
Giới thiệu
Hầu hết roadmap Data Science bắt đầu bằng “học Python, Pandas, ML…”, tức là đi thẳng vào giải pháp mà bỏ qua bức tranh tổng thể. Người học làm theo nhưng không hiểu dữ liệu đi đâu, model nằm ở đâu, nên kiến thức rời rạc. Khi gặp bài toán thực tế, họ dễ mất phương hướng và nản vì không hiểu mình đang giải quyết vấn đề gì. Bài blog này sẽ đi theo hướng ngược lại: bắt đầu từ bức tranh chung, định hướng rõ ràng, rồi mới đi vào từng phần cụ thể.
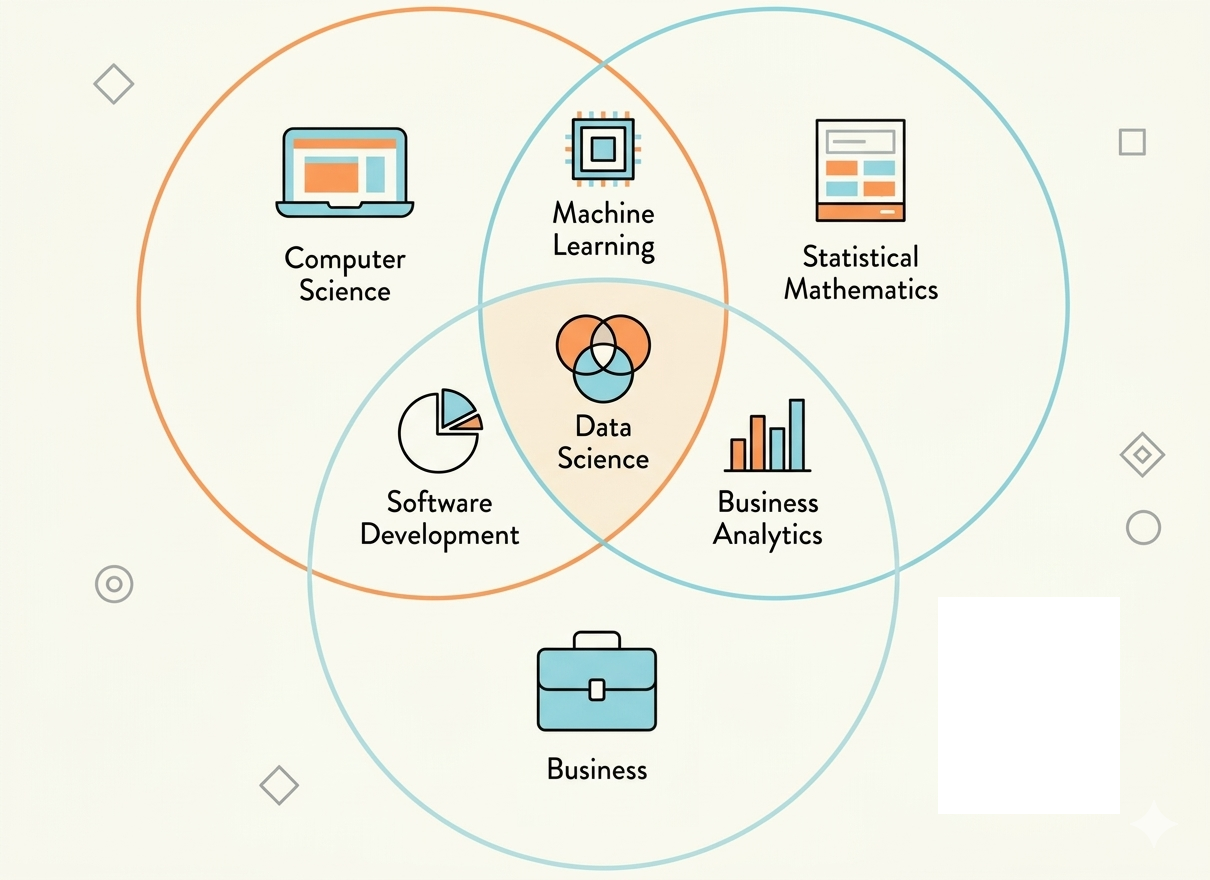
Nguồn: Phỏng theo CodeLearn
1. Mối liên hệ giữa các vai trò như thế nào?
Trong môi trường công ty, công việc và dữ liệu sẽ trở nên đồ sộ và phức tạp, khiến việc một người gánh vác tất cả là rất khó. Vì vậy, sự phối hợp của nhiều vai trò là rất cần thiết. Hãy đi qua các vai trò của từng công việc trong Data Science bằng cách xét một bài toán doanh nghiệp cung cấp dịch vụ (như Spotify, Shopee, SaaS, …): “Dự đoán khách hàng rời bỏ dịch vụ”
1.1 Data Engineer - người kết nối “Đường ống dữ liệu”
Vấn đề đầu tiên xuất hiện ngay lập tức:
Dữ liệu nằm khắp nơi (App logs | CRM, công cụ Marketing)
Dữ liệu bẩn, sai, thiếu, lỗi định dạng ({02/01/2025, 2025-01-02}, giá trị NaN)
Dữ liệu cập nhật và chảy không hiệu quả
Dữ liệu không phù hợp cho doanh nghiệp sử dụng
Đây là nơi mà các Data Engineer xuất hiện, họ sẽ:
- Đồng bộ các nguồn dữ liệu về một nơi.
- Làm sạch, chuẩn hóa dữ liệu.
- Xây pipeline tự động (công cụ Kafka), phân luồng và tải lên đám mây (dịch vụ AWS).
- Tạo “analytics-ready datasets”.
1.2 Data Analyst - Người “dịch dữ liệu thành câu chuyện”
Khi dữ liệu đã sạch và có thể truy cập được, vấn đề thứ hai xuất hiện:
Không ai biết nó đang nói lên điều gì.
- Xu hướng tăng giảm của doanh thu, số lượng truy cập thế nào?
- Nhóm khách hàng nào đang rời bỏ?
- Chiến dịch marketing vừa rồi đã giải quyết những gì?
Đây là những câu hỏi business cần được trả lời bằng dữ liệu và cần người biết cách đọc, phân tích, rồi giải thích lại cho người ra quyết định hiểu được. Đó là việc của Data Analyst.
1.3 Data Scientist - Người dự đoán tương lai
Nhưng phân tích quá khứ có giới hạn của nó. Biết rằng 30% khách hàng rời bỏ mỗi quý là thông tin hữu ích nhưng nếu biết trước được ai sắp rời để can thiệp kịp thời thì giá trị hơn nhiều.
Đây là lúc cần đi xa hơn, ta cần chuyển sang phân tích, dự đoán và tự động hoá quyết định bằng model machine learning. Đó là việc của Data Scientist.
1.4 Machine Learning Engineer - Người biến AI thành sản phẩm
Và đây là nơi vấn đề cuối cùng xuất hiện: model đã xây xong, chạy tốt trên máy tính của DS, nhưng không thể đưa vào hệ thống thực tế. Model tốt mà không dùng được thì cũng như không có.
Đây là nơi ML Engineer xuất hiện và đảm nhận:
- Tạo API, xử lý các luồng tạo và khai thác tool (gpt, whisper-ai, gg calendar)
- Scale hệ thống (AWS)
- Giám sát hệ thống hoạt động và phát hiện lỗi
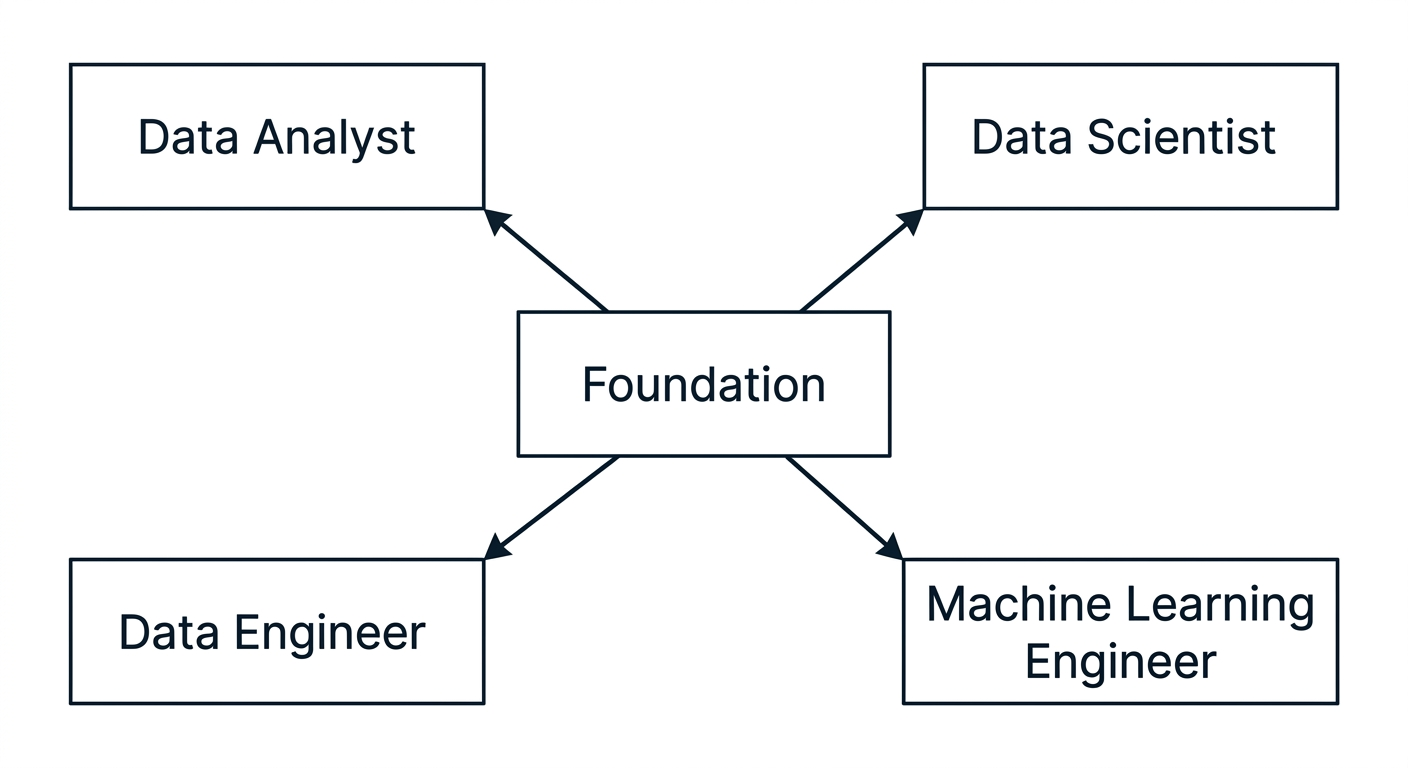
1.5 Luồng tổng thể
Data Engineer → Data Analyst → Data Scientist → ML Engineer
↓ ↓ ↓ ↓
Dữ liệu sạch → Insight → Model → Sản phẩm thực tế
2. Roadmap đúng: nền tảng chung trước, rẽ nhánh sau
Nguồn: Ảnh minh họa tạo bởi AI.
2.1 Sai lầm phổ biến
Mọi người thường chọn học theo một vai trò cụ thể quá sớm và lao ngay vào Machine Learning khi chưa nắm vững nền tảng như SQL hay xử lý dữ liệu. Điều này khiến quá trình học bị lệch hướng, thiếu hụt kiến thức cốt lõi. Về lâu dài, bạn có thể viết model nhưng không hiểu dữ liệu, khó phát triển bền vững.
2.2 Bắt đầu từ nền tảng chung
- Python cơ bản (Ngôn ngữ chung của các ngành liên quan đến AI)
- SQL cơ bản (ngôn ngữ thiết kế dữ liệu cơ bản, phù hợp cho người mới bắt đầu)
- Git (theo dõi tiến độ công việc, môi trường thử nghiệm mô hình, cung cấp CI/CD để làm việc nhóm)
- Tư duy xử lý dữ liệu (để tiến hành các bước xử lý đúng đắn, phù hợp với bộ dữ liệu và giai đoạn của mình)
2.3 Tổng quan từng ngành
Sau khi nắm được nền tảng chung, con đường học trong data sẽ bắt đầu “rẽ nhánh” rất rõ. Mỗi vai trò có trọng tâm khác nhau, và việc chọn đúng hướng giúp bạn tránh học lan man.
-
Data Analyst (DA) tập trung vào SQL nâng cao, trực quan hóa dữ liệu và storytelling để biến số liệu thành insight dễ hiểu.
-
Data Scientist (DS) đi sâu vào thống kê, machine learning, đánh giá mô hình và feature engineering để giải quyết bài toán dự đoán.
-
Data Engineer (DE) lại chú trọng xây dựng data pipeline, làm việc với Spark, Airflow, cloud và data warehouse để đảm bảo dữ liệu vận hành trơn tru.
-
Machine Learning Engineer (MLE) tập trung vào deployment, Docker, API, MLOps và monitoring để đưa model vào production một cách ổn định.
Chọn đúng nhánh không chỉ giúp bạn học hiệu quả hơn mà còn định hình rõ giá trị bạn mang lại trong hệ thống dữ liệu.
3. Chọn hướng: bạn hợp với vai trò nào?
Câu hỏi tiếp theo là chọn hướng nào? Đây là quyết định quan trọng vì nó ảnh hưởng đến toàn bộ lộ trình học và định hướng nghề nghiệp của bạn từ đây về sau. Đừng chọn dựa trên lương hay "nghe nói việc này hot". Chọn dựa trên tính cách và sở thích thực sự, và phân tích tiềm năng bạn có thể khai thác khi thực hiện vai trò này trong nhiều năm (cơ hội thăng cấp, giao lưu quốc tế, sự ổn định của thị trường).
3.1 Những câu hỏi quan trọng?
Trả lời 4 câu hỏi sau:
Câu 1: Bạn thích làm việc gần business (báo cáo, trình bày, giải thích cho sếp) hay gần hệ thống kỹ thuật (xây pipeline, viết code chạy tự động)?
Câu 2: Bạn thích thấy kết quả nhanh (dashboard, báo cáo xong trong ngày) hay chấp nhận đầu tư thời gian dài để ra sản phẩm phức tạp hơn (model, hệ thống)?
Câu 3: Bạn có nền tảng toán không - xác suất, thống kê, đại số tuyến tính? Và bạn có thích toán không?
Câu 4: Bạn thích làm việc với ý nghĩa của dữ liệu (con số này nói lên điều gì) hay với luồng chạy của dữ liệu (dữ liệu đi từ đâu đến đâu, nhanh hay chậm, đầy đủ hay thiếu)?
3.2 Hướng đi dành cho bạn
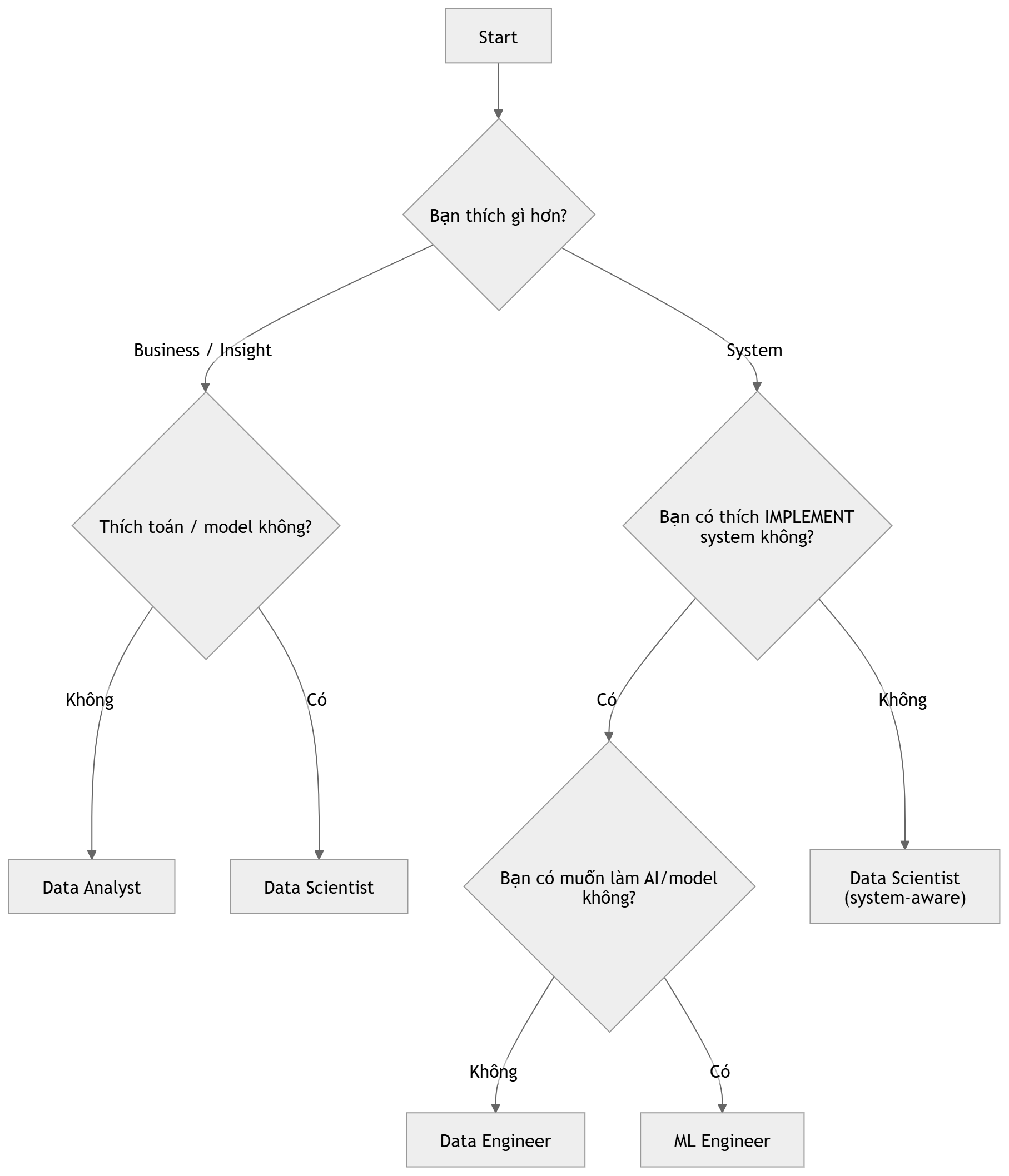
Nguồn: Ảnh minh họa tạo bởi AI.
Chưa chắc? Không sao. Bắt đầu từ Data Analyst đây là vai trò dễ vào nghề nhất, kỹ năng overlap nhiều nhất với các vai trò khác, và sẽ giúp bạn cảm nhận được mình thích phần nào hơn sau 2–3 tháng làm thực tế.
4. Lộ trình chi tiết từng vai trò
4.1 Data Analyst
4.1.1 Một ngày làm việc của Data Analyst gồm những gì?
Data Analyst không dành cả ngày để xử lý dữ liệu hay xây dashboard. Dù dữ liệu là trọng tâm, họ cần liên tục trao đổi với các team khác để hiểu bài toán kinh doanh và yêu cầu thực tế. Từ đó, các DS làm việc với dữ liệu và trình bày kết quả cho các bên liên quan nhằm hỗ trợ ra quyết định.
4.1.2 Lộ trình học theo thứ tự:
Giai đoạn 1: Excel
Khi bắt đầu học phân tích dữ liệu, Excel là điểm khởi đầu phù hợp với hầu hết mọi người. Với khả năng xử lý, trực quan hóa các dữ liệu cơ bản chỉ với những thao tác đơn giản, Excel được sử dụng trong rất nhiều doanh nghiệp. Những thứ cần học:
- Các hàm quan trọng (SUM, MATCH, VLOOKUP,... )
- Power Query
- Pivot Table
Nguồn: AI VIET NAM.
Giai đoạn 2: SQL nâng cao
Trong thực tế, dữ liệu hiếm khi được tổ chức “gọn gàng”. Do đó, SQL cơ bản chỉ đủ cho bước khởi đầu, khi xử lý bài toán phức tạp hơn, bạn cần dùng các kỹ thuật SQL nâng cao hơn như:
| Nhóm kỹ thuật | Các lệnh / thành phần |
|---|---|
| Window Functions (Analytic) | ROW_NUMBER, RANK, LAG, LEAD, OVER |
| Aggregation (Group Functions) | GROUP BY, ROLLUP, CUBE, GROUPING SETS |
| Subqueries & Table Expressions | Subquery, CTE (WITH), EXISTS |
| Joins (Multi-table Queries) | INNER JOIN, LEFT JOIN, CROSS JOIN, SELF JOIN |
| Data Transformation | PIVOT, UNPIVOT, CASE WHEN |
Giai đoạn 3: BI tools
“Báo cáo không phải dành cho bạn.”
Đây là tư duy mà mọi Data Analyst cần có. Một báo cáo tốt không để cho DA “ngắm”, mà để người khác hiểu và ra quyết định. Và các công cụ như Power BI và Tableau sinh ra là để đáp ứng yêu cầu đó.
| Tiêu chí | Power BI | Tableau |
|---|---|---|
| Chi phí | Rẻ, dễ tiếp cận | Đắt hơn |
| Modeling | Mạnh (DAX, data model rõ ràng) | Hạn chế hơn |
| Xử lý dữ liệu | Có Power Query (ETL nhẹ) | Linh hoạt, thao tác nhanh |
| Visualization | Đủ dùng | Rất mạnh, tùy biến cao |
| Phù hợp | BI nội bộ, Microsoft ecosystem | Dashboard nâng cao, storytelling |
Lưu ý: Chỉ nên tập trung học trước một tool (Power BI phổ biến hơn ở Việt Nam). Quan trọng hơn là biết chọn đúng biểu đồ cho đúng câu hỏi và trình bày các insight như một câu chuyện thay cho các số liệu khô khan.
Giai đoạn 4: Phân tích nâng cao
Thống kê ứng dụng
Các khái niệm thống kê như mean, median, độ lệch chuẩn,... là nền tảng để hiểu và phát hiện các xu hướng của dữ liệu. Bên cạnh đó, thành thạo các phương pháp phân tích nâng cao như: t-test, chi-square và A/B testing, đọc p-value sẽ biến một DA từ “đọc dữ liệu” sang đưa ra kết luận và quyết định dựa trên dữ liệu.
A/B testing
A/B Testing là phương pháp tối ưu sản phẩm bằng cách so sánh biến thể (B) của sản phẩm gốc (A) thông qua thực nghiệm và thống kê.
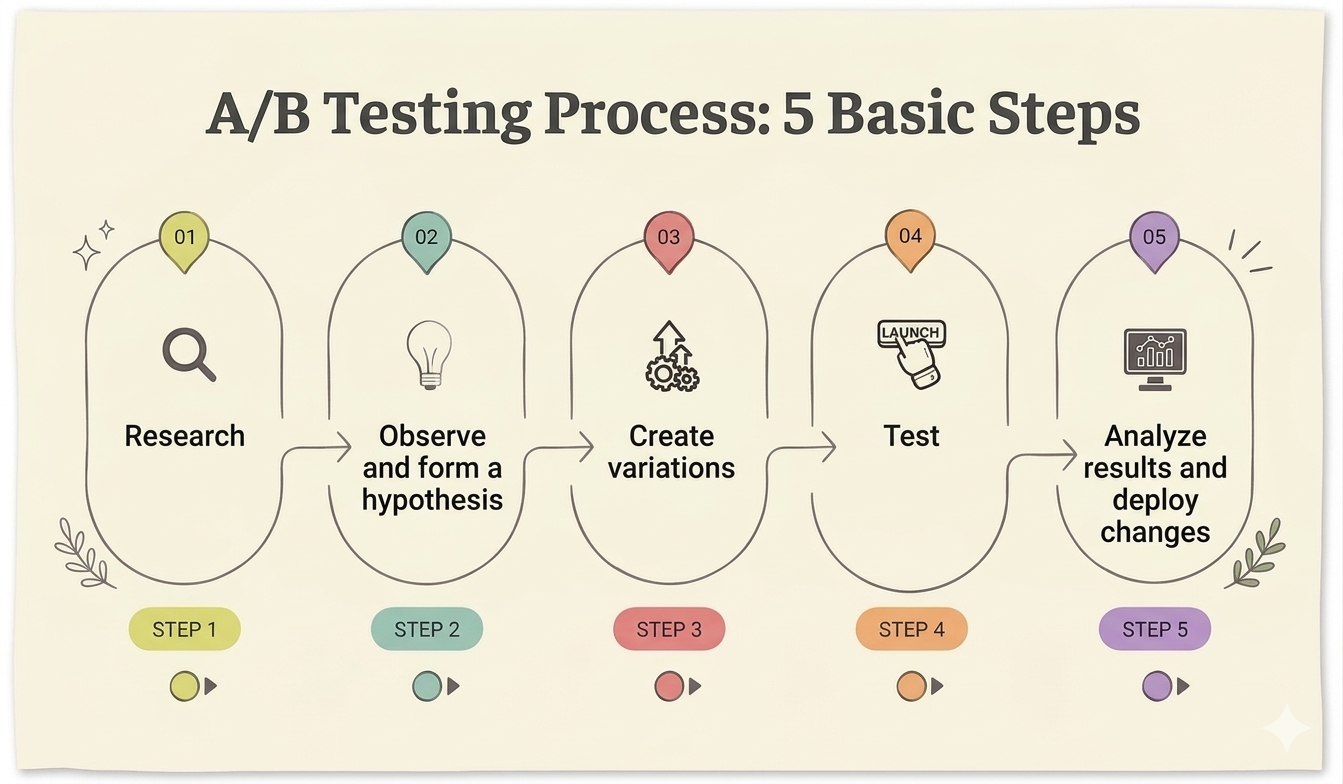
Nguồn: Phỏng theo vwo.com
Giai đoạn 5: Phân tích từ doanh nghiệp (Business Analytics)
Một Data Analyst giỏi không chỉ biết viết báo cáo hay vẽ dashboard, mà còn có thể dịch dữ liệu thành ngôn ngữ kinh doanh của doanh nghiệp. Các Business metrics và kỹ thuật phân tích hành vi là nền tảng để làm điều đó.
Kỹ thuật phân tích hành vi
Trong thực tế, các DA thường sử dụng các kỹ thuật phân tích hành vi như Cohort Analysis, Funnel Analysis hay Segmentation để hiểu người dùng và hỗ trợ ra quyết định.
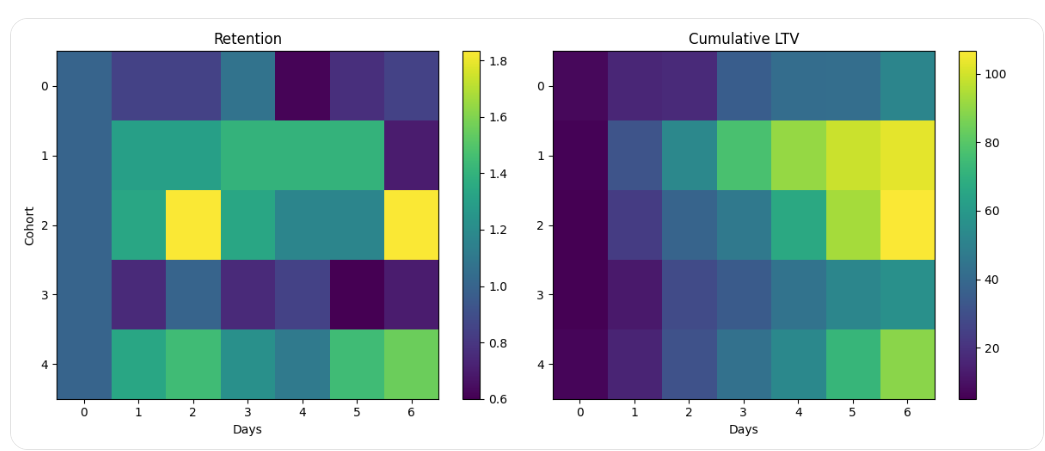
Nguồn: Ảnh minh họa tạo bởi AI
Business metrics
- Metrics: Là chỉ số có thể đo đạc được của công ty.
- KPI: Những metrics quan trọng nhất cho công ty.
- OKR: Mục tiêu, hướng đi + các chỉ số (KPI/metrics) để đo việc đạt mục tiêu.
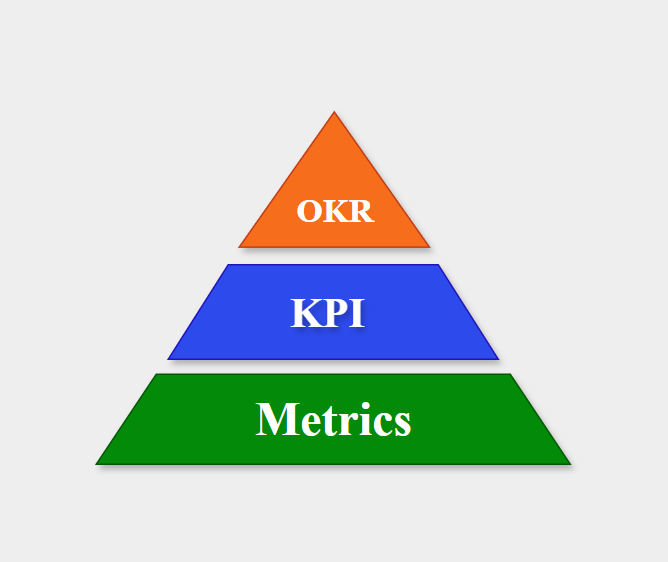
Nguồn: Tổng hợp bởi tác giả
4.1.3 Dự án thực tế
- Dự án 1: Phân tích dataset Superstore trên Kaggle — tìm ra 3 insight có ý nghĩa kinh doanh, xây dashboard Power BI, viết báo cáo một trang với recommendation cụ thể.
- Dự án 2: Thiết kế và phân tích A/B test — dùng Python simulate dữ liệu hoặc dùng dataset có sẵn, chạy chi-square test, viết kết luận cho PM.
4.2 Data Scientist
4.2.1 Một Data Scientist cần làm những gì?
Công việc của Data Scientist thường xoay quanh việc trao đổi với các DS khác và với DA. Họ nhận insight từ DA, biến thành bài toán Machine Learning, xây dựng mô hình và báo cáo lại kết quả.
4.2.2 Lộ trình học theo thứ tự:
Giai đoạn 1: Thống kê và xác suất nền tảng
Xác suất và thống kê là nền tảng của khoa học dữ liệu. Mọi thuật toán học máy, mô hình dự đoán đều dựa vào chúng. Đây là điều nhiều người bỏ qua và học thẳng ML rồi không hiểu vì sao mô hình hoạt động.
Giai đoạn 2: Machine Learning cơ bản
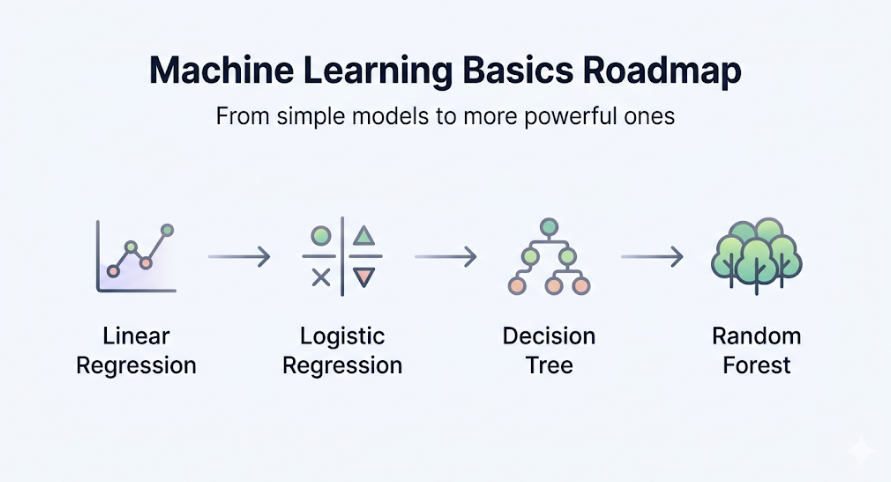
Nguồn: Ảnh minh họa tạo bởi AI
Với mỗi thuật toán, cần hiểu được ba thứ: nó giải bài toán gì, nó hoạt động như thế nào về mặt trực quan, và khi khi nào nên dùng nó thay vì thuật toán khác.
Giai đoạn 3: Đánh giá và cải thiện model
Một mô hình chạy được không có nghĩa là chạy tốt. Do đó, các DS cần sử dụng nhiều kỹ thuật để đánh giá và cải thiện mô hình. Vì một sai lầm nhỏ trong mô hình sẽ mang lại hậu quả rất lớn khi ra thực tế.
| Chủ đề | Khái niệm | Ý chính |
|---|---|---|
| Evaluation | Cross-validation | Đánh giá mô hình cách bằng chia dữ liệu thành nhiều phần |
| Model Behavior | Overfitting / Underfitting | Mô hình học vẹt hoặc không học được |
| Metrics | Accuracy / Precision / Recall / F1 / AUC-ROC | Các thước đo hiệu suất model (tùy bài toán chọn phù hợp) |
| Optimization | Hyperparameter tuning (Grid, Random, Bayesian) | Tối ưu tham số để cải thiện thuật toán. |
Giai đoạn 4: Boosting và Feature Engineering
Boosting
Boosting là nhóm kỹ thuật kết hợp nhiều mô hình, thông qua quá trình mô hình sau bổ sung lỗi sai từ mô hình trước đó. Các mô hình Boosting (XGBoost và LightGBM) thường mang lại kết quả rất tốt trong dữ liệu dạng bảng, chuỗi (là loại dữ liệu mà DS thường gặp nhất).
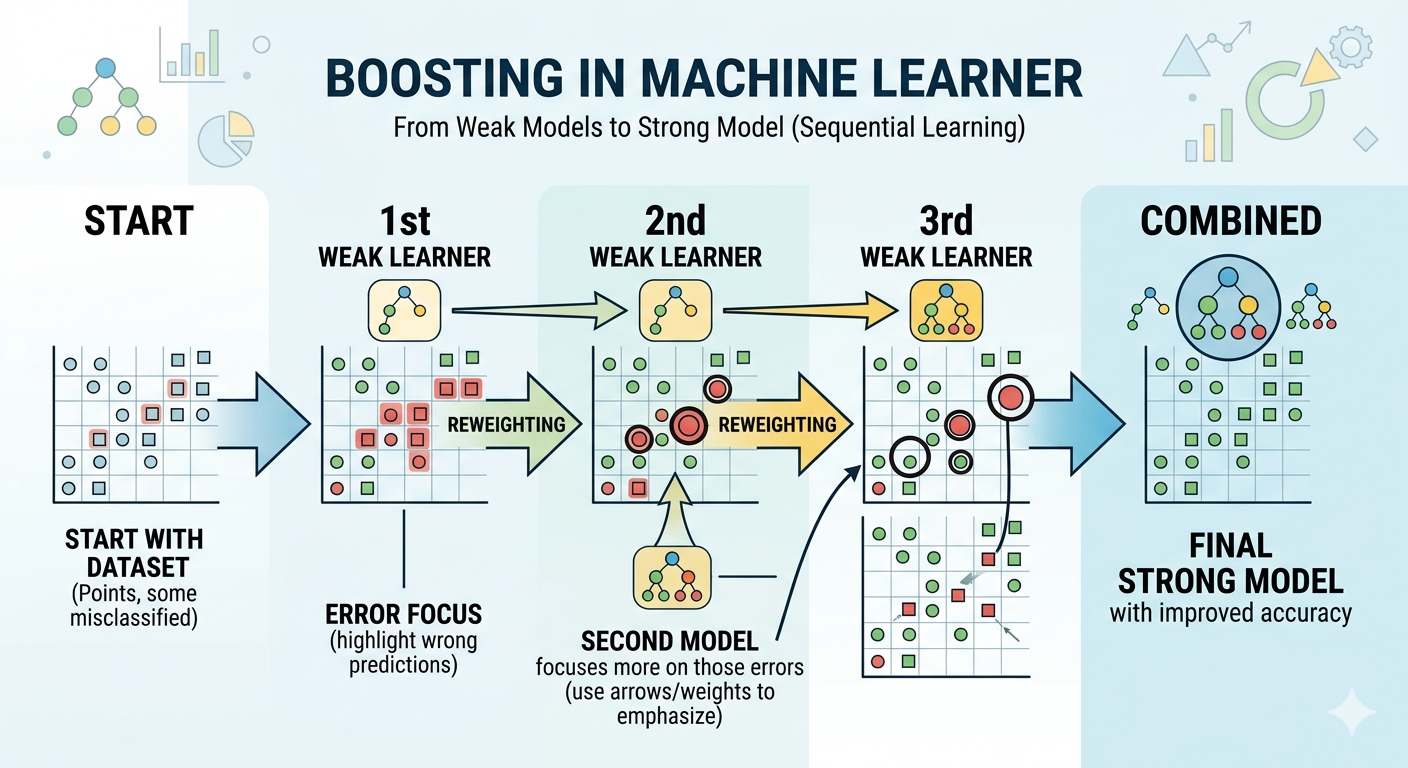
Nguồn: Ảnh minh họa tạo bởi AI
Feature Engineering
Feature engineering (kỹ thuật tạo đặc trưng) là quá trình thiết kế, chọn lọc các đặc trưng giúp các mô hình Machine Learning hoạt động hiệu quả hơn.
Các kỹ thuật thường dùng gồm:
- Feature Transformation: Biến đổi các đặc trưng sẵn có
- Feature Creation: Tạo ra đặc trưng mới từ dữ liệu
- Feature Selection: Loại bỏ những đặc trưng gây nhiễu hoặc không có nhiều giá trị
- Feature Extraction: Giảm chiều dữ liệu
Giai đoạn 5: Giải thích model
Explainable AI
LIME, SHAP là các phương pháp để trả lời câu hỏi “Tại sao lại có kết quả này?” khi sử dụng các mô hình ML. Nó đảm bảo độ tin cậy và tính công bằng của kết quả, là điều rất cần thiết nếu DS muốn sử dụng ML trong thực tế.
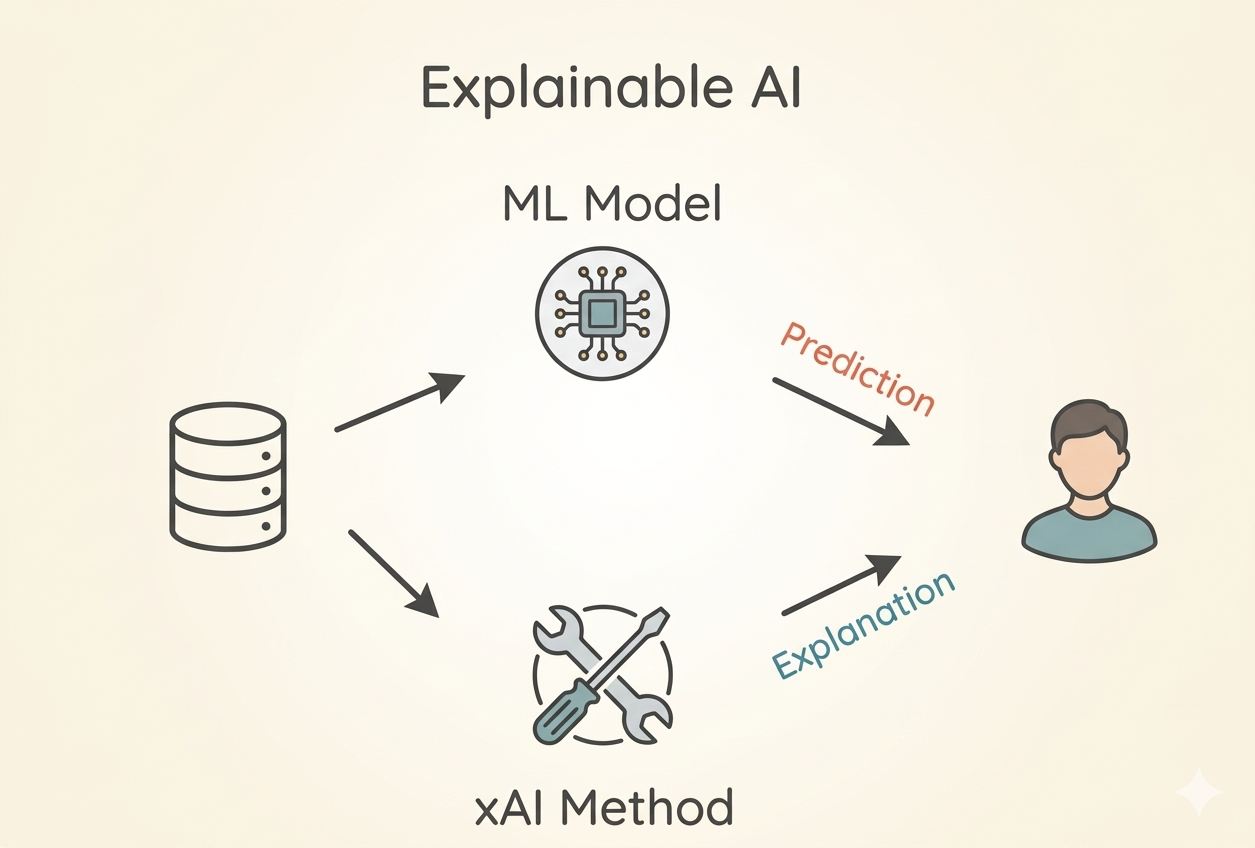
Nguồn: Ảnh minh họa tạo bởi AI
Ngoài ra, Nên học thêm về suy luận nhân quả (causal inference) nhằm phân tích kết quả phân tích được là ngẫu nhiên hay thực tế.
4.2.3 Dự án thực tế
-
Dự án 1: Xây model dự đoán giá nhà với pipeline đầy đủ so sánh ít nhất 3 thuật toán với cross-validation, dùng SHAP giải thích kết quả. Viết README giải thích methodology như một báo cáo kỹ thuật thực sự.
-
Dự án 2: Tham gia một Kaggle competition không cần thắng, nên đọc và hiểu được solution của top 10% sau khi competition kết thúc. Viết bài phân tích so sánh approach của họ với approach của mình.
4.3 Data Engineer
4.3.1 Data Engineer Làm gì hàng ngày
Hằng ngày các Data Engineer cần thiết kế, xây dựng các hệ thống dùng để thu thập, xử lý và lưu trữ lượng lớn dữ liệu. NGoài ra, DE còn cần làm việc với DA và DS để hiểu họ cần dữ liệu gì và chuẩn bị cho họ.
4.3.2 Lộ trình học theo thứ tự
Giai đoạn 1: SQL nâng cao và database
Với Data Engineer, SQL không chỉ để viết query mà còn để xây dựng, tối ưu database. Tìm hiểu các kỹ thuật SQL nâng cao và mang tính hệ thống là điều bắt buộc với các DE.
| Kỹ thuật | Tác dụng | Giải thích |
|---|---|---|
| Indexing, Query Optimization | Tăng tốc truy vấn | Tối ưu cấu trúc dữ liệu và câu lệnh truy vấn. |
| Data Modeling (Star / Snowflake) | Giúp query dễ và nhanh hơn | Sắp xếp dữ liệu gọn gàng. |
| Transactions | Đảm bảo tính nhất quán | Gom nhiều bước thành 1 bước. |
| ACID | Đảm bảo dữ liệu luôn đúng | Bộ quy tắc giúp database không bị lỗi, không mất dữ liệu |
Giai đoạn 2: Python cho Data Engineering
DE sử dụng Python không chỉ để làm mô hình như DS, mà cần xây lên các hệ thống xử lý dữ liệu. Để làm được điều đó, DE cần thuần thục các kỹ thuật sau:
* Làm việc với file và xử lý file lớn
* Làm việc với API - thư viện requests (GET, POST, PUT, DELETE, etc.,)
* Logging để debug pipeline
* Config management (env variables, YAML)
Ghi nhớ: Code của một DA không chỉ là chạy được mà cần có cấu trúc, chạy ổn định, dễ debug và dễ vận hành.
Giai đoạn 3: Data pipeline và Orchestration
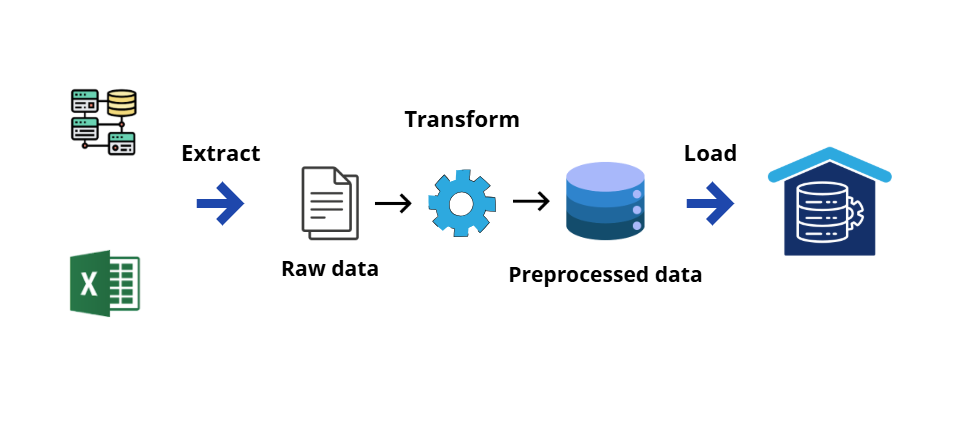
Nguồn: Phỏng theo AI VIET NAM
Pipeline là một quy trình có tính nhất quán, lặp lại được và đáng tin cậy. Các kiến thức cần nắm trong giai đoạn này bao gồm:
- ETL và ELT pipeline
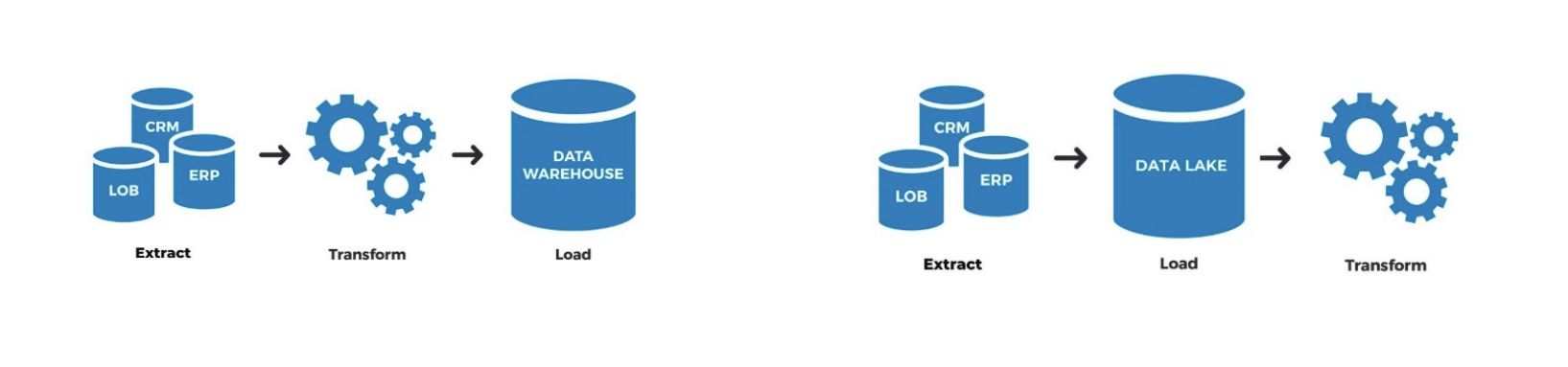
Nguồn: AI VIET NAM
- Transform dữ liệu bằng SQL trong warehouse (dùng dbt).
- DAG (Directed Acyclic Graph), Scheduling, Idempotency, điều chỉnh, alerting tự động hóa pipeline (dùng Apache Airflow).
- Cách viết data quality checks.
Giai đoạn 4: Cloud và distributed computing
Nguồn: AI VIET NAM
Gần đây, các công ty có xu hướng chuyển dịch dữ liệu sang Cloud. Điều này yêu cầu các DE bên cạnh việc "xây dựng pipeline" thì cần biết thiết kế và vận hành hệ thống dữ liệu end-to-end trên các nền tảng Cloud (AWS hay GCP).
Gợi ý: Người học nên chọn một nền tảng cụ thể: AWS, GCP, hoặc Azure để tìm hiểu sâu hơn. Các khái niệm cơ bản gồm: lưu trữ (S3/GCS), tính toán (EC2/Compute Engine), và data warehouse (Redshift/BigQuery).
4.3.3 Dự án thực tế
-
Dự án 1: Xây end-to-end pipeline — lấy dữ liệu từ một public API (ví dụ weather API hoặc GitHub API), làm sạch, transform bằng dbt, lưu vào PostgreSQL hoặc BigQuery, schedule bằng Airflow chạy mỗi ngày, có alerting khi fail.
-
Dự án 2: DataTalks.Club Data Engineering Zoomcamp có capstone project rất thực tế — nên làm project này vì có cộng đồng hỗ trợ và được review.
4.4 ML Engineer
4.4.1 ML Engineer làm gì hàng ngày
Hằng ngày ML Engineer chịu trách nhiệm đưa mô hình vào thực tế
- Đóng gói model thành API
- Xây dựng CI/CD pipeline
- Điều chỉnh và tối ưu các qui trình dữ liệu
Đồng thời, họ phối hợp với Data Scientist để hiểu yêu cầu model và với Data Engineer để đảm bảo dữ liệu đầu vào đúng định dạng.
4.4.2 Lộ trình học theo thứ tự
Giai đoạn 1: Software engineering cơ bản cho ML
MLE cần viết code tốt hơn Data Scientist, không chỉ dừng ở mức “chạy được” mà phải đảm bảo dễ đọc, dễ bảo trì và dễ kiểm tra. Cụ thể, cần nắm:
| Kỹ năng | Mục đích |
|---|---|
| OOP | Code rõ ràng, dễ sửa và tái dùng |
| Testing | Tránh lỗi khi thay đổi code |
| Virtual environment | Không bị xung đột thư viện |
| Project structure | Dễ quản lý và mở rộng |
| Logging | Dễ debug và theo dõi khi chạy |
Cấu trúc một project thường thấy.
project/
├── README.md
├── requirements.txt
├── src/
│ ├── ingestion/
│ ├── processing/
│ ├── models/
│ └── utils/
├── data/
│ ├── raw/
│ └── processed/
├── tests/
└── scripts/
Nói ngắn gọn, MLE làm nhiều phần giống “Software Engineering” hơn, nên chất lượng code là yếu tố rất quan trọng.
Giai đoạn 2: Machine learning
MLE không cần đào sâu lý thuyết như Data Scientist, nhưng phải hiểu đủ để nắm rõ:
* Model nhận gì (input), trả gì (output),
* Hành vi khi gặp dữ liệu thực tế (missing values, distribution shift, edge cases).
Ngoài ra cần nhận diện được các lỗi phổ biến khi deploy như:
| Lỗi | Mô tả ngắn |
|---|---|
| Training–serving skew | Dữ liệu train và lúc chạy khác nhau |
| Sai version feature | Dùng nhầm version dữ liệu |
| Data leakage | Lộ dữ liệu khi train |
| Latency cao | Model chạy chậm |
| Serialize/deserialize | Lỗi khi lưu hoặc đọc model |
Giai đoạn 3: MLOps
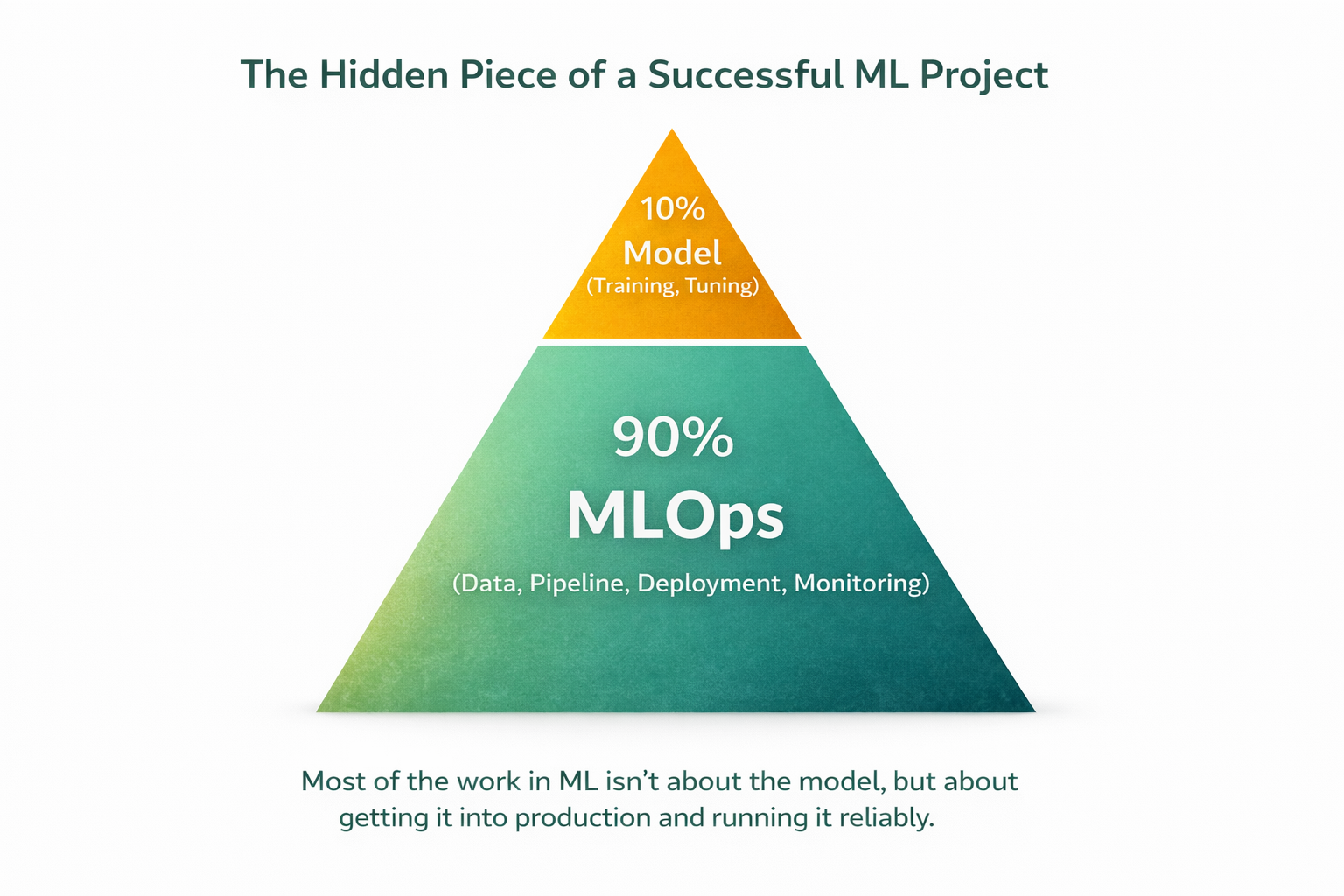
Nguồn: Ảnh minh họa bởi AI
MLOps là sự kết hợp giữa các nguyên tắc trong DevOps với các quy trình đặc thù của Machine Learning. Nó là cầu nối giữa mô hình trong nghiên cứu và thực tế. MLOps là thứ quyết định đến 90% sự thành công của một dự án ML, 10% là mô hình.

Nguồn: Ảnh minh họa bởi AI
Gợi ý: MLOps rất rộng, yêu cầu thời gian lớn để thành thạo. Người học nên chọn và thành thạo từng phần một.
Giai đoạn 4: Cloud deployment
Khi dữ liệu lớn và mô hình phức tạp hơn, các công ty thường cần chuyển dịch cloud để có đủ compute, storage và khả năng scale. Vì vậy, hiểu cloud là điều bắt buộc cần có của một MLE. Các kiến thức về Cloud cơ bản gồm:
| Nhóm | Cần biết | Dùng để làm gì | Ví dụ |
|---|---|---|---|
| Compute | -VM (CPU/GPU) | Train model, chạy inference | EC2, GCE |
| Storage | Object storage | Lưu dataset, model, log | S3, GCS |
| Database (cơ bản) | SQL / data warehouse | Lưu dữ liệu đã xử lý, feature | BigQuery, RDS |
| Networking | Public IP - Port | Kết nối service | Expose model/API ra ngoài VM + open port |
| IAM (Security) | - User Role | Permission cơ bản | Kiểm soát ai được truy cập gì IAM của Amazon Web Services |
| Monitoring | - Log Metric cơ bản | Theo dõi lỗi, hiệu năng model | CloudWatch, Stackdriver |
4.4.3 Dự án thực tế
- Dự án: Lấy model Data Scientist đã xây (ví dụ model dự đoán giá nhà), bọc lại bằng FastAPI, đóng gói bằng Docker, deploy lên Render, thiết lập GitHub Actions để tự động deploy khi push code. Kết quả là một URL công khai mà ai cũng có thể gọi được.
5. Quan sát thực tế
5.1 Ranh giới kỹ năng đang mờ dần
Xu hướng chung của ngành là các vai trò ngày càng đa năng hơn, các công ty ngày càng yêu cầu nhiều tiêu chí ở một người. Do đó, Liên tục học hỏi và mở rộng kiến thức hằng ngày là tư duy mà mọi người cần có.
5.2 Kỹ năng mềm ngày càng quan trọng
“Giao tiếp là cái nền tảng của tất cả”
Trong môi trường làm việc, bạn sẽ thường xuyên trao đổi với nhiều bên: product, business, data, engineering. Việc đặt câu hỏi đúng, làm rõ yêu cầu và trình bày kết quả một cách dễ hiểu quan trọng không kém việc xây dựng mô hình.
5.3 Tư duy hệ thống
AI giờ có thể viết code rất tốt, nên lợi thế không còn ở việc code nhanh hay thuộc nhiều syntax, mà ở khả năng nhìn toàn cảnh: hiểu bài toán, dòng chảy dữ liệu và cách hệ thống vận hành. Vì vậy, thay vì học dàn trải tool hay model mới, hãy tập trung rèn tư duy hệ thống biết chia nhỏ bài toán và thiết kế pipeline rõ ràng đó mới là nền tảng để đi lâu dài trong DS.
Lời kết
Hành trình học AI/Data không phải là cuộc đua ngắn hạn mà là một quá trình tích lũy bền bỉ. Thay vì chạy theo nhiều xu hướng cùng lúc, việc tập trung vào một hướng đi rõ ràng, xây nền tảng vững chắc và liên tục đào sâu sẽ mang lại hiệu quả lâu dài hơn. Khi đã có định hướng đúng và kỷ luật học tập, mỗi bước tiến – dù nhỏ – đều góp phần tạo nên năng lực thực sự. Cuối cùng, sự khác biệt không nằm ở việc bạn biết bao nhiêu, mà ở việc bạn hiểu sâu và áp dụng được đến đâu.
Tài liệu tham khảo
Cherian, M. (2026, February 27). A/B testing guide. VWO. https://vwo.com/ab-testing/
roadmap.sh. (n.d.). AI Engineer roadmap: Step-by-step guide to becoming an AI engineer. https://roadmap.sh/ai-engineer
Nguyễn, T. H. M., Trần, T. K., Nguyễn, Q. H., Đinh, N. K., & Nguyễn, T. M. (2026).
Toàn cảnh MLOps: Công nghệ, công cụ và quy trình triển khai ML hiệu quả.
https://aioconquer.aivietnam.edu.vn/posts/toan-canh-mlops-cong-nghe-cong-cu-va-quy-trinh-trien-khai-ml-hieu-qua
AI Vietnam. (2025). AIO 2025 – Module 3, 4 & 5 course materials.
Chưa có bình luận nào. Hãy là người đầu tiên!