
1. Giới Thiệu
Xin chào các bạn! Hôm nay, nhóm mình muốn chia sẻ một dự án thú vị: phân tích sentiment từ các đánh giá trên Amazon. Trong dự án này, chúng mình sử dụng Logistic Regression làm mô hình chính và Apache Airflow để tự động hóa toàn bộ quy trình, từ xử lý dữ liệu đến huấn luyện mô hình và lưu kết quả. Việc áp dụng lý thuyết khô khan vào một dự án thực tế sẽ giúp các bạn thấy rõ cách mọi thứ vận hành, từ lý thuyết đến production, và hiểu sâu hơn cách Logistic Regression thực sự hoạt động.
Dự án gồm hai phần: phần đầu tập trung vào lý thuyết Logistic Regression, các hàm activation như Sigmoid và Softmax. Phần hai sẽ đi sâu vào việc ứng dụng Airflow để quản lý pipeline, giúp mọi bước trong quy trình được định nghĩa rõ ràng, dễ kiểm soát và có thể chạy tự động, giống như một hệ thống ML thực tế.
2. Lý Thuyết Cơ Bản Về Logistic Regression
Logistic Regression là một trong những mô hình phân loại (classification) cổ điển và mạnh mẽ nhất trong ML, đặc biệt phù hợp cho các bài toán binary hoặc multi-class classification như sentiment analysis. Không giống Linear Regression (dự đoán giá trị liên tục), Logistic Regression sử dụng hàm logistic để dự đoán xác suất thuộc về một lớp cụ thể, giúp nó xử lý tốt các vấn đề phân loại. Hãy đi sâu vào toán học đằng sau để hiểu rõ hơn.
2.1. Logistic Regression Là Gì?
Logistic Regression là một mô hình dùng để dự đoán xác suất của một kết quả (ví dụ: có/không, đúng/sai) dựa trên các biến đầu vào (features). Công thức cơ bản của nó là:
$$ p(y=1 \mid x) = \frac{1}{1 + e^{-z}} $$
Trong đó:
- $z$ là một tổ hợp tuyến tính của các feature với các trọng số (weights), có thể viết gọn là:
$$ z = \theta^T x = w_1 x_1 + w_2 x_2 + \dots + w_n x_n + b $$
Ở đây:
- $θ = [b, w_1, w_2, ..., w_n]^T$ là vector trọng số, bao gồm các weights và bias.
- $x = [1, x_1, x_2, ..., x_n]^T$ là vector feature, trong đó giá trị $1$ dùng để nhân với bias $b$.
- $θ^T x$ về cơ bản chính là $w_1 x_1 + w_2 x_2 + ... + w_n x_n + b$.
- $p(y=1 | x)$ là xác suất mà biến đầu ra $y$ bằng 1.
Nói cách khác, Logistic Regression đầu tiên tính một giá trị tuyến tính từ các feature, rồi dùng hàm sigmoid (hoặc softmax cho nhiều lớp) để chuyển giá trị này thành xác suất, đảm bảo luôn nằm trong khoảng 0–1.
Quá trình huấn luyện mô hình thường dựa trên tối ưu hóa hàm loss(cross-entropy loss) bằng Gradient Descent, để tìm ra các trọng số $θ$ tốt nhất.
2.2. Hàm Sigmoid: Nền Tảng Cho Binary Classification Và Hàm Loss
a. Sigmoid Function
Nếu coi Logistic Regression là một cỗ máy, thì Sigmoid chính là động cơ, còn Binary Cross-Entropy là bộ điều hướng giúp cỗ máy đó đi đúng đường. Tại sao chúng ta lại cần cả hai? Hãy cùng "mổ xẻ" sâu hơn một chút nhé.
Trong bài toán hồi quy tuyến tính (Linear Regression), kết quả đầu ra $z = w^T x + b$ có thể là bất kỳ số thực nào, từ âm vô cùng đến dương vô cùng. Nhưng trong bài toán phân loại (ví dụ: email này là Spam hay Không Spam), cái chúng ta cần là một con số thể hiện xác suất (từ 0 đến 1).
Hàm Sigmoid sinh ra để giải quyết việc này. Nó "nén" (squash) mọi giá trị đầu vào (z) vào khuôn khổ:
$$ \sigma(z) = \frac{1}{1 + e^{-z}} $$
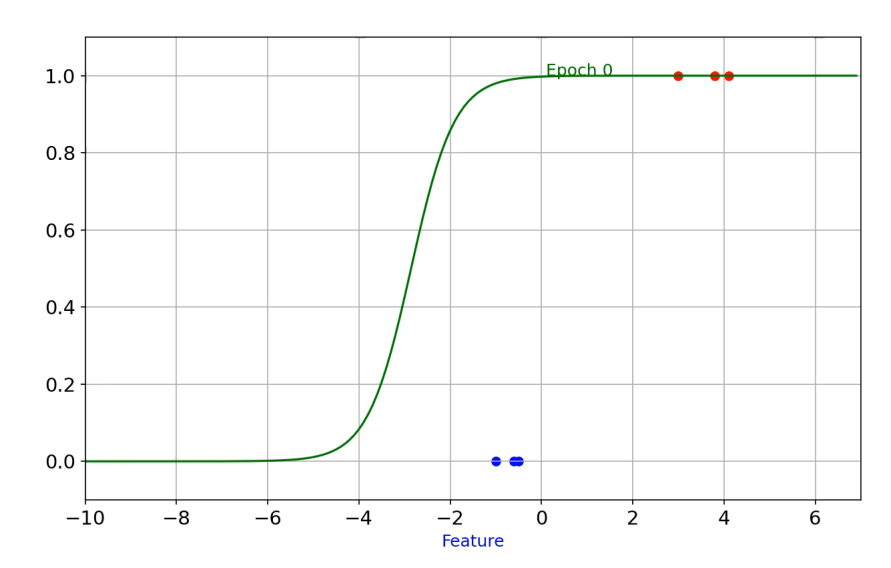
- Khi (z) tăng dần, đường cong tiệm cận về 1.
- Khi (z) giảm sâu, đường cong tiệm cận về 0.
b. Hàm Loss: Tại sao không dùng MSE?
Khi đã có dự đoán, chúng ta cần một thước đo để biết mô hình đang sai bao nhiêu so với thực tế (Ground Truth).
Trong Linear Regression, chúng ta dùng Mean Squared Error (MSE):
$$ (y - \hat{y})^2 $$
Nhiều bạn sẽ thắc mắc: "Tại sao không bê nguyên MSE sang Logistic Regression cho tiện?"
Câu trả lời nằm ở tính chất địa hình của hàm Loss. Nếu ghép Sigmoid vào MSE, hàm Loss sẽ trở nên Non-convex (không lồi).
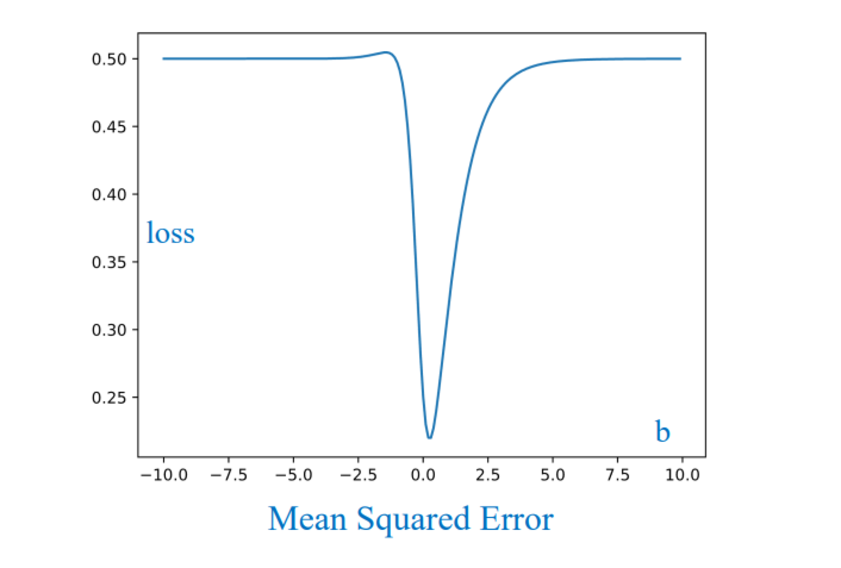
- Đồ thị MSE khi kết hợp Sigmoid không phải là hình cái bát trơn tru mà bị lồi lõm với các "vũng nước" nhỏ.
- Đây gọi là Non-convex.
- Nếu "thả" viên bi (thuật toán Gradient Descent) vào đây, nó rất dễ bị kẹt ở các thung lũng cục bộ (Local Minima) hoặc vùng phẳng (Plateau) mà không bao giờ lăn xuống đáy thấp nhất (Global Minimum).
Vì vậy, chúng ta cần một hàm Loss Convex (lồi hoàn toàn) để đảm bảo dù bắt đầu ở đâu, gradient descent cũng trượt được xuống đáy đó chính là Binary Cross-Entropy (BCE).
c. Binary Cross-Entropy
Công thức:
$$ L(y, \hat{y}) = - \big[ y \log(\hat{y}) + (1 - y) \log(1 - \hat{y}) \big] $$
Tách ra làm 2 trường hợp dựa trên nhãn thực tế (y):
Trường hợp 1: Thực tế là 1 ((y = 1))
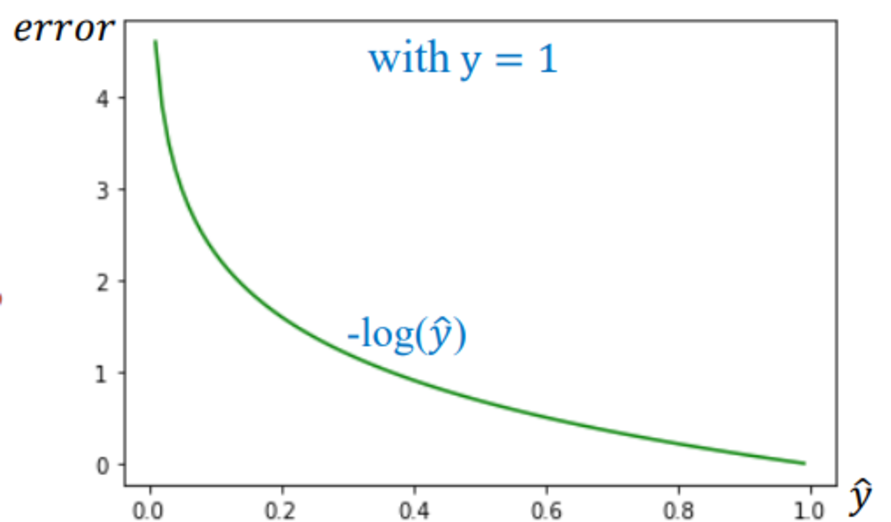
$$ L = -\log(\hat{y}) $$
- Mục tiêu: $\hat{y} \to 1$
- Nếu mô hình dự đoán sai ($\hat{y} \approx 0$), hàm $-\log(\hat{y} \approx 0)$ sẽ tiến tới vô cực → phạt cực nặng.
Trường hợp 2: Thực tế là 0 ((y = 0))
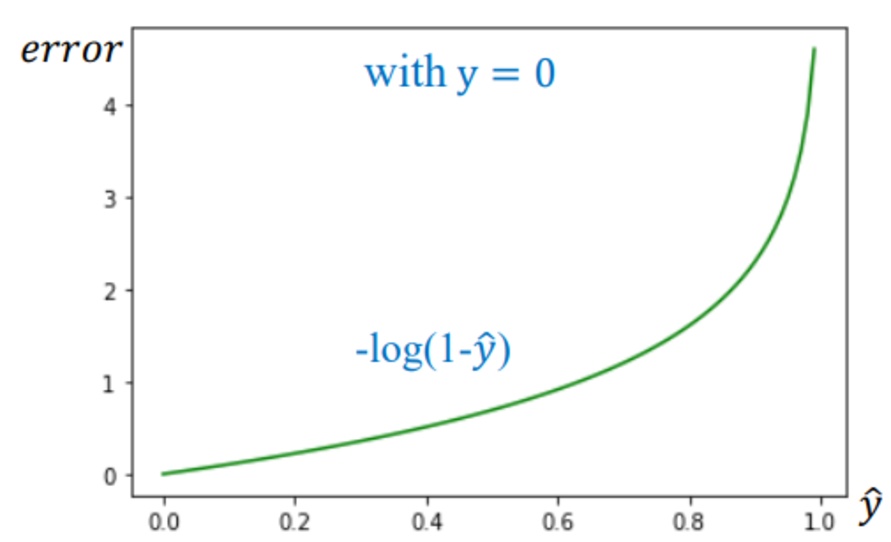
$$ L = -\log(1 - \hat{y}) $$
- Mục tiêu: $\hat{y} \to 0$
- Nếu mô hình dự đoán sai ($\hat{y} \approx 1$), hàm Loss cũng tiến tới vô cực.
Thực chất, bạn chỉ cần thay $\hat{y}$ bằng 0 hoặc 1 vào công thức tổng quát trên là sẽ ra được 2 trường hợp tôi chia bên trên.
d. Gradient
Một điều thú vị rằng là khi tính đạo hàm của BCE theo trọng số (z) (để dùng trong Gradient Descent), phép tính logarit và hàm mũ triệt tiêu nhau một cách hoàn hảo, để lại kết quả đơn giản:
$$ \frac{\partial L}{\partial z} = \hat{y} - y $$
- Sai nhiều → Gradient lớn → bước sửa lỗi lớn
- Sai ít → Gradient nhỏ → tinh chỉnh nhẹ
2.3. Hàm Softmax: Mở Rộng Cho Multi-Class Classification, Cải Tiến Và Hàm Loss
Trước khi đi sâu vào Softmax, hãy nhìn lại hàm Sigmoid mà chúng ta đã dùng ở bài toán nhị phân. Sigmoid nhận vào một giá trị thực và nén nó vào khoảng (0,1), vì vậy nó rất phù hợp để biểu diễn xác suất của một lựa chọn duy nhất: Yes hoặc No hay 0 hoặc 1.
Tuy nhiên, khi chuyển sang phân loại nhiều lớp, vấn đề nảy sinh: Nếu ta sử dụng Sigmoid cho nhiều lớp, mỗi lớp sẽ độc lập cho ra một xác suất và tổng các xác suất không đảm bảo bằng 1. Điều này không phù hợp với bản chất của phân loại multi-class, nơi ta cần mô hình đưa ra một phân phối xác suất hợp lệ cho tất cả các lớp.
Softmax ra đời để giải quyết đúng điểm hạn chế này:
-
Nó nhận vào một vector nhiều giá trị (logits)
-
Và biến chúng thành một phân phối xác suất (tổng = 1)
-
Lớp nào có logit “mạnh” nhất sẽ được đẩy lên xác suất cao nhất
Vì vậy, bạn có thể xem Softmax như một "phiên bản mở rộng" của Sigmoid dành cho các bài toán nhiều lớp.
a. Softmax Function
Ở lớp đầu ra của mô hình, chúng ta sẽ có C node (hay có bao nhiêu class thì từng đó z), mỗi node cho ra một giá trị thô gọi là logit:
$$
z = (z_0, z_1, \dots, z_{C-1})
$$
Các giá trị này có thể âm hoặc dương và không phải xác suất. Để biến chúng thành xác suất, ta dùng Softmax:
$$ \hat{y}_i = \sigma(z)_i = \frac{e^{z_i}}{\sum\limits_{j=1}^C e^{z_j}} $$
Softmax đảm nhiệm hai vai trò:
-
Hàm mũ giúp mọi giá trị thành số dương và khuếch đại sự chênh lệch.
-
Chuẩn hóa bằng cách chia cho tổng để toàn bộ trở thành phân phối xác suất.
Và khi được đặt ở cuối mạng Neural, Softmax sẽ xử lý toàn bộ các giá trị $( z_0, z_1, z_2 $) từ tầng trước rồi biến chúng thành ba xác suất tương ứng với ba lớp.
Sơ đồ dưới đây minh họa rõ điều đó: mỗi đầu ra $( z_i $) đi vào Softmax, và Softmax trả về xác suất $(\hat{y}_i = P(y = i \mid x)$).

b. Xây dựng Loss theo cách “kỳ quặc” (Awkward Way)
Giả sử ta vẫn giữ cách gán nhãn cũ:
$$ y \in \{0,\ 1,\ 2\} $$
Nếu (y = 2), ta muốn Loss phụ thuộc vào đúng $\hat{y}_2$.
Một cách viết rất “cơ học máy móc” là dùng như sau:
$$
L(\theta)
= -\, y(1-y)\,\log(\hat{y}_2)
\;-\; y(2-y)\,\log(\hat{y}_1)
\;-\; (1-y)\left(2-\frac{y}{2}\right)\log(\hat{y}_0)
$$
Ở đây nếu bạn thay $y \in \{0,\ 1,\ 2\}$ vào công thức thì nó sẽ ra như sau:
- Nếu $y = 2$: Các hạng tử liên quan đến lớp 0 và lớp 1 triệt tiêu, chỉ còn $-\log(\hat{y}_2)$.
-
Nếu $y = 1$: Hạng tử lớp 0 và lớp 2 bị triệt tiêu, chỉ còn $-\log(\hat{y}_1)$.
-
Nếu $y = 0$: Hạng tử lớp 1 và lớp 2 triệt tiêu, chỉ còn $-\log(\hat{y}_0)$.
Nói cách khác, công thức này hoạt động như một “công tắc đại số”: mỗi lần chỉ bật đúng hạng tử tương ứng với lớp thật sự.
Tuy không sai, cách này có nhiều nhược điểm:
- Không mở rộng được khi số lớp lớn
- Dài và khó đọc
- Tính đạo hàm rất rối rắm
c. One-Hot Encoding — Chìa khóa giải quyết vấn đề
Thay vì gán nhãn bằng số nguyên, ta chuyển nó thành vector one-hot:
- Nhãn 0 → $[1,0,0]^T$
- Nhãn 1 → $[0,1,0]^T$
- Nhãn 2 → $[0,0,1]^T$
Khi đó:
- $y$: vector nhãn thật
- $\hat{y}$: vector xác suất dự đoán
Lúc này, vector nhãn thật $y$ và vector xác suất dự đoán $\hat{y}$ đã có cùng kích thước, giúp việc tính toán trở nên cực kỳ đồng nhất. Nhờ One-Hot Encoding, ta có thể viết hàm Loss dưới một công thức tổng quát hơn:
$$ L(\theta) = -\sum_{i=1}^{C} y_i \log(\hat{y}_i) $$
Thoạt nhìn, dấu tổng $\sum$ có vẻ làm phức tạp vấn đề, nhưng thực chất vì vector (y) chỉ chứa một số 1 duy nhất (tại đúng class) và còn lại toàn số 0, nên dấu tổng này đóng vai trò như một bộ lọc: nó chỉ "nhặt" ra đúng số hạng quan trọng nhất.
Giả sử nhãn đúng là class 2, khi đó:
$$ y = [0, 0, 1] $$
Thay vào công thức:
$$ \begin{align*} L &= - \big[ 0 \cdot \log(\hat{y}_0) + 0 \cdot \log(\hat{y}_1) + 1 \cdot \log(\hat{y}_2) \big] \\ &= - \log(\hat{y}_2) \end{align*} $$
Kết quả cuối cùng quay về đúng bản chất: chúng ta chỉ muốn tối đa hóa xác suất của lớp đúng. Đây chính là sự mở rộng tự nhiên và hoàn hảo của Binary Cross-Entropy sang bài toán nhiều lớp.
d. Gradient
Khi kết hợp Softmax + Cross-Entropy, gradient theo logits cực kỳ đơn giản:
$$ \frac{\partial L}{\partial z} = \hat{y} - y $$
Điều này tương tự như trường hợp của sigmoid.
Lý thuyết này là nền tảng để chúng ta hiểu cách model học từ dữ liệu.
3. Apache Airflow – “Bộ não” điều phối toàn bộ pipeline
Trước khi nhảy vào dữ liệu và mô hình, mình muốn dành một phần quan trọng để giới thiệu công cụ đã biến dự án này từ “chạy trên laptop cá nhân” thành một hệ thống production thực thụ: Apache Airflow.
3.1. Apache Airflow là gì?
Apache Airflow là một platform mã nguồn mở dùng để xây dựng, lập lịch (schedule) và giám sát (monitor) các pipeline dữ liệu một cách hoàn toàn lập trình được (programmatically).
- Ra đời năm 2014 tại Airbnb
- Tháng 11/2025 → phiên bản mới nhất: 3.1
- Được các ông lớn tin dùng: NASA, Netflix, Bloomberg, Lyft, Adobe…
Thay vì quản lý pipeline bằng hàng tá script Python/Bash rời rạc, khó theo dõi log, khó scale → Airflow cho phép bạn định nghĩa toàn bộ pipeline dưới dạng code Python (gọi là DAGs – Directed Acyclic Graphs). Nhờ đó mọi thứ trở nên:
- Version control được (git)
- Dễ test, dễ tái sử dụng
- Tự động scheduling, monitoring, retry, alert
- Dễ backfill dữ liệu lịch sử
- Dễ scale ngang với hàng trăm worker
Tại sao Airflow lại cực kỳ quan trọng với ML/AI project?
| Giai đoạn | Trước khi có Airflow | Khi đã có Airflow |
|---|---|---|
| Data ingestion | Script chạy tay | Tự động theo lịch hoặc khi có file mới (Sensor) |
| Feature engineering | Notebook riêng lẻ | Task riêng, dependency rõ ràng |
| Training | Train lại từ đầu mỗi lần | Backfill dễ dàng, incremental training nếu muốn |
| Validation & Registry | So sánh tay | Tự động tính metrics, đẩy MLflow, alert nếu drift |
| Deployment | Copy file model thủ công | KubernetesPodOperator / SageMakerOperator tự deploy |
| Monitoring | Không có | Task theo dõi metrics, gửi Slack/Email khi model drift |
→ Airflow chính là backbone của hầu hết hệ thống MLOps hiện đại.
3.2. Các khái niệm cốt lõi cần nắm chắc
| Keyword | Giải thích ngắn gọn |
|---|---|
| DAG | Directed Acyclic Graph – bản thiết kế pipeline (task + dependency) |
| Task | Một bước công việc nhỏ (ví dụ: extract(), transform(), train_model()) |
| Operator | Khuôn mẫu tạo task (PythonOperator, BashOperator, KubernetesPodOperator…) |
| Sensor | Task “ngồi chờ” điều kiện (chờ file mới trên S3, chờ bảng BigQuery có data…) |
| Scheduler | Bộ não lập lịch, quyết định task nào chạy lúc nào |
| Executor + Worker | Thành phần thực thi task (có thể chạy song song trên nhiều máy) |
| Metadata DB | Lưu trạng thái, lịch sử chạy của tất cả DAG & task |
| Web Server | UI để xem graph, log, trigger thủ công… |
| XComs | Truyền dữ liệu nhỏ giữa các task |
| Variables/Connections | Lưu config & secret an toàn (không hard-code) |
3.3 Kiến Trúc Hoạt Động
Hãy nhìn vào sơ đồ kiến trúc dưới đây để hiểu cách Airflow vận hành nhé:
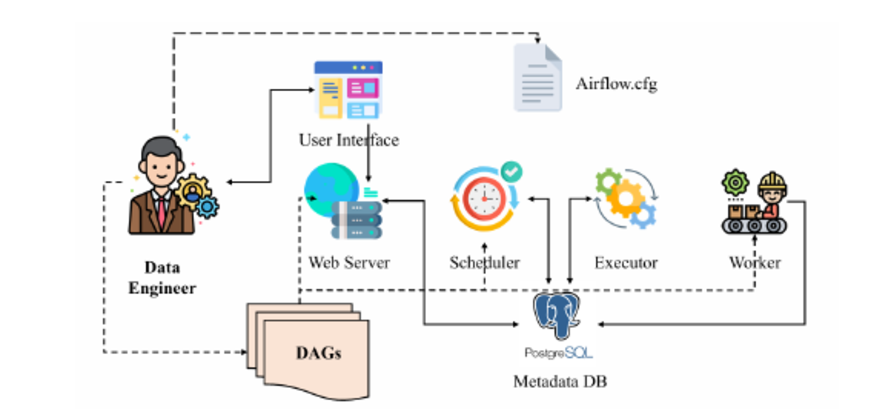
Nhìn vào hình, bạn sẽ thấy các thành phần cốt lõi tương tác với nhau như một bộ máy nhịp nhàng:
- User (Data Engineer): Viết các file DAG (kịch bản pipeline) và đẩy lên hệ thống.
- Web Server: Giao diện UI giúp theo dõi pipeline đang chạy xanh (tốt) hay đỏ (lỗi).
- Scheduler (Trái tim của Airflow): Liên tục kiểm tra thời gian và điều kiện. Khi đến giờ G, Scheduler ra lệnh "Chạy đi!".
- Metadata DB: Cuốn sổ nhật ký ghi lại mọi trạng thái: Task nào đang chạy? Task nào vừa fail?
- Executor & Worker: "Công nhân" thực thụ. Executor phân phối công việc, Worker (có thể nằm trên nhiều máy) sẽ thực thi đoạn code Python xử lý dữ liệu.
Trước khi đi vào code, chúng ta hãy làm rõ với nhau hơn những khái niệm cơ bản của Airflow nhé.
-
DAG (Directed Acyclic Graph): Đây giống như bản thiết kế tổng thể của pipeline. Nó xác định các bước cần thực hiện và thứ tự chạy. Ví dụ, DAG
"Sentiment_Analysis_Daily"sẽ định nghĩa các bước từ lấy dữ liệu, xử lý, đến huấn luyện mô hình. -
Task: Mỗi bước nhỏ trong DAG được gọi là Task. Ví dụ
extract_datalà Task lấy dữ liệu,train_modellà Task huấn luyện mô hình. Mỗi Task thực hiện một công việc cụ thể. -
Operator: Operator giống như khuôn mẫu cho Task. Nó xác định cách Task sẽ chạy. Ví dụ,
PythonOperatorsẽ gọi hàm Python, cònBashOperatorsẽ chạy lệnh terminal. -
XComs: Trong pipeline, đôi khi Task cần “nói chuyện” với nhau, truyền dữ liệu nhỏ (metadata). XComs chính là cơ chế này, giúp các Task chia sẻ thông tin khi cần.
Nắm được 4 khái niệm này là bạn đã đủ để theo dõi code. Giờ chúng ta cùng xem cách Airflow giúp tự động hóa toàn bộ pipeline trong thực hành với Python.
4. Pipeline Thực Hành Với Logistic Regression & Airflow
4.1 Khám phá dữ liệu (Metrics & Insights)
Trước khi đi vào chi tiết code, chúng ta cần biết mình đang làm việc với cái gì. Bộ dữ liệu mình sử dụng cho bài toán này là Amazon Reviews Dataset, các bạn có thể tải về tại đây:
Link Dataset: Kaggle - Amazon Reviews Dataset
Dưới đây là dashboard sentiment mà tôi đã generate từ dữ liệu (sau khi đã clean nhé), rồi sau đó tôi sẽ mô tả chi tiết các insights.
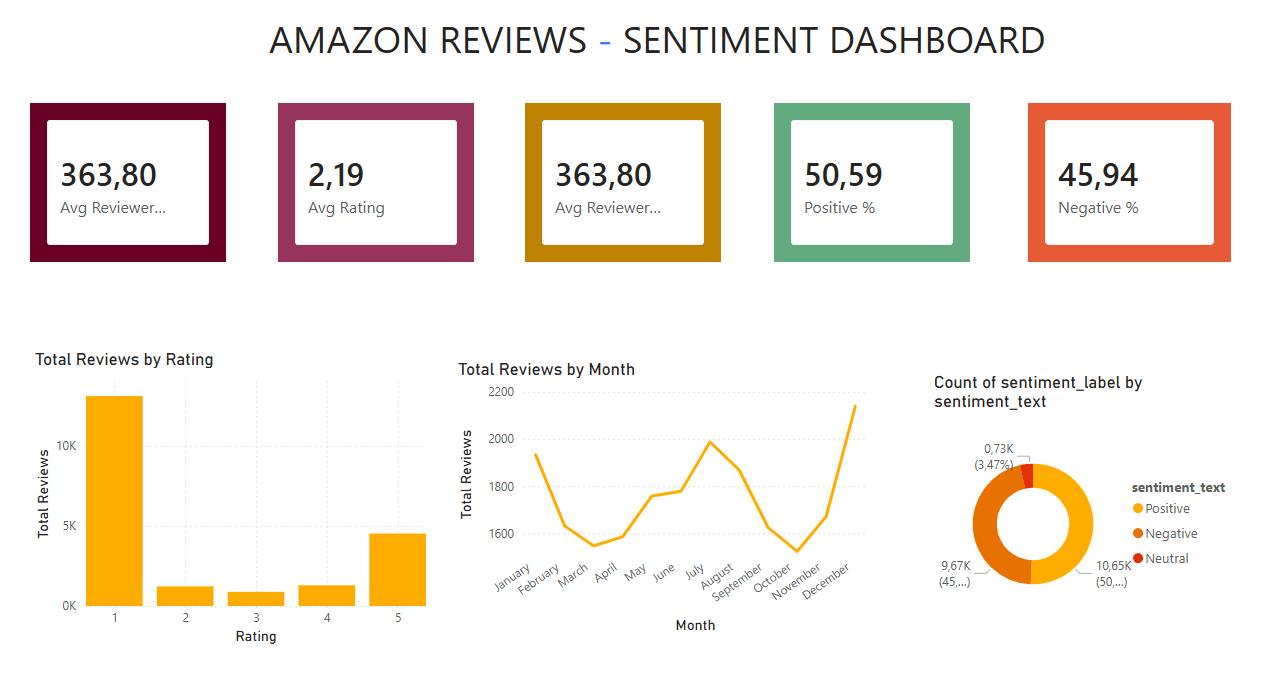
a. Tổng Quan Metrics
- Tổng Số Reviews: Khoảng 363.80 (dựa trên dashboard, có thể là 363,80 reviews trong subset – giả sử locale sử dụng dấu phẩy cho thập phân, nhưng thực tế có thể là 36380 nếu là thousand separator).
- Average Rating: 2.19 – Đánh giá trung bình khá thấp, cho thấy nhiều reviews tiêu cực.
- Average Reviewers: Lặp lại tổng số, có lẽ là tổng unique reviewers ~363.80.
- Positive %: 50.59% – Hơn nửa reviews được classify là positive.
- Negative %: 45.94% – Gần bằng positive, cho thấy dữ liệu khá cân bằng.
Lưu ý: Positive/negative ở đây dựa trên sentiment analysis sơ bộ (sử dụng rule-based hoặc pre-trained model như VADER). Chúng ta sẽ refine ở phần sau.
b. Phân Bố Reviews Theo Rating
Bar chart "Total Reviews by Rating" cho thấy:
- Rating 1 sao: Cao nhất (~15k reviews), phản ánh nhiều bất mãn.
- Rating 5 sao: Thứ hai (~5k), cho thấy một nhóm khách hàng hài lòng.
- Rating 2-4 sao: Thấp hơn, ít reviews trung lập.
Insight: Dữ liệu skewed về cực đoan (rất tốt hoặc rất tệ), phù hợp cho sentiment analysis vì text thường mang cảm xúc mạnh.
c. Xu Hướng Reviews Theo Tháng
Line chart "Total Reviews by Month":
- Bắt đầu cao ở January (~2000 reviews), giảm dần đến February, tăng ở March, fluctuate qua các tháng.
- Peak ở November/December (~2200), có lẽ do mùa mua sắm cuối năm (Black Friday, Christmas).
Insight: Sentiment có thể thay đổi theo mùa, ví dụ negative tăng ở peak do vấn đề logistics. Chúng ta cần filter timestamp khi train để tránh bias.
d. Phân Bố Sentiment Labels
Pie chart "Count of sentiment_label by sentiment_text":
- Positive: 9.67K (~45%) – Màu vàng.
- Negative: 10.65K (~50%) – Màu đỏ, chiếm đa số nhẹ.
- Neutral: 0.73K (~3.47%) – Màu cam, rất ít.
Insight: Dữ liệu hơi imbalanced (negative nhiều hơn), chúng ta cần xử lý bằng oversampling hoặc class weights khi train. Neutral ít, có thể merge vào negative nếu cần simplify thành binary.
Từ EDA, chúng ta thấy dữ liệu giàu thông tin nhưng cần cleaning: Xử lý missing values, normalize text (remove stopwords, lemmatize), và feature engineering (TF-IDF cho text). Đây là bước chuẩn bị hoàn hảo cho pipeline.
4.2. Kiến Trúc Pipeline Và Cấu Trúc Dự Án
Trước khi dive vào code, hãy nhìn tổng quan về kiến trúc. Tôi thiết kế pipeline thành hai DAGs chính để giữ sự modular: Một cho ETL cơ bản (extract & clean), và một cho ML-specific (preprocess & train). Điều này giúp dễ debug và scale – ví dụ, nếu data source thay đổi, chỉ cần update DAG 1 mà không ảnh hưởng đến training.
Cấu Trúc Thư Mục Dự Án
Để giữ code clean và organized, tôi cấu trúc như sau:
AI_VN/
├── dags/
│ ├── extract_clean_dag.py # DAG 1: Extract & Clean
│ └── preprocess_train_dag.py # DAG 2: Preprocess & Train
├── data/
│ ├── raw/ # Dữ liệu thô từ Kaggle
│ ├── clean/ # Dữ liệu đã clean
│ ├── splits/ # Train/test splits
│ ├── models/ # Trained models (.pkl)
│ └── vectorizers/ # TF-IDF vectorizers (.pkl)
├── modules/
│ ├── extract.py # Kaggle data extraction
│ ├── cleaning.py # Data cleaning logic
│ ├── preprocess.py # Feature engineering
│ └── train.py # Model training
├── docker-compose.yaml # Để run Airflow locally với PostgreSQL
└── requirements.txt # Dependencies: airflow, sklearn, nltk, kaggle, etc.
Workflow Tổng Quan
Pipeline được chia thành 2 DAGs chính:
- DAG 1: extract_clean_dag
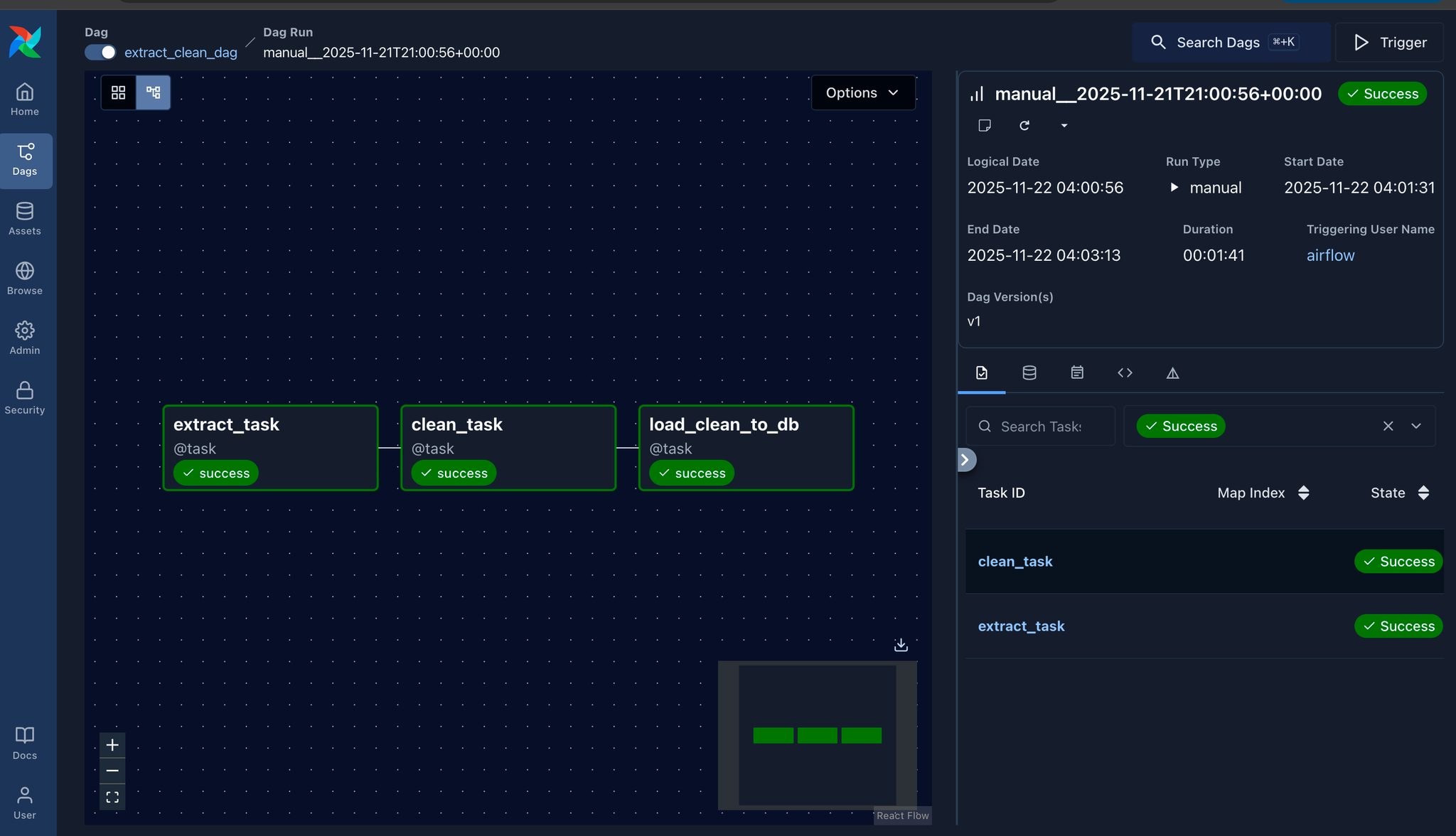
Extract (Kaggle) → Clean (NLTK + VADER) → Load to DB (PostgreSQL)
Mục tiêu: Lấy data thô, clean nó, và lưu vào DB để các bước sau sử dụng.
- DAG 2: preprocess_train_dag
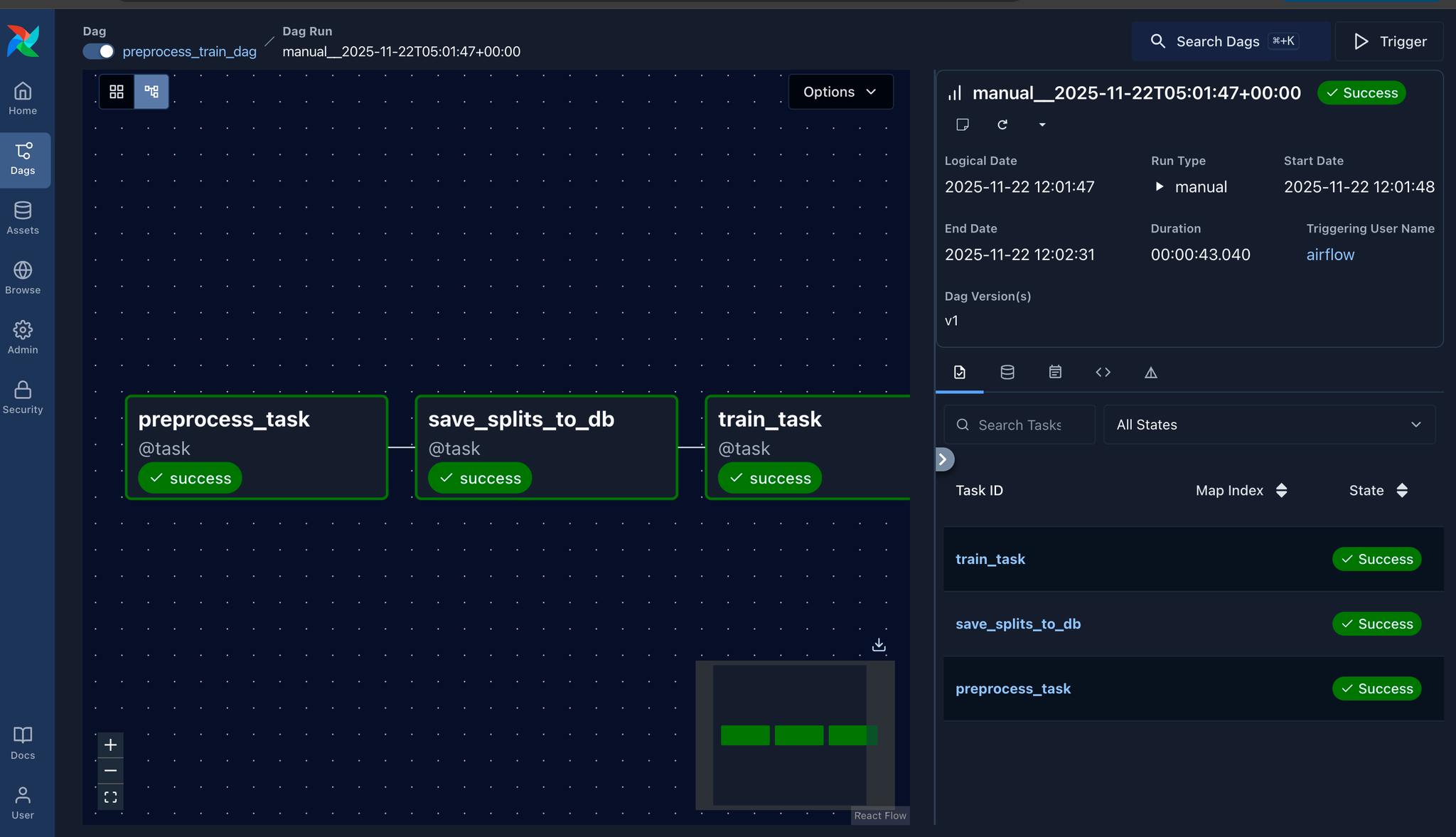
Preprocess (Split + TF-IDF) → Save Splits to DB → Train Models (Logistic Regression)
Mục tiêu: Chuẩn bị features, train model, và evaluate.
4.3. Implementation
Bây giờ, hãy đi sâu vào code. Tôi chia thành các modules riêng để dễ quản lý. Tất cả đều viết bằng Python, sử dụng libraries như NLTK cho text processing, scikit-learn cho ML, và VADER cho sentiment labeling. Vì blog này tập trung vào Airflow và Logistic Regression nên mình sẽ giải thích sâu hơn về code DAG và code train model Logistic. Những module như clean data, preprocessing các bạn có thể vào link github này để rõ hơn nha: git_click_here
a. DAG 1: Extract & Clean Pipeline
Trong dự án ETL này, pipeline sẽ làm ba bước chính: tải dữ liệu từ Kaggle → làm sạch → lưu vào database.
Cấu hình cơ bản
Trước tiên, mình định nghĩa vài đường dẫn và thông tin dataset:
# ==== CONFIG ====
RAW_DATA_DIR = "/opt/airflow/data/raw"
CLEAN_DATA_DIR = "/opt/airflow/data/clean"
RAW_FILE_PATH = f"{RAW_DATA_DIR}/Amazon_Reviews.csv"
CLEAN_FILE_PATH = f"{CLEAN_DATA_DIR}/cleaned_reviews.csv"
DATASET_NAME = "dongrelaxman/amazon-reviews-dataset"
RAW_DATA_DIR & CLEAN_DATA_DIR: nơi lưu file thô và file đã clean.DATASET_NAME: identifier trên Kaggle, dễ thay đổi nếu muốn dùng dataset khác.
Định nghĩa DAG
Airflow dùng decorator @dag để “biến” một function thành DAG:
@dag(
dag_id="extract_clean_dag",
schedule=None,
start_date=datetime(2024, 1, 1),
catchup=False,
tags=["amazon", "etl", "cleaning"],
)
def extract_clean_pipeline():
-
schedule=None: chạy thủ công, không theo lịch. -
catchup=False: tránh chạy lại các runs cũ khi mới deploy. -
tags: giúp filter DAG trong UI.
Ba task chính
Pipeline gồm ba task tuyến tính, đi từ raw → clean → DB. Mình chỉ show skeleton code, chi tiết logic để link GitHub:
@task()
def extract_task():
"""Download dataset from Kaggle → RAW folder"""
extract_kaggle_dataset(dataset=DATASET_NAME, download_dir=RAW_DATA_DIR)
return RAW_FILE_PATH
@task()
def clean_task(raw_path: str):
"""Clean data → save cleaned CSV"""
os.makedirs(CLEAN_DATA_DIR, exist_ok=True)
cleaned_csv_path = clean_dataset(raw_csv_path=raw_path, save_csv_path=CLEAN_FILE_PATH)
return cleaned_csv_path
@task()
def load_clean_to_db(clean_csv_path: str):
"""Load cleaned data to PostgreSQL"""
save_cleaned_data_to_db(cleaned_csv_path, table_name="amazon_reviews_clean")
return "Saved cleaned data to DB."
Tóm tắt các bước clean trong clean_task:
-
Chuẩn hóa dữ liệu (normalize country names)
-
Xử lý text: remove stopwords, lemmatization
-
Thêm nhãn sentiment với VADER
Flow DAG
Để xác định thứ tự chạy, chỉ cần truyền output giữa các task:
raw_file = extract_task()
cleaned_file = clean_task(raw_file)
load_clean_to_db(cleaned_file)
Airflow TaskFlow API tự động phát hiện dependencies từ đây. Cuối cùng, gọi extract_clean_pipeline() để register DAG với scheduler.
b. DAG 2: Preprocess & Train Pipeline
Pipeline này tương tự cũng sẽ làm ba bước chính: preprocess dữ liệu → lưu train/test splits vào database → train ML models.
Cấu hình cơ bản
# ==== CONFIG ====
CLEANED_CSV = "/opt/airflow/data/clean/cleaned_reviews.csv"
SPLIT_DIR = "/opt/airflow/data/splits"
VECTORIZER_DIR = "/opt/airflow/data/vectorizers"
MODEL_DIR = "/opt/airflow/data/models"
CLEANED_CSV: input từ DAG 1.SPLIT_DIR, VECTORIZER_DIR, MODEL_DIR: các thư mục riêng biệt để lưu splits, vectorizers, models, giúp quản lý artifacts dễ dàng.
Định nghĩa DAG
@dag(
dag_id="preprocess_train_dag",
schedule=None,
start_date=datetime(2024, 1, 1),
catchup=False,
tags=["amazon", "ml", "training"],
)
def preprocess_train_pipeline():
schedule=None: chạy thủ công.tags=["ml", "training"]: filter DAG liên quan ML trong Airflow UI.
Ba task chính
Xử lý feature engineering: train/test split + TF-IDF vectorizers.
@task()
def preprocess_task():
"""
- train/test split (80/20)
- TF-IDF vectorizers: word-level & ngram-level
- save vectorizers và CSV splits
"""
result_paths = preprocess_dataset(
cleaned_csv_path=CLEANED_CSV,
split_dir=SPLIT_DIR,
vectorizer_dir=VECTORIZER_DIR,
)
return result_paths
- Train/test split với random_state cố định để reproducible.
- Fit TF-IDF word-level (unigrams) và ngram-level (bigrams) chỉ trên training set.
- Transform cả train/test sets và save vectorizers + CSV splits.
- Return dictionary chứa paths tất cả artifacts.
@task()
def save_splits_to_db(_):
"""Upload train/test splits to PostgreSQL"""
save_split_to_db(split_dir=SPLIT_DIR)
return "Train/test splits saved to DB."
_parameter thể hiện dependency nhưng không cần output từ task trước.- Persist splits giúp track & share data giữa các services.
@task()
def train_task(_):
"""
Train models:
- Logistic Regression word-level
- Logistic Regression ngram-level
Save models as .pkl
"""
result = train_models(
split_dir=SPLIT_DIR,
vectorizer_dir=VECTORIZER_DIR,
model_dir=MODEL_DIR,
)
return result
- Load splits + vectorizers, transform data.
- Train và evaluate hai Logistic Regression models.
- Save models và return performance metrics.
DAG Flow
split_paths = preprocess_task()
save_db = save_splits_to_db(split_paths)
train_models_output = train_task(save_db)
- Flow tuyến tính từ: Preprocess → Save to DB → Train.
- Training chỉ bắt đầu sau khi splits đã được persist.
c. Training Logistic Regression Models
Ở đây, mình huấn luyện hai mô hình Logistic Regression riêng biệt để so sánh hiệu quả của hai loại đặc trưng:
-
Mô hình 1: dùng word-level TF-IDF (từ đơn)
-
Mô hình 2: dùng n-gram level TF-IDF (ở đây là bigram, tức các cặp từ liên tiếp)
# Model 1: Word-level
log_word = LogisticRegression(max_iter=200)
log_word.fit(X_train_word, y_train)
# Model 2: N-gram level (bigram)
log_ngram = LogisticRegression(max_iter=200)
log_ngram.fit(X_train_ngram, y_train)
Mặc dù ở đây mình dùng mỗi tham số max_iter=200 thôi nhưng để mở rộng thêm, mình sẽ giải thích các tham số quan trọng của mô hình LogisticRegression trên nhé:
-
max_iter=200: Đây là số vòng lặp tối đa mà thuật toán tối ưu (solver) được phép chạy để tìm ra bộ trọng số tối ưu. Giá trị mặc định chỉ là 100, nhưng với dữ liệu văn bản TF-IDF, số chiều đặc trưng thường lên tới vài chục nghìn → cần nhiều iterations hơn để hội tụ. Nếu để mặc định, bạn sẽ thấy warning “ConvergenceWarning” liên tục. Mình thường set 200–1000 tùy kích thước dữ liệu.
-
penalty (mặc định 'l2'): 3 Loại regularization là 'l2' (phạt bình phương các trọng số nên giữ lại hầu hết các feature), 'l1' (có thể đẩy một số trọng số về đúng 0), 'elasticnet'(kết hợp l1 + l2) và 'none'.
-
C (mặc định 1.0): Nghịch đảo của cường độ regularization, nếu C lớn (ví dụ 10, 100) thì regularization yếu, model phức tạp hơn, nếu C nhỏ (ví dụ 0.01, 0.1) regularization mạnh thì model đơn giản hơn.
-
solver (mặc định 'lbfgs'): Với tập dữ liệu ~20–50k mẫu như của mình, 'lbfgs' là lựa chọn nhanh và ổn định.
-
random_state=42: Đảm bảo kết quả tái hiện được khi chạy lại nhiều lần.
-
multi_class='multinomial' hoặc 'ovr': Vì chúng ta có 3 lớp (positive, negative, neutral), dùng 'multinomial' + softmax sẽ học trực tiếp xác suất cho cả 3 lớp trong một mô hình duy nhất, thường cho kết quả tốt hơn so với chiến lược one-vs-rest mặc định.
Chúng ta train hai model trên cùng một dòng code để dễ so sánh performance giữa word-level và ngram-level features:
- Word-level model: nắm bắt ý nghĩa của từng từ riêng lẻ, nhanh, ít tốn bộ nhớ.
- N-gram model: nắm bắt các cụm từ/phrase, ví dụ
"not good"khác"good", thường accuracy cao hơn nhưng training time lâu hơn do vocabulary lớn hơn.
Việc train song song giúp so sánh trực tiếp hiệu năng giữa hai loại features, từ đó quyết định feature selection và model choice cho project.
4.4. Modules Supporting Logic
Hai DAGs trên chịu trách nhiệm orchestrate workflow, nhưng logic thực sự nằm trong các modules:
- extract.py: sử dụng Kaggle API để authenticate và download dataset, có error handling cho missing credentials.
- cleaning.py: implement toàn bộ text preprocessing pipeline:
- country mapping cho 150+ countries
- text normalization (lowercase, remove punctuation, etc.)
- NLTK stopwords removal
- WordNetLemmatizer cho lemmatization
- VADER SentimentIntensityAnalyzer để generate polarity scores và sentiment labels
- preprocess.py: handle train/test splitting (có stratification nếu cần) và tạo TF-IDF vectorizers với
sklearn.TfidfVectorizer. - train.py: implement training loop cho Logistic Regression, evaluation với sklearn metrics, và model persistence với pickle.
- db_io.py: functions để interact với PostgreSQL sử dụng sqlalchemy hoặc psycopg2.
Như mình đã nói, các bạn có thể truy cập link github để rõ hơn nha.
4.5. Kết quả Training & Metrics
Sau khi cả hai DAGs chạy thành công, chúng ta có pipeline hoàn chỉnh từ raw data → trained models.
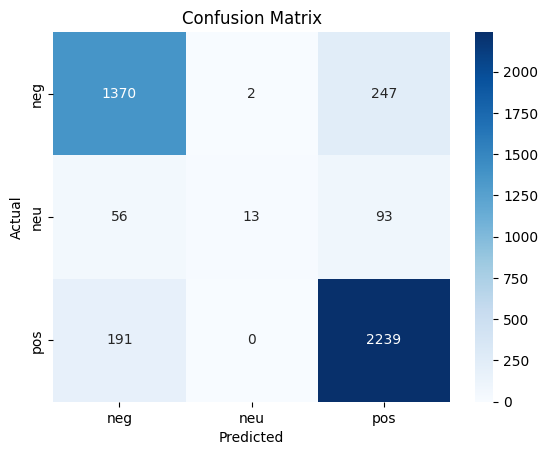
- Confusion matrix:
- Negative: 1370 true negatives, 247 false positives → misclassifications có thể do sarcasm/mixed sentiment.
- Neutral: 13 true neutrals, nhiều nhầm sang negative (56) hoặc positive (93)
- Positive: 2239 true positives, 191 false negatives
- Overall accuracy ≈ 85.9% cho baseline Logistic Regression model.

- Word Cloud Analysis:
- Prominent words: "amazon", "prime", "customer", "service", "order" → phản ánh domain rõ ràng.
- Negative indicators: "say", "want", "back", "told", "refund", "problem" → consistent với high percentage negative reviews.
- Transaction-related: "delivery", "time", "package", "item", "product"
- Strong sentiment: "never", "still", "going" → thể hiện emotional intensity.
Ta thấy rằng cleaning pipeline hoạt động tốt, remove stopwords và lemmatize words về base form.
Sau khi huấn luyện, nhóm cũng thử nghiệm nhập một số câu đánh giá mới để kiểm tra khả năng dự đoán của mô hình.
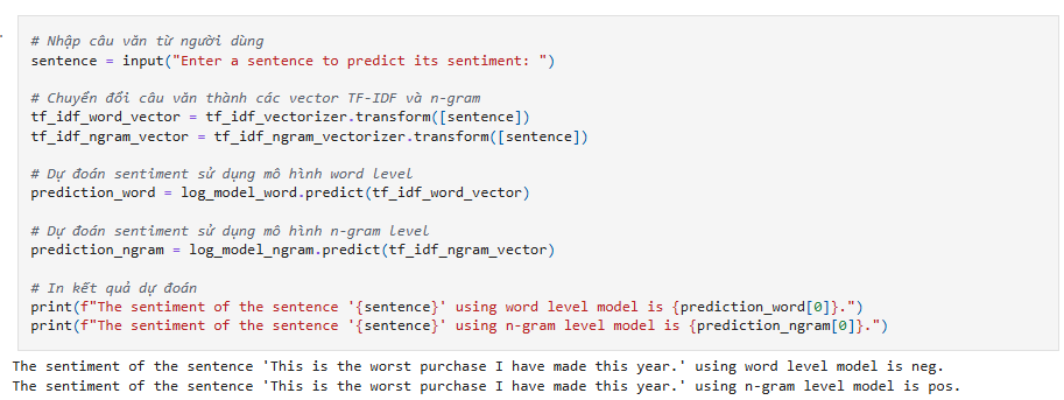
Trường hợp này minh họa rõ sự khác biệt:
-
Word-level chỉ xét từng từ riêng lẻ nên những từ mạnh như “worst” dễ khiến mô hình nghiêng về cảm xúc tiêu cực.
-
Bigram model phân tích theo cặp từ, hiểu ngữ cảnh tốt hơn (ví dụ phân biệt “not good” khác với “not” + “good”), nên đôi khi đưa ra kết luận khác.
Điều này cho thấy:
-
Bigram thường chính xác hơn trong các câu có cấu trúc ngôn ngữ phức tạp, nhưng đánh đổi thời gian huấn luyện và dung lượng từ vựng lớn hơn.
-
Trong production có thể cân nhắc:
-
Dùng bigram nếu latency cho phép
-
Hoặc tạo mô hình ensemble giữa hai thuật toán để tăng độ tin cậy.
-
Nhìn chung, mô hình với accuracy ~85.9% đã đủ mạnh để áp dụng cho các tác vụ thực tế như phân tích review khách hàng, cảnh báo xu hướng cảm xúc theo thời gian hay tự động phân loại feedback nội bộ. Tuy nhiên vẫn còn các điểm có thể cải thiện như nhận diện sarcasm, tăng dữ liệu cho lớp neutral hoặc áp dụng class weighting để giảm mất cân bằng lớp.
5. Kết Luận
Qua dự án này, chúng ta đã đi từ lý thuyết đến ứng dụng thực tiễn một cách trọn vẹn:
-
Hiểu rõ Logistic Regression
- Nắm được cách hoạt động của Sigmoid và Softmax, Binary/Multi-class Cross-Entropy, cũng như cơ chế gradient descent.
- Hiểu được tại sao Logistic Regression phù hợp với các bài toán phân loại cảm xúc và cách mở rộng từ nhị phân sang nhiều lớp bằng One-Hot Encoding. -
Ứng dụng Apache Airflow
- Xây dựng pipeline tự động, từ thu thập dữ liệu, xử lý, đến huấn luyện và lưu trữ model.
- Quản lý workflow rõ ràng, dễ kiểm soát, dễ scale và có thể tái sử dụng, giống như một hệ thống MLOps thực tế. -
Pipeline thực tế
- Dữ liệu Amazon Reviews được làm sạch, tiền xử lý và tách train/test.
- Logistic Regression models được train trên cả word-level và n-gram features, với accuracy ~85.9%.
- Phân tích kết quả cho thấy mô hình đủ mạnh để áp dụng trong các tình huống thực tế như phân tích feedback khách hàng, giám sát sentiment theo thời gian. -
Bài học & cải tiến
- Bigram model giúp hiểu ngữ cảnh tốt hơn nhưng tốn tài nguyên hơn.
- Cần cân nhắc xử lý imbalance class, sarcasm detection hoặc ensemble models để nâng cao hiệu năng.
- Airflow giúp dễ dàng mở rộng pipeline cho các dự án ML lớn hơn, từ training incremental đến deployment tự động.
Tóm lại, dự án không chỉ giúp củng cố lý thuyết Logistic Regression mà còn cung cấp trải nghiệm thực tế với pipeline dữ liệu chuyên nghiệp. Đây là bước đệm vững chắc để tiến tới các hệ thống ML production phức tạp hơn, áp dụng cho nhiều loại dữ liệu và bài toán khác nhau.
6. Reference
[1] Các hình ảnh và code được tham khảo từ slide và bài tập của tài liệu AIO2025, Module 06
Chưa có bình luận nào. Hãy là người đầu tiên!