
Vectorized Logistic Regression
Bài blog này sẽ giúp chúng ta nắm vững cách vectorize hóa cho bài toán Logistic Regression, từ trường hợp đơn giản với 1 mẫu đến xử lý nhiều mẫu (batching). Vectorization không chỉ giúp công thức ngắn gọn, dễ nhìn hơn mà còn tăng tốc độ tính toán đáng kể, đặc biệt là khi tập dataset có kích thước lớn.
1 - Nhắc lại kiến thức cơ bản
Trước khi đi vào vectorization, hãy ôn lại một số khái niệm cốt lõi về Logisc Regression và các pháp tính trên vector/ma trận.
1.1 - Logistic Regression
Logistic Regression là một mô hình phân loại tuyến tính cơ bản, thường được sử dụng cho bài toán phân loại nhị phân (binary classification), chẳng hạn như dự đoán email có phải spam hay không, hoặc bệnh nhân có mắc bệnh hay không.
Khác với Linear Regression (dự đoán giá trị liên tục), Logistic Regression sử dụng hàm kích hoạt để chuyển đổi đầu ra tuyến tính thành xác suất nằm trong khoảng $[0, 1]$.
Hàm sigmoid
Hàm sigmoid là hàm kích hoạt tiêu chuẩn trong Logistic Regression, được định nghĩa như sau:
$$ \sigma(z) = \frac{1}{1 + e^{-z}} $$
Nó chuyển đổi bất kỳ giá trị thực z nào thành khoảng [0, 1]. Đạo hàm của sigmoid là:
$$ \sigma'(z) = \sigma(z) (1 - \sigma(z)) $$
Điều này rất hữu ích trong việc tính gradient.
Hàm tanh (hyperbolic tangent)
Một biến thể khác là hàm tanh, thường dùng trong các lớp ẩn của mạng nơ-ron (nhưng được giới thiệu trước trong module này):
$$ \tanh(z) = \frac{e^z - e^{-z}}{e^z + e^{-z}} = 2\sigma(2z) - 1 $$
Đầu ra nằm trong $[-1, 1]$, với đạo hàm:
$$ \tanh'(z) = 1 - \tanh^2(z) $$
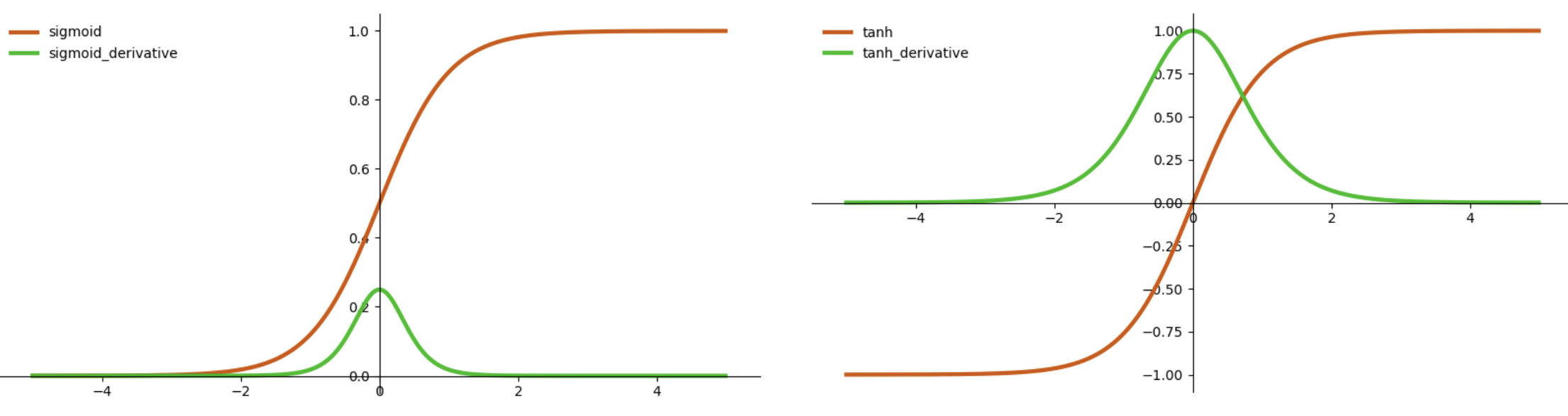
Tanh giúp gradient ít bị vanishing hơn so với sigmoid ở một số trường hợp (từ hình bên trên, ta nhận thấy đạo hàm của tanh có giá trị lớn hơn đạo hàm của sigmoid, khi lan truyền ngược sẽ ít bị làm nhỏ dần đạo hàm). Nhưng trong Logistic Regression cơ bản, sigmoid vẫn phổ biến hơn.
Hàm mất mát (Loss function)
Sử dụng Binary Cross-Entropy Loss:
$$ L(\hat{y}, y) = - [y \log(\hat{y}) + (1 - y) \log(1 - \hat{y})] $$
Trong đó, $\hat{y} = \sigma(z)$ là dự đoán, $y$ là nhãn thực ($0$ hoặc $1$). Loss này phạt nặng hơn khi dự đoán sai lệch lớn.
Quy trình huấn luyện
1. Khởi tạo trọng số $\mathbf{w}$ và bias $b$.
2. Đối với mỗi epoch: Chọn mẫu dữ liệu, tính dự đoán $\hat{y}$, tính loss, tính gradient, cập nhật $\mathbf{w}$ và $b$ bằng Gradient Descent.
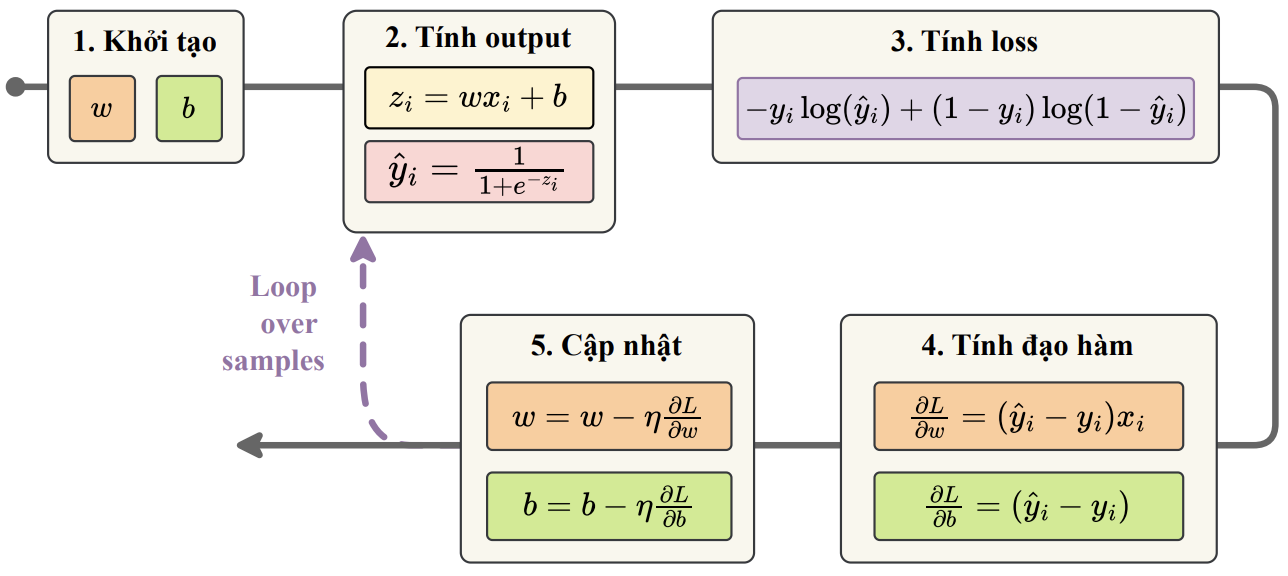
Có nhiều chiến thuật chọn lựa mẫu ở mỗi epoch khác nhau: chọn một mẫu, nhiều mẫu, tất cả mẫu huấn luyện. Chúng ta sẽ lần lượt tiếp cận hướng vectorization cho từng chiến thuật này.
1.2 - Phép tính vector/ma trận
Vectorization dựa trên các phép toán vector và ma trận, giúp tính toán song song. Dưới đây là các phép cơ bản với ví dụ minh họa (sử dụng NumPy để minh họa).
- Transpose (Chuyển vị): Chuyển vector hàng thành cột hoặc ngược lại.
Ví dụ: - Vector $\mathbf{a} = [1, 2, 3]$, transpose $\mathbf{a}^T = \begin{bmatrix} 1 \\ 2 \\ 3 \end{bmatrix}$.
- Matrix $\mathbf{A} = \begin{bmatrix} 1 & 2 & 3 \\ 4 & 5 & 6 \end{bmatrix} $,transpose $ \mathbf{A}^T = \begin{bmatrix} 1 & 2 \\ 3 & 4 \\ 5 & 6 \end{bmatrix}$.
NumPy: a.T.
- Nhân với scalar: Nhân từng phần tử với một số.
Ví dụ: - Vector: $2 \times [1, 2, 3] = [2, 4, 6]$.
- Matrix: $ 2 \times \begin{bmatrix} 1 & 2 \\ 3 & 4 \end{bmatrix} = \begin{bmatrix} 2 & 4 \\ 6 & 8 \end{bmatrix} $
NumPy: 2 * np.array([1,2,3]).
- Dot product (Tích vô hướng): Nhân hai vector và cộng tổng.
Ví dụ: $[1, 2] \cdot [3, 4] = 1*3 + 2*4 = 11$.
NumPy:np.dot(a, b)hoặca @ b.
2 - Vectorization trong Hồi Quy Logistic
Vectorization là một kỹ thuật tối ưu giúp giảm thiểu việc sử dụng vòng lặp trong tính toán, đặc biệt là khi làm việc với các bộ dữ liệu lớn. Vectorization tận dụng tính toán vector/ma trận để thực hiện các phép toán song song, giảm thời gian chạy và tăng hiệu suất. Thay vì tính toán cho từng mẫu một, ta có thể tính toán đồng thời cho tất cả các mẫu trong tập huấn luyện, giúp tiết kiệm thời gian và tài nguyên tính toán.
Trong Logistic Regression, vectorization áp dụng cho forward pass (dự đoán), tính loss và backward pass (gradient).
2.1 - Vectorization cho 1 mẫu
Đây là trường hợp Stochastic Gradient Descent (SGD), nơi mỗi epoch sử dụng chỉ một mẫu để cập nhật trọng số.
Giả sử mẫu: $\mathbf{x} \in \mathbb{R}^d$ (vector đặc trưng $d$-chiều), $y$ là nhãn.
Làm thông thường (không vectorize)
- Chọn một mẫu $(\mathbf{x}, y)$ từ dữ liệu huấn luyện.
- Tính tổng tuyến tính $z = \sum_{i=1}^d w_i x_i + b$ (sử dụng vòng lặp qua d phần tử).
Tính dự đoán $\hat{y} = \sigma(z) = \frac{1}{1+e^{-z}}$ (hoặc tanh). - Tính loss:
$$ L(\hat{y}, y) = - [y \log(\hat{y}) + (1 - y) \log(1 - \hat{y})] $$ - Tính gradient:
$$ \frac{\partial L}{\partial w_i} = (\hat{y} - y) x_i $$ (lặp qua từng $w_i$).
$$ \frac{\partial L}{\partial b} = (\hat{y} - y) $$ - Cập nhật:
$$ w_i = w_i - \eta \frac{\partial L}{\partial w_i} $$
$$ b = b - \eta \frac{\partial L}{\partial b} $$
Vectorize
Biểu diễn $\mathbf{x}$ và $\mathbf{w}$ dưới dạng vector cột:
$$ \mathbf{x} = \begin{bmatrix} 1 \\ x_1 \\ x_2 \\ \vdots \\ x_d \end{bmatrix}, \quad \theta = \begin{bmatrix} b \\ w_1 \\ w_2 \\ \vdots \\ w_d \end{bmatrix} $$
Khi đó, quy trình mới như sau:
- Chọn một mẫu $(\mathbf{x}, y)$ từ dữ liệu huấn luyện.
- Tính $z = \mathbf{x}^T \theta = \theta^T\mathbf{x}$.
Tính $\hat{y} = \sigma(z)$. - Tính loss như trên (scalar).
- Gradient vector: $\nabla_{\mathbf{w}} L = (\hat{y} - y) \mathbf{x}$.
- Cập nhật: $\theta = \theta - \eta \nabla_{\theta} L$.
Ví dụ tính toán
Giả sử $d=2$, $x = [1, 2]$, $\mathbf{w} = [0.5, -0.3]$, $b=0.1$, $y=1$, $\eta=0.1$.
Biểu diễn lại $\mathbf{x} = \begin{bmatrix} 1 \\ 1 \\ 2 \end{bmatrix}$ và $\theta = \begin{bmatrix} 0.1 \\ 0.5 \\ -0.3 \end{bmatrix} $
- $z = \mathbf{x}^T \theta = \begin{bmatrix} 1 & 1 & 2 \end{bmatrix} \times \begin{bmatrix} 0.1 \\ 0.5 \\ -0.3 \end{bmatrix}= 0.1 + 1*0.5 + 2*(-0.3) = 0.0$.
- $\hat{y} = \sigma(0) = 0.5$.
- Loss: $- [1 \log(0.5) + 0 \log(0.5)] \approx 0.693$.
- Gradient $\nabla_{\mathbf{w}} L = (0.5 - 1) \begin{bmatrix} 1 \\ 1 \\ 2 \end{bmatrix} = \begin{bmatrix} -0.5 \\ -0.5 \\ -1 \end{bmatrix}$.
- Cập nhật: $\theta = \begin{bmatrix} 0.1 \\ 0.5 \\ -0.3 \end{bmatrix} - 0.1 \begin{bmatrix} -0.5 \\ -0.5 \\ -1 \end{bmatrix} = \begin{bmatrix} 0.15 \\ 0.55 \\ -0.29 \end{bmatrix}$.
Cài đặt
Mã Python vectorized (NumPy):
import numpy as np
def sigmoid_func(z):
return 1 / (1 + np.exp(-z))
def predict(X, theta):
z = np.dot(X.T, theta)
return sigmoid_func(z)
def loss_func(y_hat, y):
return -y * np.log(y_hat) - (1 - y) * np.log(1 - y_hat)
def compute_gradient(X, y_hat, y):
return X * (y_hat - y)
def update(theta, lr, gradient):
return theta - lr * gradient
X = np.array([[1], [1], [2]])
theta = np.array([0.1, 0.5, -0.3])
y = 1
lr = 0.1
y_hat = predict(X, theta)
loss = losss_func(y_hat, y)
grad = compute_gradient(X, y_hat, y)
theta = update(theta, lr, grad)
2.2 - Vectorization cho $m$-mẫu (mini-batch)
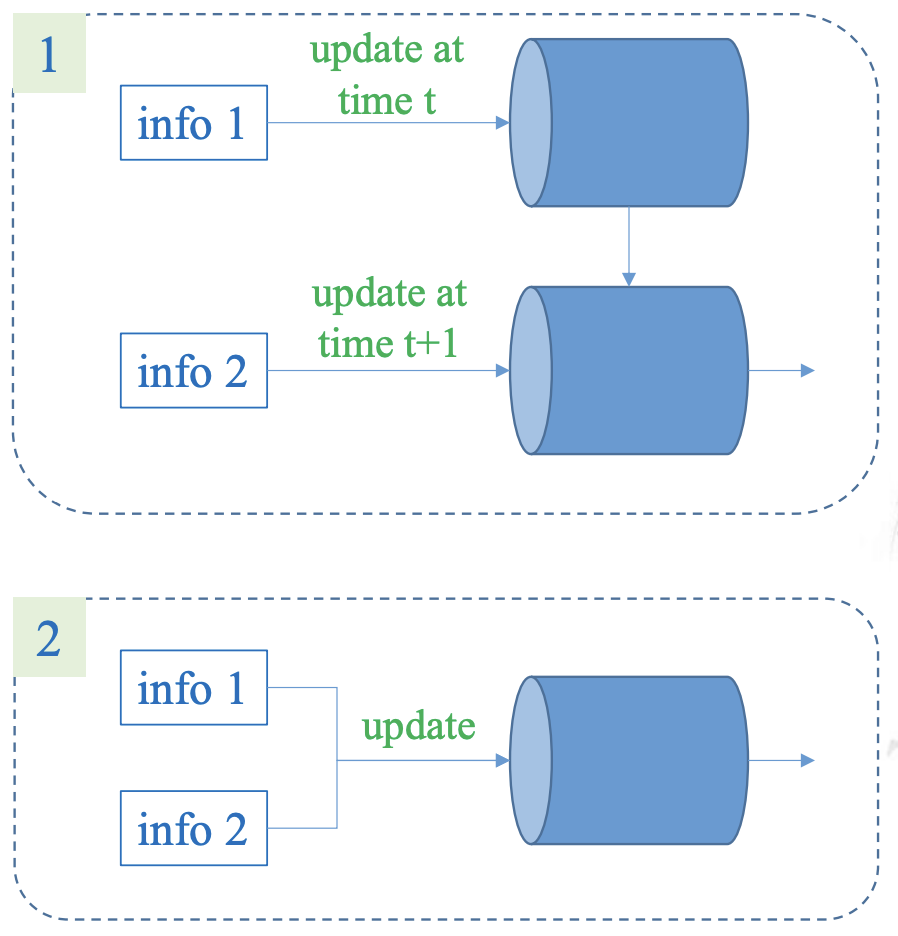
Với trường hợp dùng nhiều mẫu, chúng ta có hai cách tiếp cận là dùng một mẫu mỗi lần cập nhật (thực hiện giống như trên), hoặc trung bình cộng các loss của các mẫu rồi thực hiện cập nhật chung một lần. Thông thường, chúng ta lựa chọn hướng thứ hai. Vì lấy trung bình thông tin của nhiều mẫu là một trong những cách giúp giảm nhiễu.
Đây là trường hợp Mini-Batch Gradient Descent, sử dụng $m$ mẫu ($m < N$) mỗi epoch để cập nhật trọng số. Phương pháp này cân bằng giữa SGD (nhiễu cao nhưng cập nhật nhanh) và Full Batch (ổn định nhưng chậm).
Dữ liệu: Ma trận đặc trưng gốc $\mathbf{X}' \in \mathbb{R}^{m \times d}$ ($m$ hàng, $d$ cột), vector nhãn $\mathbf{y} \in \mathbb{R}^m$.
Làm thông thường (không vectorize)
- Chọn $m$ mẫu từ dữ liệu huấn luyện (mini-batch).
- Với từng mẫu $i$ từ $1$ đến $m$:
- Tính $z_i = \sum_{j=1}^d w_j x'_{i j} + b$ (vòng lặp nội qua d).
- $\hat{y_i} = \sigma(z_i)$ (hoặc $\tanh(z_i)$).
- Tính loss riêng: $L_i = - [y_i \log(\hat{y_i}) + (1 - y_i) \log(1 - \hat{y_i})]$. - Tính loss trung bình: $L = \frac{1}{m} \sum L_i$.
- Tính gradient: Với từng $w_j$: $\frac{\partial L}{\partial w_j} = \frac{1}{m} \sum_{i=1}^m (\hat{y_i} - y_i) x'_{i j}$ (vòng lặp kép: $m \times d$).
Tương tự cho b: $\frac{\partial L}{\partial b} = \frac{1}{m} \sum_{i=1}^m (\hat{y_i} - y_i)$. - Cập nhật: $w_j = w_j - \eta \frac{\partial L}{\partial w_j}$, $b$ tương tự.
Quá trình này tốn kém vì nhiều vòng lặp lồng nhau, đặc biệt khi $m$ và $d$ lớn.
Vectorize
Biểu diễn $\mathbf{X}$ (đã thêm cột bias) và $\theta$ dưới dạng:
$$ \mathbf{X} = \begin{bmatrix} 1 & x'_{11} & x'_{12} & \dots & x'_{1d} \\ 1 & x'_{21} & x'_{22} & \dots & x'_{2d} \\ \vdots & \vdots & \vdots & \ddots & \vdots \\ 1 & x'_{m1} & x'_{m2} & \dots & x'_{md} \end{bmatrix}, \quad \theta = \begin{bmatrix} b \\ w_1 \\ w_2 \\ \vdots \\ w_d \end{bmatrix} $$
Khi đó, quy trình mới như sau:
- Chọn $m$ mẫu từ dữ liệu huấn luyện, tạo ma trận $\mathbf{X}$ bằng cách thêm cột 1 vào ma trận đặc trưng gốc.
- Tính $\mathbf{z} = \mathbf{X} \theta$.
Tính $\hat{\mathbf{y}} = \sigma(\mathbf{z})$. - Tính loss như trên (vectorized).
- Gradient vector: $\nabla_{\theta} L = \frac{1}{m} \mathbf{X}^T (\hat{\mathbf{y}} - \mathbf{y})$.
- Cập nhật: $\theta = \theta - \eta \nabla_{\theta} L$.
Ví dụ tính toán
Giả sử $m=2$, $d=2$, ma trận đặc trưng gốc $\mathbf{X}' = \begin{bmatrix} 1 & 2 \\ 3 & 4 \end{bmatrix}$, $\theta' = \begin{bmatrix} 0.1 \\ 0.2 \end{bmatrix}$, $b = 0$, $\mathbf{y} = \begin{bmatrix} 0 \\ 1 \end{bmatrix}$, $\eta=0.1$.
Biểu diễn lại $\mathbf{X} = \begin{bmatrix} 1 & 1 & 2 \\ 1 & 3 & 4 \end{bmatrix}$, $\theta' = \begin{bmatrix} 0 \\ 0.1 \\ 0.2 \end{bmatrix}$.
- $\mathbf{z} = \mathbf{X} \theta = \begin{bmatrix} 1*0 + 1*0.1 + 2*0.2 \\ 1*0 + 3*0.1 + 4*0.2\end{bmatrix}= \begin{bmatrix} 0.5 \\ 1.1 \end{bmatrix}$.
- $\hat{\mathbf{y}} = \sigma(\mathbf{z}) \approx \begin{bmatrix} 0.622 \\ 0.750 \end{bmatrix}$.
- Loss: $\approx 0.631$.
- Gradient $\nabla_{\theta} L \approx 0.5 * \begin{bmatrix} 1 & 1 \\ 1 & 3 \\ 2 & 4 \end{bmatrix} * \begin{bmatrix} 0.622 - 0 \\ 0.750 - 1 \end{bmatrix} \approx \begin{bmatrix} 0.186 \\ -0.064 \\ 0.122 \end{bmatrix}$.
- Cập nhật: $\theta = \begin{bmatrix} 0 \\ 0.1 \\ 0.2 \end{bmatrix} - 0.1 \begin{bmatrix} 0.186 \\ -0.064 \\ 0.122 \end{bmatrix} \approx \begin{bmatrix} -0.019 \\ 0.106 \\ 0.188 \end{bmatrix}$.
Cài đặt
Mã Python vectorized (NumPy):
import numpy as np
def sigmoid_func(z):
return 1 / (1 + np.exp(-z))
def predict(X, theta):
z = np.dot(X, theta)
return sigmoid_func(z)
def loss_func(y_hat, y):
return -np.mean(y * np.log(y_hat) + (1 - y) * np.log(1 - y_hat))
def compute_gradient(X, y_hat, y):
m = X.shape[0]
return (1/m) * np.dot(X.T, (y_hat - y))
def update(theta, lr, gradient):
return theta - lr * gradient
X_orig = np.array([[1, 2], [3, 4]])
X = np.c_[np.ones(2), X_orig] # Thêm cột bias
theta = np.array([0, 0.1, 0.2])
y = np.array([0, 1])
lr = 0.1
y_hat = predict(X, theta)
loss = loss_func(y_hat, y)
grad = compute_gradient(X, y_hat, y)
theta = update(theta, lr, grad)
2.3 - Vectorization cho $N$-mẫu (full batch)
Đây là trường hợp Batch Gradient Descent (hay Full Batch), sử dụng toàn bộ $N$ mẫu ($N$ là kích thước dữ liệu) mỗi epoch để cập nhật trọng số. Việc tính toán khá giống phần 2.2 (có thể xem đây là trường hợp đặc biệt khi $m=N$)
Dữ liệu: Ma trận đặc trưng gốc $\mathbf{X}' \in \mathbb{R}^{N \times d}$, vector $\mathbf{y} \in \mathbb{R}^N$.
Làm thông thường (không vectorize)
Tương tự 2.2 nhưng với $m = N$:
- Sử dụng toàn bộ dữ liệu.
- Với từng mẫu $i$ từ $1$ đến $N$: Tính $z_i$, $\hat{y_i}$, loss riêng (vòng lặp qua $N$).
- Loss trung bình: $L = \frac{1}{N} \sum L_i$.
- Gradient: Với từng $w_j$: $\frac{\partial L}{\partial w_j} = \frac{1}{N} \sum_{i=1}^N (\hat{y_i} - y_i) x'_{i j}$ (vòng lặp kép $N \times d$, rất chậm).
- Cập nhật tương tự.
Vấn đề: Overhead lớn từ vòng lặp, không tận dụng phần cứng (CPU/GPU) cho tính toán song song.
Vectorize
Giống hệt 2.2, chỉ thay $m$ bằng $N$:
Biểu diễn $\mathbf{X}$ (đã thêm cột bias) và $\theta$ dưới dạng:
$$ \mathbf{X} = \begin{bmatrix} 1 & x'_{11} & x'_{12} & \dots & x'_{1d} \\ 1 & x'_{21} & x'_{22} & \dots & x'_{2d} \\ \vdots & \vdots & \vdots & \ddots & \vdots \\ 1 & x'_{N1} & x'_{N2} & \dots & x'_{Nd} \end{bmatrix}, \quad \theta = \begin{bmatrix} b \\ w_1 \\ w_2 \\ \vdots \\ w_d \end{bmatrix} $$
Khi đó, quy trình mới như sau:
- Tạo ma trận $\mathbf{X}$ bằng cách thêm cột 1 vào ma trận đặc trưng gốc toàn bộ dữ liệu.
- Tính $\mathbf{z} = \mathbf{X} \theta$.
Tính $\hat{\mathbf{y}} = \sigma(\mathbf{z})$. - Tính loss như trên (vectorized).
- Gradient vector: $\nabla_{\theta} L = \frac{1}{N} \mathbf{X}^T (\hat{\mathbf{y}} - \mathbf{y})$.
- Cập nhật: $\theta = \theta - \eta \nabla_{\theta} L$.
Ví dụ tính toán
Giả sử $N=3$, $d=2$, ma trận đặc trưng gốc $\mathbf{X}' = \begin{bmatrix} 1 & 2 \\ 3 & 4 \\ 5 & 6 \end{bmatrix}$, $\theta' = \begin{bmatrix} 0.1 \\ 0.2 \end{bmatrix}$, $b = 0$, $\mathbf{y} = \begin{bmatrix} 0 \\ 1 \\ 0 \end{bmatrix}$, $\eta=0.1$.
Biểu diễn lại $\mathbf{X} = \begin{bmatrix} 1 & 1 & 2 \\ 1 & 3 & 4 \\ 1 & 5 & 6 \end{bmatrix}$, $\theta = \begin{bmatrix} 0 \\ 0.1 \\ 0.2 \end{bmatrix}$
- $\mathbf{z} = \mathbf{X} \theta = \begin{bmatrix} 1*0 + 1*0.1 + 2*0.2 \\ 1*0 + 3*0.1 + 4*0.2 \\ 1*0 + 5*0.1 + 6*0.2 \end{bmatrix}= \begin{bmatrix} 0.5 \\ 1.1 \\ 1.7 \end{bmatrix}$.
- $\hat{\mathbf{y}} = \sigma(\mathbf{z}) \approx \begin{bmatrix} 0.622 \\ 0.750 \\ 0.846 \end{bmatrix}$.
- Loss: $\approx 1.043$.
- Gradient $\nabla_{\theta} L \approx \frac{1}{3} * \begin{bmatrix} 1 & 1 & 1 \\ 1 & 3 & 5 \\ 2 & 4 & 6 \end{bmatrix} * \begin{bmatrix} 0.622 - 0 \\ 0.750 - 1 \\ 0.846 - 0 \end{bmatrix} \approx \begin{bmatrix} 0.406 \\ 1.367 \\ 1.773 \end{bmatrix}$.
- Cập nhật: $\theta = \begin{bmatrix} 0 \\ 0.1 \\ 0.2 \end{bmatrix} - 0.1 \begin{bmatrix} 0.406 \\ 1.367 \\ 1.773 \end{bmatrix} \approx \begin{bmatrix} -0.041 \\ -0.037 \\ 0.023 \end{bmatrix}$.
Cài đặt
Mã Python vectorized (NumPy, giống 2.2 nhưng với $N$):
import numpy as np
def sigmoid_func(z):
return 1 / (1 + np.exp(-z))
def predict(X, theta):
z = np.dot(X, theta)
return sigmoid_func(z)
def loss_func(y_hat, y):
return -np.mean(y * np.log(y_hat) + (1 - y) * np.log(1 - y_hat))
def compute_gradient(X, y_hat, y):
m = X.shape[0]
return (1/m) * np.dot(X.T, (y_hat - y))
def update(theta, lr, gradient):
return theta - lr * gradient
X_orig = np.array([[1, 2], [3, 4], [5, 6]]) # N=3
X = np.c_[np.ones(3), X_orig] # Thêm cột bias
theta = np.array([0, 0.1, 0.2])
y = np.array([0, 1, 0])
lr = 0.1
y_hat = predict(X, theta)
loss = loss_func(y_hat, y)
grad = compute_gradient(X, y_hat, y)
theta = update(theta, lr, grad)
Kết luận
Vectorization làm cho Logistic Regression hiệu quả hơn, dễ mở rộng sang deep learning. Vừa giúp công thức dễ đọc, vừa giúp code dễ hơn, vừa tận dụng được xử lý song song giúp tính toán nhanh hơn.
Chưa có bình luận nào. Hãy là người đầu tiên!