
I. Giới thiệu
Trong các dự án Machine Learning, dữ liệu thường rất lớn (từ vài GB đến TB) và liên tục thay đổi. Những thay đổi này khiến việc tái lập thí nghiệm trở nên khó khăn: cập nhật dataset, đổi đường dẫn, hay dùng các phiên bản dữ liệu khác nhau đều có thể dẫn tới kết quả không đồng nhất — gây khó khăn trong truy vết và so sánh kết quả.
DVC (Data Version Control) được phát triển nhằm giải quyết triệt để thách thức này. DVC cung cấp giải pháp quản lý phiên bản dữ liệu (hỗ trợ dữ liệu lớn), theo dõi toàn bộ pipeline xử lý và huấn luyện, và đảm bảo khả năng tái lập thí nghiệm một cách hiệu quả — hoạt động tương tự như Git nhưng được tối ưu hóa cho dữ liệu lớn và các tài sản của mô hình ML.
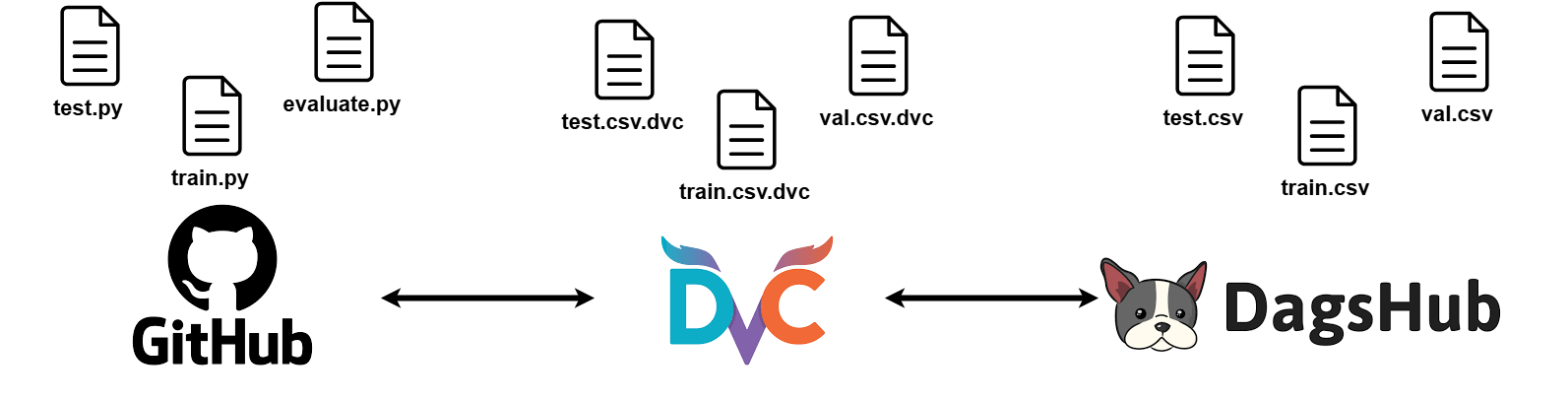
Hình 1. Minh hoạ Data Version Control (DVC)
Trong bài viết này, mình sẽ trình bày cả khía cạnh lý thuyết và thực hành nhằm giúp các bạn hiểu rõ cơ chế hoạt động của DVC, đánh giá lợi ích vượt trội so với việc chỉ sử dụng Git đơn thuần, đồng thời được cung cấp một hướng dẫn từng bước (kèm theo mã nguồn) để áp dụng DVC vào một dự án mẫu tiêu chuẩn.
II. Data Version Control (DVC)
1. DVC là gì?
DVC là một công cụ mạnh mẽ được thiết kế để giải quyết điểm yếu lớn nhất trong các dự án ML, đó là quản lý các tập dữ liệu lớn trong các hệ thống kiểm soát phiên bản truyền thống.
Các hệ thống kiểm soát phiên bản truyền thống như Git hoạt động rất tốt với code, nhưng lại gặp khó khăn khi xử lý các tập dữ liệu khổng lồ. Việc cố gắng lưu trữ trực tiếp chúng trong Git có thể dẫn đến sự chậm chạp hoặc thậm chí là lỗi hệ thống.
DVC đóng vai trò như một cầu nối giữa Git và kho lưu trữ dữ liệu lớn. Thay vì lưu toàn bộ dữ liệu trong Git, DVC tạo các file siêu dữ liệu nhỏ (chứa hash, kích thước, path) để Git theo dõi, còn dữ liệu thực được lưu ở nơi khác (local cache hoặc remote).
Tóm lại, trong quản lý "chu kỳ sống" của các dự án data science và machine learning thì DVC có những ưu điểm sau:
-
Reproducibility: DVC giúp ghi lại chính xác phiên bản dữ liệu và mô hình được sử dụng trong các thử nghiệm, giúp việc tái tạo chúng trở nên dễ dàng.
-
Experiment Management: DVC cho phép xem chính xác cách dữ liệu và mô hình đã phát triển theo thời gian. Nếu chúng ta cần xem lại một phiên bản nào đó từ vài tháng trước, DVC có thể xác định chính xác phiên bản dữ liệu nào đã được sử dụng, giúp chúng ta so sánh và phân tích dễ dàng.
-
Collaboration: Hãy tưởng tượng nếu nhóm của bạn đang nghiên cứu về một bộ dữ liệu nào đó và mỗi người đều có một phiên bản chỉnh sửa dữ liệu riêng từ dữ liệu thô ban đầu. Việc chia sẻ các phiên bản dữ liệu trên tới từng người trong team sẽ rất là rắc rối và phiền phức. DVC có thể giải quyết vấn đề trên, đảm bảo mọi người trong nhóm của đều làm việc với cùng một phiên bản dữ liệu, loại bỏ sự nhầm lẫn và lãng phí thời gian.
2. DVC hoạt động như thế nào ?
Về bản chất, DVC không phải là một hệ thống kiểm soát phiên bản vì chúng ta đã có Git. DVC không phát minh lại cơ chế cho các tệp lớn, mà sử dụng một cách giải quyết khôn ngoan để tận dụng khả năng của Git.
Giả sử ta có một tập dữ liệu lớn. Khi ta thêm một tệp hoặc thư mục lớn vào DVC bằng lệnh dvc add raw, công cụ này sẽ tạo ra một tệp siêu dữ liệu nhỏ có tên là raw.dvc. Tập raw.dvc này chứa các thông tin quan trọng như kích thước, số lượng tệp, và đặc biệt là một MD5 hash duy nhất. Bất kỳ thay đổi nhỏ nhất nào đối với tệp dữ liệu gốc cũng sẽ làm thay đổi hoàn toàn chuỗi hash này.
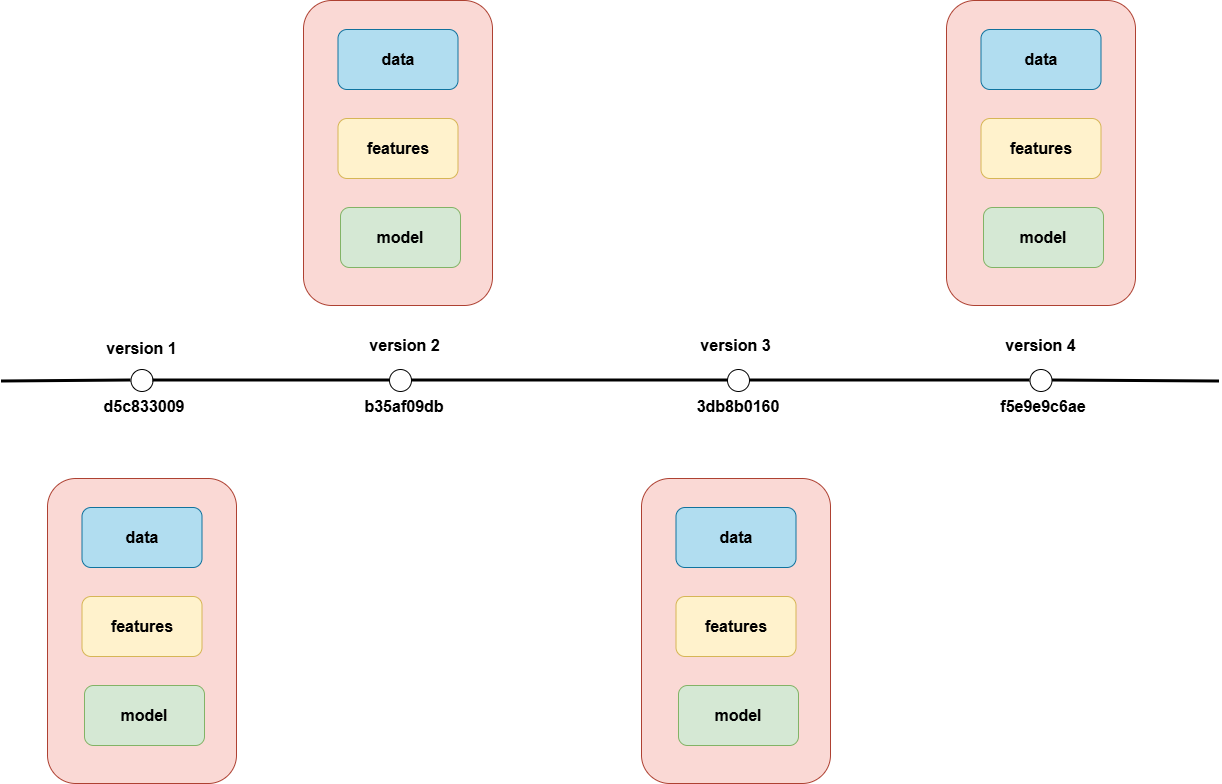
Hình 2. Cách DVC quản lý dữ liệu thông qua MD5 hash
DVC cũng tự động thêm tệp dữ liệu thực tế vào tệp .gitignore để Git bỏ qua nó. Cuối cùng, chúng ta chỉ cần theo dõi tệp siêu dữ liệu raw.dvc này bằng Git. Bằng cách sử dụng các giá trị hash trên, Git có thể theo dõi các tệp dữ liệu lớn, bất kể kích thước của chúng thông qua tệp siêu dữ liệu nhỏ gọn .dvc.
Bộ đệm dữ liệu (Cache) của DVC
Khi khởi tạo, DVC tạo một thư mục .dvc ẩn chứa nhiều cấu hình, trong đó có một thành phần quan trọng là Cache (nằm trong .dvc/cache).
Khi một tệp dữ liệu được đưa vào DVC, bản sao của nó sẽ được lưu trữ tại Cache này. Mỗi phiên bản dữ liệu sau này cũng sẽ được lưu trữ với một MD5 mới.
Đúng như tên gọi Cache, mỗi phiên bản sẽ chiếm dung lượng riêng trên máy local của bạn. DVC sẽ lưu các thay đổi từ dữ liệu của bạn vào cache, giúp tối ưu hóa đáng kể dung lượng lưu trữ so với việc sao chép toàn bộ thư mục.
Kho lưu trữ từ xa (DVC Remote)
Để có thể tối ưu hoá trong việc chia sẻ tài nguyên, DVC sử dụng kho lưu trữ đám mây để lưu trữ các tệp dữ liệu, mô hình và các phiên bản của chúng.
Khác với kho lưu trữ mã nguồn trên GitHub, DVC yêu cầu thiết lập một Remote riêng biệt để xử lý các tài sản dữ liệu lớn. Vị trí này có thể là các dịch vụ đám mây như AWS, Google Cloud Platform (GCP), hoặc Azure.
Như vậy, mỗi khi có thay đổi gì đó về dữ liệu, ta chỉ cần "đẩy" các thay đổi từ Cache cục bộ lên Remote này. Khi người khác clone Git repo, họ sẽ nhận được tệp cấu hình .dvc/config (có chứa thông tin remote) và có thể dễ dàng tải về toàn bộ dữ liệu lớn bằng lệnh dvc pull.
III. Linear Regression cùng DVC
Trong phần này, chúng ta sẽ cùng xây dựng một mô hình Linear Regression đơn giản, và sử dụng DVC để theo dõi và quản lý các phiên bản huấn luyện.
Các bạn có thể lấy mã nguồn của bài thực hành này tại đây hoặc các bạn có thể chạy lệnh sau để tải xuống nếu các bạn đã có Git.
git clone https://github.com/nphuc0311/Linear-Regression.git
Cấu trúc mã nguồn:
LinearRegression/
├── data
├── dvc.yaml
├── params.yaml
├── README.md
├── requirements.txt
├── scripts
│ ├── download.py
│ ├── evaluate.py
│ ├── preprocess.py
│ └── train.py
└── src
├── __init__.py
└── models
├── __init__.py
└── linear.py
1. Chuẩn bị môi trường
Đầu tiên, các bạn cần phải khởi tạo môi trường và cài đặt các gói cần thiết để mã nguồn có thể hoạt động:
conda create -n linear-dvc python=3.10 -y
conda activate linear-dvc
pip install -r requirements.txt
Giải thích:
-
conda create -n linear-dvc python=3.10 -y
Tạo một môi trường Conda mới tên làlinear-dvcvới phiên bản Python 3.10.
Tuỳ chọn-ygiúp tự động xác nhận quá trình cài đặt mà không cần gõ “yes”. -
conda activate linear-dvc
Kích hoạt môi trường vừa tạo. Sau khi chạy lệnh này, mọi thao tác nhưpythonhoặcpipsẽ chỉ ảnh hưởng trong môi trườnglinear-dvc, đảm bảo cách ly với hệ thống và các dự án khác. -
pip install -r requirements.txt
Cài đặt toàn bộ các thư viện cần thiết được liệt kê trong filerequirements.txt.
Đây là bước giúp dự án có đầy đủ các dependency để chạy được (ví dụ nhưpandas,torch,scikit-learn, …).
Nếu các bạn chưa có conda thì các bạn có thể xem cách cài đặt conda ở đây
2. Chuẩn bị dữ liệu
Mình sẽ dùng dữ liệu Advertising làm dữ liệu thô ban đầu để huấn luyện cho mô hình Linear Regression. Advertising là một loại dữ liệu cho bài toán Hồi quy tuyến tính, biểu diễn mối quan hệ giữa chi tiêu quảng cáo và doanh số bán hàng.
Mục tiêu chính là dự đoán Doanh số bán hàng (Sales) dựa trên chi tiêu cho quảng cáo. Tập dữ liệu này thường có 4 cột, trong đó 3 cột là biến độc lập (predictors) và 1 cột là biến phụ thuộc (target):
- TV: Chi phí quảng cáo chi tiêu trên kênh Truyền hình (TV).
- Radio: Chi phí quảng cáo chi tiêu trên kênh Đài phát thanh (Radio).
- Newspaper: Chi phí quảng cáo chi tiêu trên kênh Báo chí (Newspaper).
- Sales: Doanh số bán hàng đạt được (Đây là biến mục tiêu cần dự đoán).
Các bạn có thể tải dữ liệu tại đây hoặc các bạn có thể chạy lệnh sau để tải dữ liệu xuống:
python scripts/download.py
Dữ liệu sau khi tải được đặt trong thư mục data/raw.
data
└── raw
└── advertising.csv
3. Xử lý dữ liệu
Sau khi đã tải dữ liệu thô về thư mục data/raw, mình sẽ xử lý dữ liệu để chuẩn bị cho việc huấn luyện mô hình.
python scripts/preprocess.py
Ở đây mình sử dụng thư viện pandas để đọc file CSV từ data/raw/advertising.csv. Sau đó, mình thực hiện các bước sau:
-
Tách features và target: Lấy các cột TV, Radio, Newspaper làm features (X) và Sales làm target (y).
-
Chia tập dữ liệu: Mình chia dữ liệu thành tập huấn luyện (train), validation (val), và test theo tỷ lệ từ params.yaml (70% cho tập train, 20% cho tập val và 10% cho tập test).
-
Lưu dữ liệu: Dữ liệu sau khi xử lý thành các mảng NumPy (X_train, y_train, v.v.) sẽ được lưu dưới dạng file pickle
processed_data.pklvào thư mụcdata/processed.
Sau khi chạy, cấu trúc thư mục data sẽ được cập nhật như sau:
data
├── raw
│ └── advertising.csv
└── processed
└── processed_data.pkl
4. Huấn luyện mô hình
Sau khi đã xử lý liệu xong, mình tiến hành huấn luyện mô hình Linear Regression trên tập train. Mô hình mình sử dụng PyTorch để triển khai, với lớp mô hình được định nghĩa trong src/models/linear.py.
import torch.nn as nn
class LinearRegression(nn.Module):
"""Simple Linear Regression model using PyTorch."""
def __init__(self, input_features: int):
"""Initialize the model.
Args:
input_features (int): Number of input features
"""
super().__init__()
self.linear = nn.Linear(input_features, 1)
def forward(self, x):
"""Forward pass.
Args:
x (torch.Tensor): Input tensor of shape (batch_size, input_features)
Returns:
torch.Tensor: Predicted values
"""
return self.linear(x)
Trình tối ưu hoá mình sử dung Adam và loss MSE, kết quả sẽ được đánh giá trên tập val trong suốt quá trình training và sẽ đươc lưu trong metrics CSV.
python scripts/train.py
Sau khi chạy, bạn sẽ thấy loss giảm dần qua các epoch.
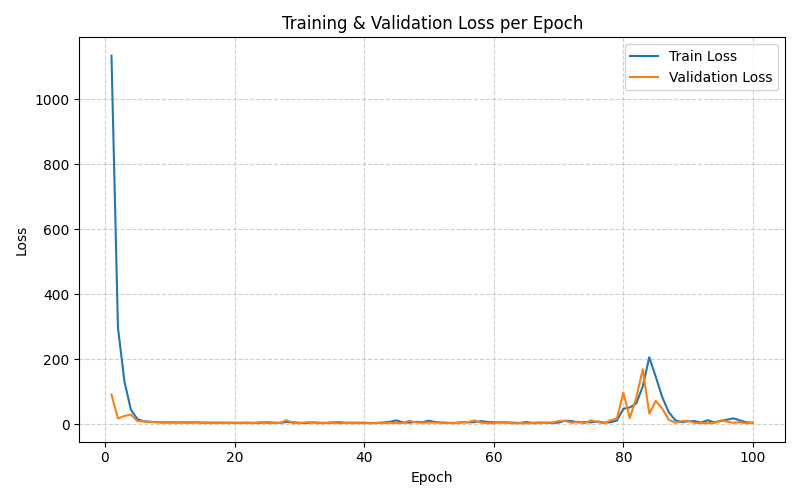
Hình 3. Biểu đồ thể hiện loss trên tập train và val
5. Đánh giá mô hình (Evaluation)
Để kiểm tra hiệu suất của mô hình, mình sẽ dự đoán trên tập test, và sử dụng các metrics như Mean Squared Error (MSE) và R-squared ($R^2$). Kết quả sẽ được lưu trong metrics/eval.csv
python scripts/evaluate.py
# Model Evaluation Results:
# MSE: 3.5359
# R2 Score: 0.8918
6. Quản lý pipeline với DVC
Lúc này bạn đã có đầy đủ các file như dữ liệu thô advertising.csv, dữ liệu đã xử lý processed_data.pkl, mô hình model.pth, và metrics train.csv / eval.csv. Bây giờ, mình sẽ quản lý chúng với DVC để có thể theo dõi thay đổi, rollback phiên bản, và so sánh các experiment.
Đầu tiên, mình cần phải khởi tạo DVC:
dvc init
DVC sẽ tạo thư mục ẩn .dvc (chứa cấu hình DVC, như cache cho dữ liệu). File .dvcignore sẽ được tạo tự động (tương tự .gitignore, dùng để loại trừ file không cần track).
Bây giờ, mình sẽ commit các file này vào Git để track .dvc/ và .dvcignore:
git add .dvc .dvcignore
git commit -m "Initialize DVC"
Để theo dõi các file dữ liệu như advertising.csv, mình sẽ sử dụng lệnh dvc add để DVC tạo hash và phát hiện thay đổi nếu dữ liệu cập nhật sau này.
dvc add data/raw/advertising.csv
dvc add data/processed/processed_data.pkl
dvc add models/model.pth
dvc add metrics/train.csv
dvc add metrics/eval.csv
Cấu trúc thư mục sau khi chạy các lệnh trên:
LinearRegression/
├── data
│ ├── processed
│ │ ├── processed_data.pkl
│ │ └── processed_data.pkl.dvc
│ └── raw
│ ├── advertising.csv
│ └── advertising.csv.dvc
├── dvc.yaml
├── metrics
│ ├── eval.csv
│ ├── eval.csv.dvc
│ ├── train.csv
│ └── train.csv.dvc
├── models
│ ├── model.pth
│ └── model.pth.dvc
├── params.yaml
├── plots
│ ├── loss_curve.png
│ ├── val_mse.png
│ └── val_r2.png
├── README.md
├── requirements.txt
├── scripts
│ ├── download.py
│ ├── evaluate.py
│ ├── preprocess.py
│ └── train.py
└── src
├── __init__.py
├── models
│ ├── __init__.py
│ ├── linear.py
│ └── __pycache__
│ ├── __init__.cpython-312.pyc
│ └── linear.cpython-312.pyc
└── __pycache__
└── __init__.cpython-312.pyc
DVC sẽ tính hash của file (dựa trên nội dung) và tạo file .dvc tương ứng (một file YAML nhỏ chứa metadata như hash MD5, kích thước file, ...). Ví dụ, file processed_data.pkl sau khi chạy sẽ tạo thành file processed_data.pkl.dvc có nội dung như sau:
outs:
- md5: ff39a5b03fbc9e9a7e857915a6087cc8
size: 6774
hash: md5
path: processed_data.pkl
Bây giờ, mình chỉ cần đẩy các file .dvc này lên Git thay vì phải đẩy toàn bộ dữ liệu. Các file .dvc chứa mã MD5 kết hợp với Cache lưu trên local thì mình hoàn toàn có thể track lại bât kỳ phiên bản dữ liệu nào trước đó.
Tuy nhiên, vì dữ liệu thực tế chỉ nằm trên máy local của mình, nên nếu muốn chia sẻ cho người khác, mình buộc phải gửi thủ công — khá bất tiện. Đây chính là lúc các remote storage (như Git LFS hay Amazon S3) phát huy tác dụng: chúng cho phép mình lưu trữ toàn bộ dữ liệu thật trên đám mây, giúp việc chia sẻ trở nên dễ dàng và chuyên nghiệp hơn.
Trong bài này, mình sẽ sử dụng DagsHub làm nơi lưu trữ dữ liệu. Nếu bạn đã chạy thành công toàn bộ pipeline ở các bước trước, thì chỉ cần:
- Tạo một repository mới trên GitHub
- Thực hiện
git pushđể đẩy dự án lên đó - Đăng nhập DagsHub bằng tài khoản GitHub của bạn và liên kết repository vừa tạo
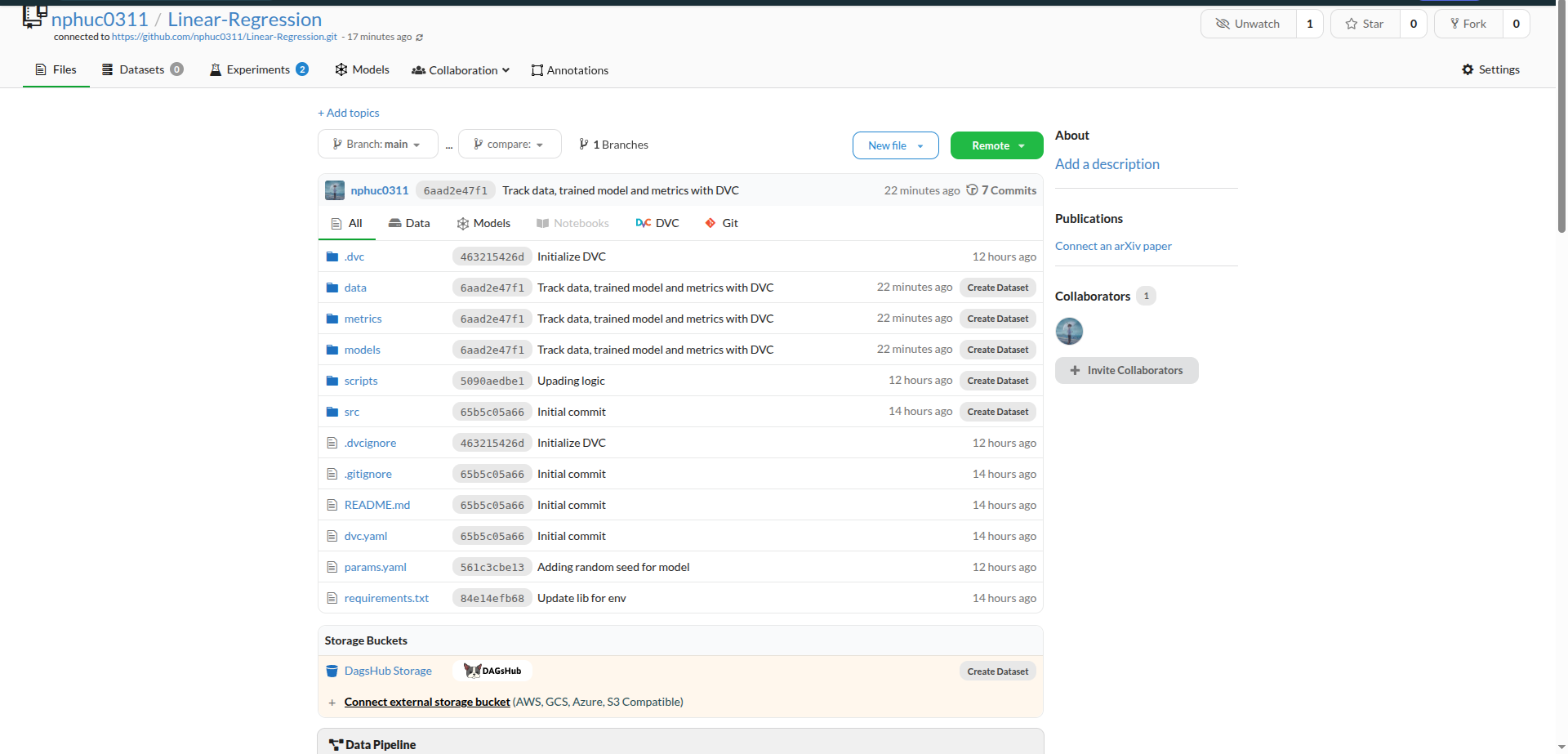
Hình 4. Repository được hiển thị trên DagsHub sau khi liên kết thành công.
Tiếp theo, để đẩy các file dữ liệu từ máy local lên DagsHub, bạn cần cấu hình remote cho DVC bằng các lệnh sau:
dvc remote add origin s3://dvc
dvc remote modify origin endpointurl "YOUR REMOTE URL"
dvc remote modify origin --local access_key_id your_token
dvc remote modify origin --local secret_access_key your_token
Sau khi chạy xong, DVC sẽ tạo ra hai file cấu hình config và config.local nằm trong thư mục .dvc như sau:
.dvc
├── cache
├── config
├── config.local
└── tmp
Giờ bạn chỉ cần chạy lệnh sau để đẩy toàn bộ dữ liệu (các file .csv, .pkl, .pth, v.v.) lên remote dựa trên hash mà DVC quản lý:
dvc push
Khi hoàn tất, bạn có thể đẩy file config lên GitHub (trừ config.local vì chứa thông tin riêng tư).
Nhờ đó, bất kỳ ai clone repository của bạn về đều có thể tải lại toàn bộ dữ liệu bằng cách chạy:
dvc pull
Với cơ chế này, mỗi khi có thay đổi về dữ liệu hay mô hình, DVC sẽ tự động phát hiện thông qua hash. Bạn chỉ cần cập nhật metadata và đẩy dữ liệu mới lên DagsHub. Ngược lại, người khác chỉ cần git checkout về đúng commit tương ứng, rồi dvc pull để khôi phục lại phiên bản dữ liệu chính xác.
7. Tích hợp Pipeline Tự Động với dvc.yaml
Sau khi đã làm quen với cách theo dõi thủ công qua dvc add, chúng ta sẽ nâng cấp lên pipeline tự động bằng file dvc.yaml và chạy với lệnh dvc repro.
stages:
train:
cmd: python scripts/train.py
deps:
- scripts/train.py
- src/models/linear.py
- data/processed/processed_data.pkl
- params.yaml
outs:
- models/model.pth
evaluate:
cmd: python scripts/evaluate.py
deps:
- scripts/evaluate.py
- src/models/linear.py
- data/processed/processed_data.pkl
- models/model.pth
plots:
- metrics/train.csv:
x: epoch
y: Loss
- train_loss
- val_loss
title: "Training and Validation Loss per Epoch"
Phần stages định nghĩa các bước độc lập trong quy trình làm việc. Mỗi bước bao gồm lệnh để chạy nó (cmd), các phụ thuộc (deps) và các tệp đầu ra (outs).
Bước train (Huấn luyện)
Đây là bước chịu trách nhiệm huấn luyện mô hình.
cmd: python scripts/train.py:- Lệnh: Chỉ định câu lệnh Python cần chạy để thực hiện việc huấn luyện.
deps:(Dependencies - Phụ thuộc):scripts/train.py: Tập lệnh chính để huấn luyện.src/models/linear.py: Định nghĩa kiến trúc mô hình (ví dụ: một mô hình tuyến tính).data/processed/processed_data.pkl: Tập dữ liệu đã được xử lý, cần thiết để huấn luyện.params.yaml: Tệp chứa các siêu tham số (hyperparameters) như tốc độ học, số epoch, v.v.
outs:(Outputs - Đầu ra):models/model.pth: Tệp mô hình đã được huấn luyện sẽ được tạo ra sau khi bước này hoàn thành thành công.
Bước evaluate (Đánh giá)
Đây là bước chịu trách nhiệm kiểm tra hiệu suất của mô hình đã huấn luyện.
cmd: python scripts/evaluate.py:- Lệnh: Chỉ định câu lệnh Python cần chạy để thực hiện việc đánh giá.
deps:(Dependencies - Phụ thuộc):scripts/evaluate.py: Tập lệnh chính để đánh giá.src/models/linear.py: Định nghĩa mô hình (để đảm bảo đánh giá cùng một kiến trúc).data/processed/processed_data.pkl: Tập dữ liệu (thường là tập kiểm tra) cần thiết để đánh giá.models/model.pth: Tệp mô hình đã huấn luyện từ bướctrain– đây là đầu vào quan trọng nhất.
Biểu đồ (Plots)
Phần plots định nghĩa các tệp dữ liệu nào cần được phân tích và hiển thị dưới dạng biểu đồ để theo dõi tiến trình hoặc kết quả.
- metrics/train.csv::- Tệp dữ liệu: Chỉ định tệp CSV (
metrics/train.csv) chứa các số liệu (metrics) được ghi lại trong quá trình huấn luyện.
- Tệp dữ liệu: Chỉ định tệp CSV (
- Cấu hình biểu đồ:
x: epoch: Trục hoành (X-axis) của biểu đồ sẽ là cột có tên làepoch(thể hiện thời điểm trong quá trình huấn luyện).y: Loss: Chỉ định rằng trục tung (Y-axis) sẽ thể hiện đại lượngLoss.- train_loss: Một chuỗi (series) trên biểu đồ sẽ sử dụng cộttrain_losslàm giá trị.- val_loss: Một chuỗi khác sẽ sử dụng cộtval_loss.
title: "Training and Validation Loss per Epoch":- Tiêu đề: Đặt tiêu đề cho biểu đồ, mô tả nội dung của nó.
Tóm lại:
- Mỗi khi thay đổi bất kỳ tệp phụ thuộc nào (mã, dữ liệu, siêu tham số), bước tương ứng sẽ chạy lại.
- Các tệp đầu ra quan trọng (như mô hình) được theo dõi phiên bản.
- Các số liệu huấn luyện và xác thực được tự động biểu đồ hóa và cũng được theo dõi phiên bản, cho phép so sánh dễ dàng giữa các lần chạy khác nhau.
IV. Tổng kết
DVC giúp lấp đầy khoảng trống lớn giữa code và dữ liệu lớn trong quy trình phát triển ML. Nó cho phép bạn theo dõi phiên bản dữ liệu, quản lý pipeline, và chia sẻ/khôi phục chính xác các phiên bản mô hình — mọi thứ cần thiết để đảm bảo reproducibility và hợp tác trong team.
Chưa có bình luận nào. Hãy là người đầu tiên!