
Ở Blog 1, chúng ta đã cùng nhau "giải mã" đạo hàm và Gradient. Chúng ta hiểu rằng đạo hàm cho biết "khi input thay đổi một chút xíu, output sẽ biến động ra sao". Và Gradient, đơn giản là một vector gom các đạo hàm riêng lại, đóng vai trò như một chiếc la bàn chỉ ra hướng thay đổi nhanh nhất của hàm số.
Nhưng câu hỏi đặt ra là: Chiếc la bàn này dùng để làm gì trong thực tế?
Trong Machine Learning, Gradient không chỉ là một khái niệm toán học khô khan. Nó chính là "động cơ" vận hành một trong những kỹ thuật mạnh mẽ nhất hiện nay: Gradient Boosting — phương pháp sử dụng Gradient để liên tục "học từ sai lầm" của quá khứ.
Tuy nhiên, để thực sự làm chủ được Gradient Boosting hay các thuật toán phức tạp khác, chúng ta cần hiểu một triết lý rộng lớn hơn: Ensemble Learning (Học kết hợp).
I. Học Kết Hợp (Ensemble Learning)
1.1 Sức mạnh của đám đông
Hãy tưởng tượng bạn đang đi lạc vào một hội chợ náo nhiệt, và ngay trước mặt là một thử thách thú vị: một lọ thủy tinh khổng lồ chứa đầy kẹo. Người tổ chức đưa ra một lời thách đố đơn giản nhưng hóc búa: "Ai đoán đúng số kẹo trong lọ sẽ là người chiến thắng!".
Bạn nheo mắt nhìn, cố gắng ước lượng... 800 viên? Hay là 1200 viên nhỉ? Thật sự rất khó để đưa ra một con số chính xác chỉ bằng mắt thường. Lúc này, bạn quay sang hỏi những người xung quanh. Một người bên cạnh quả quyết là 500, trong khi người khác lại đoán lên tới 2000. Rõ ràng, mỗi cá nhân đều có thể sai lệch rất nhiều so với thực tế, người thì đoán quá cao, người thì đoán quá thấp.
Nhưng đây mới là điều kỳ diệu của toán học và thống kê: Nếu bạn hỏi 100 người và tính trung bình tất cả các câu trả lời đó, con số thu được thường chính xác đến mức kinh ngạc — nó gần với số kẹo thật hơn bất kỳ dự đoán của cá nhân nào!
Tại sao lại có hiện tượng này? Đó là bởi vì mỗi người đều mang trong mình một sai số ngẫu nhiên riêng. Khi chúng ta thực hiện phép tính trung bình, các sai số này sẽ tự triệt tiêu lẫn nhau, chỉ để lại "tín hiệu đúng" được tích lũy. Hiện tượng này được gọi là Trí tuệ đám đông (Wisdom of the Crowd), và đây chính là triết lý nền tảng tạo nên sức mạnh của Học kết hợp (Ensemble Learning).
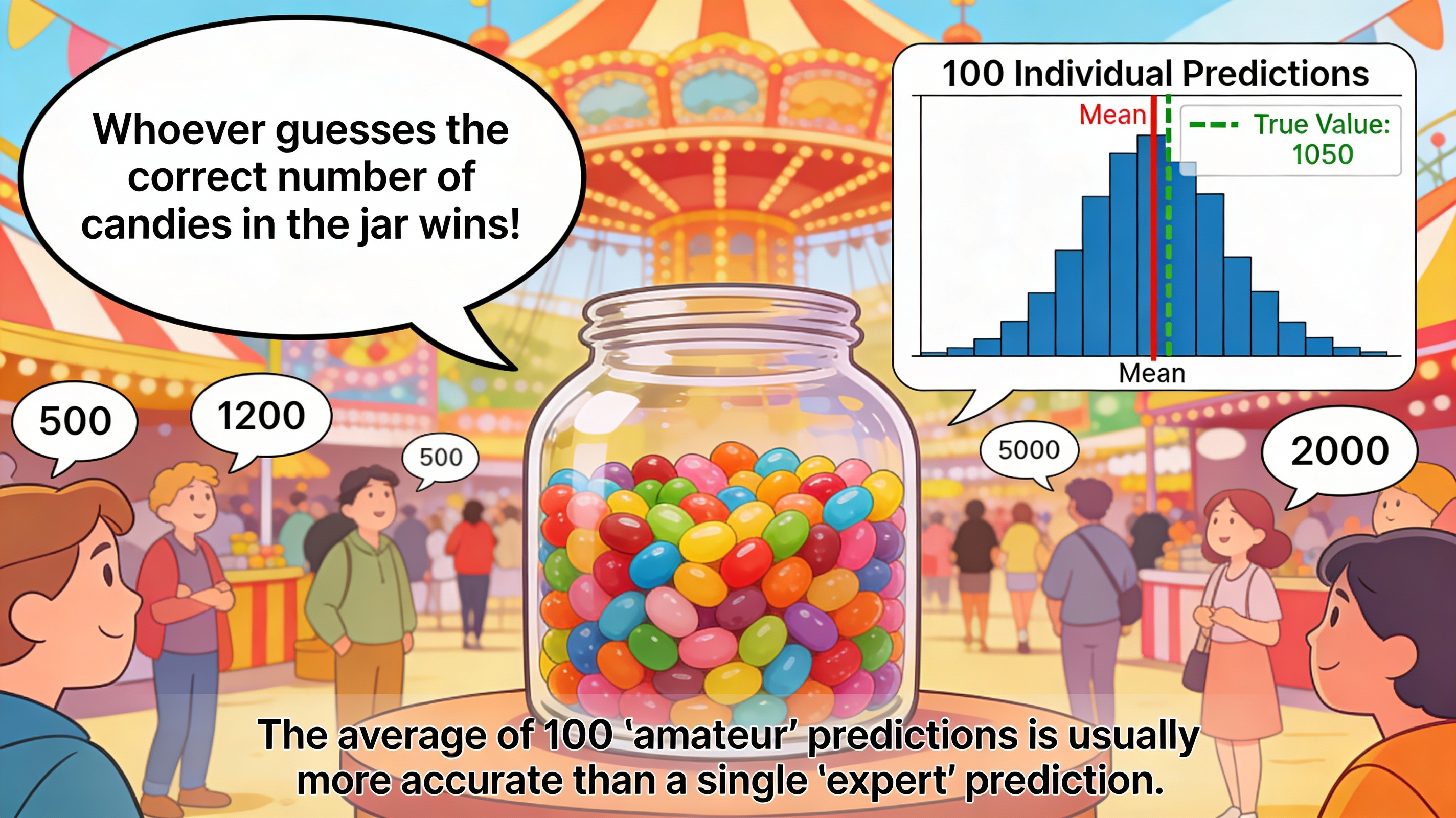
Hình 1. Trung bình của 100 dự đoán "amateur" thường chính xác hơn 1 dự đoán "expert" đơn lẻ
1.2 Ensemble Learning là gì?
Trong thế giới Machine Learning, Học kết hợp (Ensemble Learning) là phương pháp kết hợp nhiều mô hình học máy lại với nhau để giải quyết vấn đề. Những mô hình thành phần này thường được gọi là mô hình yếu (weak learners). Mục tiêu của chúng ta là gộp sức mạnh của chúng lại để tạo thành một mô hình mạnh (strong learner) vượt trội hơn.
Mỗi mô hình đơn lẻ, giống như một người đoán kẹo, có thể không hoàn hảo và dễ mắc sai lầm. Tuy nhiên, khi được kết hợp một cách thông minh, các sai lầm riêng lẻ sẽ được "san bằng", giúp kết quả cuối cùng ổn định và chính xác hơn.
Nếu quay lại ví dụ về lọ kẹo ở trên, chúng ta có thể hình dung như sau:
- Mỗi người đoán kẹo: Tương ứng với một weak learner (dự đoán có thể sai, chưa tối ưu).
- Nhóm 100 người: Tương ứng với một ensemble (tập hợp các mô hình).
- Giá trị trung bình các dự đoán: Chính là strong learner (kết quả cuối cùng với độ chính xác cao hơn).
1.3 Hai trường phái lớn: Bagging và Boosting
Mặc dù có chung mục đích là kết hợp các mô hình, nhưng trong Ensemble Learning tồn tại hai trường phái tư duy rất khác nhau về cách thực hiện: Bagging và Boosting. Sự khác biệt của chúng nằm ở cách các mô hình được xây dựng và kết nối với nhau.
1.3.1 Bagging (Bootstrap Aggregating — Kết hợp bằng lấy mẫu bootstrap)
Hãy tưởng tượng bạn là giám đốc một tập đoàn lớn và cần quyết định xem có nên rót vốn vào một dự án mới hay không. Bạn triệu tập 10 chuyên gia phân tích hàng đầu, mỗi người đều giỏi nhưng lại có những góc nhìn và quan điểm riêng biệt.
Theo cách tiếp cận này, bạn sẽ giao cho mỗi chuyên gia một bộ tài liệu hơi khác nhau một chút (cùng lấy từ dữ liệu gốc, nhưng được chọn ngẫu nhiên). Mỗi chuyên gia sẽ làm việc độc lập trong phòng riêng, không ai trao đổi với ai. Cuối cùng, bạn tổng hợp ý kiến bằng cách cho họ bỏ phiếu (Voting) hoặc lấy trung bình (Averaging). Cách này giúp đa dạng hóa quan điểm và triệt tiêu những sai sót cá nhân.
Hình 2. Bagging tạo đa dạng bằng cách cho mô hình học dữ liệu khác nhau rồi tổng hợp.
Định nghĩa kỹ thuật:
Về mặt kỹ thuật, Bagging hoạt động qua 3 bước chính:
-
Bước 1 — Lấy mẫu có hoàn lại (Bootstrap Sampling): Từ tập dữ liệu gốc, ta tạo ra nhiều "bản sao" bằng cách lấy ngẫu nhiên các điểm dữ liệu (có thể trùng lặp). Thống kê cho thấy mỗi mẫu bootstrap chứa khoảng 63% dữ liệu gốc, phần còn lại gọi là mẫu ngoài túi (Out-of-Bag samples).
-
Bước 2 — Huấn luyện song song: Mỗi mô hình con được huấn luyện độc lập trên một mẫu bootstrap. Các mô hình này hoàn toàn không "biết" về sự tồn tại của nhau.
-
Bước 3 — Tổng hợp (Aggregating): Kết quả cuối cùng được quyết định bằng cách lấy đa số phiếu bầu (đối với bài toán phân loại) hoặc lấy trung bình cộng (đối với bài toán hồi quy).
Mục tiêu tối thượng của Bagging là giảm Phương sai (Variance), giúp mô hình ổn định hơn và bớt nhạy cảm với nhiễu. Đại diện tiêu biểu nhất của trường phái này chính là Rừng ngẫu nhiên (Random Forest).
Hình 3. Bootstrap sampling tạo các bộ dữ liệu đa dạng từ cùng một nguồn gốc.
1.3.2 Boosting (Tăng cường)
Vẫn là công ty đó, nhưng lần này bạn áp dụng một chiến lược quản lý hoàn toàn khác. Bạn giao dự án cho chuyên gia thứ nhất xử lý trước. Anh ta đưa ra báo cáo, nhưng tất nhiên vẫn còn những điểm sai sót hoặc chưa chắc chắn.
Thay vì bỏ qua, bạn đánh dấu những lỗi này và giao cho chuyên gia thứ hai với chỉ thị rõ ràng: "Hãy tập trung sửa những phần mà người trước đã làm sai". Chuyên gia thứ hai hoàn thành, nhưng vẫn còn chút lỗi nhỏ. Bạn lại chuyển tiếp cho chuyên gia thứ ba để sửa tiếp... Cứ thế, người đi sau học từ sai lầm của người đi trước. Đây là cách làm việc tuần tự (sequential).
Hình 4. Boosting huấn luyện tuần tự, mô hình sau tập trung sửa lỗi mô hình trước.
Định nghĩa kỹ thuật:
Boosting vận hành dựa trên nguyên tắc học tuần tự (sequential learning):
-
Bước 1: Huấn luyện mô hình đầu tiên trên toàn bộ dữ liệu.
-
Bước 2: Xác định những điểm dữ liệu mà mô hình dự đoán sai (gọi là Residuals - Phần dư).
-
Bước 3 & 4: Huấn luyện mô hình tiếp theo, nhưng ép nó tập trung vào những điểm sai đó (bằng cách tăng trọng số hoặc học trực tiếp trên phần dư). Quá trình này lặp lại liên tục.
-
Bước 5: Kết quả cuối cùng là tổng hợp có trọng số của tất cả các mô hình trong chuỗi.
Nếu bạn còn nhớ về khái niệm Gradient trong bài blog trước, thì trong Gradient Boosting, những "sai lầm cần sửa" được xác định bằng đạo hàm (Gradient) của hàm mất mát. Mỗi mô hình mới sinh ra đều cố gắng đi theo hướng giảm sai số nhanh nhất (negative gradient). Mục tiêu chính của Boosting là giảm Độ lệch (Bias). Những đại diện nổi tiếng của trường phái này bao gồm XGBoost, LightGBM và CatBoost.
Hình 5. Mỗi cây là một bước xuống dốc giúp giảm Loss nhanh nhất.
1.4 So sánh Bagging và Boosting
Để dễ hình dung sự khác biệt giữa hai "ông lớn" này, chúng ta hãy nhìn vào bảng so sánh dưới đây:
| Đặc điểm | Bagging (Bootstrap Aggregating) | Boosting (Tăng cường) |
|---|---|---|
| Cách huấn luyện | Song song (Parallel) – Các mô hình độc lập nhau | Tuần tự (Sequential) – Mô hình sau phụ thuộc mô hình trước |
| Mô hình học từ đâu? | Mẫu Bootstrap ngẫu nhiên | Sai số (Residuals) của mô hình trước đó |
| Mục tiêu chính | Giảm Phương sai (Variance) | Giảm Độ lệch (Bias) |
| Nguy cơ Overfitting | Thấp (do cơ chế lấy trung bình) | Cao hơn (nếu train quá kỹ sẽ học cả nhiễu) |
| Đại diện tiêu biểu | Random Forest | XGBoost, LightGBM, CatBoost |
Hình 6. Bagging làm việc song song; Boosting làm việc tuần tự và sửa lỗi.
1.5 Các mô hình chúng ta sẽ khám phá
Trong loạt bài viết này, chúng ta sẽ đi sâu vào 3 mô hình theo trình tự tiến hóa từ đơn giản đến phức tạp:
1.5.1. Cây Quyết Định (Decision Tree):
Đây là viên gạch nền tảng đầu tiên. Nó là mô hình đơn giản nhất, dễ hiểu nhất, nhưng lại là thành phần cấu tạo nên những thuật toán phức tạp hơn. Hiểu về Decision Tree là tiền đề bắt buộc để bạn hiểu tại sao chúng ta cần đến Ensemble.
1.5.2. Rừng Ngẫu Nhiên (Random Forest):
Đại diện xuất sắc của trường phái Bagging. Đúng như tên gọi, đây là một "khu rừng" được tạo nên bởi hàng trăm cây quyết định. Sự kết hợp này tạo ra một mô hình cực kỳ bền vững (robust), ít bị overfitting và đặc biệt là rất dễ sử dụng vì không cần tinh chỉnh tham số quá nhiều.
Hình 7. Random Forest kết hợp sức mạnh các cây bằng phương pháp voting.
1.5.3. XGBoost (Extreme Gradient Boosting):
Đại diện của Boosting và là "vũ khí hạng nặng" trong các cuộc thi Data Science. XGBoost sử dụng Gradient để tối ưu hóa quá trình học tuần tự, sửa sai liên tục để đạt độ chính xác cực cao. Tuy nhiên, sức mạnh lớn đi kèm trách nhiệm lớn: nó cần được tinh chỉnh (tune) cẩn thận để tránh việc học vẹt (overfitting).
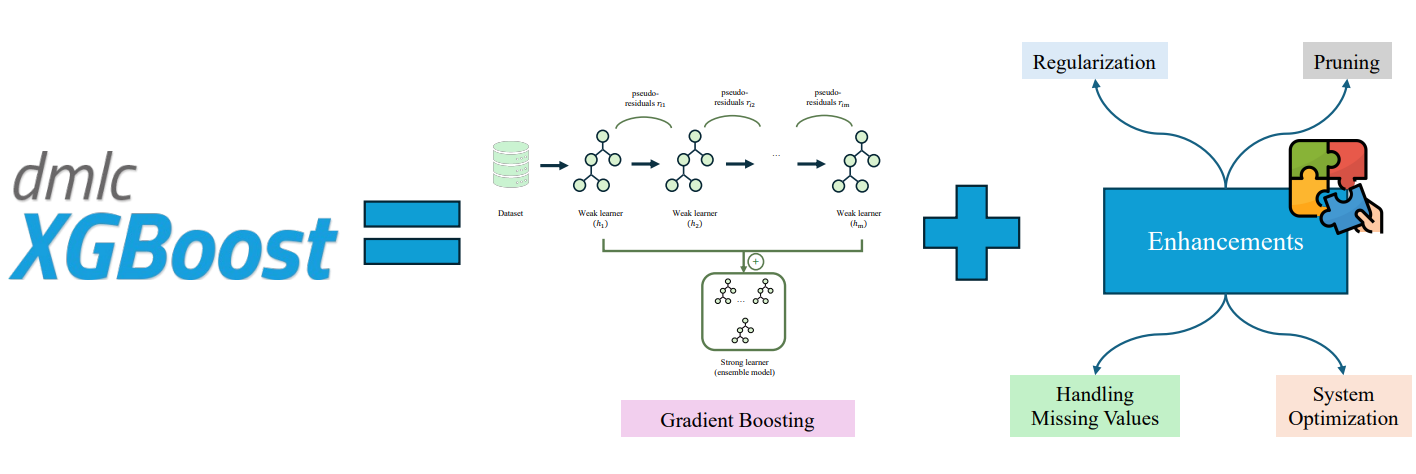
Hình 8. XGBoost gồm chuỗi cây học từ sai lầm của cây trước.
1.6 Tại sao cần hiểu cả ba?
Có thể bạn sẽ thắc mắc: "Nếu XGBoost mạnh mẽ như vậy, tại sao không học thẳng vào nó mà phải đi đường vòng?". Câu trả lời nằm ở việc hiểu rõ bản chất vấn đề.
Hành trình từ Decision Tree đến XGBoost là một câu chuyện logic về việc giải quyết từng điểm yếu của mô hình:
- Decision Tree giúp bạn hiểu cơ chế "chia để trị", nhưng nó mắc bệnh "dao động lớn" (high variance).
- Random Forest ra đời để chữa bệnh "dao động" đó bằng cách dùng Bagging để đa dạng hóa.
- XGBoost tiếp tục tiến thêm một bước để chữa bệnh "thiếu chính xác" (bias) bằng cách dùng Boosting để sửa sai triệt để.
Hình 9. Hành trình xử lý các nhược điểm từ Decision Tree đến XGBoost.
1.7 Năm lăng kính phân tích
Để thực sự làm chủ các mô hình này, chúng ta sẽ không chỉ học lý thuyết suông. Với mỗi mô hình, tôi sẽ cùng bạn phân tích chúng qua 5 khía cạnh quan trọng — giống như việc soi một viên kim cương dưới 5 góc độ ánh sáng khác nhau:
- Siêu tham số (Hyperparameters): Những cái "núm vặn" nào quan trọng nhất để điều khiển mô hình?
- Kỹ thuật tạo đặc trưng (Feature Engineering): Mô hình này thích loại dữ liệu nào? Cần xử lý features ra sao?
- Kiểm định (Validation): Làm sao để đánh giá mô hình một cách công bằng?
- Quá khớp (Overfitting): Dấu hiệu nào cho thấy mô hình đang "học vẹt" và cách phòng tránh?
- Cân bằng Độ lệch - Phương sai (Bias-Variance Tradeoff): Mô hình này đang đứng ở đâu trong bài toán cân bằng kinh điển này?
Hình 10. Mỗi mô hình được đánh giá toàn diện qua 5 lăng kính tối ưu.
II. Năm Lăng Kính Phân Tích Mô Hình
2.1 Siêu tham số (Hyperparameters)
Hãy tưởng tượng bạn đang nấu một nồi phở bò. Trong quá trình nấu, bạn nếm thử nước dùng, thấy nhạt thì thêm muối, thấy chưa ngọt thì thêm xương. Những gia vị bạn gia giảm trong lúc nấu để đạt vị ngon nhất, đó là quá trình "học".
Tuy nhiên, có những quyết định bạn bắt buộc phải đưa ra trước khi bật bếp: Bạn sẽ dùng nồi áp suất hay nồi thường? Bạn định ninh xương trong bao lâu (2 tiếng hay 8 tiếng)? Bạn để lửa to hay lửa nhỏ? Những quyết định này chắc chắn ảnh hưởng lớn đến bát phở cuối cùng, nhưng bạn không thể vừa nấu vừa đổi nồi được. Những thiết lập ban đầu đó chính là Siêu tham số.
Hình 11. Siêu tham số là các nút điều chỉnh giúp tối ưu hoạt động mô hình.
Định nghĩa:
Trong Machine Learning, Siêu tham số (Hyperparameters) là những "nút điều chỉnh" mà bạn phải thiết lập thủ công trước khi quá trình huấn luyện bắt đầu. Mô hình không thể tự học được chúng từ dữ liệu.
Cần phân biệt rõ với Tham số (Parameters):
- Tham số: Là những gì mô hình tự học và tự chỉnh sửa trong quá trình train (ví dụ: trọng số trong mạng nơ-ron, hay ngưỡng cắt trong cây quyết định - giống như việc nếm và thêm muối).
- Siêu tham số: Là những gì bạn cài đặt ban đầu (ví dụ: độ sâu của cây, số lượng cây trong rừng - giống như việc chọn nồi và thời gian ninh).
Dưới đây là một số siêu tham số quan trọng chúng ta sẽ thường xuyên gặp:
| Siêu tham số | Ý nghĩa | Thường gặp ở |
|---|---|---|
| max_depth (Độ sâu tối đa) | Giới hạn cây được phép "chia" bao nhiêu lần (cây càng sâu càng phức tạp). | Decision Tree, RF, XGBoost |
| n_estimators (Số lượng mô hình) | Số lượng cây con có trong một "khu rừng" (ensemble). | Random Forest, XGBoost |
| learning_rate (Tốc độ học) | Mức độ đóng góp/sửa sai của mỗi cây mới vào kết quả chung. | XGBoost, Gradient Boosting |
| min_samples_split | Số lượng mẫu tối thiểu cần có để tiếp tục chia một nhánh. | Decision Tree, RF, XGBoost |
2.2 Kỹ thuật tạo đặc trưng (Feature Engineering)
Hãy tưởng tượng bạn đang dạy một đứa trẻ nhận biết con chó qua các bức ảnh. Nếu bạn chỉ đưa cho trẻ xem dữ liệu thô dưới dạng các điểm ảnh (pixel) li ti với hàng triệu con số màu sắc, đứa trẻ sẽ rất khó để học được đâu là con chó.
Nhưng nếu bạn chỉ tay và nói: "Con nhìn xem, nó có 4 chân", "nó có cái đuôi dài", "nó có lớp lông xù", đứa trẻ sẽ nhận biết nhanh hơn rất nhiều. Việc bạn chuyển đổi từ những điểm ảnh vô nghĩa thành các khái niệm như "chân", "đuôi", "lông" chính là Feature Engineering. Bạn đang giúp mô hình "nhìn" ra vấn đề dễ dàng hơn.
Hình 12. Feature Engineering giúp mô hình cây nhận diện quy luật dễ dàng hơn.
Định nghĩa:
Feature Engineering là quá trình tạo ra, chọn lọc và biến đổi các đặc trưng (features) từ dữ liệu thô để giúp mô hình học hiệu quả hơn. Đây là cầu nối quan trọng nhất giữa dữ liệu thô (raw data) và thuật toán.
Đặc biệt đối với các mô hình dạng Cây (Tree-based models), kỹ thuật này cực kỳ quan trọng vì một điểm yếu cố hữu của chúng:
- Cây chỉ có thể tạo ra các đường cắt vuông góc với trục (ngang hoặc dọc).
- Nếu quy luật của dữ liệu là một đường chéo ($A \times B$ hoặc $A / B$), cây sẽ phải tạo ra rất nhiều bậc thang nhỏ để xấp xỉ đường chéo đó (rất tốn kém và kém hiệu quả).
- Tuy nhiên, nếu bạn tạo sẵn một feature mới là $C = A \times B$, cây chỉ cần đúng một đường cắt là xong!
2.3 Kiểm định (Validation)
Hãy nhớ lại thời đi học, khi bạn ôn thi đại học. Nếu bạn chỉ chăm chăm làm đi làm lại một bộ đề cũ và học thuộc lòng đáp án (A, B, C, D), chắc chắn bạn sẽ được điểm tuyệt đối trên bộ đề đó. Nhưng khi vào phòng thi thật, gặp một bộ đề mới toanh, bạn rất dễ bị "tủ đè" và trượt vỏ chuối.
Để tránh tình trạng này, bạn thường để dành một vài đề thi thử mà mình chưa từng xem qua để tự kiểm tra sát ngày thi. Nếu bạn làm tốt cả đề thi thử này, nghĩa là bạn đã thực sự hiểu bài chứ không chỉ học vẹt. Quá trình "thi thử" đó chính là Validation.

Hình 13. Chia dữ liệu hợp lý giúp đánh giá chính xác khả năng tổng quát hóa của mô hình.
Định nghĩa:
Validation là quá trình đánh giá hiệu suất của mô hình trên tập dữ liệu mà nó chưa từng thấy trong quá trình huấn luyện. Mục tiêu cốt lõi của Machine Learning không phải là "nhớ" dữ liệu cũ, mà là tổng quát hóa (generalize) để dự đoán đúng trên dữ liệu mới.
Trong thực tế, chúng ta thường chia dữ liệu thành 3 phần:
- Training set (Tập huấn luyện): Sách giáo khoa để mô hình học kiến thức.
- Validation set (Tập kiểm định): Đề thi thử để đánh giá sơ bộ và tinh chỉnh siêu tham số.
- Test set (Tập kiểm tra): Đề thi thật, chỉ dùng một lần duy nhất vào phút chót để chốt kết quả.
2.4 Quá khớp (Overfitting)
Giả sử bạn đang dạy máy tính nhận diện chữ số viết tay. Trong tập dữ liệu huấn luyện của bạn, thật tình cờ là tất cả những người viết số "7" đều thuận tay trái, nên số 7 nào cũng hơi nghiêng về bên trái.
Một mô hình bị "quá khớp" (Overfitting) sẽ học một cách máy móc rằng: "Cứ là số 7 thì bắt buộc phải nghiêng trái". Hậu quả là khi gặp một số 7 viết thẳng đứng hoặc nghiêng phải trong thực tế, nó sẽ phán: "Đây không phải số 7!". Mô hình đã học cả những cái ngẫu nhiên (nhiễu) thay vì bản chất của con số.
Hình 14. Underfitting quá đơn giản, Overfitting quá phức tạp, Good fit vừa đủ.
Định nghĩa:
Overfitting (Quá khớp) xảy ra khi mô hình quá phức tạp, đến mức nó "học thuộc lòng" cả những nhiễu (noise) trong tập huấn luyện.
Dấu hiệu nhận biết: Điểm số trên tập Train cực kỳ cao (gần như tuyệt đối), nhưng điểm trên tập Validation/Test lại thấp tệ hại. Khoảng cách (gap) giữa hai điểm số này càng lớn, overfitting càng nặng.
Ngược lại với nó là Underfitting (Dưới khớp): Xảy ra khi mô hình quá đơn giản (như người học hời hợt), không nắm bắt được quy luật của dữ liệu. Lúc này, điểm trên cả tập Train và Validation đều thấp.
2.5 Cân bằng Độ lệch - Phương sai (Bias-Variance Tradeoff)
Hãy tưởng tượng việc huấn luyện mô hình giống như việc bắn bia.
-
Trường hợp 1 (High Bias): Bạn là người có tay rất vững (ổn định), nhưng mắt bạn bị lé nên lúc nào cũng ngắm lệch sang trái. Kết quả: Các viên đạn chụm lại một chỗ, nhưng chỗ đó nằm tít ngoài vòng 10 điểm. Đây là "ngắm sai".
-
Trường hợp 2 (High Variance): Bạn ngắm rất chuẩn vào tâm, nhưng tay bạn bị run bần bật. Kết quả: Các viên đạn bay tán loạn khắp nơi quanh bia, lúc trúng lúc trượt. Đây là "tay run".
Mục tiêu: Chúng ta muốn một người vừa ngắm chuẩn, vừa tay vững (Low Bias, Low Variance).
Hình 15. Bias là ngắm sai, Variance là tay run; cần ngắm đúng và vững.
Định nghĩa:
Trong Machine Learning, luôn có một sự đánh đổi kinh điển:
- Độ lệch (Bias): Sai số do mô hình quá đơn giản, không học được pattern (Underfitting).
- Phương sai (Variance): Sai số do mô hình quá nhạy cảm với dữ liệu huấn luyện cụ thể, thay đổi dữ liệu một chút là kết quả thay đổi chóng mặt (Overfitting).
Tại sao gọi là Tradeoff (Sự đánh đổi)? Vì rất khó để giảm cả hai cùng lúc.
- Mô hình đơn giản quá -> Bias cao, Variance thấp.
- Mô hình phức tạp quá -> Bias thấp, Variance cao.
Hình 16. Điểm tối ưu là nơi cân bằng giữa Bias và Variance.
Nghệ thuật của người làm mô hình là tìm ra điểm cân bằng (sweet spot) — nơi mô hình đủ phức tạp để hiểu vấn đề, nhưng đủ đơn giản để không bị học vẹt. Các phương pháp Ensemble Learning (như Bagging và Boosting) sinh ra chính là để giải quyết bài toán cân bằng này.
III. Cây Quyết Định (Decision Tree)
3.1 Giới thiệu Decision Tree
Decision Tree là gì?
Hãy nhớ lại trò chơi tuổi thơ "20 câu hỏi". Bạn nghĩ về một con vật trong đầu, và người đối diện phải đoán ra nó bằng cách đặt các câu hỏi Yes/No.
- "Nó có 4 chân không?" → Có. (Loại bỏ gà, vịt, cá...)
- "Nó có sủa gâu gâu không?" → Không. (Loại bỏ chó)
- "Nó có thích bắt chuột không?" → Có.
- "À, là con mèo!"
Mỗi câu hỏi giúp bạn chia nhỏ không gian các đáp án có thể, loại trừ dần những phương án sai cho đến khi chỉ còn lại phương án đúng nhất. Decision Tree hoạt động y hệt như vậy. Nó là một mô hình học máy đưa ra dự đoán bằng cách thực hiện một chuỗi các câu hỏi phân loại dữ liệu.
Hình 17. Decision Tree ra quyết định bằng chuỗi câu hỏi Yes/No.
Để nói chuyện "ngôn ngữ chuyên ngành" một chút, chúng ta có các thuật ngữ sau:
- Node gốc (Root node): Câu hỏi đầu tiên, nơi toàn bộ dữ liệu bắt đầu.
- Node trong (Decision/Internal node): Các câu hỏi tiếp theo ở các nhánh con.
- Node lá (Leaf node): Điểm dừng cuối cùng, nơi mô hình đưa ra dự đoán.
- Độ sâu (Depth): Số lượng câu hỏi tối đa mà mô hình phải đi qua từ gốc đến lá.
Cách Decision Tree "học"
Làm sao cái cây biết nên hỏi câu nào trước? Tại sao lại hỏi "có 4 chân không" trước mà không hỏi "nó màu gì"?
Mục tiêu của cây là chọn câu hỏi (split) giúp phân tách dữ liệu tốt nhất. "Tốt nhất" ở đây nghĩa là sau khi chia, các nhóm con thu được phải "tinh khiết" (pure/homogeneous) hơn nhóm cha. Ví dụ, nếu một nhóm chỉ toàn là mèo, thì nhóm đó có độ tinh khiết cao.
Để đo lường độ tinh khiết này, Decision Tree sử dụng các công thức toán học cụ thể:
- Gini Impurity hoặc Entropy/Information Gain: Dùng cho bài toán phân loại (Classification).
- MSE (Mean Squared Error) hoặc Variance: Dùng cho bài toán hồi quy (Regression).
3.2 Siêu tham số (Hyperparameters) của Decision Tree
Như đã nói ở Phần 2, chúng ta cần cài đặt các "nút vặn" trước khi huấn luyện. Với Decision Tree, có 3 nút vặn quan trọng nhất quyết định hình dáng của cây.
max_depth (Độ sâu tối đa)
Quay lại trò chơi 20 câu hỏi. Nếu bạn chỉ được phép hỏi đúng 1 câu duy nhất (Depth = 1), bạn rất khó đoán đúng con vật (đây gọi là "stump" - cây cụt). Bạn đoán đại, dẫn đến sai số cao (Underfitting).
Ngược lại, nếu bạn được hỏi tới 100 câu (Depth = 100), bạn có thể hỏi những câu cực kỳ chi tiết như "Con vật này có vết sẹo ở chân trái không?". Bạn sẽ đoán trúng phóc con vật cụ thể đó, nhưng kiến thức này quá chi tiết và không áp dụng được cho con vật khác. Đó là Overfitting.
- Depth thấp: Cây đơn giản → High Bias, Low Variance → Dễ bị Underfitting.
- Depth cao: Cây phức tạp → Low Bias, High Variance → Dễ bị Overfitting.
Hình 18. Độ sâu càng lớn, biên quyết định càng phức tạp và dễ bị overfitting.
min_samples_split (Số mẫu tối thiểu để chia nhánh)
Đây là quy tắc: "Phải có đủ đông người tôi mới chia nhóm". Ví dụ, nếu một nhóm chỉ còn 3 điểm dữ liệu mà bạn đặt min_samples_split = 5, thì cây sẽ dừng lại, không chia nhỏ thêm nữa.
- Giá trị thấp (2-5): Cây chia rất kỹ → Dễ Overfitting.
- Giá trị cao (50-100): Cây dừng sớm, đại khái → Dễ Underfitting.
min_samples_leaf (Số mẫu tối thiểu tại lá)
Quy tắc này bảo vệ phần ngọn của cây: "Mỗi chiếc lá sau khi chia phải chứa ít nhất bao nhiêu điểm dữ liệu". Nếu một phép chia tạo ra một chiếc lá "cô đơn" chỉ có 1 điểm dữ liệu, phép chia đó sẽ bị cấm.
Điều này cực kỳ quan trọng để ngăn mô hình "nhớ" các điểm dữ liệu nhiễu (outliers).
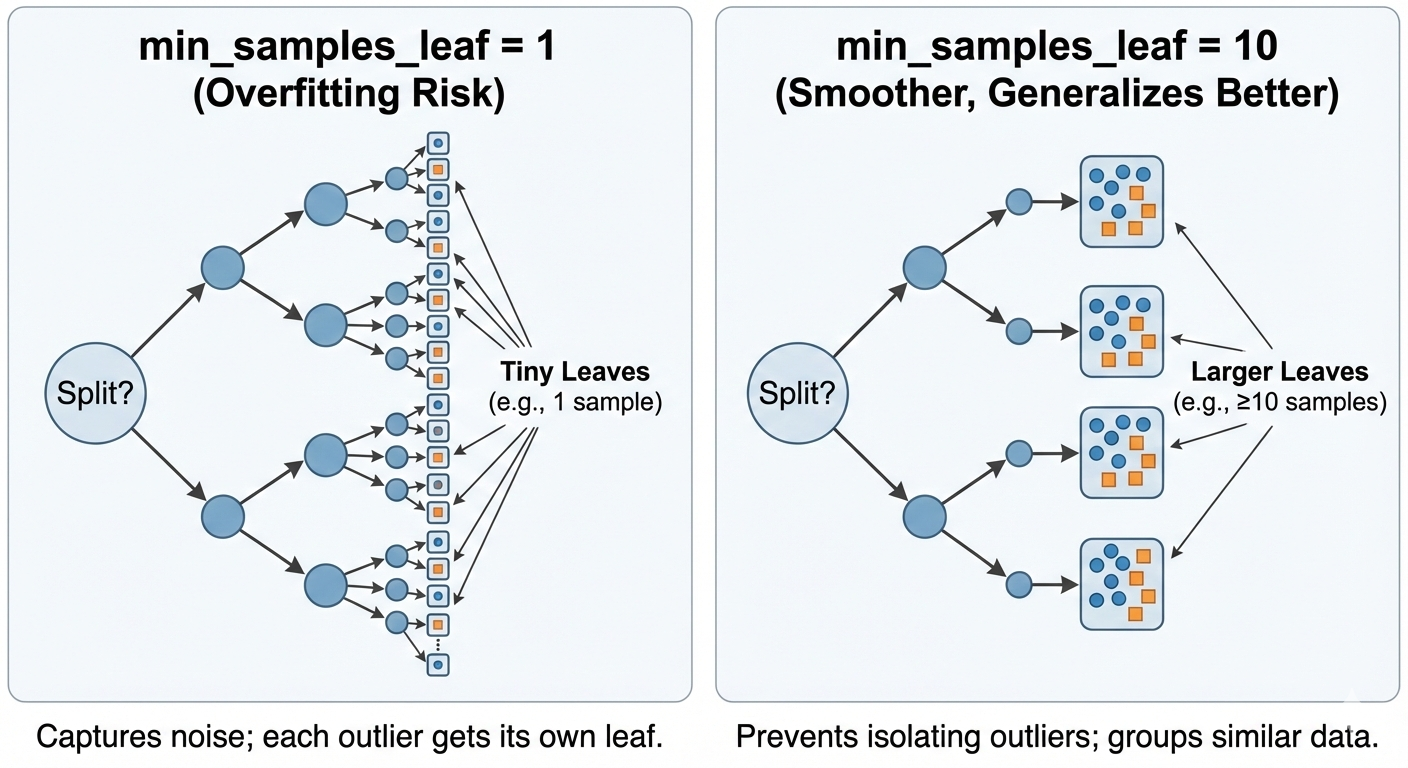
Hình 19. Tham số min_samples_leaf cao hạn chế việc tạo các vùng quyết định nhỏ.
3.3 Feature Engineering cho Decision Tree
Một trong những lý do Decision Tree được yêu thích là vì nó khá "dễ tính" với dữ liệu đầu vào.
- Không cần chuẩn hóa (Normalization): Cây chỉ quan tâm đến thứ tự lớn bé để cắt (ví dụ: $x > 5$), nên việc dữ liệu nằm trong khoảng [0, 1] hay [0, 1000] không ảnh hưởng đến cấu trúc cây.
- Xử lý tốt cả số và phân loại: Nó làm việc được với cả numerical và categorical features.
Tuy nhiên, nó có 2 điểm yếu chí mạng cần Feature Engineering bù đắp:
3.3.1. Không thể ngoại suy (Extrapolate)
Nếu dữ liệu huấn luyện của bạn chỉ có giá nhà từ 1 tỷ đến 5 tỷ, Tree sẽ không bao giờ dự đoán được căn nhà giá 10 tỷ. Vì bản chất Tree là cắt không gian thành các vùng và gán cho mỗi vùng một giá trị trung bình cố định. Ra khỏi vùng đã học, nó chỉ biết lặp lại giá trị của vùng gần nhất.
Giải pháp: Sử dụng các features thể hiện sự thay đổi hoặc sai phân (difference features) thay vì giá trị tuyệt đối.
3.3.2. Kém trong việc học quan hệ chéo (Interaction)
Giả sử quy luật thật sự là y = x₁ × x₂ (diện tích = dài × rộng). Decision Tree chỉ có thể cắt vuông góc, nên nó phải tạo ra hình bậc thang zic-zac để xấp xỉ đường cong của phép nhân này, tốn rất nhiều node.
Giải pháp: Hãy giúp nó bằng cách tạo sẵn feature x₃ = x₁ × x₂. Lúc này Tree chỉ cần đúng 1 lần cắt là xong.
Hình 20. Feature Engineering giúp cây nhận diện quy luật phức tạp dễ dàng hơn.
3.4 Validation cho Decision Tree
Decision Tree có một tính xấu là Variance cao (Độ phương sai cao). Nghĩa là chỉ cần thay đổi dữ liệu huấn luyện một chút xíu, cấu trúc cây có thể thay đổi hoàn toàn khác biệt. Điều này làm cho việc đánh giá mô hình bằng một lần chia train/test trở nên kém tin cậy - có thể bạn "ăn may" chia được tập đẹp, hoặc "xui" trúng tập xấu.
Để khắc phục, chúng ta sử dụng K-Fold Cross-Validation (Kiểm định chéo).
Thay vì chia 1 lần, chúng ta chia dữ liệu thành $K$ phần (ví dụ 5 phần). Chúng ta lần lượt dùng 4 phần để học và 1 phần để thi, lặp lại 5 lần như vậy. Kết quả cuối cùng là trung bình của 5 lần thi. Cách này giúp đánh giá ổn định và khách quan hơn nhiều.
Hình 21. K-Fold Cross-Validation giúp đánh giá mô hình ổn định và khách quan hơn.
3.5 Overfitting trong Decision Tree
Decision Tree giống như một học sinh có trí nhớ siêu phàm nhưng thiếu khả năng tư duy tổng hợp. Nếu không ai ngăn cản, nó sẽ học thuộc lòng từng dấu chấm, dấu phẩy trong sách giáo khoa (Training data), kể cả những lỗi in ấn sai (Noise).
Hệ quả là khi thi học kỳ (Validation), gặp đề mới không có lỗi in ấn đó, nó sẽ làm sai. Đây là Overfitting.
Dấu hiệu: Độ chính xác trên tập Train gần như tuyệt đối (100%), nhưng trên tập Validation lại thấp lẹt đẹt. Cây mọc rất sâu và tua tủa lá.
Để "kìm hãm" sự học vẹt này, chúng ta dùng các phương pháp Regularization (Chính quy hóa), hay còn gọi là Cắt tỉa cây (Pruning):
- Pre-pruning (Cắt tỉa trước): Thiết lập luật chơi ngay từ đầu bằng các siêu tham số max_depth, min_samples_leaf... để cây không được phép mọc quá rậm rạp.
- Post-pruning (Cắt tỉa sau): Cứ cho cây mọc thoải mái, sau đó dùng kéo cắt bỏ những cành lá thừa thãi không giúp ích gì cho việc dự đoán trên tập validation.
Hình 22. Validation error tăng khi cây overfit dù training error vẫn tiếp tục giảm.
3.6 Bias-Variance trong Decision Tree
Tóm lại, một cây quyết định đơn lẻ (Single Decision Tree) thường rơi vào tình thế tiến thoái lưỡng nan:
| Độ sâu (Depth) | Bias (Độ lệch) | Variance (Phương sai) | Tình trạng |
|---|---|---|---|
| Thấp (1-3) | Cao | Thấp | Underfitting |
| Cao (10+) | Thấp | Cao | Overfitting |
Rất khó để một cây đơn lẻ đạt được cả Low Bias và Low Variance cùng lúc. Đây chính là điểm yếu chí mạng dẫn đến sự ra đời của các phương pháp Ensemble Learning.
Tại sao phải dùng một cây khi chúng ta có thể trồng cả một khu rừng?
- Phần tiếp theo (Random Forest) sẽ dùng chiến thuật Bagging để triệt tiêu High Variance.
- Phần sau nữa (XGBoost) sẽ dùng chiến thuật Boosting để giải quyết High Bias.

Hình 23. Trung bình nhiều cây giúp giảm phương sai và mang lại kết quả ổn định.
IV. Rừng Ngẫu Nhiên (Random Forest)
Ở phần trước, chúng ta đã thấy rằng một Cây Quyết Định (Decision Tree) đơn lẻ giống như một chuyên gia có kiến thức sâu rộng nhưng lại rất bảo thủ (Variance cao) – chỉ cần dữ liệu thay đổi một chút là ý kiến thay đổi hoàn toàn.
Vậy giải pháp là gì? Thay vì tin vào một chuyên gia duy nhất, tại sao chúng ta không tham khảo ý kiến của cả một hội đồng? Đó chính là ý tưởng đằng sau Random Forest (Rừng Ngẫu Nhiên).
4.1 Giới thiệu Random Forest
Random Forest là gì?
Đúng như tên gọi, Random Forest là một "khu rừng" được tạo nên bởi rất nhiều Cây Quyết Định. Tuy nhiên, đây không phải là những cái cây giống hệt nhau. Mỗi cây trong rừng được huấn luyện trên một phiên bản dữ liệu và tập đặc trưng (features) hơi khác nhau một chút.
Kết quả cuối cùng của mô hình sẽ được quyết định bằng cơ chế tập thể:
- Với bài toán Hồi quy (Regression): Lấy trung bình cộng dự đoán của tất cả các cây.
- Với bài toán Phân loại (Classification): Bỏ phiếu đa số (Majority Voting) – lá phiếu nào được nhiều cây bầu nhất sẽ thắng.
Để tạo ra sự đa dạng này, Random Forest sử dụng hai nguồn "ngẫu nhiên" chính:
-
Bootstrap sampling (Bagging): Mỗi cây được học trên một mẫu ngẫu nhiên (có hoàn lại) từ tập dữ liệu gốc. Theo thống kê, mỗi mẫu này chỉ chứa khoảng 63% dữ liệu gốc, 37% còn lại bị bỏ qua (gọi là Out-of-Bag).
-
Feature randomization (Ngẫu nhiên hóa đặc trưng): Tại mỗi lần chia nhánh (split), cây không được phép nhìn thấy toàn bộ các features. Nó chỉ được chọn ngẫu nhiên một tập hợp con các features để xem xét (ví dụ: chỉ được chọn 3 trong 10 đặc trưng). Thường là $\sqrt{n}$ cho classification và $n/3$ cho regression.
Tại sao "ngẫu nhiên" lại tốt?
Hãy tưởng tượng bạn đang muốn dự đoán thời tiết ngày mai và đi hỏi 100 chuyên gia khí tượng.
-
Nếu 100 người này đều học cùng một trường, dùng cùng một phần mềm và đọc cùng một bản tin thời tiết, họ sẽ đưa ra 100 câu trả lời y hệt nhau. Nếu sai, cả đám cùng sai.
-
Nhưng nếu mỗi người dùng một nguồn dữ liệu riêng, người thì soi độ ẩm, người thì nhìn hướng gió, người thì đo nhiệt độ... câu trả lời của họ sẽ rất đa dạng.
Khi đó, nếu bạn lấy trung bình ý kiến của 100 người này, những sai số cá nhân (người đoán quá cao, người đoán quá thấp) sẽ triệt tiêu lẫn nhau. Cái còn lại chính là tín hiệu đúng đắn nhất.
4.2 Siêu tham số (Hyperparameters) của Random Forest
Vì Random Forest là tập hợp của các Decision Trees, nó thừa hưởng toàn bộ siêu tham số của Tree (như max_depth, min_samples_split). Tuy nhiên, nó có thêm một số "nút vặn" đặc trưng.
n_estimators (Số lượng cây)
Đây là tổng số cây trong khu rừng của bạn.
-
Ảnh hưởng: Khác với các mô hình khác, việc tăng số lượng cây trong Random Forest gần như không bao giờ gây Overfitting. Lý do là vì các cây được train độc lập, việc thêm cây chỉ giúp phép tính trung bình trở nên mượt mà và ổn định hơn mà thôi.
-
Đánh đổi: Càng nhiều cây thì độ chính xác càng tăng, nhưng tốc độ huấn luyện và dự đoán sẽ chậm đi.
-
Quy tắc ngón tay cái: Thường thì 100-500 cây là đủ. Sau ngưỡng này, lợi ích thu được sẽ bão hòa (diminishing returns) – thêm 1000 cây nữa có thể chỉ tăng độ chính xác thêm 0.01% nhưng tốn gấp đôi thời gian.
max_features (Số features xem xét mỗi split)
Đây là siêu tham số quan trọng nhất để kiểm soát sự đa dạng của rừng. Tại mỗi nút phân chia, cây chỉ được phép chọn ngẫu nhiên max_features đặc trưng để đánh giá.
-
Nếu đặt quá cao (gần bằng tổng số features): Các cây sẽ trở nên giống nhau y đúc (vì cây nào cũng chọn feature tốt nhất). Sự đa dạng giảm → Hiệu quả của việc lấy trung bình giảm.
-
Nếu đặt quá thấp: Các cây sẽ quá yếu và ngẫu nhiên, không học được quy luật gì cả.
-
Mức khuyến nghị: $\sqrt{n\_features}$ cho phân loại và $n\_features/3$ cho hồi quy.
Tại sao cây giống nhau lại là vấn đề? Hãy nhìn vào công thức variance của Random Forest:
$$Var(RF) = \rho\sigma^2 + \frac{(1-\rho)\sigma^2}{n}$$
Với $\rho$ là correlation (độ tương quan) giữa các cây. Khi max_features cao → các cây đều chọn cùng feature tốt nhất → $\rho$ tăng → phần $\rho\sigma^2$ chiếm ưu thế → averaging không còn hiệu quả. Ngược lại, max_features thấp ép các cây phải "sáng tạo" với những features khác nhau → $\rho$ giảm → variance tổng thể giảm mạnh.
max_depth (Độ sâu tối đa)
-
Để cây mọc tự nhiên (max_depth = None): Đây là mặc định của thư viện Scikit-learn. Mỗi cây sẽ rất phức tạp và có Variance cao, nhưng nhờ cơ chế lấy trung bình của rừng, Variance tổng thể sẽ giảm xuống.
-
Giới hạn độ sâu (max_depth = 10-20): Giúp mô hình nhẹ hơn, chạy nhanh hơn và đôi khi giúp tránh overfitting trên các tập dữ liệu nhỏ.
4.3 Feature Engineering cho Random Forest
Random Forest thừa hưởng sự "dễ tính" của Decision Tree:
- Không cần chuẩn hóa dữ liệu (Normalization/Standardization).
- Xử lý tốt cả dữ liệu số và dữ liệu phân loại.
Feature Importance — Vũ khí bí mật
Một điểm cực mạnh của Random Forest là khả năng tự đánh giá xem đặc trưng nào quan trọng. Nó làm điều này bằng cách đo xem một feature được dùng để chia nhánh bao nhiêu lần và giúp giảm độ nhiễu (impurity) bao nhiêu.
Chúng ta có thể dùng tính năng này để Feature Selection – loại bỏ bớt những đặc trưng vô thưởng vô phạt để mô hình chạy nhanh hơn và bớt nhiễu.
Tuy nhiên, đừng quên rằng Random Forest vẫn có điểm yếu của Tree: Không thể ngoại suy. Nếu dữ liệu train chỉ có giá trị đến 100, nó không thể dự đoán giá trị 200. Vì vậy, các kỹ thuật feature engineering tạo sai phân (difference) hoặc tỷ lệ (ratio) vẫn rất cần thiết.
4.4 Validation cho Random Forest
Random Forest có một cơ chế validation "miễn phí" và cực kỳ lợi hại gọi là Out-of-Bag (OOB) Error.
Nhớ lại rằng mỗi cây chỉ được học trên khoảng 63% dữ liệu (Bootstrap sample). Vậy 37% còn lại đi đâu? Chúng được gọi là mẫu Out-of-Bag (OOB) – những mẫu mà cây chưa bao giờ nhìn thấy.
Thay vì phải cắt riêng một tập Validation set, chúng ta có thể dùng chính những mẫu OOB này để kiểm tra năng lực của từng cây.
-
Cơ chế: Với mỗi điểm dữ liệu $X$, chúng ta chỉ lấy dự đoán từ những cây không chứa $X$ trong tập huấn luyện. Trung bình sai số của các dự đoán này chính là OOB Error.
-
Lợi ích: Tận dụng được tối đa dữ liệu để huấn luyện, đặc biệt quý giá khi bạn có ít dữ liệu.
Dù vậy, bạn vẫn nên dùng Cross-Validation truyền thống khi:
- Cần so sánh Random Forest với các thuật toán khác (như SVM, Linear Regression).
- Tinh chỉnh siêu tham số (OOB score đôi khi hơi lạc quan quá).
- Làm việc với dữ liệu chuỗi thời gian (Time Series) – vì OOB không tôn trọng thứ tự thời gian.
4.5 Overfitting trong Random Forest
Tại sao RF ít Overfit hơn cây đơn lẻ?
Bí mật nằm ở toán học: Nếu bạn có $n$ biến ngẫu nhiên độc lập cùng có phương sai $\sigma^2$, thì phương sai của trung bình cộng bọn chúng sẽ giảm xuống còn $\sigma^2/n$.
Tuy nhiên, trong thực tế các cây không hoàn toàn độc lập vì cùng học từ một nguồn dữ liệu. Công thức chính xác hơn là:
$$Var(RF) = \rho\sigma^2 + \frac{(1-\rho)\sigma^2}{n}$$
Trong đó $\rho$ là correlation (hệ số tương quan) trung bình giữa các cây.
Điều này giải thích tại sao max_features quan trọng: max_features thấp → giảm $\rho$ (các cây ít giống nhau hơn) → phép averaging hiệu quả hơn → Variance giảm mạnh hơn.
Khi nào RF vẫn có thể Overfit?
Dù rất trâu bò, Random Forest không phải là bất tử. Nó vẫn có thể "học vẹt" khi:
- Dữ liệu quá ít: Khiến các mẫu bootstrap quá giống nhau, làm mất đi sự đa dạng.
- Dữ liệu quá nhiễu: Nếu features chứa quá nhiều rác, tất cả các cây sẽ cùng học cái rác đó.
- max_features quá cao: Khiến các cây trở nên quá tương đồng (High Correlation).
4.6 Bias-Variance trong Random Forest
Đây là cách Random Forest giải quyết bài toán đánh đổi Bias-Variance:
- Bias: Nó giữ nguyên mức Bias thấp của cây quyết định (bằng cách cho phép cây mọc sâu - deep trees).
- Variance: Nó giảm mạnh Variance bằng cách lấy trung bình nhiều cây (Averaging).
Kết quả là chúng ta có một mô hình Low Bias, Low Variance – giấc mơ của mọi Data Scientist.
Tuy nhiên, có một vấn đề nhỏ: Random Forest chỉ giỏi giảm Variance (độ biến động). Nếu bản thân các cây thành phần đều "ngắm sai" (High Bias) – ví dụ như đều bỏ sót một quy luật phức tạp nào đó – thì việc lấy trung bình cũng không giúp chúng ngắm chuẩn hơn được.
Vậy làm sao để giảm cả Bias? Làm sao để các cây không chỉ học độc lập mà còn biết "sửa sai" cho nhau? Đó chính là câu chuyện của Boosting và siêu phẩm XGBoost mà chúng ta sẽ khám phá ở phần tiếp theo.
V. XGBoost
Mặc dù "chiến thuật số đông" (Bagging) giúp Rừng Ngẫu Nhiên giảm thiểu sự biến động (Variance) cực tốt, nhưng nó lại bó tay khi các thành viên trong hội đồng đều mắc lỗi giống hệt nhau. Nếu bản thân các cây đều có độ lệch cao (High Bias) – tức là đều bỏ sót một quy luật phức tạp của dữ liệu – thì việc lấy trung bình cộng cũng không thể biến sai thành đúng được.
Để giải quyết bài toán này, chúng ta không thể chỉ dựa vào việc "lấy thịt đè người" nữa. Chúng ta cần một chiến thuật tinh vi hơn: thay vì huấn luyện song song một cách độc lập, hãy huấn luyện tuần tự. Người đi sau sinh ra để sửa lỗi cho người đi trước. Đó chính là tư duy cốt lõi của Boosting, và đỉnh cao của trường phái này chính là XGBoost.
5.1 Giới thiệu XGBoost
Để hiểu cách XGBoost vận hành, hãy tưởng tượng bạn đang đứng trên đỉnh một ngọn núi mù sương và nhiệm vụ là xuống thung lũng thấp nhất (nơi có sai số thấp nhất) càng nhanh càng tốt. Vì sương mù dày đặc, bạn không thể nhìn thấy đích đến. Chiến lược khôn ngoan nhất lúc này là nhìn ngay dưới chân mình, cảm nhận xem hướng nào dốc xuống mạnh nhất và bước một bước theo hướng đó. Sau mỗi bước, bạn lại dừng lại quan sát độ dốc mới và tiếp tục đi.
Trong Machine Learning, phương pháp "dò đường" theo độ dốc này gọi là Gradient Descent. XGBoost (Extreme Gradient Boosting) áp dụng chính xác tư duy này: mỗi cái cây được sinh ra chính là một "bước đi" dẫn mô hình xuống nơi có sai số thấp hơn.
Về mặt kỹ thuật, XGBoost xây dựng các cây một cách tuần tự (sequential). Cây thứ nhất sẽ học trên dữ liệu gốc. Sau đó, chúng ta tính toán sai số (Residuals) – tức là phần chênh lệch giữa thực tế và dự đoán. Cây thứ hai được sinh ra không phải để dự đoán giá trị gốc nữa, mà để dự đoán chính cái sai số kia. Quy trình này lặp lại liên tục, với cây sau luôn cố gắng bù đắp khiếm khuyết của cây trước.
Sự khác biệt cốt lõi nằm ở chỗ: Nếu Random Forest dùng những cây sâu và phức tạp (Deep trees) để giảm Variance, thì XGBoost lại sử dụng những cây rất nông và đơn giản (Shallow trees/Weak learners) để giảm từ từ Bias.
5.2 Siêu tham số (Hyperparameters)
Sức mạnh của XGBoost đi kèm với sự phức tạp. Để điều khiển được "cỗ xe đua" này, bạn cần nắm vững những nút điều chỉnh quan trọng sau:
learning_rate ($\eta$ - eta, Tốc độ học)
Quay lại ví dụ xuống núi, learning_rate chính là độ dài sải chân của bạn. Nếu sải chân quá dài ($\eta$ cao, ví dụ 0.3), bạn xuống núi rất nhanh nhưng dễ bị trượt đà, bước quá trớn qua điểm thấp nhất và lại leo lên dốc bên kia. Ngược lại, nếu bước quá ngắn ($\eta$ thấp, ví dụ 0.01), bạn đi rất an toàn và chính xác, nhưng sẽ tốn cực kỳ nhiều thời gian (cần nhiều cây) để đến đích. Đây chính là sự đánh đổi giữa tốc độ hội tụ và độ chính xác tối ưu.
Về mặt kỹ thuật, mỗi cây mới đóng góp vào dự đoán theo công thức:
$$\hat{y}_{new} = \hat{y}_{old} + \eta \times prediction_{tree}$$
Với $\eta$ = 0.1, cây mới chỉ được "góp ý" 10% vào kết quả cuối cùng. Điều này có 2 lợi ích:
- Nếu cây mới dự đoán sai, sai số chỉ ảnh hưởng 10% thay vì 100%
- Cho phép các cây sau "tinh chỉnh" dần dần thay vì thay đổi đột ngột
n_estimators (Số lượng cây)
Khác với Random Forest nơi "càng đông càng vui", số lượng cây trong XGBoost là một con dao hai lưỡi. Vì mỗi cây sinh ra để sửa sai, nếu bạn cho phép train quá nhiều cây, đến một lúc nào đó mô hình sẽ hết lỗi "thật" để sửa và bắt đầu quay sang "sửa" luôn cả những nhiễu (noise) ngẫu nhiên. Điều này dẫn thẳng đến Overfitting. Vì vậy, trong XGBoost, chúng ta hiếm khi chọn cứng một con số n_estimators mà thường để nó tự động dừng lại bằng kỹ thuật Early Stopping.
max_depth (Độ sâu tối đa)
Trong XGBoost, chúng ta thường dùng cây rất nông, độ sâu chỉ khoảng 3-7 (khác hẳn RF thường sâu thăm thẳm). Lý do là vì tư tưởng của Boosting là kết hợp nhiều "người học yếu" (weak learners). Mỗi cây chỉ cần giải quyết một phần nhỏ của vấn đề (một pattern đơn giản). Việc cố ép một cây học quá sâu ngay từ đầu sẽ làm hỏng chiến lược sửa sai tuần tự này.
gamma ($\gamma$ - min_split_loss, Ngưỡng chia nhánh tối thiểu)
Đây là một hyperparameter quan trọng kiểm soát việc một nút có được phép chia nhánh hay không. Cụ thể, gamma quy định mức giảm Loss tối thiểu (minimum loss reduction) cần đạt được để một phép split được chấp nhận.
- gamma = 0: Mọi phép split đều được phép, miễn là giảm loss (dù chỉ 0.0001).
- gamma cao (ví dụ 1-5): Chỉ những phép split tạo ra cải thiện đáng kể mới được thực hiện → cây đơn giản hơn, ít overfitting hơn.
Nói cách khác, gamma hoạt động như một "bộ lọc" ngăn cây tạo ra những nhánh vụn vặt không có giá trị thực sự.
Các tham số chống Overfitting khác
Để giảm thiểu rủi ro học vẹt, XGBoost tích hợp hàng loạt cơ chế phòng thủ:
subsample & colsample_bytree: Mượn ý tưởng của Random Forest, mỗi cây chỉ được nhìn thấy một phần ngẫu nhiên của dữ liệu và đặc trưng.
Tại sao cần ngẫu nhiên hóa trong XGBoost? Khác với Random Forest (các cây độc lập), trong XGBoost các cây phụ thuộc nhau — cây sau học từ lỗi cây trước. Nếu mọi cây đều thấy 100% dữ liệu, chúng sẽ cùng "ám ảnh" bởi những điểm outlier hoặc noise giống nhau. subsample=0.8 nghĩa là mỗi cây chỉ thấy 80% rows ngẫu nhiên. Điểm outlier xuất hiện ở cây này có thể bị "giấu" khỏi cây kia → mô hình tổng thể bớt nhạy cảm với noise.
reg_alpha (L1) & reg_lambda (L2): Đây là điểm làm nên chữ "Extreme" trong tên gọi. Nó tích hợp sẵn các thành phần Regularization trực tiếp vào hàm mất mát để trừng phạt các mô hình quá phức tạp.
L2 Regularization (reg_lambda) hoạt động như một "thuế" đánh vào độ lớn của trọng số tại các lá. Công thức objective của XGBoost có dạng:
$$Loss = \sum(errors) + \lambda \times \sum(w^2)$$
Với $w$ là giá trị dự đoán tại mỗi lá. Khi $\lambda$ tăng:
- Mô hình bị "phạt" nếu đưa ra dự đoán quá cực đoan ($w$ quá lớn)
- Ép các lá phải "khiêm tốn" hơn → giảm overfitting
Ví dụ: Nếu 1 lá chỉ chứa 2 điểm dữ liệu và cả 2 đều có giá trị = 100, mô hình không regularization sẽ dự đoán $w$ = 100. Nhưng với $\lambda$ cao, nó sẽ dự đoán $w$ = 80 (thấp hơn) vì "chưa đủ bằng chứng để tự tin như vậy".
5.3 Feature Engineering và Xử lý dữ liệu
XGBoost thông minh hơn các mô hình cây truyền thống ở khả năng tự động xử lý Missing Values. Khi gặp giá trị bị thiếu (NaN), nó không báo lỗi mà sẽ tự học xem: "Với feature này, nếu dữ liệu bị thiếu thì nên đi theo nhánh trái hay nhánh phải để giảm sai số tốt nhất?". Do đó, bạn bớt được gánh nặng phải điền khuyết (impute) dữ liệu thủ công.
Về Feature Importance, XGBoost cung cấp cái nhìn đa chiều hơn hẳn. Bạn có thể đánh giá tầm quan trọng của một đặc trưng dựa trên Gain (nó giúp giảm bao nhiêu sai số - quan trọng nhất cho độ chính xác), Cover (độ phủ dữ liệu) hoặc Weight (tần suất xuất hiện trong cây). Tùy vào mục đích bài toán mà bạn chọn thước đo phù hợp.
5.4 Validation và Early Stopping
Vì XGBoost rất dễ Overfit nếu train quá lâu, kỹ thuật Early Stopping (Dừng sớm) gần như là bắt buộc trong thực tế. Quy trình rất đơn giản: chúng ta chia một phần dữ liệu làm tập Validation. Sau mỗi vòng lặp (khi sinh ra một cây mới), ta kiểm tra ngay sai số trên tập này. Nếu sai số không giảm trong một số vòng liên tiếp (ví dụ 10 vòng), ta lập tức dừng training và lấy mô hình tại thời điểm tốt nhất trước đó.
5.5 Overfitting trong XGBoost
Tại sao XGBoost lại dễ mắc bệnh Overfitting hơn Random Forest? Hãy hình dung việc huấn luyện XGBoost giống như một học sinh quá cầu toàn làm bài tập về nhà.
- Giai đoạn đầu: Học sinh sửa các lỗi sai công thức lớn (đây là học kiến thức thật).
- Giai đoạn sau: Khi đã hết lỗi lớn, cậu ta bắt đầu soi xét những chi tiết vụn vặt như vết mực lem hay độ nghiêng của nét chữ và cố gắng "sửa" chúng vì nghĩ đó là lỗi.
- Hậu quả: Bài làm trở nên máy móc, mất tự nhiên và không áp dụng được cho bài kiểm tra khác.
Trong XGBoost, "vết mực lem" chính là Nhiễu (Noise). Nếu chúng ta để mô hình sửa sai quá lâu, nó sẽ học thuộc lòng cả nhiễu. Để ngăn chặn điều này, chúng ta cần xây dựng nhiều lớp phòng thủ (Defense in Depth):
- Kiểm soát độ phức tạp: Dùng cây nông (max_depth thấp) và đặt
gamma> 0 để mô hình không học được các chi tiết quá nhỏ nhặt. - Ngẫu nhiên hóa: Dùng subsample và colsample_bytree (giống Random Forest) để mỗi cây chỉ nhìn thấy một phần dữ liệu, tránh việc bị ám ảnh bởi nhiễu cục bộ.
- Trừng phạt (Regularization): Tăng reg_alpha (L1) và reg_lambda (L2) để ép các trọng số của mô hình phải đơn giản hóa.
Hình 24. Các cơ chế của XGBoost giúp kiểm soát hiện tượng Overfitting hiệu quả.
5.6 Bias-Variance trong XGBoost
Cuối cùng, hãy nhìn lại vị trí của XGBoost trong bức tranh tổng thể về sự cân bằng Bias-Variance, so sánh trực tiếp với người anh em Random Forest:
| Khía cạnh | Random Forest | XGBoost |
|---|---|---|
| Thành phần | Cây sâu (Low Bias, High Variance) | Cây nông (High Bias, Low Variance) |
| Cơ chế | Lấy trung bình (Averaging) | Sửa sai tuần tự (Sequential Correction) |
| Tác dụng chính | Giảm mạnh Variance | Giảm mạnh Bias |
Cơ chế giảm Bias:
XGBoost bắt đầu với một cây rất ngây ngô (Bias cao). Nhưng qua hàng trăm lần sửa sai liên tiếp, Bias được gọt giũa dần dần về mức 0. Đây là lý do XGBoost thường đạt độ chính xác cao hơn Random Forest trên các tập dữ liệu phức tạp.
Điểm ngọt (Sweet Spot):
Tuy nhiên, cái giá phải trả là khi Bias giảm sâu thì Variance lại có xu hướng tăng lên (mô hình trở nên nhạy cảm). Nghệ thuật của người dùng XGBoost là tìm ra điểm dừng đúng lúc – nơi mà Bias đã đủ thấp (đủ chính xác) nhưng Variance chưa kịp tăng quá cao. Và công cụ đắc lực nhất để tìm ra điểm đó chính là Early Stopping mà chúng ta đã bàn ở phần 5.4.
Hình 25. Sự cân bằng giữa Bias và Variance tại điểm tối ưu đáy chữ U.
VI. Đặc thù cho Dữ liệu Chuỗi Thời Gian (Time Series)
Nếu như Random Forest hay XGBoost là những "chiến mã" mạnh mẽ, thì dữ liệu Chuỗi Thời Gian (Time Series) chính là một "trường đua" có địa hình cực kỳ hiểm trở. Nếu bạn mang tư duy của dữ liệu thông thường vào đây, khả năng cao là bạn sẽ gặp tai nạn ngay khúc cua đầu tiên.
Tại sao vậy? Vì trong Time Series, thời gian là vua.
6.1 Tại sao Time Series đặc biệt?
Đặc điểm cốt lõi:
Trong các bài toán thông thường (như nhận diện ảnh hay phân loại khách hàng), vị trí của các dòng dữ liệu không quan trọng. Bạn có thể xáo trộn (shuffle) chúng thoải mái. Nhưng với Time Series, thứ tự là bất khả xâm phạm. Một quan sát (observation) tại thời điểm $t$ luôn phụ thuộc chặt chẽ vào những gì đã xảy ra trước đó ($t-1, t-2...$).
Vấn đề với phương pháp thông thường:
Hãy tưởng tượng bạn đang đi học lớp dự đoán giá cổ phiếu. Trong lúc ôn thi, thầy giáo vô tình cho bạn xem trước đáp án giá của ngày mai. Tất nhiên, bạn sẽ làm bài kiểm tra cực tốt. Nhưng khi ra thực tế đầu tư, bạn không còn tờ đáp án đó nữa, và bạn thua lỗ nặng nề.
Trong Machine Learning, hiện tượng này gọi là Rò rỉ dữ liệu (Data Leakage).
Nếu bạn dùng phương pháp K-Fold Cross-Validation thông thường (vốn sẽ xáo trộn dữ liệu ngẫu nhiên) cho Time Series, bạn đang vô tình đưa thông tin của "tương lai" (ví dụ: tháng 3) vào tập huấn luyện để dự đoán "quá khứ" (ví dụ: tháng 2). Kết quả đánh giá sẽ cao một cách ảo tưởng và vô nghĩa.
Hình 26. K-Fold shuffle gây rò rỉ dữ liệu tương lai vào tập huấn luyện.
6.2 Các loại Features cho Time Series
Các mô hình như XGBoost hay Random Forest không tự hiểu khái niệm "hôm qua" hay "tuần trước". Chúng ta phải dạy chúng thông qua việc tạo đặc trưng (Feature Engineering).
Đặc trưng trễ (Lag Features)
Đây là cách đơn giản nhất để nói với mô hình về quá khứ.
- Định nghĩa: Giá trị của biến số tại các thời điểm trước đó.
- Ví dụ:
price_lag_1là giá hôm qua,price_lag_7là giá tuần trước. - Ý nghĩa: Nắm bắt tính Tự tương quan (Autocorrelation). Giá hôm nay thường có mối liên hệ mật thiết với giá hôm qua. Việc chọn độ trễ (lag) nào phụ thuộc vào kiến thức nghiệp vụ (Domain knowledge): với dữ liệu ngày thì lag 1, 7, 30 thường quan trọng; với dữ liệu giờ thì lag 1, 24, 168 (1 tuần).
Hình 27. Biểu đồ ACF hỗ trợ tìm các độ trễ có độ tương quan cao.
Đặc trưng cửa sổ trượt (Rolling/Window Features)
Thay vì chỉ nhìn vào một điểm quá khứ đơn lẻ, chúng ta nhìn vào một khoảng thời gian (cửa sổ) để tóm tắt xu hướng.
Các loại phổ biến:
- Rolling mean: Trung bình giá 7 ngày qua (đại diện cho xu hướng/trend).
- Rolling std: Độ lệch chuẩn 7 ngày qua (đại diện cho độ biến động/volatility).
- Rolling min/max: Đáy và đỉnh trong 7 ngày.
Chọn kích thước cửa sổ (Window size): Cửa sổ nhỏ (5-10) giúp mô hình nhạy bén với thay đổi nhanh nhưng dễ bị nhiễu. Cửa sổ lớn (20-50) cho tín hiệu mượt mà hơn (smooth) nhưng phản ứng chậm với thị trường.
Hình 28. Rolling mean với các cửa sổ khác nhau giúp nắm bắt đa khung thời gian.
Đặc trưng sai phân (Difference Features)
Nếu bạn còn nhớ Blog 1 về Đạo hàm, thì Sai phân (Difference) chính là phiên bản rời rạc của đạo hàm.
- Công thức:
diff_1 = price(t) - price(t-1). - Ý nghĩa: Giúp loại bỏ xu hướng (trend) để đưa dữ liệu về dạng ổn định (stationary). Thay vì bắt mô hình dự đoán giá Bitcoin là 50.000$ (con số tuyệt đối rất lớn và thay đổi liên tục), hãy bắt nó dự đoán xem hôm nay giá tăng hay giảm bao nhiêu so với hôm qua. Điều này dễ học hơn nhiều.
Hình 29. Sai phân xử lý xu hướng giúp mô hình tập trung vào quy luật.
Đặc trưng lịch/mùa vụ (Calendar/Seasonal Features)
Thời gian có tính chu kỳ: 23 giờ đêm và 0 giờ sáng thực ra rất gần nhau (chỉ cách 1 tiếng), nhưng về mặt con số (23 vs 0) thì lại rất xa. Nếu đưa thẳng số 0-23 vào mô hình, nó sẽ hiểu sai.
Giải pháp: Sử dụng Cyclical encoding (Mã hóa chu kỳ) bằng hàm Sin và Cos.
hour_sin = sin(2π × hour / 24)hour_cos = cos(2π × hour / 24)
Cách này giúp biến đổi thời gian lên một vòng tròn lượng giác, giữ nguyên được tính chất chu kỳ của nó.
Hình 30. Cyclical encoding giúp giữ tính liên tục của thời gian.
Lưu ý sống còn: Tránh Data Leakage
Khi tạo features, hãy cực kỳ cẩn thận. Tại thời điểm $t$, bạn chỉ được phép dùng dữ liệu đến $t-1$.
- Sai: Tính trung bình từ ngày $t-6$ đến ngày $t$ (đã lộ đề ngày $t$!).
- Đúng: Tính trung bình từ ngày $t-7$ đến ngày $t-1$.
6.3 Validation cho Time Series
Vì K-Fold thông thường bị cấm, chúng ta cần những chiến lược kiểm định tôn trọng dòng chảy thời gian.
Walk-Forward Validation (Kiểm định tiến dần)
Ý tưởng là luôn train trên quá khứ và validate trên tương lai gần, giống như việc bạn học hết lớp 1 rồi thi lớp 1, học hết lớp 2 rồi thi lớp 2.
- Split 1: Train [Tháng 1-3], Validate [Tháng 4]
- Split 2: Train [Tháng 1-6], Validate [Tháng 7]
- Split 3: Train [Tháng 1-9], Validate [Tháng 10]
Cách này mô phỏng chính xác thực tế: "Tôi có dữ liệu đến hôm qua, tôi cần dự đoán hôm nay".

Hình 31. Walk-Forward Validation duy trì tính tuần tự thời gian khi kiểm định.
Sliding Window Validation (Kiểm định cửa sổ trượt)
Khác với Walk-Forward (càng học càng nhớ nhiều), Sliding Window có bộ nhớ giới hạn. Cửa sổ train có kích thước cố định và trượt dần theo thời gian.
Cách này phù hợp khi bạn tin rằng dữ liệu quá cũ không còn giá trị, hoặc quy luật thị trường đã thay đổi (concept drift).

Hình 32. Expanding Window giữ lịch sử, Sliding Window giữ dữ liệu gần nhất.
Purging và Embargoing — Kỹ thuật nâng cao
Ngay cả khi chia đúng thời gian, leakage vẫn có thể xảy ra do các feature chồng lấn (overlap).
Ví dụ: Bạn dùng rolling_mean_7 (trung bình 7 ngày). Nếu ngày cuối cùng của tập Train là ngày 30, feature của nó chứa thông tin từ ngày 24-30. Ngày đầu tiên của tập Validation là ngày 1, feature của nó chứa thông tin từ ngày 25-31.
Rõ ràng, thông tin từ ngày 25-30 đang xuất hiện ở cả hai tập!
Giải pháp (Purging): Bỏ trống một khoảng (gap) giữa tập Train và Validation. Kích thước khoảng này phải lớn hơn độ trễ (lag) lớn nhất của feature để cắt đứt sự phụ thuộc.

Hình 33. Purge Gap hạn chế sự chồng lấn giữa các đặc trưng lag.
VII. Thực Hành — Cấu Hình Siêu Tham Số
Chúng ta đã đi một chặng đường dài: từ việc hiểu bản chất mô hình (Decision Tree, RF, XGBoost) cho đến cách xử lý dữ liệu đặc thù (Time Series). Nhưng có dữ liệu tốt và mô hình xịn mới chỉ là điều kiện cần. Để cỗ máy thực sự hoạt động trơn tru và đạt hiệu suất cao nhất, bạn cần biết cách vặn các "núm điều chỉnh" — hay còn gọi là Siêu tham số (Hyperparameters).
Việc để nguyên các giá trị mặc định (default) thường chỉ cho kết quả trung bình. Dưới đây là các cấu hình khởi điểm (baseline) được đúc kết từ thực tế, giúp bạn tiết kiệm thời gian mò mẫm.
7.1 Cấu hình cơ bản cho Decision Tree
Decision Tree là mô hình đơn giản nhất, nhưng cũng dễ "học vẹt" (overfit) nhất nếu không được kiểm soát.
Dạng khai báo (Python sklearn):
from sklearn.tree import DecisionTreeRegressor # hoặc DecisionTreeClassifier
model = DecisionTreeRegressor(
max_depth=5, # Độ sâu tối đa: chốt chặn quan trọng nhất
min_samples_split=10, # Cần ít nhất 10 mẫu mới được chia nhánh tiếp
min_samples_leaf=5, # Mỗi lá phải có ít nhất 5 mẫu (tránh lá cô đơn)
random_state=42 # Để kết quả có thể tái lập (reproducibility)
)
Bảng giá trị khởi điểm:
| Siêu tham số | Giá trị khởi điểm | Range thường dùng | Ghi chú |
|---|---|---|---|
| max_depth | 5 | 3 - 15 | Nếu để None, cây sẽ mọc tới khi lá thuần khiết (rất dễ overfit). |
| min_samples_split | 10 | 2 - 50 | Giá trị càng cao → cây càng ít chi tiết → ít overfit. |
| min_samples_leaf | 5 | 1 - 20 | Quan trọng hơn split. Ngăn chặn việc tạo ra các nhóm quá nhỏ. |
Tips từ thực tế:
- Hãy bắt đầu với
max_depth = Noneđể xem cây có thể phức tạp đến mức nào, sau đó siết chặt dần (max_depth = 10, 5...). - Trong thực tế,
min_samples_leafthường hiệu quả trong việc chống nhiễu hơn làmin_samples_split.
Hình 34. Cấu hình Decision Tree cơ bản và ý nghĩa các tham số.
7.2 Cấu hình cơ bản cho Random Forest
Random Forest "lành tính" hơn nhiều. Nhờ cơ chế lấy trung bình (averaging), nó khó bị overfit hơn cây đơn lẻ, nên bạn có thể thoải mái hơn với các tham số độ phức tạp.
Dạng khai báo (Python sklearn):
from sklearn.ensemble import RandomForestRegressor # hoặc RandomForestClassifier
model = RandomForestRegressor(
n_estimators=200, # Số lượng cây trong rừng
max_depth=None, # Để cây mọc tự nhiên (RF xử lý variance tốt nên ko sợ)
max_features='sqrt', # Số features ngẫu nhiên tại mỗi split
min_samples_leaf=1, # Mặc định
n_jobs=-1, # Dùng tất cả nhân CPU để chạy song song (quan trọng!)
random_state=42,
oob_score=True # Tận dụng OOB để validate miễn phí
)
Bảng giá trị khởi điểm:
| Siêu tham số | Giá trị khởi điểm | Range thường dùng | Ghi chú |
|---|---|---|---|
| n_estimators | 200 | 100 - 500 | Nhiều cây hơn hiếm khi làm giảm độ chính xác, chỉ tốn RAM/CPU. |
| max_depth | None | None hoặc 10-30 | None là lựa chọn phổ biến nhất vì RF tự giảm variance. |
| max_features | 'sqrt' | 'sqrt', 'log2', 0.3-0.7 | Đây là tham số quan trọng nhất cần tune của RF. |
Tips từ thực tế:
n_estimators = 100là mức tối thiểu. Trong môi trường production, thường dùng 500+.- Luôn bật
oob_score=True. Nó cho bạn một đánh giá khách quan về model mà không cần cắt riêng tập validation. - Đừng quên
n_jobs=-1. Random Forest train song song, nên hãy tận dụng hết sức mạnh phần cứng của bạn.

Hình 35. Random Forest ít cần tinh chỉnh hơn nhờ các cấu hình mặc định.
7.3 Cấu hình cơ bản cho XGBoost
Đây là phần phức tạp nhất. XGBoost giống như một chiếc xe đua F1: cực nhanh, cực mạnh, nhưng cần người lái có kỹ thuật cao.
Dạng khai báo (Python xgboost):
import xgboost as xgb
model = xgb.XGBRegressor( # hoặc XGBClassifier
n_estimators=1000, # Đặt số lớn, nhưng sẽ dừng sớm nhờ Early Stopping
learning_rate=0.05, # Tốc độ học: Chậm mà chắc
max_depth=5, # Cây nông (Shallow trees)
subsample=0.8, # Chỉ dùng 80% dữ liệu mỗi cây (chống overfit)
colsample_bytree=0.8, # Chỉ dùng 80% features mỗi cây
reg_lambda=1, # L2 Regularization
early_stopping_rounds=50, # Nếu 50 vòng ko tiến bộ -> DỪNG NGAY
random_state=42,
n_jobs=-1
)
# Training với Early Stopping (BẮT BUỘC)
model.fit(
X_train, y_train,
eval_set=[(X_valid, y_valid)], # Cần tập validation để biết khi nào dừng
verbose=False
)
Bảng giá trị khởi điểm:
| Siêu tham số | Giá trị khởi điểm | Range thường dùng | Ghi chú |
|---|---|---|---|
| n_estimators | 1000 | 100 - 5000 | Luôn đặt cao và để Early Stopping quyết định điểm dừng. |
| learning_rate | 0.05 | 0.01 - 0.3 | Thấp hơn → chính xác hơn → cần nhiều cây hơn. |
| max_depth | 5 | 3 - 10 | XGBoost thích cây nông (khác hẳn RF). |
| subsample | 0.8 | 0.5 - 0.9 | Giảm xuống để tăng tính ngẫu nhiên (chống overfit). |
Tips từ thực tế:
- Luôn dùng Early Stopping! Đây là luật bất thành văn. Đừng bao giờ đoán mò số lượng cây
n_estimators. - Có một mối quan hệ tỉ lệ nghịch:
learning_rate × n_estimators ≈ hằng số. Nếu bạn giảm Learning Rate đi một nửa, hãy chuẩn bị tinh thần số lượng cây (và thời gian train) sẽ tăng gấp đôi. - Chiến thuật nhanh: Bắt đầu với
learning_rate = 0.1để chạy thử nghiệm nhanh. Khi chốt được các tham số khác, giảm xuống0.01cho mô hình cuối cùng để vắt kiệt từng chút độ chính xác.

Hình 36. XGBoost có nhiều tham số để tinh chỉnh, nên bắt đầu từ mặc định.
7.4 So sánh nhanh cấu hình 3 mô hình
Để tổng hợp lại, hãy nhìn vào bảng so sánh dưới đây để thấy sự khác biệt trong triết lý cấu hình:
| Parameter | Decision Tree | Random Forest | XGBoost |
|---|---|---|---|
| Số mô hình con | 1 | n_estimators (100-500) | n_estimators (100-5000) |
| Độ sâu điển hình | 5-15 (Vừa phải) | None (Rất sâu - Full) | 3-7 (Rất nông - Shallow) |
| Learning rate | N/A | N/A | 0.01 - 0.1 (Quan trọng nhất) |
| Cơ chế dừng | N/A | Không cần | Early Stopping (Bắt buộc) |
| Rủi ro Overfit | Cao | Thấp | Cao (nếu không tune) |
Hình 37. So sánh trade-off: Decision Tree đơn giản, XGBoost mạnh mẽ nhưng cần tinh chỉnh nhiều.
7.5 Quy trình Tuning được khuyên dùng
Đừng thử ngẫu nhiên (random guess). Hãy tune theo quy trình khoa học sau để tiết kiệm thời gian:
-
Bước 1: Baseline với Defaults. Chạy mô hình với tham số mặc định để có mốc so sánh.
-
Bước 2: Cấu trúc cây (Tree Structure). Cố định
learning_rate=0.1. Tập trung tìmmax_depthvàmin_child_weighttối ưu. Luôn dùng Early Stopping. -
Bước 3: Sự ngẫu nhiên & Regularization. Tune
subsample,colsample_bytreevàreg_lambdađể giảm overfitting. -
Bước 4: Tinh chỉnh Learning Dynamics. Sau khi đã có bộ khung tốt, hãy giảm
learning_ratexuống thật thấp (0.01 - 0.05) và tăngn_estimatorslên để mô hình hội tụ về điểm tối ưu nhất. -
Bước 5: Final Evaluation. Đánh giá lần cuối trên tập Test set (tập này phải được giấu kín từ đầu đến giờ).
Hình 38. Tinh chỉnh từ cấu trúc đến điều tiết và động lực học.
VIII. Tổng kết & Lời kết
Chúng ta đã cùng nhau đi qua một hành trình dài, từ những khái niệm đơn giản nhất về "Trí tuệ đám đông" cho đến những kỹ thuật phức tạp như Gradient Boosting hay xử lý chuỗi thời gian. Để khép lại loạt bài viết này, tôi muốn gửi đến bạn những đúc kết quan trọng nhất – những hành trang sẽ theo bạn trong suốt sự nghiệp Data Science.
8.1 Năm Chìa Khóa Vàng (Key Takeaways)
Giữa biển kiến thức mênh mông, nếu bạn lỡ quên hết các công thức toán học, hãy chỉ cần nhớ kỹ 5 nguyên tắc cốt lõi này:
8.1.1. Bản chất của sự tiến hóa
- Decision Tree: Là viên gạch nền tảng, dễ hiểu, dễ giải thích nhưng "tâm lý yếu" (Variance cao), rất dễ bị tác động bởi dữ liệu nhiễu.
- Random Forest (Bagging): Giải quyết vấn đề bằng "số lượng". Hàng trăm cây cùng bỏ phiếu giúp kết quả ổn định và bền vững (Giảm Variance). Đây là sự lựa chọn của An toàn.
- XGBoost (Boosting): Giải quyết vấn đề bằng "sự sửa sai". Cây sau sửa lỗi cho cây trước giúp mô hình đạt độ chính xác cực cao (Giảm Bias). Đây là sự lựa chọn của Hiệu năng.
8.1.2. Chiến thuật chọn mô hình
- Bạn cần một mô hình chạy nhanh, ít phải tinh chỉnh, kết quả đủ tốt để làm mốc so sánh (Baseline)? → Hãy gọi tên Random Forest.
- Bạn cần vắt kiệt từng 0.1% độ chính xác cuối cùng để thi đấu hoặc tối ưu hóa sản phẩm? → Hãy dùng XGBoost.
8.1.3. Triết lý tinh chỉnh (Tuning)
- Với Random Forest: Đừng ngại tăng số lượng cây (
n_estimators). Hãy tập trung tinh chỉnh số lượng đặc trưng mỗi lần chia (max_features). - Với XGBoost: "Chậm mà chắc" là thượng sách. Tốc độ học thấp (
learning_ratenhỏ) kết hợp với số lượng cây lớn (và Early Stopping) luôn mang lại kết quả tốt nhất.
8.1.4. Kẻ thù lớn nhất: Overfitting
- Random Forest khó bị overfit nhờ cơ chế lấy trung bình, nhưng không phải là bất tử.
- XGBoost rất dễ bị overfit vì cơ chế học quá kỹ. Luôn chuẩn bị sẵn các "lớp giáp" phòng thủ: cây nông (
max_depththấp), chọn mẫu ngẫu nhiên (subsample), và trừng phạt mô hình (reg_lambda).
8.1.5. Cạm bẫy Thời gian
Trong Time Series, tương lai không được phép tiết lộ cho quá khứ. Hãy quên K-Fold ngẫu nhiên đi và kết thân với Walk-Forward Validation. Hãy cẩn thận với các đặc trưng bị chồng lấn (overlap) giữa tập Train và Test.
8.2 Sợi dây liên kết với Blog 1
Bạn còn nhớ câu chuyện về Gradient (Đạo hàm) trong bài blog đầu tiên không? Nó không chỉ là lý thuyết suông trên giấy.
Xuyên suốt loạt bài này, chúng ta đã thấy Gradient chính là "động cơ vĩnh cửu" vận hành bên trong XGBoost. Mỗi cây mới được sinh ra đều được dẫn đường bởi Gradient của hàm mất mát – nó chỉ cho mô hình biết phải đi hướng nào để giảm sai số nhanh nhất. Hiểu Gradient giúp bạn hiểu tại sao learning_rate lại quan trọng đến thế: nó kiểm soát độ lớn của bước chân khi chúng ta lao xuống dốc tìm điểm tối ưu.
8.3 Lời kết: Công cụ và Tư duy
Cuối cùng, tôi muốn nhắn nhủ rằng: Random Forest hay XGBoost, dù mạnh mẽ đến đâu, cũng chỉ là những công cụ. Một thanh kiếm sắc bén vào tay người không biết võ cũng trở nên vô dụng, thậm chí gây thương tích cho chính mình.
Giá trị thực sự của một Data Scientist không nằm ở việc gõ dòng lệnh import xgboost. Giá trị đó nằm ở Tư duy:
- Biết cách nhìn vào dữ liệu thô và kể ra câu chuyện của nó.
- Biết cách tạo ra những đặc trưng (features) thông minh mà mô hình có thể hiểu được.
- Biết chọn đúng thước đo (metric) cho bài toán.
- Và quan trọng nhất, biết khi nào mô hình đang "học vẹt" và biết khi nào nên dừng lại.
Hy vọng loạt bài viết này đã giúp bạn xây dựng được nền tảng tư duy đó. Con đường phía trước là của bạn, hãy lấy dữ liệu làm nguyên liệu và biến các thuật toán này thành giải pháp thực tế. Chúc bạn thành công!
Chưa có bình luận nào. Hãy là người đầu tiên!