Project 6.1: DỰ BÁO GIÁ CỔ PHIẾU FPT (100 NGÀY)
Mô hình đề xuất: Hybrid DLinear-Transformer với Cơ chế Giả lập Monte-Carlo
Phần 1. TỔNG QUAN & ĐẶT VẤN ĐỀ
1.1. Bản chất của bài toán
Dự báo giá cổ phiếu là bài toán mô hình hóa chuỗi thời gian trong môi trường nhiễu cao. Dữ liệu tài chính tại Việt Nam (như mã FPT) mang tính chất phi tuyến (non-linear) và không dừng (non-stationary) – tức là quy luật phân phối của dữ liệu thay đổi liên tục theo thời gian.
Các mô hình truyền thống thường gặp hai thái cực:
* Mô hình Tuyến tính (Linear/DLinear): Nắm bắt tốt xu hướng dài hạn (Trend) nhưng thất bại trong việc mô phỏng các biến động ngắn hạn phức tạp.
* Mô hình Transformer thuần túy: Có khả năng học ngữ cảnh tốt nhưng dễ bị "học vẹt" (overfitting) trên dữ liệu nhiễu và đòi hỏi lượng dữ liệu khổng lồ mà thị trường chứng khoán Việt Nam chưa đáp ứng đủ.
1.2. Giải pháp đề xuất
Thay vì sử dụng các kiến trúc Transformer cồng kềnh (như Autoformer hay Informer) vốn dễ bị nhiễu trên tập dữ liệu nhỏ, dự án này đề xuất kiến trúc Hybrid DLinear-Transformer.
Triết lý của mô hình là "Chia để trị" (Decomposition):
1. Thành phần Xu hướng (Trend): Được xử lý bởi mạng nơ-ron tuyến tính (MLP). Phần này chịu trách nhiệm định hướng giá dài hạn.
2. Thành phần Biến động (Seasonal/Residual): Được xử lý bởi một Transformer Encoder tinh gọn. Phần này chịu trách nhiệm học các mẫu hình nến và biến động cục bộ.
1.3. Thách thức & Chiến lược Dự báo
Việc dự báo xa tới 100 ngày (Long-term Forecasting) là một thách thức lớn. Nếu chỉ dự báo một 1 lần duy nhất trực tiếp (Direct forecast), kết quả thường sẽ hội tụ về trung bình và mất đi tính biến động thực tế.
Giải pháp: Sử dụng Autoregressive Inference kết hợp Monte-Carlo Simulation.
Bản chất là dự đoán đệ quy (Recursive forecast) nhưng thay vì chỉ đưa ra dự báo 1 lần, hệ thống sẽ chạy mô phỏng nhiều kịch bản tương lai bằng cách đưa thêm các tham số nhiễu ngẫu nhiên (Stochastic noise) vào quá trình suy diễn đệ quy. Kết quả trả về sẽ bao gồm Giá kỳ vọng (Mean) và Vùng rủi ro (Confidence Interval), phục vụ tốt hơn cho quản trị rủi ro.
Phần 2. XỬ LÝ DỮ LIỆU (DATA ENGINEERING)
Chất lượng mô hình phụ thuộc hoàn toàn vào cách nhìn nhận dữ liệu. Quy trình xử lý được thiết kế để giữ nguyên các đặc tính vật lý của thị trường.
2.1. Tiền xử lý & Làm sạch
- Log-Transformation: Áp dụng hàm logarit tự nhiên ($ln$) lên toàn bộ dữ liệu giá (Open, High, Low, Close).
- Lý do: Giá cổ phiếu tăng trưởng theo cấp số nhân, trong khi các mô hình học máy ưu thích dữ liệu phân phối chuẩn. Log-transform giúp ổn định phương sai (variance stabilization) và biến bài toán dự báo giá tuyệt đối thành dự báo tốc độ tăng trưởng (log-returns).
- Xử lý Missing Data: Thay thế các giá trị
NaNở biếndaily_return(do phép tính đạo hàm discrete) bằng 0 để bảo toàn mạch thời gian.
2.2. Feature Engineering (Kỹ thuật đặc trưng)
Hệ thống sử dụng tập đặc trưng đầu vào đa biến (Multivariate) để cung cấp ngữ cảnh toàn diện:
- Log-Prices: Cung cấp mức nền giá.
- Volume Log: Đặc trưng thanh khoản (đã log-hóa) để mô hình nhận diện các vùng giá quan trọng có dòng tiền lớn.
- Daily Return: Đạo hàm bậc 1 của giá, giúp mô hình học được động lượng (momentum) ngắn hạn.
- Time Embeddings (Cyclical Features):
- Biến đổi ngày trong tuần thành cặp giá trị
(sin, cos). - Mục đích: Giúp mô hình hiểu được tính chu kỳ của thị trường (ví dụ: hiệu ứng đầu tuần/cuối tuần) một cách liên tục mà không bị đứt gãy như one-hot encoding.
- Biến đổi ngày trong tuần thành cặp giá trị
def load_and_process_data(file_path):
df = pd.read_csv(file_path)
df['time'] = pd.to_datetime(df['time'])
df = df.sort_values('time').reset_index(drop=True)
# Feature Engineering (Log-transform & Cyclical Features)
df['open_log'] = np.log(df['open'] + 1e-8)
df['high_log'] = np.log(df['high'] + 1e-8)
df['low_log'] = np.log(df['low'] + 1e-8)
df['close_log'] = np.log(df['close'] + 1e-8)
df['volume_log'] = np.log1p(df['volume'])
# Daily Return (Xử lý NaN phiên đầu tiên)
df['daily_return'] = df['close'].pct_change().fillna(0)
# Time Embeddings
dates = pd.to_datetime(df['time'])
df['dow_sin'] = np.sin(2 * np.pi * dates.dt.dayofweek / 7)
df['dow_cos'] = np.cos(2 * np.pi * dates.dt.dayofweek / 7)
return df
Phân tích Tương quan (Correlation Check)
Ma trận tương quan cho thấy các biến giá có sự tương quan tuyến tính cực cao ($>0.99$). Tuy nhiên, Daily Return và Volume có tương quan thấp với giá đóng cửa. Điều này tốt cho mô hình, vì chúng cung cấp các thông tin bổ trợ (orthogonal information) mà bản thân chuỗi giá không có.
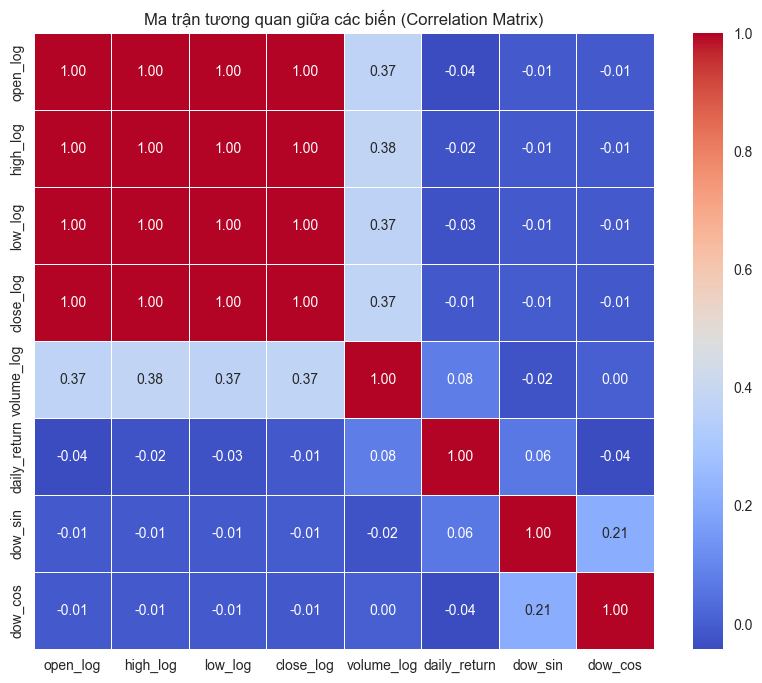
Ma trận tương quan giữa các biến
Phần 3. KIẾN TRÚC MÔ HÌNH: HYBRID DLINEAR-TRANSFORMER
Mô hình không cố gắng dự đoán trực tiếp giá cổ phiếu (vốn rất nhiễu), mà dự đoán các thành phần cấu thành nên nó.
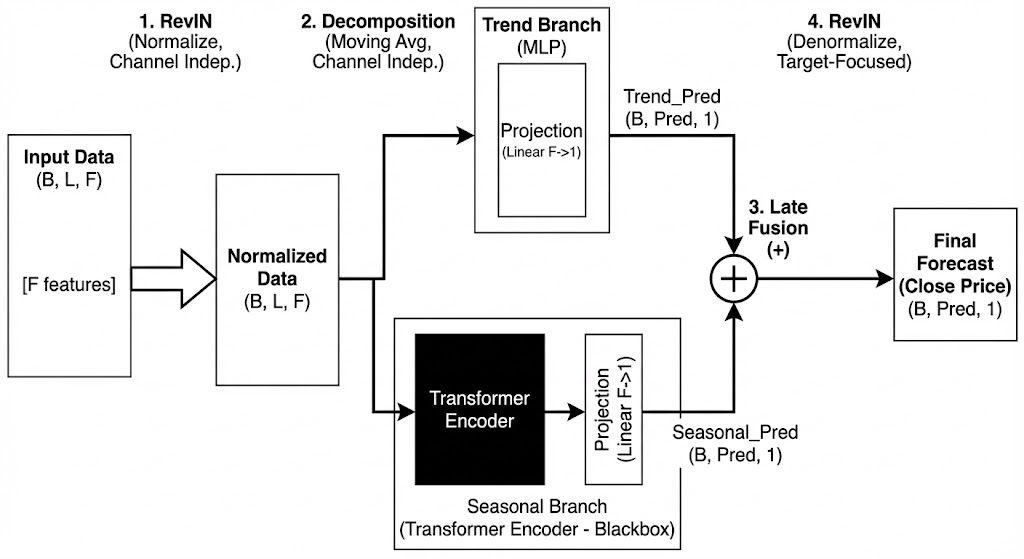
Luồng đi của dữ liệu trong kiến trúc mô hình hybrid
3.1. Cơ chế Phân rã (Decomposition)
Nhóm sử dụng thuật toán Moving Average (Trung bình trượt) để tách chuỗi thời gian đầu vào $X$ thành hai phần:
* $X_{trend}$: Xu hướng mượt, đại diện cho vận động dài hạn.
* $X_{seasonal} = X - X_{trend}$: Phần dư còn lại, chứa các biến động nhiễu và quy luật ngắn hạn.
Code thực thi sử dụng nn.Conv1d với trọng số cố định để thực hiện phép trượt này một cách hiệu quả trên GPU.
class MovingAvg(nn.Module):
"""Thành phần Decomposition (Tách Trend/Seasonal)"""
def __init__(self, kernel_size, stride):
super(MovingAvg, self).__init__()
self.kernel_size = kernel_size
self.avg = nn.AvgPool1d(kernel_size=kernel_size, stride=stride, padding=0)
def forward(self, x):
# Padding để giữ nguyên kích thước chuỗi
front = x[:, 0:1, :].repeat(1, (self.kernel_size - 1) // 2, 1)
end = x[:, -1:, :].repeat(1, (self.kernel_size - 1) // 2, 1)
x = torch.cat([front, x, end], dim=1)
x = x.permute(0, 2, 1)
x = self.avg(x)
x = x.permute(0, 2, 1)
return x
3.2. Nhánh Xu Hướng (Trend Branch: Linear Modelling)
- Input: $X_{trend}$
- Cấu trúc: Một mạng MLP đơn giản (Multi-Layer Perceptron).
- Lý do: Xu hướng dài hạn của cổ phiếu FPT thường tịnh tiến khá ổn định. Các mô hình phức tạp thường làm "quá khớp" (overfit) xu hướng này. Một lớp Linear đơn giản là đủ để ngoại suy (extrapolate) xu hướng này vào tương lai 100 ngày.
class TrendBranch(nn.Module):
"""Mạng MLP đơn giản để mô hình hóa xu hướng dài hạn"""
def __init__(self, seq_len, pred_len, num_features):
super(TrendBranch, self).__init__()
self.time_linear = nn.Linear(seq_len, pred_len)
self.feature_linear = nn.Linear(num_features, 1) # Target Focused
self.act = nn.GELU()
def forward(self, x):
# Time Mixing
x = x.permute(0, 2, 1)
x = self.time_linear(x)
# Feature Mixing (Projection to Target)
x = x.permute(0, 2, 1)
x = self.feature_linear(x)
return self.act(x)
3.3. Nhánh Biến Động (Seasonal Branch: Transformer)
- Input: $X_{seasonal}$
- Cấu trúc: Transformer Encoder (Self-Attention mechanism).
- Lý do: Phần biến động chứa đựng các mẫu hình nến phức tạp (ví dụ: mô hình hai đáy, vai-đầu-vai...). Cơ chế Self-Attention cho phép mô hình nhìn lại toàn bộ cửa sổ quá khứ, tìm kiếm các đoạn biến động tương đồng để đưa ra dự báo.
- Tinh chỉnh: Nhóm sử dụng cấu hình Transformer "nhẹ" (d_model=64/128, n_heads=2/4) để phù hợp với lượng dữ liệu hạn chế, tránh hiện tượng mô hình học thuộc lòng dữ liệu huấn luyện.
class SeasonalBranch(nn.Module):
"""Transformer để học các mẫu hình nến và biến động (Seasonal)"""
def __init__(self, seq_len, pred_len, num_features, d_model=64):
super(SeasonalBranch, self).__init__()
self.pred_len = pred_len
# Embedding
self.input_embedding = nn.Linear(num_features, d_model)
self.position_encoding = nn.Parameter(torch.randn(1, seq_len + pred_len, d_model))
# Transformer Encoder
encoder_layer = nn.TransformerEncoderLayer(d_model=d_model, nhead=2, dim_feedforward=256, dropout=0.1, batch_first=True)
self.encoder = nn.TransformerEncoder(encoder_layer, num_layers=1)
# Transformer Decoder (Simplified)
decoder_layer = nn.TransformerDecoderLayer(d_model=d_model, nhead=2, dim_feedforward=256, dropout=0.1, batch_first=True)
self.decoder = nn.TransformerDecoder(decoder_layer, num_layers=1)
self.query_token = nn.Parameter(torch.randn(pred_len, d_model))
self.projection = nn.Linear(d_model, 1) # Target Focused
def forward(self, x):
B, L, C = x.shape
# Encoding
enc_in = self.input_embedding(x) + self.position_encoding[:, :L, :]
memory = self.encoder(enc_in)
# Decoding
query = self.query_token.unsqueeze(0).repeat(B, 1, 1) + self.position_encoding[:, L:L+self.pred_len, :]
out = self.decoder(query, memory)
return self.projection(out)
3.4. Cơ chế Target-Focused & Fusion
Thay vì dự đoán lại toàn bộ các đặc trưng đầu vào (Open, High, Low, Volume...), mô hình sử dụng một lớp Projection Layer cuối cùng để tổng hợp thông tin từ tất cả các chiều đặc trưng về một đầu ra duy nhất: Close Price.
Điều này buộc mô hình phải học cách chắt lọc thông tin từ Volume và High/Low để phục vụ mục đích duy nhất là tối ưu hóa dự báo giá đóng cửa.
$$Y_{pred} = \text{TrendModel}(X_{trend}) + \text{SeasonalModel}(X_{seasonal})$$
class HybridDLinearTransformer(nn.Module):
"""Mô hình tổng hợp: Kết hợp RevIN, Decomposition, Trend & Seasonal"""
def __init__(self, seq_len, pred_len, num_features, moving_avg=25):
super(HybridDLinearTransformer, self).__init__()
self.revin = RevIN(num_features)
self.decompsition = MovingAvg(kernel_size=moving_avg, stride=1)
self.trend_model = TrendBranch(seq_len, pred_len, num_features)
self.seasonal_model = SeasonalBranch(seq_len, pred_len, num_features)
def forward(self, x, target_idx):
# 1. Normalize
x = self.revin(x, 'norm')
# 2. Decompose
trend = self.decompsition(x)
seasonal = x - trend
# 3. Modeling
trend_out = self.trend_model(trend)
seasonal_out = self.seasonal_model(seasonal)
# 4. Fusion
prediction = trend_out + seasonal_out
# 5. Denormalize (Manual for specific target)
# Lấy thống kê của cột mục tiêu (Close price)
target_mean = self.revin.mean[:, :, target_idx:target_idx+1]
target_std = self.revin.stdev[:, :, target_idx:target_idx+1]
# Công thức Denorm: y = (y_norm - bias) / weight * std + mean
if self.revin.affine:
prediction = prediction - self.revin.affine_bias[target_idx]
prediction = prediction / (self.revin.affine_weight[target_idx] + 1e-5)
prediction = prediction * target_std + target_mean
return prediction
3.5. Kỹ thuật Ổn định Phân phối: RevIN
Dữ liệu tài chính có tính chất Non-stationarity (phân phối thay đổi theo thời gian). Giá FPT năm 2020 khác xa năm 2024 về độ lớn.
Kỹ thuật RevIN (Reversible Instance Normalization) được áp dụng:
1. Normalize: Trừ trung bình, chia phương sai của từng cửa sổ đầu vào trước khi đưa vào mô hình.
2. Denormalize: Sau khi mô hình dự báo xong, nhân lại với phương sai và cộng trung bình cũ để trả về giá trị thực.
-> Giúp mô hình học được "hình dáng" của biểu đồ mà không bị nhiễu bởi độ lớn tuyệt đối của giá.
class RevIN(nn.Module):
"""Kỹ thuật Reversible Instance Normalization để xử lý Non-stationarity"""
def __init__(self, num_features, eps=1e-5, affine=True):
super(RevIN, self).__init__()
self.num_features = num_features
self.eps = eps
self.affine = affine
if self.affine:
self.affine_weight = nn.Parameter(torch.ones(num_features))
self.affine_bias = nn.Parameter(torch.zeros(num_features))
def _get_statistics(self, x):
self.mean = torch.mean(x, dim=1, keepdim=True).detach()
self.stdev = torch.sqrt(torch.var(x, dim=1, keepdim=True, unbiased=False) + self.eps).detach()
def forward(self, x, mode:str):
if mode == 'norm':
self._get_statistics(x)
x = (x - self.mean) / self.stdev
if self.affine:
x = x * self.affine_weight + self.affine_bias
elif mode == 'denorm':
if self.affine:
x = (x - self.affine_bias) / (self.affine_weight + self.eps)
x = x * self.stdev + self.mean
return x
Phần 4. CHIẾN LƯỢC HUẤN LUYỆN & SUY DIỄN (TRAINING & INFERENCE)
4.1. Hàm mất mát (Loss Function)
Sử dụng Huber Loss thay vì MSE.
* Lý do: Dữ liệu chứng khoán thường có những phiên biến động sốc (outliers). MSE (bình phương sai số) sẽ phạt quá nặng các điểm này, làm lệch mô hình. Huber Loss hoạt động như MSE ở vùng sai số nhỏ và như MAE ở vùng sai số lớn, giúp mô hình bền vững hơn trước các cú sốc giá.
4.2. Rolling Window Cross-Validation
Không sử dụng train_test_split ngẫu nhiên (tránh data leakage). Nhóm sử dụng cơ chế cửa sổ trượt theo thời gian:
* Fold 1: Train [T1..T8] -> Val [T9]
* Fold 2: Train [T1..T9] -> Val [T10]
...
Điều này mô phỏng chính xác kịch bản thực tế khi nhà đầu tư liên tục cập nhật dữ liệu mới.
4.3. Suy diễn Monte-Carlo (Monte-Carlo Inference)
Đây là điểm khác biệt chính so với các phương pháp thông thường.
Để dự báo 100 ngày, nhóm không tin tưởng vào một đường dự báo duy nhất.
Quy trình thực hiện:
1. Dự báo ngày $t+1$.
2. Thêm một lượng nhiễu ngẫu nhiên $\epsilon \sim \mathcal{N}(0, \sigma^2)$ vào kết quả dự báo (với $\sigma$ là độ biến động lịch sử).
3. Sử dụng kết quả (đã thêm nhiễu) làm đầu vào để dự báo ngày $t+2$.
4. Lặp lại quy trình này $N=50$ lần (50 simulations).
Kết quả:
* Mean Forecast: Trung bình cộng của 50 kịch bản -> Dùng làm đường giá dự báo chính.
* Confidence Interval (10%-90%): Vùng biên trên và biên dưới của 50 kịch bản -> Dùng để đánh giá rủi ro (Upside/Downside risk).
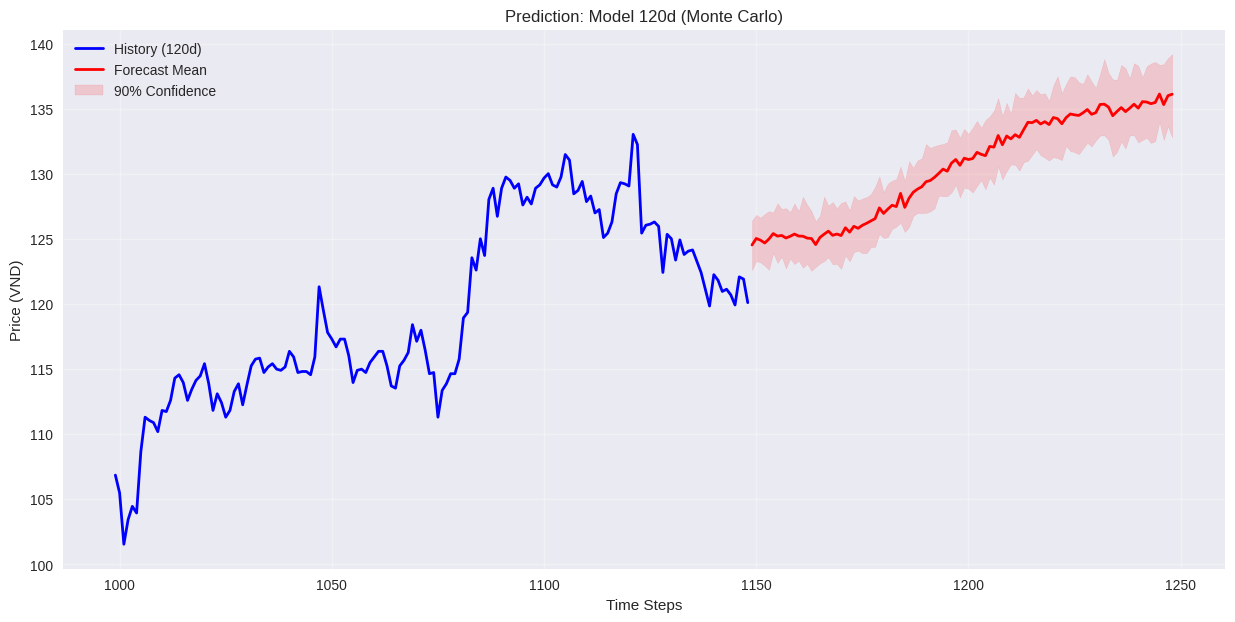
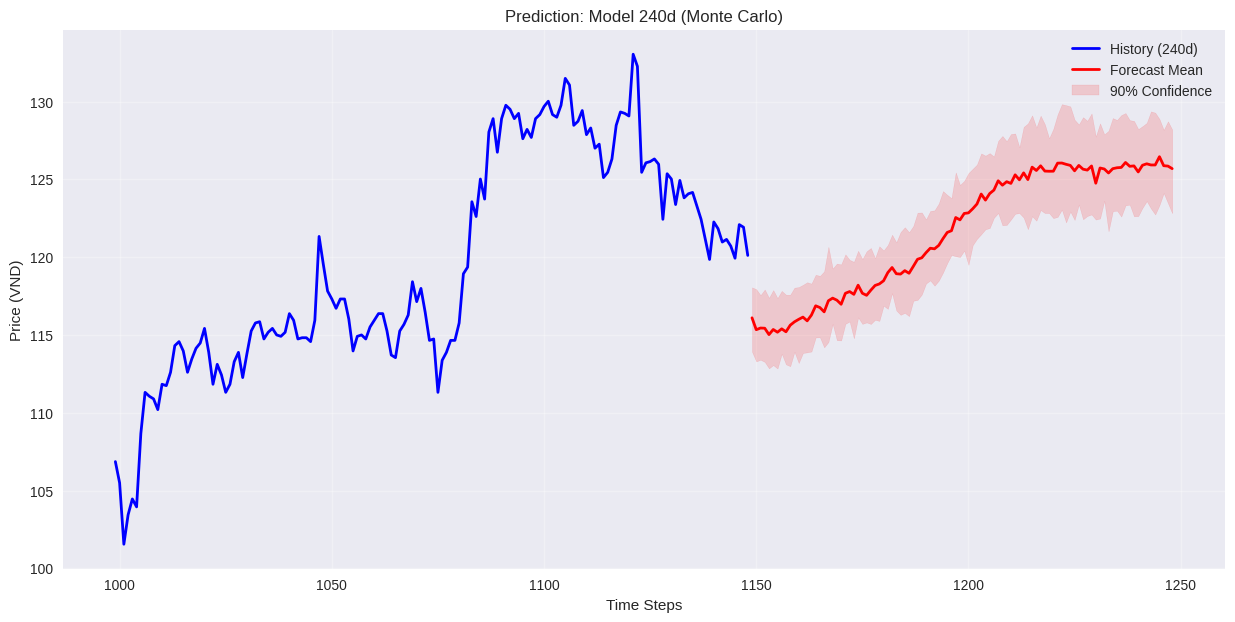
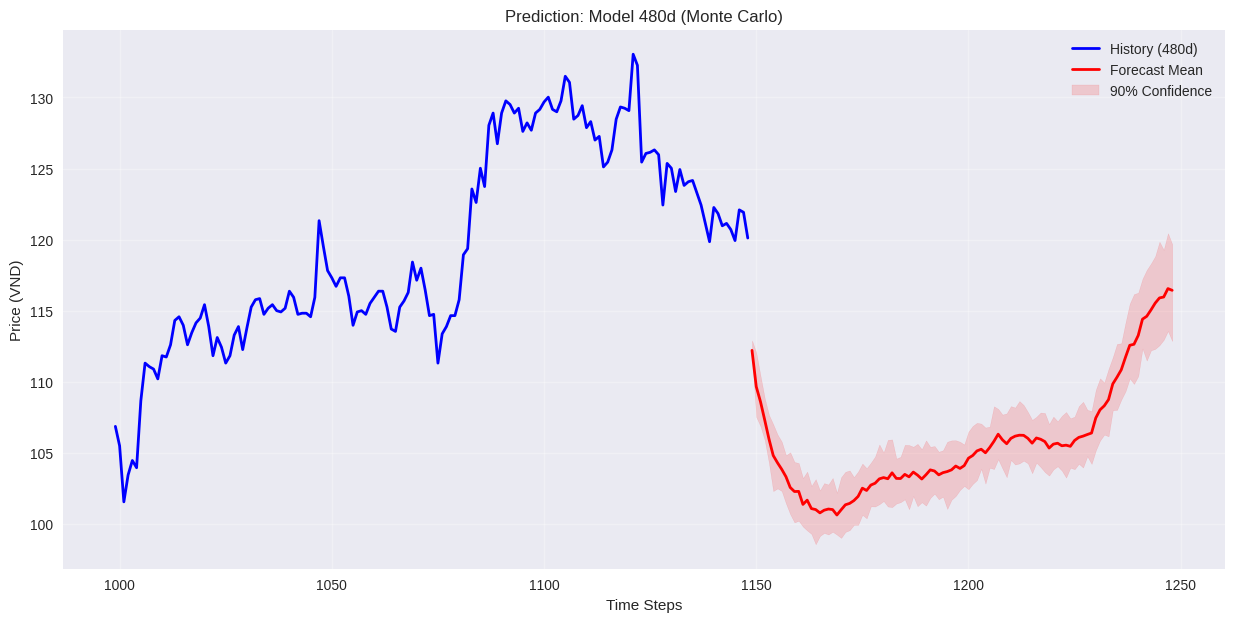
Mô hình dự đoán theo input 120,240,480 ngày. Trong đó model huấn luyện trên 480 ngày cho kết quả tốt nhất, dựa vào public test trên Kaggle.
Phần 5. KẾT LUẬN
Mô hình Hybrid DLinear-Transformer kết hợp được khả năng nắm bắt xu hướng mạnh mẽ của các thuật toán tuyến tính và khả năng học mẫu hình chi tiết của Transformer. Việc tích hợp cơ chế suy diễn Monte-Carlo biến mô hình từ một công cụ dự báo điểm (point estimation) thành một công cụ đánh giá rủi ro xác suất, phù hợp hơn với bản chất bất định của thị trường tài chính.
Chưa có bình luận nào. Hãy là người đầu tiên!