
The article is belonged to by team CONQ013
Added Co-author: Ngo Tinh Giang Nguyen
1. Overview: What to learn to program AI
1.1. What is AI programming and how does it differ from traditional programming?
In traditional programming (C, Java, Python), humans write explicit rules and the computer executes them. The machine doesn't "understand" or "learn"—all intelligence comes from the programmer.
AI programming solves a key limitation: humans cannot manually write all rules for complex problems like facial recognition, language translation, or behavior prediction. Instead, machines learn rules from data and improve over time.
- Traditional programming
boolean isSpam(String email) {
if (email.contains("free")) return true;
if (email.contains("win money")) return true;
if (email.contains("click now")) return true;
return false;
}
With traditional programming, the programmer must think of the rules themselves and write them directly into the code. The computer learns nothing, but only checks conditions and returns the corresponding results. When new spam patterns appear, the programmer is forced to fix or add more rules. The more complex the code, the harder the system is to scale and maintain.
- AI programming
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
emails = [
"free money now",
"win a prize",
"meeting at 3pm",
"project update"
]
labels = [1, 1, 0, 0] # 1: spam, 0: not spam
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(emails)
model = MultinomialNB()
model.fit(X, labels)
test_email = ["free meeting now"]
test_vector = vectorizer.transform(test_email)
print(model.predict(test_vector))
With AI programming, the programmer does not write rules. Instead, they provide the machine with sample emails labeled as spam or not spam, so the machine can learn rules from the data itself. When encountering a new email, it relies on learned patterns to estimate probabilities and make decisions. If more new data is available, the system simply needs to be retrained to become more accurate.
Therefore, instead of focusing on writing every line of logic, AI learners must care about data, models, how to evaluate results, and how the system reacts in the real world.
1.2. What is the work of an AI Engineer?
1.2.1. Data preparation
This stage is not just about cleaning; it is about transforming raw information into mathematical features that an algorithm can interpret:
- AI Engineers often source initial data from platforms like Kaggle, Hugging Face, or UCI. However, this raw data is rarely "model-ready." Engineers must perform critical transformations—such as handling missing values, normalization, and categorical encoding—to ensure the model learns signal rather than noise.
- In professional environments, AI Engineers collaborate with Backend and Data Engineering teams to integrate real-time data from APIs and logs. They ensure that the data flowing into the training pipeline accurately reflects the real-world context the model will eventually serve.
- The "Garbage In, Garbage Out" Principle: A standard workflow follows a logical path: Collection → Cleaning → EDA (Exploratory Data Analysis) → Feature Engineering. Mastering this process is vital, as AI Engineers spend 60-80% of their time in this phase.
1.2.2. Model selection
After processing the data, the AI Engineer must select an appropriate model based on the dataset's characteristics and the project goals, rather than current trends:
- Tabular data: Best suited for traditional Machine Learning (e.g., price prediction, classification).
- Image/Audio/Video: Requires Deep Learning for automatic feature extraction.
- Text/Conversation: Requires Natural Language Processing (NLP).
The core principle is that data determines the model. A successful engineer focuses on what the data allows the model to learn rather than forcing an unnecessarily complex algorithm onto the problem.
1.2.3. Model training
After selecting the appropriate model, the AI Engineer proceeds to train the model on the prepared dataset. At this step, the model is “taught” to learn hidden rules in the data by adjusting parameters and repeating the learning process many times.
Training is not simply running a model once, but a process of continuous testing and fine-tuning to achieve stable and reliable results.
1.2.4. Result evaluation
When the training process is complete, the model needs to be evaluated on unseen data to test its generalization ability. AI Engineers use appropriate metrics for each problem to measure performance and detect issues such as overfitting or data bias. The evaluation step helps answer the most important question: does this model actually solve the problem in reality?
1.2.5. Optimization & Deployment
An AI model, no matter how good the results are, will not have much meaning if it only stays in a testing environment. Therefore, the next step for the AI Engineer is to optimize the model to run faster, consume fewer resources, and fit the real system. Then, the model is put into use by integrating it into the application or operating system. During operation, the AI Engineer continues to monitor the model's performance and update it when data changes.
2. Knowledge foundations when starting to learn AI Programming
Learning AI does not start with learning model architectures, but starts with foundations. Without a foundation, learning AI will quickly fall into a state of only knowing how to use libraries but not understanding why they work.
Below are the most important foundational knowledge that I think everyone should prepare before diving deep into AI.
2.1. Programming
When learning Python for AI, you don't just learn to write programs that run, but learn to:
- Read and understand other people's code (tutorials, paper implementations)
- Write scripts to process data.
- Build and test models.
Things to master:
- Basic syntax: variables, loops, conditions, functions.
- Object-oriented programming (OOP) to organize code neatly and easily scale.
- Data structures like lists, dictionaries – which appear everywhere in data processing.
- Working with files, modules, and error handling.
2.2. Mathematics
| Field | Purpose | Core Concepts | Why It Matters |
|---|---|---|---|
| Linear Algebra | Data representation and transformation | • Vectors & Matrices • Matrix multiplication • Dot products • Eigenvalues & Eigenvectors |
Images, text, and tables are converted to numerical matrices. Neural networks use matrix operations for computations. |
| Probability & Statistics | Handling uncertainty and imperfect data | • Probability & Distributions • Mean, Median, Mode • Variance & Standard Deviation • Correlation & Covariance |
Real-world data is noisy. Statistics help evaluate model performance and understand data patterns. |
| Calculus | Understanding and optimizing learning | • Derivatives (rate of change) • Gradients (multi-dimensional derivatives) • Gradient Descent • Chain Rule (for backpropagation) |
Shows where the model makes errors and how to adjust parameters to minimize those errors during training. |
2.3. Dev tools
Learning AI is not just learning algorithms, but doing practical projects. And at this time, dev skills become extremely important.
- Git/GitHub helps manage code, track changes, and work in teams.
- Virtual environments (venv, conda) help each AI project have its own set of libraries, avoiding “breaking the environment”.
- AI Coding Assistants like GitHub Copilot help write code faster, suggest structures, and reduce minor errors (but you still need to understand the code you write).
3. Specialized Skills - From Data Processing to MLOps Deployment
A standard workflow follows a rigorous sequence:
Problem Definition → Data Processing → Modeling → Deployment → Monitoring
with Data Processing = Collection → Cleaning → EDA → Feature Engineering
This guide focuses on the hands-on technical skills: data processing (Collection → Cleaning → EDA → Feature Engineering), modeling, deployment, and monitoring — the hands-on foundations every AI Engineer must master.
3.1. Data Collection
Data is the "fuel" of AI, and collecting high-quality data from appropriate sources is the starting step that determines the project's success.
There are many different data collection methods, each suitable for specific situations and requirements:
| Method | When to Use | Primary Tools | Key Notes |
|---|---|---|---|
| Web Scraping | Public websites without APIs | BeautifulSoup (static), Scrapy (large-scale), Selenium (JS-heavy) | Check robots.txt, respect rate limits |
| API Calls | Official platform access (preferred) | requests library, Twitter/OpenWeather/Google Maps APIs | Most reliable, requires API key registration |
| Database Queries | Enterprise/production environments | SQL (PostgreSQL, MySQL), NoSQL (MongoDB), Warehouses (BigQuery) | Mandatory for real-world work |
| Kaggle Datasets | Learning & practice | Kaggle platform, pre-cleaned datasets | Ideal for beginners, read top notebooks |
3.2. Data Cleaning
After collecting raw data, the next step is cleaning it for analysis and modeling. This is the most labor-intensive stage but creates the greatest value — data quality directly determines model accuracy and reliability.
3.2.1. Handling Missing Data
Missing data is the most common problem in real-world data. No single formula works for every case — consider degree of loss, feature importance, data type, and business context.
| Method | When to Use | Best For | Notes |
|---|---|---|---|
| Drop Rows | Missing > 50% in row | Excessive missing data | Can lose information |
| Drop Column | Missing > 50% AND not important | Unimportant features | Loses entire feature |
| Mean | Missing < 50%, numerical | Normal distribution | Simple, ignores relationships |
| Median | Missing < 50%, numerical | Outliers/skewed data | Robust to outliers |
| Mode | Missing < 50%, categorical | Categorical variables | Most frequent value |
| Forward/Backward Fill | Time series | Sequential data | Preserves temporal patterns |
| KNN Imputation | Complex patterns | Similar samples exist | Advanced, more accurate |
| Regression Imputation | Strong correlations | Predictable features | Captures relationships |
3.2.2. Handling Noisy Data & Outliers
Noisy data includes abnormal values, measurement errors, input mistakes, or inconsistencies. Detection combines visualization (box plots, scatter plots, histograms) with statistics (Z-score, IQR).
Critical: Not every abnormal value is noise! Domain expertise distinguishes true outliers (errors) from valid extreme values.
Treatment strategies:
| Technique | When to Use | Description |
|---|---|---|
| Remove | Clear data errors | Faulty sensors, entry errors |
| Cap | Valid but extreme | Limit at percentiles (1st/99th) |
| Transform | Skewed distributions | Log/sqrt to reduce impact |
| Keep | Legitimate values | Real phenomena—consult expert |
3.2.3. Removing Duplicates
Duplicates distort distribution, create bias, and cause data leakage if in both train/test sets.
Some Pandas methods:
duplicated()- detect duplicatesdrop_duplicates()- remove with options:keep='first'orkeep='last'- keep one occurrencekeep=False- delete all duplicatessubset=['col1', 'col2']- based on specific columns
Critical: Check duplicates BEFORE train/test split to avoid data leakage!
3.2.4. Format Standardization
Consistent formatting prevents errors when processing multi-source data.
For examples:
| Data Type | Problem | Solution |
|---|---|---|
| Dates/Times | Different formats, timezones | Convert to ISO 8601 + UTC |
| Text | Case, whitespace, special chars | Lowercase, strip(), normalize |
| Categorical | Variants ("M", "Male", "male") | Map to single standard |
| Numerical | Mixed units (lbs/kg, m/mi) | Convert to unified unit |
3.3. Exploratory Data Analysis (EDA)
After cleaning, you must understand your data (EDA) before creating features that models can learn from (Feature Engineering).
EDA answers the crucial questions: Are your features normally distributed or heavily skewed? Which features have strong relationships with your target variable? Are there unexpected patterns or natural groupings? These insights directly inform what transformations and features you'll create in the next step.
The Two Pillars of EDA: Numbers vs. Patterns
EDA combines two complementary approaches that work together to reveal data patterns:
- Statistical Analysis provides numerical summaries—mean, median, standard deviation tell you about central tendency and spread, while correlation coefficients quantify relationships between variables. Skewness measures reveal if data is symmetrical or leans heavily to one side, guiding transformation decisions.
- Visualization reveals what numbers alone might miss. A histogram shows if your salary data has one peak or two distinct groups. Scatter plots reveal non-linear relationships that correlation coefficients would miss. Heatmaps make patterns across dozens of features instantly visible. Your brain processes visual patterns much faster than tables of numbers.
3.3.1. Univariate Analysis
Before looking at relationships, you must understand each variable independently—like getting to know each ingredient before cooking.
- Numerical features, use
describe()for a statistical "health check" (mean, median, std) and Histograms to see the distribution. - Categorical features should be checked for balance using
value_counts()and Count Plots.
Key Question: Is my data skewed or imbalanced?
3.3.2. Bivariate Analysis
Next, examine how pairs of variables relate, especially with your target variable. This reveals which features actually "drive" your model.
- Numerical vs. Numerical: Use Scatter Plots to see trends (e.g., Experience vs. Salary).
- Categorical vs. Numerical: Use Box Plots to see how distributions vary across groups (e.g., Salary by Department).
Key Question: Which features show a clear relationship with the target?
3.3.3. Correlation Analysis
Finally, step back to see how everything relates simultaneously. The Correlation Matrix, visualized as a Heatmap, is your primary tool here.
This holistic view helps you:
- Identify top predictors: Find features most correlated with your target.
- Spot redundancy: If two features correlate above 0.9, they are redundant (Multicollinearity).
- Find engineering opportunities: Discover where combining features might create a stronger signal.
Key Question: Which 3-5 features are the most critical, and which are redundant?
3.4. Feature Engineering
If EDA helps humans understand data, then Feature Engineering is the step that helps AI understand that data. Real-world data is very diverse: text, numbers, time, categories, context. However, AI cannot learn directly from these forms of information if they are not appropriately converted.
Feature Engineering is the process of designing and transforming data so that the model can learn more effectively. Feature quality often influences results more than choosing complex or simple algorithms.

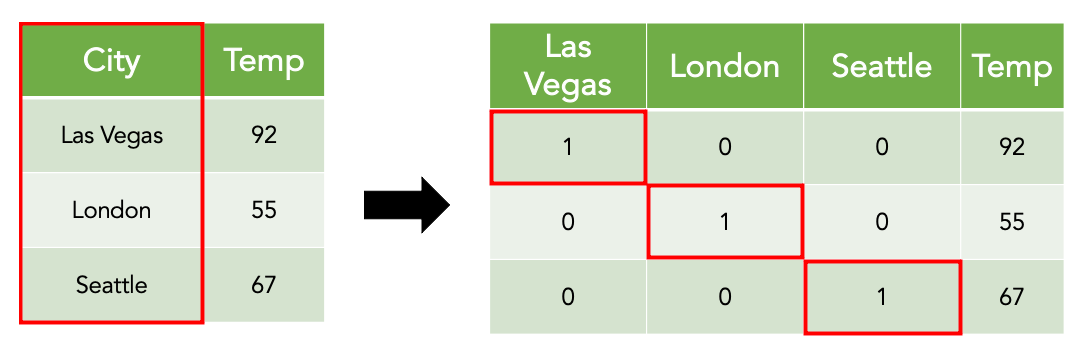
3.4.1. Encoding
Much real-world data exists as text or categorical labels, while AI only works with numbers. Encoding is the way to convert that information into numerical form while still preserving the original meaning.
The importance of encoding lies not in the specific technique, but in how the information is represented. Proper encoding helps AI correctly understand the relationship between values; conversely, inappropriate encoding can cause AI to learn incorrectly, even if the original data was perfectly accurate.
Therefore, encoding is not merely “changing words to numbers,” but a step of interpreting data for the machine in the most logical way.
3.4.2. Scaling
In a dataset, features often have very different magnitudes. If these values are fed directly into the model, the AI might be influenced by the size of the numbers rather than their true significance. This leads to the model paying more “attention” to features with large values, even if they are not necessarily more important.
One can imagine this process like making a glass of fruit juice. To have a delicious juice, what matters is not the size of each type of fruit, but the ratio between them. A large apple being bigger than a strawberry doesn't mean the apple is more important than the strawberry. If not calibrated, the “bigger” fruit will overwhelm the flavor of the rest.

Scaling in Machine Learning works on that same principle. It helps bring features onto the same playing field, so the model learns based on the actual relationships in the data, rather than being dominated by the magnitude of values. Thanks to scaling, features are “treated more fairly” during the learning process.
In practice, scaling is a very important preprocessing step. Simply scaling data correctly can create a clear difference between a poorly performing model and a more stable, reliable one.
3.4.3. Feature Construction
In the EDA stage, data visualization and statistical analysis reveal relationships, trends, and anomalies among variables. These insights directly inform Feature Construction, where new features are engineered to encode the discovered patterns into model-readable signals.
Feature construction involves combining or transforming existing attributes to create features with stronger predictive power than the original variables individually. For example, correlations observed during EDA may suggest interaction terms, ratios, or aggregated features that better represent real-world relationships.
By translating exploratory insights into structured features, this step acts as a bridge between raw data understanding and effective model learning. Well-constructed features allow downstream models to capture meaningful patterns with simpler architectures and improved generalization.
3.4.4. Feature Selection
Feature Selection serves as a critical filtering step before modeling, ensuring that only the most informative features are retained.
Guided by EDA findings and feature importance analyses, this stage removes redundant, highly correlated, or low-impact features that may introduce noise or overfitting. Techniques such as correlation thresholds, statistical tests, regularization, and model-based importance scores are commonly applied.
This strategic pruning refines the input space for the modeling stage, leading to faster training, more interpretable models, and better performance on unseen data. Together, feature construction and feature selection form the core of feature engineering, transforming exploratory insights into a compact and powerful representation for machine learning models.
3.5. Model selection
In the current AI era, hundreds or thousands of algorithms and models sprout up every month like mushrooms after rain. This can make many people feel overwhelmed and unsure of what to choose to best serve their needs. Of course, you could pick a massive model with 300 billion parameters to do a homework assignment on handwritten digit classification, but that would be like using a 1500-horsepower Bugatti La Voiture Noire to go to the grocery store (unless your house has its own hydroelectric station or your ancestors planted a magic pomelo tree that grows RTX 5090s).
Therefore, understanding what you need and understanding what each technology can do is very, very important. Machine Learning algorithms decades old can still outperform the most advanced Deep Learning models on specific problems.
Each model comes with Data Assumptions:
- Linear models: Assume the relationship between variables is linear.
- Tree-based models: Assume data has a hierarchical structure, not requiring overly strict normalization.
- Deep Learning: Assume data has complex, unstructured latent features like image pixels or text context.

The “No Free Lunch Theorem”: In mathematics and optimization, this law points out: There is no single algorithm that is optimal for every problem. If an algorithm is extremely powerful on one dataset, it usually pays the price by being inefficient on another. Don't go looking for the “best model in the world,” look for the model that best fits your data.
3.5.1. Machine Learning
Despite having existed for decades since their inception, classic Machine Learning algorithms still have a place thanks to their efficiency and simplicity. A few basic names include:
- Linear/Logistic Regression: Used for continuous value forecasting or simple binary classification problems. These algorithms are often used as a baseline to compare against other more powerful models.
- Decision Tree & Random Forest: Powerful in handling non-linear relationships and missing data. Random Forest helps mitigate Overfitting through the Ensemble Learning mechanism. With the birth and continuous improvement of XGBoost or AdaBoost, their role has only been further consolidated.
Tools: Scikit-learn remains the #1 library with a standardized process: Pipeline -> Fit -> Predict. This library is often used when you need quick and easy deployment; however, the downside is that it doesn't support very deep customization of existing models.
3.5.2. Deep Learning
Deep Learning refers to models with dozens, or even hundreds or thousands of ‘layers’ stacked on top of each other according to certain architectures. They are the supercars that cost a bowl of phở every time you hit the gas. They have the ability to learn complex relationships between data points that cannot be recognized with simple ML models.
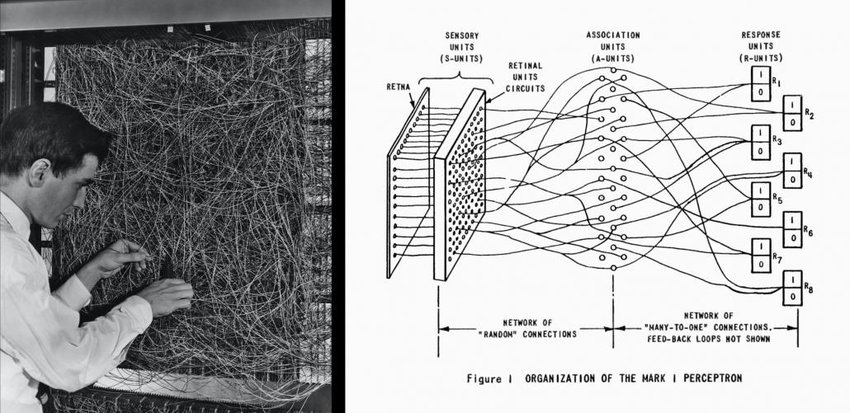
- Convolutional Neural Network (CNN): The backbone of computer vision in the pre-Transformer era in the early 2010s. CNNs learn to extract spatial features through convolutional and pooling layers, thereby recognizing objects in images automatically. Not only that, CNNs have also proven effective in Natural Language Processing (NLP) problems by treating a piece of text like an image with only one row of pixels.
- Recurrent Neural Network (RNN): If CNN is the backbone of computer vision, then RNN and its modern variants (LSTM, GRU, etc.) would be the pelvis of natural language processing (until, of course, the Transformer shapeshifting robots from Cybertron arrive to invade Earth). RNNs rely on an architecture that allows combining information from tokens (roughly called ‘words’) to make predictions for the next token.
For these powerful but also massive and complex models, the scikit-learn library will not be sufficient; instead, we need to turn to lower-level libraries to ensure performance and the ability to fine-tune according to problem requirements. The two most famous libraries are Meta's PyTorch and Google's TensorFlow, but it seems currently Tensorflow receives quite a bit of criticism, making PyTorch the optimal choice for both beginners and seasoned experts.
Question for the reader: Why do models usually stack layers on top of each other instead of spreading them into a single layer? Why do Deep Neural Networks dominate instead of Wide Neural Networks?
3.5.3. Transformer Architecture: The Foundation of Modern AI
Transformers have completely replaced recurrent networks like RNN and LSTM (though their supporters are quite unhappy and are still working hard to produce new variants to dethrone the Transformer). And with the birth of the Vision Transformer (ViT) not long after, even CNNs have fallen out of favor. To understand how the most revolutionary technology of the 21st century works, you need to master:
- Attention Mechanism: The soul of the Transformer, with the saying and also the title of the immortal paper: “Attention is all you need.” It allows the model to calculate the relevance between all words in a sentence (context-window) simultaneously, regardless of distance.
- Encoder-Decoder Structure: Understand how BERT (Encoder only), GPT (Decoder only), and T5 (both) operate.
Transformers are what stand behind the power of Large Language Models (LLMs) that have completely changed our lives in just a few years.

3.5.4. Current AI Trends: Fine-tuning and Integration
Did you know that to train GPT-4, launched on March 14, 2023, OpenAI spent about 100 million USD, but just over 2 years later, the cost to train the GPT-5 model has reached over 1 billion USD? If we include maintenance and operation costs, a model of that scale needs billions more USD and a lot of water from African children for you to chat with your ChatGPT girlfriend. Therefore, the race to build models from scratch is now mostly a playground for tech giants, and individual programmers need to learn how to apply existing models to their products.
Some skills include:
- LLMs API: Directly integrate the power of GPT-5, Claude 4, or Gemini through OpenAI/Anthropic/Google APIs to build applications quickly.
- Fine-tuning with Hugging Face: Use Parameter-Efficient Fine-Tuning (PEFT) techniques like LoRA or QLoRA to retrain models on specialized business data with much lower costs and resource requirements than training from scratch.
3.6. Evaluation and Deployment - MLOps
A machine learning model can achieve very high accuracy and perform well during testing but may fail to maintain effectiveness when put into operation. The problem often lies not in the algorithm, but in the constant fluctuation of real-world data. MLOps (Machine Learning Operations) emerged to solve this problem and has become a very useful skill in learning AI programming. Here are the 4 main steps of MLOps:
3.6.1. Model Evaluation
In a real operational environment, a model cannot be evaluated based only on standard accuracy metrics. The choice of metrics must be based on the specific characteristics of each problem.
For example, when building a credit fraud detection model, the model achieves 99% accuracy. However, in millions of transactions, it only identifies 5 fraudulent transactions and misses up to 95% of actual fraud cases. The accuracy metric becomes meaningless here because fraud is inherently very rare.
That is why we need different metrics depending on the problem:
- Precision (Accuracy on predicted results): The ratio of cases that are truly fraudulent out of the total cases the system labeled as fraud. A high precision helps minimize false alarms, ensuring the customer experience is not unreasonably interrupted.
- Recall (Detection rate): The ratio of actual fraud cases the system successfully caught compared to the total number of existing fraud cases. A high recall helps businesses control losses, ensuring fraudulent acts are not missed.
- F1 Score: A balanced metric between Precision and Recall when both need to be optimized.
Real systems often monitor multiple metrics simultaneously. A model might look very good on one metric but very poor on others:
- Overfitting: This is when a model memorizes random rules of the training data instead of learning general characteristics. The result is a model that achieves very high results in testing but fails when applied to real-world data. To control this, we need to continuously compare performance between the training dataset and the test dataset.
3.6.2. Deployment
A model sitting in a Notebook file (Jupyter) is a useless model. It needs to be connected to applications to serve real users. This process is much more complex than just uploading code to a server.
A practical model must have the technical infrastructure to ensure the system can operate 24/7, handle millions of simultaneous requests, and maintain response speeds measured in milliseconds. Some basic techniques commonly used:
- Containerization (Docker): Completely solves environment conflicts by packaging the model along with all dependent libraries into an independent entity. This ensures absolute consistency: the model will work exactly the same whether deployed on a personal computer, on-premise infrastructure, or cloud server clusters.
- API: Acts as a standardized bridge, allowing different systems to interact and retrieve prediction results from the model via HTTP protocols. Using modern frameworks helps optimize response speed (latency) and ensures security during data transmission.
- Cloud Platforms: Provide specialized tools to automate the entire model lifecycle. These platforms allow the system to automatically scale resources (autoscaling) according to actual traffic, while supporting scientific management of multiple model versions without manual infrastructure intervention.
Interactive Model Deployment (Gradio / Streamlit)
For early-stage deployment, prototyping, and demonstration purposes, tools such as Gradio and Streamlit are commonly used to expose machine learning models through interactive web interfaces with minimal engineering overhead.
These frameworks allow practitioners to quickly wrap trained models into user-facing applications, enabling stakeholders to test model behavior, visualize predictions, and validate assumptions before full-scale production deployment.
However, Gradio and Streamlit are typically not designed for high-throughput, low-latency production systems. They are best positioned as:
- Prototyping and experimentation tools
- Internal demos and proof-of-concept (PoC) deployments
- Model validation before API-based or cloud-native deployment
In mature MLOps pipelines, applications built with Gradio or Streamlit may serve as frontend layers, while the core inference logic is deployed as scalable APIs.
3.6.3. Monitoring
Unlike traditional software that only errors out when the system crashes, an AI model might still have the system running but the prediction results are no longer accurate due to changes in real data.
- Data Drift: Occurs when the characteristics of current input data differ significantly from the data used for previous training.
- Concept Drift: Occurs when the underlying relationship between data and output results has changed (e.g., consumer behavior changes after an economic fluctuation).
- Operational Monitoring: Tracking infrastructure metrics like response latency, system error rates, and traffic volume to intervene promptly before affecting end users.
3.6.4. Automation
When the number of models increases, manual management will lead to high costs in time, human resources, and high risk of error. Some basic automation solutions include:
- Continuous Retraining: Setting up data pipelines (pipelines) that automatically update models when performance degradation is detected or when enough new data is available.
- CI/CD for Machine Learning: Applying software engineering standards to automatically unit test, check performance, and determine latency before allowing a new model to be updated on the system.
- Orchestration: Using coordination tools to control the entire model lifecycle from data collection, training, to deployment. This ensures traceability and minimizes errors caused by human factors.
Conclusion
Learning AI programming is not about memorizing algorithms or chasing the newest models, but about understanding how data is transformed into decisions in real systems. From data collection and cleaning, through EDA and feature engineering, to model selection, evaluation, deployment, and monitoring, every stage in the pipeline plays a critical role in determining whether an AI system truly works outside the laboratory.
References
- Flare, C. (2023, May 22). Difference between Matplotlib VS Seaborn. Console Flare Blog. https://www.consoleflare.com/blog/matplotlib-vs-seaborn/
- GeeksforGeeks. (2025, November 8). What is Feature Engineering? GeeksforGeeks. https://www.geeksforgeeks.org/machine-learning/what-is-feature-engineering/
- Roy, B. (2025, January 21). All about Feature Scaling. Towards Data Science. https://towardsdatascience.com/all-about-feature-scaling-bcc0ad75cb35/
- Sang, D. (n.d.). Phân tích thống kê mô tả bằng SPSS – Phần 1: Thống kê trung bình - Hệ thống thông tin Thống kê KH&CN. https://thongke.cesti.gov.vn/dich-vu-thong-ke/tai-lieu-phan-tich-thong-ke/1025-phan-tich-thong-ke-mo-ta-spss-trung-binh
- Thaddeussegura. (2021, June 30). "Data encoding” explained in 200 words. Data Science - One Question at a Time. https://thaddeus-segura.com/encoding/
Chưa có bình luận nào. Hãy là người đầu tiên!