
Bài viết được thực hiện bởi nhóm CONQ013
Bổ sung Co-author: Ngo Tinh Giang Nguyen
1. Tổng quan: Học gì để lập trình AI
1.1. Lập trình AI là gì và khác gì với lập trình truyền thống?
Trong lập trình truyền thống (C, Java, Python), con người viết các quy tắc rõ ràng và máy tính thực thi chúng. Máy móc không "hiểu" hay "học" - tất cả trí thông minh đều đến từ lập trình viên.
Lập trình AI giải quyết một hạn chế quan trọng: con người không thể viết thủ công mọi quy tắc cho các vấn đề phức tạp như nhận diện khuôn mặt, dịch ngôn ngữ, hay dự đoán hành vi. Thay vào đó, máy móc học các quy tắc từ dữ liệu và cải thiện theo thời gian.
- Lập trình truyền thống
boolean isSpam(String email) {
if (email.contains("miễn phí")) return true;
if (email.contains("trúng tiền")) return true;
if (email.contains("nhấp ngay")) return true;
return false;
}
Với lập trình truyền thống, lập trình viên phải tự nghĩ ra các quy tắc và viết trực tiếp vào code. Máy tính không học được gì, mà chỉ kiểm tra điều kiện và trả về kết quả tương ứng. Khi xuất hiện các mẫu spam mới, lập trình viên buộc phải sửa hoặc thêm quy tắc. Code càng phức tạp, hệ thống càng khó mở rộng và bảo trì.
- Lập trình AI
rom sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
emails = [
"tiền miễn phí ngay",
"trúng giải thưởng",
"họp lúc 3 giờ",
"cập nhật dự án"
]
labels = [1, 1, 0, 0] # 1: spam, 0: không spam
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(emails)
model = MultinomialNB()
model.fit(X, labels)
test_email = ["họp miễn phí ngay"]
test_vector = vectorizer.transform(test_email)
print(model.predict(test_vector))
Với lập trình AI, lập trình viên không viết quy tắc. Thay vào đó, họ cung cấp cho máy móc các email mẫu được gán nhãn spam hoặc không spam, để máy móc có thể tự học quy tắc từ chính dữ liệu. Khi gặp email mới, nó dựa vào các mẫu đã học để ước tính xác suất và đưa ra quyết định. Nếu có thêm dữ liệu mới, hệ thống chỉ cần được huấn luyện lại để trở nên chính xác hơn.
Do đó, thay vì tập trung viết từng dòng logic, người học AI phải quan tâm đến dữ liệu, mô hình, cách đánh giá kết quả, và cách hệ thống phản ứng trong thế giới thực.
1.2. Công việc của một AI Engineer là gì?
1.2.1. Chuẩn bị dữ liệu
Giai đoạn này không chỉ là làm sạch; nó là việc chuyển đổi thông tin thô thành các đặc trưng toán học mà thuật toán có thể hiểu được.
-
AI Engineer thường lấy dữ liệu ban đầu từ các nền tảng như Kaggle, Hugging Face, hoặc UCI. Tuy nhiên, dữ liệu thô này hiếm khi "sẵn sàng cho mô hình". Kỹ sư phải thực hiện các phép biến đổi quan trọng - như xử lý giá trị thiếu, chuẩn hóa, và mã hóa phân loại - để đảm bảo mô hình học được tín hiệu thay vì nhiễu.
-
Trong môi trường chuyên nghiệp, AI Engineer cộng tác với các nhóm Backend và Data Engineering để tích hợp dữ liệu thời gian thực từ API và logs. Họ đảm bảo rằng dữ liệu chảy vào quy trình huấn luyện phản ánh chính xác bối cảnh thế giới thực mà mô hình cuối cùng sẽ phục vụ.
-
Nguyên tắc "Rác vào, Rác ra": Quy trình chuẩn theo con đường logic: Thu thập → Làm sạch → EDA (Phân tích Khám phá Dữ liệu) → Kỹ thuật Đặc trưng. Thành thạo quy trình này là điều sống còn, vì AI Engineer dành 60-80% thời gian ở giai đoạn này.
1.2.2. Lựa chọn mô hình
Sau khi xử lý dữ liệu, AI Engineer phải chọn mô hình phù hợp dựa trên đặc điểm của tập dữ liệu và mục tiêu dự án, chứ không phải xu hướng hiện tại.
-
Dữ liệu dạng bảng: Phù hợp nhất với Machine Learning truyền thống (ví dụ: dự đoán giá, phân loại).
-
Hình ảnh/Âm thanh/Video: Yêu cầu Deep Learning để trích xuất đặc trưng tự động.
-
Văn bản/Hội thoại: Yêu cầu Xử lý Ngôn ngữ Tự nhiên (NLP).
Nguyên tắc cốt lõi là dữ liệu quyết định mô hình. Một kỹ sư thành công tập trung vào những gì dữ liệu cho phép mô hình học, thay vì ép một thuật toán phức tạp không cần thiết vào vấn đề.
1.2.3. Huấn luyện mô hình
Sau khi chọn mô hình phù hợp, AI Engineer tiến hành huấn luyện mô hình trên tập dữ liệu đã chuẩn bị. Ở bước này, mô hình được "dạy" để học các quy tắc ẩn trong dữ liệu bằng cách điều chỉnh tham số và lặp lại quá trình học nhiều lần.
Huấn luyện không chỉ đơn giản là chạy mô hình một lần, mà là một quá trình kiểm tra và tinh chỉnh liên tục để đạt được kết quả ổn định và đáng tin cậy.
1.2.4. Đánh giá kết quả
Khi quá trình huấn luyện hoàn tất, mô hình cần được đánh giá trên dữ liệu chưa thấy để kiểm tra khả năng tổng quát hóa. AI Engineer sử dụng các chỉ số phù hợp cho từng vấn đề để đo lường hiệu suất và phát hiện các vấn đề như overfitting hoặc thiên lệch dữ liệu. Bước đánh giá giúp trả lời câu hỏi quan trọng nhất: mô hình này có thực sự giải quyết vấn đề trong thực tế không?
1.2.5. Tối ưu hóa & Triển khai
Một mô hình AI dù kết quả tốt đến đâu cũng sẽ không có nhiều ý nghĩa nếu chỉ ở lại trong môi trường thử nghiệm. Do đó, bước tiếp theo của AI Engineer là tối ưu hóa mô hình để chạy nhanh hơn, tiêu tốn ít tài nguyên hơn, và phù hợp với hệ thống thực tế. Sau đó, mô hình được đưa vào sử dụng bằng cách tích hợp vào ứng dụng hoặc hệ thống vận hành. Trong quá trình vận hành, AI Engineer tiếp tục giám sát hiệu suất của mô hình và cập nhật khi dữ liệu thay đổi.
2. Nền tảng kiến thức khi bắt đầu học Lập trình AI
Học AI không bắt đầu bằng việc học kiến trúc mô hình, mà bắt đầu bằng nền tảng. Không có nền tảng, việc học AI sẽ nhanh chóng rơi vào tình trạng chỉ biết sử dụng thư viện nhưng không hiểu tại sao chúng hoạt động.
Dưới đây là những kiến thức nền tảng quan trọng nhất mà tôi nghĩ mọi người nên chuẩn bị trước khi đi sâu vào AI.
2.1. Lập trình
Khi học Python cho AI, bạn không chỉ học viết chương trình chạy được, mà học để:
- Đọc và hiểu code của người khác (hướng dẫn, triển khai paper)
- Viết script để xử lý dữ liệu
- Xây dựng và kiểm tra mô hình
Những điều cần thành thạo:
- Cú pháp cơ bản: biến, vòng lặp, điều kiện, hàm
- Lập trình hướng đối tượng (OOP) để tổ chức code gọn gàng và dễ mở rộng
- Cấu trúc dữ liệu như list, dictionary – xuất hiện ở khắp nơi trong xử lý dữ liệu
- Làm việc với file, module, và xử lý lỗi
2.2. Toán học
| Lĩnh vực | Mục đích | Khái niệm Cốt lõi | Tại sao Quan trọng |
|---|---|---|---|
| Đại số Tuyến tính | Biểu diễn và chuyển đổi dữ liệu | • Vector & Ma trận • Phép nhân ma trận • Tích vô hướng • Giá trị riêng & Vector riêng |
Hình ảnh, văn bản, và bảng được chuyển thành ma trận số. Mạng neural sử dụng phép toán ma trận để tính toán. |
| Xác suất & Thống kê | Xử lý sự không chắc chắn và dữ liệu không hoàn hảo | • Xác suất & Phân phối • Trung bình, Trung vị, Mode • Phương sai & Độ lệch chuẩn • Tương quan & Hiệp phương sai |
Dữ liệu thực tế có nhiễu. Thống kê giúp đánh giá hiệu suất mô hình và hiểu các mẫu dữ liệu. |
| Giải tích | Hiểu và tối ưu hóa quá trình học | • Đạo hàm (tốc độ thay đổi) • Gradient (đạo hàm đa chiều) • Gradient Descent • Quy tắc Chuỗi (cho backpropagation) |
Chỉ ra vị trí mô hình mắc lỗi và cách điều chỉnh tham số để giảm thiểu lỗi đó trong quá trình huấn luyện. |
2.3. Công cụ Dev
Học AI không chỉ là học thuật toán, mà còn là làm các dự án thực tế. Và lúc này, kỹ năng dev trở nên cực kỳ quan trọng.
- Git/GitHub giúp quản lý code, theo dõi thay đổi, và làm việc nhóm
- Môi trường ảo (venv, conda) giúp mỗi dự án AI có bộ thư viện riêng, tránh "phá môi trường"
- Trợ lý Lập trình AI như GitHub Copilot giúp viết code nhanh hơn, gợi ý cấu trúc, và giảm lỗi nhỏ (nhưng bạn vẫn cần hiểu code mình viết)
3. Kỹ năng Chuyên môn - Từ Xử lý Dữ liệu đến Triển khai MLOps
Một quy trình chuẩn tuân theo trình tự nghiêm ngặt:
| Định nghĩa Vấn đề → Xử lý Dữ liệu → Mô hình hóa → Triển khai → Giám sát |
|---|
với Xử lý Dữ liệu = Thu thập → Làm sạch → EDA → Kỹ thuật Đặc trưng
Bài blog hướng dẫn này tập trung vào các kỹ năng kỹ thuật thực hành: xử lý dữ liệu (Thu thập → Làm sạch → EDA → Kỹ thuật Đặc trưng), mô hình hóa, triển khai, và giám sát — những nền tảng thực hành mà mọi AI Engineer phải thành thạo.
3.1. Thu thập Dữ liệu
Dữ liệu là "nhiên liệu" của AI, và việc thu thập dữ liệu chất lượng cao từ các nguồn phù hợp là bước khởi đầu quyết định sự thành công của dự án.
Có nhiều phương pháp thu thập dữ liệu khác nhau, mỗi phương pháp phù hợp với tình huống và yêu cầu cụ thể:
| Phương pháp | Khi nào Sử dụng | Công cụ Chính | Lưu ý Quan trọng |
|---|---|---|---|
| Web Scraping | Website công khai không có API | BeautifulSoup (tĩnh), Scrapy (quy mô lớn), Selenium (nhiều JS) | Kiểm tra robots.txt, tôn trọng giới hạn tần suất |
| API Calls | Truy cập nền tảng chính thức (ưu tiên) | thư viện requests, Twitter/OpenWeather/Google Maps APIs | Đáng tin cậy nhất, yêu cầu đăng ký API key |
| Database Queries | Môi trường doanh nghiệp/sản xuất | SQL (PostgreSQL, MySQL), NoSQL (MongoDB), Warehouses (BigQuery) | Bắt buộc cho công việc thực tế |
| Kaggle Datasets | Học tập & thực hành | Nền tảng Kaggle, tập dữ liệu đã làm sạch | Lý tưởng cho người mới, đọc các notebook hàng đầu |
3.2. Làm sạch Dữ liệu
Sau khi thu thập dữ liệu thô, bước tiếp theo là làm sạch nó để phân tích và mô hình hóa. Đây là giai đoạn tốn nhiều công sức nhất nhưng tạo ra giá trị lớn nhất — chất lượng dữ liệu quyết định trực tiếp độ chính xác và độ tin cậy của mô hình.
3.2.1. Xử lý Dữ liệu Thiếu
Dữ liệu thiếu là vấn đề phổ biến nhất trong dữ liệu thực tế. Không có công thức nào phù hợp cho mọi trường hợp — cần xem xét mức độ mất mát, tầm quan trọng của đặc trưng, loại dữ liệu, và bối cảnh kinh doanh.
| Phương pháp | Khi nào Sử dụng | Tốt nhất Cho | Lưu ý |
|---|---|---|---|
| Xóa Hàng | Thiếu > 50% trong hàng | Dữ liệu thiếu quá nhiều | Có thể mất thông tin |
| Xóa Cột | Thiếu > 50% VÀ không quan trọng | Đặc trưng không quan trọng | Mất toàn bộ đặc trưng |
| Mean | Thiếu < 50%, số | Phân phối chuẩn | Đơn giản, bỏ qua mối quan hệ |
| Median | Thiếu < 50%, số | Outliers/dữ liệu lệch | Bền vững với outliers |
| Mode | Thiếu < 50%, phân loại | Biến phân loại | Giá trị xuất hiện nhiều nhất |
| Forward/Backward Fill | Chuỗi thời gian | Dữ liệu tuần tự | Bảo toàn mẫu thời gian |
| KNN Imputation | Mẫu phức tạp | Mẫu tương tự tồn tại | Nâng cao, chính xác hơn |
| Regression Imputation | Tương quan mạnh | Đặc trưng có thể dự đoán | Nắm bắt mối quan hệ |
3.2.2. Xử lý Dữ liệu Nhiễu & Outliers
Dữ liệu nhiễu bao gồm giá trị bất thường, lỗi đo lường, nhập sai, hoặc không nhất quán. Phát hiện kết hợp trực quan hóa (biểu đồ hộp, biểu đồ phân tán, biểu đồ tần suất) với thống kê (Z-score, IQR).
Quan trọng: Không phải giá trị bất thường nào cũng là nhiễu! Kiến thức chuyên môn phân biệt outliers thực sự (lỗi) khỏi giá trị cực đoan hợp lệ.
Chiến lược xử lý:
| Kỹ thuật | Khi nào Sử dụng | Mô tả |
|---|---|---|
| Loại bỏ | Lỗi dữ liệu rõ ràng | Cảm biến hỏng, lỗi nhập liệu |
| Giới hạn | Hợp lệ nhưng cực đoan | Giới hạn ở phân vị (1%/99%) |
| Biến đổi | Phân phối lệch | Log/sqrt để giảm tác động |
| Giữ lại | Giá trị hợp pháp | Hiện tượng thực—tham khảo chuyên gia |
3.2.3. Loại bỏ Trùng lặp
Trùng lặp làm méo mó phân phối, tạo thiên lệch, và gây rò rỉ dữ liệu nếu có trong cả tập train/test.
Một số phương thức Pandas:
-
duplicated()- phát hiện trùng lặp -
drop_duplicates()- loại bỏ với các tùy chọn: -
keep='first'hoặckeep='last'- giữ một lần xuất hiện -
keep=False- xóa tất cả trùng lặp -
subset=['col1', 'col2']- dựa trên các cột cụ thể
Quan trọng: Kiểm tra trùng lặp TRƯỚC KHI chia train/test để tránh rò rỉ dữ liệu!
3.2.4. Chuẩn hóa Định dạng
Định dạng nhất quán ngăn ngừa lỗi khi xử lý dữ liệu đa nguồn.
Ví dụ:
| Loại Dữ liệu | Vấn đề | Giải pháp |
|---|---|---|
| Ngày/Giờ | Định dạng khác nhau, múi giờ | Chuyển sang ISO 8601 + UTC |
| Văn bản | Viết hoa, khoảng trắng, ký tự đặc biệt | Chữ thường, strip(), chuẩn hóa |
| Phân loại | Biến thể ("M", "Nam", "nam") | Map sang một chuẩn duy nhất |
| Số | Đơn vị hỗn hợp (kg/lbs, m/dặm) | Chuyển sang đơn vị thống nhất |
3.3. Phân tích Khám phá Dữ liệu (EDA)
Sau khi làm sạch, bạn phải hiểu dữ liệu của mình (EDA) trước khi tạo các đặc trưng mà mô hình có thể học (Kỹ thuật Đặc trưng).
EDA trả lời các câu hỏi quan trọng: Các đặc trưng của bạn có phân phối chuẩn hay lệch nhiều? Đặc trưng nào có mối quan hệ mạnh với biến mục tiêu? Có mẫu bất ngờ hoặc nhóm tự nhiên nào không? Những hiểu biết này trực tiếp thông báo cho các phép biến đổi và đặc trưng bạn sẽ tạo ở bước tiếp theo.
Hai Trụ cột của EDA: Số liệu vs. Mẫu
EDA kết hợp hai cách tiếp cận bổ sung làm việc cùng nhau để tiết lộ các mẫu dữ liệu:
- Phân tích Thống kê cung cấp các bản tóm tắt số—trung bình, trung vị, độ lệch chuẩn cho bạn biết về xu hướng trung tâm và độ phân tán, trong khi các hệ số tương quan định lượng mối quan hệ giữa các biến. Đo lường độ lệch tiết lộ nếu dữ liệu đối xứng hay nghiêng mạnh về một phía, hướng dẫn quyết định biến đổi.
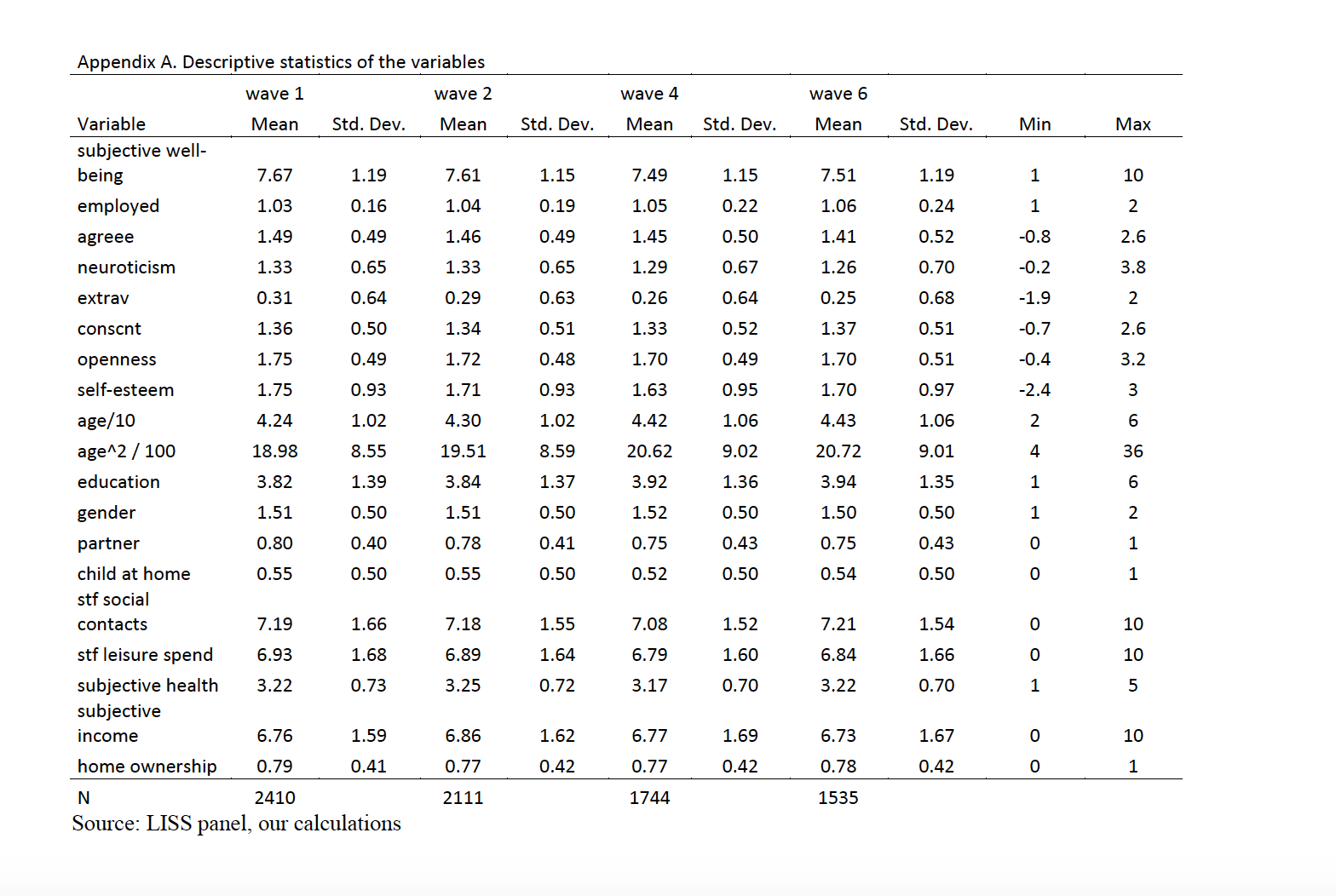
- Trực quan hóa tiết lộ những gì chỉ số đơn thuần có thể bỏ lỡ. Biểu đồ tần suất cho thấy dữ liệu lương của bạn có một đỉnh hay hai nhóm riêng biệt. Biểu đồ phân tán tiết lộ mối quan hệ phi tuyến mà các hệ số tương quan sẽ bỏ lỡ. Bản đồ nhiệt làm cho các mẫu trên hàng chục đặc trưng hiển thị ngay lập tức. Bộ não của bạn xử lý các mẫu hình ảnh nhanh hơn nhiều so với bảng số.
3.3.1. Phân tích Đơn biến
Trước khi xem xét các mối quan hệ, bạn phải hiểu từng biến một cách độc lập—giống như làm quen với từng nguyên liệu trước khi nấu ăn.
- Đặc trưng số, sử dụng
describe()cho "kiểm tra sức khỏe" thống kê (mean, median, std) và Biểu đồ tần suất để xem phân phối. - Đặc trưng phân loại nên được kiểm tra cân bằng bằng value_counts() và Biểu đồ đếm.
Câu hỏi Chính: Dữ liệu của tôi có lệch hoặc mất cân bằng không?
3.3.2. Phân tích Song biến
Tiếp theo, kiểm tra cách các cặp biến liên quan, đặc biệt với biến mục tiêu của bạn. Điều này tiết lộ đặc trưng nào thực sự "điều khiển" mô hình của bạn.
- Số vs. Số: Sử dụng Biểu đồ Phân tán để xem xu hướng (ví dụ: Kinh nghiệm vs. Lương).
- Phân loại vs. Số: Sử dụng Biểu đồ Hộp để xem phân phối thay đổi như thế nào giữa các nhóm (ví dụ: Lương theo Phòng ban).
Câu hỏi Chính: Đặc trưng nào cho thấy mối quan hệ rõ ràng với mục tiêu?
3.3.3. Phân tích Tương quan
Cuối cùng, lùi lại để xem mọi thứ liên quan đồng thời như thế nào. Ma trận Tương quan, được trực quan hóa dưới dạng Bản đồ Nhiệt, là công cụ chính của bạn ở đây.
Cái nhìn toàn diện này giúp bạn:
- Xác định các yếu tố dự đoán hàng đầu: Tìm các đặc trưng tương quan nhất với mục tiêu của bạn.
- Phát hiện dư thừa: Nếu hai đặc trưng tương quan trên 0.9, chúng dư thừa (Đa cộng tuyến).
- Tìm cơ hội cho kỹ thuật đặc trưng: Khám phá nơi kết hợp các đặc trưng có thể tạo ra tín hiệu mạnh hơn.
Câu hỏi Chính: 3-5 đặc trưng nào quan trọng nhất, và đặc trưng nào dư thừa?
3.4. Kỹ thuật Đặc trưng
Nếu EDA giúp con người hiểu dữ liệu, thì Kỹ thuật đặc trưng giúp AI hiểu được dữ liệu đó.
Dữ liệu thế giới thực rất đa dạng: văn bản, số, thời gian, danh mục, ngữ cảnh. Tuy nhiên, AI không thể học trực tiếp từ các dạng thông tin này nếu chúng không được chuyển đổi phù hợp.Kỹ thuật Đặc trưng là quá trình thiết kế và chuyển đổi dữ liệu sao cho mô hình có thể học hiệu quả hơn. Chất lượng đặc trưng thường ảnh hưởng đến kết quả nhiều hơn việc chọn thuật toán phức tạp hay đơn giản.

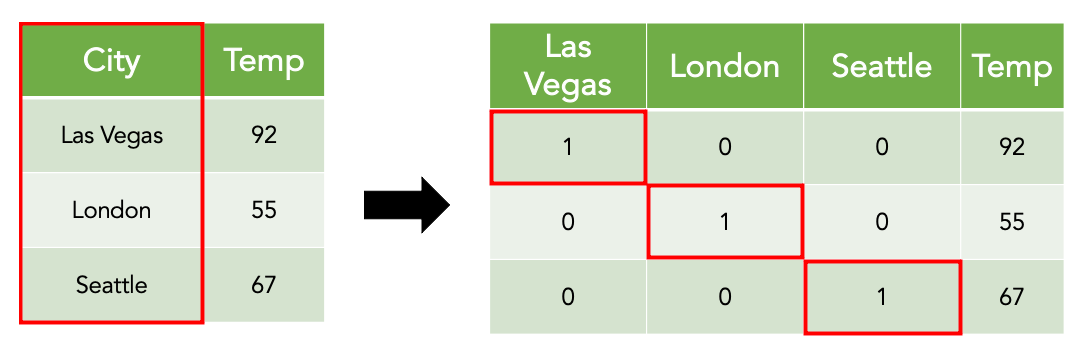
3.4.1. Mã hóa (Encoding)
Nhiều dữ liệu thế giới thực tồn tại dưới dạng văn bản hoặc nhãn phân loại, trong khi AI chỉ hoạt động với số. Mã hóa là cách chuyển đổi thông tin đó thành dạng số trong khi vẫn bảo toàn ý nghĩa ban đầu.
Tầm quan trọng của mã hóa không nằm ở kỹ thuật cụ thể, mà ở cách thông tin được biểu diễn. Mã hóa đúng cách giúp AI hiểu đúng mối quan hệ giữa các giá trị; ngược lại, mã hóa không phù hợp có thể khiến AI học sai, ngay cả khi dữ liệu gốc hoàn toàn chính xác.Do đó, mã hóa không chỉ đơn thuần là "đổi chữ thành số", mà là một bước diễn giải dữ liệu cho máy móc theo cách logic nhất.
3.4.2. Scaling (Chuẩn hóa)
Trong một tập dữ liệu, các đặc trưng thường có độ lớn rất khác nhau. Nếu những giá trị này được đưa trực tiếp vào mô hình, AI có thể bị ảnh hưởng bởi kích thước của số thay vì ý nghĩa thực sự của chúng. Điều này dẫn đến mô hình "chú ý" nhiều hơn đến các đặc trưng có giá trị lớn, ngay cả khi chúng chưa chắc quan trọng hơn.
Có thể tưởng tượng quá trình này như pha một ly nước trái cây. Để có ly nước ngon, điều quan trọng không phải là kích thước của từng loại trái cây, mà là tỷ lệ giữa chúng. Một quả táo lớn to hơn dâu tây không có nghĩa là táo quan trọng hơn dâu. Nếu không hiệu chỉnh, loại trái cây "to hơn" sẽ át đi hương vị của phần còn lại.

Scaling trong Machine Learning hoạt động theo nguyên tắc tương tự. Nó giúp đưa các đặc trưng về cùng sân chơi, để mô hình học dựa trên mối quan hệ thực tế trong dữ liệu, thay vì bị chi phối bởi độ lớn của giá trị. Nhờ scaling, các đặc trưng được "đối xử công bằng hơn" trong quá trình học.
Trong thực tế, scaling là một bước tiền xử lý rất quan trọng. Chỉ đơn giản scaling dữ liệu đúng cách có thể tạo ra sự khác biệt rõ rệt giữa một mô hình hoạt động kém và một mô hình ổn định, đáng tin cậy hơn.
3.4.3. Xây dựng Đặc trưng (Feature Construction)
Trong giai đoạn EDA, trực quan hóa dữ liệu và phân tích thống kê tiết lộ các mối quan hệ, xu hướng và bất thường giữa các biến. Những hiểu biết này trực tiếp thông báo cho Xây dựng Đặc trưng, nơi các đặc trưng mới được thiết kế để mã hóa các mẫu được phát hiện thành tín hiệu mà mô hình có thể đọc.
Xây dựng đặc trưng bao gồm việc kết hợp hoặc chuyển đổi các thuộc tính hiện có để tạo các đặc trưng có sức mạnh dự đoán mạnh hơn các biến gốc riêng lẻ. Ví dụ, các tương quan được quan sát trong EDA có thể gợi ý các số hạng tương tác, tỷ lệ, hoặc các đặc trưng tổng hợp đại diện tốt hơn các mối quan hệ thế giới thực.
Bằng cách dịch các hiểu biết khám phá thành các đặc trưng có cấu trúc, bước này hoạt động như cầu nối giữa hiểu biết dữ liệu thô và học tập mô hình hiệu quả. Các đặc trưng được xây dựng tốt cho phép các mô hình xuôi dòng nắm bắt các mẫu có ý nghĩa với kiến trúc đơn giản hơn và khả năng tổng quát hóa được cải thiện.
3.4.4. Lựa chọn Đặc trưng (Feature Selection)
Lựa chọn Đặc trưng đóng vai trò là bước lọc quan trọng trước khi mô hình hóa, đảm bảo rằng chỉ những đặc trưng có nhiều thông tin nhất được giữ lại.
Được hướng dẫn bởi các phát hiện EDA và phân tích tầm quan trọng của đặc trưng, giai đoạn này loại bỏ các đặc trưng dư thừa, tương quan cao, hoặc tác động thấp có thể gây nhiễu hoặc overfitting. Các kỹ thuật như ngưỡng tương quan, kiểm định thống kê, chính quy hóa, và điểm tầm quan trọng dựa trên mô hình thường được áp dụng.
Việc cắt tỉa các đặc trưng (prunning) tinh chỉnh không gian đầu vào cho giai đoạn mô hình hóa, dẫn đến huấn luyện nhanh hơn, mô hình dễ diễn giải hơn, và hiệu suất tốt hơn trên dữ liệu chưa thấy. Cùng nhau, xây dựng đặc trưng và lựa chọn đặc trưng tạo thành cốt lõi của kỹ thuật đặc trưng, chuyển đổi các hiểu biết khám phá thành biểu diễn nhỏ gọn và mạnh mẽ cho các mô hình machine learning.
3.5. Lựa chọn Mô hình
Trong kỷ nguyên AI hiện nay, hàng trăm hoặc hàng nghìn thuật toán và mô hình mọc lên mỗi tháng như nấm sau mưa. Điều này có thể khiến nhiều người cảm thấy choáng ngợp và không chắc chắn nên chọn gì để phục vụ tốt nhất nhu cầu của họ. Tất nhiên, bạn có thể chọn một mô hình khổng lồ với 300 tỷ tham số để làm bài tập về phân loại chữ số viết tay, nhưng điều đó giống như sử dụng Bugatti La Voiture Noire 1500 mã lực để đi chợ (trừ khi nhà bạn có nhà máy thủy điện riêng hoặc tổ tiên bạn trồng cây bưởi thần mọc RTX 5090).
Do đó, hiểu những gì bạn cần và hiểu những gì mỗi công nghệ có thể làm là rất, rất quan trọng. Các thuật toán Machine Learning hàng thập kỷ tuổi vẫn có thể vượt trội hơn các mô hình Deep Learning tiên tiến nhất trên các vấn đề cụ thể.
Mỗi mô hình đi kèm với Giả định Dữ liệu:
- Mô hình tuyến tính: Giả định mối quan hệ giữa các biến là tuyến tính.
- Mô hình dựa trên cây: Giả định dữ liệu có cấu trúc phân cấp, không yêu cầu chuẩn hóa quá nghiêm ngặt.
- Deep Learning: Giả định dữ liệu có các đặc trưng tiềm ẩn phức tạp, không có cấu trúc như pixel hình ảnh hoặc ngữ cảnh văn bản.

Định lý "No Free Lunch": Trong toán học và tối ưu hóa, định lý này chỉ ra: Không có thuật toán duy nhất tối ưu cho mọi vấn đề. Nếu một thuật toán cực kỳ mạnh mẽ trên một tập dữ liệu, nó thường trả giá bằng việc không hiệu quả trên tập khác. Đừng đi tìm "mô hình tốt nhất thế giới," hãy tìm mô hình phù hợp nhất với dữ liệu của bạn.
3.5.1. Học Máy - Machine Learning
Mặc dù đã tồn tại hàng thập kỷ kể từ khi ra đời, các thuật toán Machine Learning cổ điển vẫn có chỗ đứng nhờ hiệu quả và đơn giản của chúng. Một vài tên cơ bản bao gồm:
- Linear/Logistic Regression: Dùng để dự báo giá trị liên tục hoặc bài toán phân loại nhị phân đơn giản. Những thuật toán này thường được sử dụng làm baseline để so sánh với các mô hình mạnh mẽ khác.
- Decision Tree & Random Forest: Mạnh mẽ trong việc xử lý mối quan hệ phi tuyến và dữ liệu thiếu. Random Forest giúp giảm thiểu Overfitting thông qua cơ chế Ensemble Learning. Với sự ra đời và cải tiến liên tục của XGBoost hoặc AdaBoost, vai trò của chúng chỉ được củng cố thêm.
Công cụ: Scikit-learn vẫn là thư viện số 1 với quy trình chuẩn hóa: Pipeline -> Fit -> Predict. Thư viện này thường được sử dụng khi bạn cần triển khai nhanh và dễ dàng; tuy nhiên, nhược điểm là nó không hỗ trợ tùy chỉnh rất sâu các mô hình hiện có.
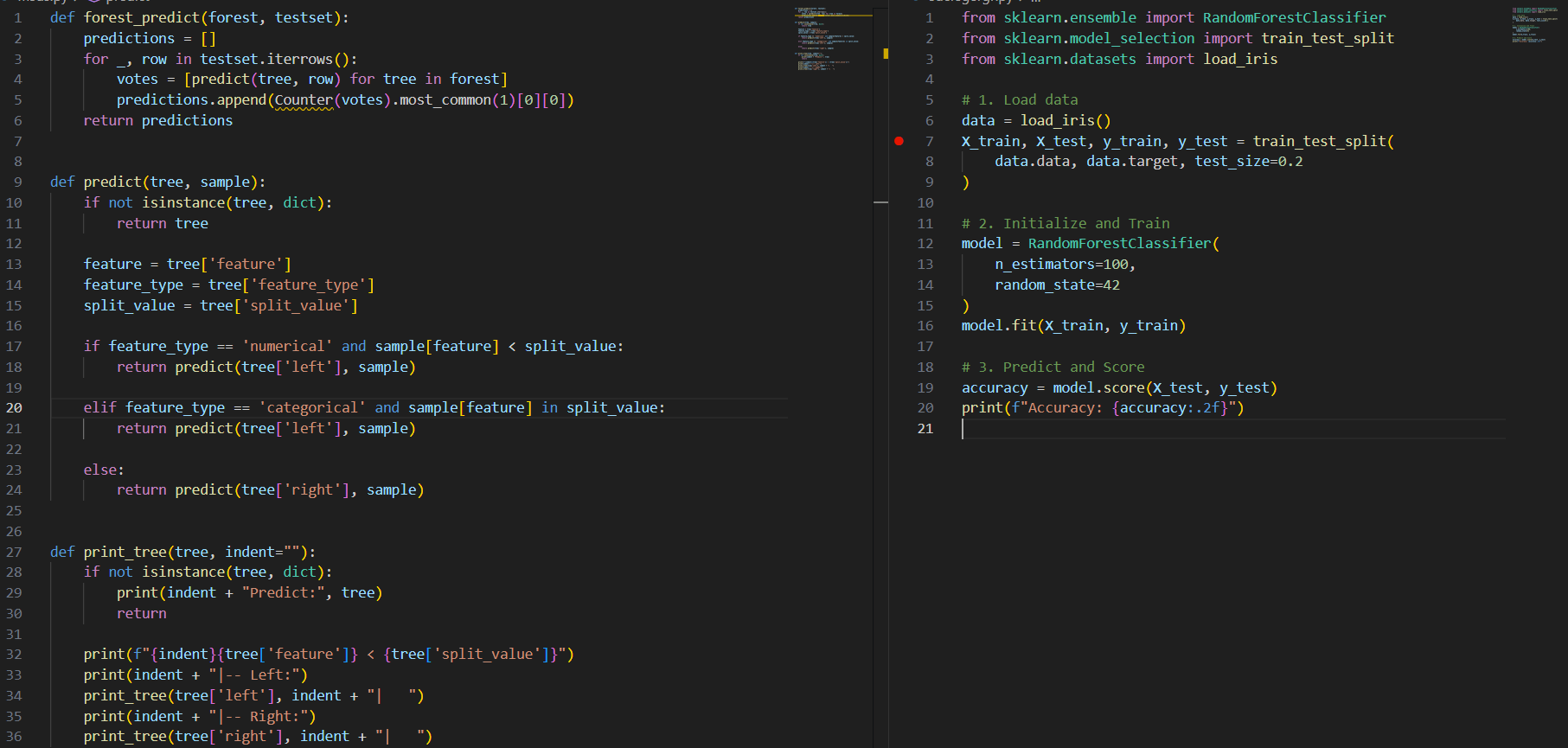
3.5.2. Deep Learning
Deep Learning đề cập đến các mô hình với hàng chục, thậm chí hàng trăm hoặc hàng nghìn 'tầng' chồng lên nhau theo các kiến trúc nhất định. Chúng là những siêu xe tốn một bát phở mỗi lần bạn đạp ga. Chúng có khả năng học các mối quan hệ phức tạp giữa các điểm dữ liệu mà không thể nhận ra với các mô hình ML đơn giản.
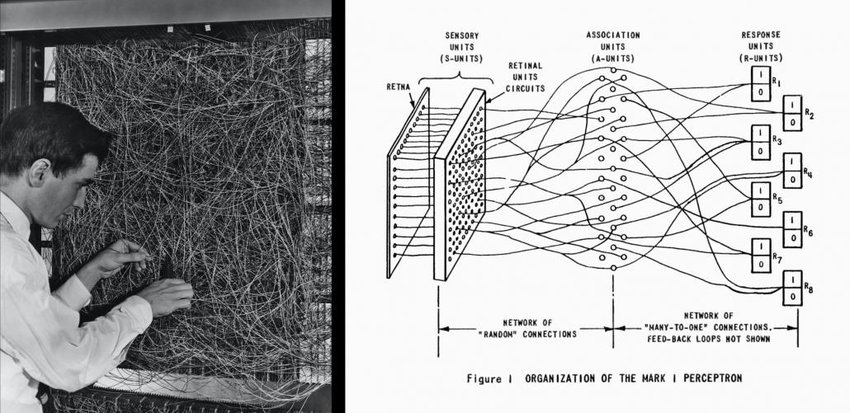
- Convolutional Neural Network (CNN): Xương sống của computer vision trong kỷ nguyên tiền-Transformer vào đầu những năm 2010. CNN học cách trích xuất các đặc trưng không gian thông qua các lớp tích chập và pooling, từ đó tự động nhận diện các đối tượng trong hình ảnh. Không chỉ vậy, CNN cũng đã chứng minh hiệu quả trong các vấn đề Xử lý Ngôn ngữ Tự nhiên (NLP) bằng cách xem một đoạn văn bản như một hình ảnh chỉ có một hàng pixel.
- Recurrent Neural Network (RNN): Nếu CNN là xương sống của computer vision, thì RNN và các biến thể hiện đại của nó (LSTM, GRU, v.v.) sẽ là xương chậu của xử lý ngôn ngữ tự nhiên (cho đến khi, tất nhiên, các robot biến hình Transformer từ Cybertron đến xâm chiếm Trái đất). RNN dựa vào một kiến trúc cho phép kết hợp thông tin từ các token (gọi tạm là 'từ') để đưa ra dự đoán cho token tiếp theo.
Đối với những mô hình mạnh mẽ nhưng cũng khổng lồ và phức tạp này, thư viện scikit-learn sẽ không đủ; thay vào đó, chúng ta cần chuyển sang các thư viện cấp thấp hơn để đảm bảo hiệu suất và khả năng tinh chỉnh theo yêu cầu vấn đề. Hai thư viện nổi tiếng nhất là PyTorch của Meta và TensorFlow của Google, nhưng có vẻ hiện tại Tensorflow nhận khá nhiều chỉ trích, khiến PyTorch trở thành lựa chọn tối ưu cho cả người mới bắt đầu và chuyên gia dày dạn kinh nghiệm.
Câu hỏi cho người đọc: Tại sao các mô hình thường chồng các lớp lên nhau thay vì trải chúng thành một lớp duy nhất? Tại sao Deep Neural Networks thống trị thay vì Wide Neural Networks?
3.5.3. Kiến trúc Transformer: Nền tảng của AI Hiện đại
Transformer đã hoàn toàn thay thế các mạng hồi quy như RNN và LSTM (mặc dù những người ủng hộ họ khá bất mãn và vẫn đang làm việc chăm chỉ để tạo ra các biến thể mới để truất ngôi Transformer). Và với sự ra đời của Vision Transformer (ViT) không lâu sau đó, ngay cả CNN cũng mất đi sự ưa chuộng. Để hiểu công nghệ cách mạng nhất của thế kỷ 21 hoạt động như thế nào, bạn cần thành thạo:
- Attention Mechanism: Linh hồn của Transformer, với câu nói và cũng là tiêu đề của bài báo bất tử: "Attention is all you need." Nó cho phép mô hình tính toán mức độ liên quan giữa tất cả các từ trong một câu (context-window) đồng thời, bất kể khoảng cách.
- Cấu trúc Encoder-Decoder: Hiểu cách BERT (chỉ Encoder), GPT (chỉ Decoder), và T5 (cả hai) hoạt động.
Transformer là thứ đứng sau sức mạnh của các Large Language Models (LLMs) đã hoàn toàn thay đổi cuộc sống của chúng ta chỉ trong vài năm.

3.5.4. Xu hướng AI Hiện tại: Fine-tuning và Tích hợp
Bạn có biết rằng để huấn luyện GPT-4, ra mắt ngày 14 tháng 3 năm 2023, OpenAI đã chi khoảng 100 triệu USD, nhưng chỉ hơn 2 năm sau, chi phí để huấn luyện mô hình GPT-5 đã lên tới hơn 1 tỷ USD? Nếu tính cả chi phí bảo trì và vận hành, một mô hình có quy mô đó cần thêm hàng tỷ USD và rất nhiều nước từ trẻ em châu Phi để bạn có thể trò chuyện với người bạn gái ChatGPT. Do đó, cuộc đua xây dựng mô hình từ đầu hiện nay chủ yếu là sân chơi cho các gã khổng lồ công nghệ, và các lập trình viên cá nhân cần học cách áp dụng các mô hình hiện có vào sản phẩm của họ. Một số kỹ năng bao gồm:
- LLMs API: Tích hợp trực tiếp sức mạnh của GPT-5, Claude 4, hoặc Gemini thông qua OpenAI/Anthropic/Google APIs để xây dựng ứng dụng nhanh chóng.
- Fine-tuning với Hugging Face: Sử dụng các kỹ thuật Parameter-Efficient Fine-Tuning (PEFT) như LoRA hoặc QLoRA để huấn luyện lại mô hình trên dữ liệu kinh doanh chuyên biệt với chi phí và yêu cầu tài nguyên thấp hơn nhiều so với huấn luyện từ đầu.
3.6. Đánh giá và Triển khai - MLOps
Một mô hình machine learning có thể đạt độ chính xác rất cao và hoạt động tốt trong quá trình thử nghiệm nhưng có thể không duy trì được hiệu quả khi đưa vào vận hành. Vấn đề thường không nằm ở thuật toán, mà ở sự biến động liên tục của dữ liệu thế giới thực. MLOps (Machine Learning Operations) ra đời để giải quyết vấn đề này và đã trở thành một kỹ năng rất hữu ích trong việc học lập trình AI. Dưới đây là 4 bước chính của MLOps:
3.6.1. Đánh giá Mô hình
Trong môi trường vận hành thực tế, một mô hình không thể được đánh giá chỉ dựa trên các chỉ số độ chính xác chuẩn. Việc lựa chọn chỉ số phải dựa trên đặc điểm cụ thể của từng vấn đề.
Ví dụ, khi xây dựng mô hình phát hiện gian lận tín dụng, mô hình đạt 99% độ chính xác. Tuy nhiên, trong hàng triệu giao dịch, nó chỉ xác định được 5 giao dịch gian lận và bỏ lỡ tới 95% các trường hợp gian lận thực tế. Chỉ số độ chính xác trở nên vô nghĩa ở đây vì gian lận vốn dĩ rất hiếm.
Đó là lý do tại sao chúng ta cần các chỉ số khác nhau tùy thuộc vào vấn đề:
-
Precision (Độ chính xác trên kết quả dự đoán): Tỷ lệ các trường hợp thực sự gian lận trong tổng số trường hợp hệ thống gán nhãn là gian lận. Precision cao giúp giảm thiểu báo động giả, đảm bảo trải nghiệm khách hàng không bị gián đoạn vô lý.
-
Recall (Tỷ lệ phát hiện): Tỷ lệ các trường hợp gian lận thực tế mà hệ thống bắt được thành công so với tổng số trường hợp gian lận hiện có. Recall cao giúp doanh nghiệp kiểm soát tổn thất, đảm bảo các hành vi gian lận không bị bỏ sót.
-
F1 Score: Một chỉ số cân bằng giữa Precision và Recall khi cả hai cần được tối ưu hóa.
Hệ thống thực tế thường giám sát nhiều chỉ số đồng thời. Một mô hình có thể trông rất tốt trên một chỉ số nhưng rất kém trên các chỉ số khác:
- Overfitting: Đây là khi một mô hình ghi nhớ các quy tắc ngẫu nhiên của dữ liệu huấn luyện thay vì học các đặc điểm chung. Kết quả là một mô hình đạt kết quả rất cao trong thử nghiệm nhưng thất bại khi áp dụng cho dữ liệu thế giới thực. Để kiểm soát điều này, chúng ta cần liên tục so sánh hiệu suất giữa tập dữ liệu huấn luyện và tập dữ liệu thử nghiệm.
3.6.2. Triển khai
Một mô hình nằm trong file Notebook (Jupyter) là một mô hình vô dụng. Nó cần được kết nối với các ứng dụng để phục vụ người dùng thực. Quá trình này phức tạp hơn nhiều so với chỉ tải code lên máy chủ.
Một mô hình thực tế phải có cơ sở hạ tầng kỹ thuật để đảm bảo hệ thống có thể hoạt động 24/7, xử lý hàng triệu yêu cầu đồng thời, và duy trì tốc độ phản hồi tính bằng mili giây. Một số kỹ thuật cơ bản thường được sử dụng:
-
Containerization (Docker): Hoàn toàn giải quyết xung đột môi trường bằng cách đóng gói mô hình cùng với tất cả các thư viện phụ thuộc thành một thực thể độc lập. Điều này đảm bảo tính nhất quán tuyệt đối: mô hình sẽ hoạt động chính xác như nhau dù được triển khai trên máy tính cá nhân, cơ sở hạ tầng tại chỗ, hay cụm máy chủ đám mây.
-
API: Hoạt động như một cầu nối chuẩn hóa, cho phép các hệ thống khác nhau tương tác và lấy kết quả dự đoán từ mô hình qua giao thức HTTP. Sử dụng các framework hiện đại giúp tối ưu hóa tốc độ phản hồi (latency) và đảm bảo bảo mật trong quá trình truyền dữ liệu.
-
Cloud Platforms: Cung cấp các công cụ chuyên biệt để tự động hóa toàn bộ vòng đời mô hình. Các nền tảng này cho phép hệ thống tự động mở rộng tài nguyên (autoscaling) theo lưu lượng thực tế, đồng thời hỗ trợ quản lý khoa học nhiều phiên bản mô hình mà không cần can thiệp cơ sở hạ tầng thủ công.
Triển khai Deployment trên Gradio / Streamlit
Đối với triển khai giai đoạn đầu, tạo mẫu và mục đích trình diễn, các công cụ như Gradio và Streamlit thường được sử dụng để hiển thị các mô hình machine learning thông qua giao diện web tương tác với chi phí kỹ thuật tối thiểu.
Các framework này cho phép người thực hành nhanh chóng gói các mô hình đã huấn luyện thành các ứng dụng hướng đến người dùng, cho phép các bên liên quan kiểm tra hành vi mô hình, trực quan hóa dự đoán, và xác thực giả định trước khi triển khai sản xuất quy mô đầy đủ.
Tuy nhiên, Gradio và Streamlit thường không được thiết kế cho các hệ thống sản xuất thông lượng cao, độ trễ thấp. Chúng được định vị tốt nhất là:
- Công cụ tạo mẫu và thử nghiệm
- Demo nội bộ và triển khai bằng chứng khái niệm (PoC)
- Xác thực mô hình trước khi triển khai dựa trên API hoặc đám mây
Trong các quy trình MLOps thực tế, các ứng dụng được xây dựng với Gradio hoặc Streamlit có thể phục vụ như các lớp giao diện người dùng, trong khi logic suy luận cốt lõi được triển khai dưới dạng API để có thể mở rộng.
3.6.3. Giám sát
Không giống như phần mềm truyền thống chỉ lỗi khi hệ thống gặp sự cố, một mô hình AI có thể vẫn có hệ thống đang chạy nhưng kết quả dự đoán không còn chính xác do thay đổi trong dữ liệu thực.
-
Data Drift: Xảy ra khi đặc điểm của dữ liệu đầu vào hiện tại khác biệt đáng kể so với dữ liệu được sử dụng để huấn luyện trước đó.
-
Concept Drift: Xảy ra khi mối quan hệ cơ bản giữa dữ liệu và kết quả đầu ra đã thay đổi (ví dụ: hành vi tiêu dùng thay đổi sau biến động kinh tế).
-
Giám sát Vận hành: Theo dõi các chỉ số cơ sở hạ tầng như độ trễ phản hồi, tỷ lệ lỗi hệ thống, và lưu lượng truy cập để can thiệp kịp thời trước khi ảnh hưởng đến người dùng cuối.
3.6.4. Tự động hóa
Khi số lượng mô hình tăng lên, quản lý thủ công sẽ dẫn đến chi phí cao về thời gian, nguồn nhân lực, và rủi ro lỗi cao. Một số giải pháp tự động hóa cơ bản bao gồm:
-
Continuous Retraining: Thiết lập các pipeline dữ liệu tự động cập nhật mô hình khi phát hiện suy giảm hiệu suất hoặc khi có đủ dữ liệu mới.
-
CI/CD for Machine Learning: Áp dụng các tiêu chuẩn kỹ thuật phần mềm để tự động kiểm tra đơn vị, kiểm tra hiệu suất, và xác định độ trễ trước khi cho phép một mô hình mới được cập nhật trên hệ thống.
-
Orchestration: Sử dụng các công cụ phối hợp để kiểm soát toàn bộ vòng đời mô hình từ thu thập dữ liệu, huấn luyện, đến triển khai. Điều này đảm bảo khả năng truy xuất nguồn gốc và giảm thiểu lỗi do yếu tố con người.
Lời kết
Học lập trình AI không phải là ghi nhớ các thuật toán hoặc theo đuổi các mô hình mới nhất, mà là hiểu cách dữ liệu được chuyển đổi thành quyết định trong các hệ thống thực. Từ thu thập và làm sạch dữ liệu, qua EDA và kỹ thuật đặc trưng, đến lựa chọn mô hình, đánh giá, triển khai, và giám sát, mỗi giai đoạn trong quy trình đóng vai trò quan trọng trong việc xác định liệu một hệ thống AI có thực sự hoạt động bên ngoài phòng thí nghiệm hay không.
Tài liệu Tham khảo
Flare, C. (2023, May 22). Difference between Matplotlib VS Seaborn. Console Flare Blog. https://www.consoleflare.com/blog/matplotlib-vs-seaborn/
GeeksforGeeks. (2025, November 8). What is Feature Engineering? GeeksforGeeks. https://www.geeksforgeeks.org/machine-learning/what-is-feature-engineering/
Roy, B. (2025, January 21). All about Feature Scaling. Towards Data Science. https://towardsdatascience.com/all-about-feature-scaling-bcc0ad75cb35/
Sang, D. (n.d.). Phân tích thống kê mô tả bằng SPSS – Phần 1: Thống kê trung bình - Hệ thống thông tin Thống kê KH&CN. https://thongke.cesti.gov.vn/dich-vu-thong-ke/tai-lieu-phan-tich-thong-ke/1025-phan-tich-thong-ke-mo-ta-spss-trung-binh
Thaddeussegura. (2021, June 30). "Data encoding" explained in 200 words. Data Science - One Question at a Time. https://thaddeus-segura.com/encoding/
Chưa có bình luận nào. Hãy là người đầu tiên!