
The article is produced by team CONQ013
Added Co-author: Ngo Tinh Giang Nguyen
I. Overview: What is AI and the Main Domains of AI
Artificial Intelligence (AI) is a broad field of computer science that focuses on creating systems capable of performing tasks considered to require “human intelligence,” such as learning from data, recognizing patterns, understanding language, and making decisions. AI is not a single technology, but an ecosystem consisting of many different domains, each solving a specific group of problems with its own set of tools and characteristic algorithms. Understanding these domains from the beginning is important for choosing the right learning direction and accurately positioning your career.
Real-world problems are very diverse: some involve images/videos, some involve language, others involve tabular data, and each type of problem requires specific knowledge and techniques to solve. Typical domains in AI today include:
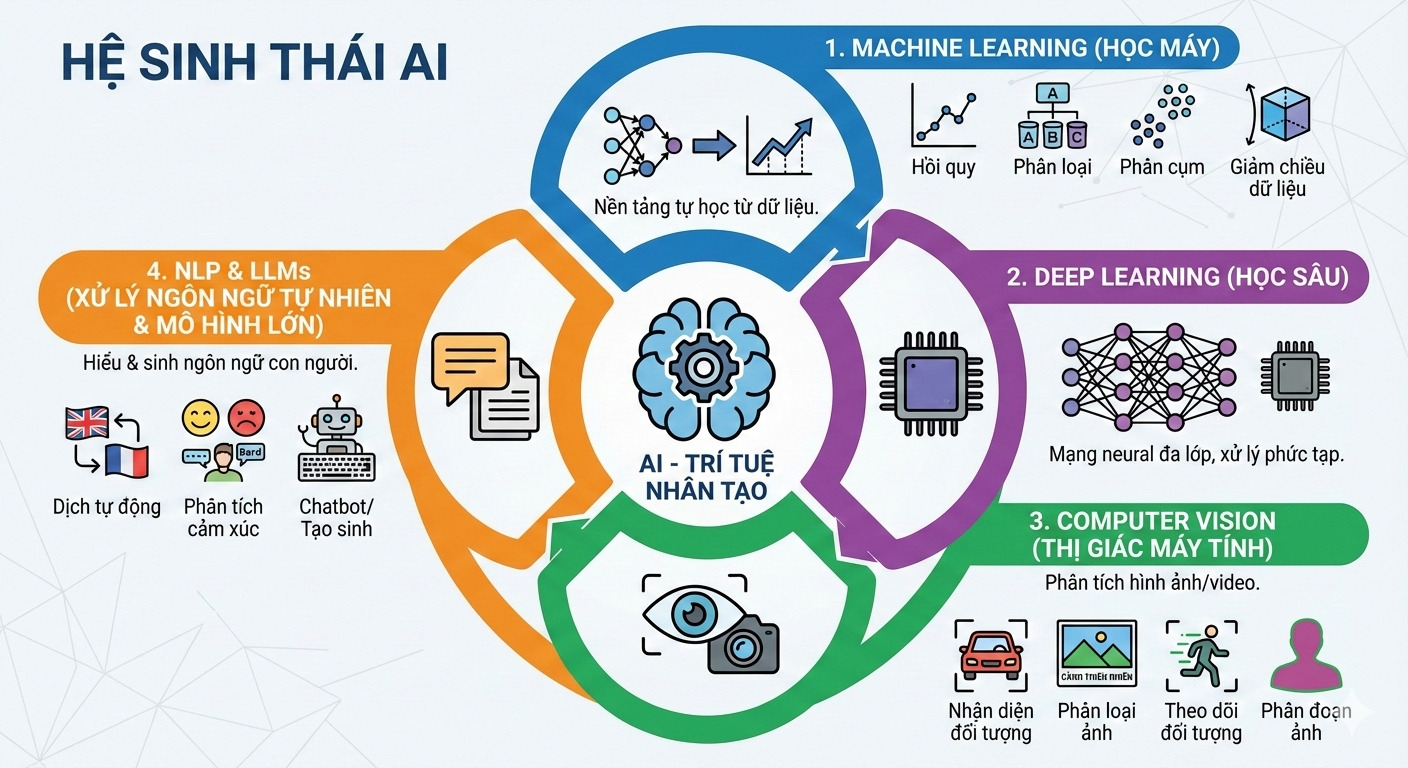
The image was generated by AI Nano Banana Pro based on the team’s content
1. Machine Learning (ML)
This is the foundation that allows machines to learn from data and improve performance over time without manually programming rules. It provides algorithms to find patterns, make predictions, classify, and detect trends in big data. This is the broadest domain, acting as the “operating system” for most other domains.
In practice:
- Main applications: Recommendation systems (Netflix, YouTube), email spam filtering, price/cost prediction, financial risk analysis, user behavior modeling.
Common tasks included:
-
Regression: Predict continuous values (e.g., revenue prediction, house price prediction).
-
Classification: Classify data into different groups/labels (e.g., predicting whether customers are likely to churn or stop purchasing).
-
Clustering: Group unlabeled data based on similarity.
-
Dimensionality Reduction: Reduce the number of input features to speed up computation and reduce noise while retaining the most important information.
Each task has classic algorithms (e.g., linear regression, decision trees, k-means, PCA, etc.). Mastering these concepts is the first important step in building any AI application.
2. Deep Learning (DL)
Deep learning is a branch of machine learning that uses multilayer neural networks to process complex data. These models simulate the structure of the human brain through many layers of “neurons,” helping to automatically learn and extract high-level features. Thanks to this flexible structure, deep learning provides great power for most advanced AI systems today.
- For example, modern computer vision applications, machine translation, speech recognition, and autonomous vehicles all rely on deep learning. Many large deep learning models (such as Transformer) are also the foundation of large language models (LLMs), powering generative applications like ChatGPT or Bard.
3. Computer Vision (CV)
Computer vision is the technology that allows machines to automatically recognize and analyze images or videos. CV systems use AI/ML to extract features from images and perform tasks such as:
- Object Detection: Identify and locate objects in images/videos (e.g., detecting pedestrians and vehicles in traffic images).
- Image Classification: Determine the class of an image (e.g., classifying an image as “nature,” “street,” “interior”).
- Object Tracking: Track movement of detected objects across video frames.
- Segmentation: Divide images into regions corresponding to objects (e.g., precisely marking shapes of cars and people).
Modern CV systems often apply deep networks like CNN to increase accuracy. For example, security cameras can analyze video and automatically alert when suspicious movement is detected.
4. Natural Language Processing (NLP) & Large Language Models (LLMs)
NLP includes techniques that help machines understand and generate human language. Applications include machine translation, text summarization, sentiment analysis, chatbots. LLMs are deep learning models trained on huge amounts of text, enabling them to understand and generate natural language for various tasks. Thanks to this capability, LLMs have become core technology for intelligent chatbots and NLP applications. Techniques like Prompt Engineering and RAG allow models to retrieve external knowledge before generating answers.
II. AI Processing Pipeline & Corresponding Roles in Real Systems
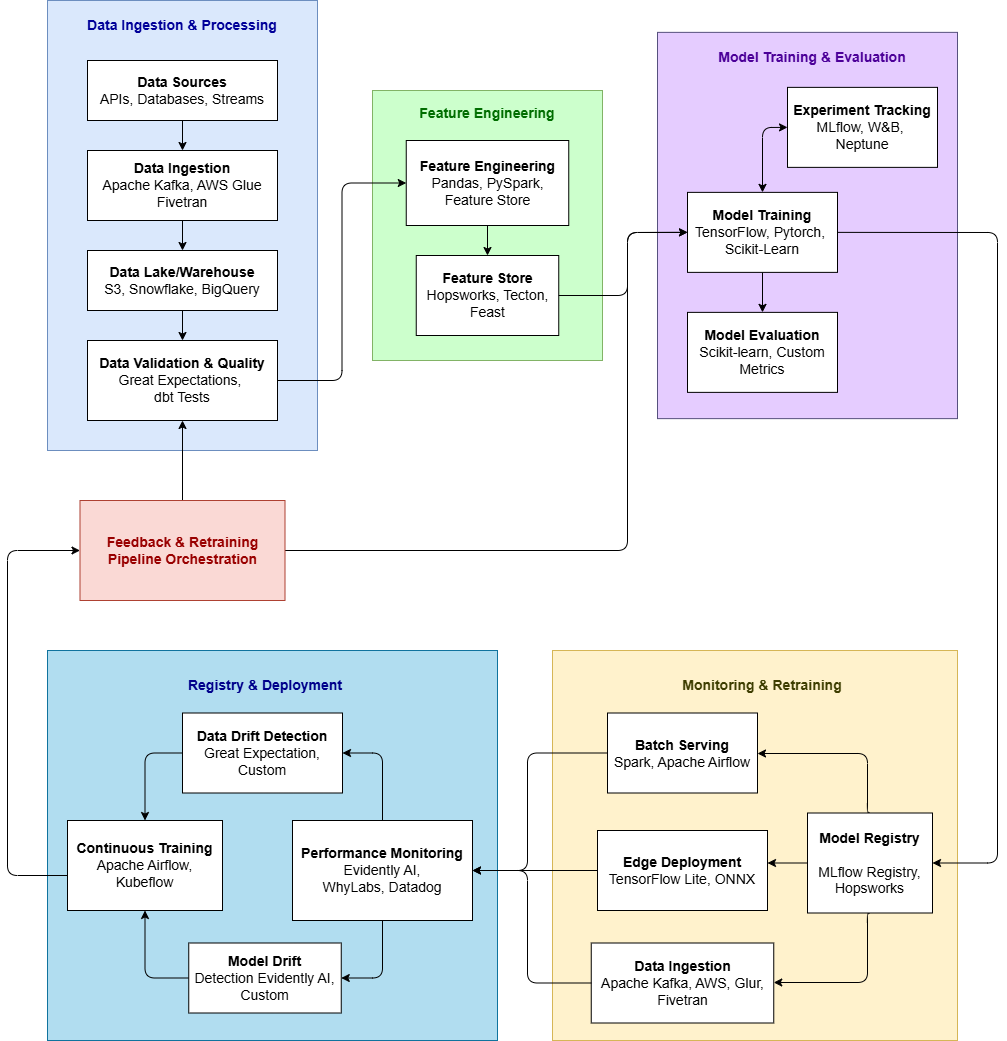
Diagram describing end-to-end AI/ML pipeline
The table below shows the entire AI/ML development and operation cycle, attached to main and supporting roles at each step.
| No | Stage | Main goal | Core content | Typical tools | Mainly responsible | Support roles | Responsibility |
|---|---|---|---|---|---|---|---|
| 1 | Data Collection | Collect raw data from multiple sources | Connect DB, API, IoT; preserve original data | Kafka, AWS Glue, Fivetran | Data Engineer | MLE, MLOps, DS | Design & operate ingestion pipeline; manage schema |
| 2 | Data Processing & Transformation | Standardize data for ML | Cleaning, handle missing/outlier, normalization, preprocessing | Pandas, Spark, PySpark, dbt | Data Engineer | Analytics Eng, DS | Clean & standardize data; create standard training data |
| 3 | Feature Store | Store & reuse features | Ensure feature consistency between training & deployment | Feast, Tecton, Hopsworks | MLOps Engineer | Data Eng, DS | Manage feature store & data consistency |
| 4 | Model Training & Experimentation | Find the best model & configuration | Select algorithms, hyperparameter tuning, cross-validation | Scikit-learn, PyTorch, TensorFlow | Data Scientist / AI Engineer | ML Engineer | Train model, tune, document experiments |
| 5 | Model Evaluation | Validate real-world performance | Evaluate on test/validation set with appropriate metrics | Accuracy, Precision, Recall, F1 | Data Scientist | Product Manager, AI Engineer | Compare models and select the best one |
| 6 | Model Registry | Manage model lifecycle | Store versions, reproducibility, stage/approve models | MLflow, Hopsworks | MLOps Engineer | DS, ML Engineer, AI Engineer | Store & track model versions |
| 7 | Model Deployment | Deploy model to production | Real-time/batch/edge inference; expose model via API | FastAPI, Triton, Airflow | ML Engineer / AI Engineer | MLOps, DevOps | Deploy & operate model for users/system |
| 8 | Monitoring | Detect performance degradation | Track accuracy, latency, data/concept drift | Evidently AI, WhyLabs, Prometheus | MLOps Engineer / ML Engineer | DS, AI Engineer | Monitor model & data performance |
| 9 | Continuous Training | Keep model up to date | Automatic retraining based on time/data/performance | Airflow, Kubeflow, Prefect | MLOps Engineer / AI Engineer | ML Engineer, DS | Automatically trigger retraining when needed |
III. AI Fundamental Knowledge
- Mathematics: Linear Algebra, Calculus, Probability & Statistics
- Programming: Python, data processing
- Machine Learning: types and metrics
- Deep Learning: CNN, RNN, Transformer
- Generative AI & LLMs: Prompting, Fine-tuning, RAG
1. Mathematics
Mathematics helps describe data as numbers, measure model errors, and show how to adjust to learn better.
1.1. Linear Algebra
Machines do not have senses like humans, so everything must be converted into numbers. Linear Algebra provides representation through vectors and matrices.
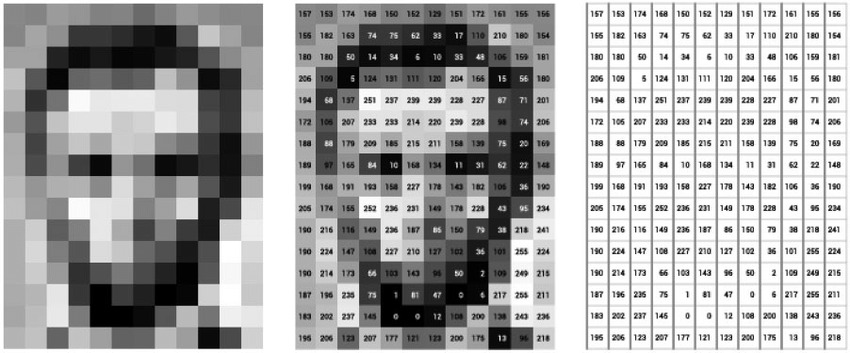
Text is converted into embeddings:

1.2. Calculus
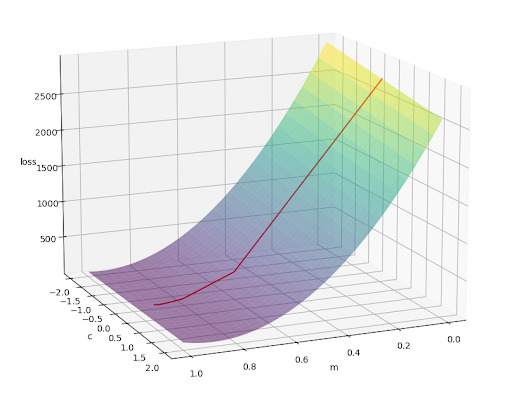
Once the data has been converted into numerical form, AI begins to learn by making predictions. However, these initial predictions are almost always wrong. This is where Calculus comes into play to help the AI adjust itself. Derivatives tell the AI not just whether it is right or wrong, but how large the error is and in which direction the adjustment should be made. This process is called Gradient Descent: the AI gradually updates its parameters to reduce the “loss,” which represents the overall level of error. You can think of derivatives as a way of knowing how far off track you are and how to turn back in the right direction, rather than simply realizing that you are wrong.
1.3. Probability & Statistics
Even after training is complete, AI is rarely absolutely certain. Instead of saying “right” or “wrong,” AI usually expresses conclusions in terms of likelihood, such as “it is highly probable that…”. Probability enables AI to handle uncertainty, while Statistics helps humans assess whether the AI’s results are reliable. Concepts like probability, distributions, and Bayes allow AI to “update its beliefs” when new data arrives, much like humans change their minds when they gain more information. At the same time, Statistics forms the foundation of the evaluation metrics mentioned in the Machine Learning section, helping us understand where the AI performs well and where it struggles, rather than relying on a single number.
Conclusion: Mathematics in AI is not meant to turn you into a mathematician. It exists to answer three very practical questions: in what form does the machine see the world, how much does the machine know it is wrong, and how reliable is this result. Once you understand that, you will no longer see mathematics as a nightmare or a barrier as it once was, but rather as a practical and intuitive tool that helps you “communicate” with AI.
2. Programming
Why is Python the main language in AI?
Python is not the fastest or most complex language, but it has become the primary language in AI because it is easy to read, easy to write, and easy to experiment with. Python’s syntax is close to human thinking, allowing learners to focus on problem logic rather than complicated syntax. Its rich library ecosystem has also made Python the “common language” of the AI community, from research to real-world applications.
NumPy
In AI, data often exists in the form of vectors and matrices, as mentioned in the mathematics section. NumPy is the library that enables efficient manipulation of these structures. Instead of writing complex loops, NumPy allows processing thousands or even millions of numbers at once. NumPy can be seen as the direct bridge between theoretical Linear Algebra and practical computation.
Pandas
Real-world data is rarely as clean as in textbooks. It can be missing, incorrect, duplicated, or messy. Pandas exists to help work with tabular data: filtering, sorting, merging, and cleaning data before feeding it into models. In many AI projects, most of the time is not spent on training models, but on processing data—and Pandas is the main tool for that.

Frameworks for ML & DL
* Scikit-learn: The standard library for traditional Machine Learning algorithms—provides simple APIs to train, test, and compare models such as regression, classification, and clustering.
-
PyTorch: A popular Deep Learning framework, suitable for research, prototyping, and deploying deep neural models.
-
TensorFlow: A Deep Learning framework suitable for large-scale and production applications, with a diverse ecosystem and multi-platform deployment support.
3. Machine Learning
Machine Learning is the way computers learn by trying to give answers, receiving feedback on right or wrong, and adjusting to do better next time. Unlike humans, machines do not need to understand why an answer is correct—they only need to know how wrong they were and how to adjust.
A familiar meme illustrates how Machine Learning works: an interviewer asks, “What is 9 + 10?” The first answer is 3—completely wrong. The interviewer only says, “Wrong, it must be 19.” Next time the answer is adjusted to 16, then 18, and finally 19. Even though it took four attempts to get the correct result, the candidate still gets hired.
The responder does not understand addition at all, but through repeated corrections, the answer gets closer to the truth. That is Machine Learning: not learning by understanding concepts, but by continuously reducing error based on feedback.

3.1. Types of MLs
| Learning Type | Labeled? | Learning Approach | Common Applications |
|---|---|---|---|
| Supervised Learning | Labeled | Model predicts → compare with ground truth → adjust error over multiple iterations | Image recognition, spam email filtering, price prediction |
| Semi-Supervised Learning | Partially labeled | Combine a small amount of labeled data + large amount of unlabeled data to learn better | Image recognition, NLP with limited labeled data |
| Unsupervised Learning | Unlabeled | Model discovers patterns and structures based on similarity | Customer segmentation, content recommendation, dimensionality reduction |
| Reinforcement Learning | No predefined answer | Take action → receive reward/penalty → adjust strategy | Game AI, robotics, self-driving cars, control systems |
3.2. Evaluation metrics
In Machine Learning, a model that runs does not mean it works well in reality. Metrics such as Accuracy, Precision, Recall, and F1-Score help evaluate models from multiple perspectives rather than relying on a single number.
| Metric | Measures | Why it matters |
|---|---|---|
| Accuracy | Correct predictions / total | Misleading on imbalanced data |
| Precision | Among predicted positives, how many are correct | Important when false positives are costly |
| Recall | Among real positives, how many detected | Important when missing is dangerous |
| F1-Score | Balance between Precision & Recall | Useful for imbalanced data |
4. Deep Learning
Deep Learning is a special branch of Machine Learning that allows AI to automatically extract features from large and complex raw data without humans specifying what to look for. It is widely used in vision and language.
4.1. CNN (Convolutional Neural Network)
CNN is used when data has spatial structure like images and videos. Instead of viewing the whole image at once, CNN observes small regions and combines them—similar to how human eyes scan details before recognizing the whole picture.
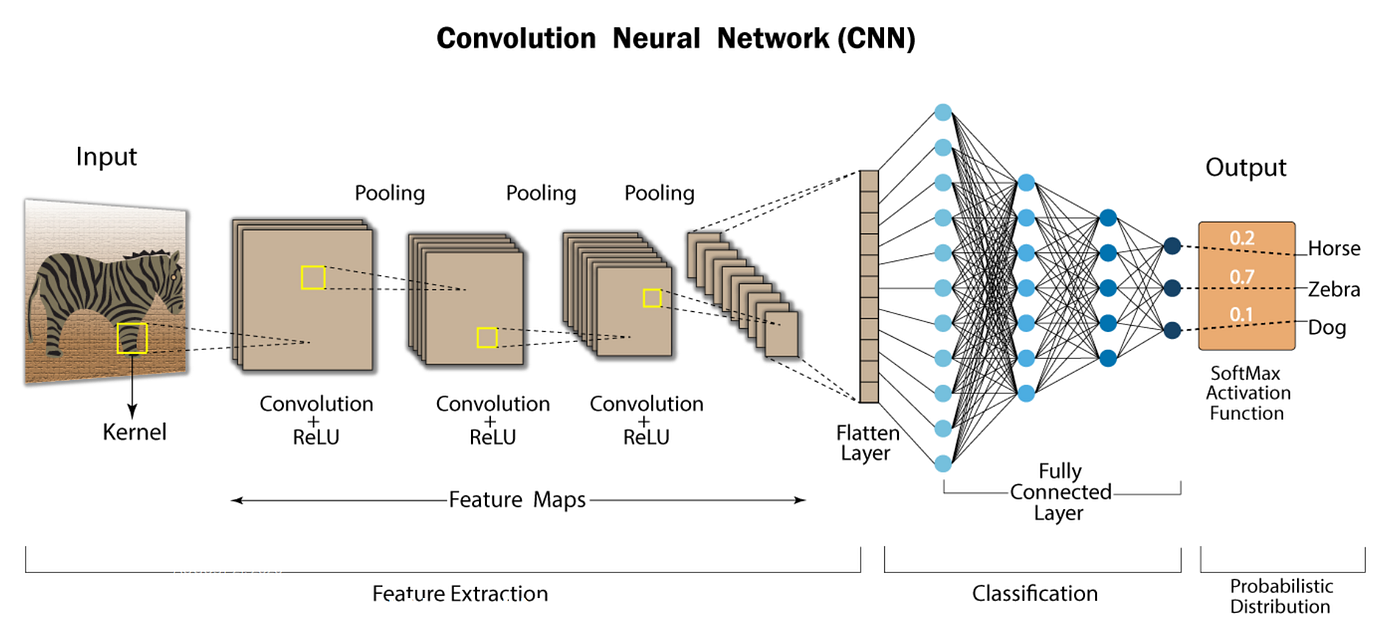
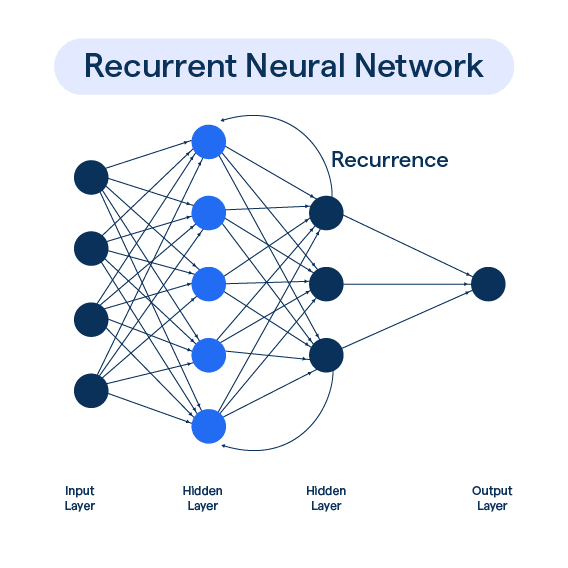
4.2. RNN (Recurrent Neural Network)
RNN is designed for sequential data such as text or audio. It processes step by step and remembers previous information. However, with long sequences, RNN tends to “forget,” like a person forgetting the beginning of a long story.
4.3. Transformer
Transformer solves this by using self-attention to view the entire sequence at once and determine which parts are important. Most modern language models like ChatGPT are based on Transformer architecture.
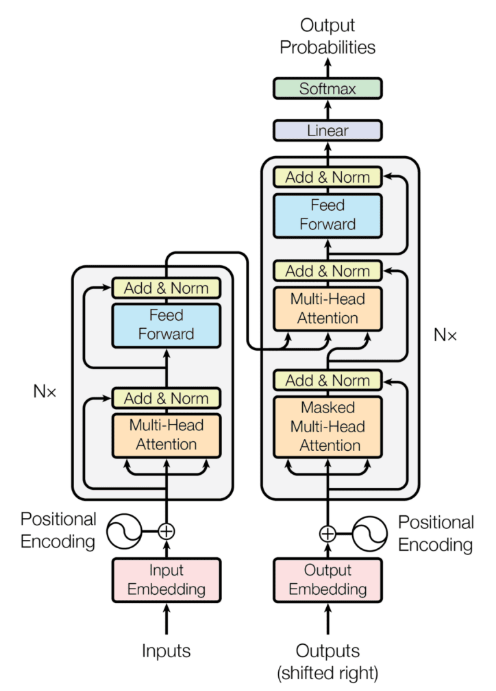
5. Generative AI & LLMs
Generative AI can create new content such as text, images, audio, or code instead of just predicting or classifying. LLMs are Generative AI specialized for language. They do not truly “understand” the world—they predict the next token based on massive data, and when large enough, this looks like reasoning.
5.1. Prompting
An LLM does not know your goal unless you clearly state it. Prompting is the way of asking questions and providing context to guide the LLM toward the desired output. The more ambiguous the prompt, the more likely the result will deviate; the clearer the role, context, and output requirements, the more stable the result becomes. Prompting can be compared to assigning a task to a newcomer: the more specific the instructions, the more accurately the task will be completed. Prompting does not make AI smarter, but it helps you leverage the capabilities that the AI already possesses.
5.2. Fine-tuning
When a fixed style, internal terminology, or consistent behavior is required, prompting is often not enough. Fine-tuning is the process of adjusting a model using private data to “shape” its responses. It is similar to training an employee according to company culture: not teaching new general knowledge, but teaching how to respond and behave according to specific standards. However, fine-tuning requires significant effort in data preparation and careful control to avoid bias or overfitting.
5.3. RAG (Retrieval-Augmented Generation)
A well-known problem of LLMs is hallucination: answers that sound confident but are incorrect, especially when information is lacking. RAG solves this by allowing the LLM to retrieve real documents before generating an answer. The simple workflow is: question → search for relevant sources (database, internal documents) → inject those sources into context → LLM answers based on them. Thanks to this, RAG reduces fabrication because the AI does not have to “remember” everything but can “open the book” when needed. Compared to fine-tuning, RAG is more flexible when data changes frequently.
IV. AI Roles Currently “Working” in Enterprises
The next step is identifying suitable career roles in the market. In reality, the AI industry has many positions, but the three core roles most commonly mentioned are AI Researcher, ML Engineer, and AI Engineer. Each role has its own focus, required skills, and development path. However, the boundaries between these roles are becoming increasingly blurred, especially between ML Engineers and AI Engineers. The most important thing is to build a solid foundation in mathematics, programming, and machine learning, then flexibly develop in a direction that matches personal interests and career opportunities. No matter which path you choose, continuous learning and knowledge updating are mandatory in this rapidly evolving AI industry.
| Role | Main Focus | Typical Tasks | Suitable For | Education Goal |
|---|---|---|---|---|
| AI Researcher | Develop new theories and algorithms | Read & analyze scientific papers; propose & validate hypotheses; design experiments; write & present at NeurIPS/ICML/CVPR | People who love research, enjoy solving unsolved problems, strong in math & theory | Master/PhD (PhD preferred) |
| ML Engineer | Bring models from research to real products | Build data pipelines; train & optimize models; deploy models; monitor performance | People who like building end-to-end systems with software & big data | Bachelor (Master helpful) |
| AI Engineer | Build complete AI applications | Design & integrate AI apps; use LLM/GenAI; build RAG, prompt engineering; ensure AI safety | People who want to create real AI products, love new tech & product mindset | Bachelor (Master is a plus) |
-
AI Researchers often require deep academic background and publications; many positions demand PhD or Master due to high theoretical research nature and the need to read/write scientific papers.
-
ML Engineers are highly technical—productionizing real models, suitable for those with a bachelor’s degree in related fields and skills in software engineering + ML pipeline.
-
AI Engineers focus on applying AI into real products, especially LLM integration and building complete solutions; usually require at least a bachelor’s degree and more emphasis on implementation and product thinking than complex model theory.
V. AI Competency Map for Career Development
1.Assessing Levels of Understanding
In a vast and intricate field like AI, there are countless tools and libraries that can be used with just a few simple lines of code. However, this convenience can be a double-edged sword, making learners easily feel overwhelmed by the enormous amount of knowledge and unsure where to start or what to focus on. Therefore, in this section, we aim to clearly divide levels of understanding so readers can self-assess and build a more effective learning path.
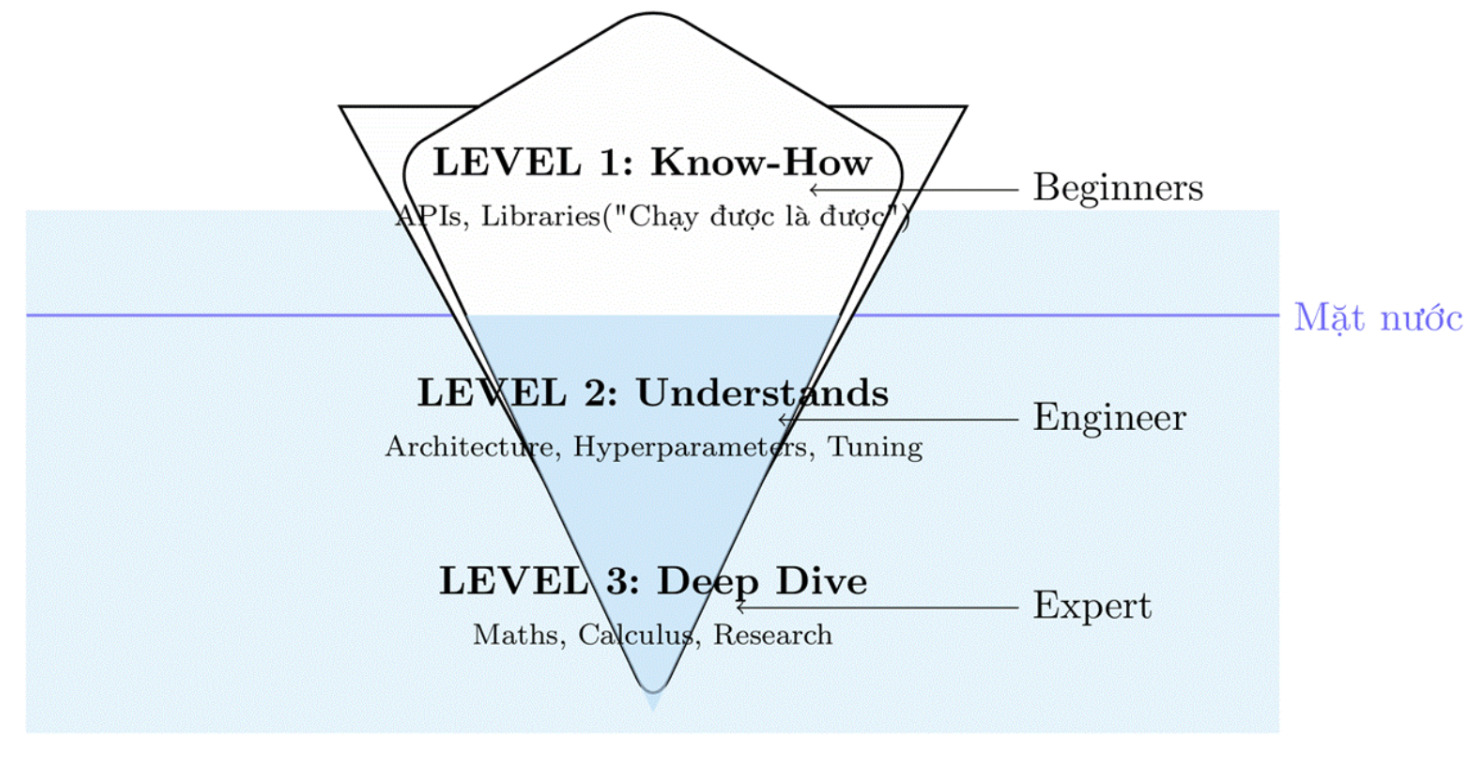
| Level | Brief Description | Concrete Indicators |
|---|---|---|
| Level 1 – Know-How | Able to use AI tools/libraries without understanding inner mechanisms | • Call OpenAI API• Use scikit-learn to train basic models• Run sample code on GitHub |
| Level 2 – Understands | Start digging into how things work, understand data flow | • Understand input/output of neural layers• Know overfitting and prevention• Understand RAG flow• Fine-tune models on Hugging Face |
| Level 3 – Deep Dive | Able to build & optimize AI systems, question fundamentals | • Re-code algorithms from scratch• Read new research papers• Optimize model architecture• Replicate research results |
2. Professional Skills
In the previous sections, we focused on the three roles most visible to AI beginners: ML Engineer, AI Engineer, and AI Researcher. We divide necessary skills into four groups: Math & Theory, Coding & Engineering, Data Processing, and Paper Reading.
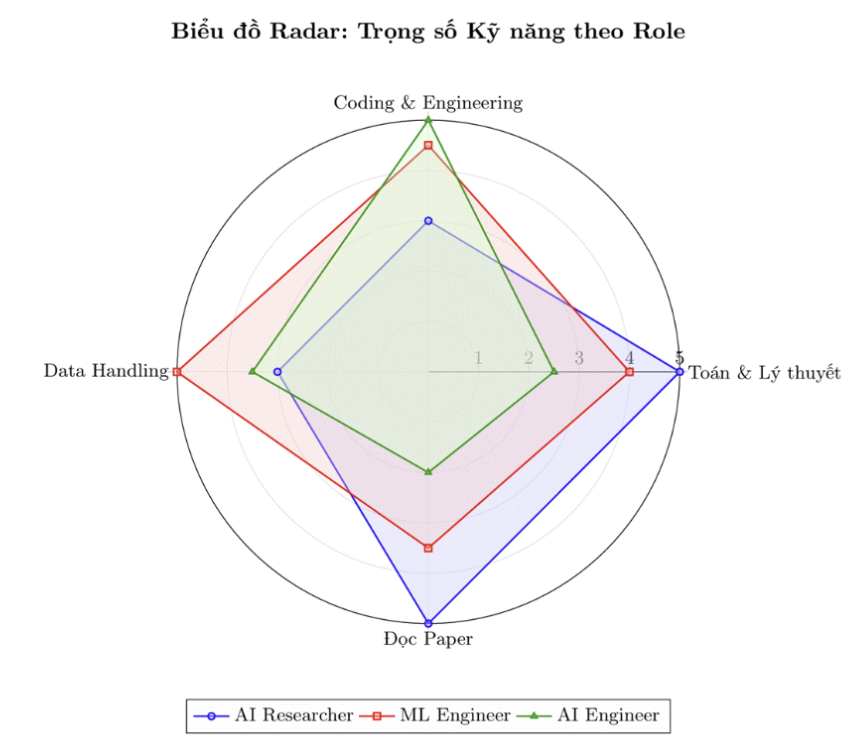
Radar diagram for essential skills for each roles, ranked from 1 to 5 (Low to High)
It can be seen that AI Researchers require very deep theoretical and mathematical foundations to develop new knowledge and algorithms, while ML Engineers are closer to research in the sense of understanding and building models end-to-end for real products. In contrast, AI Engineers focus more on applying existing models into products, requiring software development mindset and system deployment skills rather than discovering new algorithms.
| Area | AI Researcher | ML Engineer | AI Engineer |
|---|---|---|---|
| Mathematics | Very deep | Necessary | Basic |
| Machine Learning | Research-oriented | Proficient | Clear understanding |
| Deep Learning | Very deep | Proficient | Application level |
| Programming | Strong research coding | Production-level | Backend & integration |
| MLOps / Deployment | Low | Very high | Medium |
| LLM & GenAI | Research | Applied | Very high |
| Research Skills | Essential | Low | Optional |
3. Supporting Skills
Besides the specialized skills required to build and operate AI systems, there are several foundational technical skills and soft skills that anyone working in AI or software should equip themselves with. These skills not only help you perform technical tasks effectively but also support long-term career growth in the rapidly changing AI environment.
3.1. Foundational Technical Skills
Before diving into specific roles, there are some essential technical skills that anyone working in AI should have:
-
Version Control (Git & GitHub): GitHub is not just a place to store code. In today’s world, where project development often requires collaboration among many people, knowing how to use version control tools is a vital skill for any researcher or developer.
-
Linux: Most AI servers run on Linux. Being proficient with terminal commands (ssh, grep, chmod, nvidia-smi) is mandatory when working with training servers, instead of relying solely on graphical interfaces.
-
Technical English: The pace of AI advancement is measured in weeks. The ability to read and understand documentation and research papers in English is the key to staying up to date and avoiding being left behind.
3.2. Soft Skills & Mindset
In an era where AI tools can write code, generate models, or suggest solutions with just a few lines of instructions, the following skills are what help humans stand out:
-
Product Thinking: Not every problem requires AI. A good engineer must know when to use a simple if-else statement instead of building a complex neural network that wastes resources. You need to understand the economic value of the model you are developing.
-
Communication Skills: Unless you are an all-knowing genius, no one will want to hire or listen to someone who cannot communicate well. Communication is also a way to show respect to your audience. Being articulate demonstrates your understanding when you can explain complex technical problems to non-experts (a.k.a. your boss).
-
Critical Thinking: Critical thinking helps you evaluate models, compare algorithms, detect bias in data, and contribute better solutions instead of passively accepting results.
Conclusion
By the end of this article, you and our team have gone through a journey from understanding the true nature of AI, recognizing different levels of mastery, to orienting your career according to real-world roles such as AI Researcher, ML Engineer, and AI Engineer, and expanding toward the specialized and supporting skills needed for success in the field. The most important point is that AI is not just a tool, but a way of thinking — where you need to combine foundational knowledge, programming skills, product mindset, and continuous learning to truly work with AI rather than just use it passively.
In the future, adaptability and continuous learning will be the decisive factors for success — because AI changes faster than we expect, and those who maintain a lifelong learning mindset will have the greatest advantage in this game.
Chưa có bình luận nào. Hãy là người đầu tiên!