
Vectorized Linear Regression and Loss Functions
1. Mục tiêu bài học
- Hiểu lại bản chất của hồi quy tuyến tính đơn (Simple Linear Regression) và cách tối ưu tham số bằng Gradient Descent.
- Nhận diện hạn chế của việc triển khai mô hình thủ công.
- Làm quen và áp dụng tư duy vector hóa để xây dựng mô hình hồi quy tuyến tính hiệu quả, gọn gàng và có thể mở rộng cho nhiều đặc trưng hơn.
2. Ôn tập: Simple Linear Regression
2.1. Giới thiệu Simple Linear Regression
Mô hình hồi quy tuyến tính đơn được xây dựng nhằm mô tả mối quan hệ tuyến tính giữa một biến đầu vào (x) và một biến đầu ra (y) thông qua phương trình:
$$\hat{y} = wx + b$$
Trong đó:
- ŷ: giá trị dự đoán (predicted value),
- w: hệ số góc (weight - xác định độ dốc của đường hồi quy),
- b: hệ số chặn (bias - giao điểm với trục tung),
- x: đầu vào (input feature).
Mục tiêu của mô hình là tìm giá trị w và b sao cho đường hồi quy dự đoán gần với dữ liệu thực tế nhất - tức là lỗi (error) giữa giá trị dự đoán và giá trị thực nhỏ nhất.
Để đo mức sai lệch này, ta sử dụng hàm mất mát (loss function), thường là Mean Squared Error (MSE) hay Squared Loss:
$$L(\hat{y}, y) = (\hat{y} - y)^2$$
Trong quá trình huấn luyện, ta sẽ thực hiện các bước sau:
- Khởi tạo ngẫu nhiên w và b.
- Tính giá trị dự đoán ŷ = wx + b.
- So sánh với giá trị thực y để tính mất mát (loss).
- Tính đạo hàm (gradient) của hàm mất mát theo từng tham số
Áp dụng công thức Chain rule:
$$Với\ L = f(g(x))\,, ta\ có:\\
\frac{dL}{dx} = \frac{df}{dg} \cdot \frac{dg}{dx}$$
ta được:
$$\frac{\partial L}{\partial w} = 2x(\hat{y} - y) \quad ; \quad \frac{\partial L}{\partial b} = 2(\hat{y} - y)$$
- Cập nhật các tham số bằng thuật toán Gradient Descent:
$$w = w - \eta \frac{\partial L}{\partial w}, \quad b = b - \eta \frac{\partial L}{\partial b}$$
trong đó η là tốc độ học (learning rate), xác định bước di chuyển của mô hình khi giảm sai số.
Quy trình này được lặp lại liên tục qua nhiều epoch để mô hình hội tụ – tức là khi giá trị loss giảm dần và ổn định.
Mục tiêu của huấn luyện là tìm ra giá trị của các tham số mà mô hình có thể điều chỉnh được (tức là tham số nội bộ của mô hình) để giảm sai số (loss) giữa dự đoán $\hat{y}$ và $y$
2.2. Hạn chế của Simple Linear Regression (Limitation)
Trong hồi quy tuyến tính đơn, mô hình chỉ xem xét một đặc trưng duy nhất (x) để dự đoán một biến đầu ra (y), chẳng hạn như mối quan hệ giữa kinh nghiệm làm việc và mức lương. Tuy nhiên, trong thực tế, kết quả đầu ra thường bị ảnh hưởng bởi nhiều yếu tố đồng thời. Ví dụ, mức lương không chỉ phụ thuộc vào kinh nghiệm mà còn bị tác động bởi trình độ học vấn, vị trí công việc, kỹ năng, khu vực sinh sống…
Khi mở rộng sang trường hợp đa biến (Multivariate Linear Regression), mô hình cần xem xét nhiều đầu vào x₁, x₂, x₃, …, xₙ, được biểu diễn bằng phương trình:
$$\hat{y} = w_1x_1 + w_2x_2 + \cdots + w_nx_n + b$$
Vấn đề phát sinh là, nếu tiếp tục triển khai mô hình bằng cách thủ công như trong Simple Linear Regression, mỗi khi thêm một biến đầu vào, ta phải tự viết lại công thức, thêm tham số mới và cập nhật từng phần trong code. Điều này khiến mô hình trở nên rườm rà, dễ sai sót, kém hiệu quả và khó mở rộng.
Bên cạnh đó, việc xử lý từng mẫu dữ liệu riêng lẻ trong vòng lặp khiến cho tốc độ huấn luyện chậm, đặc biệt khi kích thước tập dữ liệu lớn. Hệ thống sẽ phải lặp lại hàng nghìn lần phép nhân, cộng, trừ đơn lẻ - điều hoàn toàn không tối ưu trong lập trình hiện đại.
2.3. Computational Graph (Đồ thị tính toán)
2.3.1. Biểu diễn
Quá trình tính toán của mô hình có thể biểu diễn bằng đồ thị có hướng như sau:
$$x → (×w) → t → (+b) → ŷ → (ŷ - y)² → L$$
Mỗi nút là một phép tính, và việc tính gradient được thực hiện bằng quy tắc chuỗi (Chain Rule) khi lan truyền ngược (backpropagation).
2.3.2. Lan truyền thuận (Forward pass)
- Nhận giá trị $x, y$
- Tính $\hat{y} = wx + b$
- Tính $L = (\hat{y} - y)^2$
2.3.3. Lan truyền ngược (Backward pass)
- Tính đạo hàm từng bước theo quy tắc chuỗi
- Cập nhật tham số $w, b$
3. Vectorized Linear Regression
Từ những hạn chế nêu trên, có thể thấy việc vector hóa (vectorization) là một bước tiến tất yếu trong quá trình phát triển mô hình học máy. Phương pháp này cho phép xử lý toàn bộ tập dữ liệu cùng lúc thông qua các phép tính ma trận, thay vì thực hiện từng phép tính riêng lẻ. Nhờ đó, quá trình huấn luyện trở nên nhanh hơn, chính xác hơn và dễ mở rộng cho các bài toán có nhiều đặc trưng đầu vào. Đây cũng chính là nền tảng để tiến tới việc triển khai Vectorized Linear Regression -một cách tiếp cận tối ưu, hiện đại hơn so với mô hình hồi quy tuyến tính đơn truyền thống.
3.1. Vectorized Linear Regression theo Simple Linear Regression
Hãy cùng biểu diễn dạng vector hóa này từ bài toán Simple Linear Regression (có một đặc trưng (x) và xử lý một mẫu dữ liệu tại một thời điểm) trước.
3.1.1. Biểu diễn lại mô hình bằng vector
Như phần trên đã đề cập, trong hồi quy tuyến tính đơn, công thức dự đoán được viết là:
$\hat{y} = wx + b$
Để đưa mô hình này về dạng vector hóa, ta nhóm các tham số w và b thành một vector duy nhất θ, đồng thời thêm phần tử 1 vào vector đầu vào x để biểu diễn hệ số bias b:
$$\mathbf{x} =
\begin{bmatrix}
1 \\
x
\end{bmatrix},
\quad
\boldsymbol{\theta} =
\begin{bmatrix}
b \\
w
\end{bmatrix}$$
Khi đó, công thức dự đoán có thể được viết lại dưới dạng tích vô hướng (dot product):
$$\hat{y} = \boldsymbol{\theta}^T \mathbf{x} = b \cdot 1 + w \cdot x = b + wx$$
Cách biểu diễn này cho phép ta xử lý mô hình một cách thống nhất và gọn gàng hơn, đồng thời dễ dàng mở rộng sang trường hợp nhiều đặc trưng.
3.1.2. Hàm mất mát và đạo hàm trong dạng vector
Hàm mất mát (loss function) vẫn được định nghĩa tương tự như trong hồi quy tuyến tính đơn:
$$L(\hat{y}, y) = (\hat{y} - y)^2$$
Đạo hàm của hàm mất mát theo từng tham số được biểu diễn dưới dạng vector như sau:
$$\nabla_{\boldsymbol{\theta}} L = 2\mathbf{x}(\hat{y} - y)$$
Trong đó, ∇θL là vector gradient, bao gồm hai thành phần:
$$\frac{\partial L}{\partial b} = 2(\hat{y} - y), \quad
\frac{\partial L}{\partial w} = 2x(\hat{y} - y)$$
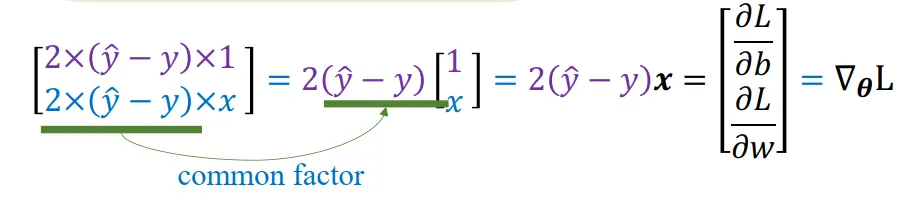
3.1.3. Cập nhật tham số bằng Gradient Descent
Thay vì cập nhật từng tham số riêng biệt w và b, ta có thể cập nhật toàn bộ vector tham số θ chỉ trong một phép trừ vector duy nhất:
$$\boldsymbol{\theta} = \boldsymbol{\theta} - \eta \nabla_{\boldsymbol{\theta}} L$$
với η là tốc độ học (learning rate).
Điều này tương đương với:
$$b = b - \eta \frac{\partial L}{\partial b}, \quad
w = w - \eta \frac{\partial L}{\partial w}$$

3.2. Vectorized Linear Regression cho N-samples, m-samples với nhiều đặc trưng
3.2.1. Biểu diễn dữ liệu và mô hình
Thay vì xử lý từng mẫu riêng biệt như trước, toàn bộ dữ liệu huấn luyện được biểu diễn dưới dạng ma trận đặc trưng (feature matrix):
$$\mathbf{X} =
\begin{bmatrix}
1 & x_{11} & x_{12} & \dots & x_{1n} \\
1 & x_{21} & x_{22} & \dots & x_{2n} \\
\vdots & \vdots & \vdots & \ddots & \vdots \\
1 & x_{N1} & x_{N2} & \dots & x_{Nn}
\end{bmatrix}$$
Trong đó:
- Mỗi hàng tương ứng với một mẫu dữ liệu (sample).
- Cột đầu tiên là toàn các số 1 để tính hệ số bias b.
- n là số đặc trưng (features), N là số mẫu (samples).
Vector tham số của mô hình là:
$$\boldsymbol{\theta} =
\begin{bmatrix}
b \\
w_1 \\
w_2 \\
\vdots \\
w_n
\end{bmatrix}$$
Khi đó, dự đoán đầu ra cho toàn bộ N mẫu được tính bằng một phép nhân ma trận duy nhất:
$$\hat{\mathbf{y}} = \mathbf{X}\boldsymbol{\theta}$$
3.2.2. Hàm mất mát tổng quát cho N-samples
Hàm mất mát (loss function) được tính bằng trung bình bình phương sai số (Mean Squared Error) của toàn bộ tập dữ liệu:
$$L(\hat{\mathbf{y}}, \mathbf{y}) = \frac{1}{N}(\hat{\mathbf{y}} - \mathbf{y})^T(\hat{\mathbf{y}} - \mathbf{y})$$
Cách viết này tương đương với việc cộng dồn lỗi của từng mẫu, rồi lấy trung bình – nhưng giờ được gói gọn trong một phép nhân vector duy nhất, giúp việc tính toán trở nên nhanh chóng và chính xác hơn.
3.2.3. Đạo hàm (gradient) trong dạng vector hóa
Thay vì tính đạo hàm riêng lẻ cho từng tham số, ta tính gradient tổng quát cho tất cả tham số cùng lúc:
**** $$\nabla_{\theta}L = \frac{1}{N} \cdot 2X^{T}(X\theta - y)\\
= \frac{2}{N} X^{T}(\hat{y} - y)$$
Trong đó:
- X^T là ma trận chuyển vị của X.
- (ŷ - y) là vector sai số của toàn bộ N mẫu.
- Kết quả ∇θL là một vector có cùng kích thước với θ, chứa gradient tương ứng cho từng tham số b, w₁, w₂, …,
3.2.4. Cập nhật tham số bằng Gradient Descent
Sau khi tính được gradient, ta cập nhật vector tham số bằng công thức:
$$\boldsymbol{\theta} = \boldsymbol{\theta} - \eta \nabla_{\boldsymbol{\theta}} L$$
hay viết cụ thể hơn:
$$\boldsymbol{\theta} = \boldsymbol{\theta} - \frac{2\eta}{N}\mathbf{X}^T(\mathbf{X}\boldsymbol{\theta} - \mathbf{y})$$
Công thức này cho phép cập nhật tất cả trọng số đồng thời, thay vì từng phần như trong Simple Linear Regression

3.2.5. Mini-batch (m-samples)
Trong quá trình huấn luyện mô hình học máy, đặc biệt là Linear Regression, dữ liệu gốc thường có N mẫu (samples). Tuy nhiên, ta không nhất thiết phải sử dụng toàn bộ N mẫu cùng lúc để tính toán và cập nhật trọng số. Thay vào đó, ta có thể lấy ngẫu nhiên m mẫu (m ≤ N) trong mỗi lần huấn luyện, được gọi là mini-batch.
Khi dùng mini-batch, ta chia tập dữ liệu N mẫu thành nhiều nhóm nhỏ có kích thước m (ví dụ 32, 64, 128) gọi là batch.
Ở mỗi bước huấn luyện, chỉ tính gradient trên batch hiện tại:
$$\nabla_{\theta}^{(batch)} L = \frac{2}{m} X_{batch}^{T} (X_{batch}\theta - y_{batch})$$
Cập nhật tham số:
$$\theta = \theta - \eta \nabla_{\theta}^{(batch)} L$$
Trong thực tế, việc chia dữ liệu huấn luyện thành các mini-batch nhỏ (thay vì xử lý toàn bộ tập dữ liệu cùng lúc) mang lại rất nhiều lợi ích.
1. Tăng tốc độ huấn luyện:
Nếu dữ liệu có hàng triệu mẫu, việc tính toán gradient trên toàn bộ tập dữ liệu (full batch) cho mỗi lần cập nhật sẽ rất chậm và tốn bộ nhớ.
Khi chia thành mini-batch, mô hình chỉ xử lý một nhóm nhỏ mẫu (ví dụ 32 hoặc 64 mẫu) mỗi lần, giúp:
- Giảm thời gian tính toán cho mỗi bước cập nhật.
- Tận dụng tối đa khả năng song song của GPU/TPU.
2. Giảm tiêu thụ bộ nhớ:
Khi tính gradient với mini-batch, ta chỉ cần nạp mẫu của batch hiện tại vào bộ nhớ thay vì toàn bộ dữ liệu. Điều này cực kỳ quan trọng khi làm việc với tập dữ liệu lớn (như hình ảnh, âm thanh hoặc văn bản).
3. Giúp mô hình học “tốt hơn” nhờ nhiễu vừa phải:
Mỗi mini-batch là một ước lượng nhỏ của toàn bộ tập dữ liệu, nên gradient tính được có một chút “dao động” (noise).
Điều này giúp mô hình:
- Không bị “mắc kẹt” trong cực tiểu cục bộ,
- Và có khả năng tổng quát hóa (generalize) tốt hơn cho dữ liệu mới.
4. Dễ dàng điều chỉnh linh hoạt:
Tùy cấu hình phần cứng, bạn có thể chọn kích thước batch phù hợp:
- Batch nhỏ → học nhanh hơn nhưng nhiễu hơn.
- Batch lớn → ổn định hơn nhưng chậm hơn.
Mỗi lần đi qua hết các mini-batch (huấn luyện qua toàn bộ dữ liệu) được gọi là 1 epoch.
Khi huấn luyện mô hình , ta có:
$$\theta = [b, w_1, w_2, ..., w_n]$$
- Ở epoch 1, các trọng số này được khởi tạo ngẫu nhiên (hoặc theo một phân phối nhất định).
-
Sau khi mô hình dự đoán, tính loss và cập nhật theo gradient descent, ta có trọng số mới:
$$\theta^{(1)} = \theta^{(0)} - \eta \nabla_{\theta} L^{(1)}$$ -
Ở epoch 2, mô hình bắt đầu huấn luyện với $\theta^{(1)}$ chứ không phải khởi tạo lại.
Và cứ thế:
$$\theta^{(t+1)} = \theta^{(t)} - \eta \nabla_{\theta} L^{(t)}$$
Hàm mất mát (loss) giảm dần qua từng epoch, thể hiện rằng mô hình đang tiến gần hơn đến điểm tối ưu.
Các epoch sau liên tục tinh chỉnh dựa trên kết quả từ epoch trước, nhờ đó nó “thông minh hơn” qua từng vòng lặp
3.3. Ưu điểm của cách vector hóa
Việc xử lý toàn bộ tập dữ liệu trong một phép tính duy nhất mang lại nhiều lợi ích:
- Tốc độ huấn luyện nhanh hơn nhiều do giảm thiểu vòng lặp qua từng mẫu.
Cụ thể ta có thể so sánh hiệu suất của 2 cách cài đặt, một bên dùng Vectorized Linear Regression, một bên cài đặt bình thường mà không dùng vectorized như sau:

- Mã nguồn ngắn gọn và tổng quát, dễ mở rộng sang nhiều đặc trưng hoặc tập dữ liệu lớn.
- Giảm sai sót khi triển khai thủ công, vì toàn bộ quy trình – từ tính dự đoán đến cập nhật tham số – được thực hiện bằng các phép toán ma trận chuẩn.
- Là nền tảng cho các mô hình học sâu (Deep Learning), vốn đều dựa trên nguyên lý vector hóa trong huấn luyện.
4. Loss Functions
4.1. Điều kiện cho loss fuctions
Nhìn từ góc độ tối ưu hoá, hàm mất mát cần phải thoả mãn các điều kiện sau
- Continueity (Liên tục)
- $f(a) \text{ xác định}$
- $\lim_{x \to a} f(x) \text{ tồn tại}$
- $\lim_{x \to a} f(x) = f(a)$
Một hàm số được gọi là liên tục (continuous function) nếu nó thỏa mãn ba điều kiện liên tục đó tại mọi điểm trong miền xác định của nó.
Lý do mà hàm mất mát phải liên tục:
- Một hàm liên tục đảm bảo rằng khi ta thay đổi tham số một lượng nhỏ, thì giá trị loss cũng chỉ thay đổi một lượng nhỏ:
$$\lim_{\Delta \theta \to 0} L(\theta + \Delta \theta) = L(\theta)$$
→ Điều này cực kỳ quan trọng, vì quá trình tối ưu (Gradient Descent) liên tục cập nhật các tham số:
$$w_{t+1} = w_t - \eta \frac{\partial L}{\partial w}, \quad b_{t+1} = b_t - \eta \frac{\partial L}{\partial b}$$
- Ngược lại, nếu không liên tục, ta có thể gặp: “bước nhảy loss”
→ gradient không xác định, mô hình dao động quanh điểm tối ưu mà không hội tụ.
- Differentiability (Khả vi)
Một hàm số được gọi là khả vi tại một điểm nếu đạo hàm của nó tồn tại tại điểm đó, tức là giới hạn sau tồn tại:
$$f'(a) = \lim_{h \to 0} \frac{f(a + h) - f(a)}{h}$$
Khi giới hạn này tồn tại và hữu hạn, ta nói hàm khả vi tại điểm . Nếu điều này đúng với mọi điểm trong miền xác định, thì hàm được gọi là hàm khả vi (differentiable function).
Trong linear regression, hàm Loss phải khả vi để:
-
Tính gradient: Khả vi cho phép ta lấy đạo hàm của hàm mất mát theo các tham số, từ đó xác định được hướng mà mô hình cần đi để giảm loss
$$\frac{\partial L}{\partial w}, \quad \frac{\partial L}{\partial b} \begin{cases}w_{t+1} = w_t - \eta \frac{\partial L}{\partial w} \\b_{t+1} = b_t - \eta \frac{\partial L}{\partial b}\end{cases}$$ -
Đảm bảo độ trơn (smoothness) của quá trình tối ưu: Khi hàm khả vi, đồ thị của nó “mượt” và gradient thay đổi liên tục. Điều này giúp quá trình cập nhật tham số hội tụ ổn định về cực tiểu toàn cục.
- Nếu hàm không khả vị(đạo hàm tại một điểm nào đó không tồn tại), thì khi Gradient Descent tới gần điểm đó sẽ bị bối rối.
Ví dụ: $L(x)$ = $|x|$ , không có đạo hàm tại $x=0$ (đạo hàm cận trái và cận phải khác nhau). Khi Gradient Descent tới gần 0 thì sẽ không biết phải chọn hướng nào để đi tiếp. Nhưng trong thực tế, vấn đề này vẫn có thể được giải quyết bởi các phương pháp subgradient.
4.2. Mean Absolute Error (MAE)
MAE đo trung bình độ lệch tuyệt đối giữa giá trị dự đoán và giá trị thật.
$$L_{MAE} = \frac{1}{n} \sum_{i=1}^{n} |y_i - \hat{y}_i|$$
- Vì lấy trị tuyệt đối, nên không phân biệt hướng sai số (dự đoán cao hay thấp hơn đều tính như nhau).
- Ít bị ảnh hưởng bởi outliers và dễ diễn giải hơn. Liên tục nhưng không khả vi tại 0 nên khó tối ưu hơn khi dùng cho gradient descent
4.3. Mean Squared Error (MSE)
MAE đo trung bình bình phương sai số giữa giá trị dự đoán và giá trị thật.
$$L_{MSE} = \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2$$
- Là hàm liên tục và khả vi toàn phần nên được dùng phổ biến trong gradient descent cho linear regression
- Độ nhạy với outliers cao và có hình dạng là một parabol lồi với 1 cực tiểu toàn cục
MSE tốt hơn MAE khi dùng learning rate cố định vì:
- Gradient Descent sẽ di chuyển ngược hướng đạo hàm (gradient) để giảm loss:
$$x_{\text{new}} = x_{\text{old}} - \eta f'(x)$$
Với MAE:
- Gradient luôn bằng nhau, dù xa hay gần điểm tối ưu.
- Mỗi lần cập nhật, bước di chuyển luôn bằng nhau.
→ Khi gần điểm tối ưu, bước đó vẫn to, dễ nhảy qua lại, dao động, không hội tụ mượt.
Với MSE:
- Khi xa điểm tối ưu: gradient to → cập nhật mạnh, giúp học nhanh.
- Khi gần 0: gradient nhỏ → bước nhỏ dần, mô hình ổn định và hội tụ.
Kết luận:
MSE tốt hơn với learning rate cố định vì gradient của nó tự điều chỉnh kích thước bước đi. Trong khi đó, MAE luôn cập nhật với cùng tốc độ, nên dễ bị “nhảy qua nhảy lại” quanh điểm tối ưu.
4.4. Huber Loss (Smooth L1 Loss)
Huber Loss là một loại hàm mất mát được thiết kế để kết hợp ưu điểm của MSE và MAE, giúp mô hình ổn định hơn trước nhiễu và outliers.
Với giá trị sai số :
$$r = y - \hat{y}$$
$$L_\delta(r) =\begin{cases}\frac{1}{2}r^2, & \text{nếu } |r| \le \delta \\\delta(|r| - \frac{1}{2}\delta), & \text{nếu } |r| > \delta\end{cases}$$
Trong đó:
$\delta > 0$ là ngưỡng (threshold), thường do ta chọn trước
$r$ nhỏ ⇒ dùng bình phương lỗi (giống MSE).
$r$ lớn ⇒ chuyển sang tuyến tính (giống MAE).

Linear Regression cổ điển dùng MSE:
$$L = \frac{1}{2n} \sum (y_i - \hat{y_i})^2$$
Nhưng nếu dữ liệu có outliers, MSE bị ảnh hưởng mạnh (vì bình phương).
→ Dùng Huber Loss thay thế sẽ:
- Giảm ảnh hưởng của các điểm bất thường,
- Giữ được tính khả vi (đạo hàm tồn tại ở mọi điểm),
- Vẫn tối ưu được bằng Gradient Descent.
1. Đạo hàm của Huber Loss theo $r:$
$$\frac{dL}{dr} =\begin{cases}r, & \text{nếu } |r| \le \delta \\\delta \cdot \text{sign}(r), & \text{nếu } |r| > \delta\end{cases}$$
Với sign($r$):
$$\text{sign}(r) =\begin{cases}1, & r > 0 \\-1, & r < 0\end{cases}$$
Ý nghĩa: Cho biết độ dốc của hàm Loss so với mức sai số
- Đạo hàm của Huber Loss theo $\hat{y}$:
$$\frac{dL_\delta}{d\hat{y}} =\begin{cases}- r, & \text{nếu } |r| \le \delta \\- \delta \cdot \text{sign}(r), & \text{nếu } |r| > \delta\end{cases}$$
Trong mô hình hồi quy, ta không trực tiếp điều khiển r mà điều khiển $\hat{y}$ (giá trị dự đoán của mô hình).
Vì: $$r = y - \hat{y} → \frac{dr}{d\hat{y}} = -1$$
Nên theo quy tắc chuỗi (chain rule):
$$\frac{dL_\delta}{d\hat{y}} = \frac{dL_\delta}{dr} \cdot \frac{dr}{d\hat{y}} = -\frac{dL_\delta}{dr}$$
Ý nghĩa: Là gradient thực tế được dùng trong tối ưu mô hình.
Cách cài đặt trong Python:
5. Data Normalization & Regularization
5.1. Data Normalization
Trong hồi quy tuyến tính và các mô hình học máy nói chung, chuẩn hoá dữ liệu giúp:
- Đưa các đặc trưng về cùng thang đo → đảm bảo mỗi feature có tầm ảnh hưởng tương tự khi tính gradient.
- Tăng tốc hội tụ trong quá trình huấn luyện bằng gradient descent.
- Giảm khả năng sai lệch trong ước lượng trọng số khi dữ liệu có đơn vị khác nhau (VD: “mét” và “ngàn đô”).
Các loại chuẩn hóa phổ biến:
5.1.1. Min–Max Scaling
$$x'=\frac{x - x_{\min}}{x_{\max} - x_{\min}}$$
- Đưa dữ liệu về khoảng [0, 1] (hoặc [−1, 1] tuỳ chọn).
- Dễ hiểu và nhanh, nhưng nhạy cảm với ngoại lệ (outliers).
- Thường dùng cho dữ liệu đã được cắt bỏ giá trị ngoại lai.
5.1.2. Standardization (Z-score Normalization)
$$x' = \frac{x - \mu}{\sigma}$$
Trong đó:
$$\mu \: giá\ trị\ trung\ bình\\
\sigma : độ\ lệch\ chuẩn$$
- Trung bình = 0, độ lệch chuẩn = 1.
- Không bị ảnh hưởng nhiều bởi outliers (so với Min–Max).
- Phù hợp cho Linear Regression, Logistic Regression, SVM, Neural Networks.
5.1.3. Robust Scaling
$$x' = \frac{x - \text{median}(x)}{IQR(x)}$$
Trong đó:
$IQR(x) = Q_3 - Q_1$ : khoảng tứ phân vị
$median(x)$ : trung vị
- Sử dụng trung vị và khoảng tứ phân vị (IQR).
- Rất hiệu quả khi dữ liệu có outlier mạnh.
- Dùng nhiều trong các bài toán thực tế khi dữ liệu "bẩn".
5.2. Data Generalization
Regularization giúp chống overfitting và ổn định nghiệm bằng cách thêm ràng buộc lên trọng số. Thay vì chỉ tối ưu sai số huấn luyện, ta thêm hàm phạt (penalty) vào loss:
$$L = \text{Loss(data)} + \lambda \cdot \text{Penalty(weights)}$$
Các loại chuẩn hoá tham số phổ biến:
5.2.1. L1 Regularization (Lasso Regression)
$$L = \sum_i (y_i - \hat{y_i})^2 + \lambda \sum_j |w_j|$$
Đặc điểm:
- Làm nhiều trọng số bằng 0 → tự động chọn feature (feature selection).
- Không có nghiệm đóng (closed-form), phải dùng thuật toán tối ưu như coordinate descent.
- Tốt khi số feature lớn và ta nghi ngờ nhiều trong số đó không quan trọng.
Gradient (dạng đạo hàm phụ):
$$\frac{\partial L}{\partial w_j} = -2x_j(y - \hat{y}) + \lambda \, \text{sign}(w_j)$$
5.2.2. L2 Regularization (Ridge Regression)
$$L = \sum_i (y_i - \hat{y_i})^2 + \lambda \sum_j w_j^2$$
Đặc điểm:
- Giảm độ lớn của các trọng số $w_j$.
- Không triệt tiêu trọng số, chỉ làm chúng nhỏ lại.
- Nghiệm có dạng giải tích:
$$w = (X^T X + \lambda I)^{-1} X^T y$$
- Giảm vấn đề đa cộng tuyến (multicollinearity).
Gradient:
$$\frac{\partial L}{\partial w_j} = -2x_j(y - \hat{y}) + 2\lambda w_j$$
Cập nhật trọng số:
$$w_j \leftarrow w_j - \eta \frac{\partial L}{\partial w_j}$$
5.2.3. Elastic Net (L1 + L2 Regularization)
$$L = \sum_i (y_i - \hat{y_i})^2 + \lambda_1 \sum_j |w_j| + \lambda_2 \sum_j w_j^2$$
- Kết hợp điểm mạnh của Lasso (feature selection) và Ridge (ổn định nghiệm).
- Dùng khi dữ liệu có nhiều feature tương quan mạnh.
6. Code Python tổng hợp Linear Regression
import numpy as np
# Huber Loss
def huber_gradient(y_true, y_pred, delta=1.0):
error = y_pred - y_true
grad = np.where(np.abs(error) <= delta, error, delta * np.sign(error))
return grad
def huber_loss(y_true, y_pred, delta=1.0):
error = y_pred - y_true
small = np.abs(error) <= delta
return np.where(small, 0.5 * error ** 2, delta * (np.abs(error) - 0.5 * delta))
# Mini-Batch
def linear_regression_minibatch(X, y, lr=0.01, epochs=100, batch_size=16, delta=1.0):
n_samples, n_features = X.shape
w = np.zeros(n_features)
b = 0.0
losses = []
for epoch in range(epochs):
# Xáo trộn dữ liệu
indices = np.random.permutation(n_samples)
X_shuffled, y_shuffled = X[indices], y[indices]
for start in range(0, n_samples, batch_size):
end = start + batch_size
X_batch = X_shuffled[start:end]
y_batch = y_shuffled[start:end]
# Dự đoán
y_pred = X_batch.dot(w) + b
# Gradient theo công thức Huber
grad_yhat = huber_gradient(y_batch, y_pred, delta)
grad_w = (grad_yhat @ X_batch) / len(X_batch)
grad_b = np.mean(grad_yhat)
# Cập nhật tham số
w -= lr * grad_w
b -= lr * grad_b
# Tính loss trung bình mỗi epoch
epoch_loss = np.mean(huber_loss(y, X.dot(w) + b, delta))
losses.append(epoch_loss)
if epoch % 10 == 0:
print(f"Epoch {epoch}: Loss = {epoch_loss:.4f}")
return w, b, losses
np.random.seed(0)
X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X[:, 0] + np.random.randn(100)
w, b, losses = linear_regression_minibatch(X, y, lr=0.05, epochs=100, batch_size=10, delta=1.0)
print("Trọng số học được:", w)
print("Bias học được:", b)
Chưa có bình luận nào. Hãy là người đầu tiên!