1: "Nỗi ám ảnh" chọn phim cuối tuần và sự ra đời của Recommender System
Cuối tuần đến. Bạn mở Netflix — hoặc FPT Play, hoặc bất kỳ nền tảng nào đang trả phí hàng tháng — nằm dài trên sofa và bắt đầu cuộn. Cuộn qua hàng trăm poster sặc sỡ, đọc lướt vài dòng mô tả, bấm vào một trailer rồi thoát ra, lại cuộn tiếp. Mười lăm phút trôi qua. Ba mươi phút. Một tiếng. Cuối cùng, bạn tắt app, mở Tiktok xem mấy clip ngắn cho đỡ buồn, rồi đi ngủ — mà chẳng xem được bộ phim nào.
Nghe quen không? Bạn không cô đơn đâu. Đây là một vấn đề có tên gọi hẳn hoi trong giới sản phẩm: nghịch lý của sự lựa chọn — khi có quá nhiều lựa chọn, người ta không hạnh phúc hơn mà ngược lại, họ cảm thấy ngợp và cuối cùng không chọn gì cả.

Nghịch lý của sự lựa chọn — càng nhiều phim, càng khó chọn.
Nguồn: Hình minh họa tạo bởi AI.
Với các nền tảng giải trí, bài toán này rất đau đầu. Thư viện nội dung ngày càng phình to — hàng chục nghìn bộ phim, thể loại chồng chéo, tiêu đề khó phân biệt. Trong khi đó, mỗi người lại mang một khẩu vị hoàn toàn khác nhau: người thích phim kinh dị Hàn Quốc, người mê tài liệu khoa học, người chỉ xem phim hài để thư giãn. Và điểm chung duy nhất là không ai muốn mất hàng giờ chỉ để tìm một bộ phim. Khi trải nghiệm tìm kiếm trở nên mệt mỏi, người dùng rời đi — và đó là điều mà không nền tảng nào muốn thấy.
Vậy làm sao để giải quyết? Câu trả lời nằm ở Recommender System — hệ thống gợi ý.
Mỗi khi Netflix đề xuất "Vì bạn đã xem Inception", hay Spotify tạo playlist "Khám phá hàng tuần", hay Shopee gợi ý "Sản phẩm bạn có thể thích" — đằng sau đó đều là một Recommender System đang âm thầm làm việc. Cụ thể hơn, phương pháp mà chúng mình sử dụng trong project này là Collaborative Filtering — lọc cộng tác. Ý tưởng cốt lõi rất trực giác: nếu bạn và một người lạ từng thích những bộ phim giống nhau trong quá khứ, thì rất có thể những bộ phim người đó thích mà bạn chưa xem cũng sẽ phù hợp với bạn. Hệ thống không cần biết bạn là ai, thích thể loại gì — nó chỉ cần dữ liệu hành vi: ai đã xem phim nào, và cho bao nhiêu sao. Từ đó, nó suy ra mức độ quan tâm của từng người dùng đối với từng bộ phim, và đưa ra gợi ý cá nhân hóa thực sự. Nhờ vậy, người dùng không còn phải cuộn qua hàng trăm tiêu đề nữa — những đề xuất phù hợp xuất hiện gần như ngay lập tức.
Và đó chính là điều nhóm chúng mình quyết định xây dựng từ con số 0.
Tổng quan project
Trong project này, nhóm xây dựng một pipeline end-to-end: đi từ dữ liệu thô đến một demo tương tác cho phép tra cứu gợi ý phim theo từng người dùng. Dữ liệu đầu vào là MovieLens 33M — tập dữ liệu kinh điển trong lĩnh vực Recommender System, chứa khoảng 33 triệu lượt đánh giá từ hàng trăm nghìn người dùng thực, trải rộng trên hơn 86.000 bộ phim.
Toàn bộ quá trình được triển khai trên Apache Spark và Delta Lake, cho phép xử lý dữ liệu lớn một cách ổn định và sẵn sàng mở rộng trong môi trường production. Về mặt kiến trúc, chúng mình áp dụng mô hình Medallion (Bronze → Silver → Gold) để tách rõ các bước: từ ingest dữ liệu thô, làm sạch và khám phá, cho đến feature engineering phục vụ huấn luyện mô hình. Thuật toán cốt lõi là ALS (Alternating Least Squares) từ Spark MLlib — một phương pháp Collaborative Filtering được tối ưu để chạy trên dữ liệu phân tán — kết hợp với grid search và cross-validation để tìm bộ siêu tham số tốt nhất. Kết quả: mô hình đạt RMSE ≈ 0.78, cải thiện khoảng 26% so với baseline dự đoán trung bình toàn cục. Cuối cùng, một demo Streamlit được xây dựng để hiển thị top 10 bộ phim gợi ý cho từng người dùng, tích hợp poster từ TMDB để tăng trải nghiệm trực quan.

Tổng quan pipeline: MovieLens → Medallion (Bronze/Silver/Gold) → ALS Model → Demo gợi ý.
Nguồn: Tác giả tổng hợp.
Có thể thấy, đằng sau những gợi ý tưởng chừng đơn giản trên màn hình là cả một hành trình xử lý dữ liệu quy mô lớn, kết hợp với thuật toán học máy phù hợp. Ở các phần tiếp theo, chúng ta sẽ cùng đi qua từng chặng của hành trình đó: bắt đầu từ cách dữ liệu MovieLens được tổ chức và xử lý qua kiến trúc Medallion; đến "bộ não" của hệ thống — thuật toán ALS; rồi cách mô hình được đóng gói và đưa vào demo tương tác; và cuối cùng là những bài học cùng hướng phát triển tiếp theo. Hãy bắt đầu với câu chuyện về dữ liệu.
2. Data Pipeline: Sự kết hợp giữa Apache Spark, Delta Lake và Kiến trúc Medallion
Trong thế giới dữ liệu, dữ liệu thô giống như quặng chưa qua tinh chế — có giá trị tiềm tàng, nhưng không thể sử dụng trực tiếp. Để biến 33 triệu dòng đánh giá phim thành nguồn dữ liệu sạch, sẵn sàng cho thuật toán học máy, chúng mình cần một dây chuyền xử lý bài bản. Phần này sẽ đi qua từng lựa chọn công nghệ và cách dữ liệu chảy qua hệ thống.
2.1. Tập dữ liệu MovieLens — "Sân tập" kinh điển của Recommender System
Trước khi xây bất kỳ mô hình nào, chúng mình cần dữ liệu. Và trong lĩnh vực Recommender System, có một tập dữ liệu được coi như "tiêu chuẩn vàng" — đó là MovieLens, được phát hành bởi nhóm nghiên cứu GroupLens tại Đại học Minnesota.
Phiên bản chúng mình sử dụng là MovieLens 33M, bao gồm khoảng 33 triệu lượt đánh giá từ hàng trăm nghìn người dùng thực, trải rộng trên hơn 86.000 bộ phim. Mỗi bản ghi chứa các thông tin cốt lõi: người dùng nào đã xem phim nào, cho bao nhiêu sao (thang 0.5–5.0), và đánh giá vào thời điểm nào. Ngoài ra còn có thông tin bổ sung như thể loại phim, năm phát hành, và các tag do người dùng tự gắn.
Tại sao MovieLens lại phổ biến đến vậy? Bởi vì nó đủ lớn để thể hiện các thách thức thực tế — ma trận thưa, phân phối lệch, hiệu ứng long-tail — nhưng cũng đủ sạch để có thể tập trung vào việc xây dựng mô hình thay vì mất hàng tuần xử lý dữ liệu lỗi.

Cấu trúc tập dữ liệu MovieLens 33M — các bảng chính và mối quan hệ giữa chúng.
Nguồn: Tác giả tổng hợp.
2.2. Tại sao Apache Spark mà không phải Pandas?
Đây là câu hỏi mà bất kỳ ai làm dữ liệu đều sẽ đặt ra: "MovieLens chỉ vài GB, Pandas dư sức xử lý, tại sao phải dùng Spark?"
Câu trả lời nằm ở hai chữ: tầm nhìn.
Đúng, với tập dữ liệu vài triệu bản ghi, Pandas hoàn toàn đáp ứng được. Nhưng Pandas hoạt động trên RAM của một máy duy nhất — khi dữ liệu phình to lên hàng tỷ dòng (ví dụ một nền tảng streaming 200 triệu người dùng), bộ nhớ sẽ không còn đủ. Apache Spark giải quyết vấn đề này bằng cơ chế xử lý phân tán: chia nhỏ dữ liệu thành nhiều phần, xử lý song song trên nhiều node, rồi gom kết quả lại.
Quan trọng hơn, Spark MLlib — thư viện Machine Learning tích hợp sẵn — cung cấp thuật toán ALS đã được tối ưu để chạy trên dữ liệu phân tán. Nghĩa là từ data pipeline đến model training, mọi thứ nằm trong cùng một hệ sinh thái, không cần chuyển đổi qua lại giữa các công cụ.
Chúng mình chọn Spark không phải vì dữ liệu hiện tại quá lớn, mà vì muốn xây dựng một pipeline sẵn sàng mở rộng — khi dữ liệu tăng gấp 100 lần vẫn không cần viết lại từ đầu.
2.3. Tại sao cần Delta Lake?
Lưu dữ liệu vào CSV hay Parquet thông thường nghe có vẻ đơn giản, nhưng trong thực tế sẽ gặp nhiều rủi ro: ghi file bị lỗi giữa chừng, dữ liệu không nhất quán giữa các lần chạy, hoặc không thể quay lại phiên bản trước khi phát hiện sai sót. Delta Lake xuất hiện như một lớp bảo vệ phía trên, mang đến ba lợi ích quan trọng: ACID Transactions đảm bảo quá trình ghi dữ liệu luôn toàn vẹn — không có chuyện "ghi lỗi một nửa"; Time Travel cho phép quay ngược về các phiên bản dữ liệu cũ, rất hữu ích khi cần debug; và Schema Enforcement ngăn chặn dữ liệu có định dạng sai lệch tràn vào hệ thống.
Trong project này, mỗi tầng dữ liệu (Bronze, Silver, Gold) đều được lưu dưới dạng Delta Table — giúp toàn bộ pipeline có thể tái tạo và kiểm tra lại bất kỳ lúc nào.
2.4. Kiến trúc Medallion: Ba tầng tinh chế dữ liệu
Dữ liệu trong project được tổ chức theo kiến trúc Medallion — một mô hình phổ biến trong Data Engineering, chia luồng xử lý thành ba tầng với mức độ tinh chế tăng dần:
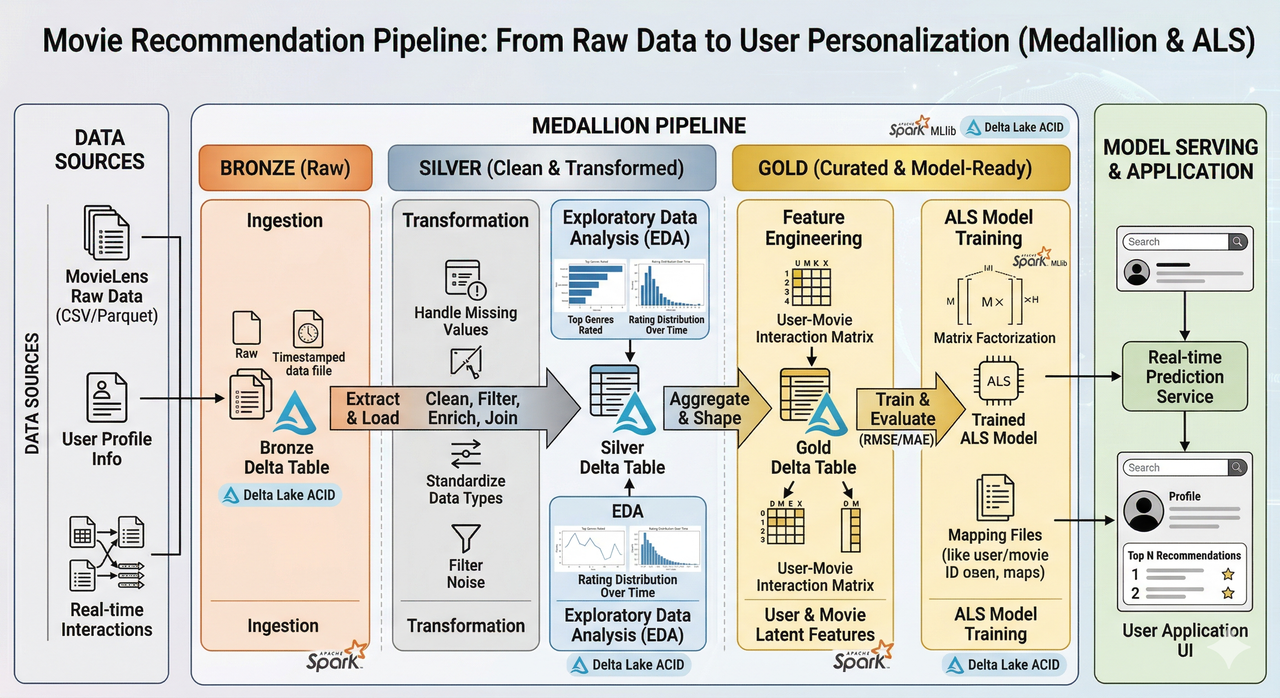
Quy trình xử lý dữ liệu từ Raw đến ALS Model qua kiến trúc Medallion.
Nguồn: Hình minh họa tạo bởi AI.
Tầng Bronze — Dữ liệu thô
Đây là tầng "nguyên liệu". Chúng mình ingest toàn bộ file CSV gốc từ MovieLens vào Delta Table, kèm theo metadata (thời gian ingest, tên file nguồn, batch ID) để truy vết sau này. Điểm quan trọng: dữ liệu ở tầng này được giữ nguyên trạng, không sửa đổi gì cả — mục tiêu là có một bản sao hoàn chỉnh để có thể tái tạo lại toàn bộ quy trình nếu cần.
Thay vì để Spark tự suy luận kiểu dữ liệu (inferSchema), chúng mình định nghĩa schema rõ ràng cho từng bảng:
# Định nghĩa schema tường minh — không dùng inferSchema
schemas = {
"ratings": StructType([
StructField("userId", IntegerType(), True),
StructField("movieId", IntegerType(), True),
StructField("rating", DoubleType(), True),
StructField("timestamp", LongType(), True),
]),
# ... tương tự cho movies, tags, links, genome-scores, genome-tags
}
# Ingest với metadata tracking
def ingest_to_bronze(file_key, schema):
df = spark.read.option("header", "true").schema(schema).csv(csv_file)
df_with_meta = (
df.withColumn("ingest_time", current_timestamp())
.withColumn("source_file", lit(f"{file_key}.csv"))
.withColumn("batch_id", lit(batch_id))
)
df_with_meta.write.format("delta").mode("overwrite").save(output_path)
Tầng Silver — Làm sạch và chuẩn hóa
Trước khi làm sạch, chúng mình thực hiện EDA (Exploratory Data Analysis) trên dữ liệu Bronze để hiểu rõ "bệnh" của dữ liệu. Một số phát hiện quan trọng từ quá trình EDA:
- Phân phối rating bị lệch trái — người dùng có xu hướng cho điểm cao (trung bình ~3.5/5). Điều này sẽ được xử lý bằng user-bias normalization ở tầng Gold.
- Phân phối long-tail ở cả user lẫn movie — phần lớn user chỉ đánh giá rất ít phim, và phần lớn phim chỉ có rất ít lượt đánh giá. Đây là cơ sở để quyết định ngưỡng lọc ở tầng Gold.
- Ma trận User-Item cực kỳ thưa (~99.7% ô trống) — đặc trưng điển hình của bài toán recommendation, và cũng là lý do ALS (matrix factorization) phù hợp hơn các phương pháp khác.

Phân phối rating lệch trái — rating 4.0 chiếm tỷ lệ cao nhất (26.1%), xác nhận xu hướng đánh giá tích cực của người dùng.
Nguồn: Tác giả phân tích từ dữ liệu MovieLens 33M.

Phân phối long-tail: phần lớn user đánh giá rất ít phim. Với ngưỡng lọc ≥ 15 ratings (đường nét đứt), vẫn giữ lại 76.8% user.
Nguồn: Tác giả phân tích từ dữ liệu MovieLens 33M.
Dựa trên những phát hiện này, tầng Silver thực hiện ba việc chính: loại bỏ bản ghi trùng lặp (giữ lại đánh giá mới nhất), trích xuất thông tin từ tên phim (tách riêng tên sạch và năm phát hành), và chuẩn hóa kiểu dữ liệu.
Ví dụ, với bảng ratings, thay vì dùng dropDuplicates() đơn giản (giữ bản ghi ngẫu nhiên), chúng mình dùng Window function để đảm bảo luôn giữ đánh giá mới nhất:
# Dedup ratings — giữ đánh giá mới nhất theo (userId, movieId)
window_latest = Window.partitionBy("userId", "movieId") \
.orderBy(col("timestamp").desc())
silver_ratings = (
df_ratings_cast
.withColumn("_rn", row_number().over(window_latest))
.filter(col("_rn") == 1)
.drop("_rn")
)
Với bảng movies, tên phim gốc có dạng "Toy Story (1995)" — chúng mình tách thành title_clean = "Toy Story" và release_year = 1995, đồng thời chuyển chuỗi thể loại "Action|Adventure" thành mảng ["Action", "Adventure"] để phục vụ phân tích sau này.
Tầng Gold — Dữ liệu sẵn sàng cho mô hình
Tầng Gold là nơi dữ liệu được tinh chế lần cuối trước khi đưa vào thuật toán ALS. Ở đây, chúng mình thực hiện ba bước feature engineering chính, tất cả đều được justify bởi kết quả EDA:
- Lọc nhiễu: loại bỏ user có ít hơn 15 đánh giá và phim có ít hơn 10 đánh giá — những bản ghi này tín hiệu quá yếu cho collaborative filtering.
- Time decay weighting: đánh giá gần đây được gán trọng số cao hơn đánh giá cũ, phản ánh thực tế rằng sở thích người dùng thay đổi theo thời gian.
- User-bias normalization: chuẩn hóa điểm đánh giá theo trung bình của từng user — vì có người luôn cho 5 sao, có người khắt khe chỉ cho 2-3 sao, và nếu không xử lý thì mô hình sẽ bị thiên lệch.
Sau tầng Gold, dữ liệu đã sạch, đã được làm giàu với các feature bổ sung, và sẵn sàng trở thành "nguồn dinh dưỡng" cho thuật toán ALS ở phần tiếp theo.
3. Giải mã "Bộ não" của hệ thống — Thuật toán Collaborative Filtering (ALS)
Dữ liệu đã đi qua ba tầng tinh chế của kiến trúc Medallion. Sau khi lọc nhiễu và feature engineering ở tầng Gold, chúng mình còn lại một tập dữ liệu chất lượng cao — sẵn sàng để "dạy" cho máy tính hiểu sở thích xem phim của con người. Nhưng cụ thể thì máy tính "học" bằng cách nào từ hàng chục triệu con số đánh giá? Đó là lúc "bộ não" của hệ thống phát huy sức mạnh.
3.1. Collaborative Filtering và bản chất toán học (Matrix Factorization)
Ý tưởng cốt lõi của Collaborative Filtering đã được nhắc đến ở phần 1: nếu bạn và một người lạ từng thích những bộ phim giống nhau, hệ thống sẽ gợi ý cho bạn những phim mà người đó thích mà bạn chưa xem. Nhưng để biến ý tưởng trực giác đó thành thuật toán, chúng mình cần đi sâu hơn một chút vào toán học.
Bước đầu tiên là xây dựng ma trận User-Item — một bảng khổng lồ trong đó hàng là người dùng ($u$), cột là bộ phim ($i$), và mỗi ô chứa điểm đánh giá ($r_{ui}$) của người dùng đó cho bộ phim đó. Vấn đề là ma trận này cực kỳ thưa — EDA ở phần trước đã cho thấy ~99.7% ô trống, bởi mỗi người chỉ xem và đánh giá một phần rất nhỏ trong hàng chục nghìn bộ phim.
Làm sao để "điền" được những ô trống đó? Đây chính là lúc kỹ thuật Matrix Factorization (Phân rã ma trận) phát huy tác dụng. Ý tưởng là "ép" ma trận lớn $R$ thành tích của hai ma trận nhỏ hơn:
- $U$ (Ma trận đặc trưng Người dùng): Kích thước $M \times k$
- $V$ (Ma trận đặc trưng Bộ phim): Kích thước $N \times k$
Trong đó $k$ là số chiều không gian ẩn — có thể hiểu nôm na là số "khía cạnh tâm lý" mà hệ thống dùng để mô tả sở thích. Ví dụ, một chiều có thể đại diện cho mức độ thích phim hành động, chiều khác cho xu hướng thích phim có cốt truyện phức tạp, v.v. Điểm dự đoán của người dùng $u$ cho bộ phim $i$ sẽ là tích vô hướng:
$$\hat{r}_{ui} = u_u^T v_i$$
Để tìm ra hai ma trận $U$ và $V$ tốt nhất, chúng mình cần tối thiểu hóa hàm mất mát (Loss Function) — đo độ lệch giữa dự đoán và thực tế, kết hợp với L2 Regularization (tham số $\lambda$) để chống overfitting:
$$L(U, V) = \sum_{(u,i)} (r_{ui} - u_u^T v_i)^2 + \lambda \left( \sum_u ||u_u||^2 + \sum_i ||v_i||^2 \right)$$
Trong đó:
- $r_{ui}$: Điểm số (rating) thực tế mà người dùng $u$ đã chấm cho bộ phim $i$.
- $u_u$: Vector đặc trưng ẩn (latent vector) đại diện cho sở thích của người dùng $u$.
- $v_i$: Vector đặc trưng ẩn (latent vector) đại diện cho các thuộc tính của bộ phim $i$.
- $\lambda$ (Lambda): Regularization parameter — càng lớn thì mô hình càng đơn giản, giảm nguy cơ overfitting.
- $||u_u||^2$ và $||v_i||^2$: Bình phương chuẩn L2 (L2 Norm) của các vector.
3.2. Tại sao ALS? Và cách triển khai trên Spark MLlib
Bài toán tối ưu hàm Loss ở trên không đơn giản — vì cả $U$ và $V$ đều là ẩn số, hàm Loss không phải là lồi (convex). Đây là lúc thuật toán ALS (Alternating Least Squares) thể hiện sự khéo léo: thay vì cố giải cả hai ma trận cùng lúc, ALS cố định một ma trận và tối ưu ma trận còn lại, rồi đổi vai. Cụ thể:
- Cố định $U$, hàm Loss trở thành phương trình bậc hai theo $V$ → giải được bằng Least Squares.
- Cố định $V$, hàm Loss trở thành phương trình bậc hai theo $U$ → giải tương tự.
- Lặp lại cho đến khi hội tụ.
Điều quan trọng: khi cố định một bên, các phép tính cho từng user (hoặc từng movie) độc lập với nhau — và đây chính là lý do ALS "hợp cạ" với Spark. Spark có thể chia nhỏ công việc, phân phối cho nhiều node tính toán song song, rồi gom kết quả lại. Đó cũng là lý do Spark MLlib chọn ALS làm thuật toán recommendation mặc định.
Triển khai trên Spark MLlib khá gọn:
from pyspark.ml.recommendation import ALS
als = ALS(
userCol="userId",
itemCol="movieId",
ratingCol="rating",
coldStartStrategy="drop", # bỏ qua user/movie không có trong tập train
nonnegative=True, # giữ latent factors dương → dễ diễn giải hơn
)
Tuy nhiên, hiệu quả của mô hình phụ thuộc rất lớn vào việc chọn đúng hyperparameters. Chúng mình thiết lập Grid Search kết hợp 3-fold Cross Validation để tìm bộ tham số tốt nhất:
from pyspark.ml.tuning import CrossValidator, ParamGridBuilder
param_grid = (
ParamGridBuilder()
.addGrid(als.rank, [15, 20]) # số đặc trưng ẩn k
.addGrid(als.regParam, [0.05, 0.1]) # tham số điều chuẩn λ
.addGrid(als.maxIter, [10, 15]) # số vòng lặp
.build()
)
cv = CrossValidator(
estimator=als,
estimatorParamMaps=param_grid,
evaluator=rmse_evaluator,
numFolds=3,
parallelism=2, # chạy song song 2 model — an toàn cho 14GB RAM
)
Tổng cộng 24 lần fit mô hình (8 tổ hợp tham số × 3 folds). Bộ tham số tốt nhất mà Cross Validation trả về:
rank = 20— sở thích xem phim khá phức tạp, cần đến 20 "chiều ẩn" để mô tả.regParam = 0.05— mức regularization vừa phải.maxIter = 15— đủ vòng lặp để hội tụ.
3.3. Đánh giá kết quả huấn luyện
Để đánh giá mô hình, chúng mình sử dụng ba metrics phổ biến trong bài toán regression:
-
MSE (Mean Squared Error):
$$MSE = \frac{1}{N} \sum_{i=1}^{N} (y_i - \hat{y}_i)^2$$ -
RMSE (Root Mean Squared Error):
$$RMSE = \sqrt{\frac{1}{N} \sum_{i=1}^{N} (y_i - \hat{y}_i)^2}$$ -
MAE (Mean Absolute Error):
$$MAE = \frac{1}{N} \sum_{i=1}^{N} |y_i - \hat{y}_i|$$
Trong đó:
- $y_i$: Điểm đánh giá thực tế.
- $\hat{y}_i$: Điểm đánh giá dự đoán.
Kết quả trên tập test:
| Metric | ALS Model | Baseline (Global Mean) | Cải thiện |
|---|---|---|---|
| RMSE | 0.7834 | 1.0607 | 26.1% |
| MSE | 0.6137 | — | — |
| MAE | 0.6002 | 0.8399 | — |
Con số MAE = 0.6002 có nghĩa là gì trong thực tế? Trung bình mỗi lần dự đoán, hệ thống chỉ lệch khoảng 0.6 sao so với cảm nhận thực sự của người dùng. Nếu hệ thống đoán bạn sẽ chấm một bộ phim 4.5 sao, điểm thực tế rất có thể nằm trong khoảng 3.9 đến 5.0 sao — một mức sai số khá chấp nhận được.
Để đặt con số này vào context: Baseline Global Mean — mô hình đơn giản nhất, lấy điểm trung bình của toàn bộ tập train rồi gán cho mọi cặp user-movie — cho RMSE = 1.0607. Thuật toán ALS kéo giảm xuống còn 0.7834, tương đương cải thiện 26.1%. Sự khác biệt này đến từ khả năng phân rã ma trận và tìm ra các đặc trưng ẩn riêng của từng người dùng, thay vì "cào bằng" tất cả.

Phân tích dự đoán: sai số tập trung quanh 0 (trái), mô hình bám sát đường perfect prediction (giữa), MAE thấp nhất ở vùng rating trung bình (phải).
Nguồn: Tác giả phân tích từ kết quả huấn luyện mô hình ALS.
Nhìn vào biểu đồ phân tích, chúng mình rút ra một số nhận xét: sai số phân bố đối xứng quanh 0, cho thấy mô hình không bị lệch bias một cách hệ thống. Tuy nhiên, mô hình có xu hướng kéo các dự đoán về vùng trung bình — dự đoán cao hơn thực tế với những phim bị chấm điểm thấp, và thấp hơn thực tế với những phim được chấm điểm cao. Đây là đặc trưng phổ biến của matrix factorization khi làm việc với dữ liệu thưa và mất cân bằng. Tổng thể, mô hình hoạt động ổn định ở vùng rating trung bình (3.0–4.0) và có thể cải thiện thêm ở các trường hợp cực đoan bằng các kỹ thuật nâng cao — điều chúng mình sẽ bàn ở phần 5.
4. Từ Notebook đến Demo — Đóng gói mô hình thành prototype tương tác
4.1. Mô hình tốt trên Notebook thì vẫn chỉ là notebook
Mô hình ALS đã huấn luyện xong, đạt RMSE = 0.7834, cải thiện 26% so với baseline. Nhưng một mô hình nằm trong Jupyter Notebook thì chẳng khác gì một công thức nấu ăn ngon mà không ai được thử món. Để kiểm chứng kết quả một cách trực quan hơn — và cũng để tập làm quen với bước "serving" trong vòng đời ML — chúng mình quyết định đóng gói thành một demo tương tác bằng Streamlit.
Cần nói rõ: đây là một prototype minh họa, không phải một ứng dụng production. Gợi ý được tính toán trước (precompute) cho một tập user cố định, lưu thành file JSON tĩnh — không có khả năng xử lý user mới, không cập nhật real-time, và người dùng phải nhập User ID thay vì đăng nhập bằng tài khoản thật. Nhưng với mục đích của project này — trải nghiệm toàn bộ pipeline từ dữ liệu thô đến một giao diện có thể tương tác — nó đã hoàn thành vai trò của mình.
4.2. Quá trình Export và Serving
Chiến lược của chúng mình là precompute — tính toán trước toàn bộ gợi ý cho 30.000 người dùng, lưu thành file JSON, để demo chỉ cần tra cứu mà không cần chạy Spark lúc serving. Quá trình này gồm bốn bước:
Bước 1 — Nạp lại mô hình và dữ liệu. Mô hình ALS đã lưu từ bước training được load lại, đồng thời các bảng Silver/Gold cũng được đọc lên:
# Load mô hình ALS đã huấn luyện
best_model = ALSModel.load(model_path)
# Load dữ liệu từ Silver & Gold
df_ml = spark.read.format("delta").load(f"{gold_path}/gold_train_features_ml")
df_movies = spark.read.format("delta").load(f"{silver_path}/movies_clean")
df_ratings = spark.read.format("delta").load(f"{silver_path}/ratings_clean")
df_links = spark.read.format("delta").load(f"{silver_path}/links_clean")
Bước 2 — Tính top 10 gợi ý cho toàn bộ user. Chúng mình chọn 30.000 user đầu tiên (sắp xếp theo userId để đảm bảo reproducibility), rồi dùng hàm recommendForUserSubset để sinh gợi ý:
# Chọn 30.000 user để serving
target_users = (
df_ml.select("userId").distinct()
.orderBy(asc("userId"))
.limit(30000)
)
# Sinh top-10 gợi ý cho mỗi user
user_recs = best_model.recommendForUserSubset(target_users, 10)
Bước 3 — Hậu xử lý và ghép metadata. Điểm dự đoán được clip về khoảng [0.5, 5.0] để tránh giá trị bất hợp lý, sau đó ghép thêm thông tin phim (tên, thể loại, điểm cộng đồng) vào từng gợi ý:
final_serving = (
user_recs
.withColumn("rec", explode("recommendations"))
.select(
col("userId").cast("string"),
col("rec.movieId").alias("movieId"),
# Clip điểm dự đoán về khoảng hợp lệ [0.5, 5.0]
F.least(F.lit(5.0), F.greatest(F.lit(0.5),
F.round(col("rec.rating"), 2)
)).alias("pred_rating")
)
.join(
df_movie_metadata.select(
"movieId", "title_clean", "genres", "tmdbId", "avg_rating", "release_year"
),
"movieId", "left"
)
)
Bước 4 — Ghi ra JSON để serving. Kết quả được gom theo từng User ID và lưu thành file serving_recs.json. Từ đây, mỗi khi người dùng nhập ID vào demo, Streamlit chỉ cần tra cứu đúng key — nhanh tức thì, không cần chạy Spark:
# Gom gợi ý theo userId → list of recommendations
serving_df = (
final_serving
.groupBy("userId")
.agg(
collect_list(
struct("movieId", "title_clean", "genres",
"pred_rating", "avg_rating", "tmdbId", "release_year")
).alias("recs")
)
)
# Export ra JSON
with open(f"{assets_path}/serving_recs.json", "w", encoding="utf-8") as f:
json.dump(serving_dict, f, ensure_ascii=False)
Khi demo Streamlit khởi động, các file JSON được nạp vào bộ nhớ và cache bằng @st.cache_data, đảm bảo mọi yêu cầu tra cứu tiếp theo chỉ tốn vài mili giây:
@st.cache_data
def load_assets():
with open(os.path.join(assets_path, "model_info.json"), "r") as f:
model_info = json.load(f)
with open(os.path.join(assets_path, "serving_recs.json"), "r") as f:
serving_data = json.load(f)
return model_info, serving_data
4.3. Demo CineMatch
Toàn bộ quá trình trên được đóng gói thành demo CineMatch, xây dựng trên nền tảng Streamlit. Mục tiêu không phải là một sản phẩm hoàn chỉnh, mà là một prototype đủ để minh họa kết quả của mô hình ALS dưới dạng trực quan. Giao diện được thiết kế theo phong cách tối màu (Dark Mode) hiện đại, đậm chất điện ảnh. Demo có hai chức năng chính, được tách thành hai tab rõ ràng:
Tab "Gợi ý cá nhân" — đây là chức năng cốt lõi. Người dùng nhập User ID, hệ thống tra cứu trong serving_recs.json và trả về danh sách phim phù hợp, có thể lọc thêm theo thể loại:
if submitted:
uid = str(user_id_input).strip()
if uid not in all_recs:
st.markdown(f"User ID {uid} is not in the precomputed set...")
else:
recs = all_recs[uid]
# Lọc theo thể loại nếu người dùng chọn
if selected_genres:
recs = [
r for r in recs
if any(g in (r.get("genres") or "") for g in selected_genres)
]
# Hiển thị dạng grid 5 cột
cols_per_row = 5
for row_start in range(0, len(recs), cols_per_row):
row_movies = recs[row_start : row_start + cols_per_row]
cols = st.columns(cols_per_row)
for col, movie in zip(cols, row_movies):
with col:
render_movie_card(movie, show_pred=True)
Mỗi thẻ phim hiển thị poster, tên phim, năm phát hành, thể loại, điểm dự đoán riêng cho người dùng đó và điểm trung bình cộng đồng. Ví dụ với User 510, hệ thống gợi ý các bộ phim như Forrest Gump (4.38 điểm), Aladdin (4.25 điểm), Koko-di Koko-da (4.66 điểm) — phản ánh sở thích cá nhân của người dùng này:

Kết quả gợi ý cho User 510 — mỗi thẻ phim hiển thị poster, điểm dự đoán và điểm cộng đồng.
Nguồn: Demo CineMatch.
Tab "Tìm kiếm phim" — cho phép tìm phim theo tên và lọc theo thể loại. Danh sách kết quả được sắp xếp theo công thức kết hợp điểm trung bình với số lượt đánh giá, tránh trường hợp phim ít người xem nhưng điểm cao bất thường lọt lên đầu. Khi không có từ khóa, tab này mặc định hiển thị top 10 phim được đánh giá cao nhất toàn tập dữ liệu:

Tab "Tìm kiếm phim" — top 10 phim được đánh giá cao nhất, sắp xếp theo Bayesian Average.
Nguồn: Demo CineMatch.
Một chi tiết nhỏ nhưng quan trọng cho trải nghiệm: mỗi thẻ phim cần poster để hiển thị. Demo gọi API TMDB dựa vào tmdbId đã lưu trong metadata, kết quả được cache 1 giờ để tránh gọi lặp. Nếu không có API key hoặc gọi thất bại, demo tự động dùng ảnh placeholder để đảm bảo giao diện không bị vỡ trong mọi trường hợp.
Từ một mô hình nằm im trong notebook, chúng mình đã đóng gói nó thành một demo tương tác — chưa phải ứng dụng production, nhưng đủ để bất kỳ ai cũng có thể mở lên, nhập User ID, và kiểm chứng kết quả gợi ý một cách trực quan. Nhưng hành trình chưa dừng ở đây — ở phần cuối, chúng mình sẽ nhìn lại những bài học rút ra và những hướng đi tiếp theo để hệ thống này thực sự sẵn sàng cho production.
5. Bài học đúc kết và hướng phát triển
5.1. Nhìn lại hành trình: Từ file CSV đến một hệ thống gợi ý hoàn chỉnh
Nếu nhìn lại toàn bộ project từ đầu đến cuối, chúng mình đã đi qua một hành trình khá trọn vẹn của một dự án Data/ML thực tế — không chỉ dừng lại ở việc "train một model rồi in kết quả ra notebook", mà là xây dựng cả một pipeline end-to-end từ dữ liệu thô cho đến một giao diện mà người dùng có thể tương tác được.
Cụ thể, có bốn trụ cột kỹ thuật cốt lõi đã được áp dụng xuyên suốt project:
Thứ nhất, xử lý dữ liệu lớn với Apache Spark. Thay vì dùng Pandas — vốn chỉ hoạt động tốt khi dữ liệu nằm gọn trong bộ nhớ của một máy — chúng mình đã tận dụng Spark để xử lý dữ liệu phân tán. Với tập MovieLens hiện tại, Pandas vẫn "chạy được", nhưng kiến trúc Spark cho phép hệ thống sẵn sàng mở rộng (scale) khi lượng rating tăng lên hàng trăm triệu hay hàng tỷ dòng mà không cần viết lại code từ đầu. Đây là tư duy thiết kế cho tương lai, không chỉ cho hiện tại.
Thứ hai, xây dựng Data Pipeline chuyên nghiệp với kiến trúc Medallion và Delta Lake. Việc tổ chức dữ liệu thành ba tầng Bronze → Silver → Gold không chỉ giúp pipeline dễ debug và bảo trì, mà còn đảm bảo tính nhất quán và khả năng truy vết dữ liệu (data lineage). Delta Lake bổ sung thêm các tính năng quan trọng như ACID transactions và time travel, giúp chúng mình yên tâm rằng dữ liệu không bị hỏng hay mất mát trong quá trình xử lý. Đây là cách các đội Data Engineering ở các công ty lớn vận hành hệ thống của họ hàng ngày.
Thứ ba, ứng dụng thuật toán Machine Learning — cụ thể là Collaborative Filtering với ALS. Chúng mình đã biến một ý tưởng đơn giản ("người có gu giống nhau sẽ thích những phim giống nhau") thành một mô hình toán học cụ thể thông qua Matrix Factorization. Spark MLlib cung cấp một implementation của ALS đã được tối ưu hóa cho xử lý phân tán, giúp quá trình training diễn ra hiệu quả ngay cả trên tập dữ liệu lớn. Việc đánh giá mô hình bằng RMSE và MAE cũng cho chúng mình một cái nhìn định lượng về chất lượng dự đoán, thay vì chỉ dựa vào cảm tính.
Thứ tư, đưa mô hình ra khỏi notebook và đóng gói thành demo tương tác. Đây là bước mà rất nhiều dự án ML dừng lại và không bao giờ hoàn thành. Việc export model, tạo các file mapping, và xây dựng một giao diện UI để người dùng thực sự tương tác được với hệ thống gợi ý — chính là khoảng cách giữa một "bài tập trên notebook" và một "prototype có giao diện". Để đi từ prototype đến sản phẩm thật, còn cần thêm nhiều bước nữa — và đó chính là nội dung phần 5.3. Dù ở quy mô nhỏ, bước này đã cho chúng mình trải nghiệm thực tế về quá trình model serving.
5.2. Những thách thức còn bỏ ngỏ
Không có hệ thống nào là hoàn hảo, và hệ thống gợi ý của chúng mình cũng không ngoại lệ. Có một số bài toán khó mà project hiện tại chưa giải quyết triệt để.
Cold Start Problem — "Kẻ thù số một" của Collaborative Filtering. Đây là thách thức lớn nhất và cũng là hạn chế cố hữu của phương pháp Lọc cộng tác. Hệ thống hoạt động dựa trên lịch sử tương tác (rating) của người dùng, vậy điều gì xảy ra khi một người dùng hoàn toàn mới đăng ký tài khoản và chưa rate bất kỳ bộ phim nào? Hoặc khi một bộ phim mới ra mắt mà chưa có ai đánh giá? Trong cả hai trường hợp, ma trận User-Item không có dữ liệu để mô hình "học" và đưa ra gợi ý có ý nghĩa. Hiện tại, hệ thống sẽ rơi vào trạng thái "không biết gợi ý gì" cho những trường hợp này — một lỗ hổng lớn nếu triển khai ở quy mô thực tế, nơi lượng người dùng mới gia nhập liên tục.
Popularity Bias — Thiên kiến về phim nổi tiếng. Collaborative Filtering có xu hướng gợi ý những bộ phim đã được nhiều người xem và đánh giá cao, vô tình bỏ qua những bộ phim ít tên tuổi hơn (niche films) mà thực ra có thể rất phù hợp với gu của người dùng. Điều này dẫn đến hiện tượng "rich get richer" — phim phổ biến ngày càng được gợi ý nhiều hơn, còn phim ít người biết đến thì dần bị "chìm" trong hệ thống.
Sparsity Problem — Ma trận thưa. Trong thực tế, số lượng phim mà mỗi người dùng đã xem và đánh giá chỉ chiếm một phần rất nhỏ so với tổng số phim có trong hệ thống. Ma trận User-Item vì thế cực kỳ thưa (sparse), với phần lớn ô trống. Khi dữ liệu thưa, việc tìm ra các latent features chính xác trở nên khó khăn hơn, ảnh hưởng trực tiếp đến chất lượng gợi ý.
Khả năng giải thích (Explainability). Khi mô hình gợi ý phim A cho người dùng B, chúng mình khó có thể giải thích rõ ràng "tại sao". Các latent features trong Matrix Factorization là những vector số trừu tượng, không mang ý nghĩa ngữ nghĩa cụ thể như "thể loại hành động" hay "đạo diễn Christopher Nolan". Điều này khiến việc xây dựng niềm tin của người dùng với hệ thống trở nên khó khăn — người dùng thường muốn biết lý do đằng sau một gợi ý, không chỉ đơn thuần nhận gợi ý.
5.3. Hướng phát triển tiếp theo
Từ những thách thức trên, có một số hướng phát triển rõ ràng để nâng cấp hệ thống.
Kết hợp Content-Based Filtering để tạo Hybrid Model. Đây là bước tiến tự nhiên nhất. Thay vì chỉ dựa vào hành vi rating của người dùng (Collaborative Filtering), chúng mình có thể bổ sung thêm thông tin về nội dung phim — thể loại (genre), đạo diễn, diễn viên, mô tả phim (synopsis), thậm chí cả poster và trailer. Một mô hình Hybrid kết hợp cả hai nguồn tín hiệu này sẽ khắc phục được phần nào bài toán Cold Start: dù người dùng mới chưa có lịch sử rating, hệ thống vẫn có thể gợi ý dựa trên sở thích thể loại mà họ chọn khi đăng ký, hoặc dựa trên đặc trưng nội dung của những bộ phim tương tự.
Thử nghiệm các kiến trúc Deep Learning. Các mô hình Recommender System hiện đại đã vượt xa Matrix Factorization truyền thống. Những kiến trúc như Neural Collaborative Filtering (NCF), Variational Autoencoders (VAE) cho Recommendation, hay thậm chí các mô hình dựa trên Transformer (như SASRec — Self-Attentive Sequential Recommendation) có khả năng nắm bắt các mối quan hệ phi tuyến phức tạp hơn giữa người dùng và phim. Đặc biệt, các mô hình Sequential Recommendation còn có thể tận dụng thứ tự thời gian của các lượt rating để hiểu sự thay đổi sở thích của người dùng theo thời gian — một điều mà ALS truyền thống không làm được.
Deploy lên Cloud để scale hệ thống thực sự. Hiện tại, toàn bộ hệ thống đang chạy trên môi trường local. Để đưa hệ thống vào vận hành thực tế với hàng nghìn, hàng triệu người dùng, chúng mình cần triển khai lên các nền tảng Cloud như AWS, GCP hoặc Azure. Cụ thể hơn, pipeline xử lý dữ liệu có thể chạy trên các dịch vụ như AWS EMR hoặc Databricks, model serving có thể triển khai qua API endpoint với AWS SageMaker hoặc GCP Vertex AI, và toàn bộ quy trình huấn luyện lại mô hình (retraining) có thể được tự động hóa bằng các công cụ orchestration như Apache Airflow hoặc Prefect.
Bổ sung Implicit Feedback. Trong project hiện tại, chúng mình sử dụng explicit feedback (rating mà người dùng chủ động đánh giá). Tuy nhiên, trong thực tế, phần lớn tín hiệu từ người dùng là implicit — lượt xem, thời gian xem, hành vi tạm dừng, thêm vào danh sách yêu thích, hay thậm chí là hành vi bỏ xem giữa chừng. Tích hợp các tín hiệu này sẽ giúp mô hình hiểu sâu hơn về sở thích thật sự của người dùng, thay vì chỉ dựa vào những lần họ "bận tâm" đủ để để lại một rating.
Nhìn tổng thể, project này không chỉ là một bài tập về thuật toán gợi ý. Đó là hành trình trải nghiệm toàn bộ vòng đời của một dự án dữ liệu: từ thu thập và xử lý dữ liệu thô, khám phá và làm sạch dữ liệu, huấn luyện và đánh giá mô hình, cho đến đóng gói thành một prototype mà người dùng có thể tương tác trực tiếp. Mỗi bước đều có những bài học riêng, và quan trọng hơn cả, mỗi thách thức chưa giải quyết được chính là động lực để tiếp tục cải thiện và phát triển hệ thống trong tương lai.
Kết nối với chúng mình
Nếu bạn quan tâm đến project này, muốn xem chi tiết code, hoặc có bất kỳ góp ý nào — chúng mình rất vui được trao đổi!
Hãy để lại comment bên dưới nếu bạn có câu hỏi, hoặc nếu bạn đã thử xây dựng hệ thống gợi ý của riêng mình — chúng mình rất muốn nghe câu chuyện của bạn!
Tài liệu tham khảo
-
F. Maxwell Harper & Joseph A. Konecny, The MovieLens Datasets: History and Context, ACM Transactions on Interactive Intelligent Systems, 2015. — https://grouplens.org/datasets/movielens/
-
Yehuda Koren, Robert Bell & Chris Volinsky, Matrix Factorization Techniques for Recommender Systems, IEEE Computer, 2009.
-
Apache Spark Documentation — MLlib Collaborative Filtering (ALS). — https://spark.apache.org/docs/latest/ml-collaborative-filtering.html
-
Delta Lake Documentation — ACID Transactions, Time Travel, Schema Enforcement. — https://docs.delta.io/latest/index.html
-
Databricks, Medallion Architecture: Bronze, Silver, Gold. — https://www.databricks.com/glossary/medallion-architecture
-
Hu, Y., Koren, Y. & Volinsky, C., Collaborative Filtering for Implicit Feedback Datasets, IEEE ICDM, 2008.
-
Streamlit Documentation — Build and share data apps. — https://docs.streamlit.io/
-
TMDB (The Movie Database) API Documentation. — https://developer.themoviedb.org/docs
Chưa có bình luận nào. Hãy là người đầu tiên!