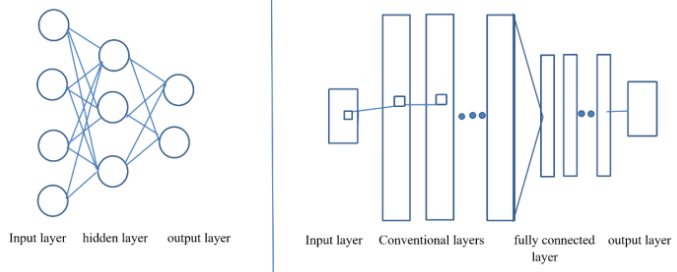
1. Giới Thiệu: Khi MLP trở nên bất lực trước dữ liệu hình ảnh
Hãy bắt đầu với một bức ảnh rất quen thuộc: ảnh màu kích thước 224 × 224.
Với con người, đây chỉ đơn giản là một hình ảnh.
Nhưng với máy tính, bức ảnh này tương đương 150.528 giá trị số (224 × 224 × 3).
Vấn đề đặt ra là: chúng ta sẽ đưa khối dữ liệu khổng lồ này vào mô hình học máy như thế nào?
Một cách tiếp cận trực tiếp và từng rất phổ biến là sử dụng MLP (Multi-Layer Perceptron) – mạng nơ-ron kết nối đầy đủ, nơi mỗi pixel được nối với mọi neuron ở lớp tiếp theo. Cách làm này có vẻ hợp lý, nhưng khi áp dụng cho dữ liệu ảnh, nó nhanh chóng bộc lộ những giới hạn nghiêm trọng.
1.1. Bùng nổ số lượng tham số
Giả sử lớp đầu tiên của MLP có 1.000 neuron.
- Số pixel đầu vào: 224 × 224 × 3 = 150.528
- Mỗi pixel kết nối với 1.000 neuron
→ Tổng số tham số ≈ 150.528 × 1.000 ≈ 150 triệu weights
Con số này chưa bao gồm bias, chưa tính các lớp phía sau, và cũng chưa xét đến việc mô hình cần phải sâu hơn để học được những đặc trưng phức tạp.
Hệ quả rất rõ ràng:
- Mô hình tiêu tốn bộ nhớ lớn và khó mở rộng.
- Quá trình huấn luyện chậm, chi phí tính toán cao.
- Nguy cơ overfitting lớn nếu không có tập dữ liệu đủ khổng lồ.
Nghịch lý nằm ở chỗ: dù có số lượng tham số khổng lồ, MLP vẫn không thực sự “hiểu” hình ảnh.
1.2. MLP và sự thiếu hụt cấu trúc không gian (Spatial Structure)
Hình ảnh không phải là một tập hợp ngẫu nhiên các con số. Chúng có cấu trúc không gian rất rõ ràng:
- Các pixel gần nhau thường mang thông tin liên quan.
- Cạnh, góc và họa tiết là những đặc trưng cục bộ lặp lại ở nhiều vị trí.
- Một đối tượng vẫn giữ nguyên bản chất dù vị trí của nó trong ảnh thay đổi nhẹ.
Tuy nhiên, MLP không khai thác được bất kỳ đặc điểm nào trong số đó.
Trong MLP, mỗi pixel được xem như một đặc trưng độc lập, không tồn tại khái niệm “gần” hay “xa” trong không gian ảnh. Pixel ở góc ảnh và pixel ở trung tâm được xử lý hoàn toàn giống nhau.
Điều này dẫn đến các hạn chế cốt lõi:
- Mô hình không tận dụng được mối quan hệ cục bộ giữa các pixel.
- Không học được các đặc trưng mang tính lặp lại trong ảnh.
- Chỉ một dịch chuyển nhỏ trong ảnh cũng có thể khiến mô hình phản ứng như với một dữ liệu hoàn toàn mới.
1.3. Nút thắt cần một cách tiếp cận mới
Từ những vấn đề trên, một yêu cầu tự nhiên được đặt ra:
- Làm thế nào để mô hình tập trung vào đặc trưng cục bộ thay vì toàn bộ ảnh?
- Làm thế nào để giảm mạnh số lượng tham số nhưng vẫn học hiệu quả?
- Làm thế nào để mô hình tôn trọng cấu trúc không gian vốn có của dữ liệu hình ảnh?
Câu trả lời cho những câu hỏi này chính là Convolutional Neural Network (CNN).
Phần tiếp thao sẽ được đi sâu vào cơ chế Convolution, nơi các khái niệm kernel, local connections và shared weights tạo nên nền tảng giúp CNN giải quyết triệt để những vấn đề mà MLP gặp phải.
2. Convolutional layer
Convolutional layer là lớp tích chập là thành phần quan trọng nhất của CNN, chịu trách nhiệm trích xuất các đặc trưng từ dữ liệu đầu vào. Lớp này sử dụng một bộ lọc (kernel) quét qua từng vùng nhỏ của hình ảnh và thực hiện phép nhân tích chập (convolution) giữa các giá trị pixel với trọng số của bộ lọc. Kết quả của quá trình này tạo thành bản đồ đặc trưng (feature map), giúp mô hình phát hiện các đặc điểm như cạnh, góc, màu sắc hoặc kết cấu trong ảnh.
Các tham số quan trọng của lớp tích chập bao gồm: Số lượng bộ lọc, Stride (bước di chuyển của bộ lọc) và Padding (giữ kích thước ảnh).
2.1 Bộ lọc ( Kernel / Filter)
Kernel trong xử lý ảnh là một ma trận kích thước nhỏ được sử dụng tích chập với ảnh trong nhiều tác vụ như làm mờ, làm sắc nét, phát hiện biên cạnh. Kernel thực hiện phép tích chập để tính toán giá trị mới cho các pixel trong Feature Map ( thường là ảnh xám) . Điều này giúp tìm ra các đặc trưng trong tín hiệu đầu vào. Giá trị của Kernel được cập nhật thông qua quá trình huấn luyện của mạng nơ-ron.
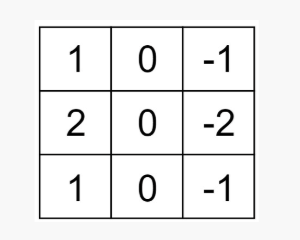
2.2 Stride
Stride được định nghĩa là số bước mà kernel di chuyển. Ví dụ với stride bằng 1 thì kernel sẽ trượt trên 1 dòng hoặc 1 cột tại một thời điểm.
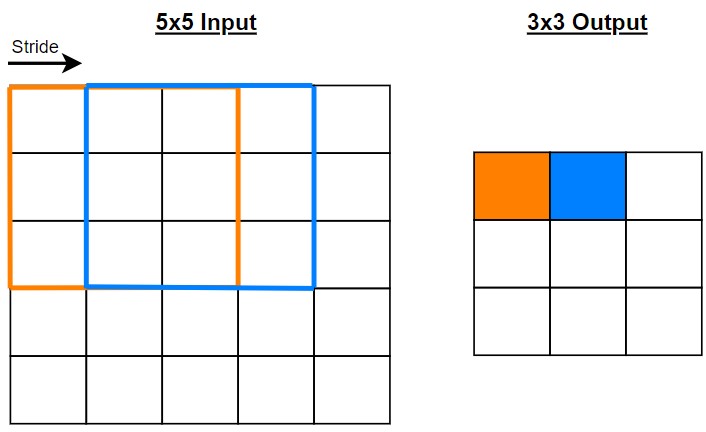
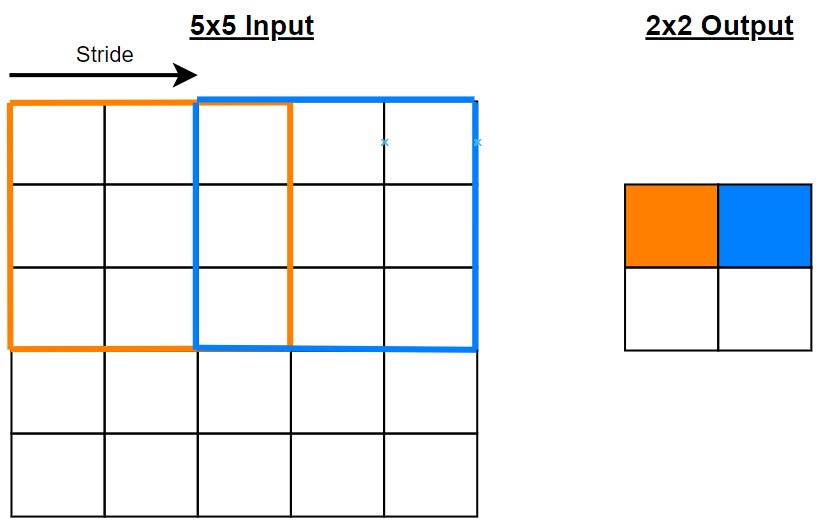
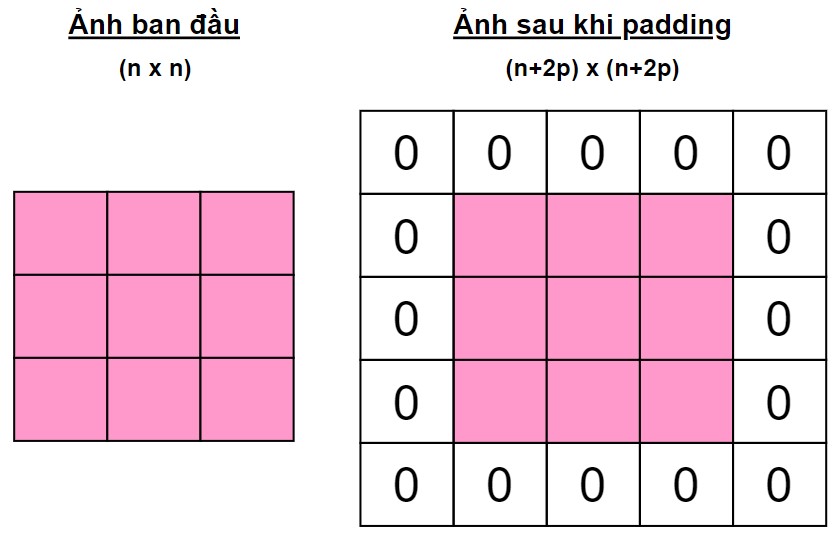
2.3 Padding
Đôi khi kernel không phù hợp với hình ảnh đầu vào. Ta có thể áp dụng phương pháp Zero padding: Làm dày các phần biên của ma trận khi thực hiện phép tích chập.
2.4 Cách tính output Shape (convolution)
2.4.1 Để tính convolution trong CNN, chúng ta cần để ý những tham số sau
- Shape của input: gồm resolution (height, width) và số channel.
- Shape của filter (hay kernel size), là matrix chứa các trọng số. Ban đầu, các giá trị của matrix này được gán trước ngẫu nhiên hay dùng pre-trained weight. Quá trình training cập nhật các tham số này để cho giá trình hàm loss giảm. Nói lý thuyết hơn là để labels/ground-truth = network(input), trong đó network là hàm ánh xạ input cho labels.
- Resolution cho filter là tham số, thông thường dùng 3x3 hay 5x5. Số channel cho filter = số channel của input.
- Padding: bình thường resolution của output sẽ nhỏ hơn resolution của input. Padding là kĩ thuật làm cho resolution của input lớn hơn, để resolution của output tính được có resolution lớn hơn (xem thêm ví dụ 1).
- Stride: Bước nhẩy của filter. Padding và stride có thể áp dụng riêng cho height và width; nhưng bình thường khi nói stride=1 được hiểu là bước nhẩy cho height = 1 là cho width = 1.
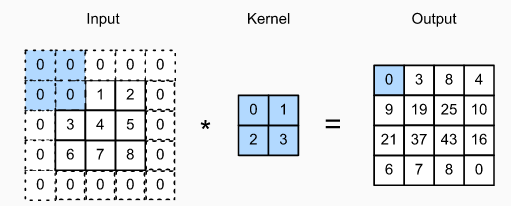
Giải thích cho ví dụ 1:
input shape trước khi padding: 3x3x1
- Padding = 1
- Input shape sau khi padding: 5x5x1
- Filter shape: 2x2x1
- Output shape: 4x4x1
- Stride = 1
Lưu ý quan trọng:
⚠️ Pooling KHÔNG thay đổi số channels (depth)
📌 Thường dùng Pool_size = 2×2, Stride = 2 để giảm một nửa kích thước
2.4.2 Công thức tính
Width_out = ⌊(W_in - K_width + 2×P) / S⌋ + 1
Height_out = ⌊(H_in - K_height + 2×P) / S⌋ + 1
Depth_out = Số Filters
Giả sử cho bài toán sau:
**Đề bài:**
Input: 32×32×3 (ảnh RGB kích thước 32×32)
Kernel: 5×5
Filters: 16
Stride: 1
Padding: 0 (Valid Padding)
Bước 1: Xác định các tham số
- W_in = 32, H_in = 32, C_in = 3
- K = 5
- S = 1
- P = 0
- F = 16
Bước 2: Áp dụng công thức
-
Width_out = ⌊(32 - 5 + 2×0) / 1⌋ + 1
= ⌊27 / 1⌋ + 1
= 27 + 1
= 28 -
Height_out = ⌊(32 - 5 + 2×0) / 1⌋ + 1
= 28 -
Depth_out = 16 (số filters)
Đáp án: Output = 28×28×16
3. CÁC LỚP CƠ BẢN TRONG MẠNG CNN

CNN được xây dựng bằng cách chồng nhiều lớp tích chập (Convolutional Layers), xen kẽ với lớp pooling (Pooling Layers) và kết thúc bằng lớp kết nối đầy đủ (Fully Connected Layers), giúp xử lý và phân loại hình ảnh. Ngoài ra, các hàm kích hoạt phi tuyến ($ReLU$, $Tanh$) được sử dụng để tăng khả năng biểu diễn của mô hình. Mỗi lớp trong CNN đảm nhận một nhiệm vụ cụ thể, từ trích xuất đặc trưng đến giảm kích thước và cuối cùng là phân loại hình ảnh.
Cấu trúc cơ bản của CNN có thể chia thành ba phần chính: trường tiếp nhận cục bộ (Local Receptive Field), trọng số chia sẻ (Shared Weights and Bias) và lớp tổng hợp (Pooling Layer).
Trường tiếp nhận cục bộ (Local receptive field):
- Là nơi dữ liệu đầu vào được phân tách thành từng vùng nhỏ để xử lý. Thay vì kết nối toàn bộ các điểm ảnh (pixels) của một hình ảnh với tất cả các nơ-ron ở lớp tiếp theo, CNN chỉ kết nối từng vùng nhỏ (local receptive field) với một nơ-ron nhất định. Như vậy mỗi nơ-ron sẽ chỉ nhận diện đặc trưng của một khu vực cục bộ. Điều này giúp mô hình có khả năng nhận diện các đặc trưng quan trọng theo từng khu vực nhỏ trong ảnh trước khi tổng hợp thành thông tin lớn hơn ở các lớp tiếp theo.
Trọng số chia sẻ (Shared Weights and Bias):
- Giúp giảm đáng kể số lượng tham số cần huấn luyện trong mô hình. Trong một lớp tích chập, các bộ lọc (filters) được quét trên toàn bộ hình ảnh theo cơ chế tích chập (convolution), với mỗi bộ lọc đảm nhận nhiệm vụ phát hiện một đặc trưng cụ thể, chẳng hạn như cạnh, góc, màu sắc hoặc hình dạng. Việc sử dụng chung các trọng số giữa các vùng trong ảnh giúp CNN có thể học được các mẫu đặc trưng một cách hiệu quả và tiết kiệm tài nguyên tính toán.
Lớp tổng hợp (Pooling Layer):
- Đóng vai trò giảm kích thước dữ liệu đầu ra, giúp tối ưu mô hình và tránh dư thừa thông tin. Pooling giúp mô hình trở nên bất biến với các thay đổi như dịch chuyển, co giãn hoặc xoay hình ảnh, đảm bảo CNN vẫn có thể nhận diện đúng đối tượng dù chúng xuất hiện ở các vị trí khác nhau trong ảnh. Có hai loại pooling phổ biến: Max Pooling, lấy giá trị lớn nhất trong vùng quét để giữ lại đặc trưng quan trọng nhất, và Average Pooling, tính giá trị trung bình của các điểm trong vùng quét để làm mịn dữ liệu.
Với cơ chế kết hợp giữa các lớp này, Convolutional Neural Networks có khả năng xây dựng biểu diễn trừu tượng từ cấp độ thấp đến cao, từ các đặc điểm đơn giản như cạnh và góc cho đến các hình dạng phức tạp hơn như khuôn mặt hoặc vật thể. Bên cạnh đó, trong suốt quá trình huấn luyện, CNN tự động điều chỉnh các bộ lọc và trọng số thông qua backpropagation, và thuật toán tối ưu hóa, giúp mô hình học cách trích xuất đặc trưng và nhận diện hình ảnh một cách hiệu quả.
4. Lớp Pooling
Sau các lớp Convolution, mạng CNN thường chèn thêm Pooling layers nhằm mục đích giảm kích thước không gian của đặc trưng (feature maps), đồng thời cải thiện khả năng khái quát hóa của mô hình. Pooling đóng vai trò quan trọng trong việc kiểm soát độ phức tạp của mạng và tăng tính ổn định đối với các biến đổi nhỏ trong dữ liệu đầu vào.
4.1. Khái niệm và cơ chế hoạt động
Pooling là một phép toán downsampling, được thực hiện độc lập trên từng feature map. Thay vì học tham số như Convolution, Pooling sử dụng các phép toán thống kê đơn giản trên một vùng cục bộ (local region), phổ biến nhất là:
- Max Pooling: lấy giá trị lớn nhất trong vùng pooling
- Average Pooling: lấy giá trị trung bình trong vùng pooling
Ví dụ, với Max Pooling kích thước (2 \times 2), mỗi vùng (2 \times 2) trên feature map đầu vào sẽ được ánh xạ thành một giá trị duy nhất – giá trị lớn nhất trong vùng đó.
4.2. Giảm chiều dữ liệu và số lượng tham số
Một trong những lợi ích cốt lõi của Pooling là giảm kích thước không gian (spatial dimensions) của feature maps. Điều này dẫn đến:
- Giảm số lượng phép tính ở các lớp phía sau
- Giảm nguy cơ overfitting
- Tăng tốc độ huấn luyện và suy luận
Ví dụ, nếu một feature map có kích thước (28 \times 28), sau khi áp dụng Max Pooling (2 \times 2) với stride = 2, kích thước sẽ giảm xuống còn (14 \times 14), tức là giảm 75% số phần tử.
4.3. Tính bất biến theo phép tịnh tiến (Translation Invariance)
Một đặc tính quan trọng mà Pooling mang lại là Translation Invariance – tính bất biến đối với các dịch chuyển nhỏ của đối tượng trong ảnh.
Cụ thể:
- Nếu một đặc trưng (ví dụ: cạnh, góc, hoặc hoa văn) bị dịch chuyển nhẹ trong ảnh đầu vào
- Giá trị sau Pooling (đặc biệt là Max Pooling) vẫn gần như không đổi
Điều này giúp CNN:
- Nhận diện đối tượng tốt hơn dù vị trí của chúng thay đổi nhẹ
- Tập trung vào sự tồn tại của đặc trưng thay vì vị trí chính xác của nó
Đây là yếu tố then chốt giúp CNN vượt trội so với MLP trong các bài toán thị giác máy tính.
4.4. Các biến thể và xu hướng hiện đại
Bên cạnh Max Pooling và Average Pooling, một số biến thể khác cũng được sử dụng trong các kiến trúc hiện đại:
- Global Average Pooling (GAP): lấy trung bình toàn bộ feature map, thường dùng trước lớp phân loại cuối cùng
- Strided Convolution: trong một số mô hình, Pooling được thay thế hoàn toàn bằng Convolution có stride > 1
Xu hướng gần đây cho thấy Pooling không còn là thành phần bắt buộc trong mọi kiến trúc CNN, tuy nhiên nó vẫn giữ vai trò quan trọng trong việc tạo tính bất biến và giảm độ phức tạp mô hình.
4.5. Tóm tắt vai trò của Pooling
Tóm lại, lớp Pooling đóng góp ba vai trò chính trong CNN:
- Giảm chiều dữ liệu và chi phí tính toán
- Hạn chế overfitting bằng cách giảm độ nhạy với nhiễu
- Tạo tính bất biến theo phép tịnh tiến (translation invariance)
Nhờ Pooling, CNN có thể học được các biểu diễn đặc trưng mạnh mẽ và ổn định hơn, tạo nền tảng cho các kiến trúc sâu và hiệu quả trong Deep Learning.
5. Vấn đề Vanishing Gradient: Hiện tượng "cạn đạo hàm" khi mạng quá sâu
Vanishing Gradient (biến mất gradient hay cạn đạo hàm) là một hiện tượng quan trọng trong quá trình huấn luyện mạng nơ-ron sâu, nơi các gradient (đạo hàm riêng của hàm mất mát theo các tham số mạng) được lan truyền ngược (backpropagation) trở nên cực kỳ nhỏ, gần như bằng 0 khi đi từ lớp đầu ra về các lớp đầu tiên của mạng. Khi gradient tiến tới 0, trọng số của các lớp này gần như không được cập nhật, làm cho quá trình học bị chậm lại hoặc hoàn toàn dừng lại ở những lớp đầu tiên.
Đây là một trong những thách thức lớn nhất khi xây dựng các mạng neural network sâu, vì lý thuyết cho rằng mạng càng sâu thì khả năng biểu diễn và học hỏi càng mạnh, nhưng thực tế lại thường là ngược lại khi không được kiểm soát tốt.
5.1. Quan sát và hiện tượng
Khi huấn luyện một mạng nơ-ron sâu mà gặp phải vấn đề vanishing gradient, có thể quan sát được một số hiện tượng đặc trưng rất cụ thể và dễ nhận diện trong quá trình đánh giá mô hình.
5.1.1. Loss không giảm hoặc giảm cực kỳ chậm
Hiện tượng này là dấu hiệu rõ ràng nhất của vanishing gradient. Hàm mất mát (loss) gần như đứng yên, giảm rất ít sau hàng trăm epochs:
- Ví dụ cụ thể: Với mạng 5 hidden layers, loss giảm từ 2,307 xuống chỉ 2,303 sau 300 epochs - tức là chỉ giảm 0,04 (khoảng 1,7%).
- Tương phản: Mạng nông hơn (3 hidden layers) có loss giảm từ 2,3 xuống 0,7 trong cùng số epochs, tức là giảm 1,6 (khoảng 70%).
Sự chênh lệch này cho thấy rằng mạng sâu hơn không học tốt như mạng nông hơn, điều này trái ngược với lý thuyết rằng mạng sâu hơn phải có khả năng biểu diễn tốt hơn.
5.1.2. Độ chính xác không cải thiện
Cùng với loss đứng yên, Độ chính xác (accuracy) cũng không tăng đáng kể:
- Train accuracy gần như không tăng, dao động quanh một giá trị cố định.
- Ví dụ: Accuracy gần 10% (tương đương phỏng đoán ngẫu nhiên) trên bài toán phân loại 10 classes.
Hiện tượng này cho thấy rằng mô hình không học được, hay nói cách khác, nó chỉ như một bộ phân loại ngẫu nhiên.
5.1.3. Gradient trở nên rất nhỏ ở các lớp đầu
Khi phân tích phân bố của các gradient trong quá trình huấn luyện ta thấy:
- Mạng với hàm sigmoid: phân bố của các gradient rất nhỏ, tập trung quanh 0 hạn chế khả năng truyền tải thông tin qua các lớp mạng.
- Hiệu ứng tích lũy: hiệu ứng này trở nên rõ rệt hơn khi gradients truyền ngược qua các lớp. Nếu mỗi lớp nhân gradient với một giá trị nhỏ hơn 1 (ví dụ 0,25 với sigmoid), thì sau 30 lớp, gradient sẽ là $ 0,25^{30} ≈ 10^{-19} $, gần như không thể phát hiện được trong máy tính.
5.1.4. Các lớp đầu không học được
Hiện tượng này là hệ quả trực tiếp của gradient quá nhỏ:
- Các lớp gần input (early layers) không cập nhật trọng số một cách có ý nghĩa.
- Trọng số gần như đóng băng: Vì gradient quá nhỏ, công thức cập nhật trọng số $Δw = learningRate × gradient$ tạo ra các thay đổi không đáng kể.
Kết quả: Các lớp này không học được các đặc trưng cơ bản và nền tảng từ dữ liệu (như cạnh, góc trong hình ảnh), làm hạn chế khả năng của các lớp sau trong việc xây dựng các đặc trưng phức tạp hơn.
5.1.5. Hội tụ chậm hoặc không hội tụ
Vanishing gradient dẫn đến các vấn đề về hội tụ:
- Slow Convergence: Mạng mất rất nhiều thời gian (hoặc không bao giờ) để đạt đến một giải pháp tối ưu.
- Stagnation: Mô hình có thể đạt đến một "plateau" - tình trạng nằm yên, không cải thiện hơn nữa.
- Limited Depth: Khi thêm nhiều lớp hơn, mô hình trở nên khó huấn luyện hơn (trái với mong đợi).
Các hiện tượng quan sát được khi gặp vanishing gradient rất dễ nhận biết thông qua việc theo dõi loss, accuracy, và gradient distributions trong quá trình huấn luyện.
5.2. Nguyên nhân của hiện tượng cạn đạo hàm
Cạn đạo hàm là kết quả của sự tương tác giữa nhiều yếu tố trong kiến trúc mạng nơ-ron sâu và quá trình huấn luyện. Dưới đây là phân tích chi tiết các nguyên nhân chính:
5.2.1 Hàm Kích Hoạt Sigmoid/Tanh có đạo hàm nhỏ
Đây là nguyên nhân sâu sắc nhất của vanishing gradient.
Sigmoid:
- Đạo hàm: $σ'(z) = σ(z)(1 - σ(z))$
- Giá trị tối đa: 0,25 (khi $z = 0$)
- Phạm vi: Luôn ≤ 0,25
Tanh:
- Đạo hàm tối đa: 1,0
- Phạm vi: (0, 1)
Hệ quả: Mỗi lần gradient lan truyền ngược qua một lớp, nó bị nhân với một số ≤ 1. Khi có 20-30 lớp, gradient bị nhân liên tiếp: $ 0,25^{30} ≈ 10^{-19} $ - gần như bằng 0.
5.2.2 Tích lũy gradient qua nhiều lớp và độ sâu của mạng
Vấn đề vanishing gradient không chỉ do một lớp, mà do sự tích lũy của gradient qua nhiều lớp.
Quá trình toán học:
$$ ∂L/∂W₁ = (∂L/∂Wₙ) × (∂σₙ/∂zₙ) × (∂zₙ/∂σₙ₋₁) × ... × (∂σ₁/∂z₁) $$
Nếu mỗi thành phần đạo hàm là 0,25:
- 1 lớp: 0,25
- 5 lớp: (0,25)^5 = 9,77 × 10^(-4)
- 10 lớp: (0,25)^10 = 9,54 × 10^(-8)
- 30 lớp: (0,25)^30 = 8,67 × 10^(-19) gần như bằng 0
Sự suy giảm theo hàm mũ: Gradient giảm theo hàm mũ với số lớp, khiến gradient ở các lớp đầu trở nên gần như bằng không.
5.2.3. Khởi tạo trọng số không hợp lý
Nếu trọng số khởi tạo quá nhỏ hoặc quá lớn, sẽ làm cho vấn đề vanishing hoặc exploding gradient trở nên nặng hơn.
Ví dụ tác động:
* Std = 0,05 (quá nhỏ): Gradient cực kỳ nhỏ, vanishing nặng nề
* Std = 1,0 (vừa phải): Gradient tốt hơn
* Std = 10,0 (quá lớn): Có thể gây exploding gradient
Lý do: Trọng số nhỏ → tín hiệu nhỏ → gradient nhỏ hơn nữa → vanishing tệ hơn
5.2.4. Kiến trúc mạng truyền thống không hỗ trợ dòng chảy gradient
Mạng truyền thống có chỉ một đường dẫn duy nhất để gradient truyền. Nếu bất kỳ lớp nào làm gradient nhỏ đi, toàn bộ dòng chảy bị ảnh hưởng. Không có "đường thoát" khác cho gradient.
5.3. Lịch Sử Và Tác Động: Hành Trình Khắc Phục Vanishing Gradient
Vanishing gradient không chỉ là một vấn đề kỹ thuật - nó đã định hình toàn bộ lịch sử Deep Learning hiện đại. Dưới đây là những bước ngoặt lịch sử:
5.3.1. Thời kỳ tối tăm Của Neural Networks (1990-2000s)
Trong thời kỳ này, mặc dù neural networks được phát minh từ những năm 1950-1960, nhưng chúng gần như bị quên lãng vì vấn đề vanishing gradient bởi vì các nguyên nhân sau:
- Không thể huấn luyện mạng sâu hiệu quả (quá 3-4 lớp)
- Các mạng sâu hội tụ chậm, không tốt hơn các phương pháp khác
- Support Vector Machines (SVM) trở thành lựa chọn ưa thích vì có bài toán tối ưu lồi
Hệ quả:
- Nghiên cứu neural networks bị "chính thức từ bỏ" bởi cộng đồng khoa học
- Không có ứng dụng thực tế đáng kể trong công nghiệp
- Các nhà khoa học chuyển sang các phương pháp khác
5.3.2. Geoffrey Hinton - sự phục hồi với Deep Belief Networks (2006)
Năm 2006, Geoffrey Hinton đã đề xuất Deep Belief Networks (DBNs) - một giải pháp tiên phong để khắc phục vanishing gradient thông qua pretraining (huấn luyện trước).
Ý tưởng chính - Train Layers Separately:
- Thay vì huấn luyện toàn bộ mạng một lần, huấn luyện từng lớp một bằng Restricted Boltzmann Machines (RBM)
- Mỗi lớp được huấn luyện độc lập, gradient được "giải phóng" tại mỗi lớp
- Sau đó, các lớp được kết hợp lại và fine-tune toàn bộ mạng
Tác động:
- Lần đầu tiên chứng minh rằng có thể huấn luyện các mạng sâu một cách hiệu quả
- Khơi mở lại hứng thú nghiên cứu về deep learning
- Đạo tạo nên một thế hệ các nhà khoa học Deep Learning
Hạn chế:
- Quá trình pretraining phức tạp và tốn thời gian tính toán
- Không phải là giải pháp "hoàn hảo" cho vanishing gradient, còn nhu cầu cải tiến
5.3.3. AlexNet - cuộc cách mạng với ReLU (Better Activation) (2012)
Năm 2012, Alex Krizhevsky, Ilya Sutskever, và Geoffrey Hinton đã đệ trình AlexNet thi ImageNet Large Scale Visual Recognition Challenge (ILSVRC).
Điểm chính - Better Activation Functions:
- Sử dụng ReLU thay vì Sigmoid/Tanh - giải pháp đơn giản nhưng cực kỳ hiệu quả
- ReLU có đạo hàm bằng 1 khi x > 0, không bị suy giảm như sigmoid (0,25)
- Không cần pretraining phức tạp - chỉ cần huấn luyện end-to-end với backpropagation thông thường
Phát hiện quan trọng:
- ReLU cho phép huấn luyện 6 lần nhanh hơn sigmoid trên cùng dữ liệu
- Lần đầu tiên chứng minh ReLU vượt trội so với activation functions cũ
Kết quả:
- Giành chiến thắng ImageNet 2012 với độ chính xác top-5 error rate: 15,3% (so với 26,2% của phương pháp tốt nhất trước đó)
- Chứng minh rằng deep learning hoạt động hiệu quả trên dữ liệu thực tế và quy mô lớn
Tác động Lịch Sử:
- Khởi đầu "Deep Learning Renaissance" - một cuộc cách mạng trong AI
- Thay đổi cách cộng đồng nhìn nhận neural networks
- Dẫn đến bùng nổ đầu tư vào Deep Learning từ các công ty lớn (Google, Facebook, Microsoft)
- Mở ra kỷ nguyên của các ứng dụng AI thực tế hiện nay
5.3.4. Batch Normalization & Normalize inside Network (2015)
Cùng năm với sự ra đời của các kiến trúc mới, Batch Normalization được phát triển để chuẩn hóa bên trong mạng, giúp ổn định gradient flow.
Cơ Chế:
- Chuẩn hóa activation của mỗi lớp: $(x - mean) / \sqrt{variance}$
- Giữ input của các lớp sau trong vùng mà đạo hàm là tốt
- Tránh được hiện tượng internal covariate shift
Tác Động:
- Cho phép learning rate cao hơn
- Giảm độ nhạy với weight initialization
- Kết hợp tốt với ReLU, amplify tác dụng khắc phục vanishing gradient
5.3.5. ResNet - giải pháp tối ưu: Skip Connections (2015)
Năm 2015, Kaiming He, Xiangyu Zhang, Shaoqing Ren, và Jian Sun từ Microsoft Research đã đề xuất Residual Networks (ResNet) với khái niệm skip connections (hay residual connections).
Ý tưởng cách mạng - Shortcut Back / Skip Connections. Skip connections tạo những đường tắt cho gradient truyền ngược. Gradient không bị buộc phải đi qua toàn bộ các lớp sequentially. Có thể bỏ qua các lớp trung gian, tránh tích lũy vanishing.
Thay vì học trực tiếp từ input → output, mạng học residual (phần dư):
- Cách truyền thống: $y = F(x)$
- ResNet: $y = F(x) + x $ (skip connection)
Gradient có hai đường đi:
- Qua các lớp: $∂F/∂x$ (có thể nhỏ)
- Trực tiếp qua skip: $ ∂x/∂x = 1$ (luôn = 1)
Kết quả: $∂y/∂x = ∂F/∂x + 1$ (không bao giờ ≈ 0)
Thành tích:
- Huấn luyện thành công ResNet-152 (152 lớp) - một mạng sâu chưa từng thấy trước đó
- So sánh: Trước ResNet, máy tính không thể huấn luyện hiệu quả các mạng với hơn 20-30 lớp
- Giành chiến thắng ImageNet 2015 với top-5 error rate: 3,6% (cải thiện từ 4,8% của phương pháp trước)
Tác Động:
- Chứng minh rằng "sâu hơn là tốt hơn" - nếu được thiết kế đúng
- Các mạng sau này (VGGNet, DenseNet, EfficientNet) đều áp dụng skip connections
- Nền tảng cho hàng loạt ứng dụng hiện đại: nhận diện hình ảnh, xử lý ngôn ngữ tự nhiên, ...
5.3.6. Sự trưởng thành của deep learning (2016 +)
Sau các bước ngoặt lịch sử trên, cộng đồng Deep Learning tiếp tục phát triển:
Các Giải Pháp Bổ Sung:
- Better Optimizer (Adam, AdamW): Giúp điều chỉnh gradient tự động cho mỗi parameter
- Weight Initialization (He, Xavier): Khởi tạo hợp lý từ đầu
- Gradient Normalization (Gradient Clipping): Giới hạn magnitude gradient, đặc biệt cho RNN/Transformer
- Dense Connections & Multi-scale Shortcuts: Tạo nhiều đường dẫn cho gradient (DenseNet, ResNeXt)
Kết Quả:
- Transformers (2017) chinh phục NLP, sử dụng Layer Normalization + Multi-head Attention
- Vision Transformers (2021) áp dụng transformer cho Computer Vision
- Large Language Models (GPT, BERT, v.v.) với hàng tỷ parameters - điều không thể 10 năm trước
5.4. Kết luận
Bảng Tóm Tắt: Tiến Trình Lịch Sử
| Giai Đoạn | Năm | Sự Kiện | Giải Pháp | Kết Quả |
|---|---|---|---|---|
| Thời Tối | 1990-2000 | Vanishing gradient chiếm ưu thế | Không có | Neural networks bị quên lãng |
| Phục Hồi | 2006 | DBN (Hinton) | Train Layers Separately | Chứng minh deep learning khả thi |
| Cách Mạng | 2012 | AlexNet + ReLU | Better Activation | Chiến thắng ImageNet, khởi đầu Deep Learning |
| Ổn Định | 2015 | Batch Norm + ResNet | Normalize + Skip Connections | Huấn luyện 150+ layers, 3,6% error |
| Trưởng Thành | 2016+ | Transformer, Vision Transformer | Multi-scale shortcuts, Grad. Clipping | LLMs với tỷ tỷ parameters |
Hành trình này cho thấy:
-
Tầm Quan Trọng Của Một Vấn Đề: Vanishing gradient không chỉ là một "chi tiết kỹ thuật" - nó hoàn toàn ngăn cản sự phát triển của neural networks trong 30 năm.
-
Giải Pháp Đơn Giản Có Thể Có Tác Động Lớn: ReLU chỉ là một hàm toán học đơn giản (max(0, x)), nhưng nó thay đổi cả ngành công nghiệp.
-
Sự Tiến Hóa Của Các Giải Pháp:
- 2006: Train Layers Separately (phức tạp nhưng hiệu quả)
- 2012: Better Activation (đơn giản, hiệu quả)
- 2015: Normalize + Skip Connections (kết hợp toàn diện)
- 2016+: Multi-faceted approach (nhiều giải pháp cùng lúc) -
Kết Hợp Nhiều Kỹ Thuật: Thành công không đến từ một giải pháp duy nhất mà từ sự kết hợp:
- ReLU (hàm kích hoạt tốt)
- Batch Normalization (ổn định huấn luyện)
- Skip Connections (dòng chảy gradient)
- Các optimizer hiện đại (Adam, AdamW)
- Weight initialization hợp lý (He, Xavier) -
Từ Lý Thuyết Đến Thực Hành:
- Geoffrey Hinton (2006) cung cấp nền tảng lý thuyết
- AlexNet (2012) chứng minh khả thi trên quy mô lớn
- ResNet (2015) hoàn thiện công nghệ
- Transformer & LLMs (2017+) tận dụng toàn bộ các kiến thức
Vanishing gradient đã "giết chết" neural networks vào những năm 1990-2000, nhưng thông qua các bước đột phá của Hinton (Train Layers Separately), AlexNet (Better Activation - ReLU), Batch Normalization (Normalize Inside Network), và ResNet (Skip Connections / Shortcut Back), nó được hoàn toàn khắc phục.
Ngày nay, khi kết hợp tất cả 8 giải pháp (Weight Initialization + Better Activation + Better Optimizer + Normalize Inside Network + Skip Connections + Gradient Normalization + các phương pháp hỗ trợ), chúng ta có thể xây dựng và huấn luyện các mạng neural network rất sâu và mạnh mẽ - một điều mà các nhà khoa học 20 năm trước chỉ có thể mơ ước.
6. Sự Chuyển dịch Kiến trúc từ Thị giác Máy tính sang Xử lý Ngôn ngữ Tự nhiên – Phân tích Toàn diện về TextCNN và Vai trò Nền tảng của Convolutional Neural Networks
6.1. Giới thiệu: Sự Tiến hóa của Các Mô hình Nhận thức và Nhu cầu Mở rộng
Trong lịch sử phát triển của Trí tuệ Nhân tạo đặc biệt là lĩnh vực Deep Learning, ít có kiến trúc nào đạt được sự phổ biến và tầm ảnh hưởng sâu rộng như Convolutional Neural Networks (CNN - Mạng nơ-ron tích chập).
Khởi nguồn từ những nghiên cứu về vỏ não thị giác của động vật và được LeCun cùng các cộng sự hoàn thiện vào cuối thập niên 90 để nhận diện chữ viết tay, CNN đã trở thành tiêu chuẩn vàng cho các bài toán Thị giác Máy tính.
Khả năng vượt trội của CNN trong việc xử lý dữ liệu dạng lưới như hình ảnh 2D đã tạo nên cuộc cách mạng trong nhận diện vật thể, phân đoạn ảnh và chẩn đoán y tế.
Tuy nhiên, khoa học máy tính không bao giờ chấp nhận sự giới hạn trong biên giới của một miền dữ liệu.
Một trong những bước chuyển mình thú vị và giàu tri thức nhất của thập kỷ qua là việc áp dụng thành công kiến trúc CNN – vốn được sinh ra cho không gian hình học – vào miền dữ liệu Xử lý Ngôn ngữ Tự nhiên.
Đây là một lĩnh vực mà dữ liệu mang tính tuần tự, biểu tượng và rời rạc, khác biệt hoàn toàn với tính chất liên tục và không gian của hình ảnh.
Báo cáo này, đóng vai trò như một phân tích mở rộng và kết luận chuyên sâu cho chuyên đề về CNN, sẽ đi sâu vào cơ chế của mô hình TextCNN.
Chúng ta sẽ giải mã lý do tại sao phép tích chập lại hoạt động hiệu quả trên văn bản, phân tích các thành phần cốt lõi như convolution 1D, bộ lọc n-gram, và max-pooling.
Đồng thời, báo cáo sẽ đặt TextCNN lên bàn cân so sánh với các kiến trúc hiện đại khác như RNN hay Transformers để làm nổi bật ưu điểm thực tiễn về hiệu suất và tốc độ.
Cuối cùng, chúng ta sẽ tổng hợp lại vai trò nền tảng của CNN như một "bộ trích xuất đặc trưng vạn năng" (universal feature extractor), đánh dấu sự trưởng thành của Deep Learning từ việc giải quyết các hạn chế của MLP đến việc thống nhất các phương pháp xử lý đa phương tiện.1
6.2. Cơ sở Lý thuyết: Tại sao Convolution phù hợp với Dữ liệu Văn bản?
Để hiểu được sự chuyển dịch từ CV sang NLP, chúng ta cần phá vỡ định kiến rằng "tích chập chỉ dành cho hình ảnh".
Về bản chất toán học, phép tích chập là một công cụ dùng để phát hiện sự hiện diện của các mẫu cục bộ bất kể vị trí của chúng trong dữ liệu đầu vào.
Sự thành công của CNN trên văn bản không đến từ việc ép buộc văn bản phải giống ảnh, mà đến từ việc tìm ra cách biểu diễn văn bản sao cho các đặc tính cục bộ của nó được bộc lộ dưới dạng cấu trúc không gian.4
6.2.1. Từ "Túi từ" (Bag-of-Words) đến Không gian Vector (Word Embeddings)
Trước khi Deep Learning thống trị, các phương pháp truyền thống như Naive Bayes hay SVM thường xử lý văn bản dưới dạng "Bag-of-Words" (BoW).
Trong BoW, một câu văn chỉ là tập hợp các từ đếm được, mất hoàn toàn thông tin về thứ tự và cấu trúc.
"Dog bites man" và "Man bites dog" sẽ có biểu diễn giống hệt nhau nếu không sử dụng n-grams phức tạp.
Hơn nữa, BoW tạo ra các vector cực kỳ thưa thớt (sparse) với số chiều bằng kích thước từ điển (có thể lên tới hàng trăm nghìn), gây khó khăn cho việc tính toán.6
Bước ngoặt cho việc áp dụng CNN vào NLP chính là sự ra đời của Word Embeddings (như Word2Vec, GloVe, FastText).
Word Embeddings ánh xạ mỗi từ rời rạc vào một vector liên tục trong không gian $d$ chiều (thường là 100, 300 hoặc 768).
Trong không gian này, các từ có ngữ nghĩa tương đồng sẽ nằm gần nhau về khoảng cách Euclid hoặc Cosine.
Khi đó, một câu văn có độ dài $n$ từ không còn là một chuỗi ký tự vô hồn, mà trở thành một ma trận số thực có kích thước $n \times d$.
- Chiều dọc (Height - $n$): Tương ứng với trục thời gian hoặc thứ tự từ trong câu.
- Chiều ngang (Width - $d$): Tương ứng với các đặc trưng ngữ nghĩa của từ (embedding dimension).
Dưới góc nhìn này, một đoạn văn bản trông rất giống một bức ảnh đơn sắc (grayscale image).
Tuy nhiên, có một sự khác biệt cơ bản về bản chất "cục bộ" mà chúng ta cần phân tích kỹ lưỡng.
6.2.2. Sự Tương đồng và Khác biệt về Cấu trúc Không gian
Trong Thị giác Máy tính, tính cục bộ tồn tại trên cả hai chiều: một pixel có mối quan hệ chặt chẽ với các pixel bên cạnh nó theo cả chiều ngang và chiều dọc.
Một cạnh có thể chạy theo bất kỳ hướng nào.
Do đó, các bộ lọc (kernels) trong CV thường là ma trận vuông (ví dụ: $3 \times 3$ hoặc $5 \times 5$) trượt qua cả hai chiều của ảnh.
Ngược lại, trong NLP, tính cục bộ chỉ tồn tại dọc theo trục thời gian (chiều dọc - thứ tự từ).
Từ thứ $i$ có quan hệ ngữ pháp và ngữ nghĩa chặt chẽ với từ thứ $i-1$ và $i+1$ (ví dụ: cụm danh từ, động từ ghép).
Tuy nhiên, dọc theo chiều vector nhúng (chiều ngang), các giá trị không có mối quan hệ thứ tự không gian.
Chiều thứ $j$ và chiều thứ $j+1$ trong vector Word2Vec là các đặc trưng ẩn (latent features) độc lập, không nhất thiết phải "đứng cạnh nhau" để tạo nên ý nghĩa.
Chính vì lý do này, việc áp dụng CNN vào văn bản đòi hỏi một sự điều chỉnh kiến trúc quan trọng: chuyển từ Tích chập 2D sang Tích chập 1D (hoặc tích chập 2D với chiều rộng kernel cố định bằng chiều rộng vector).
Đây là điểm mấu chốt giải thích tại sao CNN vẫn "hiểu" được văn bản: nó không tìm kiếm các hình khối 2D, mà tìm kiếm các mẫu hình tuần tự (sequential patterns) dọc theo trục thời gian.9
6.2.3. Trực giác về "Cửa sổ Trượt" trên Ngôn ngữ
Hãy hình dung quá trình đọc của con người.
Chúng ta không đọc từng từ riêng lẻ và độc lập.
Mắt chúng ta quét qua một nhóm từ (chunking) để nắm bắt ý nghĩa cục bộ trước khi tổng hợp thành ý nghĩa toàn câu.
Khi nhìn thấy cụm "không hề thích", não bộ lập tức nhận diện đây là một cấu trúc phủ định mạnh.
Khi thấy "trí tuệ nhân tạo", chúng ta hiểu đây là một thuật ngữ chuyên ngành, không phải là sự kết hợp ngẫu nhiên của "trí tuệ" và "nhân tạo".
Phép tích chập trong TextCNN mô phỏng chính xác quá trình này.
Một bộ lọc (kernel) trượt dọc theo câu văn đóng vai trò như một cửa sổ quan sát (sliding window).
Nếu cửa sổ có kích thước $h=3$, nó sẽ quan sát 3 từ cùng một lúc (trigrams).
Thông qua quá trình huấn luyện (training), các trọng số trong bộ lọc này sẽ tự động điều chỉnh để "kích hoạt" (tạo ra giá trị đầu ra lớn) khi nó gặp các mẫu n-gram mang thông tin quan trọng cho tác vụ đang xét.11
Như vậy, CNN chuyển đổi bài toán xử lý ngôn ngữ từ việc phân tích cú pháp phức tạp (syntactic parsing) sang bài toán nhận diện mẫu hình cục bộ (local pattern recognition), tận dụng sức mạnh tính toán song song của đại số tuyến tính.
6.3. Giải phẫu Chi tiết Mô hình TextCNN: Từ Ý tưởng đến Kiến trúc
Mô hình TextCNN, được Yoon Kim giới thiệu trong bài báo seminal "Convolutional Neural Networks for Sentence Classification" (EMNLP 2014), là sự kết tinh của sự đơn giản và hiệu quả.
Mặc dù đã ra đời hơn một thập kỷ, kiến trúc này vẫn là một chuẩn mực (baseline) mạnh mẽ và được sử dụng rộng rãi trong công nghiệp.
Chúng ta hãy đi sâu vào từng thành phần cấu tạo nên mô hình này.1
6.3.1. Lớp Input: Chiến lược Đa kênh (Multichannel Strategy)
Một trong những đóng góp sáng tạo nhất của Yoon Kim là việc đề xuất sử dụng đầu vào đa kênh, lấy cảm hứng từ các kênh màu RGB trong xử lý ảnh.
Trong văn bản, "kênh" được định nghĩa là các phiên bản khác nhau của word embeddings:
- Kênh Tĩnh (Static Channel): Sử dụng các vector được huấn luyện trước (pre-trained) như Word2Vec (trên Google News) hoặc GloVe. Các vector này được giữ cố định (frozen) trong suốt quá trình huấn luyện mô hình TextCNN. Mục tiêu là tận dụng tri thức phổ quát (general knowledge) mà vector đã học được từ hàng tỷ từ vựng bên ngoài, tránh hiện tượng overfitting khi tập dữ liệu huấn luyện hiện tại quá nhỏ.
- Kênh Động (Non-static Channel): Là một bản sao của kênh tĩnh (hoặc khởi tạo ngẫu nhiên) nhưng cho phép tinh chỉnh (fine-tuning) thông qua lan truyền ngược (backpropagation). Kênh này cho phép mô hình học các sắc thái ngữ nghĩa đặc thù của tác vụ (task-specific).
Insight: Sự kết hợp này giải quyết bài toán lưỡng nan giữa "Tổng quát hóa" (Generalization) và "Chuyên biệt hóa" (Specialization).
Ví dụ, trong ngữ cảnh chung, từ "tốt" và "gần gũi" có thể có khoảng cách xa nhau.
Nhưng trong bài toán phân tích cảm xúc, mô hình có thể điều chỉnh kênh động để kéo hai từ này lại gần nhau (vì cùng mang nghĩa tích cực), trong khi kênh tĩnh vẫn giữ nguyên ý nghĩa gốc của chúng.4
6.3.2. Convolution 1D và Các Bộ lọc N-gram Học được
Đây là trái tim của TextCNN.
Giả sử câu văn được biểu diễn bởi ma trận $X \in \mathbb{R}^{n \times d}$.
Một bộ lọc (filter/kernel) $w \in \mathbb{R}^{h \times d}$ sẽ thực hiện phép tích chập dọc theo chiều $n$.
Chú ý rằng chiều rộng của kernel luôn bằng $d$ (chiều rộng của vector từ), nghĩa là bộ lọc luôn xem xét trọn vẹn vector biểu diễn của từ, không bao giờ cắt xẻ vector đó.
Phép toán tạo ra một đặc trưng $c_i$ từ cửa sổ từ $x_{i:i+h-1}$ được mô tả như sau:
$$ c_i = f(w \cdot x_{i:i+h-1} + b) $$
Trong đó $f$ là hàm kích hoạt phi tuyến (thường là ReLU hoặc Tanh) và $b$ là bias.
Kết quả của việc trượt bộ lọc qua toàn bộ câu là một bản đồ đặc trưng (feature map):
$$ c = [c_1, c_2,..., c_{n-h+1}] $$
Điểm đặc sắc: TextCNN không sử dụng chỉ một kích thước bộ lọc.
Nó triển khai song song nhiều bộ lọc với các kích thước cửa sổ khác nhau (ví dụ: $h \in \{3, 4, 5\}$).
- Bộ lọc $h=2, 3$: Đóng vai trò như bộ phát hiện Bigrams/Trigrams (cụm từ ngắn, phủ định cục bộ).
- Bộ lọc $h=4, 5$: Đóng vai trò phát hiện các cụm từ dài hơn, thành ngữ hoặc cấu trúc câu ngắn.
Khác với n-grams truyền thống là cố định và rời rạc, các bộ lọc này là n-grams mềm (soft n-grams) và học được (learned).
Chúng không đếm tần suất xuất hiện chính xác của cụm từ "New York", mà học cách nhận diện đặc trưng phân bố của các vector đại diện cho "New York", giúp mô hình có khả năng khái quát hóa tốt hơn (ví dụ: nhận diện được "Los Angeles" có vai trò tương tự dù chưa gặp trong tập train nếu vector của chúng gần nhau).11
6.3.3. Max-Over-Time Pooling: Cơ chế Chọn lọc Tinh hoa
Sau lớp tích chập, chúng ta thu được hàng trăm bản đồ đặc trưng với độ dài thay đổi tùy thuộc vào độ dài câu đầu vào.
Để đưa vào lớp phân loại (Fully Connected Layer) vốn yêu cầu đầu vào kích thước cố định, TextCNN sử dụng cơ chế Max-Over-Time Pooling.
Công thức toán học rất đơn giản:
$$ \hat{c} = \max\{c\} = \max\{c_1, c_2,..., c_{n-h+1}\} $$
Tuy nhiên, ý nghĩa thực tiễn và trực giác đằng sau nó là vô cùng sâu sắc 12:
- Trích xuất đặc trưng nổi bật (Salient Feature Extraction): Giá trị lớn nhất trong bản đồ đặc trưng tương ứng với mức độ kích hoạt mạnh nhất của bộ lọc. Phép toán này tương đương với câu hỏi: "Trong toàn bộ câu này, đặc trưng mà bộ lọc này tìm kiếm (ví dụ: sự giận dữ, sự phủ định) có xuất hiện hay không và tín hiệu mạnh nhất là bao nhiêu?" Nó bỏ qua các tín hiệu yếu (nhiễu, hư từ).
- Bất biến với vị trí (Location Invariance): Trong phân loại văn bản (như Sentiment Analysis), việc cụm từ "tuyệt vời" xuất hiện ở đầu câu hay cuối câu thường không thay đổi nhãn cảm xúc của toàn câu. Max-pooling giúp mô hình tập trung vào sự tồn tại của thông tin quan trọng thay vì vị trí cụ thể của nó. Điều này giải phóng mô hình khỏi việc phải học các quy tắc vị trí cứng nhắc.
- Nén dữ liệu hiệu quả: Nó nén toàn bộ thông tin của một câu dài (có thể hàng trăm từ) thành một vector đặc trưng duy nhất, giúp giảm thiểu đáng kể số lượng tham số cho các lớp sau, ngăn chặn overfitting.
6.3.4. Regularization và Penultimate Layer
Sau khi gộp (pooling), các đặc trưng từ tất cả các bộ lọc được nối lại (concatenated) thành một vector dài duy nhất.
Trước khi đưa vào lớp Softmax để phân loại, TextCNN áp dụng Dropout – một kỹ thuật tắt ngẫu nhiên các nơ-ron trong quá trình huấn luyện.
Yoon Kim cũng áp dụng một ràng buộc chuẩn L2 (L2-norm constraint) lên các vector trọng số ($||w||_2 = s$ nếu $||w||_2 > s$).
Sự kết hợp giữa Dropout và L2 constraint đóng vai trò quan trọng trong việc ngăn cản các bộ lọc "đồng thích nghi" (co-adaptation), ép buộc mỗi bộ lọc phải học các đặc trưng độc lập và mạnh mẽ, từ đó cải thiện khả năng tổng quát hóa trên dữ liệu kiểm thử.1
6.4. Ưu điểm Thực tiễn: Tại sao TextCNN vẫn sống khỏe trong kỷ nguyên Transformer?
Mặc dù các mô hình dựa trên Transformer (như BERT, GPT) và Cơ chế Chú ý (Attention Mechanism) đang thống trị các bảng xếp hạng (SOTA) trong NLP hiện đại, TextCNN vẫn giữ một vị trí không thể thay thế trong hộp công cụ của các kỹ sư AI và Data Scientist.
Sự tồn tại bền bỉ này đến từ những ưu điểm thực tiễn về hiệu suất/chi phí (performance/cost trade-off).18
6.4.1. Tốc độ và Hiệu suất Tính toán (Computational Efficiency)
So với RNN (LSTM/GRU) và Transformer, TextCNN vượt trội về tốc độ:
- Song song hóa (Parallelization): RNN phải xử lý tuần tự từng từ một ($t$ phụ thuộc vào trạng thái ẩn của $t-1$), khiến việc tận dụng GPU gặp hạn chế lớn. Ngược lại, CNN có thể tính toán tích chập cho toàn bộ câu cùng một lúc nhờ các phép nhân ma trận song song.
- Độ phức tạp thuật toán (Complexity): Cơ chế Self-Attention của Transformer có độ phức tạp là $O(N^2)$ đối với độ dài chuỗi $N$, khiến nó trở nên cực kỳ nặng nề với văn bản dài. TextCNN có độ phức tạp tuyến tính $O(N \times k)$ (với $k$ là kích thước kernel), giúp nó xử lý văn bản dài nhanh hơn rất nhiều.
Dữ liệu thực nghiệm từ các nghiên cứu so sánh cho thấy trên các tác vụ phân loại văn bản ngắn (short text classification), TextCNN có thể đạt tốc độ suy luận (inference speed) nhanh hơn BERT từ hàng chục đến hàng trăm lần trên CPU, trong khi độ chính xác chỉ thấp hơn một khoảng nhỏ không đáng kể.21
6.4.2. "Nhẹ" về Tham số và Tài nguyên (Lightweight & Low Footprint)
Trong bối cảnh AI trên thiết bị biên (Edge AI / On-device AI) đang lên ngôi, việc triển khai một mô hình BERT 110 triệu tham số lên một chiếc điện thoại di động hay thiết bị IoT là một thách thức lớn về pin và bộ nhớ.
TextCNN, với cấu trúc nông (shallow architecture) và số lượng tham số ít (thường chỉ vài trăm nghìn đến vài triệu), là lựa chọn lý tưởng.
Các ứng dụng như phát hiện tin nhắn rác (spam detection) trên điện thoại, phân loại ý định (intent classification) trong chatbot nhúng, hay phân tích cảm xúc thời gian thực trên luồng dữ liệu lớn thường ưu tiên TextCNN.19
6.4.3. Hiệu quả trong Nhiệm vụ "Keyword-Spotting"
Bản chất của tích chập và max-pooling biến TextCNN thành một bộ phát hiện từ khóa cực kỳ hiệu quả.
Trong nhiều bài toán thực tế như phân loại chủ đề hay phân tích cảm xúc, nhãn của văn bản thường được quyết định bởi sự xuất hiện của một vài cụm từ đặc trưng ("n-gram keys").
Ví dụ: Nếu câu chứa cụm "dịch vụ tồi tệ", khả năng cao nó là tiêu cực, bất kể cấu trúc ngữ pháp còn lại ra sao.
TextCNN bắt các tín hiệu này cực nhạy.
Ngược lại, với các bài toán đòi hỏi suy luận logic phức tạp, hiểu quan hệ phụ thuộc xa hay cấu trúc câu đảo ngữ, TextCNN sẽ bộc lộ hạn chế so với LSTM hay BERT.7
Bảng so sánh tổng quan:
| Đặc điểm | TextCNN | RNN (LSTM/GRU) | Transformer (BERT) |
|---|---|---|---|
| Cơ chế cốt lõi | Tích chập (Local N-grams) | Tuần tự (Memory State) | Self-Attention (Global) |
| Khả năng song song | Rất cao | Thấp (Tuần tự) | Cao |
| Độ phức tạp | $O(N)$ | $O(N)$ (sequential) | $O(N^2)$ |
| Tầm vực phụ thuộc | Cục bộ (Local) | Dài (Long-term) | Toàn cục (Global) |
| Tài nguyên | Rất nhẹ | Trung bình | Rất nặng |
| Ứng dụng tối ưu | Phân loại văn bản, Sentiment, Spam | Dịch máy, Chuỗi thời gian | QA, Tóm tắt, Hiểu ngôn ngữ sâu |
6.5. Kết luận: Vai trò Nền tảng của CNN trong Bức tranh Deep Learning
Hành trình mở rộng CNN từ Computer Vision sang Natural Language Processing thông qua TextCNN không chỉ là một câu chuyện về kỹ thuật, mà là minh chứng cho tính thống nhất và khả năng mở rộng của các nguyên lý Deep Learning hiện đại.
6.5.1. Giải quyết Hạn chế của MLP và Feature Engineering
TextCNN đánh dấu sự chấm dứt của kỷ nguyên Feature Engineering thủ công trong phân loại văn bản.
Trước đó, các kỹ sư phải đau đầu thiết kế các bộ trích xuất đặc trưng phức tạp, cân nhắc nên dùng bigram hay trigram, xử lý stemming hay lemmatization ra sao.
TextCNN tự động hóa toàn bộ quy trình này.
Nó thay thế các lớp kết nối đầy đủ (Fully Connected) cồng kềnh của MLP bằng các lớp tích chập chia sẻ trọng số (weight sharing), giảm thiểu số lượng tham số cần học và tránh được lời nguyền số chiều (curse of dimensionality).2
6.5.2. Kiến trúc Chung cho Đa miền Dữ liệu (Unified Architecture)
Sự thành công của TextCNN khẳng định rằng CNN là một Meta-Architecture (Kiến trúc siêu hình) cho việc trích xuất đặc trưng từ bất kỳ dữ liệu nào có cấu trúc topo (topology).
Nếu dữ liệu là lưới 2D (ảnh), ta dùng Conv2D.
Nếu dữ liệu là chuỗi 1D (văn bản, âm thanh, tín hiệu điện tâm đồ), ta dùng Conv1D.
Nếu dữ liệu là khối 3D (video, ảnh y tế CT/MRI), ta dùng Conv3D.
CNN đã chứng minh khả năng "học biểu diễn" (representation learning) vạn năng.
Nó dạy cho cộng đồng AI một bài học quan trọng: Cấu trúc dữ liệu quyết định kiến trúc mô hình.
Khi chúng ta biểu diễn văn bản dưới dạng vector nhúng, chúng ta đã biến ngôn ngữ thành một cấu trúc không gian, cho phép các công cụ toán học mạnh mẽ của xử lý ảnh được tái sử dụng một cách ngoạn mục.
6.5.3. Hướng tới Tương lai: Sự Kết hợp (Hybrid Models)
Mặc dù Transformers đang là xu hướng, tư duy của CNN vẫn không hề lỗi thời.
Các nghiên cứu tiên tiến hiện nay đang hướng tới các mô hình lai (Hybrid Models), kết hợp tốc độ và khả năng trích xuất đặc trưng cục bộ cực tốt của CNN ở các lớp dưới, với khả năng mô hình hóa ngữ cảnh toàn cục của Transformer hoặc RNN ở các lớp trên.
Các biến thể như Dilated CNN (Tích chập giãn nở) hay Hierarchical Attention Networks vẫn đang vay mượn các nguyên lý cốt lõi từ TextCNN để đạt được sự cân bằng tối ưu giữa hiệu suất và tài nguyên.24
Tóm lại, TextCNN là một cột mốc quan trọng, một cầu nối tri thức giúp chúng ta hiểu rằng ranh giới giữa các miền dữ liệu (hình ảnh, âm thanh, văn bản) mỏng manh hơn chúng ta tưởng.
Việc nắm vững TextCNN không chỉ giúp giải quyết các bài toán NLP cụ thể mà còn trang bị cho người làm kỹ thuật một tư duy hệ thống về cách xây dựng mô hình dựa trên đặc tính cấu trúc của dữ liệu – chìa khóa để làm chủ thế giới Deep Learning luôn biến động.
Cảm ơn bài viết của bạn!