
Phát hiện điểm bất thường trong dữ liệu chuỗi thời gian

Hình 1. Ứng dụng của việc phát hiện điểm bất thường trong dữ liệu đời sống (hình tạo sinh bởi Artlist.io).
Toàn bộ nội dung bài viết được xây dựng dựa trên tài liệu tham khảo dưới đây.
[1] Boniol, P., Liu, Q., Huang, M., Palpanas, T., & Paparrizos, J. (2024). Dive into time-series anomaly detection: A decade review. arXiv. https://arxiv.org/abs/2412.20512
Những tiến bộ gần đây trong công nghệ thu thập dữ liệu, cùng với sự gia tăng không ngừng về khối lượng và tốc độ của dữ liệu dạng dòng (streaming data), đã khẳng định nhu cầu thiết yếu đối với các phương pháp phân tích chuỗi thời gian. Trong bối cảnh đó, việc phát hiện bất thường trong dữ liệu dạng chuỗi thời gian đã trở thành một hướng nghiên cứu quan trọng, với nhiều ứng dụng trong các lĩnh vực như an ninh mạng, thị trường tài chính, thực thi pháp luật và chăm sóc sức khỏe.

Hình 2. Phát hiện điểm bất thường trở thành hướng nghiên cứu quan trọng trong nhiều lĩnh vực (hình tạo sinh bởi Artlist.io).
Trong khi các nghiên cứu truyền thống về phát hiện bất thường chủ yếu dựa trên các thước đo thống kê, sự gia tăng nhanh chóng của các thuật toán học máy trong những năm gần đây đã đặt ra nhu cầu xây dựng một khung đặc trưng hóa có hệ thống và tổng quát cho các phương pháp nghiên cứu trong phát hiện bất thường chuỗi thời gian. Bài khảo sát này tiến hành phân nhóm và tóm tắt các phương pháp phát hiện bất thường hiện có dựa trên một hệ phân loại theo hướng quy trình (process-centric taxonomy) trong bối cảnh chuỗi thời gian.
Bên cạnh việc đề xuất một cách phân loại mang tính hệ thống đối với các phương pháp phát hiện bất thường, nghiên cứu còn thực hiện một phân tích tổng hợp (meta-analysis) các công trình liên quan, đồng thời chỉ ra những xu hướng chung trong lĩnh vực phát hiện bất thường chuỗi thời gian.
Khái niệm và phân loại điểm bất thường
Khái niệm điểm bất thường
Sự phát triển nhanh chóng về cả số lượng và ứng dụng thực tế của các cảm biến, mạng, lưu trữ và xử lý dữ liệu với chi phí hiệu quả đặt ra nhu cầu thu thập và lưu trữ một lượng khổng lồ các dữ liệu theo thời gian. Việc ghi lại các dữ liệu này tạo ra một chuỗi có thứ tự các điểm dữ liệu dạng số thực, thường được gọi là chuỗi thời gian (time series).
Việc phân tích trên dữ liệu chuỗi thời gian là nhu cầu cấp thiết trong hầu hết mọi ngành khoa học và các lĩnh vực công nghiệp. Tuy nhiên, sự phức tạp vốn có trong quá trình tạo dữ liệu của các hệ thống này, kết hợp với những sai sót trong hệ thống đo lường cũng như sự can thiệp của các tác nhân bên ngoài, thường dẫn đến những hiện tượng bất thường. Những sự kiện bất thường này sau đó xuất hiện trong dữ liệu thu thập được dưới dạng các anomaly (điểm bất thường). Với thuật ngữ bất thường (anomalies), chúng ta đề cập đến các điểm dữ liệu hoặc nhóm các điểm dữ liệu không tuân theo một khái niệm nào đó về tính bình thường hoặc hành vi được kỳ vọng dựa trên dữ liệu đã quan sát trước đó.
Việc phát hiện bất thường trong chuỗi thời gian (time series) đã nhận được nhiều sự quan tâm trong cả học thuật và công nghiệp trong hơn sáu thập kỷ qua. Tùy thuộc vào ứng dụng, các bất thường có thể được phân loại thành
1. Nhiễu hoặc dữ liệu lỗi, gây cản trở quá trình phân tích dữ liệu;
2. Dữ liệu thực sự có giá trị cần quan tâm.
Trong trường hợp thứ nhất, các bất thường là dữ liệu không mong muốn và sẽ bị loại bỏ hoặc được chỉnh sửa. Trong trường hợp thứ hai, các bất thường có thể chỉ ra những sự kiện có ý nghĩa, chẳng hạn như sự cố hoặc sự thay đổi trong hành vi, là cơ sở cho các phân tích tiếp theo.
Chính vì vậy, việc phát hiện anomaly (bất thường) trong time series (chuỗi thời gian) mang lại rất nhiều lợi ích quan trọng, đặc biệt trong các hệ thống thực tế như IoT, tài chính, sản xuất, và y tế.
Thứ nhất, việc phát hiện điểm bất thường giúp nhận diện các dấu hiệu bất thường trước khi sự cố nghiêm trọng xảy ra. Ví dụ như khi server có lưu lượng truy cập tăng đột biến, hệ thống phát hiện điểm bất thường sẽ phát cảnh báo có nguy cơ tấn công hoặc lỗi hệ thống. Việc phát hiện điểm bất thường lúc này sẽ giúp giảm chi phí downtime và chi phí sửa chữa.
Thứ hai, về mặt bảo trì, việc phát hiện các điểm bất thường giúp cho người vận hành hệ thống tránh khỏi việc bảo trì không cần thiết.
 Hình 3. Cấu trúc hệ thống lưu trữ dữ liệu dạng chuỗi thời gian (hình tạo sinh bởi ChatGPT).
Hình 3. Cấu trúc hệ thống lưu trữ dữ liệu dạng chuỗi thời gian (hình tạo sinh bởi ChatGPT).
Đặc biệt, việc phát hiện gian lận trong những giao dịch ngân hàng hay thương mại điện tử cũng là một ứng dụng mang tính thực tiễn cao của những mô hình phát hiện điểm bất thường.
Để nhận biết những điểm bất thường, một số nhóm phương pháp đã và đang được nghiên cứu như sau.
- Nhóm các phương pháp đề xuất bước biến đổi (transformation) để chuyển thông tin thời gian sang một không gian vector phù hợp, sau đó áp dụng các kỹ thuật phát hiện outlier truyền thống bằng Machine Learning như XGBoost, Decision Tree, v.v.
- Một nhóm phương pháp khác sử dụng khoảng cách hoặc độ tương đồng chuyên biệt cho chuỗi thời gian để xác định các chuỗi thời gian hoặc các đoạn chuỗi bất thường.
- Nhóm các phương pháp thuộc cộng đồng deep learning tận dụng các kiến trúc mạng chuyên biệt có khả năng mã hóa thông tin thời gian, chẳng hạn như recurrent neural networks (RNN) hoặc các phương pháp dựa trên convolution.
Phân loại điểm bất thường
Do tính chất phụ thuộc theo thời gian của dữ liệu, các bất thường có thể xuất hiện dưới dạng một điểm đơn lẻ hoặc dưới dạng các chuỗi con. Trong bối cảnh bất thường điểm (point anomaly), mục tiêu là xác định các điểm dữ liệu nằm xa phân phối giá trị thông thường, vốn đại diện cho trạng thái hoạt động bình thường. Trong khi đó, đối với bất thường chuỗi (sequence anomaly), mục tiêu là phát hiện các chuỗi con bất thường; những chuỗi này thường không phải là các điểm ngoại lai riêng lẻ mà thể hiện các mẫu hiếm gặp và do đó mang tính bất thường. Trong các ứng dụng thực tế, việc phân biệt giữa bất thường điểm và bất thường chuỗi là đặc biệt quan trọng, bởi lẽ một điểm dữ liệu riêng lẻ có thể trông bình thường so với các điểm lân cận, nhưng hình dạng tổng thể của chuỗi các điểm đó lại có thể biểu hiện hành vi bất thường.
Về mặt hình thức, có thể phân loại bất thường trong chuỗi thời gian thành ba dạng chính: bất thường điểm (point anomalies), bất thường theo ngữ cảnh (contextual anomalies) và bất thường tập thể (collective anomalies).
-
Bất thường điểm (point anomalies) là các điểm dữ liệu có sự sai lệch đáng kể so với phần còn lại của tập dữ liệu. Trong trường hợp này, giá trị của điểm bất thường nằm ngoài phạm vi giá trị bình thường kỳ vọng.
-
Bất thường theo ngữ cảnh (contextual anomalies) là các điểm dữ liệu vẫn nằm trong phạm vi của phân phối tổng thể (khác với bất thường điểm), nhưng lại sai lệch so với phân phối kỳ vọng khi xét trong một ngữ cảnh cụ thể, chẳng hạn như trong một cửa sổ thời gian cục bộ.
-
Bất thường tập thể (collective anomalies) là các chuỗi điểm dữ liệu không tuân theo các mẫu điển hình đã được quan sát trước đó, tức là biểu hiện các cấu trúc hoặc hành vi bất thường ở cấp độ chuỗi.
Hai loại đầu tiên, bao gồm bất thường điểm và bất thường theo ngữ cảnh, thường được gọi chung là bất thường dựa trên điểm (point-based anomalies), trong khi bất thường tập thể được phân loại là bất thường dựa trên chuỗi (sequence-based anomalies).
Ngoài ra, cần lưu ý một trường hợp khác của bài toán phát hiện bất thường chuỗi con, được gọi là phát hiện bất thường trên toàn bộ chuỗi (whole-sequence detection), nhằm phân biệt với phát hiện bất thường tại từng điểm (point detection). Trong trường hợp này, chu kỳ của chuỗi con tương ứng với toàn bộ chuỗi thời gian, và toàn bộ chuỗi được xem xét như một thực thể thống nhất để đánh giá tính bất thường.
Cách tiếp cận này thường xuất hiện trong các bài toán làm sạch dữ liệu cảm biến, nơi các nhà nghiên cứu quan tâm đến việc xác định một cảm biến hoạt động bất thường trong số nhiều cảm biến đang vận hành bình thường.
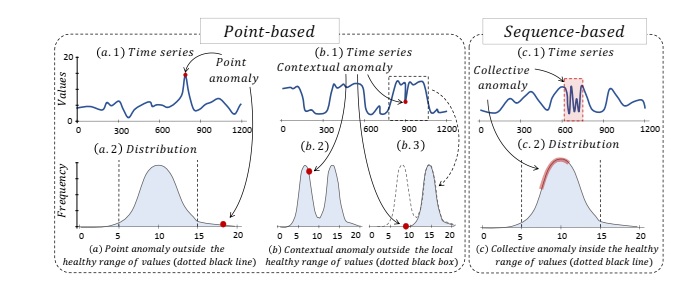 Hình 4. Phân loại dữ liệu chuỗi thời gian [1].
Hình 4. Phân loại dữ liệu chuỗi thời gian [1].
Các phương pháp nhận biết điểm bất thường dựa trên khoảng cách
Phương pháp Distance-based xác định các điểm bất thường trong dữ liệu chuỗi thời gian dựa trên khoảng cách giữa các điểm dữ liệu (ví dụ: khoảng cách Euclidean).
Phương pháp Các mô hình tiêu biểu có thể được chia ra thành 3 nhóm:
Dựa trên mức độ lân cận (Proximity-based)
Các phương pháp thuộc nhóm xem 1 đoạn con (sub-sequence) trong time-series là một điểm dữ liệu trong không gian nhiều chiều (multi-dimensional point), từ đó đánh giá một điểm dữ liệu là bất thường nếu nó nằm cô lập với so với các điểm lân cận gần nhất của nó.
Mô hình tiêu biểu:
- Kth Nearest Neighbor (KNN)
- Local Outlier Factor (LOF)
Dựa trên phân cụm (Clustering-based)
Phân chia các đoạn con trong time-series thành các cụm khác nhau. Một điểm được đánh giá là bất thường nếu nó không thuộc về cụm nào, hoặc nằm quá xa so với tâm của cụm gần nhất.
Mô hình tiêu biểu:
- K-means
- DBSCAN
- MCOD
Discord-based (Dựa trên sự bất đồng)
Phương pháp này tìm kiếm các "discord" – những chuỗi con có khoảng cách đến điểm lân lớn nhất, so với tất cả các chuỗi khác.
Mô hình tiêu biểu:
- Matrix Profile
- HOT SAX
- DAD
Điểm mạnh và Điểm yếu
Distance-based thường đảm bảo tính nguyên bản của dữ liệu time-series, tránh việc biến đổi hoặc thêm thuộc tính mới vào dữ liệu và tương đối dễ triển khai. Tuy nhiên, trong trường hợp các điểm bất thường co cụm lại thành các nhóm nhỏ, các kỹ thuật truyền thống như KNN có thể gặp khó khăn.
Trường hợp sử dụng
Chủ yếu áp dụng hiệu quả trong bài toán học không có giám sát (unsupervised), dữ liệu huấn luyện không có nhãn thường, hoặc yêu cầu phát hiện các điểm dữ liệu bất thường nằm ngoài phân phối của dữ liệu huấn liệu.
Nhóm phương pháp nhận biết điểm bất thường dựa trên mật độ (Density-based Method)
Các phương pháp Density-based chuyển đổi dữ liệu chuỗi thời gian thành các kiểu dữ liệu (data structures) phức tạp hơn để đo lường mật độ của các điểm dữ liệu hoặc chuỗi con.
Dựa trên phân phối (Distribution-based)
Sử dụng các đặc trưng thống kê về phân phối (var, std, etc.) của chuỗi con bình thường để xây dựng một phân phối chuẩn để phân biệt các điểm dữ liệu bất thường.
Mô hình tiêu biểu:
- Minimum Covariance Determinant (MCD)
- One-Class SVM (OCSVM)
- Histogram-based Outlier Score (HBOS)
Dựa trên đồ thị (Graph-based)
Biểu diễn chuỗi thời gian dưới dạng đồ thị, trong đó nút (node) là các chuỗi con và cạnh (edge) là tần suất chuyển tiếp giữa chúng. Điểm bất thường được phát hiện thông qua các đặc điểm đồ thị như đường đi bất thường, bậc của nút thấp hoặc trọng số cạnh thấp.
Mô hình tiêu biểu:
- Finite State Machine (FSM)
- Series2Graph
Dựa trên dữ liệu dạng cây (Tree-based)
Sử dụng các cấu trúc dữ liệu dạng cây để phân tách dữ liệu. Điểm bất thường là những nodes bị cô lập (ở nodes thấp) so với phần còn lại của dữ liệu.
Mô hình tiêu biểu:
- Isolation Forest (IForest)
Dựa trên mã hóa (Encoding-based)
Mã hóa hoặc nén chuỗi thời gian thành các biểu tượng rời rạc. Điểm bất thường được xác định dựa trên việc biểu diễn đã mã hóa khớp với dữ liệu mới tốt đến đâu.
Mô hình tiêu biểu:
- Principal Component Analysis (PCA)
- GrammarViz
- Hidden Markov Model (HMM)
- Dynamic Bayesian Network
Điểm mạnh và Điểm yếu
Rất hiệu quả trong việc nắm bắt các điểm phức tạp, chu kỳ hoặc các đặc trưng có cấu trúc liên kết, thay vì chỉ xét điểm dữ liệu đơn lẻ. Tuy nhiên, thuật toán có thể phức tạp trong bước tiền xử lý hoặc yêu cầu biểu diễn dữ liệu chính xác.
Trường hợp sử dụng
Có thể ứng dụng tốt trên dữ liệu nhiễu và thường được dùng phổ biến trên dữ liệu đa biến (multivariate time series), phù hợp với các thiết lập bán giám sát (semi-supervised).
Các phương pháp nhận biết điểm bất thường dựa trên dự đoán (Prediction-based Methods)
Các phương pháp dựa trên dự đoán nhằm mục đích phát hiện các bất thường bằng cách dự đoán các hành vi bình thường dự kiến dựa trên một tập huấn luyện gồm các chuỗi thời gian hoặc chuỗi con (có chứa bất thường hoặc không). Ví dụ, hãy tưởng tượng bạn đang theo dõi biểu đồ giá của các mã cổ phiếu như PNJ hay FPT..., những biến động chệch hướng hoàn toàn so với xu hướng chung chính là những 'tín hiệu' mà chúng ta cần bắt được.
Để giải quyết bài toán này, phương pháp dựa trên dự đoán là một trong những hướng tiếp cận mạnh mẽ nhất. Có hai loại cấp độ của phương pháp này là dựa trên dự báo và dựa trên tái thiết. Chúng tôi đã liệt kê tất cả các phương pháp đã đề cập trong Bảng 1 dưới đây.
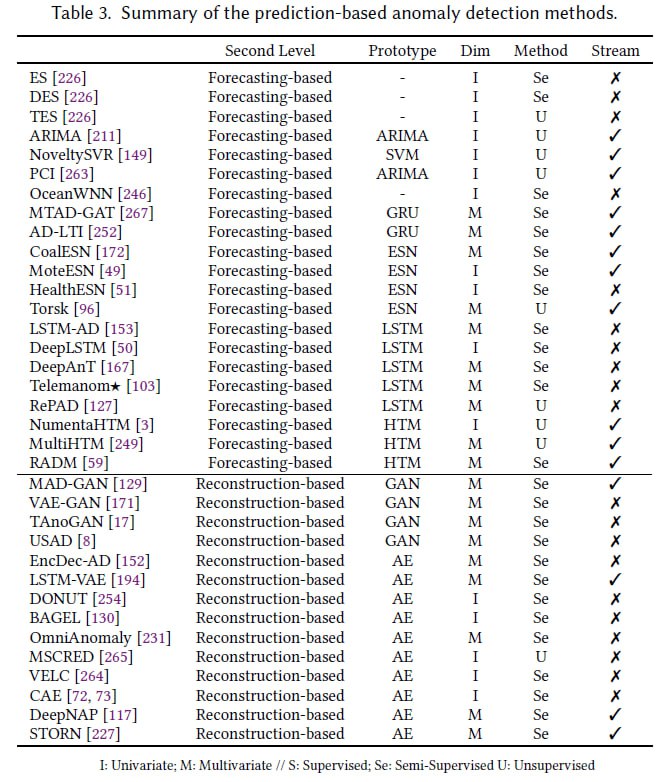
Bảng 1. Tóm tắt các phương pháp phát hiện bất thường dựa trên dự đoán [1].
Phương pháp dựa trên dự báo (Forecasting-based Methods)
Các phương pháp dựa trên dự báo hoạt động dựa trên một nguyên tắc cốt lõi: sử dụng các điểm hoặc chuỗi dữ liệu trong quá khứ để huấn luyện một mô hình dự đoán giá trị tiếp theo. Kết quả dự báo này gắn liền trực tiếp với các quan sát trước đó trong chuỗi thời gian. Các điểm dữ liệu sau đó sẽ được so sánh với giá trị gốc; độ lệch (sai số dự báo) càng lớn thì khả năng điểm đó là bất thường càng cao.
Exponential Smoothing (Làm phẳng số mũ)
Nguyên lý hoạt động: Exponential Smoothing là một trong những kỹ thuật dự báo sớm nhất được đề xuất trong tài liệu học thuật. Đây là một phương pháp làm phẳng phi tuyến, dự đoán các điểm dữ liệu bằng cách sử dụng dữ liệu quá khứ và gán các trọng số giảm dần theo cấp số nhân cho các quan sát cũ hơn.
Về mặt toán học, giá trị ước lượng tại thời điểm hiện tại là sự kết hợp tuyến tính của các điểm dữ liệu trước đó. Tham số $\alpha \in [0,1]$ là hệ số làm mượt (smoothing factor); $\alpha$ càng nhỏ thì các điểm dữ liệu trong quá khứ càng xa vẫn có ảnh hưởng lớn hơn đến giá trị dự đoán.
Giá trị dự đoán tại thời điểm $i$, ký hiệu là $\hat{T}_i$, được xác định như sau:
$$ \hat{T}_i = (1-\alpha)^{N-1}T_{i-N} + \sum_{j=1}^{N-1}\alpha(1-\alpha)^{j-1}T_{i-j}, \quad \alpha \in [0,1] $$
Các biến thể tiêu biểu:
- Double Exponential Smoothing (DES): Được thiết kế cho các chuỗi thời gian không dừng (non-stationary), bổ sung thêm một tham số để làm phẳng xu hướng (trend) của dữ liệu.
- Triple Exponential Smoothing (TES): Tương tự DES nhưng có thêm khả năng xử lý tính mùa vụ (seasonality) thông qua một tham số thứ ba.
Các phương pháp dựa trên dự báo khác (Other Forecasting-based Methods)
Về cơ bản, bất kỳ mô hình hồi quy nào có khả năng dự đoán giá trị tương lai từ dữ liệu lịch sử đều có thể được sử dụng làm lõi dự báo. Một số kiến trúc cụ thể khác được ứng dụng bao gồm:
- OceanWNN: Sử dụng Mạng nơ-ron Wavelet (Wavelet-Neural Networks).
- NoveltySVR: Sử dụng các kỹ thuật hồi quy cổ điển, cụ thể là thuật toán Máy vectơ hỗ trợ (Support Vector Machine - SVM) đóng vai trò làm đơn vị dự báo lõi.
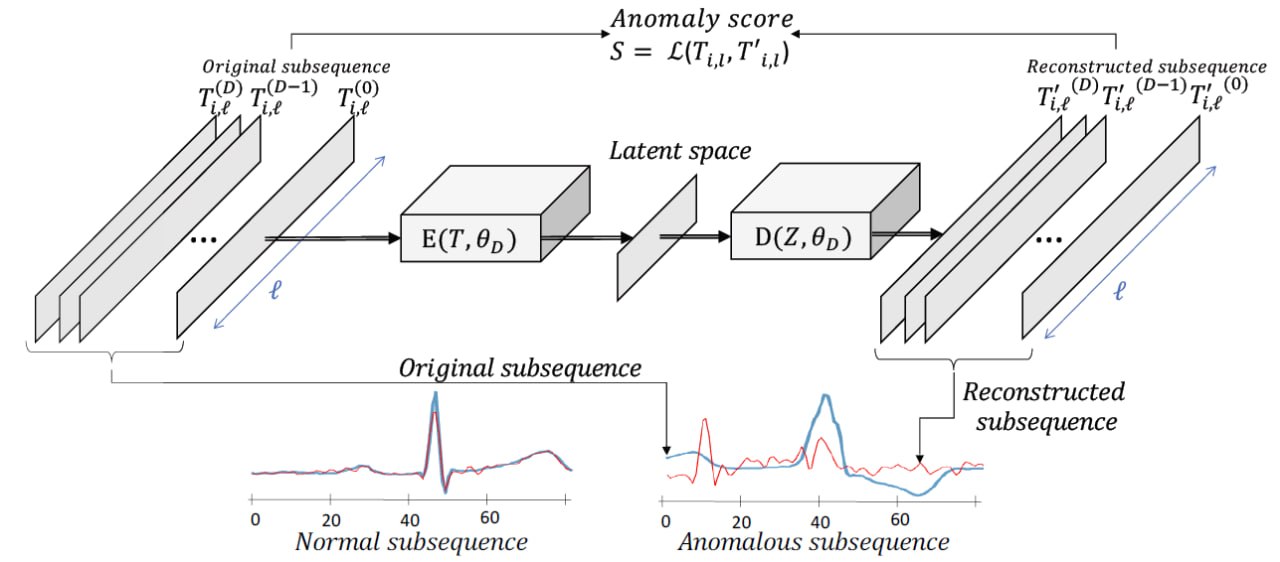 Hình 5. Tổng quan về các phương pháp autoencoder để phát hiện bất thường trong chuỗi thời gian [1]
Hình 5. Tổng quan về các phương pháp autoencoder để phát hiện bất thường trong chuỗi thời gian [1]
Phương pháp Dựa trên Tái thiết (Reconstruction-based Methods)
Phương pháp tái thiết đại diện cho hành vi bình thường bằng cách mã hóa các chuỗi con (sub-sequences) của một chuỗi thời gian huấn luyện bình thường vào một không gian chiều thấp (low-dimensional space). Sau đó, các chuỗi con này được tái thiết (giải mã) từ không gian chiều thấp đó và được đem ra so sánh trực tiếp với các chuỗi con nguyên bản ban đầu. Sự khác biệt giữa chuỗi tái thiết và chuỗi ban đầu (còn gọi là sai số tái thiết) được sử dụng để phát hiện các điểm bất thường. Nhìn chung, dữ liệu đầu vào cho quá trình tái thiết này là các chuỗi con từ tập dữ liệu huấn luyện (training sub-sequences).
Bộ mã hóa tự động (Autoencoder)
Nguyên lý hoạt động:
Autoencoder là một dạng mạng nơ-ron nhân tạo được thiết kế để học cách tái tạo lại tập dữ liệu đầu vào thông qua một kích thước mã hóa (encoding) nhỏ hơn kích thước ban đầu, nhằm tránh việc mạng chỉ đơn thuần học cách sao chép y hệt dữ liệu (identity reconstruction). Là một ý tưởng cốt lõi, autoencoder sẽ cố gắng học được biểu diễn tiềm ẩn (latent representation) tốt nhất thông qua một hàm mất mát tái thiết (reconstruction loss). Do đó, nó sẽ học cách nén tập dữ liệu thành một đoạn mã ngắn, sau đó giải nén đoạn mã này thành một tập dữ liệu khớp nhất có thể so với bản gốc ban đầu.
Về mặt hình thức, với hai hàm ánh xạ $E$ và $D$ (tương ứng với bộ mã hóa encoder và bộ giải mã decoder), nhiệm vụ của một mô hình tự mã hóa (autoencoder) có thể được mô tả như sau:
$$ \begin{aligned} \phi &: \mathbb{T}_\ell \rightarrow \mathbb{Z} \\ \psi &: \mathbb{Z} \rightarrow \mathbb{T}_\ell \\ \phi, \psi &= \arg \min_{\phi, \psi} \mathcal{L}\big(T_{i,\ell}, \psi(\phi(T_{i,\ell}))\big) \end{aligned} $$
Trong đó, $\mathcal{L}$ là hàm mất mát, thường được lựa chọn là sai số toàn phương trung bình (Mean Squared Error - MSE) giữa dữ liệu đầu vào và bản tái thiết của nó:
$$ \|T_{i,\ell} - \psi(\phi(T_{i,\ell}))\|^2 $$
Hàm mất mát này đặc biệt phù hợp cho bài toán xử lý các chuỗi con trong chuỗi thời gian, do nó tương ứng trực tiếp với khoảng cách Euclid giữa tín hiệu gốc và tín hiệu tái thiết.
Sai số tái thiết đóng vai trò như một điểm số bất thường (anomaly score) trong bài toán phát hiện dị thường. Do mô hình Autoencoder chỉ được huấn luyện trên các chuỗi con bình thường (không chứa dị thường), nó được tối ưu hóa để tái thiết tốt các mẫu dữ liệu "khỏe mạnh". Vì vậy, các chuỗi con có đặc trưng khác biệt so với phân phối huấn luyện sẽ dẫn đến sai số tái thiết lớn hơn.
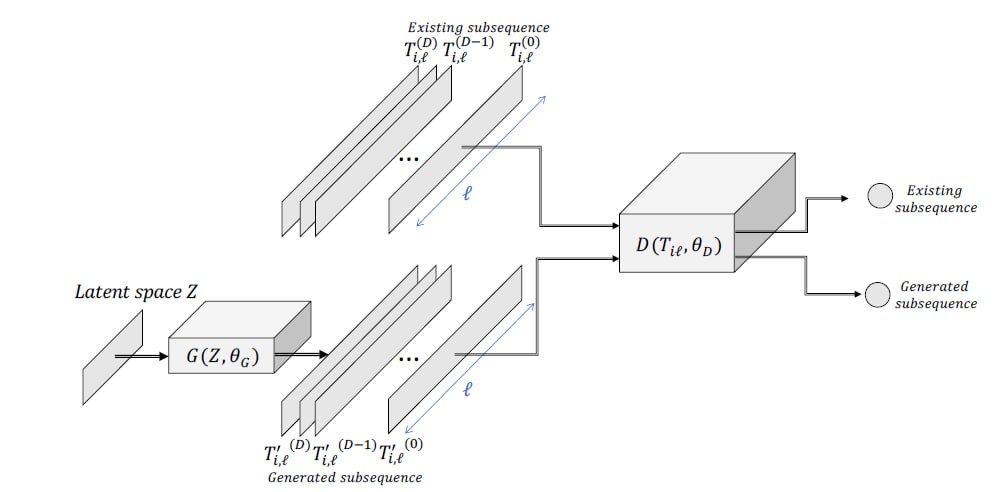 Hình 6. Tổng quan về các phương pháp GAN để phát hiện bất thường trong chuỗi thời gian [1].
Hình 6. Tổng quan về các phương pháp GAN để phát hiện bất thường trong chuỗi thời gian [1].
Các biến thể / Khung ứng dụng tiêu biểu:
-
EncDec-AD: Là một trong những mô hình đầu tiên áp dụng kiến trúc encoder–decoder kết hợp sai số tái thiết để đánh giá mức độ bất thường.
-
LSTM-VAE và MSCRED: Tích hợp các cơ chế ghi nhớ như LSTkM và Convolutional LSTM vào kiến trúc autoencoder nhằm khai thác tốt hơn thông tin chuỗi thời gian.
-
OmniAnomaly: Phương pháp dựa trên autoencoder sử dụng mạng GRU kết hợp với kỹ thuật planar normalizing flow để mô hình hóa phân phối phức tạp của dữ liệu.
-
STORN và DONUT: Hai phương pháp này sử dụng Variational Autoencoder (VAE) cho phát hiện dị thường. Đặc biệt, DONUT bổ sung bước tiền xử lý để xử lý dữ liệu thiếu thông qua phương pháp MCMC.
-
BAGEL: Phiên bản cải tiến của DONUT, sử dụng kiến trúc conditional VAE thay vì VAE truyền thống.
-
VELC: Áp dụng các ràng buộc bổ sung lên VAE, trong đó bộ giải mã (decoder) được điều chuẩn dựa trên các mẫu bất thường có sẵn nhằm hạn chế khả năng tái thiết tốt cả dữ liệu dị thường.
-
CAE (Convolutional Autoencoder): Sử dụng mạng tích chập để ánh xạ chuỗi thời gian sang không gian biểu diễn dạng ảnh. Đồng thời, thuật toán tận dụng SAX (Symbolic Aggregate approXimation) để tăng tốc tìm kiếm thông qua biểu diễn nhúng.
-
DeepNAP: Mô hình autoencoder dạng sequence-to-sequence với khả năng pre-detection, cho phép phát hiện bất thường trước khi chúng thực sự xảy ra.
Mạng đối nghịch sinh (Generative Adversarial Networks - GAN)
Nguyên lý hoạt động:
Mạng đối nghịch sinh (GAN) ban đầu được đề xuất riêng cho mục đích tạo ảnh, nhưng kiến trúc này cũng hoàn toàn có thể được dùng để tạo ra các chuỗi dữ liệu thời gian. GAN bao gồm hai thành phần thiết yếu: (i) Một bộ phận dùng để sinh/tạo ra chuỗi thời gian mới, và (ii) một bộ phận dùng để phân biệt chuỗi thời gian đang có. Cả hai thành phần này đều đóng vai trò then chốt để phát hiện bất thường.
Cụ thể hơn, mạng GAN gồm hai mạng nơ-ron hoạt động cạnh tranh. Đầu tiên là Generator (Bộ sinh) $G(z,\theta_{g})$ với $\theta_{g}$ là các tham số của nó. Mạng thứ hai là Discriminator (Bộ phân biệt) $D(x,\theta_{d})$ với $\theta_{d}$ là các tham số tương ứng. Đầu ra của Discriminator là một giá trị vô hướng (scalar) đại diện cho xác suất chứng minh mẫu dữ liệu đầu vào thực sự đến từ tập dữ liệu gốc. Việc huấn luyện hai mạng này được coi là một bài toán tối ưu hóa hai người chơi (two-player optimization): Mạng Discriminator cố gắng tối đa hóa độ chính xác của nó, trong khi Generator thì cố gắng giảm thiểu độ chính xác của Discriminator bằng cách tạo ra dữ liệu giả mạo giống hệt đồ thật.
Đối với mục đích tìm kiếm bất thường, Generator sẽ được huấn luyện để chỉ sinh ra các chuỗi con được dán nhãn là "bình thường", và Discriminator được huấn luyện để phân định rạch ròi giữa dữ liệu thật (bình thường) và dữ liệu giả (bất thường). Do đó, ta có thể dùng song song cả Discriminator và Generator để tìm ra điểm bất thường:
- Đầu tiên, do Discriminator được huấn luyện để phân biệt giữa dữ liệu thật và dữ liệu giả, nên bản thân nó có thể được sử dụng trực tiếp như một công cụ phát hiện bất thường.
-
Tuy nhiên, Generator cũng đóng vai trò quan trọng không kém. Vì được huấn luyện để sinh ra các chuỗi con mang đặc trưng "bình thường", nó sẽ gặp khó khăn (tạo ra sai số lớn) khi cố gắng tái tạo các chuỗi có đặc tính bất thường. Do đó, khoảng cách Euclid giữa chuỗi con cần đánh giá và chuỗi được sinh bởi Generator là một chỉ số quan trọng để xác định mức độ bất thường.
Các biến thể / Khung ứng dụng tiêu biểu: -
MAD-GAN, USAD và TAnoGAN: Đây là nhóm các phương pháp đề xuất huấn luyện kiến trúc GAN trên các phân đoạn bình thường của chuỗi thời gian. Điểm số bất thường (anomaly score) được xác định dựa trên sự kết hợp giữa tổn thất của Discriminator (discriminator loss) và tổn thất tái thiết (reconstruction loss).
-
VAE-GAN: Mô hình này kết hợp ưu điểm của GAN và Variational Autoencoder (VAE). Trong đó, Generator được thiết kế như một VAE và cạnh tranh trực tiếp với Discriminator. Điểm số bất thường cũng được tính toán theo cơ chế tương tự như trong MAD-GAN và USAD.
Kết luận (Conclusions)
Trong bài khảo sát này, chúng tôi đã xem xét toàn diện bài toán phát hiện bất thường trong chuỗi thời gian. Bài viết bắt đầu bằng việc xây dựng một hệ thống phân loại (taxonomy) chi tiết về các loại chuỗi thời gian, các dạng bất thường và các phương pháp phát hiện. Các phương pháp này được phân nhóm theo lăng kính quy trình (process-centric categories). Từ đó, chúng tôi mô tả chi tiết các thuật toán phổ biến nhất trong từng nhóm và cung cấp một danh sách mở rộng các phương pháp hiện có. Cuối cùng, bài viết thảo luận chuyên sâu về vấn đề đánh giá hiệu năng (benchmarking), liệt kê các tập dữ liệu chuẩn, các thước đo truyền thống cùng với hạn chế của chúng, cũng như những nỗ lực gần đây nhằm điều chỉnh các thước đo này cho phù hợp với đặc thù của chuỗi thời gian.
Thách thức hiện tại
Dù đã trải qua nhiều thập kỷ nghiên cứu, phát hiện bất thường trong chuỗi thời gian vẫn là một bài toán đầy thách thức. Trong lịch sử, các cộng đồng nghiên cứu thường tiếp cận vấn đề một cách rời rạc và phát triển các phương pháp dựa trên nền tảng lý thuyết riêng biệt. Sự thiếu thống nhất trong việc sử dụng chung các thước đo và tập dữ liệu đánh giá đã khiến việc đo lường tiến bộ thực tế trở nên khó khăn. Tuy nhiên, những nỗ lực xây dựng các bộ dữ liệu chuẩn (benchmarks) gần đây \cite{113, 185} đã đóng góp tích cực vào việc đánh giá sự phát triển và lựa chọn phương pháp phù hợp cho các bài toán cụ thể.
Định hướng nghiên cứu tương lai
Mặc dù đã đạt được nhiều tiến bộ đáng kể, lĩnh vực này vẫn mở ra nhiều hướng nghiên cứu tiềm năng trong tương lai:
-
Thống nhất bộ dữ liệu chuẩn (Benchmarking): Hiện vẫn chưa có sự đồng thuận về một bộ benchmark chung cho toàn bộ cộng đồng. Các bộ dữ liệu hiện có còn tồn tại nhiều hạn chế về tính đa dạng của chuỗi thời gian, loại hình bất thường cũng như độ tin cậy của nhãn. Do đó, việc xây dựng một hệ thống đánh giá chuẩn hóa và toàn diện hơn là rất cần thiết.
-
Lựa chọn mô hình và Học máy tự động (AutoML): Với sự xuất hiện của nhiều phương pháp mới mỗi năm, các nghiên cứu gần đây cho thấy không tồn tại một mô hình duy nhất tối ưu cho mọi tập dữ liệu. Điều này thúc đẩy các hướng tiếp cận như kết hợp mô hình (ensembling), lựa chọn mô hình và AutoML. Một số thực nghiệm cho thấy việc sử dụng các mô hình phân loại chuỗi thời gian cơ bản để hỗ trợ lựa chọn mô hình phát hiện bất thường có thể cải thiện đáng kể độ chính xác, thậm chí lên tới gấp đôi trong một số trường hợp.
-
Mở rộng sang các dạng dữ liệu phức tạp: Phần lớn các phương pháp không giám sát hiện nay chủ yếu tập trung vào chuỗi thời gian đơn biến (univariate), trong khi các bài toán thực tế thường phức tạp hơn. Các nghiên cứu trong tương lai cần hướng đến các kịch bản như: chuỗi đa biến (multivariate), dữ liệu dòng thời gian thực (streaming), dữ liệu bị thiếu (missing values), nhãn thời gian không liên tục, dữ liệu không đồng nhất (heterogeneous), hoặc sự kết hợp của các yếu tố này. Việc phát triển các phương pháp mạnh mẽ và chính xác cho các trường hợp này là một yêu cầu cấp thiết.
[1] Boniol, P., Liu, Q., Huang, M., Palpanas, T., & Paparrizos, J. (2024). Dive into time-series anomaly detection: A decade review. arXiv. https://arxiv.org/abs/2412.20512
Chưa có bình luận nào. Hãy là người đầu tiên!