
Khi bắt đầu làm dữ liệu, chúng ta thường dựa vào các script thủ công hoặc Cron job đơn giản. Tuy nhiên, khi hệ thống mở rộng với hàng loạt tác vụ phụ thuộc lẫn nhau, cách làm này nhanh chóng bộc lộ rủi ro: khó kiểm soát lỗi, thiếu tính ổn định và không thể giám sát tập trung.
Đó là lúc bạn cần một 'Nhạc trưởng' thực thụ. Apache Airflow ra đời như giải pháp tối ưu để điều phối và tự động hóa các luồng dữ liệu phức tạp. Bài viết này sẽ mang đến cái nhìn tổng quan về Airflow, kiến trúc cốt lõi và những gì công cụ này có thể làm để nâng tầm hệ thống Data & AI của bạn.
1. Tại sao chúng ta cần một "Nhạc trưởng" (Orchestrator)?
Trong khoa học dữ liệu (Data Science), khi nhắc đến các tác vụ hay hoạt động liên quan đến dữ liệu, chúng ta thường gặp thuật ngữ “pipeline”. Đây là một chuỗi quy trình nhằm điều phối các tác vụ độc lập hoặc có mối quan hệ phụ thuộc lẫn nhau, trong đó đầu vào và đầu ra của từng tác vụ đều được xác định rõ ràng.
Tuy nhiên, khoảng cách từ lý thuyết đến vận hành thực tế thường phát sinh rất nhiều vấn đề nếu không có công cụ quản lý phù hợp.
Vấn đề của phương pháp truyền thống (Manual Scripts & Cron)
Thông thường, có nhiều cách để vận hành một data pipeline, chẳng hạn như sử dụng scheduler như Cron hoặc viết các script (Bash/Python) để thực thi tuần tự từng bước. Ví dụ: bạn chạy craw_data.py, sau đó đến processing.py, rồi cuối cùng nạp đầu ra vào load_data.py sau khi chuẩn bị xong dữ liệu ta train model với train.py.
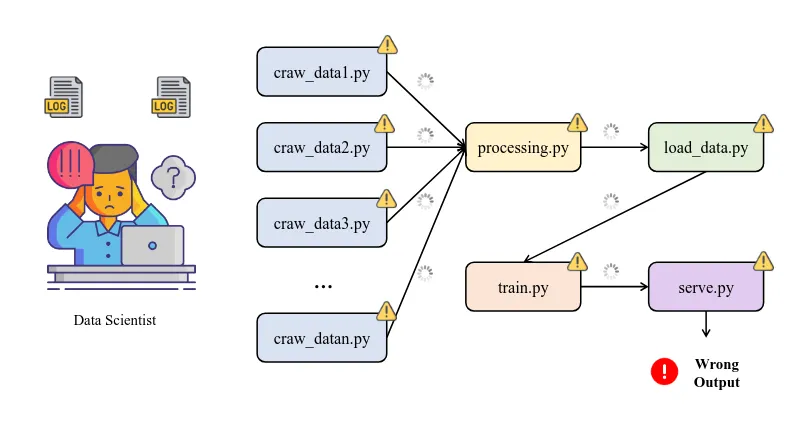
Hình 1: Sự quá tải trong việc tìm kiếm, xử lý các vấn đề gây ra lỗi trong quy trình dữ liệu. [ 1 ]
Cách làm này có vẻ ổn với các dự án nhỏ, nhưng khi pipeline trở nên phức tạp với nhiều nhánh và các tác vụ phụ thuộc lẫn nhau, việc dùng script thủ công sẽ bộc lộ những hạn chế nghiêm trọng:
-
Thiếu quản lý sự phụ thuộc (Lack of dependency management):Giả sử một tác vụ trong pipeline bị lỗi, các tác vụ phụ thuộc vào nó sẽ không thể chạy (hoặc tệ hơn là chạy với dữ liệu sai). Khi số lượng tác vụ và mối liên kết tăng lên, việc duy trì các script trở nên rối rắm, dễ sai sót và cực kỳ khó bảo trì cho người đến sau.
-
Thiếu tính trực quan (Lack of operational visibility): Hãy tưởng tượng bạn có một pipeline dài xử lý song song. Khi một nhánh bị lỗi, bạn phải truy cập trực tiếp vào server, kiểm tra hàng loạt log files để tìm lỗi rồi mới khắc phục thủ công. Việc giám sát (monitoring) gần như bằng không, trừ khi bạn tự code thêm các cơ chế bắt lỗi phức tạp vào từng script.
-
Khó mở rộng (Poor scalability):Khi dữ liệu và số lượng máy chủ tăng lên, cách vận hành thủ công khiến pipeline trở nên rủi ro, không đáng tin cậy và khó mở rộng. Bạn thiếu hoàn toàn một bảng điều khiển (dashboard) tập trung để quan sát và quản lý hệ thống.
Trước những hạn chế đó, Apache Airflow ra đời như một giải pháp điều phối (orchestration solution) mạnh mẽ nhằm khắc phục các vấn đề của data pipelines truyền thống.Thay vì để các script chạy rời rạc "mạnh ai nấy làm", Airflow đóng vai trò như một người "nhạc trưởng", đảm bảo mọi tác vụ trong hệ thống AI/ML của bạn đều được thực thi đúng trình tự, đúng thời điểm và được giám sát chặt chẽ trên một giao diện trực quan.
2. Apache Airflow và các thành phần chính
Apache Airflow là gì?
Apache Airflow, ban đầu được Airbnb phát triển vào năm 2014 và hiện là dự án Top-Level của Apache Software Foundation, là một nền tảng mã nguồn mở mạnh mẽ cho phép xây dựng, lập lịch và giám sát các quy trình làm việc (workflows) hoàn toàn dưới dạng mã. Vận hành dựa trên triết lý cốt lõi "Pipeline as Code", Airflow thay thế việc cấu hình thủ công hay thao tác kéo thả giao diện bằng sức mạnh linh hoạt của ngôn ngữ Python; điều này giúp các pipeline dữ liệu được quản lý chuyên nghiệp như một dự án phần mềm thực thụ với đầy đủ khả năng quản lý phiên bản (version control), kiểm thử và cộng tác nhóm hiệu quả.
Cốt lõi của Airflow: DAG (Directed Acyclic Graph)
Nếu ví Airflow như một công xưởng vận hành tự động, thì DAG chính là "bản thiết kế" (blueprint) chi tiết cho dây chuyền sản xuất đó.
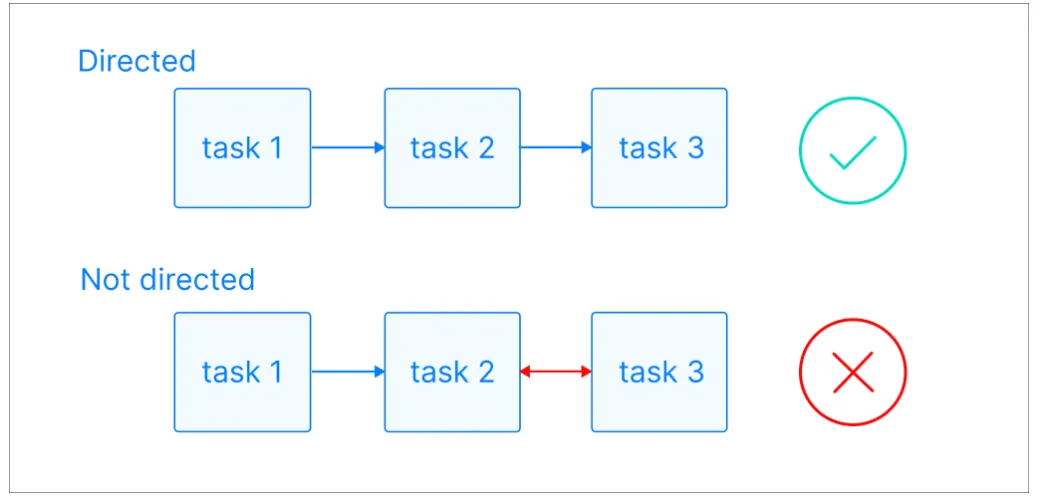
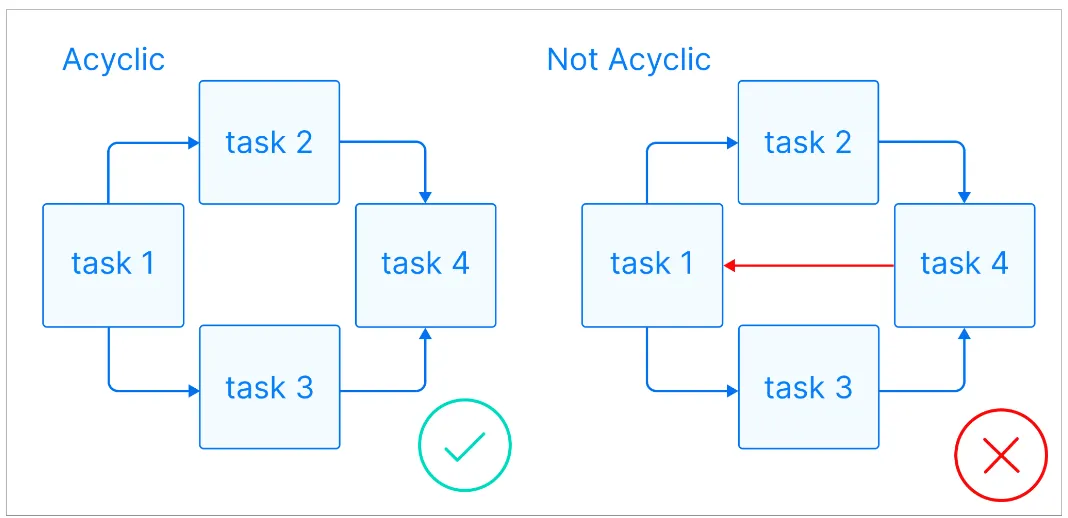
Về mặt kỹ thuật, DAG là tập hợp các tác vụ (tasks) được tổ chức chặt chẽ dựa trên 3 nguyên tắc toán học cốt lõi, tạo nên chính cái tên của nó:
-
Directed (Có hướng): Các tác vụ được kết nối bằng những mũi tên một chiều. Nếu có mũi tên từ Task A sang Task B (A→B), nghĩa là Task A bắt buộc phải hoàn thành thì Task B mới được phép khởi chạy. Điều này giúp hệ thống quản lý sự phụ thuộc (dependency) một cách tuyệt đối.
-
Acyclic (Không chu trình): Luồng công việc phải luôn đi về phía trước đến điểm kết thúc, tuyệt đối không được quay ngược lại (Ví dụ: A→B→A là không hợp lệ). Nguyên tắc này đảm bảo pipeline của bạn không bao giờ bị kẹt trong một vòng lặp vô tận (infinite loop).
-
Graph (Đồ thị): Cấu trúc này cho phép pipeline cực kỳ linh hoạt. Không chỉ chạy tuần tự (Sequential) như một đường thẳng, các task còn có thể rẽ nhánh, chạy song song (Parallel) hoặc gộp lại từ nhiều luồng xử lý phức tạp khác nhau.
|
|
Hình 2: Các nguyên tắc cơ bản của DAG [2]
Các khối xây dựng cơ bản (Building Blocks)
Trong Apache Airflow, mọi quy trình làm việc (workflow) đều được cấu thành từ những viên gạch nền tảng vững chắc. Đơn vị công việc nhỏ nhất trong một DAG được gọi là Task. Mỗi task đại diện cho một bước xử lý cụ thể và riêng biệt trong toàn bộ pipeline, chẳng hạn như việc tải dữ liệu, làm sạch dữ liệu hay ghi kết quả vào kho lưu trữ. Để xác định chính xác cách thức thực thi của từng task này, chúng ta sử dụng Operator. Về bản chất, Operator đóng vai trò là một khuôn mẫu (template) định nghĩa loại công việc cụ thể mà task sẽ thực hiện. Airflow cung cấp sẵn một thư viện Operator phong phú để đáp ứng đa dạng các nhu cầu kỹ thuật:
-
BashOperator: Dùng để chạy các lệnh hoặc script Bash.
-
EmailOperator: Dùng để gửi email thông báo trạng thái hoặc kết quả xử lý.
-
Cloud/ML Operators: Các operator chuyên dụng để kết nối với hệ thống bên ngoài như Kubernetes PodOperator hay SageMaker Operator
Bên cạnh các tác vụ thực thi, Airflow còn sở hữu một loại operator đặc biệt gọi là Sensor. Khác với các operator thông thường, nhiệm vụ duy nhất của Sensor là "đứng chờ" (wait) cho đến khi một điều kiện nhất định được thỏa mãn. Thay vì chỉ chạy dựa trên thời gian cố định, Sensor cho phép pipeline phản ứng linh hoạt theo sự kiện thực tế, ví dụ như chờ một file xuất hiện trong thư mục hoặc chờ bảng dữ liệu được cập nhật mới. Cơ chế này giúp chuyển đổi quy trình từ dạng tĩnh sang dạng "hướng sự kiện" (event-driven trigger), tối ưu hóa sự phối hợp giữa các luồng công việc
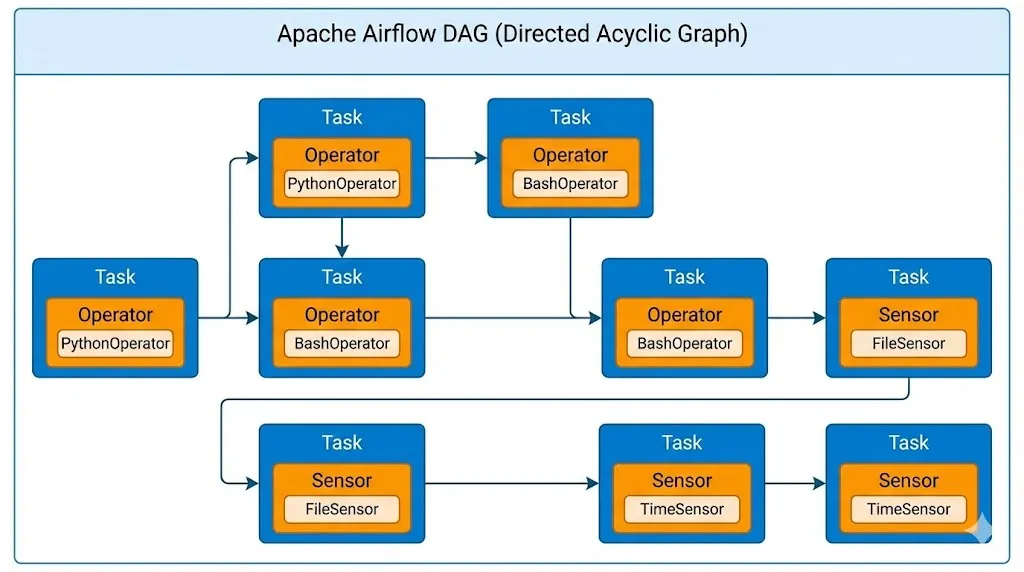
Hình 3: Các thành phần cơ bản của DAG [3]
Để tạo nên một quy trình làm việc (workflow) hoàn chỉnh trong Airflow, bạn cần lắp ghép các thành phần cốt lõi sau. Chúng đóng vai trò như những viên gạch nền tảng để xây dựng nên ngôi nhà dữ liệu của bạn.
3. Kiến trúc & Cơ chế vận hành
Một hệ thống Airflow tiêu chuẩn không phải là một khối liền (monolithic) mà là một hệ thống phân tán với thiết kế phân lớp (modular architecture), đảm bảo khả năng mở rộng và độ tin cậy cao. Để dễ hình dung, hãy tưởng tượng Airflow như một nhà máy vận hành quy trình sản xuất tự động với 4 trụ cột chính phối hợp nhịp nhàng với nhau
3.1 Kiến trúc 4 Trụ cột (The 4 Pillars)
Dựa trên nguyên lý hoạt động, Airflow bao gồm các thành phần cốt lõi sau:
Scheduler (Bộ lập lịch - "Người quản lý"):Đây là thành phần chịu trách nhiệm lên lịch và kích hoạt các task. Scheduler liên tục quét các file DAG và kiểm tra trạng thái từ cơ sở dữ liệu. Nhiệm vụ của nó là quyết định "khi nào" một task cần được chạy dựa trên thời gian hoặc điều kiện phụ thuộc. Khi mọi điều kiện thỏa mãn, nó sẽ giao nhiệm vụ cho Executor để xử lý.
Executor & Workers (Bộ phận thực thi - "Quản đốc & Công nhân")
-
Executor: Đóng vai trò quản lý tài nguyên và quyết định cách thức task được thực thi (ví dụ: chạy cục bộ Local, chạy trên Docker, hoặc Kubernetes)
-
Workers: Là những "nhân công" thực thụ. Worker nhận task do Executor phân phối và trực tiếp thực thi mã lệnh (Python, Bash...). Hệ thống có thể có nhiều Worker chạy song song để tăng tốc độ xử lý
Metadata Database (Cơ sở dữ liệu - "Sổ ghi chép trung tâm"):Thường là PostgreSQL hoặc MySQL. Đây là "nguồn chân lý" (source of truth) lưu trữ mọi thông tin của hệ thống: từ định nghĩa DAG, lịch sử chạy, trạng thái task cho đến thông tin người dùng. Cả Web Server và Scheduler đều phải truy cập vào đây để đồng bộ thông tin
Web Server (Giao diện quản trị):Cung cấp giao diện người dùng (UI) trực quan giúp bạn giám sát pipeline, xem log, và kiểm tra trạng thái các task. Web Server đọc dữ liệu từ Metadata Database để hiển thị cho người dùng, giúp việc quản lý hệ thống trở nên dễ dàng hơn.
3.2 Cơ chế luân chuyển dữ liệu (Data Passing)
Trong Apache Airflow, luồng dữ liệu không chảy trực tiếp giữa các task mà được phân chia rõ ràng dựa trên dung lượng để đảm bảo hiệu năng hệ thống. Đối với các thông tin nhẹ như tham số, ID hoặc đường dẫn file, chúng ta sử dụng XComs (Cross-Communications) – một cơ chế "trao đổi tin nhắn" tích hợp sẵn, nhưng cần lưu ý tuyệt đối không nhồi nhét dữ liệu lớn vào đây để tránh làm quá tải Metadata Database. Ngược lại, với các khối dữ liệu "hạng nặng" thực tế như file CSV hay Model AI, Airflow áp dụng chiến lược External Storage (Lưu trữ ngoài); khi đó, hệ thống chỉ đóng vai trò người chỉ đường: Task A lưu file vào kho chứa (như S3, MinIO) và chỉ truyền đường dẫn (filepath) qua XCom cho Task B tự truy xuất, giúp quy trình vận hành luôn nhẹ nhàng và tối ưu.
| Tiêu chí | XComs (Cross-Communications) | External Storage (Lưu trữ ngoài) |
|---|---|---|
| Bản chất | Cơ chế "gửi tin nhắn" nội bộ tích hợp sẵn trong Airflow1. | Hệ thống lưu trữ dữ liệu chuyên dụng (S3, GCS, MinIO, HDFS...). |
| Nơi lưu trữ | Nằm trực tiếp trong Metadata Database (PostgreSQL/MySQL) của Airflow. | Nằm trên Cloud hoặc Server lưu trữ riêng biệt. |
| Dung lượng | Siêu nhỏ. Chỉ dành cho metadata, tham số, ID, hoặc đường dẫn file2. | Lớn đến Khổng lồ. Dành cho file CSV, DataFrame, Video, Model AI... |
| Cơ chế | Task A Push (đẩy) giá trị $\rightarrow$ Task B Pull (kéo) giá trị về3333. | Task A Upload file $\rightarrow$ Gửi đường dẫn (Link) qua XCom $\rightarrow$ Task B Download file. |
| Rủi ro | Nếu cố lưu dữ liệu lớn $\rightarrow$ Sập Database, làm treo toàn bộ hệ thống Airflow. | Cần quản lý kết nối (Connection ID) và dọn dẹp file rác sau khi xử lý xong. |
| Ví dụ | Gửi filepath = "s3://bucket/data.csv" từ task này sang task kia. | Lưu file data.csv nặng 5GB. |
4. Airflow Được Sử Dụng Như Thế Nào Trong Thực Tế?
Khi đã tìm hiểu qua các thành phần của Apache Airflow, bây giờ ta cùng xem một bước để nhìn bức tranh toàn cảnh. Tại sao các "ông lớn" công nghệ như NASA, Airbnb, Netflix, Lyft hay Bloomberg đều chọn Airflow làm xương sống cho hệ thống dữ liệu của họ? Không phải ngẫu nhiên mà công cụ này trở thành tiêu chuẩn ngành.
A. Data Warehousing & ETL Cổ Điển
Đây là ứng dụng phổ biến nhất, nơi Airflow tỏa sáng như một "người vận chuyển" cần mẫn.
Bài toán: Dữ liệu của công ty nằm rải rác khắp nơi: đơn hàng ở MySQL, log hành vi người dùng trong MongoDB, dữ liệu quảng cáo trên Google Ads. Sếp yêu cầu một báo cáo doanh thu tổng hợp chính xác vào đúng 8:00 sáng mỗi ngày.
Giải pháp của Airflow: Nó đóng vai trò điều phối quy trình ETL (Extract - Transform - Load):
-
Extract: Kích hoạt các task để rút dữ liệu từ đa nguồn về vùng lưu trữ thô (Raw Zone).
-
Transform: Đẩy lệnh sang Spark hoặc Data Warehouse (như Snowflake/BigQuery) để làm sạch, gộp bảng và tính toán chỉ số.
-
Load: Nạp kết quả sạch vào Data Warehouse để các công cụ BI (Tableau, PowerBI) hiển thị báo cáo.
Điểm mạnh: Khả năng chịu lỗi. Nếu bước nạp dữ liệu thất bại lúc 3 giờ sáng, Airflow sẽ tự động thử lại (retry) hoặc gửi cảnh báo ngay lập tức qua Slack/Email cho kỹ sư, đảm bảo báo cáo buổi sáng không bị gián đoạn.
B. MLOps: Tự Động Hóa Vòng Đời Machine Learning
Đối với kỹ sư AI, Airflow không chỉ là công cụ ETL. Nó là chìa khóa để biến những file Notebook chạy thủ công thành một hệ thống AI tự động hóa toàn diện (End-to-end Pipeline), bao gồm toàn bộ vòng đời từ thu thập dữ liệu đến giám sát mô hình
Bài toán: Bạn vận hành một hệ thống Gợi ý sản phẩm (Recommendation System).
Luồng xử lý trong Airflow:
-
Data Ingestion: Tự động thu thập dữ liệu hành vi khách hàng mới nhất.
-
Model Retraining: Sử dụng các operator chuyên dụng (như SageMaker Operator) để huấn luyện lại mô hình trên dữ liệu mới, giúp cập nhật xu hướng tiêu dùng
-
Model Evaluation: Trước khi đưa vào sử dụng, Airflow chạy task đánh giá tự động. Nếu các chỉ số (như Accuracy, F1-Score) thấp hơn phiên bản cũ, pipeline sẽ dừng lại và báo lỗi
-
Deployment: Nếu mô hình đạt chuẩn, Airflow tự động cập nhật API để phục vụ người dùng (Serving).
C. Event-Driven Pipelines (Xử lý theo sự kiện)
Thế giới thực không phải lúc nào cũng vận hành theo giờ cố định (Cron). Đôi khi, chúng ta cần hành động ngay khi sự việc phát sinh.
Bài toán: Một đối tác tải file CSV chứa dữ liệu giao dịch quan trọng lên S3/MinIO vào một thời điểm bất kỳ trong ngày. Hệ thống cần phát hiện và xử lý ngay lập tức, không được phép chờ đợi.
Giải pháp của Airflow: Sử dụng sức mạnh của Sensor
-
Thay vì lập lịch chạy định kỳ (polling) gây lãng phí tài nguyên, bạn thiết lập một task sử dụng
FileSensorđể "đứng canh" -
Ngay khi file xuất hiện trong folder đích, Sensor sẽ lập tức kích hoạt toàn bộ pipeline xử lý phía sau (Trigger)
Điểm mạnh: Chuyển đổi tư duy từ "Chạy theo giờ" sang "Chạy theo sự kiện", giúp hệ thống phản ứng nhanh nhạy (Real-time reaction).
5. Kết luận
Apache Airflow đã biến việc quản lý quy trình dữ liệu từ một công việc thủ công, rủi ro thành một hệ thống kỹ thuật tự động, có thể đo lường và giám sát được. Đối với các kỹ sư AI và Data, việc làm chủ Airflow không chỉ là học một công cụ mới, mà là học tư duy hệ thống hóa - bước chuyển mình quan trọng từ việc xây dựng mô hình (Building Models) sang xây dựng hệ thống vận hành mô hình (Building Systems).
Tài liệu tham khảo
[1] Tutorial: Apache Airflow. Tài liệu khóa học AI VIETNAM (AIO2025)
[2] Apache Airflow for scheduling and orchestration [Slide bài giảng]
[3] Ảnh được tạo bởi Gemini
Chưa có bình luận nào. Hãy là người đầu tiên!