
Experiment source code: AIO_CQ01_Project_Handwritten_digit_recognization_using_softmax_regression
Slide: google drive
Video demo: google drive
Source code Demo (UI Streamlit): google drive
1. Cơ sở lý thuyết
1.1. Bài toán phân loại đa lớp
Bài toán phân loại đa lớp (multi-class classification) là một trong những bài toán cơ bản của học máy, trong đó mỗi mẫu dữ liệu đầu vào được gán duy nhất một nhãn thuộc tập hữu hạn các lớp xác định trước. Cho tập dữ liệu huấn luyện
$$\mathcal{D} = \{(x_i, y_i)\}_{i=1}^{N}
$$
trong đó $\mathbf{x}_i \in \mathbb{R}^d$ là vector đặc trưng của mẫu thứ $i$ và $y_i \in \{0, 1, \dots, K-1\}$ là nhãn lớp tương ứng, với $K$ là số lớp cần phân loại. Mục tiêu của bài toán là học một hàm ánh xạ
$$f_{\theta} : \mathbb{R}^d \to \{0, 1, \ldots, K - 1\},
$$
hoặc tương đương, một mô hình ước lượng phân phối xác suất có điều kiện $p(y \mid \mathbf{x}; \theta)$, sao cho xác suất dự đoán đúng nhãn là lớn nhất.
Đối với bộ dữ liệu MNIST, mỗi mẫu dữ liệu là một ảnh chữ số viết tay được biểu diễn bởi vector đặc trưng $d = 28 \times 28$, và số lớp phân loại là $K = 10$, tương ứng với các chữ số từ 0 đến 9.
1.2. Mô hình Softmax Regression
Softmax Regression, hay Multinomial Logistic Regression, là một mô hình phân loại tuyến tính mở rộng của Logistic Regression cho trường hợp đa lớp. Mô hình giả định rằng mối quan hệ giữa đặc trưng đầu vào và các lớp có thể được mô tả thông qua một phép biến đổi:
$$\mathbf{z} = \mathbf{W}\mathbf{x} + \mathbf{b},
$$
trong đó $W \in \mathbb{R}^{K \times d}$ là ma trận trọng số, $\mathbf{b} \in \mathbb{R}^{K}$ là vector bias, và $\mathbf{z} \in \mathbb{R}^{K}$ được gọi là vector logits.
Các logits này sau đó được chuyển thành xác suất thông qua hàm softmax:
$$p(y = j \mid \mathbf{x})
= \frac{\exp(z_j)}{\sum_{k=1}^{K} \exp(z_k)},
\quad j = 0, \ldots, K - 1.$$
Hàm softmax đảm bảo rằng các giá trị đầu ra luôn không âm và có tổng bằng 1, từ đó có thể diễn giải như một phân phối xác suất trên các lớp. Vì chỉ bao gồm một lớp tuyến tính, Softmax Regression có biên quyết định tuyến tính trong không gian đặc trưng, và vì vậy có năng lực biểu diễn hạn chế khi áp dụng cho các dữ liệu có cấu trúc phi tuyến phức tạp.
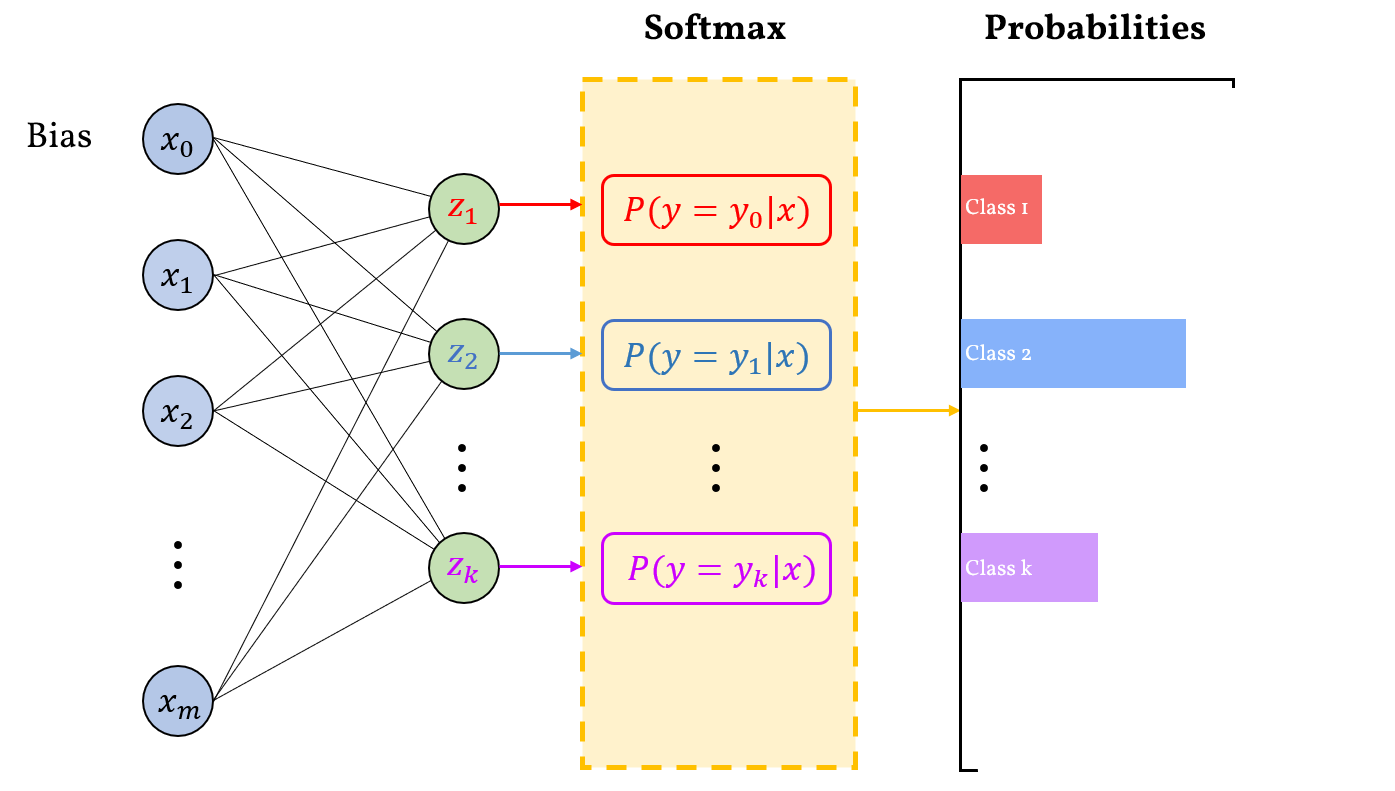
Hình 1. Mô phỏng đơn giản về Softmax Regression trong mạng nơ-ron.
1.3. Hàm mất mát Cross-Entropy
Để huấn luyện mô hình Softmax Regression, một hàm mất mát phù hợp cho phân loại đa lớp là cần thiết. Hàm mất mát cross-entropy đo lường mức độ khác biệt giữa phân phối xác suất dự đoán của mô hình và phân phối nhãn thực (thường được biểu diễn dưới dạng one-hot). Với một mẫu dữ liệu $(\mathbf{x}, y)$ hàm mất mát được định nghĩa như sau:
$$\mathcal{L}(\mathbf{x}, y)
= - \sum_{j=1}^{K} \mathbb{I}(y = j)\,\log p(y = j \mid \mathbf{x}),$$
trong đó $\mathbb{I}(\cdot)$ là hàm chỉ báo.
Từ góc độ xác suất, việc tối thiểu hóa hàm mất mát cross-entropy tương đương với việc cực đại hoá log-likelihood của dữ liệu huấn luyện dưới giả định mô hình.
1.4. Gradient Descent
Quá trình huấn luyện mô hình Softmax Regression được thực hiện bằng cách tối ưu các tham số $\theta = \{W, \mathbf{b}\}$ nhằm cực tiểu hóa hàm mất mát trên tập train. Phương pháp phổ biến nhất là Gradient Descent, trong đó các tham số được cập nhật theo hướng ngược với gradient của hàm mất mát:
$$\theta \leftarrow \theta - \eta \nabla_\theta \mathcal{L},
$$
với $\eta > 0$ là learning rate.
Trong thực tế, để cân bằng giữa hiệu quả tính toán và độ ổn định của quá trình học, Gradient Descent thường được triển khai dưới dạng Mini-batch Stochastic Gradient Descent (SGD), trong đó gradient được ước lượng trên các tập con nhỏ (mini-batch) của dữ liệu huấn luyện. Cách tiếp cận này cho phép mô hình cập nhật tham số thường xuyên hơn so với full-batch gradient descent, đồng thời giảm nhiễu so với stochastic gradient descent thuần túy.
Việc lựa chọn learning rate và kích thước mini-batch đóng vai trò quan trọng trong tốc độ hội tụ và chất lượng nghiệm tối ưu của mô hình.
1.5. Quy trình huấn luyện mô hình học sâu
Quy trình huấn luyện một mô hình học máy có giám sát (supervised learning) thường được thực hiện theo các bước lặp lại cho đến khi hội tụ. Trước hết, tại mỗi vòng lặp huấn luyện, một mini-batch dữ liệu được đưa vào mô hình để thực hiện lan truyền xuôi (forward pass), trong đó mô hình sinh ra các giá trị dự đoán dưới dạng logits. Dựa trên các giá trị này và nhãn thực tương ứng, hàm mất mát được tính nhằm định lượng mức độ sai lệch của mô hình trên mini-batch hiện tại.
Tiếp theo, quá trình lan truyền ngược (backpropagation) được áp dụng để tính gradient của hàm mất mát đối với các tham số của mô hình. Các gradient này sau đó được sử dụng bởi thuật toán tối ưu để cập nhật tham số theo hướng làm giảm giá trị hàm mất mát. Một lần duyệt qua toàn bộ tập huấn luyện được gọi là một epoch, và quá trình huấn luyện thường bao gồm nhiều epoch nhằm đảm bảo mô hình có đủ thời gian học được cấu trúc của dữ liệu.
Việc huấn luyện theo mini-batch cho phép cân bằng giữa hiệu quả tính toán và độ ổn định của gradient, đồng thời phù hợp với các hệ thống tính toán song song hiện đại như GPU.
1.6. Các tiêu chí đánh giá mô hình phân loại
Để đánh giá hiệu quả của mô hình phân loại, nhiều chỉ số khác nhau có thể được sử dụng. Trong nghiên cứu này, tiêu chí đánh giá chính là độ chính xác (accuracy), được định nghĩa là tỷ lệ giữa số lượng mẫu được dự đoán đúng và tổng số mẫu trong tập đánh giá:
$$\mathrm{Accuracy}
= \frac{1}{N} \sum_{i=1}^{N} \mathbb{I}(\hat{y}_i = y_i),$$
trong đó $\hat{y}_i$ là nhãn dự đoán và $y_i$ là nhãn thực của mẫu thứ $i$.
Ngoài ra, ma trận nhầm lẫn (confusion matrix) cung cấp cái nhìn chi tiết hơn về hành vi của mô hình, cho phép phân tích các kiểu lỗi đặc trưng giữa các lớp. Ngoài ra, phân bố xác suất softmax của các dự đoán cũng phản ánh mức độ tự tin của mô hình, qua đó hỗ trợ đánh giá khả năng tổng quát hóa và độ tin cậy của các quyết định phân loại.
2. Thực nghiệm
Phần thực nghiệm nhằm đánh giá hiệu quả của mô hình Softmax Regression trên bài toán phân loại chữ số viết tay MNIST. Các thí nghiệm được thiết kế để khảo sát quá trình hội tụ trong huấn luyện, khả năng tổng quát hóa của mô hình, cũng như phân tích các đặc điểm lỗi và mức độ tự tin trong dự đoán.
Toàn bộ quy trình thực nghiệm bao gồm việc chuẩn bị dữ liệu, xây dựng và huấn luyện mô hình, lựa chọn siêu tham số, và đánh giá hiệu suất thông qua các chỉ số định lượng và trực quan hóa phù hợp.
2.1. Bộ dữ liệu MNIST
Bộ dữ liệu MNIST (Modified National Institue of Standards and Technology) là một bộ dữ liệu Đây là một trong những bộ dữ liệu phổ biến nhất trong cộng đồng nghiên cứu học máy và học sâu. Bộ dữ liệu MNIST bao gồm 60.000 ảnh chữ số viết tay dùng cho huấn luyện, tương ứng với các chữ số từ 0 đến 9, và 10.000 ảnh dùng cho kiểm tra. Do đó, MNIST là một bài toán phân loại với $10$ lớp khác nhau. Mỗi ảnh chữ số viết tay được biểu diễn dưới dạng một ma trận kích thước $28 \times 28$, trong đó mỗi phần tử tương ứng với một giá trị mức xám của điểm ảnh.
Bộ dữ liệu MNIST (Modified National Institute of Standards and Technology) là một chuẩn đánh giá được sử dụng rộng rãi trong việc kiểm nghiệm các mô hình nhận dạng chữ số viết tay. Bộ dữ liệu này bao gồm các ảnh mức xám, mỗi ảnh biểu diễn một chữ số viết tay duy nhất từ 0 đến 9, được căn giữa trong một lưới điểm ảnh kích thước $28 \times 28$. Cường độ của mỗi điểm ảnh được biểu diễn bằng một giá trị trong khoảng từ 0 (đen) đến 255 (trắng), tương ứng với 784 đặc trưng đầu vào khi sử dụng cho mô hình MLP. Bộ dữ liệu được chia thành hai tập riêng biệt:
- Training set (tập huấn luyện): bao gồm 60.000 ảnh để huấn luyện mô hình.
- Test set (tập kiểm thử): gồm 10.000 ảnh sử dụng để đánh giá hiệu suất của mô hình sau huấn luyện.
Cần lưu ý rằng trong thực nghiệm này, tập test gốc của MNIST được sử dụng làm tập validation nhằm phục vụ quá trình phát triển mô hình.

Hình 2. Các ảnh chữ số viết tay tiêu biểu từ bộ dữ liệu MNIST.
2.2. Cài đặt môi trường và tập dữ liệu
Khai báo các thư viện cần thiết để tiến hành thực nghiệm
import torch
import torch.nn as nn # contains common layers, operators
import torch.optim as optim # contains optimization algorithms
import torch.nn.functional as F # contains activation functions, e.g., sigmoid
from torch.utils.data import DataLoader # a library that helps us to handle big datasets that don't fit computer memory.
import torchvision.datasets as datasets
import torchvision.transforms as transforms
Thiết lập tối ưu phần cứng tính toán cho toàn bộ thực nghiệm
# Set device
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(device)
Lần lượt khai báo các siêu tham số (hyperparameters) cho việc huấn luyện mô hình
# Hyperparameters
input_size = 784 # 28x28 image
num_classes = 10 # 10 digits 0, 1, 2, ...., 9
learning_rate = 0.001
batch_size = 64 # We would divide our dataset into smaller batches. Each batch contains 64 images.
num_epochs = 50
Gắn (mount) Google Drive vào Colab để đọc/ghi dữ liệu và cache dataset ở thư mục Drive, tránh phải tải lại mỗi lần chạy
from google.colab import drive
drive.mount('/content/drive')
Tải và chuẩn hoá dataset MNIST
# Load the dataset to our Google Drive
train_dataset = datasets.MNIST(root='/content/drive/MyDrive/datasets/mnist',
train=True,
transform=transforms.ToTensor(),
download=True)
test_dataset = datasets.MNIST(root='/content/drive/MyDrive/datasets/mnist',
train=False,
transform=transforms.ToTensor(),
download=True)
Đóng gói dataset thành các mini-batch và cung cấp dữ liệu tuần tự cho vòng lặp huấn luyện/đánh giá
train_loader = DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=False)
Hãy phân tích một chút về tập train và tập test:
-
Tập train
- Dataset: MNIST
- Number of datapoints: 60,000
- Root location: data
- Split: Train
- Transform: ToTensor()
-
Tập test
- Dataset: MNIST
- Number of datapoints: 10,000
- Root location: data
- Split: Test
- Transform: ToTensor()
Ta cũng kiểm tra về shape (hình dạng) và size (kích thước) của dataset.:
print("train data:", train_dataset.data.shape) # torch.Size([60000, 28, 28])
print("test data:", test_dataset.data.shape) # torch.Size([10000, 28, 28])
print("train targets:", train_dataset.targets.shape) # torch.Size([60000])
print("test targets:", test_dataset.targets.shape) # torch.Size([10000])
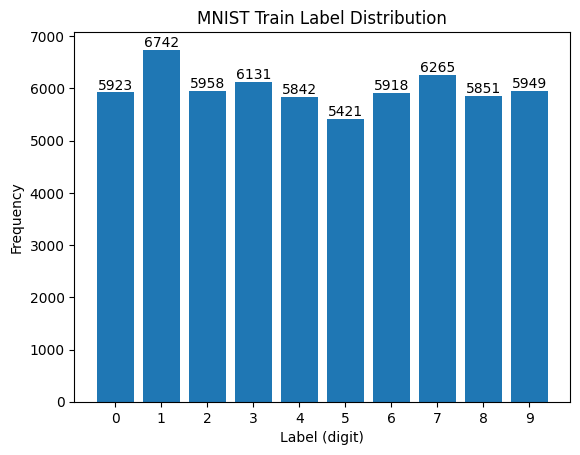
Hình 3. Phân bố nhãn trong tập huấn luyện của bộ dữ liệu MNIST.
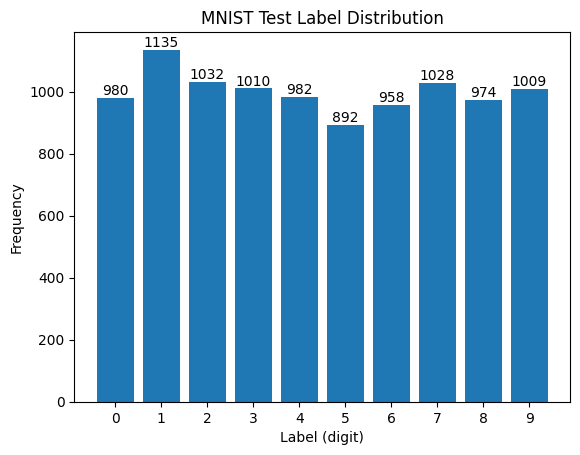
Hình 4. Phân bố nhãn trong tập kiểm tra của bộ dữ liệu MNIST.

Hình 5. 20 ảnh MNIST đầu tiên kèm label (nhãn) thuộc tập train đã được xử lý.
2.2. Xây dựng mô hình
# Create a Softmax Regression Model
class SoftmaxRegression(nn.Module):
def __init__(self, input_size, num_classes): # digits 0, 1, 2, ..., 9
super(SoftmaxRegression, self).__init__() # Python syntax
self.layer = nn.Linear(in_features=input_size, out_features=num_classes)
def forward(self, x):
out = self.layer(x)
return out
Ta bắt đầu cài đặt một mô hình Softmax Regression cho bài toán phân loại chữ số viết tay MNIST, sử dụng framework PyTorch.
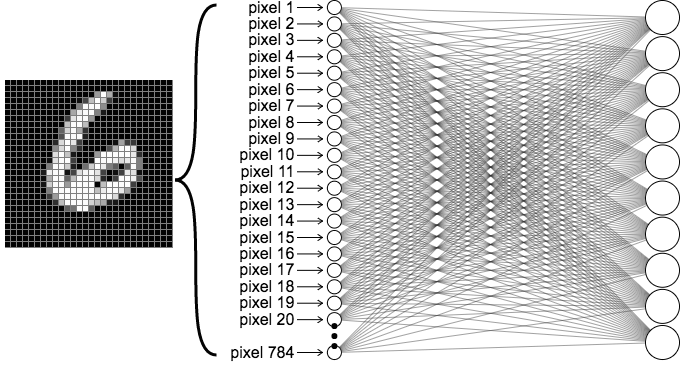
Hình 6. Kiến trúc Softmax Regression không sử dụng tầng ẩn cho bài toán MNIST. Ảnh chữ số viết tay được làm phẳng thành vector 784 chiều và đưa trực tiếp vào một lớp tuyến tính kết nối đầy đủ với 10 nút đầu ra, mỗi nút tương ứng với một chữ số.
Mô hình được định nghĩa dưới dạng một lớp kế thừa từ nn.Module, cho phép tích hợp trực tiếp vào quy trình huấn luyện và đánh giá chuẩn của PyTorch. Trong hàm khởi tạo, một lớp tuyến tính duy nhất nn.Linear(input_size), num_classes) được sử dụng để ánh xạ vector đặc trưng đầu vào $\mathbf{x} \in \mathbb{R}^{d}$ sang không gian nhãn $\mathbb{R}^{C}$, với $d=784$ tương ứng với ảnh MNIST kích thước $28 \times 28$ sau khi được làm phẳng, và $C=10$ là số lớp chữ số từ 0 đến 9. Phép biến đổi này có dạng:
$$\mathbf{z} = W\mathbf{x} + \mathbf{b},$$
trong đó $W$ và $\mathbf{b}$ là các tham số học được của mô hình.
Hàm forward mô tả quá trình lan truyền xuôi của mạng, trong đó đầu vào được đưa trực tiếp qua lớp tuyến tính để thu được vector logits $\mathbf{z}$.
# Create the model
model = SoftmaxRegression(input_size=input_size, num_classes=num_classes).to(device) #.to(device) puts our model on the GPU if available
Ta tạo một đối tượng mô hình từ lớp SoftmaxRegression đã định nghĩa trước đó. Tại thời điểm này, các tham số học được của mô hình (ma trận trọng số $W$ và vector sai lệch $\mathbf{b}$ của lớp tuyến tính) được khởi tạo theo cơ chế mặc định của PyTorch, sẵn sàng cho quá trình tối ưu trong giai đoạn huấn luyện.
# Define the loss and the optimization algorithms
criterion = nn.CrossEntropyLoss() # In PyTorch, Softmax + NLL
optimizer = optim.SGD(model.parameters(), lr=learning_rate)
Tiếp tục thiết lập hàm mất mát (loss function) và thuật toán tối ưu (optimization algorithm) cho quá trình huấn luyện mô hình.
Hàm mất mát được xác định là CrossEntropyLoss, một lựa chọn tiêu chuẩn cho bài toán phân loại đa lớp. Trong PyTorch, hàm mất mát này nhận đầu vào là các logits do mô hình sinh ra và nhãn lớp tương ứng, đồng thời thực hiện nội bộ phép biến đổi log-softmax kết hợp với negative log-likelihood. Phương án này giúp ổn định về mặt số học và phù hợp với đặc điểm của mô hình softmax regression, trong đó mỗi mẫu dữ liệu chỉ thuộc về một lớp duy nhất trong tập nhãn. Việc sử dụng CrossEntropyLoss cho phép mô hình trực tiếp tối ưu hóa xác suất dự đoán đúng nhãn lớp.
Thuật toán tối ưu được lựa chọn là Stochastic Gradient Descent (SGD), được khởi tạo với tập các tham số học được của mô hình và tốc độ học $\eta$ đã xác định trước. SGD cập nhật các tham số của mô hình theo hướng ngược với gradient của hàm mất mát, ước lượng trên từng mini-batch dữ liệu.
2.3. Huấn luyện mô hình
# Train our Softmax Regression model
for epoch in range(num_epochs):
for batch_idx, (data, targets) in enumerate(train_loader):
# Put the batch to GPU if available
data = data.to(device) # Put images to the GPU if GPU is available
targets = targets.to(device) # Put labels to the GPU if available
# Our (batch) data here is in the form (batch_size, color_channel, width, height) ???
# We need to change it to (batch_size, w*h)
# (64, 1, 28, 28) ----> (64, 784)
data = data.reshape(data.shape[0], -1) # data.shape[0] ~ batch_size
# forward pass
scores = model(data) # Pass one batch of training examples through our model.
loss = criterion(scores, targets) # Compute the loss function value J for this batch
# backward pass
optimizer.zero_grad() # Empty the memory
loss.backward() # Compute the gradient dJ/dw
optimizer.step() # One step of gradient descent
# Track the loss function values.
if (batch_idx+1) % 100 == 0:
print(f'Epoch {epoch+1}/{num_epochs}, Batch {batch_idx+1}, Loss {loss.item():.2f}')
Quá trình huấn luyện mô hình Softmax Regression lặp qua nhiều epoch và các mini-batch lấy từ train_loader. Ở mỗi mini-batch, dữ liệu ảnh data và nhãn targets được chuyển sang cùng thiết bị tính toán device để đảm bảo mô hình và dữ liệu nằm trên cùng một nơi thực thi (GPU nếu khả dụng, nếu không thì CPU). Do ảnh MNIST sau bước tiền xử lý có dạng tensor $(B, 1, 28, 28)$, trong khi mô hình tuyến tính nn.Linear yêu cầu đầu vào dạng ma trận $(B, 784)$, nên mỗi batch được làm phẳng bằng reshape(data.shape[0], -1) nhằm chuyển từng ảnh thành vector 784 chiều. Sau đó, mô hình thực hiện lan truyền xuôi để tạo ra các logits scores, và giá trị hàm mất mát được tính bằng criterion(scores, targets) để đo mức sai lệch giữa dự đoán và nhãn thực trên batch hiện tại. Tiếp theo, trước khi lan truyền ngược, lệnh optimizer.zero_grad() được gọi để xóa gradient còn lưu từ bước trước, tránh hiện tượng tích lũy gradient không mong muốn; sau đó loss.backward() tính gradient của hàm mất mát theo các tham số mô hình, và optimizer.step() cập nhật trọng số theo thuật toán tối ưu SGD. Cuối cùng, để theo dõi tiến trình hội tụ, chương trình in ra loss định kỳ sau mỗi 100 mini-batch, cung cấp một chỉ báo trực tiếp về việc mô hình đang học tốt hay không trong suốt quá trình huấn luyện.
2.4. Đánh giá hiệu suất mô hình
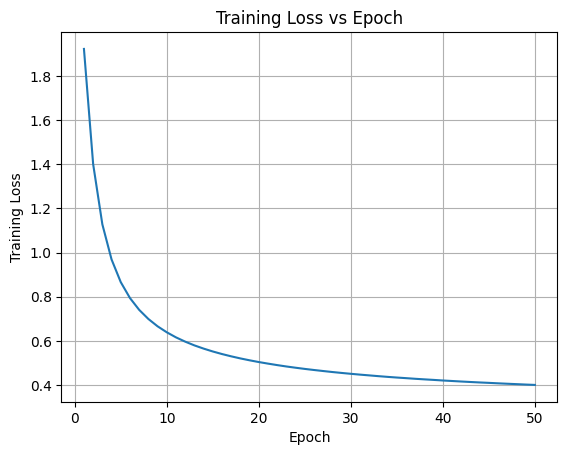
Hình 7. Đường cong hàm mất mát huấn luyện (training loss) theo số epoch đối với mô hình Softmax Regression trên bộ dữ liệu MNIST.
Đường cong hàm mất mát huấn luyện cho thấy giá trị loss giảm mạnh trong các epoch đầu và sau đó giảm chậm dần khi số epoch tăng lên, tiến tới trạng thái bão hòa sau khoảng 20–30 epoch. Việc này phản ánh quá trình tối ưu ổn định của mô hình, trong đó các tham số nhanh chóng hội tụ về vùng nghiệm tốt trong giai đoạn đầu huấn luyện, còn các cải thiện ở giai đoạn sau chỉ mang tính cận biên. Việc loss không dao động mạnh cũng cho thấy quá trình huấn luyện bằng mini-batch gradient descent được thiết lập hợp lý và không gặp vấn đề về mất ổn định số học.
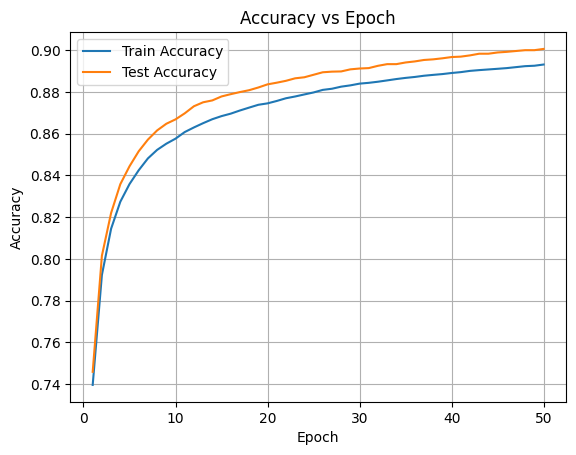
Hình 8. Độ chính xác (accuracy) theo số epoch trên tập huấn luyện và tập kiểm tra đối với mô hình Softmax Regression trên bộ dữ liệu MNIST.
Biểu đồ độ chính xác theo epoch cho thấy accuracy trên cả tập huấn luyện và tập kiểm tra tăng nhanh trong những epoch đầu, sau đó dần đạt trạng thái bão hòa. Giá trị accuracy cuối cùng đạt xấp xỉ 0.89 trên tập huấn luyện và khoảng 0.90 trên tập kiểm tra. Khoảng cách nhỏ giữa hai đường cong, cùng với việc test accuracy không thấp hơn train accuracy, cho thấy mô hình không bị overfitting đáng kể. Ngược lại, hiện tượng accuracy sớm bão hòa phản ánh giới hạn năng lực biểu diễn của mô hình tuyến tính, dẫn đến underfitting nhẹ trên bài toán MNIST.
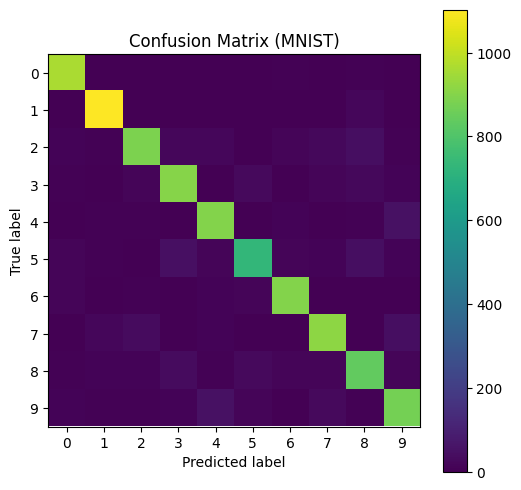
Hình 9. Ma trận nhầm lẫn (confusion matrix) của mô hình Softmax Regression trên bộ dữ liệu MNIST.
Ma trận nhầm lẫn cho thấy các phần tử trên đường chéo chính chiếm ưu thế, chứng minh rằng phần lớn các mẫu trong tập kiểm tra được phân loại đúng. Tuy nhiên, vẫn tồn tại các lỗi phân loại tập trung ở một số cặp chữ số có hình dạng tương đồng (3 - 5; 4 - 9 ...). Kiểu lỗi này mang tính hệ thống và thường gặp khi áp dụng các mô hình tuyến tính trực tiếp trên dữ liệu ảnh, lý do là bởi mô hình không khai thác được cấu trúc không gian và các đặc trưng cục bộ của hình ảnh.
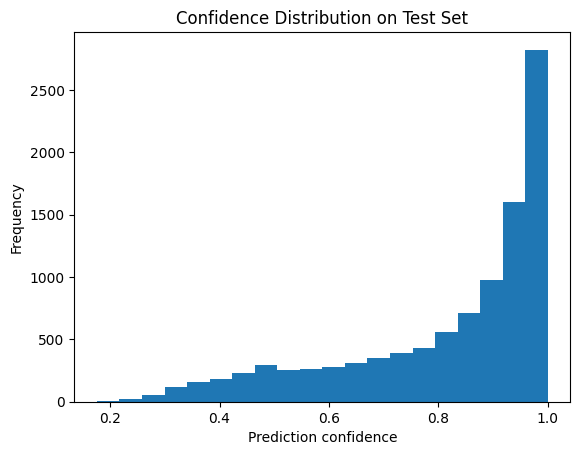
Hình 10. Phân bố độ tự tin (prediction confidence) của mô hình Softmax Regression trên tập kiểm tra MNIST.
Phân bố độ tự tin của mô hình trên tập kiểm tra cho thấy phần lớn các dự đoán có xác suất softmax cao, tập trung trong khoảng từ 0.8 đến 1.0, cho thấy mô hình thường đưa ra các quyết định với mức độ tự tin tương đối lớn. Tuy nhiên, vẫn tồn tại một số dự đoán có độ tự tin ở mức thấp, ứng với các mẫu khó hoặc bị phân loại sai.
3. Kết luận
Tổng hợp các kết quả thực nghiệm cho thấy mô hình Softmax Regression hội tụ ổn định trên bộ dữ liệu MNIST và đạt hiệu năng phân loại ở mức baseline hợp lý. Giá trị hàm mất mát huấn luyện giảm đều theo số epoch, trong khi độ chính xác trên tập kiểm tra đạt xấp xỉ 90%, cho thấy mô hình học được các biên quyết định có ý nghĩa mà không xuất hiện dấu hiệu overfitting rõ rệt. Phân tích ma trận nhầm lẫn và phân bố độ tự tin cho thấy các lỗi phân loại chủ yếu xuất phát từ sự tương đồng hình dạng giữa các chữ số, phản ánh giới hạn nội tại của mô hình tuyến tính khi làm việc trực tiếp trên dữ liệu ảnh thô. Những kết quả này khẳng định vai trò của Softmax Regression như một mô hình cơ sở hiệu quả, đồng thời nhấn mạnh nhu cầu sử dụng các kiến trúc phi tuyến có năng lực biểu diễn cao hơn để cải thiện hiệu suất trong các nghiên cứu tiếp theo.
4. Tài liệu tham khảo
[1] Q.-V. Dinh, Softmax Regression (Multi-class Classification), bài giảng môn học, 2025.
[2] B. Enrizky, “PyTorch Handwritten Digit Recognition,” GitHub repository, truy cập: 2024. [Online]. Available: https://github.com/bily-enrizky/Pytorch-Handwritten-Digit-Recognition
[3] M. A. Nguyen, “Artificial Neural Networks for Handwritten Digit Recognition,” School of Science, Computing and Engineering Technologies, Swinburne University of Technology, Hawthorn, VIC, Australia, pp. 1–7, 2024.
Chưa có bình luận nào. Hãy là người đầu tiên!