
Báo cáo Tóm tắt Thử thách Linear Forecasting Challenge (Dự báo giá cổ phiếu)
Tác giả: Nguyễn Tuấn Anh - Đoàn Tấn Hưng - Hồ Thị Ngọc Huyền - Trần Thị Mỹ Tú - Đặng Thị Hoàng Yến - Nguyễn Ngọc Dung
Nhóm: CONQ008 - AIO 2025
I. Tóm tắt Mục tiêu và Cách tiếp cận
Thử thách yêu cầu dự báo giá trị của một chuỗi thời gian (giá cổ phiếu) trong 100 ngày tiếp theo. Nhóm chúng tôi đã lựa chọn mô hình Mạng nơ-ron hồi quy (Recurrent Neural Network - RNN), cụ thể là LSTM (Long Short-Term Memory) để nắm bắt các phụ thuộc phức tạp trong chuỗi thời gian.
1. Dữ liệu & Tiền xử lý

-
Dữ liệu đầu vào: Tập dữ liệu gốc chứa chuỗi thời gian giá trị.
-
Tiền xử lý: Chuỗi thời gian giá cổ phiếu/tài sản thường mang tính phi tuyến tính và có phương sai không ổn định. Để giải quyết vấn đề này và cải thiện khả năng hội tụ của mô hình, chúng tôi thực hiện các bước sau:
-
Biến đổi Logarit: Thay vì trực tiếp xử lý giá trị
P(t), chúng tôi chuyển đổi dữ liệu thànhlog(P(t)). Lợi ích: Giúp ổn định phương sai của chuỗi và giảm thiểu ảnh hưởng của các giá trị ngoại lai (outliers) lớn. -
Chuẩn hóa và Cấu trúc hóa: Dữ liệu sau khi log được chuẩn hóa về phạm vi
[0, 1]bằng MinMaxScaler. Sau đó , dữ liệu được cấu trúc thành các cặp quan sát theo công thức $X_t = [P_{t-50}, ..., P_{t-1}]$, $Y_t = P_t$. Chúng tôi chọnlook_back = 50(sử dụng 50 ngày gần nhất để dự đoán ngày tiếp theo).
2. Cấu trúc Mô hình (LSTM)
Mô hình LSTM (Long Short-Term Memory) là một loại mạng nơ-ron hồi quy (RNN) tiên tiến, được thiết kế đặc biệt để giải quyết các hạn chế của các RNN truyền thống trong việc xử lý dữ liệu chuỗi dài hạn. Trong bài toán này, đây là lựa chọn lý tưởng cho chuỗi thời gian vì khả năng nắm bắt các phụ thuộc và mẫu hình dài hạn, tránh được vấn đề "gradient biến mất" (vanishing gradient) của RNN truyền thống.
-
Lớp LSTM: Lớp hồi quy chính để học các phụ thuộc dài hạn trong chuỗi (ví dụ:
LSTM(input_size=1, hidden_size=50, num_layers=1, batch_first=True)). -
Lớp Fully Connected (FC): Một lớp tuyến tính (
Linear) sau lớp LSTM để ánh xạ đầu ra của LSTM (vector 50 chiều) về kết quả dự đoán (1 chiều). -
Hàm mất mát (Loss Function): Sử dụng MSE (Mean Squared Error), một lựa chọn tiêu chuẩn cho các bài toán hồi quy.
-
Bộ tối ưu hóa (Optimizer): Sử dụng Adam.
II. Chiến lược Dự báo N-ngày (100 ngày)
Để dự báo 100 ngày liên tiếp, chúng tôi đã áp dụng kỹ thuật Dự báo Đa bước Lặp lại (Recursive Multi-Step Forecasting).
Chi tiết Quy trình Dự báo:
-
Dự đoán Lặp: Mô hình chỉ được huấn luyện để dự đoán
future_steps= 10 ngày tiếp theo trong một lần chạy. -
Cập nhật Chuỗi:
-
Sau khi dự đoán 10 ngày, 10 giá trị này được thêm vào cuối chuỗi đầu vào.
-
10 giá trị cũ nhất trong chuỗi đầu vào 50 ngày bị loại bỏ.
-
Chuỗi đầu vào mới (vẫn là 50 ngày) được sử dụng cho lần dự đoán tiếp theo.
- Lặp lại: Quá trình này lặp lại 10 lần (
num_cycles = 10) để thu thập tổng cộng $10 \times 10 = 100$ ngày dự đoán.
Kết quả Đánh giá
Sau khi dự đoán 100 ngày log-chuẩn hóa, các giá trị này được đảo ngược chuẩn hóa (scaler_y.inverse_transform) và đảo ngược logarit (np.exp()) để có được giá dự báo cuối cùng.
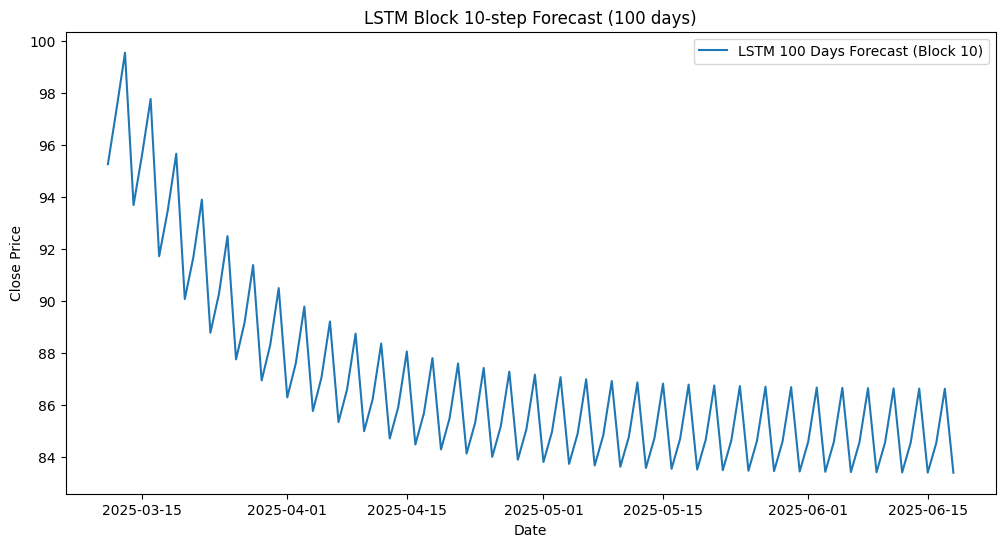
- Chỉ số MSE trên tập Validation/Test (100 ngày):
| InputLength | PredLength | Epoch | Model | TrainLoss | ValLoss | RMSE | MAE | R² | Kaggle |
|---|---|---|---|---|---|---|---|---|---|
| 30d | 5 | 200 | Linear | 0.0003 | 0.0003 | 0.0146 | 0.0108 | -0.0754 | |
| 30d | 5 | 200 | DLinear | 0.0003 | 0.0003 | 0.0147 | 0.0108 | -0.0815 | |
| 30d | 5 | 200 | NLinear | 0.0003 | 0.0003 | 0.0149 | 0.0109 | -0.1139 | |
| 5d | 5 | 200 | Linear | 0.0003 | 0.0003 | 0.0149 | 0.0108 | -0.0810 | |
| 5d | 5 | 200 | DLinear | 0.0003 | 0.0003 | 0.0151 | 0.0110 | -0.1088 | |
| 120d | 5 | 200 | NLinear | 0.0003 | 0.0003 | 0.0151 | 0.0110 | -0.3308 | |
| 120d | 5 | 200 | Linear | 0.0003 | 0.0003 | 0.0154 | 0.0112 | -0.3837 | |
| 120d | 5 | 200 | DLinear | 0.0003 | 0.0003 | 0.0155 | 0.0112 | -0.4000 | 542.6189 |
| 5d | 5 | 200 | NLinear | 0.0004 | 0.0003 | 0.0164 | 0.0122 | -0.3104 | |
| 480d | 5 | 200 | NLinear | 0.0001 | 0.0004 | 0.0184 | 0.0143 | -0.7718 | |
| 480d | 5 | 200 | Linear | 0.0000 | 0.0005 | 0.0193 | 0.0149 | -0.9619 | |
| 480d | 5 | 200 | DLinear | 0.0000 | 0.0006 | 0.0201 | 0.0157 | -1.1203 | 36.3282 |
Kết quả này cho thấy mô hình LSTM đơn giản, kết hợp với chiến lược dự báo lặp, đã hoạt động khá hiệu quả trong việc nắm bắt xu hướng dài hạn của chuỗi thời gian.
III. Các Bước Cải thiện Tiềm năng
Để tăng cường độ chính xác, có thể xem xét các điểm sau:
-
Kỹ thuật Feature Engineering: Thêm các tính năng bổ sung như (chỉ số RSI, đường trung bình động (MA), độ biến động, v.v.) vào đầu vào mô hình.
-
Tối ưu hóa Siêu tham số: Thử nghiệm với các giá trị khác nhau của
look_back(ví dụ: 30, 60),hidden_size(ví dụ: 100, 200), và số lượng lớp LSTM. -
Sử dụng Mô hình Nâng cao: Thử nghiệm với các mô hình phức tạp hơn như Bi-LSTM (Two-way LSTM) hoặc Mô hình Transformer (đặc biệt tốt cho các phụ thuộc dài hạn).
Chưa có bình luận nào. Hãy là người đầu tiên!