
Retrieval: Trình Truy xuất Thông tin và Cuộc Cách mạng Hóa Trí tuệ Nhân tạo Hiện đại
Mở đầu
Sự bùng nổ của các mô hình ngôn ngữ lớn (Large Language Models - LLMs) đã đánh dấu một kỷ nguyên mới trong tương tác giữa người và máy. Tuy nhiên, khi đi sâu vào thực tế triển khai, các nhà phát triển và nghiên cứu đều đối mặt với hai rào cản lớn: sự lạc hậu của dữ liệu huấn luyện (knowledge cutoff) và hiện tượng ảo giác (hallucination).
Để giảm đáng kể những vấn đề này, khái niệm Retrieval (Truy xuất thông tin) đã trở thành một thành phần không thể tách rời trong nhiều hệ thống AI hiện đại, đóng vai trò là "chiếc mỏ neo" giúp hệ thống bám sát thực tế và tăng tính chính xác. Bài viết này là nỗ lực tổng hợp từ 5 góc nhìn chuyên môn, đi từ bản chất lý thuyết đến kiến trúc hệ thống, nhằm cung cấp một cái nhìn toàn cảnh về hạ tầng truy xuất trong kỷ nguyên AI.
Phần 1: Bản chất của Retrieval trong Hệ sinh thái AI
Trong khoa học máy tính truyền thống, Retrieval thường được hiểu đơn giản là việc truy vấn một tập dữ liệu có cấu trúc để tìm kiếm kết quả trùng khớp chính xác. Tuy nhiên, trong bối cảnh trí tuệ nhân tạo hiện đại, khái niệm này đã tiến hóa thành một quy trình phức tạp hơn: Tìm kiếm nội dung dựa trên sự tương quan về ngữ nghĩa và ngữ cảnh.
1.1. Từ "Học thuộc lòng" sang "Tra cứu có chọn lọc"
Các mô hình AI truyền thống hoạt động dựa trên tri thức được nén bên trong các trọng số (weights) sau quá trình huấn luyện. Điều này tương tự như một học sinh cố gắng học thuộc lòng toàn bộ thư viện.
Ngược lại, một hệ thống tích hợp Retrieval trang bị cho AI khả năng của một nhà nghiên cứu: khi nhận được câu hỏi, thay vì chỉ lục tìm trong trí nhớ hữu hạn, nó sẽ truy cập vào một kho lưu trữ bên ngoài để tìm những tài liệu liên quan nhất. Điều này cho phép hệ thống tiếp cận được với dữ liệu thời gian thực và các tài liệu nội bộ mà mô hình chưa từng được thấy trong quá trình pre-training.
1.2. Vai trò của Retrieval trong việc giảm thiểu Hallucination
Một trong những ứng dụng quan trọng nhất của Retrieval là cung cấp "Nguồn sự thật" (Source of Truth). Khi một mô hình ngôn ngữ được cung cấp các đoạn văn bản (context) phù hợp thông qua quá trình truy xuất, nhiệm vụ của nó chuyển từ sáng tạo nội dung tự do sang tổng hợp và trích xuất thông tin.
Nguyên lý cốt lõi: Chất lượng đầu ra của một hệ thống AI phụ thuộc mạnh vào độ chính xác và tính liên quan của dữ liệu được truy xuất ở đầu vào.
Cần lưu ý rằng Retrieval không giải quyết triệt để hallucination. Nó giúp giảm đáng kể hiện tượng này khi dữ liệu truy xuất tốt, ngữ cảnh đủ rõ, và prompt được thiết kế hợp lý.
1.3. Cấu trúc cơ bản của một hệ thống Retrieval hiện đại
Một quy trình Retrieval tiêu chuẩn không chỉ dừng lại ở việc tìm kiếm, mà bao gồm ba giai đoạn chiến lược:
- Biểu diễn (Representation): Chuyển hóa các câu hỏi tự nhiên của con người thành các định dạng mà máy tính có thể hiểu được. Trong kỷ nguyên hiện nay, đây thường là các vector toán học (embeddings).
- Đo lường sự tương quan (Similarity Scoring): Sử dụng các hàm đo khoảng cách hoặc độ tương đồng để xác định mức độ gần gũi giữa câu hỏi và tài liệu. Các phương pháp phổ biến bao gồm:
- Cosine Similarity: Đo góc giữa hai vector trong không gian đa chiều.
- Euclidean Distance: Đo khoảng cách giữa hai điểm vector.
- Dot Product: Thường được dùng trong nhiều hệ embedding hiện đại. - Lọc và Xếp hạng (Filtering & Ranking): Lựa chọn $k$ kết quả có điểm số tương quan cao nhất để đưa vào mô hình xử lý ngôn ngữ (generator).
Việc hiểu rõ bản chất này là nền tảng để đi sâu hơn vào các kỹ thuật NLP và kiến trúc vector database ở các phần tiếp theo.
Phần 2: Từ Keyword đến “Hiểu Ý Nghĩa” — AI đã thay đổi cách tìm kiếm như thế nào?
(Góc nhìn của kỹ sư NLP)
Nếu Phần 1 trả lời câu hỏi “Vì sao Retrieval quan trọng?”, thì Phần 2 đi vào một câu hỏi thực tế hơn: hệ thống quyết định tài liệu nào đủ liên quan để lấy ra bằng cách nào?
Đây chính là điểm bẻ lái giữa tìm kiếm truyền thống và tìm kiếm trong kỷ nguyên AI. Trong một hệ thống RAG, LLM chỉ có thể trả lời tốt nếu tầng retrieval kéo đúng các đoạn văn bản ngay từ đầu. Vì vậy, sự chuyển dịch từ so khớp từ khóa sang tìm kiếm theo ý nghĩa không chỉ là một cải tiến về trải nghiệm tìm kiếm, mà còn là nền tảng của chất lượng câu trả lời.
2.1. Giai đoạn đầu: Lexical Search và so khớp từ khóa
Các hệ thống tìm kiếm truyền thống chủ yếu dựa trên lexical signals - tức là các từ thực sự xuất hiện trong query và trong tài liệu. Những phương pháp như TF-IDF hay BM25 thường đánh giá độ liên quan dựa trên:
- Từ nào trong query xuất hiện trong tài liệu
- Từ đó xuất hiện bao nhiêu lần
- Từ đó hiếm hay phổ biến trong toàn bộ tập dữ liệu
- Trong một số hệ thống, từ đó xuất hiện ở đâu, chẳng hạn tiêu đề hay heading
Nếu người dùng gõ “cách giảm cân hiệu quả”, một hệ thống lexical tự nhiên sẽ ưu tiên các bài có chứa trực tiếp các từ như giảm cân và hiệu quả.
Query: "cách giảm cân hiệu quả"
Lexical search chủ yếu thưởng cho việc trùng từ:
Doc A: "Cách giảm cân hiệu quả tại nhà" khớp mạnh
Doc B: "Làm sao để đốt mỡ an toàn" khớp yếu hơn
Doc C: "Thói quen ăn uống lành mạnh lâu dài" khớp yếu hơn
Cách làm này vẫn rất giá trị vì nó nhanh, dễ giải thích, và đặc biệt chính xác khi người dùng cần tìm đúng một chuỗi ký tự cụ thể.
2.2. Vì sao keyword search vẫn hữu ích - và nó vấp ở đâu?
Tìm kiếm theo từ khóa đặc biệt hiệu quả khi truy vấn mang tính chính xác cao, ví dụ:
- mã sản phẩm
- mã lỗi hệ thống
- tên API
- điều khoản pháp lý cụ thể
- tên người, tên tổ chức, tên riêng
Nếu bạn tìm ERR_CONNECTION_RESET hoặc SKU-A19, phần lớn thời điểm bạn thực sự muốn những tài liệu có chứa đúng các token đó.
Nhưng điểm yếu xuất hiện ngay khi ngôn ngữ của người dùng khác ngôn ngữ của tài liệu.
Ví dụ, một người dùng hỏi chatbot hỗ trợ:
“Tôi có thể lấy lại tiền trong vòng một tháng không?”
Trong khi tài liệu nội bộ lại viết:
“Sản phẩm số được hỗ trợ hoàn tiền trong vòng 30 ngày.”
Một hệ thống chỉ dựa trên lexical matching có thể không xem “lấy lại tiền” và “hoàn tiền” là đủ gần nhau, dù về mặt ý nghĩa chúng gần như tương đương. Đây chính là khoảng cách giữa mặt chữ và ý định thực sự - và đó là lý do retrieval hiện đại buộc phải tiến hóa.
2.3. Semantic Search: biến ý nghĩa thành thứ có thể tìm kiếm
Semantic search thay đổi bản chất của bài toán. Thay vì chỉ hỏi “Tài liệu nào chứa những từ giống với query?”, hệ thống bắt đầu hỏi:
“Tài liệu nào đang diễn đạt cùng một ý?”
Để làm được điều đó, cả query và tài liệu sẽ được chuyển thành embeddings - các vector dày đặc mang thông tin ngữ nghĩa. Trong không gian biểu diễn này, những nội dung gần nghĩa sẽ nằm gần nhau ngay cả khi cách dùng từ khác nhau.
Một cách hình dung đơn giản:
Không gian ngữ nghĩa (mô phỏng trực quan)
"giảm cân" ●
"đốt mỡ an toàn" ● <- gần nhau vì cùng ý định
"ăn uống thâm hụt calo" ●
"cách sửa Wi-Fi" ●
Chúng ta không nhìn thấy trực tiếp các tọa độ toán học đó, nhưng có thể hiểu trực giác như sau: những ý tưởng liên quan sẽ tạo thành các "cụm nghĩa" gần nhau.
Vì vậy, khi người dùng tìm “cách giảm cân hiệu quả”, hệ thống semantic có thể kéo về cả những nội dung như:
- đốt mỡ an toàn
- chế độ ăn lành mạnh
- thâm hụt calo
- kế hoạch tập luyện để giảm mỡ
Đây là bước chuyển quan trọng nhất: hệ thống không còn chỉ so khớp chuỗi ký tự, mà bắt đầu so khớp ý định, chủ đề và ngữ cảnh.
2.4. Vì sao điều này đặc biệt quan trọng với Retrieval và RAG?
Trong web search thông thường, việc trả về vài kết quả "na ná" đôi khi vẫn chấp nhận được. Nhưng trong Retrieval cho chatbot hay RAG, mức độ chính xác của khâu tìm kiếm trở nên quan trọng hơn rất nhiều.
Lý do là vì người dùng và tài liệu hiếm khi "nói cùng một ngôn ngữ".
Người dùng có thể hỏi:
- “Làm sao để hủy gói dịch vụ?”
- “Tại sao thanh toán của tôi bị từ chối?”
- “Sau 30 ngày tôi còn được hoàn tiền không?”
Trong khi tài liệu lại dùng các cụm:
- “subscription termination policy”
- “payment failure conditions”
- “refund eligibility window”
Nếu tầng retrieval chỉ dựa vào việc trùng chữ, LLM có thể không bao giờ nhận được đúng context. Và một khi context đã sai hoặc thiếu, ngay cả một model mạnh cũng rất dễ trả lời yếu, trả lời chung chung, hoặc tệ hơn là trả lời sai nhưng nghe vẫn hợp lý.
Nói cách khác, trước khi bàn đến chuyện generate tốt đến đâu, hệ thống phải giải được một bài toán khó hơn: tìm đúng bằng chứng để trả lời.
2.5. So sánh trực quan hai kiểu tìm kiếm
| Cách tìm | Hệ thống chủ yếu nhìn vào đâu? | Điểm mạnh | Điểm yếu |
|---|---|---|---|
| Lexical search | Từ khóa trùng hoặc gần trùng | Mạnh với mã lỗi, tên riêng, thuật ngữ chính xác | Yếu khi gặp diễn đạt khác nhau |
| Semantic search | Ý nghĩa và ý định | Mạnh với câu hỏi tự nhiên, diễn đạt linh hoạt | Có thể bỏ sót từ khóa cực kỳ quan trọng |
Vì vậy, semantic search không phải là "phiên bản thay thế hoàn toàn" cho lexical search. Nó là bước mở rộng giúp hệ thống tìm kiếm được nhiều loại liên quan hơn, đặc biệt trong bối cảnh ngôn ngữ tự nhiên.
Sự chuyển đổi từ keyword search sang semantic search không chỉ là nâng cấp kỹ thuật. Nó thay đổi luôn vai trò của tìm kiếm trong hệ thống AI.
Tìm kiếm kiểu cũ trả lời câu hỏi:
“Tài liệu nào chứa những từ này?”
Còn Retrieval hiện đại phải trả lời câu hỏi:
“Mẩu thông tin nào có khả năng giúp giải đúng ý định của người dùng nhất?”
Chính bước chuyển đó khiến các hệ thống ngày nay hữu ích hơn, linh hoạt hơn, và phù hợp hơn nhiều với chatbot, assistant, cũng như RAG. Đồng thời, nó cũng tạo nền cho các phần tiếp theo: dữ liệu sẽ được chunk như thế nào, embedding ra sao, index ở đâu, và cuối cùng được đưa vào LLM như thế nào để tạo thành một câu trả lời đáng tin cậy.
Phần 3: Quy Trình "Sơ Chế" Dữ Liệu
(Góc nhìn của Data Architect)
Nếu Retrieval là “cỗ máy tìm kiếm”, thì dữ liệu chính là “nguyên liệu đầu vào”. Và giống như trong nấu ăn, nguyên liệu không được sơ chế kỹ thì dù hệ thống có tốt đến đâu, kết quả vẫn khó tối ưu.
Một hệ thống Retrieval hiệu quả không bắt đầu từ model, mà bắt đầu từ cách bạn chuẩn bị dữ liệu. Quy trình này thường xoay quanh 3 bước cốt lõi: Chunking → Embedding → Indexing.
3.1. Chunking – Chia nhỏ để giữ trọn ý nghĩa
Các mô hình AI không “đọc” văn bản như con người. Nếu bạn đưa cho hệ thống một tài liệu dài hàng chục trang, rất dễ xảy ra hai vấn đề:
- Quá tải ngữ cảnh (context overflow)
- Làm loãng thông tin quan trọng
Vì vậy, bước đầu tiên là chia nhỏ tài liệu thành các đoạn (chunks).
Các phương pháp chunking phổ biến:
- Fixed-size chunking
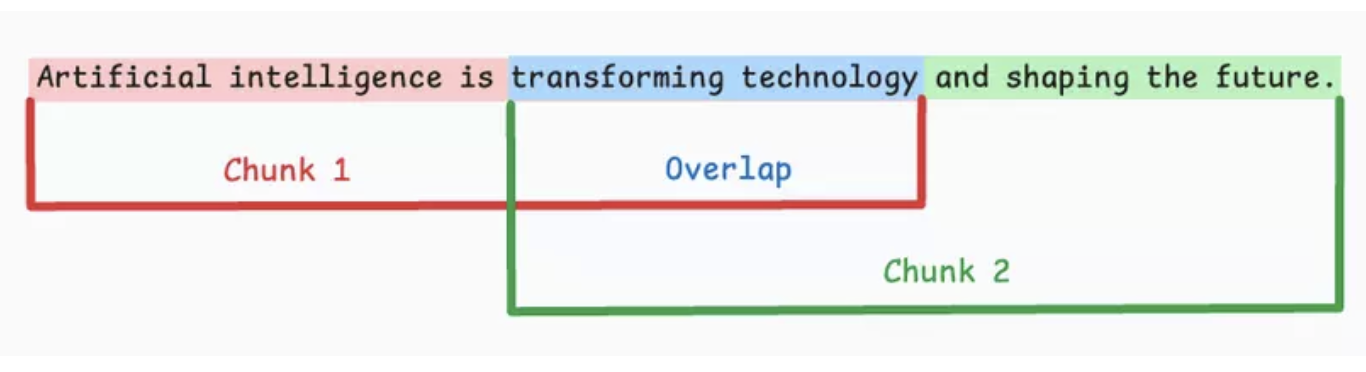
Hình 3.1. Chia chunk theo kích thước cố định.
Chia văn bản theo kích thước cố định (ký tự/từ/token), thường thêm overlap để giảm đứt mạch nội dung.
Ưu điểm: Dễ triển khai, xử lý hàng loạt tốt.
Nhược điểm: Dễ cắt ngang câu hoặc ý quan trọng.
- Semantic chunking
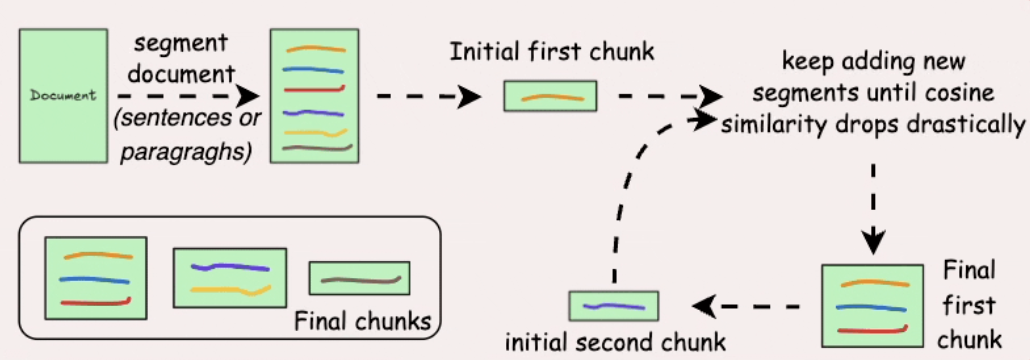
Hình 3.2. Chia chunk theo ngữ nghĩa.
Chia theo đơn vị ngữ nghĩa (câu/đoạn), dùng embedding + similarity để gộp các phần liên quan.
Ưu điểm: Chunk mạch lạc hơn, retrieval chính xác hơn.
Nhược điểm: Phụ thuộc ngưỡng similarity và tốn compute hơn.
- Recursive chunking
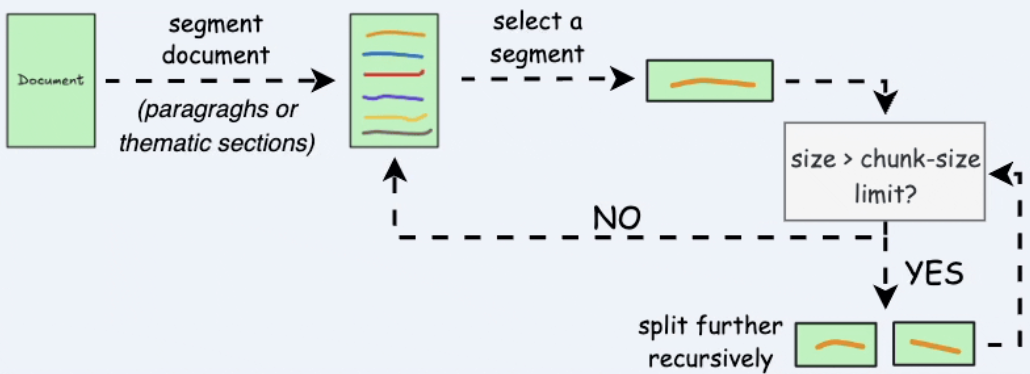
Hình 3.3. Chia chunk đệ quy theo ranh giới tự nhiên.
Tách theo ranh giới tự nhiên (\n\n, \n, khoảng trắng), nếu còn quá dài thì tách đệ quy tiếp.
Ưu điểm: Cân bằng giữa ngữ nghĩa và giới hạn kích thước.
Nhược điểm: Triển khai phức tạp hơn fixed-size.
- Document structure-based chunking
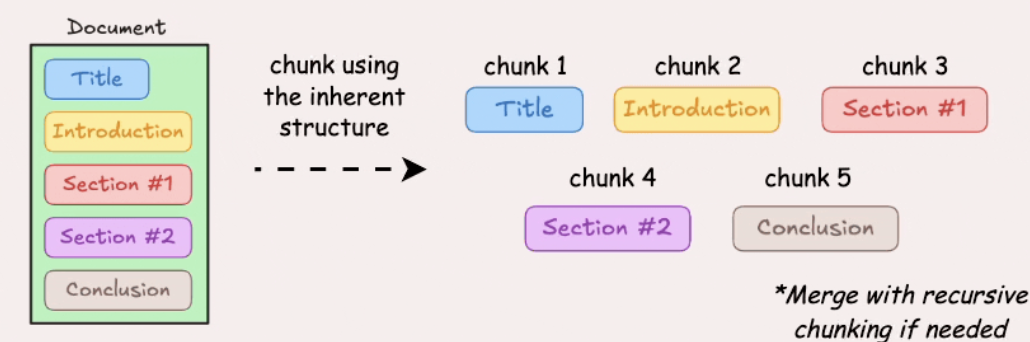
Hình 3.4. Chia chunk theo cấu trúc tài liệu.
Tận dụng cấu trúc tài liệu (heading, section, list, table, paragraph) để xác định ranh giới chunk.
Ưu điểm: Giữ tốt logic tài liệu gốc.
Nhược điểm: Phụ thuộc vào tài liệu có cấu trúc rõ; chunk có thể không đồng đều.
- LLM-based chunking
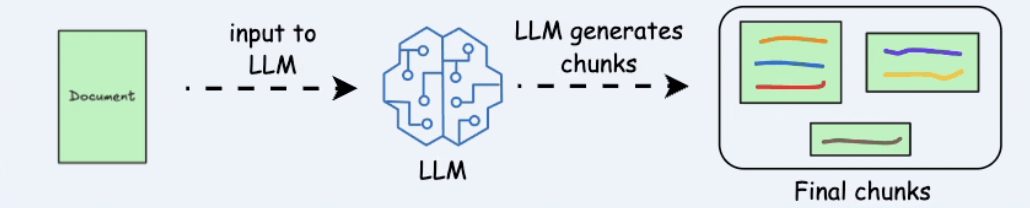
Hình 3.5. Chia chunk với sự hỗ trợ của LLM.
Dùng LLM xác định ranh giới chunk theo chủ đề hoặc đơn vị ý nghĩa hoàn chỉnh.
Ưu điểm: Có tiềm năng rất tốt về chất lượng ngữ nghĩa.
Nhược điểm: Chi phí cao, chậm hơn, phụ thuộc prompt và context window.
Insight quan trọng: Không có phương pháp “tốt nhất tuyệt đối”. Trong thực tế, người ta thường dùng hybrid chunking để cân bằng chất lượng, tốc độ và chi phí.
3.2. Embedding – Biến ngôn ngữ thành tọa độ
Sau khi có các chunks, bước tiếp theo là chuyển chúng thành dạng mà máy có thể “hiểu” và so sánh: vector embeddings.
Embedding model (ví dụ như text-embedding-3) sẽ biến mỗi đoạn văn thành một vector trong không gian nhiều chiều.
Điều này cho phép hệ thống:
- Đo lường độ tương đồng ngữ nghĩa
- Tìm các đoạn “có nghĩa giống nhau” dù không trùng từ
Ví dụ thực tế (Embedding):
Giả sử hệ thống có 3 chunks:
C1: “Cách nấu phở bò tại nhà”C2: “Hướng dẫn nấu phở truyền thống”C3: “Mẹo bảo dưỡng xe máy mùa mưa”
Với query: “Làm sao nấu phở bò ngon?”
sim(query, C1) = 0.91sim(query, C2) = 0.88sim(query, C3) = 0.15
Kết quả: hệ thống ưu tiên C1, C2 vì gần nghĩa, dù câu chữ không trùng hoàn toàn.
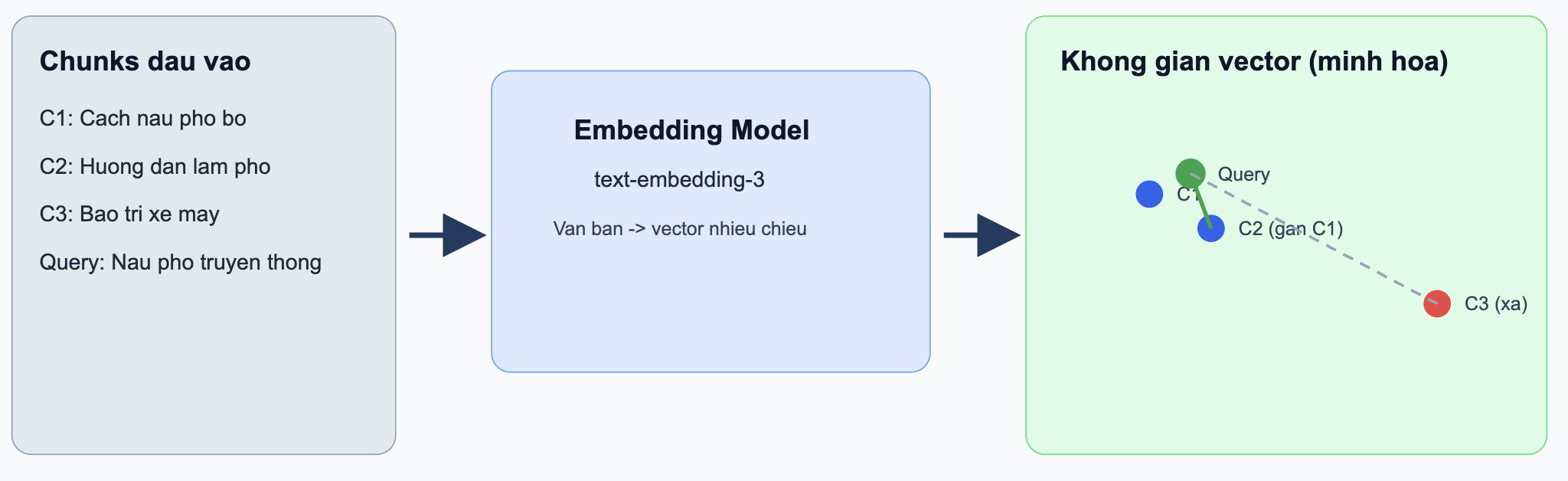
Hình 3.6. Embedding biểu diễn văn bản dưới dạng vector.
Insight quan trọng: Embedding chính là cầu nối giữa ngôn ngữ con người và toán học của máy học.
3.3. Indexing – Tổ chức để tìm kiếm trong mili-giây
Sau khi có vector, bạn cần một nơi để lưu trữ và truy xuất chúng thật nhanh — đó là lúc Vector Database xuất hiện.
Một số hệ phổ biến:
- Pinecone
- Milvus
- Weaviate
Khác với database truyền thống (SQL), vector database được tối ưu cho:
- Tìm kiếm gần đúng (Approximate Nearest Neighbor - ANN)
- Xử lý hàng triệu đến hàng tỷ vector với độ trễ thấp
Quy trình indexing gồm:
- Lưu vector + metadata (nguồn, tiêu đề, timestamp…)
- Tạo cấu trúc chỉ mục (index structure) để tăng tốc tìm kiếm
- Tối ưu cho truy vấn similarity (cosine similarity, dot product…)
Ví dụ thực tế (Indexing + Retrieval):
Giả sử bạn đã index 1 triệu chunks tài liệu nội bộ. Khi có câu hỏi “Chính sách hoàn tiền trong 30 ngày hoạt động thế nào?”:
- Câu hỏi được embedding thành
q_vector - Vector DB dùng ANN index để tìm
top-kvector gần nhất trong mili-giây - Trả về các chunk liên quan nhất, ví dụ:
-chunk_2451(score0.93) - mục hoàn tiền sản phẩm
-chunk_8712(score0.89) - điều kiện áp dụng
-chunk_1022(score0.84) - các trường hợp ngoại lệ
Các chunk này sẽ được đưa vào context cho LLM để tạo câu trả lời cuối cùng.
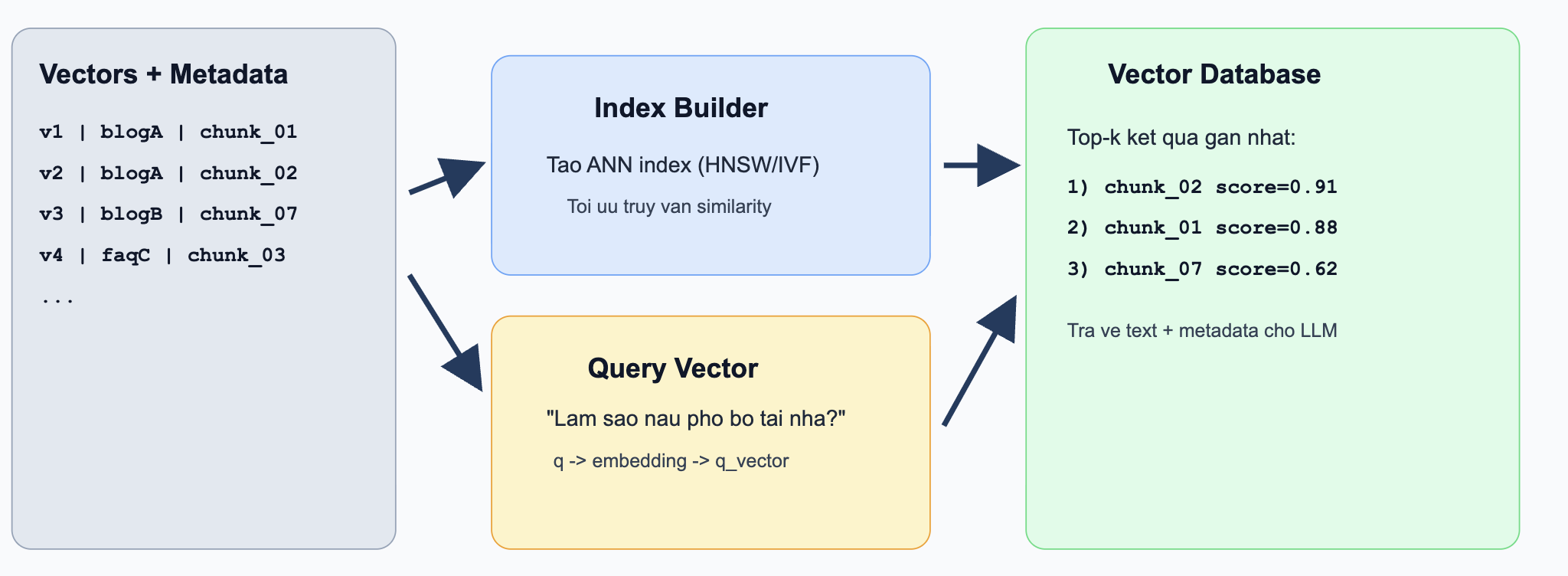
Hình 3.7. Quy trình truy xuất bằng vector.
Khi người dùng đặt câu hỏi:
- Câu hỏi được embedding thành vector
- Hệ thống tìm các vector gần nhất trong database
- Trả về các chunks liên quan nhất
Retrieval tốt bắt đầu từ dữ liệu tốt
Ba bước này tạo thành nền tảng cho toàn bộ hệ thống Retrieval:
- Chunking → Quyết định AI sẽ “nhìn” dữ liệu như thế nào
- Embedding → Quyết định AI “hiểu” dữ liệu ra sao
- Indexing → Quyết định AI tìm dữ liệu nhanh đến mức nào
Nếu làm tốt phần này, bạn đã quyết định phần lớn chất lượng retrieval của hệ thống RAG sau này.
Một câu nói đáng nhớ trong giới Data Architect:
“Garbage in, garbage out — nhưng với Retrieval, nó là: Chunk tệ, search sai; embedding kém, hiểu sai.”
Phần 4: RAG — Đỉnh cao thực tiễn của Retrieval
(Góc nhìn của AI Developer)
Nếu Phần 2 nói về sự tiến hóa của tìm kiếm, Phần 3 nói về quy trình chuẩn bị dữ liệu, thì Phần 4 là nơi mọi thứ hội tụ trong sản phẩm thực tế:
RAG (Retrieval-Augmented Generation).
RAG không phải là một model hoàn toàn mới, mà là một kiến trúc kết hợp:
- Retriever (truy xuất tri thức liên quan)
- Generator (LLM tạo câu trả lời)
Thay vì buộc LLM phải “nhớ hết”, ta cho LLM khả năng “đọc tài liệu đúng lúc”.
4.1. Vì sao RAG quan trọng trong sản phẩm thật
Khi chỉ dùng LLM thuần, thường gặp 3 vấn đề:
- Hallucination: trả lời trôi chảy nhưng sai.
- Giới hạn tri thức: model không biết dữ liệu mới hoặc dữ liệu nội bộ.
- Thiếu truy vết nguồn: khó biết câu trả lời dựa trên tài liệu nào.
RAG giúp giải quyết trực tiếp các vấn đề này theo những cách sau:
- Neo câu trả lời vào tài liệu được truy xuất.
- Cập nhật tri thức bằng cách cập nhật kho dữ liệu, không cần train lại model.
- Có thể hiển thị trích dẫn để tăng độ tin cậy.
4.2. Luồng RAG cốt lõi (end-to-end)
Câu hỏi người dùng
↓
Embedding query
↓
Truy xuất từ Vector DB (top-k chunks)
↓
(Tùy chọn) Rerank kết quả
↓
Tạo prompt cuối cùng với context
↓
LLM sinh câu trả lời + nguồn tham chiếu
Trong triển khai, RAG thường gồm 4 khối:
ingestion: chunk + embedding + indexing tài liệu.retrieval: lấy các chunks liên quan theo query.prompting: ghép instruction + context + câu hỏi.generation: gọi LLM và định dạng output.
4.3. Blueprint triển khai tối thiểu
Bước A — Lấy context
- Biến câu hỏi thành embedding vector.
- Tìm kiếm trên vector database (
top_k = 5hoặc10). - Lọc theo metadata (sản phẩm, ngôn ngữ, thời gian).
Bước B — Ghép prompt an toàn
- Đặt rule hệ thống rõ ràng: “Chỉ trả lời dựa trên context cung cấp.”
- Đưa các chunk vào khối
CONTEXT. - Thêm hành vi fallback: “Nếu không đủ thông tin, hãy nói rõ.”
Bước C — Sinh câu trả lời + trích dẫn
- Yêu cầu model trả về:
- câu trả lời ngắn gọn
- nguồn tham chiếu (
doc_id, tiêu đề, link)
Cấu trúc này giúp giảm mạnh các câu trả lời “nghe hợp lý nhưng sai”.
4.4. Ví dụ thực tế
Người dùng hỏi:
“Chính sách hoàn tiền 30 ngày cho sản phẩm số hoạt động thế nào?”
Retriever trả về:
policy_refund_v2.md(điều kiện hoàn tiền)faq_payments.md(các ngoại lệ)terms_service.md(giới hạn theo khu vực)
LLM nhận prompt chứa các chunk này và trả lời:
- áp dụng hoàn tiền trong 30 ngày nếu thỏa điều kiện sử dụng,
- nêu các gói bị loại trừ,
- đính kèm link chính sách chính thức.
Nếu không dùng RAG, model có thể trả lời chung chung. Có RAG, câu trả lời bám sát tài liệu thật của hệ thống.
4.5. Những đánh đổi kỹ thuật sẽ gặp
- Latency vs chất lượng
- Lấy nhiều chunk hơn có thể tăng recall nhưng chậm hơn. - Kích thước chunk vs toàn vẹn ngữ cảnh
- Chunk quá nhỏ mất ý; chunk quá lớn tốn token. - Chi phí vs độ tin cậy
- Reranking và context lớn tăng chất lượng nhưng tăng cost.
Một cấu hình production phổ biến:
- Hybrid retrieval (BM25 + vector)
- Recall top 20 → rerank còn top 5
- Prompt có grounding + output có citation
4.6. Đánh giá hệ thống RAG như thế nào
Không nên chỉ đánh giá kiểu “câu trả lời nghe hay”. Hãy đo:
- Retrieval Recall@k: có lấy được chunk thực sự liên quan không?
- Groundedness/Faithfulness: câu trả lời có bám context không?
- Độ chính xác trích dẫn: nguồn có đúng và hữu ích không?
- Latency (P95) và chi phí mỗi request.
RAG tốt là bài toán hệ thống, không chỉ là bài toán model.
Phần 5: Thách Thức & Tương Lai Của Retrieval
(Góc nhìn của Quản Lý Sản Phẩm)
Dẫn Nhập
Bốn phần trước đã vẽ nên một bức tranh hoàn chỉnh về Retrieval — từ khái niệm nền tảng, sự tiến hóa của kỹ thuật tìm kiếm, quy trình xử lý dữ liệu, đến ứng dụng đỉnh cao là RAG. Nhưng không có công nghệ nào là hoàn hảo.
Là một người quản lý sản phẩm, câu hỏi tôi luôn đặt ra không phải là "Công nghệ này hoạt động như thế nào?" mà là "Công nghệ này thất bại ở đâu, và bước tiếp theo là gì?"
Những Thách Thức Hiện Tại
5.1. Độ Trễ (Latency) — Kẻ Thù Thầm Lặng Của Trải Nghiệm Người Dùng
Một hệ thống Retrieval phải thực hiện hàng loạt tác vụ trong tích tắc:
[Câu hỏi của người dùng]
↓
Embedding query
↓
Vector similarity search
↓
Fetch & rerank documents
↓
Gửi context → LLM generate
↓
[Câu trả lời]
Mỗi bước đều tốn thời gian. Nếu tổng thời gian phản hồi vượt quá 2–3 giây, người dùng bắt đầu mất kiên nhẫn. Đây là một thách thức kỹ thuật lớn, đặc biệt khi cơ sở dữ liệu có hàng triệu vector.
Hướng giải quyết đang được nghiên cứu hoặc triển khai rộng rãi gồm:
- Approximate Nearest Neighbor (ANN) để tìm kiếm nhanh hơn, chấp nhận sai số nhỏ.
- Caching kết quả cho các truy vấn phổ biến.
- Streaming response để người dùng thấy câu trả lời được tạo ra theo thời gian thực.
5.2. Độ Nhiễu (Noise) — "Rác Vào, Rác Ra"
Retrieval chỉ mạnh khi nó lấy đúng dữ liệu. Trên thực tế, hệ thống có thể:
- Trả về những đoạn văn bản có vẻ liên quan nhưng không thực sự trả lời câu hỏi.
- Lấy phải thông tin lỗi thời hoặc mâu thuẫn nhau từ nhiều nguồn.
- Bị “đánh lừa” bởi các từ ngữ trùng hợp về mặt ngữ nghĩa nhưng khác về ngữ cảnh.
Ví dụ thực tế: Người dùng hỏi "Chính sách hoàn tiền trong vòng 30 ngày", hệ thống lại lấy về đoạn văn bản về "Chính sách bảo hành 30 tháng" — hai chủ đề hoàn toàn khác nhau.
Khi LLM nhận phải context sai, nó không "biết" mình đang được cung cấp thông tin nhiễu — và có thể sẽ trả lời sai một cách rất tự tin.
5.3. Vấn Đề Về Chunking & Context Window
Như đã đề cập ở Phần 3, việc chia nhỏ văn bản (chunking) là cần thiết — nhưng cũng là con dao hai lưỡi. Chunk quá nhỏ thì mất ngữ cảnh; chunk quá lớn thì loãng ý nghĩa và tốn token không cần thiết.
Hiện chưa có một công thức “vàng” nào áp dụng được cho mọi loại dữ liệu.
Tương Lai Thuộc Về Ai?
Hybrid Search — Lấy Điểm Mạnh Của Cả Hai Thế Giới
Cộng đồng AI đang hướng tới Hybrid Search — sự kết hợp giữa:
| Phương pháp | Điểm mạnh | Điểm yếu |
|---|---|---|
| Lexical Search (BM25) | Chính xác với từ khóa cụ thể, mã sản phẩm, tên riêng | Không hiểu ngữ nghĩa |
| Semantic Search (Vector Search) | Hiểu ý định, ngữ cảnh | Có thể bỏ sót từ khóa quan trọng |
| Hybrid Search | Tận dụng cả hai | Phức tạp hơn để triển khai |
Hybrid Search không phải là “chọn một trong hai”, mà là chạy cả hai song song, sau đó dùng thuật toán như Reciprocal Rank Fusion (RRF) để hợp nhất kết quả.
Reranking — Bộ Lọc Tinh Tế Ở Tầng Cuối
Ngay cả khi Retrieval trả về 20 đoạn văn bản, không phải tất cả đều có giá trị như nhau. Reranking là bước bổ sung, dùng một model chuyên biệt (như Cohere Rerank hoặc Cross-encoder) để:
- Đọc lại từng cặp (câu hỏi — đoạn văn bản).
- Chấm điểm mức độ liên quan thực sự.
- Sắp xếp lại thứ tự trước khi đưa vào LLM.
Reranking tốn thêm thời gian, nhưng thường cải thiện chất lượng câu trả lời đáng kể — đây là sự đánh đổi mà nhiều sản phẩm AI production sẵn sàng chấp nhận.
Agentic Retrieval — Khi AI Tự Quyết Định Cách Tìm Kiếm
Xu hướng mới là trao cho AI khả năng tự lập kế hoạch truy xuất thông tin. Thay vì một lần tìm kiếm duy nhất, AI agent có thể:
- Phân tích câu hỏi phức tạp và chia nhỏ thành nhiều sub-query.
- Thực hiện nhiều vòng Retrieval, mỗi vòng tinh chỉnh dựa trên kết quả trước.
- Tự đánh giá: "Thông tin tôi có đủ để trả lời chưa?"
Đây là hướng đi của các hệ thống như Deep Research hay Agentic RAG, và hiện được xem là một hướng phát triển rất tiềm năng cho các hệ thống retrieval thế hệ tiếp theo.
Nhìn Từ Góc Độ Sản Phẩm
Là người xây dựng sản phẩm, tôi nhận ra rằng Retrieval không chỉ là bài toán kỹ thuật — đó còn là bài toán thiết kế trải nghiệm:
- Khi nào nên hiển thị nguồn trích dẫn để người dùng tin tưởng?
- Làm thế nào để xử lý tốt trường hợp không tìm thấy thông tin liên quan?
- Metrics nào để đo “độ tốt” của Retrieval trong sản phẩm thực?
Một insight quan trọng: Người dùng không quan tâm đến vector hay embedding. Họ chỉ quan tâm đến một điều duy nhất — câu trả lời có đúng không, và có nhanh không.
Retrieval đang ở giai đoạn trưởng thành nhanh chóng. Những thách thức về latency, noise và chunking đang dần được giải quyết thông qua Hybrid Search, Reranking và Agentic Retrieval.
Nhưng bài học lớn nhất từ góc nhìn quản lý sản phẩm là: công nghệ tốt nhất không phải là công nghệ phức tạp nhất — mà là công nghệ giải quyết đúng vấn đề của người dùng, một cách đáng tin cậy và nhất quán.
Retrieval là nền tảng — và nền tảng đó đang ngày càng vững chắc hơn.
Tài liệu tham khảo
https://viblo.asia/p/toi-uu-hoa-rag-kham-pha-5-chien-luoc-chunking-hieu-qua-ban-can-biet-EvbLbPGW4nk
Chưa có bình luận nào. Hãy là người đầu tiên!