1. GIỚI THIỆU DỰ ÁN

Hình minh họa cho nội dung/ý tưởng chính của dự án,Simple Sentiment Analysis with Python and Gradio
Nguồn: Ảnh minh họa tạo bằng AI.
1.1. Tổng quan và Mục tiêu dự án
Trí tuệ nhân tạo (AI) và Xử lý ngôn ngữ tự nhiên (NLP) thường được xem là những "hộp đen" phức tạp. Là một người mới bước chân vào lĩnh vực này, nhóm chúng tôi thực hiện dự án Simple Sentiment Analysis with Python and Gradio không nhằm cạnh tranh với các mô hình ngôn ngữ lớn (LLMs), mà mang tính chất là một dự án học tập (Educational Project).
Mục tiêu cốt lõi của dự án bao gồm:
-
Giải mã quy trình NLP: Minh bạch hóa từng bước đi của dữ liệu, từ lúc là những dòng chữ vô tri (Raw Text) qua các bước làm sạch, chuẩn hóa đến khi trở thành kết quả phân tích.
-
Xây dựng AI giải thích được (Explainable AI): Tạo ra hệ thống có khả năng trả lời câu hỏi "Tại sao?". Người dùng không chỉ nhận kết quả (Tích cực/Tiêu cực/Trung lập) mà còn thấy rõ các từ khóa dẫn chứng và biểu đồ định lượng.
-
Chia sẻ kiến thức: Cung cấp mã nguồn mở và tư duy giải quyết vấn đề (problem-solving) cơ bản, đóng vai trò là "bài học vỡ lòng" về cấu trúc dữ liệu và logic lập trình cho cộng đồng người mới bắt đầu.
1.2. Phương pháp tiếp cận (Methodology)

Sự đánh đổi trong lựa chọn mô hình: Phương pháp Lexicon-based ưu tiên tính minh bạch và khả năng giải thích (White-box), trong khi Deep Learning mạnh về xử lý phức tạp nhưng thiếu tính tường minh (Black-box).
Nguồn: Ảnh minh họa tạo bằng AI.
Để đảm bảo tính minh bạch và dễ kiểm soát, dự án lựa chọn phương pháp Lexicon-based (Dựa trên từ điển) kết hợp với Rule-based Logic, thay vì sử dụng các mô hình Deep Learning "hộp đen".
Cơ chế hoạt động dựa trên 3 trụ cột chính:
-
Chiến lược đa ngôn ngữ: Sử dụng bước trung gian là dịch tự động sang tiếng Anh. Việc này giúp tận dụng nguồn tài nguyên từ điển chuẩn phong phú của tiếng Anh mà không cần xây dựng lại bộ dữ liệu cho từng ngôn ngữ riêng biệt.
-
So khớp từ điển (Lexicon Matching): Hệ thống quét văn bản và đối chiếu với hai tập từ điển cảm xúc định sẵn (Positive & Negative).
-
Xử lý ngữ cảnh (Contextual Rules): Áp dụng thuật toán Window-3 để giải quyết vấn đề phủ định (Negation). Ví dụ: cụm từ "not bad" thay vì bị hiểu sai sẽ được thuật toán đảo chiều thành ý nghĩa tích cực, giúp kết quả chính xác hơn so với việc đếm từ đơn thuần.
1.3. Công nghệ và Công cụ thực hiện
Dự án được xây dựng với tiêu chí tối giản, sử dụng hệ sinh thái Python mã nguồn mở để người học dễ dàng đọc hiểu và tùy biến:
-
Python: Ngôn ngữ lập trình chính xử lý logic và thuật toán.
-
Deep-translator & Langdetect: Module xử lý rào cản ngôn ngữ (nhận diện và dịch thuật).
-
Gradio: Framework xây dựng giao diện web tương tác (Interactive UI) nhanh chóng, giúp trực quan hóa đầu vào và đầu ra.
-
Matplotlib: Thư viện vẽ biểu đồ, giúp minh họa sự phân bố điểm số cảm xúc một cách trực quan.
2. Kiến trúc hệ thống và cơ chế hoạt động
Để biến một văn bản thô đa ngôn ngữ thành một kết quả phân tích cảm xúc có tính giải thích được (Explainable), hệ thống Rule-based Multilingual Sentiment Analyzer được thiết kế như một pipeline xử lý khép kín, tương tự một dây chuyền sản xuất.
Dưới đây là cái nhìn tổng quan về cách dữ liệu di chuyển qua “nhà máy” xử lý của hệ thống.
2.1. Sơ đồ luồng dữ liệu (Data Pipeline)
Thay vì xử lý riêng lẻ từng ngôn ngữ, hệ thống áp dụng chiến lược “Quy về một mối”:
mọi dữ liệu đầu vào đều được dịch về tiếng Anh trước khi đi vào bộ máy phân tích logic.
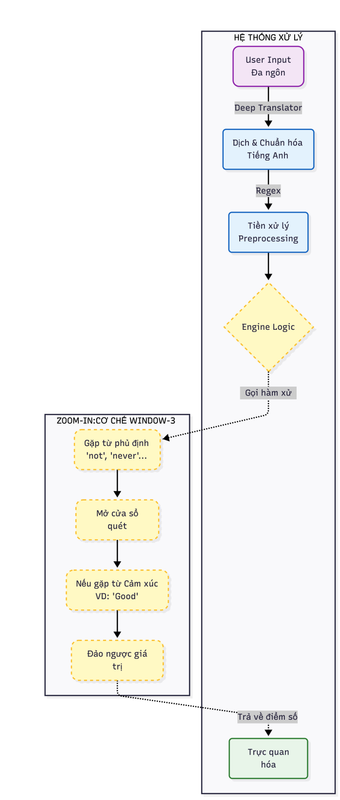
Kiến trúc luồng dữ liệu và cơ chế xử lý phủ định (Window-3 Logic) của hệ thống.
-
User Input: Văn bản tự do từ người dùng.
-
Translation Layer: Dịch về tiếng Anh nếu cần.
-
Preprocessing: Làm sạch và chuẩn hóa dữ liệu.
-
Core Logic: Phân tích cảm xúc bằng luật.
2.2. Cơ chế xử lý ngôn ngữ & tiền xử lý dữ liệu
2.2.1. Nhận diện và dịch ngôn ngữ
Hệ thống sử dụng các thư viện chuyên dụng để chuẩn hóa đầu vào:
langdetect: Để xác định ngôn ngữ đầu vào.deep-translator(GoogleTranslator): Để dịch sang tiếng Anh.
Ví dụ:
Input: "Món này không ngon"
⬇️
Output: "This dish is not good"
Lợi ích của việc chuẩn hóa về tiếng Anh:
* Không cần xây dựng bộ từ điển (lexicon) cho từng ngôn ngữ riêng biệt.
* Đảm bảo tính nhất quán trong phân tích logic.
2.2.2. Tiền xử lý (Preprocessing)
Trước khi phân tích, văn bản được làm sạch qua các bước:
- Lowercase: Chuyển toàn bộ về chữ thường.
- Regex: Loại bỏ ký tự đặc biệt và dấu câu.
- Tokenization: Tách câu thành các tokens (từ đơn).
Ví dụ:
"This dish is not good!"
# → ["this", "dish", "is", "not", "good"]
2.3. Core Logic – Thuật toán Rule-based Window-3
Đây là "trái tim" của hệ thống, nơi toàn bộ quyết định cảm xúc được đưa ra dựa trên luật rõ ràng và có thể giải thích.
2.3.1. Bộ từ điển và tập luật
Hệ thống định nghĩa sẵn ba tập từ quan trọng:
| Tập từ | Mô tả | Ví dụ |
|---|---|---|
| POSITIVE | Các từ mang sắc thái tích cực | good, great, amazing, excellent, love... |
| NEGATIVE | Các từ mang sắc thái tiêu cực | bad, terrible, awful, hate, poor... |
| NEGATIONS | Các từ phủ định | not, never, hardly, don't, isn't... |
2.3.2. Cơ chế Window-3 N-grams
Khi quét qua từng token trong câu:
- Nếu KHÔNG gặp từ phủ định: Từ cảm xúc được tính điểm như bình thường.
- Nếu GẶP từ phủ định (NEGATIONS): Hệ thống kích hoạt cửa sổ quan sát 3 từ tiếp theo.
- Hành động: Nếu trong cửa sổ xuất hiện từ cảm xúc → Đảo chiều polarity (Flip Polarity).
Minh họa logic:
Input: "not very good"
Tokens:
["not", "very", "good"]
- Gặp "not" → Mở Window-3.
- Phát hiện "good" trong cửa sổ.
- "good" (+1) → Bị đảo thành (-1).
👉 Kết quả: Negative
So sánh hiệu quả:
* Cộng điểm đơn thuần: Neutral (Sai)
* Window-3 Rule-based: Negative (Đúng)
2.3.3. Tính điểm cảm xúc (Sentiment Scoring)
Điểm cảm xúc cuối cùng được tính bằng công thức:
$$Score = \sum(Tín\_hiệu\_Tích\_cực) - \sum(Tín\_hiệu\_Tiêu\_cực)$$
- Score > 0: Positive
- Score < 0: Negative
- Score = 0: Neutral
Toàn bộ quá trình đều minh bạch, mỗi từ ảnh hưởng đến kết quả đều có thể truy vết và giải thích.
2.4. Trực quan hóa & Giải thích kết quả
Hệ thống sử dụng Gradio UI để trình bày kết quả một cách trực quan:
Các thành phần giao diện:
- Highlighter Engine:
- 🟢 Màu xanh: Từ tích cực.
- 🔴 Màu đỏ: Từ tiêu cực hoặc từ bị phủ định đảo chiều.
- Sentiment Card: Hiển thị kết luận cuối cùng (Positive / Negative / Neutral).
- Statistical Chart: Biểu đồ cột so sánh số lượng tín hiệu tích cực và tiêu cực trong câu.
Kết quả: Nhờ đó, người dùng không chỉ thấy kết quả, mà còn hiểu rõ: "Vì sao hệ thống lại đưa ra kết luận này?"
3. Triển khai hệ thống
Sau khi nắm được kiến trúc và cơ chế hoạt động của hệ thống, chúng ta sẽ tiến hành áp dụng vào dự án thực tế. Dưới đây là các bước để xây dựng một hệ thống phân tích cảm xúc đa ngôn ngữ qua bình luận của khách hàng.
Bước 1: Khởi tạo môi trường và xây dựng các cấu trúc dữ liệu
Đầu tiên, chúng ta khai báo các thư viện cần thiết và định nghĩa hai tập dữ liệu quan trọng:
- POSITIVE: Lưu danh sách các từ mang ý nghĩa tích cực, mô tả sự hài lòng về dịch vụ, chất lượng,...
- NEGATIVE: Bao gồm các từ mang ý nghĩa tiêu cực, chỉ sự thất vọng hoặc mô tả vấn đề đang gặp phải.
POSITIVE = {
# General positive
"good", "great", "excellent", "amazing", "awesome", "perfect",
"nice", "love", "like", "enjoy", "satisfied",
# Quality / experience
"comfortable", "clean", "cozy", "quiet", "spacious",
"modern", "beautiful", "convenient", "reliable",
# Service / people
"friendly", "helpful", "professional", "polite", "attentive",
# Food / restaurant / hotel
"tasty", "delicious", "fresh", "yummy",
# Value
"affordable", "reasonable", "worth", "value",
# Location / travel
"central", "conveniently", "accessible",
# Stay / usage
"pleasant", "smooth", "easy", "fast", "efficient"
}
NEGATIVE = {
# General negative
"bad", "terrible", "awful", "poor", "worst", "hate",
# Quality / condition
"dirty", "old", "outdated", "broken", "damaged",
"uncomfortable", "noisy", "crowded", "small",
# Service
"rude", "unhelpful", "slow", "careless", "unprofessional",
# Food
"tasteless", "cold", "stale", "bland",
# Value / price
"expensive", "overpriced", "costly",
# Technical / facilities
"slow", "unstable", "laggy", "disconnect",
# Experience
"disappointed", "frustrating", "annoying", "problematic"
}
- Ngoài ra, danh sách tên ngôn ngữ được lưu trữ dưới dạng từ điển (dictionary) cung cấp danh sách trực quan cho người dùng, đồng thời cung cấp tham số chính xác cho hàm dịch thuật.
LANG_MAP = {
"Auto detect": "auto",
"Vietnamese": "vi",
"German": "de",
"French": "fr",
"Japanese": "ja",
"Korean": "ko",
"Chinese": "zh"
}
Bước 2: Tiền xử lý và chuẩn hóa ngôn ngữ
Để hệ thống có thể xử lý được chính xác dữ liệu từ nhiều ngôn ngữ khác nhau, bước đầu tiên và quan trọng nhất là phải đưa dữ liệu về một "mặt bằng chung". Để làm được điều này, quy trình tiền xử lý và chuẩn hóa được xây dựng thông qua ba công đoạn chính.
1. Nhận diện ngôn ngữ đầu vào
Hệ thống sử dụng thư viện langdetect để tự động xác định ngôn ngữ mà người dùng đang sử dụng.
from langdetect import detect, DetectorFactory
DetectorFactory.seed = 0
def detect_language(text):
try:
return detect(text)
except:
return "unknown" # Tránh lỗi nếu văn bản đầu vào không đúng định dạng
- Hàm
detectsử dụng mô hình xác suất dựa trên đặc điểm các cụm ký tự trong văn bản để nhận diện ngôn ngữ đang sử dụng. - Để đảm bảo tính nhất quán cho kết quả, hệ thống được thiết lập
DetectorFactory.seed = 0.Việc này giúp loại bỏ sự biến động ngẫu nhiên của thuật toán xác suất, đảm bảo cùng một văn bản đầu vào sẽ luôn trả về một mã ngôn ngữ duy nhất.
2. Dịch thuật chuẩn hóa sang Tiếng Anh
Thay vì xây dựng hàng trăm bộ từ điển cho từng ngôn ngữ, chúng ta sử dụng phương pháp Standardlization (Chuẩn hóa). Toàn bộ văn bản sau khi nhận diện sẽ được dịch qua Tiếng Anh thông qua thư viện GoogleTranslator.
from deep_translator import GoogleTranslator
def translate(text, src, tgt):
try:
if src in ["auto", "unknown", "zh", "zh-cn", "zh-tw"]:
return GoogleTranslator(target=tgt).translate(text)
# Tận dụng cơ chế tự động nhận diện mạnh mẽ của Google
else:
return GoogleTranslator(source=src, target=tgt).translate(text)
except Exception:
return "[Translation error]"
Chiến lược chuẩn hóa cho phép hệ thống sử dụng tài nguyên ngôn ngữ phong phú của tiếng Anh mà không làm mất đi ý nghĩa gốc của người dùng.
3. Làm sạch dữ liệu với Regular Expressions (Regex)
Thông thường, một bình luận thường chứa nhiều "nhiễu" như dấu câu, các ký tự đặc biệt hay số thứ tự. Vì vậy, để hệ thống nhận diện và phân loại dễ dàng hơn, chúng ta sử dụng thư viện re với hàm re.sub() để tiền xử lý văn bản.
import re
def sentiment_window3(text_en): # Chi tiết về hàm này được thực hiện ở Bước 3
clean = re.sub(r"[^a-z\s']", "", text_en.lower()) # --> Làm sạch dữ liệu
...
- Loại bỏ ký tự thừa: Biểu thức
r"[^a-z\s']"giúp loại bỏ các ký tự không phải là chữ cái và khoảng trắng. - Giữ lại dấu nháy đơn: Đặc biệt, dấu nháy đơn (
') cần được giữ lại để đảm độ chính xác cho các từ phủ định nhưdon't,can't,isn't,... phục vụ cho bước phân tích cảm xúc tiếp theo. - Chuyển toàn bộ về chữ thường: Hàm
lower()giúp chuyển toàn bộ chữ cái trong văn bản thành chữ thường.
Bước 3: Xử lý Phủ định & Thuật toán N-grams (The Core Logic)
Trong các hệ thống phân tích cảm xúc dựa trên từ điển (Lexicon-based), thách thức lớn nhất không nằm ở việc nhận diện từ, mà là hiểu ngữ cảnh.
Nếu chỉ dùng Unigram (quét từng từ đơn lẻ), hệ thống sẽ gặp lỗi nghiêm trọng với câu: "The service is not good". Máy sẽ thấy từ "good" và đánh giá là Tích cực (Positive), bỏ qua hoàn toàn từ "not" đứng trước. Để giải quyết vấn đề này, mình áp dụng kỹ thuật Window-3 Scanning.

Minh họa cơ chế N-grams với cửa sổ ngữ cảnh (Window-3) trong xử lý phủ định.
1. Logic đảo chiều cảm xúc (Sentiment Flipping)
Hệ thống định nghĩa bộ quy tắc tính điểm rõ ràng, xử lý ba trạng thái cảm xúc chính:
| Ngữ cảnh phát hiện | Trạng thái gốc | Logic sau phủ định | Điểm số |
|---|---|---|---|
| NEGATION + POSITIVE | Tích cực | Đảo thành Tiêu cực | -1 |
| NEGATION + NEGATIVE | Tiêu cực | Đảo thành Tích cực | +1 |
| Không có cảm xúc | Trung tính | Giữ nguyên | 0 |
2. Sơ đồ luồng xử lý (Flowchart)

Sơ đồ luồng xử lý thuật toán Window-3 Negation.
3. Thiết lập Từ điển & Cấu hình
Đầu tiên, chúng ta cần định nghĩa các tập từ vựng. Đặc biệt là tập NEGATIONS - những từ đóng vai trò "công tắc" kích hoạt thuật toán xử lý ngữ cảnh.
# Tập hợp các từ phủ định kích hoạt thuật toán
NEGATIONS = {
"not", "no", "never", "hardly", "rarely",
"dont", "don't", "cannot", "can't",
"didnt", "didn't", "doesnt", "doesn't"
}
4. Thuật toán Window-3 & Pointer Jumping
Đây là "trái tim" của hệ thống. Thay vì quét tuyến tính đơn thuần, hệ thống sử dụng một cửa sổ trượt (sliding window) linh hoạt.
Mời bạn xem đoạn code cốt lõi dưới đây:
def sentiment_window3(text_en):
clean = re.sub(r"[^a-z\s']", "", text_en.lower())
tokens = clean.split()
score = 0
pos_cnt = 0
neg_cnt = 0
highlights = {}
used_indexes = set() # 👈 THÊM
i = 0
while i < len(tokens):
word = tokens[i]
norm = word.replace("'", "")
# Negation handling
if norm in NEGATIONS:
for j in range(1, 4):
if i + j >= len(tokens):
break
nxt = tokens[i + j].replace("'", "")
phrase = " ".join(tokens[i:i + j + 1])
if nxt in POSITIVE:
score -= 1
neg_cnt += 1
highlights[phrase] = "neg"
# 👇 ĐÁNH DẤU TOKEN ĐÃ DÙNG
for k in range(i, i + j + 1):
used_indexes.add(k)
i += j + 1
break
if nxt in NEGATIVE:
score += 1
pos_cnt += 1
highlights[phrase] = "pos"
for k in range(i, i + j + 1):
used_indexes.add(k)
i += j + 1
break
else:
i += 1
continue
# Normal sentiment (CHỈ NẾU CHƯA BỊ CONSUME)
if i not in used_indexes:
if norm in POSITIVE:
score += 1
pos_cnt += 1
highlights[word] = "pos"
elif norm in NEGATIVE:
score -= 1
neg_cnt += 1
highlights[word] = "neg"
i += 1
sentiment = "Positive" if score > 0 else "Negative" if score < 0 else "Neutral"
return sentiment, score, pos_cnt, neg_cnt, highlights
Giải thích kỹ thuật:
-
used_indexes (Bộ nhớ đệm): Đây là chìa khóa để tránh lỗi Double Counting. Nếu cụm "not good" đã được xử lý, từ "good" sẽ bị đánh dấu. Khi vòng lặp chạy đến từ "good", hệ thống sẽ kiểm tra if i not in used_indexes và bỏ qua nó, không cộng điểm sai lệch.
-
Pointer Jumping (i += j + 1): Kỹ thuật tối ưu hiệu năng. Khi đã xử lý xong một cụm 3 từ, con trỏ i sẽ nhảy cóc qua cả 3 từ đó, thay vì nhích từng bước một.
Bước 4: Trực quan hóa & Cơ chế Minh bạch (Visualization Engine)
Khác với các hộp đen công nghệ thường thấy, mục tiêu của dự án này là sự minh bạch (Transparency). Người dùng không chỉ cần biết kết quả là "Tốt" hay "Xấu", họ cần nhìn thấy bằng chứng cụ thể trong câu văn.
Để làm được điều này, chúng ta xây dựng 3 thành phần trực quan hóa dựa trên dữ liệu thô đã xử lý ở Bước 3.
1. Highlighter Engine (Cơ chế tô màu bằng chứng)
Đây là tính năng quan trọng nhất giúp "giải mã" quyết định của thuật toán. Chúng ta sử dụng kỹ thuật HTML Injection để can thiệp trực tiếp vào văn bản, chèn màu nền cho các từ khóa đã kích hoạt điểm số.
-
🟢 Màu xanh: Cụm từ mang nghĩa tích cực.
-
🔴 Màu đỏ: Cụm từ mang nghĩa tiêu cực (hoặc đã bị đảo nghĩa bởi từ phủ định).

Sentiment Card
def render_highlight_en(text, highlights):
html = text
spans = [] # lưu (start, end, label)
# 1️⃣ Tìm tất cả match, phrase dài ưu tiên trước
for phrase in sorted(highlights, key=len, reverse=True):
label = highlights[phrase]
for m in re.finditer(re.escape(phrase), text, flags=re.IGNORECASE):
s, e = m.span()
# ❌ nếu span này nằm TRONG span đã có → bỏ
if any(s >= ps and e <= pe for ps, pe, _ in spans):
continue
spans.append((s, e, label))
break # mỗi phrase chỉ highlight 1 lần
# 2️⃣ Render từ trái sang phải
spans.sort(key=lambda x: x[0])
result = ""
last = 0
for s, e, label in spans:
color = "#c8f7c5" if label == "pos" else "#f7c5c5"
result += text[last:s]
result += (
f"<span style='background:{color};padding:4px 6px;border-radius:6px'>"
f"{text[s:e]}"
"</span>"
)
last = e
result += text[last:]
return f"<div style='font-size:16px;line-height:1.8' markdown="1">{result}</div>"
2. Sentiment Card (Thẻ trạng thái)
Thay vì chỉ in ra một dòng chữ đơn điệu, chúng ta tạo một thẻ tóm tắt (Summary Card) hiển thị trạng thái cảm xúc và điểm số tin cậy (Intensity Score).
def sentiment_card(sentiment, score):
if sentiment == "Positive":
bg = "#d1fae5" # xanh nhạt
icon = "😊"
symbol = "✔"
elif sentiment == "Negative":
bg = "#fee2e2" # đỏ nhạt
icon = "😠"
symbol = "✖"
else:
bg = "#e5e7eb" # xám
icon = "😐"
symbol = "•"
return f"""
<div style="
background:{bg};
border-radius:20px;
padding:24px;
margin-bottom:20px;
text-align:center;
color:#000;
opacity:1 !important;
" markdown="1">
<div style="font-size:46px; line-height:1;" markdown="1">
{icon}
</div>
<div style="
font-size:32px;
font-weight:800;
margin-top:6px;
color:#000;
" markdown="1">
{symbol} {sentiment}
</div>
<div style="
font-size:18px;
margin-top:10px;
color:#000;
" markdown="1">
Score: {score}
</div>
</div>
"""

Thẻ kết quả giúp người dùng nắm bắt nhanh trạng thái cảm xúc.
3. Statistical Chart (Biểu đồ định lượng)
Một câu nói có thể chứa cả khen lẫn chê. Biểu đồ này giúp người dùng thấy được tỷ lệ giữa các tín hiệu, từ đó hiểu được tại sao hệ thống lại đưa ra kết luận cuối cùng.
def sentiment_chart(pos, neg):
fig, ax = plt.subplots(figsize=(6, 3))
ax.bar(["Summary"], [pos], width=0.4, label="Positive")
ax.bar(["Summary"], [neg], bottom=[pos], width=0.4, label="Negative")
ax.set_title("Sentiment Signals Overview")
ax.set_ylabel("Signal Count (rule-based)")
ax.legend()
ax.set_ylim(0, max(pos + neg + 1, 3))
return fig

Biểu đồ trực quan hóa số lượng tín hiệu cảm xúc phát hiện được.
Bước 5: Tích hợp Giao diện & Triển khai (UI & Deployment)
Để logic nghiệp vụ trở thành một sản phẩm thực tế, chúng ta cần một giao diện người dùng (UI). Tôi sử dụng thư viện Gradio vì khả năng tích hợp nhanh với Python và hỗ trợ tốt cho việc hiển thị HTML/Biểu đồ.
1. Kiến trúc luồng dữ liệu (Data Pipeline)
Trước khi vẽ giao diện, cần một hàm "tổng chỉ huy" để kết nối các module rời rạc từ Bước 3 và Bước 4 lại với nhau.
# Hàm xử lý trung tâm kết nối Logic và Giao diện
def analyze(text, lang_choice):
lang = detect_language(text) if LANG_MAP[lang_choice] == "auto" else LANG_MAP[lang_choice]
en = translate(text, lang, "en")
sentiment, score, pos, neg, highlights = sentiment_window3(en)
return (
lang.upper(),
en,
sentiment_card(sentiment, score),
sentiment_chart(pos, neg),
render_highlight_en(en, highlights),
)
2. Thiết kế giao diện với Gradio Blocks
Sử dụng gr.Blocks để chia cột, tạo bố cục chuyên nghiệp:
with gr.Blocks(title="Explainable Multilingual Sentiment Analyzer") as demo:
gr.HTML("""
<style>
.gradio-container { max-width: 100% !important; }
</style>
""")
gr.Markdown("""
<h1 style='text-align:center'>🌍 Explainable Multilingual Sentiment Analyzer</h1>
<p style='text-align:center;color:gray'>
Rule-based • Negation-aware • Interpretable NLP
</p>
""")
with gr.Row():
with gr.Column():
input_text = gr.Textbox(label="Nhập comment", lines=5)
lang_select = gr.Dropdown(
choices=list(LANG_MAP.keys()),
value="Auto detect",
label="Ngôn ngữ đầu vào"
)
btn = gr.Button("Phân tích", variant="primary")
with gr.Column():
out_lang = gr.Textbox(label="Ngôn ngữ")
out_trans = gr.Textbox(label="English translation", lines=4)
gr.Markdown("## 🧠 Sentiment Summary")
sentiment_html = gr.HTML()
gr.Markdown("## 🇬🇧 Highlight sentiment (English)")
highlight_en = gr.HTML()
gr.Markdown("## 📊 Sentiment Overview")
chart = gr.Plot()
btn.click(
analyze,
[input_text, lang_select],
[out_lang, out_trans, sentiment_html, chart, highlight_en]
)
gr.Examples(
examples=[
["この商品はデザインがとても良くて使いやすいし、品質も良いと思いますが、バッテリーの持ちはあまり良くなく、価格も少し高いです。ただし、全体的には満足しています。", "Auto detect"],
["I don't like this product but the quality is good and the price is not very good", "Auto detect"],
["Tôi thích sản phẩm này nhưng pin không tốt lắm", "Auto detect"]
],
inputs=[input_text, lang_select]
)
if __name__ == "__main__":
demo.launch()
3. Triển khai lên Hugging Face Spaces
Để chia sẻ công cụ này cho cộng đồng mà không cần server riêng, tôi deploy nó lên Hugging Face Spaces. Đây là nền tảng hosting miễn phí cực kỳ phổ biến cho các ứng dụng Python demo.
Quy trình thực hiện:Tạo tài khoản tại huggingface.co.
1. Tạo New Space $\rightarrow$
2. Chọn SDK là Gradio.
3. Tạo file requirements.txt để khai báo các thư viện cần thiết:
gradio
matplotlib
deep-translator
langdetect
- Upload file code app.py.

Triển khai lên HuggingFace.
Sau vài phút build, ứng dụng sẽ chạy trực tiếp trên web browser, cho phép bất kỳ ai cũng có thể vào trải nghiệm cơ chế xử lý ngôn ngữ mà chúng ta vừa xây dựng.

Giao diện HuggingFace hoàn chỉnh.
4. Tổng kết và Hướng phát triển
4.1. Đánh giá kết quả
Hệ thống phân tích cảm xúc đa ngôn ngữ được xây dựng dựa trên phương pháp Lexicon-based kết hợp tiền xử lý ngôn ngữ và xử lý phủ định đã cho thấy hiệu quả rõ rệt trong việc phân tích các bình luận ngắn của người dùng thuộc nhiều ngôn ngữ khác nhau.
Thông qua chiến lược chuẩn hóa ngôn ngữ về tiếng Anh, hệ thống có thể tận dụng một bộ từ điển cảm xúc thống nhất, giảm đáng kể độ phức tạp trong thiết kế và bảo trì. Việc kết hợp nhận diện ngôn ngữ tự động, dịch thuật và làm sạch dữ liệu giúp đảm bảo đầu vào nhất quán cho thuật toán phân tích cảm xúc ở các bước xử lý tiếp theo.
Đặc biệt, việc xử lý từ phủ định (Negation Handling) đóng vai trò quan trọng trong việc nâng cao độ chính xác của hệ thống, khắc phục hạn chế phổ biến của các mô hình Unigram truyền thống khi chỉ xét từ đơn lẻ mà bỏ qua ngữ cảnh.
Ưu điểm
- Dễ triển khai và dễ mở rộng:Hệ thống được xây dựng dựa trên các cấu trúc dữ liệu đơn giản (set, dictionary) và các thư viện phổ biến, phù hợp cho mục đích học tập, nghiên cứu và xây dựng prototype.
- Hỗ trợ đa ngôn ngữ hiệu quả :Thông qua bước nhận diện và dịch thuật, hệ thống có thể xử lý bình luận từ nhiều ngôn ngữ khác nhau mà không cần xây dựng từ điển riêng cho từng ngôn ngữ.
- Phù hợp cho giai đoạn khởi đầu: Giúp người học tiếp cận khái niệm ban đầu về xử lý ngôn ngữ tự nhiên.
Hạn chế
- Phụ thuộc vào chất lượng từ điển cảm xúc: Hệ thống chỉ có thể nhận diện các cảm xúc đã được định nghĩa trong tập positive và negative, dẫn đến việc bỏ sót các cách diễn đạt mới hoặc mang tính ngữ cảnh cao.
- Khả năng hiểu ngữ cảnh kém: Không ghi nhớ hay suy luận được ngữ cảnh trong hội thoại dài hoặc phức tạp.
- Độ chính xác phụ thuộc vào dịch thuật: Sai lệch trong quá trình dịch có thể ảnh hưởng trực tiếp đến kết quả phân tích cảm xúc.
4.2. Hướng phát triển
Mặc dù hệ thống phân tích cảm xúc dựa trên từ điển kết hợp xử lý phủ định đã đạt được hiệu quả tốt trong các kịch bản bình luận ngắn và có cấu trúc rõ ràng, phương pháp này vẫn tồn tại những hạn chế nhất định trong việc hiểu ngữ cảnh và ngữ nghĩa sâu. Để khắc phục các điểm hạn chế đó, hệ thống có thể được mở rộng và nâng cấp theo các hướng sau:
4.2.1. Tích hợp mô hình BERT cho phân tích cảm xúc

Quy trình của BERT.
Nguồn: https://www.geeksforgeeks.org/nlp/explanation-of-bert-model-nlp/
Một hướng phát triển quan trọng là tích hợp các mô hình Transformer, đặc biệt là BERT (Bidirectional Encoder Representations from Transformers), vào hệ thống phân tích cảm xúc.
Khác với phương pháp Lexicon-based, BERT có khả năng:
- Hiểu ngữ cảnh hai chiều của câu, giúp nắm bắt mối quan hệ giữa các từ trong toàn bộ câu.
- Xử lý hiệu quả các câu chứa phủ định phức tạp, cấu trúc ngữ pháp đa dạng và cách diễn đạt gián tiếp.
- Giảm sự phụ thuộc vào từ điển cố định, từ đó nâng cao khả năng thích ứng với ngôn ngữ tự nhiên trong thực tế.
Mô hình BERT có thể được huấn luyện hoặc fine-tune trên các tập dữ liệu gán nhãn cảm xúc để dự đoán trực tiếp nhãn cảm xúc của câu đầu vào.
4.2.2. Mô hình lai (Hybrid Approach: Lexicon-based + BERT)
Thay vì thay thế hoàn toàn hệ thống hiện tại, một mô hình lai có thể được áp dụng nhằm tận dụng ưu điểm của cả hai phương pháp:
- Lexicon-based được sử dụng cho các trường hợp cảm xúc rõ ràng, giúp hệ thống hoạt động nhanh, minh bạch và dễ giải thích.
- BERT được sử dụng cho các trường hợp mơ hồ, câu dài hoặc khi kết quả từ phương pháp từ điển có độ tin cậy thấp.
Cách tiếp cận này không chỉ cải thiện độ chính xác mà còn giữ được tính minh bạch của hệ thống, đồng thời nâng cao khả năng hiểu ngữ cảnh sâu.
TÀI LIỆU THAM KHẢO
-
ScienceDirect. (n.d.). Lexicon-based approach. ScienceDirect Topics. https://www.sciencedirect.com/topics/computer-science/lexicon-based-approach
-
Taboada, M., Brooke, J., Tofiloski, M., Voll, K., & Stede, M. (2011). Lexicon-based methods for sentiment analysis. Computational Linguistics, 37(2), 267–307. https://www.sfu.ca/~mtaboada/docs/research/Taboada_etal_SO-CAL.pdf
📦 TÀI NGUYÊN VÀ MÃ NGUỒN
🔗 Links quan trọng
| Nền tảng | Mô tả | Link |
|---|---|---|
| 🤗 Hugging Face | Demo trực tuyến - Thử ngay không cần cài đặt | 🚀 Live Demo |
| 💻 GitHub | Mã nguồn đầy đủ - Clone về và chạy local | ⭐ Source Code |
Chưa có bình luận nào. Hãy là người đầu tiên!