
1. Giới thiệu
Chắc hẳn ai làm việc với Machine Learning cũng một nghịch lý tưởng như vô lý sau: một mô hình rất “xịn” nhưng cho kết quả tệ, trong khi đó một mô hình trung bình lại hoạt động tốt. Nghe có vẻ khó tin, nhưng sự thật là: nguyên nhân không nằm ở thuật toán, mà nằm ở cách chúng ta xử lý dữ liệu đầu vào.
Nói cách khác, mô hình không sai - dữ liệu mới là thứ quyết định nó học được gì.
Thầy Andrew Ng - chuyên gia AI nổi tiếng, từng nhận định:
Coming up with features is difficult, time-consuming, requires expert knowledge. “Applied machine learning” is basically feature engineering.
Tạm dịch: “Việc xây dựng đặc trưng là một công việc khó, tiêu tốn nhiều thời gian và yêu cầu hiểu biết chuyên sâu về miền bài toán. Trên thực tế, “machine learning ứng dụng” phần lớn chính là feature engineering.”
Nhận định này cho thấy một sự thật quan trọng: thuật toán chỉ là công cụ, còn chất lượng dữ liệu và cách ta “kể câu chuyện” cho mô hình nghe mới là yếu tố cốt lõi. Nếu dữ liệu đầu vào không phản ánh đúng bản chất của bài toán, thì dù thuật toán có tối ưu đến đâu, nó cũng chỉ học được những mối quan hệ sai lệch hoặc nông cạn.
Bài viết này sẽ giải thích cho bạn tại sao Feature engineering (kỹ thuật tạo đặc trưng) lại vô cùng quan trọng trong các bài toán Machine Learning cùng với minh họa trực quan.
2. Feature Engineering là gì?
Feature engineering (kỹ thuật tạo đặc trưng) là quá trình thiết kế, chọn lọc các đặc trưng (features) giúp phản ánh đúng bản chất bài toán và các mô hình Machine Learning hoạt động hiệu quả hơn.
Quá trình này thường bao gồm các nhóm công việc chính:
-
Feature Transformation: Biến đổi các đặc trưng sẵn có (ví dụ: lấy Logarithm để xử lý dữ liệu bị lệch, Scaling để đưa dữ liệu về cùng một khoảng giá trị).
-
Feature Creation: Tạo ra đặc trưng mới từ dữ liệu cũ (ví dụ: từ "Kinh độ" và "Vĩ độ" tạo ra đặc trưng "Khoảng cách").
-
Feature Selection: Loại bỏ những đặc trưng gây nhiễu hoặc không đóng góp giá trị để mô hình gọn nhẹ hơn.
-
Feature Extraction: Giảm chiều dữ liệu (như PCA) để trích xuất những thông tin cốt lõi nhất từ một tập hợp dữ liệu phức tạp.
3. Tại sao Feature Engineering cực kỳ quan trọng?
- Cải thiện hiệu suất mô hình
Chất lượng của đặc trưng đầu vào có ảnh hưởng trực tiếp đến hiệu suất của mô hình machine learning. Feature engineering tốt giúp mô hình phát hiện các pattern có ý nghĩa trong dữ liệu, từ đó cải thiện cả độ chính xác (accuracy) lẫn khả năng tổng quát hóa (generalization) trên dữ liệu.
Một ví dụ điển hình là bài toán dự đoán giá nhà. Nếu sử dụng trực tiếp biến năm xây dựng (1995, 2000, 2002), mô hình phải tự suy luận mối quan hệ giữa con số này và giá trị căn nhà - một mối quan hệ không tuyến tính và phụ thuộc vào thời điểm hiện tại. Trong khi đó, việc chuyển đổi biến này thành tuổi nhà (năm hiện tại trừ năm xây dựng) giúp đặc trưng trở nên trực quan và có ý nghĩa hơn, phản ánh trực tiếp mức độ hao mòn và giá trị sử dụng của căn nhà. Nhờ đó, mô hình dễ học hơn, hội tụ nhanh hơn và thường cho kết quả dự đoán chính xác hơn.
- Tăng tính phù hợp của dữ liệu với thuật toán
Trên thực tế, nhiều mô hình chỉ hoạt động hiệu quả khi dữ liệu đầu vào được biểu diễn dưới định dạng số phù hợp và có phân bố ổn định. Nếu số nhà là chục trong khi giá tiền là hàng tỷ, các thuật toán dựa trên khoảng cách sẽ bị choáng bởi đặc trưng giá tiền mà bỏ qua đặc trưng còn lại.
Feature engineering đóng vai trò cầu nối giữa dữ liệu thực tế và yêu cầu toán học của thuật toán, đưa các đặc trưng vào một “sân chơi công bằng”. Thông qua các kỹ thuật Feature transformation, dữ liệu tương thích với mô hình thuật toán hơn, giúp tăng hiệu quả học.
- Giảm độ phức tạp và thời gian training
Dữ liệu thô có thể chứa các đặc trưng dư thừa, gây nhiễu và khiến mô hình phải tốn thời gian huấn luyện trên thông tin không hữu ích. Điều này không chỉ tăng thời gian huấn luyện mà còn có thể gây ra vấn đề overfitting (học vẹt dữ liệu nhiễu).
Thông qua Feature Engineering, dữ liệu được chuẩn hóa và không gian đầu vào được giảm chiều một cách hiệu quả, giúp mô hình chỉ tập trung vào những đặc trưng chứa nhiều thông tin. Nhờ đó, tài nguyên tính toán (RAM/CPU) và thời gian huấn luyện được tối ưu.
4. So sánh khi có và không có Feature Engineering
Ví dụ ngắn sau đây sẽ cho thấy sự khác biệt khi chúng ta có sử dụng và không sử dụng Feature Engineering trong bài toán ML.
Bối cảnh: Trong lĩnh vực vận tải công nghệ, việc dự đoán chính xác thời gian tài xế đến điểm đón (ETA) là yếu tố sống còn để giảm tỷ lệ hủy chuyến và tối ưu trải nghiệm khách hàng. Ta sẽ mô phỏng bài toán dự đoán ETA.
-
Sự khác biệt giữa dữ liệu thô và dữ liệu sau xử lý:
-
Dữ liệu thô (Raw Data): Chỉ sử dụng các biến số nguyên bản là
Distance_km(Khoảng cách),Hour(Giờ trong ngày), vàIs_Raining(Trời mưa hay không). Mặc dù có biếnHourvàIs_Raining, nhưng mô hình phải tự mình tìm hiểu mối quan hệ phức tạp giữa chúng. Nó xem giờ cao điểm cũng giống như bao khung giờ khác, chưa biết cách "nhấn mạnh" vào những thời điểm nhạy cảm này. -
Sau Feature Engineering: Ta bổ sung thêm feature nhờ Domain knowledge.
-
Is_Rush_Hour(Giờ cao điểm): Gom nhóm các khung giờ (7-9h và 16-19h) để định danh rõ ràng đây là lúc tắc đường. -
Rain_Impact(Tác động của mưa): Đây là một Interaction Feature (đặc trưng tương tác). Nó giúp mô hình hiểu rằng: Mưa vào ban đêm không ảnh hưởng nhiều bằng mưa vào giờ cao điểm.
-
-
Code demo Python so sánh hiệu suất:
Đoạn code này mô phỏng việc huấn luyện hai mô hình: một chỉ dùng dữ liệu ban đầu và một dùng thêm các tính năng đã qua xử lý.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_absolute_error
# 1. Giả lập dữ liệu Uber/Grab
data = {
'Distance_km': [2, 5, 2, 8, 3, 10, 2, 6, 1, 4, 3, 7],
'Hour': [8, 8, 23, 17, 12, 18, 2, 17, 9, 21, 8, 16],
'Is_Raining': [1, 0, 0, 1, 0, 1, 0, 0, 1, 0, 1, 0],
'Actual_ETA': [18, 20, 6, 45, 10, 55, 5, 25, 12, 12, 22, 28] # Thời gian thực tế (phút)
}
df = pd.DataFrame(data)
# --- TRƯỚC FE ---
X_raw = df[['Distance_km', 'Hour', 'Is_Raining']]
model_raw = RandomForestRegressor(n_estimators=100, max_depth=3, random_state=42).fit(X_raw, df['Actual_ETA'])
mae_raw = mean_absolute_error(df['Actual_ETA'], model_raw.predict(X_raw))
# --- SAU FE ---
# Tạo đặc trưng 'Is_Rush_Hour': Giờ cao điểm từ 7-9h và 16-19h
df['Is_Rush_Hour'] = df['Hour'].apply(lambda x: 1 if (7 <= x <= 9) or (16 <= x <= 19) else 0)
# Tạo đặc trưng 'Rain_Impact': Tác động kép khi vừa mưa vừa cao điểm
df['Rain_Impact'] = df['Is_Raining'] * df['Is_Rush_Hour']
X_fe = df[['Distance_km', 'Hour', 'Is_Raining', 'Is_Rush_Hour', 'Rain_Impact']]
model_fe = RandomForestRegressor(n_estimators=100, max_depth=3, random_state=42).fit(X_fe, df['Actual_ETA'])
mae_fe = mean_absolute_error(df['Actual_ETA'], model_fe.predict(X_fe))
# 2. Vẽ biểu đồ so sánh sai số (Plotting)
labels = ['Raw Data', 'After FE']
errors = [mae_raw, mae_fe]
plt.figure(figsize=(10, 6))
bars = plt.bar(labels, errors, color=['#e74c3c', '#2ecc71'])
plt.ylabel('Mean Absolute Error (Minutes)')
plt.title('ETA Prediction Performance: Before vs After Feature Engineering')
plt.show()
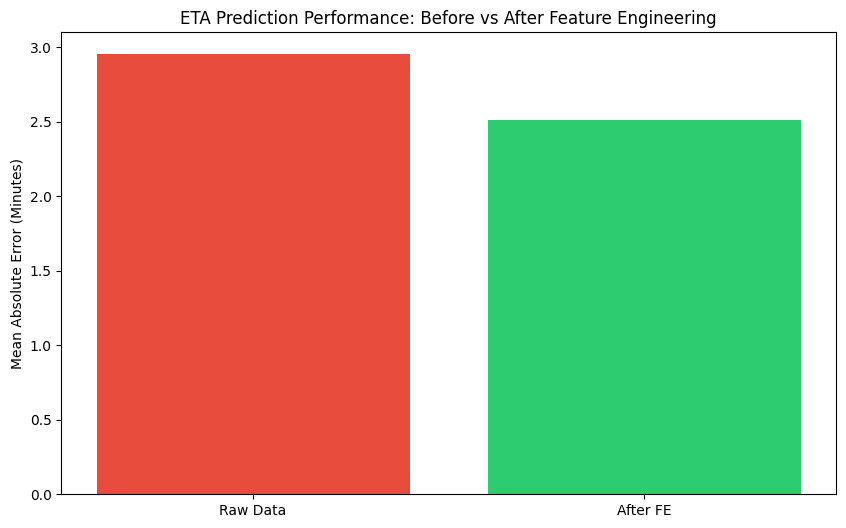
- Biểu đồ đánh giá:
Khi chạy đoạn code trên, bạn sẽ thấy sai số (MAE) giảm chỉ với bước Feature Engineering đơn giản
5. Các nhóm kĩ thuật chính trong Feature Engineering
Tiền xử lý dữ liệu (Data Preprocessing)
Trước khi nói đến feature engineering, chúng ta cần làm một việc kém “hào nhoáng” hơn: làm sạch dữ liệu.
Mục tiêu chung
Trong thực tế, dữ liệu hiếm khi gọn gàng ngay từ đầu. Giá trị bị thiếu, định dạng không nhất quán, hay thậm chí dữ liệu bị trùng lặp là điều xảy ra thường xuyên, chứ không phải ngoại lệ. Preprocessing chính là bước giúp dữ liệu trở nên an toàn để làm việc trước khi ta cố gắng khiến nó trở nên hữu ích cho mô hình học máy.
Nếu bỏ qua preprocessing, sẽ có khả năng:
-
Mô hình có thể không train được
-
Thống kê bị bóp méo
-
Model học nhầm noise thay vì signal
Vì vậy, preprocessing không nhằm “làm đẹp dữ liệu”, mà nhằm đảm bảo rằng dữ liệu phản ánh đúng bản chất bài toán và có thể học được một cách ổn định.
1. Xử lý các giá trị thiếu
Mục đích
Hầu hết các thuật toán học máy đều giả định rằng mỗi đầu vào đều là một giá trị hợp lệ. Chỉ cần một giá trị nullcũng có thể khiến quá trình huấn luyện mô hình thất bại. Ngay cả khi thuật toán có thể xử lý dữ liệu thiếu, chúng vẫn làm sai lệch các thống kê cơ bản như trung bình, phương sai hay tương quan. Vì vậy, ta cần đảm bảo dataset không chứa giá trị rỗng gây lỗi huấn luyện hoặc làm sai lệch phân tích.
Giá trị thiếu thường xuất hiện do:
-
Người dùng không cung cấp thông tin
-
Lỗi thu thập dữ liệu
-
Một số trường không áp dụng cho mọi đối tượng
Phương pháp phổ biến
-
Điền giá trị thay thế
-
Điền giá trị bằng trung vị (Median imputation): Áp dụng cho biến số liệu. Trung vị ít bị ảnh hưởng bởi các giá trị cực đoan hơn so với trung bình, nên an toàn hơn khi phân phối bị lệch hoặc có outlier.
-
Điền giá trị bằng mode: Áp dụng cho biến phân loại. Ta thay các giá trị thiếu bằng danh mục xuất hiện nhiều nhất, giúp giữ nguyên tập nhãn hợp lệ mà không tạo ra giá trị “giả”.
df['age'] = df['age'].fillna(df['age'].median())
df['city'] = df['city'].fillna(
df['city'].mode()[0])
- Loại bỏ đặc trưng: Khi một cột có quá nhiều giá trị thiếu và không mang nhiều thông tin, việc loại bỏ có thể hợp lí hơn thay thế.
2. Xử lý outlier
Mục đích
Outlier quan trọng vì chúng có thể ảnh hưởng mạnh đến thống kê và hành vi của mô hình. Một số thuật toán rất nhạy với giá trị cực đoan, trong khi những thuật toán khác có thể học quá mức (overfit) vào các trường hợp hiếm nhưng không quan trọng. Tuy nhiên, không phải outlier nào cũng là lỗi. Nhiều giá trị cực đoan phản ánh những trường hợp thực tế hiếm gặp.
Một cách đơn giản để kiểm tra outlier là trực quan hóa phân phối dữ liệu. Ở đây là ví dụ liên quan về giá vé Titanic:
sns.boxplot(titanic['fare'].dropna())
plt.title("Fare distribution")
plt.show()
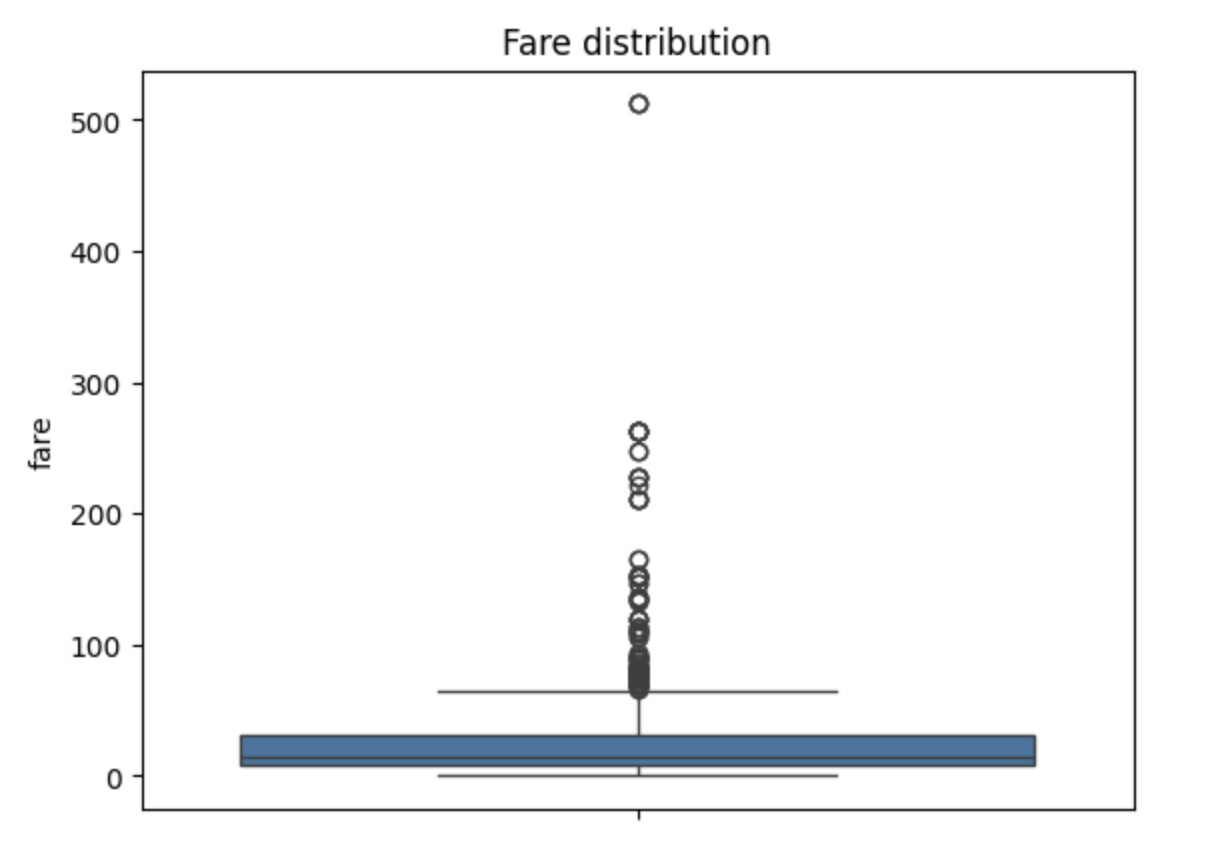
Biểu đồ cho thấy nhiều giá vé rất cao. Thoạt nhìn, chúng có vẻ là outlier “điển hình”. Nhưng để quyết định đây là nhiễu hay tín hiệu, bối cảnh dữ liệu nên đóng một vai trò then chốt.
Trên tàu Titanic, giá vé chênh lệch rất lớn giữa các hạng ghế. Hành khách hạng nhất trả mức giá cao hơn nhiều, và những giá trị lớn này phản ánh sự khác biệt kinh tế có thật, chứ không phải lỗi dữ liệu. Nếu loại bỏ các giá vé cao, ta sẽ vô tình xóa đi thông tin quan trọng liên quan đến hạng vé và mức độ giàu có, những yếu tố có khả năng ảnh hưởng đến khả năng sống sót.
Vì vậy, trong trường hợp này, chúng ta không loại bỏ outlier ở bước preprocessing. Điều này minh họa một nguyên tắc quan trọng:
Preprocessing là để bảo vệ tính toàn vẹn của dữ liệu, chứ không phải ép dữ liệu trông “đẹp” hơn.
Kỹ thuật phổ biến
Trong trường hợp outliers cần được xử lý, ta có thể:
- Loại bỏ outlier hoàn toàn: Phù hợp khi các giá trị cực đoan rõ ràng là sai hoặc chỉ là nhiễu. Một cách phổ biến là sử dụng phương pháp Interquartile Range (IQR) (GeeksforGeeks, 2025).
q1 = titanic['fare'].quantile(0.25)
q3 = titanic['fare'].quantile(0.75)
iqr = q3 - q1
df_no_outliers = titanic[
(titanic['fare'] >= q1 - 1.5 * iqr) &
(titanic['fare'] <= q3 + 1.5 * iqr)
]
- Thay thế hoặc giới hạn giá trị cực đoan (capping): Cách này giữ nguyên số lượng mẫu nhưng giảm ảnh hưởng của các giá trị quá lớn.
# Capping extreme values
df['fare_capped'] = df['fare'].clip(
lower=q1 -1.5 * iqr,
upper=q3 +1.5 * iqr
)
# Transforming distribution
titanic['fare_log'] = np.log1p(titanic['fare'])
3. Định dạng và tính nhất quán của kiểu dữ liệu
Mục đích
Đảm bảo dữ liệu có định dạng nhất quán, tránh hiểu sai khi phân tích và huấn luyện. Để kiểm tra nhanh kiểu dữ liệu của từng cột, ta có thể dùng hàm dtypes
Các vấn đề thường gặp:
-
Datetime lưu dưới dạng string
-
Category không thống nhất (
"Male"vs"male") -
Số được lưu dưới dạng text
Chuẩn hóa các kiểu dữ liệu
- Chuẩn hóa thời gian
df['purchase_date'] = pd.to_datetime(df['purchase_date'])
- Chuẩn hóa vặn bản
df['gender'] = df['gender'].str.lower().str.strip()
4. Loại bỏ dữ liệu trùng lặp
Mục đích
Dữ liệu trùng lặp không làm hỏng code, nhưng chúng làm lệch mô hình bằng cách khiến một số quan sát bị “đếm nhiều lần”. Vì vậy, đây là một bước kiểm tra nhanh nhưng rất đáng làm.
Dữ liệu trùng lặp thường xuất hiện do:
-
Ghi log nhiều lần
-
Merge dữ liệu từ nhiều nguồn
-
Lỗi pipeline thu thập
Nếu không xử lý, ta có thể khiến:
-
Một số quan sát bị đếm nhiều lần
-
Phân phối dữ liệu bị lệch
-
Model học sai tần suất thực
# Kiểm tra số dòng trùng
df.duplicated().sum()
# Loại bỏ dòng trùng
df = df.drop_duplicates()
5.1. Biến đổi đặc trưng (Feature Transformation)
Mục tiêu chung
Sau bước preprocessing, dữ liệu của chúng ta đã sạch và đáng tin cậy. Nhưng “sạch” chưa đồng nghĩa với “học được”.
Các mô hình machine learning không hiểu ý nghĩa hay ngữ cảnh như con người, chúng chỉ hiểu con số và hình học. Feature transformation là bước chúng ta tái cấu trúc dữ liệu sạch sao cho các mô hình toán học thực sự có thể học được từ nó.
Mục tiêu của bước này là làm cho các đặc trưng:
-
Có thang đo so sánh được
-
Có ý nghĩa về mặt số học
-
Dễ tối ưu hơn cho mô hình
-
Ít nhạy cảm với phân phối bị lệch
1. Chuẩn hóa các biến số
Mục đích
Trong nhiều bài toán, các biến số có đơn vị và phạm vi rất khác nhau. Một số mô hình như logistic regression, SVM, neural networks rất nhạy cảm với độ lớn của giá trị đặc trưng.
Ví dụ:
| Feature | Khoảng giá trị |
|---|---|
| Age | 0 - 80 |
| Income | 1,000 - 200,000 |
| Distance | 0 - 10 |
Tuy nhiên, chúng ta không nên chuẩn hóa:
-
Các biến nhị phân (0/1)
-
Các biến thứ tự (ordinal) nếu chưa được mã hóa rõ ràng
Kỹ thuật phổ biến
- Standardization (Z-score scaling)
Một lựa chọn phổ biến là standardization (Z-score scaling), phương pháp đưa dữ liệu về trung bình 0 và độ lệch chuẩn 1.
Về mặt toán học, mỗi giá trị xxx được biến đổi theo công thức:
$$ z=\frac{x - \mu}{\sigma} $$
Trong đó:
-
$z$ là giá trị gốc của feature
-
$\mu$ là giá trị trung bình (mean) của feature
-
$\sigma$ là độ lệch chuẩn (standard deviation)
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
df['price_scaled'] = scaler.fit_transform(
df['price']
)
Phương pháp này đặt biệt phù hợp với Linear models, SVM, Neural networks, và các thuật toán tối ưu bằng gradient.
- Normalization (Min-Max Scaling)
Một kỹ thuật khác rất phổ biến là Min–Max Scaling, đưa toàn bộ giá trị về khoảng $[0, 1]$.
$$ x′= \frac{x - x_{\min}}{x_{\max} - x_{\min}} $$
Phương pháp này:
-
Giữ nguyên hình dạng phân phối
-
Dễ diễn giải
-
Phù hợp khi đặc trưng có giới hạn rõ ràng
Tuy nhiên, phương pháp này rất nhạy cảm với outliers. Chỉ một giá trị cực đoan cũng có thể kéo giãn toàn bộ thang đo.
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
df['price_minmax''] = scaler.fit_transform(
df['price']
)
- Robust scaling
Khi dữ liệu chứa nhiều outliers, RobustScaler là lựa chọn an toàn hơn. Phương pháp này sử dụng Median (trung vị) và Interquartile Range (IQR) thay vì mean và standard deviation.
from sklearn.preprocessing import RobustScaler
scaler = RobustScaler()
df['price'] = scaler.fit_transform(
df['price']
)
2. Mã hóa các biến phân loại
Mục đích
Mô hình học máy không thể làm việc trực tiếp với chuỗi như "male" hay "female". Vì vậy, các biến phân loại cần được chuyển sang dạng số, nhưng không được tạo ra một trật tự giả.
Kỹ thuật phổ biến
- One-hot encoding
Đây thường là lựa chọn an toàn nhất cho các biến danh nghĩa (không có thứ tự). Kỹ thuật này tạo ra các cột nhị phân và không áp đặt thứ tự giả lên dữ liệu.
Ví dụ, ta encode màu sắc lần lượt là Red, Blue, Green từ trên xuống theo hàng, nhưng không có nghĩa Red > Blue.
pd.get_dummies(df, columns=['color'], drop_first=True)
- Label encoding
Gán các con số như 0, 1, 2 cho các nhãn. Phương pháp này chỉ nên dùng cho dữ liệu có thứ tự tự nhiên, vì nó ngầm giả định rằng các nhãn có quan hệ lớn – nhỏ.
Ví dụ, ta encode cấp bậc học:
education_map = {
'High school': 0,
'Bachelor': 1,
'Master': 2,
'PhD': 3
}
df['education_encoded'] = df['education'].map(education_map)
Nếu ta áp dụng label encoding cho category không có thứ tự, điều này sẽ tạo ra sự thiên vị nghiêm trọng khi huấn luyện mô hình.
3. Biến đổi phân phối bị lệch
Mục đích
Nhiều đặc trưng trong thực tế phân phối right-skewed, với nhiều giá trị nhỏ và một số ít có giá trị rất lớn.
Các biến có phân phối lệch thường gây ra:
-
Mô hình hội tụ chậm
-
Hiệu suất kém với các mô hình tuyến tính
-
Quá nhấn mạnh vào các trường hợp hiếm
Thay vì loại bỏ outlier, một cách tiếp cận tốt hơn là biến đổi hình dạng phân phối, ví dụ bằng log transform.
Ví dụ thực tế với phân phối right-skewed
import numpyas np
df['fare_log'] = np.log1p(df['fare'])
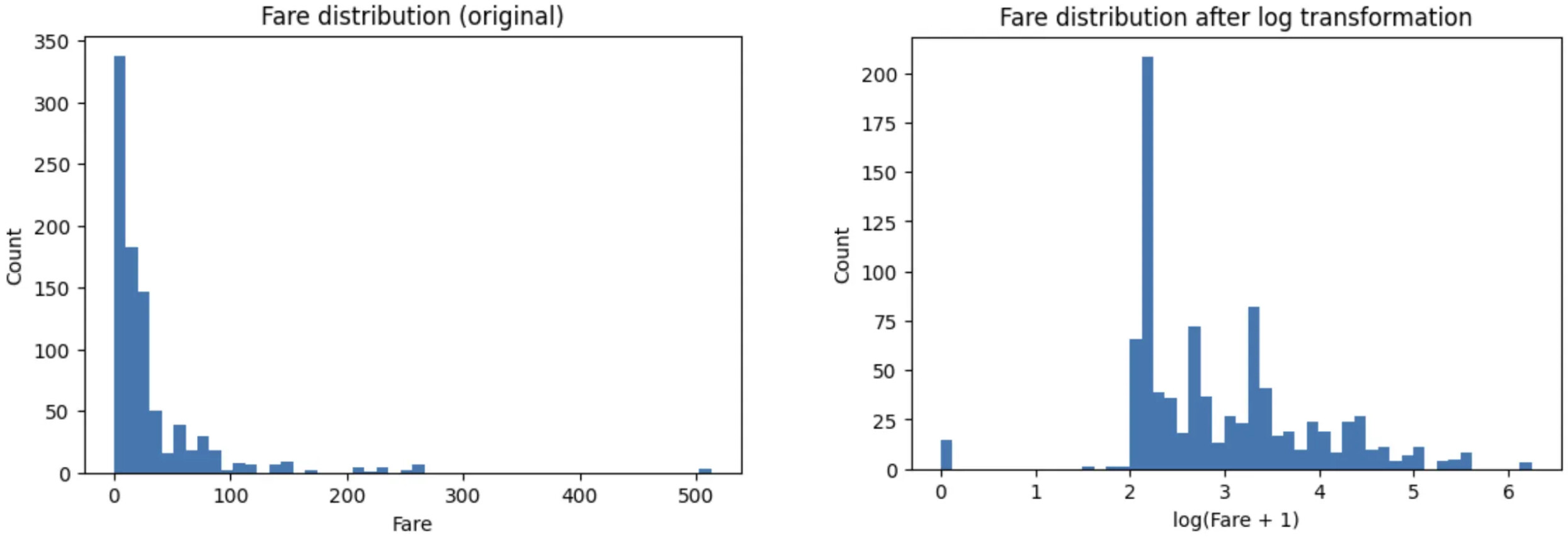
So sánh hai biểu đồ, ta có thể thấy:
-
Trước biến đổi: vài giá trị cực lớn kéo giãn toàn bộ trục
-
Sau log transform:
-
Các giá trị lớn được nén lại, không bị loại bỏ
-
Phần lớn dữ liệu được trải đều hơn
-
Phân phối trở nên gần đối xứng
-
Thứ tự tương đối giữa các giá trị vẫn được giữ nguyên
Điều này giúp mô hình học mối quan hệ tuyến tính hiệu quả hơn.
4. Rời rạc hóa
Mục đích
Rời rạc hóa là việc chuyển một biến số liên tục thành một số ít nhóm (bins). Kỹ thuật này hữu ích khi:
-
Giá trị chính xác chứa nhiều nhiễu
Ví dụ, trong phân tích tuổi tác làm việc, sự khác biệt giữa người 29 tuổi và 30 tuổi gần như không có ý nghĩa thực tế.
-
Mối quan hệ với target không tuyến tính
-
Các khoảng giá trị mang ý nghĩa thực tế
Các nhóm tuổi như trẻ em, thiếu niên, người trưởng thành hay người cao tuổi có sự khác biệt rõ ràng về hành vi và xã hội.
Ví dụ, ta có thể chia tuổi thành các nhóm như sau:
df['age_group'] = pd.cut(
df['age'],
bins=[0, 12, 18, 35, 60, 100],
labels=['child', 'teen', 'adult', 'middle_aged', 'senior']
)
Lúc này, age không còn là một con số chính xác nữa, mà trở thành một khái niệm.
Ngược lại, ta nên tránh rời rạc hóa khi:
-
Dùng các mô hình cây (chúng xử lý phi tuyến rất tốt)
-
Giá trị số chính xác mang nhiều thông tin
-
Dữ liệu đủ lớn để mô hình học mượt mà
Nói cách khác, rời rạc hóa không phải bước mặc định. Nó là một công cụ, và ta chỉ áp dụng khi có lý do rõ ràng.
5.2. Tạo và Trích xuất đặc trưng (Feature Creation & Extraction)
Mục tiêu chung
Mục tiêu cốt lõi của phần này là biến đổi dữ liệu thô thành các thông tin giàu ý nghĩa hơn cho mô hình học máy. Trên cùng một tập dữ liệu, các cách tạo đặc trưng khác nhau có thể dẫn đến kết quả mô hình hoàn toàn khác biệt, ngay cả khi thuật toán không đổi. Đây chính là lý do Feature Engineering thường đóng vai trò quan trọng hơn cả việc lựa chọn Model.
Trong mục này, ta phân biệt rõ hai khái niệm:
-
Feature Creation (Tạo đặc trưng): Sử dụng kiến thức chuyên môn và logic nghiệp vụ để tạo ra các biến mới thủ công.
-
Feature Extraction (Trích xuất đặc trưng): Sử dụng thuật toán để tự động rút gọn hoặc biểu diễn dữ liệu phức tạp (ảnh, văn bản) thành các vector số.
1. Feature Creation: Tạo đặc trưng từ kiến thức domain
Feature Creation là quá trình kết hợp, biến đổi hoặc suy luận từ các đặc trưng sẵn có để tạo ra đặc trưng mới có ý nghĩa hơn đối với bài toán.
Điểm quan trọng:
-
Không phải thuật toán tự nghĩ ra
-
Con người chủ động thiết kế
-
Phụ thuộc mạnh vào domain knowledge (kiến thức chuyên môn)
Các phép toán cơ bản thường dùng:
| Kiểu | Ví dụ |
|---|---|
| Tổng | A + B |
| Hiệu | A - B |
| Tỷ lệ | A / B |
| Tương tác | A * B |
| Log / Power | log(A), A², √A |
import pandas as pd
df = pd.DataFrame({
"weight_kg": [60, 72, 80],
"height_m": [1.65, 1.70, 1.75],
"A": [10, 20, 30],
"B": [2, 5, 6],
})
df["BMI"] = df["weight_kg"] / (df["height_m"] ** 2)
df["A_plus_B"] = df["A"] + df["B"]
df["A_div_B"] = df["A"] / df["B"]
df["A_mul_B"] = df["A"] * df["B"]
Ví dụ thực tế: Những feature này thường không có sẵn trong dữ liệu thô (raw data) nhưng lại phản ánh trực tiếp bản chất của bài toán kinh doanh:
-
Bài toán bán hàng
-
Doanh thu = Giá × Số lượng -
Tỷ lệ chiết khấu = Giảm giá / Giá gốc -
Doanh thu trên mỗi khách hàng -
Bài toán y tế (Ví dụ về BMI): Cân nặng hay chiều cao khi đứng riêng lẻ chưa nói lên nhiều điều, nhưng chỉ số BMI lại phản ánh tình trạng cơ thể chính xác hơn:
$$ \mathrm{BMI}=\frac{\text{Can nang (kg)}}{\text{Chieu cao (m)}^2} $$
-
Nếu chỉ đưa
weight,heightcho model: Model vẫn có thể học được mối quan hệ này nhưng cần nhiều dữ liệu hơn và dễ bị overfit. -
Khi tạo sẵn BMI: Giúp giảm độ phức tạp, tăng tính giải thích (explainability) và tăng hiệu quả của mô hình.
Bảng: Feature Creation trong thực tế Data Science
| Lĩnh vực | Feature Creation |
|---|---|
| Finance | Debt / Income, Volatility |
| Marketing | CTR, Conversion Rate |
| Education | Điểm trung bình, tỷ lệ hoàn thành |
| E-commerce | Giá sau giảm, giá trên mỗi sản phẩm |
| AI CV | Aspect ratio, object density |
| NLP | Độ dài câu, số từ khóa |
2. Feature Extraction: Trích xuất đặc trưng từ dữ liệu phức tạp
Feature Extraction là quá trình sử dụng thuật toán để biến đổi dữ liệu phi cấu trúc hoặc dữ liệu nhiều chiều thành các vector số mà mô hình có thể học được.
Đặc điểm:
-
Dùng thuật toán tự động.
-
Áp dụng cho: Datetime, Text, Image, Audio, Dữ liệu số nhiều chiều
a. Trích xuất đặc trưng từ Datetime:
Dữ liệu thời gian không nên để nguyên dạng timestamp. Ta có thể "bóc tách" nó thành nhiều thông tin nhỏ nhưng cực kỳ mạnh mẽ cho các bài toán dự đoán nhu cầu hoặc phân tích hành vi.
Ví dụ: 2025-01-21 19:30:00
Ta có thể trích xuất:
| Feature | Ý nghĩa |
|---|---|
| Day of week | Thứ trong tuần |
| Is weekend | Hành vi khác ngày thường |
| Month | Mùa vụ |
| Quarter | Chu kỳ kinh doanh |
| Hour | Hành vi theo giờ |
| Season | Xuân – Hạ – Thu – Đông |
import pandas as pd
df = pd.DataFrame({
"timestamp": pd.to_datetime(["2025-01-21 19:30:00", "2025-03-02 08:10:00"])
})
df["dow"] = df["timestamp"].dt.dayofweek # 0=Mon ... 6=Sun
df["month"] = df["timestamp"].dt.month
df["quarter"] = df["timestamp"].dt.quarter
df["is_weekend"] = (df["dow"] >= 5).astype(int)
b. Trích xuất đặc trưng từ Text
Text là dữ liệu phi cấu trúc, cần chuyển sang dạng vector số hóa. Hai phương pháp kinh điển là Bag of Words (BoW) và TF-IDF.
| Tiêu chí | Bag of Words (BoW) | TF-IDF |
|---|---|---|
| Ý tưởng chính | Đếm số lần từ xuất hiện trong văn bản | Cân bằng giữa tần suất từ trong văn bản và độ hiếm của từ trong toàn corpus |
| Cách biểu diễn | Vector đếm (count vector) | Vector trọng số TF × IDF |
| Độ thưa (sparse) | Rất thưa | Rất thưa |
| Từ phổ biến (stopwords) | Bị ảnh hưởng mạnh | Bị giảm trọng số |
| Ưu điểm | Đơn giản, dễ hiểu, dễ triển khai | Mạnh hơn BoW, phản ánh mức độ quan trọng của từ |
| Nhược điểm | Không phân biệt từ quan trọng / không quan trọng | Không hiểu ngữ cảnh, vẫn tuyến tính |
| Độ phức tạp | Thấp | Thấp – Trung bình |
| Phù hợp cho | Baseline, bài toán đơn giản | Text Classification, Search, Clustering |
| Thư viện phổ biến | CountVectorizer (sklearn) | TfidfVectorizer (sklearn) |
c. Trích xuất đặc trưng từ Image
Ảnh là dữ liệu cao chiều (H × W × C). Các phương pháp xử lý phổ biến bao gồm:
-
Flatten pixel: Duỗi thẳng ma trận ảnh (cách cũ, kém hiệu quả)
-
Histogram màu: Thống kê phân bố màu sắc.
-
CNN / Vision Transformer (Hiện đại): Sử dụng các mô hình Deep Learning để trích xuất Embedding vector.
-
Output: Thường là vector có kích thước 512, 768 hoặc 1024 chiều.
-
Ứng dụng: Vector này giữ lại thông tin ngữ nghĩa của hình ảnh, dùng cho Classification, Retrieval, Clustering, hoặc Similarity search.
d. PCA (Principal Component Analysis)
PCA là kỹ thuật giảm chiều dữ liệu (Dimensionality Reduction).
-
Cơ chế: Tạo ra các trục tọa độ mới (principal components) sao cho các trục này không tương quan với nhau và giữ lại được nhiều phương sai (thông tin) nhất có thể.
-
Mục tiêu: Chỉ giữ lại một số ít trục quan trọng nhất để biểu diễn dữ liệu.
-
Hiểu đơn giản: PCA xoay lại hệ trục tọa độ để ta nhìn thấy dữ liệu "rõ nét" nhất với số chiều ít hơn.
Tổng kết: Feature Creation vs Feature Extraction
| Feature Creation | Feature Extraction |
|---|---|
| Dựa vào con người | Dựa vào thuật toán |
| Mang tính domain (nghiệp vụ) | Mang tính toán học |
| Dễ giải thích | Khó giải thích (Hộp đen) |
| Thường it chiều | Có thể rất nhiều chiều |
| Quan trọng trong Business/ Tabular data | Quan trọng trong AI (Image, Text, Audio) |
5.3. Chọn lọc đặc trưng (Feature Selection)
Mục tiêu chung
Mục tiêu của Feature Selection là: Giữ lại những đặc trưng thực sự giúp dự đoán và loại bỏ những đặc trưng gây nhiễu còn lại.
Khác với các bước trước:
-
Không tạo ra feature mới (như Feature Creation).
-
Không biến đổi dữ liệu (như Feature Extraction).
-
Tập trung vào câu hỏi cốt lõi: "Feature nào thực sự cần thiết cho mô hình?"
Sau khi đã tạo thêm đặc trưng và trích xuất đặc trưng từ dữ liệu, một vấn đề rất thường gặp là: số lượng feature tăng lên quá nhiều. Không phải feature nào cũng giúp mô hình dự đoán tốt hơn. Ngược lại, nhiều feature dư thừa còn làm mô hình học chậm và dễ Overfit. Feature Selection giúp mô hình "nhẹ gánh" hơn bằng cách lọc bỏ nhiễu.
Note: Trong thực tế có nhiều kỹ thuật chọn lọc (Filter, Wrapper, Embedded), nhưng bước nền tảng nhất luôn là Filter Methods – sử dụng các tính chất thống kê để loại bỏ ngay những feature "rác" trước khi đưa vào huấn luyện mô hình.
Dưới đây là 4 loại feature cần bị loại bỏ:
1. Loại bỏ feature có phương sai thấp (Low Variance)
Đây là những feature mà giá trị của chúng gần như không đổi trên toàn bộ tập dữ liệu. Nếu dữ liệu không có sự biến thiên, mô hình sẽ không học được gì từ nó.
Ví dụ: Trong dataset nhân sự 1000 người:
-
Cột
Quoc_Tich: 999 người là "Vietnam", chỉ 1 người là "Other” -
Cột
Is_Human: 100% là "Yes".
Những cột này chứa lượng thông tin gần bằng 0 nên chúng cần được loại bỏ đầu tiên.
2. Loại bỏ feature định danh (Irrelevant IDs)
Đây là những đặc trưng hoàn toàn không mang thông tin dự báo cho biến mục tiêu (target).
Ví dụ: Dataset dự đoán giá nhà với các cột:
| Feature | Mô tả |
|---|---|
| Area | Diện tích |
| Rooms | Số phòng |
| Distance | Khoảng cách tới trung tâm |
| House_ID | Mã căn nhà |
Python code:
import numpy as np
import pandas as pd
np.random.seed(42)
n = 200
# House_ID chỉ là mã định danh (không mang thông tin dự đoán)
df_house = pd.DataFrame({
"House_ID": np.arange(1, n+1),
"Area": np.random.normal(80, 20, n).clip(30, 200),
"Rooms": np.random.randint(1, 6, n),
"Distance": np.random.normal(8, 3, n).clip(0.5, 25),
})
# Price phụ thuộc Area, Rooms, Distance + noise
noise = np.random.normal(0, 15, n)
df_house["Price"] = 2.5*df_house["Area"] + 18*df_house["Rooms"] - 6*df_house["Distance"] + noise
# 1) Loại cột ID theo rule "mã định danh"
drop_cols = ["House_ID"]
X = df_house.drop(columns=drop_cols)
Trong bài toán này, Area, Num_Rooms, Distance đều có liên quan trực tiếp tới giá nhà. Ngược lại, House_ID chỉ là mã định danh, mỗi căn nhà có một giá trị riêng nhưng không mang thông tin về giá. Dù dữ liệu đầy đủ, cột này nên được loại bỏ ngay lập tức để tránh làm mô hình bị nhiễu loạn.
3. Loại bỏ feature có tương quan thấp với target
Những feature có hệ số tương quan (correlation) quá thấp với biến mục tiêu thường chỉ đóng vai trò là "nhiễu" (noise) hơn là "tín hiệu" (signal).
Ví dụ: Xét tiếp bài toán dự đoán doanh thu bán hàng, với các feature:
| Feature | Tương quan với Revenue |
|---|---|
| Marketing_Spend | 0.62 |
| Store_Size | 0.48 |
| Employee_ID | 0.01 |
Python code:
corr = df.corr(numeric_only=True)["Revenue"].drop("Revenue")
print(corr)
Kết quả:
Marketing_Spend 0.62
Store_Size 0.48
Employee_ID 0.01
Employee_ID có hệ số tương quan gần bằng 0 với doanh thu. Điều này cho thấy feature này gần như không cung cấp thông tin dự đoán, nên việc giữ lại chỉ làm mô hình thêm nhiễu. Feature này nên bị loại bỏ.
4. Loại bỏ feature đa cộng tuyến (Multicollinearity)
Đa cộng tuyến xảy ra khi các feature đầu vào có mối quan hệ phụ thuộc tuyến tính chặt chẽ với nhau. Điều này khiến mô hình (đặc biệt là Hồi quy tuyến tính) bị bối rối vì thông tin bị trùng lặp.
Ví dụ: Trong một bài toán phân tích hành vi khách hàng, dataset có các cột:
| Feature | Ý nghĩa |
|---|---|
| Total_Purchases | Tổng số lần mua |
| Total_Spending | Tổng tiền chi |
| Avg_Order_Value | Giá trị trung bình mỗi đơn |
Python code:
import pandas as pd
df = pd.DataFrame({
"Total_Purchases": [5, 10, 15, 20],
"Avg_Order_Value": [20, 22, 21, 23],
})
df["Total_Spending"] = df["Total_Purchases"] * df["Avg_Order_Value"]
df.corr()
Trên thực tế, ta có mối quan hệ toán học rõ ràng:
$$ \text{Total\_Spending} \approx \text{Total\_Purchases} \times \text{Avg\_Order\_Value} $$
Nếu đưa cả 3 feature này vào mô hình, trọng số sẽ không ổn định. Cách chọn lọc hợp lý là:
-
Giữ lại
Total_Spending(vì nó phản ánh trực tiếp giá trị khách hàng - mục tiêu cuối cùng). -
Loại bỏ
Total_PurchaseshoặcAvg_Order_Value(hoặc cả hai, tùy thuộc vào việc feature nào tương quan mạnh hơn với target).
6. Kết luận
Thuật toán Machine Learning ngày nay ngày càng mạnh và ngày càng dễ tiếp cận. Chỉ với vài dòng code, ta có thể dùng các mô hình hiện đại như XGBoost, Random Forest hay thậm chí Deep Learning. Tuy nhiên, thuật toán không thể tự hiểu dữ liệu nếu dữ liệu đầu vào không mang thông tin đúng. Mô hình chỉ học được từ những gì ta đưa vào, và đó chính là vai trò cốt lõi của Feature Engineering.
Feature Engineering giúp biến dữ liệu thô thành dữ liệu “có thể học được”. Từ việc tạo ra những đặc trưng phản ánh bản chất bài toán, trích xuất thông tin từ dữ liệu phức tạp, cho đến việc loại bỏ những feature dư thừa hoặc gây nhiễu, tất cả đều trực tiếp quyết định chất lượng mô hình. Trong nhiều trường hợp thực tế, một mô hình đơn giản với bộ feature tốt có thể vượt trội hơn một mô hình phức tạp nhưng feature kém.
Điều quan trọng là Feature Engineering không phải là một bước kỹ thuật thuần túy, mà là sự kết hợp giữa hiểu dữ liệu, hiểu domain và tư duy mô hình hóa. Đây cũng là phần mà kinh nghiệm của người làm dữ liệu thể hiện rõ nhất, bởi không có công thức chung cho mọi bài toán.
Vì vậy, câu trả lời cho câu hỏi “Feature Engineering có quan trọng hơn thuật toán không?” trong phần lớn các bài toán Machine Learning thực tế là: có. Thuật toán tốt là cần thiết, nhưng feature tốt mới là nền tảng. Khi dữ liệu đã được thiết kế đúng cách, việc chọn thuật toán thường chỉ còn là bước tối ưu cuối cùng, chứ không phải yếu tố quyết định thành bại của mô hình.
7. Tham khảo
-
GeeksforGeeks. (2025). Interquartile Range to detect outliers in data. GeeksforGeeks. https://www.geeksforgeeks.org/machine-learning/interquartile-range-to-detect-outliers-in-data/
-
Theng, D., & Bhoyar, K. K. (2023). Feature selection techniques for machine learning: a survey of more than two decades of research. Knowledge and Information Systems.
https://link.springer.com/article/10.1007/s10115-023-02010-5(Springer) -
Poslavskaya, E., & Korolev, A. (2023). Encoding categorical data: Is there yet anything ‘hotter’ than one-hot encoding? arXiv.
https://arxiv.org/abs/2312.16930(arXiv) -
Guo, C., & Berkhahn, F. (2016). Entity Embeddings of Categorical Variables. arXiv.
https://arxiv.org/abs/1604.06737(arXiv)
Chưa có bình luận nào. Hãy là người đầu tiên!