

1. Giới thiệu chatbot và xác định phạm vi hoạt động
1.1 Giới thiệu chatbot
Ở bài viết này, ta tạo ra một chatbot có thể trả lời các câu hỏi mà người dùng nhập vào. Chatbot sẽ được triển khai trên server, không phải trên máy tính cá nhân, do đó người dùng có thể truy cập thông qua trình duyệt và chatbot luôn sẵn sàng trả lời bất cứ lúc nào.

Hình 1.1. Sơ đồ minh họa
Vai trò của từng khối:
- User: Người sử dụng chatbot, đặt ra yêu cầu và câu hỏi cho chatbot.
- Web UI: Giao diện người dùng trên web, giúp người dùng tương tác với chatbot và các chức năng khác thông qua trình duyệt.
- Chatbot Backend: Trung tâm xử lí logic và luồng hội thoại, câu hỏi của người dùng sẽ được xử lí để tạo ra câu trả lời.
- AI Model: Cung cấp khả năng hiểu ngôn ngữ của người dùng, từ đó sinh ra câu trả lời.
- Response: Phản hồi từ chatbot sẽ được sinh ra và hiển thị trên trình duyệt.
1.2 Xác định các chức năng và phạm vi của chatbot:
Vì blog này tập trung vào việc xây dựng một chatbot đơn giản và triển khai trên web, do đó các yêu cầu về chức năng và phạm vi sẽ được giới hạn để phù hợp với công suất phản hồi:
Only accept text input:
Giới hạn đầu vào của chatbot là câu hỏi dạng chuỗi để tiết kiệm thời gian phản hồi. Phạm vi câu hỏi không giới hạn.
Customizable system prompt / personality:
Đây là các tính năng được tích hợp trên Web UI, người dùng có thể tùy chỉnh các thông số để phản hồi của chatbot đa dạng hơn:
- Multilingual support: Người dùng có thể input câu hỏi dạng song ngữ (cụ thể là tiếng Anh hoặc tiếng Việt)
- Basic safety / content filtering: Lọc các từ khóa, từ ngữ nhạy cảm.
- Temperature / creativity slider: Điều chỉnh mức độ thông minh của chatbot. Người dùng có thể tinh chỉnh bằng cách kéo thanh trượt (Slide bar).
- Response length control: Giới hạn độ dài của phản hồi.
- Clear chat / restart button: Xóa lịch sử đoạn hội thoại.
2. Triển khai code chatbot
2.1 Choose tech stack
Ở blog này ta sẽ lựa chọn các công cụ chính sau để làm chatbot:
Ngôn ngữ lập trình: Python
- Python được chọn làm ngôn ngữ chính để thiết kế chatbot dựa trên ưu điểm về cú pháp đơn giản, lượng thư viện lớn trong quá trình làm chatbot.
Model framework: Hugging Face
- Hugging Face là nền tảng mã nguồn mở về AI, bao gồm các tập dữ liệu, mô hình AI lớn. Việc sử dụng Hugging Face sẽ giúp chúng ta dễ dàng tìm kiếm và sử dụng các mô hình AI phù hợp.
Model deployment: Hugging Face Space
- Hugging Face Space hỗ trợ triển khai model đơn giản, phù hợp với các dự án nhỏ.
Web deployment: Streamlit
- Streamlit được chọn để tạo Web UI cho chatbot nhờ vào khả năng tương thích với Python cao, dễ phát triển, phù hợp với dự án chatbot nhỏ và không yêu cầu kiến thức lớn về lập trình frontend.
2.2 Core code structure – Cấu trúc code chatbot
Phần này sẽ đi trực tiếp vào code của project, giải thích từng thành phần chính để thấy rõ chatbot được xây dựng như thế nào, từ giao diện đến AI model.
Toàn bộ project có cấu trúc như sau:
├── requirements.txt # Danh sách thư viện cần cài
└── src
├── app.py # Giao diện chatbot + logic xử lý chat
└── llm.py # Load LLM và sinh câu trả lời
Giao diện chatbot (app.py)
Giao diện chatbot được xây dựng bằng Streamlit, với mục tiêu:
- Đơn giản
- Dễ dùng
- Dễ deploy
Giao diện chỉ gồm 2 phần chính:
[ User input box ]
[ Bot response area ]
Ngoài ra có thêm sidebar để cấu hình chatbot.
Cache model để tránh load lại
Model AI chỉ được load một lần duy nhất khi user truy cập vào trang web nhờ @st.cache_resource:
@st.cache_resource
def get_chatbot():
return Chatbot(model_name="Qwen/Qwen2.5-1.5B-Instruct", use_gpu=False)
Điều này giúp ứng dụng chạy mượt hơn và tiết kiệm tài nguyên tránh việc load lại model nhiều lần.
Quản lý trạng thái chat (Session State)
Streamlit không tự lưu trạng thái giữa các lần tương tác, vì vậy lịch sử chat được lưu bằng st.session_state. Khi ứng dụng khởi động, nếu chưa có lịch sử chat, hệ thống sẽ khởi tạo sẵn một system prompt:
def initialize_session_state():
if CHAT_HISTORY_KEY not in st.session_state:
st.session_state[CHAT_HISTORY_KEY] = [
{
"role": "system",
"content": "You are a helpful AI assistant. Your answers are concise and to the point."
}
]
System prompt này đóng vai trò định hình tính cách và hành vi của chatbot.
Hiển thị lịch sử chat
Giao diện hội thoại sẽ được render mỗi lần người dùng tương tác:
def display_chat_history():
for message in st.session_state[CHAT_HISTORY_KEY]:
if message["role"] != "system":
with st.chat_message(message["role"]):
st.markdown(message["content"])
Mỗi message đều có role (user hoặc assistant), giúp Streamlit hiển thị đúng vai trò hội thoại.
Xử lý input và sinh câu trả lời
Khi người dùng nhập câu hỏi, toàn bộ luồng xử lý diễn ra trong hàm handle_user_input().
Luồng logic cụ thể:
- Nhận input từ người dùng
- Lưu input vào lịch sử chat
- Giới hạn số lượt chat được nhớ
- Gửi lịch sử chat cho AI model
- Nhận và hiển thị câu trả lời
if user_input := st.chat_input("Ask something..."):
Sau khi thêm câu hỏi vào lịch sử chat, hệ thống sẽ cắt bớt lịch sử cũ nếu vượt quá số lượt cho phép:
if len(st.session_state[CHAT_HISTORY_KEY]) > (max_history * 2) + 1:
st.session_state[CHAT_HISTORY_KEY] = [
st.session_state[CHAT_HISTORY_KEY][0]
] + st.session_state[CHAT_HISTORY_KEY][-(max_history * 2 + 1):]
Điều này giúp:
- Giảm độ dài prompt
- Tăng tốc độ phản hồi
- Tránh quá tải bộ nhớ
Vì làm việc trên các môi trường miễn phí thì tài nguyên rất hạn chết nên chúng ta chỉ nên giới hạn ghi nhớ từ 1-10 đoạn chat trước đó.
Sidebar cấu hình chatbot
Người dùng có thể điều chỉnh cấu hình cơ bản của chatbot trực tiếp trên giao diện:
- Temperature: độ sáng tạo
- Chat memory: số lượt chat được nhớ
- Max tokens: độ dài câu trả lời
- Clear chat: reset hội thoại
temperature = st.slider("Temperature", 0.0, 1.0, 0.7, 0.1)
max_history = st.selectbox("Chat memory", range(1, 11), index=2)
max_tokens = st.selectbox("Max Tokens", [256, 512, 1024], index=1)
AI Model & Logic sinh câu trả lời (llm.py)
Phần xử lý AI được tách riêng trong file llm.py thông qua class Chatbot. Việc tách biệt này giúp code rõ ràng hơn, dễ bảo trì, đồng thời cho phép thay đổi mô hình AI mà không ảnh hưởng đến phần giao diện hay luồng chat.
Load model Qwen
Model sử dụng trong project là:
Qwen/Qwen2.5-1.5B-Instruct
Model được load ở chế độ CPU để dễ chạy local và deploy lên các nền tảng miễn phí với tài nguyên hạn chế:
self.model = AutoModelForCausalLM.from_pretrained(
self.model_name,
device_map="cpu",
torch_dtype=torch.float32,
low_cpu_mem_usage=True
)
Tokenizer cũng được load tương ứng:
self.tokenizer = AutoTokenizer.from_pretrained(
self.model_name,
return_token_type_ids=False
)
Sinh câu trả lời từ lịch sử chat
Hàm generate_response() nhận vào toàn bộ lịch sử chat và sinh câu trả lời.
Bước 1: Ghép lịch sử chat thành prompt
text = self.tokenizer.apply_chat_template(
chat_history,
tokenize=False,
add_generation_prompt=True
)
Bước 2: Tokenizer
model_inputs = self.tokenizer([text], return_tensors="pt").to(self.device)
Bước 3: Generate output
generated_ids = self.model.generate(
**model_inputs,
max_new_tokens=max_tokens,
temperature=temperature,
do_sample=True,
pad_token_id=self.tokenizer.eos_token_id
)
Bước 4: Decode token thành text
response = self.tokenizer.batch_decode(
generated_ids,
skip_special_tokens=True
)[0]
Kết quả cuối cùng là một câu trả lời tự nhiên, được hiển thị trực tiếp lên giao diện.
2.3 Testing locally
Sau khi hoàn thành code, bước tiếp theo là chạy thử chatbot trên máy local trước khi deploy.
Cài đặt môi trường
Cài đặt thư viện cần thiết:
pip install -r requirements.txt
Chạy ứng dụng:
streamlit run streamlit_app.py
Mở trình duyệt tại:
http://localhost:8501
Kiểm tra các chức năng chính
Sau khi chatbot đã chạy ổn định, bước tiếp theo là kiểm tra các chức năng cốt lõi để đảm bảo hệ thống hoạt động đúng như kỳ vọng, không chỉ “trả lời được” mà còn trả lời đúng và nhất quán.
Một số điểm cần kiểm tra:
-
Chat nhiều lượt liên tiếp:
-
Thực hiện các cuộc hội thoại dài để kiểm tra khả năng ghi nhớ ngữ cảnh (memory). Chatbot cần hiểu được những gì đã nói trước đó, thay vì phản hồi như mỗi câu hỏi là một phiên mới.
-
Điều chỉnh temperature
-
Thay đổi giá trị temperature để quan sát mức độ sáng tạo của câu trả lời:
-
Giá trị thấp → trả lời ổn định, ít biến thể
-
Giá trị cao → trả lời linh hoạt, sáng tạo hơn (nhưng dễ lan man)
-
Thay đổi max_tokens
-
Dùng để kiểm soát độ dài phản hồi, tránh tình trạng chatbot trả lời quá ngắn hoặc quá dài so với mong muốn.
-
Clear chat
-
Kiểm tra chức năng xóa lịch sử hội thoại
-
Lịch sử chat được reset hoàn toàn
-
System prompt được khởi tạo lại đúng cách
-
Điều này giúp đảm bảo chatbot không “mang ký ức cũ” sang một phiên mới.
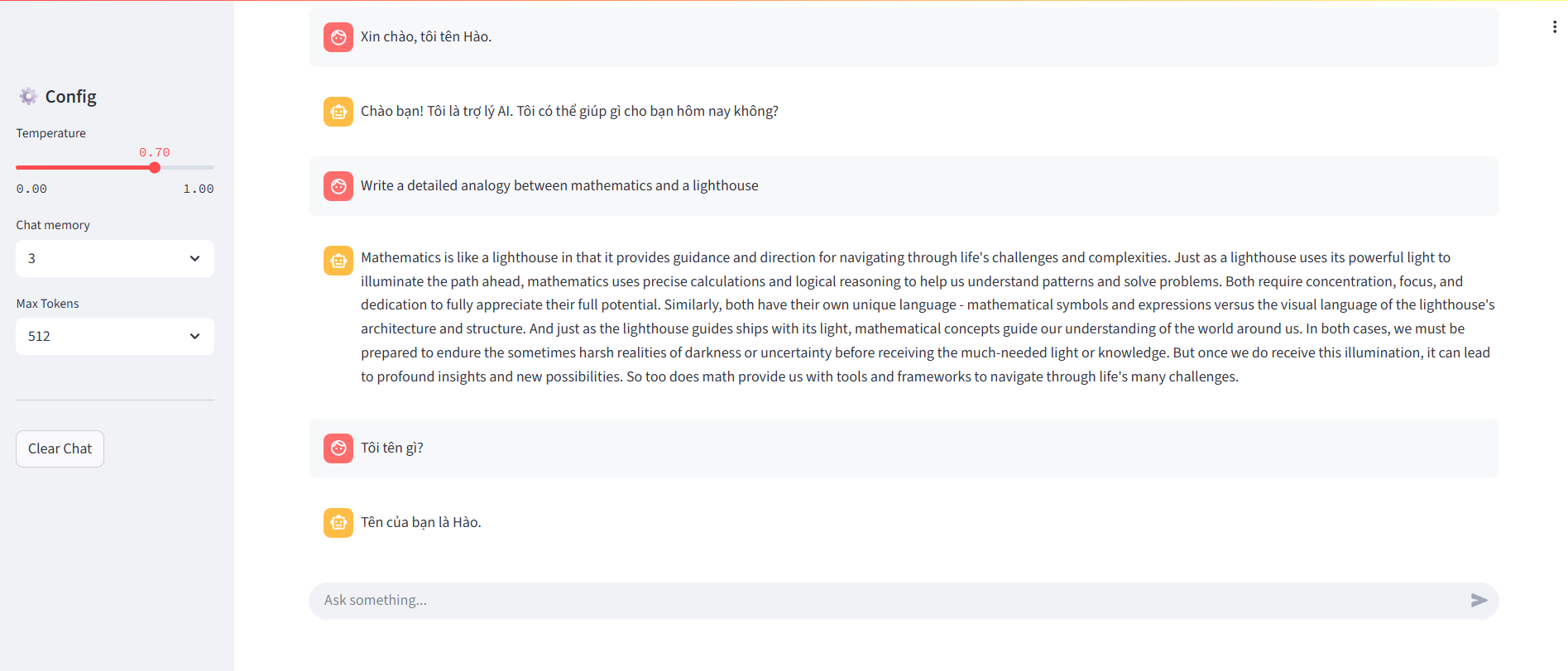
Hình 2.1. Giao diện của một AI chatbot đơn giản
Kiểm tra tốc độ phản hồi trên CPU, đánh giá thời gian phản hồi khi chạy trên CPU để xem chatbot có đáp ứng được nhu cầu sử dụng thực tế hay không, đặc biệt trong môi trường không có GPU.
Bước kiểm tra này giúp phát hiện sớm các vấn đề về logic, hiệu năng và trải nghiệm người dùng, trước khi chatbot được đưa vào demo hoặc triển khai thực tế.
Full source code tại Github**
Lưu ý khi test local
- Lần load model đầu tiên sẽ khá chậm
- Chạy CPU không phù hợp với các model có tham số lớn
- Không nên test nhiều user cùng lúc
Tuy nhiên, với mục tiêu demo và học tập, cấu hình này là hoàn toàn phù hợp trước khi đưa chatbot lên cloud.
Đề xuất và triển khai chatbot
3.1. Đề xuất các nền tảng triển khai
Khi triển khai một AI chatbot, việc chọn nền tảng deploy phù hợp ảnh hưởng trực tiếp đến độ dễ triển khai, chi phí và trải nghiệm demo. Hiện nay có nhiều lựa chọn khác nhau, mỗi nền tảng phù hợp với một mục tiêu riêng.
Bảng dưới đây so sánh một số nền tảng phổ biến để deploy chatbot, từ demo học tập cho đến ứng dụng thực tế.
| Platform | Hugging Face Spaces | Streamlit Cloud | Render | Cloudflare Workers | Vercel |
|---|---|---|---|---|---|
| Hỗ trợ UI chatbot | Có sẵn (Gradio, Streamlit) | Có sẵn (Streamlit) | Không có sẵn | Không có | Không có |
| Triển khai model AI | Rất phù hợp cho ML/LLM | Phù hợp demo nhẹ | Phải tự cấu hình | Không phù hợp model nặng | Không phù hợp model nặng |
| Thiết lập ban đầu | Tạo Space, upload code | Kết nối GitHub | Cấu hình service | Viết worker script | Cấu hình project |
| Chi phí | Miễn phí cho demo | Miễn phí giới hạn | Có free tier | Miễn phí theo request | Miễn phí giới hạn |
| Hiệu năng | Trung bình | Trung bình | Tốt | Rất tốt (API) | Rất tốt (frontend/API) |
| Mục đích phù hợp | Demo, học tập, showcase AI | Demo nhanh | App backend nhỏ | API backend | Web app + API |
Bảng 3.1 Bảng so sánh các nền tảng triển khai
Nhận xét nhanh từng nền tảng
-
Hugging Face Spaces
Là lựa chọn phù hợp nhất cho demo chatbot AI vì hỗ trợ trực tiếp các mô hình học máy và có sẵn UI chat. Phù hợp cho sinh viên, blog kỹ thuật và showcase project. -
Streamlit Cloud
Phù hợp khi chatbot được xây dựng bằng Streamlit. Dễ dùng nhưng khả năng chạy mô hình nặng và tùy chỉnh hệ thống thấp hơn Hugging Face Spaces. -
Render
Phù hợp để deploy backend chatbot dạng API. Tuy nhiên, cần tự xây dựng giao diện và cấu hình nhiều hơn, không lý tưởng cho demo nhanh. -
Cloudflare Workers
Rất mạnh cho API và hệ thống production nhẹ, nhưng không phù hợp để chạy trực tiếp mô hình AI lớn. Thường dùng khi chatbot gọi AI API bên ngoài. -
Vercel
Phù hợp cho frontend và API serverless. Tuy nhiên, việc deploy chatbot AI thường cần kết hợp với dịch vụ AI khác, không tối ưu cho demo LLM chạy trực tiếp.
Vì sao blog này chọn Hugging Face Spaces?
Với mục tiêu deploy chatbot miễn phí, dễ triển khai và có demo trực quan, Hugging Face Spaces đáp ứng tốt nhất các yêu cầu:
- Không cần thiết lập DevOps phức tạp
- Hỗ trợ sẵn UI chat bằng Gradio
- Có thể chạy trực tiếp mô hình AI
- Phù hợp để chia sẻ link demo trong blog và GitHub README
Do đó, Hugging Face Spaces được chọn làm nền tảng triển khai cho chatbot trong bài viết này.
3.2 Triển khai chatbot lên Hugging Face Spaces
Sau khi đã chạy thử nghiệm thành công ở local, bước tiếp theo là đưa AI chatbot của chúng ta lên cloud để mọi người cùng trải nghiệm..
3.2.1 Clone mã nguồn và chuẩn bị
Để bắt đầu, hãy clone repository mẫu mà nhóm đã chuẩn bị sẵn. Repository này đã được cấu hình tối ưu để chạy trên Docker của Hugging Face.
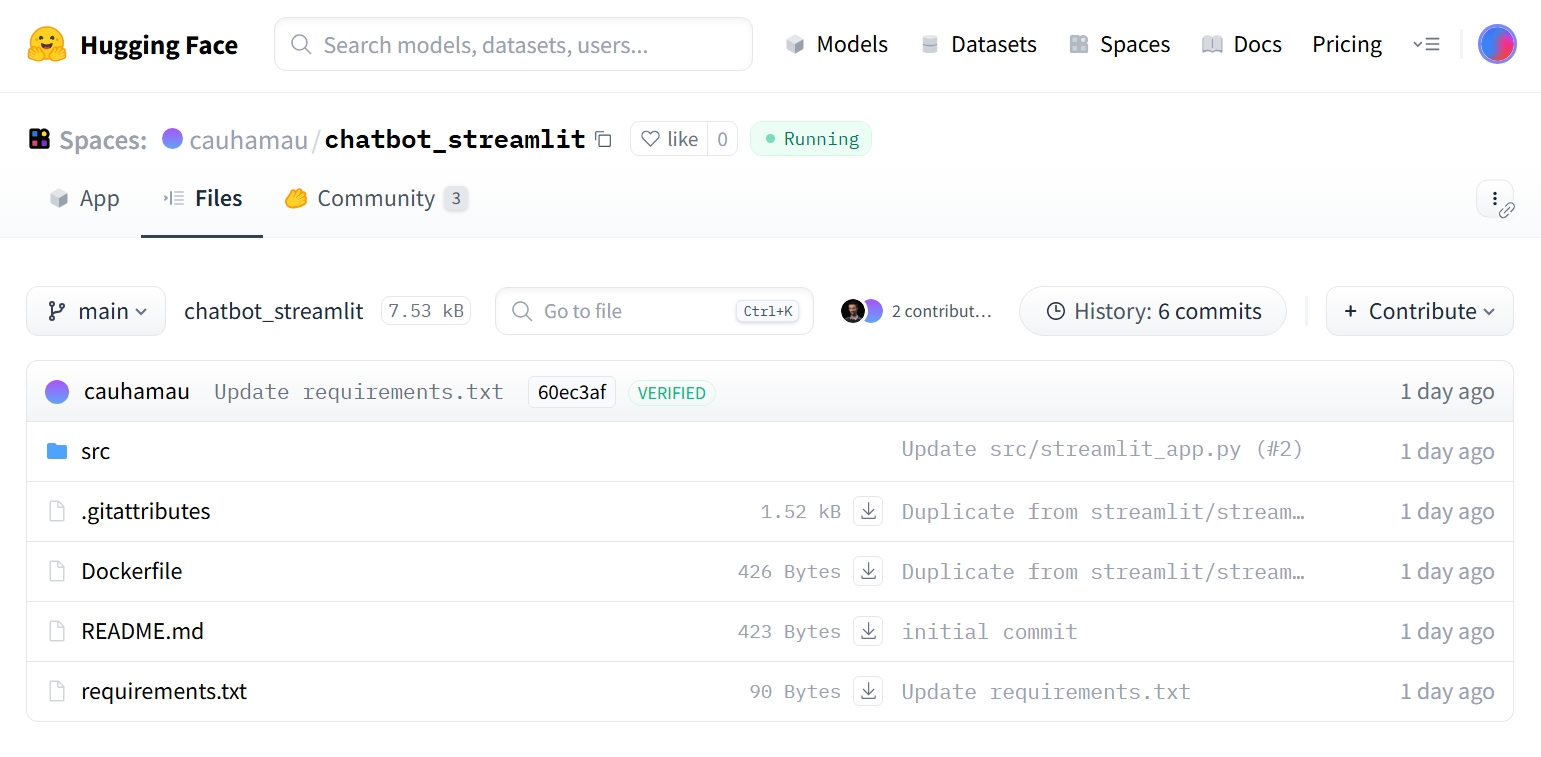
Hình 3.2.1 AI chatbot repository mẫu
Sử dụng terminal và chạy lệnh:
git clone https://huggingface.co/spaces/cauhamau/chatbot_streamlit
cd chatbot_streamlit
Cấu trúc thư mục chính:
* src/streamlit_app.py: Giao diện ứng dụng Streamlit.
* src/llm.py: Logic xử lý model LLM (tải model, generate text).
* Dockerfile: Tệp cấu hình môi trường server.
* requirements.txt: Danh sách các thư viện Python cần thiết (torch, transformers, bitsandbytes...).
3.2.2 Tùy chỉnh
Trước khi đẩy lên cloud, bạn có thể thay đổi một vài thông số để chatbot mang dấu ấn cá nhân hơn:
-
Thay đổi Model: Mặc định code đang sử dụng
Qwen/Qwen2.5-1.5B-Instruct. Nếu bạn muốn chatbot phản hồi nhanh hơn (đánh đổi độ chính xác một chút), bạn có thể đổi sang bản nhẹ hơn là0.5Btrong filesrc/llm.py:
python # Trong src/llm.py hoặc src/streamlit_app.py return Chatbot(model_name="Qwen/Qwen2.5-0.5B-Instruct", use_gpu=False) -
Chỉnh sửa giao diện: Mở file
src/streamlit_app.pyđể đổi tên tiêu đề (st.title) hoặc thêm phần giới thiệu riêng của bạn ở sidebar.
3.2.3 Các bước triển khai lên Hugging Face
Bước 1: Tạo New Space trên Hugging Face
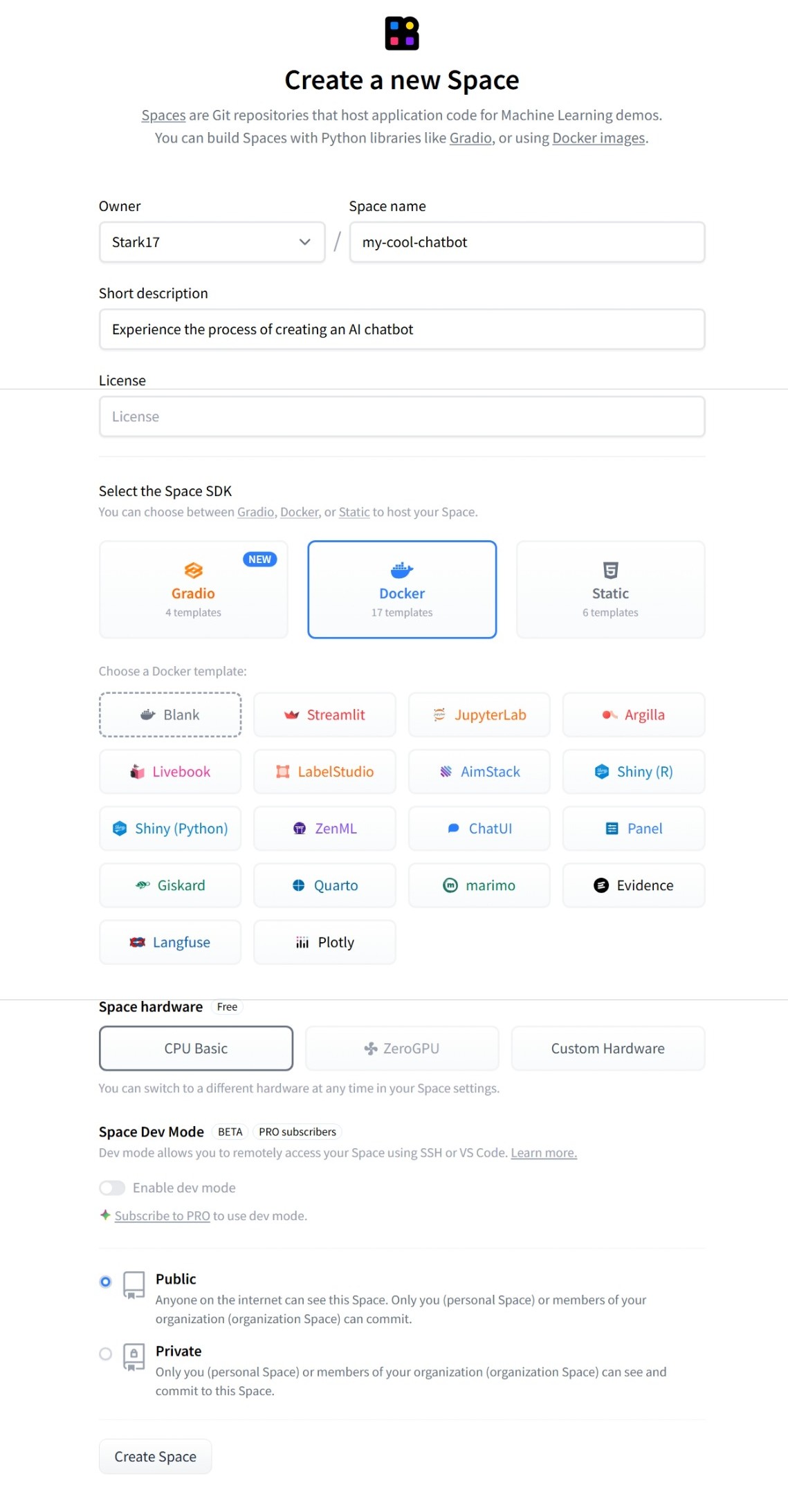
Hình 3.2.2 Tạo New Space trên Hugging Face
- Truy cập huggingface.co và đăng nhập.
- Nhấn vào nút New (góc trên bên phải) -> chọn Space.
- Đặt tên cho Space (ví dụ:
my-cool-chatbot). - Select the Space SDK: Chọn Docker. Sau đó, tại phần Docker template, hãy chọn Streamlit (vì mã nguồn của chúng ta được xây dựng dựa trên framework này). Việc dùng Docker giúp đảm bảo các thư viện nặng như PyTorch chạy ổn định nhất.
- Hardware: Chọn CPU basic (Miễn phí) hoặc nâng cấp GPU nếu bạn có kinh phí.
- Nhấn Create Space.
Bước 2: Upload mã nguồn
Hugging Face sẽ hướng dẫn bạn cách đẩy code lên. Bạn có 2 cách chính:
- Cách A: Dùng Git (Khuyên dùng): Kết nối folder hiện tại với Space mới tạo và push code.
bash git remote set-url origin https://huggingface.co/spaces/YOUR_USERNAME/YOUR_SPACE_NAME git push origin main - Cách B: Upload thủ công: Vào tab Files trên Space, chọn Add file -> Upload files và kéo thả toàn bộ thư mục
src,Dockerfile,requirements.txtvào.
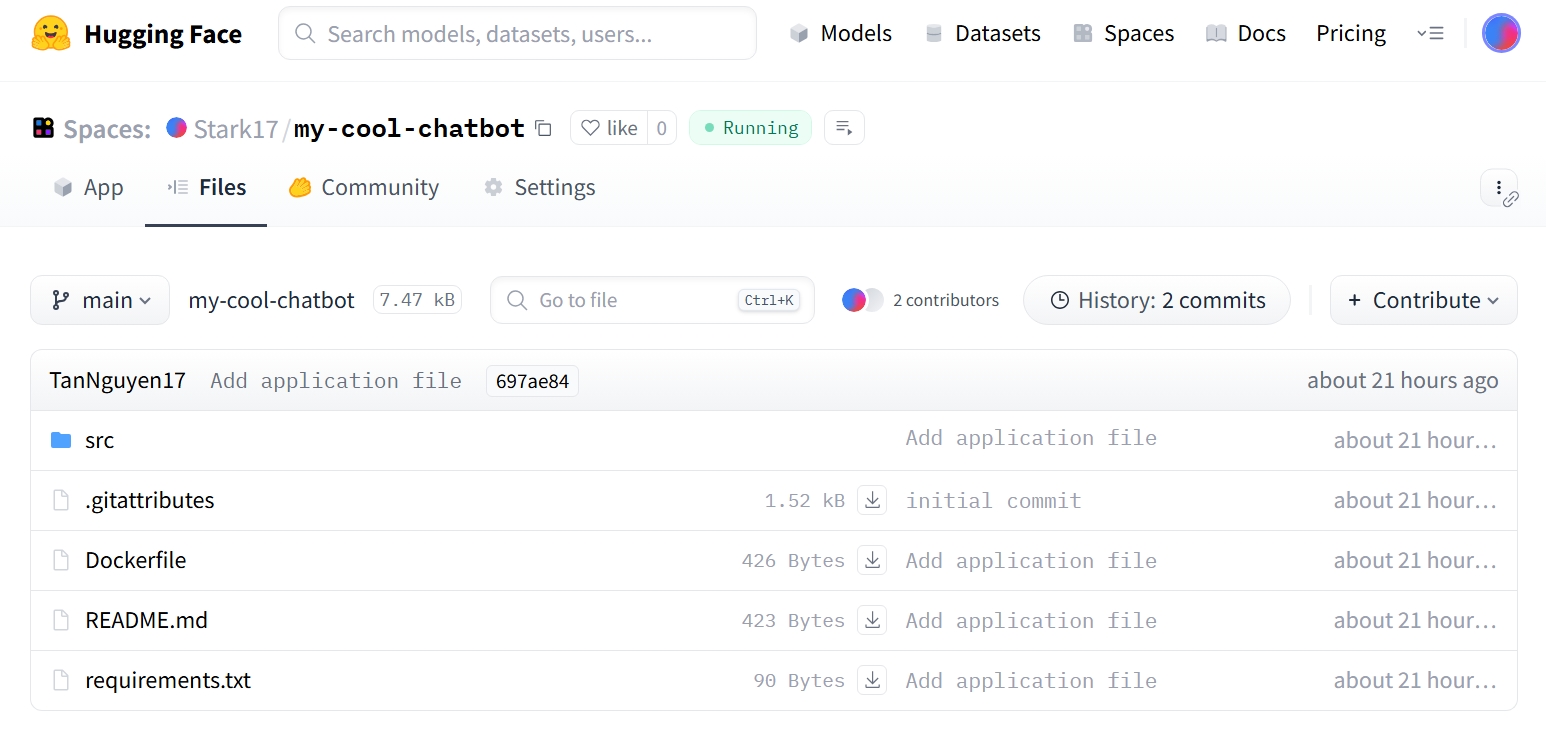
Hình 3.2.3 Code repository sau khi upload code lên Hugging Face Space
Bước 3: Chờ đợi và Trải nghiệm
Sau khi đẩy code lên, Hugging Face sẽ tự động nhận diện Dockerfile và bắt đầu quá trình Building.
Hình 3.2.4 AI chatbot đang trong quá trình deploy trên HuggingFace
- Bạn có thể theo dõi tiến trình ở tab Logs. Quá trình cài đặt thư viện và tải model có thể mất khoảng 3-5 phút ở lần đầu tiên.
- Khi trạng thái chuyển sang màu xanh Running, chatbot của bạn đã sẵn sàng!
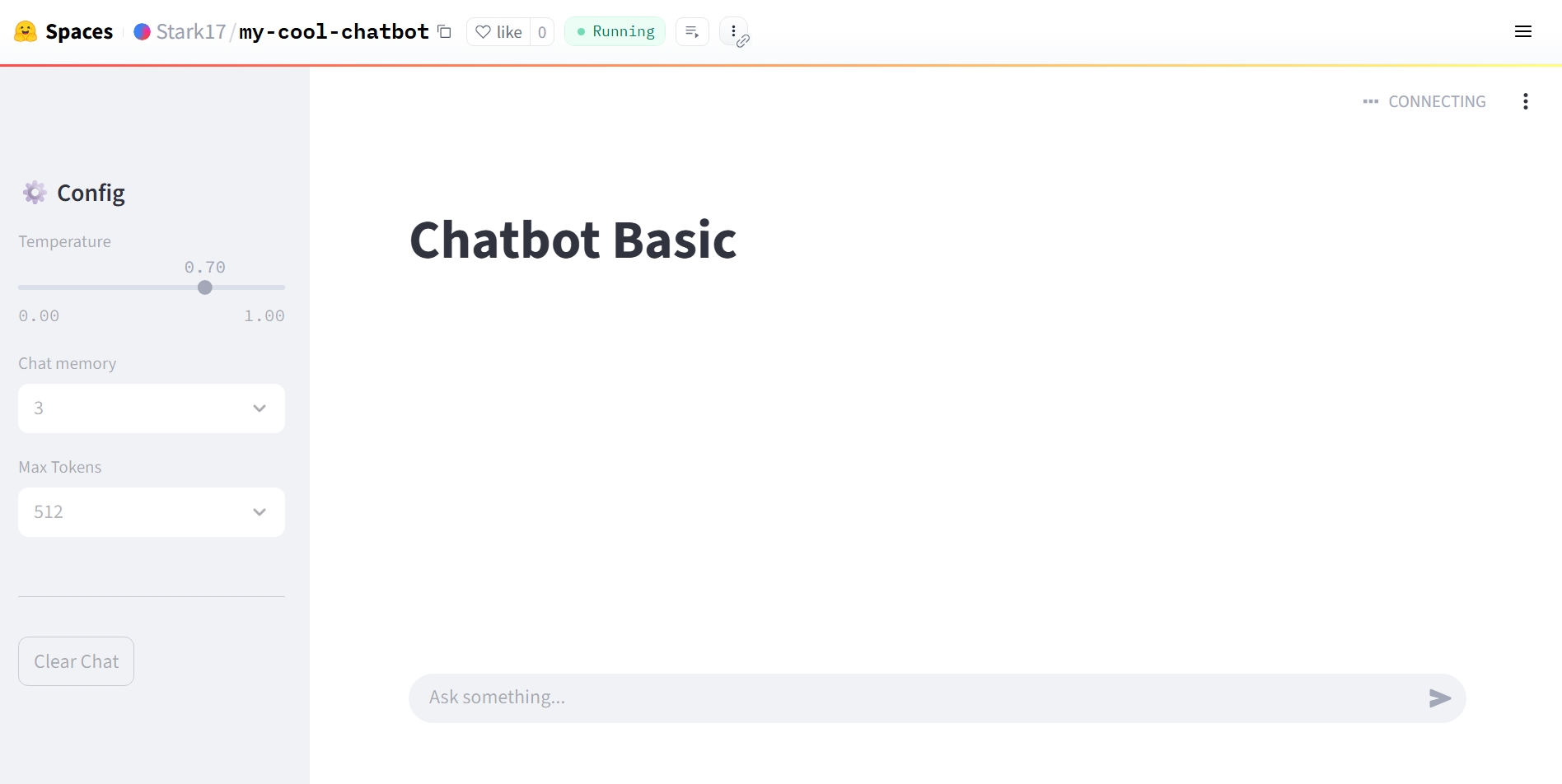
Hình 3.2.5 AI chatbot đã sẵn sàng để trải nghiệm
Mẹo nhỏ: Nếu ứng dụng bị lỗi "Out of Memory", hãy cân nhắc sử dụng model nhỏ hơn (như Qwen 0.5B) hoặc sử dụng kỹ thuật Quantization 4-bit (đã được cấu hình sẵn trong llm.py).
4. Những giới hạn của bản deploy miễn phí
Việc deploy chatbot bằng các nền tảng miễn phí như Hugging Face Spaces mang lại rất nhiều lợi ích cho học tập và demo. Tuy nhiên, để sử dụng hiệu quả và không kỳ vọng sai, cần hiểu rõ những giới hạn thực tế của mô hình deploy này.
4.1. Giới hạn về hiệu năng và tốc độ phản hồi
Một trong những điểm dễ nhận thấy nhất khi sử dụng bản deploy miễn phí là tốc độ phản hồi không ổn định. Chatbot có thể trả lời chậm hơn so với khi chạy local hoặc trên hạ tầng mạnh, đặc biệt trong các trường hợp:
- Mô hình cần thời gian tải lại sau khi không có người dùng (cold start)
- Nhiều người truy cập cùng lúc
- Câu hỏi yêu cầu sinh câu trả lời dài
Điều này xuất phát từ việc nền tảng miễn phí chỉ cung cấp tài nguyên CPU và bộ nhớ ở mức giới hạn. Tuy nhiên, với mục tiêu demo và học tập, độ trễ này vẫn ở mức chấp nhận được.
4.2. Giới hạn tài nguyên tính toán
Các nền tảng miễn phí thường giới hạn:
- Dung lượng RAM
- Thời gian chạy liên tục
- Khả năng sử dụng GPU
Do đó, chatbot deploy miễn phí không phù hợp để chạy các mô hình quá lớn hoặc xử lý tác vụ phức tạp trong thời gian dài. Trong thực tế, demo nên ưu tiên:
- Mô hình nhẹ hoặc đã được tối ưu
- Giới hạn số token sinh ra
- Tránh xử lý song song nhiều yêu cầu
Đây cũng là lý do tại sao việc xác định phạm vi chatbot ngay từ đầu là rất quan trọng, như đã đề cập ở các phần trước.
4.3. Giới hạn về khả năng mở rộng
Bản deploy miễn phí không được thiết kế cho môi trường production. Khi số lượng người dùng tăng lên, chatbot có thể gặp các vấn đề như:
- Phản hồi chậm dần
- Lỗi timeout
- Tạm thời không truy cập được
Vì vậy, chatbot deploy miễn phí không phù hợp cho các hệ thống cần độ ổn định cao hoặc phục vụ số lượng lớn người dùng, mà chủ yếu dùng cho mục đích trình diễn và thử nghiệm ý tưởng.
4.4. Giới hạn về bảo mật và kiểm soát hệ thống
Trong môi trường miễn phí, khả năng kiểm soát sâu về bảo mật, logging hay monitoring thường bị hạn chế. Nhà phát triển không thể:
- Tùy chỉnh sâu hệ thống mạng
- Thiết lập cơ chế bảo mật phức tạp
- Theo dõi chi tiết hành vi người dùng
Do đó, chatbot demo nên tránh xử lý dữ liệu nhạy cảm và chỉ sử dụng cho các tình huống không yêu cầu bảo mật cao.
4.5. Vì sao các giới hạn này vẫn chấp nhận được?
Mặc dù tồn tại nhiều giới hạn, deploy chatbot miễn phí vẫn là lựa chọn rất hợp lý trong bối cảnh:
- Demo cho giảng viên hoặc người xem
- Học tập và nghiên cứu AI chatbot
- Trình bày ý tưởng và kiến trúc hệ thống
Quan trọng hơn, việc làm việc trong môi trường có giới hạn giúp người phát triển hiểu rõ hơn các ràng buộc thực tế, từ đó có tư duy tốt hơn khi triển khai chatbot ở quy mô lớn trong tương lai.
Tóm lại, bản deploy miễn phí không nhằm thay thế hạ tầng production, mà đóng vai trò như một bước trung gian: giúp chatbot đi từ demo local sang một ứng dụng có thể sử dụng và chia sẻ ngay trên web.
5. Kết luận
Deploy là bước giúp chatbot chuyển từ một chương trình chạy local thành một sản phẩm có thể sử dụng ngay trên trình duyệt. Thông qua việc deploy chatbot bằng Gradio và Hugging Face Spaces, chúng ta có thể tạo ra một bản demo hoàn chỉnh mà không cần đầu tư hạ tầng phức tạp hay chi phí cao.
Quan trọng hơn, quá trình deploy giúp người phát triển hiểu rõ hơn về vòng đời của một ứng dụng AI thực tế: từ thiết kế phạm vi, triển khai code, cho đến đưa sản phẩm lên môi trường cloud. Khi tư duy triển khai đã rõ ràng, việc mở rộng chatbot trong tương lai chẳng hạn như cải thiện giao diện, tối ưu hiệu năng hoặc tích hợp dữ liệu riêng sẽ trở nên dễ dàng hơn rất nhiều.
Không cần hệ thống phức tạp hay ngân sách lớn, bất kỳ ai cũng có thể deploy một AI chatbot online nếu đi đúng hướng và chọn đúng công cụ.
Trích dẫn
KDNuggets. (2025). 7 Best FREE Platforms to Host Machine Learning Models. Retrieved from https://www.kdnuggets.com/7-best-free-platforms-to-host-machine-learning-models
Thakur, P. (2024, December 30). Deploy Gradio Apps on Hugging Face Spaces. PyImageSearch. Retrieved from https://pyimagesearch.com/2024/12/30/deploy-gradio-apps-on-hugging-face-spaces/
ShafiqulAI Blogs. (2025). Deploy Gradio App to Hugging Face Spaces – Full Step by Step Guide. Retrieved from https://shafiqulai.github.io/blogs/blog_5.html
DeepWiki. (2025). Deployment and Hosting (Gradio Guides). In justinms/gradio-guides. Retrieved from https://deepwiki.com/justinms/gradio-guides/6-deployment-and-hosting
Chưa có bình luận nào. Hãy là người đầu tiên!