
Nghiên cứu và Thực hiện Trực quan hóa Dữ liệu bằng Python
1. Mở đầu: Tầm quan trọng của trực quan hóa dữ liệu
 Hình 1: Ví dụ về trực quan hóa dữ liệu
Hình 1: Ví dụ về trực quan hóa dữ liệu
Trong phân tích dữ liệu hiện đại, trực quan hóa không đơn thuần là việc trình bày các con số dưới dạng hình ảnh, mà là một quy trình thiết yếu để chuyển hóa thông tin thô thành tri thức hữu dụng. Như Cole Nussbaumer Knaflic đã khẳng định trong tác phẩm Storytelling With Data: A Data Visualization Guide for Business Professionals:
"Trực quan hóa dữ liệu là sự giao thoa giữa khoa học và nghệ thuật. Nó không chỉ đơn giản là tạo ra những biểu đồ đẹp mắt, mà là hiểu rõ bối cảnh, lựa chọn cách hiển thị phù hợp và loại bỏ những yếu tố gây nhiễu để tập trung vào thông điệp cốt lõi."
Việc bỏ qua bước trực quan hóa và chỉ dựa vào các chỉ số thống kê tổng hợp có thể dẫn đến những sai lầm nghiêm trọng trong việc nhận diện bản chất của hiện tượng và đưa ra quyết định sai lệch.
1.1. Phân tích thực nghiệm qua Bộ tứ Anscombe (Anscombe's Quartet)
Để minh chứng cho tầm quan trọng của việc quan sát dữ liệu bằng hình ảnh, nhà thống kê Francis Anscombe đã xây dựng bốn bộ dữ liệu (được ký hiệu là I, II, III, IV). Mặc dù các bộ dữ liệu này có cấu trúc điểm dữ liệu khác nhau hoàn toàn, chúng lại sở hữu các đặc trưng thống kê mô tả gần như đồng nhất.
Dữ liệu thô và Thống kê mô tả
Trước khi quan sát bằng biểu đồ, việc xem xét dữ liệu thô và các chỉ số thống kê là bước đầu tiên trong quy trình phân tích. Bảng dưới đây trình bày chi tiết các cặp giá trị $(x, y)$ của bốn tập dữ liệu:
| STT | Tập I (x) | Tập I (y) | Tập II (x) | Tập II (y) | Tập III (x) | Tập III (y) | Tập IV (x) | Tập IV (y) |
|---|---|---|---|---|---|---|---|---|
| 1 | 10.0 | 8.04 | 10.0 | 9.14 | 10.0 | 7.46 | 8.0 | 6.58 |
| 2 | 8.0 | 6.95 | 8.0 | 8.14 | 8.0 | 6.77 | 8.0 | 5.76 |
| 3 | 13.0 | 7.58 | 13.0 | 8.74 | 13.0 | 12.74 | 8.0 | 7.71 |
| 4 | 9.0 | 8.81 | 9.0 | 8.77 | 9.0 | 7.11 | 8.0 | 8.84 |
| 5 | 11.0 | 8.33 | 11.0 | 9.26 | 11.0 | 7.81 | 8.0 | 8.47 |
| 6 | 14.0 | 9.96 | 14.0 | 8.10 | 14.0 | 8.84 | 8.0 | 7.04 |
| 7 | 6.0 | 7.24 | 6.0 | 6.13 | 6.0 | 6.08 | 8.0 | 5.25 |
| 8 | 4.0 | 4.26 | 4.0 | 3.10 | 4.0 | 5.39 | 19.0 | 12.50 |
| 9 | 12.0 | 10.84 | 12.0 | 9.13 | 12.0 | 8.15 | 8.0 | 5.56 |
| 10 | 7.0 | 4.82 | 7.0 | 7.26 | 7.0 | 6.42 | 8.0 | 7.91 |
| 11 | 5.0 | 5.68 | 5.0 | 4.74 | 5.0 | 5.73 | 8.0 | 6.89 |
Kết quả tính toán các chỉ số cơ bản trên cả bốn bộ dữ liệu cho thấy sự tương đồng tới chữ số thập phân thứ hai:
| Chỉ số thống kê | Giá trị |
|---|---|
| Số lượng quan sát ($n$) | 11 |
| Giá trị trung bình của biến $x$ ($\bar{x}$) | 9.0 |
| Giá trị trung bình của biến $y$ ($\bar{y}$) | 7.50 |
| Phương sai của biến $x$ ($s^2_x$) | 11.0 |
| Phương sai của biến $y$ ($s^2_y$) | 4.12 |
| Hệ số tương quan Pearson ($r$) | 0.816 |
| Phương trình hồi quy tuyến tính | $y = 3.00 + 0.500x$ |
Kết quả trực quan hóa
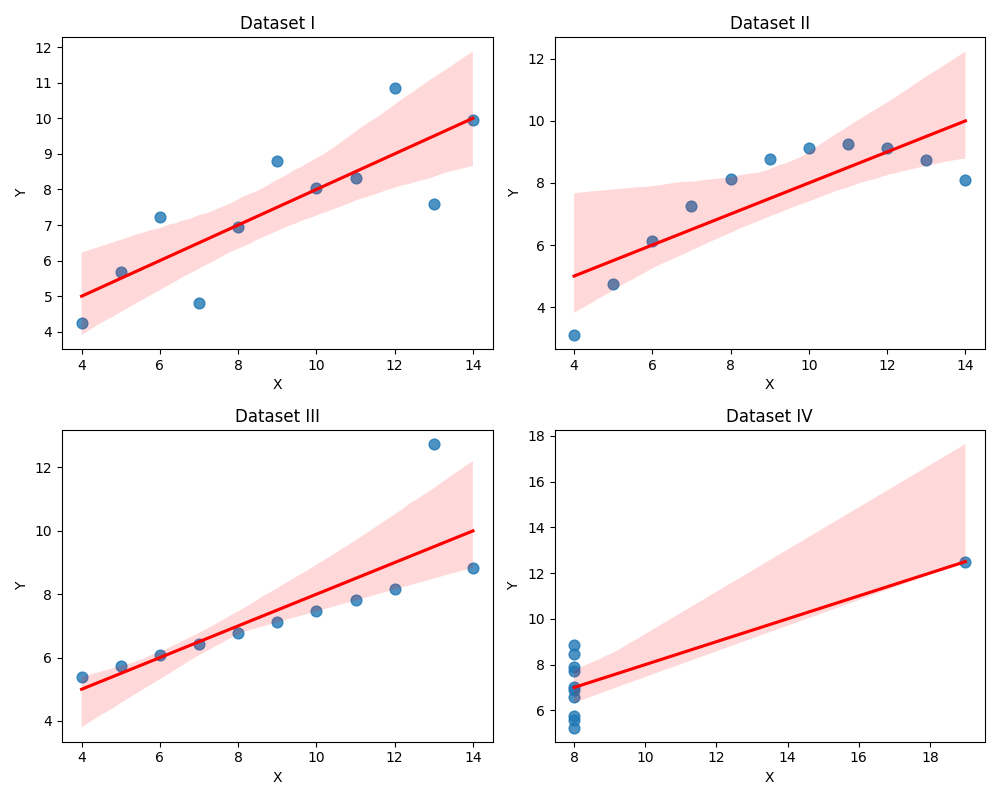 Hình 2: Anscombe trực quan hóa dữ liệu.
Hình 2: Anscombe trực quan hóa dữ liệu.
Tuy nhiên, khi thực hiện vẽ biểu đồ phân tán (Scatter Plot) kết hợp đường hồi quy, sự khác biệt về bản chất của các tập dữ liệu được bộc lộ rõ rệt:
- Bộ dữ liệu I: Tuân thủ mô hình tuyến tính với một độ lệch chuẩn nhất định xung quanh đường hồi quy. Đây là trường hợp lý tưởng cho các thuật toán hồi quy đơn giản.
- Bộ dữ liệu II: Dữ liệu có mối quan hệ phi tuyến tính rõ rệt (dạng parabol). Việc áp dụng mô hình tuyến tính ở đây là không phù hợp và dẫn đến sai số dự báo lớn.
- Bộ dữ liệu III: Tồn tại một mối quan hệ tuyến tính hoàn hảo nhưng bị sai lệch bởi một điểm dữ liệu ngoại lai (outlier) nằm xa trục chính, làm thay đổi đáng kể hệ số góc của đường hồi quy.
- Bộ dữ liệu IV: Cho thấy cấu trúc dữ liệu không bình thường khi các giá trị $x$ không đổi (ngoại trừ một điểm), khiến mô hình hồi quy không phản ánh đúng xu hướng thực tế của phần lớn dữ liệu.
Kết luận từ thực nghiệm này khẳng định rằng: Trực quan hóa dữ liệu là bước bắt buộc để kiểm chứng các giả định thống kê trước khi tiến hành các phân tích chuyên sâu.
1.2. Hệ sinh thái thư viện Python: Matplotlib và Seaborn
Trong môi trường lập trình Python, việc triển khai trực quan hóa được hỗ trợ chủ yếu bởi hai thư viện trọng tâm:
- Matplotlib: Đóng vai trò là thư viện nền tảng (low-level), cung cấp các giao diện lập trình để điều chỉnh chi tiết cấu trúc biểu đồ, từ trục tọa độ cho đến các thuộc tính hình học phức tạp.
- Seaborn: Là thư viện bậc cao (high-level) được xây dựng trên nền tảng Matplotlib. Thư viện này tối ưu hóa cho các phân tích thống kê, hỗ trợ trực tiếp cấu trúc dữ liệu DataFrame của Pandas và tự động hóa việc thiết lập thẩm mỹ đồ họa, giúp quy trình làm việc trở nên hiệu quả hơn.
2. Các dạng biểu đồ phổ biến và cách áp dụng thực tế
Để việc tìm hiểu về trực quan hóa dữ liệu không bị khô khan và chỉ dừng lại ở lý thuyết, chúng ta sẽ thực hành vẽ các biểu đồ này trên một bộ dữ liệu thực tế: student_performance_interactions.csv (Dữ liệu về kết quả học tập của học sinh). Việc áp dụng ngay vào một bài toán phân tích thật sẽ giúp chúng ta dễ dàng hình dung biểu đồ nào dùng để trả lời cho câu hỏi nào, đồng thời khám phá ra những sự thật thú vị (insights) đang ẩn giấu đằng sau những con số.
Để mô hình hồi quy đạt hiệu quả, chúng ta sẽ xem xét các nhóm đặc trưng sau để giải thích cho sự thay đổi của điểm số:
Nhóm Lịch sử học tập (4 biến):
- previous_score: Điểm trung bình tổng quát kỳ trước.
- math_prev_score: Điểm môn Toán kỳ trước.
- science_prev_score: Điểm môn Khoa học kỳ trước.
- language_prev_score: Điểm môn Ngôn ngữ kỳ trước.
Nhóm Hành vi học tập (3 biến):
daily_study_hours: Số giờ tự học mỗi ngày.attendance_percentage: Tỷ lệ có mặt trên lớp (%).homework_completion_rate: Tỷ lệ hoàn thành bài tập về nhà (%).
Nhóm Lối sống & Sức khỏe (3 biến):
- sleep_hours: Số giờ ngủ mỗi đêm.
- screen_time_hours: Số giờ sử dụng thiết bị điện tử.
- physical_activity_minutes: Số phút hoạt động thể chất mỗi ngày.
Nhóm Tâm lý (2 biến):
motivation_score: Chỉ số động lực học tập.exam_anxiety_score: Chỉ số lo lắng khi thi cử.
Nhóm Môi trường & Gia đình (2 biến - Cần mã hóa):
parent_education_level: Trình độ học vấn phụ huynh (Định tính).study_environment: Môi trường học tập (Định tính: Quiet, Moderate, Noisy).
Chúng ta sẽ bắt đầu với nhóm biểu đồ đầu tiên:
Tương quan dữ liệu (Comparison)
Nhóm biểu đồ này được sử dụng khi bạn có nhu cầu đối chiếu sự khác biệt về độ lớn, số lượng, hoặc tỷ lệ giữa các hạng mục/nhóm đối tượng khác nhau.
2.1. Biểu đồ cột (Bar Chart): So sánh giá trị giữa các nhóm phân loại
Biểu đồ cột là công cụ hoàn hảo và phổ biến nhất khi bạn muốn so sánh một đại lượng cụ thể giữa các nhóm riêng biệt.
- Trải nghiệm với Matplotlib:
Giả sử chúng ta muốn trả lời câu hỏi: "Môi trường học tập ảnh hưởng thế nào đến điểm cuối kỳ của học sinh?"
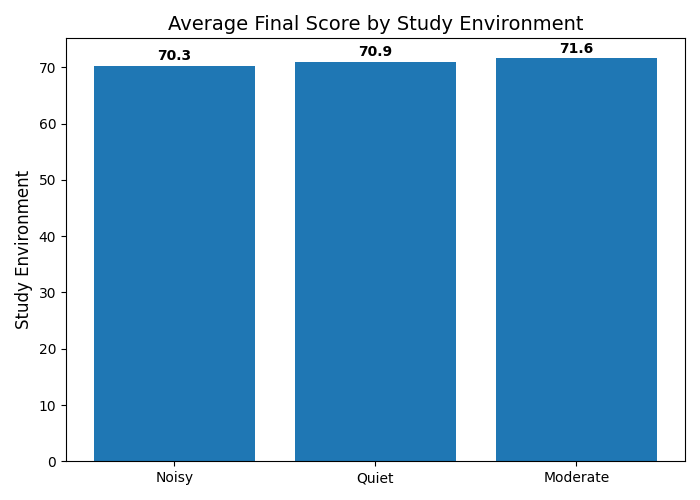 Hình 3: Điểm theo môi trường học tập.
Hình 3: Điểm theo môi trường học tập.
Insight thú vị từ biểu đồ: Theo trực giác, ta thường nghĩ môi trường "Yên tĩnh" (Quiet) sẽ mang lại kết quả tốt nhất. Tuy nhiên, khi nhìn vào biểu đồ thực tế, nhóm học sinh học trong môi trường "Vừa phải" (Moderate) lại có điểm trung bình cao nhất (71.59 điểm), nhỉnh hơn một chút so với Quiet (70.94) và Noisy (70.26). Đây chính là minh chứng rõ ràng nhất cho việc tại sao phân tích dữ liệu phải dựa trên biểu đồ thực tế thay vì phỏng đoán!
- Trải nghiệm với Seaborn:
Seaborn giúp chúng ta tiến xa hơn một bước khi so sánh đa chiều. Lần này, chúng ta muốn xem xét điểm số dựa trên Trình độ học vấn của phụ huynh, nhưng lại muốn tách nhỏ thêm theo Môi trường học tập để xem có sự tương tác nào không.
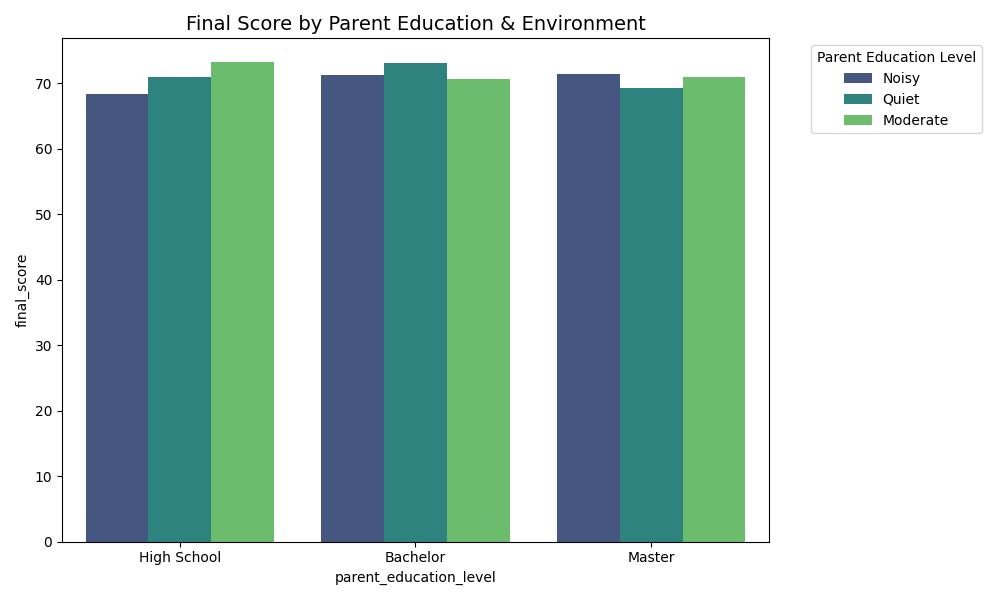 Hình 4: Điểm theo học vấn phụ huynh và môi trường.
Hình 4: Điểm theo học vấn phụ huynh và môi trường.
2.2. Biểu đồ đường (Line Chart): Theo dõi sự thay đổi, xu hướng (Trend)
Mặc dù biểu đồ đường thường được dùng phổ biến nhất cho chuỗi thời gian (time-series), nó vẫn cực kỳ hiệu quả khi bạn muốn thể hiện sự thay đổi liên tục của một biến theo một biến định lượng khác (ví dụ: biến X tăng thì biến Y thay đổi theo quỹ đạo nào).
- Trải nghiệm với Matplotlib:
Chúng ta sử dụng Matplotlib để theo dõi xu hướng thay đổi của Điểm cuối kỳ khi Số giờ tự học mỗi ngày của học sinh tăng dần lên.
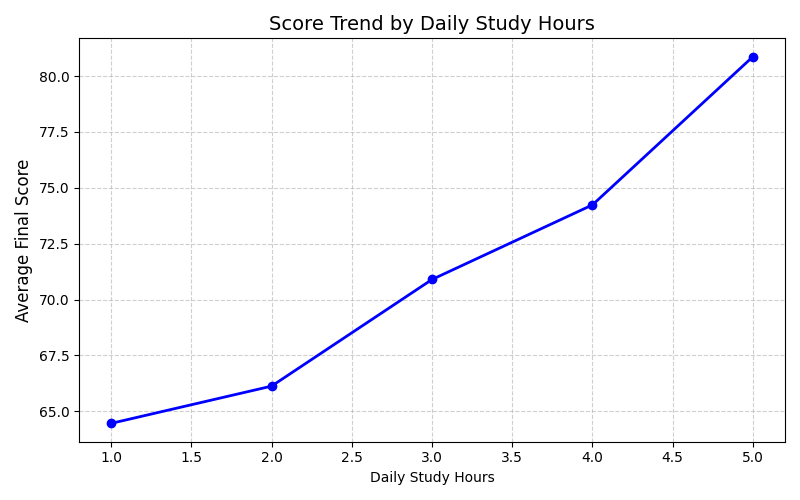 Hình 5: Xu hướng điểm theo giờ tự học.
Hình 5: Xu hướng điểm theo giờ tự học.
- Trải nghiệm với Seaborn:
Với Seaborn, chúng ta sẽ phân tích tác động của Tỷ lệ chuyên cần (điểm danh) đến điểm số.
Trong thực tế, tại cùng một mức tỷ lệ chuyên cần, sẽ có rất nhiều học sinh đạt các điểm số khác nhau. Thay vì vẽ ra một đường zigzag rối mắt từ điểm này sang điểm khác, Seaborn sẽ tự động tính toán và vẽ ra một quỹ đạo trung bình mượt mà. Tuyệt vời hơn nữa, nó tự động bao quanh đường trung bình đó bằng một dải màu mờ — đây chính là "khoảng tin cậy" (confidence interval) trong thống kê, giúp bạn ngay lập tức đánh giá được mức độ dao động và phân tán của dữ liệu tại từng mốc chuyên cần.
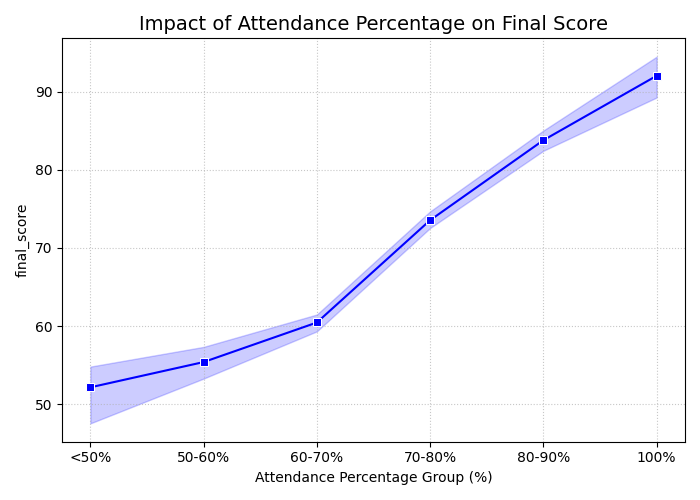 Hình 6: Ảnh hưởng của chuyên cần đến điểm.
Hình 6: Ảnh hưởng của chuyên cần đến điểm.
Phân phối dữ liệu (Distribution)
Phần này tập trung vào các biểu đồ phân phối dữ liệu — một trong những công cụ quan trọng nhất để hiểu rõ cách dữ liệu được phân bố. Khác với Tương quan dữ liệu tập trung vào đối chiếu các nhóm, "Phân phối" giúp trả lời:
- "Dữ liệu phân bố ra sao?"
- "Có bao nhiêu outliers?"
- "Dữ liệu theo phân phối chuẩn hay không?"
2.3. Biểu đồ Histogram: Tần suất xuất hiện của các khoảng giá trị
Biểu đồ Histogram hiển thị tần suất xuất hiện của các khoảng giá trị (bins) — nó giúp chúng ta nhìn thấy "hình dáng" của dữ liệu một cách trực quan.
Trải nghiệm với Matplotlib vs Seaborn:
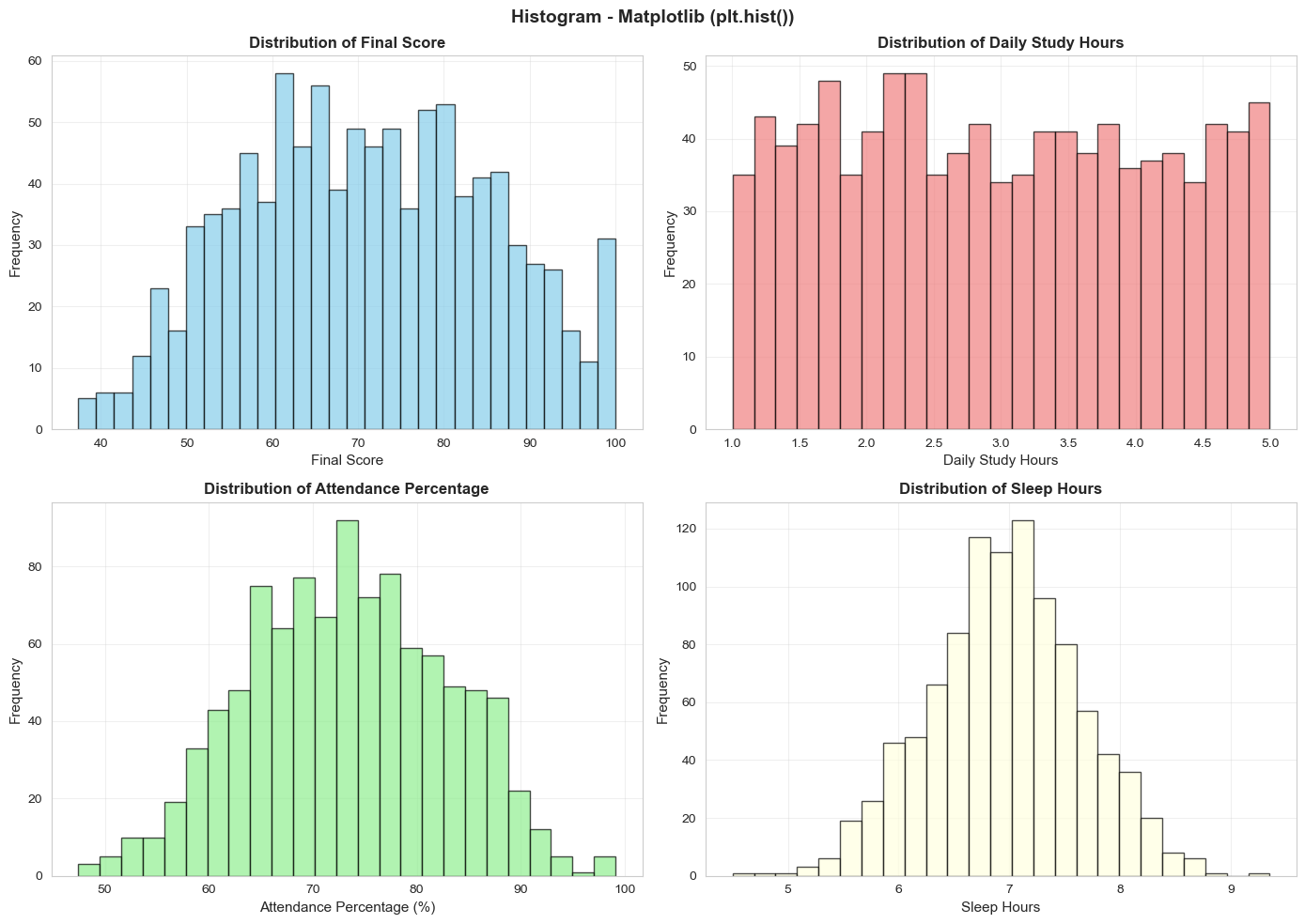 Hình 7: Histogram các biến chính.
Hình 7: Histogram các biến chính.
Matplotlib (plt.hist()): Đơn giản, nhanh chóng. Từ biểu đồ:
- Final Score: Phân phối khá đều 40-100, tập trung 60-80
- Daily Study Hours: Phần lớn 1-3 giờ/ngày, có nhóm học rất nhiều (4-5 giờ)
- Attendance: Có hai "nhóm" rõ: 60-70% (không chuyên cần) và 85-95% (chuyên cần)
- Sleep Hours: Hầu hết 6-8 giờ/ngày (hợp lý)
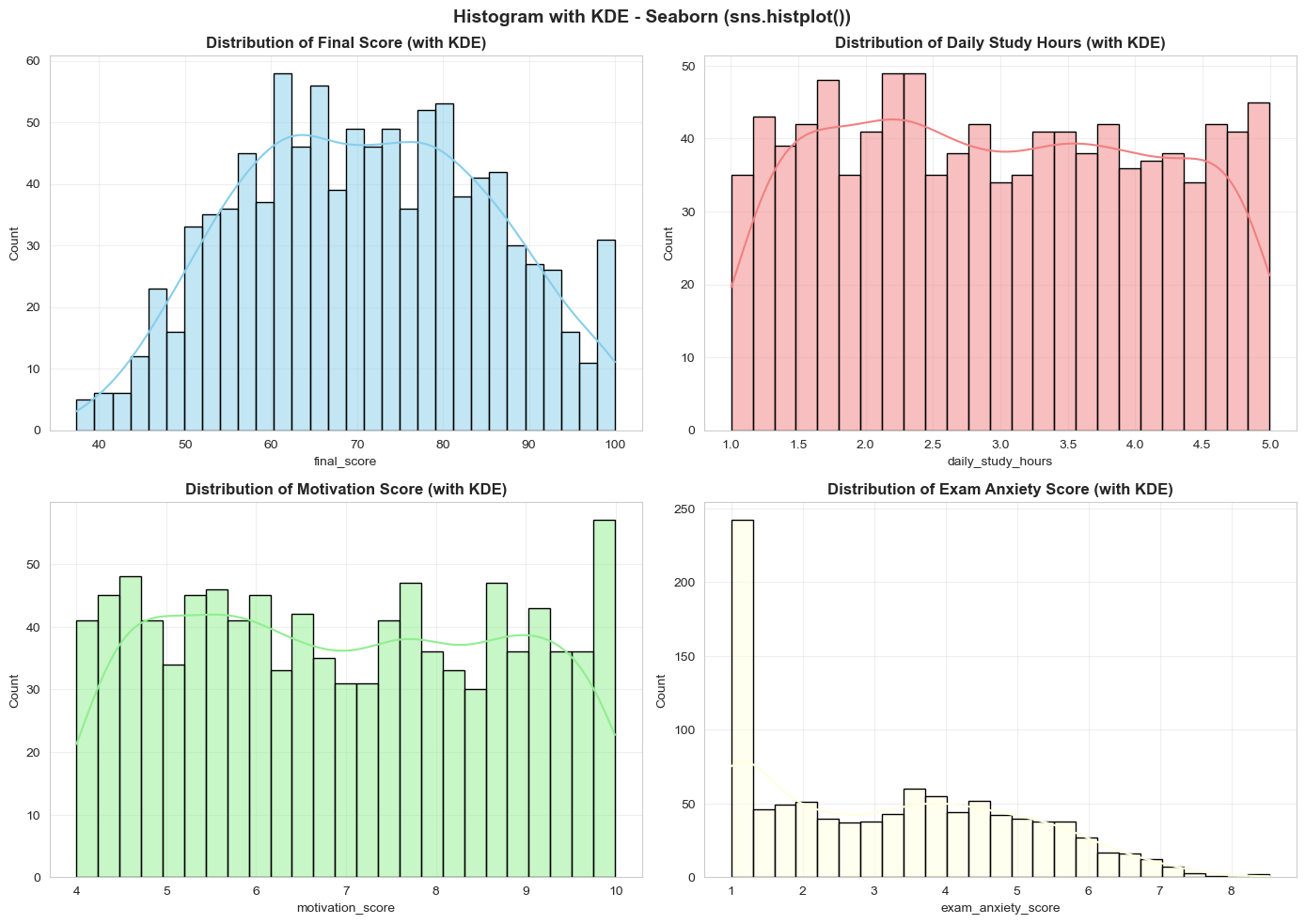 Hình 8: Histogram + KDE.
Hình 8: Histogram + KDE.
Seaborn (sns.histplot + KDE): Thêm đường KDE giúp xác định hình dáng phân phối rõ ràng hơn
- Final Score: Phân phối gần chuẩn, hơi lệch trái
- Motivation Score: Tập trung cao (4-9), hầu hết học sinh có động lực tốt
2.4. Biểu đồ KDE Plot: Hiểu rõ hình dáng phân phối
Nếu Histogram là "ảnh chụp" tường gạch, thì KDE Plot là "tranh vẽ" mượt mà của cùng một bức ảnh. Đây là công cụ hoàn hảo để tập trung vào dạng phân phối.
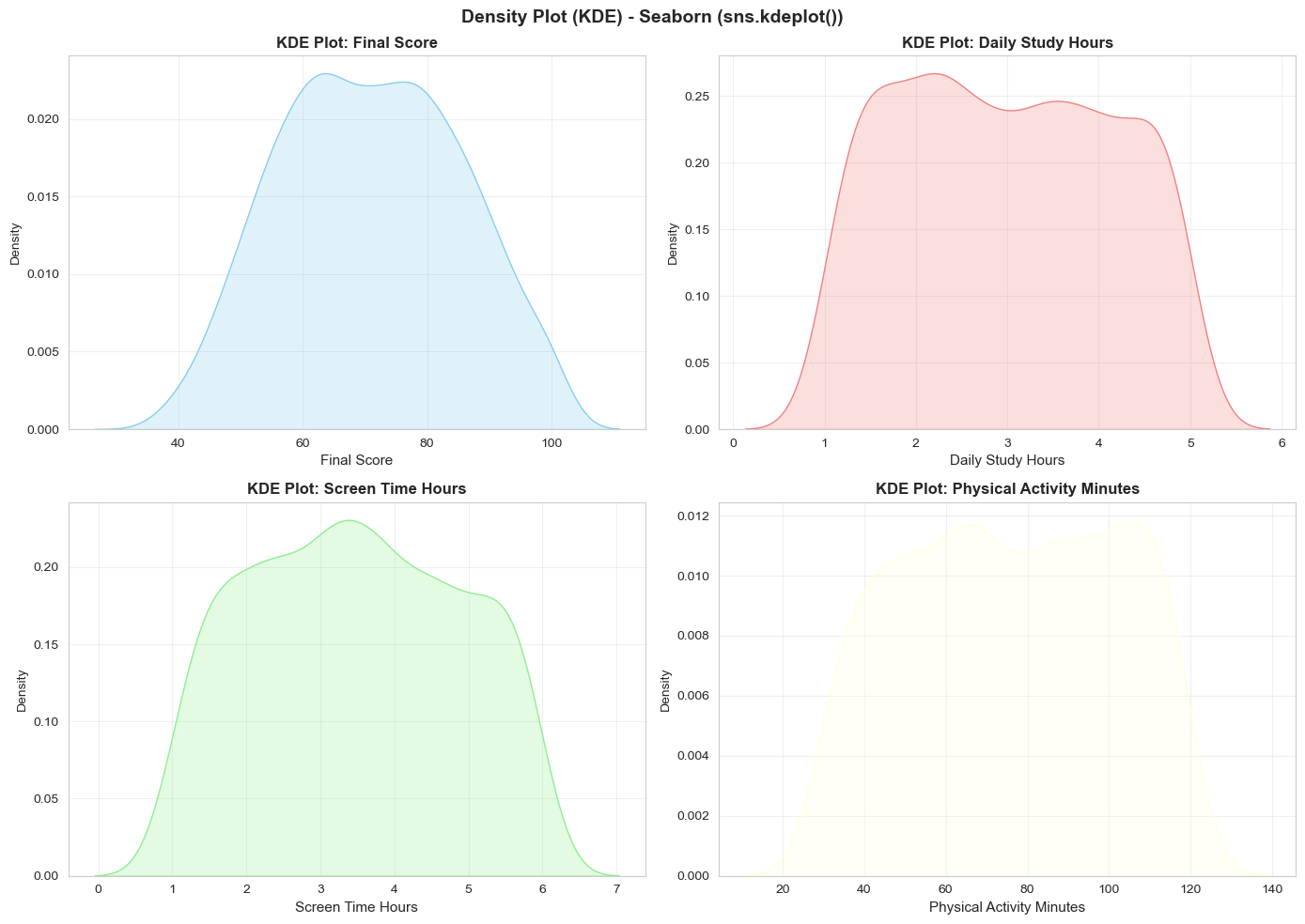 Hình 9: Dạng phân phối qua KDE.
Hình 9: Dạng phân phối qua KDE.
Hiểu biết từ KDE Plot:
- Final Score: Đường cong gần đối xứng, mode ở 60-70 điểm
- Daily Study Hours: Phân phối lệch phải (right-skewed), tập trung 1-3 giờ
- Physical Activity Minutes: Có hai "tâm" — nhóm thích ngồi (30-60 phút) và nhóm vận động (90-120 phút)
2.5. Biểu đồ Hộp (Boxplot): Phát hiện ngoại lệ và so sánh
Biểu đồ hộp (Boxplot) là một trong những công cụ mạnh mẽ nhất để hiểu rõ cấu trúc dữ liệu:
- Hộp (Box): Chứa 50% dữ liệu ở giữa (từ Q1 đến Q3)
- Đường ngang bên trong hộp: Là trung vị (Median - Q2)
- Đường dài phía trên và dưới: Là "mũi ngoài" (whiskers) - chứa khoảng 95% dữ liệu
- Những điểm đỏ lẻ: Là những ngoại lệ (Outliers)
Boxplot đơn biến:
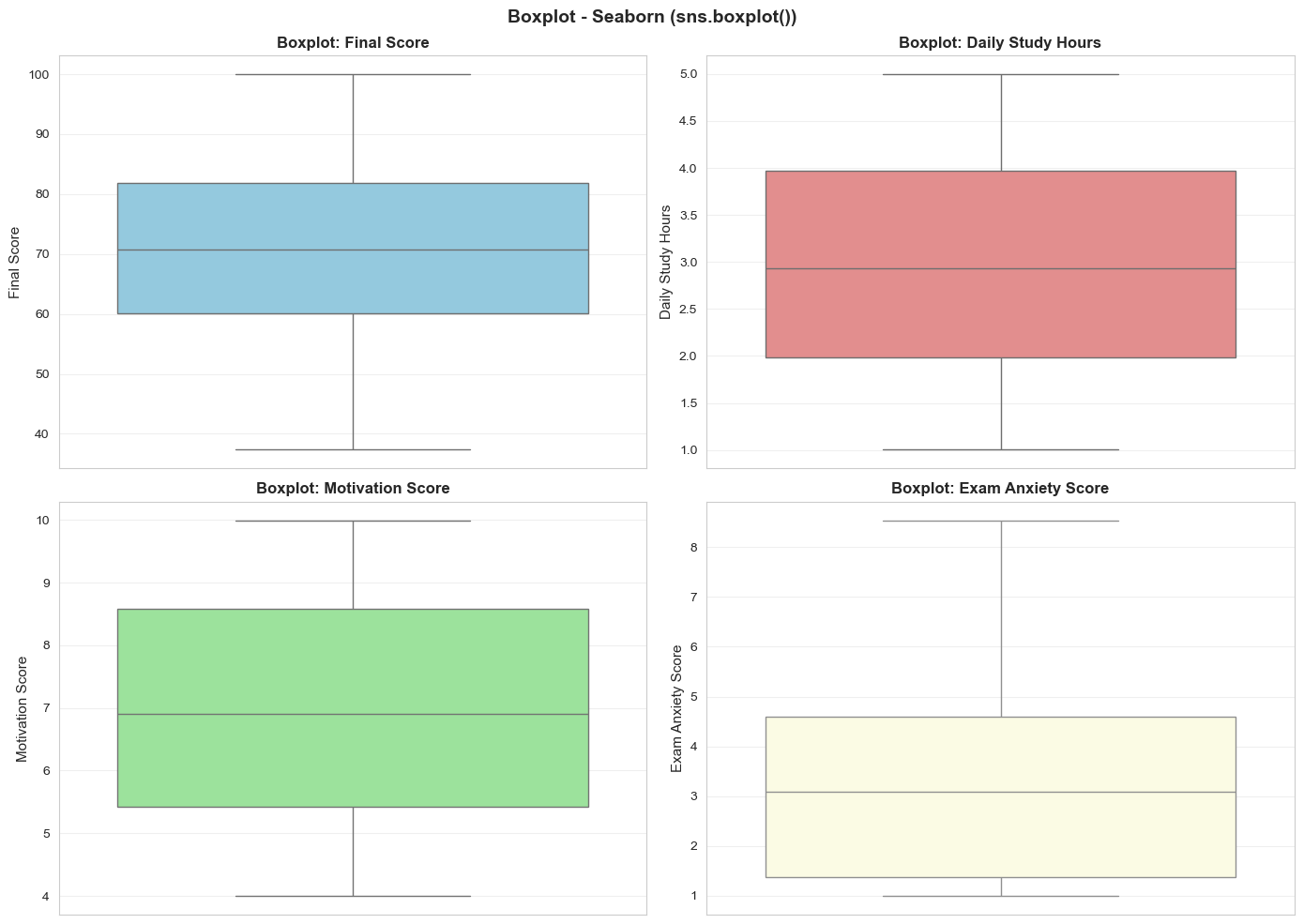 Hình 10: Boxplot đơn biến và ngoại lệ.
Hình 10: Boxplot đơn biến và ngoại lệ.
- Final Score: Không có nhiều outliers, tập trung tốt từ 45-95
- Daily Study Hours: Có outliers ở hai đầu (rất ít hoặc rất nhiều)
- Motivation Score: Hầu hết 3-8, những học sinh dưới 1.5 cần thúc đẩy
- Exam Anxiety: Một số học sinh có lo lắng rất cao (>9)
Boxplot theo Loại điểm:
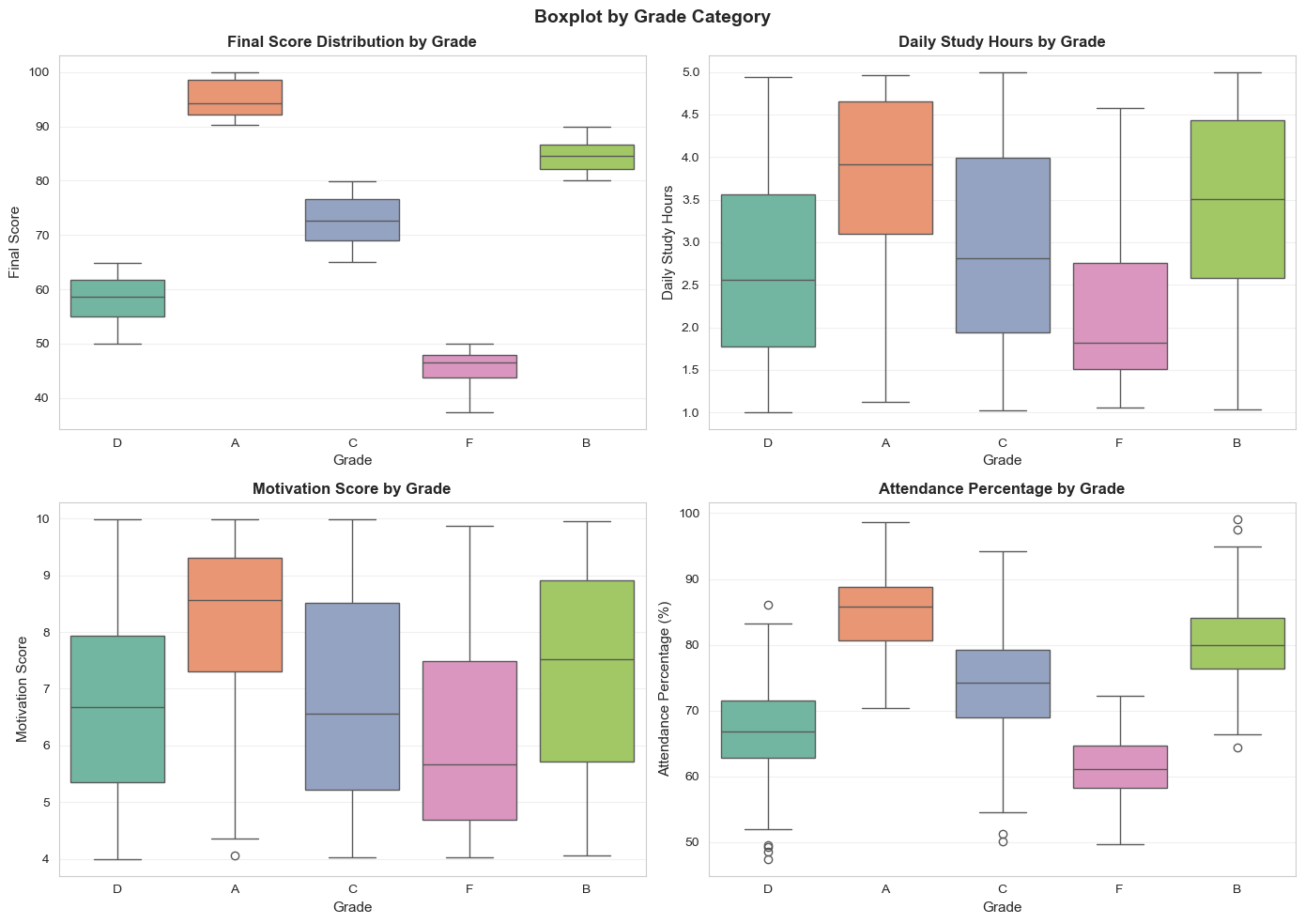 Hình 11: Boxplot theo loại điểm.
Hình 11: Boxplot theo loại điểm.
Phát hiện:
- Loại A → B → C → D → F có điểm giảm dần (rõ ràng)
- Loại A KHÔNG học nhiều hơn loại B, C → chất lượng > số lượng
- Loại A có motivation cao hơn F
- Loại A có chuyên cần cao hơn F, nhưng không 100%
Boxplot theo Môi trường:
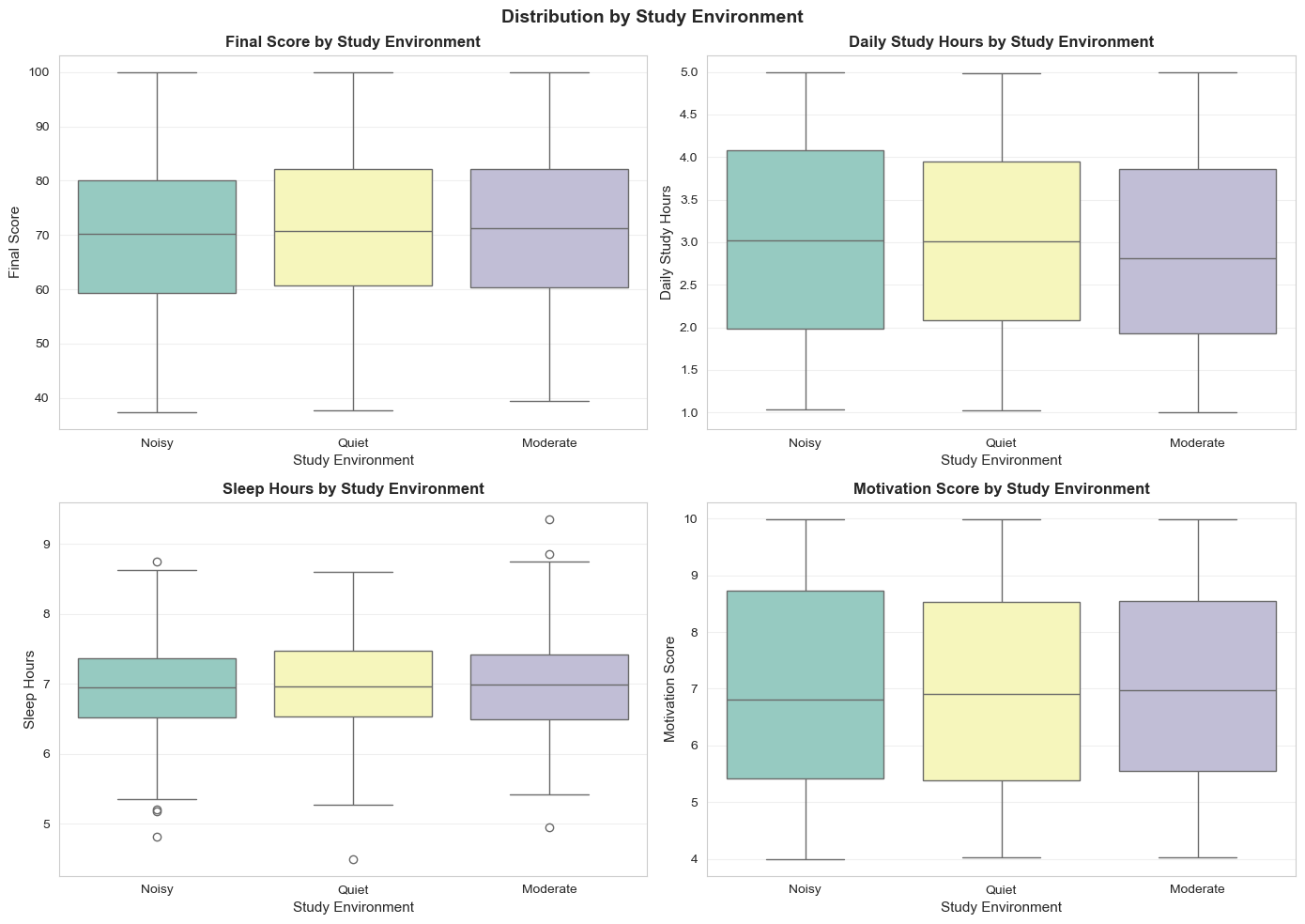 Hình 12: Boxplot theo môi trường học tập.
Hình 12: Boxplot theo môi trường học tập.
- Quiet: median ~72 (cao nhất), nhưng biến thiên rộng
- Noisy: median ~70 (thấp hơn 2-3 điểm)
- Giờ học: 3 môi trường không khác → hiệu quả > giờ học
- Motivation: Không khác biệt → yếu tố nội tại
2.6. Phát hiện ngoại lệ (Outlier Detection)
Một trong những ứng dụng quan trọng nhất của Boxplot là phát hiện outliers. Chúng ta sử dụng công thức IQR (Interquartile Range):
Outliers = Giá trị nằm ngoài [Q1 - 1.5×IQR, Q3 + 1.5×IQR]
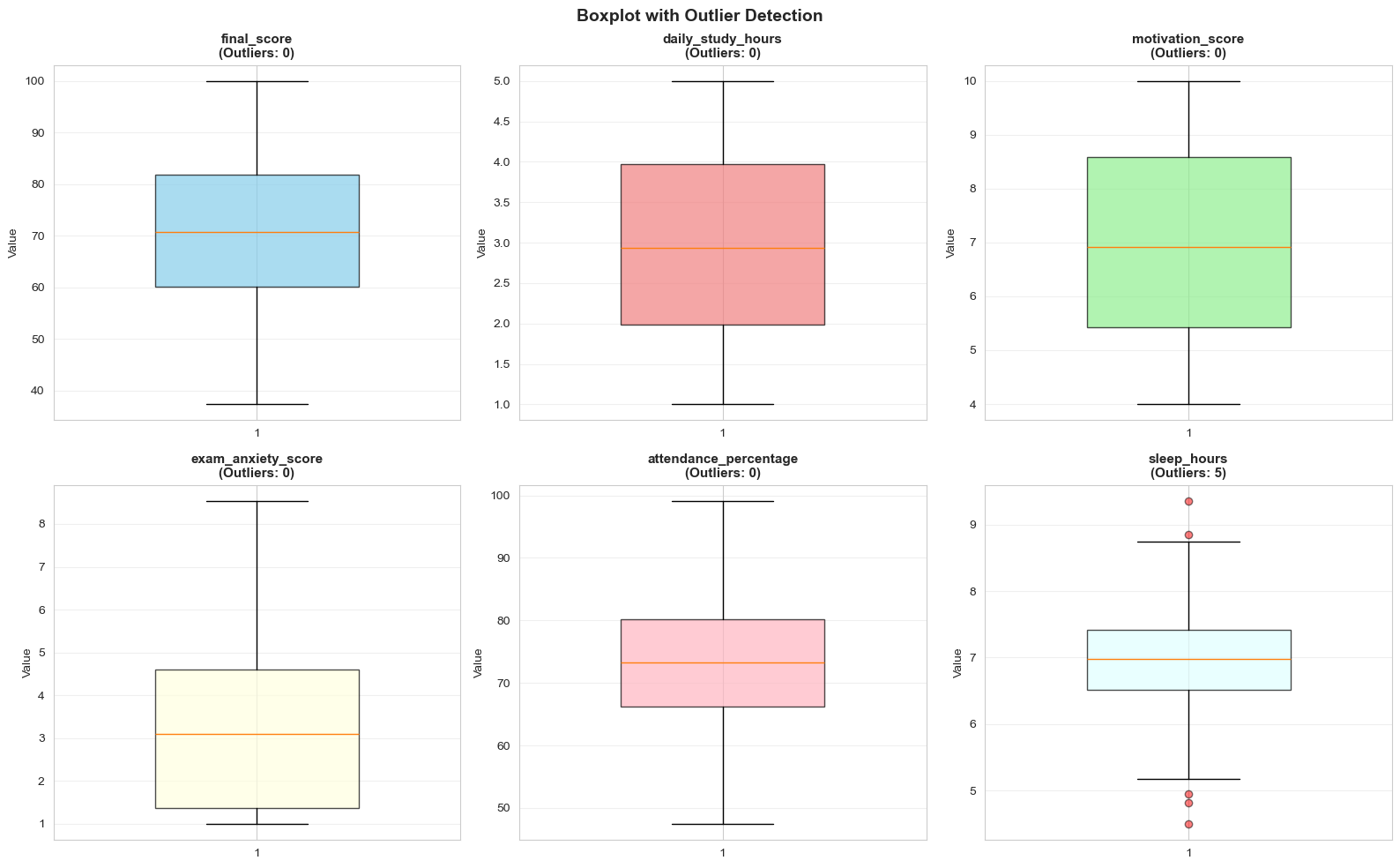 Hình 13: Outliers theo quy tắc IQR.
Hình 13: Outliers theo quy tắc IQR.
- Final Score: ~4-5% outliers
- Daily Study Hours: ~15-18% outliers (hành vi học tập bất thường)
- Motivation Score: ~8-10% (siêu motivated hoặc mất động lực)
- Attendance: ~3-5% (rất chuyên cần hoặc rất vắng mặt)
Cách xử lý: Kiểm tra lỗi nhập liệu trước. Nếu thật, giữ chúng vì có thể chứa thông tin quý báu.
2.7. Phân tích kết hợp: Histogram + Boxplot
Để có cái nhìn toàn diện nhất, chúng ta kết hợp Histogram và Boxplot cạnh nhau:
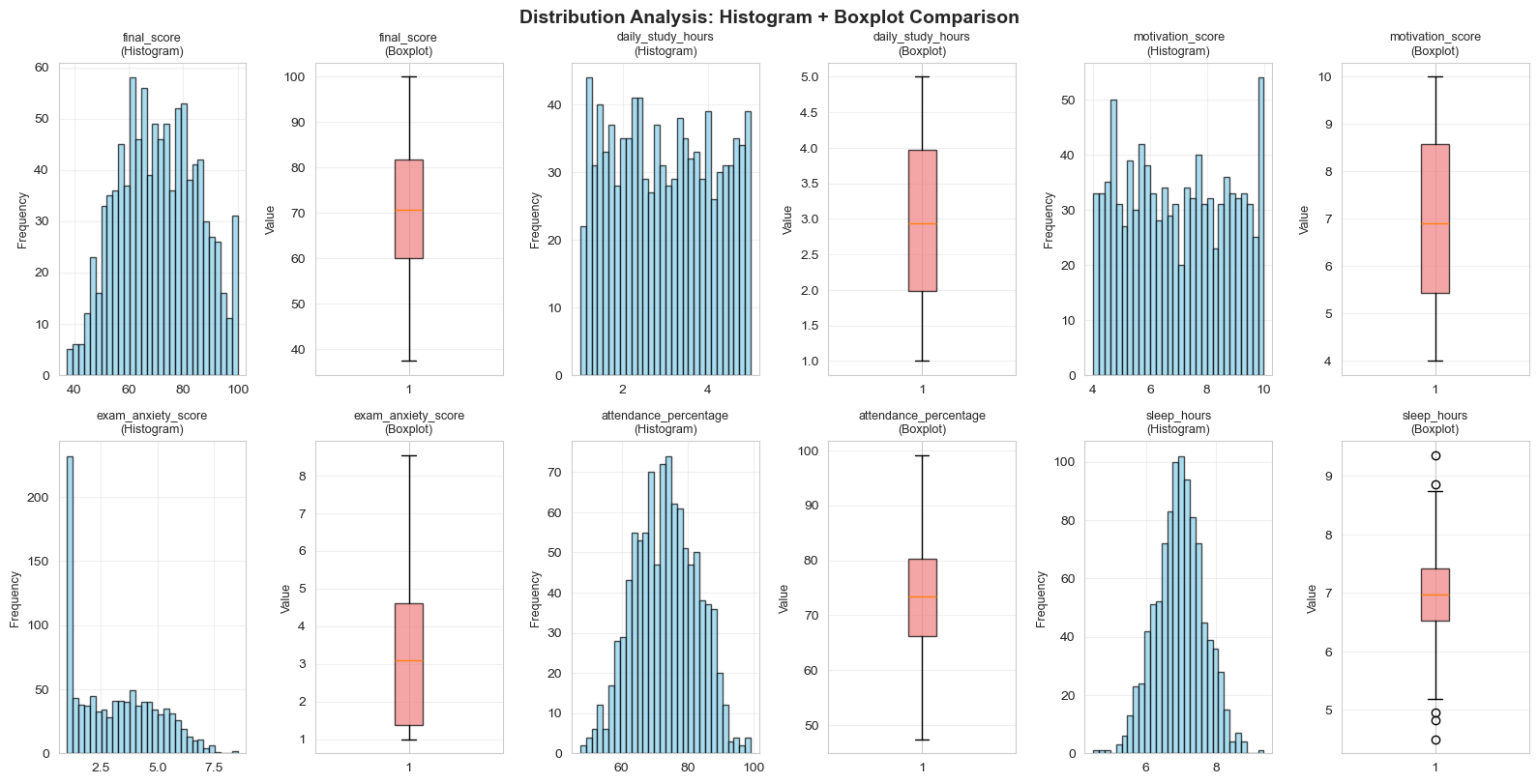 Hình 14: Histogram kết hợp boxplot.
Hình 14: Histogram kết hợp boxplot.
Lợi ích của kết hợp:
- Histogram cho thấy "toàn cảnh" — tần suất chi tiết từng khoảng
- Boxplot cho thấy "bộ xương" — cấu trúc chính của dữ liệu
- Nhìn cả hai cùng lúc, chúng ta có thể xác định hình dáng phân phối, phát hiện outliers, và quyết định cách xử lý dữ liệu tiếp theo
Mối quan hệ giữa các biến (Relationship)
Trong trực quan hoá dữ liệu, việc phân tích mối quan hệ giữa các biến là một bước quan trọng trong quá trình khám phá dữ liệu (Exploratory Data Analysis - EDA). Việc này giúp chúng ta hiểu được liệu các biến có liên hệ với nhau hay không, mức độ liên hệ mạnh hay yếu, cũng như xu hướng của dữ liệu.
Thông qua các biểu đồ trực quan, chúng ta có thể dễ dàng nhận ra:
- Xu hướng tăng hoặc giảm giữa các biến
- Mức độ tương quan giữa các biến
- Các mẫu (patterns) tiềm ẩn trong dữ liệu
- Các điểm ngoại lệ (outliers)
Hai loại biểu đồ thường được sử dụng để phân tích mối quan hệ giữa các biến là Scatter Plot và Heatmap.
2.8. Biểu đồ phân tán (Scatter Plot)
Scatter Plot là biểu đồ dùng để thể hiện mối quan hệ giữa hai biến số. Mỗi điểm trên biểu đồ đại diện cho một cặp giá trị của hai biến.
Scatter Plot giúp chúng ta:
- Xác định tương quan dương (biến X tăng thì biến Y cũng tăng)
- Xác định tương quan âm (biến X tăng thì biến Y giảm)
- Phát hiện mối quan hệ tuyến tính hoặc phi tuyến
- Nhận diện outliers trong dữ liệu
Ví dụ, ta có thể sử dụng Scatter Plot để phân tích các mối quan hệ như:
- Thời gian học và điểm số
- Diện tích nhà và giá nhà
- Chi phí quảng cáo và doanh thu
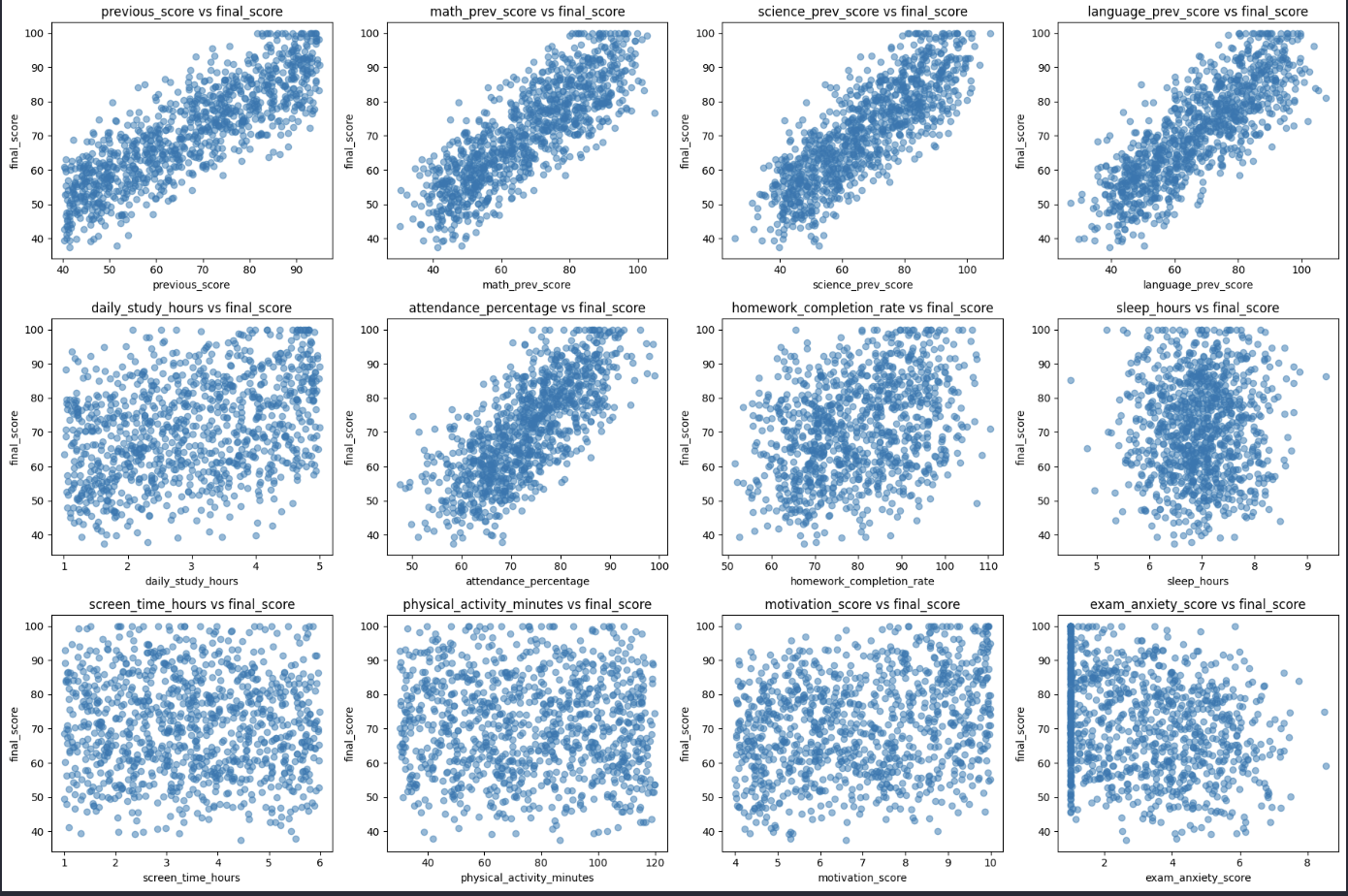 Hình 15: Scatter plot mối quan hệ biến.
Hình 15: Scatter plot mối quan hệ biến.
2.9. Biểu đồ nhiệt (Heatmap)
Heatmap là biểu đồ sử dụng màu sắc để biểu diễn giá trị. Trong phân tích dữ liệu, heatmap thường được sử dụng để hiển thị ma trận tương quan (Correlation Matrix) giữa nhiều biến.
Ma trận tương quan cho biết mức độ liên hệ giữa các biến số trong tập dữ liệu.
Giá trị tương quan thường nằm trong khoảng:
1: tương quan dương hoàn hảo-1: tương quan âm hoàn hảo0: không có tương quan
Heatmap giúp:
- Xác định nhanh các biến có tương quan mạnh
- Phát hiện các biến có thể trùng lặp thông tin
- Hỗ trợ feature selection trong Machine Learning
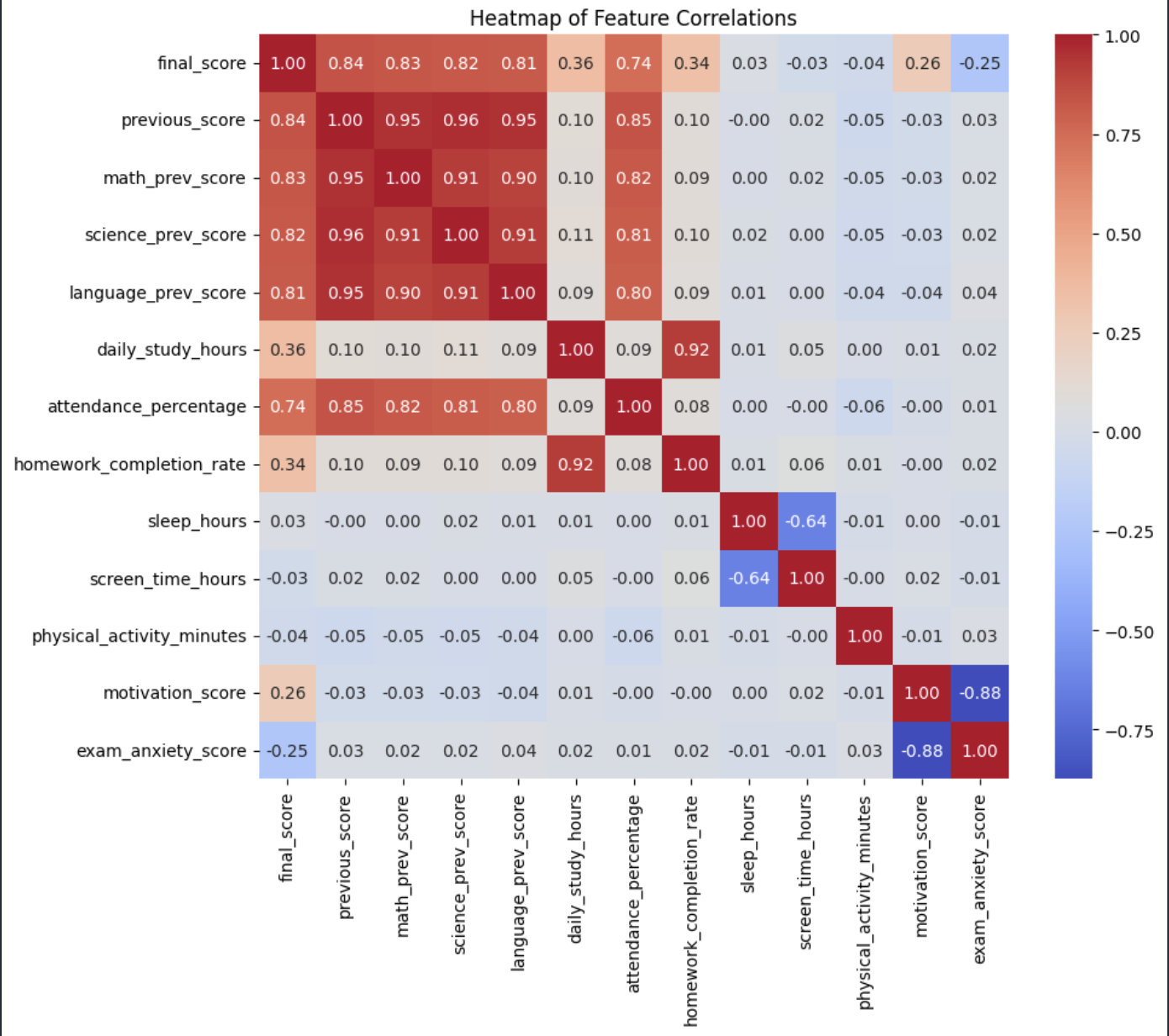 Hình 16: Heatmap ma trận tương quan.
Hình 16: Heatmap ma trận tương quan.
Thông thường:
- Màu đỏ biểu thị tương quan dương mạnh
- Màu xanh biểu thị tương quan âm mạnh
- Màu trung tính biểu thị tương quan yếu
Như vậy: Việc kết hợp Scatter Plot và Heatmap giúp nhà phân tích nhanh chóng khám phá các mối quan hệ quan trọng trong dữ liệu, từ đó hỗ trợ tốt hơn cho quá trình phân tích dữ liệu và xây dựng mô hình.
3. Quy trình 5 bước để vẽ biểu đồ chuyên nghiệp
3.1. Giới thiệu dataset
Trong bài này, bộ dữ liệu được sử dụng là student_performance_interactions.csv. Đây là tập dữ liệu về kết quả học tập của học sinh/sinh viên trong một số môn học cùng với nhiều yếu tố liên quan như điểm môn học trước đó, thời gian học mỗi ngày, tỷ lệ chuyên cần, mức độ hoàn thành bài tập, thời gian ngủ, thời gian dùng thiết bị, động lực học tập, mức độ lo âu khi thi, trình độ học vấn của phụ huynh và môi trường học tập.
Dataset này cũng có cả 2 loại biến số thể hiện rõ các loại dữ liệu khác nhau:
- Biến số liên tục như final_score, previous_score, daily_study_hours, attendance_percentage
- Biến phân loại như grade, pass_fail, parent_education_level, study_environment
-> Có thể sử dụng nhiều loại biểu đồ khác nhau để tính toán.
3.2. Quy trình 5 bước để vẽ biểu đồ chuyên nghiệp
Biểu đồ đóng vai trò vô cùng quan trọng trong trực quan hoá số liệu, miêu tả dataset, và góp phần to lớn vào những công việc sau này. Nếu biểu đồ được thể hiện tốt, người đọc có thể có được góc nhìn sâu sắc về dataset này.
Để code không bị rối và biểu đồ tạo ra rõ ràng, dễ đọc, nên tuân thủ quy trình 5 bước sau:
Bước 1. Chuẩn bị dữ liệu
Ở bước này, ta import các thư viện cần thiết và nạp dữ liệu vào bằng Pandas. Pandas là một thư viện mạnh mẽ trong khoản xử lý dữ liệu. Đây là bước đầu tiên để kiểm tra dữ liệu, chọn biến phù hợp và chuẩn bị cho việc vẽ biểu đồ.
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
df = pd.read_csv("student_performance_interactions.csv")
print(df.head())
import ... as ...: nạp các thư viện cần dùng và đặt bí danh ngắn để code dễ đọc (pd,plt,sns).pd.read_csv(...): đọc file CSV vào DataFramedf.df.head(): in 5 dòng đầu để kiểm tra nhanh dữ liệu đã đọc đúng cột, đúng định dạng hay chưa.
student_id final_score ... parent_education_level study_environment
0 S0001 60.137241 ... Master Noisy
1 S0002 99.021977 ... High School Quiet
2 S0003 70.522955 ... High School Moderate
3 S0004 63.448537 ... High School Noisy
4 S0005 66.483019 ... Master Quiet
- Kết quả này cho thấy dữ liệu đã được nạp thành công.
- Bạn cũng nhìn thấy ngay các cột quan trọng như
final_score,parent_education_level,study_environmentđể chuẩn bị chọn biến vẽ biểu đồ.
Bước 2. Khởi tạo không gian vẽ
Sau khi có dữ liệu, ta tạo không gian vẽ bằng Matplotlib. Cách làm phổ biến là sử dụng fig, ax = plt.subplots() để dễ kiểm soát bố cục và tùy chỉnh biểu đồ.
Lúc này ta sẽ có 1 không gian trống.
fig, ax = plt.subplots(figsize=(8, 5))
figlà toàn bộ khung hình,axlà vùng trục dùng để vẽ biểu đồ.figsize=(8, 5)đặt kích thước biểu đồ theo tỷ lệ dễ đọc trong báo cáo/blog.- Tách
figvàaxgiúp bạn kiểm soát bố cục tốt hơn khi cần thêm tiêu đề, nhãn trục hoặc nhiều biểu đồ con.
Bước 3. Vẽ biểu đồ chính
Tiếp theo, ta chọn loại biểu đồ phù hợp rồi gọi hàm từ Seaborn hoặc Matplotlib để vẽ. Có rất nhiều loại biểu đồ khác nhau, mỗi biểu đồ lại có cách vẽ, cách khai báo và biểu diễn số liệu khác nhau. Để có thể biểu diễn số liệu một cách trực quan nhất, ta cần biết loại số liệu nào phù hợp với biểu đồ nào. Ví dụ, nếu muốn xem phân phối điểm cuối kỳ thì có thể dùng histogram.
sns.histplot(data=df, x="final_score", bins=20, kde=True, ax=ax)
sns.histplot(...)vẽ histogram cho biếnfinal_score.bins=20chia miền giá trị thành 20 khoảng để quan sát tần suất rõ hơn.kde=Truethêm đường mật độ mượt để nhìn nhanh hình dạng phân phối.ax=axvẽ đúng vào vùng trục đã tạo ở Bước 2.
Hoặc nếu muốn xem mối quan hệ giữa điểm trước đó và điểm cuối kỳ, có thể dùng scatter plot:
sns.scatterplot(data=df, x="previous_score", y="final_score", ax=ax)
- Mỗi điểm là một học sinh với cặp giá trị (
previous_score,final_score). - Nhìn xu hướng phân bố điểm giúp đánh giá mối quan hệ đồng biến/nghịch biến giữa hai biến.
- Nếu xuất hiện điểm nằm tách hẳn khỏi cụm chính, đó có thể là outlier cần kiểm tra thêm.
Bước 4. Tùy chỉnh (Styling)
Nếu như chỉ vẽ thôi, người đọc sẽ không thể hiểu được các đồ thị biểu diễn cho loại số liệu nào, vì vậy sau khi vẽ biểu đồ chính, cần thêm các thành phần mô tả để biểu đồ dễ hiểu hơn như tiêu đề, nhãn trục và chú thích.
ax.set_title("Mối quan hệ giữa điểm trước đó và điểm cuối kỳ")
ax.set_xlabel("Previous Score")
ax.set_ylabel("Final Score")
ax.legend(title="Nhóm dữ liệu")
set_title(...): đặt tiêu đề để người đọc biết biểu đồ đang trả lời câu hỏi gì.set_xlabel(...)vàset_ylabel(...): ghi rõ ý nghĩa hai trục, tránh hiểu sai biến.legend(...): thêm chú thích khi biểu đồ có nhiều nhóm màu/ký hiệu.
Nếu biểu đồ không cần chú thích thì có thể bỏ legend(). Ngoài ra, có thể dùng plt.tight_layout() để bố cục gọn hơn.
plt.tight_layout()
- Tự động căn chỉnh khoảng cách giữa tiêu đề, nhãn trục và vùng vẽ.
- Giúp tránh hiện tượng chữ bị chạm mép hoặc chồng lấn khi xuất hình.
Bước 5. Hiển thị hoặc lưu biểu đồ
Cuối cùng, sau khi hoàn tất biểu đồ, ta có thể hiển thị trực tiếp trên màn hình hoặc lưu lại dưới dạng file ảnh để chèn vào báo cáo, slide hoặc tài liệu.
plt.show()
- Hiển thị biểu đồ trực tiếp trong môi trường chạy code (Notebook/IDE).
- Phù hợp khi đang phân tích thử và muốn kiểm tra nhanh kết quả.
Hoặc lưu thành file:
plt.savefig("bieu_do.png", dpi=300, bbox_inches="tight")
savefig(...)lưu biểu đồ ra file ảnh để chèn vào báo cáo hoặc blog.dpi=300cho chất lượng in/đăng cao, nét hơn so với mặc định.bbox_inches="tight"cắt gọn phần rìa thừa để ảnh sạch và cân đối hơn.
3.3. Ví dụ hoàn chỉnh
Dưới đây là một ví dụ hoàn chỉnh áp dụng đủ 5 bước:
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# Bước 1: Chuẩn bị dữ liệu
df = pd.read_csv("student_performance_interactions.csv")
# Bước 2: Khởi tạo không gian
fig, ax = plt.subplots(figsize=(8, 5))
# Bước 3: Vẽ biểu đồ chính
sns.scatterplot(data=df, x="previous_score", y="final_score", ax=ax)
# Bước 4: Tùy chỉnh
ax.set_title("Mối quan hệ giữa điểm trước đó và điểm cuối kỳ")
ax.set_xlabel("Previous Score")
ax.set_ylabel("Final Score")
plt.tight_layout()
# Bước 5: Hiển thị
plt.show()
Ta sẽ được kết quả như sau:
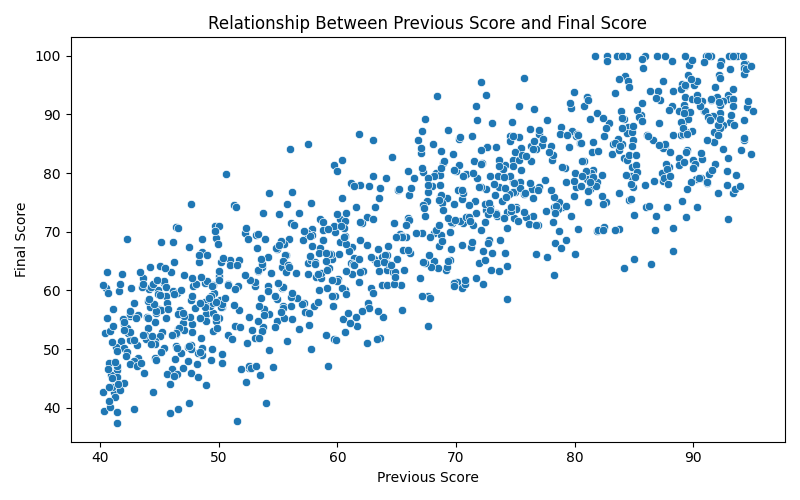 Hình 17: Ví dụ hoàn chỉnh 5 bước vẽ biểu đồ.
Hình 17: Ví dụ hoàn chỉnh 5 bước vẽ biểu đồ.
4. Kết luận và Các nguyên tắc tối ưu hóa
4.1. Lựa chọn loại hình biểu đồ phù hợp
Việc lựa chọn sai dạng biểu đồ có thể dẫn đến sự hiểu lầm về quy mô hoặc mối quan hệ của dữ liệu.
-
Hạn chế biểu đồ tròn (Pie Chart): Trong phân tích chuyên sâu, biểu đồ tròn thường bị hạn chế, đặc biệt khi số lượng danh mục vượt quá 3-5 nhóm. Khả năng nhận diện sự khác biệt về diện tích góc của mắt người kém hơn so với việc so sánh độ dài (biểu đồ cột).
-
Khuyến nghị: Sử dụng biểu đồ cột ngang (Horizontal Bar Chart) để thay thế khi có nhiều danh mục hoặc tên danh mục dài, giúp đảm bảo tính dễ đọc và so sánh chính xác.
4.2. Nguyên tắc tối giản và loại bỏ yếu tố gây nhiễu (Chartjunk)
Dựa trên lý thuyết của Edward Tufte, hiệu suất của một biểu đồ được đo bằng tỷ lệ "Mực-Dữ liệu" (Data-Ink ratio).
-
Loại bỏ Chartjunk: Cần lược bỏ các đường lưới (gridlines) quá đậm, các hiệu ứng đổ bóng 3D không cần thiết, hoặc các khung viền rườm rà.
-
Tập trung vào thông tin cốt lõi: Việc giữ cho biểu đồ sạch sẽ giúp người xem tập trung ngay lập tức vào các xu hướng hoặc điểm dữ liệu ngoại lai quan trọng.
4.3. Chiến lược sử dụng màu sắc và bảng màu (Palettes)
Màu sắc trong Seaborn và Matplotlib không chỉ mang tính thẩm mỹ mà còn mang tính chức năng:
-
Sử dụng Color Palettes: Cần chọn bảng màu phù hợp với tính chất dữ liệu:
-
Qualitative palettes: Dùng cho dữ liệu phân loại không có thứ tự.
-
Sequential palettes: Dùng cho dữ liệu có sự biến thiên liên tục (thấp đến cao).
-
Diverging palettes: Dùng để nhấn mạnh sự khác biệt từ một điểm trung tâm (ví dụ: tăng trưởng âm và dương).
-
4.4. Tổng kết
Trực quan hóa dữ liệu bằng Seaborn và Matplotlib không chỉ dừng lại ở việc thực thi mã nguồn, mà là quá trình tư duy để lựa chọn phương thức biểu đạt trung thực nhất đối với bản chất của dữ liệu. Việc tuân thủ các nguyên tắc về sự đơn giản và tính chính xác sẽ giúp nhà phân tích chuyển đổi các tập dữ liệu phức tạp thành những thông tin có giá trị thực tiễn cao.
Tài liệu tham khảo
Anscombe, F. J. (1973). Graphs in Statistical Analysis. The American Statistician, 27(1), 17-21.
Knaflic, C. N. (2015). Storytelling with Data. Wiley.
Tukey, J. W. (1977). Exploratory Data Analysis.
Dataset: student_performance_interactions.csv
Chưa có bình luận nào. Hãy là người đầu tiên!