
Giới thiệu Unet
Trước khi đi vào giới thiệu Unet, ta hãy cùng xem qua bài toán sau:
1. Đôi chút về Image Segmentation
1.1 Image Segmentation là gì?
Trong Computer Vision, ta sẽ cần phải chia bức ảnh này thành nhiều vùng khác nhau, loại bỏ đi những chi tiết thừa thãi với mục tiêu là giúp dữ liệu dễ dàng phân tích hơn, việc làm này được gọi là Image Segmentation. Image Segmentation sẽ tập trung xác định vị trí và đường biên của các đối tượng, chính xác hơn, đây là quá trình phân loại nhãn (Classification) cho các pixel sao cho các pixel của cùng một đối tượng sẽ được nhóm lại với nhau.

Hình 1: Ảnh thường và ảnh Segmentation
1.2 Phân loại Image Segmentation
Chúng ta có thể chia Image Segmentation thành 3 loại chính:
1. Semantic Segmentation (Phân vùng theo ngữ nghĩa)
Nhóm tất cả các pixel của cùng một loại đối tượng (class) vào chung một nhãn thống nhất. Nó không quan tâm có bao nhiêu vật thể, chỉ quan tâm pixel đó thuộc "loại" gì.
2. Instance Segmentation (Phân vùng theo cá thể)
Loại này tiên tiến hơn, nó nhận diện và tách biệt từng cá thể (instance) riêng lẻ của một loại đối tượng. Tuy nhiên, nó thường chỉ tập trung vào các vật thể đếm được (gọi là things như người, xe, động vật) và thường bỏ qua phần nền (gọi là stuff như bầu trời, mặt đường, bãi cỏ).
3. Panoptic Segmentation (Phân vùng toàn cảnh)
Đây là sự kết hợp hoàn hảo của cả hai loại trên. Nó vừa tách biệt từng cá thể cho các vật thể đếm được (things), lại vừa phân loại ngữ nghĩa cho toàn bộ các khu vực nền không đếm được (stuff).
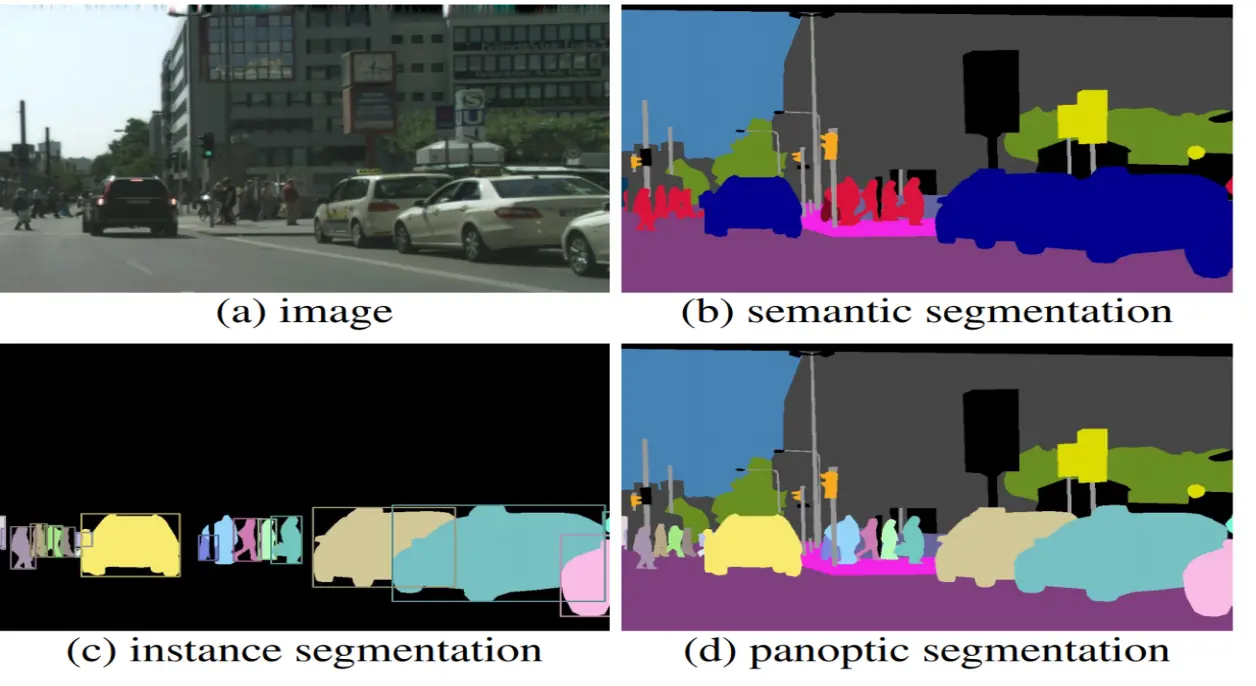
Hình 2: Semantic vs Instance vs Panoptic (Nguồn: https://www.v7labs.com/blog/instance-segmentation-guide)
1.3 Các phương pháp để thực hiện Image Segmentation
Có rất nhiều cách để máy tính làm được việc này, từ các thuật toán toán học cơ bản đến mạng nơ-ron phức tạp:
1. Phương pháp truyền thống (Traditional Image Processing)
Sử dụng các đặc trưng vật lý của pixel như độ sáng, màu sắc để chia tách.
2. Học sâu (Deep Learning - AI)
Đây là tiêu chuẩn của ngành hiện nay, mang lại độ chính xác cực cao, sử dụng các Mạng nơ-ron tích chập (CNN). Các mô hình nổi tiếng có thể kể đến U-Net, Mask R-CNN, hay FCN.
2. Vậy Unet là gì?
Như đã nói ở trên, Unet là một kiến trúc Mạng nơ-ron tích chập (Convolutional Neural Network - CNN) dùng để giải quyết bài toán Image Segmentation. Unet được giới thiệu vào năm 2015, ban đầu nó được thiết kế dành riêng cho việc phân vùng ảnh y tế y sinh học (như ảnh chụp hiển vi tế bào), nhưng sau đó đã trở thành tiêu chuẩn vàng cho rất nhiều bài toán phân vùng ảnh nói chung.
Tên gọi "U-Net" xuất phát từ việc kiến trúc mạng lưới của nó khi vẽ ra trên giấy có hình dạng đối xứng giống hệt chữ U.
Đi vào chi tiết kiến trúc của Unet
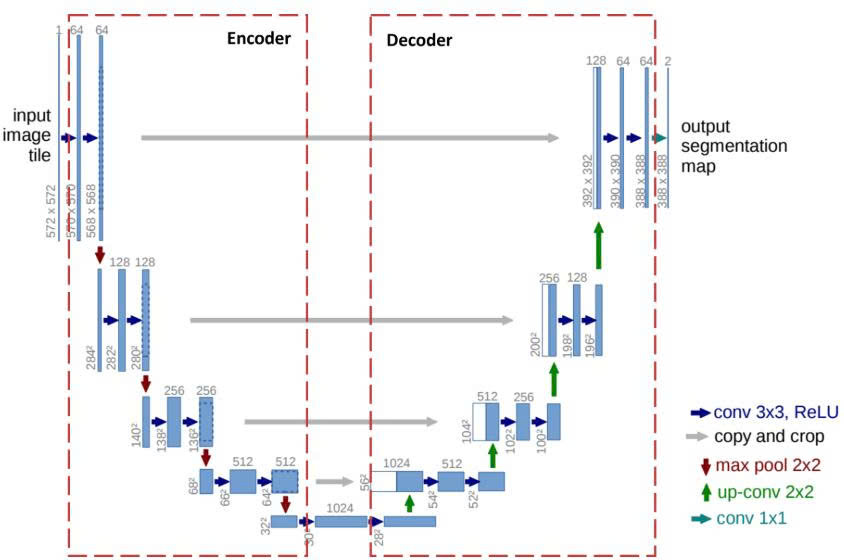
Hình 3: Kiến trúc mạng Unet
Như đã nói ở trên, cấu trúc Unet dùng để thực hiện 2 việc chính sau đây:
1. Giải quyết bài toán phân loại, trả lời câu hỏi: "Vật đang được khoanh vùng là cái gì?". Để làm được điều này, Unet sẽ nén bức ảnh lại
2. Xác định tọa độ của vật được khoanh vùng trong không gian ảnh. Để làm được điều này, Unet cần phải giữ nguyên kích thước bức ảnh để không làm mất đi độ sắc nét của các đường viền.
U-Net giải quyết mâu thuẫn này bằng hình dáng chữ U: Nửa bên trái chịu trách nhiệm "Nén để hiểu", nửa bên phải chịu trách nhiệm "Giải nén để tìm lại tọa độ", và các "cây cầu" bắc ngang để ghép hai thông tin này lại.
2.1 Các phương pháp được sử dụng trong cấu trúc Unet
Trước khi đi sâu vào cấu trúc của Unet, ta cần làm rõ một vài khái niệm sau đây.
2.1.1 Skip Connections
Trong các mô hình mạng dạng encoder-decoder, quá trình giảm kích thước ảnh (downsampling) ở nhánh mã hóa thường dẫn đến sự suy hao đáng kể về mặt dữ liệu. Để giải quyết rào cản này, kết nối tắt (skip connections) được ứng dụng như một kỹ thuật thiết yếu. Thay vì ép toàn bộ luồng thông tin phải truyền qua "nút thắt cổ chai" (bottleneck), skip connections thiết lập một kênh truyền tải trực tiếp từ encoder sang decoder. Điều này giúp giảm thiểu tối đa rủi ro mất mát dữ liệu do các phép gộp (pooling) gắt gao gây ra. Quan trọng hơn, cơ chế này khắc phục triệt để vấn đề mất thông tin không gian (spatial dimension). Nếu mạng giải mã chỉ phụ thuộc vào bản đồ đặc trưng từ bottleneck, tọa độ chi tiết của các điểm ảnh sẽ bị hao hụt trong quá trình khôi phục độ phân giải. Nhờ luồng thông tin nguyên bản được luân chuyển trực tiếp từ mạng mã hóa, decoder được cung cấp đầy đủ dữ liệu không gian, từ đó tái tạo chính xác vị trí của từng pixel.
2.1.2 Phép tích chập (Convolution) và phép tích chập chuyển vị (Transposed Convolution)
Phép tích chập (Convolution) đóng vai trò cốt lõi trong mạng nơ-ron tích chập (CNN), hoạt động bằng cách trượt một bộ lọc (kernel) qua dữ liệu đầu vào để tạo ra các bản đồ đặc trưng (feature maps). Quá trình này thường thu gọn không gian chiều của dữ liệu, giúp trích xuất hiệu quả các đặc điểm cục bộ như góc, cạnh hay họa tiết.
Các bước thực hiện Convolution:
- B1: Đặt Kernel (Filter): Đặt một ma trận nhỏ (kernel) lên trên ma trận đầu vào (input) tại vị trí bắt đầu (thường là góc trên cùng bên trái).
-
B2: Thêm các vòng giá trị 0 quanh ảnh đầu vào. Mục đích là để giữ nguyên kích thước ảnh hoặc cho phép kernel quét qua các phần mép ảnh (nơi chứa thông tin quan trọng) nếu cần (Padding).
-
B3: Nhân từng phần tử (Element-wise multiplication): Nhân các giá trị của kernel với các giá trị tương ứng của vùng input mà nó đang đè lên.
-
B4: Cộng dồn (Summation): Cộng tất cả các kết quả vừa nhân được để có một giá trị duy nhất cho ma trận đầu ra (feature map).
-
B5: Trượt (Sliding): Dịch chuyển kernel sang phải (hoặc xuống dưới) theo một khoảng cách gọi là Stride và lặp lại bước 2, 3 cho đến khi quét hết input.
Ví dụ cụ thể:
Giả sử ta có:Input ($3 \times 3$):$$\begin{bmatrix} 1 & 2 & 3 \\ 4 & 5 & 6 \\ 7 & 8 & 9 \end{bmatrix}$$Kernel ($2 \times 2$):$$\begin{bmatrix} 1 & 0 \\ 0 & 1 \end{bmatrix}$$
Stride: 1, Padding: 0.
Bước 1: Tính giá trị đầu tiên (Vị trí hàng 1, cột 1)
Vùng input tương ứng: $\begin{bmatrix} 1 & 2 \\ 4 & 5 \end{bmatrix}$
Tính toán: $(1 \times 1) + (2 \times 0) + (4 \times 0) + (5 \times 1) = 1 + 0 + 0 + 5 = \mathbf{6}$
Bước 2: Trượt sang phải 1 đơn vị (Vị trí hàng 1, cột 2)
Vùng input tương ứng: $\begin{bmatrix} 2 & 3 \\ 5 & 6 \end{bmatrix}$
Tính toán: $(2 \times 1) + (3 \times 0) + (5 \times 0) + (6 \times 1) = 2 + 0 + 0 + 6 = \mathbf{8}$
Kết quả cuối cùng: Ma trận đầu ra sẽ là $\begin{bmatrix} 6 & 8 \\ 12 & 14 \end{bmatrix}$ (Kích thước giảm xuống).
Ngược lại với quá trình thu gọn này, Tích chập chuyển vị (Transposed Convolution hay Deconvolution) được sử dụng để phóng to kích thước dữ liệu. Kỹ thuật này đặc biệt quan trọng trong các tác vụ như Phân vùng ảnh (Image Segmentation) hay Sinh ảnh (Image Generation), nơi mô hình cần khôi phục lại độ phân giải ban đầu.
Các bước thực hiện Transposed Convolution:
-
B1: Lấy giá trị Input: Xét từng pixel một trên ma trận input nhỏ.
-
B2: Nhân với Kernel: Nhân giá trị của pixel đó với toàn bộ các trọng số trong ma trận Kernel. Ta thu được một ma trận trung gian có kích thước bằng Kernel.
-
B3: Đặt vào Output: Đặt ma trận trung gian này vào ma trận đầu ra tại vị trí tương ứng với pixel đang xét.
-
B4: Cộng dồn vùng chồng lấn (Overlapping): Nếu các ma trận trung gian đè lên nhau, ta cộng các giá trị tại vị trí đó lại.
-
B5: Xử lí Stride và Padding: Trong Transposed Convolution, Stride không phải là bước nhảy của Kernel trên Input, mà là độ giãn cách giữa các pixel Input trên ma trận Output.
Ví dụ cụ thể:
Input ($2 \times 2$): $\begin{bmatrix} a & b \\ c & d \end{bmatrix}$Kernel ($2 \times 2$): $\begin{bmatrix} x & y \\ z & t \end{bmatrix}$
Stride = 1, Padding = 0.
Bước 1: Xử lý pixel $a$ (tại vị trí 0,0)
Kết quả 1 = $a \times \text{Kernel} = \begin{bmatrix} ax & ay \\ az & at \end{bmatrix}$
Đặt Kết quả 1 vào góc (0,0) của ma trận đầu ra.
Bước 2: Xử lý pixel $b$ (tại vị trí 0,1)
Kết quả 2 = $b \times \text{Kernel} = \begin{bmatrix} bx & by \\ bz & bt \end{bmatrix}$
Vì Stride = 1, ta đặt Kết quả 2 dịch sang phải 1 đơn vị.
Lúc này cột cuối của Kết quả 1 và cột đầu của Kết quả 2 sẽ chồng lên nhau.
Bước 3: Cộng dồn vùng chồng lấn
Tại cột 1, giá trị sẽ là: $ay + bx$.
Về bản chất, nếu Convolution dùng kernel để gộp các điểm ảnh thành một đặc trưng, thì Transposed Convolution làm điều ngược lại: ánh xạ một đặc trưng phân tán thành nhiều điểm ảnh để mở rộng feature map (thông qua việc điều chỉnh padding và stride).
Điểm ưu việt của Transposed Convolution so với các kỹ thuật nội suy cơ bản (như Nearest Neighbors, Bi-Linear Interpolation hay Max-Unpooling) nằm ở khả năng tự học các trọng số trong quá trình huấn luyện, từ đó tái tạo các chi tiết không gian một cách sắc nét và chính xác hơn.
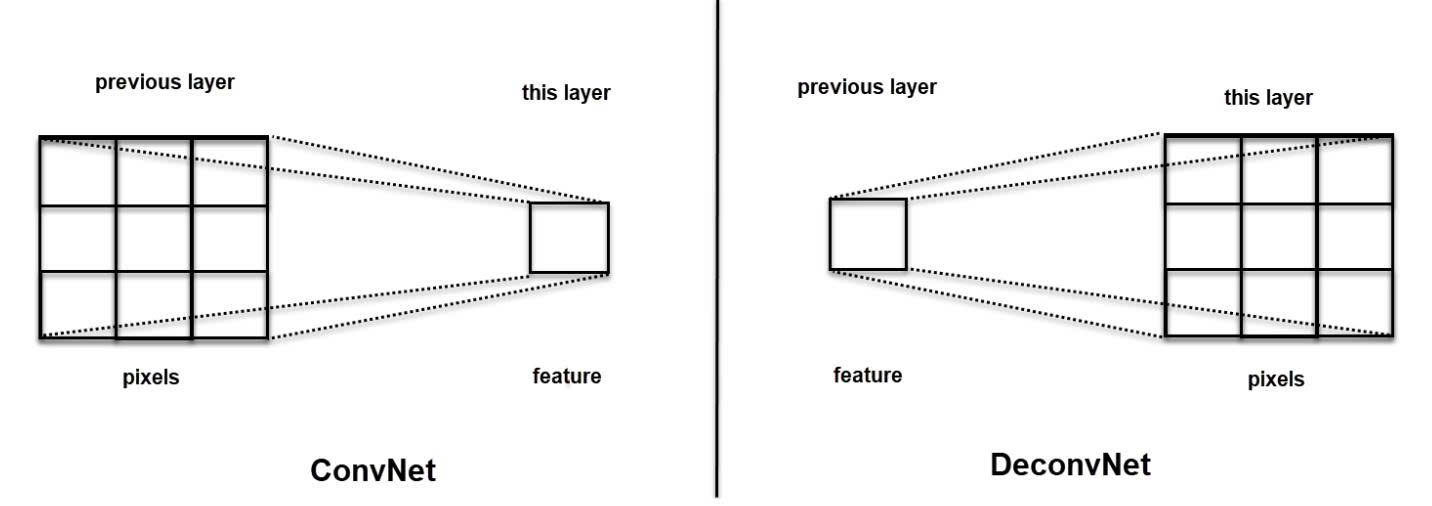
Hình 4: ConvNet và DeconvNet
2.1.3 Max pooling
Max Pooling (Gộp tối đa) là một kỹ thuật giảm kích thước (downsampling) cực kỳ phổ biến trong mạng nơ-ron tích chập. Nhiệm vụ của nó là lướt qua các bản đồ đặc trưng (feature maps) do lớp Convolution tạo ra trước đó, và chỉ giữ lại giá trị lớn nhất (đại diện cho đặc trưng nổi bật nhất) trong từng vùng mà nó đi qua.
Để thực hiện Max Pooling, chúng ta cần xác định 2 tham số chính: kích thước cửa sổ (Filter size) và bước trượt (Stride). Kích thước phổ biến nhất thường là cửa sổ 2x2 với bước trượt là 2.
Cửa sổ này sẽ trượt dọc và ngang trên ma trận dữ liệu. Ở mỗi vị trí, nó sẽ nhìn vào các con số nằm gọn trong cửa sổ, nhặt ra con số lớn nhất và vứt bỏ các con số còn lại.

Hình 5: Max Pooling (Nguồn: https://www.geeksforgeeks.org/deep-learning/cnn-introduction-to-pooling-layer/)
2.2 Nhánh thu hẹp (The Contracting Path / Encoder) - Bên trái chữ U
Mục đích của nhánh này là trích xuất đặc trưng (Feature Extraction). Bức ảnh sẽ đi qua nhiều "bậc thang" đi xuống. Càng xuống sâu, ảnh càng nhỏ lại về kích thước chiều dài/rộng, nhưng lại dày lên về số lượng kênh (channels).
Tại mỗi bậc thang đi xuống, kiến trúc sẽ thực hiện 2 thao tác:
1. Hai lớp Tích chập (Convolution 3x3) + Hàm kích hoạt ReLU: Các bộ lọc (filters) kích thước 3x3 sẽ trượt qua toàn bộ bức ảnh để tìm kiếm các đặc trưng (cạnh, góc, màu sắc...). Hàm ReLU sẽ giữ nguyên các giá trị dương và biến các giá trị âm thành 0 để tạo tính phi tuyến.
- Lớp Max Pooling 2x2: Kéo một cửa sổ 2x2 trượt qua bản đồ đặc trưng, trong mỗi ô 2x2, nó chỉ giữ lại giá trị lớn nhất (pixel nổi bật nhất) và vứt bỏ 3 pixel còn lại. Thao tác này khiến chiều dài và chiều rộng của ảnh giảm đi chính xác một nửa.
Quá trình Convolution và Max Pooling này lặp lại nhiều lần, đưa chúng ta xuống đáy chữ U.
2.3 Phần Đáy (Bottleneck)
Đây là nơi bức ảnh bị nén ở mức tối đa. Không có Max Pooling ở đây.
Cơ chế: Gồm 2 lớp Convolution 3x3 + ReLU nối tiếp nhau. Tại đây, số lượng kênh (chiều sâu của dữ liệu) đạt mức cao nhất (thường là 1024 kênh).
2.4 Nhánh Mở Rộng (Decoder) - Nửa bên phải chữ U
Bây giờ là lúc mạng U-Net phải leo lên từng bậc thang để khôi phục lại kích thước ảnh ban đầu.
Tại mỗi bậc thang đi lên, mạng thực hiện các bước sau:
-
Tích chập ngược (Up-convolution / Transposed Convolution 2x2): Kỹ thuật này nhân đôi kích thước chiều dài và chiều rộng của ma trận, đồng thời giảm số lượng kênh đi một nửa để nhẹ bớt dữ liệu.
-
Kết nối tắt (Skip Connection) - Phần quan trọng nhất: Để khắc phục việc "vỡ nét" ở bước 1, U-Net nối thẳng (Concatenate) bản đồ đặc trưng từ nhánh Encoder (bên trái) sang nhánh Decoder (bên phải) ở cùng một cấp độ.
-
Hai lớp Tích chập (Convolution 3x3) + ReLU: Sau khi được "dán" dữ liệu từ Skip Connection, ảnh sẽ chạy qua 2 lớp Convolution nữa để trộn lẫn, làm mịn và học cách kết hợp thông tin không gian + ngữ nghĩa lại một cách hoàn hảo nhất.
Quá trình Transposed convolution, Skip Connection và Convolution + hàm kích hoạt này lặp lại cho đến khi ảnh trở về kích thước ban đầu.
2.5 Khối đầu ra (Output Layer)
Sau khi đã thực hiện xong quá trình Up-convolution, Skip Connection và Convolution của nhánh mở rộng, ta sẽ thu được một khối dữ liệu có kích thước đúng bằng kích thước ảnh gốc. U-Net sử dụng một lớp Tích chập kích thước 1x1 (1x1 Convolution). Lớp này không làm thay đổi chiều dài/rộng, nó chỉ dùng để giảm số kênh xuống còn đúng bằng với số lượng nhãn bạn muốn phân loại.
2.6 Hàm kích hoạt
Hàm kích hoạt giúp mô hình học được các mối quan hệ phi tuyến tính phức tạp trong dữ liệu ảnh. Trong U-Net, chúng ta thường chia làm hai nhóm sử dụng chính:
2.6.1 Tại các lớp ẩn (Hidden Layers):
Trong suốt quá trình Encoder và Decoder (ngoại trừ lớp cuối cùng), U-Net sử dụng phổ biến nhất là hàm ReLU (Rectified Linear Unit).
Công thức: $f(x) = \max(0, x)$
Đặc điểm: Nếu giá trị đầu vào là âm, nó sẽ trả về 0. Nếu là dương, nó giữ nguyên giá trị đó.Lý do sử dụng: ReLU giúp mô hình huấn luyện nhanh hơn rất nhiều và giảm thiểu hiện tượng "biến mất đạo hàm" (vanishing gradient) so với các hàm đời cũ như Sigmoid hay Tanh.
2.6.2. Tại lớp đầu ra (Output Layer):
Đây là phần cực kỳ quan trọng vì nó quyết định định dạng kết quả dự đoán của bạn. Tùy vào bài toán cụ thể mà chúng ta chọn hàm khác nhau. Một số hàm kích hoạt thường dùng trong phần này là softmax, sigmoid,...
2.6.2.1. Sigmoid
Sử dụng khi chỉ cần phân biệt giữa 2 lớp: đối tượng và background.
Công thức: $$\sigma(x) = \frac{1}{1 + e^{-x}}$$
Miền giá trị: $[0, 1]$
2.6.2.2. Softmax
Sử dụng khi cần phải làm việc với nhiều lớp đối tượng.
Công thức: $$\text{Softmax}(x_i) = \frac{e^{x_i}}{\sum e^{x_j}}$$
3. Thực hành Image Segmentation với U-Net trong PyTorch
3.1. Import thư viện
Đầu tiên, chúng ta cần import các thư viện cần thiết để xử lý dữ liệu và xây dụng mô hình.
%matplotlib inline
import numpy as np
import random
import time
import copy
from collections import defaultdict
from functools import reduce
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.optim import lr_scheduler
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f'Sử dụng device: {device}')
3.2. Tạo dữ liệu giả lập
Để dễ dàng hơn cho việc thực hành, chúng ta sẽ tự tạo một bộ dữ liệu hình ảnh. Mỗi bức ảnh sẽ chứa 6 hình dạng khác nhau, bao gồm:
1. Hình vuông tô đặc (filled square)
2. Hình tròn tô đặc (filled circle)
3. Hình tam giác (triangle)
4. Hình tròn rỗng (circle outline)
5. Hình vuông lưới (mesh)
6. Dấu cộng (plus)
Mục tiêu của mô hình là từ bức ảnh đầu vào (chứa tất cả hình dạng chồng lên nhau), mô hình phải tạo ra 6 mask riêng biệt, mỗi mask xác định vị trí của một loại hình dạng.
Dưới đây là các hàm để tạo dữ liệu:
# ============================================================
# Các hàm vẽ hình dạng cơ bản
# ============================================================
def logical_and(arrays):
"""Thực hiện AND logic trên nhiều mảng cùng lúc."""
new_array = np.ones(arrays[0].shape, dtype=bool)
for a in arrays:
new_array = np.logical_and(new_array, a)
return new_array
def add_filled_square(arr, x, y, size):
"""Vẽ hình vuông tô đặc tại vị trí (x, y)."""
s = int(size / 2)
xx, yy = np.mgrid[:arr.shape[0], :arr.shape[1]]
return np.logical_or(arr, logical_and([xx > x - s, xx < x + s, yy > y - s, yy < y + s]))
def add_mesh_square(arr, x, y, size):
"""Vẽ hình vuông dạng lưới (mesh) tại vị trí (x, y)."""
s = int(size / 2)
xx, yy = np.mgrid[:arr.shape[0], :arr.shape[1]]
return np.logical_or(arr, logical_and([xx > x - s, xx < x + s, xx % 2 == 1, yy > y - s, yy < y + s, yy % 2 == 1]))
def add_triangle(arr, x, y, size):
"""Vẽ hình tam giác tại vị trí (x, y)."""
s = int(size / 2)
triangle = np.tril(np.ones((size, size), dtype=bool))
arr[x-s:x-s+triangle.shape[0], y-s:y-s+triangle.shape[1]] = triangle
return arr
def add_circle(arr, x, y, size, fill=False):
"""Vẽ hình tròn (tô đặc hoặc viền) tại vị trí (x, y)."""
xx, yy = np.mgrid[:arr.shape[0], :arr.shape[1]]
circle = np.sqrt((xx - x) ** 2 + (yy - y) ** 2)
new_arr = np.logical_or(arr, np.logical_and(circle < size, circle >= size * 0.7 if not fill else True))
return new_arr
def add_plus(arr, x, y, size):
"""Vẽ dấu cộng (+) tại vị trí (x, y)."""
s = int(size / 2)
arr[x-1:x+1, y-s:y+s] = True
arr[x-s:x+s, y-1:y+1] = True
return arr
def get_random_location(width, height, zoom=1.0):
"""Tạo vị trí ngẫu nhiên trong khung hình."""
x = int(width * random.uniform(0.1, 0.9))
y = int(height * random.uniform(0.1, 0.9))
size = int(min(width, height) * random.uniform(0.06, 0.12) * zoom)
return (x, y, size)
# ============================================================
# Hàm tạo ảnh và mask
# ============================================================
def generate_img_and_mask(height, width):
"""
Tạo MỘT bức ảnh và 6 mask tương ứng.
Returns:
arr: Ảnh đầu vào (1, H, W) - tất cả hình chồng lên nhau
masks: 6 mask riêng biệt (6, H, W) - mỗi mask cho một loại hình
"""
shape = (height, width)
# Tạo vị trí ngẫu nhiên cho mỗi hình
triangle_location = get_random_location(*shape)
circle_location1 = get_random_location(*shape, zoom=0.7)
circle_location2 = get_random_location(*shape, zoom=0.5)
mesh_location = get_random_location(*shape)
square_location = get_random_location(*shape, zoom=0.8)
plus_location = get_random_location(*shape, zoom=1.2)
# Tạo ảnh đầu vào: vẽ TẤT CẢ hình lên cùng một bức ảnh
arr = np.zeros(shape, dtype=bool)
arr = add_triangle(arr, *triangle_location)
arr = add_circle(arr, *circle_location1)
arr = add_circle(arr, *circle_location2, fill=True)
arr = add_mesh_square(arr, *mesh_location)
arr = add_filled_square(arr, *square_location)
arr = add_plus(arr, *plus_location)
arr = np.reshape(arr, (1, height, width)).astype(np.float32)
# Tạo target mask: mỗi hình dạng có MỘT mask riêng
masks = np.asarray([
add_filled_square(np.zeros(shape, dtype=bool), *square_location), # Mask 0: Hình vuông
add_circle(np.zeros(shape, dtype=bool), *circle_location2, fill=True),# Mask 1: Hình tròn đặc
add_triangle(np.zeros(shape, dtype=bool), *triangle_location), # Mask 2: Tam giác
add_circle(np.zeros(shape, dtype=bool), *circle_location1), # Mask 3: Vòng tròn
add_filled_square(np.zeros(shape, dtype=bool), *mesh_location), # Mask 4: Hình lưới
add_plus(np.zeros(shape, dtype=bool), *plus_location) # Mask 5: Dấu cộng
]).astype(np.float32)
return arr, masks
def generate_random_data(height, width, count):
"""
Tạo `count` bức ảnh ngẫu nhiên cùng mask tương ứng.
Returns:
X: Ảnh đầu vào (count, H, W, 3) - RGB
Y: Target masks (count, 6, H, W)
"""
x, y = zip(*[generate_img_and_mask(height, width) for i in range(0, count)])
X = np.asarray(x) * 255
X = X.repeat(3, axis=1).transpose([0, 2, 3, 1]).astype(np.uint8)
Y = np.asarray(y)
return X, Y
# ============================================================
# Hàm hiển thị
# ============================================================
def plot_img_array(img_array, ncol=3):
"""Hiển thị một mảng ảnh dưới dạng lưới."""
nrow = len(img_array) // ncol
_, plots = plt.subplots(nrow, ncol, sharex='all', sharey='all', figsize=(ncol * 4, nrow * 4))
for i in range(len(img_array)):
plots[i // ncol, i % ncol].imshow(img_array[i])
plt.tight_layout()
def plot_side_by_side(img_arrays):
"""Hiển thị nhiều nhóm ảnh cạnh nhau để so sánh."""
flatten_list = reduce(lambda x, y: x + y, zip(*img_arrays))
plot_img_array(np.array(flatten_list), ncol=len(img_arrays))
def masks_to_colorimg(masks):
"""
Chuyển 6 mask (mỗi mask là 1 kênh) thành một ảnh RGB màu.
Mỗi loại hình dạng sẽ được tô một màu khác nhau.
"""
colors = np.asarray([
(201, 58, 64), # Đỏ - Hình vuông
(242, 207, 1), # Vàng - Hình tròn đặc
(0, 152, 75), # Xanh lá - Tam giác
(101, 172, 228), # Xanh dương - Vòng tròn
(56, 34, 132), # Tím - Hình lưới
(160, 194, 56) # Xanh lục - Dấu cộng
])
colorimg = np.ones((masks.shape[1], masks.shape[2], 3), dtype=np.float32) * 255
channels, height, width = masks.shape
for y in range(height):
for x in range(width):
selected_colors = colors[masks[:, y, x] > 0.5]
if len(selected_colors) > 0:
colorimg[y, x, :] = np.mean(selected_colors, axis=0)
return colorimg.astype(np.uint8)
3.3. Trực quan dữ liệu giả lập
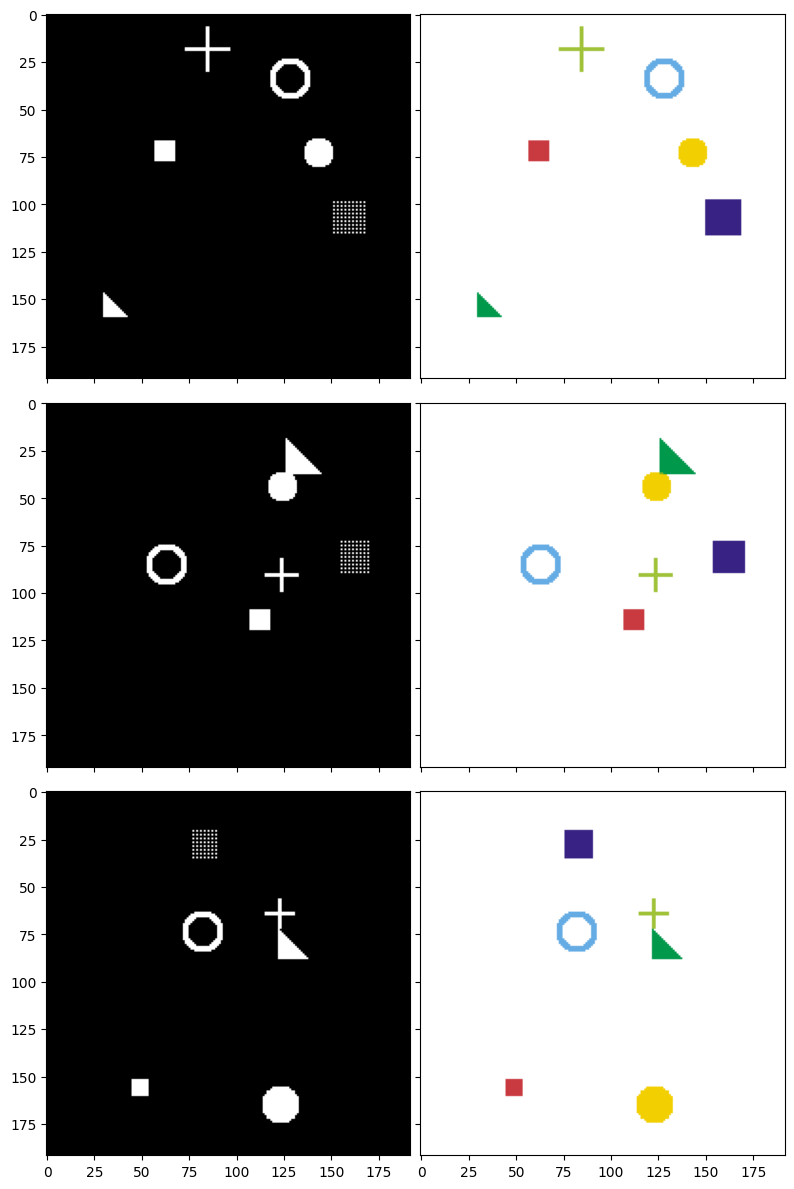
Sau khi định nghĩa các hàm vẽ, hãy cùng tạo một số dữ liệu mẫu để hình dung rõ hơn về mục tiêu của mô hình. Dưới đây là 3 ví dụ kèm theo mask tương ứng. Các cặp ảnh sẽ được hiển thị theo từng dòng:
- Cột trái (Ảnh đầu vào): Bạn thấy tất cả các hình dạng được vẽ chồng lên nhau trên nền đen. Đây là những gì mô hình sẽ "nhìn thấy".
- Cột phải (Mask mục tiêu): Mỗi hình dạng được tô một màu riêng biệt. Đây là "đáp án" mà mô hình cần học để dự đoán.
Chúng ta sẽ xây dựng mô hình U-Net để nhận ảnh từ cột trái và dự đoán ra mask giống cột phải nhất có thể.
# Tạo 3 ảnh mẫu
input_images, target_masks = generate_random_data(192, 192, count=3)
# Chuyển mask sang ảnh màu để dễ nhìn
input_images_rgb = [x.astype(np.uint8) for x in input_images]
target_masks_rgb = [masks_to_colorimg(x) for x in target_masks]
# Hiển thị: Trái = Ảnh đầu vào, Phải = Mask mục tiêu
plot_side_by_side([input_images_rgb, target_masks_rgb])
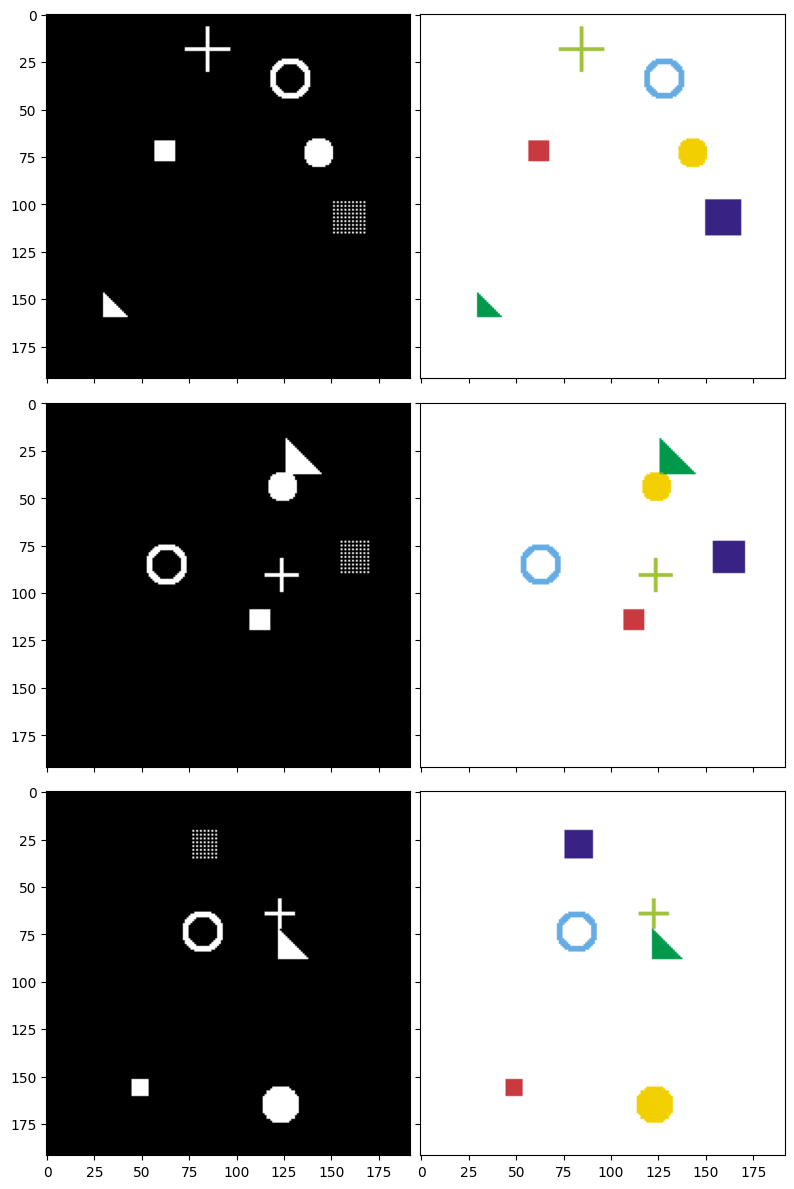
Hình 6: Ảnh đầu vào (trái) và mask mục tiêu tương ứng (phải) — mỗi màu đại diện cho một loại hình dạng cần phân đoạn.
Xem chi tiết từng mask riêng lẻ
Để hiểu rõ hơn, hãy xem 6 mask riêng biệt của một bức ảnh:
# Xem từng mask riêng lẻ của ảnh đầu tiên
mask_names = ['Hình vuông đặc', 'Hình tròn đặc', 'Tam giác', 'Vòng tròn', 'Hình vuông lưới', 'Dấu cộng']
fig, axes = plt.subplots(2, 4, figsize=(16, 8))
# Ảnh gốc
axes[0, 0].imshow(input_images[0])
axes[0, 0].set_title('Ảnh đầu vào', fontsize=12)
# Mask tổng hợp
axes[0, 1].imshow(target_masks_rgb[0])
axes[0, 1].set_title('Mask tổng hợp (có màu)', fontsize=12)
# Ẩn 2 ô trống
axes[0, 2].axis('off')
axes[0, 3].axis('off')
# 6 mask riêng lẻ
colors_map = ['Reds', 'YlOrBr', 'Greens', 'Blues', 'Purples', 'YlGn']
for i in range(6):
row = (i + 2) // 4
col = (i + 2) % 4
axes[row, col].imshow(target_masks[0][i], cmap=colors_map[i])
axes[row, col].set_title(f'Mask {i}: {mask_names[i]}', fontsize=11)
plt.tight_layout()
plt.show()
Hình 7: Ảnh đầu vào và 6 mask ground truth tương ứng — mỗi mask chứa duy nhất một loại hình dạng cần phân đoạn
3.4. Tạo Dataset và DataLoader
PyTorch sử dụng hai khái niệm quan trọng:
- Dataset: Nơi chứa dữ liệu, cung cấp cách truy cập từng mẫu
- DataLoader: Tự động chia dữ liệu thành các batch, xáo trộn (shuffle), v.v.
Chúng ta sẽ tạo:
- 2000 ảnh cho tập huấn luyện (train)
- 200 ảnh cho tập kiểm tra (validation)
class SimDataset(Dataset):
"""
Dataset chứa các ảnh hình dạng ngẫu nhiên.
Kế thừa từ torch.utils.data.Dataset.
"""
def __init__(self, count, transform=None):
# Tạo tất cả ảnh ngay khi khởi tạo dataset
self.input_images, self.target_masks = generate_random_data(192, 192, count=count)
self.transform = transform
def __len__(self):
return len(self.input_images)
def __getitem__(self, idx):
image = self.input_images[idx]
mask = self.target_masks[idx]
if self.transform:
image = self.transform(image)
return [image, mask]
# Transform: chuyển numpy array → PyTorch Tensor
trans = transforms.Compose([
transforms.ToTensor(), # Chuyển (H, W, C) → (C, H, W) và scale [0, 255] → [0, 1]
])
# Tạo dataset
train_set = SimDataset(2000, transform=trans)
val_set = SimDataset(200, transform=trans)
# Tạo DataLoader
batch_size = 25
dataloaders = {
'train': DataLoader(train_set, batch_size=batch_size, shuffle=True, num_workers=0),
'val': DataLoader(val_set, batch_size=batch_size, shuffle=True, num_workers=0)
}
dataset_sizes = {x: len(ds) for x, ds in zip(['train', 'val'], [train_set, val_set])}
# Kiểm tra một batch dữ liệu
def reverse_transform(inp):
"""Chuyển tensor (C, H, W) về numpy RGB (H, W, C) để hiển thị."""
inp = inp.numpy().transpose((1, 2, 0))
inp = np.clip(inp, 0, 1)
inp = (inp * 255).astype(np.uint8)
return inp
inputs, masks = next(iter(dataloaders['train']))
print(f'Batch inputs shape: {inputs.shape}') # (25, 3, 192, 192)
print(f'Batch masks shape: {masks.shape}') # (25, 6, 192, 192)
# Hiển thị một ảnh từ batch
plt.figure(figsize=(5, 5))
plt.imshow(reverse_transform(inputs[0]))
plt.title('Một ảnh mẫu từ training batch')
plt.axis('off')
plt.show()
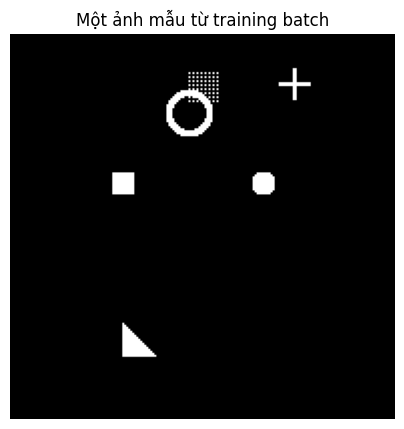
Hình 8: Đầu vào mà mô hình nhận được: 6 hình dạng được vẽ ngẫu nhiên chồng lên nhau trên nền đen.
3.5. Xây dựng mô hình U-Net
Double Convolution Block
Đây là "viên gạch" cơ bản của U-Net. Mỗi tầng trong U-Net đều sử dụng 2 lớp Convolution liên tiếp:
Input → Conv2d(3×3) → ReLU → Conv2d(3×3) → ReLU → Output
- Conv2d(3×3): Lớp tích chập với kernel 3×3,
padding=1để giữ nguyên kích thước - ReLU: Hàm kích hoạt, giúp mạng học được các quan hệ phi tuyến
Chúng ta sử dụng 2 lớp Conv liên tiếp để giúp mạng trích xuất đặc trưng phong phú hơn tại mỗi mức.
def double_conv(in_channels, out_channels):
"""
Khối Double Convolution: Conv → ReLU → Conv → ReLU
Giữ nguyên kích thước spatial (H, W) nhờ padding=1.
"""
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),
nn.ReLU(inplace=True)
)
Mô hình U-Net hoàn chỉnh
Dưới đây là mô hình U-Net với cấu trúc:
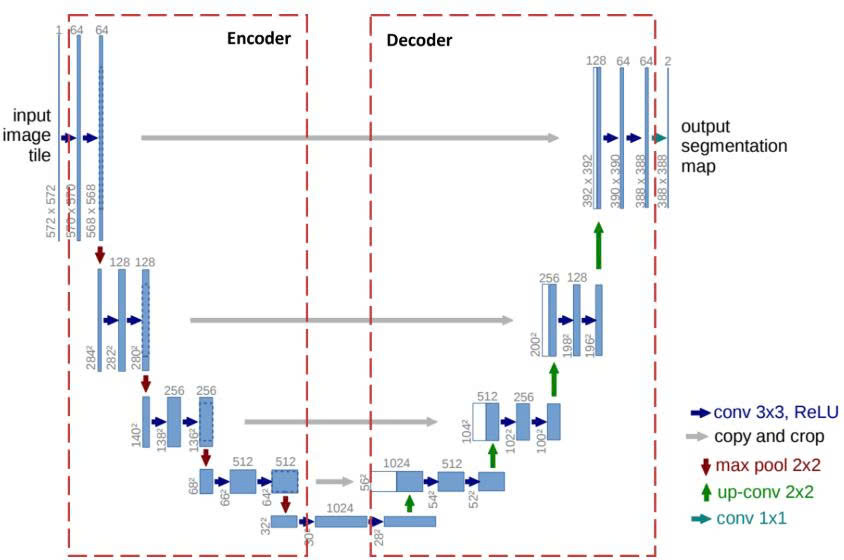
Hình 9: Cấu trúc U-Net [2]
Chú ý: Ở Decoder, khi ta nối (concatenate) feature map từ Encoder qua skip connection, số kênh sẽ cộng lại. Ví dụ: 512 (từ Bottleneck) + 256 (từ skip) = 768 kênh đầu vào cho dconv_up3.
class UNet(nn.Module):
"""
Mô hình U-Net cho Image Segmentation.
Args:
n_class: Số lượng lớp cần phân đoạn (= số mask đầu ra)
"""
def __init__(self, n_class):
super().__init__()
# === ENCODER (đường đi xuống) ===
self.dconv_down1 = double_conv(3, 64) # (3, H, W) → (64, H, W)
self.dconv_down2 = double_conv(64, 128) # (64, H/2, W/2) → (128, H/2, W/2)
self.dconv_down3 = double_conv(128, 256) # (128, H/4, W/4) → (256, H/4, W/4)
self.dconv_down4 = double_conv(256, 512) # (256, H/8, W/8) → (512, H/8, W/8) ← Bottleneck
# MaxPool giảm kích thước đi một nửa
self.maxpool = nn.MaxPool2d(2)
# Upsample tăng kích thước lên gấp đôi
self.upsample = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
# === DECODER (đường đi lên) ===
# Chú ý: số kênh đầu vào = upsample channels + skip channels
self.dconv_up3 = double_conv(256 + 512, 256) # (768, H/4, W/4) → (256, H/4, W/4)
self.dconv_up2 = double_conv(128 + 256, 128) # (384, H/2, W/2) → (128, H/2, W/2)
self.dconv_up1 = double_conv(128 + 64, 64) # (192, H, W) → (64, H, W)
# Lớp cuối: chuyển 64 kênh → n_class kênh (mỗi kênh = 1 mask)
self.conv_last = nn.Conv2d(64, n_class, kernel_size=1)
def forward(self, x):
# ========== ENCODER ==========
conv1 = self.dconv_down1(x) # Lưu lại cho skip connection
x = self.maxpool(conv1) # Giảm kích thước ×2
conv2 = self.dconv_down2(x) # Lưu lại cho skip connection
x = self.maxpool(conv2) # Giảm kích thước ×2
conv3 = self.dconv_down3(x) # Lưu lại cho skip connection
x = self.maxpool(conv3) # Giảm kích thước ×2
# ========== BOTTLENECK ==========
x = self.dconv_down4(x) # Biểu diễn cô đọng nhất
# ========== DECODER ==========
x = self.upsample(x) # Phóng to ×2
x = torch.cat([x, conv3], dim=1) # Nối với skip connection từ encoder
x = self.dconv_up3(x)
x = self.upsample(x) # Phóng to ×2
x = torch.cat([x, conv2], dim=1) # Nối với skip connection
x = self.dconv_up2(x)
x = self.upsample(x) # Phóng to ×2
x = torch.cat([x, conv1], dim=1) # Nối với skip connection
x = self.dconv_up1(x)
# Lớp cuối: chuyển về n_class kênh
out = self.conv_last(x)
return out
3.6. Loss Function — Hàm mất mát
Để huấn luyện mô hình, ta cần một loss function để tính được mô hình dự đoán sai bao nhiêu so với đáp án. Chúng ta sẽ kết hợp 2 loss function phổ biến cho bài toán segmentation:
3.6.1. Binary Cross-Entropy (BCE)
Hàm mất mát này thực hiện phân loại nhị phân cho từng điểm ảnh, giúp mô hình nhận diện chính xác mỗi pixel có nằm trong vùng của hình dạng X hay không.
3.6.2. Dice Loss
Dice Loss là một hàm mất mát quan trọng dùng để đo lường mức độ trùng khớp giữa vùng dự đoán và vùng thực tế trong các bài toán phân đoạn hình ảnh. Giá trị của Dice Loss dao động trong khoảng từ 0 đến 1, tương ứng với các trạng thái từ trùng khớp hoàn toàn cho đến không có điểm chung nào. Ưu điểm vượt trội của hàm này là khả năng xử lý hiệu quả tình trạng mất cân bằng lớp (class imbalance), đặc biệt hữu ích khi vùng đối tượng cần phân đoạn chiếm diện tích rất nhỏ so với tổng thể bức ảnh.
Về mặt toán học, công thức Dice Loss được xác định như sau:
$$\text{Dice} = 1 - \frac{2 \times |A \cap B|}{|A| + |B|}$$
Trong đó, $A$ đại diện cho vùng dự đoán của mô hình, $B$ là vùng thực tế (ground truth), và $|A \cap B|$ biểu thị phần giao nhau giữa hai vùng này.
3.6.3. Kết hợp BCE + Dice
Chúng ta kết hợp 2 hàm loss trên thành loss function chính:
$$\text{Loss} = 0.5 \times \text{BCE} + 0.5 \times \text{Dice}$$
Sự kết hợp này giúp mô hình vừa phân loại đúng từng pixel (BCE), vừa đảm bảo hình dạng tổng thể chính xác (Dice).
def dice_loss(pred, target, smooth=1.):
"""
Tính Dice Loss giữa prediction và target.
Args:
pred: Dự đoán của mô hình (đã qua sigmoid), shape (N, C, H, W)
target: Mask thực tế, shape (N, C, H, W)
smooth: Hệ số làm mượt, tránh chia cho 0
"""
pred = pred.contiguous()
target = target.contiguous()
# Tính phần giao nhau (intersection)
intersection = (pred * target).sum(dim=2).sum(dim=2)
# Tính Dice coefficient rồi chuyển thành loss
loss = (1 - ((2. * intersection + smooth) /
(pred.sum(dim=2).sum(dim=2) + target.sum(dim=2).sum(dim=2) + smooth)))
return loss.mean()
def calc_loss(pred, target, metrics, bce_weight=0.5):
"""
Tính tổng loss = BCE + Dice.
Đồng thời ghi nhận các metrics để theo dõi.
"""
bce = F.binary_cross_entropy_with_logits(pred, target)
pred = torch.sigmoid(pred) # Chuyển logits → xác suất [0, 1]
dice = dice_loss(pred, target)
loss = bce * bce_weight + dice * (1 - bce_weight)
metrics['bce'] += bce.data.cpu().numpy() * target.size(0)
metrics['dice'] += dice.data.cpu().numpy() * target.size(0)
metrics['loss'] += loss.data.cpu().numpy() * target.size(0)
return loss
3.7. Huấn luyện mô hình
3.7.1. Vòng lặp huấn luyện (Training Loop)
Đây là phần "động cơ" của quá trình huấn luyện. Mỗi epoch gồm 2 giai đoạn:
- Training phase: Mô hình học từ dữ liệu, cập nhật trọng số
- Validation phase: Đánh giá mô hình trên dữ liệu chưa thấy, không cập nhật trọng số
Chúng ta cũng lưu lại mô hình tốt nhất (có val loss thấp nhất) để sử dụng sau.
def print_metrics(metrics, epoch_samples, phase):
"""In các metrics của một phase."""
outputs = []
for k in metrics.keys():
outputs.append("{}: {:.4f}".format(k, metrics[k] / epoch_samples))
print("{}: {}".format(phase, ", ".join(outputs)))
def train_model(model, optimizer, scheduler, num_epochs=25):
"""
Vòng lặp huấn luyện chính.
Args:
model: Mô hình U-Net
optimizer: Thuật toán tối ưu (Adam)
scheduler: Điều chỉnh learning rate
num_epochs: Số epoch huấn luyện
Returns:
model: Mô hình với trọng số tốt nhất
"""
best_model_wts = copy.deepcopy(model.state_dict())
best_loss = 1e10
# Lưu lịch sử loss để vẽ biểu đồ
history = {'train_loss': [], 'val_loss': []}
for epoch in range(num_epochs):
print(f'Epoch {epoch}/{num_epochs - 1}')
print('-' * 30)
since = time.time()
# Mỗi epoch có 2 phase: train và val
for phase in ['train', 'val']:
if phase == 'train':
model.train() # Bật chế độ training (dropout, batchnorm hoạt động)
else:
model.eval() # Bật chế độ evaluation
metrics = defaultdict(float)
epoch_samples = 0
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
# Xóa gradient cũ
optimizer.zero_grad()
# Forward pass
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
loss = calc_loss(outputs, labels, metrics)
# Backward + update chỉ khi training
if phase == 'train':
loss.backward()
optimizer.step()
epoch_samples += inputs.size(0)
print_metrics(metrics, epoch_samples, phase)
epoch_loss = metrics['loss'] / epoch_samples
# Ghi lại loss
if phase == 'train':
history['train_loss'].append(epoch_loss)
else:
history['val_loss'].append(epoch_loss)
# Lưu mô hình tốt nhất
if phase == 'val' and epoch_loss < best_loss:
print(" → Lưu mô hình tốt nhất!")
best_loss = epoch_loss
best_model_wts = copy.deepcopy(model.state_dict())
# Cập nhật learning rate
scheduler.step()
time_elapsed = time.time() - since
print(f'Thời gian: {time_elapsed // 60:.0f}m {time_elapsed % 60:.0f}s\n')
print(f'\n🏆 Best val loss: {best_loss:.4f}')
# Load trọng số tốt nhất
model.load_state_dict(best_model_wts)
return model, history
3.7.2. Huấn luyện mô hình
Chúng ta sẽ sử dụng:
- Adam optimizer: Thuật toán tối ưu phổ biến, tự động điều chỉnh learning rate cho từng parameter
- Learning rate = 1e-4: Tốc độ học ban đầu
- StepLR scheduler: Giảm learning rate đi 10 lần mỗi 25 epoch
- 40 epoch: Số lần lặp qua toàn bộ dữ liệu
num_class = 6 # Số mask cần dự đoán
# Khởi tạo lại mô hình (đảm bảo bắt đầu từ đầu)
model = UNet(num_class).to(device)
# Optimizer: Adam với learning rate = 0.0001
optimizer = optim.Adam(model.parameters(), lr=1e-4)
# Scheduler: giảm LR ×0.1 mỗi 25 epoch
scheduler = lr_scheduler.StepLR(optimizer, step_size=25, gamma=0.1)
# Bắt đầu huấn luyện
model, history = train_model(model, optimizer, scheduler, num_epochs=40)
Biểu đồ Loss qua các epoch
Sau khi hoàn tất huấn luyện, hãy xem loss giảm dần như thế nào trong quá trình huấn luyện:
# Vẽ biểu đồ training/validation loss
plt.figure(figsize=(10, 5))
plt.plot(history['train_loss'], label='Train Loss', linewidth=2)
plt.plot(history['val_loss'], label='Validation Loss', linewidth=2)
plt.xlabel('Epoch', fontsize=12)
plt.ylabel('Loss', fontsize=12)
plt.title('Training & Validation Loss qua các Epoch', fontsize=14)
plt.legend(fontsize=12)
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
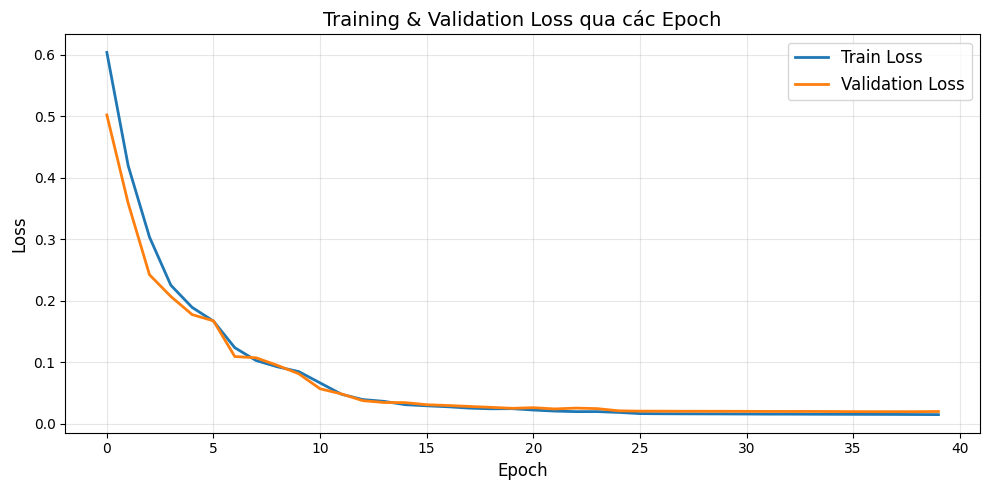
Hình 10: Quá trình huấn luyện mô hình
Chúng ta thấy rằng loss giảm nhanh trong 10 epoch đầu (từ 0.6 xuống 0.05), cho thấy mô hình học được các đặc trưng chính của dữ liệu rất sớm. Sau epoch 15, cả hai đường cong gần như phẳng và hội tụ về giá trị rất thấp (~0.02), chứng tỏ mô hình đã học tốt và ổn định. Chúng ta cũng thấy rằng train loss và Validation loss bám sát nhau suốt quá trình huấn luyện, cho thấy mô hình không bị overfitting.
3.8. Kiểm tra kết quả — Mô hình đã học được gì?
Chúng ta sẽ tạo dữ liệu mới (mô hình chưa từng thấy) và xem mô hình dự đoán như thế nào. Để kiểm tra kết quả của mô hình và so sánh, chúng ta sẽ hiển thị 3 cột:
1. Ảnh đầu vào: Những gì mô hình "nhìn thấy"
2. Mask thực tế (Ground Truth): Đáp án đúng
3. Dự đoán của mô hình (Prediction): Kết quả mô hình đưa ra
# Chuyển mô hình sang chế độ đánh giá
model.eval()
# Tạo dữ liệu test MỚI (mô hình chưa từng thấy)
test_dataset = SimDataset(3, transform=trans)
test_loader = DataLoader(test_dataset, batch_size=3, shuffle=False, num_workers=0)
# Lấy một batch
inputs, labels = next(iter(test_loader))
inputs = inputs.to(device)
labels = labels.to(device)
# Dự đoán (không cần tính gradient)
with torch.no_grad():
pred = model(inputs)
pred = pred.data.cpu().numpy()
print(f'Output shape: {pred.shape}') # (3, 6, 192, 192)
# Chuẩn bị ảnh để hiển thị
input_images_rgb = [reverse_transform(x) for x in inputs.cpu()]
target_masks_rgb = [masks_to_colorimg(x) for x in labels.cpu().numpy()]
pred_rgb = [masks_to_colorimg(x) for x in pred]
# Hiển thị kết quả
print('Trái → Phải: Ảnh đầu vào | Mask thực tế | Dự đoán của mô hình')
print('=' * 60)
plot_side_by_side([input_images_rgb, target_masks_rgb, pred_rgb])
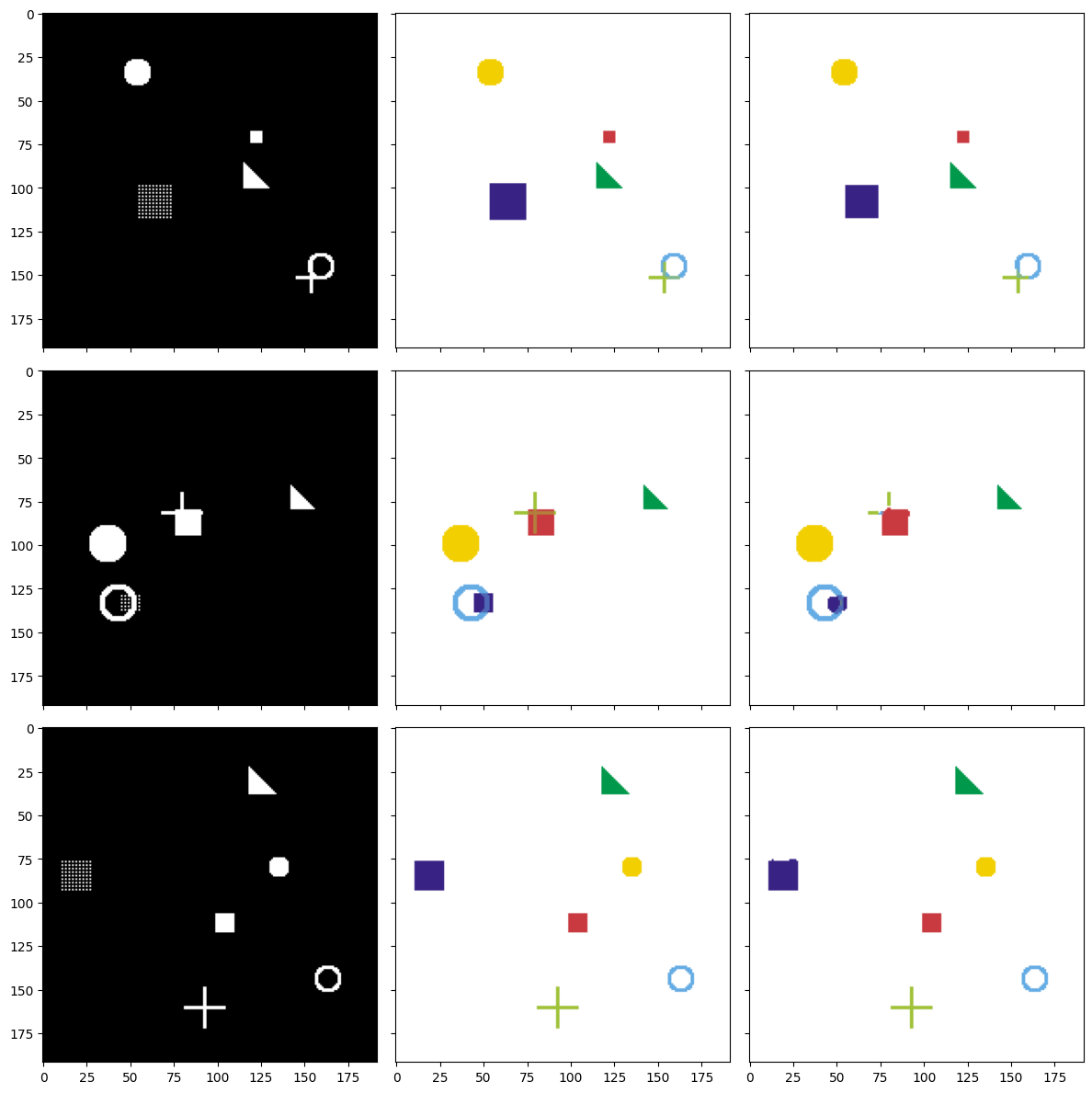
Hình 11: Ba mẫu test: ảnh đầu vào (trái) — mask thực tế (giữa) — dự đoán của mô hình (phải).
Phân tích kết quả
Nhìn vào hình vẽ, chúng ta nhận thấy cột Dự đoán (phải) gần giống với cột Mask thực tế (giữa). Điều này cho thấy mô hình đã học được cách phân biệt các hình dạng khác nhau, xác định đúng vị trí của từng đối tượng trong ảnh và tạo ra mask riêng biệt cho mỗi loại hình.
Dự đoán có thể chưa hoàn hảo 100%, đặc biệt ở các cạnh — điều đó hoàn toàn bình thường. Trong thực tế, có thể cải thiện kết quả bằng cách thêm dữ liệu huấn luyện, tăng số epoch, áp dụng các kỹ thuật như Batch Normalization, Dropout, hoặc sử dụng Data Augmentation.
Xem chi tiết từng mask dự đoán
Hãy so sánh từng mask một cách chi tiết:
# So sánh chi tiết từng mask cho ảnh đầu tiên
mask_names = ['Hình vuông', 'Hình tròn đặc', 'Tam giác', 'Vòng tròn', 'Hình lưới', 'Dấu cộng']
fig, axes = plt.subplots(6, 3, figsize=(12, 24))
fig.suptitle('So sánh chi tiết từng mask (Ảnh #1)', fontsize=16, y=1.01)
for i in range(6):
# Cột 1: Ảnh gốc
axes[i, 0].imshow(input_images_rgb[0])
axes[i, 0].set_title(f'Ảnh gốc' if i == 0 else '')
axes[i, 0].set_ylabel(mask_names[i], fontsize=12, rotation=0, labelpad=80)
# Cột 2: Mask thực tế
axes[i, 1].imshow(labels.cpu().numpy()[0][i], cmap='gray')
axes[i, 1].set_title('Ground Truth' if i == 0 else '')
# Cột 3: Mask dự đoán (áp dụng sigmoid để chuyển về [0, 1])
pred_sigmoid = 1 / (1 + np.exp(-pred[0][i])) # sigmoid
axes[i, 2].imshow(pred_sigmoid, cmap='gray')
axes[i, 2].set_title('Prediction' if i == 0 else '')
for ax in axes.flat:
ax.set_xticks([])
ax.set_yticks([])
plt.tight_layout()
plt.show()

Hình 12: So sánh Ground Truth và Prediction cho từng mask riêng lẻ
Nhìn vào từng cặp Ground Truth - Prediction, có thể thấy mô hình dự đoán rất chính xác vị trí và hình dạng của tất cả 6 lớp. Đặc biệt, các hình có đường nét rõ ràng như vòng tròn, tam giác và dấu cộng được tái tạo gần như hoàn hảo. Đối với hình lưới (mesh square), mô hình dự đoán ra một hình vuông đặc thay vì lưới điểm — điều này hợp lý vì mask ground truth của hình lưới cũng được biểu diễn dưới dạng hình vuông đặc trong quá trình tạo dữ liệu. Nhìn chung, kết quả cho thấy U-Net đã học tốt bài toán phân đoạn này chỉ sau 40 epoch huấn luyện.
3.9. Hướng phát triển tiếp
Nếu bạn muốn tìm hiểu thêm, hãy thử:
- Thay đổi kiến trúc: Thêm Batch Normalization, Dropout, hoặc dùng ResNet làm Encoder
- Thử với dữ liệu thực: Sử dụng dataset như COCO, Pascal VOC, hoặc ảnh y tế
- Data Augmentation: Xoay, lật, thay đổi màu sắc... để mô hình tổng quát hơn
- Các biến thể U-Net: U-Net++, Attention U-Net, V-Net (3D)
Tài liệu tham khảo
[1] N. Usuyama, "pytorch-unet," GitHub, [Online]. Available: https://github.com/usuyama/pytorch-unet. [Accessed: 15-Mar-2026]
[2] O. Ronneberger, P. Fischer, and T. Brox, "U-Net: Convolutional Networks for Biomedical Image Segmentation," arXiv:1505.04597, May 2015. [Online]. Available: https://arxiv.org/pdf/1505.04597. [Accessed: 15-Mar-2026]
Chưa có bình luận nào. Hãy là người đầu tiên!