1. Khi cái nhìn tổng thể che giấu sự thật

Simpson's Paradox — Hai nhóm dữ liệu riêng lẻ cho thấy xu hướng tăng, nhưng khi gộp lại xu hướng đảo ngược hoàn toàn.
Nguồn: Ảnh minh họa tạo bởi AI.
Hãy thử một tình huống quen thuộc: bạn đang review kết quả A/B test. Variant B thắng ở mọi phân khúc người dùng — mobile, desktop, new user, returning user. Nhưng khi nhìn vào số tổng, Variant A lại có conversion rate cao hơn. Bạn sẽ ship cái nào?
Hoặc một ví dụ khác: một loại thuốc mới cho tỉ lệ hồi phục cao hơn thuốc cũ ở cả bệnh nhân nặng lẫn bệnh nhân nhẹ — nhưng tính tổng lại, thuốc cũ lại "hiệu quả hơn". Điều đó có thể xảy ra không?
Câu trả lời là có. Và đây chính là Nghịch lý Simpson.
Hãy nhìn vào số liệu cụ thể để thấy nghịch lý này hoạt động như thế nào:
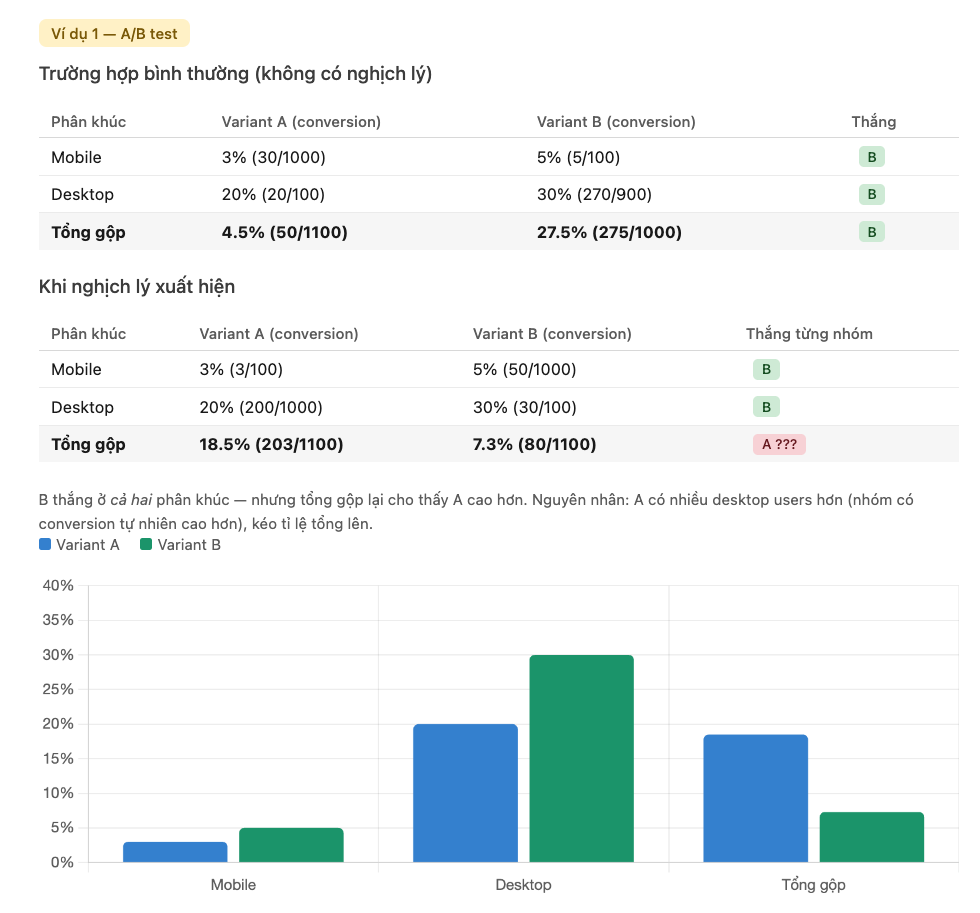
Nghịch lý Simpson trong A/B test — Variant B thắng từng phân khúc nhưng thua tổng gộp.
Nguồn: Tác giả tổng hợp.
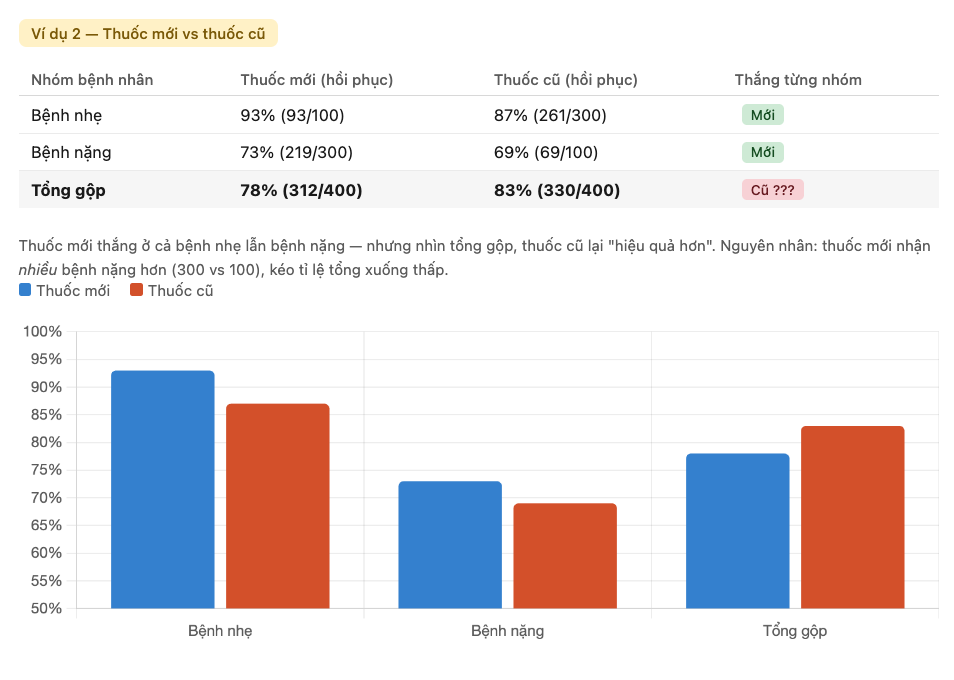
Nghịch lý Simpson trong y học — Thuốc mới hiệu quả hơn ở từng nhóm nhưng thua khi gộp chung.
Nguồn: Tác giả tổng hợp.
Nghịch lý Simpson là gì?
Nghịch lý Simpson (Simpson's Paradox) là một hiện tượng trong xác suất và thống kê, trong đó một xu hướng xuất hiện ở từng nhóm dữ liệu riêng lẻ lại biến mất hoặc đảo ngược hoàn toàn khi các nhóm đó được gộp lại với nhau.
Tên gọi "Nghịch lý Simpson" được giới thiệu lần đầu bởi Colin R. Blyth vào năm 1972, dù hiện tượng này đã được mô tả trong nhiều tài liệu trước đó. Nó còn được gọi là nghịch lý đảo ngược, nghịch lý gộp, hoặc hiệu ứng Yule–Simpson.
Về mặt kỹ thuật, hiệu ứng này xảy ra khi mối liên hệ không kiểm soát (marginal association — tức mối quan hệ giữa hai biến khi chưa tính đến các yếu tố khác) giữa hai biến phân loại (categorical variable) khác biệt về mặt định tính so với mối liên hệ từng phần — tức mối quan hệ giữa hai biến đó sau khi đã kiểm soát một hoặc nhiều biến khác.
Nói đơn giản hơn: con số tổng hợp có thể nói dối. Khi ta gộp nhiều nhóm dữ liệu lại, một mối quan hệ rõ ràng giữa hai biến có thể bị đảo chiều hoặc biến mất hoàn toàn. Đây không phải lỗi tính toán hay sai số ngẫu nhiên — mà là hệ quả trực tiếp từ cấu trúc ẩn trong dữ liệu: những biến trung gian hoặc sự chênh lệch về kích thước nhóm đang thao túng kết quả tổng quát mà ta không hay biết.
Đây là một trong những lời cảnh báo mạnh mẽ nhất dành cho người làm dữ liệu. Vì vậy, trước khi tin vào một tỉ lệ hay một xu hướng "toàn cục", hãy luôn tự hỏi: Có cấu trúc ẩn nào đang bị che khuất không?
Bài viết này sẽ đưa bạn đi đâu?
Trong các phần tiếp theo, bài viết sẽ:
- Giải thích cơ chế đằng sau nghịch lý — để hiểu khi nào nó xuất hiện và tại sao nó nguy hiểm
- Mổ xẻ ví dụ kinh điển về câu chuyện tuyển sinh tại Đại học UC Berkeley — nơi nghịch lý Simpson từng được dùng làm bằng chứng trong một vụ kiện phân biệt giới tính
- Điểm qua các nghiên cứu thực tế mà nghịch lý này đã từng xuất hiện và dẫn đến kết luận sai lầm
- Rút ra bài học thực tiễn cho bất kỳ ai đang làm việc với dữ liệu
Hãy bắt đầu bằng việc hiểu tại sao nghịch lý này tồn tại.
2. Cơ chế của Nghịch lý Simpson: Khi các con số "đánh lừa" thị giác
Nghịch lý Simpson không chỉ là một hiện tượng kỳ thú mà còn là một bài học đắt giá về việc diễn giải dữ liệu. Nó xảy ra khi mối liên quan giữa hai biến số bị đảo ngược hoàn toàn khi ta thêm vào một biến thứ ba — gọi là biến gây nhiễu (confounding variable).
Hiểu được cơ chế đằng sau nghịch lý này không chỉ giúp bạn tránh bẫy mà còn giúp bạn đặt đúng câu hỏi trước khi đưa ra bất kỳ kết luận nào từ dữ liệu.
2.1. Sự trỗi dậy của biến ẩn (Lurking Variables)
Cơ chế cốt lõi của nghịch lý này là sự thay đổi trọng số khi gộp dữ liệu. Khi chúng ta chỉ nhìn vào con số tổng quát (aggregated data), chúng ta đang ngầm giả định rằng các nhóm thành phần có cấu trúc tương đương nhau. Nhưng trong thực tế, điều đó hầu như không bao giờ đúng.
Các biến ẩn — những yếu tố không được kiểm soát hoặc bị bỏ qua trong phân tích — luôn tồn tại và âm thầm làm lệch bức tranh thực sự.
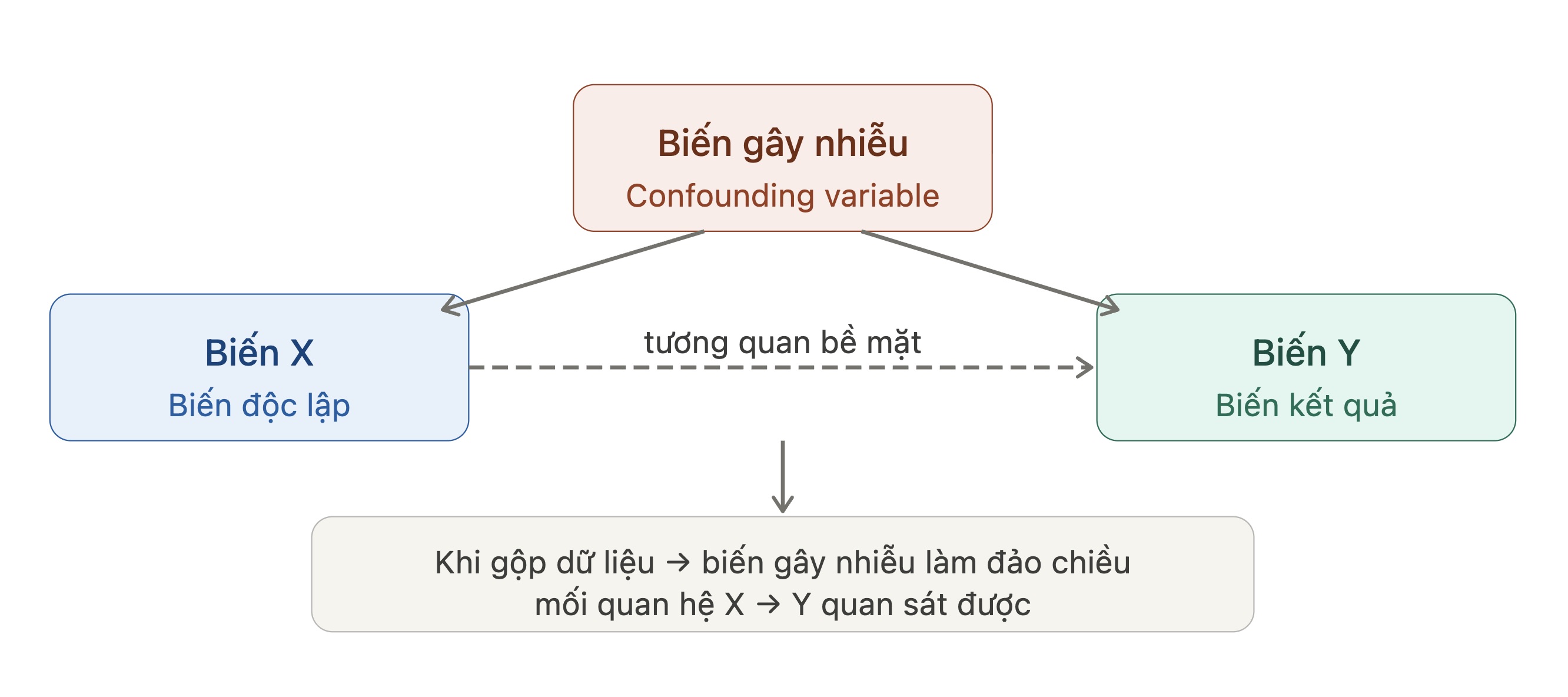
Biến gây nhiễu (confounding variable) tác động lên cả biến X lẫn biến Y, tạo ra mối tương quan bề mặt sai lệch khi gộp dữ liệu.
Nguồn: Tác giả tổng hợp.
Về mặt toán học, giả sử ta so sánh tỷ lệ thành công giữa phương pháp A và B trên hai nhóm:
- Nhóm 1: $P(\text{Success}|A) < P(\text{Success}|B)$
- Nhóm 2: $P(\text{Success}|A) < P(\text{Success}|B)$
Nhưng khi gộp chung: $P(\text{Success}|A,\ \text{Tổng}) > P(\text{Success}|B,\ \text{Tổng})$
Điều này hoàn toàn có thể xảy ra — và không phải do lỗi tính toán. Đây là hệ quả trực tiếp của việc kích thước mẫu giữa các nhóm bị phân bổ không đồng đều.
2.2. Giải thích bằng hình học vector
Một cách trực quan để hiểu cơ chế này là thông qua biểu diễn vector trên mặt phẳng tọa độ:
- Mỗi nhóm dữ liệu được biểu diễn bằng một vector, với độ dốc tương ứng là tỷ lệ thành công ($\text{thành công} / \text{tổng số thử nghiệm}$).
- Khi gộp dữ liệu, ta thực hiện phép cộng các vector thành phần.
- Do độ dài (kích thước mẫu) của các vector khác nhau, vector tổng hợp có thể có độ dốc hoàn toàn khác biệt — thậm chí ngược chiều — so với từng vector thành phần ban đầu.
Nói cách khác: nhóm nào có mẫu lớn hơn sẽ "kéo" vector tổng về phía mình mạnh hơn, bất kể hiệu quả thực sự của nhóm đó là bao nhiêu.
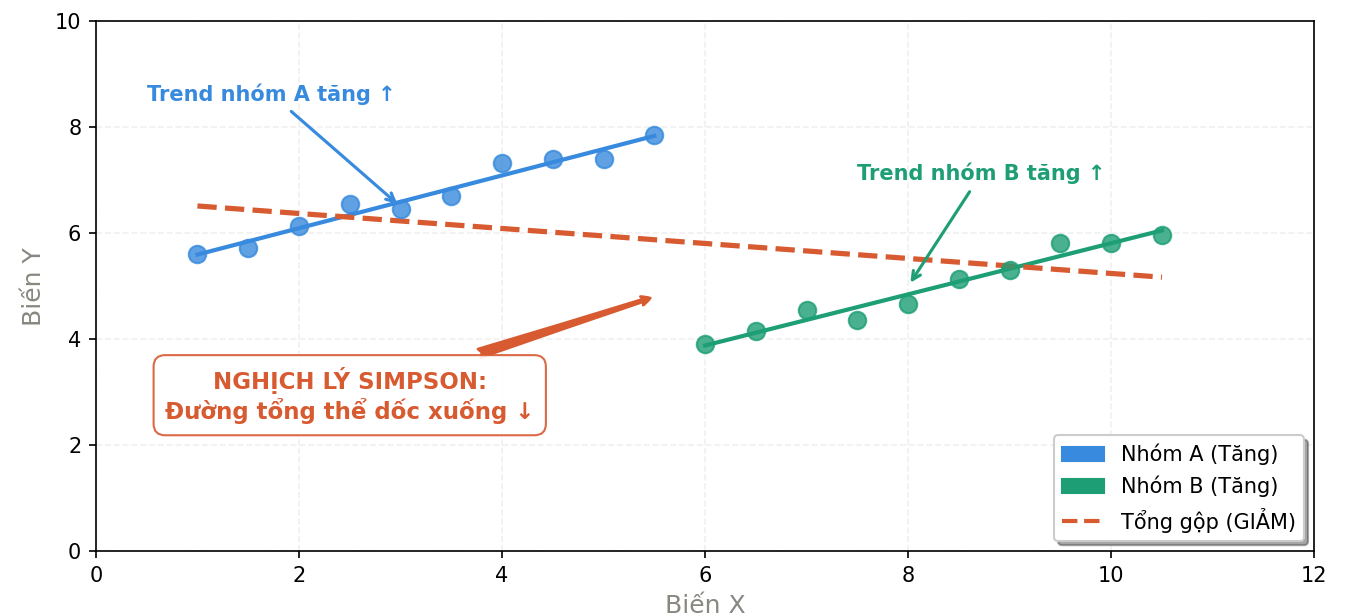
Nhóm A (xanh) và Nhóm B (xanh lá) đều có xu hướng tăng riêng lẻ — nhưng đường trend tổng gộp (đỏ, nét đứt) lại đảo chiều xuống do hai nhóm nằm ở hai vùng giá trị khác nhau.
Nguồn: Tác giả tổng hợp.
2.3. Tác động của kích thước mẫu và "trọng số độc hại"
Nghịch lý thường xuất hiện khi kích thước mẫu tỉ lệ nghịch với hiệu quả — tức là nhóm có mẫu lớn lại có kết quả kém, và ngược lại:
Trường hợp 1 — Mẫu lớn, hiệu quả thấp: Một nhóm có số lượng quan sát khổng lồ nhưng kết quả kém sẽ kéo tụt giá trị trung bình tổng thể, che khuất những thành công ở các nhóm nhỏ hơn.
Trường hợp 2 — Mẫu nhỏ, hiệu quả cao: Những kết quả tốt trong một nhóm nhỏ thường bị "nuốt chửng" khi đứng cạnh các nhóm có quy mô lớn hơn nhiều.
Đây chính là lý do tại sao tỷ lệ phần trăm không phải lúc nào cũng đủ — bạn cần biết con số đó được tính trên bao nhiêu quan sát, và liệu các nhóm có được phân bổ cân đối không.
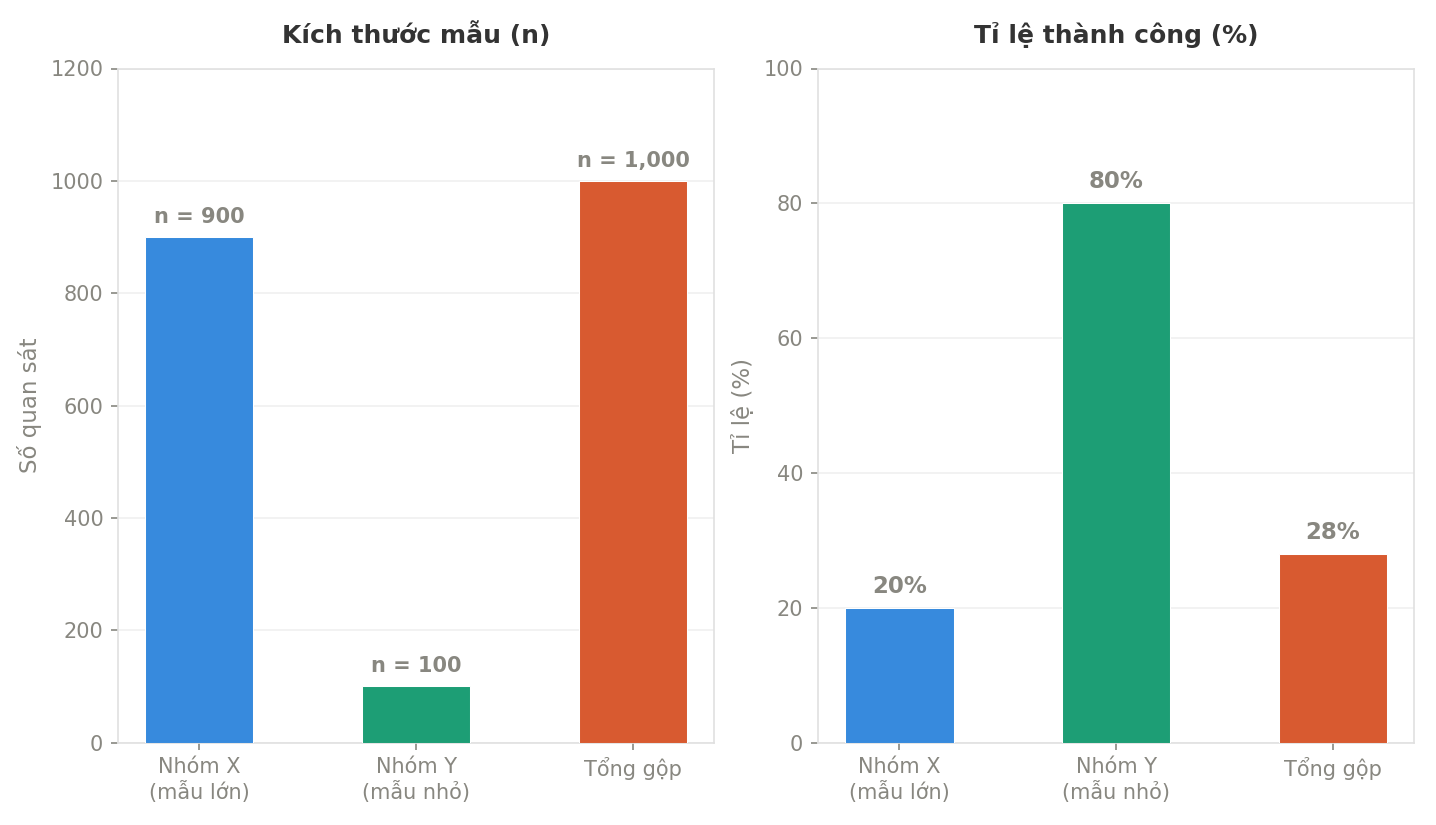
Nhóm X (n=900, tỉ lệ 20%) áp đảo về kích thước mẫu, kéo tỉ lệ tổng gộp xuống 28% — dù Nhóm Y đạt tới 80%.
Nguồn: Tác giả tổng hợp.
2.4. Sự nguy hiểm trong nghiên cứu quan sát
Nghịch lý Simpson đặc biệt nguy hiểm trong nghiên cứu quan sát — tức là các nghiên cứu không có sự phân bổ ngẫu nhiên (non-randomized studies). Trong những trường hợp này, các đối tượng tự "chọn" vào nhóm của mình, dẫn đến sự chênh lệch có hệ thống giữa các nhóm mà ta không kiểm soát được.
Hệ quả thực tế rất đáng lo ngại:
- Sai lầm trong quyết sách: Một nhà quản lý có thể loại bỏ một phương án tốt — đạt kết quả cao trong từng phân khúc — chỉ vì con số tổng quát trông có vẻ tệ hơn.
- Nguy cơ trong y khoa: Một loại thuốc có thể giúp ích cho mọi nhóm bệnh nhân, nhưng nếu dữ liệu tổng quát cho thấy nó kém hơn giả dược (do bệnh nhân nặng dùng thuốc mới nhiều hơn bệnh nhân nhẹ), nó có thể bị loại khỏi danh mục điều trị một cách oan uổng.
Cách phòng tránh:
- Phân tầng dữ liệu (Stratification): Luôn chia nhỏ dữ liệu theo các biến đặc tính trước khi kết luận — tuổi tác, giới tính, mức độ nghiêm trọng, hay bất kỳ biến nào có thể ảnh hưởng đến kết quả.
- Trực quan hóa theo nhóm: Vẽ scatter plot hoặc bar chart theo từng nhóm trước khi gộp chung — nhiều nghịch lý sẽ lộ ra ngay ở bước này.
- Kiểm tra trọng số: Luôn đặt câu hỏi: "Kích thước mẫu của các nhóm có quá chênh lệch không? Nhóm nào đang chiếm tỷ trọng lớn nhất trong tổng?"
Nghịch lý Simpson là lời nhắc nhở rằng phân tích dữ liệu không chỉ là tính toán — mà còn là đặt câu hỏi đúng trước khi tin vào con số.
3. Ví dụ kinh điển — Trường Đại học UC Berkeley
Nếu Nghịch lý Simpson cần một "bằng chứng sống" để đi vào sách giáo khoa, thì câu chuyện tuyển sinh tại Đại học California, Berkeley năm 1973 chính là ứng viên hoàn hảo nhất.
3.1. Bối cảnh
Vào mùa thu năm 1973, Ban Sau đại học của Đại học California, Berkeley công bố số liệu thống kê về toàn bộ hồ sơ ứng tuyển vào các chương trình sau đại học của trường. Mục tiêu ban đầu rất rõ ràng: kiểm tra xem liệu có thiên kiến giới tính (gender bias) trong quy trình tuyển sinh hay không — một vấn đề có tầm quan trọng lớn cả về pháp lý lẫn đạo đức trong bối cảnh xã hội lúc bấy giờ.
Kết quả thu được khiến nhiều người giật mình.
3.2. Đi sâu vào dữ liệu
Nhìn vào dữ liệu tổng quát trên toàn trường, con số hiện ra rất rõ ràng:
| Số đơn nộp | Tỉ lệ trúng tuyển | |
|---|---|---|
| Nam | 8.442 | 44% |
| Nữ | 4.321 | 35% |
| Tổng | 12.763 | — |
Chênh lệch 9 điểm phần trăm — và các kiểm định chi-square xác nhận xác suất để sự chênh lệch này xảy ra ngẫu nhiên là cực kỳ thấp. Mọi dấu hiệu đều trỏ đến một kết luận: Berkeley đang phân biệt đối xử với phụ nữ.
Nhưng câu chuyện chưa kết thúc ở đây.
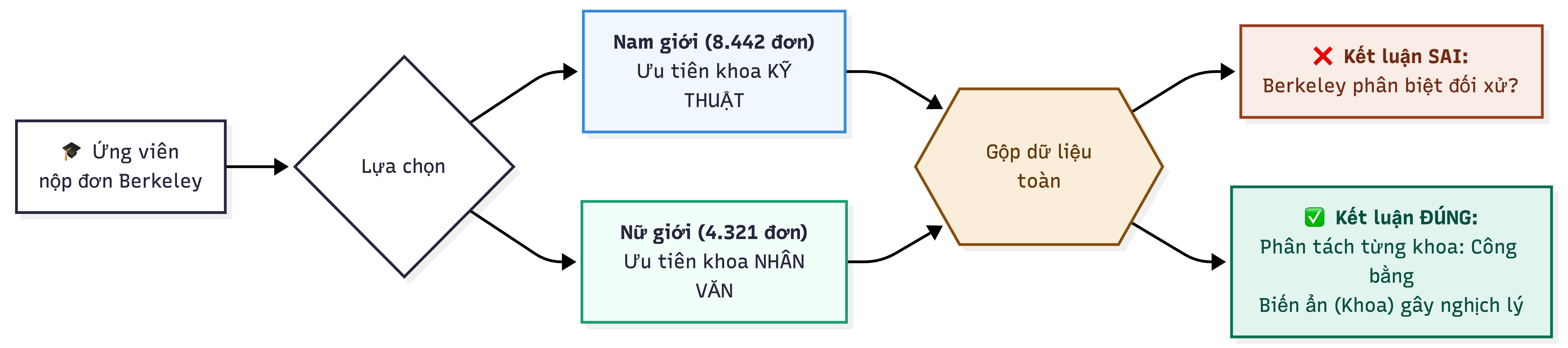
Toàn bộ luồng nhân quả dẫn đến Nghịch lý Simpson trong tuyển sinh Berkeley — nhìn tổng cho kết luận sai, phân tách theo khoa mới thấy sự thật.
Nguồn: Tác giả tổng hợp.
3.3. Giải mã nghịch lý
Khi các nhà nghiên cứu bắt đầu phân tách dữ liệu theo từng khoa, bức tranh hoàn toàn thay đổi.
Khi xem xét riêng lẻ từng khoa — đặc biệt là 6 khoa lớn nhất — sự thiên kiến có lợi cho nam giới biến mất hoàn toàn. Thậm chí ở một số khoa, dữ liệu còn cho thấy sự ưu tiên nhẹ dành cho ứng viên nữ.
Vậy điều gì đã xảy ra?
Nguyên nhân thực sự nằm ở một biến bị bỏ qua hoàn toàn trong phân tích ban đầu: sự lựa chọn khoa của ứng viên.
- Phụ nữ có xu hướng nộp đơn vào các khoa có tỉ lệ cạnh tranh cao và khó trúng tuyển — như các ngành khoa học nhân văn — nơi tỉ lệ chấp nhận thấp cho cả hai giới.
- Nam giới ngược lại, thường nộp đơn vào các khoa có tỉ lệ trúng tuyển cao hơn — như các ngành kỹ thuật.
Hệ quả: dù từng khoa xét tuyển hoàn toàn công bằng, tỉ lệ trúng tuyển tổng của nữ vẫn thấp hơn nam — chỉ vì hai nhóm đang "chơi trên hai sân khác nhau".
3.4. Kết luận về ví dụ
Nghiên cứu được công bố trên tạp chí Science năm 1975 (Bickel, Hammel & O'Connell) đưa ra hai kết luận quan trọng:
Về quy trình tuyển sinh: Không có bằng chứng về sự phân biệt đối xử có hệ thống từ phía hội đồng tuyển sinh các khoa. Quy trình diễn ra khá công bằng — sự chênh lệch trong dữ liệu tổng quát phản ánh các yếu tố xã hội và giáo dục sâu xa hơn, khiến nam và nữ có xu hướng lựa chọn ngành học khác nhau.
Về mặt thống kê: Đây trở thành ví dụ kinh điển của Nghịch lý Simpson, minh họa rằng việc gộp dữ liệu từ các nhóm có tính chất khác nhau — ở đây là các khoa với độ cạnh tranh khác nhau — có thể dẫn đến kết luận ngược hoàn toàn với bản chất thực sự của từng nhóm.
Bài học cốt lõi: Khi phân tích dữ liệu về sự công bằng, nhìn vào con số tổng quát là chưa đủ. Cần xem xét các biến trung gian — như lựa chọn ngành học — để hiểu đúng mối quan hệ nhân quả thực sự đằng sau dữ liệu.
4. Nghịch lý Simpson dưới góc nhìn của nghiên cứu hiện đại
Câu chuyện UC Berkeley xảy ra hơn 50 năm trước — nhưng Nghịch lý Simpson không hề lỗi thời. Trong kỷ nguyên Big Data và AI, khi khối lượng dữ liệu tăng theo cấp số nhân, nguy cơ bị nghịch lý này "đánh lừa" càng lớn hơn bao giờ hết. Dưới đây là một số nghiên cứu gần đây cho thấy nghịch lý này vẫn đang hiện diện — và ngày càng phức tạp hơn.
4.1. Học máy và sự công bằng của thuật toán
Một trong những ứng dụng đáng lo ngại nhất của Nghịch lý Simpson là trong lĩnh vực công bằng thuật toán (algorithmic fairness) — câu hỏi liệu các mô hình AI có đối xử công bằng với mọi nhóm người hay không.
Nghiên cứu của Babaei và cộng sự (2025) đặt vấn đề trong bối cảnh cho vay tín dụng tại New York: một mô hình AI có thể trông hoàn toàn công bằng khi phân tích tổng thể, nhưng lại ẩn chứa sự phân biệt đối xử khi xét riêng từng nhóm dân số. Nghịch lý Simpson chính là cơ chế che giấu sự bất công đó.
Để phát hiện những thiên kiến ẩn này, nhóm tác giả đề xuất sử dụng Giá trị Shapley (Shapley values) — một phương pháp đo lường mức độ ảnh hưởng của từng biến lên quyết định của mô hình. Kết quả cho thấy: chỉ nhìn vào độ chính xác tổng thể của mô hình là chưa đủ — cần phải "mổ xẻ" theo từng phân nhóm mới thấy bức tranh thực sự.
4.2. Nghịch lý Simpson trong dữ liệu xã hội
Nghịch lý Simpson cũng xuất hiện ở những nơi ít ngờ tới hơn — như trong phân tích phản ứng của dư luận trên mạng xã hội.
Liu và Son (2025) phân tích mối liên hệ giữa mức độ nghiêm trọng của dịch COVID-19 và lượng tin tức, dư luận trên mạng xã hội tại Trung Quốc trong giai đoạn 2020–2022. Khi nhìn vào toàn bộ 3 năm gộp lại, dữ liệu cho thấy một mối tương quan âm đáng ngạc nhiên: dịch bệnh càng tăng, lượng tin tức phản hồi lại càng giảm.
Tuy nhiên khi chia dữ liệu theo từng năm riêng lẻ, kết quả đảo chiều hoàn toàn — mối tương quan dương xuất hiện rõ ràng: số ca bệnh tăng dẫn đến lượng tin tức tăng theo. Nghiên cứu kết luận rằng việc gộp dữ liệu đa giai đoạn có thể che giấu các phản ứng tâm lý và cảm xúc thực sự của dư luận theo từng thời điểm — một cảnh báo quan trọng cho bất kỳ ai phân tích dữ liệu chuỗi thời gian.
4.3. Vượt ra ngoài khái niệm "biến gây nhiễu"
Trong nhiều năm, chuyên gia hàng đầu về suy luận nhân quả Judea Pearl lập luận rằng Nghịch lý Simpson về bản chất là hệ quả của biến gây nhiễu — kiểm soát được biến đó là giải quyết được nghịch lý.
Nhưng nghiên cứu của Dong và cộng sự (2024) thách thức quan điểm này. Nhóm tác giả chỉ ra rằng nghịch lý có thể phát sinh từ nhiều nguyên nhân khác nhau, không phải lúc nào cũng liên quan đến nhân quả — ví dụ như sự biến động ngẫu nhiên trong dữ liệu sinh học tiến hóa, hoặc đơn giản là việc định nghĩa sai ranh giới giữa các nhóm khi gộp dữ liệu.
Theo một hướng khác, Sarkar và Bandyopadhyay (2021) nhấn mạnh rằng để thực sự giải quyết Nghịch lý Simpson trong thực tế, không thể chỉ dựa vào một công cụ duy nhất. Cần kết hợp giữa tư duy nhân quả, công cụ thống kê và khả năng phán đoán ngữ cảnh — vì đôi khi nghịch lý không có một "đáp án đúng" duy nhất, mà phụ thuộc vào câu hỏi bạn đang thực sự cố gắng trả lời.
Nhìn chung, các nghiên cứu hiện đại cho thấy Nghịch lý Simpson không chỉ là một bài toán thống kê cần "sửa" — mà là một lời nhắc nhở căn bản: dữ liệu không tự nói lên sự thật, người phân tích mới là người quyết định câu hỏi đúng cần đặt ra.
5. Kết luận và bài học
Từ câu chuyện tuyển sinh ở Berkeley năm 1973, cho đến các mô hình AI cho vay tín dụng năm 2025 — Nghịch lý Simpson đã đi một hành trình dài, nhưng thông điệp cốt lõi của nó không thay đổi: con số tổng hợp có thể che giấu sự thật, và đôi khi che giấu một cách hoàn hảo.
5.1. Tóm lại nghịch lý đã dạy chúng ta điều gì
Nghịch lý Simpson là một minh chứng và cũng là một lời cảnh tỉnh sâu sắc: dữ liệu thống kê không phải lúc nào cũng là chân lý tuyệt đối nếu thiếu đi bối cảnh. Bản thân dữ liệu không "biết nói dối" — chính cách chúng ta gom nhóm, đơn giản hóa và nhìn nhận chúng một cách hời hợt đã vô tình che khuất bản chất thực sự của vấn đề.
Hiện tượng này cho thấy sự nguy hiểm của việc mù quáng tin tưởng vào các con số trung bình hay tỷ lệ tổng quát. Khi bỏ qua các yếu tố ẩn hoặc sự chênh lệch về kích thước giữa các nhóm, chúng ta rất dễ rơi vào cạm bẫy nhận thức — từ đó đưa ra những đánh giá sai lệch có sức tàn phá lớn trong thực tế, dù đó là chính sách tuyển sinh, phác đồ điều trị y tế hay chiến lược kinh doanh.
Nhìn lại toàn bộ bài viết, có bốn bài học quan trọng mà bất kỳ người làm việc với dữ liệu nào cũng nên ghi nhớ:
Luôn hoài nghi những "con số tổng quát". Đừng bao giờ vội thỏa mãn với bức tranh toàn cảnh. Khi đứng trước một tỷ lệ trung bình hay kết quả tổng gộp, hãy tập thói quen tự hỏi: "Liệu có yếu tố phân nhóm nào — như độ tuổi, giới tính, khu vực, tính chất công việc — có thể làm thay đổi hoàn toàn cục diện nếu ta chia nhỏ dữ liệu ra không?"
Truy tìm biến số gây nhiễu (confounding variables). Bức tranh tổng thể thường bị bóp méo bởi một yếu tố thứ ba chưa được xét đến — như mức độ khó của các ngành học trong câu chuyện UC Berkeley. Việc phân rã dữ liệu thành các nhóm nhỏ có tính đồng nhất cao là thao tác bắt buộc để bóc tách sự thật.
Hiểu rõ bối cảnh sinh ra dữ liệu. Kỹ năng tính toán giỏi là chưa đủ. Một người làm việc với dữ liệu cần phải hiểu rõ câu chuyện đằng sau nó: dữ liệu được thu thập như thế nào? Cách phân bổ các mẫu có ngẫu nhiên và đồng đều không? Bối cảnh chính là chiếc chìa khóa để giải mã những nghịch lý thống kê.
Thận trọng khi kết luận quan hệ nhân quả. Nghịch lý Simpson nhắc nhở rằng mối tương quan ở cấp độ tổng thể có thể đảo ngược hoàn toàn ở cấp độ chi tiết. Cần cực kỳ cẩn trọng khi sử dụng dữ liệu quan sát (observational data) để khẳng định rằng yếu tố A là nguyên nhân trực tiếp dẫn đến kết quả B.
5.2. Checklist thực hành cho người làm dữ liệu
Lần tới khi bạn nhìn vào một con số tổng hợp — dù là kết quả A/B test, báo cáo hiệu suất, hay số liệu y tế — hãy tự hỏi:
1. Dữ liệu có được phân tầng chưa?
Chia nhỏ theo các biến đặc tính quan trọng (độ tuổi, giới tính, khu vực, phân khúc sản phẩm...) trước khi kết luận.2. Kích thước mẫu các nhóm có chênh lệch lớn không?
Nhóm nào đang chiếm tỷ trọng lớn nhất? Nó có đang kéo kết quả tổng về phía mình không?3. Có biến nào chưa được kiểm soát không?
Các đối tượng có tự "chọn" vào nhóm của mình không? Nếu có, yếu tố nào ảnh hưởng đến sự lựa chọn đó?4. Xu hướng tổng và xu hướng từng nhóm có nhất quán không?
Nếu không — đó là dấu hiệu cần điều tra thêm, không phải bỏ qua.
5.3. Lời kết
Nghịch lý Simpson là một trong những lý do tại sao phân tích dữ liệu vừa là khoa học, vừa là nghệ thuật. Các công cụ thống kê ngày càng mạnh hơn, dữ liệu ngày càng nhiều hơn — nhưng khả năng bị đánh lừa bởi những con số tổng quát không vì thế mà giảm đi.

Sự thật không nằm ở bức tranh tổng thể — mà ẩn trong từng mảnh ghép nhỏ.
Nguồn: Ảnh minh họa tạo bởi AI.
Hiểu được nghịch lý này không có nghĩa là bạn sẽ không bao giờ mắc sai lầm. Nhưng nó trang bị cho bạn một thói quen quan trọng: luôn đặt câu hỏi trước khi tin vào một con số — dù nó trông có vẻ hiển nhiên đến đâu.
Bởi vì đôi khi, sự thật không nằm ở bức tranh tổng thể — mà ẩn trong từng mảnh ghép nhỏ mà bạn chưa kịp nhìn vào.
Tài liệu tham khảo
Babaei, G., Giudici, P., & Neelakantan, P. (2025). Explainability, fairness and the Simpson's paradox in credit lending. Physica A: Statistical Mechanics and its Applications, 680, 131030. https://doi.org/10.1016/j.physa.2025.131030
Bickel, P. J., Hammel, E. A., & O'Connell, J. W. (1975). Sex bias in graduate admissions: Data from Berkeley. Science, 187(4175), 398–404. https://doi.org/10.1126/science.187.4175.398
Blyth, C. R. (1972). On Simpson's paradox and the sure-thing principle. Journal of the American Statistical Association, 67(338), 364–366. https://doi.org/10.2307/2284382
Dong, Z., Cai, W., & Zhao, S. (2024). Simpson's paradox beyond confounding. European Journal for Philosophy of Science, 14(44). https://doi.org/10.1007/s13194-024-00610-8
Kievit, R. A., Frankenhuis, W. E., Waldorp, L. J., & Borsboom, D. (2013). Simpson's paradox in psychological science: A practical guide. Frontiers in Psychology, 4, 513. https://doi.org/10.3389/fpsyg.2013.00513
Liu, Q., & Son, H. (2025). Simpson's paradox of social media opinion's response to COVID-19. Frontiers in Public Health, 13, 1448811. https://doi.org/10.3389/fpubh.2025.1448811
Sarkar, P., & Bandyopadhyay, P. S. (2021). Simpson's paradox: A singularity of statistical and inductive inference. arXiv preprint arXiv:2103.16860v2. https://arxiv.org/abs/2103.16860
Simpson, E. H. (1951). The interpretation of interaction in contingency tables. Journal of the Royal Statistical Society, Series B, 13(2), 238–241. https://doi.org/10.1111/j.2517-6161.1951.tb00088.x
Chưa có bình luận nào. Hãy là người đầu tiên!