếu
- $\alpha_{ij}$: trọng số chú ý (attention weight)
- $L$: độ dài chuỗi (sequence length)
- $D_j$: biểu diễn gốc (input representation) của token
- $y_j$: biểu diễn mới (contextualized representation) của token $j$
- Mỗi hàng của ma trận $\alpha$ là một phân phối (softmax).
Keynote: token $i$ có thể lấy thông tin từ token $j$ trong một bước, không cần truyền qua chuỗi dài như RNN. Đây chính là nhảy vọt về long-range dependencies.
6. Attention → Self-Attention: từ “chọn cái cần nhìn” đến “tự nhìn trong cùng một câu”
6.1. Attention cơ bản làm gì?
Chúng ta xây dựng ma trận trọng số $A = [\alpha_{ij}] \in R^{L\times L}$, sau đó:
$$Y = AX$$
Trong đó:
- $X \in R^{L\times d}$: embedding/hidden state
- $Y \in R^{L\times d}$: biểu diễn đã trộn ngữ cảnh
6.2. “Nút thắt mới” của attention: chi phí $O(L^2)$
- Điểm “hay” nhất của self-attention là token ở cuối câu có thể nhìn token ở đầu câu chỉ trong một bước, không cần truyền qua chuỗi dài như RNN. Nhưng cái giá phải trả cũng rất rõ: để token nào cũng “nhìn” được token nào, ta phải tính một ma trận chú ý kích thước $L \times L$
- Nói cách khác, nếu câu dài gấp đôi thì số cặp tương tác không tăng gấp đôi mà tăng gần gấp bốn. Về mặt tính toán và bộ nhớ, self-attention có độ phức tạp xấp xỉ $O(L^2)$ theo độ dài chuỗi.
- Vì vậy, Transformer vượt trội khi cần nắm quan hệ xa và tận dụng song song hoá, nhưng khi bước sang các bài toán văn bản rất dài (long document), người ta thường phải dùng thêm các biến thể “efficient attention” hoặc chiến lược cắt–ghép ngữ cảnh để giảm chi phí.
6.3. Vấn đề "chưa có gì được học"
Nếu chúng ta tính tương đồng trực tiếp từ $D$ thì cơ thế attention bị dính chặt vào embedding hiện tại, không thể thay đổi được trong quá trình học.
=> Ta đưa các ma trận chiếu $W_Q, W_K, W_V$ để mô hình tự học cách so khớp và trộn thông tin thay vì phụ thuộc cứng vào embedding thô.
7. Q–K–V và scaled dot-product attention
Chúng ta muốn token “it” trong câu “The pizza came out… and it tasted good” nhìn về “pizza”.
Nếu dùng $XX^T$ trực tiếp, “thước đo tương đồng” bị khóa vào không gian embedding hiện tại, lúc này sẽ khó linh hoạt cho việc trainning mô hình.
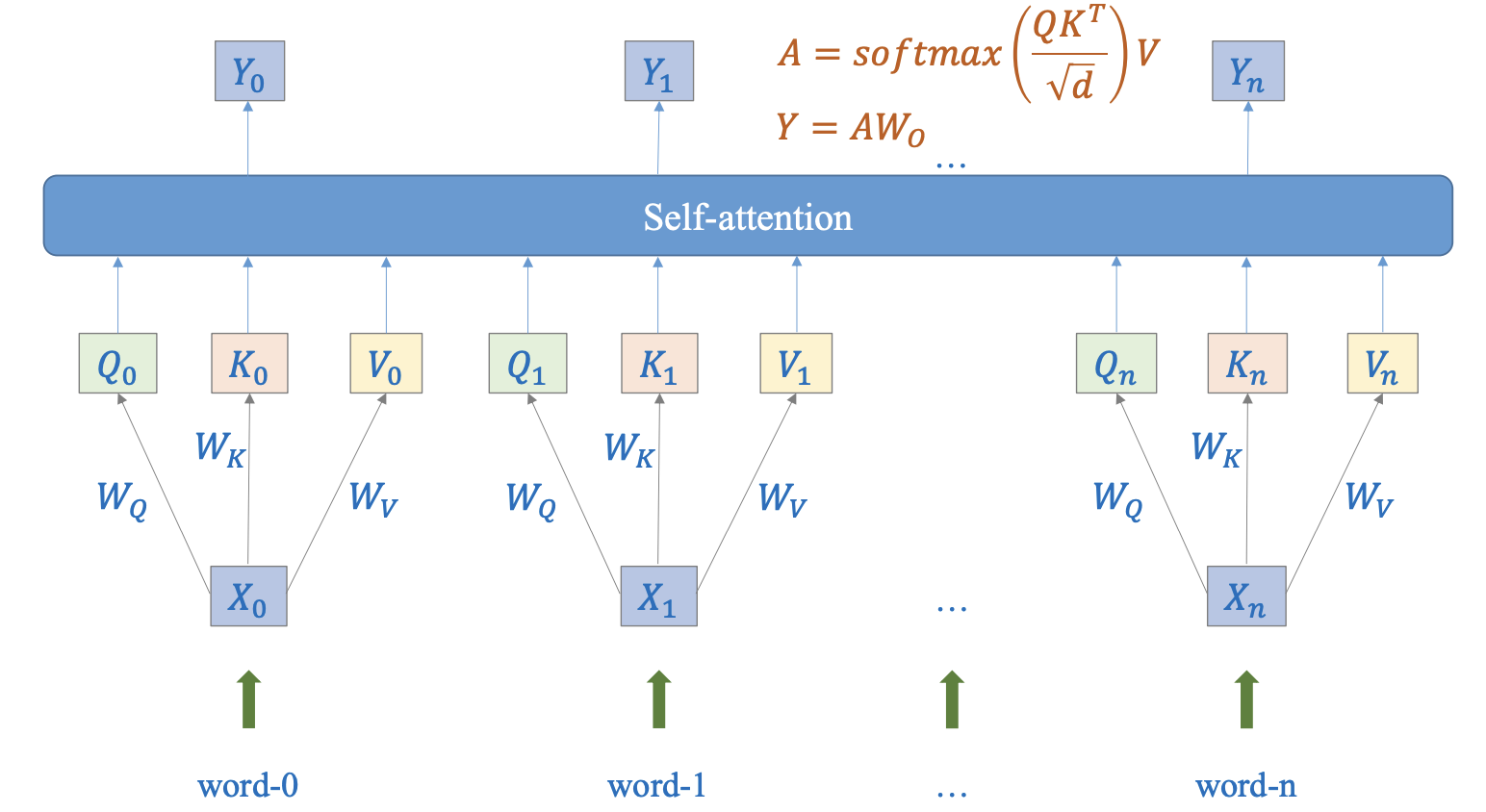
Hình 3: Ma trận tham chiếu Q-K-V (Nguồn: AI Vietnam)
Transformer giải bằng cách cho mô hình tự học ba phép nhìn:
Với ma trận input của encoder $X \in R^{L\times d}$:
$$Q = XW_Q, \ K=XW_K, \ V = XW_V$$
$$Attn(Q,K,V) = softmax(\frac{QK^T}{\sqrt{d_k}})V$$
- $L$: độ dài chuỗi (sequence length)
- $d$: embedding dimension
- $Q$: Query matrix
- $K$: Key matrix
- $V$: Value matrix
- $W_Q, W_K, W_V$: ma trận trọng số học được (learnable parameters)
- $\sqrt{d_k}$: hệ số chuẩn hoá (scaling factor)
Có thể hiểu như sau:
- Q(Query): "tôi đang cần gì?"
- K(Key): “tôi có gì để người khác match?”
- V(Value): “thông tin thật sự của tôi là gì?”
Nói đơn giản: $Q/K$ là “kính lọc” để so khớp, $V$ là “thông tin đưa đi”
Vì sao chia $\sqrt{d_k}$?
Để logits không quá lớn khi $d_k$ tăng -> softmax không bão hoà -> gradient ổn định
8. Multi-head attention: vì sao cần nhiều “góc nhìn”
Một head attention giống như một cách đo liên hệ. Nhưng ngôn ngữ phức tạp: cùng lúc có cú pháp, đồng tham chiếu, sentiment cues, thực thể…
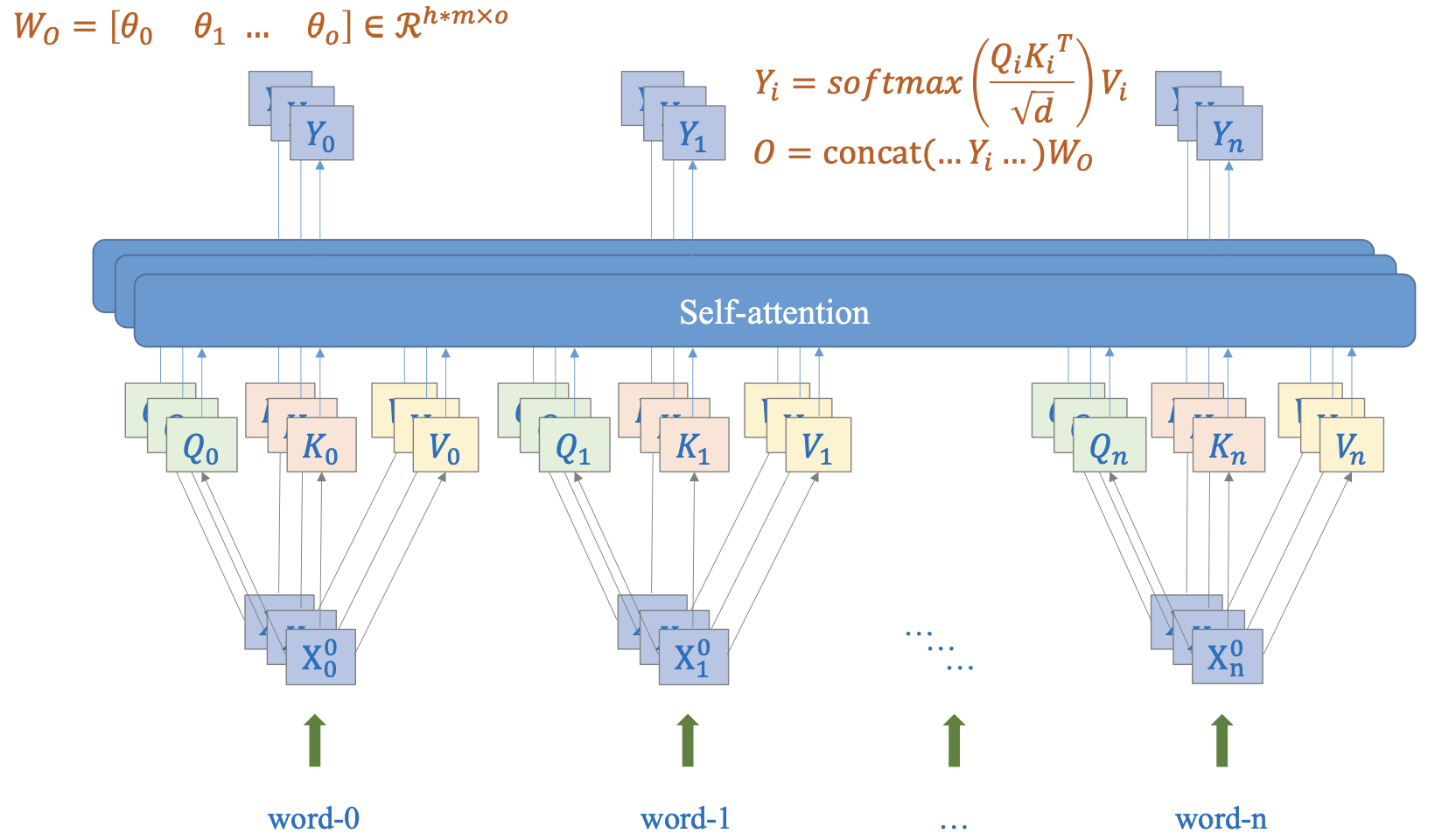
Hình 4: Minh hoạ Multi-head attention (Nguồn: AI Vietnam)
Multi-head làm điều rất thực dụng:
- Chia không gian biểu diễn thành nhiều nhánh nhỏ (heads)
- Mỗi head có không gian con kích thước $d_k = d_{model}/h$, giúp mô hình học nhiều kiểu quan hệ song song thay vì ép một ma trận attention phải gánh hết.
- Ghép (concat) lại và chiếu về $d_{model}$
Tưởng tượng cho mô hình nhiều “cặp mắt” nhìn quan hệ theo các tiêu chí khác nhau, rồi tổng hợp lại.
9. Positional encoding
Transformer bỏ recurrence → mất “thứ tự tự nhiên” vốn có của RNN.
Nếu chúng ta chỉ dùng attention, mô hình có thể xem token như một tập hợp (set) thay vì chuỗi (sequence). Vì vậy phải bơm thông tin vị trí:
$$\tilde{X} = X + PE$$
Trong đó:
- $\tilde{X}$: embedding đầu vào thực sự của Transformer
- $X∈R^{L×d}$: ma trận embedding đầu vào
- $PE∈R^{L×d}$: ma trận positional encoding
Sinusoidal positional encoding
Trong Transformer gốc (Vaswani et al., 2017), một lựa chọn kinh điển là sinusoidal positional encoding: mỗi vị trí được mã hoá bằng các cặp $sin/cos$ ở nhiều tần số khác nhau (multi-frequency). Công thức:
$$PE(pos, 2i) = sin(\frac{pos}{10000^{\frac{2i}{d}}})$$ $$PE(pos, 2i+1) = cos(\frac{pos}{10000^{\frac{2i}{d}}})$$
Trong đó:
- $pos$: vị trí của token trong chuỗi
- $i$: chỉ số chiều (dimension index)
- $d$: embedding dimension của mô hình
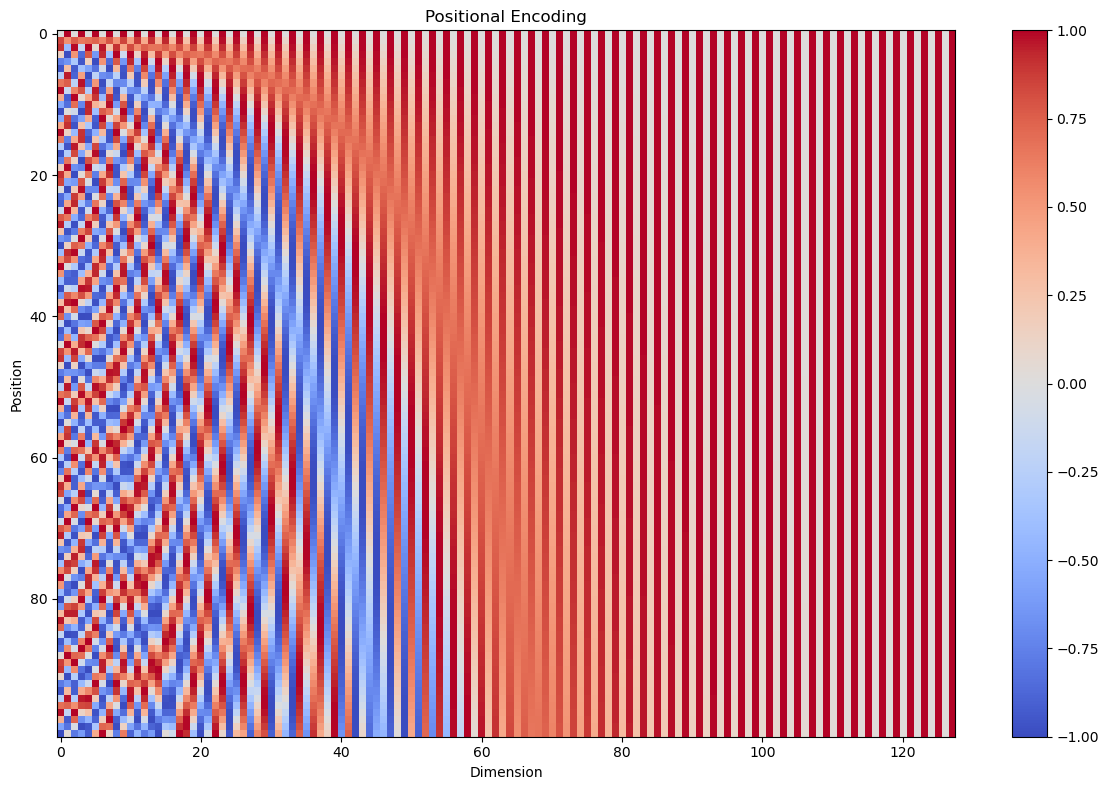
Hình 5: Sinusoidal positional encoding (Nguồn: Vaswani et al., 2017)
Trực giác đa tần số
- Mỗi cặp chiều $(2i, 2i+1)$ tạo thành một vector 2D $[sin(\theta), cos(\theta)]$, giống như một điểm trên đường tròn đơn vị.
- Khi $i$ tăng, số mẫu $10000^{\frac{2i}{d}}$ tăng theo cấp số nhân -> góc $\theta$ thay đổi chậm hơn, tương ứng bước sóng dài hơn.
- Vì vậy, PE kết hợp: tần số cao để phân biệt tốt các vị trí gần nhau, tần số thấp để giữ cấu trúc cho khoảng cách xa.
Keynote: PE dạng $sin/cos$ có tính chu kỳ ở từng chiều (mỗi sóng tự nó tuần hoàn), nhưng vì dùng nhiều tần số không đồng bộ nên toàn bộ vector PE gần như không “lặp lại” trong phạm vi độ dài ngữ cảnh thường dùng.
Ngoài Sinusoidal positional encoding, còn các phương pháp khác được ứng dụng như:
- Learnable positional embedding (học được vector vị trí)
- Các kiểu “relative position”, nhiều model hiện đại dùng biến thể này.
10. Transformer encoder block: “cục gạch” lặp đi lặp lại
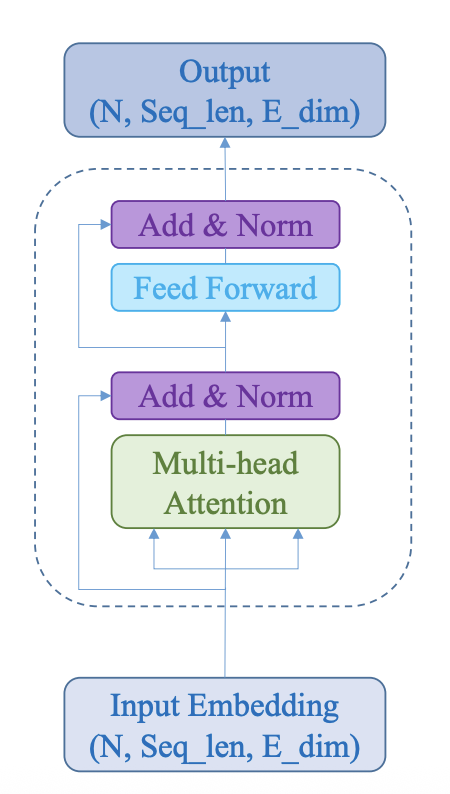
Hình 6: Minh hoạ Transformer Block (Nguồn: AI Vietnam)
Một encoder block gồm hai phần chính:
- Self-attention: trộn ngữ cảnh
- FFN: biến đổi phi tuyến theo từng token để tăng năng lực biểu diễn. Công thức:
$$FFN(x) = W_2 \sigma (W_1x + b_1) + b_2$$
Trong đó:
- $FFN$: Feed-Forward Network
- $x$: biểu diễn đầu vào của một token
- $W_1, W_2$: ma trận trọng số của lớp tuyến tính thứ nhất, thứ hai
- $b_1, b_2$: vector bias của lớp tuyến tính thứ nhất
- $\sigma$: hàm kích hoạt phi tuyến
FFN chạy theo từng token độc lập (position-wise), thường mở rộng lên $d_{ff}$ rồi co về $d_{model}$
Và mỗi phần đều có:
- Residual (Add): giữ đường tắt cho gradient
- LayerNorm: ổn định phân phối, dễ train
Chúng ta có thể hình dung block như sau:
- Attention giúp token “biết nhau”
- FFN giúp token “xử lý thông tin đã trộn” theo kiểu phi tuyến
- Add&Norm giúp việc stack nhiều block không bị “nổ” hoặc “lụt” gradient
Tóm lại, Transformer encoder giải bài toán ‘mã hoá chuỗi’ bằng cách cho mỗi token nhìn toàn bộ câu trong một bước (self-attention), rồi dùng FFN để biến đổi phi tuyến theo từng token. Việc còn lại cho text classification là: từ $H$ sau N blocks, ta chọn một cách gom về vector câu (CLS/mean pooling/attention pooling) và gắn classifier lên trên.
11. Từ token-level representation đến vector câu để phân loại (sentence pooling)
Sau $N$ encoder blocks, Transformer không trả ra “một vector cho cả câu”, mà trả ra một vector cho mỗi token. Nếu câu có
$L$ token, mỗi token có embedding kích thước $d$, thì output của encoder là:
$$H = [h_1, h_2, ..., h_L] \in R^{L \times d}$$
Trong đó:
- $H$: output của Transformer encoder
- $h$: biểu diễn ngữ cảnh của token thứ $i$
- $L$: độ dài chuỗi (sequence length)
- $d$: embedding dimension
Encoder cho chúng ta $L$ mảnh thông tin, mỗi mảnh là “câu đã được hiểu trong ngữ cảnh” tại vị trí token đó. Nhưng bài toán text classification lại cần một quyết định duy nhất cho cả câu (positive/negative, spam/ham,…). Mà classifier (thường là Linear + Softmax) lại mong input dạng:
$$s \in R^{d}$$
Với $s$ là vector đại diện cho toàn bộ câu (Sentence-level representation)
Tức là một vector duy nhất đại diện cho câu.
Vì vậy, giữa encoder và classifier luôn có một bước rất quan trọng: gom $H$ về vector câu $s$. Đây chính là sentence pooling.
11.1. Cách 1 — [CLS] token: cử một “đại diện” đứng ra tổng kết
Một cách rất phổ biến (đặc biệt trong các mô hình kiểu BERT) là thêm một token đặc biệt $[CLS]$ ở đầu câu:
$$[CLS], x_1, x_2, ..., x_L$$
Vì $[CLS]$ cũng tham gia self-attention như mọi token khác, nên qua nhiều layer, nó có thể “nghe” toàn bộ câu và học cách dồn thông tin cần cho nhiệm vụ vào chính nó. Khi đó ta lấy:
$$s = h_{CLS}$$
Giống như trong một nhóm thảo luận, bạn cử một người làm “người tổng kết”. Người đó nghe mọi ý kiến, cuối cùng đứng lên chốt lại nội dung.
- Ưu điểm: đơn giản, đúng chuẩn pipeline của nhiều pretrained model.
- Hiệu quả phụ thuộc việc mô hình có được huấn luyện/finetune tốt để $[CLS]$ thật sự “gánh vai trò tổng kết” hay không.
11.2. Cách 2 — Mean pooling / Max pooling: gom ý kiến của “tất cả token”
Nếu không muốn phụ thuộc vào một token đại diện, ta có thể gom tất cả token lại.
(a) Mean pooling
$$s = \frac{1}{L} \sum_{i=1}^{L}h_i$$
Trong đó:
- $s$: sentence-level representation
- $L$: độ dài chuỗi (sequence length)
- $h$: biểu diễn ngữ cảnh của token thứ $i$
Vấn đề thực tế: padding
Trong huấn luyện theo batch, câu ngắn thường bị padding để có cùng độ dài. Ví dụ câu thật có 6 token nhưng ta pad lên 10 token, thì 4 vị trí cuối là $[PAD]$. Nếu ta trung bình cả $[PAD]$, vector câu sẽ bị loãng sai.
Vì vậy, người ta dùng mask $m_i$:
$$s = \frac{1}{\sum_{i=1}^{L}} \sum_{i=1}^{L}m_ih_i$$
Trong đó:
- $s$: sentence-level representation
- $L$: độ dài chuỗi (sequence length)
- $h$: biểu diễn ngữ cảnh của token thứ $i$
- $m_i$ = 1 nếu là token thật
- $m_i$ = 0 nếu là padding
=> Thay vì trung bình tất cả, ta chỉ trung bình “những người thật sự có ý kiến”, bỏ qua những chỗ chỉ là “ghế trống” (padding).
(b) Max pooling (lấy tín hiệu mạnh nhất)
Với từng chiều $k$ của vector, lấy giá trị lớn nhất trong toàn bộ token:
$$s_k = max(h_{i, k})$$
=> Nếu trong câu có một “tín hiệu rất mạnh” (ví dụ từ khoá cực tiêu cực/độc hại), max pooling thường bắt được tín hiệu đó tốt hơn mean pooling. Nhưng đổi lại, nó có thể hơi “nhạy”, dễ bị một token lẻ chi phối.
11.3. Cách 3 — Attention pooling
Attention pooling cho mô hình tự học token nào đáng chú ý hơn đối với nhiệm vụ phân loại.
Cách triển khai
1. Tính “điểm quan trọng” cho mỗi token:
$$e_i = w^Th_i$$
Trong đó:
- $h_i \in R^{d}$: biểu diễn ngữ cảnh của token thứ $i$ (output encoder)
- $w \in R^{d}$: vector trọng số học được (attention query for poolong)
- $e_i \in R$: score tích vô hướng đo mức độ quan trọng của token $i$ đối với nhiệm vụ phân loại
- Chuẩn hoá thành trọng số (softmax):
$$\alpha_{i} = softmax(e_i)$$
$\alpha_i$: mức độ mà token $i$ được lắng nghe khi tổng hợp câu - Gom có trọng số:
$$s = \sum_{i=1}^{L} \alpha_{i}h_i$$
$s$ là vector đại diện cho toàn bộ câu, mỗi token đóng góp vào $s$ theo tầm quan trọng đó học $\alpha_i$
=> Khi tóm tắt một review, những token như “tệ”, “xuất sắc”, "không bao giờ quay lại” nên được trọng số lớn hơn các token trung tính như “tôi”, “là”, “hôm nay”. Attention pooling giúp mô hình tự học đúng kiểu chọn điểm rơi đó.
Phần 2: Transformer cho Text Classification
Ở phần 1, chúng ta đã hiểu đầy đủ cơ chế Transformer: self-attention giúp mỗi token “nhìn” toàn câu trong một bước, multi-head cho nhiều góc nhìn, positional encoding bơm thứ tự, encoder block lặp lại để tăng năng lực biểu diễn, và cuối cùng phải có pooling để gom token-level representation về vector câu.
Trong phần này, chúng ta sẽ triển khai theo 2 hướng:
- From scratch - Toy: tự lắp một “mini Transformer classifier” để thấy rõ self-attention + Add&Norm + FFN + pooling hoạt động ra sao. Mục tiêu là overfit nhanh (đúng kiểu lab kiểm chứng).
- Pretrained + fine-tune: dùng mô hình pretrained (DistilBERT/BERT) rồi fine-tune cho classification theo chuẩn thực tế.
1. Build from scratch (tối giản): Mini Transformer cho text classification
1.1. Mục tiêu
- Nhìn thấy Transformer block nằm ở đâu trong code
- Hiểu đúng shape
- Biết mask và pooling làm gì
- Chứng minh “mô hình học được” bằng cách overfit toy dataset.
1.2. Kiến trúc “chuẩn Transformer”
- Token embedding
- Positional embedding
- Self-attention + residual + layer norm
- FFN (2 linear + GELU) + residual + layer norm
- Pooling (masked mean)
- Classifier head
1.3. Code mini model
import torch
import torch.nn as nn
import torch.nn.functional as F
class MiniTransformerTextCls(nn.Module):
def __init__(self, vocab_size, pad_id, num_classes=2,
seq_len=32, embed_dim=64, num_heads=2, dropout=0.1):
super().__init__()
self.pad_id = pad_id
self.seq_len = seq_len
# 1) Token embedding
self.embedding = nn.Embedding(vocab_size, embed_dim)
# 2) Positional embedding (learnable) - cực gọn để bơm thứ tự
self.pos_emb = nn.Embedding(seq_len, embed_dim)
# 3) Self-attention (batch_first=True => input (B,L,E))
self.attn = nn.MultiheadAttention(
embed_dim=embed_dim,
num_heads=num_heads,
dropout=dropout,
batch_first=True
)
self.norm1 = nn.LayerNorm(embed_dim)
# 4) FFN chuẩn Transformer (position-wise)
self.ffn = nn.Sequential(
nn.Linear(embed_dim, embed_dim * 4),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(embed_dim * 4, embed_dim),
nn.Dropout(dropout),
)
self.norm2 = nn.LayerNorm(embed_dim)
# 5) Classifier head
self.classifier = nn.Linear(embed_dim, num_classes)
def forward(self, input_ids):
"""
input_ids: (B, L)
return logits: (B, num_classes)
"""
B, L = input_ids.shape
device = input_ids.device
# attention_mask: 1 = token thật, 0 = PAD
attention_mask = (input_ids != self.pad_id).long() # (B, L)
# Embedding + positional
x = self.embedding(input_ids) # (B, L, E)
pos_ids = torch.arange(L, device=device).unsqueeze(0).expand(B, L)
x = x + self.pos_emb(pos_ids) # (B, L, E)
# key_padding_mask của MultiheadAttention: True ở PAD
key_padding_mask = (attention_mask == 0) # (B, L)
# --- Encoder block (pre-norm/post-norm tối giản bằng residual + LN) ---
# (a) Self-attention + residual + norm
x_saved = x
attn_out, _ = self.attn(x, x, x, key_padding_mask=key_padding_mask)
x = self.norm1(x_saved + attn_out)
# (b) FFN + residual + norm
x_saved = x
x = self.ffn(x)
x = self.norm2(x_saved + x)
# Pooling: masked mean (bỏ PAD)
m = attention_mask.unsqueeze(-1).float() # (B, L, 1)
pooled = (x * m).sum(dim=1) / m.sum(dim=1).clamp(min=1.0) # (B, E)
logits = self.classifier(pooled) # (B, C)
return logits
3.4. Toy dataset + training loop
vocab = {"[PAD]": 0, "i": 1, "love": 2, "this": 3, "movie": 4, "hate": 5, "boring": 6}
pad_id = vocab["[PAD]"]
def encode(sent, seq_len=8):
ids = [vocab.get(w, 0) for w in sent.split()]
ids = ids[:seq_len]
ids = ids + [pad_id] * (seq_len - len(ids))
return ids
seq_len = 8
texts = ["i love this movie", "i hate this boring movie"]
labels = [1, 0] # 1=positive, 0=negative
input_ids = torch.tensor([encode(t, seq_len) for t in texts], dtype=torch.long) # (B=2, L)
y = torch.tensor(labels, dtype=torch.long) # (B,)
# ----- Train -----
device = "cuda" if torch.cuda.is_available() else "cpu"
model = MiniTransformerTextCls(
vocab_size=len(vocab),
pad_id=pad_id,
num_classes=2,
seq_len=seq_len,
embed_dim=64,
num_heads=2,
dropout=0.1
).to(device)
input_ids = input_ids.to(device)
y = y.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=3e-3)
for step in range(1, 301):
logits = model(input_ids)
loss = criterion(logits, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if step % 50 == 0:
pred = logits.argmax(dim=-1)
acc = (pred == y).float().mean().item()
print(f"step={step:03d} loss={loss.item():.4f} acc={acc:.2f}")
# Inference demo
with torch.no_grad():
probs = torch.softmax(model(input_ids), dim=-1)
print("probs:\n", probs)
Ở đây, chúng ta dùng một ví dụ tối giản để thấy rõ từng khối của Transformer: embedding + positional, self-attention, Add&Norm, FFN, pooling và classifier. Mục tiêu để kiểm chứng rằng cơ chế attention và pooling thật sự giúp mô hình học được quyết định phân loại.
Khi chuyển sang bài toán thật (IMDB, tweets, dữ liệu lớn và đa dạng), huấn luyện từ scratch thường đòi hỏi nhiều dữ liệu và thời gian. Nếu dataset nhỏ, mô hình dễ overfit. Vì vậy, chúng ta chuyển sang cách làm thực tế: dùng mô hình Transformer pretrained (ví dụ DistilBERT/BERT) rồi fine-tune cho text classification. Khi đó, giao diện vẫn y hệt (input_ids + attention_mask → logits), nhưng backbone đã có sẵn “kiến thức ngôn ngữ” học từ corpora rất lớn.
2. Fine-tuning Transformers (Pretrained) cho Text Classification bằng Hugging Face
Link code
Để làm bài toán hiệu quả, cách phổ biến nhất hiện nay là fine-tune một mô hình Transformer pretrained (ví dụ DistilBERT/BERT).
Ý tưởng của fine-tune:
- Ta lấy một backbone đã học ngôn ngữ từ dữ liệu cực lớn (pretrained).
- Ta gắn một classification head (thường đã có sẵn).
- Ta fine-tune vài epoch với learning rate nhỏ để mô hình “thích nghi” với nhãn bài toán.
Trong ví dụ này, chúng ta dùng IMDB sentiment classification (positive/negative) từ Hugging Face Datasets và fine-tune distilbert-base-uncased.
2.1. Setup & Data Loading
from datasets import load_dataset
import numpy as np
import evaluate
from transformers import (
AutoTokenizer,
AutoModelForSequenceClassification,
DataCollatorWithPadding,
TrainingArguments,
Trainer,
pipeline
)
Load dữ liệu IMDB:
# Dataset IMDB trên Hugging Face
ds = load_dataset("imdb")
# Lấy subset để demo chạy nhanh
train_data = ds["train"].shuffle(seed=42).select(range(2000))
test_data = ds["test"].shuffle(seed=42).select(range(500))
2.2. Tokenizer: biến text → input_ids + attention_mask
model_name = "distilbert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
def tokenize(batch):
return tokenizer(batch["text"], truncation=True, max_length=256)
train_ds = train_data.map(tokenize, batched=True, remove_columns=["text"]).rename_column("label", "labels")
test_ds = test_data.map(tokenize, batched=True, remove_columns=["text"]).rename_column("label", "labels")
Vì sao cần DataCollatorWithPadding?
Nó sẽ padding động theo batch thay vì pad cứng mọi câu về max_length, giúp tiết kiệm compute.
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
2.3. Model pretrained cho classification
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)
2.4. Metric: Accuracy
Trainer sẽ trả logits. Ta lấy argmax để ra predicted label:
accuracy = evaluate.load("accuracy")
def compute_metrics(eval_pred):
# Trainer truyền vào một object có predictions/label_ids
logits = eval_pred.predictions if hasattr(eval_pred, "predictions") else eval_pred[0]
labels = eval_pred.label_ids if hasattr(eval_pred, "label_ids") else eval_pred[1]
preds = np.argmax(logits, axis=-1)
return accuracy.compute(predictions=preds, references=labels)
2.5. TrainingArguments: cấu hình fine-tune
Fine-tuning thường dùng learning rate nhỏ (1e-5 ~ 5e-5). Ở đây dùng 2e-5 là mức “an toàn” cho DistilBERT.
args = TrainingArguments(
output_dir="demo_transformer_cls",
learning_rate=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=32,
num_train_epochs=1, # demo blog: 1 epoch cho nhanh (muốn tốt hơn: 2-3)
weight_decay=0.01,
evaluation_strategy="epoch", # đánh giá sau mỗi epoch
save_strategy="no", # demo: không lưu checkpoint giữa chừng
logging_steps=50,
)
2.6. Trainer: train + evaluate
trainer = Trainer(
model=model,
args=args,
train_dataset=train_ds,
eval_dataset=test_ds,
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics,
)
trainer.train()
print(trainer.evaluate())
2.7. Save model + inference demo
trainer.save_model("demo_transformer_cls")
tokenizer.save_pretrained("demo_transformer_cls")
Chạy thử dự đoán:
clf = pipeline(
"text-classification",
model="demo_transformer_cls",
tokenizer="demo_transformer_cls"
)
texts = [
"This movie was awesome, I loved it!",
"It was boring and way too long."
]
print(clf(texts))
Keynote: Sau khi fine-tune mô hình pretrained (ví dụ DistilBERT) trên IMDB, điều dễ thấy nhất là: mô hình hội tụ rất nhanh và cho kết quả tốt chỉ sau vài epoch. Đây là khác biệt lớn nhất so với huấn luyện từ scratch.
2.8. Vì sao fine-tuning hiệu quả hơn train from scratch?
- Trong mục 1, mô hình bắt đầu từ tham số ngẫu nhiên nên phải “tự học” cách biểu diễn ngôn ngữ từ đầu. Với dữ liệu nhỏ, mô hình có thể overfit toy example nhưng khó tổng quát ra dữ liệu thật.
- Trong mục 2, backbone pretrained đã học được rất nhiều kiến thức nền: từ collocation, cú pháp, ngữ nghĩa, đến những pattern phổ biến trong văn bản. Khi fine-tune, ta chủ yếu “chỉnh” mô hình để phù hợp với nhãn sentiment -> cần ít dữ liệu hơn và học nhanh hơn.
KẾT LUẬN
Nhìn lại toàn bộ bài, mục tiêu là chúng ta cần hiểu rõ Transformer giải quyết đúng “bài toán mã hoá chuỗi” như thế nào và vì sao nó trở thành lựa chọn mặc định cho rất nhiều bài toán NLP hiện đại.
Ở Phần 1, chúng ta đi từ RNN/LSTM để thấy rõ điểm nghẽn của mô hình tuần tự: khó song song hoá, khó giữ quan hệ dài hạn, và thông tin bị nén trong một trạng thái. Transformer thay đổi cuộc chơi bằng self-attention: thay vì truyền tin qua thời gian, nó cho phép mỗi token kết nối trực tiếp với mọi token khác, học trọng số chú ý một cách linh hoạt thông qua Q–K–V, và dùng multi-head để nhìn quan hệ dưới nhiều “góc” khác nhau. Khi đã hiểu bản chất này, positional encoding, residual, layer norm và FFN không còn là những “mảnh ghép rời”, mà là các thành phần giúp mô hình train ổn định và đủ năng lực biểu diễn khi xếp nhiều lớp.
Sang Phần 2, ta thấy được các triển khai hai hướng
- Train from scratch giúp chúng ta “nhìn thấy” Transformer chạy thật: attention + Add&Norm + FFN + pooling → logits. Đây giống như một bài test đơn vị: mô hình phải học được trên ví dụ nhỏ thì mới có ý nghĩa bàn tiếp đến tổng quát hoá.
- Fine-tune pretrained: thay vì học ngôn ngữ từ số 0, chúng ta có thể tận dụng một backbone đã được huấn luyện trên dữ liệu lớn và chỉ tinh chỉnh cho bài toán phân loại. Khi đó, mọi thứ trở nên gọn và hiệu quả hơn rất nhiều, nhưng vẫn dựa trên đúng “hợp đồng” cốt lõi:
input_ids+attention_mask→logits.
Transformer mạnh không phải vì “nhiều lớp”, mà vì nó biến việc hiểu ngữ cảnh thành một phép toán có thể học được và song song hoá tốt, chính điều đó làm nền cho các mô hình pretrained hiện đại.
Chưa có bình luận nào. Hãy là người đầu tiên!