
1. Giới thiệu
Có thể nói Deep Learning được xây dựng dựa trên mạng nơ-ron nhân tạo, đã và đang trở thành nền tảng kỹ thuật cốt lõi của nhiều hệ thống trí tuệ nhân tạo, đặc biệt hiệu quả với các bài toán nhận dạng hình ảnh và xử lý ngôn ngữ tự nhiên. Trong đó Multi-layer Perceptron (MLP) đóng vai trò như mô hình nền tảng, giúp hình thành và phát triển các kiến trúc phức tạp hơn sau này.
MLP được xây dựng từ các thành phần cơ bản như Perceptron, trọng số (weight), độ chệch (bias), hàm kích hoạt, và được tổ chức theo cấu trúc nhiều tầng (layer). Thông qua cơ chế lan truyền thuận (forward propagation) và lan truyền ngược (backpropagation) kết hợp với Gradient Descent, mô hình có khả năng học từ dữ liệu và cải thiện dần độ chính xác của dự đoán. Việc hiểu rõ từng thành phần này là điều kiện cần thiết để không chỉ sử dụng được mô hình, mà còn có thể giải thích, phân tích và điều chỉnh mô hình sao cho tối ưu với bài toán nhất có thể.
Xuất phát từ yêu cầu đó, nhóm chọn đề tài Xây dựng mô hình MLP để dự đoán chữ số viết tay, tập trung vào việc xây dựng và phân tích một mô hình Multi-layer Perceptron để dự đoán chữ số viết tay từ 0 đến 9. Đây là một bài toán kinh điển trong lĩnh vực học máy, thường được sử dụng như ví dụ nhập môn, vừa đủ đơn giản để làm rõ bản chất của mô hình, vừa đủ thực tế để phản ánh đầy đủ quy trình xây dựng một hệ thống học máy hoàn chỉnh.
Mục tiêu của dự án
Bài báo cáo hướng tới các mục tiêu chính sau:
- Trình bày lại các khái niệm nền tảng của Perceptron và MLP, bao gồm trọng số, độ chệch, hàm kích hoạt và cấu trúc tầng.
- Làm rõ cơ chế hoạt động của mạng nơ-ron thông qua lan truyền thuận và lan truyền ngược.
- Áp dụng các kiến thức lý thuyết vào việc xây dựng mô hình MLP cho bài toán nhận dạng chữ số viết tay.
- Mô tả quy trình triển khai mô hình từ dữ liệu đầu vào, huấn luyện, đến đánh giá kết quả.
- Rèn luyện khả năng liên kết giữa lý thuyết - thuật toán - cài đặt thực tế bằng công cụ lập trình (PyTorch).
Qua đó giúp người đọc có thể xây dựng được nền tảng vững chắc về mạng nơ-ron nhân tạo, từ đó tạo tiền đề để tiếp cận các mô hình Deep Learning phức tạp hơn trong các bài toán thực tế sau này.
2. Perceptron
Perceptron là một trong những thuật toán đầu tiên giải quyết bài toán phân loại nhị phân (binary classification). Bên cạnh đó, nó còn là nền móng của các mạng nơ-ron nhân tạo (ANNs) hiện đại và là khối xây dựng cơ bản để tạo nên các mô hình học sâu (deep learning) phức tạp hơn. Nó hoạt động bằng cách kết hợp các dữ liệu đầu vào (inputs) cùng các trọng số (weights), sau đó cộng thêm một độ chệch (bias) và đưa ra kết quả th sử dụng một hàm kích hoạt.
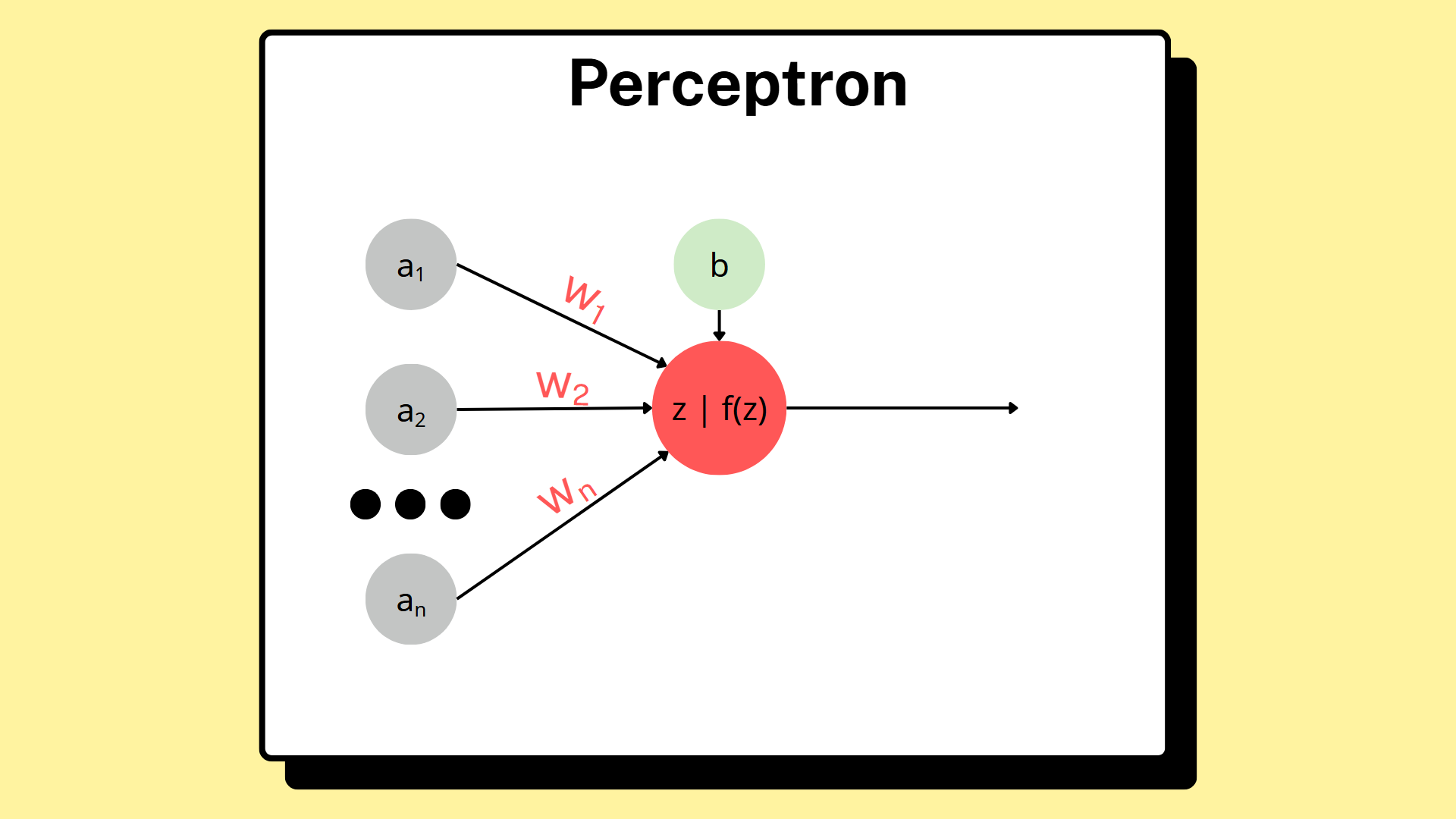
2.1. Trọng số và độ chệch
Trọng số là tham số quyết định mức độ quan trọng của từng dữ liệu đầu vào trong việc đưa ra dự đoán cuối cùng. Dữ liệu đầu vào có trọng số càng lớn đồng nghĩa dữ liệu đó có độ ảnh hưởng càng lớn với dự đoán cuối cùng.
Độ chệch là một giá trị được thêm vào tổng của các dữ liệu đầu vào đã được nhân với các trọng số. Độ chệch được thêm vào để điều chỉnh kết quả dự đoán theo hướng phù hợp.
2.2. Hàm kích hoạt
Hàm kích hoạt (activation function) là một hàm toán học được áp dụng lên đầu ra tuyến tính của một nơ-ron. Nó là một phần quan trọng của mạng nơ-ron, được dùng để giới thiệu tính phi tuyến cho mạng nơ-ron, từ đó cho phép các mô hình sử dụng mạng nơ-ron có thể học và biểu diễn được các dữ liệu phức tạp trong thực tế. Nếu không sử dụng các hàm kích hoạt, các mạng nơ-ron dù nhiều lớp thế nào cũng sẽ chỉ tương đương với một mô hình hồi quy tuyến tính (Linear Regression) đơn giản. Khi đó mô hình sẽ chỉ học được các mối quan hệ đơn giản giữa dữ liệu đầu vào và đầu ra.
Sau đây là bảng giới thiệu một số hàm kích hoạt:
| Ký hiệu | Tên đầy đủ | Công thức |
|---|---|---|
| Linear | Linear (Identity) Function | $$f(x) = x$$ |
| Step | Binary Step Function | $$f(x)=\begin{cases}1 & x \ge 0 \\ 0 & x < 0\end{cases}$$ |
| $\sigma(x)$ | Sigmoid Function | $$f(x)=\frac{1}{1+e^{-x}}$$ |
| $\tanh(x)$ | Hyperbolic Tangent Function | $$f(x)=\frac{e^x-e^{-x}}{e^x+e^{-x}}$$ |
| ReLU | Rectified Linear Unit Function | $$f(x)=\begin{cases}x & x>0 \\ 0 & x \le 0\end{cases}$$ |
| LReLU | Leaky Rectified Linear Unit Function | $$f(x)=\begin{cases}x & x>0 \\ \alpha x & x \le 0\end{cases}$$ |
| Softplus | Softplus Function | $$f(x)=\ln(1+e^x)$$ |
| Softmax | Softmax Function | $$f(x_i)=\frac{e^{x_i}}{\sum_{j=1}^{K} e^{x_j}}$$ |
Việc lựa chọn hàm kích hoạt phù hợp là một công đoạn then chốt trong thiết kế mạng nơ-ron. Nó không chỉ ảnh hưởng đến khả năng mô hình học được các đặc trưng của dữ liệu huấn luyện, mà còn tác động đến tốc độ học và khả năng tổng quát hóa trên các dữ liệu khi mang mô hình ra thực tế.
3. Tầng
Trong Multi-layer Perceptron, tầng (layer) là đơn vị tổ chức các nơ-ron nhằm thực hiện từng bước biến đổi dữ liệu trong quá trình học. Việc chia mạng thành nhiều tầng không chỉ là một lựa chọn kỹ thuật, mà xuất phát từ nhu cầu mở rộng năng lực biểu diễn của mô hình so với các phương pháp tuyến tính truyền thống.
Các nơ-ron cùng chung một tầng nếu khoảng cách xa nhất đi từ tầng đầu vào đến chúng là bằng nhau.
4. Perceptron đơn tầng
4.1. Cấu trúc của Perceptron đơn tầng
Single-layer Perceptron, hay Perceptron đơn tầng, là dạng đơn giản nhất của mạng nơ-ron - một mạng chỉ gồm lớp đầu vào và một lớp perceptron duy nhất nối thẳng tới đầu ra, không có lớp ẩn nào ở giữa. Về mặt cấu trúc, nó bao gồm bốn thành phần chính làm việc theo trình tự.
Thành phần thứ nhất là vectơ đầu vào hay còn gọi là vectơ đặc trưng. Nó có dạng $\mathbf{x} = [x_1, x_2, ..., x_m]^T$. Ví dụ, khi quyết định có nên đi xem phim không, bạn có thể xem xét thời tiết $x_1$, tâm trạng $x_2$, số tiền trong túi $x_3$, và chất lượng phim $x_4$. Mỗi đặc trưng này là một chiều thông tin mà mô hình sẽ sử dụng để đưa ra dự đoán.
Thành phần thứ hai là các trọng số (weights), chúng đo mức độ quan trọng của từng đặc trưng và được viết dưới dạng $\mathbf{w} = [w_1, w_2, ..., w_m]^T$. Ví dụ, khi xem phim, chất lượng phim quan trọng nhất với bạn nên có trọng số cao $x_4 = 0.5$, trong khi thời tiết ít quan trọng hơn nên có trọng số thấp $x_1 = 0.1$. Các trọng số này chính là những gì mô hình sẽ học từ dữ liệu - ban đầu chúng được khởi tạo ngẫu nhiên, sau đó được điều chỉnh dần qua quá trình huấn luyện để phản ánh đúng tầm quan trọng của từng đặc trưng.
Tiếp theo là độ chệch (bias) $b$ - ngưỡng quyết định của bạn. Giống như "mức độ dễ tính", độ chệch dương cao tương đương xu hướng đồng ý dễ; độ chệch âm thấp tương đương khó tính hơn. Về mặt toán học, độ chệch dịch chuyển ranh giới quyết định độc lập với giá trị đầu vào.
Và cuối cùng là hàm kích hoạt (activation function) - đưa ra quyết định cuối cùng. Trong perceptron cổ điển, hàm kích hoạt thường là hàm step (bậc thang) - một hàm rất đơn giản chỉ cho ra giá trị 1 nếu $z$ lớn hơn hoặc bằng $0$, và cho ra $0$ (hoặc $-1$) nếu $z$ nhỏ hơn $0$.
$$ f(z) = \begin{cases} 1 & , z \ge 0\\ 0 & , z \lt 0 \end{cases} $$
4.2. Quy trình tính toán
Quy trình tính toán gồm ba bước:
-
Bước 1: Nhận vectơ đầu vào $\mathbf{x}$.
-
Bước 2: Tính tổng có trọng số $z = w_1x_1 + w_2x_2 + ... + w_2x_2 + b$. Hoặc viết theo dạng vectơ $z = \mathbf{w}^T \mathbf{x} + b$.
-
Bước 3: Áp dụng hàm kích hoạt $y = f(z)$.
Toàn bộ quá trình chỉ là các phép nhân và cộng đơn giản, diễn ra cực nhanh nhưng tạo nên khả năng phân loại cơ bản đầu tiên của máy học.
Áp dụng thực tế
Ví dụ, ta muốn mô hình hoá việc bản thân chỉ được đi chơi khi và chỉ khi đã làm xong bài tập và được bố mẹ cho phép. Ta nhận thấy, đây thực chất đây là hàm AND. Hàm AND chỉ cho $y=1$ khi cả hai $x_1$ và $x_2$ đều bằng 1. Ta có bảng chân trị:
| $x_1$ (đã làm xong bài) | $x_2$ (được cho phép) | $y$ |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 0 |
| 1 | 0 | 0 |
| 1 | 1 | 1 |
Để biểu diễn hàm AND bằng Single-layer Perceptron, ta thiết lập trọng số cho perceptron như sau $w_1 = 1$, $w_2 = 1$, $b = -1.5$.
Với $x_1 = 0$ và $x_2 = 0$, đây là trường hợp chưa làm bài và chưa được phép đi chơi. Ta có $z = 1 \times 0 + 1 \times 0 - 1.5 = -1.5$. Vì $z \lt 0$ nên $y = f(z) = 0$. Suy ra ta chưa được đi chơi.
Với $x_1 = 0$ và $x_2 = 1$, đây là trường hợp chưa làm bài và được phép đi chơi. Ta có $z = 1 \times 0 + 1 \times 1 - 1.5 = -0.5$. Vì $z \lt 0$ nên $y = f(z) = 0$. Suy ra ta chưa được đi chơi.
Với $x_1 = 1$ và $x_2 = o$, đây là trường hợp đã làm xong bài và chưa được phép đi chơi. Ta có $z = 1 \times 1 + 1 \times 0 - 1.5 = -0.5$. Vì $z \lt 0$ nên $y = f(z) = 0$. Suy ra ta chưa được đi chơi.
Trường hợp cuối cùng, $x_1 = 1$ và $x_2 = o$, đây là trường hợp đã làm xong bài và được phép đi chơi. Ta có $z = 1 \times 1 + 1 \times 1 - 1.5 = 0.5$. Vì $z \gt 0$ nên $y = f(z) = 1$. Nên ta được đi chơi.
4.3. Hạn chế của Perceptron đơn tầng
Single-layer Perceptron chỉ có thể phân loại các dữ liệu linearly separable - tức là có thể vẽ một đường thẳng (hoặc siêu phẳng) để phân chia hai lớp.
Một thất bại kinh điển của khi cố gắng biểu diễn hàm XOR bằng Single-layer Perceptron. Hàm XOR trả kết quả $y = 1$ khi và chỉ khi $x_1$ và $x_2$ khác nhau. Dưới đây là bảng chân trị của hàm XOR:
| $x_1$ | $x_2$ | $y$ |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
Vẽ 4 điểm này lên mặt phẳng: hai điểm có $y = 1$ là $(0,1)$ và $(1,0)$ ở hai góc đối diện, hai điểm $y = 1$ là $(0,0)$ và $(1,1)$ ở hai góc đối diện còn lại. Chúng tạo hình chữ "X" xen kẽ - không có đường thẳng nào tách được. Bất kỳ đường thẳng nào cũng phải cắt qua cả hai lớp.
Tác động lịch sử: Năm 1969, Minsky và Papert chứng minh perceptron đơn tầng không thể học XOR, dẫn đến "mùa đông AI" đầu tiên - kinh phí cạn kiệt, các nhà khoa học rời bỏ lĩnh vực, AI đóng băng gần 2 thập kỷ.
5. Perceptron đa tầng
5.1. Kiến trúc
Như đã thảo luận ở phần trước, Perceptron đơn tầng vốn dĩ bị giới hạn trong việc học các biên quyết định tuyến tính. Mặc dù các mô hình này đơn giản và dễ diễn giải, chúng về bản chất không có khả năng biểu diễn các mối quan hệ phi tuyến phức tạp thường xuất hiện trong dữ liệu thực tế.
Multi-Layer Perceptron (MLP) khắc phục hạn chế này không phải bằng cách thay đổi đơn vị tính toán cơ bản, mà bằng cách tổ chức các perceptron thành một hệ thống phân cấp các tầng có cấu trúc. Sự mở rộng về mặt kiến trúc này cho phép mô hình biểu diễn các hàm ngày càng phức tạp thông qua sự hợp thành của các phép biến đổi đơn giản hơn. Trước khi xem xét cách thông tin lan truyền trong mạng hoặc cách mô hình được huấn luyện, điều thiết yếu là phải hiểu rõ cấu trúc kiến trúc này.
5.1.1. Góc nhìn tổng quan về kiến trúc MLP
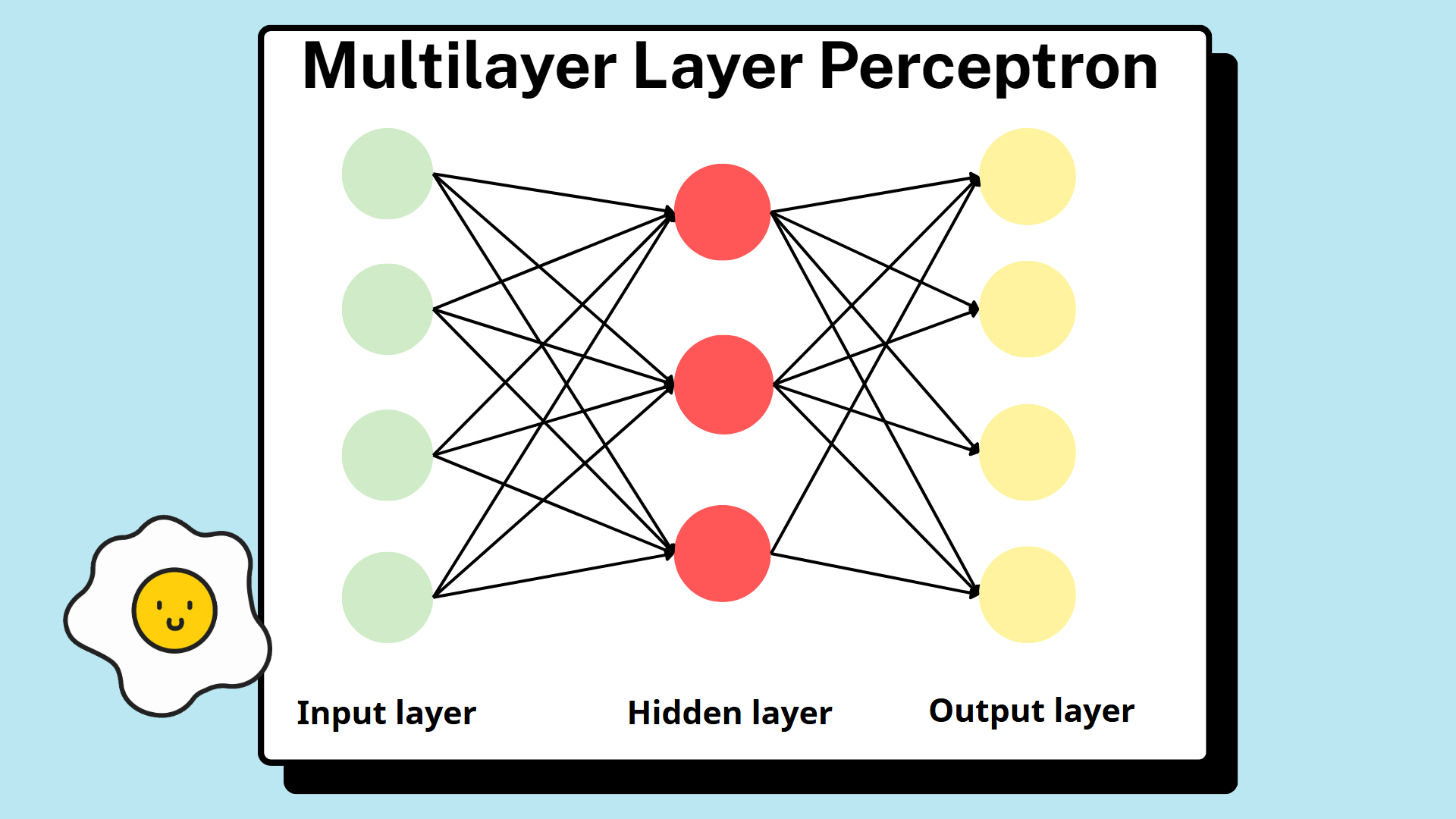
Từ góc độ kiến trúc, MLP là một mạng nơ-ron truyền thẳng (feedforward neural network), bao gồm nhiều tầng nơ-ron được sắp xếp tuần tự. Mạng gồm ba thành phần cơ bản:
- Tầng đầu vào (Input layer)
- Một hoặc nhiều tầng ẩn (Hidden layers)
- Tầng đầu ra (Output layer)
Các nơ-ron trong một tầng thường được kết nối đầy đủ với các nơ-ron ở tầng kế tiếp, tạo thành một cấu trúc có hướng và không chu trình. Thông tin chỉ di chuyển theo một chiều duy nhất - từ tầng đầu vào đến tầng đầu ra - theo các kết nối được xác định bởi kiến trúc mạng.
Đặc trưng cốt lõi của MLP là sự tồn tại của các tầng ẩn, cho phép mạng biến đổi dữ liệu đầu vào thô thành các biểu diễn nội bộ ngày càng giàu thông tin hơn. Cách tổ chức theo tầng này chính là yếu tố phân biệt MLP với các mô hình một tầng và tạo nên năng lực biểu diễn mạnh mẽ của chúng.
5.1.2. Các thành phần kiến trúc cốt lõi
Tầng đầu vào (Input Layer)
Tầng đầu vào đóng vai trò là giao diện giữa dữ liệu thô và mạng nơ-ron. Nhiệm vụ của tầng này là tiếp nhận các đặc trưng đầu vào và truyền trực tiếp chúng đến tầng ẩn đầu tiên.
Quan trọng là tầng đầu vào không thực hiện bất kỳ quá trình học hay biến đổi nào. Số chiều của tầng này hoàn toàn được quyết định bởi cách biểu diễn dữ liệu đầu vào đã lựa chọn.
Các tầng ẩn (Hidden Layers)
Các tầng ẩn tạo nên lõi biểu diễn của MLP. Mỗi tầng ẩn bao gồm một tập các nơ-ron thực hiện các phép biến đổi đã được học lên đầu ra của tầng trước đó.
Bằng cách xếp chồng nhiều tầng ẩn, MLP hình thành một hệ phân cấp các biểu diễn. Các tầng sớm thường nắm bắt những mẫu đơn giản, trong khi các tầng sâu hơn kết hợp những mẫu này thành các đặc trưng trừu tượng hơn. Số lượng tầng ẩn và số nơ-ron trong mỗi tầng là các quyết định thiết kế kiến trúc, ảnh hưởng trực tiếp đến khả năng biểu diễn các hàm phức tạp của mô hình.
Tầng đầu ra (Output Layer)
Tầng đầu ra tạo ra kết quả cuối cùng của mạng. Cấu trúc của tầng này phụ thuộc vào loại bài toán cần giải, chẳng hạn như hồi quy hoặc phân loại.
Từ góc độ kiến trúc, tầng đầu ra hoàn tất chuỗi biến đổi bằng cách ánh xạ biểu diễn cuối cùng của tầng ẩn sang không gian đầu ra của mô hình.
5.1.3. Tính toán ở cấp độ nơ-ron
Ở mức độ kiến trúc, mỗi nơ-ron trong tầng ẩn hoặc tầng đầu ra được xác định bởi hai thành phần khái niệm:
- Phép biến đổi tuyến tính của các đầu vào, được tham số hóa bởi ma trận trọng số $W^{(l)}$ và vectơ độ chệch (bias) $b^{(l)}$
- Hàm kích hoạt phi tuyến, tạo ra vectơ kích hoạt $a^{(l)}$
Mối quan hệ này có thể được biểu diễn dưới dạng ký hiệu toán học như sau:
$$ a^{(l)} = f\left( W^{(l)T} a^{(l-1)} + b^{(l)} \right) $$
Ở giai đoạn này, chỉ cần nhận thức rằng chính sự hợp thành cấu trúc lặp lại này — chứ không phải bản thân quá trình tính toán riêng lẻ — là yếu tố mang lại cho MLP khả năng biểu diễn các mối quan hệ phi tuyến phức tạp.
Với kiến trúc MLP đã được xác định và số chiều của đầu vào đã được cố định theo cách biểu diễn dữ liệu đã lựa chọn, bước tiếp theo là xem xét cách thông tin lan truyền qua cấu trúc này thông qua lan truyền thuận (forward propagation).
5.2. Lan truyền thuận
Các thuật toán phổ biến nhất để tối ưu mô hình MLP thường vẫn là Gradient Descent và các biến thể của nó (Adam, Momentum, RMSProp,...). Đặc điểm chung của chúng là đều cần phải tính vectơ đầu ra dự đoán $\mathbf{\hat{y}}$ tương ứng với vectơ đặc trưng $\mathbf{x}$.
Bước này thực hiện bằng cách tính các kích hoạt (activations) ở từng tầng, lần lượt từ trước ra sau. Vì lẽ đó, nó mang cái tên lan truyền thuận.
Cụ thể, gọi $\mathbf{a^{(0)} = \mathbf{x}}$ là đầu vào. Với mỗi tầng $l = 1, 2, 3, ..., L$ ta có:
$$\mathbf{z}^{(l)} = \mathbf{W}^{(l)T} \mathbf{a}^{(l-1)} + \mathbf{b}^{(l)},$$
$$\mathbf{a}^{(l)} = f_l(\mathbf{z}^{(l)}).$$
Tại tầng đầu ra:
$$\mathbf{\hat{y}} = \mathbf{a}^{(L)}.$$
Trong đó:
- $\mathbf{x} \in \mathbb{R}^{d^{0}}$ là vectơ đặc trưng.
- $\mathbf{a}^{(0)} = \mathbf{x}$ là vectơ kích hoạt ở tầng đầu vào.
- $L$ là tổng số tầng của mô hình.
- $l \in \{1,2,...,L\}$ là chỉ mục của các tầng trong mô hình.
- $d^{(l)}$ là tổng số nơ-ron ở tầng $l$.
- $\mathbf{W}^{(l)} \in \mathbb{R}^{d^{(l-1)}} \times \mathbb{R}^{d^{(l)}}$ là ma trận trọng số ở tầng $l$.
- $\mathbf{W}^{(l)T} \in \mathbb{R}^{d^{(l)}} \times \mathbb{R}^{d^{(l-1)}}$ là ma trận chuyển vị của $\mathbf{W}^{(l)}$.
- $\mathbf{b}^{(l)} \in \mathbb{R}^{d^{(l)}}$ là vectơ độ chệch ở tầng $l$.
- $\mathbf{z}^{(l)} \in \mathbb{R}^{d^{(l)}}$ là vectơ tiền kích hoạt ở tầng $l$.
- $f_l(\cdot) \in \mathbb{R}^{d^{(l)}} \mapsto \mathbb{R}^{d^{(l)}}$ là hàm kích hoạt ở tầng $l$.
- $\mathbf{a}^{(l)} \in \mathbb{R}^{d^{(l)}}$ là vectơ kích hoạt ở tầng $l$.
- $\mathbf{\hat{y}} = \mathbf{a}^{(L)}$ là giá trị đầu ra của mô hình.
Khi ta huấn luyện mô hình với $N$ mẫu cùng một lúc ta chỉ cần xếp các vectơ đặc trưng $x_n$ theo chiều ngang tạo thành ma trận $X \in \mathbb{R}^{d^{(0)} \times N}$. Tương tự, ma trận $Y \in \mathbb{R}^{d^{(L)} \times N}$ gồm $N$ vectơ kết quả $y_n$ xếp kế bên nhau.
Mỗi vectơ $x_n$ trong $X$, thông qua lan truyền thuận, tạo các vectơ kích hoạt $a_n$ tương đương với các cột của $A^{(l)} \in \mathbb{R}^{d^{(l)} \times N}$. Ta được:
$$ \mathbf{A^{(0)} = \mathbf{X}}, $$
$$\mathbf{Z}^{(l)} = \mathbf{W}^{(l)T} \mathbf{A}^{(l-1)} + \mathbf{b}^{(l)},$$
$$\mathbf{A}^{(l)} = f_l(\mathbf{Z}^{(l)}),$$
$$\mathbf{\hat{Y}} = \mathbf{A}^{(L)}.$$
5.3. Lan truyền ngược
Sau khi tìm được $\mathbf{\hat{y}}$, bước tiếp theo của các thuật toán tối ưu dựa vào gradient (Gradient Descent, Adam,...) là tìm đạo hàm của hàm mất mát theo các trọng số và độ chệch.
Phương pháp phổ biến giúp tính gradient là sử dụng giải thuật lan truyền ngược (Backpropagation). Ý tưởng chính của phương pháp là ban đầu tính gradient ở tầng cuối cùng, rồi dựa vào quy tắc dây chuyền (chain rule) để tìm gradient ở tầng liền kề trước đó. Thuật toán lặp đi lặp bước này, lần lượt tính hết đạo hàm ở các tầng theo thứ tự từ sau ra trước (theo hướng từ tầng đầu ra đến tầng đầu vào).
Giả sử $J(\theta, \mathbf{X}, \mathbf{Y})$ là hàm mất mát, trong đó, $\theta$ là tập hợp tất cả các ma trận trọng số và vectơ độ chệch của từng tầng, $\theta \in \{\mathbf{W}^{(1)}, \mathbf{b}^{(1)}, \mathbf{W}^{(1)}, \mathbf{b}^{(1)}, ..., \mathbf{W}^{(L)}, \mathbf{b}^{(L)}\}$. $\mathbf{X}, \mathbf{Y}$ là tập các cặp huấn huyện $\mathbf{x}, \mathbf{y}$. Thì để tính đạo hàm của $J$ theo $\mathbf{W}$ và $\mathbf{b}$, ta cần tính với lần lượt $l=1,2,...,L$:
$$ \frac{\partial J}{\partial \mathbf{W}^{(l)}}, \; \frac{\partial J}{\partial \mathbf{b}^{(l)}}. $$
5.3.1. Biểu diễn đạo hàm theo từng thành phần
Đây là cách biểu diễn tính đạo hàm theo từng thành phần của $\mathbf{W}^{(l)}, \mathbf{b}^{(l)}$.
Cụ thể , ở tầng đầu ra ta có các đạo hàm sau:
$$ \frac{\partial J}{\partial w_{ij}^{(L)}} = \frac{\partial J}{\partial z_{j}^{(L)}} \frac{\partial z_{j}^{(L)}}{\partial w_{ij}^{(L)}} = e_{j}^{(L)} a_{i}^{(L-1)}, $$
$$ \frac{\partial J}{\partial b_{j}^{(L)}} = \frac{\partial J}{\partial z_{j}^{(L)}} \frac{\partial z_{j}^{(L)}}{\partial b_{j}^{(L)}} = e_{j}^{(L)}. $$
Trong đó, $e_{j}^{(L)} = \frac{\partial J}{\partial z_{j}^{(L)}}$ là một đại lượng dễ dàng tính toán và $\frac{\partial z_{j}^{(L)}}{\partial w_{ij}^{(L)}} = a_{i}^{(L-1)}$ và $\frac{\partial z_{j}^{(L)}}{\partial b_{j}^{(L)}} = 1$ vì $z_{j}^{(L)} = \mathbf{w}_{j}^{(L)T} \mathbf{a}^{(L)} + b_{j}^{(L)}$.
Đối với các tầng ẩn, đạo hàm được tính bằng:
$$ \begin{aligned} \frac{\partial J}{\partial w_{ij}^{(l)}} &= \frac{\partial J}{\partial z_{j}^{(l)}} \frac{\partial z_{j}^{(l)}}{\partial w_{ij}^{(l)}} \\ &= e_{j}^{(l)} a_{i}^{(l-1)}, \end{aligned} $$
với:
$$ \begin{aligned} e_{j}^{(l)} &= \frac{\partial J}{\partial z_{j}^{(l)}} = \frac{\partial J}{\partial a_{j}^{(l)}} \frac{\partial a_{j}^{(l)}}{\partial z_{j}^{(l)}} \\ &= \left( \sum_{k=1}^{d^{(l+1)}} \frac{\partial J}{\partial z_{k}^{(l+1)}} \frac{\partial z_{k}^{(l+1)}}{\partial a_{j}^{(l)}} \right) f_{l}^{\prime}(z_{j}^{(L)}) \\ &= \left( \sum_{k=1}^{d^{(l+1)}} e_{k}^{(l+1)} w_{jk}^{(l+1)} \right) f_{l}^{\prime}(z_{j}^{(L)}) \\ &= \left( \mathbf{w}_{j:}^{(l+1)} \mathbf{e}^{(l+1)} \right) f_{l}^{\prime}(z_{j}^{(L)}), \end{aligned} $$
trong đó $\mathbf{e}^{(l+1)} = [e_{1}^{(l+1)}, e_{2}^{(l+1)}, ..., e_{d^{(l+1)}}^{(l+1)}]^T \in \mathbb{R}^{d^{(l+1)} \times 1}$ và $\mathbf{w}_{j:}^{(l+1)}$ là cột thứ $j$ của ma trận $\mathbf{W}^{(l+1)}$.
Tương tự, ta có:
$$ \frac{\partial J}{\partial b_{j}^{(l)}} = \frac{\partial J}{\partial z_{j}^{(l)}} \frac{\partial z_{j}^{(l)}}{\partial b_{j}^{(l)}} = e_{j}^{(l)}. $$
5.3.2. Biểu diễn đạo hàm dưới dạng vectơ
Để tăng tốc độ tính toán của thuật toán ta cần đưa các biểu thức đạo hàm về dạng dưới dạng vectơ hoặc ma trận. Đối với Stochastic Gradient Descent, ta sẽ biểu diễn chúng dưới dạng vectơ.
Ở tầng đầu ra, ta cần tính:
$$ \mathbf{e}^{(L)} = \frac{\partial J}{\partial \mathbf{z}^{(L)}}, $$
$$ \frac{\partial J}{\partial \mathbf{W}^{(L)}} = \mathbf{a}^{(L-1)} \mathbf{e}^{(L)T}, $$
$$ \frac{\partial J}{\partial \mathbf{b}^{(L)}} = \mathbf{e}^{(L)}. $$
Đối với các tầng ẩn, ta có:
$$ \mathbf{e}^{(l)} = \left( \mathbf{W}^{(l+1)} \mathbf{e}^{(l+1)} \right) \odot f_l^\prime(z^{(l)}), $$
$$ \frac{\partial J}{\partial \mathbf{W}^{(l)}} = \mathbf{a}^{(l-1)} \mathbf{e}^{(l)T}, $$
$$ \frac{\partial J}{\partial \mathbf{b}^{(l)}} = \mathbf{e}^{(l)}. $$
Trong đó, $\odot$ là phép nhân từng phần tử (element-wise/Hadamard product)
5.3.3. Biểu diễn đạo hàm dưới dạng ma trận
Trong trường hợp ta dùng Batch hay Mini-batch Gradient Descent, ta cần biểu diễn chúng dưới dạng ma trận.
Giả sử mỗi kì huấn luyện ta sử dụng $N$ mẫu. Vậy ma trận $X \in \mathbb{R}^{d^{(0)} \times N}$ sẽ có dạng $N$ vectơ đặc trưng $x_n$ được xếp liên tiếp nhau theo hàng ngang. Tương tự, ma trận $Y \in \mathbb{R}^{d^{(L)} \times N}$ gồm $N$ vectơ kết quả $y_n$ xếp kế bên nhau.
Mỗi vectơ trong $X$ sẽ tính được các vectơ kích hoạt, sai số tương đương với các cột của $A^{(l)} \in \mathbb{R}^{d^{(l)} \times N}$ và $E^{(l)} \in \mathbb{R}^{d^{(l)} \times N}$.
Ở tầng đầu ra, ta cần tính:
$$ \mathbf{E}^{(L)} = \frac{\partial J}{\partial \mathbf{Z}^{(L)}}, $$
$$ \frac{\partial J}{\partial \mathbf{W}^{(L)}} = \mathbf{A}^{(L-1)} \mathbf{E}^{(L)T}, $$
$$ \frac{\partial J}{\partial \mathbf{b}^{(L)}} = \sum_{n=1}^{N} \mathbf{e}_n^{(L)}. $$
Đối với các tầng ẩn, ta có:
$$ \mathbf{E}^{(l)} = \left( \mathbf{W}^{(l+1)} \mathbf{E}^{(l+1)} \right) \odot f_l^\prime(z^{(l)}), $$
$$ \frac{\partial J}{\partial \mathbf{W}^{(l)}} = \mathbf{A}^{(l-1)} \mathbf{E}^{(l)T}, $$
$$ \frac{\partial J}{\partial \mathbf{b}^{(l)}} = \sum_{n=1}^{N} \mathbf{e}_n^{(l)}. $$
5.4. Cập nhật tham số
Sau khi tính được đạo hàm, các thuật toán tối ưu dựa trên gradient điều chỉnh các tham số theo hướng ngược với gradient. Giả sử thuật toán tối ưu ta chọn là Gradient Descent, tham số của mô hình ở lần lặp thứ $t$:
$$ \theta^{(t)} = \theta^{(t-1)} - \eta \frac{\partial J}{\partial \theta^{(t-1)}}, \;\;\; \theta \in \{\mathbf{W}^{(1)}, \mathbf{b}^{(1)}, \mathbf{W}^{(1)}, \mathbf{b}^{(1)}, ..., \mathbf{W}^{(L)}, \mathbf{b}^{(L)}\}, $$
với $\eta$ là tốc độ học.
6. Mô tả dự án
6.1. Đề tài
Mục tiêu của nhóm là tạo ra một trang web đơn giản - nhận đầu vào một bức ảnh RGB với 2 màu chủ đạo, một màu cho nền và màu còn lại cho chữ số từ 0 đến 9. Hệ thống sẽ trả về kết quả dự đoán con số đó.
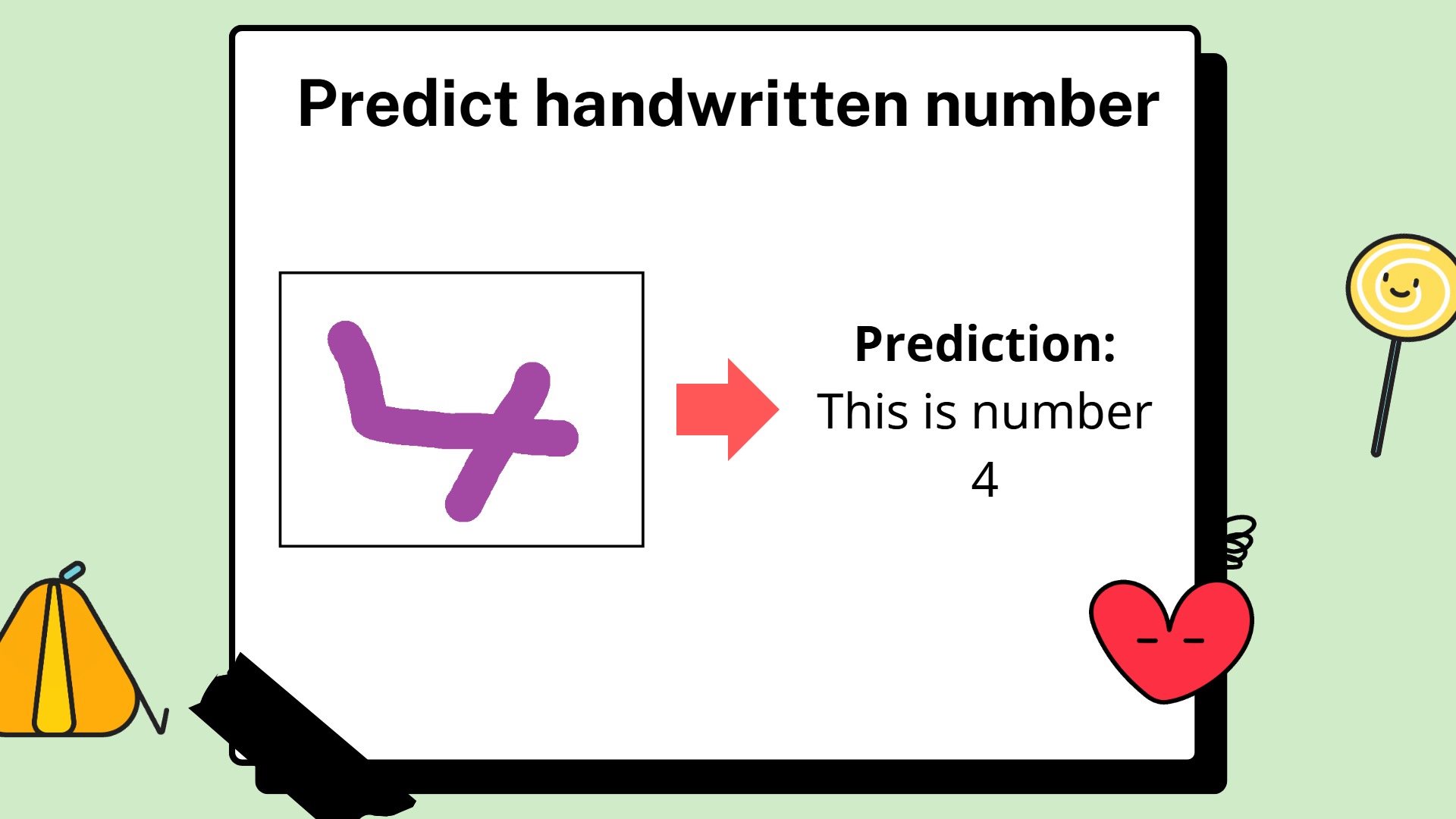
6.2. Thực hiện
6.2.1. Xử lí tập huấn luyện
Để huấn luyện cho mô hình phân loại chữ số viết tay, hiện nay phổ biến nhất là tập dữ liệu MNIST - tổng hợp 70 000 tấm hình chữ viết tay trắng đen (grayscale). Mỗi tấm hình có 28 điểm ảnh ở cả chiều dài và rộng, tổng là $28 \times 28 = 784$ điểm ảnh. Mỗi điểm ảnh có giá trị từ 0 đến 255, với 0 là màu đen - nền của bức ảnh; và 255 là màu trắng - màu chủ đạo của các chữ số viết tay.
Kết hợp với mỗi tấm hình là nhãn, thể hiện chính xác giá trị con số được ghi trong tấm hình đó, cùng nhau tạo nên những một mẫu (sample) - dùng để huấn luyện hoặc đánh giá mô hình.
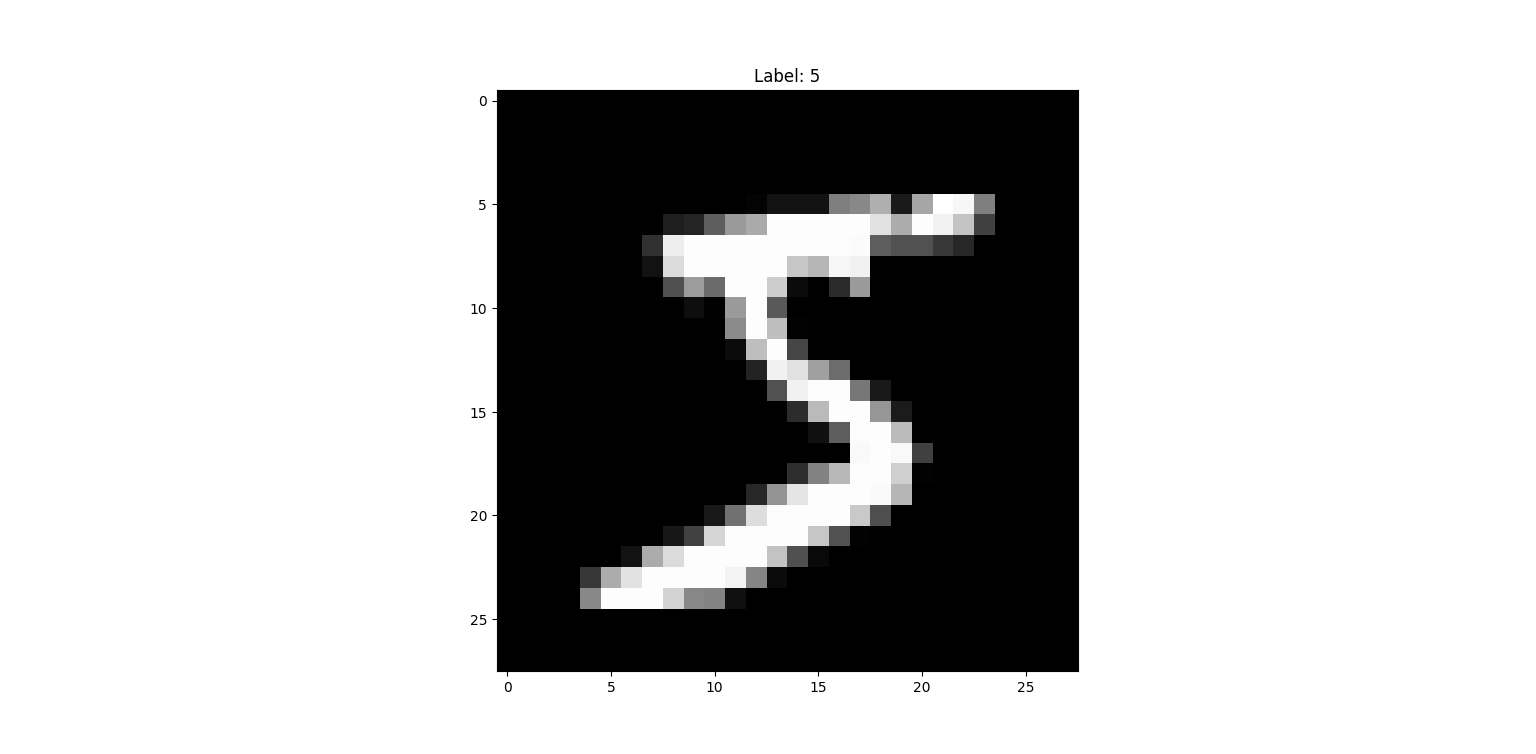
Để tăng độ hiệu quả cho mô hình, dữ liệu đầu vào được chỉnh tỉ lệ từ 0 đến 255 thành 0 đến 1. May thay, Pytorch có cung cấp các hàm dùng chuyên dụng.
import os
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
from tqdm.auto import tqdm
transform = transforms.Compose([
transforms.ToTensor()
])
root = os.path.join(os.getcwd(), "data")
train_ds = datasets.MNIST(root=root, train=True, download=True, transform=transform)
val_ds = datasets.MNIST(root=root, train=False, download=True, transform=transform)
Cụ thể, phương thức .ToTensor chuyển dữ liệu từ dạng ảnh sang tenxơ và thay đổi giá trị các điểm ảnh từ 0-255 thành 0-1. Và các biến train_ds và val_ds lần lượt là tập huấn luận và kiểm thử.
6.2.2. Kiến trúc mô hình MLP
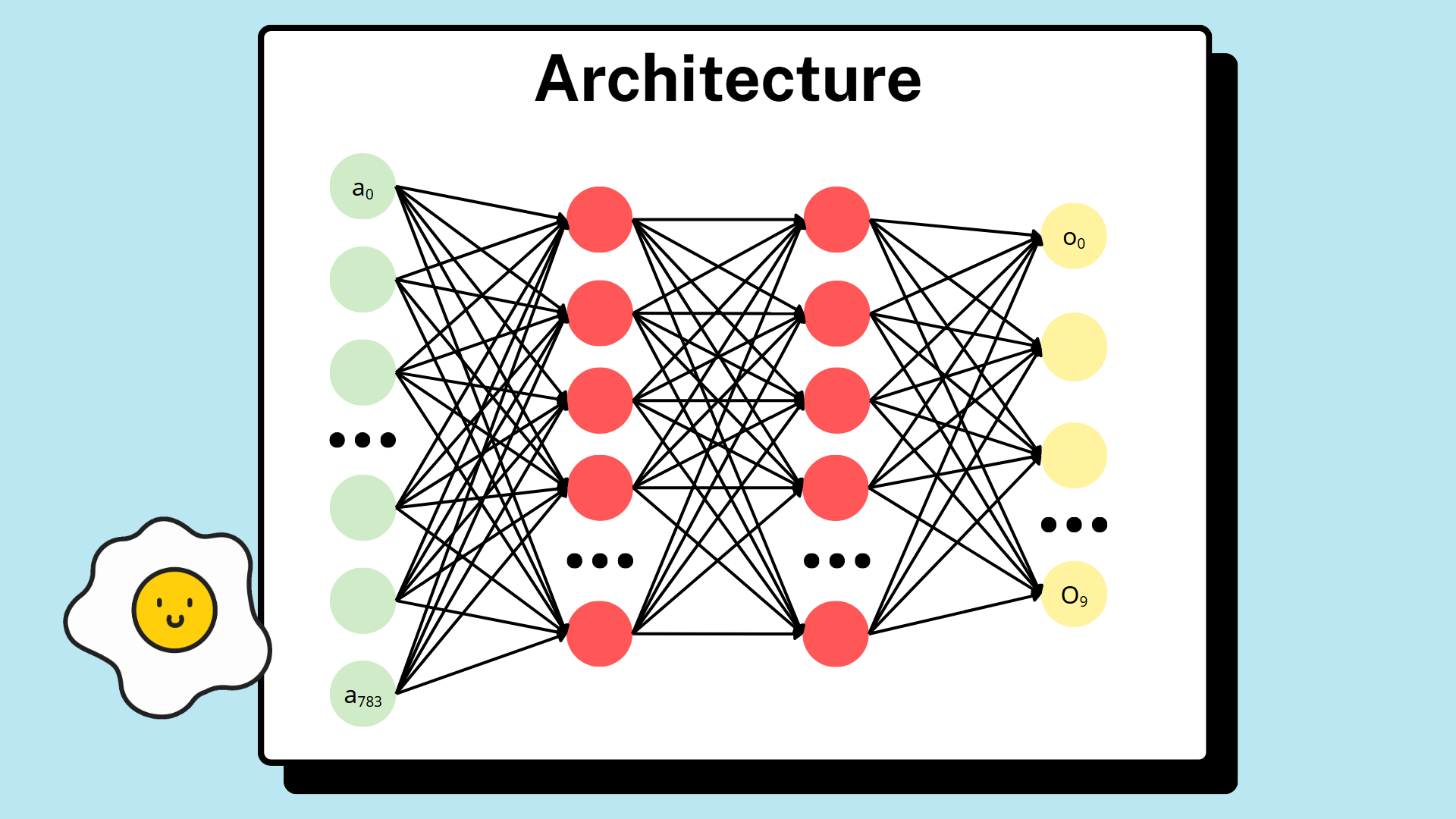
Mô hình MLP đơn giản mà nhóm chọn để giải quyết đề tài có cấu trúc gồm 1 tầng đầu vào, 2 tầng ẩn và 1 tầng đầu ra.
Tầng đầu vào có nhiệm vụ làm phẳng hình ảnh 2 chiều dạng sang mảng một chiều đúng với kiến trúc của mô hình MLP, điều đó đồng nghĩa với có 784 nơ-ron ở tầng này (mỗi nơ-ron cho một điểm ảnh). Hai tầng ẩn sau đó đều sử dụng ReLU làm hàm kích hoạt, khác với tầng đầu ra - sử dụng hàm Softmax. Tầng đầu ra có 10 nơ-ron, giá trị của mỗi nơ-ron tương ứng với xác suất của 10 chữ số (từ 0-9) là chữ số trong tấm hình. Nói cách khác, giá trị của nơ-ron thứ nhất là xác suất số trong hình là 0; giá trị của nơ-ron thứ hai là xác suất số trong bức hình là 1;... Xác suất số nào cao nhất thì mô hình sẽ trả về kết quả đó.
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
INPUT_SIZE = 28 * 28
HIDDEN_SIZE_1 = 512
HIDDEN_SIZE_2 = 256
OUTPUT_SIZE = 10
model = nn.Sequential(
nn.Flatten(),
nn.Linear(INPUT_SIZE, HIDDEN_SIZE_1),
nn.ReLU(),
nn.Linear(HIDDEN_SIZE_1, HIDDEN_SIZE_2),
nn.ReLU(),
nn.Linear(HIDDEN_SIZE_2, OUTPUT_SIZE)
).to(DEVICE)
Đoạn mã trên là phần định nghĩa mô hình đúng với phần mô tả phía trên. Điều khác biệt duy nhất là nhóm chưa định nghĩa hàm kích hoạt Softmax cho tầng đầu ra. Có sự khác biệt này là bởi hàm mất mát Cross-Entropy, sẽ được định nghĩa ở phần huấn luyện, đã có tích hợp sẵn hàm lớp kích hoạt Softmax ở phía trước nó; vì thể ta không cần phải định nghĩa nó đây.
6.2.3. Huấn luyện và kiểm thử
Để tăng tốc cho quá trình huấn luyện và kiểm thử, nhóm không đưa cùng lúc 60 000 mẫu vào thẳng mô hình mà chia nhỏ ra thành các lô (batch) với kích thước của mỗi lô (batch size) là 64 mẫu.
BATCH_SIZE = 64
train_loader = DataLoader(train_ds, batch_size=BATCH_SIZE, shuffle=True)
val_loader = DataLoader(val_ds, batch_size=BATCH_SIZE, shuffle=False)
Một trong những thuật toán tối ưu phổ biến nhất để huấn luyện mô hình là Adam, một cải tiến từ Gradient Descent. Nó được cài đặt như sau, trong đó lr là tốc độ học (learning rate).
lr = 1e-3
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
Hàm huấn luyện và kiểm thử lần lượt được đĩnh nghĩa như sau:
def train_one_epoch(model, loader, optimizer):
model.train()
total, correct, total_loss = 0, 0, 0.0
for x, y in tqdm(loader, leave=False):
x, y = x.to(DEVICE), y.to(DEVICE)
logits = model(x)
loss = F.cross_entropy(logits, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item() * x.size(0)
preds = logits.argmax(dim=1)
correct += (preds == y).sum().item()
total += x.size(0)
return total_loss / total, correct / total
def evaluate(model, loader):
model.eval()
total, correct, total_loss = 0, 0, 0.0
with torch.no_grad():
for x, y in loader:
x, y = x.to(DEVICE), y.to(DEVICE)
logits = model(x)
loss = F.cross_entropy(logits, y)
total_loss += loss.item() * x.size(0)
preds = logits.argmax(dim=1)
correct += (preds == y).sum().item()
total += x.size(0)
return total_loss / total, correct / total
Sau đó, ta huấn luyện và kiểm thử mô hình:
epochs = 5
for ep in range(1, epochs+1):
t_loss, t_acc = train_one_epoch(model, train_loader, optimizer)
v_loss, v_acc = evaluate(model, val_loader)
print(f"Epoch {ep}: train_loss={t_loss:.4f} train_acc={t_acc:.4f} | val_loss={v_loss:.4f} val_acc={v_acc:.4f}")

Và cuối cùng, nhóm lưu lại các tham số mô hình để dùng cho hệ thống.
PATH = "model.pt"
torch.save(model.state_dict(), PATH)
6.2.4. Xử lí ảnh từ người dùng
Hiện mô hình chỉ mới học được các ảnh trắng đen từ tập MNIST, mà mục tiêu của dự án là các bức hình RGB với 2 màu chủ đạo. Bởi thế, ta cần phải xử lí hình mà người dùng tải lên hệ thống. Sau đâu là các bước xử lí hình ảnh:
- Bước 1: Chuyển ảnh từ RGB thành trắng đen
- Bước 2: Thay đổi kích thước ảnh thành $28 \times 28$ để vừa với đầu vào của mô hình
- Bước 3: Đảo màu nếu chữ số đen, nền trắng (ảnh MNIST nền đen số trắng, ngược với yêu cầu dự án)
- Bước 4: Làm sạch ảnh sử dụng thresholding, ảnh chỉ còn 2 giá trị 0 cho đen và 255 cho trắng
- Bước 5: Căn giữa cho chữ số (ảnh MNIST các con số đều được căn giữa)
- Bước 6: Chỉnh tỉ lệ cho giá trị điểm ảnh từ 0 đến 255 thành 0 đến 1, để trùng với giá trị điểm ảnh của tập MNIST mà mô hình được huấn luyện
- Bước 7: Thay đổi cấu trúc (reshape) để phù hợp với đầu vào của mô hình.
- Bước 8: Chuyển bức hình về dạng tenxơ.
import cv2
def preprocess_for_mnist_pytorch(image):
# 1. Chuyển từ RGB (Gradio) sang Grayscale
gray = cv2.cvtColor(image, cv2.COLOR_RGB2GRAY)
# 2. Resize ảnh về kích thước 28x28
resized = cv2.resize(gray, (28, 28), interpolation=cv2.INTER_AREA)
# 3. Đảo màu nếu là chữ đen nền trắng
corners = [resized[0,0], resized[0,-1], resized[-1,0], resized[-1,-1]]
if np.mean(corners) > 127:
resized = cv2.bitwise_not(resized)
# 4. Otsu Thresholding để làm sạch ảnh tuyệt đối (0 hoặc 255)
_, clean = cv2.threshold(resized, 127, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
# 5. Căn giữa theo trọng tâm
centered = center_digit(clean)
# 6. Đưa về khoảng [0,1]
scaled = centered.astype('float32') / 255.0
# 7. Reshape để phù hợp với đầu vào của mô hình
reshaped = scaled.reshape(1, 1, 28, 28)
# 8. Chuyển ảnh sang pytorch tensor
final = torch.from_numpy(reshaped).float()
return final
Trong đó, hàm căn giữa center_digit được định nghĩa như sau:
def center_digit(img):
# img là ảnh nhị phân 28x28 (chữ trắng nền đen)
# Công thức M_{ij} = \sum x^i * y^j * giá trị pixel (độ sáng)
# Ví dụ m00 = \sum x^0 * y^0 * giá trị pixel = tổng độ sáng bức hình
# Tương tự m10 = \sum x * giá trị pixel = trung bình trọng số độ sáng theo x
# Tương tự m01 = \sum y * giá trị pixel = trung bình trọng số độ sáng theo y
M = cv2.moments(img)
if M['m00'] != 0:
cx = int(M['m10'] / M['m00']) # Tọa độ x của trọng tâm (x ngang)
cy = int(M['m01'] / M['m00']) # Tọa độ y của trọng tâm (y dọc)
# Tính toán độ lệch so với tâm hình học (14, 14)
shift_x = 14 - cx
shift_y = 14 - cy
# Ma trận dịch chuyển
M_shift = np.float32([[1, 0, shift_x], [0, 1, shift_y]])
# Lấy toạ độ từng pixel của img nhân với ma trận dịch chuyển,
# Nếu ra ngoài 28*28 thì bỏ, các ô chưa có thông tin mặc định = 0
centered_img = cv2.warpAffine(img, M_shift, (28, 28))
return centered_img
return img
6.2.5. Tạo ứng dụng
Về phần mô hình dự đoán, nhóm sẽ tạo một mô hình có cùng kiến trúc với mô hình đã huấn luyện. Sau đó nạp các tham số từ mô đã huấn luyện vào mô hình mới tạo này.
import torch
import torch.nn as nn
INPUT_SIZE = 28 * 28
HIDDEN_SIZE_1 = 512
HIDDEN_SIZE_2 = 256
OUTPUT_SIZE = 10
model = nn.Sequential(
nn.Flatten(),
nn.Linear(INPUT_SIZE, HIDDEN_SIZE_1),
nn.ReLU(),
nn.Linear(HIDDEN_SIZE_1, HIDDEN_SIZE_2),
nn.ReLU(),
nn.Linear(HIDDEN_SIZE_2, OUTPUT_SIZE)
).to(DEVICE)
# Tải các tham số từ mô hình đã huấn luyện
PATH = 'model.pt'
state_dict = torch.load(PATH)
# Nạp các tham số vào mô hình mới
model.load_state_dict(state_dict)
# Chuyển mô hình sang chế độ suy luận
model.eval()
Về phần giao diện, nhóm sử dụng thư viện Gradio. Chỉ với một vài dòng lệnh đơn giản, nhóm đã tạo được một giao diện trông có vẻ ổn.
import gradio as gr
def predict_number(image):
if image is None:
return "Bạn chưa tải ảnh lên"
input = preprocess_for_mnist_pytorch(image)
logit = model(input)
prediction = logit.argmax(dim=1)
return f"Đây là số: {prediction.item()}"
demo = gr.Interface(
fn=predict_number,
inputs=gr.Image(label="Tải ảnh chữ số của bạn"),
outputs=gr.Textbox(label="Kết quả"),
api_name="Predict handwritten digits",
title="Dự đoán chữ số viết tay từ 0-9",
description="Dự án của nhóm CONQ027, chương trình AIO Conquer 2026"
)
demo.launch()
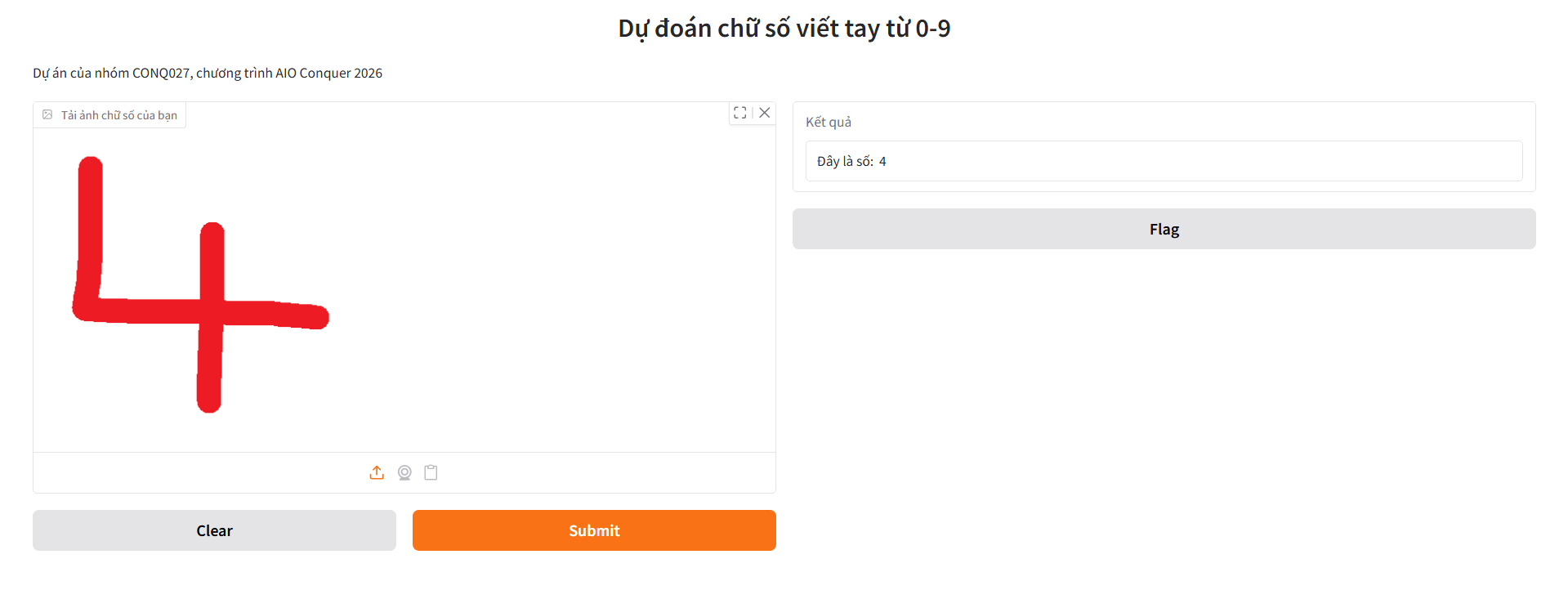
Dưới đây là giao diện của ứng dụng. Bên trái có 1 cửa sổ để người dùng tải hình ảnh lên. Sau khi người dùng tải ảnh lên và nhấn "submit", cửa sổ bên phải sẽ trả về kết quả dự đoán chữ số trong bức hình.
7. Kết Luận
Mô hình Multi-layer Perceptron tuy cũ kĩ, đơn giản và không hiệu quả bằng các mô hình được phát triển sau này, nhưng những kiến thức xung quanh nó là nền tảng của Deep Learning. Dự án đã hoàn thành từ nghiên cứu lí thuyết đến xây dựng và thực nghiệm mô hình Multi-layer Perceptron (MLP) cho bài toán nhận dạng chữ số viết tay, qua giúp nhóm củng cố và hiểu hơn những kiến thức đã học.
8. Tài liệu tham khảo
Vu, H. T. (2017). Multi-layer Perceptron and Backpropagation. Machine Learning cơ bản. https://machinelearningcoban.com/2017/02/24/mlp
Tran, H. D., Duong, D. T., Dinh, Q. V. (2025). Step-by-Step: Multi-layer Perceptron
Regression. AI VIET NAM. https://lms.aivietnam.edu.vn/api/files/6919b01eeb7f1890ba6b65ce/Documents%2F2025-10%2FM06W03-StudyGuide%26Reading%2FM06W03_Reading_MLP.pdf
Chưa có bình luận nào. Hãy là người đầu tiên!