
Phần 1: "Nỗi đau" của việc khai thác dữ liệu Reels
1.1 Sức hấp dẫn không thể chối từ của Reels
Trong kỷ nguyên nội dung ngắn lên ngôi, Reels không chỉ đơn thuần là tính năng giải trí mà đã thực sự trở thành một "mỏ vàng" dữ liệu khổng lồ. Từng giây trôi qua, hàng triệu video mang theo những xu hướng mới nhất, hàng loạt các bài đánh giá và review sản phẩm chân thực, và những thông tin thấu hiểu người dùng vô giá liên tục được sinh ra. Bất kỳ cá nhân hay tổ chức nào nắm bắt được luồng dữ liệu này sẽ có lợi thế cạnh tranh cực lớn.
1.2 Nút thắt kỹ thuật: Khi dữ liệu giá trị bị "nhốt"
Thế nhưng, nhìn thấy tiềm năng là một chuyện, khai thác được hay không lại là một bài toán làm đau đầu dân kỹ thuật. Khác biệt hoàn toàn với văn bản tĩnh truyền thống vốn dễ thu thập và phân tích, nền tảng Reels vận hành trên cơ chế cuộn vô hạn.
Nút thắt lớn nhất nằm ở định dạng: toàn bộ thông tin giá trị nhất đang bị "nhốt" chặt trong các luồng âm thanh và chuỗi hình ảnh động. Hậu quả là, các hệ thống máy móc và bộ phân tích thông thường gần như "mù" trước kho dữ liệu này. Chúng ta không thể thực hiện các thao tác truy vấn để tìm ra thông tin, hay lập chỉ mục trực tiếp lên một video như cách vẫn làm với cơ sở dữ liệu dạng text thông thường.

Hình 1.1: Dữ liệu quý giá bị "khóa chặt" trong định dạng đa phương tiện, khiến các hệ thống thu thập tự động thông thường trở nên bất lực. (Nguồn ảnh: Gemini)
1.3 Giải pháp đề xuất: Phá vỡ rào cản với AI Pipeline
Để giải phóng khối lượng dữ liệu khổng lồ này khỏi luồng video, chúng ta cần một quy trình xử lý thông minh và bài bản. Giải pháp tối ưu nhất hiện nay là xây dựng một pipeline tự động hóa gồm 2 bước cốt lõi:
1. Thu thập dữ liệu thô: Xây dựng một cơ chế tự động "cào" và lưu trữ khối dữ liệu nguyên bản gồm Video và Audio từ nền tảng.
2. Chuyển hóa bằng AI: Ứng dụng sức mạnh của Trí tuệ nhân tạo (như các mô hình Speech-to-Text) để xử lý dữ liệu thô, "bóc băng" và chuyển đổi toàn bộ luồng thông tin đa phương tiện thành định dạng văn bản.
Chỉ khi dữ liệu được "mở khóa" và quy chuẩn về dạng văn bản, các nút thắt kỹ thuật mới thực sự được tháo gỡ, sẵn sàng cho những bước phân tích insight sâu hơn.
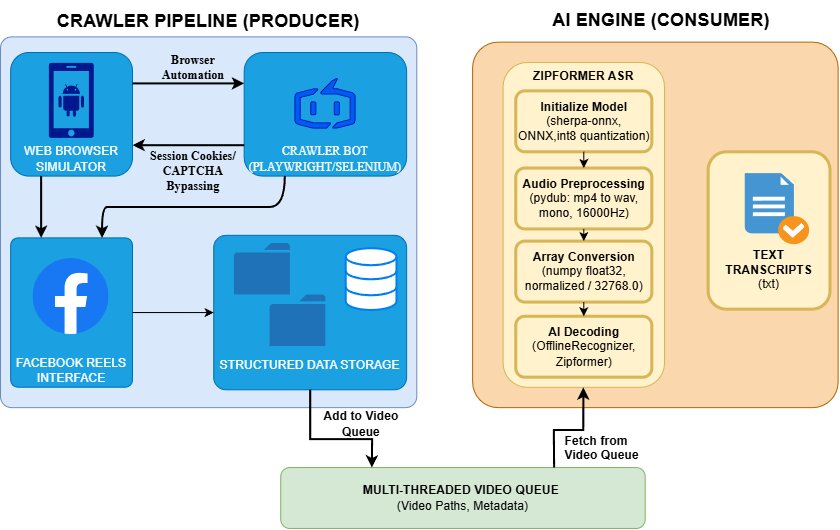
Hình 1.2: Sơ đồ luồng kiến trúc tổng thể của hệ thống trích xuất nội dung từ Reels, minh họa mô hình Producer-Consumer giữa Crawler (màu xanh) và AI Engine (màu cam).
Phần 2: Thu thập và Tổ chức dữ liệu (The Crawler Pipeline)
2.1 Vượt qua rào cản "Cuộn vô hạn" với Playwright/Selenium
Facebook Reels không phải là một kho lưu trữ tĩnh mà bạn có thể dễ dàng dùng các lệnh HTTP Request thông thường (như thư viện requests trong Python) để tải về. Nội dung trên nền tảng này được phân phối qua cơ chế tải động (dynamic loading) – các tệp video mới chỉ thực sự được gọi khi người dùng thao tác cuộn hoặc tương tác trực tiếp trên giao diện.
Để giải quyết bài toán này, chúng ta cần một công cụ có khả năng mô phỏng lại chính xác hành vi của người thật. Thư viện tự động hóa trình duyệt như Selenium hoặc Playwright là những ứng dụng hoàn hảo cho nhiệm vụ này. Chúng cho phép lập trình một "con bot" có khả năng tự động khởi chạy trình duyệt ẩn, truy cập vào luồng Reels, liên tục cuộn trang để kích hoạt cơ chế tải nội dung và tóm gọn các đường link video gốc.
2.2 Chiến lược "Luồn lách": Xử lý rào cản CAPTCHA
Khi bot tự động hóa hoạt động với tần suất cao, hệ thống phòng thủ của Facebook sẽ ngay lập tức "đánh hơi" thấy sự bất thường và tung ra các biện pháp ngăn chặn như yêu cầu giải CAPTCHA hoặc khóa quyền truy cập.
Hình 2.1: Ảnh minh họa captcha
Để Crawler hoạt động mượt mà và bền bỉ, chúng ta áp dụng một chiến lược "ngụy trang" hiệu quả: Quản lý Session Cookies. Thay vì để bot tự động điền tài khoản mật khẩu (hành vi rất dễ bị thuật toán đánh cờ), chúng ta sẽ đăng nhập Facebook thủ công một lần trên trình duyệt thông thường. Sau đó, hệ thống sẽ trích xuất toàn bộ cookies của phiên làm việc đó và nạp (inject) lại vào trình duyệt tự động của Playwright. Cách tiếp cận này giúp bot kế thừa trạng thái xác thực và vượt qua các lớp kiểm tra tự động một cách êm ái.

Hình 2.2: Cookies được trích xuất và sử dụng
2.3 Tải video và Thiết lập hàng đợi (The Producer)
Sau khi Crawler thu thập được danh sách URL, hệ thống sẽ tiến hành tải trực tiếp các tệp .mp4 về máy chủ. Tuy nhiên, nếu chỉ ném tất cả vào một thư mục dùng chung, quá trình xử lý AI phía sau sẽ rất dễ xảy ra tình trạng lộn xộn, khó tracking và gây nghẽn cổ chai.
Do đó, pipeline được thiết kế để tự động phân loại và lưu trữ video vào một cấu trúc thư mục chuẩn hóa theo dòng thời gian như sau:
dataset/
├── videos/
│ ├── 2026-03-11/
│ ├── 2026-03-12/
Nút thắt quan trọng của hệ thống: Ngay khi một tệp .mp4 được tải xuống và lưu trữ thành công vào cấu trúc thư mục trên, Crawler (đóng vai trò là nhà sản xuất - Producer) sẽ lập tức đẩy đường dẫn (file path) của video đó vào một hàng đợi đa luồng (video_queue).
Nhờ cơ chế này, hệ thống không cần phải ngồi đợi tải xong toàn bộ. Mọi thứ lúc này đã ở trạng thái sẵn sàng để được "đánh thức" bởi khối óc AI.
Bằng cách áp dụng phương pháp trên, chúng ta sẽ thu thập được một lượng lớn data. Dưới đây là một số hình ảnh minh họa về kết quả đạt được:
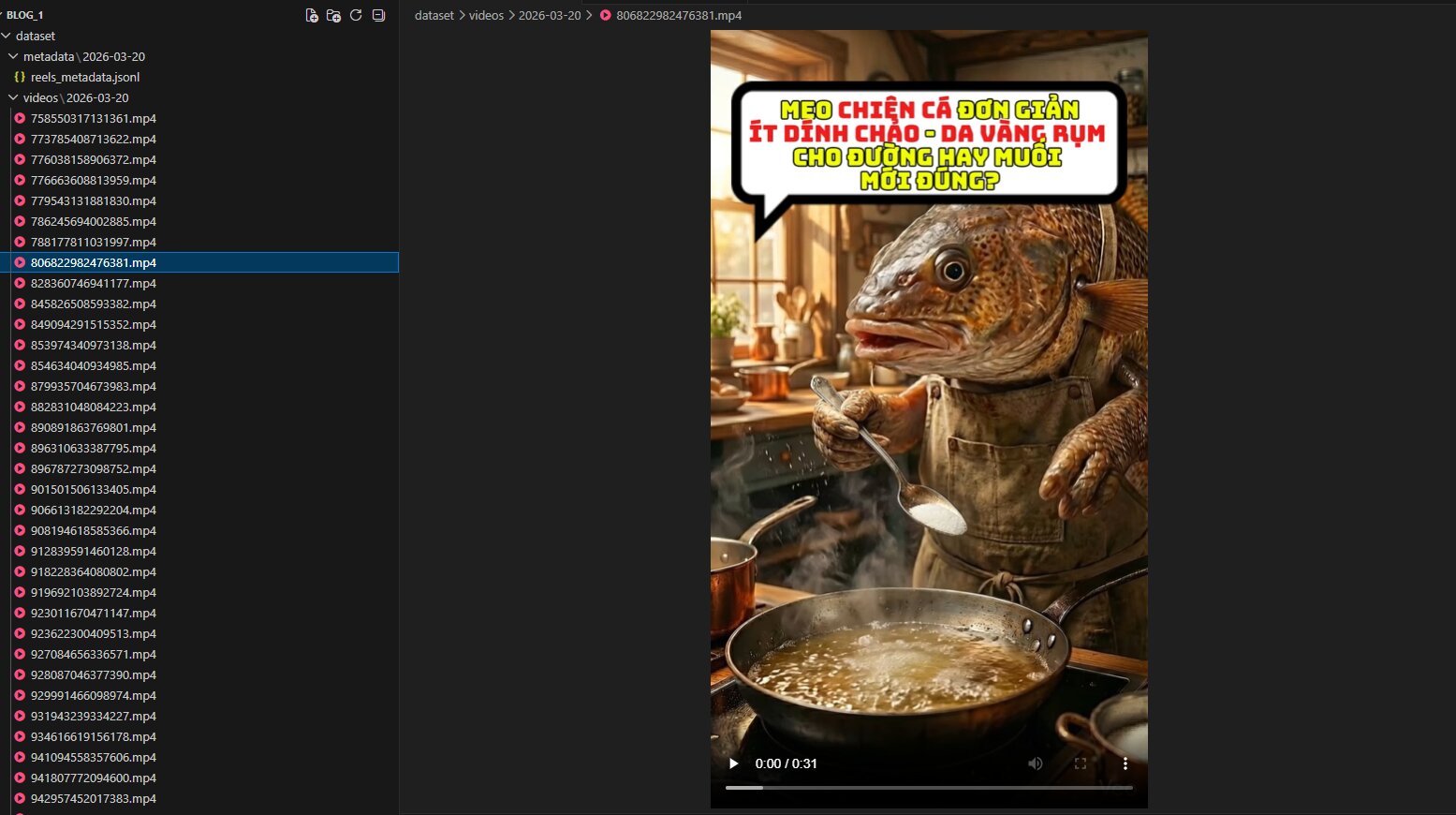
Hình 2.3: Crawler hoạt động thành công, tải và phân loại hàng loạt video .mp4 vào đúng cấu trúc thư mục theo ngày tháng.
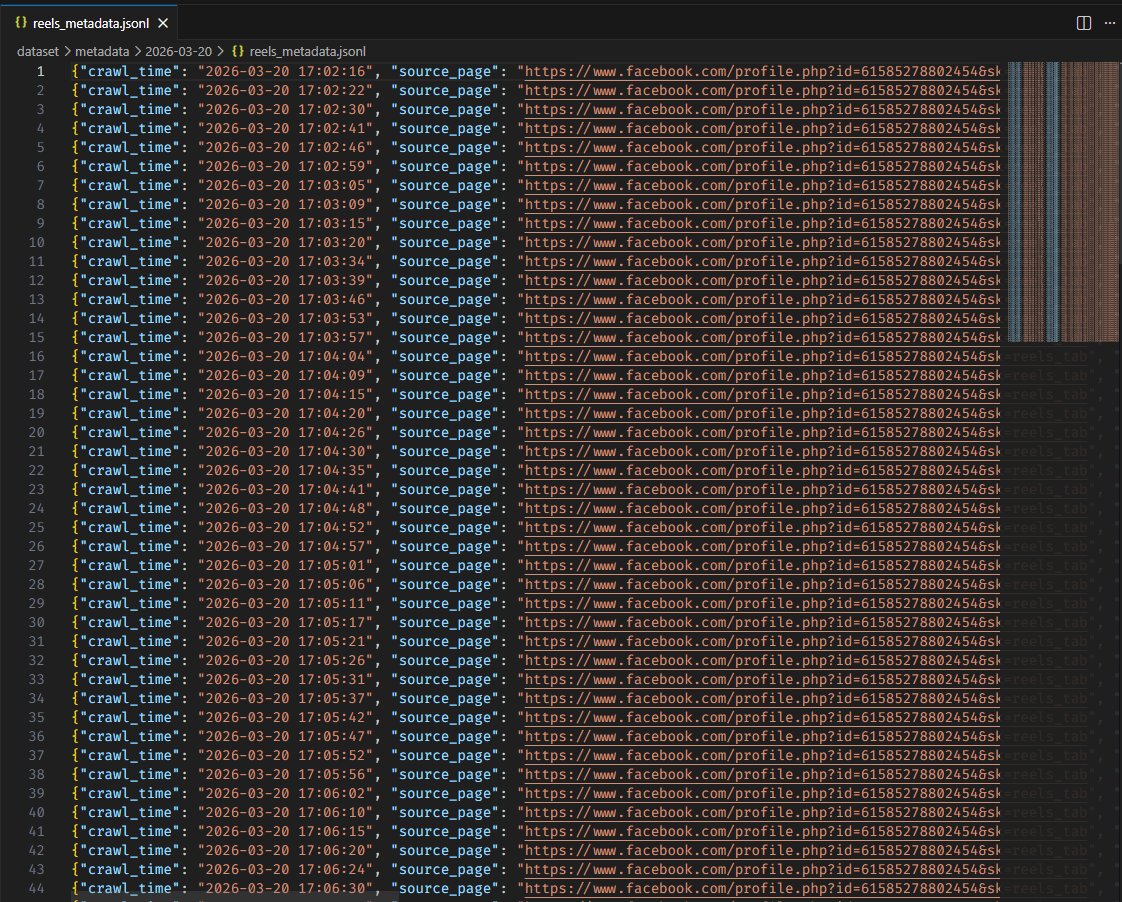
Hình 2.4: Hệ thống không chỉ tải video, mà còn trích xuất thành công bộ dữ liệu metadata (file reels_metadata.jsonl), lưu vết chính xác thời gian cào và đường dẫn gốc.
Phần 3: Đánh thức dữ liệu bằng Zipformer (The AI Engine)
3.1 Thách thức về hiệu năng: Tốc độ và Tối ưu hóa tài nguyên
Sau khi đã có trong tay hàng nghìn tệp video Reels được tổ chức ngăn nắp ở Phần 2, thách thức thực sự là xử lý lượng âm thanh khổng lồ mà không làm quá tải hệ thống. Các mô hình ASR (Speech-to-Text) phổ biến như Whisper đòi hỏi sức mạnh tính toán lớn từ GPU và RAM, dễ gây ra tình trạng "thắt cổ chai" nếu chạy trên CPU thông thường.
Hệ thống sử dụng Zipformer (thuộc hệ sinh thái Kaldi) làm nhân tố cốt lõi để giải quyết bài toán này. Zipformer sử dụng phiên bản lượng tử hóa (int8) định dạng ONNX, giúp tối ưu kích thước mô hình và cho phép chạy mượt mà trên CPU với tốc độ xử lý cực cao. Đồng thời, mô hình vẫn duy trì khả năng nhận diện tiếng Việt và đa ngôn ngữ xuất sắc.
3.2 Quy trình "bóc băng" tự động (The AI Workflow)
Quá trình xử lý dữ liệu được tổ chức theo mô hình Sản xuất - Tiêu thụ (Producer - Consumer) thông qua hàng đợi đa luồng. Crawler liên tục thu thập dữ liệu, trong khi AI Worker thực hiện quy trình 4 giai đoạn:
Giai đoạn 1: Khởi tạo mô hình (Model Initialization)
Hệ thống sử dụng thư viện sherpa_onnx để nạp mô hình trực tiếp từ các tệp trọng số đã được lượng tử hóa. Việc tách biệt các module encoder, decoder và joiner giúp tối ưu hóa luồng suy luận.
recognizer = sherpa_onnx.OfflineRecognizer.from_transducer(
encoder=required[0], decoder=required[1],
joiner=required[2], tokens=required[3],
num_threads=4) # Chạy đa luồng trên CPU
Giai đoạn 2: Tiếp nhận và Tiền xử lý âm thanh (Audio Preprocessing)
Khi nhận được một video mới từ video_queue, AI không đọc trực tiếp file .mp4. Thông qua thư viện pydub, hệ thống bóc tách riêng lớp âm thanh, ép chuẩn về tần số mẫu 16000Hz và chuyển sang dạng đơn kênh (mono - 1 channel). Đây là định dạng chuẩn bắt buộc để mô hình AI có thể hiểu được.
# Tách âm thanh và chuẩn hóa
audio = AudioSegment.from_file(video_path)
audio = audio.set_frame_rate(16000).set_channels(1)
audio.export(audio_tmp, format="wav")
Giai đoạn 3: Trích xuất mảng dữ liệu (Array Conversion)
Tệp âm thanh .wav tiếp tục được đọc dưới dạng các khung hình (frames) và chuyển đổi thành mảng số thực numpy (float32). Dữ liệu được chuẩn hóa biên độ bằng cách chia cho 32768.0.
with wave.open(audio_tmp, "rb") as f:
num_frames = f.getnframes()
sample_rate = f.getframerate()
buf = f.readframes(num_frames)
samples = np.frombuffer(buf, dtype=np.int16).astype(np.float32) / 32768.0
Giai đoạn 4: Giải mã AI và Xuất file (Decoding & Output)
Cuối cùng, mảng âm thanh được đẩy vào luồng (stream) của bộ nhận diện. Zipformer sẽ nội suy, giải mã và trả về kết quả dạng văn bản thô (text), sau đó ghi trực tiếp ra tệp .txt với cùng tên gốc của video trong cấu trúc thư mục đã được tổ chức.
stream = recognizer.create_stream()
stream.accept_waveform(sample_rate, samples)
recognizer.decode_stream(stream)
text_result = stream.result.text.strip()
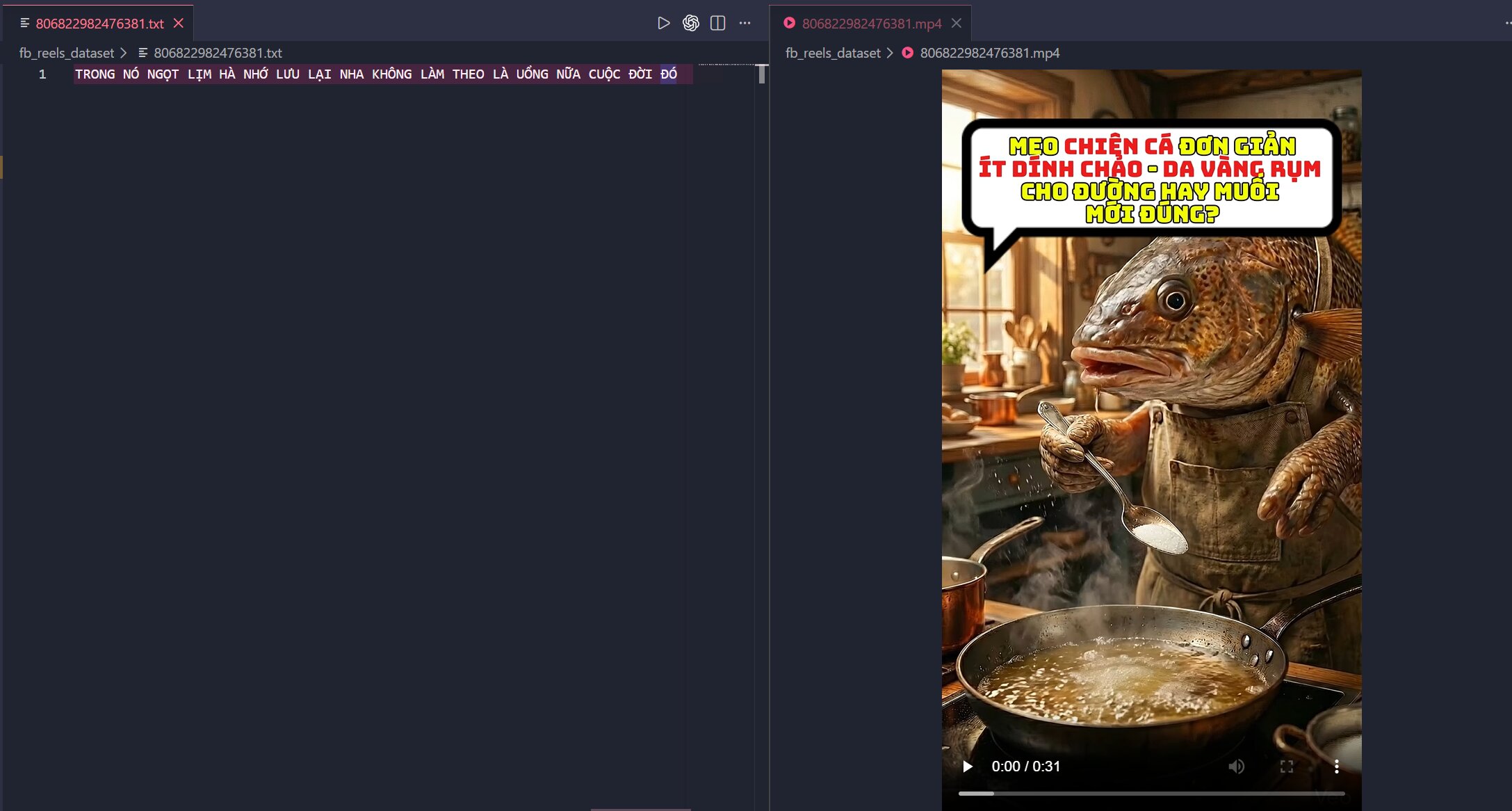
Hình 3.1: Trực quan hóa kết quả ở mức độ nội dung (Content level). Chứng minh AI đã "nghe" và viết lại chính xác lời thoại của một video cụ thể.
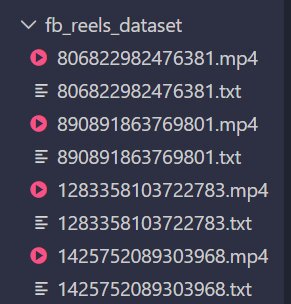
Hình 3.2: Trực quan hóa kết quả ở mức độ hệ thống. Chứng minh pipeline hoạt động trơn tru với số lượng lớn, tự động map (ghép cặp) file .txt với file .mp4 cùng tên.
Phần 4: Kết luận & Mở rộng
4.1. Tổng kết: Sức mạnh cộng hưởng giữa Tự động hóa và Zipformer
Quy trình trích xuất nội dung từ Facebook Reels không chỉ dừng lại ở việc thu thập video, mà là sự kết hợp giữa hai thành phần cốt lõi: hệ thống tự động hóa để thu thập dữ liệu thô và mô hình Zipformer để chuyển đổi dữ liệu âm thanh thành văn bản. Trong đó, bước crawling giúp tiếp cận nguồn dữ liệu Reels có tính động cao, còn Zipformer đóng vai trò trung tâm khi biến luồng âm thanh khó khai thác thành transcript có cấu trúc và có thể tiếp tục xử lý.
Việc lựa chọn Zipformer làm "trái tim" của hệ thống là phù hợp vì mô hình này đáp ứng tốt yêu cầu xử lý số lượng lớn tệp âm thanh với tốc độ cao, chi phí tài nguyên thấp và khả năng tích hợp thuận tiện vào pipeline tự động. Nhờ đó, hệ thống không chỉ dừng ở mức thu thập dữ liệu, mà còn có thể chuyển hóa dữ liệu Reels thành dạng văn bản sẵn sàng cho các bài toán phân tích tiếp theo.
Tuy nhiên, cần lưu ý rằng thành phần crawling có tính phụ thuộc lớn vào cơ chế vận hành của nền tảng Facebook và có thể bị ảnh hưởng khi nền tảng thay đổi các biện pháp chống bot hoặc cơ chế tải nội dung động. Vì vậy, giá trị của hệ thống không nằm ở tính ổn định tuyệt đối, mà ở cách tiếp cận linh hoạt trong việc kết hợp công cụ tự động hóa và AI để giải quyết bài toán thực tế.
4.2. Hướng mở rộng
Các transcript thu được từ hệ thống là nguồn dữ liệu đầu vào có giá trị cho nhiều hướng nghiên cứu và ứng dụng khác nhau. Trước hết, dữ liệu này có thể được sử dụng cho bài toán phân tích cảm xúc nhằm đánh giá thái độ của người dùng hoặc nhà sáng tạo nội dung đối với thương hiệu, sản phẩm hoặc sự kiện cụ thể. Bên cạnh đó, transcript cũng có thể được đưa vào các mô hình gom cụm từ khóa hoặc phân loại chủ đề để nhận diện nhanh các xu hướng nội dung nổi bật trên Reels. Xa hơn, hệ thống còn có thể được mở rộng sang các bài toán tìm kiếm nội dung, tóm tắt video, hoặc xây dựng cơ sở dữ liệu phục vụ phân tích truyền thông số.
Chưa có bình luận nào. Hãy là người đầu tiên!