Giải Thích Mô Hình Với LIME & ANCHOR – Ứng Dụng Trong XAI
Nhóm: CONQ024
Học viên: Lê Hồ Anh Duy
Tổ chức: AI Việt Nam – AIO 2025
Ngày: 19/10/2025
1. Giới thiệu tổng quan
Explainable Artificial Intelligence (XAI) là lĩnh vực giúp con người hiểu và tin tưởng kết quả của mô hình học máy.
Hai phương pháp nổi bật trong XAI là LIME (Local Interpretable Model-Agnostic Explanations) và ANCHOR (High-Precision Model-Agnostic Explanations).
| Phương pháp | Mục tiêu chính |
|---|---|
| LIME | Giải thích cục bộ (local) bằng mô hình tuyến tính xấp xỉ |
| ANCHOR | Giải thích logic bằng tập luật điều kiện chính xác cao |
2. LIME – Local Interpretable Model-Agnostic Explanations
2.1. Ý tưởng chính
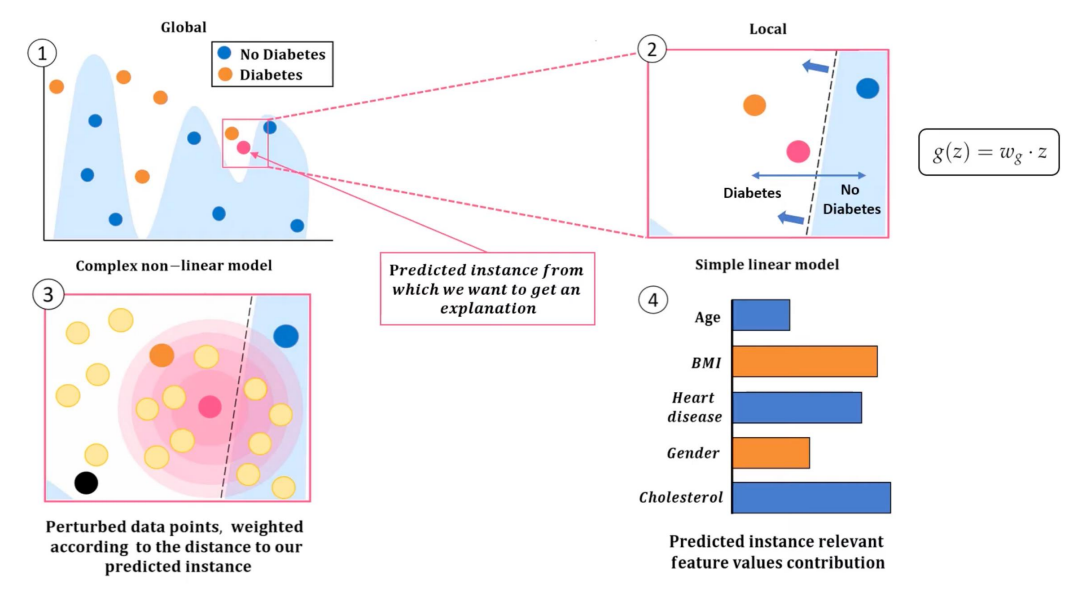
LIME giải thích một dự đoán cụ thể của mô hình phức tạp bằng một mô hình tuyến tính đơn giản huấn luyện trên dữ liệu “giả lập” xung quanh điểm cần giải thích.
Công thức tổng quát:
$$\text{argmin}_{g \in G} \; L(f, g, \pi_x) + \Omega(g)$$
Trong đó:
- $f$: mô hình gốc (black-box).
- $g$: mô hình tuyến tính xấp xỉ (white-box).
- $\pi_x$: trọng số khoảng cách (điểm càng gần $x$, trọng số càng lớn).
- $\Omega(g)$: độ phức tạp của mô hình xấp xỉ.
Tư tưởng: Mô hình phức tạp $f$ được “chiếu” thành một mô hình tuyến tính $g$ ở vùng lân cận điểm cần giải thích.
2.2. Quy trình hoạt động của LIME
- Chọn mẫu cần giải thích $x_0$.
- Sinh dữ liệu giả lập xung quanh $x_0$.
- Tính dự đoán của mô hình gốc $f(x_i)$.
- Tính trọng số theo khoảng cách giữa $x_i$ và $x_0$.
- Huấn luyện mô hình tuyến tính $g$ bằng dữ liệu có trọng số.
- Giải thích kết quả: Hệ số $w_i$ của $g$ thể hiện mức ảnh hưởng của từng feature.
2.3. Minh họa bằng Python
import lime
import lime.lime_tabular
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
# Dữ liệu
X, y = load_iris(return_X_y=True)
model = RandomForestClassifier().fit(X, y)
# Tạo bộ giải thích
explainer = lime.lime_tabular.LimeTabularExplainer(X, feature_names=['sepal_length','sepal_width','petal_length','petal_width'], class_names=['setosa','versicolor','virginica'], discretize_continuous=True)
# Chọn mẫu và giải thích
i = 10
exp = explainer.explain_instance(X[i], model.predict_proba, num_features=2)
exp.show_in_notebook(show_table=True)
Trong đó:
- $i$: là mẫu cần giải thích ( dòng thứ 10 )
- model.predict_proba: Hàm dự đoán xác suất của mô hình gốc
- num_features=2: Chỉ hiển thị 2 đặc trưng quan trọng nhất ảnh hưởng đến quyết định.
2.4. Ưu và nhược điểm của LIME
| Ưu điểm | Nhược điểm |
|---|---|
| Giải thích dễ hiểu, trực quan | Không ổn định nếu dữ liệu lân cận thay đổi |
| Áp dụng cho mọi mô hình (model-agnostic) | Tốn thời gian khi nhiều mẫu cần giải thích |
| Có thể dùng cho dữ liệu tabular, ảnh, text | Phụ thuộc cách sinh mẫu giả lập |
3. ANCHOR – High-Precision Model-Agnostic Explanations
3.1. Ý tưởng chính
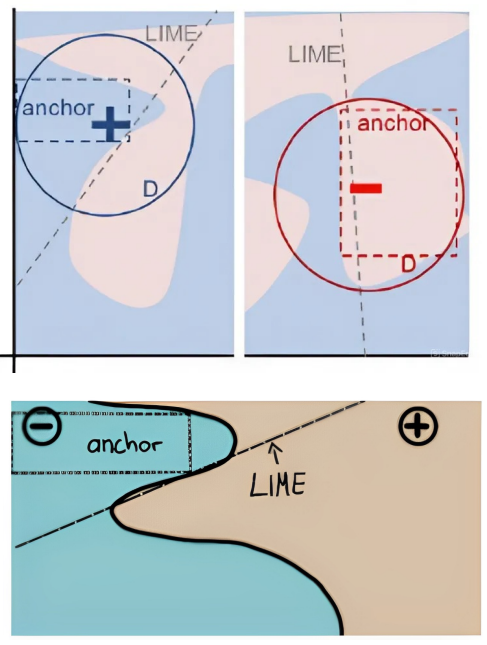
ANCHOR khắc phục điểm yếu của LIME bằng cách tạo tập luật điều kiện (if–then rules) có độ chính xác cao (precision),
bảo đảm rằng khi luật đúng → mô hình dự đoán cùng kết quả với xác suất cao.
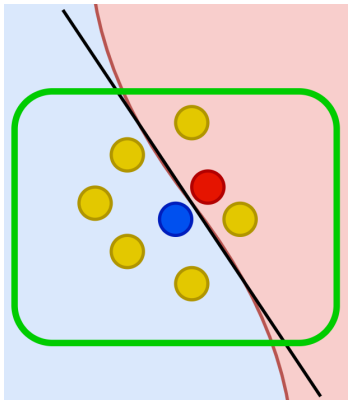
Ví dụ:
Nếuincome > 50kvàage > 30→ mô hình dự đoán "Chấp nhận vay" với xác suất 97%.
3.2. Cơ chế tìm “anchor”
- Input: điểm cần giải thích $x_0$.
- Output: tập luật $A = \{a_1, a_2, ...\}$ sao cho:
$$ P(f(x) = f(x_0) \mid A(x)) \ge \tau $$
với $\tau$ là ngưỡng độ tin cậy (thường 0.95 hoặc 0.99).
Thuật toán:
1. Tạo ra nhiều điều kiện ứng viên
( ví dụ: "petal_length > 4", "petal_width > 1.5" )
2. Đánh giá mức “precision” của từng tổ hợp điều kiện.
( xem trong các mẫu thỏa điều kiện đó, có bao nhiêu mẫu mô hình dự đoán giống điểm cần giải thích )
3. Chọn tập nhỏ nhất nhưng có độ chính xác cao nhất.
3.3. Ví dụ minh họa với Python
import anchor
from anchor import anchor_tabular
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
X, y = load_iris(return_X_y=True)
model = RandomForestClassifier().fit(X, y)
explainer = anchor_tabular.AnchorTabularExplainer(
class_names=['setosa', 'versicolor', 'virginica'],
feature_names=['sepal_length','sepal_width','petal_length','petal_width'],
train_data=X
)
i = 20
exp = explainer.explain_instance(X[i], model.predict, threshold=0.95)
print('Anchor:', exp.names())
3.4. So sánh LIME và ANCHOR
| Tiêu chí | LIME | ANCHOR |
|---|---|---|
| Loại giải thích | Tuyến tính cục bộ | Tập luật logic (if–then) |
| Độ ổn định | Nhạy với dữ liệu sinh ngẫu nhiên | Ổn định, rõ ràng hơn |
| Độ chính xác | Trung bình | Cao (≥ 95%) |
| Dạng kết quả | Trọng số của feature | Tập luật điều kiện |
| Thời gian xử lý | Nhanh hơn | Chậm hơn (tìm luật tối ưu) |
| Tính diễn giải | Dễ hiểu với mô hình tuyến tính | Dễ hiểu cho người không chuyên kỹ thuật |
4. Kết luận và hướng phát triển
4.1. Kết luận
- LIME cung cấp giải thích cục bộ bằng mô hình tuyến tính.
- ANCHOR cung cấp giải thích logic với độ chính xác cao hơn.
- Cả hai đều là phương pháp model-agnostic, giúp “mở hộp đen” AI.
- Chọn phương pháp phụ thuộc vào mục tiêu ứng dụng: cần trực quan hay cần độ tin cậy cao.
4.2. Hướng phát triển
- Kết hợp LIME & ANCHOR để tạo giải thích vừa ổn định vừa chính xác.
- Tích hợp XAI vào pipeline MLOps để tự động sinh giải thích khi triển khai.
- Áp dụng với mô hình Deep Learning (CNN, Transformer) và dữ liệu lớn.
- Trực quan hóa kết quả giải thích bằng dashboard tương tác.
Chưa có bình luận nào. Hãy là người đầu tiên!