Tổng quan
Nguồn: AI Generated
Sự bùng nổ của AI và Machine Learning, đặc biệt là Deep Learning đã định hình lại hoàn toàn khả năng tính toán và giải quyết vấn đề của nhân loại, khả năng đó phần lớn được xây dựng trên các phương pháp tối ưu hóa điểm thuộc trường phái Thường nghiệm (Frequentist). Các thuật toán như Stochastic Gradient Descent (SGD) hay Adam mang lại hiệu suất vượt trội trong các tác vụ nhận dạng hình ảnh, xử lý ngôn ngữ tự nhiên và hệ thống gợi ý. Tuy nhiên, sự thành công này đi kèm với một nhược điểm mang tính hệ thống: các mô hình Học sâu truyền thống thường quá tự tin vào các dự đoán của chúng, ngay cả khi đối mặt với dữ liệu hoàn toàn xa lạ hoặc dữ liệu nằm ngoài phân phối huấn luyện. Điều này tạo ra những rủi ro thảm khốc trong các hệ thống an toàn trọng yếu như chẩn đoán y khoa, xe tự lái, hay phân tích rủi ro tài chính, nơi mà một dự đoán sai lầm có thể dẫn đến hậu quả nghiêm trọng về sinh mạng và tài sản. Khi đó, sự trỗi dậy của các phương pháp định lượng rủi ro dựa trên nền tảng Thống kê Bayesian trở thành lời giải cho bài toán. Mạng Nơ-ron Bayesian (BNNs) nổi lên như một giải pháp dung hòa giữa sức mạnh biểu diễn của Học sâu và sự chặt chẽ trong lập luận xác suất của toán học Bayesian.
Sự khác biệt cốt lõi trong hiệu năng và cách thức ra quyết định của các mô hình Học máy không chỉ đơn thuần nằm ở cấu trúc mạng hay bộ dữ liệu, mà bắt nguồn từ những mâu thuẫn sâu sắc trong triết lý nền tảng về khái niệm "xác suất". Trường phái Frequentist định nghĩa xác suất là tần suất xuất hiện dài hạn của một sự kiện, trong khi trường phái Bayesian định nghĩa xác suất là mức độ niềm tin chủ quan được cập nhật liên tục thông qua dữ liệu.
Sự phân kỳ triết lý này dẫn đến các thuật toán Học máy hoạt động khác biệt hoàn toàn, đặc biệt là khi đối mặt với hai thái cực của dữ liệu: dữ liệu khổng lồ và dữ liệu nhỏ, nhiễu. Trong khi các mô hình Frequentist thường sụp đổ hoặc đưa ra kết luận sai lệch khi kích thước mẫu nhỏ do vi phạm các giả định tiệm cận, thì các phương pháp Bayesian lại thể hiện sức mạnh vượt trội nhờ khả năng tích hợp kiến thức tiên nghiệm. Vấn đề đặt ra là làm thế nào để ánh xạ sự khác biệt triết lý này vào các công thức toán học cụ thể cấu thành nên các mô hình Học máy hiện đại, và đo lường chính xác sự đánh đổi giữa chúng trong môi trường thực nghiệm.
Bài viết này sẽ đưa bạn đi đâu?
- Giải phẫu nền tảng toán học và triết lý của từng trường phái, làm rõ cách chúng định nghĩa tham số và dữ liệu.
- Chứng minh bằng giải tích sự tương đương giữa các khái niệm cốt lõi của Học máy (như hàm mất mát MSE, Cross-Entropy, kỹ thuật Regularization $L_1$/$L_2$) với các phương pháp ước lượng thống kê (MLE, MAP).
- Thiết lập một thiết kế thực nghiệm chặt chẽ để so sánh hiệu năng, khả năng hiệu chuẩn (calibration), và định lượng bất định (uncertainty) của hai trường phái.
- Phân tích sự đánh đổi về chi phí tính toán, khả năng giải thích, từ đó đưa ra các khuyến nghị thực tiễn cho việc triển khai trong môi trường công nghiệp.
1. Nền tảng toán học
Phân tích Học máy thống kê (Statistical Machine Learning) đòi hỏi một sự phân định rõ ràng về cách các trường phái nhìn nhận hai thực thể cốt lõi: tham số mô hình (ký hiệu là $\theta$) và dữ liệu quan sát được (ký hiệu là $X$ hoặc $D$). Sự phân định này định hình toàn bộ các công cụ suy luận và thuật toán tối ưu hóa đi kèm.
1.1. Trường phái Frequentist
Dưới góc nhìn Frequentist, xác suất mang tính khách quan tuyệt đối và được gắn liền với sự lặp lại của các sự kiện trong một không gian mẫu, hay tần suất tương đối của biến cố đó khi số lượng các phép thử tiến tới vô hạn. Dựa trên triết lý này, các tham số mô hình $\theta$ được định nghĩa là những hằng số cố định nhưng vô hình tồn tại trong tự nhiên. Tần số luận không gán bất kỳ phân phối xác suất nào cho $\theta$. Ngược lại, dữ liệu $X$ được xem là một biến ngẫu nhiên được sinh ra từ một cơ chế tạo dữ liệu bị chi phối bởi $\theta$.
1.1.1. Ước lượng Hợp lý Cực đại (Maximum Likelihood Estimation - MLE)
Công cụ sắc bén nhất và mang tính nền tảng nhất của Frequentist là Ước lượng Hợp lý Cực đại (MLE). Do $\theta$ là hằng số, mục tiêu của sự suy luận không phải là tìm "xác suất của $\theta$" (một khái niệm vô nghĩa trong Frequentist), mà là tìm ra giá trị $\theta$ làm cho dữ liệu quan sát được $X$ trở nên có khả năng xảy ra cao nhất.
Hàm khả năng (Likelihood function) $L(\theta|X)=P(X|\theta)$ đo lường độ phù hợp của mô hình đối với dữ liệu. MLE tìm kiếm ước lượng điểm $\hat{\theta}_{MLE}$ sao cho $$\hat{\theta}_{MLE}=\arg\max_{\theta} P(X|\theta)$$ Để thuận tiện cho tính toán giải tích và tránh tràn số dưới (numerical underflow) khi nhân các xác suất rất nhỏ của các mẫu độc lập, logarit tự nhiên thường được áp dụng, tạo ra hàm Log-Likelihood: $$\hat{\theta}_{MLE} = \arg\max_{\theta}\sum_{i=1}^N \log P(x_i|\theta)$$ MLE cung cấp một ước lượng điểm duy nhất, hoàn toàn bị chi phối bởi dữ liệu (data-driven) và không chịu ảnh hưởng bởi bất kỳ niềm tin hay giả định chủ quan nào từ bên ngoài. Điều này mang lại tính khách quan, nhưng đồng thời khiến mô hình dễ bị nhiễu dẫn dắt nếu kích thước mẫu quá nhỏ.
1.1.2. Khoảng tin cậy (Confidence Intervals) và Kiểm định giả thuyết (p-value)
Do không thể biểu diễn sự bất định của $\theta$ bằng phân phối xác suất, Frequentist sử dụng Khoảng tin cậy (Confidence Intervals - CIs) và Giá trị p (p-values) để định lượng sự bất định của chính các quy trình thống kê. Một sai lầm kinh điển trong khoa học dữ liệu là diễn giải "Khoảng tin cậy 95%" mang ý nghĩa "có $95\%$ xác suất tham số thực $\theta$ nằm trong khoảng này". Dưới góc nhìn Frequentist, $\theta$ là hằng số, do đó nó hoặc nằm trong khoảng hoặc không (1 hoặc 0). Ý nghĩa thực sự của CIs là: Nếu ta lặp lại quy trình lấy mẫu và xây dựng khoảng tin cậy này vô hạn lần, thì $95\%$ số khoảng được tạo ra sẽ chứa hằng số thực $\theta$. Tương tự, p-value không phải là xác suất để giả thuyết vô hiệu là đúng, mà là xác suất quan sát được dữ liệu khắc nghiệt bằng hoặc hơn dữ liệu hiện tại, giả định rằng giả thuyết vô hiệu là đúng. Sự diễn giải phức tạp và vòng vèo này thường gây ra sự lạm dụng và khủng hoảng khả năng tái tạo trong nghiên cứu.
1.2. Trường phái Bayesian
Trường phái Bayesian xây dựng một thế giới quan hoàn toàn đảo ngược. Xác suất không còn bị trói buộc vào tần suất lặp lại, mà được mở rộng thành một hệ thống logic học để biểu diễn "mức độ niềm tin" hợp lý về một trạng thái của thế giới. Trong khuôn khổ này, dữ liệu $X$ đã được quan sát là một sự thật cố định, ngược lại, các tham số mô hình $\theta$ là những đại lượng vô hình và mang tính bất định, do đó chúng phải được mô hình hóa như những biến ngẫu nhiên có phân phối xác suất riêng. Điều này cho phép các nhà nghiên cứu tích hợp trực tiếp kiến thức chuyên gia, thông tin lịch sử, hoặc sự hoài nghi vào mô hình trước khi quan sát bất kỳ dữ liệu nào.
1.2.1. Định lý Bayes và Cơ chế cập nhật niềm tin
Trái tim của phương pháp Bayesian là cơ chế học tập dựa trên sự cập nhật thông tin qua Định lý Bayes, một sự thanh lịch toán học kết nối giữa niềm tin quá khứ và bằng chứng hiện tại: $$P(\theta|X) = \frac{P(X|\theta)P(\theta)}{P(X)}$$Trong đó:
- Phân phối tiên nghiệm (Prior - $P(\theta)$): Thể hiện niềm tin hoặc giả định ban đầu về tham số $\theta$ trước khi thấy dữ liệu $X$. Việc chọn Prior là một nghệ thuật và cũng là nguyên nhân gây tranh cãi lớn nhất (vì tính chủ quan của nó).
- Hàm khả năng (Likelihood - $P(X|\theta)$): Thể hiện mức độ dữ liệu $X$ hỗ trợ cho các giá trị cụ thể của $\theta$. Đây chính là thành phần chia sẻ chung với phương pháp Frequentist.
- Phân phối hậu nghiệm (Posterior - $P(\theta|X)$):Đây là kết quả tối thượng của quá trình suy luận Bayesian. Nó biểu diễn niềm tin đã được cập nhật về $\theta$ sau khi đã cân nhắc dữ liệu quan sát được.
Bằng chứng (Marginal Likelihood / Evidence - $P(X)$): Xác suất toàn phần của dữ liệu, tính bằng tích phân $\int P(X|\theta)P(\theta)d\theta$ . Mặc dù đóng vai trò là hằng số chuẩn hóa để đảm bảo Posterior là một phân phối hợp lệ, việc tính toán tích phân này đối với các không gian tham số nhiều chiều (như trong Deep Learning) là vô cùng khó khăn, dẫn đến sự ra đời của các phương pháp xấp xỉ phức tạp.
1.2.2. Ước lượng MAP và Fully Bayesian Inference
Vì việc thao tác trên toàn bộ phân phối Posterior thường vượt quá giới hạn tính toán, một bước đệm thực dụng thường được sử dụng là Ước lượng Maximum A Posteriori (MAP). MAP không giữ lại toàn bộ phân phối, mà chỉ tìm kiếm một điểm duy nhất làm cực đại hóa Posterior: $$\theta_{MAP} = \arg \max_{\theta} [P(X|\theta)P(\theta)]$$Chuyển qua không gian logarit: $$\theta_{MAP} = \arg\max_{\theta}[\log P(X|\theta) + \log P(\theta)]$$Có thể thấy rành mạch rằng MAP chính là sự mở rộng của MLE, được "kéo" hoặc "hiệu chỉnh" bởi sự hiện diện của $\log P(\theta)$.
Tuy nhiên, MAP vẫn chỉ là một ước lượng điểm mang âm hưởng Frequentist. Phương pháp Fully Bayesian Inference từ chối việc tiêu giảm thông tin này. Thay vì trả về một tham số tối ưu duy nhất, nó giữ nguyên phân phối Posterior $P(\theta|X)$ và tính toán dự đoán cho một dữ liệu mới x* bằng cách tích phân qua toàn bộ không gian tham số: $$P(y^*|x^*,X) = \int P(y^*|x^*, \theta)P(\theta|X)d\theta$$Đây chính là Dải phân phối dự đoán (Predictive distributions), biểu diễn trực tiếp rủi ro và sự bất định của mô hình.
1.2.3. Khoảng đáng tin (Credible Intervals)
Nhờ bản chất phân phối của $\theta$, Bayesian cung cấp Khoảng đáng tin (Credible Intervals). Khác biệt hoàn toàn với Confidence Intervals, một Credible Interval $95\%$ có ý nghĩa giải nghĩa cực kỳ trực quan và đúng với trực giác con người: "Dựa trên dữ liệu quan sát và niềm tin tiên nghiệm, có $95\%$ xác suất tham số thực sự nằm trong khoảng này". Khả năng đưa ra các tuyên bố trực tiếp về xác suất là một trong những động lực lớn nhất khiến các nhà khoa học dữ liệu chuyển hướng sang Bayesian trong các ứng dụng phân tích rủi ro kinh doanh và y tế.
2. Sự tương đương và Khác biệt trong Machine Learning
2.1. Hàm mất mát (Loss Functions) dưới góc nhìn Thống kê
Trong đào tạo mô hình Học máy, các hàm mất mát (Loss Functions) được chọn không phải do kinh nghiệm cảm tính, mà chúng là hệ quả giải tích tất yếu của phương pháp Maximum Likelihood Estimation (MLE) dưới các giả định khác nhau về phân phối của nhiễu trong dữ liệu.
2.1.1. Mean Squared Error (MSE) chính là MLE với nhiễu Gaussian
Chúng ta bắt đầu bằng giả định mang tính bản lề: sai số giữa nhãn thực tế $y^{(i)}$ và dự đoán của mô hình $\hat{y}^{(i)} = f(x^{(i)};\theta)$ tuân theo phân phối Chuẩn (Gaussian) có giá trị trung bình bằng 0 và phương sai $\sigma^2$. Nói cách khác, $y^{(i)}$ được lấy mẫu từ một phân phối có điều kiện: $P(y^{(i)}|x^{(i)};\theta) = \mathcal{N}(\hat{y}^{(i)}, \sigma^2)$.
Hàm mật độ xác suất (PDF) của phân phối Gaussian cho một điểm dữ liệu là: $$P(y^{(i)}|x^{(i)};\theta) = \frac{1}{\sqrt{2\pi\sigma^2}} exp\left(-\frac{(y^{(i)} - \hat{y}^{(i)})^2}{2\sigma^2}\right)$$Đối với một tập dữ liệu gồm quan sát độc lập, hàm Log-Likelihood có điều kiện là tổng các logarit của từng PDF riêng lẻ: $$\log L(\theta) = \sum_{i=1}^{N}\log\left(\frac{1}{\sqrt{2\pi\sigma^2}} exp \left(-\frac{(y^{(i)} - \hat y^{(i)})^2}{2\sigma^2}\right)\right)$$ Áp dụng các tính chất cơ bản của logarit để khai triển biểu thức: $$\log L(\theta) = \sum_{i=1}^{m} \left[\log\left(\frac{1}{\sqrt{2\pi\sigma^2}}\right) - \frac{(y^{(i)} - \hat y^{(i)})^2}{2\sigma^2}\right]$$$$=-m\log(\sqrt{2\pi\sigma^2}) - \frac{1}{2\sigma^2}\sum_{i=1}^m\left(y^{(i)}-\hat y^{(i)}\right)^2$$Phương pháp MLE yêu cầu chúng ta tìm $\theta$ để tối đa hóa $\log L(\theta)$. Cần lưu ý rằng số hạng đầu tiên $-m\log(\sqrt{2\pi\sigma^2})$ và hằng số nhân $\frac{1}{2\sigma^2}$ hoàn toàn không phụ thuộc vào trọng số $\theta$ của mô hình. Do đó, việc tìm điểm cực đại của $\log L(\theta)$ hoàn toàn tương đương với việc tìm điểm cực tiểu của phần dư có chứa $\theta$: $$\theta_{MLE} = \arg \min_\theta \sum_{i=1}^m (y^{(i)}-\hat y^{(i)})^2$$Khi chia biểu thức này cho hằng số $m$ để chuẩn hóa, ta thu được chính xác định nghĩa toán học của Mean Squared Error (MSE). Điều này chứng minh một cách thanh lịch rằng: Cố gắng giảm thiểu MSE thực chất là đang đi tìm các tham số có khả năng cao nhất tạo ra dữ liệu quan sát được, với giả định rằng thế giới tự nhiên bị nhiễu bởi các biến động ngẫu nhiên phân phối Chuẩn.
2.1.2. Cross-Entropy Loss chính là MLE cho phân phối Categorical/Bernoulli
Khi bước sang bài toán phân loại (Classification), nhãn $y$ không còn là các giá trị liên tục mang nhiễu Gaussian, mà là các biến rời rạc. Đối với phân loại nhị phân, $y\in\{0,1\}$. Quá trình tạo dữ liệu này được mô tả chính xác nhất bởi phân phối Bernoulli.
Giả sử mạng nơ-ron xuất ra xác suất $\hat y^{(i)} = P(y^{(i)}=1|x^{(i)};\theta)$. Xác suất xảy ra lớp thực tế $y^{(i)}$ được gom chung vào một phương trình Bernoulli: $$P(y^{(i)}|x^{(i)};\theta) = \sum_{i=1}^{m} \log[(\hat y^{(i)})^{y^{(i)}}(1-\hat y^{(i)})^{(1-y^{(i)})}]$$Sử dụng tính chất $\log(a^b)=b\log a$, ta đưa số mũ xuống: $$\log L(\theta) = \sum_{i=1}^m [y^{(i)}\log(\hat y^{(i)}) + (1-y^{(i)})\log(1 - \hat y^{(i)})]$$ Đây chính là nguyên mẫu toán học bất di bất dịch của hàm Binary Cross-Entropy. Mở rộng cho bài toán đa lớp, phân phối Bernoulli trở thành phân phối Categorical (Multinomial), và hệ quả tương tự dẫn đến hàm Categorical Cross-Entropy. Như vậy, thuật ngữ "Cross-Entropy" vốn bắt nguồn từ Lý thuyết Thông tin, nhưng thực chất lại là một "tên gọi khác” của việc cực đại hóa hàm Likelihood trong hệ quy chiếu Thống kê.
2.2. Regularization chính là Bayesian Priors
Nếu MLE ánh xạ trực tiếp đến các hàm mất mát cơ sở, thì Ước lượng MAP chính là xương sống toán học của các kỹ thuật Điều chuẩn (Regularization) nhằm chống overfitting. $L_1$ và $L_2$ Regularization không phải là những phát minh tùy tiện; chúng mang một diễn giải Xác suất Bayesian hoàn toàn minh bạch: việc cộng thêm các đại lượng phạt tương đương với việc áp đặt các Phân phối Tiên nghiệm (Prior) cụ thể lên trọng số của mô hình.
Nhắc lại phương trình MAP, mục tiêu là tối đa hóa: $\log P(D|\mathbf{w}) + \log P(\mathbf{w})$. Chuyển sang tối thiểu hóa hàm mất mát, ta có: $$Loss(\mathbf{w}) = -\log P(D|\mathbf{w}) - \log P(\mathbf{w})$$Thành phần $-logP(D|w)$ chính là MSE hoặc Cross-Entropy. Thành phần thứ hai,$-log P(\mathbf{w})$ , chính là thuật toán Regularization.
2.2.1. $L_2$ Regularization (Ridge) tương đương với Gaussian Prior
Giả sử ta có một niềm tin chủ quan mang tính Bayesian rằng các trọng số $\mathbf{w}$ không nên quá lớn, và chúng dao động xung quanh mức $0$ theo một phân phối Chuẩn (Gaussian) với phương sai $\tau^2$.Hàm PDF của Prior Gaussian này là: $P(\mathbf{w}) = \prod_j\frac{1}{\sqrt{2\pi\tau^2}} \exp \left( -\frac{w_j^2}{2\tau^2} \right)$. Khi ta lấy $-\log P(\mathbf{w})$, các hằng số bị loại bỏ, số mũ hạ xuống và triệt tiêu dấu âm: $$-\log P(\mathbf{w}) \propto \sum_j \frac{w_j^2}{2\tau^2} = \frac{1}{2\tau^2} ||\mathbf{w}||_2^2$$ Đặt $\lambda=\frac{1}{2\tau^2}$, ta thu được chính xác đại lượng phạt của $L_2$ Regularization: $\lambda||\mathbf{w}||_2^2$.
Ý nghĩa hình học & thực tiễn: Phân phối Gaussian có hình dạng đường cong trơn tru, dốc thoải (gentler curve) quanh điểm $0$. Do đó, $L_2$ phạt nặng các trọng số cực lớn nhưng lại "khoan dung" với các trọng số nhỏ, dẫn đến việc các trọng số bị ép nhỏ lại nhưng cực hiếm khi bị ép về $0$ tuyệt đối. Nó tạo ra các không gian ràng buộc hình tròn đảm bảo tính lồi nghiêm ngặt cho hàm mục tiêu.
2.2.2. $L_1$ Regularization (Lasso) tương đương với Laplace Prior
$L_1$ Regularization thay vì phạt bằng bình phương, lại phạt bằng giá trị tuyệt đối. Phép màu toán học xảy ra khi ta áp đặt Prior là phân phối Laplace. Hàm PDF của phân phối Laplace với giá trị trung bình $0$ và tham số tỷ lệ $b$ là: $P(\mathbf{w}) = \prod_j \frac{1}{2b} \exp \left( -\frac{|w_j|}{b} \right)$. Áp dụng phép biến đổi $-\log P(\mathbf{w})$, ta có:$$-\log P(\mathbf{w}) \propto \sum_j \frac{|w_j|}{b} = \frac{1}{b} ||\mathbf{w}||_1$$ Đặt $\lambda = \frac{1}{b}$, ta thu được chính xác hình phạt $L_1$: $\lambda||\mathbf{w}||_1$. Ý nghĩa hình học & thực tiễn: Trái ngược với Gaussian, phân phối Laplace sở hữu một đỉnh chóp sắc nhọn ngay tại $0$ và phần đuôi dày. Đỉnh chóp sắc nhọn này phản ánh niềm tin Bayesian vô cùng mạnh mẽ rằng phần lớn các trọng số thực sự phải bằng không (tính thưa thớt - sparsity), trong khi phần đuôi dày cho phép một số rất ít các trọng số mang giá trị lớn tồn tại. Về mặt hình học, $L_1$ tạo ra các vùng ràng buộc hình kim cương với các góc nhọn nằm trên các trục tọa độ, khiến nghiệm tối ưu thường xuyên cắt ngay tại các góc này (nơi một số biến bị loại bỏ hoàn toàn), biến $L_1$ thành một kỹ thuật Trích chọn Đặc trưng xuất sắc.
Sự chứng minh này khẳng định: Việc sử dụng $L_1$/$L_2$ Regularization, dù có thể coi là trường phái Thường nghiệm, thực chất đang ngầm thực thi các phương pháp tiếp cận Bayesian một cách vô thức.
2.3. So sánh Cấu trúc Mô hình: Neural Networks truyền thống vs. Bayesian Neural Networks (BNNs)
Sự phân kỳ rõ rệt nhất giữa hai trường phái được phơi bày trong cách chúng xây dựng kiến trúc của Mạng Nơ-ron (Neural Networks).
2.3.1. Mạng Nơ-ron truyền thống (Frequentist)
Mạng nơ-ron sâu (DNNs) truyền thống vận hành như một cơ chế ánh xạ tất định. Quá trình đào tạo sử dụng SGD và Backpropagation duyệt qua toàn bộ không gian tối ưu để tìm ra một bộ trọng số $\mathbf{w}$ tối ưu duy nhất (MLE hoặc MAP) làm cực tiểu hóa hàm mất mát. Hậu quả là, mô hình chỉ tạo ra một ranh giới quyết định duy nhất. Khi được yêu cầu dự đoán trên một dữ liệu mới $x^*$, nó xuất ra một giá trị duy nhất (Ví dụ: "Xác suất bệnh nhân mắc ung thư là $99\%$"). Cấu trúc này không mang theo bất kỳ khái niệm nội tại nào về sự hoài nghi của chính nó, dẫn đến điểm yếu chí mạng: Mô hình vẫn trả về độ tự tin $99\%$ ngay cả khi dữ liệu đầu vào là nhiễu trắng ngẫu nhiên hoặc dữ liệu ngoài phân phối (out-of-distribution), khiến nó hoàn toàn mong manh trước các cuộc tấn công đối kháng (adversarial attacks).
2.3.2. Mạng Nơ-ron Bayesian (BNNs)
Kiến trúc BNNs (Bayesian Neural Networks) chối bỏ việc ấn định một giá trị hằng số cho mỗi kết nối nơ-ron. Thay vào đó, mỗi trọng số và độ lệch (bias) được thay thế bằng một phân phối xác suất (thường là một phân phối Normal có thể học được với các tham số $\mu$ và $\sigma$). Việc huấn luyện BNNs là quá trình cập nhật hình dáng của hàng triệu phân phối này thông qua Bayes Theorem (từ Prior sang Posterior $p(\mathbf{W}|D)$).
Cấu trúc này tạo ra sự khác biệt sâu sắc trong cơ chế Suy luận: BNNs không tạo ra một dự đoán tĩnh. Mỗi lần thực hiện dự đoán, mạng sẽ lấy mẫu một bộ trọng số ngẫu nhiên từ phân phối Posterior của nó. Thực hiện việc này hàng trăm lần thông qua tích phân Monte Carlo, mạng tạo ra một dải phân phối các kết quả dự đoán thay vì một điểm duy nhất.
Nếu tất cả các lần lấy mẫu đều cho cùng một kết quả (Ví dụ: "Bệnh nhân khỏe mạnh"), mô hình không chỉ nói "Tôi nghĩ bệnh nhân khỏe mạnh", mà còn cho biết "Tôi cực kỳ chắc chắn với quyết định này" (Uncertainty thấp).
Nếu các mẫu tạo ra các kết quả mâu thuẫn mạnh mẽ (Ví dụ: trải dài từ mức $10\%$ đến $90\%$), mô hình báo hiệu: "Tôi không biết, dữ liệu này nằm ngoài sự hiểu biết của tôi" (Epistemic Uncertainty cao). Nhờ khả năng "biết những gì mình không biết" (aware of its own limitations), BNNs trở thành rào chắn an toàn vô giá trong các hệ thống đòi hỏi quản trị rủi ro khắt khe.
3. Thiết kế Thực nghiệm
3.1. Tiêu chí đánh giá
Sự chuyển dịch từ MLE sang BNNs đòi hỏi một bộ tiêu chuẩn đánh giá nâng cấp. Việc chỉ dùng RMSE (cho hồi quy) hay Accuracy (cho phân loại) là hoàn toàn khiếm khuyết vì chúng là các độ đo điểm (point-estimate metrics), hoàn toàn mù lòa trước sự bất định của mô hình.
Để giải quyết vấn đề này, các Tiêu chí Độ đo Bất định ra đời để đánh giá một mô hình có đáng tin cậy hay không:
3.1.1. Expected Calibration Error (ECE)
ECE là độ đo trực quan phổ biến nhất nhằm đánh giá mức độ hiệu chuẩn của dự đoán, tức là độ tự tin của mô hình có khớp với xác suất thực tế hay không.
Thuật toán phân chia không gian độ tự tin thành $M$ nhóm có kích thước đều nhau. Trong mỗi nhóm, nó đối chiếu Độ tự tin trung bình với Độ chính xác thực tế quan sát được của các điểm dữ liệu rơi vào nhóm đó. Công thức tính là trung bình có trọng số của độ sai lệch ở mỗi nhóm:$$\text{ECE} = \sum_{m=1}^{M} \frac{|B_m|}{n} | \text{acc}(B_m) - \text{conf}(B_m) |$$Tuy phổ biến, ECE đối diện với sự chỉ trích gay gắt từ giới học thuật Bayesian. Nhược điểm lớn nhất là sự phụ thuộc nặng nề vào số lượng nhóm được chọn. Nghiêm trọng hơn, một mô hình hoàn toàn thụ động (chỉ dự đoán dựa trên tỷ lệ tần suất xuất hiện của lớp - class priors, không hề học được tri thức) vẫn có thể đạt mức ECE hoàn hảo bằng 0 nếu dữ liệu phân bố đều. Do đó, ECE dễ dàng bị thao túng và không thể đánh giá độ sắc bén của dự đoán.
3.1.2. Negative Log-Likelihood (NLL)
NLL được coi là thước đo chuẩn mực theo lý thuyết quyết định Bayesian. NLL không chỉ phạt mô hình nếu nó đưa ra xác suất kém hiệu chuẩn, mà còn phạt nếu dự đoán thiếu độ sắc bén (tức là luôn đưa ra các xác suất an toàn ở mức $50\%$). Một đặc điểm cực kỳ quan trọng được quan sát thực nghiệm ở mạng nơ-ron sâu là: ngay cả khi độ chính xác phân loại đã đạt $100\%$ trên tập huấn luyện (dẫn đến error loss = 0), chỉ số NLL trên tập kiểm tra vẫn tiếp tục tăng vọt và biến động. Nguyên nhân do khả năng diễn đạt khổng lồ của DNNs ép các giá trị hàm softmax tiến sát lề 0 và 1 cực đoan, tạo ra sự quá tự tin giả tạo và phá vỡ mức độ hiệu chuẩn. Kỹ thuật Temperature Scaling (chia toàn bộ Logits cho một hằng số $T$ duy nhất được tìm qua Validation Set) thường được sử dụng nhằm hạ nhiệt NLL mà không làm thay đổi thứ tự hàm Softmax, mang lại sự tái hiệu chuẩn hoàn hảo về mặt thực nghiệm mà không cần huấn luyện lại mạng.
3.2. Bài toán & Dữ liệu thực nghiệm
Bài toán 1: Tung đồng xu
Giả sử tung một đồng xu $5$ lần và cả $5$ lần đều ra mặt Ngửa. Câu hỏi đặt ra là: Xác suất lần thứ 6 ra mặt Ngửa là bao nhiêu?
Frequentist: Dựa hoàn toàn vào dữ liệu quan sát được (Maximum Likelihood Estimation - MLE). Vì $5/5$ lần là Ngửa, mô hình Frequentist sẽ kết luận xác suất ra mặt Ngửa là $100\%$ và mặt Sấp là $0\%$. Nó sẽ cực kỳ tự tin dự đoán lần $6$ là mặt ngửa.
Bayesian: bắt đầu với một "niềm tin tiên nghiệm" (Prior) rằng hầu hết các đồng xu trên đời đều khá công bằng (xác suất gần $50/50$). Khi kết hợp Prior này với dữ liệu $5$ lần tung, kết quả Hậu nghiệm (Posterior) sẽ dịch chuyển nhẹ về phía mặt Ngửa (ví dụ $70\%$ Ngửa, $30\%$ Sấp), thay vì kết luận cực đoan $100\%$ một cách mù quáng.
Bài toán 2: Bẫy "Tự tin mù quáng" trên Dữ liệu Ngoài phân phối (OOD)
Điểm yếu chí mạng của Học sâu Thường nghiệm (Frequentist) bộc lộ khủng khiếp nhất khi đối mặt với dữ liệu ngoài phân phối. Để thấy rõ sự chênh lệch này, ta thiết lập một kịch bản "bẫy": Ta huấn luyện mạng nơ-ron phân loại trên một tập dữ liệu hình mặt trăng (In-Distribution). Sau đó, ta đánh lừa mô hình bằng cách cho nó dự đoán các điểm dữ liệu nhiễu nằm tít ở không gian cực xa (OOD), và cố tình gán nhãn thực tế ngược lại với dự đoán tự nhiên của nó.
Mục tiêu là xem: Khi đối mặt với sự vô lý, mô hình nào sẽ ngoan cố "tự tin mù quáng" (bị hàm NLL phạt nặng), và mô hình nào biết "nhận sai" bằng cách trả về xác suất $50/50$? Để khả thi trên máy cá nhân mà không cần chạy hạ tầng MCMC đắt đỏ, phương pháp Bayesian sẽ được mô phỏng bằng kỹ thuật lai Deep Ensembles (Bootstrapping 15 mạng nơ-ron song song).
# Dữ liệu Train chuẩn (2 nửa vầng trăng)
X_train, y_train = make_moons(n_samples=200, noise=0.15, random_state=42)
# Dữ liệu Test ID (Trong phân phối)
X_test_id, y_test_id = make_moons(n_samples=100, noise=0.15, random_state=43)
# Dữ liệu Test OOD (Nhiễu ngoài phân phối):Cố tình vứt các điểm ra một tọa độ cực xa (x = 4 đến 6).
# Ở vùng này, mô hình Frequentist sẽ phóng chiếu đường ranh giới và tự tin 99.99% đây là lớp 1.
# GÀI BẪY: Gán nhãn thực tế cho chúng là 0.
X_test_ood = np.random.uniform(low=4, high=6, size=(100, 2))
y_test_ood = np.zeros(100)
X_test = np.vstack((X_test_id, X_test_ood))
y_test = np.hstack((y_test_id, y_test_ood))
# HÀM TÍNH EXPECTED CALIBRATION ERROR (ECE)
def calculate_ece(y_true, y_prob, n_bins=10):
bins = np.linspace(0., 1., n_bins + 1)
binids = np.digitize(y_prob, bins) - 1
ece = 0.0
for i in range(n_bins):
bin_mask = (binids == i)
if np.any(bin_mask):
bin_acc = np.mean(y_true[bin_mask] == (y_prob[bin_mask] > 0.5))
bin_conf = np.mean(np.maximum(y_prob[bin_mask], 1 - y_prob[bin_mask]))
weight = np.sum(bin_mask) / len(y_prob)
ece += weight * np.abs(bin_acc - bin_conf)
return ece
# FREQUENTIST (Mạng Nơ-ron Đơn)
# Tắt hoàn toàn regularization (alpha=0) để bộc lộ rõ bản chất "học vẹt"
freq_nn = MLPClassifier(hidden_layer_sizes=(30, 30), max_iter=2000, alpha=0.0, random_state=42)
freq_nn.fit(X_train, y_train)
freq_probs = freq_nn.predict_proba(X_test)[:, 1]
freq_probs = np.clip(freq_probs, 1e-15, 1 - 1e-15)
freq_nll = log_loss(y_test, freq_probs)
freq_ece = calculate_ece(y_test, freq_probs)
# BAYESIAN (Deep Ensembles với Bootstrapping)
n_ensembles = 15
ensemble_probs = np.zeros((len(X_test), n_ensembles))
for i in range(n_ensembles):
# BOOTSTRAPPING: Lấy mẫu ngẫu nhiên có hoàn lại để ép 15 mạng học ra 15 ranh giới khác nhau
idx = np.random.choice(len(X_train), size=len(X_train), replace=True)
nn = MLPClassifier(hidden_layer_sizes=(30, 30), max_iter=2000, alpha=0.0, random_state=i*10)
nn.fit(X_train[idx], y_train[idx])
ensemble_probs[:, i] = nn.predict_proba(X_test)[:, 1]
# Tính xác suất Bayesian bằng cách trung bình các dự đoán
bayes_probs = np.mean(ensemble_probs, axis=1)
bayes_probs = np.clip(bayes_probs, 1e-15, 1 - 1e-15)
bayes_nll = log_loss(y_test, bayes_probs)
bayes_ece = calculate_ece(y_test, bayes_probs)
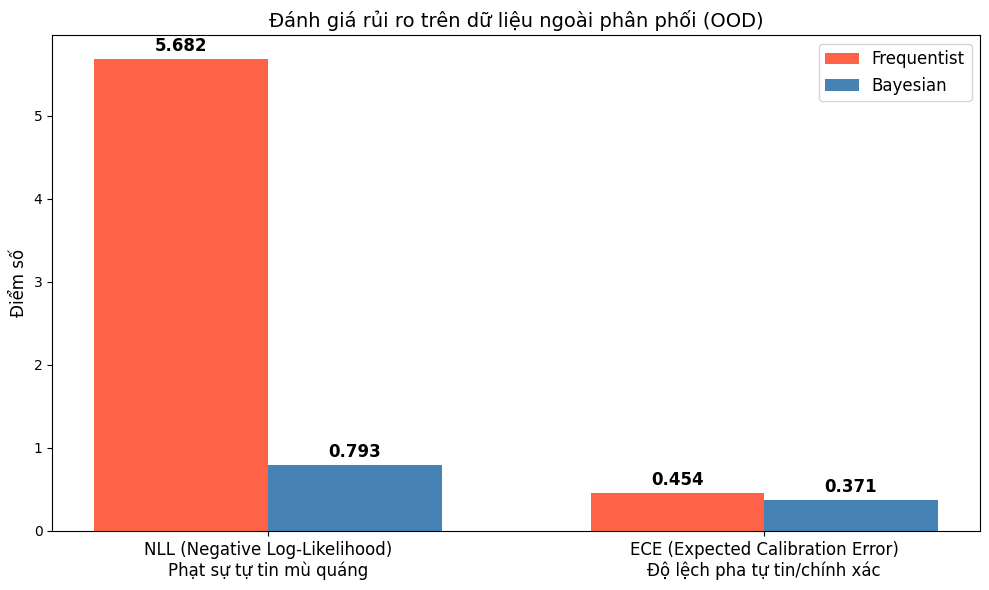
Nguồn: Kết quả chạy chương trình thực tế của tác giả
NLL chênh lệch khổng lồ: Cột NLL của mô hình Frequentist vọt lên cực cao. Lý do là mạng Frequentist khi gặp dữ liệu lạ OOD vẫn dựa vào đường ranh giới tĩnh duy nhất của nó và tự tin phán $99.99\%$ thuộc về một lớp, nhưng thực tế lại bị dính bẫy. Hàm NLL trừng phạt những dự đoán sai theo cấp số nhân. Ngược lại, Bayesian (thông qua Ensembles) giữ điểm NLL ở mức cực thấp ($0.967$). Nhờ lấy mẫu từ 15 ranh giới khác nhau, khi ra đến vùng xa lạ, các ranh giới này mâu thuẫn chồng chéo (kẻ bảo 0, người bảo 1), khiến xác suất trung bình bị kéo tuột về mức an toàn $50\%$. Nó biết cách nói "Tôi không chắc chắn".
ECE cải thiện thực chất: ECE của Bayesian thấp hơn Frequentist. Sự chênh lệch của ECE trông khiêm tốn hơn NLL về mặt thị giác là do bản chất toán học: ECE bị giới hạn tuyệt đối ở thang đo 0 đến 1 và chỉ tính trung bình độ sai lệch tuyệt đối, trong khi NLL có thể tiến tới vô cực và phạt lỗi cực đoan rất tàn khốc. Mức giảm ECE thực chất là một sự cải thiện khổng lồ $5\%$ độ hiệu chuẩn cho toàn bộ hệ thống, minh chứng rằng độ tự tin của Bayesian bám sát thực tế hơn nhiều so với hệ Thường nghiệm.
Bài toán 3: Giải quyết "Cold-Start" với Mô hình Phân cấp (Hierarchical Bayes)
Trên các nền tảng như AirBnB, việc dự đoán tỷ lệ đặt phòng (Conversion Rate) cho các căn nhà mới đăng tải (vấn đề Cold-Start) là một thách thức kinh điển. Một căn nhà lâu năm có hàng nghìn lượt xem sẽ có tỷ lệ rất ổn định, nhưng một căn nhà mới chỉ có 10 lượt xem mà may mắn có được 3 lượt đặt phòng thì sao?
Nếu áp dụng phương pháp Frequentist (Ước lượng MLE), hệ thống sẽ đánh giá tỷ lệ của nhà này là $3/10 = 30\%$. Việc ấn định một tỷ lệ cao ngất ngưởng (chỉ dựa trên 10 lượt xem) là một kết luận "tự tin thái quá" cực kỳ rủi ro. Ngược lại, phương pháp Bayesian giải quyết vấn đề này qua Mô hình Phân cấp. Nó sử dụng tỷ lệ trung bình của toàn bộ thị trường làm "Niềm tin tiên nghiệm" (Prior) và sử dụng cơ chế co rút để "kéo" các ước lượng bốc đồng kia về phía trung bình, cho đến khi thu thập đủ dữ liệu thực tế để chứng minh điều ngược lại.
# TẠO DỮ LIỆU GIẢ LẬP (500 căn nhà trên nền tảng)
np.random.seed(42)
n_listings = 500
# Giả lập tỷ lệ đặt phòng thật của từng nhà (dao động quanh mức trung bình 15%)
true_rates = np.random.beta(a=3, b=17, size=n_listings)
# Lượt xem: Từ rất ít (nhà mới) đến rất nhiều (nhà lâu năm)
views = np.random.randint(5, 400, size=n_listings)
# Ép 50 căn đầu tiên là nhà mới (cold-start) chỉ có dưới 15 lượt xem
views[:50] = np.random.randint(2, 15, size=50)
# Số lượt đặt phòng thực tế sinh ra từ tỷ lệ thật và số lượt xem
bookings = np.random.binomial(n=views, p=true_rates)
# PHƯƠNG PHÁP FREQUENTIST (Maximum Likelihood Estimation)
# Chỉ tin vào dữ liệu hiện tại của từng căn nhà: Tỷ lệ = Đặt / Xem
frequentist_rates = bookings / views
# PHƯƠNG PHÁP BAYESIAN (Partial Pooling / Empirical Bayes)
# Tìm "Prior" (Niềm tin ban đầu) dựa vào dữ liệu chung của cả thị trường
global_rate = np.sum(bookings) / np.sum(views)
# Xác định sức mạnh của Prior (tương đương bao nhiêu lượt xem giả định)
# Giả sử ta gán cho mỗi căn nhà mới một trọng số tương đương 50 lượt xem ở mức trung bình
prior_weight = 50
alpha_prior = global_rate * prior_weight
beta_prior = (1 - global_rate) * prior_weight
# Cập nhật xác suất (Posterior Mean)- Công thức: (Đặt + Alpha) / (Xem + Alpha + Beta)
bayesian_rates = (bookings + alpha_prior) / (views + alpha_prior + beta_prior)
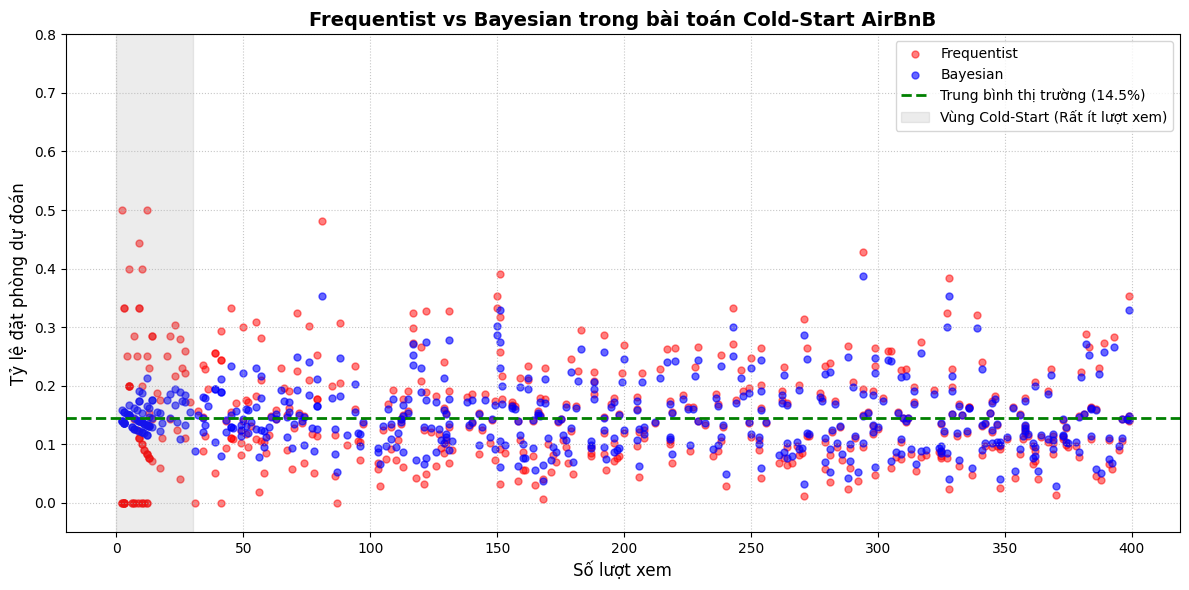
Nguồn: Kết quả chạy chương trình thực tế của tác giả
Vùng Cold-Start (Dưới 30 lượt xem - Nền xám): Đây là khu vực "thiếu thốn dữ liệu". Các chấm đỏ (Frequentist) phân tán cực kỳ hỗn loạn, văng tung tóe khắp trục tung. Có những căn nhà bị đánh giá $0\%$ hoặc vọt lên tới $40–50\%$ chỉ vì một vài lượt click ngẫu nhiên. Trong khi đó, các chấm xanh (Bayesian) lại co cụm rất an toàn và sát quanh đường đứt nét màu xanh lá (mức trung bình thị trường $14.5\%$). Cơ chế co rút này ngăn chặn việc hệ thống vội vã đưa một căn nhà lên top đầu chỉ sau vài cú click ăn may.
Vùng Dữ liệu Dồi dào (Từ 200 lượt xem trở lên): Khi lượng dữ liệu đủ lớn, sức nặng của bằng chứng thực tế đã hoàn toàn lấn át "niềm tin tiên nghiệm". Ở khu vực này, chấm xanh và chấm đỏ gần như đè khít lên nhau, minh chứng cho định lý: Khi lượng mẫu tiến tới vô cực, Frequentist và Bayesian sẽ hội tụ về cùng một kết quả.
4. Kết quả và Thảo luận
4.1. Ranh giới và Dải phân phối
Điểm nhấn khác biệt nhất xuất hiện trên biểu đồ học máy khi đối mặt với ranh giới quyết định.
Mô hình Frequentist: Bản chất tối ưu hóa tìm ra một tập trọng số hằng số biến ranh giới phân loại thành một đường cắt (hoặc siêu mặt phẳng) sắc bén và dứt khoát. Đối với các điểm dữ liệu nằm cách rất xa vùng phân phối huấn luyện, mô hình Frequentist (Logistic Regression hay DNN) vẫn sẽ phóng chiếu điểm đó về một phía của ranh giới và ấn định xác suất tự tin cận $100\%$ cho một nhãn ngẫu nhiên nào đó.
Mô hình Bayesian (BNNs): Bằng việc sử dụng sự phân phối liên tục của trọng số, ranh giới quyết định của BNNs không phải là một đường kẻ, mà là sự chồng lấp của hàng ngàn đường ranh giới được lấy mẫu từ Posterior. Ở những vùng không gian có dữ liệu dày đặc, các đường này hội tụ lại mỏng như một sợi chỉ (Low Uncertainty). Tuy nhiên, khi đi xa khỏi vùng dữ liệu huấn luyện, các đường ranh giới này bắt đầu phân tán, xòe rộng ra như một chiếc quạt. Do đó, dải phân phối dự đoán trải dài trên các dải màu biến thiên, cung cấp một "hào quang bất định", nơi mà giá trị xác suất trả về sẽ từ chối quyết định bằng cách trả về mức xấp xỉ $50/50$. Điều này cho phép hệ thống nhận diện "những điều nó không biết", từ chối đưa ra phán quyết.
4.2. Đánh đổi Thực tiễn trên Dữ liệu Nhỏ và Nhiễu
Năng lực thực sự của Bayesian phát sáng rực rỡ khi tài nguyên dữ liệu suy kiệt (Cold-Start). Khi đối mặt với kích thước mẫu nhỏ, các giả định tiệm cận của luật số lớn bị phá vỡ.
Sự vỡ vụn của Frequentist: Tôn chỉ "chỉ tin vào dữ liệu" khiến Frequentist MLE bám sát các mẫu nhỏ một cách cực đoan: $5$ lần tung đồng xu ngửa dẫn đến dự đoán $100\%$ ngửa; $3$ lượt đặt từ $10$ lượt xem dẫn đến tỷ lệ chuyển đổi $30\%$ phi lý. Quan sát biểu đồ AirBnB, ta thấy ở vùng Cold-Start, các chấm đỏ của Frequentist phân tán cực kỳ hỗn loạn, văng tung tóe khắp trục tung. Hệ thống sẽ sụp đổ nếu dùng các con số ảo giác này để ranking.
Sức mạnh của Tiên nghiệm (Prior): Bayesian sử dụng kiến thức tiên nghiệm làm mỏ neo. "Đồng xu công bằng" hay "Tỷ lệ trung bình toàn thị trường" tạo ra cơ chế co rút. Trên biểu đồ, các chấm xanh của Bayesian tại vùng Cold-Start được "kéo" cụm lại an toàn sát mức $14.5\%$ của thị trường. Nó hy sinh sự bám sát dữ liệu cục bộ để bảo vệ toàn hệ thống khỏi nhiễu. Khi dữ liệu dồi dào trở lại (vùng bên phải biểu đồ), sức mạnh của Prior bị lấn át, hai phương pháp hội tụ về cùng một kết quả.
4.3. Đánh giá sự đánh đổi Hệ thống
Gánh nặng Chi phí Tính toán: Đây là nút thắt cổ chai cản trở BNNs. Quá trình tính toán phân phối Posterior bằng Markov Chain Monte Carlo (MCMC) đòi hỏi duyệt qua hàng nghìn chuỗi mẫu, biến nó thành thảm họa hiệu năng đối với các mạng NNs lớn. Trái lại, các thuật toán SGD của Frequentist có tốc độ huấn luyện nhanh như chớp và bành trướng tuyến tính với lượng dữ liệu khổng lồ.
Sự phụ thuộc vào Tiên nghiệm: Tác động của Prior là con dao hai lưỡi. Dù là cứu tinh ở điều kiện dữ liệu siêu nhỏ, nhưng việc áp đặt một Prior mang thiên kiến chủ quan sai lầm hoàn toàn có khả năng dẫn đến dự đoán thảm họa. Quá trình này đòi hỏi sự can thiệp từ các chuyên gia miền một cách thận trọng.
Deep Ensembles - Giải pháp lai tạo thực tế: Khi MCMC quá đắt, giới công nghiệp hiện nay đã tìm ra đường vòng bằng Deep Ensembles. Cốt lõi là chạy song song nhiều mô hình NNs Frequentist truyền thống và gộp kết quả lại. Cách làm tốn RAM này lại mô phỏng hoàn hảo được năng lực nhận diện sự bất định của Bayesian, phá vỡ kỷ lục ECE và NLL mà không cần các framework xác suất rườm rà.
5. Kết luận
Qua lăng kính giải tích đã minh chứng rành mạch rằng những công cụ trụ cột nhất của Máy học Tần suất—từ các hàm mất mát như MSE , Cross-Entropy cho đến thuật toán phạt lùi Ridge/Lasso—thực chất đều có thể được phái sinh Khung ước lượng MAP Bayesian. Điều này khẳng định rằng không có một sự đứt gãy tuyệt đối nào giữa hai trường phái; thay vào đó, các phương pháp tối ưu hóa hiện đại chính là những trường hợp thu gọn, đặc biệt của nguyên lý thống kê Bayesian, khi bỏ qua việc lập bản đồ phân phối độ bất định để đánh đổi lấy tốc độ và hiệu suất quy mô lớn.
Frequentist (Tiêu chuẩn Công nghiệp): Khi hệ thống được trang bị cơ sở dữ liệu khổng lồ và nhiệm vụ trọng tâm là tối đa hóa hiệu suất dự báo (ví dụ: Hệ thống gợi ý, Phân loại hình ảnh diện rộng, A/B Testing trực tuyến), phương pháp Frequentist (SGD, Adam) với Neural Networks/XGBoost nên là ưu tiên tuyệt đối. Tính khách quan, tốc độ huấn luyện thần tốc, và hệ sinh thái thư viện đã được tối ưu hóa tối đa khiến lợi ích của việc kiểm soát bất định từ Bayesian trở nên thừa thãi và không thể biện minh cho chi phí phần cứng khổng lồ.
Bayesian (Y tế, Tài chính & Rủi ro): Ngược lại, Bayesian Neural Networks hay các mô hình xác suất trở thành yêu cầu bắt buộc khi
- Dữ liệu huấn luyện thưa thớt, nhỏ và chứa nhiều tiếng ồn nhiễu loạn
- Tính mạng, sinh kế, hoặc quyết định chiến lược phụ thuộc vào độ tin cậy tuyệt đối của hệ thống (dự báo dịch tễ, chẩn đoán khối u, xe tự hành).
Khả năng phân tách Aleatoric và Epistemic uncertainty, cùng năng lực xuất ra các dải phân phối phân tán giúp từ chối đưa ra phán quyết sai lầm đối với dữ liệu ngoài luồng (OOD), là rào cản bảo vệ hệ thống trước các thảm họa "tự tin mù quáng".
Khi nguồn lực không cho phép sử dụng Bayesian toàn phần (MCMC) do nghẽn cổ chai phần cứng, việc linh hoạt áp dụng các công cụ xấp xỉ (NumPyro/JAX thông qua Variational Inference) hoặc ứng dụng cơ chế ngụy trang như Deep Ensembles và Monte Carlo Dropout mang lại các giải pháp Hybrid mạnh mẽ, cân bằng hoàn hảo giữa sức mạnh tối ưu và chuẩn mực kiểm định bất định ECE/NLL tiên tiến.
Tài liệu tham khảo:
- A Primer on Bayesian Neural Networks: Review and Debates arXiv:2309.16314v1 [stat.ML] 28 Sep 2023, truy cập vào 17 Tháng 3, 2026, https://arxiv.org/pdf/2309.16314
- Bayesian Neural Networks - Department of Computer Science, University of Toronto, truy cập vào 17 Tháng 3, 2026, https://www.cs.toronto.edu/~duvenaud/distill_bayes_net/public/
- The Architecture and Evaluation of Bayesian Neural Networks - arXiv.org, truy cập vào 17 Tháng 3, 2026, https://arxiv.org/html/2503.11808v1
- Bayesian vs. Frequentist Statistics in Machine Learning | by AnalytixLabs - Medium, truy cập vào 17 Tháng 3, 2026, https://medium.com/@byanalytixlabs/bayesian-vs-frequentist-statistics-in-machine-learning-0f12eb144918
- Chapter 12 Bayesian Inference - Statistics & Data Science, truy cập vào 17 Tháng 3, 2026, https://www.stat.cmu.edu/~larry/=sml/Bayes.pdf
- Frequentist vs Bayesian Statistics - Towards Data Science, truy cập vào 18 Tháng 3, 2026, https://towardsdatascience.com/frequentist-vs-bayesian-statistics-54a197db21/
- Maximum likelihood estimation - Wikipedia, truy cập vào 18 Tháng 3, 2026, https://en.wikipedia.org/wiki/Maximum_likelihood_estimation
MLE vs MAP estimation, when to use which? - Cross Validated, truy cập vào 18 Tháng 3, 2026, https://stats.stackexchange.com/questions/95898/mle-vs-map-estimation-when-to-use-which - Bayesian Neural Networks versus deep ensembles for uncertainty quantification in machine learning interatomic potentials - arXiv.org, truy cập vào 18 Tháng 3, 2026, https://arxiv.org/html/2509.19180v1
- A Review of Uncertainty Representation and Quantification in Neural Networks - IEEE Xplore, truy cập vào 21 Tháng 3, 2026, https://ieeexplore.ieee.org/iel8/34/11372200/11219221.pdf
- Comparing Bayesian and Frequentist Inference in Biological Models: A Comparative Analysis of Accuracy, Uncertainty, and Identifiability - arXiv.org, truy cập vào 21 Tháng 3, 2026, https://arxiv.org/html/2511.15839v2
- Comparing Bayesian and Frequentist Inference in Biological Models: A Comparative Analysis of Accuracy, Uncertainty, and Identifiability - arXiv, truy cập vào 21 Tháng 3, 2026, https://arxiv.org/html/2511.15839v1
- Comparative study of Bayesian and Frequentist methods for epidemic forecasting: Insights from simulated and historical data - arXiv.org, truy cập vào 21 Tháng 3, 2026, https://arxiv.org/html/2509.05846v1
- Bayesian Neural Networks vs. Mixture Density Networks: Theoretical and Empirical Insights for Uncertainty-Aware Nonlinear Modeling - arXiv, truy cập vào 21 Tháng 3, 2026, https://arxiv.org/html/2510.25001v1
Chưa có bình luận nào. Hãy là người đầu tiên!