
Bài viết được thực hiện bởi nhóm CONQ013 - AIO2026
Giới thiệu
Trong bài viết này, chúng ta sẽ cùng nhau xây dựng một dự án Machine Learning "Dự đoán điểm thi của học sinh" hoàn chỉnh từ phân tích data cho đến triển khai mô hình bằng Gradio. Việc dự đoán điểm thi của học sinh sẽ được dựa trên các đặc trưng có trong dữ liệu như study_hours, study_method, sleep_hours, class_attendance,... Đây là một bài toán regression điển hình, rất phù hợp cho những ai mới bắt đầu với ML hoặc muốn có một dự án thực tế để bổ sung vào portfolio.
1. Tổng quan Bài toán & Metrics đánh giá
Mục tiêu: Xây dựng mô hình dự đoán điểm thi của học sinh dựa trên các yếu tố đầu vào như số giờ học, thói quen học tập, chất lượng giấc ngủ...
1.1. Xác định Bài toán
Đây là bài toán Regression - một dạng bài toán Supervised Learning trong Machine Learning.
Regression là bài toán dự đoán một giá trị liên tục thay vì phân loại thành các nhóm rời rạc. Chẳng hạn, thay vì dự đoán một học sinh "Đỗ hay Trượt" (Classification), mô hình Regression có thể trả về con số cụ thể về điểm thi như 75.5 hay 82.3 điểm — tương tự cách người ta dự đoán giá nhà hay nhiệt độ.
Trong bài toán này, biến mục tiêu cần dự đoán là exam_score — một biến liên tục có giá trị từ 0 đến 100 điểm.
1.2. Metrics Đánh giá
Trong bài toán Regression, chúng ta không sử dụng Accuracy làm thước đo vì chỉ số này vốn chỉ dành cho bài toán Classification. Thay vào đó, hiệu suất của mô hình sẽ được đánh giá thông qua bộ ba chỉ số quan trọng là RMSE, MAE và R² Score.
1. RMSE (Root Mean Squared Error) - Sai số bình phương trung bình đo lường sai số trung bình giữa giá trị dự đoán và thực tế, với đơn vị giống với biến mục tiêu (điểm số):
$$RMSE = \sqrt{\frac{\sum_{i=1}^{n} (y_i - \hat{y}_i)^2}{n}}$$
Trong đó, $y_i$ là điểm thi thực tế, $\hat{y}_i$ là điểm thi mô hình dự đoán, và $n$ là tổng số học sinh trong tập dữ liệu.
Giá trị càng thấp càng tốt, ví dụ RMSE = 8 nghĩa là mô hình sai lệch trung bình ±8 điểm. Điểm cần lưu ý là RMSE khá nhạy cảm với outliers, vì nó phạt nặng hơn những sai số lớn.
2. MAE (Mean Absolute Error) - Sai số tuyệt đối trung bình cũng đo sai số trung bình nhưng theo giá trị tuyệt đối, không phân biệt chiều âm hay dương:
$$MAE = \frac{1}{n} \sum_{i=1}^{n} |y_i - \hat{y}_i|$$
So với RMSE, MAE dễ hiểu hơn và ít bị ảnh hưởng bởi outliers, MAE = 3 đơn giản có nghĩa là trung bình mô hình sai lệch 3 điểm.
3. R² Score (Coefficient of Determination) - Hệ số xác định đo lường mức độ mô hình giải thích được sự biến động của dữ liệu:
$$R^2 = 1 - \frac{SS_{residual}}{SS_{total}}$$
Trong đó:
-
$SS_{residual}$: Tổng bình phương sai số dư (phần biến động mô hình chưa giải thích được).
-
$SS_{total}$: Tổng bình phương sai lệch toàn bộ (tổng biến động của toàn bộ dữ liệu).
Giá trị $R^2$ thường nằm trong khoảng từ $0$ đến $1$, ví dụ $R^2 = 0.85$ có nghĩa là mô hình giải thích được $85\%$ variance của dữ liệu, giá trị càng gần $1$ thì mô hình càng tối ưu.
Với bài toán đã được định nghĩa rõ ràng và bộ metrics phù hợp, bước tiếp theo là đi sâu vào phân tích dữ liệu.
2. Thu thập Dữ liệu
Trong dự án này, chúng ta sử dụng nguồn dữ liệu từ nền tảng Kaggle:
- Link dataset: Predicting Student Test Scores
- Nguồn gốc: Dữ liệu thuộc cuộc thi Kaggle Tabular Playground Series (Season 6, Episode 1).
Đây là tập dữ liệu được tạo tổng hợp (synthetically-generated) dựa trên các mô hình Deep Learning. Đặc điểm của loại dữ liệu này là tạo ra một môi trường sandbox an toàn cho việc thực hành Machine Learning, giúp người học tập trung vào việc xây dựng pipeline mà không lo ngại về các vấn đề bảo mật thông tin thực tế.
3. Phân tích Khám phá Dữ liệu - Exploratory Data Analysis (EDA)
EDA là bước cực kỳ quan trọng trong quy trình ML với bất kỳ dữ liệu dạng bảng nào - đây là nơi bạn thực sự "làm quen" với dữ liệu của mình. Một EDA tốt giúp hiểu sâu về phân bố và đặc điểm của từng biến, phát hiện các vấn đề tiềm ẩn như missing values, duplicates hay outliers, đồng thời khám phá mối quan hệ giữa các features với biến mục tiêu.
3.1. Load và Khảo sát dữ liệu ban đầu
Bước đầu tiên là nắm bắt bức tranh tổng quan về dữ liệu :
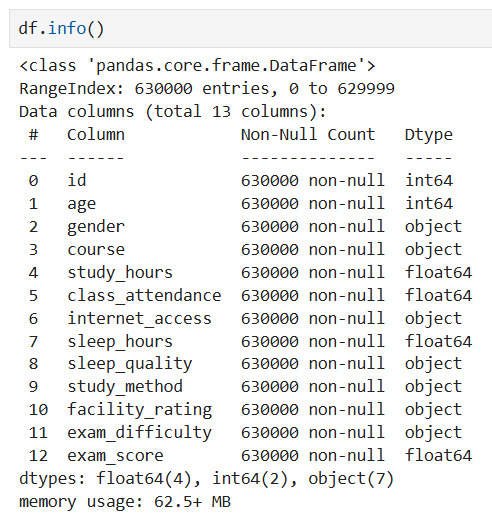
Nhận xét:
-
Dataset gồm 630,000 bản ghi với 13 cột, trong đó tất cả các cột đều có đúng 630,000 non-null values — tức không có bất kỳ missing value nào
-
Về kiểu dữ liệu, các cột numerical
(study_hours, class_attendance, sleep_hours, exam_score)được lưu đúng dạng float64, các biến categorical dạng object - không có trường hợp sai lệch kiểu dữ liệu nào đáng lo ngại. Đây là tập dữ liệu khá lý tưởng, cho phép ta bỏ qua bước xử lý missing values và tập trung vào các bước phân tích tiếp theo.
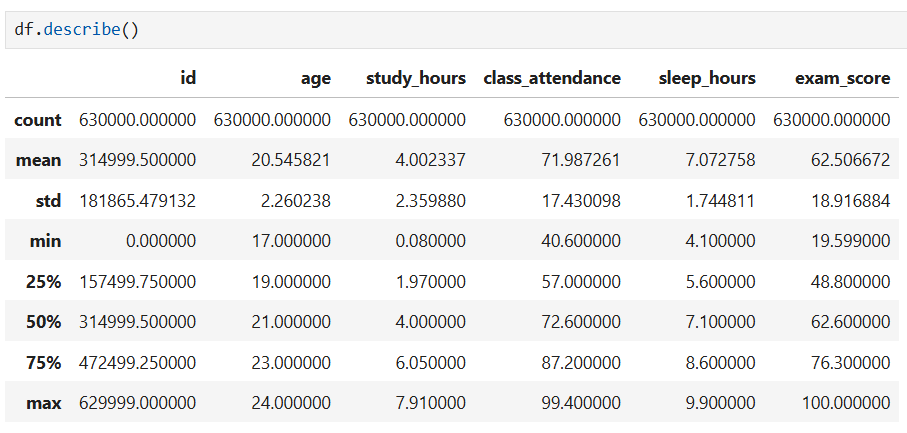
Nhận xét:
- Quy mô dữ liệu lớn: Tập dữ liệu rất lớn với 630,000 bản ghi cho thấy độ tin cậy thống kê cao.
- Phân phối điểm thi rộng: Điểm thi trung bình là 62.5 điểm, nhưng có sự phân tán rất lớn từ 19.6 đến 100 điểm, cho thấy sự khác biệt đáng kể về kết quả học tập giữa các sinh viên.
- Thời gian học trung bình: Sinh viên dành trung bình khoảng 4 giờ cho việc học và ngủ khoảng 7 giờ mỗi ngày.
3.2. Kiểm tra dữ liệu
Dù dữ liệu trông có vẻ sạch ở bước khảo sát ban đầu, ta vẫn cần kiểm tra kỹ hơn trước khi kết luận. Bước này gồm bốn nội dung chính:
3.2.1. Kiểm tra dữ liệu bị thiếu (Missing values)
Dữ liệu thiếu là vấn đề phổ biến nhất trong các dự án thực tế. Cách xử lý phụ thuộc vào mức độ nghiêm trọng:
- nếu dưới 5% có thể xóa dòng hoặc điền đơn giản bằng mean/median;
- từ 5–30% nên dùng các phương pháp impute nâng cao hơn như KNN;
- còn trên 30% thì cần cân nhắc xóa cột hoặc tạo thêm cột đánh dấu thiếu.
missing = df.isnull().sum()
3.2.2. Kiểm tra các dòng dữ liệu trùng lặp (Duplicate records)
Các dòng trùng lặp nếu không được xử lý có thể khiến mô hình bị overfitting hoặc dẫn đến data leakage - khi thông tin từ tập test vô tình "rò rỉ" vào quá trình huấn luyện.
duplicates = df.duplicated().sum()
3.2.3. Kiểm tra biến ngoại lai (Outliers)
Sau khi xử lý missing và duplicates, bước tiếp theo là phát hiện các giá trị bất thường bằng phương pháp IQR. Tuy nhiên, không phải outlier nào cũng cần xóa - đôi khi đó chính là học sinh xuất sắc hoặc yếu kém thật sự, và việc loại bỏ có thể làm mất đi thông tin quan trọng. Chỉ xóa khi chắc chắn đó là lỗi nhập liệu.
for col in numeric_cols:
Q1 = df[col].quantile(0.25)
Q3 = df[col].quantile(0.75)
IQR = Q3 - Q1
lower = Q1 - 1.5 * IQR
upper = Q3 + 1.5 * IQR
3.2.4. Kiểm tra định dạng và logic của dữ liệu
Bước này kiểm tra ba khía cạnh:
- Kiểm tra kiểu dữ liệu: Rà soát và ngăn chặn tình trạng sai lệch giữa ký tự (chuỗi) và số (giá trị số), đảm bảo tính đồng nhất cho việc tính toán.
- Xác thực định dạng: Đối soát các trường thông tin có cấu trúc cố định (ví dụ như Ngày tháng, Email, và Số điện thoại theo tiêu chuẩn hệ thống)
- Logic nghiệp vụ: Áp dụng các thuật toán kiểm tra tùy biến theo đặc thù của từng biến số, đảm bảo dữ liệu không chỉ đúng cấu trúc mà còn phù hợp với ngữ cảnh thực tế (ví dụ: Điểm thi phải từ 0-100, Giờ học không thể âm,...)
Nhận xét:
Tập synthetic dataset Predicting Student Test Scores này về cơ bản đã sạch, không có missing value, outliers, logic error => giúp giảm tải bước Data Cleaning!
3.3. Làm sạch dữ liệu (Data Cleaning)
Vì dữ liệu đã được kiểm tra và không phát sinh vấn đề nào ở bước 3.2, bước làm sạch ở đây khá nhẹ nhàng.
Tuy nhiên, trong các dự án thực tế, Data Cleaning thường là bước tốn nhiều công sức. Bảng dưới tổng hợp các vấn đề thường gặp và hướng xử lý tương ứng để tham khảo:
| Vấn đề phát hiện | Cách kiểm tra | Tiêu chí đánh giá | Cách xử lý |
|---|---|---|---|
| Dữ liệu thiếu | df.isnull().sum() |
Thiếu < 5% / 5-30% / > 30% | < 5%: Xóa dòng hoặc điền đơn giản (mean/median/mode) 5-30%: Điền nâng cao (KNN, Iterative) > 30%: Xóa cột hoặc tạo cột đánh dấu thiếu |
| Dữ liệu trùng lặp | df.duplicated().sum() |
Số lượng và % trùng lặp | Xóa: df.drop_duplicates()Giữ dòng đầu/cuối: keep='first' |
| Giá trị ngoại lai | IQR: lower = Q1-1.5*IQRupper = Q3+1.5*IQR |
% ngoại lai so với tổng dữ liệu | Giữ lại: Nếu là giá trị thực Winsorization: Giới hạn ở phân vị (1%, 99%) Biến đổi: Log, sqrt Xóa: Chỉ khi chắc chắn là lỗi |
| Kiểu dữ liệu sai | df.dtypesdf.info() |
Cột số bị object, cột ngày tháng bị chuỗi |
Chuyển đổi: pd.to_numeric()Phân tích ngày: pd.to_datetime() |
| Giá trị ngoài phạm vi | df[df['score'] > 100]df[df['age'] < 0] |
Vi phạm quy tắc nghiệp vụ | Giới hạn giá trị: Hạn chế trong khoảng hợp lệ Chuyển thành NaN rồi điền Xóa: Nếu là lỗi nghiêm trọng |
| Định dạng không đồng nhất | df['column'].unique() |
Nhiều định dạng khác nhau | Chuẩn hóa về 1 định dạng duy nhất Làm sạch bằng Regex Xóa khoảng trắng |
| Phân loại với nhiều nhóm | df['col'].nunique()df['col'].value_counts() |
Quá nhiều giá trị duy nhất | Gom nhóm: Gộp các nhóm nhỏ thành "Khác" Mã hóa lại: Tạo nhóm mới có ý nghĩa |
| Dữ liệu mất cân bằng | df['target'].value_counts() |
Tỷ lệ nhóm chênh lệch lớn | Tăng mẫu: SMOTE Giảm mẫu: Tomek links Trọng số nhóm trong mô hình |
| Tên không nhất quán | Kiểm tra thủ công | Khoảng trắng, viết hoa/thường | str.strip(), str.lower(), str.replace() |
3.4. Kiểm tra Phân bố của các biến (Distribution Analysis)
Sau khi làm sạch dữ liệu sơ bộ, bây giờ ta khám phá sâu để tìm insights và mối quan hệ.
3.4.1. Biến số (Numerical Features)
Mục đích: Hiểu dữ liệu phân bố như thế nào - chuẩn, lệch, có outliers không?
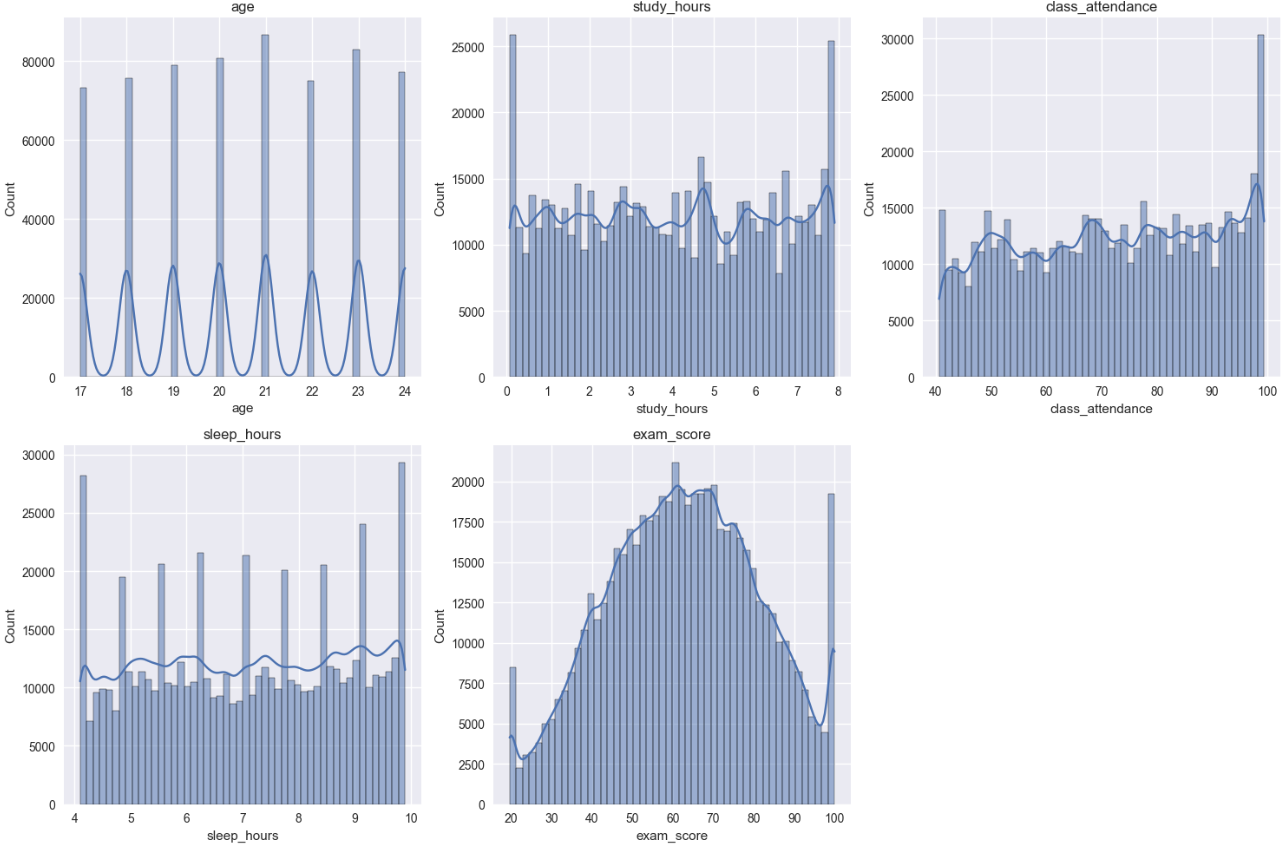
Nhận xét:
Nhìn chung, các biến numerical có phân bố khá đồng đều và không có outlier rõ rệt. Đáng chú ý, biến mục tiêu exam_score có phân phối chuẩn (normal distribution) hình chuông — đây là đặc điểm lý tưởng cho bài toán regression, cho thấy dữ liệu synthetic này có chất lượng cao.
3.4.2. Biến phân loại (Categorical Features)
Mục đích: Xem tần suất xuất hiện của các nhóm
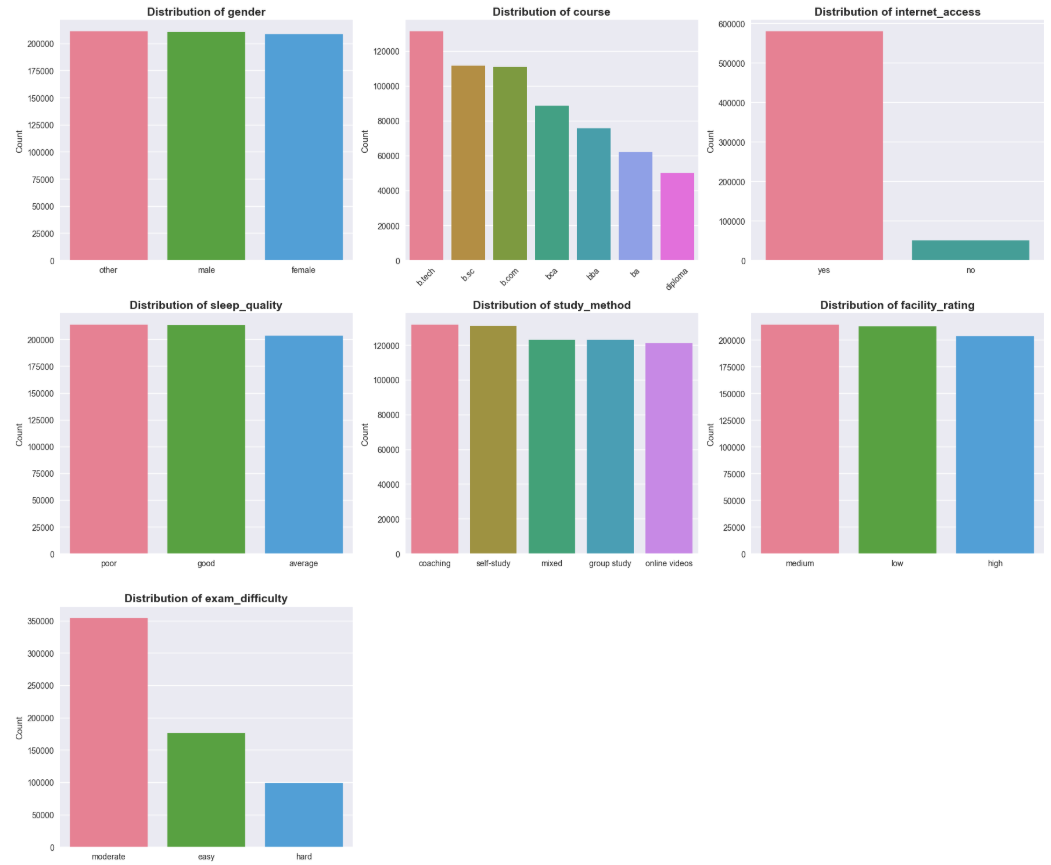
Nhận xét:
Các biến phân loại cho thấy sự phân bố dữ liệu khá đồng đều ở hầu hết các nhóm, ngoại trừ internet_access có tỷ lệ người dùng "yes" áp đảo và exam_difficulty tập trung chủ yếu ở mức "moderate".
3.5. Mối quan hệ giữa Features và Target
Sau khi hiểu phân bố của từng biến, bước tiếp theo là khám phá mối quan hệ giữa các features với biến mục tiêu. Vì exam_score là biến số liên tục, ta sử dụng Correlation Matrix để đo lường mức độ tương quan tuyến tính.
Tương quan tuyến tính (Correlation Matrix)
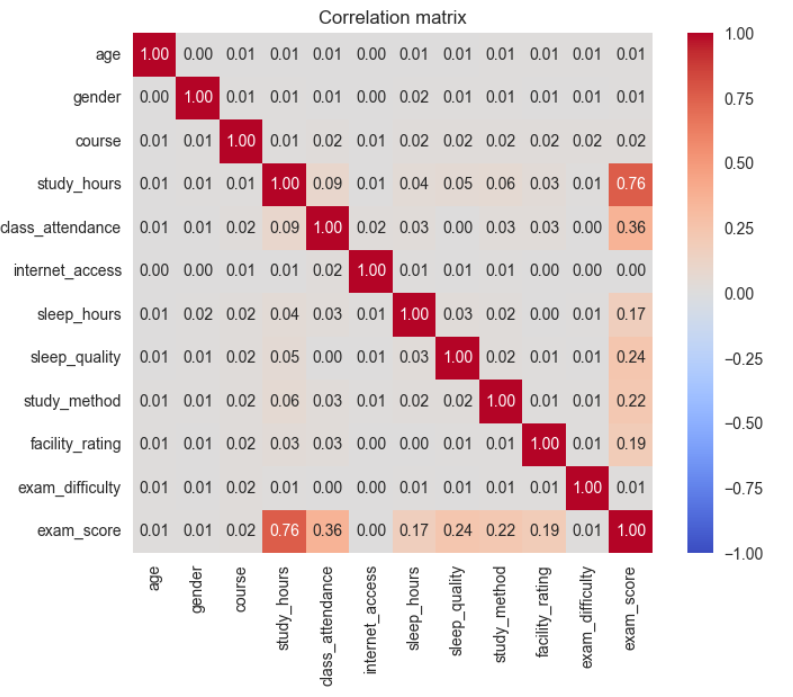
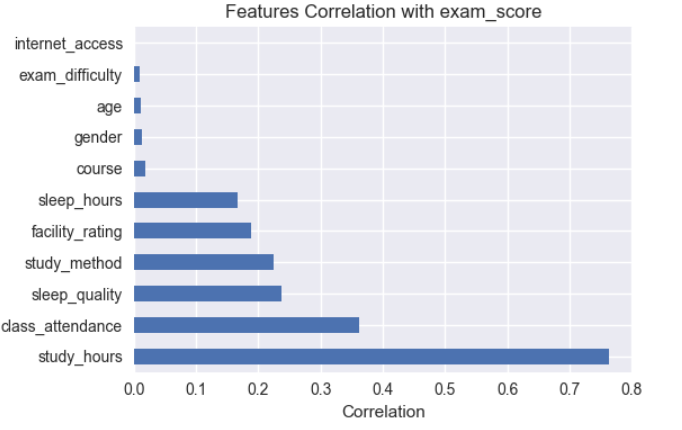
Kết luận:
- Phân tích tương quan chủ yếu phản ánh mối quan hệ tuyến tính giữa các đặc trưng và biến mục tiêu.
study_hourscó tương quan tuyến tính mạnh với biến mục tiêu (r = 0.76), cho thấy đây là một đặc trưng quan trọng.class_attendance,sleep_qualityvàstudy_methodcó tương quan tuyến tính yếu đến trung bình, gợi ý khả năng tồn tại mối quan hệ phi tuyến.- Các đặc trưng
age,genderhầu như không có tương quan tuyến tính với biến mục tiêu.
Ngoài ra, không phát hiện hiện tượng đa cộng tuyến (multicollinearity) nghiêm trọng giữa các đặc trưng.
Đa cộng tuyến (Multicollinearity) là hiện tượng các biến độc lập (đặc trưng đầu vào) có mối quan hệ tương quan quá chặt chẽ với nhau, dẫn đến việc chúng cung cấp thông tin trùng lặp cho mô hình. Điều này khiến các linear models khó xác định chính xác mức độ ảnh hưởng riêng biệt của từng biến lên điểm thi và làm giảm độ ổn định của các hệ số dự báo.
Ví dụ: Hệ số tương quan giữa
study_hoursvàsleep_hourschỉ là 0.04 (gần bằng 0). Điều này cho thấy hai biến này hoàn toàn độc lập, cung cấp những thông tin khác biệt cho mô hình và không xảy ra hiện tượng đa cộng tuyến. Nếu con số này tiến gần đến 1.00 (ví dụ 0.90), chúng ta mới gặp vấn đề thông tin bị trùng lặp.
4. Kỹ thuật Xây dựng Đặc trưng (Feature Engineering)
Ở giai đoạn này, các features được chọn lọc, tổ chức lại và bổ sung thêm nhằm giúp mô hình khai thác tốt hơn các mối quan hệ phức tạp trong dữ liệu.
Nguyên tắc "GARBAGE IN - GARBAGE OUT: Dữ liệu kém → Model dự đoán kém
4.1. Loại bỏ Features không cần thiết
Để đảm bảo quyết định loại bỏ là chính xác, không chỉ dựa trên kết quả phân tích tương quan từ EDA, nhóm đã train thêm một baseline LightGBM với toàn bộ features và phân tích Feature Importance để có cơ sở loại bỏ chắc chắn hơn:
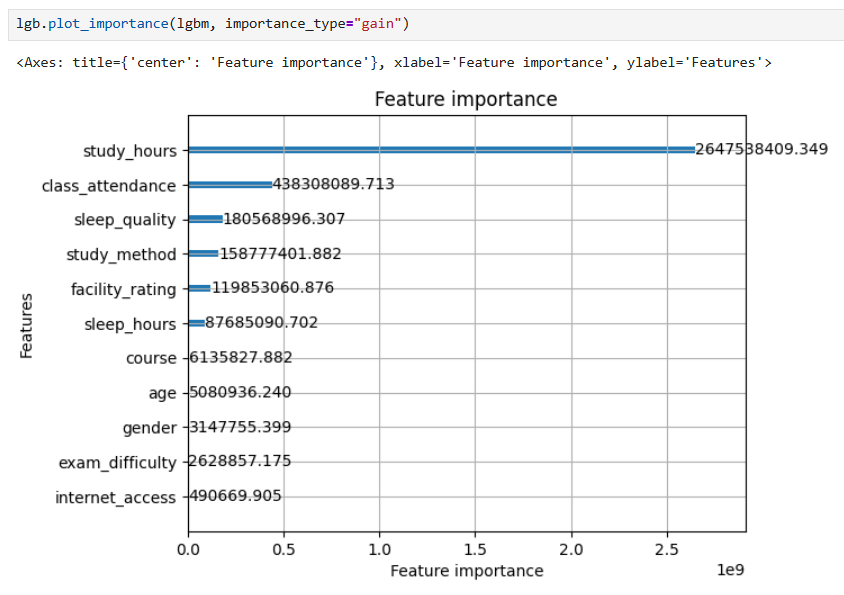
Kết quả từ cả hai phương pháp đều thống nhất, xác nhận việc loại bỏ bốn features sau:
drop_cols = [
'id', # không mang thông tin dự đoán
'age', # Correlation = 0.01
'gender', # Correlation = 0.01
'internet_access' # Correlation = 0.00
]
df = df.drop(columns=drop_cols, errors='ignore')
Riêng exam_difficulty và course được giữ lại dù importance thấp, vì cả hai có ý nghĩa nghiệp vụ rõ ràng và có thể ảnh hưởng đến kết quả trong các điều kiện cụ thể.
4.2. Xây dựng Features mới
Dữ liệu gốc chỉ phản ánh từng yếu tố riêng lẻ, trong khi kết quả học tập thực tế thường là kết quả của sự kết hợp nhiều yếu tố cùng lúc. Dựa trên domain knowledge về giáo dục và insights từ EDA, nhóm tạo thêm 5 features mới chia thành ba nhóm:
def add_features(df: pd.DataFrame) -> pd.DataFrame:
df = df.copy()
# 1. Binary Indicators
df['high_study'] = (df['study_hours'] > 6).astype(int)
df['low_attendance'] = (df['class_attendance'] < 60).astype(int)
# 2. Interaction Features
df['study_efficiency'] = df['study_hours'] * df['class_attendance']
df['sleep_attend_product'] = df['sleep_hours'] * df['class_attendance']
# 3. Deviation Feature
df['sleep_deviation'] = (df['sleep_hours'] - 7).abs()
return df
-
Binary Indicators tạo ngưỡng phân loại rõ ràng:
high_studyđánh dấu học sinh học trên 6 giờ/ngày — nhóm có xu hướng kết quả tốt hơn rõ rệt theo EDA;low_attendancecảnh báo tỷ lệ đi học dưới 60% — ngưỡng quan trọng trong hệ thống giáo dục. -
Interaction Features nắm bắt hiệu ứng kết hợp mà các features đơn lẻ không thể hiện được:
study_efficiencykết hợpstudy_hoursvàclass_attendance— học nhiều nhưng không đi học đều thì hiệu quả vẫn thấp;sleep_attend_productnắm bắt tương tác giữa chất lượng nghỉ ngơi và mức độ chuyên cần. -
Deviation Feature xử lý mối quan hệ phi tuyến dạng chữ U:
sleep_deviationđo độ lệch so với mức ngủ lý tưởng 7 giờ — ngủ quá ít hay quá nhiều đều ảnh hưởng tiêu cực đến kết quả, và feature này giúp mô hình nhận ra điều đó.
💡 Lưu ý: Feature Engineering là bước đòi hỏi sự kết hợp giữa kỹ năng kỹ thuật và domain knowledge — không có công thức chung cho mọi bài toán.
Vậy làm sao biết một feature mới có thực sự hữu ích hay không? Câu trả lời nằm ở việc kết hợp ba thứ: domain knowledge để có cơ sở tạo feature có ý nghĩa, correlation analysis để kiểm tra nhanh mối quan hệ với target, và Feature Importance từ model để xác nhận feature đó có thực sự được model khai thác hay không. Nếu một feature mới không cải thiện được validation score sau khi train, đó là tín hiệu rõ ràng để loại bỏ. FE hiệu quả không phải là mò đại - mà là đưa ra giả thuyết có cơ sở, rồi dùng dữ liệu để kiểm chứng.
Bảng chi tiết từng nhóm features
| Nhóm | Feature | Công thức | Ý nghĩa |
|---|---|---|---|
| Binary Indicators | high_study |
study_hours > 6 |
Đánh dấu học sinh học nhiều — EDA cho thấy nhóm > 6h có kết quả tốt hơn rõ rệt |
low_attendance |
class_attendance < 60 |
Cảnh báo nguy cơ kết quả kém — 60% là ngưỡng quan trọng trong giáo dục | |
| Interaction Features | study_efficiency |
study_hours × class_attendance |
Hiệu quả học tập tổng hợp — học nhiều nhưng không đi học đều thì hiệu quả vẫn thấp |
sleep_attend_product |
sleep_hours × class_attendance |
Tương tác giữa giấc ngủ và chuyên cần — ngủ đủ giúp tập trung hơn khi đi học | |
| Deviation Feature | sleep_deviation |
abs(sleep_hours - 7) |
Quan hệ phi tuyến dạng chữ U — ngủ quá ít hoặc quá nhiều đều ảnh hưởng tiêu cực |
4.3. Mã hóa đặc trưng (Feature Encoding)
Trước khi đưa vào mô hình, toàn bộ features cần được chuyển về dạng số thông qua encoding. Tuy nhiên, không phải feature nào cũng encode theo cùng một cách - phương pháp encoding phụ thuộc vào bản chất của từng nhóm biến.
Bước 1: StandardScaler cho Numerical Features
num_base = ['study_hours', 'class_attendance', 'sleep_hours']
('num', StandardScaler(), num_features)
Mặc dù LightGBM là tree-based model và không nhạy cảm với scale, StandardScaler vẫn cần thiết để đảm bảo tính thống nhất của pipeline, ổn định phân phối các interaction features có range lớn và tạo điều kiện so sánh công bằng nếu thử nghiệm thêm các model khác như Linear Regression hay SVM.
Bước 2: OrdinalEncoder cho Ordinal Features
cat_ordinal = [
'sleep_quality', # poor < average < good
'facility_rating', # low < medium < high
'exam_difficulty' # easy < moderate < hard
]
('ord', OrdinalEncoder(
categories=[
['poor', 'average', 'good'],
['low', 'medium', 'high'],
['easy', 'moderate', 'hard']
]
), cat_ordinal)
Các biến ordinal được mã hóa theo đúng thứ tự tự nhiên:
sleep_quality: poor → 0, average → 1, good → 2facility_rating: low → 0, medium → 1, high → 2exam_difficulty: easy → 0, moderate → 1, hard → 2
Việc encode này giúp giữ được thứ tự logic, model học được mức độ cao-thấp.
Bước 3: OneHotEncoder cho Nominal Features
cat_onehot = ['study_method', 'course']
('onehot', OneHotEncoder(
drop='first', # bỏ category đầu tiên để tránh multicollinearity
handle_unknown='ignore', # category mới trong test set → tất cả cột = 0
sparse_output=False # trả về numpy array thay vì sparse matrix
), cat_onehot)
Kết quả:
- study_method (3 categories) → 2 cột nhị phân
- course (5 categories) → 4 cột nhị phân
5. Huấn luyện và Đánh giá Mô hình (Model Training and Evaluation)
5.1. Chuẩn bị dữ liệu
from sklearn.model_selection import train_test_split
# Tách features và target
X = df.drop('target', axis=1)
y = df['target']
# Chia train/test (80/20)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
Tỷ lệ 80/20 là lựa chọn phổ biến cho dataset lớn - với 630,000 bản ghi, 20% tương đương 126,000 mẫu test là đủ để đánh giá độ tin cậy. random_state=42 đảm bảo kết quả chia luôn nhất quán mỗi lần chạy, giúp kết quả có thể tái hiện được.
5.2. Các Models sử dụng
| Mô hình | Loại mô hình | Ưu điểm | Nhược điểm | Khi nào sử dụng |
|---|---|---|---|---|
| Linear Regression (Baseline) | Tuyến tính | Đơn giản, dễ hiểu, huấn luyện nhanh | Giả định quan hệ tuyến tính, nhạy với outliers, dễ overfitting | Dùng làm baseline để so sánh |
| Ridge Regression (L2) | Tuyến tính | Giảm overfitting, xử lý tốt multicollinearity | Không tự động loại bỏ feature | Khi có nhiều feature tương quan cao |
| Lasso Regression (L1) | Tuyến tính | Tự động chọn lọc feature (đưa hệ số về 0), giảm overfitting | Không ổn định khi các feature tương quan mạnh | Khi cần loại bỏ các feature không quan trọng |
| LightGBM | Tree-based (phi tuyến) | Nhẹ và nhanh hơn XGBoost, xử lý tốt dữ liệu lớn, học được quan hệ phi tuyến và feature interaction | Khó diễn giải hơn mô hình tuyến tính | Khi dữ liệu phức tạp, quan hệ phi tuyến, cần hiệu năng cao |
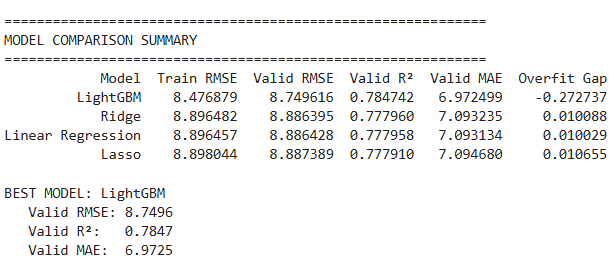
Kết quả so sánh cho thấy LightGBM vượt trội rõ rệt so với các mô hình tuyến tính với Valid RMSE = 8.75 và R² = 0.78 — nghĩa là mô hình giải thích được 78% sự biến động của điểm thi. Trong khi đó, Ridge, Linear Regression và Lasso cho kết quả gần như tương đương nhau (Valid RMSE ≈ 8.89).
6. Triển khai mô hình với Gradio (Model Deployment)
Sau khi huấn luyện xong, mô hình LightGBM được đóng gói thành một ứng dụng dự đoán đơn giản bằng Gradio. Người dùng nhập các thông tin đầu vào như số giờ học, tỷ lệ đi học, chất lượng giấc ngủ và phương pháp học tập - dữ liệu này sẽ đi qua đúng pipeline Feature Engineering đã dùng lúc huấn luyện trước khi được đưa vào model, đảm bảo tính nhất quán giữa hai giai đoạn. Kết quả trả về là điểm thi dự đoán tương ứng.
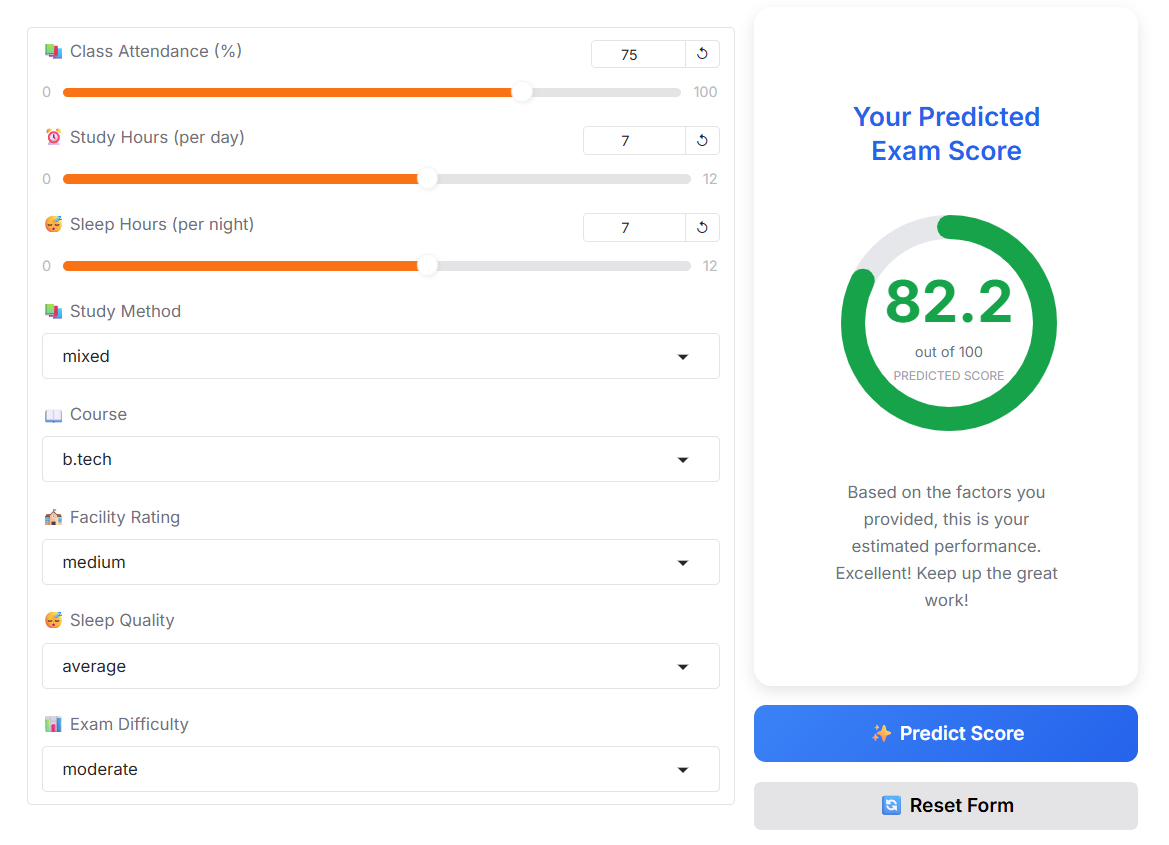
Kết luận
Qua bài viết này, chúng ta đã xây dựng một pipeline Machine Learning hoàn chỉnh cho bài toán dự đoán exam score — từ EDA, Feature Engineering cho đến Model Training và Evaluation.
Kết quả cho thấy:
- Các yếu tố hành vi học tập như số giờ học, tỷ lệ đi học và chất lượng giấc ngủ đóng vai trò quan trọng nhất trong việc dự đoán kết quả điểm số.
- LightGBM vượt trội so với các mô hình tuyến tính nhờ khả năng khai thác feature interaction và non-linearity.
Trong tương lai, mô hình có thể được cải thiện theo 2 hướng:
- Về phía dữ liệu: Feature Engineering vẫn còn nhiều không gian để khai thác — có thể thử nghiệm thêm các interaction features phức tạp hơn, polynomial features, hoặc áp dụng target encoding cho các biến categorical thay vì One-Hot Encoding.
- Về phía mô hình: pipeline có thể được củng cố thêm thông qua cross-validation để đánh giá hiệu năng ổn định hơn, hyperparameter tuning chuyên sâu bằng Optuna hay Bayesian Optimization, và ensemble methods như stacking hay blending để kết hợp sức mạnh của nhiều model.
Tuy nhiên, với phạm vi dự án như hiện tại thì pipeline đã đủ hoàn chỉnh để triển khai thực tế và sử dụng như một project ML có giá trị cho portfolio.
Chưa có bình luận nào. Hãy là người đầu tiên!