1. MỞ ĐẦU
" Cứ mỗi 1000 bài hát được phát hành trên Spotify, chỉ khoảng 6 bài có thể trở thành một bản HIT thực thụ "
Điều này có nghĩa là 99.4% bài hát được ra mắt dù được đầu tư bao nhiêu công sức, tài năng hay thời gian trong phòng thu cũng không bao giờ thực sự bứt phá. Vậy điều gì khiến một số rất ít bài hát đó có thể vươn tới đỉnh cao? Liệu có tồn tại một công thức "thần thánh" đằng sau những bản hit hay thành công trong âm nhạc chỉ đơn giản là một cú JACKPOT trong xác suất thống kê?!
Để tìm hiểu câu hỏi này, tôi sẽ phân tích dataset "550k Spotify Songs - Audio, Lyrics and Genres" trên Kaggle bao gồm hơn 550 nghìn bài hát cùng các đặc điểm như thông tin nghệ sĩ, thể loại nhạc và lời bài hát....
Mục tiêu của bài viết là xem liệu các bài hát thành công có cùng những pattern, đặc điểm chung hay không? Chẳng hạn như danceability cao hơn, nhiều năng lượng hơn, hoặc một mức loudness đặc trưng có tạo được sự khác biệt so với phần lớn các bài hát còn lại.
2. GIẢI THÍCH DATASET
Trong bài viết này, tôi sẽ sử dụng bộ dataset có sẵn trên Kaggle.
Dataset "550k Spotify Songs - Audio, Lyrics and Genres":
https://www.kaggle.com/datasets/serkantysz/550k-spotify-songs-audio-lyrics-and-genres/data
Bộ dataset này gồm hai file chính:
- songs.csv — chứa 550.622 bài hát với 24 cột dữ liệu, bao gồm các đặc điểm như tên album (album_name), tên nghệ sĩ (artists), lời nhạc (lyrics),... và độ phổ biến (popularity) trên Spotify.
- artists.csv — chứa 71.440 nghệ sĩ với 6 cột dữ liệu, bao gồm số lượng người theo dõi (followers), độ phổ biến của nghệ sĩ (popularity), và thể loại âm nhạc chính (main_genre)…
songs.csv
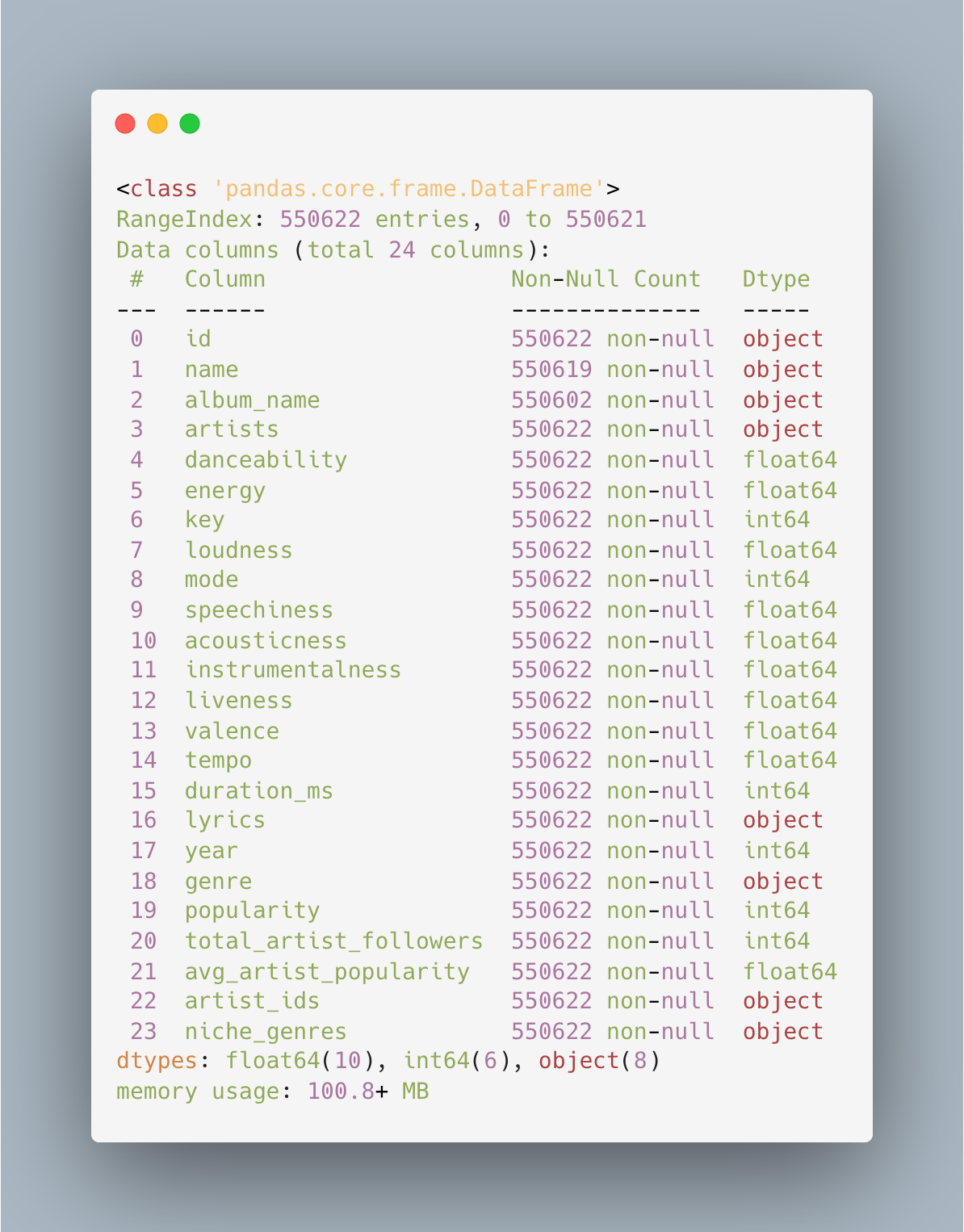
artists.csv

3. LÀM SẠCH DỮ LIỆU
3.1. Phát hiện vấn đề trong dữ liệu
Đây là bước quan trọng nhất trước khi phân tích — phát hiện các vấn đề có thể làm sai lệch kết quả.
3.1.1. Kiểm tra dữ liệu bị thiếu
artists.csv
print("=== GIÁ TRỊ THIẾU: artists.csv ===")
print(artists_raw.isnull().sum())
print(f"\nTổng số dòng: {len(artists_raw)}")
Dữ liệu thiếu rất ít: chỉ có 2 giá trị thiếu ở cột name (0.003%). Vì tỉ lệ dưới 5%, ta có thể xóa trực tiếp các dòng này.
songs.csv
print("=== GIÁ TRỊ THIẾU: songs.csv ===")
print(songs_raw.isnull().sum())
print(f"\nTổng số dòng: {len(songs_raw)}")
Tương tự, songs.csv chỉ có 3 tên bài hát và 20 tên album bị thiếu — không đáng kể trên tổng 550,000+ bản ghi. Các dòng thiếu ở những cột quan trọng (name, artists, year, genre, popularity, danceability, energy, loudness, valence, tempo) sẽ được xóa.
3.1.2. Kiểm tra dữ liệu trùng lặp
artists.csv
print("=== TRÙNG LẶP: artists.csv ===")
print(f"Trùng ID: {artists_raw.duplicated(subset=['id']).sum()}")
print(f"Trùng tên (chính xác): {artists_raw.duplicated(subset=['name']).sum()}")
name_lower = artists_raw['name'].str.strip().str.lower()
print(f"Trùng tên (không phân biệt hoa/thường): {name_lower.duplicated().sum()}")
- Trùng ID: 0
- Trùng tên (chính xác): 1,796
- Trùng tên (không phân biệt hoa/thường): 2,098
Việc trùng tên không phân biệt hoa/thường khá nghiêm trọng — cùng một nghệ sĩ có thể xuất hiện dưới nhiều cách viết khác nhau (ví dụ: "the weeknd" và "The Weeknd"). Cần xử lý bằng cách giữ lại bản ghi có điểm phổ biến cao nhất.
songs.csv
print("=== TRÙNG LẶP: songs.csv ===")
print(f"Trùng ID: {songs_raw.duplicated(subset=['id']).sum()}")
songs_raw['_name_lower'] = songs_raw['name'].str.strip().str.lower()
songs_raw['_artists_lower'] = songs_raw['artists'].astype(str).str.strip().str.lower()
n_case_dups = songs_raw.duplicated(subset=['_name_lower', '_artists_lower']).sum()
print(f"Trùng tên bài + nghệ sĩ (không phân biệt hoa/thường): {n_case_dups}")
songs_raw.drop(columns=['_name_lower', '_artists_lower'], inplace=True)
- Trùng ID: 0
- Trùng tên bài hát + nghệ sĩ (không phân biệt hoa/thường): 50,056
Hơn 50,000 bài hát có cùng tên và nghệ sĩ — nhiều khả năng đến từ việc phát hành lại, album tổng hợp, hoặc các phiên bản theo khu vực. Chỉ giữ lại phiên bản có điểm phổ biến cao nhất để tránh trùng lặp.
3.1.3. Kiểm tra giá trị ngoại lai & logic dữ liệu
# --- songs.csv ---
print("=== LOGIC DỮ LIỆU: songs.csv ===")
print(f"Khoảng popularity: {songs_raw['popularity'].min()} - {songs_raw['popularity'].max()}")
print(f"Số bài có popularity = 0: {(songs_raw['popularity'] == 0).sum()}")
print(f"Khoảng năm: {songs_raw['year'].min()} - {songs_raw['year'].max()}")
print(f"Khoảng thời lượng: {songs_raw['duration_ms'].min()/60000:.1f} - {songs_raw['duration_ms'].max()/60000:.1f} phút")
# --- artists.csv ---
print("=== LOGIC DỮ LIỆU: artists.csv ===")
print(f"Khoảng popularity: {artists_raw['popularity'].min()} - {artists_raw['popularity'].max()}")
print(f"Khoảng followers: {artists_raw['followers'].min()} - {artists_raw['followers'].max()}")
- Điểm phổ biến (popularity) phải nằm trong khoảng 0–100. Các giá trị ngoài phạm vi này sẽ bị loại bỏ.
- Bài hát có popularity = 0 nhiều khả năng là các bài chưa được nghe hoặc không còn hoạt động. Trước khi xóa: 402,974 dòng, trung bình popularity 17.74. Sau khi xóa: 303,142 dòng, trung bình popularity 23.58.
- Khoảng năm phát hành: Dữ liệu gốc trải dài từ 1900–2025. Vì phân tích tập trung vào xu hướng âm nhạc hiện đại, ta chỉ giữ lại các bài từ năm 2000 trở đi.
3.1.4. Kiểm tra định dạng dữ liệu
# --- artists.csv ---
print("=== KIỂU DỮ LIỆU: artists.csv ===")
print(artists_raw.dtypes)
# --- songs.csv ---
print("=== KIỂU DỮ LIỆU: songs.csv ===")
print(songs_raw.dtypes)
- Các cột số (danceability, energy, key, loudness, mode, speechiness, acousticness, instrumentalness, liveness, valence, tempo, duration_ms, year, popularity, total_artist_followers, avg_artist_popularity) được chuyển đổi sang đúng kiểu số bằng
pd.to_numeric(errors='coerce'). - Cột
followersvàpopularitytrong artists.csv cũng được chuyển đổi tương tự, các giá trị không hợp lệ được thay bằng 0.
3.2. Các bước làm sạch
Sau khi phát hiện các vấn đề, ta thực hiện các bước làm sạch sau:
artists.csv:
- Xóa 2 dòng thiếu tên nghệ sĩ
- Kiểm tra trùng ID (0 trường hợp)
- Xử lý 2,097 tên trùng lặp không phân biệt hoa/thường — giữ bản ghi có điểm phổ biến cao nhất
- Chuyển đổi
followersvàpopularitysang kiểu số - Lọc điểm phổ biến trong phạm vi [0, 100] (0 dòng bị xóa)
Kết quả: 71,440 → 69,341 dòng
songs.csv:
- Lọc năm ≥ 2000 (550,622 → 453,033 dòng)
- Xóa 3 dòng thiếu dữ liệu ở các cột quan trọng
- Kiểm tra trùng ID (0 trường hợp)
- Xử lý 50,056 bản ghi trùng tên bài hát + nghệ sĩ — giữ phiên bản có điểm phổ biến cao nhất
- Chuyển đổi các cột sang đúng kiểu số
- Tạo cột
Status(Flop / Average / Hit) - Xóa các bài có popularity = 0 (402,974 → 303,142 dòng)
- Chuyển đổi
duration_mssang phút
Kết quả: 550,622 → 303,142 bài hát, trong đó có 1,776 bài hit
Chỉ số Popularity và phân loại Hit
Mỗi bài hát trong dataset đều có một điểm popularity do Spotify gán, nằm trong khoảng từ 0 đến 100. Chỉ số này được tính toán bằng thuật toán, dựa trên nhiều yếu tố như tổng số lượt nghe, độ mới của lượt nghe, và các dạng tương tác khác của người dùng.
Để giúp chỉ số liên tục này dễ diễn giải hơn khi phân tích ở phần sau, tôi sẽ chuyển nó thành ba nhóm phân loại:
| Trạng thái (Status) | Khoảng phổ biến | Tỷ lệ (%) trên tổng thể |
|---|---|---|
| Flop | 0 – 30 | 69.13 |
| Average | 31 – 70 | 30.28 |
| Hit | 71 – 100 | 0.59 |
4. Các phân phối đặc trưng của dữ liệu
4.1. Phân phối các biến số theo Status
Để hiểu rõ sự khác biệt giữa các nhóm Flop, Average và Hit, ta vẽ biểu đồ phân bố (histogram + KDE) cho từng đặc trưng âm thanh, chia theo 3 nhóm Status.
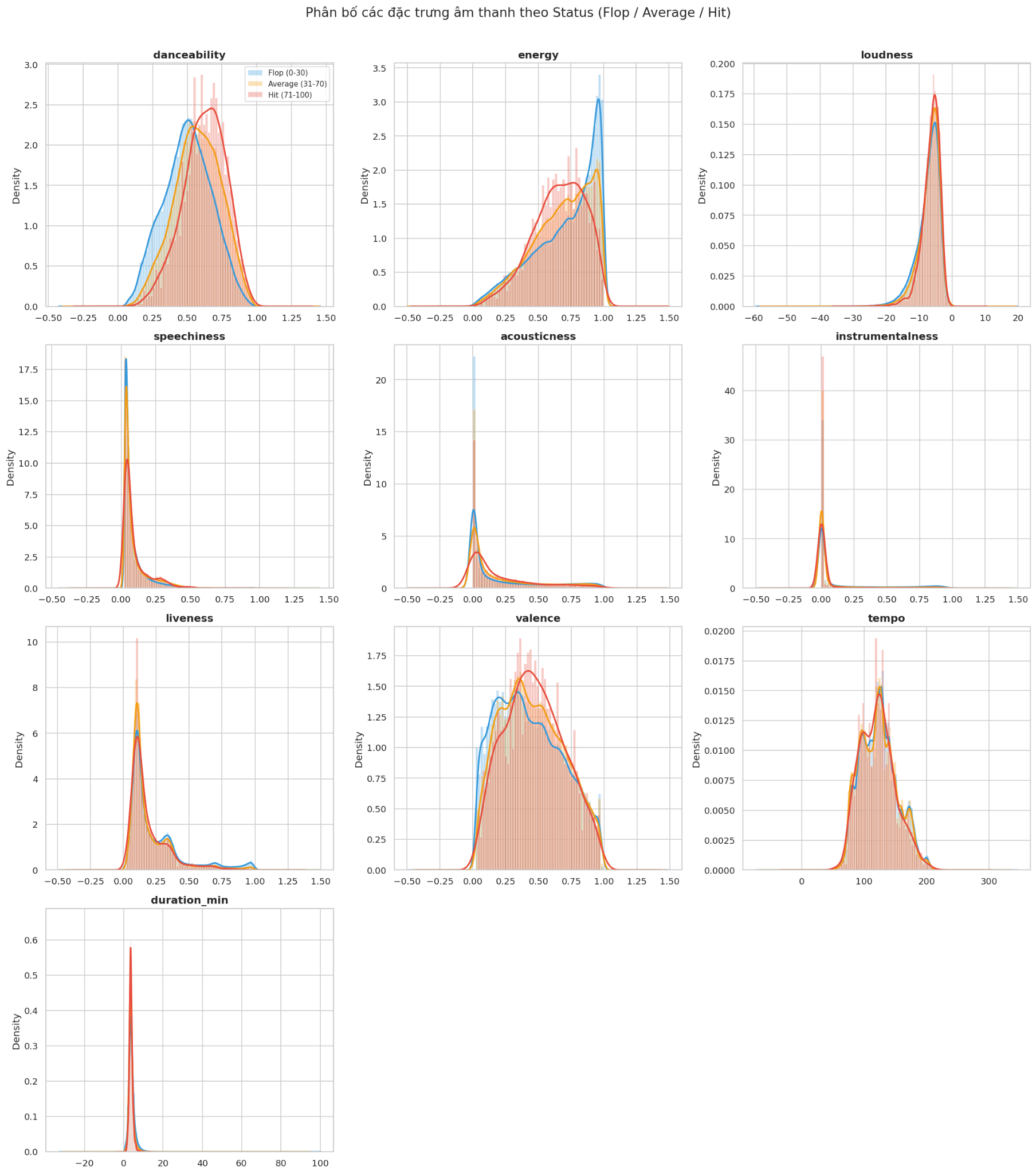
Nhận xét:
- Danceability cho thấy sự khác biệt rõ rệt nhất giữa 3 nhóm. Đường KDE của Hit lệch phải đáng kể so với Flop - bài hit tập trung quanh vùng 0.55–0.75, trong khi Flop trải rộng hơn và đỉnh ở vùng thấp hơn (\~0.40). Nhịp điệu mạnh, ổn định rõ ràng là một đặc trưng phổ biến ở bài hát thành công.
- Instrumentalness là biến có sự phân tách mạnh nhất. Cả 3 nhóm đều tập trung gần 0, nhưng Flop có đuôi phân bố kéo dài sang phải rõ rệt - nghĩa là bài nhạc thuần nhạc cụ (không có giọng hát) gần như không xuất hiện trong nhóm Hit.
- Loudness: Hit có đỉnh KDE cao và hẹp quanh vùng −5 đến −10 dB, trong khi Flop trải rộng hơn về phía âm lượng thấp (−30 đến −50 dB). Bài hát to hơn, nghe chuyên nghiệp hơn có xu hướng phổ biến hơn.
- Energy, Valence, Speechiness, Acousticness, Liveness: Sự khác biệt giữa 3 nhóm không quá rõ ràng - các đường KDE chồng lấn nhiều. Điều này cho thấy các biến này đơn lẻ không phải là yếu tố phân biệt mạnh giữa Hit và Flop.
- Tempo và Duration: Phân bố gần như giống nhau giữa 3 nhóm, cho thấy tốc độ bài hát và thời lượng không đóng vai trò quan trọng trong việc quyết định mức độ phổ biến.
4.2 Phân phối các biến phân loại
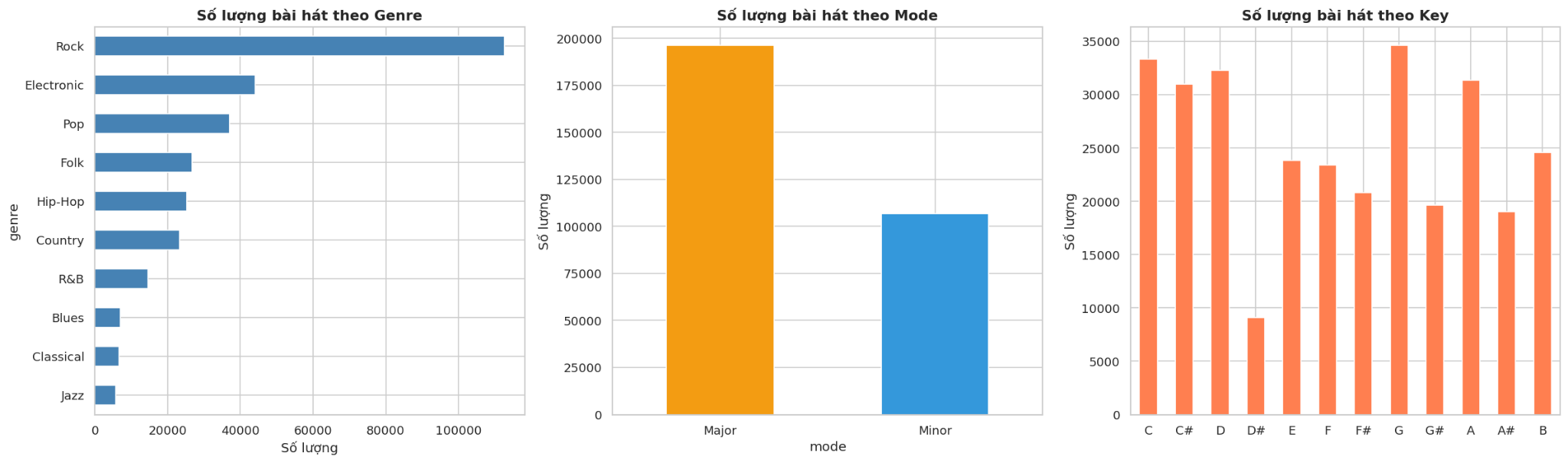
Nhận xét:
- Genre: Rock chiếm số lượng áp đảo (hơn 100,000 bài), tiếp theo là Electronic và Pop (khoảng 35,000–40,000 bài). Các thể loại như Blues, Classical và Jazz chiếm tỉ lệ rất nhỏ. Tuy nhiên, số lượng nhiều không đồng nghĩa với tỉ lệ hit cao - đây chỉ phản ánh sự phân bố của dữ liệu, không phải mức độ thành công.
- Mode: Khoảng 2/3 bài hát sử dụng thang âm Major (\~195,000) và 1/3 là Minor (\~110,000). Thang âm Major thường mang lại cảm giác tươi sáng, vui vẻ hơn - phù hợp với thị hiếu âm nhạc đại chúng.
- Key: Các key phổ biến nhất là C, C#, D, G và F# (khoảng 30,000–35,000 bài mỗi key). D# là key ít phổ biến nhất (\~8,000 bài). Sự phân bố tương đối đều giữa các key cho thấy không có key nào chiếm ưu thế tuyệt đối.
4.3 Ma trận tương quan giữa các đặc trưng âm thanh và mức độ phổ biến
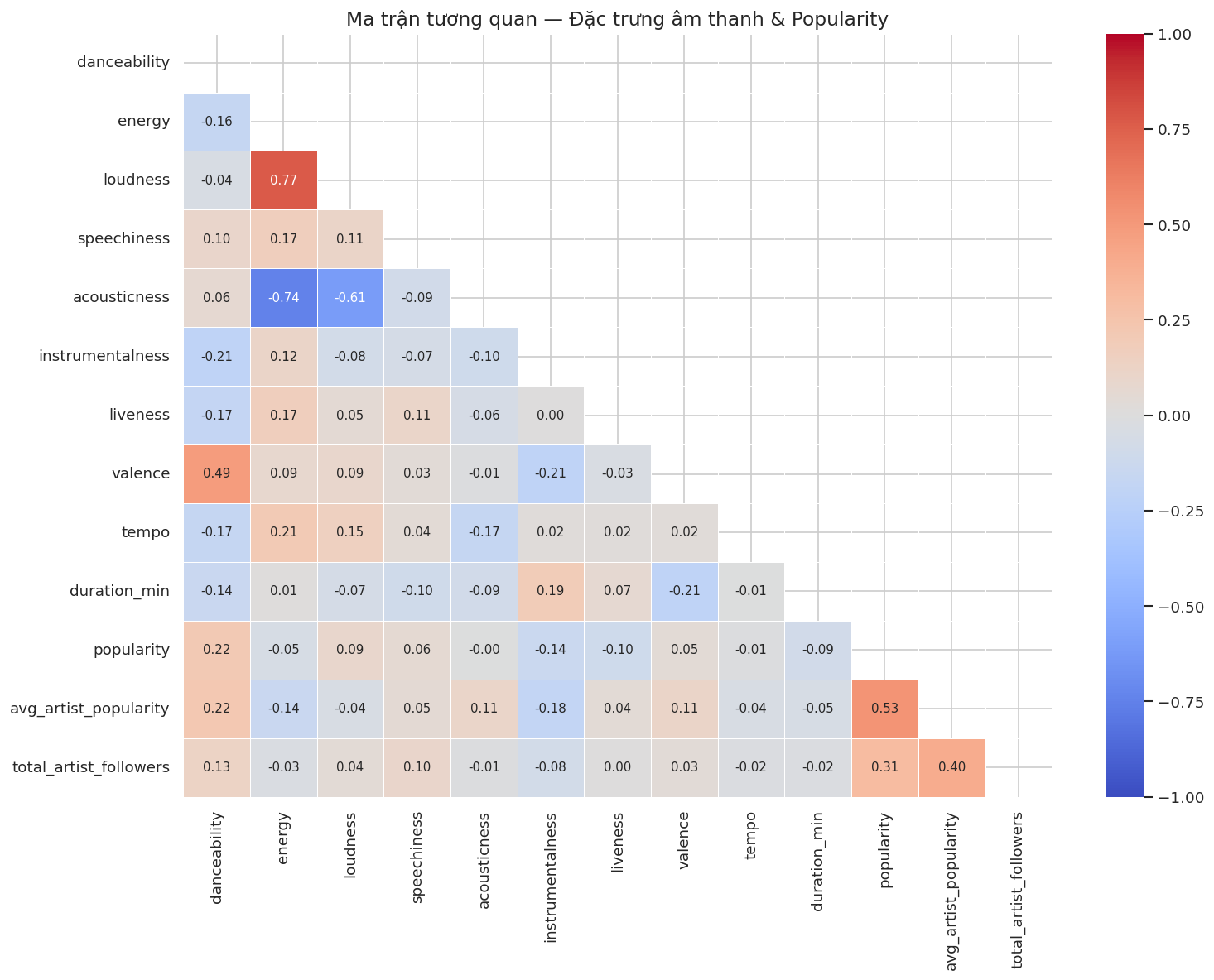
Nhận xét:
- Tương quan dương mạnh nhất với popularity: avg_artist_popularity (r \= 0.53) và total_artist_followers (r \= 0.31). Độ nổi tiếng sẵn có của nghệ sĩ là yếu tố dự đoán mạnh nhất cho sự thành công của bài hát - mạnh hơn hẳn mọi đặc trưng âm thanh.
- Đặc trưng âm thanh tương quan dương: danceability (r \= 0.22) là biến âm thanh có tương quan cao nhất với popularity, tiếp theo là loudness (r \= 0.09) và speechiness (r \= 0.06).
- Tương quan âm đáng chú ý: instrumentalness (r \= −0.14) và liveness (r \= −0.10) là hai biến âm thanh có tương quan nghịch rõ nhất - bài hát không lời và mang âm hưởng live thường kém phổ biến hơn.
- Giữa các biến với nhau: energy và loudness tương quan rất cao (r \= 0.77), energy và acousticness tương quan nghịch mạnh (r \= −0.74). Hai cặp này mang thông tin chồng lấn - cần lưu ý nếu đưa vào mô hình dự đoán sau này.
- Gần như không tương quan: acousticness (r \= −0.00), tempo (r \= −0.01) và duration_min (r \= −0.09) gần như không liên quan đến mức độ phổ biến.
5. NGHỆ SĨ TẠO HIT HAY HIT TẠO NGHỆ SĨ?
Dựa trên bảng mức độ tương quan, ta có thể nhận thấy rằng độ phổ biến của bài hát có mối quan hệ rõ ràng nhất đối với độ phổ biến của nghệ sĩ tạo ra nó. Ở mục này, tôi sẽ đào sâu hơn về mối quan hệ này.
5.1. Mối quan hệ giữa độ phổ biến của bài hát và độ phổ biến của nghệ sĩ
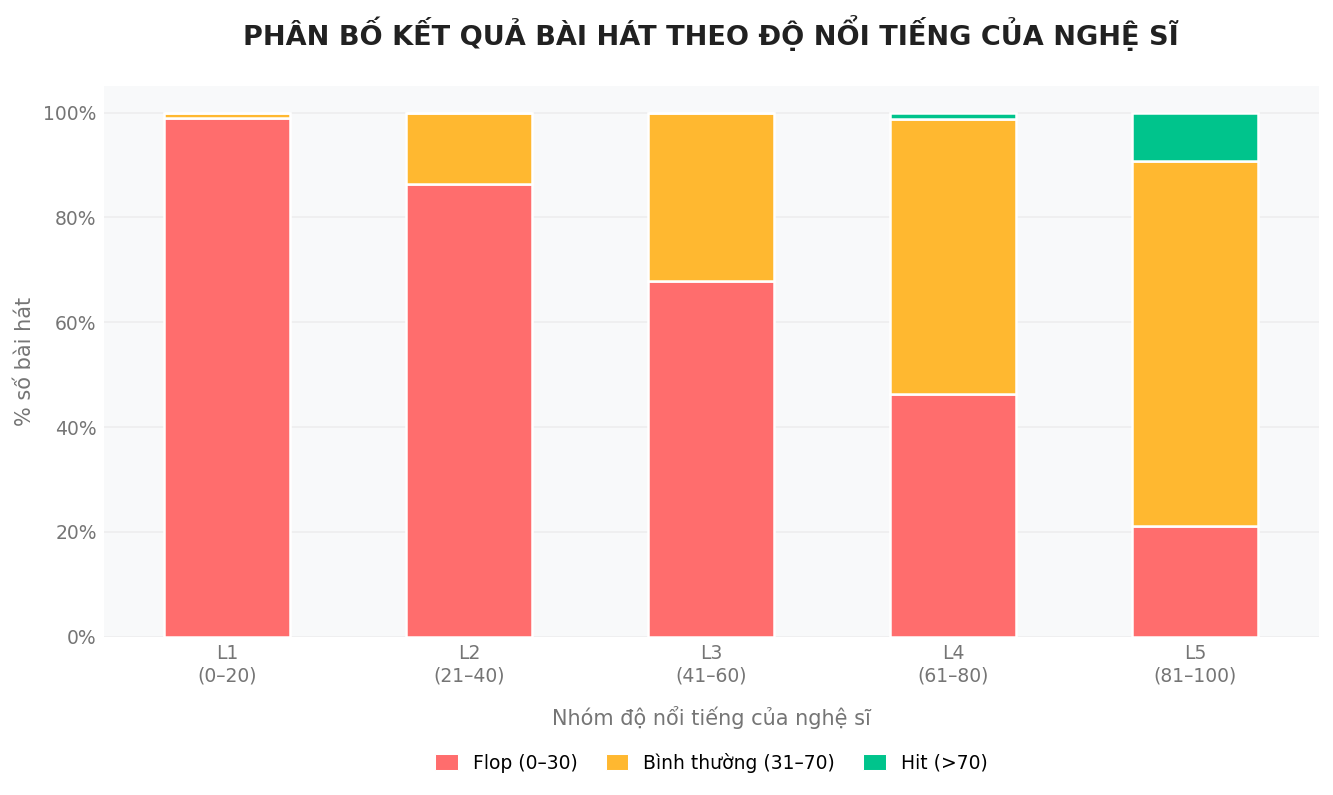
Từ bảng dữ liệu trên, có thể thấy rằng các bài hát HIT phần lớn đến từ những nghệ sĩ đã có độ phổ biến khá cao, thường từ mức 61 trở lên, và tập trung nhiều nhất ở nhóm 81–100. Điều này gợi ý rằng danh tiếng của nghệ sĩ có thể đóng vai trò quan trọng trong việc giúp bài hát nhanh chóng tiếp cận được với đông đảo khán giả. Khi một nghệ sĩ đã có lượng fan lớn, mỗi sản phẩm mới của họ gần như đã có sẵn một "đường băng" để lan tỏa.
Tuy nhiên, dữ liệu hiện tại vẫn chưa thể trả lời hoàn toàn câu hỏi: Nghệ sĩ nổi tiếng tạo HIT hay HIT tạo ra nghệ sĩ nổi tiếng hay cả 2?
Mối quan hệ này có thể mang tính hai chiều, nhưng việc xác định chính xác nguyên nhân – kết quả nằm ngoài phạm vi phân tích của nhóm trong bài blog này.
5.2. Ảnh hưởng của việc hợp tác giữa các nghệ sĩ lên sản phẩm
Để đào sâu hơn về ảnh hưởng của nghệ sĩ lên sản phẩm, nhóm quyết định sẽ khám phá thêm một khía cạnh khác: HỢP TÁC.
Những màn kết hợp giữa các nghệ sĩ từ lâu đã trở thành một phần thú vị của thị trường âm nhạc. Chẳng hạn như sự kết hợp giữa Sơn Tùng M-TP và Snoop Dogg hay Rosé và Bruno Mars – những màn collab thường mang lại trải nghiệm mới lạ cho khán giả.
Điều này đặt ra câu hỏi: Liệu việc hợp tác giữa các nghệ sĩ có thực sự giúp bài hát trở nên phổ biến hơn?
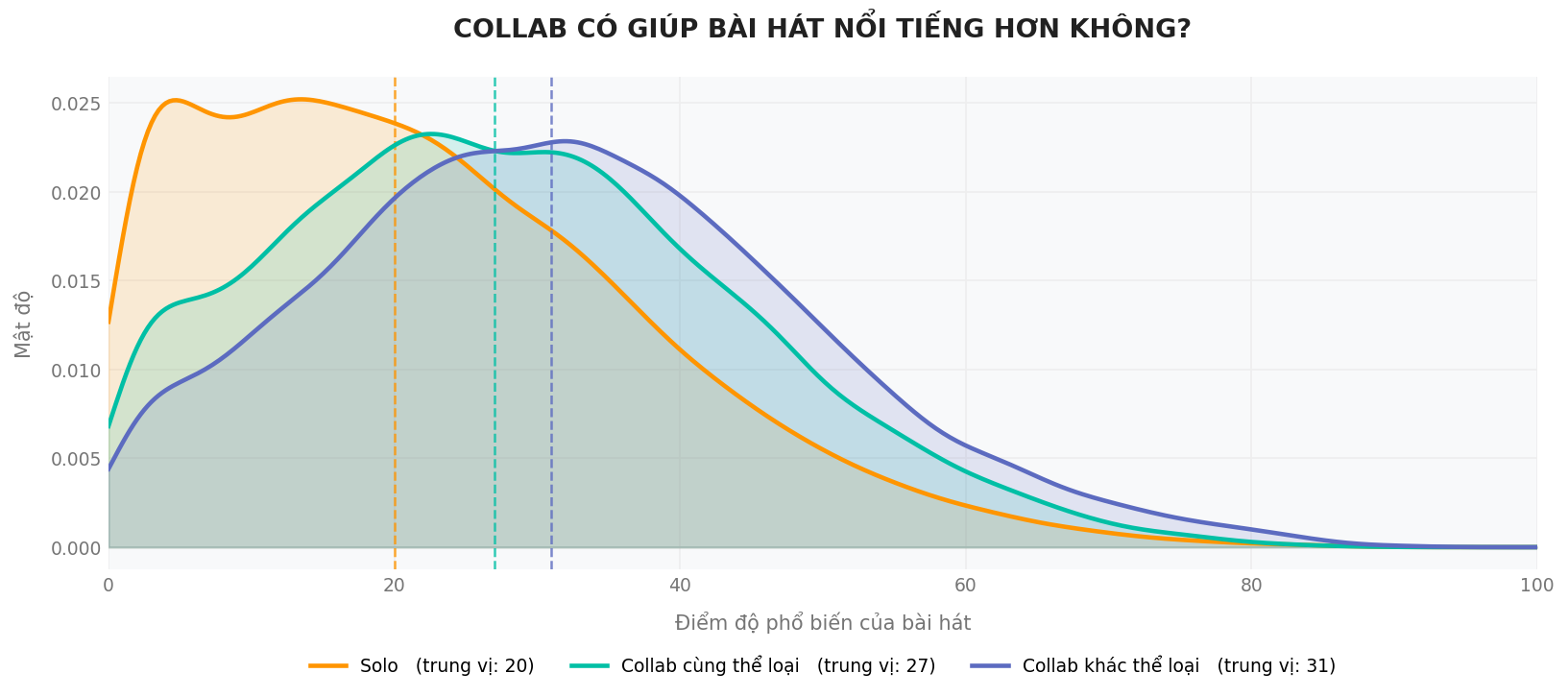
Kết quả phân tích cho thấy rằng phân bố độ phổ biến của các bài hát có sự hợp tác nhìn chung cao hơn so với các bài solo. Đặc biệt, những ca khúc được tạo ra bởi các nghệ sĩ thuộc những dòng nhạc khác nhau có mức độ phổ biến cao nhất, với trung vị đạt khoảng 31. Tuy nhiên, vấn đề được đặt ra ở đây là liệu việc hợp tác giữa các nghệ sĩ thật sự sẽ khiến tác phẩm dễ phổ biến hơn hay những nghệ sĩ hợp tác với nhau vốn dĩ đã nổi tiếng hơn từ đầu?
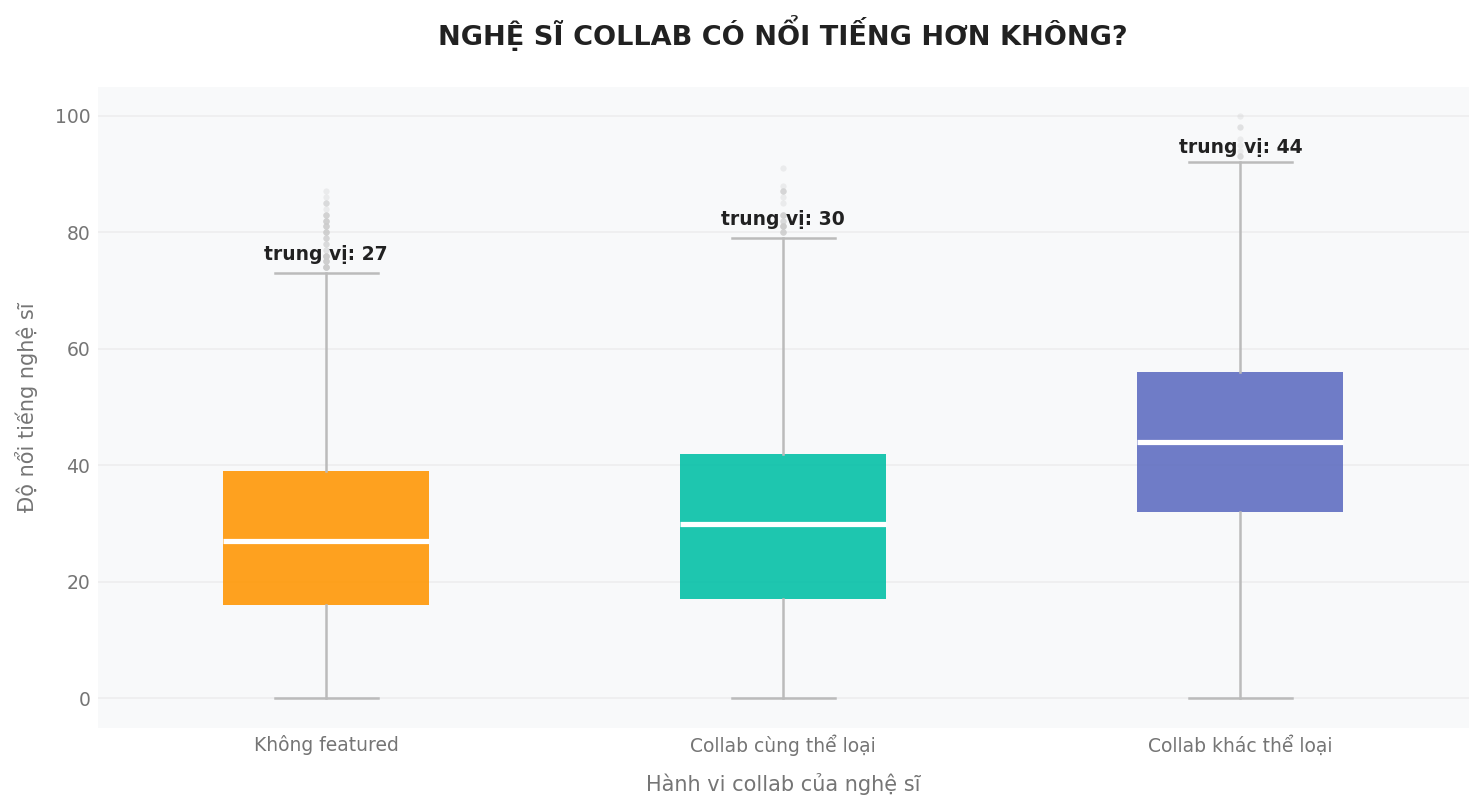
Theo đồ thị, ta có thể thấy được rằng độ nổi tiếng của nghệ sĩ hợp tác với nhau (đặc biệt đối với những nghệ sĩ khác dòng nhạc) cao hơn so với những nghệ sĩ chưa từng hợp tác. Điều này có thể cho thấy rằng những nghệ sĩ nổi tiếng thường có nhiều cơ hội được mời hợp tác hơn, từ đó khiến các sản phẩm collab cũng có xu hướng phổ biến hơn.
5.3. Tuổi đời của người nghệ sĩ
Câu hỏi cuối cùng tôi muốn tìm hiểu trong phần này là liệu tuổi đời của người nghệ sĩ có liên quan đến khả năng tạo HIT của họ hay không? tôi đo lường tuổi đời của người nghệ sĩ bằng cách lấy năm của bài hát gần nhất trừ cho năm của bài hát đầu tiên mà nghệ sĩ phát hành.
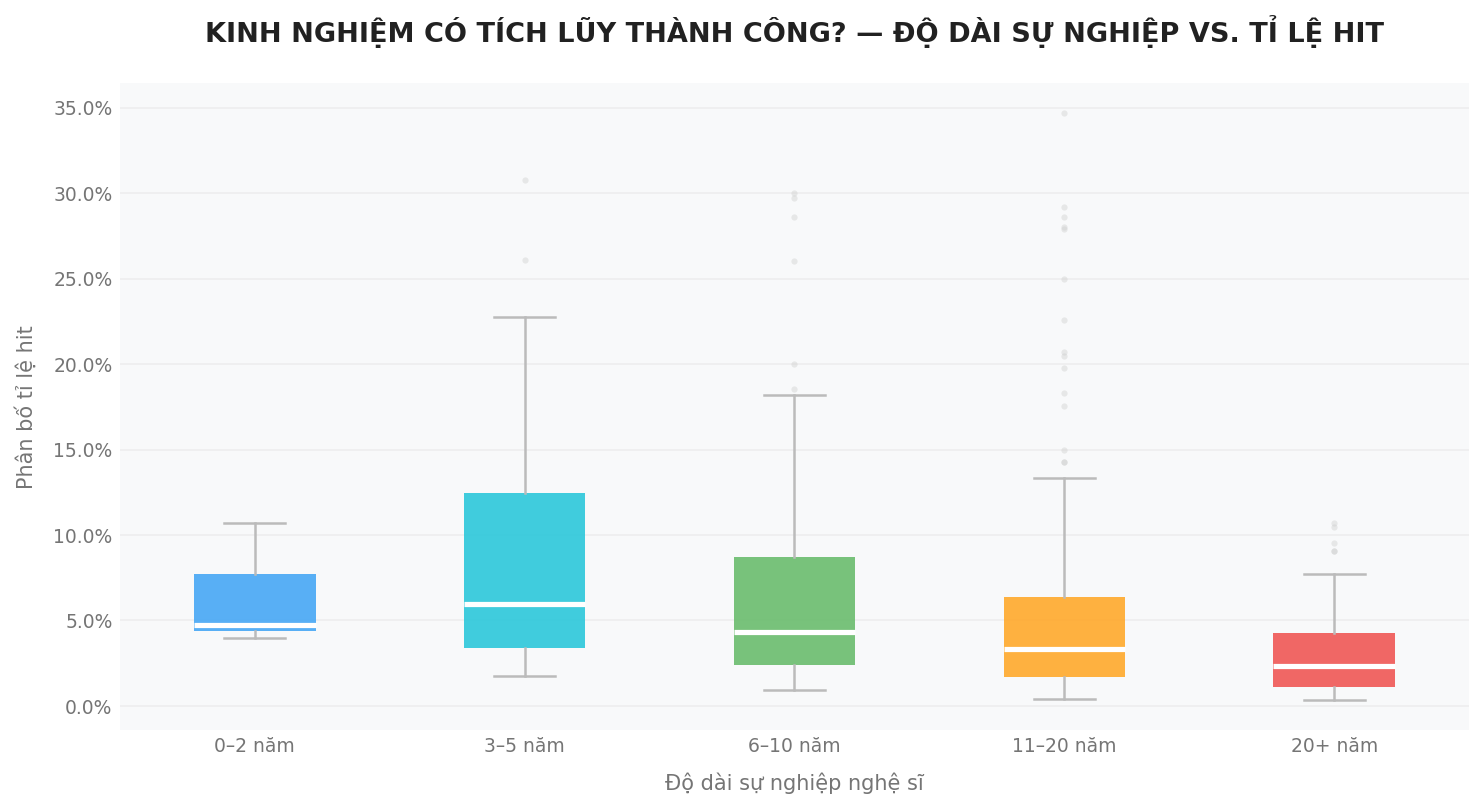
Dữ liệu cho ta một quan sát rất thú vị: Trung vị của tỉ lệ tạo HIT tăng nhẹ khi chuyển từ nhóm nghệ sĩ có 0–2 năm hoạt động sang nhóm 3–5 năm, nhưng sau đó giảm dần ở các nhóm có tuổi nghề cao hơn.
Điều này có thể gợi ý rằng tỉ lệ tạo HIT của nghệ sĩ có xu hướng tăng nhẹ trong những năm đầu sự nghiệp và đạt mức cao nhất ở giai đoạn đầu này (khoảng 0–5 năm). Sau đó, tỉ lệ sẽ giảm dần theo thời gian, có thể xuất phát từ việc âm nhạc không còn phù hợp với thị hiếu của đại chúng và thị trường.
Ngoài ra, độ phân tán dữ liệu trong nhóm nghệ sĩ có tuổi đời từ 3–5 năm cao hơn so với các nhóm khác. Điều này có thể phản ánh rằng đây là giai đoạn bùng nổ của nhiều nghệ sĩ, khi một số người vươn lên mạnh mẽ và trở thành những HITmaker thực thụ.
Tóm lại, ta có thể thấy được sự tương quan tương đối rõ ràng giữa người nghệ sĩ và độ nổi tiếng của tác phẩm của họ, đặc biệt về khía cạnh độ nổi tiếng của người nghệ sĩ. Tuy nhiên, để có thể xác nhận xem liệu người nghệ sĩ có phải là yếu tố gây ảnh hưởng lên độ nổi tiếng hay không, ta cần nhiều nghiên cứu xa hơn (chẳng hạn A/B Test).
6. CUỘC CHIẾN CỦA CÁC THỂ LOẠI
Bạn có bao giờ tự hỏi tại sao những giai điệu "quốc dân" từng làm mưa làm gió những năm 2000 giờ đây lại trở nên hiếm hoi trên các bảng xếp hạng? Liệu gu âm nhạc của chúng ta thực sự thay đổi, hay chính "thuật toán" và dữ liệu đang âm thầm định hình lại khái niệm về một bài Hit? Hãy cùng tôi lật lại lịch sử âm nhạc 25 năm qua dưới lăng kính Data để xem những "đế chế" nào đã sụp đổ và ai đang thực sự nắm giữ vương miện Popularity ngày nay.
6.1. Correlation Ratio giữa Thể loại và Độ nổi tiếng
Correlation Ratio (ký hiệu là η — Eta) là một chỉ số thống kê dùng để đo lường mức độ mối quan hệ giữa một biến phân loại (như genre) và một biến số liên tục (như popularity).
Ý tưởng cốt lõi: Thuật toán này dựa trên việc so sánh sự biến thiên của dữ liệu theo hai cách:
- Sự biến thiên nội bộ (Within-group variance): Độ phân tán của điểm Popularity bên trong từng thể loại.
- Sự biến thiên giữa các nhóm (Between-group variance): Độ chênh lệch về điểm Popularity trung bình giữa các thể loại khác nhau.
Chỉ số η được tính bằng công thức:
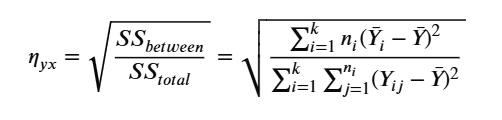
Trong đó:
- k: Tổng số các nhóm (thể loại nhạc). Ví dụ: Pop, Rock, Jazz...
- nᵢ: Số lượng bài hát có trong thể loại thứ i.
- ȳᵢ: Điểm Popularity trung bình của riêng thể loại thứ i (ví dụ: trung bình điểm của riêng dòng nhạc Rock).
- ȳ: Điểm Popularity trung bình cộng của tất cả các bài hát trong toàn bộ tập dữ liệu.
- yᵢⱼ: Điểm Popularity của bài hát thứ j nằm trong thể loại thứ i.
Giá trị η nằm trong khoảng từ 0 đến 1:
- η = 0: Thể loại nhạc không có liên quan gì đến độ nổi tiếng. Điểm trung bình của dòng Rock, Pop, Blues... đều như nhau.
- η = 1: Thể loại nhạc quyết định hoàn toàn độ nổi tiếng. Nếu biết bài hát là Rock, bạn có thể đoán chính xác 100% điểm Popularity của nó.
- Thực tế: Trong dữ liệu âm nhạc, η thường nằm ở mức 0.1 – 0.3. Điều này có nghĩa là thể loại nhạc có ảnh hưởng, nhưng vẫn còn nhiều yếu tố khác (nghệ sĩ, thời điểm phát hành, marketing) tác động vào.
Triển khai bằng code Python:
def calculate_correlation_ratio1(categories, measurements):
fcat = categories.values
fmeas = measurements.values
y_avg_all = np.mean(fmeas)
tmp_df = pd.DataFrame({'cat': fcat, 'meas': fmeas})
group_stats = tmp_df.groupby('cat')['meas'].agg(['mean', 'count'])
ss_between = np.sum(group_stats['count'] * (group_stats['mean'] - y_avg_all)**2)
ss_total = np.sum((fmeas - y_avg_all)**2)
eta = np.sqrt(ss_between / ss_total)
return eta
Sau khi kiểm tra độ tương quan, với kết quả của thể loại (Genre) η = 0.2480, nằm trong khoảng có ảnh hưởng về sự thành công của bài hát. Vì vậy chúng ta sẽ đào sâu vào chi tiết về sự tác động của thể loại khi làm nhạc.
6.2. Sự phân bổ độ nổi tiếng theo từng Thể loại
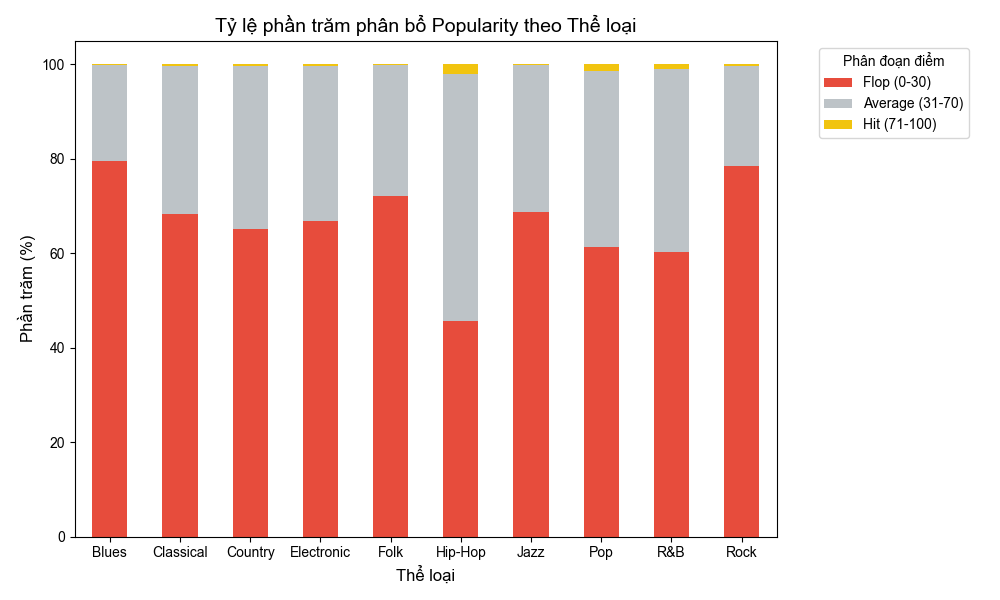
Vương miện gọi tên Hip-Hop: Trong khi đa số các thể loại khác đều bị "nhấn chìm" bởi tỷ lệ thất bại (Flop) chiếm từ 60% đến gần 80%, thì Hip-Hop là dòng nhạc duy nhất giữ được tỉ lệ Average (trung bình) và Hit (thành công) cao vượt trội. Với gần 55% bài hát nằm trên mức an toàn, Hip-Hop chứng minh mình không chỉ là một trào lưu nhất thời mà là một "cỗ máy" tạo hit bền bỉ.
Nỗi buồn của Blues và Rock: Trái ngược với ánh hào quang đó, Blues và Rock đang trải qua một giai đoạn đầy thách thức. Tỉ lệ Flop (0–30 điểm) của hai dòng nhạc này cao ngất ngưỡng (xấp xỉ 80%), khiến phân đoạn Hit (màu vàng) trở nên mỏng manh như một sợi chỉ.
Vùng an toàn (Average): Các thể loại như Pop và R&B đang làm rất tốt nhiệm vụ duy trì sự hiện diện của mình khi có một lượng lớn bài hát nằm ở vùng trung gian, tạo nên nền tảng ổn định cho thị trường âm nhạc đại chúng.
6.3. Độ phân tán độ nổi tiếng
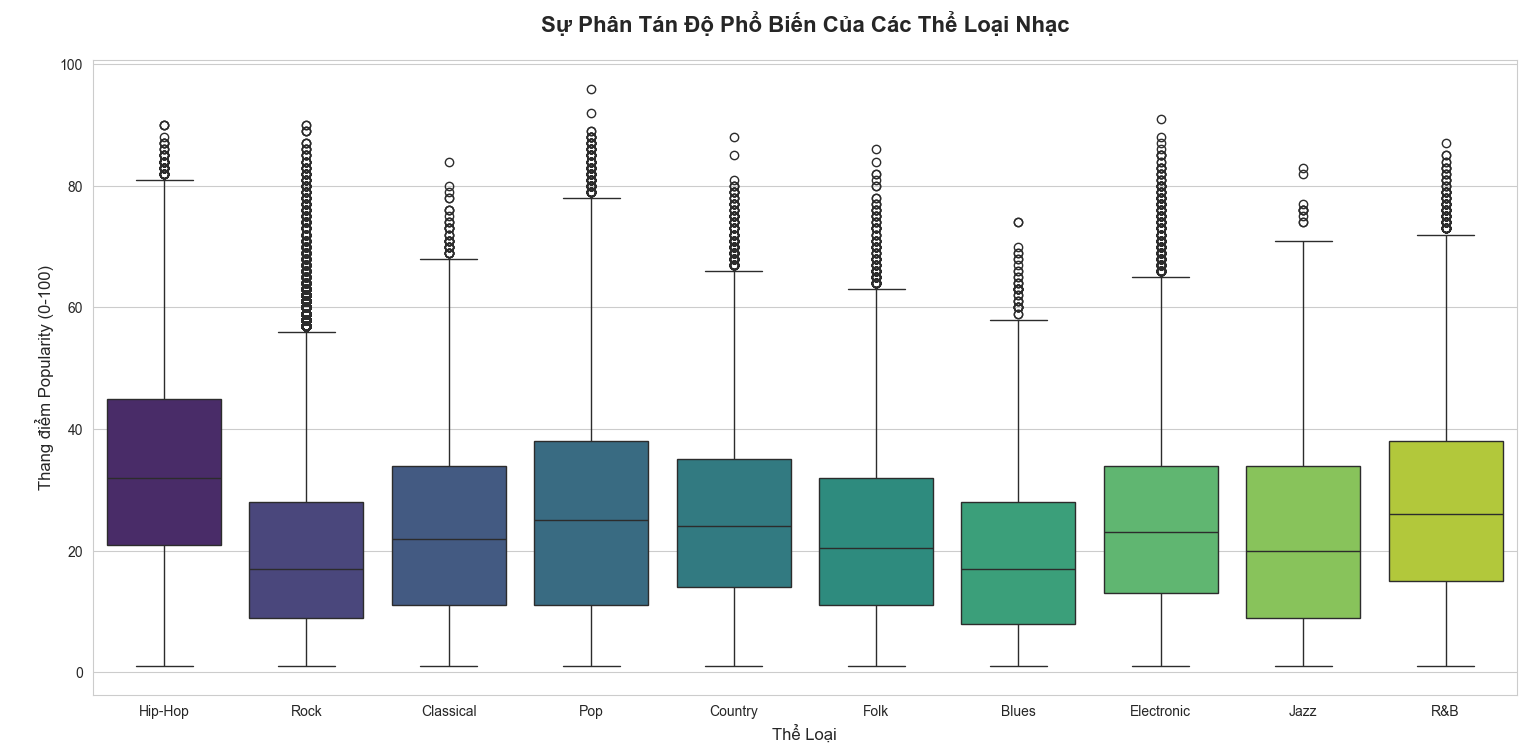
Hip-Hop là "Vua" mặt bằng chung: Có giá trị trung vị cao nhất. Điều này nghĩa là một bài hát Hip-Hop bất kỳ có xác suất nổi tiếng cao hơn tất cả các thể loại còn lại.
Sự phân hóa cực đại của Pop & Rock: Dù "hộp" nằm ở vùng thấp (nhiều bài Flop), nhưng lại sở hữu dàn Outliers dày đặc và cao nhất. Đây là nhóm "được ăn cả, ngã về không" — hoặc là mất tích, hoặc là trở thành siêu bản hit toàn cầu.
Blues & Jazz thiếu sức bật: Khoảng biến thiên hẹp và râu trên ngắn. Dữ liệu cho thấy hai dòng nhạc này có độ phổ biến ổn định nhưng cực kỳ khó bứt phá để tiếp cận khán giả đại chúng.
6.4. Sự Hoán Đổi Ngôi Vương: Cuộc Di Cư Của Những Bản Hit
Xu hướng top 5 thể loại đạt Hit theo thời gian
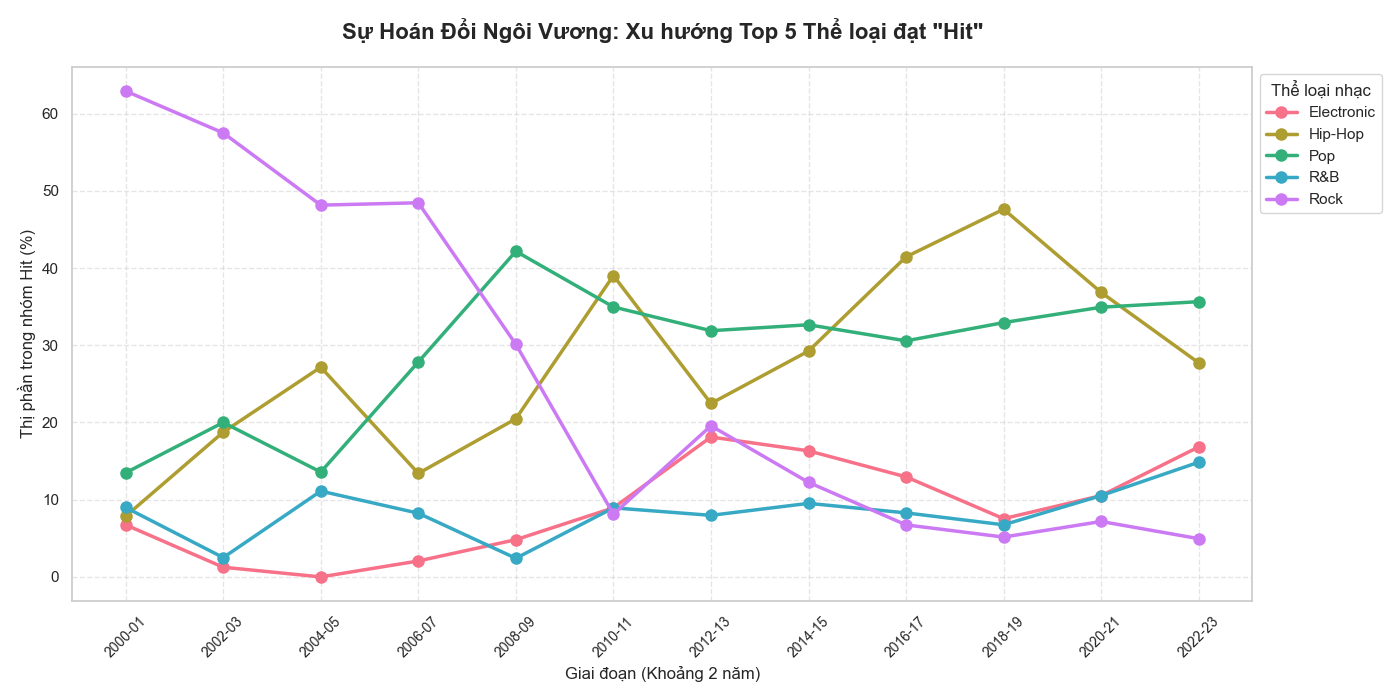
Sự thoái trào của "Đế chế" Rock: Bắt đầu ở đỉnh cao chót vót (hơn 60% thị phần Hit) vào năm 2000–01, Rock liên tục lao dốc và hiện chỉ còn duy trì ở mức dưới 10%. Đây là sự sụp đổ của một kỷ nguyên. Rock không còn giữ được vị thế "độc tôn" mà dần nhường chỗ cho các dòng nhạc có tính bắt tai và phù hợp với xu hướng streaming hơn.
Hip-Hop & Pop: Cuộc đua giành ngôi bá chủ
- Hip-Hop (Đường vàng): Có sự tăng trưởng bền bỉ và mạnh mẽ nhất. Đỉnh điểm vào năm 2018–19, Hip-Hop chiếm gần 50% tổng số Hit trên thị trường. Dù có sự sụt giảm nhẹ ở giai đoạn cuối, nhưng đây vẫn là thế lực chi phối mạnh nhất.
- Pop (Đường xanh lá): Là đối thủ đáng gờm nhất của Hip-Hop. Pop duy trì phong độ cực kỳ ổn định trong vùng 30–40%. Sự giao thoa giữa Pop và Hip-Hop vào khoảng năm 2022–23 cho thấy thị hiếu người nghe đang có sự cân bằng giữa hai dòng nhạc này.
Nhóm "Tiềm năng" (Electronic & R&B): Cả hai đều có xu hướng đi lên trong 2–3 năm gần đây. Đặc biệt là Electronic đang cho thấy dấu hiệu hồi phục và tăng trưởng trở lại sau một giai đoạn trầm lắng kéo dài.
Biểu đồ này chính là bằng chứng thép cho thấy âm nhạc không đứng yên. Nếu năm 2000 là sàn diễn của Rock, thì năm 2025 là cuộc chơi của Hip-Hop và Pop. Một sự hoán đổi ngôi vương hoàn hảo được thực hiện trong vòng hơn hai thập kỷ.
7. Khi ngôn từ lên tiếng
Sau khi đã khám phá sự đa dạng về thể loại bài hát, chúng ta thường tự hỏi: Liệu còn điều gì giữ chân thính giả ở lại lâu hơn với một bài hát? Câu trả lời nằm ở lời bài hát (Lyrics). Lời nhạc không chỉ là những câu chữ vô hồn, mà là cầu nối cảm xúc giữa nghệ sĩ và người nghe. Trong phần này, nhóm chúng mình sẽ dùng "lăng kính dữ liệu" để bóc tách xem độ dài bao nhiêu là vừa đủ và những từ khóa nào đang thực sự thống trị các bảng xếp hạng.
Để đo lường luận điểm này, chúng mình đã sử dụng hệ số tương quan để kiểm chứng. Kết quả cho thấy số lượng từ (word_count) có mức ảnh hưởng đáng kể đến khả năng lọt Top của một bài hát.
Công thức tính tương quan chúng mình áp dụng:
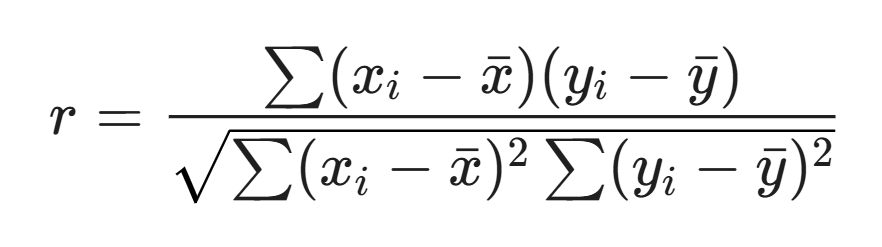
Trong đó x là số lượng từ và y là chỉ số Popularity.
7.1. Tiền xử lý lời bài hát
Tôi đã xử lý cột lyrics trong dataset ra thành hai cột đếm tổng số lượng từ và các từ duy nhất trong một bài hát, để thuận tiện hơn cho việc xử lý WordCloud (ở phần 7.3), sau đó tính mối tương quan giữa độ nổi tiếng và bộ từ ngữ cũng như độ dài lời bài hát
df\['word\_count'\] \= df\['lyrics'\].apply(lambda x: len(str(x).split()))
df\['unique\_word\_count'\] \= df\['lyrics'\].apply(lambda x: len(set(str(x).lower().split())))
\# Tính Lexical Diversity (Độ đa dạng từ vựng)
df\['lexical\_diversity'\] \= df\['unique\_word\_count'\] / df\['word\_count'\]
df.loc\[df\['word\_count'\] \== 0, 'lexical\_diversity'\] \= 0
cols\_to\_check \= \['popularity', 'word\_count', 'unique\_word\_count', 'lexical\_diversity'\]
correlation \= df\[cols\_to\_check\].corr()

Kết quả cho thấy các từ ngữ có tương quan với độ nổi tiếng với r \= 0.209684 và r \= 0.142862 lần lượt đến từ tổng số từ trong bài hát và danh sách các từ không trùng lặp. Ở đây chúng ta thấy có cơ sở để một bài hát trở nên nổi tiếng dựa trên độ dài lyrics và sự đa dạng từ ngữ.
7.2. Vùng đất "Vừa đủ": Tại sao bài hát quá dài hay quá ngắn đều khó thành Hit?
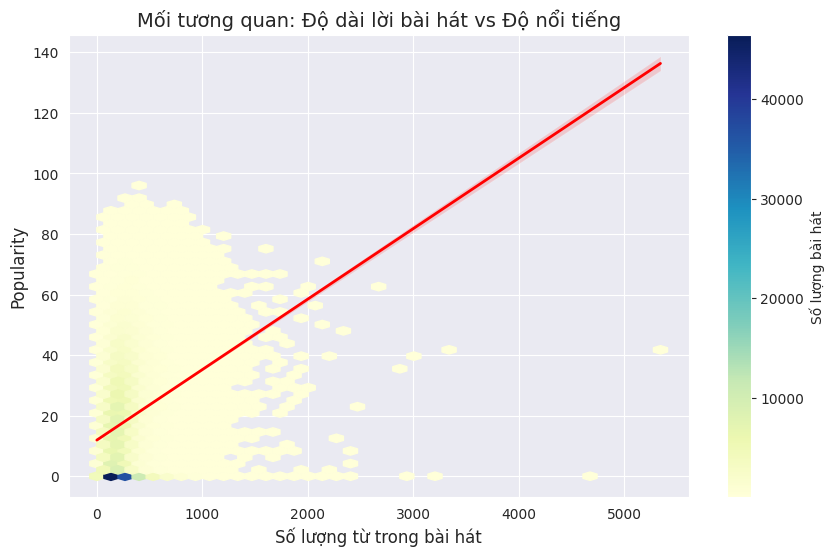
Biểu đồ mật độ lục giác (Hex Bin) cho thấy một sự tập trung cực cao (vùng màu sáng nhất) ở khoảng 200 đến 500 từ. Đây chính là "tọa độ vàng" của nội dung. Nó chứng minh rằng thính giả hiện nay ưa chuộng những bài hát có cấu trúc lời đủ để kể một câu chuyện (Storytelling) nhưng không quá dàn trải gây mệt mỏi. Những bài hát nằm ngoài vùng này (ví dụ trên 1000 từ) thường có độ phổ biến thấp hơn, cho thấy việc "nhồi nhét" từ ngữ không phải lúc nào cũng hiệu quả trong việc tạo ra một bản hit đại chúng.
7.3. Từ điển của những siêu phẩm: Những từ khóa "ám ảnh" tâm trí thính giả
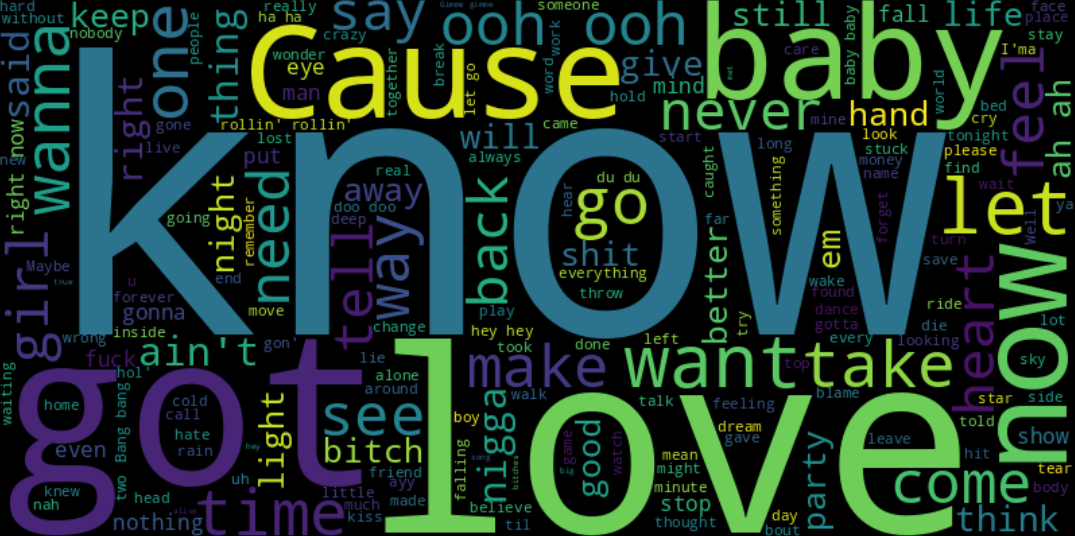
Hình ảnh Đám mây từ ngữ (Word Cloud) đã bóc tách được linh hồn của các bản nhạc thành công nhất. Sự hiện diện khổng lồ của các từ như "Love", "Baby", "Know", và "Feel" cho thấy hai thái cực chủ đạo: Sự kết nối cảm xúc và Sự tự khẳng định. Thính giả tìm đến âm nhạc để được thấu hiểu (qua từ "Love", "Time", “Feel”) nhưng cũng để tìm thấy sức mạnh cá nhân (qua các động từ mạnh như "Know", "Will", "Can"). Đây chính là bộ từ khóa "vạn năng" giúp bài hát dễ dàng chạm tới trái tim của hàng triệu người.
Hai điều trên cho thấy một lời bài hát thành công không chỉ nằm ở việc bạn nói gì, mà còn là bạn nói bao nhiêu. Dữ liệu của chúng mình đã chỉ ra rằng: một cấu trúc nội dung vừa vặn (300-500 từ) kết hợp với những thông điệp xoay quanh tình yêu và sự tự khẳng định chính là "chìa khóa" để mở cánh cửa Popularity. Lời bài hát chính là nơi nghệ thuật gặp gỡ toán học, nơi những con số tần suất từ ngữ tạo nên những rung động cảm xúc mãnh liệt nhất.
8. Kết luận - Liệu có tồn tại công thức cho một bài hit?
Sau khi phân tích lượng bài hát khổng lồ từ những năm 2000-2025 trên Spotify, ta có thể đưa ra câu trả lời ngắn gọn là: tất cả đều có một pattern nhất định, nhưng không có một công thức “thần thánh” nào cả
Dữ liệu cho thấy những bài hit không phải ngẫu nhiên - chúng có xu hướng chia sẻ một số đặc điểm chung. Bài hát thành công thường dễ nhảy hơn (danceability cao), to hơn (loudness cao), ít nhạc cụ thuần túy hơn (instrumentalness thấp), và mang âm thanh thu âm studio chuyên nghiệp thay vì phong cách biểu diễn trực tiếp (liveness thấp). Tuy nhiên, các đặc trưng âm thanh này đơn lẻ chỉ cho thấy mức tương quan yếu đến trung bình với popularity - mạnh nhất cũng chỉ là danceability với r \= 0.22.
Yếu tố có ảnh hưởng rõ ràng nhất lại không nằm ở bản thân bài hát, mà ở người nghệ sĩ đứng sau nó. Với r \= 0.53, độ phổ biến của nghệ sĩ là chỉ số dự đoán mạnh nhất cho sự thành công của một bài hát - mạnh hơn hẳn mọi đặc trưng âm thanh cộng lại. Nghệ sĩ đã nổi tiếng sở hữu sẵn một "đường băng" để mỗi sản phẩm mới nhanh chóng tiếp cận khán giả. Bên cạnh đó, việc hợp tác giữa các nghệ sĩ - đặc biệt là hợp tác khác thể loại - cũng cho thấy mức độ phổ biến cao hơn so với các bài solo. Và thú vị hơn, tuổi nghề 3–5 năm dường như là giai đoạn vàng để tạo hit, trước khi tỉ lệ thành công giảm dần theo thời gian.
Về mặt thể loại, Hip-Hop đã chứng minh mình là "cỗ máy" tạo hit bền bỉ nhất trong hơn hai thập kỷ qua, trong khi Rock - từng thống trị với hơn 60% thị phần hit vào năm 2000 - nay chỉ còn dưới 10%. Pop duy trì phong độ ổn định, và sự giao thoa giữa Pop và Hip-Hop trong những năm gần đây phản ánh rõ nét sự dịch chuyển thị hiếu của người nghe.
Tóm lại, thành công trong âm nhạc là đa yếu tố. Đặc trưng âm thanh định hình một "chân dung" phổ biến của bài hit, nhưng chúng không đủ để đảm bảo thành công. Danh tiếng nghệ sĩ, xu hướng thể loại, thời điểm phát hành, chiến lược marketing, và cả sự hợp tác đều đóng vai trò quan trọng. Và với chỉ 0.59% bài hát vượt qua ngưỡng hit, rõ ràng không có con đường tắt nào dẫn đến đỉnh cao.
Dữ liệu có thể chỉ ra những pattern đằng sau thành công nhưng phép màu của âm nhạc vẫn luôn dành chỗ cho sự bất ngờ - và có lẽ đó chính là điều khiến âm nhạc mãi hấp dẫn.
Chưa có bình luận nào. Hãy là người đầu tiên!