1. Giới thiệu
Hồi quy Logistic là một mô hình phân biệt (discriminative model) cơ bản được sử dụng cho các bài toán phân loại nhị phân, trong đó mô hình ánh xạ một tổ hợp tuyến tính của các đặc trưng đầu vào sang xác suất thông qua hàm sigmoid.
Mô hình này có thể xem như một phiên bản mở rộng của Linear Regression nhưng dành cho phân loại thay vì dự đoán giá trị liên tục, cụ thể:
- Cả hai mô hình đều giả định mối quan hệ tuyến tính giữa đầu vào và tham số.
- Linear Regression sử dụng tổ hợp tuyến tính để dự đoán giá trị thực, trong khi Logistic Regression đưa giá trị này qua hàm sigmoid nhằm tạo ra xác suất thuộc lớp trong [0,1].
Logistic Regression cũng có thể được mở rộng tự nhiên sang bài toán phân loại đa lớp bằng cách thay thế hàm sigmoid bằng hàm softmax, tạo thành mô hình Softmax Regression.
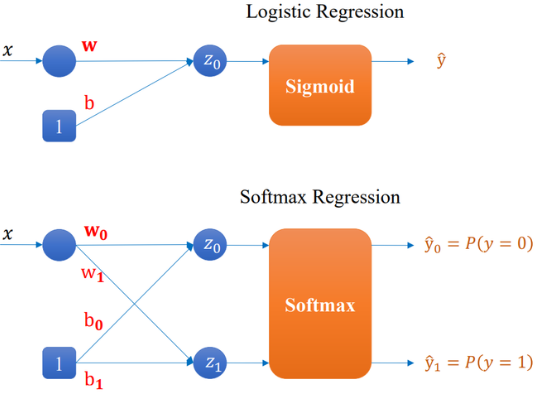
Dù có cấu trúc đơn giản, hồi quy logistic vẫn được sử dụng rộng rãi nhờ các ưu điểm:
- Tính giải thích cao (interpretability).
- Hội tụ nhanh khi tối ưu.
- Là nền tảng của các mô hình phức tạp hơn như GLM và Neural Networks.
2. Mô hình và Ký hiệu
2.1 Thiết lập bài toán
Giả sử ta có một tập dữ liệu huấn luyện gồm $N$ mẫu:
$$(x^{(i)}, y^{(i)}), \quad i = 1, 2, \dots, N$$
với:
- $x^{(i)} \in \mathbb{R}^d$: vector đặc trưng đầu vào (feature vector)
- $y^{(i)} \in \{0, 1\}$: nhãn đầu ra (0 = negative, 1 = positive)
Mục tiêu của hồi quy logistic là ước lượng xác suất một mẫu thuộc lớp 1, ký hiệu là:
$$ P(y=1 \mid x; \theta) $$
2.2 Biểu diễn tuyến tính (Linear model)
Trước tiên, ta ánh xạ đặc trưng đầu vào sang một biểu diễn tuyến tính thông qua vector trọng số $\theta$:
$$ z = \theta_0 + \theta_1 x_1 + \theta_2 x_2 + \dots + \theta_d x_d = \theta^\top \tilde{x} $$
Trong đó:
- $\theta = [\theta_0, \theta_1, \dots, \theta_d]^\top$ là vector tham số (bias + trọng số)
- $\tilde{x} = [1, x_1, x_2, \dots, x_d]^\top$ là vector đặc trưng có thêm phần tử bias $1$
Khi đó $z$ được gọi là logit hay linear score.
2.3 Hàm kích hoạt (Sigmoid)
Để biến đổi giá trị thực $z$ thành xác suất trong khoảng $(0,1)$, ta sử dụng hàm sigmoid:
$$ \sigma(z) = \frac{1}{1 + e^{-z}} $$
Xác suất mẫu thuộc lớp 1 là:
$$ \hat{y} = P(y=1 \mid x; \theta) = \sigma(z) = \frac{1}{1 + e^{-(\theta^\top \tilde{x})}} $$
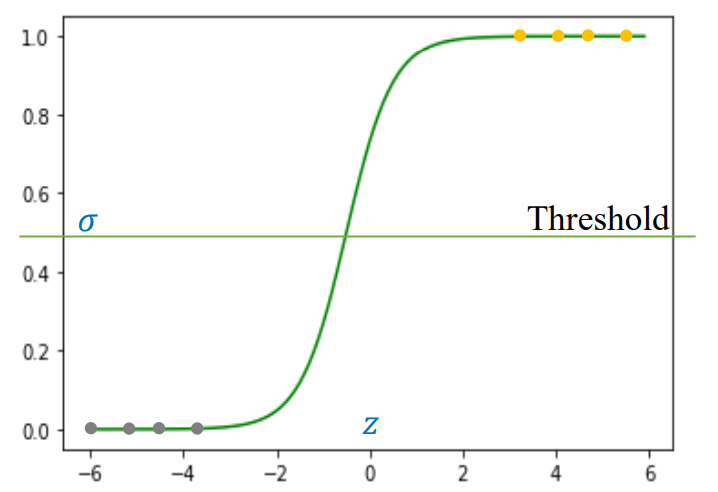
2.4 Quy tắc dự đoán
Từ xác suất $\hat{y}$, ta có thể đưa ra quyết định phân loại nhị phân:
$$ \hat{y} = \begin{cases} 1, & \text{nếu } \hat{y} \ge 0.5 \\\\ 0, & \text{nếu } \hat{y} < 0.5 \end{cases} $$
Giá trị ngưỡng 0.5 có thể thay đổi tuỳ bài toán (ví dụ nếu dữ liệu mất cân bằng).
2.5 Mở rộng sang bài toán đa lớp (Softmax Regression)
Khi bài toán có $K$ lớp ($K > 2$), hồi quy logistic được mở rộng thành hồi quy softmax (hay còn gọi là multinomial logistic regression).
Ta định nghĩa ma trận trọng số:
$$ W = \begin{bmatrix} — & \theta^{(1)} & — \\\\ — & \theta^{(2)} & — \\\\ & \vdots & \\\\ — & \theta^{(K)} & — \end{bmatrix} \in \mathbb{R}^{K \times (d+1)} $$
Với mỗi lớp $k$, logit tương ứng là:
$$ z_k = {\theta^{(k)}}^\top \tilde{x} $$
Softmax biến đổi toàn bộ các logit này thành xác suất:
$$ y_k = \frac{e^{z_k}}{\sum_{j=1}^K e^{z_j}}, \quad k = 1, 2, \dots, K $$
Trong đó $p_k$ biểu diễn xác suất mẫu thuộc lớp $k$, và:
$$ \sum_{k=1}^K y_k = 1 $$
Mẫu được gán nhãn:
$$ \hat{y} = \arg\max_k \; y_k $$
3. Hàm mất mát (Loss Function) – Giải thích trực quan
3.1 Ý tưởng chính
Trong Logistic Regression, mô hình không dự đoán trực tiếp nhãn $y = 0$ hoặc $1$, mà dự đoán xác suất thuộc lớp 1, ký hiệu là $\hat{y}$.
- Nếu $y = 1$ (mẫu dương), ta muốn $\hat{y}$ càng gần 1 càng tốt.
- Nếu $y = 0$ (mẫu âm), ta muốn $\hat{y}$ càng gần 0 càng tốt.
Hàm mất mát chính là cách đo “mức độ sai lệch” giữa dự đoán $\hat{y}$ và nhãn thực $y$.
3.2 Binary Cross-Entropy (BCE)
Hàm BCE (còn gọi là log-loss) cho một mẫu:
$$ \ell(y, \hat{y}) = - \big[ y \log \hat{y} + (1-y) \log (1-\hat{y}) \big] $$
- Nếu $y = 1$, phần $- \log(\hat{y})$ sẽ lớn nếu $\hat{y}$ nhỏ → phạt nặng.
- Nếu $y = 0$, phần $- \log(1-\hat{y})$ sẽ lớn nếu $\hat{y}$ gần 1 → phạt nặng.
Trên toàn bộ tập dữ liệu $N$ mẫu, trung bình BCE:
$$ L(\theta) = -\frac{1}{N} \sum_{i=1}^{N} \big[ y_i \log \hat{y}_i + (1-y_i) \log (1-\hat{y}_i) \big] $$
Trực giác: BCE “đo khoảng cách” giữa phân phối thực tế ($y$) và phân phối dự đoán ($\hat{y}$).
3.3 Gradient của BCE
Với $\hat{y} = \sigma(z)$ (sigmoid):
$$ \frac{\partial \ell}{\partial z} = \hat{y} - y $$
Và đạo hàm theo trọng số:
$$ \nabla_\theta \ell = (\hat{y} - y) \tilde{x} $$
Ý nghĩa:
- Nếu $\hat{y}$ lớn hơn $y$, gradient dương → giảm trọng số.
- Nếu $\hat{y}$ nhỏ hơn $y$, gradient âm → tăng trọng số.
Đây là công thức cơ bản để cập nhật tham số trong Logistic Regression.
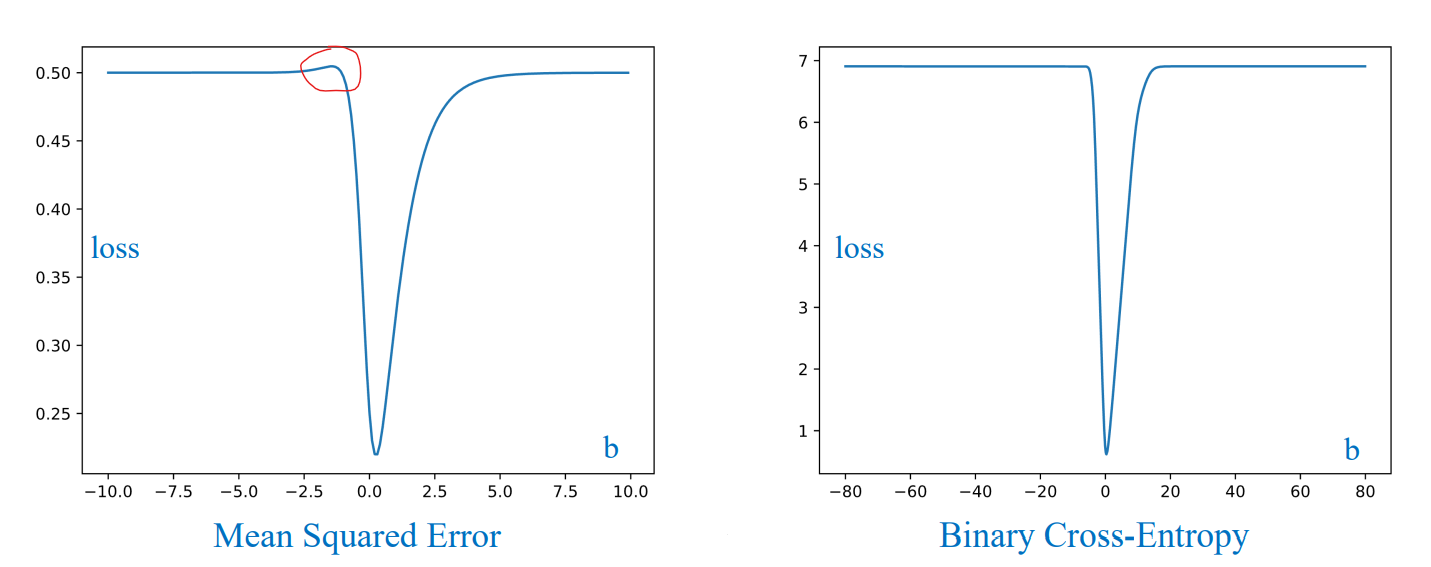
3.4 Tại sao không dùng MSE?
Hàm MSE:
$$ \ell_{MSE} = \frac{1}{2} (\hat{y} - y)^2 $$
Nhược điểm khi kết hợp với sigmoid:
- Không lồi: Gradient descent dễ mắc kẹt ở cực tiểu cục bộ.
- Vanishing gradient: Khi $\hat{y}$ gần 0 hoặc 1, gradient rất nhỏ → mô hình học chậm.
- Không phản ánh độ tin cậy xác suất: MSE không phạt đủ nếu dự đoán chưa chắc chắn.
=> Vì vậy, BCE được dùng phổ biến hơn cho Logistic Regression.
3.5 So sánh BCE và MSE
| Đặc điểm | Binary Cross-Entropy (BCE) | Mean Squared Error (MSE) |
|---|---|---|
| Nguồn gốc | Xác suất Bernoulli | Hồi quy tuyến tính |
| Độ lồi | Lồi | Không lồi |
| Ý nghĩa xác suất | Có | Không rõ |
| Tốc độ hội tụ | Nhanh, ổn định | Chậm, dễ kẹt |
| Gradient | Tuyến tính theo $(\hat{y} - y)$ | Bị suy giảm mạnh khi sigmoid bão hòa |
| Ứng dụng | Phân loại nhị phân | Hồi quy giá trị thực |
3.6 Mở rộng sang đa lớp (Softmax / Categorical Cross-Entropy)
Khi bài toán có $K > 2$ lớp, ta dùng Softmax để chuyển các logit $z_k$ thành xác suất cho từng lớp $k$:
$$ \hat{y}_k = \frac{e^{z_k}}{\sum_{j=1}^K e^{z_j}}, \quad k = 1, 2, \dots, K $$
Hàm mất mát cho toàn bộ tập dữ liệu:
$$ L(\theta) = - \frac{1}{N} \sum_{i=1}^N \sum_{k=1}^K y_i^{(k)} \log \hat{y}_i^{(k)} $$
Trong đó $y_i^{(k)}$ là nhãn one-hot:
- 1 nếu mẫu thuộc lớp $k$
- 0 nếu mẫu không thuộc lớp $k$
Trực giác: Mỗi lớp đều có BCE riêng, tổng hợp thành Categorical Cross-Entropy.
Mục tiêu: tăng xác suất cho lớp đúng ($y_i^{(k)} = 1$) và giảm xác suất cho các lớp sai ($y_i^{(k)} = 0$).
Gradient cho mỗi lớp $k$:
$$ \nabla_\theta \ell_k = (\hat{y}_k - y_k) \tilde{x} $$
Tương tự BCE, nhưng áp dụng cho tất cả $K$ lớp, đảm bảo tối ưu đồng thời trên mọi lớp.
4. Gradient và Vector hóa
4.1 Mục tiêu của việc tính gradient
Sau khi đã định nghĩa hàm mất mát $L(\theta)$ (ví dụ: BCE), mục tiêu của quá trình huấn luyện là tìm tham số $\theta$ làm giảm giá trị mất mát nhỏ nhất:
$$ \theta^\ast = \arg\min_\theta L(\theta) $$
Ta sử dụng Gradient Descent — phương pháp lặp dần cập nhật tham số ngược hướng gradient của hàm mất mát:
$$ \theta \leftarrow \theta - \eta \, \nabla_\theta L $$
Trong đó:
- $\eta$ là learning rate (tốc độ học)
- $\nabla_\theta L$ là gradient của mất mát theo $\theta$
4.2 Gradient cho một mẫu (Binary Logistic Regression)
Hàm mất mát cho một mẫu:
$$ \ell = -[y \log(\hat{y}) + (1 - y)\log(1 - \hat{y})] $$
với $\hat{y} = \sigma(z)$ và $z = \theta^\top \tilde{x}$.
Bước 1. Đạo hàm theo $\hat{y}$:
$$ \frac{\partial \ell}{\partial \hat{y}} = -\frac{y}{\hat{y}} + \frac{1-y}{1-\hat{y}} $$
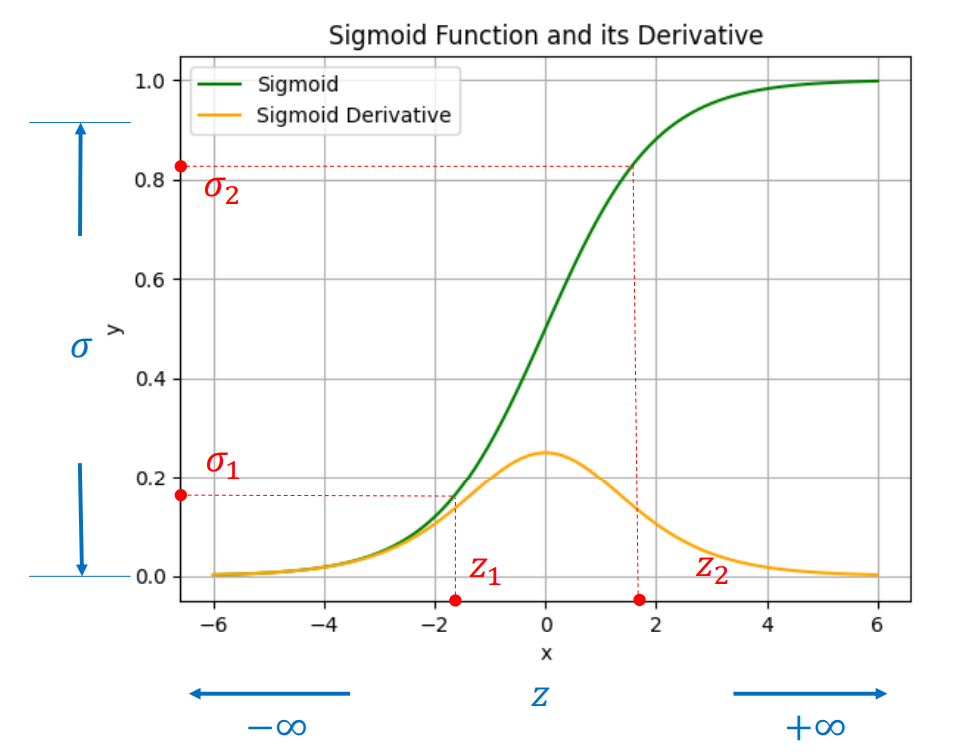
Bước 2. Đạo hàm theo $z$ (do $\hat{y} = \sigma(z)$):
$$ \frac{\partial \hat{y}}{\partial z} = \hat{y}(1 - \hat{y}) $$
Bước 3. Áp dụng quy tắc chuỗi (chain rule):
$$ \frac{\partial \ell}{\partial z} = \frac{\partial \ell}{\partial \hat{y}} \cdot \frac{\partial \hat{y}}{\partial z} = \bigg(-\frac{y}{\hat{y}} + \frac{1-y}{1-\hat{y}}\bigg) \hat{y}(1-\hat{y}) = \hat{y} - y $$
Bước 4. Gradient theo $\theta$:
$$ \nabla_\theta \ell = (\hat{y} - y)\tilde{x} $$
Trực giác:
- Nếu $\hat{y} > y$, gradient dương → giảm $\theta$ để dự đoán thấp hơn.
- Nếu $\hat{y} < y$, gradient âm → tăng $\theta$ để dự đoán cao hơn.
4.3 Dạng vector hóa (nhiều mẫu)
Với $N$ mẫu, ta gộp toàn bộ vào ma trận:
- $X \in \mathbb{R}^{N \times (d+1)}$: mỗi hàng là $\tilde{x}_i^\top$
- $y \in \mathbb{R}^{N \times 1}$: vector nhãn thật
- $\hat{y} = \sigma(X\theta) \in \mathbb{R}^{N \times 1}$
Hàm mất mát trung bình:
$$
L(\theta) = -\frac{1}{N} \sum_{i=1}^N [y_i \log(\hat{y}_i) + (1 - y_i)\log(1 - \hat{y}_i)]
$$
Lấy đạo hàm toàn phần:
$$ \nabla_\theta L = \frac{1}{N} X^\top (\hat{y} - y) $$
Và cập nhật tham số:
$$
\theta \leftarrow \theta - \eta \, \nabla_\theta L
$$
Ý nghĩa trực quan:
Dạng vector hóa cho phép tính gradient cả batch cùng lúc bằng phép nhân ma trận — cực kỳ hiệu quả với GPU/NumPy/PyTorch.
4.4 Mini-batch Gradient Descent
Với dữ liệu lớn, ta chia thành mini-batch kích thước $B$:
$$ \nabla_\theta L_{batch} = \frac{1}{B} X_{batch}^\top (\hat{y}_{batch} - y_{batch}) $$
Cập nhật từng batch giúp:
- Tăng tốc huấn luyện
- Gradient mượt hơn, giảm dao động
- Dễ mở rộng trên GPU
4.5 Gradient cho Softmax Regression (đa lớp)
Với $K$ lớp:
- $X \in \mathbb{R}^{N \times (d+1)}$
- $W \in \mathbb{R}^{K \times (d+1)}$
- $Y \in \mathbb{R}^{N \times K}$ là ma trận one-hot
- $\hat{Y} = \text{softmax}(XW^\top) \in \mathbb{R}^{N \times K}$
Hàm mất mát cross-entropy:
$$ L(W) = -\frac{1}{N} \sum_{i=1}^N \sum_{k=1}^K y_{ik}\log(\hat{y}_{ik}) $$
Gradient theo $W$:
$$ \nabla_W L = \frac{1}{N} (\hat{Y} - Y)^\top X $$
Giải thích:
- $(\hat{Y} - Y)$ là ma trận sai lệch giữa dự đoán và nhãn thật
- Nhân với $X$ để tổng hợp đóng góp từ đặc trưng
- Tương tự BCE nhưng mở rộng cho nhiều lớp
4.6 Cập nhật tham số Softmax
Công thức cập nhật:
$$ W \leftarrow W - \eta \, \nabla_W L $$
Mỗi hàng $W_k$ là trọng số riêng cho lớp $k$, điều chỉnh để giảm lỗi lớp đó.
4.7 Ghi chú kỹ thuật
- Chuẩn hóa dữ liệu đầu vào (zero mean, unit variance) để tránh logit $z$ quá lớn → tràn số
- Có thể thêm regularization:
$$ \nabla_\theta L_{reg} = \frac{1}{N} X^\top (\hat{y} - y) + \lambda \theta $$ - Thường không regularize bias.
5. Numerical Stability
5.1 Tại sao cần ổn định số?
Trong Logistic Regression (nhị phân) và Softmax Regression (đa lớp), ta thường tính các phép toán dạng:
- $e^z$ khi $z$ lớn → overflow
- $\log(1 - y\_hat)$ khi $y\_hat \approx 1$ → underflow
- $\log(0)$ → sinh NaN (not-a-number)
Nếu giá trị $z$ hoặc $y\_hat$ vượt quá giới hạn kiểu số (float64), mô hình có thể:
- Sinh NaN hoặc
inftrong loss - Gradient bằng NaN → huấn luyện bị dừng hoặc hội tụ sai
Vì vậy, cần biến đổi toán học ổn định mà vẫn giữ giá trị tương đương.
5.2 Sigmoid ổn định (y_hat nhị phân)
Sigmoid tiêu chuẩn:
$$ y\_hat = \sigma(z) = \frac{1}{1 + e^{-z}} $$
Khi $z$ quá âm (ví dụ $z=-1000$), $e^{-z} = e^{1000}$ gây overflow.
Ta chia làm 2 trường hợp để tránh số quá lớn:
$$ y\_hat = \begin{cases} \frac{1}{1 + e^{-z}}, & z \ge 0 \\ \frac{e^z}{1 + e^z}, & z < 0 \end{cases} $$
- Hai biểu thức tương đương toán học, nhưng tránh overflow.
- Áp dụng cho tất cả công thức liên quan đến y_hat.
Cài đặt Python an toàn:
import numpy as np
def sigmoid(z):
out = np.empty_like(z, dtype=float)
pos = z >= 0
neg = ~pos
out[pos] = 1 / (1 + np.exp(-z[pos])) # z >= 0
exp_z = np.exp(z[neg])
out[neg] = exp_z / (1 + exp_z) # z < 0
return out
6. Regularization (Chuẩn hóa trọng số)
6.1 Động cơ: Tại sao cần regularization?
Khi mô hình có nhiều đặc trưng hoặc tập huấn luyện nhỏ, các trọng số $\theta$ (hoặc ma trận $W$ trong softmax) có thể trở nên rất lớn để khớp hoàn toàn dữ liệu huấn luyện.
Điều này dẫn đến overfitting — mô hình học thuộc dữ liệu huấn luyện nhưng dự đoán kém trên dữ liệu mới.
Regularization giúp:
- Giới hạn độ phức tạp của mô hình
- Buộc trọng số không phát triển quá lớn
- Tăng khả năng tổng quát hóa (generalization)
Áp dụng được cả cho Logistic (2 lớp) và Softmax (K lớp). Điểm khác là Logistic dùng vector trọng số $\theta$, Softmax dùng ma trận $W$.
6.2 Nguyên tắc chung
Thêm một hạng tử phạt (penalty) vào hàm mất mát gốc:
$$ L_{reg} = L_{data} + \lambda \, \Omega(\theta \text{ hoặc } W) $$
Trong đó:
- $L_{data}$: hàm mất mát gốc (BCE cho Logistic, Categorical Cross-Entropy cho Softmax)
- $\Omega(\theta)$ hay $\Omega(W)$: hàm phạt mô tả “độ lớn” của trọng số
- $\lambda > 0$: hệ số điều chỉnh mức độ phạt (hyperparameter)
6.3 Regularization $\ell_2$ (Ridge / Weight Decay)
Hình thức phổ biến nhất là $\ell_2$ regularization, phạt theo bình phương độ lớn trọng số:
$$ \Omega(\theta) = \frac{1}{2} ||\theta_{1:}||_2^2 = \frac{1}{2}\sum_{j=1}^d \theta_j^2 $$
- Thường không phạt bias ($\theta_0$ hoặc cột bias của $W$)
- Hàm mất mát tổng hợp:
$$ L_{reg} = L + \frac{\lambda}{2} ||\theta_{1:}||_2^2 $$
hoặc cho Softmax:
$$ L_{reg} = L + \frac{\lambda}{2} ||W_{1:}||_F^2 $$
với $||W||_F$ là chuẩn Frobenius (tổng bình phương tất cả phần tử trừ bias).
Gradient được hiệu chỉnh:
- Logistic: $\nabla_\theta L_{reg} = \nabla_\theta L + \lambda \theta$
- Softmax: $\nabla_W L_{reg} = \nabla_W L + \lambda W$
Trực giác:
- $\ell_2$ ép trọng số gần 0 → mô hình “mềm hơn”, giảm overfitting
- Trong deep learning, còn gọi là Weight Decay:
$$
\theta \leftarrow (1 - \eta \lambda)\theta - \eta \nabla_\theta L
$$
6.4 Regularization $\ell_1$ (Lasso)
$\ell_1$ regularization phạt tuyến tính theo độ lớn trọng số:
$$ \Omega(\theta) = ||\theta_{1:}||_1 = \sum_{j=1}^d |\theta_j| $$
- Xu hướng ép một số trọng số về 0 → tạo mô hình thưa (sparse)
- Không khả vi tại 0 → cần thuật toán đặc biệt (coordinate descent, subgradient)
Softmax: áp dụng tương tự cho ma trận $W$, mỗi phần tử W_{kj} bị phạt theo $|W_{kj}|$.
6.5 So sánh $\ell_1$ vs $\ell_2$
| Đặc điểm | $\ell_2$ Regularization | $\ell_1$ Regularization |
|---|---|---|
| Công thức | $\frac{\lambda}{2}\sum \theta_j^2$ | $\lambda \sum |\theta_j|$ |
| Hiệu ứng | Trọng số nhỏ hơn, mượt (smooth) | Một số trọng số = 0, thưa (sparse) |
| Mô hình kết quả | Phân bố trọng số đều | Chọn lọc đặc trưng |
| Khả vi tại 0 | Có | Không |
| Giải thích xác suất | Prior Gaussian | Prior Laplace |
| Ứng dụng | Deep learning, Logistic/Softmax | Feature selection, dữ liệu nhiều chiều |
6.6 Lựa chọn hệ số $\lambda$
- $\lambda$ điều khiển mức độ phạt:
- Lớn → trọng số nhỏ → mô hình đơn giản → có thể underfit
- Nhỏ → phạt nhẹ → mô hình phức tạp → dễ overfit
- Chọn bằng cross-validation (k-fold)
- Deep learning: thường $\lambda \in [10^{-5}, 10^{-2}]$
6.7 Điểm chung và khác nhau Logistic vs Softmax
| Đặc điểm | Logistic | Softmax |
|---|---|---|
| Cấu trúc trọng số | Vector $\theta \in \mathbb{R}^{d+1}$ | Ma trận $W \in \mathbb{R}^{K \times (d+1)}$ |
| Hàm mất mát gốc | Binary Cross-Entropy | Categorical Cross-Entropy |
| Gradient | $(y_{hat} - y) x$ | $(\hat{P} - Y)^\top X$ |
| Regularization | Thêm vào $\theta$ | Thêm vào toàn bộ $W$ (ngoại trừ bias) |
| Cập nhật | $\theta \leftarrow \theta - \eta (\nabla_\theta L + \lambda \theta)$ | $W \leftarrow W - \eta (\nabla_W L + \lambda W)$ |
| Tương đồng | Cả hai dùng “dự đoán – thực” trong gradient, ép trọng số nhỏ | Cả hai ép trọng số nhỏ để giảm overfitting |
Trực giác: về cơ bản, Regularization hoạt động giống nhau trên Logistic và Softmax. Khác nhau chỉ ở cách biểu diễn trọng số và số lớp.
7. Xử lý dữ liệu mất cân bằng — SMOTE
7.1 Vấn đề dữ liệu mất cân bằng
Trong nhiều bài toán phân loại thực tế, đặc biệt là phát hiện gian lận, chẩn đoán bệnh hiếm, hoặc phân tích cảm xúc, số lượng mẫu thuộc lớp dương (positive class) thường ít hơn rất nhiều so với lớp âm (negative class).
Hiện tượng này gọi là data imbalance.
Ví dụ:
- Trong bài toán Credit Card Fraud Detection, chỉ khoảng 0.1–0.2% giao dịch là gian lận.
- Mô hình huấn luyện có thể đạt độ chính xác cao, nhưng thực chất chỉ dự đoán tất cả là “không gian lận” → hoàn toàn vô dụng.
Khi dữ liệu mất cân bằng, mô hình có xu hướng thiên lệch về lớp đa số, bỏ qua lớp thiểu số.
Do đó, accuracy không còn là thước đo phù hợp, mà cần dùng các chỉ số:
- Precision: tỷ lệ dự đoán đúng trong các mẫu được dự đoán là dương.
- Recall: tỷ lệ mẫu dương thực tế được nhận diện đúng.
- F1-score: trung bình điều hòa giữa Precision và Recall.
- ROC-AUC: đo khả năng phân tách giữa các lớp trên toàn bộ các ngưỡng.
7.2 Các chiến lược xử lý mất cân bằng
Ba nhóm kỹ thuật phổ biến:
(1) Re-sampling dữ liệu
- Over-sampling: nhân bản hoặc tạo thêm mẫu lớp thiểu số.
- Under-sampling: giảm số mẫu lớp đa số để cân bằng.
- Hybrid: kết hợp cả hai.
(2) Sử dụng trọng số lớp (Class weights)
Trong hàm mất mát, thêm hệ số trọng số ngược với tần suất xuất hiện:
$$ L = -\frac{1}{N}\sum_i w_{y_i}\,[y_i \log(y_{\text{hat},i}) + (1 - y_i)\log(1 - y_{\text{hat},i})] $$
với:
$$ w_{y_i} = \frac{N}{2N_{y_i}} $$
- Logistic: xử lý vector nhãn 0/1
- Softmax (đa lớp): cần áp dụng riêng cho từng lớp thiểu số
(3) Tạo mẫu tổng hợp — SMOTE
- SMOTE (Synthetic Minority Over-sampling Technique) tạo mẫu tổng hợp mới bằng nội suy tuyến tính giữa các mẫu thiểu số hiện có.
- Tránh overfitting so với nhân bản mẫu cũ.
7.3 Nguyên lý SMOTE
Chọn mẫu thiểu số $x_i$ và một láng giềng gần $x_{NN}$, tạo mẫu mới:
$$ x_{\text{new}} = x_i + \delta \cdot (x_{NN} - x_i), \quad \delta \sim U(0, 1) $$
- $\delta = 0$ → trùng $x_i$
- $\delta = 1$ → trùng $x_{NN}$
- $0 < \delta < 1$ → nằm giữa $x_i$ và $x_{NN}$
Ý tưởng: mở rộng không gian đặc trưng của lớp thiểu số, giúp mô hình học ranh giới quyết định tốt hơn.
7.4 Ưu / nhược điểm SMOTE
| Ưu điểm | Nhược điểm |
|---|---|
| Giảm overfitting so với nhân bản mẫu | Có thể tạo mẫu nằm vùng chồng lấn giữa các lớp, gây nhiễu |
| Mở rộng ranh giới lớp thiểu số | Không hiệu quả nếu dữ liệu phân bố rời rạc hoặc nhiễu mạnh |
Dễ cài đặt (imbalanced-learn) |
Cần chọn đúng số láng giềng $k$ |
7.5 Ứng dụng thực tế
- Phát hiện gian lận: tăng khả năng phát hiện giao dịch bất thường
- Y học: cải thiện độ nhạy khi bệnh hiếm
- Phân tích cảm xúc: cân bằng nhãn “positive / neutral / negative”
7.6 Triển khai trong Python (scikit-learn / NumPy)
from imblearn.over_sampling import SMOTE
from sklearn.model_selection import train_test_split
# Chia dữ liệu train/test, stratify giữ tỉ lệ lớp
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, stratify=y
)
# Áp dụng SMOTE
smote = SMOTE(random_state=42, k_neighbors=5)
X_resampled, y_resampled = smote.fit_resample(X_train, y_train)
print("Kích thước trước SMOTE:", X_train.shape)
print("Kích thước sau SMOTE:", X_resampled.shape)
Lưu ý:
- Với Softmax / đa lớp, SMOTE cần tạo mẫu tổng hợp cho từng lớp thiểu số.
- k_neighbors điều khiển mức “gần” của mẫu mới, ảnh hưởng chất lượng dữ liệu tổng hợp.
8. Tối ưu hóa và Huấn luyện
8.1 Mục tiêu tối ưu hóa
Mục tiêu huấn luyện là tìm tham số tối ưu $\theta^*$ để giảm hàm mất mát:
$$ \theta^* = \arg\min_\theta L(\theta) $$
Do hàm mất mát thường không có nghiệm đóng, ta dùng các thuật toán tối ưu hóa lặp.
8.2 Thuật toán tối ưu hóa cơ bản
(1) Gradient Descent (GD)
Cập nhật tham số theo hướng ngược gradient toàn tập:
$$ \theta \leftarrow \theta - \eta \, \nabla_\theta L $$
- $\eta$ là learning rate (tốc độ học).
- Ưu điểm: đơn giản, ổn định với tập nhỏ.
- Nhược điểm: chậm với dữ liệu lớn.
(2) Stochastic Gradient Descent (SGD)
Cập nhật theo từng mẫu ngẫu nhiên:
$$ \theta \leftarrow \theta - \eta \, \nabla_\theta \ell^{(i)} $$
- Nhiễu cao nhưng cập nhật nhanh.
- Giúp thoát khỏi cực tiểu cục bộ.
(3) Mini-batch Gradient Descent
Cập nhật theo nhóm nhỏ (batch) $B$:
$$ \theta \leftarrow \theta - \eta \, \nabla_\theta L_{batch}, \quad L_{batch} = \frac{1}{B} \sum_{i\in batch} \ell^{(i)} $$
- Ưu điểm: cân bằng giữa tốc độ và ổn định.
- Tận dụng vectorization trên GPU.
8.3 Thuật toán nâng cao
(1) Momentum
Tăng tốc hội tụ, giảm dao động:
$$
v_t = \beta v_{t-1} + (1 - \beta) \nabla_\theta L_t
$$
$$
\theta \leftarrow \theta - \eta v_t
$$
- $\beta$ thường ~0.9
(2) Adam (Adaptive Moment Estimation)
Kết hợp Momentum và RMSProp, điều chỉnh tốc độ học riêng cho từng tham số:
$$
m_t = \beta_1 m_{t-1} + (1 - \beta_1) g_t
$$
$$
v_t = \beta_2 v_{t-1} + (1 - \beta_2) g_t^2
$$
$$
\hat{m}_t = \frac{m_t}{1 - \beta_1^t}, \quad \hat{v}_t = \frac{v_t}{1 - \beta_2^t}
$$
$$
\theta \leftarrow \theta - \eta \frac{\hat{m}_t}{\sqrt{\hat{v}_t} + \epsilon}
$$
- $\beta_1 = 0.9$, $\beta_2 = 0.999$, $\epsilon = 10^{-8}$.
- Ưu điểm: hội tụ nhanh, ổn định, ít cần tinh chỉnh hyperparameter.
8.4 Learning Rate Schedule
Giúp mô hình học nhanh lúc đầu, tinh chỉnh khi gần hội tụ:
- Exponential decay: $\eta_t = \eta_0 e^{-\alpha t}$
- Step decay: giảm theo từng epoch cố định
- Cosine annealing: dao động mượt, tránh local minima
8.5 Theo dõi huấn luyện
- Training loss – lỗi trên tập huấn luyện
- Validation loss – lỗi trên tập kiểm định
- Accuracy, Precision, Recall, F1-score – đánh giá mô hình, phát hiện over/underfit
Nếu thấy:
- Training loss ↓, Validation loss ↑ → overfitting
- Cả hai loss không giảm → cần tăng capacity hoặc learning rate
8.6 Kỹ thuật cải thiện huấn luyện
- Early stopping: dừng khi validation loss không giảm
- Gradient clipping: giới hạn độ lớn gradient
- Weight decay: tương đương $\ell_2$ regularization
- Batch normalization: chuẩn hóa đầu vào từng lớp
- Shuffling dữ liệu: đảm bảo phân phối batch ngẫu nhiên
8.7 Minh họa huấn luyện Logistic Regression (SGD / Adam)
def train_logistic(X, y, lr=0.1, epochs=100, batch_size=64, optimizer="sgd"):
N, D = X.shape
theta = np.zeros(D)
v, m = 0, 0 # Momentum / Adam
for ep in range(epochs):
perm = np.random.permutation(N)
for i in range(0, N, batch_size):
xb = X[perm[i:i+batch_size]]
yb = y[perm[i:i+batch_size]]
y_hat = sigmoid(xb.dot(theta))
grad = xb.T.dot(y_hat - yb) / batch_size
if optimizer == "adam":
beta1, beta2, eps = 0.9, 0.999, 1e-8
m = beta1*m + (1-beta1)*grad
v = beta2*v + (1-beta2)*(grad**2)
m_hat = m / (1 - beta1**(ep+1))
v_hat = v / (1 - beta2**(ep+1))
theta -= lr * m_hat / (np.sqrt(v_hat) + eps)
else:
theta -= lr * grad
loss = compute_bce(sigmoid(X.dot(theta)), y)
print(f"Epoch {ep+1}: Loss = {loss:.4f}")
return theta
9. Nhiệt độ trong Softmax
9.1 Định nghĩa và ý nghĩa
Trong Softmax Regression hoặc mạng neural đa lớp, hàm softmax chuyển vector logit $z$ (đầu ra tuyến tính) thành phân bố xác suất:
$$ p_i = \frac{e^{z_i}}{\sum_{j=1}^K e^{z_j}} $$
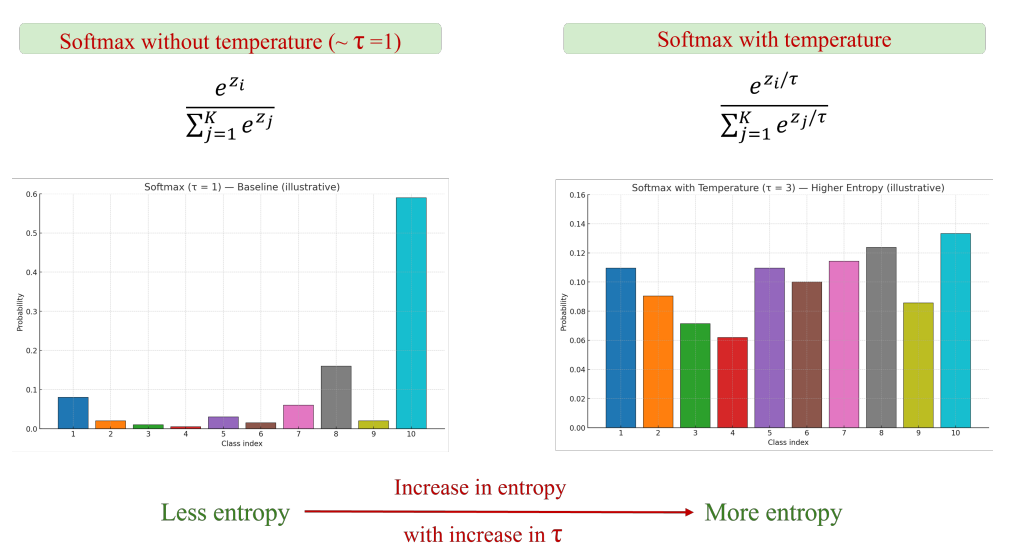
Ta có thể điều chỉnh độ “mềm” của phân bố này bằng tham số nhiệt độ $\tau$:
$$ p_i = \frac{e^{z_i / \tau}}{\sum_{j=1}^K e^{z_j / \tau}} $$
- $\tau > 0$ điều khiển độ sắc nét (sharpness) của phân bố xác suất.
9.2 Ảnh hưởng của $\tau$
- $\tau \to 0$: phân bố rất sắc nét, gần vector one-hot → mô hình rất tự tin.
- $\tau = 1$: phân bố chuẩn, dùng mặc định trong huấn luyện Softmax Regression.
- $\tau \to \infty$: phân bố gần đồng đều, mô hình ít chắc chắn hơn, thể hiện sự mơ hồ cao.
9.3 Trực giác toán học
$\tau$ hoạt động như hệ số làm mờ (smoothing factor):
- Nhỏ → xác suất tập trung vào logit lớn nhất
- Lớn → xác suất phân tán đều hơn giữa các lớp
Ví dụ: logit $z = [3, 1, 0]$
| $\tau$ | Softmax$(z/\tau)$ | Diễn giải |
|---|---|---|
| 0.5 | [0.91, 0.08, 0.01] | Rất sắc nét, gần one-hot |
| 1.0 | [0.84, 0.11, 0.05] | Chuẩn mặc định |
| 2.0 | [0.63, 0.23, 0.14] | Mềm hơn, ít chắc chắn hơn |
9.4 Ứng dụng
(1) Knowledge Distillation
- Teacher model tạo phân bố mềm ($\tau>1$) → phản ánh mối quan hệ giữa các lớp.
- Student model học để bắt chước phân bố này thay vì chỉ học nhãn cứng (0 hoặc 1).
Hàm mất mát thường dùng:
$$ L = \tau^2 \cdot \text{CE}\big(\text{softmax}(z_t / \tau), \text{softmax}(z_s / \tau)\big) $$
- $z_t$: logit teacher
- $z_s$: logit student
- CE: cross-entropy
- $\tau^2$ cân bằng độ lớn gradient khi thay đổi $\tau$
Khi $\tau$ cao, student học được “kiến thức mềm” về mối quan hệ giữa các lớp.
(2) Temperature Sampling trong mô hình sinh (LLMs, GPT,…)
- $\tau < 1$: chọn token bảo thủ, ít ngẫu nhiên → kết quả ổn định.
- $\tau > 1$: tăng ngẫu nhiên, sáng tạo, kết quả đa dạng hơn.
Ví dụ:
p = softmax(logits / temperature)
token = np.random.choice(vocab, p=p)
| Temperature | Hành vi mô hình |
|---|---|
| 0.7 | Văn bản có tính hợp lý cao, ít ngẫu nhiên |
| 1.0 | Cân bằng giữa hợp lý và sáng tạo |
| 1.5 | Tăng tính ngẫu nhiên, đôi khi phi logic nhưng đa dạng hơn |
10. Cài đặt bằng NumPy
10.1 Hồi quy logistic nhị phân
import numpy as np
def sigmoid(z):
pos = z >= 0
out = np.empty_like(z, dtype=float)
out[pos] = 1 / (1 + np.exp(-z[pos]))
exp_z = np.exp(z[~pos])
out[~pos] = exp_z / (1 + exp_z)
return out
def predict_proba(X, theta):
return sigmoid(X.dot(theta))
def compute_bce(y_hat, y, eps=1e-12):
y_hat = np.clip(y_hat, eps, 1-eps)
return -np.mean(y*np.log(y_hat)+(1-y)*np.log(1-y_hat))
def gradient(X, y, y_hat):
return X.T.dot(y_hat - y)/X.shape[0]
def train_logistic(X, y, lr=0.1, epochs=100, batch_size=64, l2=0.0):
N, D = X.shape
theta = np.zeros(D)
for ep in range(epochs):
perm = np.random.permutation(N)
for i in range(0, N, batch_size):
xb = X[perm[i:i+batch_size]]
yb = y[perm[i:i+batch_size]]
yhat = predict_proba(xb, theta)
grad = gradient(xb, yb, yhat)
grad[1:] += (l2/N)*theta[1:]
theta -= lr*grad
return theta
10.2 Hồi quy softmax đa lớp
def stable_softmax(Z):
Zm = Z - Z.max(axis=1, keepdims=True)
exp_Z = np.exp(Zm)
return exp_Z / exp_Z.sum(axis=1, keepdims=True)
def predict_multi(X, W):
return stable_softmax(X.dot(W.T))
def cross_entropy(Y_hat, Y):
Y_hat = np.clip(Y_hat,1e-12,1-1e-12)
return -np.mean(np.sum(Y*np.log(Y_hat),axis=1))
def grad_softmax(X,Y,Y_hat):
return (Y_hat - Y).T.dot(X)/X.shape[0]
def train_softmax(X,Y,lr=0.1,epochs=50,batch_size=256,l2=0.0):
N,D = X.shape
K = Y.shape[1]
W = np.random.randn(K,D)*0.01
for ep in range(epochs):
perm = np.random.permutation(N)
for i in range(0,N,batch_size):
xb = X[perm[i:i+batch_size]]
yb = Y[perm[i:i+batch_size]]
yhat = predict_multi(xb,W)
g = grad_softmax(xb,yb,yhat)
g += (l2/N)*W
W -= lr*g
return W
11. Đánh giá và chẩn đoán cho Logistic/Softmax Regression
11.1 Mục tiêu
Đánh giá mô hình Logistic/Softmax Regression dựa trên:
- Xác suất dự đoán $\hat{p}(x)$.
- Khả năng phân loại nhị phân (Logistic) hoặc đa lớp (Softmax).
- Phát hiện imbalanced data, overfitting, underfitting.
11.2 Confusion matrix & các chỉ số chính
(1) Ma trận nhầm lẫn (Confusion Matrix)
- Binary Logistic: 2 lớp
| Dự đoán Dương | Dự đoán Âm | |
|---|---|---|
| Thực Dương | TP | FN |
| Thực Âm | FP | TN |
- Softmax (Multi-class): NxN, hàng = nhãn thật, cột = nhãn dự đoán.
(2) Accuracy
$$
Accuracy = \frac{TP + TN}{TP + TN + FP + FN}
$$
- Binary/Softmax đều dùng được, nhưng dễ bị ảnh hưởng nếu lớp lệch.
(3) Precision, Recall, F1-Score
- Tính cho từng lớp khi multi-class:
$$ Precision_i = \frac{TP_i}{TP_i + FP_i}, \quad Recall_i = \frac{TP_i}{TP_i + FN_i}, \quad F1_i = 2 \frac{Precision_i \cdot Recall_i}{Precision_i + Recall_i} $$
11.3 ROC Curve & AUC (Binary)
- Logistic Regression xuất ra xác suất Sigmoid: $\hat{p} \in [0,1]$.
- Vẽ ROC: TPR vs FPR theo threshold.
- AUC đánh giá khả năng phân biệt 2 lớp:
- 1.0: hoàn hảo, 0.5: ngẫu nhiên.
11.4 Calibration (xác suất)
- Sigmoid/Softmax output $\hat{p}(x)$ đôi khi không đúng tỉ lệ thực tế.
- Đánh giá bằng Brier score:
$$ Brier = \frac{1}{N} \sum_i (\hat{p}_i - y_i)^2 $$ - Hiệu chỉnh: Platt Scaling hoặc Isotonic Regression.
11.5 Theo dõi quá trình huấn luyện
- Ghi loss train/val theo epoch:
train_loss ↓, val_loss ↑→ overfittingtrain_loss ↑, val_loss ↑→ underfitting- Softmax Regression dùng Categorical Cross-Entropy, Logistic dùng Binary Cross-Entropy.
- Dùng Early Stopping khi val_loss không giảm.
Ghi chú thực tiễn
- Logistic/Softmax Regression: mô hình linearly separable, output trực tiếp là xác suất, dễ giải thích.
- Evaluation nên dựa trực tiếp vào xác suất đầu ra, ma trận nhầm lẫn, F1, AUC (binary), hoặc macro/micro F1 (multi-class).
12. Tổng kết
Logistic/Softmax Regression là mô hình nền tảng, nhanh, dễ giải thích, vẫn hữu ích trong nhiều tình huống:
- Tốc độ huấn luyện nhanh, dễ triển khai.
- Trực quan, giải thích được trọng số và xác suất.
- Mở rộng được cho phân loại đa lớp (Softmax).
Hiệu quả mô hình phụ thuộc vào:
- Hàm mất mát phù hợp (BCE / Categorical Cross-Entropy).
- Tối ưu Gradient Descent và vector hóa.
- Ổn định số khi tính Sigmoid/Softmax.
- Regularization tránh overfitting.
- Xử lý dữ liệu lệch lớp (SMOTE, weighting, class balancing).
Phần này cung cấp nền tảng cho:
- Nghiên cứu sâu về mô hình tuyến tính.
- Giảng dạy trực quan ML cơ bản.
- Ứng dụng thực tế cần mô hình nhẹ, giải thích rõ ràng.
Chưa có bình luận nào. Hãy là người đầu tiên!