
Retrieval: The Universal Key in the Age of AI
Introduction
The explosion of Large Language Models (LLMs) has marked a new era in human-machine interaction. However, during real-world implementation, developers and researchers face two major hurdles: knowledge cutoff (the obsolescence of training data) and hallucination.
To significantly reduce these issues, the concept of Retrieval has become an indispensable component in many modern AI systems, serving as an "anchor" that helps keep systems grounded in reality and improve accuracy. This article is a synthesis from five professional perspectives, ranging from theoretical foundations to system architecture, with the goal of providing a comprehensive view of retrieval infrastructure in the AI era.
Part 1: The Essence of Retrieval in the AI Ecosystem
In traditional computer science, Retrieval is often understood simply as querying a structured dataset to find exact matches. However, in the context of modern Artificial Intelligence, this concept has evolved into a more complex process: Searching for content based on semantic and contextual correlation.
1.1. From "Rote Memorization" to "Selective Research"
Traditional AI models operate based on knowledge compressed within weights during the training process. This is analogous to a student attempting to memorize an entire library.
In contrast, an integrated Retrieval system equips AI with the capabilities of a researcher: when a query is received, instead of only searching through finite memory, it accesses a large external repository to find the most relevant documents. This allows the system to reach real-time data and internal documents that the model never encountered during pre-training.
1.2. The Role of Retrieval in Mitigating Hallucination
One of the most important applications of Retrieval is providing a "Source of Truth." When a language model is supplied with relevant text segments (context) through the retrieval process, its task shifts from free-form content creation to information synthesis and extraction.
Core Principle: The output quality of an AI system depends strongly on the accuracy and relevance of the data retrieved at the input stage.
It is important to note that Retrieval does not eliminate hallucination entirely. It helps reduce it significantly when the retrieved data is good, the context is sufficiently clear, and the prompt is designed properly.
1.3. Basic Structure of a Modern Retrieval System
A standard Retrieval workflow goes beyond simple searching and includes three strategic stages:
- Representation: Transforming natural language queries into formats that computers can understand. In the current era, these are typically mathematical vectors (embeddings).
- Similarity Scoring: Using distance or similarity functions to determine how close a query is to documents. Common methods include:
- Cosine Similarity: Measuring the angle between two vectors in a multi-dimensional space.
- Euclidean Distance: Measuring the distance between two vector points.
- Dot Product: Commonly used in many modern embedding systems. - Filtering & Ranking: Selecting the top $k$ results with the highest correlation scores to be fed into the language model (generator).
Understanding this foundation is essential before diving deeper into NLP techniques and vector database architectures in the following sections.
Part 2: From Keywords to Meaning — How AI Changed the Way We Search
(Perspective of an NLP Engineer)
If Part 1 explained why Retrieval matters, then Part 2 answers a more practical question: how does a system decide which documents are relevant enough to retrieve in the first place?
This is the real turning point between traditional search and AI-era search. In a RAG system, the LLM can only answer well if the retrieval layer pulls the right chunks from the start. So the move from keyword matching to meaning-based search is not just a better search experience. It is a foundation for answer quality.
2.1. The first era: lexical search and exact matching
Traditional search systems relied mainly on lexical signals - the actual words that appear in the query and the document. Methods such as TF-IDF and later BM25 usually estimate relevance based on:
- which query terms appear in the document
- how often they appear
- whether those terms are rare or common across the corpus
- in some systems, where they appear, such as the title or heading
If a user searches for “how to lose weight effectively”, a lexical system naturally favors documents that directly contain terms like lose weight and effectively.
Query: "how to lose weight effectively"
Lexical search mostly rewards direct term overlap:
Doc A: "How to lose weight effectively at home" strong match
Doc B: "How to stay fit and burn fat safely" weaker match
Doc C: "Healthy eating habits for long-term health" weaker match
This approach remains valuable because it is fast, interpretable, and extremely precise when users need an exact string.
2.2. Why keyword search still matters - and where it breaks
Keyword-based retrieval works especially well when the query depends on exact form, for example:
- product codes
- error messages
- API names
- specific legal terms
- person, organization, or product names
If I search for ERR_CONNECTION_RESET or SKU-A19, I usually want documents that contain those exact tokens.
But the weakness appears as soon as the user’s wording differs from the document’s wording.
Imagine a support bot user asks:
“Can I get my money back within a month?”
But the internal policy document says:
“Digital products are eligible for refunds within 30 days.”
A purely lexical system may not treat “money back” and “refund” as close enough, even though they express almost the same intent. This gap between surface wording and actual meaning is one of the main reasons modern retrieval had to evolve.
2.3. Semantic search: turning meaning into something searchable
Semantic search changes the problem. Instead of asking only, “Which documents contain the same words?”, the system starts asking:
“Which documents express the same idea?”
To do that, both queries and documents are converted into embeddings - dense vectors that encode semantic information. In that representation space, texts with similar meaning are placed close together even when they use different words.
A simple mental model looks like this:
Conceptual semantic space
"lose weight" ●
"burn fat safely" ● <- close because the intent is similar
"healthy calorie deficit" ●
"fix Wi-Fi router" ●
We do not see the actual mathematical coordinates, but the intuition is simple: related ideas form neighborhoods.
So when a user asks “how to lose weight effectively”, the system can also retrieve content about:
- burning fat safely
- healthy eating habits
- calorie deficit strategies
- exercise plans for weight reduction
This is the key shift: the system is no longer matching only strings. It is matching intent, topic, and context.
2.4. Why this matters so much in Retrieval and RAG
In normal web search, returning a few “close enough” results may still be acceptable. In Retrieval for chatbots or RAG, the bar is much higher.
That is because users and documents rarely speak in exactly the same language.
Users may ask:
- “How do I cancel my plan?”
- “Why was my payment rejected?”
- “Can I still get a refund after 30 days?”
But the documents may use phrases such as:
- “subscription termination policy”
- “payment failure conditions”
- “refund eligibility window”
If the retrieval layer depends only on exact word overlap, the LLM may never receive the right context. And once the wrong context is retrieved, even a powerful model can produce a weak, generic, or misleading answer.
In other words, before generation becomes a model problem, Retrieval must first solve a harder problem: finding the right evidence.
2.5. A side-by-side comparison
| Search style | What it mainly looks at | Strength | Weakness |
|---|---|---|---|
| Lexical search | Exact or near-exact words | Strong for codes, names, and precise terms | Weak with paraphrases |
| Semantic search | Meaning and user intent | Strong for natural language questions | Can miss critical exact keywords |
So semantic search is not a total replacement for lexical search. It is an expansion of what search can do, especially in natural language settings.
The transition from keyword search to semantic search is not just a technical upgrade. It changes the role of search inside AI systems.
Traditional search asked:
“Which documents contain these words?”
Modern Retrieval must ask:
“Which pieces of information are most likely to help answer this user’s intent?”
That shift is what makes today’s systems more flexible, more useful, and much better suited for chatbots, assistants, and RAG applications. It also prepares the ground for the next stages of the pipeline: how data is chunked, embedded, indexed, and finally brought into the LLM as trustworthy context.
Part 3: The Data "Preprocessing" Pipeline
(From a Data Architect's Perspective)
If Retrieval is the “search engine,” then data is the “input ingredient.” And just like in cooking, if ingredients are not prepared properly, even a strong system will struggle to produce the best result.
An effective Retrieval system does not start with the model. It starts with how you prepare the data. This process usually revolves around three core steps: Chunking → Embedding → Indexing.
3.1. Chunking – Splitting While Preserving Meaning
AI models do not “read” text the way humans do. If you feed the system a document that is dozens of pages long, two issues often appear:
- Context overflow
- Dilution of important information
So the first step is to split documents into chunks.
Common chunking methods:
- Fixed-size chunking
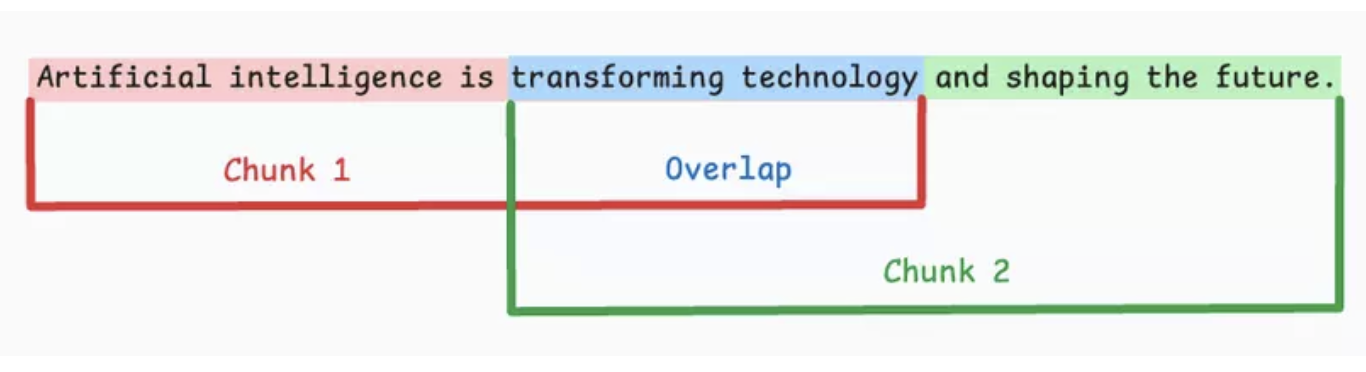
Figure 3.1. Fixed-size chunking.
Split text by a fixed size (characters/words/tokens), often with overlap to reduce abrupt context breaks.
Pros: Easy to implement and good for batch processing.
Cons: Important sentences or ideas can be split in half.
- Semantic chunking
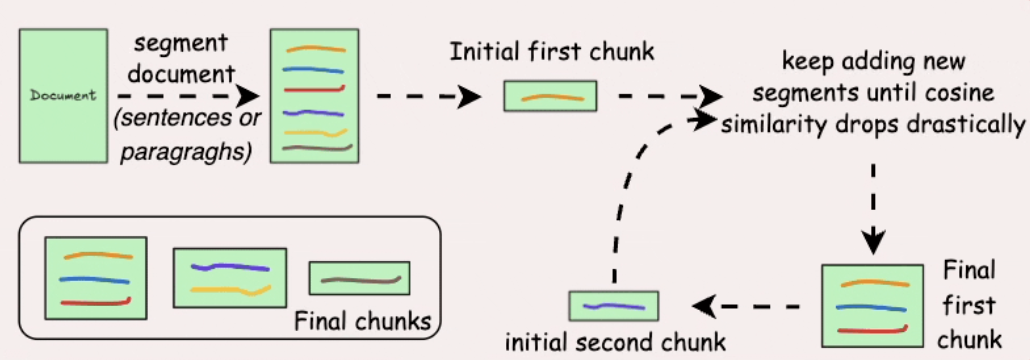
Figure 3.2. Semantic chunking.
Split by semantic units (sentences/paragraphs), then use embeddings + similarity to merge related parts.
Pros: Chunks are more coherent, improving retrieval accuracy.
Cons: Depends on choosing a good similarity threshold and requires more compute.
- Recursive chunking
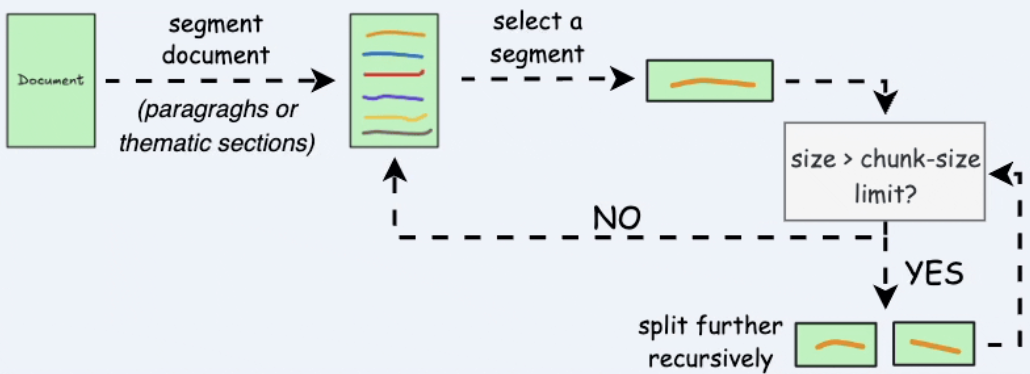
Figure 3.3. Recursive chunking.
Split by natural boundaries first (\n\n, \n, spaces); if still too long, keep splitting recursively.
Pros: Balances semantic integrity with size limits.
Cons: More complex to implement than fixed-size chunking.
- Document structure-based chunking
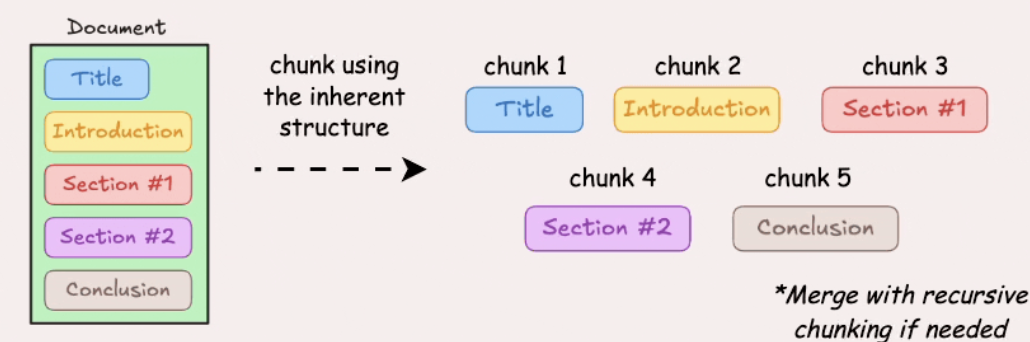
Figure 3.4. Structure-based chunking.
Use document structure (headings, sections, lists, tables, paragraphs) as chunk boundaries.
Pros: Preserves the original logical structure well.
Cons: Depends on well-structured documents; chunk sizes may be uneven.
- LLM-based chunking
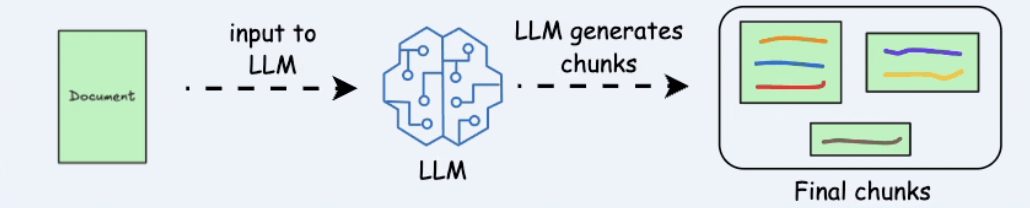
Figure 3.5. LLM-based chunking.
Use an LLM to determine chunk boundaries by topic or complete semantic units.
Pros: Has very strong potential semantic quality.
Cons: More expensive, slower, and dependent on prompt quality and context window.
Key insight: There is no absolute “best” method. In practice, strong systems often use hybrid chunking to balance quality, speed, and cost.
3.2. Embedding – Turning Language into Coordinates
After creating chunks, the next step is converting them into a format machines can “understand” and compare: vector embeddings.
An embedding model (such as text-embedding-3) transforms each text chunk into a vector in a high-dimensional space.
This allows the system to:
- Measure semantic similarity
- Retrieve text with similar meaning even when keywords do not exactly match
Practical example (Embedding):
Assume the system has 3 chunks:
C1: “How to cook pho bo at home”C2: “Guide to making traditional pho”C3: “Motorbike maintenance tips for rainy season”
With the query: “How can I cook delicious pho bo?”
sim(query, C1) = 0.91sim(query, C2) = 0.88sim(query, C3) = 0.15
Result: the system prioritizes C1 and C2 because they are semantically closer, even though the wording is not identical.
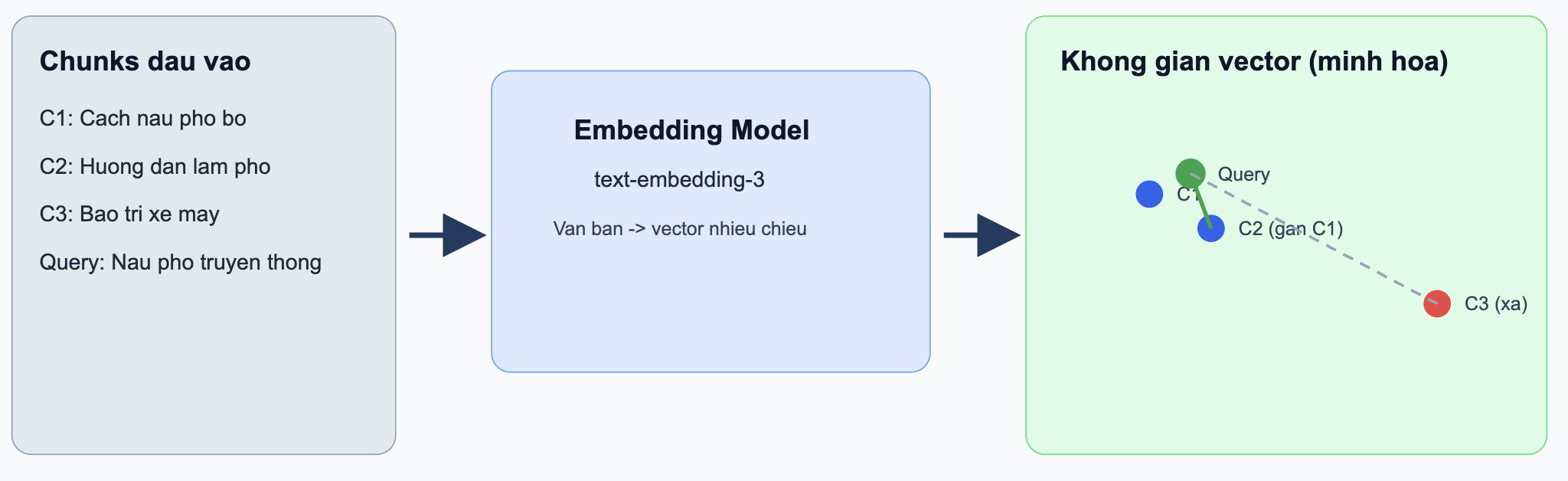
Figure 3.6. Embeddings in vector space.
Key insight: Embedding is the bridge between human language and the mathematics of machine learning.
3.3. Indexing – Organizing for Millisecond Search
Once you have vectors, you need a place to store and retrieve them quickly. That is where a Vector Database comes in.
Popular options include:
- Pinecone
- Milvus
- Weaviate
Unlike traditional databases (SQL), vector databases are optimized for:
- Approximate Nearest Neighbor (ANN) search
- Handling millions to billions of vectors with low latency
The indexing process includes:
- Storing vectors + metadata (source, title, timestamp, etc.)
- Building index structures to speed up search
- Optimizing similarity queries (cosine similarity, dot product, etc.)
Practical example (Indexing + Retrieval):
Assume you have indexed 1 million chunks of internal documents. When a user asks, “How does the 30-day refund policy work?”
- The question is embedded into
q_vector - The vector DB uses an ANN index to find the nearest
top-kvectors in milliseconds - It returns the most relevant chunks, for example:
-chunk_2451(score0.93) - refund policy section
-chunk_8712(score0.89) - eligibility conditions
-chunk_1022(score0.84) - exception cases
These chunks are then passed into the LLM context to generate the final answer.
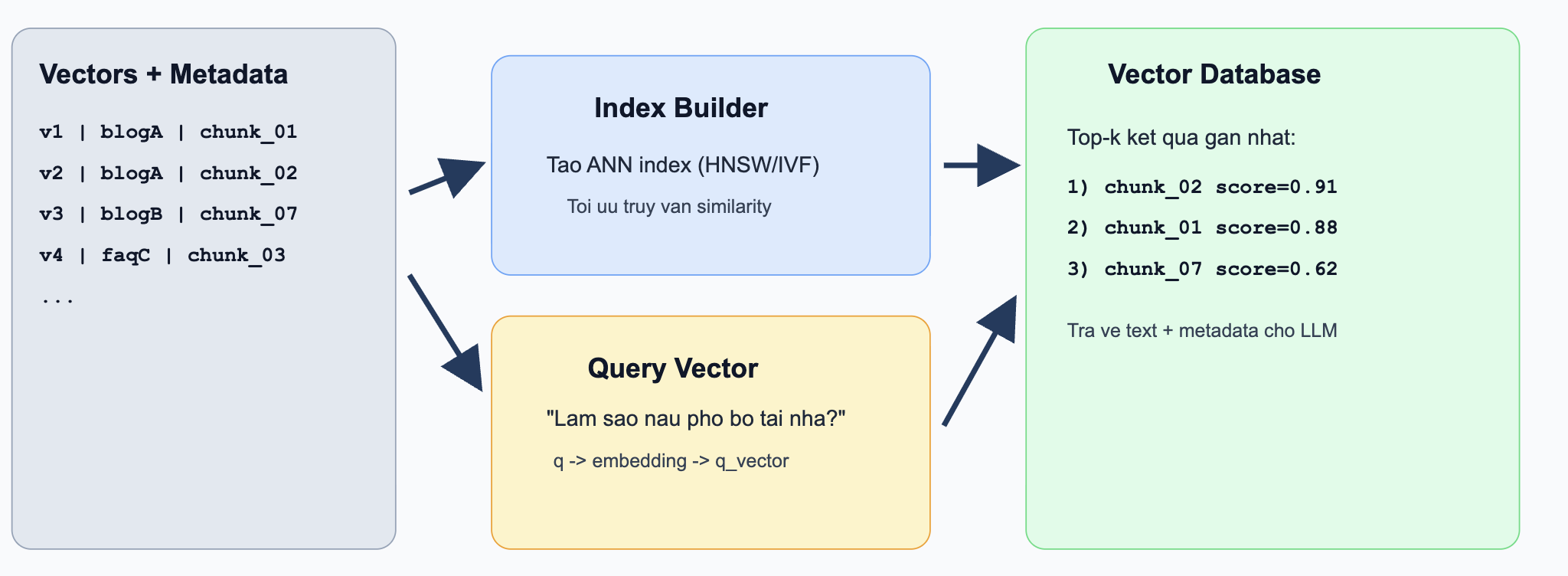
Figure 3.7. Vector retrieval workflow.
When users ask a question:
- The question is embedded into a vector
- The system finds nearest vectors in the database
- The system returns the most relevant chunks
Good Retrieval Starts with Good Data
These three steps form the foundation of the entire Retrieval pipeline:
- Chunking → Determines how AI “sees” data
- Embedding → Determines how AI “understands” data
- Indexing → Determines how fast AI can find data
If you do this well, you have already determined a large part of the retrieval quality of a later RAG system.
A memorable quote in the Data Architect world:
“Garbage in, garbage out — and for Retrieval: bad chunks lead to bad search; weak embeddings lead to wrong understanding.”
Part 4: RAG — The Practical Peak of Retrieval
(From an AI Developer’s Perspective)
If Part 2 explained how search evolved, and Part 3 explained how data is prepared, then Part 4 is where everything comes together in real products:
RAG (Retrieval-Augmented Generation).
RAG is not a brand-new model. It is an architecture that combines:
- A Retriever (to fetch relevant knowledge)
- A Generator (LLM) (to produce the final answer)
Instead of forcing the LLM to answer only from memory, we let it read the right documents at the right time.
4.1. Why RAG matters in real products
A pure LLM setup often faces 3 issues:
- Hallucination: answers sound fluent but can be wrong.
- Knowledge cutoff: the model may not know new or internal data.
- No traceability: it is hard to show which documents support an answer.
RAG helps address these issues in the following ways:
- Grounds answers in retrieved documents.
- Keeps knowledge up to date by updating the data store, without retraining the model.
- Enables source citation to improve trust.
4.2. Core RAG flow (end-to-end)
User Question
↓
Embed query
↓
Vector DB retrieval (top-k chunks)
↓
(Optional) Rerank retrieved chunks
↓
Build final prompt with context
↓
LLM generates answer + citations
In implementation terms, RAG usually has 4 modules:
ingestion: chunk + embed + index documents.retrieval: fetch relevant chunks for each query.prompting: compose instructions + context + question.generation: call the LLM and format the response.
4.3. A minimal implementation blueprint
Step A — Retrieve context
- Convert user query to embedding.
- Search the vector database (
top_k = 5or10). - Filter by metadata (product, language, date).
Step B — Compose prompt safely
- Add a clear system rule: “Answer only using provided context.”
- Put retrieved chunks into a
CONTEXTblock. - Include fallback behavior: “If context is insufficient, say so.”
Step C — Generate + cite
- Ask the model to return:
- a concise answer
- cited sources (
doc_id, title, link)
This structure helps reduce “creative but wrong” outputs significantly.
4.4. Practical example
User asks:
“How does the 30-day refund policy work for digital products?”
Retriever returns:
policy_refund_v2.md(refund conditions)faq_payments.md(exceptions)terms_service.md(regional limitations)
LLM receives a prompt containing these chunks and returns:
- the policy applies within 30 days if usage criteria are met,
- exceptions for specific plans,
- links to official policy documents.
Without RAG, the model might produce a generic answer. With RAG, the answer stays grounded in real system documents.
4.5. Engineering trade-offs you will face
- Latency vs quality
- More retrieved chunks can improve recall but slow generation. - Chunk size vs context integrity
- Too small loses meaning; too large wastes tokens. - Cost vs reliability
- Reranking and larger context windows improve quality but increase cost.
A common production setup:
- Hybrid retrieval (BM25 + vector)
- Top 20 recall → rerank to top 5
- Grounded prompt + citation output
4.6. How to evaluate a RAG system
Do not evaluate only by “the answer sounds good.” Track:
- Retrieval Recall@k: did we fetch truly relevant chunks?
- Groundedness/Faithfulness: does the answer match the context?
- Citation accuracy: are references correct and useful?
- Latency (P95) and cost per request
Good RAG is a system problem, not just a model problem.
Part 5: Challenges & the Future of Retrieval
(From the Perspective of a Product Manager)
Introduction
The previous four parts have painted a complete picture of Retrieval — from foundational concepts, the evolution of search techniques, and the data processing pipeline, to its most powerful application: RAG. But no technology is perfect.
As a product manager, the question I always ask is not “How does this technology work?” but rather “Where does this technology fail, and what comes next?”
Current Challenges
5.1. Latency — The Silent Enemy of User Experience
A Retrieval system must execute a series of tasks in an instant:
[User query]
↓
Embedding query
↓
Vector similarity search
↓
Fetch & rerank documents
↓
Send context → LLM generate
↓
[Answer]
Every step takes time. If total response time exceeds 2–3 seconds, users start losing patience. This is a major technical challenge, especially when the database contains millions of vectors.
Approaches currently being explored or widely deployed include:
- Approximate Nearest Neighbor (ANN) for faster search, accepting a small margin of error.
- Caching results for frequently asked queries.
- Streaming responses so users can see the answer being generated in real time.
5.2. Noise — "Garbage In, Garbage Out"
Retrieval is only as strong as the data it fetches. In practice, the system may:
- Return passages that appear relevant but do not actually answer the question.
- Pull outdated or contradictory information from multiple sources.
- Be “fooled” by terms that overlap semantically but differ in context.
Real-world example: A user asks about “a 30-day refund policy”, but the system retrieves a passage about “a 30-month warranty policy” — two entirely different topics.
When an LLM receives incorrect context, it does not “know” that the information is noisy — and may answer incorrectly with a high degree of confidence.
5.3. Chunking & Context Window Issues
As discussed in Part 3, splitting text into chunks is necessary — but it is also a double-edged sword. Chunks that are too small lose context; chunks that are too large dilute meaning and waste tokens unnecessarily.
There is currently no single “golden formula” that applies to every type of data.
What Does the Future Look Like?
Hybrid Search — Taking the Best of Both Worlds
The AI community is moving toward Hybrid Search — a combination of:
| Method | Strengths | Weaknesses |
|---|---|---|
| Lexical Search (BM25) | Precise with specific keywords, product codes, and proper nouns | Does not understand meaning |
| Semantic Search (Vector Search) | Understands intent and context | May miss important keywords |
| Hybrid Search | Leverages both | More complex to implement |
Hybrid Search is not about choosing one or the other. It runs both approaches in parallel, then uses an algorithm like Reciprocal Rank Fusion (RRF) to merge the results.
Reranking — The Fine Filter at the Final Stage
Even when Retrieval returns 20 passages, not all of them carry equal value. Reranking is an additional step that uses a specialized model (such as Cohere Rerank or a Cross-encoder) to:
- Re-read each pair (query — passage).
- Score the actual degree of relevance.
- Re-order the results before passing them to the LLM.
Reranking adds latency, but often improves answer quality significantly — a trade-off that many production AI products are willing to make.
Agentic Retrieval — When AI Decides How to Search
A newer trend is giving AI the ability to plan its own retrieval process. Rather than a single search pass, an AI agent can:
- Decompose a complex question into multiple sub-queries.
- Perform multiple rounds of Retrieval, each refined based on previous results.
- Self-evaluate: “Do I have enough information to answer this?”
This is the direction of systems such as Deep Research and Agentic RAG, and it is currently considered a highly promising direction for next-generation retrieval systems.
A Product Perspective
As someone who builds products, I have come to realize that Retrieval is not only a technical problem — it is also an experience design problem:
- When should citations be shown to build user trust?
- How should the system handle cases where no relevant information is found?
- What metrics should be used to measure Retrieval quality in a real product?
One key insight: users do not care about vectors or embeddings. They care about one thing — is the answer correct, and is it fast?
Conclusion of Part 5
Retrieval is maturing rapidly. The challenges around latency, noise, and chunking are gradually being addressed through Hybrid Search, Reranking, and Agentic Retrieval.
But the biggest lesson from a product management perspective is this: the best technology is not the most complex one — it is the one that solves the right problem for the user in a reliable and consistent way.
Retrieval is the foundation — and that foundation is becoming stronger over time.
Reference
https://viblo.asia/p/toi-uu-hoa-rag-kham-pha-5-chien-luoc-chunking-hieu-qua-ban-can-biet-EvbLbPGW4nk
Chưa có bình luận nào. Hãy là người đầu tiên!