
Retrieval-Augmented Generation (RAG) Model
Large language models (Large Language Models – LLMs) after the pre-training stage are able to absorb and store a large amount of knowledge from training data. This knowledge is encoded in the model parameters (weights), so it is often viewed as parametric memory or an “implicit knowledge base”, allowing the model to reason and generate text without accessing external memory.
However, relying primarily on parametric memory also comes with several limitations:
- Learned knowledge is difficult to expand, update, or edit without intervening in the training/fine-tuning process.
- The model has difficulty providing transparent evidence/explanations for its predictions.
- There is a risk of hallucination, i.e., generating content that appears plausible but is not supported by trustworthy data sources.
In addition, many LLMs are constrained by knowledge cutoff, meaning the model may lack or be inconsistent regarding information that emerges after the training data ends. Moreover, LLMs are typically not trained directly on personal data, internal organizational data, or sensitive/proprietary data, which limits deployment in contexts requiring specialized knowledge. Although this can be partially addressed through retraining or fine-tuning, these solutions often require substantial computational cost, consume energy, and are not flexible when knowledge needs frequent updates.
In response to these limitations, many Hybrid Models approaches have been proposed to combine parametric memory with non-parametric memory based on retrieval-based mechanisms. In particular, Retrieval-Augmented Generation (RAG) enables an LLM to access and use external data at inference time to support answer generation, thereby reducing dependence on “closed” knowledge in parameters and improving the ability to update/verify information without necessarily retraining the model.
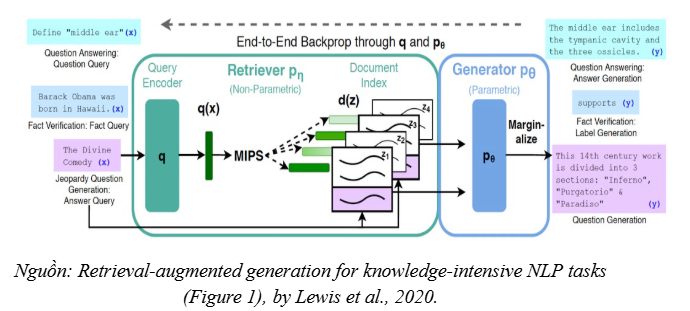
The paper introduces Retrieval-Augmented Generation (RAG) as a hybrid probabilistic model, where the generation process is enhanced by a retrieval mechanism to combine two forms of “memory”:
- Parametric memory: Knowledge encoded in the parameters/weights of a pre-trained sequence generation model (a pre-trained seq2seq Transformer), responsible for expression, reasoning, and producing language outputs.
- Non-parametric memory: Explicit knowledge stored outside the model in the form of a retrieval index (in the paper, a vector index built from Wikipedia) and accessed via a pre-trained neural retriever (a pre-trained neural retriever).
Within RAG’s probabilistic framework, retrieved documents can be viewed as latent documents: the model first estimates a probability distribution over relevant documents given the query, then conditions the generation process on these documents. This approach helps the model “ground” answers in retrieved evidence, thereby improving its ability to provide in-depth information and reducing the tendency to generate unsupported content.
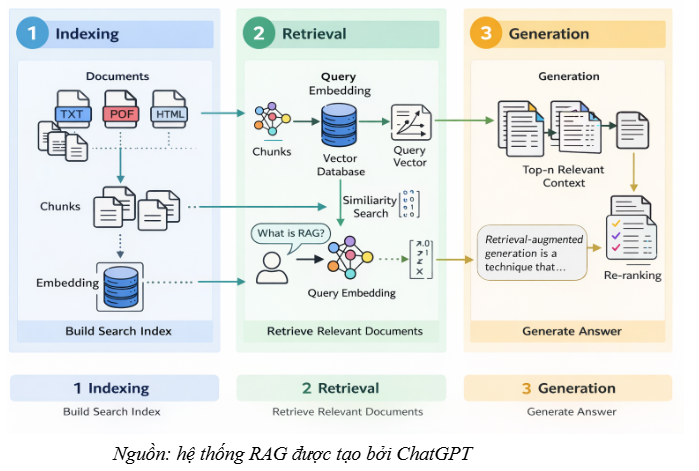
From a system implementation perspective, modern RAG architectures are often described as a three-stage pipeline:
- Indexing: Normalize data and build a retrieval index.
- Retrieval: Find the text passages most relevant to the query.
- Generation: The LLM uses the retrieved passages as context to synthesize and generate an answer.
Common RAG Techniques
1. Classic RAG
Classic RAG is the basic RAG architecture: the system retrieves relevant text passages (chunks) from a data corpus, then directly inserts these passages into the prompt/context so the LLM can generate an answer.
Typical applications
- Internal document Q&A (FAQs, user manuals, technical documentation)
- Enterprise virtual assistants, customer-support chatbots
Workflow
1. Chunk documents into meaningful small segments.
2. Create embeddings for each chunk and store them in a vector database.
3. When a question arrives: create an embedding for the question and perform vector search to retrieve the top-k relevant chunks.
4. Insert the top-k chunks into the context/prompt, then the LLM generates the answer.
2. Multi-Document RAG
Multi-Document RAG extends Classic RAG by retrieving from multiple documents/sources, then synthesizing an answer. The key is to manage provenance and context for each retrieved passage effectively.
Typical applications
- Legal search, medical record synthesis
- Aggregating reports/minutes from multiple data sources
Workflow
1. Store embeddings of chunks from multiple documents along with metadata (source name, time, department, document type, …).
2. Retrieve top-k from multiple sources simultaneously, optionally:
- Group by source (group-by source) to avoid “context mixing”.
- Cluster/aggregate by topic (clustering/topic) before sending to the LLM.
3. Hybrid RAG (combining multiple retrievers)
Hybrid RAG combines multiple retrieval methods to improve accuracy, most commonly by integrating:
- Dense retrieval (semantic/vector search): strong when queries use different wording but the same meaning.
- Sparse retrieval (keyword/BM25): strong when exact keywords, proper nouns, IDs, or technical terms matter.
- Rule-based / metadata filtering: filter by source, time, document type, etc.
Typical applications
- Large-scale enterprise search (many documents, many specialized terms)
- High-precision Q&A systems (medical, legal, technical)
Workflow
1. Run multiple retrievers in parallel (vector + BM25 + filters).
2. Merge results (merge/dedup/fusion).
3. Apply reranking to select the best top-n chunks before sending them to the LLM.
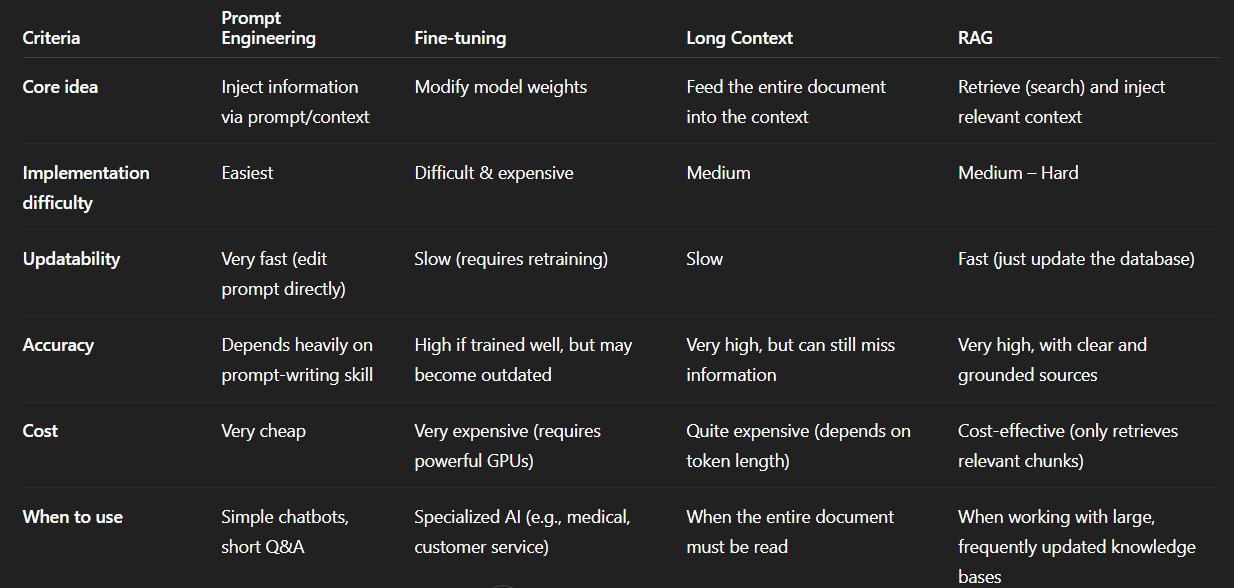
Comparing RAG with other techniques in LLM chatbots
Example:

Comparison table
II. RAG ARCHITECTURE AND WORKFLOW
1. Indexing: Chunking and Embeddings
The Indexing stage is responsible for converting raw data into a searchable vector format. This offline processing step plays a crucial role in ensuring that subsequent retrieval operations are both efficient and semantically accurate.
1.1. Document Loading (Content Extraction)
The first step involves collecting and normalizing data from multiple sources to produce a unified format for processing.
- Extraction: The system should be able to handle diverse file formats (PDF, HTML, CSV, TXT) and remove complex formatting elements such as fonts or layout to preserve plain text.
- Metadata collection: Extracting text alone is not sufficient for a robust system. Collecting accompanying metadata—such as page number, publication date, author, or document title—is essential to support pre-filtering during retrieval. For example, metadata enables the system to narrow the search scope to “documents published in 2023” before performing vector matching.
1.2. Text Splitting (Chunking)
Chunking is the process of splitting long documents into smaller units (called chunks) for easier management and retrieval. This step is necessary to comply with the LLM’s context window limits and to improve search accuracy by increasing the “semantic focus” of each chunk.
Chunking strategies:
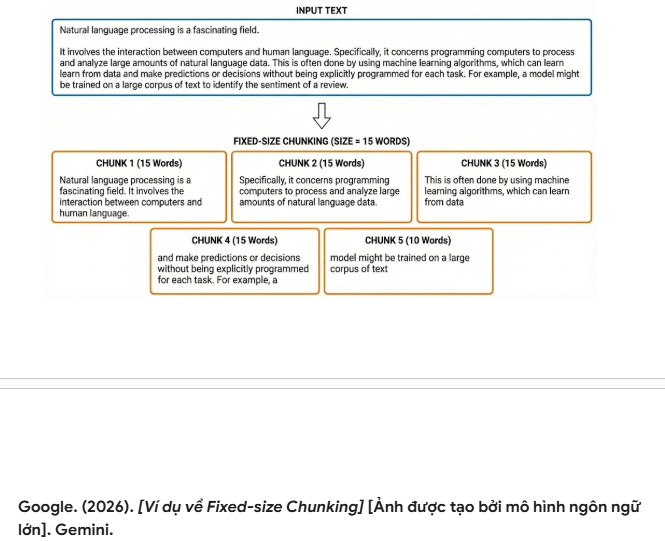
- Fixed-size Chunking: This method splits text based on a strictly defined number of characters or tokens (e.g., 500 characters, 15 words). While computationally simple, it risks losing semantic context if the cut point falls in the middle of a sentence or disrupts a continuous line of reasoning.
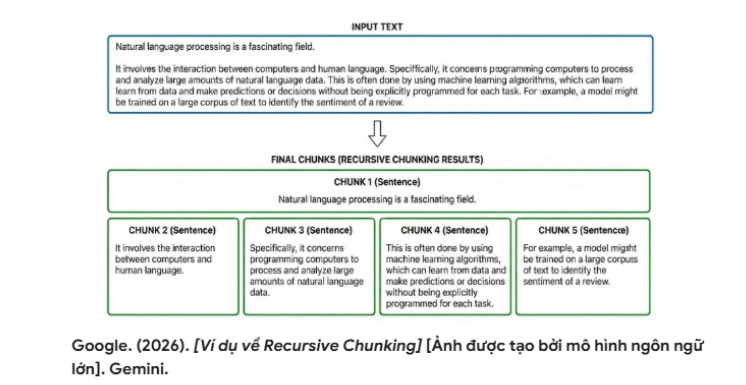
- Recursive Chunking: This is a structure-aware method that prioritizes natural boundaries in the document. The system attempts to split the text in a preferred order: paragraph breaks (\n\n), line breaks (\n), punctuation marks, and finally whitespace. If the desired chunk size is still not reached, the algorithm continues splitting recursively using lower-level separators until each chunk meets the target size. This method better preserves the integrity of sentences and paragraphs.
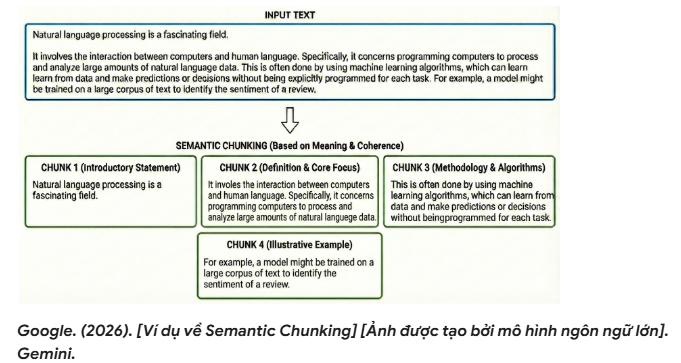
- Semantic Chunking: This is a dynamic and more “advanced” approach that uses an embedding model to measure semantic similarity between consecutive sentences/segments. The system detects topic shift points when similarity drops below a certain threshold, and uses those points to decide chunk boundaries. This helps each chunk focus on a coherent concept, reduces the risk of “breaking” semantic continuity, and often improves retrieval quality compared to fixed-size splitting.
Advanced indexing strategies
These strategies directly influence where the system searches and the context blocks that get retrieved, aiming to balance precision and coverage.
-
Parent–Child Indexing (Small-to-Big): Documents are split into larger (parent) chunks and smaller (child) chunks. The system indexes the smaller chunks to improve retrieval precision. However, when a relevant match is found, the system can also retrieve the parent chunk (or nearby sections) to provide more complete context for the LLM during the Generation stage.
-
Summary Indexing: Use an LLM to generate summaries for a document or for each chunk. These summaries are indexed to support high-level (more general) queries, while the full original text can still be retrieved during answer generation when detailed evidence is needed.
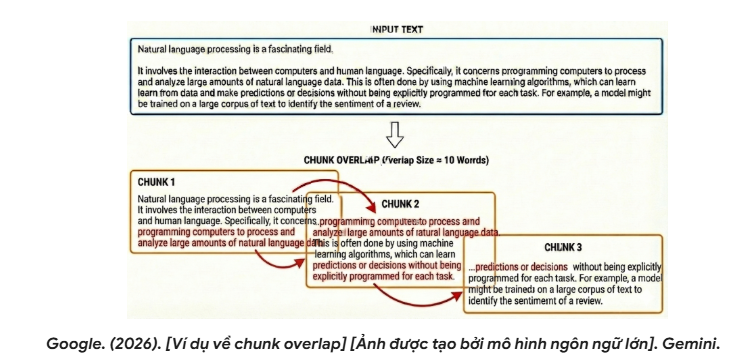
Chunk Overlap
To ensure semantic continuity at chunk boundaries, a chunk overlap parameter is often used. Chunk overlap is typically set to around 10–20% of the chunk size, meaning the end of the previous chunk is repeated at the beginning of the next chunk. This reduces the risk of losing information at cut points and improves coherence when context is fed into the LLM.
1.3. Creating vector embeddings
Embedding models convert each text chunk (after splitting) into a dense vector—a list of real-valued numbers in a high-dimensional space. This vector serves as the “semantic representation” of the passage, enabling the system to perform similarity-based search.
Mechanism:
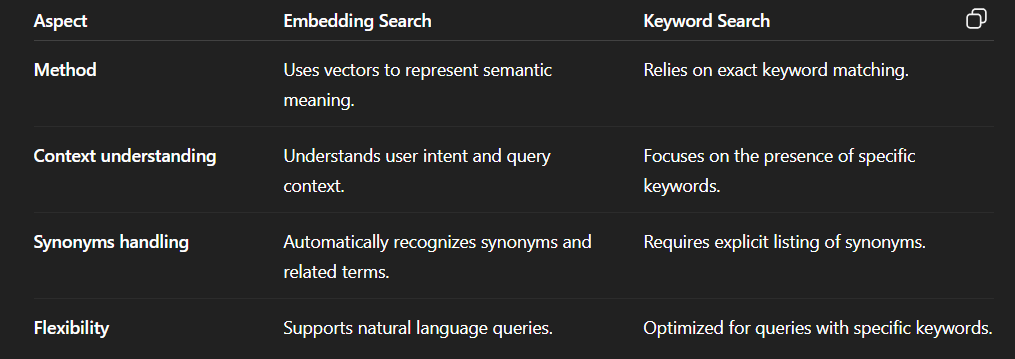
The core principle is that text passages with similar meaning are mapped to vectors that are close to each other in vector space (under a distance/similarity metric such as cosine similarity). As a result, the system can retrieve relevant passages even when the query and the document do not share the same wording.
The next section will compare the difference between embedding-based search (semantic search) and traditional keyword search.
Similarity Metrics
To quantify the relevance between a query vector $\vec{A}$ and a document vector $\vec{B}$, systems commonly use Cosine Similarity or Euclidean Distance. Cosine similarity measures the cosine of the angle between two vectors:
$$ \text{similarity}=\cos(\theta)=\frac{\vec{A}\cdot\vec{B}}{\|\vec{A}\|\,\|\vec{B}\|} $$
Where:
- $\vec{A}$ and $\vec{B}$: the two vectors being compared. In the RAG context, $\vec{A}$ is typically the vector for the query, and $\vec{B}$ is the vector for a document chunk.
- $\theta$ (theta): the angle formed by $\vec{A}$ and $\vec{B}$ in high-dimensional space.
- $\vec{A}\cdot\vec{B}$: the dot product of the two vectors, indicating how much the vectors “point” in the same direction.
- $\|\vec{A}\|$ and $\|\vec{B}\|$: the magnitude (Euclidean norm) of each vector.
Magnitude formula for $\vec{A}$:
$$ \|\vec{A}\|=\sqrt{\sum_{i=1}^{n} A_i^2} $$
A Cosine Similarity value closer to 1 typically indicates higher semantic similarity, while a value near 0 indicates low similarity (almost unrelated).
Euclidean Distance
Euclidean distance measures the straight-line distance between two vectors in an $n$-dimensional space:
$$ d(\vec{A},\vec{B})=\|\vec{A}-\vec{B}\| =\sqrt{\sum_{i=1}^{n}(A_i-B_i)^2} $$
Where:
- $d(\vec{A},\vec{B})$: the shortest (straight-line) distance between vectors $\vec{A}$ and $\vec{B}$.
- $n$: the number of embedding dimensions (e.g., 768, 1024, 1536).
- $i$: an index from $1$ to $n$, representing each specific dimension.
- $A_i$ and $B_i$: the coordinate values of $\vec{A}$ and $\vec{B}$ at dimension $i$.
- $\sum$ (Sigma): the summation operator; the formula squares coordinate differences, sums them, then takes the square root.
Note: The smaller $d(\vec{A},\vec{B})$ is (the closer the vectors are), the more similar the vectors are. This is opposite to Cosine Similarity (higher cosine means more similar).
1.4. Storing in a vector database
After being converted into vectors, the data is stored in a specialized database (vector database/vector store) optimized for similarity search. Some popular systems include Pinecone, Milvus, Weaviate, and Chroma.
A vector store typically stores three main types of information:
- The embedding for each split text segment (chunk embedding)
- Metadata (source, title, time, position in the document, document type, …)
- The original text content of the chunk so it can be returned to the model during retrieval
These databases support approximate nearest neighbor search, i.e., efficiently finding text passages that are “close” in vector space. As a result, the system can retrieve passages with similar meaning, rather than relying only on exact keyword matching.
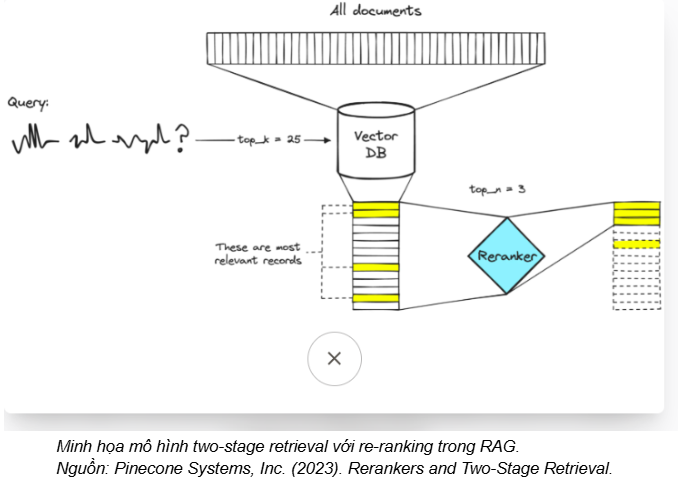
2. Retrieve: Re-ranking
When building LLM-based question–answering systems, retrieving the right documents is critical to answer quality. Although chunking + embedding + vector search enables fast search over large datasets, it is often not enough to ensure the system always selects the “best” passages as context. Therefore, re-ranking is introduced as an additional step to improve retrieval accuracy in RAG systems.
In a RAG system, the processing flow can be summarized as:
- Indexing: split documents (chunking) and create embeddings to retrieve an initial top-k set of relevant passages.
- Re-ranking: re-evaluate the top-k passages and select those most relevant to the user’s query.
- Generation: the LLM uses the selected passages as context to generate an answer.
Why re-ranking before answer generation?
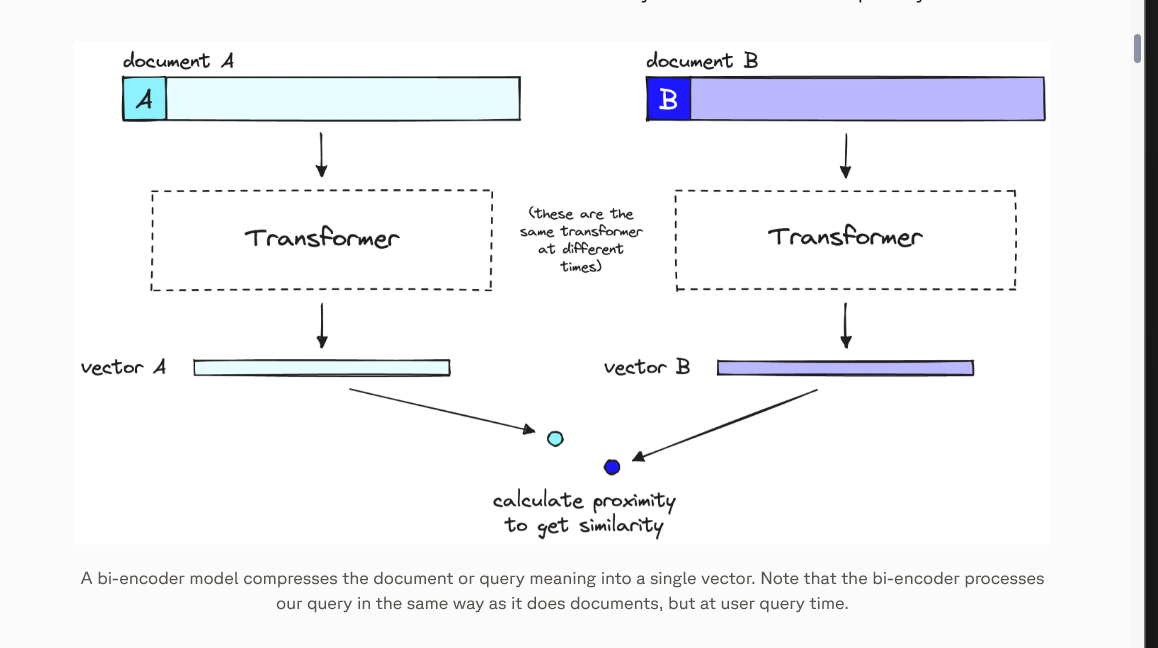
- Re-ranking models are usually slower but more accurate than embedding-based models (bi-encoders) at estimating relevance between a query and a document. This is because bi-encoders encode the query and document independently, then match them via vector similarity, which can miss subtle semantic relationships (fine-grained relevance).
In addition, to keep chunks short, text is often split before embedding—so embeddings reflect local meaning and may lack broader context for the query.
- Re-ranking allows the system to “read more carefully” over retrieved candidates. At this step, the system re-evaluates chunks in the top-k list by examining the direct relationship between the query and each chunk’s content. This helps select the truly most relevant passages to feed into the LLM, improving both answer accuracy and completeness.
How re-ranking works in RAG
- Cross-encoder:
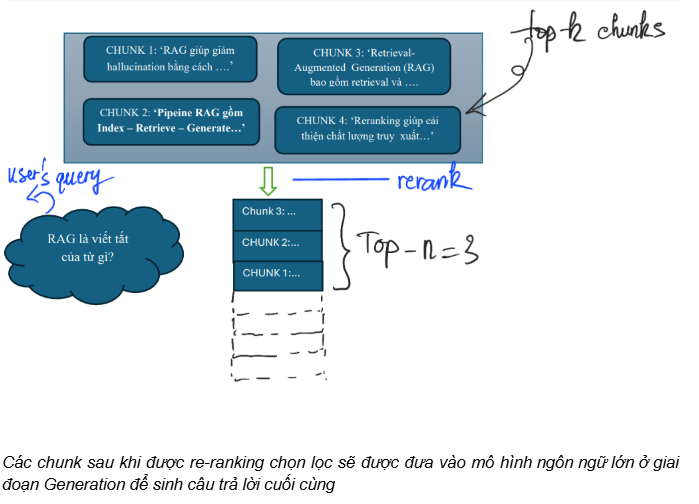
This method works by feeding the query and each candidate chunk together into a Transformer model to predict a relevance score (relevance/similarity score). After obtaining a score for each (query, chunk) pair, the system re-ranks the chunks in descending order of score and keeps only the top-n chunks as input context for the LLM.
Because it “jointly reads” the query and the document, a cross-encoder typically produces higher-quality rankings than a bi-encoder—helping reduce noise and improve answer accuracy during the Generation step (at the cost of higher computation).
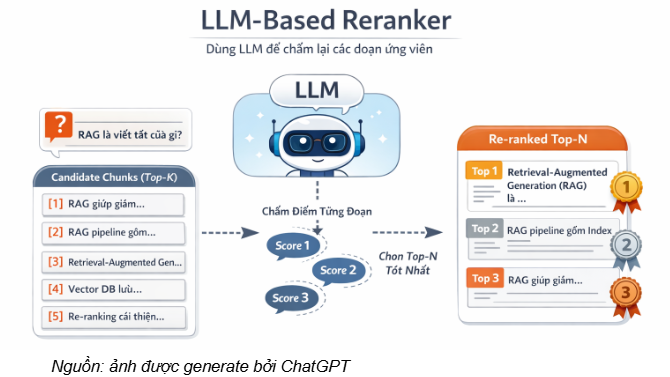
- LLM-based Reranker:
LLM-based re-ranking treats a large language model (LLM) as a relevance scoring function between the user query and the candidate text passages (candidate chunks) retrieved during the retrieval step (often the top-k results from a bi-encoder/vector search). For each (query, chunk) pair (or for the entire candidate list), the LLM assigns a relevance score (relevance/similarity score) and then re-orders the chunks accordingly. Finally, the system keeps the top-n best passages as input context for the Generation stage.
This approach helps reduce noise, prioritizes passages that contain direct evidence for the question, and often improves the accuracy of a RAG system—especially for queries requiring deep contextual understanding or distinguishing between very similar passages.
LLM-based re-ranking is often implemented in a zero-shot manner, meaning it directly leverages the LLM’s reasoning ability via prompts and scoring criteria, without retraining the model on dedicated ranking data. Two common implementation schemes are:
-
Pointwise LLM Re-ranking (scoring each candidate):
In the pointwise setting, the LLM evaluates each candidate independently by taking in a (query, chunk) pair and outputting a relevance score. The candidate list is then sorted in descending order by score to select the top-n. This is similar to scoring each passage separately and producing a ranking based on the total score. -
Listwise LLM Re-ranking (ranking the whole list):
In the listwise setting, the LLM is given the query together with the entire candidate set (top-k chunks), allowing it to use relative comparison and reasoning to determine the ranking. By seeing the full list in a unified context, the model can better judge differences among very similar chunks and select the most suitable top-n candidates.
3. Generation
Generation is the final stage in the Retrieval-Augmented Generation (RAG) architecture, where a large language model (LLM) synthesizes information from the user’s query and the retrieved chunks/documents from the Retrieve stage to produce an answer that is accurate, coherent, and evidence-based. Note that Generation quality depends heavily on the previous Indexing and Retrieval stages: if the retrieved context is incomplete or incorrect, the answer may still be inaccurate even with a well-designed LLM. Therefore, in practice, the goal of Generation is to increase groundedness (sticking to evidence in the context) and reduce the risk of hallucination, rather than claiming to eliminate hallucinations entirely.
For beginners in AI, a simple way to think about this is: in RAG, the LLM is expected to answer primarily based on the retrieved context, rather than guessing beyond the provided data. Hence, Generation is not just “calling the LLM”, but a sequence of design steps to ensure the model prioritizes information with clear provenance, while also being able to acknowledge limitations and “refuse to answer” when evidence in the context is insufficient. The key steps in Generation are described next.
3.1. Context preparation: the foundation for correct answers
Generation does not start when the model begins producing text—it starts with how we assemble the context. After the reranking step in Retrieve, the system typically keeps only a small number of the most relevant passages (e.g., 3–5 passages, depending on the task and token limits) to feed into the LLM. These passages are collectively called the context. In essence, this is the set of “reference materials” the model is allowed to use to produce an answer.
Context normalization is important. If passages are inserted in a messy way without clear separation, the model may confuse document content with the user’s question or mix information from different sources. Therefore, in real-world RAG systems, context is usually presented in a clear structure: segmented, source-labeled (document name, section/title, citation location), and separated from the question. This organization helps the model recognize that it is referencing multiple pieces of evidence rather than a single continuous paragraph.
Another challenge is the context window limit. Each LLM has a maximum number of tokens it can process in one call, so Generation must balance including enough necessary information without “overloading” the model. As a result, some systems apply iterative refinement/compaction, where the model reads and updates the answer step by step instead of loading the entire document in one pass. This helps handle long technical documents more effectively and reduces noise in the provided context.
3.2. Controlled prompting: constraints to reduce hallucination risk
Once the context is prepared, the next step in Generation is prompt design (instructions sent to the LLM). Prompts in RAG differ from ordinary chat prompts: the goal is not to encourage creativity, but to constrain the model to follow the data and reduce speculation beyond evidence.
An effective RAG prompt often includes clear requirements, such as:
(i) use only the information in the context
(ii) if the needed information is not found, explicitly acknowledge “insufficient data”
(iii) in high-stakes domains (e.g., medical, legal), require the model to cite sources for key claims. Citations help users verify information and also act as a “soft constraint” that pushes the model to stay grounded—claims without evidence are harder to attach to sources.
3.3. Answer synthesis: from fragments to a conclusion
After receiving the prompt and context, the LLM generates the answer. However, in RAG, this process should be designed as controlled evidence synthesis, rather than simply “rewriting” or stitching sentences together.
A common approach is to ask the model to extract key points from each passage first, then synthesize a final answer. This reduces the chance of the model generating statements that are not present in the documents. Some systems also implement multi-turn answering: each turn reads an additional portion of context and revises the previous answer, which is useful for complex technical documents or long instructions.
From a theoretical perspective, this aligns with the core idea in the original RAG paper: generation is conditioned on retrieved documents to increase groundedness. Even though modern implementations may differ (pipelines, rerankers, prompt templates, etc.), the core principle remains: answers should be the result of evidence synthesis, not free-form guessing.
3.4. Post-generation checking
A point beginners often miss is that Generation does not end as soon as the LLM returns an answer. In real systems, there is often a post-generation checking step to evaluate whether the answer is actually supported by the context (groundedness/faithfulness).
This check can be implemented at different levels: from simple rules (e.g., verifying citations, detecting strong claims without sources) to using another model as a verifier/judge to review statements that lack clear evidence. If issues are detected, the system may trigger re-retrieval, ask the user to clarify the query, or respond that the current information is insufficient to conclude.
For sensitive applications, this serves as a “safety guardrail” that increases RAG reliability rather than relying solely on the LLM’s language generation ability.
III. Example prompt templates for RAG
In the Retrieval-Augmented Generation (RAG) architecture, after the system completes the Retrieval stage, the Generation stage is not simply “calling an LLM to produce an answer.” It also includes prompt design to guide the model to use the retrieved context correctly. In other words, a prompt in RAG can be seen as an instruction set that helps the LLM: stay grounded in document evidence, limit speculation beyond provided data, and clearly express limits when context is insufficient.
You can think of a prompt as a coordinator assigning a reading task. If you only say “read and answer,” the reader might interpret freely or add outside information. In contrast, if you explicitly instruct “use only the provided documents; if information is missing, say so; and cite sources for conclusions,” the answer becomes more reliable and verifiable. RAG prompts work similarly: they define the allowed information scope and how the model should respond when evidence is insufficient.
A good RAG prompt usually targets three main goals:
- Limit information sources: use only the content in the context.
- Prevent speculation: do not add “plausible-sounding” information without evidence.
- Valid refusal behavior: clearly state when the documents do not contain the needed information.
What happens when prompts lack constraints
When prompts are too minimal, LLMs tend to “complete” answers by filling gaps with pretrained knowledge, leading to hallucination or missing conditions. Common risks include:
- Inference beyond the documents: If a document only says “follow legal regulations” without a specific number, the model may supply a common number instead of admitting “not specified in the document.”
- Source mixing: The model blends context content with background knowledge without clearly distinguishing official information, reducing verifiability.
- Ignoring conditions: A policy may differ for “full-time employees” vs “probation,” but if the prompt doesn’t require conditions, the model may answer without context, causing misunderstanding.
In high-risk domains such as healthcare, law, or enterprise customer support, an answer that “sounds right” but lacks evidence can cause serious harm. Therefore, a RAG prompt is not just “asking a question”—it must define behavioral boundaries: what the model may do, what it must not do, and how it should respond when evidence is missing.
Some example prompt types
1) Zero-shot prompting: The most basic prompt
Zero-shot is the simplest technique: give a direct instruction without providing any examples.

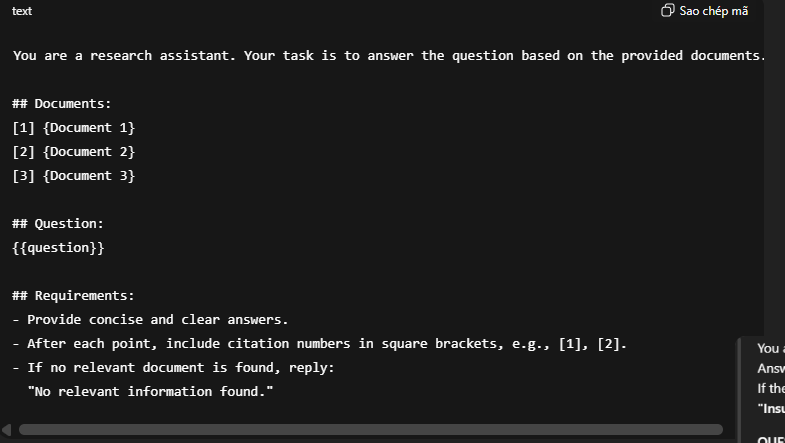
2) Few-shot prompting: Learning from examples
Few-shot is a technique where the model is shown a few example demonstrations before being asked to handle the actual query. This allows the model to learn the desired format and response style from the examples, improving output consistency (e.g., presentation structure, citation style, and how to refuse when information is missing).
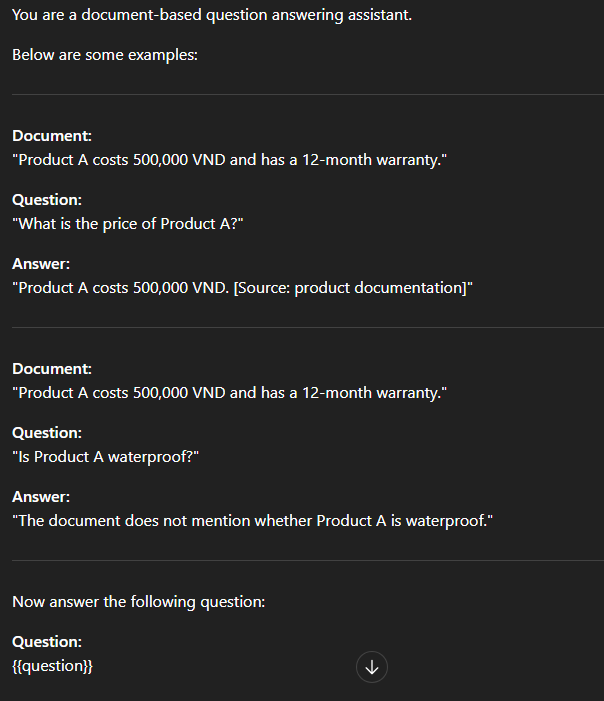
3) Adding constraints to reduce hallucination risk
When tighter control over the model’s behavior is needed, the prompt should include clear constraints regarding (i) the model’s role, (ii) the scope of information it is allowed to use, and (iii) the required output format/standards. These constraints help the model prioritize staying grounded in the retrieved context, limit speculation beyond the provided data, and improve the consistency of the answers.
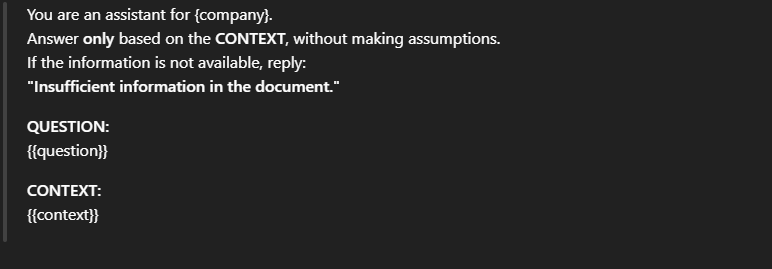
4) Requiring citations (Citation)
In applications that require transparency and easy verification—such as research, legal work, or enterprise customer support—requiring citations helps users validate the information in the answer. At the same time, citations act as a “soft constraint” that encourages the model to stay grounded in the retrieved context, because statements without evidence are difficult to attach to corresponding citations.
5) Chain-of-Thought (CoT) — Step-by-step reasoning
Chain-of-Thought (CoT) asks the model to perform reasoning in steps before providing the final answer, instead of responding immediately. This technique is especially useful when a question requires synthesizing multiple pieces of information from the context or involves multi-hop reasoning, because it encourages structured reasoning and reduces the chance of missing important conditions.

References
Abdallah, A., Piryani, B., Mozafari, J., Ali, M., & Jatowt, A. (2025). How good are LLM-based rerankers? An empirical analysis of state-of-the-art reranking models [Preprint]. arXiv. https://arxiv.org/abs/2508.16757
AI Vietnam. (n.d.). RAG [PDF]. Retrieved January 18, 2026, from https://tutorial.aivietnam.edu.vn/pdf/48
Guu, K., Lee, K., Tung, Z., Pasupat, P., & Chang, M.-W. (2020). REALM: Retrieval-augmented language model pre-training. In Proceedings of the 37th International Conference on Machine Learning (ICML 2020) (Proceedings of Machine Learning Research, Vol. 119, pp. 3929–3938). PMLR. https://arxiv.org/abs/2002.08909
Ji, Z., Lee, N., Frieske, R., Yu, T., Su, D., Xu, Y., Ishii, E., Bang, Y. J., Madotto, A., & Fung, P. (2023). Survey of hallucination in natural language generation. ACM Computing Surveys, 55(12), Article 248, 1–38. https://doi.org/10.1145/3571730
Le, H. (n.d.). Tổng hợp về RAG [Notion page]. Notion. Retrieved January 18, 2026, from https://spiffy-attention-05a.notion.site/T-ng-h-p-v-RAG-220e1a3b0e448002b18aea461f59f01d
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W.-t., Rocktäschel, T., Riedel, S., & Kiela, D. (2020). Retrieval-augmented generation for knowledge-intensive NLP tasks. Advances in Neural Information Processing Systems, 33, 9459–9474. https://arxiv.org/abs/2005.11401
Movin, S., & Hauff, C. (2025). Zero-shot reranking with large language models and precomputed ranking features: Opportunities and limitations. In Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’25). Association for Computing Machinery. https://doi.org/10.1145/3726302.3730119
Pinecone Systems, Inc. (n.d.). Rerankers and two-stage retrieval. Pinecone Learn. Retrieved January 18, 2026, from https://www.pinecone.io/learn/series/rag/rerankers/
Chưa có bình luận nào. Hãy là người đầu tiên!