
Bài viết được thực hiện bởi nhóm CONQ026 - Warm Up 02
Giới thiệu
Data Science đang là một trong những ngành hot nhất hiện nay. Trong bài viết này, chúng ta sẽ đi tìm hiểu: Data Science là gì, công việc thực tế trông như thế nào, quy trình làm dự án chuẩn ra sao, và các vai trò trong ngành thực sự khác nhau ở điểm nào. Không có thuật ngữ phức tạp, không có lý thuyết suông, chỉ là những thứ thực sự hữu ích.
1. Data Science là gì - và nó đứng ở đâu trong bức tranh AI?
Trước khi hiểu Data Science là gì, hãy cùng phân biệt 4 khái niệm mà hầu hết người mới đều hay nhầm lẫn: AI, Machine Learning, Deep Learning và Data Science.
Nhìn vào sơ đồ bên dưới, bạn sẽ thấy ngay điều thú vị: Data Science không nằm trong AI - nó là một vòng tròn riêng, có vùng giao nhau nhưng hoàn toàn độc lập.
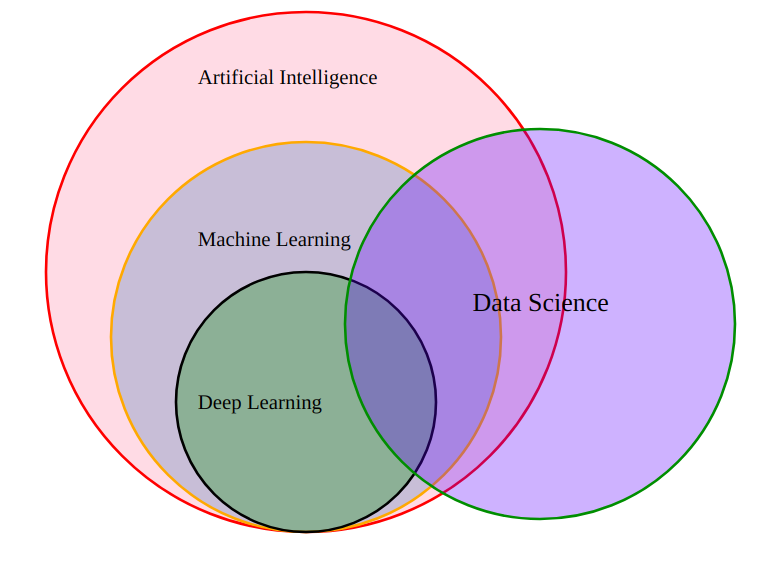
- Artificial Intelligence (AI) - Vòng tròn lớn nhất
AI là lĩnh vực rộng nhất, với mục tiêu mô phỏng trí tuệ con người để máy tính có thể tự suy nghĩ, học hỏi và ra quyết định. Mọi thứ bên dưới bao gồm Machine Learning hay Deep Learning đều nằm trong AI.
- Machine Learning (ML) - Nằm trong AI
ML là một nhánh của AI. Thay vì lập trình cứng từng quy tắc, ML cho phép máy tính tự học từ dữ liệu. Ví dụ: thay vì viết code "nếu email có chữ 'khuyến mãi' thì là spam", ML tự học nhận ra spam sau khi xem hàng nghìn email mẫu.
- Deep Learning (DL) - Nằm trong ML
DL là một nhánh của ML, dùng mạng nơ-ron nhiều tầng để giải quyết các bài toán phức tạp hơn như nhận diện khuôn mặt, dịch ngôn ngữ, hay tạo ra hình ảnh. Đây là công nghệ đằng sau ChatGPT, Midjourney hay các mô hình AI generative mà bạn thấy ngày nay.
- Data Science - Vòng tròn độc lập
Data Science không hoàn toàn nằm trong AI. Data Science là ngành kết hợp toán học, thống kê, lập trình và kiến thức lĩnh vực để thu thập, xử lý và phân tích dữ liệu, với mục tiêu là tìm ra thông tin có giá trị và đưa ra quyết định tốt hơn.
DS có vùng giao nhau với ML và DL, vì Data Scientist có thể dùng ML/DL như công cụ phân tích. Nhưng một Data Scientist giỏi có thể không cần đến Deep Learning, mà vẫn tạo ra giá trị rất lớn chỉ bằng thống kê, SQL và khả năng kể chuyện bằng dữ liệu.
Bảng dưới đây tóm tắt sự khác biệt giữa cả bốn khái niệm:
| AI | Machine Learning | Deep Learning | Data Science | |
|---|---|---|---|---|
| Là gì? | Mô phỏng trí tuệ con người | Máy tự học từ dữ liệu | ML dùng mạng nơ-ron nhiều tầng | Khai thác thông tin từ dữ liệu |
| Mục tiêu | Tự động hóa tư duy | Dự đoán từ pattern | Giải bài toán phức tạp | Hỗ trợ quyết định bằng dữ liệu |
| Công cụ | ML, DL, Rule-based... | Scikit-learn, XGBoost | PyTorch, TensorFlow | SQL, Python, Tableau, R, thống kê |
| Ví dụ | Xe tự lái, chatbot | Lọc spam, gợi ý phim | Nhận diện khuôn mặt | Phân tích doanh thu, dự báo |
2. Công việc thực tế trong ngành Data gồm những gì?
Do Data Science là ngành mang tính chất liên ngành, nên công việc của một nhà Khoa học Dữ liệu (Data Scientist) bao gồm rất nhiều nhiệm vụ khác nhau từ thu thập dữ liệu, xử lý dữ liệu cho đến phân tích và trực quan hóa. Những công việc này tạo thành một quy trình để biến một dữ liệu thô thành những thông tin có ý nghĩa.
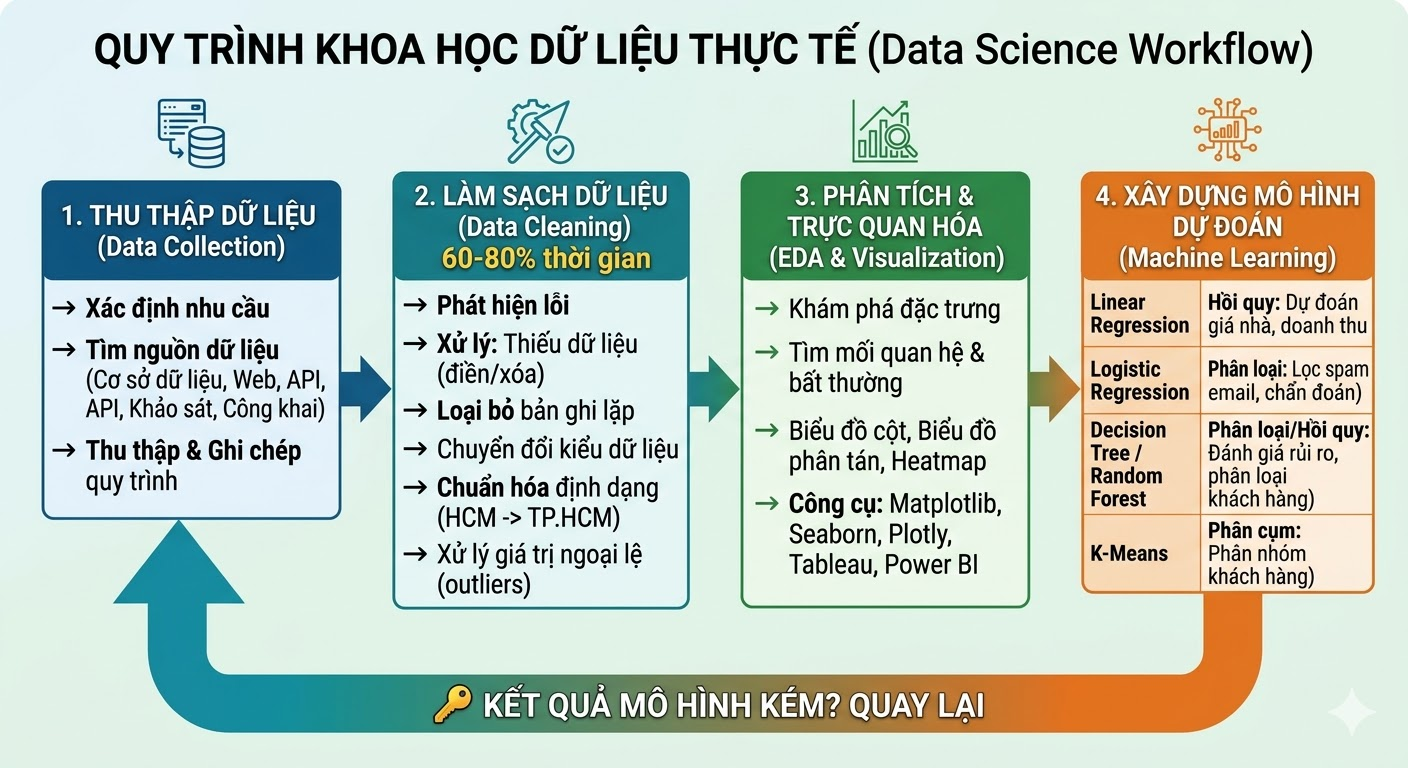
2.1. Thu thập dữ liệu (Data Collection)
Nguyên tắc vàng của ngành: "Rác vào, rác ra" (Garbage In - Garbage Out). Dữ liệu đầu vào kém thì dù có thuật toán xịn đến mấy, kết quả cũng không đáng tin.
Thu thập dữ liệu tốt nghĩa là xác định rõ mình cần gì, lấy từ đâu, và ghi chép lại cẩn thận từng bước. Nguồn dữ liệu có thể là cơ sở dữ liệu nội bộ, web scraping, API, khảo sát người dùng, hoặc các bộ dữ liệu công khai.
2.2. Làm sạch dữ liệu (Data Cleaning)
Đây là phần "không được kể" trong các bài quảng cáo về Data Science, nhưng lại là phần tốn thời gian nhất, thường chiếm từ 60% đến 80% tổng thời gian dự án.
Dữ liệu thực tế luôn có vấn đề. Giá trị bị thiếu, bản ghi bị lặp, định dạng không nhất quán ("HCM", "Ho Chi Minh", "TP.HCM", cùng một thứ nhưng ba cách viết), giá trị bất thường làm lệch kết quả. Tất cả đều phải được phát hiện và xử lý trước khi phân tích.
| Lỗi thường gặp | Mô tả | Cách xử lý |
|---|---|---|
| Thiếu dữ liệu | Giá trị trống hoặc không được ghi nhận | Điền giá trị trung bình/trung vị, hoặc xóa bản ghi |
| Dữ liệu bị lặp | Một bản ghi xuất hiện nhiều lần | Loại bỏ bản ghi trùng lặp |
| Sai kiểu dữ liệu | Số được lưu dưới dạng chuỗi ký tự | Chuyển đổi về đúng kiểu dữ liệu |
| Không đồng nhất | Cùng thông tin nhưng nhiều cách viết | Chuẩn hóa về một định dạng thống nhất |
| Giá trị ngoại lệ | Quá lớn hoặc quá nhỏ so với phần còn lại | Phát hiện và xử lý: loại bỏ hoặc giới hạn giá trị |
2.3. Phân tích & Trực quan hóa (EDA & Data Visualization)
Sau khi dữ liệu đã sạch, đây là lúc bắt đầu "đọc" dữ liệu. Exploratory Data Analysis (EDA) là quá trình tìm hiểu đặc trưng của dữ liệu phân bố thế nào, các biến có liên quan gì với nhau, có điểm bất thường nào không.
Trong EDA, bạn sẽ tìm câu trả lời cho những câu hỏi như:
-
Dữ liệu phân bố thế nào? Có lệch (skewed) hay cân bằng không?
-
Các biến có tương quan với nhau không? Biến nào ảnh hưởng đến biến mục tiêu?
-
Còn sót giá trị bất thường (outlier) nào chưa xử lý ở bước Cleaning không?
-
Có pattern hoặc xu hướng nào thú vị ẩn trong dữ liệu không?
Trực quan hóa là công cụ chính của EDA. Mỗi loại biểu đồ giúp bạn nhìn dữ liệu từ một góc khác nhau, cụ thể như trong hình minh họa bên dưới:
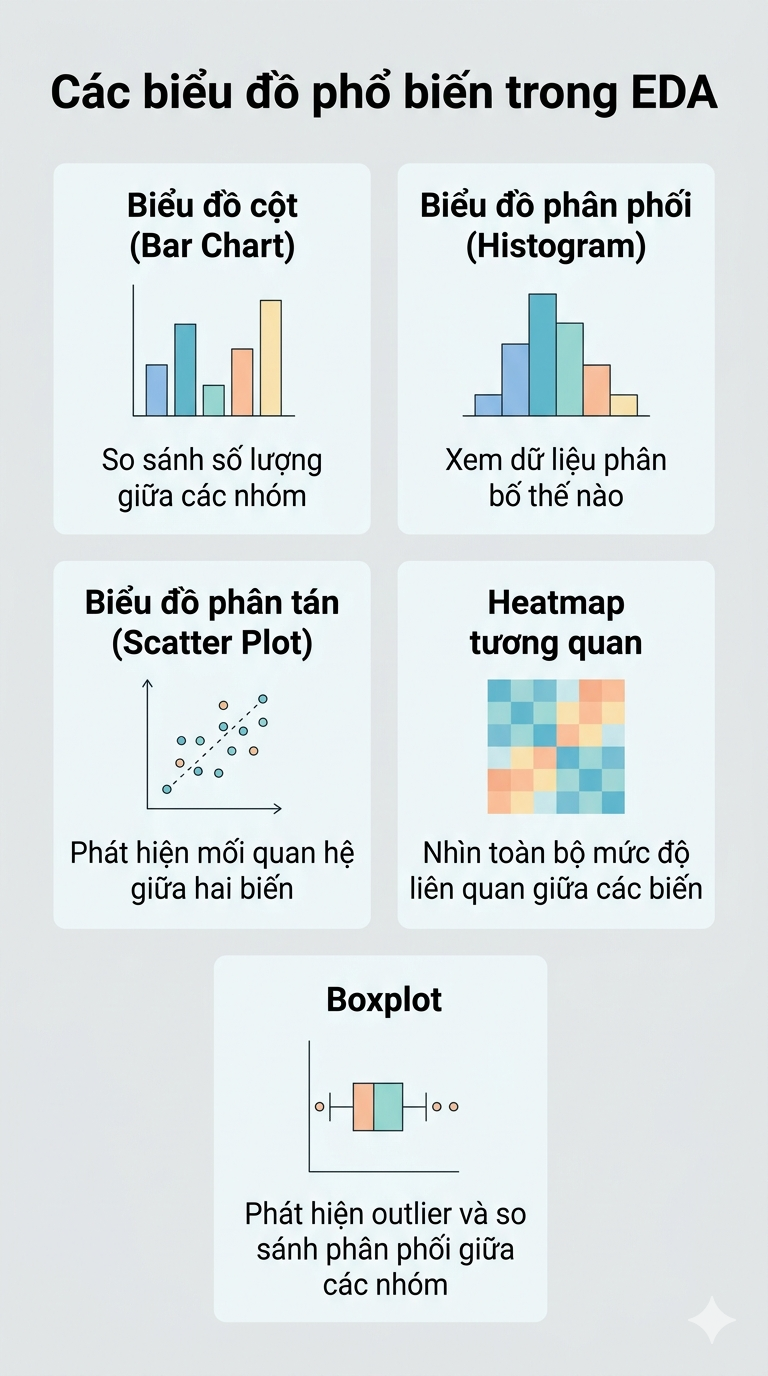
Lưu ý thực tế
EDA không có một khuôn mẫu cố định. Đôi khi bạn phát hiện vấn đề trong dữ liệu ở bước này và phải quay lại bước Cleaning để xử lý thêm, điều đó hoàn toàn bình thường và là một phần của quy trình.
2.4. Xây dựng mô hình dự đoán (Machine Learning)
Đây là bước nhiều người nghĩ đến đầu tiên khi nghe về Data Science, nhưng thực ra nó chỉ chiếm một phần nhỏ thời gian tổng thể. Các thuật toán học máy phổ biến bao gồm:
| Thuật toán | Loại bài toán | Ứng dụng thực tế |
|---|---|---|
| Linear Regression | Hồi quy | Dự đoán giá nhà, doanh thu, nhiệt độ |
| Logistic Regression | Phân loại | Lọc spam email, chẩn đoán bệnh |
| Decision Tree | Phân loại / Hồi quy | Đánh giá rủi ro tín dụng, phân loại khách hàng |
| Random Forest | Phân loại / Hồi quy | Kết hợp nhiều cây để tăng độ chính xác |
| K-Means | Phân cụm | Phân nhóm khách hàng theo hành vi mua sắm |
🔑 Điểm cần nhớ
Bốn bước trên không phải là một đường thẳng mà là một vòng lặp. Kết quả mô hình kém có thể dẫn bạn quay lại làm sạch dữ liệu thêm, hoặc thu thập thêm dữ liệu mới. Đây là bản chất thực tế của công việc.
3. Quy trình làm dự án Data Science chuẩn: CRISP-DM
Biết các kỹ thuật chưa đủ, bạn còn cần biết cách tổ chức một dự án để nó thực sự giải quyết được vấn đề của doanh nghiệp. Đó là lý do CRISP-DM ra đời.
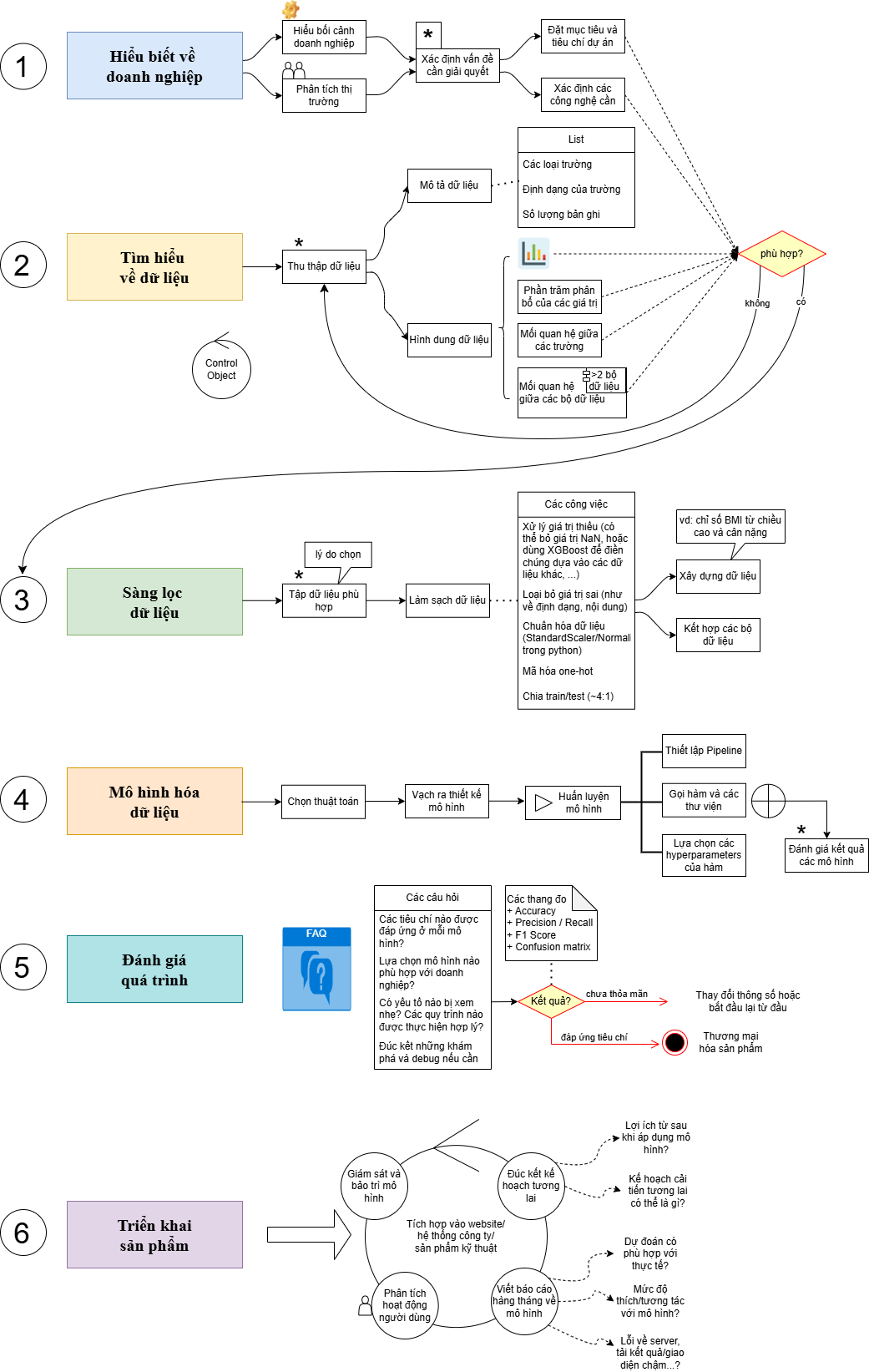
CRISP-DM (Cross-Industry Standard Process for Data Mining) là quy trình chuẩn công nghiệp phổ biến nhất để thực hiện các dự án Data Science và Machine Learning. Ra đời năm 1996, được phát triển bởi một tập đoàn gồm Daimler, SPSS và NCR.
Gồm 6 giai đoạn tuần tự:
| Bước | Giai đoạn | Nhiệm vụ trọng tâm |
|---|---|---|
| 1 | Business Understanding | Xác định mục tiêu dự án, KPI, các ràng buộc và tiêu chí thành công |
| 2 | Data Understanding | Thu thập dữ liệu, khám phá sơ bộ, xác định các vấn đề ban đầu |
| 3 | Data Preparation | Làm sạch, chuẩn hóa, feature engineering - bước tốn thời gian nhất |
| 4 | Modeling | Chọn thuật toán, huấn luyện và tinh chỉnh mô hình |
| 5 | Evaluation | Đánh giá mô hình có thực sự giải quyết được bài toán kinh doanh ban đầu không |
| 6 | Deployment | Tích hợp vào production, theo dõi hiệu suất, lên kế hoạch cải thiện |
4. Các vai trò trong ngành Data - Bạn hợp với vị trí nào?
Trong một dự án dữ liệu hay AI, không ai làm tất cả mọi thứ một mình. Mỗi vai trò là một mắt xích trong chuỗi từ dữ liệu thô đến quyết định kinh doanh. Dưới đây là bức tranh toàn cảnh:
4.1. Tổng quan năm vai trò chính
| Vai trò | Nhiệm vụ chính | Sản phẩm đầu ra | Công cụ & Kỹ năng |
|---|---|---|---|
| Data Analyst | Phân tích dữ liệu · Trực quan hóa · Báo cáo hỗ trợ ra quyết định | Dashboard · Báo cáo · Insights | SQL · Excel · Power BI / Tableau |
| BI Analyst | Theo dõi KPI · Xây hệ thống báo cáo tự động · Phát hiện bất thường | Dashboard KPI · Báo cáo chiến lược tự động | Power BI · Tableau · SQL · Qlik |
| Data Scientist | Xây mô hình dự đoán · Phân tích chuyên sâu · Kiểm định giả thuyết | Mô hình ML · Thuật toán dự báo · Phân tích tương quan | Python · R · Scikit-learn · PyTorch · SQL |
| Data Engineer | Xây pipeline dữ liệu · Quản lý hạ tầng lưu trữ · Đảm bảo dữ liệu sạch và bảo mật | Pipeline · Data Warehouse / Data Lake | Spark · Kafka · Airflow · Docker · Cloud |
| ML Engineer | Triển khai mô hình lên production · Xây CI/CD cho ML · Giám sát và tối ưu hiệu năng | API mô hình · Pipeline MLOps · Dịch vụ AI ổn định | Docker · Kubernetes · Cloud · MLOps |
4.2. Ba vai trò bạn nên hiểu trước tiên
4.2.1. Data Analyst (DA)
Người kể chuyện bằng dữ liệu
DA là cầu nối giữa dữ liệu và người ra quyết định. Họ dùng SQL để lấy dữ liệu, Python hoặc Excel để phân tích, rồi Power BI hay Tableau để biến những con số khô khan thành câu chuyện mà ban lãnh đạo có thể hiểu và hành động được.
- Ví dụ thực tế: Một chuỗi thời trang nhận thấy doanh thu tháng 3 sụt giảm đột ngột. DA vào cuộc, truy vấn dữ liệu và phát hiện: doanh thu giảm chủ yếu ở mảng đồ đông do năm nay nắng nóng đến sớm hơn. Từ đó, họ kiến nghị tung sớm bộ sưu tập hè - một quyết định trực tiếp từ dữ liệu.
4.2.2. Data Scientist (DS)
Người xây hệ thống dự đoán
DS tiến xa hơn DA bằng cách xây dựng các mô hình có khả năng dự đoán tương lai. Họ cần nền tảng toán học và thống kê vững hơn, và thường làm việc sâu hơn với các thuật toán học máy.
- Ví dụ thực tế: Một ngân hàng muốn giảm rủi ro cho vay. DS xây dựng mô hình chấm điểm tín dụng dựa trên lịch sử giao dịch, độ tuổi và nghề nghiệp của hàng triệu khách hàng. Khi có người nộp đơn vay, mô hình tự động tính xác suất rủi ro và hỗ trợ ngân hàng ra quyết định chỉ trong vài giây.
4.2.3. Data Engineer (DE)
Người xây đường ống dữ liệu
Nếu DS và DA là người "dùng" dữ liệu, thì DE là người đảm bảo dữ liệu đó tồn tại, sạch sẽ và sẵn sàng để dùng. Họ xây dựng các pipeline tự động hóa việc thu thập, xử lý và lưu trữ dữ liệu ở quy mô lớn.
- Ví dụ thực tế: Một app giao đồ ăn có hàng nghìn tài xế di chuyển liên tục. DE xây dựng pipeline tự động thu thập tọa độ GPS từng giây, loại bỏ dữ liệu rác, rồi đổ vào kho dữ liệu để DS có thể dùng ngay tính toán thời gian giao hàng dự kiến cho hàng triệu đơn mỗi ngày.
Dưới đây là bảng tổng hợp 3 vai trò quan trọng trong lĩnh vực DS:
| Đặc điểm | Data Analyst | Data Scientist | Data Engineer |
|---|---|---|---|
| Mục tiêu | Giải thích quá khứ & Hiện tại (Cung cấp insight để ra quyết định) | Dự báo tương lai & Tối ưu hóa (Xây dựng mô hình thông minh) | Xây dựng hạ tầng & Đường ống (Đảm bảo dữ liệu sạch, sẵn sàng) |
| Công cụ chính | SQL, Excel, Biểu đồ (Power BI, Tableau, Looker) | Python/R, Machine Learning (Scikit-learn), Deep Learning (PyTorch) | Spark, Airflow, Kafka, Cloud (AWS/Azure/GCP), Docker |
| Độ khó kỹ thuật | Trung bình | Cao (Thiên về Toán/Thuật toán) | Cao (Thiên về Hệ thống/Hạ tầng) |
| Dễ vào nghề? | ✓ Dễ nhất (Phù hợp cho người chuyển ngành) | Trung bình (Yêu cầu nền tảng học thuật/toán tốt) | Khó nhất (Yêu cầu kinh nghiệm lập trình/hệ thống) |
5. Bạn nên bắt đầu từ đâu?
Sau khi đọc đến đây, câu hỏi bạn có thể tự đặt ra cho bản thân mình là: "Vậy tôi nên đi theo hướng nào?" Đây là một gợi ý nhanh dựa trên tính cách và sở thích:
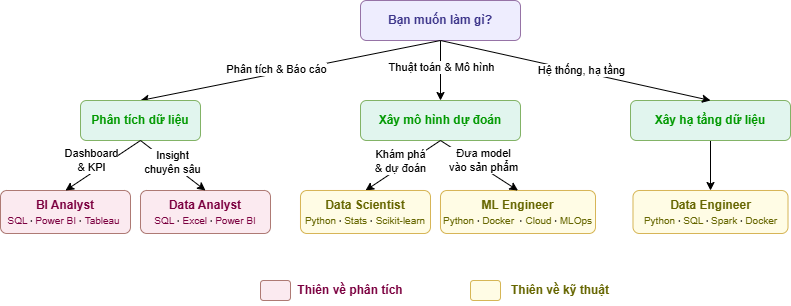
| Nếu bạn... | Hướng phù hợp | Bắt đầu với |
|---|---|---|
| Thích phân tích, kể chuyện, làm báo cáo | → Data Analyst / BI Analyst | SQL + Excel + Power BI |
| Thích toán, thuật toán, xây mô hình | → Data Scientist | Python + Statistics + Scikit-learn |
| Thích đưa mô hình vào sản phẩm thực tế | → ML Engineer | Python + Docker + Cloud + MLOps |
| Thích hệ thống, backend, xây hạ tầng | → Data Engineer | Python + SQL + Spark + Docker |
| Mới bắt đầu tìm hiểu | → Bắt đầu từ DA | SQL là kỹ năng đầu tiên nên học |
Lời khuyên thực tế:
Dù bạn chọn hướng nào, SQL và Python cơ bản là hai kỹ năng nền tảng bắt buộc. Hãy bắt đầu từ đây trước khi lo đến mọi thứ khác.
Kết - Và bước tiếp theo của bạn
Data Science không phải một con đường duy nhất mà là một hệ sinh thái với nhiều vai trò, nhiều hướng đi và nhiều cách để tạo ra giá trị từ dữ liệu.
Bài viết này là bức tranh tổng quan - nhưng chỉ là điểm khởi đầu. Sau khi đã xác định được hướng đi mong muốn rồi, bước tiếp theo chúng ta sẽ đi sâu hơn vào từng vai trò, từng công cụ, và từng bước cụ thể trong lộ trình học.
Chưa có bình luận nào. Hãy là người đầu tiên!