
I. KHÁI NIỆM VỀ RAG
Mô hình Retrieval-Augmented Generation (RAG)
Các mô hình ngôn ngữ lớn (Large Language Models – LLMs) sau giai đoạn tiền huấn luyện có khả năng tiếp thu và lưu trữ một lượng lớn tri thức từ dữ liệu huấn luyện. Phần tri thức này được mã hóa trong tham số mô hình (các trọng số), do đó thường được xem như một dạng bộ nhớ tham số (parametric memory) hoặc “cơ sở tri thức ẩn” (implicit knowledge base), cho phép mô hình suy luận và sinh văn bản mà không cần truy cập bộ nhớ ngoài (external memory).
Tuy nhiên, việc phụ thuộc chủ yếu vào bộ nhớ tham số cũng kéo theo nhiều hạn chế:
- Tri thức đã “học” khó mở rộng, cập nhật hoặc chỉnh sửa mà không can thiệp vào quá trình huấn luyện/tinh chỉnh.
- Mô hình khó cung cấp căn cứ/giải thích một cách minh bạch cho các dự đoán.
- Có nguy cơ phát sinh ảo giác (hallucination), tức tạo ra nội dung có vẻ hợp lý nhưng không được bảo chứng bởi nguồn dữ liệu đáng tin cậy.
Bên cạnh đó, nhiều LLM chịu ràng buộc bởi hiện tượng độ trễ tri thức (knowledge cutoff), nghĩa là mô hình có thể thiếu hoặc không nhất quán đối với các thông tin mới phát sinh sau thời điểm dữ liệu huấn luyện kết thúc. Ngoài ra, LLM thường không được huấn luyện trực tiếp trên dữ liệu cá nhân, dữ liệu nội bộ của tổ chức hoặc dữ liệu nhạy cảm/bảo mật, dẫn đến hạn chế khi triển khai trong các bối cảnh yêu cầu tri thức đặc thù. Mặc dù có thể khắc phục một phần bằng huấn luyện lại hoặc tinh chỉnh (fine-tuning), các giải pháp này thường đòi hỏi chi phí tính toán đáng kể, tiêu tốn năng lượng và không linh hoạt khi tri thức cần cập nhật thường xuyên.
Trước các hạn chế trên, nhiều hướng tiếp cận mô hình lai (Hybrid Models) đã được đề xuất nhằm kết hợp bộ nhớ tham số với bộ nhớ phi tham số (non-parametric memory) dựa trên cơ chế truy xuất (retrieval-based). Tiêu biểu, cơ chế Retrieval-Augmented Generation (RAG) cho phép LLM truy cập và sử dụng nguồn dữ liệu bên ngoài tại thời điểm suy luận để hỗ trợ tạo sinh câu trả lời, qua đó giảm phụ thuộc vào tri thức “đóng” trong tham số và tăng khả năng cập nhật/kiểm chứng thông tin mà không nhất thiết phải huấn luyện lại mô hình.
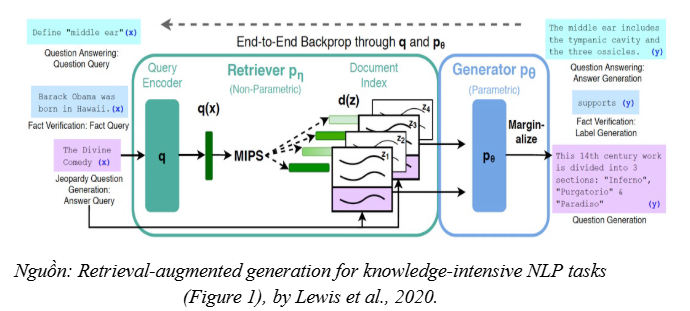
Bài báo giới thiệu Retrieval-Augmented Generation (RAG) như một mô hình xác suất lai (hybrid probabilistic model), trong đó quá trình tạo sinh được tăng cường bởi cơ chế truy xuất nhằm kết hợp hai dạng “bộ nhớ”:
- Bộ nhớ tham số (parametric memory): Tri thức được mã hóa trong các tham số/trọng số của mô hình sinh chuỗi đã tiền huấn luyện (pre-trained seq2seq Transformer), chịu trách nhiệm diễn đạt, suy luận và tạo đầu ra ngôn ngữ.
- Bộ nhớ phi tham số (non-parametric memory): Tri thức tường minh được lưu trữ bên ngoài mô hình dưới dạng chỉ mục truy xuất (trong bài báo là chỉ mục vector xây dựng từ Wikipedia) và được truy cập thông qua bộ truy xuất nơ-ron đã tiền huấn luyện (pre-trained neural retriever).
Trong khuôn khổ xác suất của RAG, các tài liệu được truy xuất có thể được xem như một biến tiềm ẩn (latent documents): mô hình trước hết ước lượng phân phối xác suất của các tài liệu liên quan theo truy vấn, sau đó điều kiện hóa quá trình tạo sinh dựa trên các tài liệu này. Cách tiếp cận này giúp mô hình “gắn” câu trả lời với bằng chứng truy xuất, qua đó cải thiện khả năng cung cấp thông tin chuyên sâu và giảm xu hướng tạo sinh không có căn cứ.
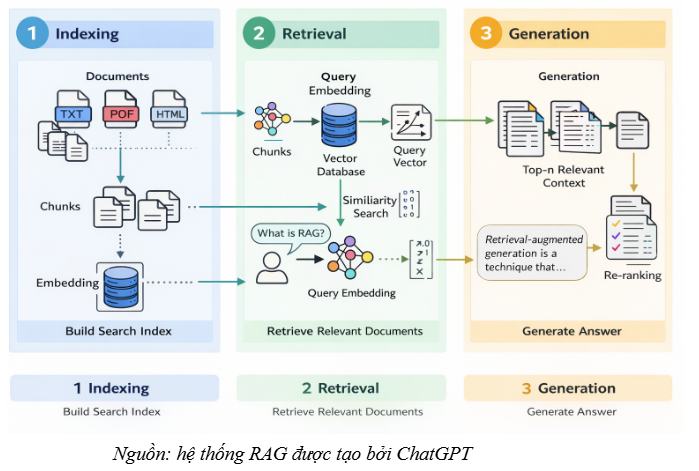
Ở góc nhìn triển khai hệ thống, các kiến trúc RAG hiện đại thường được mô tả như một pipeline gồm 3 giai đoạn chính:
- Lập chỉ mục (indexing): Chuẩn hóa dữ liệu và xây dựng chỉ mục truy xuất.
- Truy xuất (retrieval): Tìm các đoạn văn bản liên quan nhất với truy vấn.
- Tạo sinh (generation): LLM sử dụng các đoạn truy xuất làm ngữ cảnh để tổng hợp và tạo câu trả lời.
Các kỹ thuật RAG phổ biến
1. RAG cổ điển (Classic RAG)
Classic RAG là kiến trúc RAG cơ bản: hệ thống truy xuất các đoạn văn bản liên quan (chunks) từ kho dữ liệu, sau đó đưa trực tiếp các đoạn này vào prompt/ngữ cảnh (context) để LLM sinh câu trả lời.
Ứng dụng tiêu biểu
- Hỏi đáp tài liệu nội bộ (FAQ, hướng dẫn sử dụng, tài liệu kỹ thuật)
- Trợ lý ảo doanh nghiệp, chatbot hỗ trợ khách hàng
Quy trình
1. Chunking tài liệu thành các đoạn nhỏ có nghĩa.
2. Tạo embedding cho từng chunk và lưu vào vector database.
3. Khi có câu hỏi: tạo embedding cho câu hỏi, thực hiện vector search để lấy top-k chunks liên quan.
4. Đưa top-k chunks vào context/prompt, từ đó LLM tạo câu trả lời.
2) RAG đa tài liệu (Multi-Document RAG)
Multi-Document RAG mở rộng Classic RAG theo hướng truy xuất từ nhiều tài liệu/nguồn khác nhau, sau đó tổng hợp để trả lời. Điểm quan trọng là quản lý tốt nguồn gốc và ngữ cảnh của từng đoạn truy xuất.
Ứng dụng tiêu biểu
- Tìm kiếm pháp lý, tổng hợp hồ sơ bệnh án
- Tổng hợp báo cáo/biên bản từ nhiều nguồn dữ liệu
Quy trình
1. Lưu embedding của chunks từ nhiều tài liệu, kèm metadata (tên nguồn, thời gian, phòng ban, loại tài liệu…).
2. Truy xuất top-k từ nhiều nguồn đồng thời, có thể:
- Gom nhóm theo nguồn (group-by source) để tránh “trộn ngữ cảnh”.
- Tổng hợp theo chủ đề (clustering/topic) trước khi đưa vào LLM.
3) RAG lai (Hybrid RAG – kết hợp nhiều retriever)
Hybrid RAG kết hợp nhiều phương pháp truy xuất để tăng độ chính xác, phổ biến nhất là phối hợp:
- Dense retrieval (semantic/vector search): mạnh khi câu hỏi diễn đạt khác từ nhưng cùng ý.
- Sparse retrieval (keyword/BM25): mạnh khi cần đúng từ khóa, tên riêng, mã số, thuật ngữ.
- Rule-based / filter theo metadata: lọc theo nguồn, thời gian, loại tài liệu…
Ứng dụng tiêu biểu
- Tìm kiếm doanh nghiệp quy mô lớn (nhiều tài liệu, nhiều thuật ngữ)
- Hệ thống hỏi đáp chuyên sâu (y tế, pháp lý, kỹ thuật)
Quy trình
1. Chạy nhiều retriever song song (vector + BM25 + filter).
2. Hợp nhất kết quả (merge/dedup/fusion).
3. Reranking để chọn top-n chunks tốt nhất trước khi đưa vào LLM.
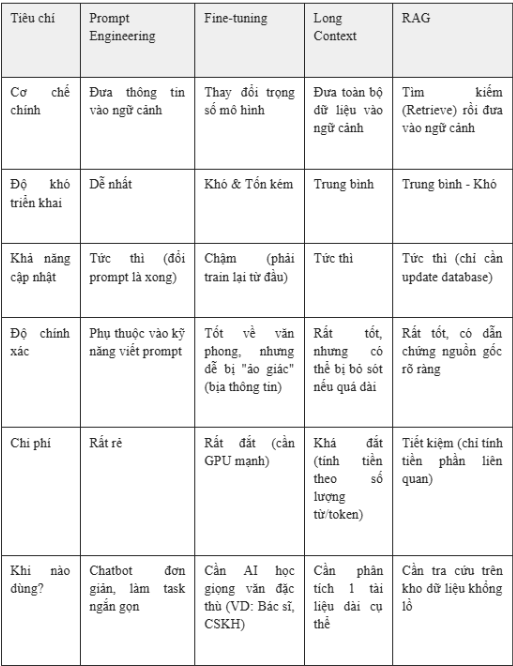
So sánh RAG với các kỹ thuật khác trong LLM Chatbot
Ví dụ:

Bảng so sánh
II. KIẾN TRÚC, LUỒNG HOẠT ĐỘNG CỦA RAG
1. Indexing: Chunking và Embeddings
Giai đoạn Indexing có nhiệm vụ chuyển đổi dữ liệu thô thành định dạng vector có thể tìm kiếm được. Bước xử lý offline này đóng vai trò then chốt để đảm bảo các thao tác truy xuất về sau vừa hiệu quả vừa chính xác về mặt ngữ nghĩa.
1.1. Document Loading (Trích xuất nội dung)
Bước đầu tiên bao gồm việc thu thập và chuẩn hóa dữ liệu từ nhiều nguồn khác nhau để tạo ra một định dạng thống nhất cho quá trình xử lý.
- Trích xuất (Extraction): Hệ thống cần có khả năng xử lý đa dạng các định dạng tệp (PDF, HTML, CSV, TXT) và loại bỏ các thành phần định dạng phức tạp như font chữ hay layout để giữ lại phần văn bản thuần túy.
- Thu thập metadata: Chỉ trích xuất văn bản là chưa đủ đối với một hệ thống mạnh mẽ. Việc thu thập các metadata đi kèm—như số trang, ngày xuất bản, tác giả, hoặc tiêu đề tài liệu—là rất cần thiết để hỗ trợ lọc trước (pre-filtering) trong truy xuất. Ví dụ, metadata cho phép hệ thống thu hẹp phạm vi tìm kiếm vào các “tài liệu được xuất bản năm 2023” trước khi thực hiện so khớp vector.
1.2. Text Splitting (Chunking – Chia nhỏ văn bản)
Chunking là quá trình chia nhỏ các tài liệu dài thành các đơn vị nhỏ hơn (gọi là chunks) để dễ quản lý và truy xuất. Bước này cần thiết để tuân thủ giới hạn context window của LLM và cải thiện độ chính xác của tìm kiếm bằng cách tăng độ “tập trung ngữ nghĩa” của từng đoạn.
Các chiến lược phân đoạn:
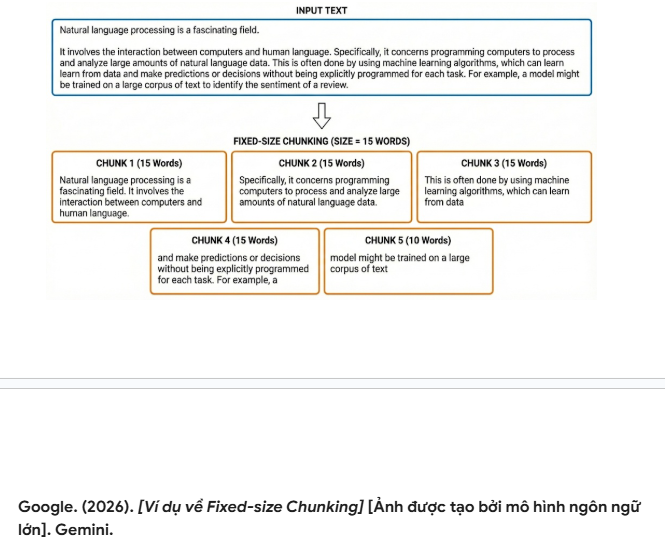
- Fixed-size Chunking (Chia theo kích thước cố định): Phương pháp này chia văn bản dựa trên số lượng ký tự hoặc token được quy định chặt chẽ (ví dụ: 500 ký tự, 15 từ). Mặc dù đơn giản về mặt tính toán, cách này có rủi ro làm mất ngữ cảnh ngữ nghĩa nếu điểm cắt rơi vào giữa câu hoặc làm gián đoạn mạch suy nghĩ liên tục.
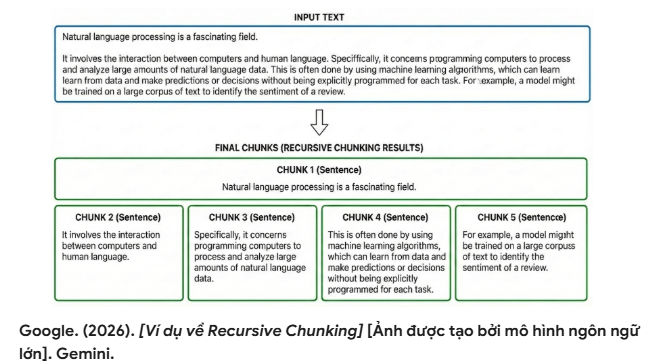
- Recursive Chunking (Chia đệ quy): Đây là phương pháp nhận biết cấu trúc, ưu tiên các dấu ngắt tự nhiên của tài liệu. Hệ thống sẽ cố gắng chia văn bản theo thứ tự ưu tiên: ngắt theo đoạn văn (
\n\n), xuống dòng (\n), dấu chấm câu, và cuối cùng là khoảng trắng. Nếu vẫn không đạt được kích thước mong muốn, thuật toán sẽ tiếp tục chia nhỏ theo cách đệ quy với các dấu tách cấp thấp hơn cho đến khi mỗi chunk đạt kích thước yêu cầu. Phương pháp này giúp bảo toàn tốt hơn cấu trúc trọn vẹn của câu và đoạn văn.
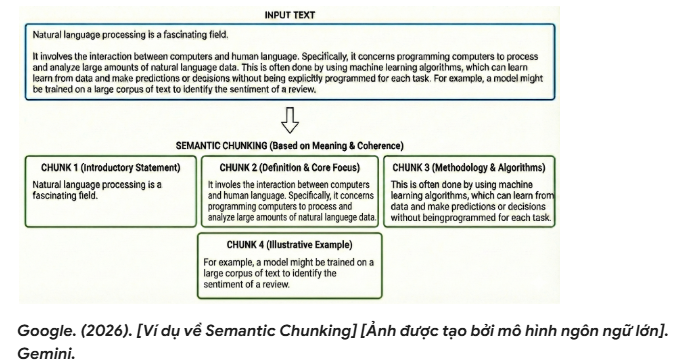
- Semantic Chunking (Chia theo ngữ nghĩa): Đây là phương pháp động và “nâng cao” hơn, sử dụng mô hình embedding để đo độ tương đồng ngữ nghĩa giữa các câu/đoạn liên tiếp. Hệ thống sẽ phát hiện các “điểm chuyển chủ đề” (topic shift) khi độ tương đồng giảm xuống dưới một ngưỡng nhất định, từ đó quyết định ranh giới chia chunk. Cách này giúp mỗi chunk tập trung vào một khái niệm mạch lạc, giảm nguy cơ “cắt gãy” ngữ nghĩa và thường cải thiện chất lượng truy xuất so với chia theo kích thước cố định.
Các chiến lược Indexing nâng cao
Các chiến lược này tác động trực tiếp đến vị trí tìm kiếm và khối ngữ cảnh được truy xuất, nhằm cân bằng giữa độ chính xác và độ bao quát.
- Parent–Child Indexing (Small-to-Big): Tài liệu được chia thành các chunk lớn (parent) và các chunk nhỏ hơn (child). Hệ thống index các chunk nhỏ để tăng độ chính xác khi truy xuất. Tuy nhiên, khi tìm thấy kết quả phù hợp, hệ thống có thể truy xuất thêm chunk parent (hoặc vùng lân cận) để cung cấp ngữ cảnh đầy đủ hơn cho LLM trong giai đoạn Generation.
- Summary Indexing: Sử dụng LLM để tạo bản tóm tắt cho tài liệu hoặc từng chunk. Bản tóm tắt được index để phục vụ truy xuất khi câu hỏi mang tính khái quát (high-level), trong khi văn bản gốc đầy đủ vẫn có thể được truy xuất ở giai đoạn tạo sinh câu trả lời khi cần bằng chứng chi tiết.
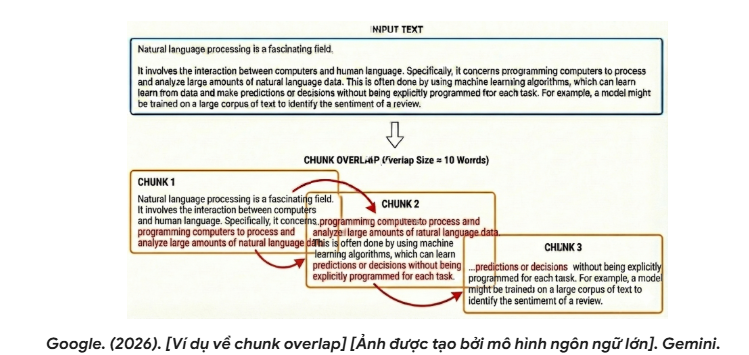
Chunk Overlap (Phần giao thoa)
Để đảm bảo tính liên tục về ngữ nghĩa tại các ranh giới cắt, một tham số chunk overlap thường được sử dụng. Chunk overlap thường được thiết lập khoảng 10–20% kích thước chunk, nghĩa là phần cuối của chunk trước sẽ được lặp lại ở đầu chunk kế tiếp. Cơ chế này giúp giảm nguy cơ mất thông tin tại điểm cắt và tăng tính mạch lạc khi đưa context vào LLM.
1.3. Tạo vector embedding
Các mô hình embedding chuyển đổi mỗi chunk văn bản (sau khi đã phân đoạn) thành một vector dày đặc (dense vector)—tức một danh sách các giá trị số thực trong không gian nhiều chiều. Vector này đóng vai trò như “đại diện ngữ nghĩa” của đoạn văn bản, giúp hệ thống có thể thực hiện tìm kiếm theo mức độ tương đồng.
Cơ chế:
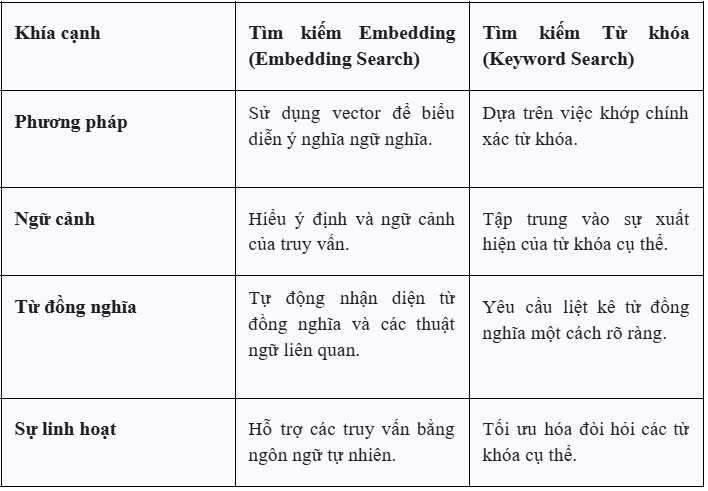
Nguyên tắc cốt lõi là: các đoạn văn bản có ý nghĩa tương tự sẽ được ánh xạ thành các vector gần nhau trong không gian vector (theo một thước đo khoảng cách/tương đồng như cosine similarity). Nhờ đó, hệ thống có thể tìm các đoạn liên quan ngay cả khi câu hỏi và tài liệu không trùng khớp từ ngữ.
Phần tiếp theo sẽ so sánh sự khác biệt giữa tìm kiếm dựa trên embedding (semantic search) và tìm kiếm từ khóa truyền thống (keyword search).
Độ đo tương đồng (Similarity Metric)
Để định lượng mức độ liên quan giữa vector truy vấn $\vec{A}$ và vector tài liệu $\vec{B}$, các hệ thống thường sử dụng độ tương đồng Cosine (Cosine Similarity) hoặc khoảng cách Euclidean (Euclidean Distance). Độ tương đồng Cosine đo cosin của góc giữa hai vector:
$$ \text{similarity}=\cos(\theta)=\frac{\vec{A}\cdot\vec{B}}{\|\vec{A}\|\,\|\vec{B}\|} $$
Với:
- $\vec{A}$ và $\vec{B}$: hai vector đang được so sánh. Trong ngữ cảnh RAG, $\vec{A}$ thường là vector của câu truy vấn (query) và $\vec{B}$ là vector của đoạn văn bản (document chunk).
- $\theta$ (theta): góc tạo bởi hai vector $\vec{A}$ và $\vec{B}$ trong không gian nhiều chiều.
- $\vec{A}\cdot\vec{B}$: tích vô hướng (dot product) của hai vector, thể hiện mức độ hai vector “cùng hướng”.
- $\|\vec{A}\|$ và $\|\vec{B}\|$: độ lớn (magnitude) hay độ dài (Euclidean norm) của vector.
Công thức tính độ lớn của vector $\vec{A}$:
$$ \|\vec{A}\|=\sqrt{\sum_{i=1}^{n} A_i^2} $$
Giá trị Cosine Similarity càng gần 1 thường biểu thị mức độ tương đồng ngữ nghĩa càng cao, trong khi giá trị gần 0 biểu thị mức độ tương đồng thấp (gần như không liên quan).
Khoảng cách Euclidean (Euclidean Distance)
Khoảng cách Euclidean đo khoảng cách đường thẳng giữa hai điểm vector trong không gian $n$-chiều:
$$ d(\vec{A},\vec{B})=\|\vec{A}-\vec{B}\| =\sqrt{\sum_{i=1}^{n}(A_i-B_i)^2} $$
Với:
- $d(\vec{A},\vec{B})$: khoảng cách ngắn nhất (đường thẳng) giữa hai vector $\vec{A}$ và $\vec{B}$.
- $n$: số chiều (dimensions) của vector embedding (ví dụ: 768, 1024, 1536).
- $i$: chỉ số chạy từ $1$ đến $n$, đại diện cho từng chiều cụ thể trong vector.
- $A_i$ và $B_i$: giá trị (tọa độ) của $\vec{A}$ và $\vec{B}$ tại chiều thứ $i$.
- $\sum$ (Sigma): ký hiệu tính tổng; công thức yêu cầu bình phương hiệu từng cặp tọa độ, cộng lại và lấy căn bậc hai.
Lưu ý: Giá trị $d(\vec{A},\vec{B})$ càng nhỏ (khoảng cách càng gần) thì hai vector càng tương đồng; điều này ngược chiều với Cosine Similarity (Cosine càng lớn thì càng giống).
1.4. Lưu vào vector database
Dữ liệu sau khi được chuyển thành vector sẽ được lưu trong một cơ sở dữ liệu chuyên biệt (vector database/vector store), tối ưu cho tìm kiếm theo độ tương đồng. Một số hệ thống phổ biến gồm Pinecone, Milvus, Weaviate và Chroma.
Một vector store thường lưu ba nhóm thông tin chính:
- Embedding của từng đoạn văn bản đã chia nhỏ (chunk embedding)
- Metadata (nguồn, tiêu đề, thời gian, vị trí trong tài liệu, loại tài liệu, …)
- Nội dung gốc của đoạn văn để có thể trả lại cho mô hình khi truy xuất
Những cơ sở dữ liệu này hỗ trợ tìm kiếm xấp xỉ (approximate nearest neighbor search), tức tìm các đoạn văn bản “gần” nhau trong không gian vector. Nhờ đó, hệ thống có thể truy xuất các đoạn có ý nghĩa tương tự, thay vì chỉ dựa trên việc trùng khớp từ khóa.
2. Retrieve: Re-ranking
Khi xây dựng hệ thống hỏi–đáp dựa trên LLM, việc truy xuất đúng tài liệu đóng vai trò quyết định đến chất lượng câu trả lời. Mặc dù chunking + embedding + vector search giúp tìm kiếm nhanh trên tập dữ liệu lớn, chúng thường chưa đủ để đảm bảo hệ thống luôn chọn được các đoạn văn bản “đúng nhất” làm ngữ cảnh. Vì vậy, re-ranking được đề xuất như một bước bổ sung nhằm cải thiện độ chính xác của truy xuất trong các hệ thống RAG.
Trong hệ thống RAG, quy trình xử lý thường có thể khái quát như sau:
- Indexing: chia nhỏ tài liệu (chunking) và tạo embedding để truy xuất sơ bộ top-k đoạn liên quan.
- Re-ranking: đánh giá lại các đoạn top-k và chọn ra những đoạn phù hợp nhất với truy vấn người dùng.
- Generation: LLM sử dụng các đoạn đã chọn làm ngữ cảnh để sinh câu trả lời.
Vì sao cần re-ranking trước khi sinh câu trả lời?
- Mô hình re-ranking thường chậm hơn nhưng chính xác hơn so với mô hình embedding (bi-encoder) trong việc xác định mức độ liên quan giữa truy vấn và tài liệu. Nguyên nhân là bi-encoder mã hóa truy vấn và tài liệu độc lập, sau đó so khớp bằng độ tương đồng vector, nên có thể bỏ sót các quan hệ ngữ nghĩa tinh tế (fine-grained relevance).
Ngoài ra, để hạn chế độ dài, văn bản thường được chia thành chunks trước khi embedding, dẫn đến việc embedding phản ánh ngữ nghĩa “cục bộ” và có thể thiếu ngữ cảnh cho truy vấn.
- Re-ranking cho phép “đọc kỹ hơn” các ứng viên đã truy xuất. Ở bước này, hệ thống đánh giá lại các chunks trong danh sách top-k bằng cách xem xét mối quan hệ trực tiếp giữa truy vấn và nội dung của từng đoạn. Nhờ vậy, hệ thống có thể chọn ra các đoạn thực sự liên quan nhất để đưa vào LLM, từ đó nâng cao độ chính xác và mức độ đầy đủ của câu trả lời.
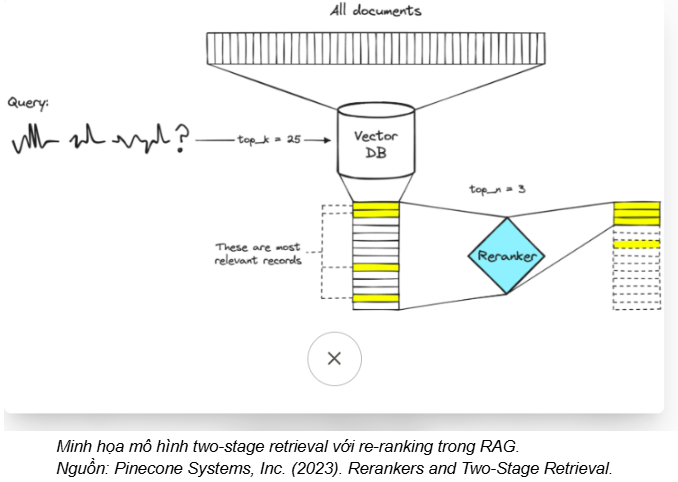
Cách re-rank trong RAG
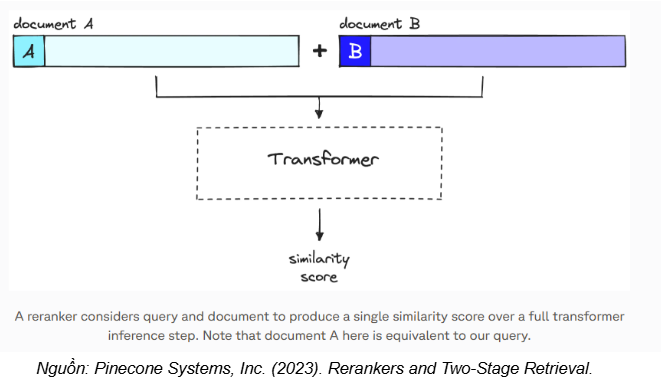
- Cross-encoder:
Phương pháp này hoạt động bằng cách đưa đồng thời câu truy vấn và từng chunk ứng viên vào một mô hình Transformer để dự đoán điểm liên quan (relevance/similarity score). Sau khi có điểm số cho mỗi cặp (query, chunk), hệ thống sắp xếp lại (re-rank) các chunks theo thứ tự giảm dần của score và chỉ giữ lại top-n chunks làm ngữ cảnh đầu vào cho LLM.
Nhờ cơ chế “đọc chung” truy vấn và tài liệu, cross-encoder thường cho chất lượng xếp hạng tốt hơn bi-encoder, giúp giảm nhiễu và tăng độ chính xác của câu trả lời ở bước Generation (đổi lại chi phí tính toán cao hơn).
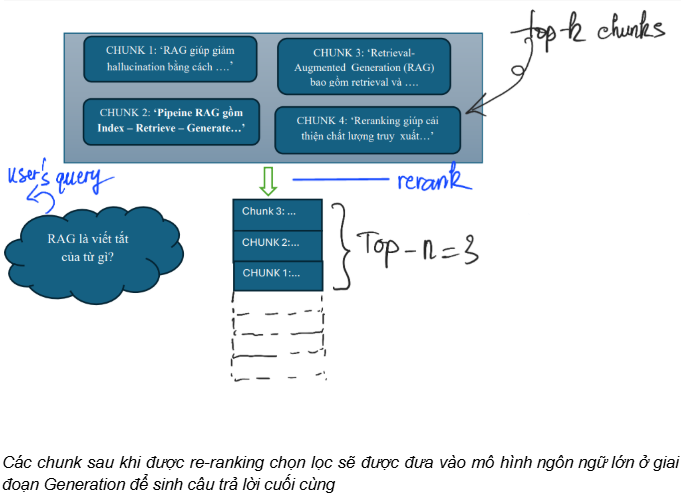
- LLM-based Reranker:
LLM-based re-ranking xem mô hình ngôn ngữ lớn (LLM) như một hàm đánh giá mức độ liên quan giữa câu truy vấn và các đoạn văn bản ứng viên (candidate chunks) đã được truy xuất ở bước retrieval (thường là top-k sau bi-encoder/vector search). Với mỗi cặp (query, chunk) (hoặc với cả danh sách ứng viên), LLM sẽ chấm điểm liên quan (relevance/similarity score) và từ đó sắp xếp lại các chunks theo thứ tự phù hợp. Cuối cùng, hệ thống giữ lại top-n đoạn tốt nhất làm ngữ cảnh đầu vào cho giai đoạn Generation.
Cách tiếp cận này giúp giảm nhiễu, ưu tiên các đoạn có bằng chứng trực tiếp cho câu hỏi và thường cải thiện độ chính xác của hệ thống RAG, đặc biệt trong các truy vấn cần hiểu ngữ cảnh sâu hoặc phân biệt các đoạn gần giống nhau.
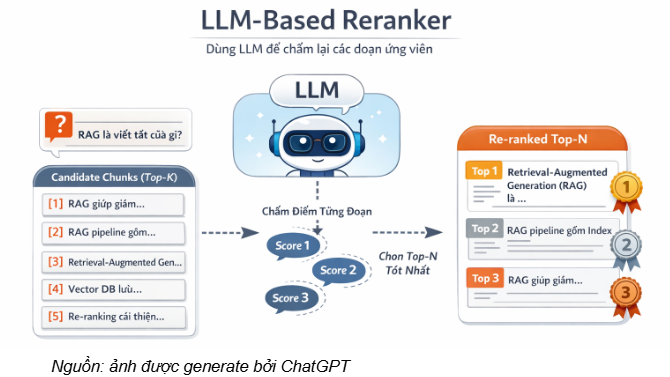
LLM-based re-ranking thường được triển khai theo hướng zero-shot, tức sử dụng trực tiếp khả năng suy luận của LLM thông qua prompt và tiêu chí chấm điểm, mà không cần huấn luyện lại mô hình trên dữ liệu xếp hạng chuyên biệt. Hai cơ chế triển khai phổ biến gồm:
-
Pointwise LLM Re-ranking (chấm điểm theo từng ứng viên):
Ở cơ chế pointwise, LLM đánh giá độc lập từng ứng viên bằng cách nhận vào từng cặp (query, chunk) và xuất ra một điểm liên quan. Danh sách ứng viên sau đó được sắp xếp giảm dần theo điểm số để chọn top-n. Cách tiếp cận này tương tự như việc chấm điểm riêng lẻ từng đoạn và đưa ra thứ hạng dựa trên điểm tổng. -
Listwise LLM Re-ranking (xếp hạng cả danh sách):
Ở cơ chế listwise, LLM được cung cấp đồng thời query và toàn bộ tập ứng viên (top-k chunks), từ đó tận dụng khả năng so sánh và suy luận “tương đối” để quyết định thứ hạng. Bằng cách nhìn toàn bộ danh sách trong một ngữ cảnh thống nhất, mô hình có thể đánh giá tốt hơn sự khác biệt giữa các chunks gần giống nhau và lựa chọn top-n ứng viên phù hợp nhất.
3. Generation
Generation là giai đoạn cuối trong kiến trúc Retrieval-Augmented Generation (RAG), nơi mô hình ngôn ngữ lớn (LLM) được sử dụng để tổng hợp thông tin từ truy vấn (query) của người dùng và các đoạn văn bản (chunks/documents) đã được truy xuất ở giai đoạn Retrieve, nhằm tạo ra câu trả lời chính xác, mạch lạc và có căn cứ. Cần lưu ý rằng chất lượng Generation phụ thuộc mạnh vào hai giai đoạn trước là Indexing và Retrieval: nếu ngữ cảnh truy xuất không đầy đủ hoặc sai lệch, câu trả lời vẫn có thể kém chính xác ngay cả khi LLM được thiết kế tốt. Do đó, trong thực tiễn, mục tiêu của Generation là tăng groundedness (bám theo bằng chứng trong ngữ cảnh) và giảm nguy cơ hallucination, thay vì cam kết loại bỏ hoàn toàn hiện tượng này.
Đối với người mới học AI, có thể hiểu đơn giản rằng: trong RAG, LLM được kỳ vọng trả lời dựa chủ yếu trên ngữ cảnh đã truy xuất (retrieved context), thay vì suy đoán vượt ra ngoài phạm vi dữ liệu được cung cấp. Vì vậy, Generation không chỉ là “gọi LLM”, mà là một chuỗi bước thiết kế nhằm đảm bảo mô hình ưu tiên sử dụng thông tin có nguồn gốc rõ ràng, đồng thời có thể thừa nhận giới hạn và “từ chối trả lời” khi bằng chứng trong ngữ cảnh không đủ. Các bước chính trong Generation được trình bày ở phần tiếp theo.
3.1. Chuẩn bị ngữ cảnh: nền tảng để sinh câu trả lời đúng
Generation không bắt đầu từ thời điểm mô hình sinh văn bản, mà bắt đầu ngay từ cách chúng ta đóng gói ngữ cảnh (context assembly). Sau bước reranking ở giai đoạn Retrieve, hệ thống thường chỉ giữ lại một số đoạn văn bản liên quan nhất (ví dụ 3–5 đoạn, tùy theo bài toán và giới hạn token) để đưa vào LLM. Những đoạn này được gọi chung là context. Về bản chất, đây là tập “tài liệu tham khảo” mà mô hình được phép sử dụng để tạo câu trả lời.
Việc chuẩn hóa context có ý nghĩa quan trọng. Nếu các đoạn văn được đưa vào một cách lộn xộn, không có phân tách rõ ràng, mô hình có thể nhầm lẫn giữa nội dung tài liệu và câu hỏi của người dùng, hoặc trộn lẫn các nguồn khác nhau. Do đó, trong các hệ thống RAG thực tế, context thường được trình bày theo cấu trúc rõ ràng: có phân đoạn, có đánh dấu nguồn (tài liệu, tiêu đề/mục, vị trí trích dẫn), và tách bạch phần câu hỏi. Cách tổ chức này giúp mô hình nhận biết rằng nó đang tham chiếu nhiều bằng chứng thay vì một đoạn văn liền mạch.
Một thách thức khác là giới hạn độ dài ngữ cảnh (context window). Mỗi LLM đều có giới hạn số token xử lý trong một lần gọi, nên Generation phải cân đối giữa việc đưa đủ thông tin cần thiết và tránh làm “quá tải” mô hình. Vì vậy, một số hệ thống áp dụng chiến lược tổng hợp theo nhiều lượt (iterative refinement/compaction), trong đó mô hình đọc và cập nhật câu trả lời theo từng bước thay vì nạp toàn bộ tài liệu trong một lượt. Cách làm này giúp xử lý hiệu quả các tài liệu dài và giảm nhiễu trong ngữ cảnh đưa vào.
3.2. Prompting có kiểm soát: ràng buộc để giảm nguy cơ hallucination
Khi context đã được chuẩn bị, bước tiếp theo trong Generation là thiết kế prompt (chỉ dẫn gửi cho LLM). Prompt trong RAG khác với prompt trò chuyện thông thường: mục tiêu không phải khuyến khích tính sáng tạo, mà là ràng buộc mô hình tuân thủ dữ liệu và giảm suy đoán ngoài bằng chứng.
Một prompt RAG hiệu quả thường bao gồm các yêu cầu rõ ràng, chẳng hạn:
(i) chỉ sử dụng thông tin trong context
(ii) nếu không tìm thấy thông tin cần thiết thì phải thừa nhận “không đủ dữ liệu”
(iii) trong các miền yêu cầu độ chính xác cao (ví dụ: y tế, pháp lý), có thể yêu cầu mô hình trích dẫn nguồn cho các luận điểm quan trọng. Việc trích dẫn không chỉ giúp người dùng kiểm chứng, mà còn gián tiếp buộc mô hình bám sát ngữ cảnh, vì các khẳng định không có bằng chứng sẽ khó gắn với nguồn tương ứng.
3.3. Tổng hợp câu trả lời: từ nhiều mảnh thông tin đến một kết luận
Sau khi nhận prompt và context, LLM tiến hành sinh câu trả lời. Tuy nhiên, trong RAG, quá trình này nên được thiết kế như một hoạt động tổng hợp bằng chứng có kiểm soát, thay vì đơn thuần “viết lại” hoặc ghép câu.
Một cách tiếp cận phổ biến là yêu cầu mô hình trích xuất các ý chính từ từng đoạn tài liệu trước, sau đó mới tổng hợp thành câu trả lời cuối cùng. Cách làm này giúp giảm khả năng mô hình tạo ra các mệnh đề không có trong tài liệu. Một số hệ thống còn triển khai cơ chế trả lời theo nhiều lượt: mỗi lượt đọc thêm một phần ngữ cảnh và điều chỉnh câu trả lời trước đó, phù hợp khi xử lý tài liệu kỹ thuật phức tạp hoặc hướng dẫn dài.
Ở góc độ lý thuyết, nguyên lý này tương thích với ý tưởng trong bài báo RAG gốc: mô hình sinh được điều kiện hóa trên các tài liệu truy xuất để tăng tính có căn cứ. Dù các triển khai hiện đại có thể khác (pipeline, reranker, prompt template…), nguyên lý cốt lõi vẫn là: câu trả lời nên là kết quả của tổng hợp bằng chứng, không phải suy đoán tự do.
3.4. Kiểm tra sau sinh (Post-generation checking)
Một điểm người mới học RAG thường bỏ sót là Generation chưa kết thúc ngay khi LLM trả về câu trả lời. Trong các hệ thống thực tế, thường có bước post-generation checking nhằm đánh giá mức độ câu trả lời được hỗ trợ bởi context (groundedness/faithfulness).
Bước kiểm tra này có thể triển khai theo nhiều mức độ: từ các quy tắc đơn giản (ví dụ kiểm tra trích dẫn, phát hiện khẳng định mạnh nhưng thiếu nguồn) đến việc dùng một mô hình khác làm verifier/judge để rà soát các mệnh đề không có bằng chứng rõ ràng. Nếu phát hiện vấn đề, hệ thống có thể kích hoạt truy xuất lại dữ liệu, yêu cầu người dùng làm rõ truy vấn, hoặc phản hồi rằng thông tin hiện tại chưa đủ để kết luận.
Đối với các ứng dụng nhạy cảm, đây là lớp “hàng rào an toàn” giúp RAG tăng độ tin cậy, thay vì chỉ dựa vào khả năng sinh ngôn ngữ của LLM.
III. Ví dụ về prompt mẫu cho RAG
Trong kiến trúc Retrieval-Augmented Generation (RAG), sau khi hệ thống hoàn tất giai đoạn Retrieval, giai đoạn Generation không chỉ đơn thuần là “gọi LLM để sinh câu trả lời”, mà còn bao gồm bước thiết kế prompt nhằm hướng dẫn mô hình sử dụng ngữ cảnh truy xuất (retrieved context) một cách đúng đắn. Nói cách khác, prompt trong RAG có thể được xem như một bộ quy tắc vận hành (instruction set) giúp LLM: bám sát bằng chứng từ tài liệu, hạn chế suy đoán ngoài dữ liệu cung cấp, và thể hiện rõ giới hạn khi thông tin trong ngữ cảnh chưa đủ.
Có thể hình dung prompt giống như việc người điều phối giao cho một người đọc tài liệu nhiệm vụ trả lời câu hỏi. Nếu chỉ yêu cầu “đọc rồi trả lời”, người đọc có thể tự diễn giải theo hiểu biết cá nhân hoặc bổ sung thông tin từ nguồn ngoài. Ngược lại, nếu hướng dẫn cụ thể “chỉ dựa trên các tài liệu được cung cấp; nếu không thấy thông tin thì nói không có; và trích dẫn nguồn khi kết luận”, câu trả lời sẽ đáng tin cậy và dễ kiểm chứng hơn. Prompt trong RAG hoạt động theo logic tương tự: nó quy định phạm vi sử dụng thông tin và cách mô hình phản ứng khi bằng chứng không đủ.
Một prompt tốt trong RAG thường hướng đến ba mục tiêu chính:
- Giới hạn nguồn thông tin: chỉ sử dụng nội dung trong context.
- Ngăn suy đoán: không tự bổ sung thông tin “có vẻ hợp lý” nhưng không có bằng chứng.
- Cơ chế từ chối hợp lệ: nêu rõ khi tài liệu không chứa thông tin cần thiết.
Hệ quả khi prompt thiếu ràng buộc
Khi prompt quá sơ sài, LLM có xu hướng “hoàn thiện câu trả lời” bằng cách lấp các khoảng trống bằng tri thức huấn luyện sẵn, dẫn đến hallucination hoặc trả lời thiếu điều kiện. Có thể mô tả các rủi ro thường gặp như sau:
- Suy diễn ngoài tài liệu: Nếu tài liệu chỉ ghi “thực hiện theo quy định pháp luật” nhưng không nêu con số cụ thể, mô hình có thể tự đưa ra một con số phổ biến thay vì thừa nhận “không có thông tin trong tài liệu”.
- Trộn lẫn nguồn: Mô hình kết hợp nội dung context với “kiến thức nền” mà không phân biệt rõ đâu là thông tin chính thức, làm giảm tính kiểm chứng.
- Bỏ qua điều kiện: Tài liệu có thể phân biệt “nhân viên chính thức” và “thử việc”, nhưng nếu prompt không yêu cầu nêu điều kiện, mô hình có thể trả lời thiếu ngữ cảnh, dẫn đến hiểu sai chính sách.
Trong các miền rủi ro cao như y tế, pháp lý hoặc chăm sóc khách hàng doanh nghiệp, một câu trả lời “nghe có vẻ đúng” nhưng thực tế không có căn cứ có thể gây hậu quả nghiêm trọng. Vì vậy, prompt trong RAG không chỉ là “đặt câu hỏi”, mà cần định nghĩa ranh giới hành vi: mô hình được phép làm gì, không được làm gì, và phải phản hồi thế nào khi thiếu bằng chứng.
Một số dạng prompt mẫu
1) Zero-shot prompting: Prompt cơ bản nhất
Zero-shot là kỹ thuật đơn giản nhất: đưa ra yêu cầu trực tiếp mà không cần cung cấp ví dụ mẫu nào.

2) Few-shot prompting: Học từ ví dụ mẫu
Few-shot là kỹ thuật cho mô hình xem một vài ví dụ mẫu trước khi yêu cầu xử lý câu hỏi thực tế. Nhờ đó, mô hình có thể học theo định dạng (format) và phong cách trả lời mong muốn từ các ví dụ, từ đó tăng tính nhất quán của đầu ra (ví dụ: cách trình bày, cách trích dẫn, cách từ chối khi thiếu thông tin).

3) Thêm ràng buộc để giảm nguy cơ hallucination
Khi cần kiểm soát hành vi của mô hình chặt chẽ hơn, prompt nên bổ sung các ràng buộc rõ ràng về (i) vai trò của mô hình, (ii) phạm vi thông tin được phép sử dụng, và (iii) định dạng/tiêu chuẩn đầu ra. Những ràng buộc này giúp mô hình ưu tiên bám sát ngữ cảnh truy xuất, hạn chế suy đoán ngoài dữ liệu và tăng tính nhất quán của câu trả lời.

4) Yêu cầu trích dẫn nguồn (Citation)
Trong các ứng dụng cần minh bạch và dễ kiểm chứng như nghiên cứu, pháp lý hoặc hỗ trợ khách hàng doanh nghiệp, việc yêu cầu trích dẫn nguồn giúp người dùng xác thực thông tin trong câu trả lời. Đồng thời, cơ chế citation cũng tạo “ràng buộc mềm” buộc mô hình phải bám sát retrieved context, vì các mệnh đề không có bằng chứng sẽ khó gắn với trích dẫn tương ứng.

5) Chain-of-Thought (CoT) — Suy luận từng bước
Chain-of-Thought (CoT) yêu cầu mô hình thực hiện suy luận theo từng bước trước khi đưa ra câu trả lời cuối cùng, thay vì trả lời ngay lập tức. Kỹ thuật này đặc biệt hữu ích khi câu hỏi cần tổng hợp nhiều mảnh thông tin từ ngữ cảnh hoặc đòi hỏi suy luận gián tiếp (multi-hop reasoning), vì nó khuyến khích mô hình lập luận có cấu trúc và giảm bỏ sót các điều kiện quan trọng.

Tài liệu tham khảo
Abdallah, A., Piryani, B., Mozafari, J., Ali, M., & Jatowt, A. (2025). How good are LLM-based rerankers? An empirical analysis of state-of-the-art reranking models [Preprint]. arXiv. https://arxiv.org/abs/2508.16757
AI Vietnam. (n.d.). RAG [PDF]. Retrieved January 18, 2026, from https://tutorial.aivietnam.edu.vn/pdf/48
Guu, K., Lee, K., Tung, Z., Pasupat, P., & Chang, M.-W. (2020). REALM: Retrieval-augmented language model pre-training. In Proceedings of the 37th International Conference on Machine Learning (ICML 2020) (Proceedings of Machine Learning Research, Vol. 119, pp. 3929–3938). PMLR. https://arxiv.org/abs/2002.08909
Ji, Z., Lee, N., Frieske, R., Yu, T., Su, D., Xu, Y., Ishii, E., Bang, Y. J., Madotto, A., & Fung, P. (2023). Survey of hallucination in natural language generation. ACM Computing Surveys, 55(12), Article 248, 1–38. https://doi.org/10.1145/3571730
Le, H. (n.d.). Tổng hợp về RAG [Notion page]. Notion. Retrieved January 18, 2026, from https://spiffy-attention-05a.notion.site/T-ng-h-p-v-RAG-220e1a3b0e448002b18aea461f59f01d
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W.-t., Rocktäschel, T., Riedel, S., & Kiela, D. (2020). Retrieval-augmented generation for knowledge-intensive NLP tasks. Advances in Neural Information Processing Systems, 33, 9459–9474. https://arxiv.org/abs/2005.11401
Movin, S., & Hauff, C. (2025). Zero-shot reranking with large language models and precomputed ranking features: Opportunities and limitations. In Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’25). Association for Computing Machinery. https://doi.org/10.1145/3726302.3730119
Pinecone Systems, Inc. (n.d.). Rerankers and two-stage retrieval. Pinecone Learn. Retrieved January 18, 2026, from https://www.pinecone.io/learn/series/rag/rerankers/
Ray Team. (2025). Improve RAG with prompt engineering. Ray Docs. https://docs.ray.io/en/latest/ray-overview/examples/e2e-rag-notebooks/05_Improve_RAG_with_Prompt_Engineering.html
Chưa có bình luận nào. Hãy là người đầu tiên!