XAI, LIME VÀ ANCHOR: Giải thích Mô hình Học máy
I. Tổng quan về XAI và Lý do cần Khả năng Diễn giải (Interpretability)
1. Khái niệm Cơ bản
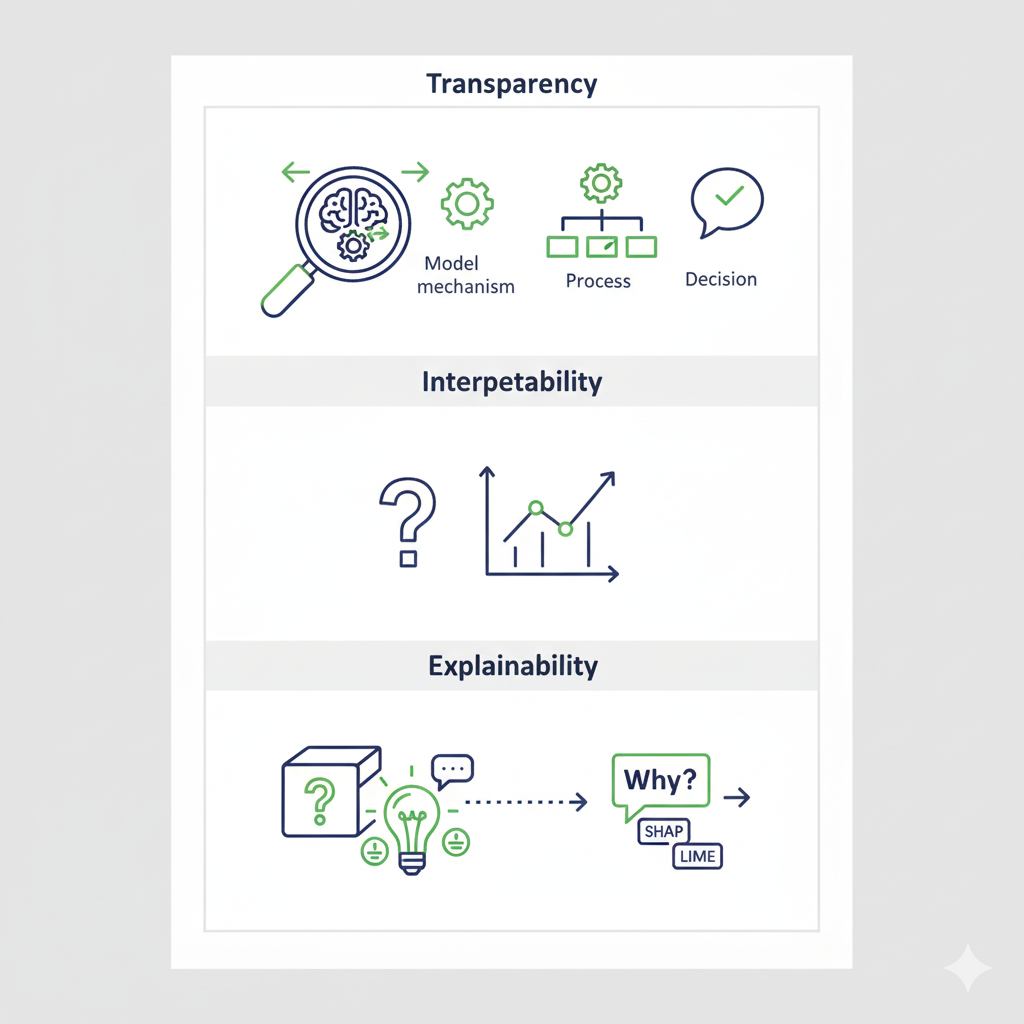
Hình 1: Minh họa các khái niệm cơ bản [1]
| Thuật ngữ | Định nghĩa | Phân loại |
|---|---|---|
| Transparency (Tính Minh bạch) | Mức độ rõ ràng trong hoạt động bên trong của mô hình, cách dữ liệu được xử lý và quyết định được đưa ra. | Model (cơ chế nội bộ), Process (xử lý dữ liệu), Decision (lý do quyết định). |
| Interpretability (Khả năng Diễn giải) | Khả năng hiểu trực tiếp cách mô hình hoạt động thông qua cấu trúc đơn giản (ví dụ: Hồi quy tuyến tính). | Trả lời câu hỏi: "Tôi có thể hiểu được tại sao mô hình làm điều đó không?" |
| Explainability (Khả năng Giải thích) | Tập trung vào việc giải thích lý do và bằng chứng cho quyết định của các mô hình phức tạp (hộp đen). |
2. Vấn đề "Hộp đen" và Nhu cầu XAI
Các mô hình AI phức tạp (đặc biệt là Deep Learning) thường là Hộp đen (Black Box), khiến người dùng không thể hiểu được cơ sở của quyết định.
Lý do cần XAI:
- Niềm tin & Trách nhiệm (Trust & Accountability): Cực kỳ quan trọng trong các lĩnh vực rủi ro cao (y tế, tài chính, pháp luật).
- Gỡ lỗi & Cải tiến (Debugging & Improvement): Giúp cải thiện hiệu suất và độ công bằng của mô hình.
- Tuân thủ Pháp lý (Regulatory Compliance): Đáp ứng các yêu cầu về công bằng và giải trình.
3. Phân loại Khả năng Diễn giải (Taxonomy)
Các phương pháp XAI được phân loại dựa trên:
| Tiêu chí | Loại | Mô tả | Ví dụ |
|---|---|---|---|
| Thời điểm | Intrinsic (Ante-hoc) | Mô hình vốn đã dễ hiểu. | Cây quyết định, Hồi quy tuyến tính. |
| Post-hoc | Áp dụng sau khi mô hình đã được huấn luyện. | LIME, ANCHOR, SHAP. | |
| Phạm vi | Local (Cục bộ) | Giải thích cho một dự đoán cụ thể. | LIME, ANCHOR. |
| Global (Toàn cục) | Giải thích tổng thể hành vi của mô hình. | - |
Có sự đánh đổi: Mô hình đơn giản có Interpretability cao nhưng Performance (hiệu suất) có thể thấp.
4. Bối cảnh của LIME và ANCHOR
Cả LIME và ANCHOR đều là các thuật toán:
- Post-hoc: Áp dụng sau huấn luyện.
- Model-agnostic: Hoạt động độc lập với cấu trúc mô hình gốc.
- Local explanations: Giải thích cho một mẫu dữ liệu cụ thể.
II. LIME (Local Interpretable Model-Agnostic Explanations)
LIME hoạt động dựa trên ý tưởng xấp xỉ hành vi cục bộ của mô hình phức tạp bằng một mô hình đơn giản, dễ hiểu (Surrogate Model), như Hồi quy tuyến tính.
1. Cơ chế hoạt động (6 Bước)
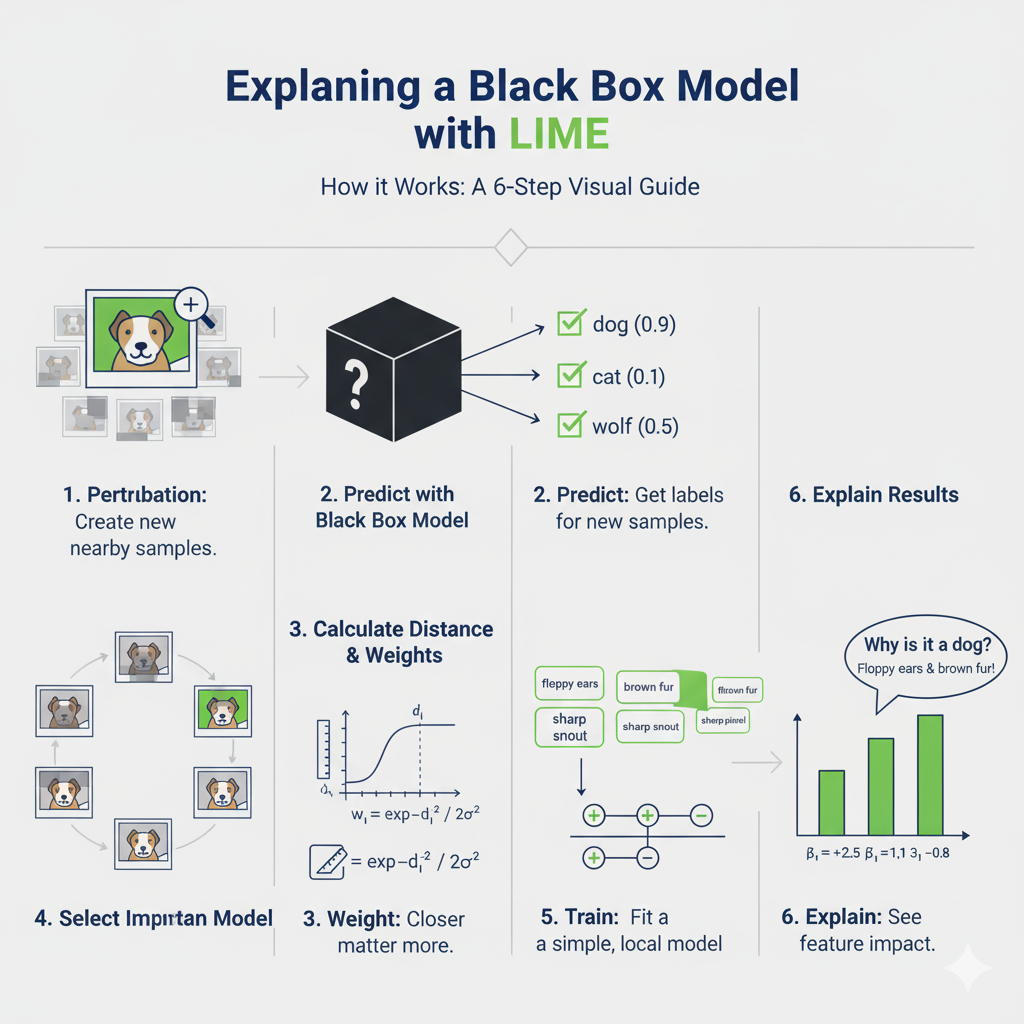
Hình 2: Quy trình giải thích mô hình phức tạp của LIME với 6 bước [1]
- Tạo mẫu dữ liệu lân cận (Perturbation): Sinh ra các mẫu giả xung quanh điểm gốc bằng cách thêm nhiễu hoặc thay đổi đặc trưng (ví dụ: bật/tắt superpixels trong ảnh).
- Dự đoán bằng mô hình gốc: Dùng mô hình "hộp đen" để dự đoán nhãn cho các mẫu giả này.
- Tính khoảng cách và trọng số: Đo khoảng cách (d_i) từ mẫu giả đến mẫu gốc. Trọng số (w_i) được tính bằng hàm kernel mũ (càng gần, trọng số càng cao):
$$w_i = \exp(-d_i^2 / 2\sigma^2)$$
- Chọn đặc trưng quan trọng: Chọn ra tập hợp nhỏ các đặc trưng có ảnh hưởng mạnh nhất.
- Huấn luyện mô hình đơn giản: Dùng các mẫu giả, nhãn dự đoán và trọng số để huấn luyện một mô hình tuyến tính cục bộ.
- Giải thích kết quả: Các hệ số (\beta) của mô hình tuyến tính cho biết tầm quan trọng và ảnh hưởng cục bộ của từng đặc trưng.
2. Minh họa Dữ liệu Ảnh
Cơ chế hoạt động trên Dữ liệu Ảnh
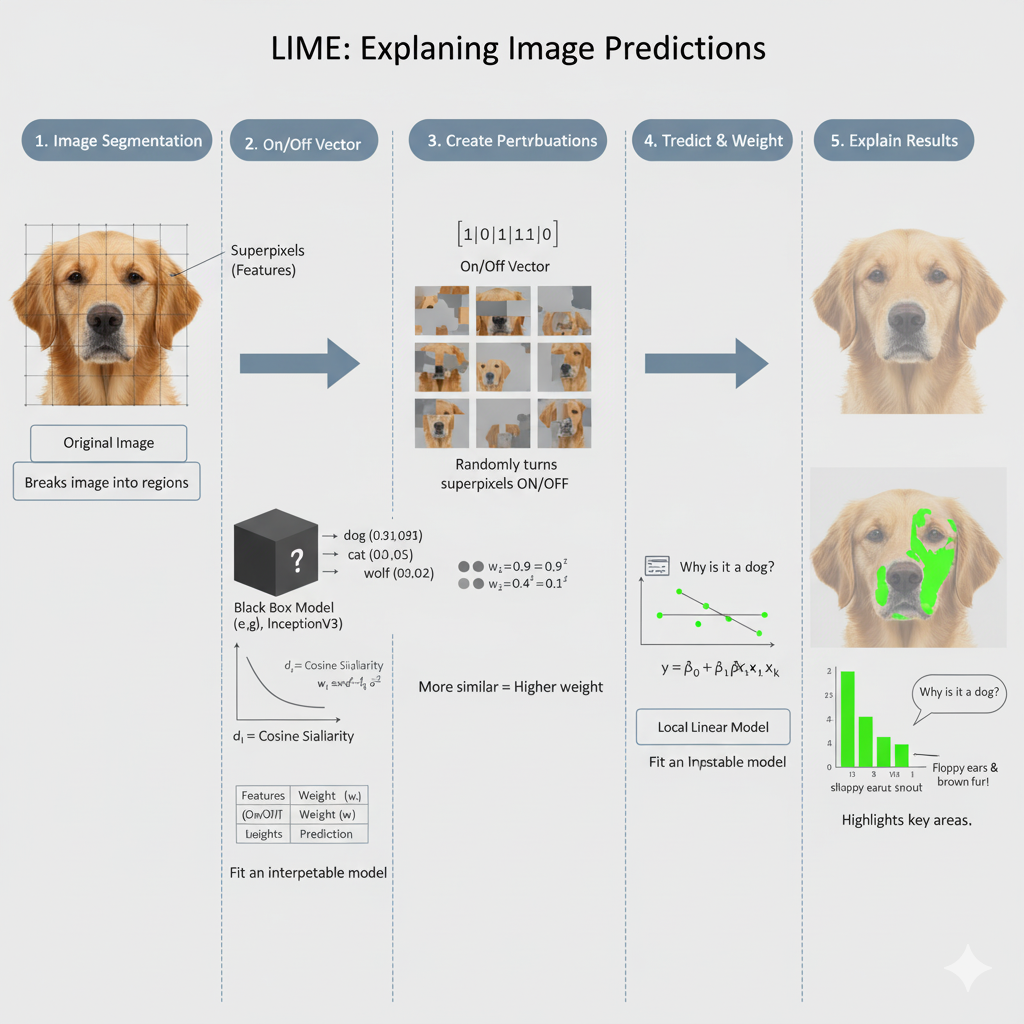
Hình 3: Cơ chế hoạt động của LIME trên ảnh [1]
Quy trình diễn giải một dự đoán ảnh (ví dụ: mô hình Inception V3 hoặc ResNet50) diễn ra qua các bước cụ thể sau:
a) Phân đoạn Ảnh (Segmentation)
Thay vì xử lý từng pixel riêng lẻ, LIME sử dụng các thuật toán phân đoạn (ví dụ: SLIC hoặc Quickshift) để chia ảnh gốc thành các vùng có màu sắc hoặc kết cấu đồng nhất, được gọi là superpixels.
Mỗi superpixel được coi là một đặc trưng đơn lẻ (tương tự như một từ trong văn bản hoặc một cột trong dữ liệu bảng).

Hình 4: Mô tả quá trình lấy các siêu điểm ảnh (superpixels) của hình ảnh [2]
b) Tạo mẫu Lân cận (Perturbation)

Hình 5: Mô tả quá trình lấy mẫu các điểm xung quanh X [2]
Đây là bước sinh mẫu dữ liệu giả xung quanh ảnh gốc. LIME thực hiện việc này bằng cách bật/tắt (hiển thị/ẩn) ngẫu nhiên một số superpixels.
- "Bật" có nghĩa là giữ nguyên vùng superpixel đó.
- "Tắt" có nghĩa là thay thế vùng đó bằng một màu đồng nhất (thường là màu xám hoặc đen).
Mỗi mẫu ảnh mới này sẽ có một tập hợp superpixels khác nhau được bật hoặc tắt.
c) Dự đoán Mô hình Gốc và Tính Trọng số
- Các mẫu ảnh giả này được đưa vào mô hình "Hộp đen" phức tạp ban đầu để nhận dự đoán (xác suất nhãn).
- Khoảng cách giữa mỗi ảnh giả và ảnh gốc được tính (ví dụ: bằng Cosine Similarity), và sau đó được chuyển thành trọng số thông qua hàm kernel mũ.
- Ảnh giả nào càng giống ảnh gốc (khoảng cách nhỏ), trọng số càng cao.

Hình 6: Minh họa việc sử dụng mô hình phức tạp để dự đoán nhãn cho từng mẫu [2]
d) Huấn luyện Mô hình Đơn giản (Surrogate Model)
LIME sử dụng các mẫu ảnh giả (với vector đặc trưng là trạng thái bật/tắt của các superpixels), nhãn dự đoán và trọng số tương ứng để huấn luyện một mô hình tuyến tính cục bộ (ví dụ: Hồi quy tuyến tính).
e) Giải thích Kết quả
Sau khi huấn luyện, hệ số $\beta$ của mô hình tuyến tính cho mỗi superpixel được phân tích.
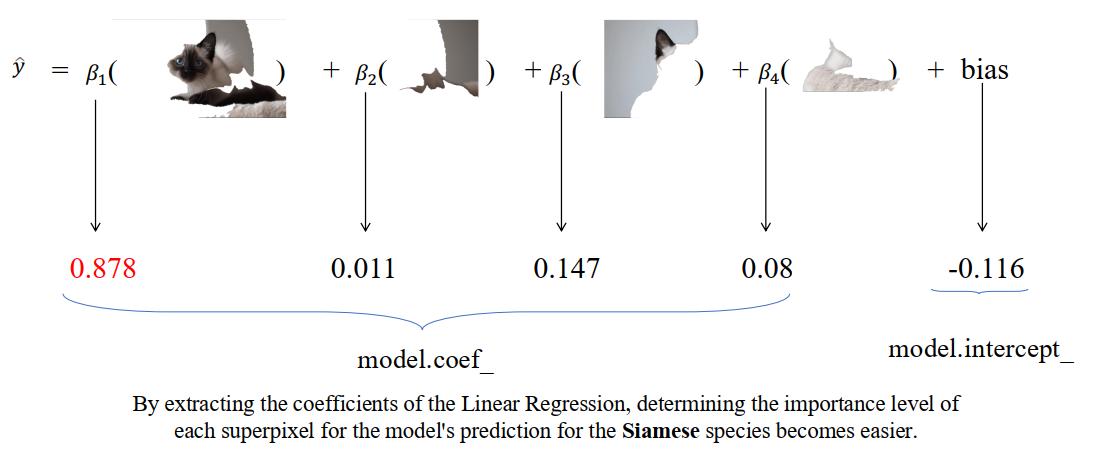
Hình 7: Sử dụng mô hình đơn giản để giải thích [2]
- Superpixel có hệ số $\beta$ lớn nhất và cùng dấu với dự đoán là vùng ảnh có tác động cao nhất và đóng góp chính cho quyết định của mô hình.
Kết quả cuối cùng là một bản đồ (mask) cho thấy rõ ràng phần nào của bức ảnh đã khiến mô hình đưa ra dự đoán cụ thể đó.
3. Ưu nhược điểm của LIME
Bảng dưới đây tóm tắt các ưu điểm (Advantage) và nhược điểm (Disadvantage) của thuật toán LIME, dựa trên nội dung đã phân tích:
| Ưu điểm (Advantage) | Nhược điểm (Disadvantage) |
|---|---|
| Popular (Phổ biến) | Concerns about instability (Lo ngại về tính không ổn định) |
| Easy to understand (Dễ hiểu) | Computationally expensive (Tốn kém về mặt tính toán) |
| Easy to implement (Dễ triển khai) | Unstable explanations (Giải thích không ổn định) |
| Counterfactual examples can be unrealistic (Các ví dụ phản thực tế có thể không thực tế) | |
| Requires a large number of samples around the instance being explained (Yêu cầu số lượng mẫu lớn xung quanh mẫu cần giải thích) |
III. ANCHOR (High-Precision Model-Agnostic Explanations)
ANCHOR được phát triển để tìm kiếm các luật logic (IF-THEN) có độ chính xác cao hơn để giải thích quyết định của mô hình.
1. Khái niệm cơ bản
- Anchor (A): Tập hợp các điều kiện trên đặc trưng của mẫu (ví dụ: "Nếu câu có từ 'not bad' thì...").
- Precision (Độ chính xác): Xác suất các mẫu thỏa mãn anchor có cùng dự đoán với mẫu gốc (đạt ngưỡng $\tau$ tối thiểu).
- Coverage (Độ bao phủ): Tỷ lệ mẫu trong không gian dữ liệu thỏa mãn anchor.
- Bài toán tối ưu: Tối đa hóa Coverage sao cho Precision đạt ngưỡng (\tau).
$$\max \text{cov}(A) \quad \text{s.t.} \quad P(\text{prec}(A) \geq \tau) \geq 1 - \delta$$
2. Quy trình của ANCHOR
a. Sinh luật Ứng viên (Generate Candidate Rules)
Quá trình này sử dụng chiến lược Greedy Beam Search (Tìm kiếm chùm Tham lam) và xây dựng Anchor theo phương pháp bottom-up (từ đơn giản đến phức tạp).

Hình 8: Tạo siêu điểm ảnh cho hình ảnh đầu vào [2]
- Bắt đầu: Anchor ban đầu là tập rỗng ($A = \emptyset$), áp dụng cho mọi trường hợp.
- Mở rộng: Trong mỗi vòng lặp, thuật toán mở rộng Anchor hiện tại bằng cách thêm một điều kiện/đặc trưng (predicate $a_i$) mới vào luật.
- Ví dụ: $A^{\prime} = A \cup \{a_i\}$
- Beam Search: Thay vì kiểm tra tất cả các luật mở rộng, thuật toán chỉ giữ lại $B$ luật tốt nhất (Beam Width $B$) sau mỗi vòng.
Chiến lược này ưu tiên các luật ngắn và có tiềm năng đạt độ chính xác cao.
b. Tạo mẫu Lân cận và Ước lượng Precision
Thay vì huấn luyện mô hình tuyến tính như LIME, ANCHOR tập trung vào việc ước tính độ chính xác của luật ứng viên bằng cách tạo mẫu dữ liệu biến đổi (perturbation).

Hình 9: Lấy mẫu xung quanh 𝑋 liên quan đến mỏ neo A [2]
- Tạo mẫu Lân cận (Perturbation):
- Đối với mẫu $x$ cần giải thích, ANCHOR sinh ra các mẫu $z$ mới từ phân phối $D$ với điều kiện chúng phải thỏa mãn luật Anchor đang xét.
-
Việc này được thực hiện bằng cách cố định các đặc trưng nằm trong Anchor và thay đổi/thêm nhiễu vào các đặc trưng không nằm trong Anchor.
-
Dự đoán và Ước lượng Độ chính xác ($\hat{p}$):
- Mô hình gốc (Black-box $f$) được gọi để dự đoán nhãn $f(z)$ cho từng mẫu $z$.
- Độ chính xác ước lượng ($\hat{p}$) được tính bằng tỷ lệ số mẫu $z$ có dự đoán khớp với dự đoán gốc $f(x)$:
$$ \hat{p} = \frac{\text{Số mẫu } z \text{ có } f(z) = f(x)}{\text{Tổng số mẫu } n \text{ được lấy}} $$
c. Kiểm tra Độ tin cậy bằng KL-LUCB
Đây là bước quan trọng giúp ANCHOR vượt trội so với LIME về mặt đảm bảo thống kê.
Thay vì chỉ dựa vào $\hat{p}$ đơn thuần, ANCHOR sử dụng thuật toán KL-LUCB (Kullback-Leibler Lower Confidence Bound) để tìm ra giới hạn tin cậy dưới cho độ chính xác thật của Anchor.
- Mục tiêu:
Đảm bảo rằng Độ chính xác thật ($p$) của Anchor $\ge$ Ngưỡng $\tau$ (ví dụ: $95\%$), với Xác suất cao ($\ge 1 - \delta$):
$$ P(\text{prec}(A) \ge \tau) \ge 1 - \delta $$
- Tính Biên dưới ($p_L$): KL-LUCB giúp tính $p_L$ (Lower Bound).
$$ \text{KL}(\hat{p} \| p_L) = \frac{\log(2/\delta)}{n} $$
Trong đó, $\text{KL}(\hat{p} \| p_L)$ là độ phân kỳ Kullback-Leibler giữa ước lượng $\hat{p}$ và biên dưới $p_L$.
Độ phân kỳ Kullback-Leibler được định nghĩa là:
$$ \text{KL}(\hat{p} \| q) = \hat{p} \log\left(\frac{\hat{p}}{q}\right) + (1-\hat{p}) \log\left(\frac{1-\hat{p}}{1-q}\right) $$
Trong bối cảnh này, $q = p_L$ là giá trị biên dưới cần tìm.
Nếu $p_L \ge \tau$, Anchor được chấp nhận là đáng tin cậy.
- Quyết định Dừng/Tiếp tục:
- Nếu $p_L \ge \tau$, luật ứng viên được chấp nhận và quá trình tìm kiếm kết thúc.
Anchor có Coverage cao nhất trong số các luật được chấp nhận sẽ được chọn làm lời giải thích cuối cùng. - Nếu $p_L < \tau$, thuật toán tiếp tục lấy thêm mẫu ($n$ tăng) và tính lại $p_L$ để cố gắng làm cho biên dưới chặt hơn (hoặc loại bỏ luật nếu không thể đạt $\tau$).
d. Tính toán Độ bao phủ (Coverage)
Sau khi tìm được Anchor đáp ứng yêu cầu về Độ chính xác ($\tau$),
Độ bao phủ $\text{cov}(A)$ được đo lường để đánh giá phạm vi áp dụng của luật đó.
- Công thức:
Độ bao phủ được tính là tỷ lệ mẫu trong tập dữ liệu (hoặc tập kiểm tra) thỏa mãn điều kiện của Anchor $A$:
$$ \text{cov}(A) = \frac{\text{Số lượng mẫu thỏa mãn Anchor } A}{\text{Tổng số mẫu trong tập dữ liệu}} $$
- Kết quả:
Anchor cuối cùng được chọn là Anchor đơn giản nhất (ít điều kiện nhất) và có Độ bao phủ cao nhất trong số các Anchor đã vượt qua kiểm tra KL-LUCB.
3. Hạn chế của ANCHOR
- Khó cài đặt: Cần thiết kế hàm perturbation riêng biệt cho từng loại dữ liệu.
- Đánh đổi Coverage – Precision: Anchor càng cụ thể (Precision cao) thì Coverage càng thấp.
- Tốn thời gian: Yêu cầu nhiều lần gọi mô hình để kiểm tra luật.
- Định nghĩa Coverage không phổ quát: Khó áp dụng đồng nhất cho các loại dữ liệu khác nhau (như ảnh).
IV. Thực hành áp dụng LIME và ANCHOR
1. Thực hành LIME trên Dữ liệu Ảnh
Chúng ta sử dụng mô hình VGG16 đã huấn luyện trên ImageNet và áp dụng LIME để giải thích dự đoán trên một bức ảnh cụ thể.
A. Chuẩn bị và Tải Mô hình
- Cài thư viện
import numpy as np
from PIL import Image
import tensorflow as tf
from tensorflow.keras.applications import vgg16
from tensorflow.keras.preprocessing import image
from lime import lime_image
from skimage.segmentation import mark_boundaries
import os
- Tải mô hình và tiền xử lý
# 1. Tải mô hình hộp đen (VGG16)
model = vgg16.VGG16(weights='imagenet')
# 2. Hàm tải và tiền xử lý ảnh
def load_and_preprocess_image(img_path):
img = image.load_img(img_path, target_size=(224, 224))
img_array = image.img_to_array(img)
img_array_norm = img_array / 255.0 # chuẩn hóa 0-1 cho LIME
processed_image = np.expand_dims(img_array, axis=0)
processed_image = vgg16.preprocess_input(processed_image)
return img_array_norm, processed_image
# 3. Hàm dự đoán (Hộp đen)
def predictor(images_normalized):
temp = images_normalized * 255.0
return model.predict(vgg16.preprocess_input(temp))
img_path = r"C:\Users\ADMIN\Downloads\hinh-anh-meo-hai-huoc-yodyvn51.jpg"
if not os.path.exists(img_path):
print(f"LỖI: Không tìm thấy tệp tại đường dẫn: {img_path}")
exit()
image_to_explain, processed_image = load_and_preprocess_image(img_path)
B. Áp dụng LIME và Trực quan hóa
# 4. Khởi tạo Explainer LIME
explainer = lime_image.LimeImageExplainer()
# 5. Tạo Giải thích Cục bộ (1000 mẫu lân cận)
print("Đang tạo giải thích LIME...")
explanation = explainer.explain_instance(
image_to_explain,
predictor,
top_labels=5,
hide_color=0,
num_samples=1000
)
# 6. Trực quan hóa và lưu kết quả
top_label_index = explanation.top_labels[0]
predicted_label_name = tf.keras.applications.vgg16.decode_predictions(
model.predict(processed_image), top=1)[0][0][1]
# Lấy mask với 5 superpixels quan trọng nhất
temp, mask = explanation.get_image_and_mask(
top_label_index,
positive_only=True,
num_features=5,
hide_rest=False
)
img_boundary = mark_boundaries(temp, mask)
output_image = Image.fromarray((img_boundary * 255).astype(np.uint8))
output_filename = 'lime_explanation_meo.png'
output_image.save(output_filename)
print(f" Mô hình dự đoán: **{predicted_label_name}**")
print(f" Bản đồ LIME đã được lưu vào **'{output_filename}'**")

Hình 10: Kết quả bản đồ giải thích LIME
Bản đồ LIME này là một lời giải thích rõ ràng và hợp lý về hành vi cục bộ của mô hình: Vùng tập trung: LIME làm nổi bật (viền vàng) Mắt, Mũi và các đặc điểm khuôn mặt chính của con mèo.
Tính hợp lý & tin cậy:
- Mô hình đang tập trung vào các đặc trưng quan trọng (vùng nhận dạng con mèo cơ bản).
- Nó cho thấy mô hình không bị ảnh hưởng bởi các yếu tố gây nhiễu trong nền (như biểu tượng trái tim hay khăn quàng), chứng tỏ mô hình không học các mối tương quan sai (spurious correlation).
Kết luận: LIME thành công trong việc cung cấp một lời giải thích trực quan: "Mô hình dự đoán đây là mèo vì nó nhìn thấy các đặc điểm khuôn mặt chính của loài mèo."
2. Thực hành ANCHOR trên Dữ liệu Bảng
Sử dụng Random Forest để phân loại dữ liệu Iris và áp dụng ANCHOR để tìm luật logic giải thích cho một dự đoán cụ thể.
A. Chuẩn bị Dữ liệu và Mô hình
- Cài đặt thư viện
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
from anchor import anchor_tabular
- Tải mô hình và tiền xử lý
# 1. Tải và chia dữ liệu Iris
data = load_iris()
X, y = data.data, data.target
feature_names = data.feature_names
class_names = data.target_names
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 2. Huấn luyện Random Forest
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# 3. Hàm dự đoán
def predict_fn(x):
return model.predict(x)
# 4. Khởi tạo Explainer ANCHOR
explainer = anchor_tabular.AnchorTabularExplainer(
class_names=class_names,
feature_names=feature_names,
train_data=X_train,
categorical_names={}
)
B. Áp dụng ANCHOR và In luật
# 5. Chọn một Mẫu cụ thể để Giải thích
idx_to_explain = 10
instance = X_test[idx_to_explain]
predicted_label_index = model.predict(instance.reshape(1, -1))[0]
predicted_label = class_names[predicted_label_index]
print(f"--- Giải thích cho Mẫu #{idx_to_explain} ---")
print(f"Nhãn Dự đoán: {predicted_label}")
print(f"Đặc trưng đầu vào: {instance}")
# 6. Tạo Giải thích ANCHOR (Đã sửa)
# 1. Định nghĩa Ngưỡng và dùng biến này
ANCHOR_THRESHOLD = 0.85 # Giảm ngưỡng yêu cầu xuống 85%
explanation = explainer.explain_instance(
instance,
predict_fn,
threshold=ANCHOR_THRESHOLD, # Sử dụng ngưỡng mới
tau=0.15
)
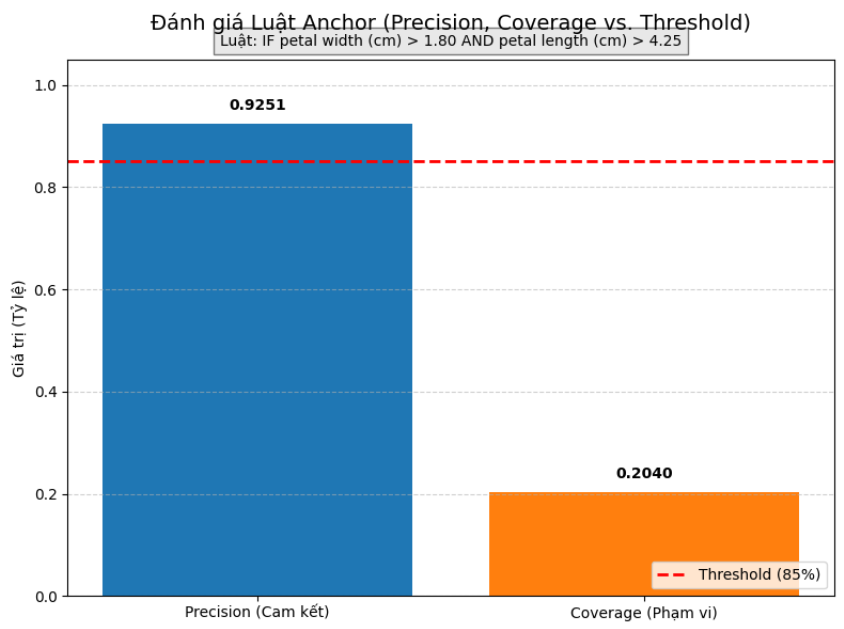
Hình 10: Đánh giá kết quả của Luật Anchor (Precision, Coverage vs. Threshold)
- Độ chính xác (Precision): Đạt 0.9251 (92.51%), cao hơn đáng kể so với ngưỡng yêu cầu Threshold (đường đứt nét màu đỏ) là 85%.
- Điều này có nghĩa là luật "IF petal width (cm) > 1.80 AND petal length (cm) > 4.25" là một lời giải thích rất mạnh mẽ và cam kết cho dự đoán virginica.
- Độ bao phủ (Coverage): Đạt 0.2040 (20.40%), cho thấy luật này áp dụng được cho khoảng $20\%$ tổng số mẫu trong tập dữ liệu.
Tổng kết
LIME và ANCHOR là hai công cụ XAI quan trọng giúp "mở hộp đen AI" bằng cách cung cấp các giải thích dễ hiểu:
- LIME: Sử dụng mô hình tuyến tính để xấp xỉ hành vi cục bộ.
- ANCHOR: Sử dụng luật logic IF-THEN có độ chính xác cao.
Cả hai đều là bước tiến hướng tới việc xây dựng các hệ thống AI minh bạch và đáng tin cậy hơn.
Refernces
[1] DeepMind, "Gemini," Large language model, 2025. [Online]. Available: https://gemini.ai/. [Accessed: Oct. 19, 2025].
[2] Ảnh được lấy từ tài liệu khóa học AIO Module 05 Tuần 01
Chưa có bình luận nào. Hãy là người đầu tiên!