Explainable AI với SHAP: Từ lý thuyết đến ứng dụng
Nhóm: CONQ024
Học viên: Lê Hồ Anh Duy
Lớp: AI Việt Nam – AIO 2025
Ngày: 22/10/2025
1. Giới thiệu tổng quát
Trong kỷ nguyên trí tuệ nhân tạo bùng nổ, các mô hình học máy (Machine Learning) như Random Forest, XGBoost hay Deep Neural Networks đạt được độ chính xác vượt trội trong nhiều bài toán — từ nhận diện khuôn mặt đến dự đoán rủi ro tài chính. Tuy nhiên, “độ chính xác cao” không đồng nghĩa với “độ tin cậy cao”. Nhiều mô hình vận hành như một “hộp đen” (black box)“ khiến con người không thể biết vì sao chúng đưa ra quyết định cụ thể nào đó. Điều này đặt ra thách thức nghiêm trọng về tính minh bạch, thiên vị dữ liệu (bias) và trách nhiệm giải trình trong ứng dụng AI.
Explainable AI (XAI) xuất hiện như một hướng tiếp cận nhằm “mở nắp hộp đen”, giúp con người hiểu rõ logic bên trong mô hình, đảm bảo rằng các quyết định của AI có thể giải thích được, đáng tin cậy và công bằng.
Trong số nhiều phương pháp XAI, SHAP (SHapley Additive exPlanations) nổi bật nhờ cơ sở lý thuyết vững chắc. Dựa trên giá trị Shapley trong lý thuyết trò chơi (Game Theory), SHAP định lượng mức đóng góp của từng đặc trưng (feature) vào kết quả dự đoán. Điều này giúp các nhà phân tích không chỉ biết “mô hình dự đoán gì”, mà còn hiểu “vì sao mô hình dự đoán như vậy” — một bước tiến lớn trong hành trình xây dựng AI có thể được con người tin tưởng.
2. Nhu cầu của XAI
Tại sao cần XAI?
Các lý do chi tiết bao gồm:
-
Tăng niềm tin (Trustworthiness):
Người dùng có thể nhìn thấy các đặc trưng và cơ chế mà mô hình dựa vào để đưa ra dự đoán. Điều này đặc biệt quan trọng trong các quyết định y tế, tài chính hay tuyển dụng, nơi mà sự tin tưởng vào AI là yếu tố then chốt để chấp nhận hoặc triển khai rộng rãi. Một mô hình không thể giải thích được thường dễ bị hoài nghi, dù có độ chính xác cao. -
Hỗ trợ ra quyết định (Decision Support):
XAI cho phép các chuyên gia con người hiểu rõ logic dự đoán, từ đó có thể xác nhận, điều chỉnh hoặc phản biện kết quả.
Ví dụ, trong y tế, bác sĩ có thể biết vùng nào trên ảnh X-quang hoặc giá trị xét nghiệm nào ảnh hưởng nhiều nhất đến dự đoán chẩn đoán của AI, giúp cải thiện quyết định lâm sàng. -
Phát hiện bias và vấn đề đạo đức (Bias Detection & Ethics):
Mô hình học máy có thể học các thiên vị từ dữ liệu huấn luyện mà không rõ ràng. XAI giúp phát hiện ra các đặc trưng (feature) gây ảnh hưởng không công bằng, chẳng hạn như chủng tộc, giới tính, độ tuổi hoặc khu vực, từ đó giảm thiểu rủi ro sai lệch và cải thiện công bằng của mô hình. -
Tuân thủ quy định và tiêu chuẩn (Regulatory Compliance):
Các luật mới như EU AI Act, GDPR, hay các tiêu chuẩn ngành yêu cầu các tổ chức phải có khả năng giải thích cách AI đưa ra quyết định, đặc biệt khi những quyết định đó ảnh hưởng trực tiếp đến quyền lợi và an toàn của con người. XAI cung cấp công cụ minh bạch để chứng minh tính hợp pháp và trách nhiệm của hệ thống AI.
Ví dụ minh họa:
Một mô hình AI chẩn đoán viêm phổi từ ảnh X-quang đạt độ chính xác 98%. Nếu chỉ nhìn vào kết quả, mô hình có vẻ rất hiệu quả. Tuy nhiên, khi áp dụng XAI (như SHAP hoặc Grad-CAM), người ta phát hiện rằng mô hình chỉ dựa vào “dấu kim loại” trên ảnh chụp — dấu hiệu liên quan đến bệnh nhân nặng — thay vì vùng phổi bị viêm thực sự.
Nhờ XAI, các nhà phát triển có thể điều chỉnh dữ liệu và mô hình, từ đó cải thiện tính chính xác, giảm bias và đảm bảo quyết định y tế trở nên an toàn, đáng tin cậy.
3. Cơ sở lý thuyết – Shapley Value
Nguồn gốc
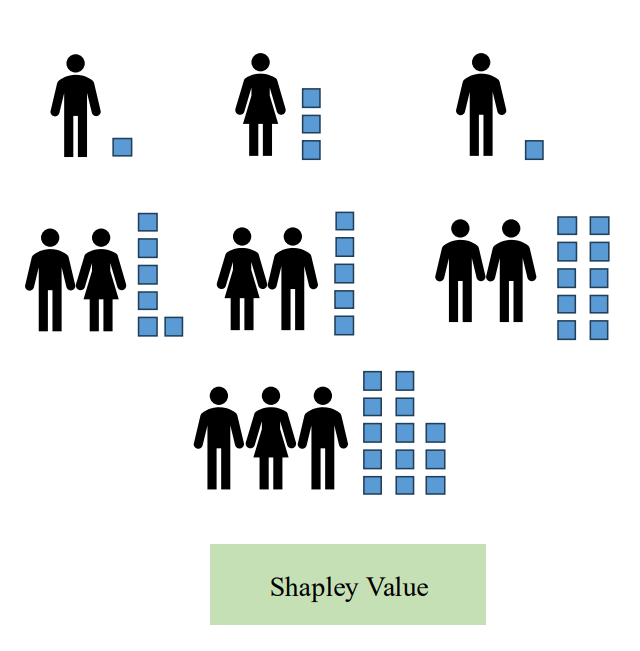
Shapley Value được giới thiệu bởi Lloyd Shapley vào năm 1953 trong lý thuyết trò chơi (Game Theory) nhằm giải quyết vấn đề phân chia công bằng phần thưởng trong các trò chơi hợp tác giữa nhiều người chơi. Mục tiêu là xác định mức đóng góp công bằng của từng người chơi vào tổng phần thưởng, bất kể thứ tự tham gia hoặc tương tác giữa các người chơi.
Điểm mạnh của Shapley Value là công bằng, ổn định và lý thuyết vững chắc, nhờ đó trở thành tiêu chuẩn trong phân bổ đóng góp trong nhiều lĩnh vực từ kinh tế, chính trị cho đến khoa học dữ liệu.
Ứng dụng trong Machine Learning
Trong Machine Learning, mỗi feature (đặc trưng) được coi là một "người chơi", và mỗi dự đoán của mô hình là "phần thưởng" cần chia. Shapley Value giúp trả lời câu hỏi: “Feature này đóng góp bao nhiêu vào dự đoán của mô hình?”
Cách tính cơ bản:
- Tạo tất cả các tập con (subset) của các feature.
- So sánh dự đoán khi feature đang xét tham gia trong subset với dự đoán khi feature đó không có.
- Trung bình hóa đóng góp cận biên qua tất cả các tập con để đảm bảo công bằng và ổn định.
Đặc điểm nổi bật:
- Công bằng: Mỗi feature được đánh giá dựa trên tất cả các kịch bản có thể.
- Trực quan: Có thể hiển thị bằng biểu đồ waterfall, beeswarm, hay force plot để giải thích kết quả dự đoán.
- Phổ quát: Áp dụng cho mọi loại mô hình, từ tuyến tính đến phi tuyến, mạng nơ-ron sâu.
Công thức tổng quát
$$f(x) = \sum_i \phi_i + E_X[f(X)] $$
Trong đó:
- $f(x)$: dự đoán của mô hình cho mẫu $x$
- $E_X[f(X)]$: giá trị trung bình của mô hình trên toàn bộ dữ liệu (base value)
- $\phi_i$: mức đóng góp của feature ( i )
Cách hiểu trực quan: Base value là điểm xuất phát trung bình, các (\phi_i) là lực “đẩy” hoặc “kéo” dự đoán của từng feature để đi từ giá trị trung bình đến giá trị dự đoán cụ thể.
Ba tính chất cơ bản của Shapley Value
- Local Accuracy: Tổng các $\phi_i$ bằng đúng dự đoán thực tế:
$$f(x) = \phi_0 + \sum_i \phi_i$$ - Missingness: Nếu một feature bị loại ra, đóng góp của nó bằng 0, đảm bảo không có feature nào bị tính trùng hoặc bỏ sót.
- Consistency (Tính nhất quán): Nếu một feature ảnh hưởng mạnh hơn trong mô hình mới, giá trị Shapley không được giảm. Điều này giúp đảm bảo rằng các đánh giá về feature luôn phản ánh đúng tầm quan trọng thực sự.
Ví dụ trực quan
Giả sử một mô hình dự đoán giá nhà dựa trên 3 feature: diện tích, số phòng, khu vực.
- Base value: 200.000 USD (giá trung bình toàn bộ dữ liệu)
- Shapley Value: $\phi_\text{diện tích}=50.000$, $\phi_\text{số phòng}=30.000$, $\phi_\text{khu vực}=20.000$
→ Dự đoán cho căn nhà cụ thể: 200.000 + 50.000 + 30.000 + 20.000 = 300.000 USD
Điều này giải thích mức đóng góp riêng của từng feature vào dự đoán cuối cùng, minh bạch và dễ hiểu cho người dùng.
Tầm quan trọng trong XAI
Shapley Value cung cấp cơ sở toán học vững chắc cho các giải thuật giải thích hiện đại như SHAP, giúp:
- Giải thích cả dự đoán cục bộ (local explanation) và toàn cục (global explanation)
- Hỗ trợ phát hiện bias và các yếu tố bất thường trong mô hình
- Là nền tảng cho các biến thể nâng cao như Kernel SHAP, Tree SHAP, Deep SHAP
4. Giải thuật SHAP (SHapley Additive exPlanation)
SHAP kế thừa tư tưởng của Shapley Value và áp dụng trực tiếp vào Machine Learning, nhằm phân bổ công bằng mức đóng góp của từng feature vào dự đoán của mô hình.
Mô hình tuyến tính giải thích (Additive Model):
$$f(x) \approx \phi_0 + \sum_i \phi_i$$
Trong đó:
- $\phi_0$: base value, giá trị dự đoán trung bình của mô hình trên toàn bộ dữ liệu.
- $\phi_i$: mức đóng góp riêng lẻ của feature i cho dự đoán $f(x)$.
Ưu điểm của SHAP:
- Công bằng: dựa trên lý thuyết trò chơi, đảm bảo mỗi feature nhận phần thưởng tương xứng với đóng góp.
- Trực quan: dễ hình dung qua waterfall plot, beeswarm plot, giúp giải thích từng dự đoán.
- Phổ quát: có thể áp dụng cho hầu hết các loại mô hình ML từ tree-based, linear, đến deep learning.
Mở rộng chuyên sâu:
- SHAP không chỉ đánh giá ảnh hưởng riêng lẻ của từng feature, mà còn phản ánh tương tác giữa các feature nhờ vào cách tính Shapley Value trên tất cả các tập con feature.
- Khi áp dụng cho các mô hình phi tuyến mạnh, SHAP vẫn giữ nguyên tính additive, cho phép tổng các (\phi_i) cộng với (\phi_0) khớp chính xác dự đoán thực tế, đảm bảo local accuracy.
- Kết hợp với các plot trực quan, SHAP giúp phát hiện bias, hiểu sai lệch mô hình, và là công cụ then chốt trong Explainable AI hiện đại.
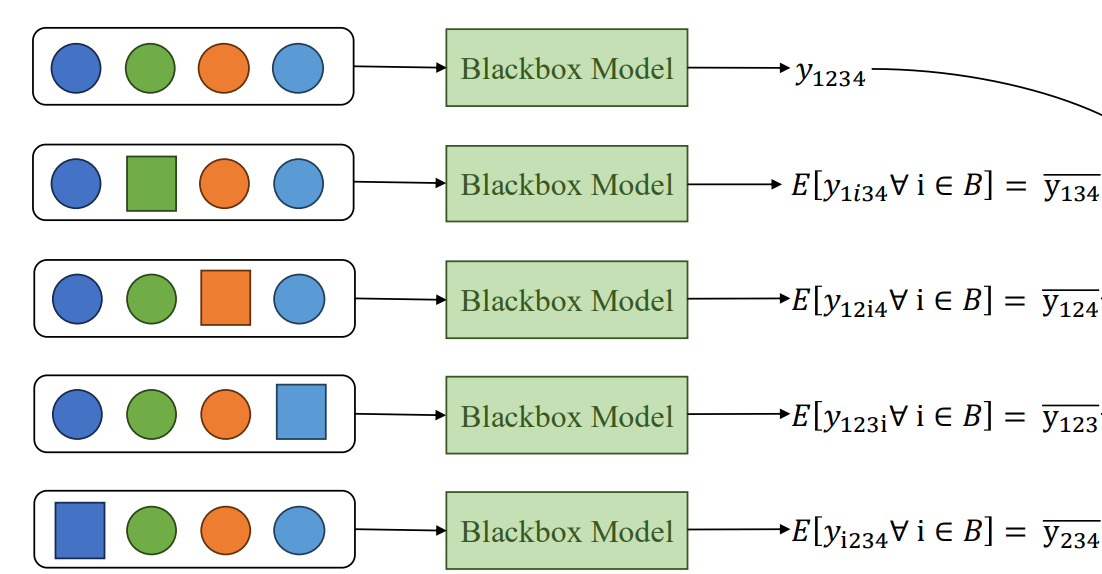
5. Kernel SHAP – Cách tính xấp xỉ Shapley Value
Tính toán Shapley Value chính xác cho tất cả các tập con feature là rất tốn kém về thời gian và tài nguyên. Ví dụ, với 32 feature, số tổ hợp cần tính là $2^{32} - 1 \approx 4.3 \text{tỷ}$, điều này gần như không khả thi trong thực tế.
Do đó, Kernel SHAP ra đời để ước lượng xấp xỉ Shapley Value bằng Weighted Linear Regression.
Các bước thực hiện Kernel SHAP:
1. Sinh các tổ hợp feature (subsets): Chọn ngẫu nhiên các tập con của feature để giảm số lượng tính toán.
2. Tính dự đoán của mô hình cho từng subset: Với mỗi tập con, thay các feature không có trong subset bằng giá trị background (ví dụ trung bình hoặc ngẫu nhiên từ tập dữ liệu).
3. Tạo trọng số cho mỗi subset (kernel weight):
$w(C) = \frac{(M-1)}{\binom{M}{|C|} \cdot |C| \cdot (M - |C|)}$
x
Trong đó:
- $M$ = tổng số feature
- $|C|$ = số feature trong subset (C)
Trọng số này đảm bảo rằng các tập con nhỏ và lớn đều được cân nhắc công bằng theo lý thuyết Shapley.
4. Huấn luyện mô hình hồi quy tuyến tính có trọng số (Weighted Linear Regression): Dùng các dự đoán subset làm mục tiêu và kernel weight làm trọng số.
→ Hệ số hồi quy thu được chính là Shapley Value $\phi_i$ xấp xỉ cho từng feature.
Ưu điểm Kernel SHAP:
- Giữ nguyên công bằng theo lý thuyết Shapley.
- Giảm chi phí tính toán đáng kể so với việc tính toán chính xác.
- Có thể áp dụng cho mọi loại mô hình mà không cần truy cập vào cấu trúc bên trong (model-agnostic).
Mở rộng chuyên sâu:
- Kernel SHAP còn hỗ trợ tính tương tác giữa các feature bằng cách mở rộng trọng số và tập con.
- Trong thực hành, số lượng subset được chọn thường giới hạn để cân bằng độ chính xác vs. chi phí tính toán.
- Có thể kết hợp với sampling techniques như Monte Carlo để cải thiện tốc độ mà vẫn giữ độ tin cậy cao.
6. Ứng dụng minh họa
Dữ liệu bảng (Tabular)
Ví dụ: dự đoán giá nhà dựa trên diện tích, số phòng, khu vực.
SHAP giữ nguyên một số feature, thay phần còn lại bằng giá trị nền (background set) rồi đo mức thay đổi trong dự đoán → mức đóng góp của từng feature.
Code ví dụ với XGBoost và SHAP:
import shap
import xgboost as xgb
import pandas as pd
# Load dữ liệu
X, y = shap.datasets.boston()
model = xgb.XGBRegressor().fit(X, y)
# Tính SHAP values
explainer = shap.Explainer(model, X)
shap_values = explainer(X)
# Hiển thị summary plot
shap.summary_plot(shap_values, X)
Code ví dụ với mạng CNN và SHAP:
import shap
import tensorflow as tf
from tensorflow.keras.applications.resnet50 import ResNet50, preprocess_input, decode_predictions
import numpy as np
from skimage.io import imread
# Load model
model = ResNet50(weights="imagenet")
# Load ảnh mẫu
img = imread("cat.jpg")
img = np.resize(img, (224,224,3))
img_input = np.expand_dims(img, axis=0)
img_input = preprocess_input(img_input)
# Explainer
explainer = shap.GradientExplainer(model, img_input)
shap_values = explainer.shap_values(img_input)
# Visualize
shap.image_plot(shap_values, img_input)
Giải thích: mỗi vùng ảnh có giá trị SHAP → vùng màu đỏ tăng xác suất lớp dự đoán, xanh giảm xác suất.
7. Global SHAP – Giải thích toàn cục
Global Importance:
$$Importance_j = \frac{1}{n} \sum_{i=1}^n |\phi_{ij}|$$
- Đây là giá trị trung bình tuyệt đối của SHAP values cho feature j trên toàn bộ dataset.
- Ý nghĩa: feature có giá trị lớn → đóng góp quan trọng vào dự đoán tổng thể.
- Giúp đánh giá mức độ ảnh hưởng chung của từng feature, không chỉ ở từng mẫu riêng lẻ.
Beeswarm Plot – trực quan hóa:
- Mỗi chấm = một mẫu dữ liệu
- Trục X = giá trị SHAP (tác động + hoặc - lên dự đoán)
- Màu sắc:
- Đỏ → giá trị feature cao
- Xanh → giá trị feature thấp
- Hướng tác động:
- Chấm bên phải → tăng dự đoán
- Chấm bên trái → giảm dự đoán
- Tầng trên cùng → feature quan trọng nhất, tầng dưới → ít quan trọng hơn
Code ví dụ với dữ liệu bảng:
import shap
import xgboost as xgb
# Load dữ liệu
X, y = shap.datasets.boston()
model = xgb.XGBRegressor().fit(X, y)
# Tính SHAP values
explainer = shap.Explainer(model, X)
shap_values = explainer(X)
# Beeswarm plot
shap.plots.beeswarm(shap_values)
8. Deep SHAP – Cho mạng nơ-ron sâu
Ý tưởng chính:
Deep SHAP là sự kết hợp giữa:
- DeepLIFT: đo mức thay đổi của các neuron khi giá trị đầu vào thay đổi, giúp hiểu tác động nội bộ mạng.
- Shapley Value: đảm bảo sự phân bổ công bằng đóng góp của từng feature.
Cách hoạt động:
- Sử dụng chain rule để lan truyền đóng góp từ từng neuron trong mạng đến các feature gốc.
- Kết quả: mỗi feature đầu vào sẽ có giá trị SHAP thể hiện mức ảnh hưởng đến dự đoán cuối cùng.
- Phù hợp với các mô hình CNN, Transformer, MLP,…
Ưu điểm:
- Tạo ra saliency map chính xác hơn so với phương pháp đơn giản.
- Giúp trực quan hóa vùng quan trọng trong ảnh hoặc các feature quan trọng trong dữ liệu chuỗi.
Ví dụ minh họa với CNN (ảnh):
import shap
import tensorflow as tf
from tensorflow.keras.applications.vgg16 import VGG16, preprocess_input
from tensorflow.keras.preprocessing import image
import numpy as np
# Load model CNN
model = VGG16(weights="imagenet")
# Load ảnh mẫu
img_path = 'dog.jpg'
img = image.load_img(img_path, target_size=(224, 224))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
# Tạo explainer Deep SHAP
explainer = shap.DeepExplainer(model, x)
shap_values = explainer.shap_values(x)
# Vẽ bản đồ saliency map
shap.image_plot(shap_values, x)
9. Hạn chế và hướng phát triển
Hạn chế hiện tại của SHAP:
-
Giả định tuyến tính cục bộ:
SHAP giả định mô hình tuyến tính trong phạm vi cục bộ của mỗi mẫu. Với những vùng dữ liệu phi tuyến mạnh, ước lượng có thể không chính xác. -
Thiếu ổn định do random seed:
Kết quả SHAP có thể thay đổi nếu quá trình sampling tổ hợp feature sử dụng random seed khác nhau. Điều này gây khó khăn khi cần giải thích đáng tin cậy. -
Chi phí tính toán cao:
Tính toán Shapley Value chính xác là combinatorial, với nhiều feature (>30) sẽ tốn hàng tỷ phép tính → cần Kernel SHAP hoặc các xấp xỉ khác.
Hướng phát triển:
-
HEDGE SHAP (NLP):
- Mỗi token trong văn bản được tô màu theo mức đóng góp.
- Giúp trực quan hóa cách mô hình xử lý từng từ trong dự đoán. -
SHAP Flow:
- Biến SHAP thành đồ thị quan hệ giữa các feature.
- Thích hợp cho dữ liệu có cấu trúc phức tạp (graph, network). -
Kernel riêng cho từng loại mô hình:
- TreeSHAP: tối ưu cho cây quyết định/ensemble (XGBoost, LightGBM, Random Forest).
- TextSHAP: dành cho dữ liệu NLP, token/embedding.
- GraphSHAP: dành cho dữ liệu đồ thị, node/edge ảnh hưởng. -
Kết hợp Deep SHAP + Approximation:
- Tăng tốc độ tính toán trên mạng nơ-ron sâu mà vẫn giữ độ chính xác cao.
Ghi chú: Hướng phát triển nhắm đến tăng tốc, cải thiện độ ổn định, mở rộng sang các loại dữ liệu mới, đồng thời giữ tính công bằng và trực quan của SHAP.
10. Kết luận
SHAP hiện được coi là chuẩn mực vàng của Explainable AI (XAI) nhờ các lý do chính sau:
-
Nền tảng toán học vững chắc:
Dựa trên Shapley Value trong lý thuyết trò chơi, đảm bảo phân bổ đóng góp feature một cách công bằng và hợp lý. -
Giải thích minh bạch và trực quan:
SHAP không chỉ cung cấp số liệu về mức đóng góp của feature mà còn trực quan hóa qua các biểu đồ như waterfall, beeswarm, saliency map, giúp người dùng nhanh chóng hiểu quyết định của mô hình. -
Phổ quát và linh hoạt:
Có thể áp dụng cho mọi loại mô hình: tree-based (TreeSHAP), deep learning (DeepSHAP), NLP (TextSHAP), graph data (GraphSHAP). -
Ứng dụng rộng rãi:
- Y tế: Giải thích dự đoán chẩn đoán, phát hiện bias trong dữ liệu bệnh nhân.
- Tài chính: Phân tích rủi ro, giải thích quyết định cho khoản vay, tín dụng.
-
Pháp lý / Quy định: Đáp ứng yêu cầu minh bạch theo GDPR, EU AI Act.
-
Lưu ý triển khai thực tế:
- Chi phí tính toán cao với dữ liệu lớn → cần xấp xỉ bằng Kernel SHAP hoặc sampling.
- Kết quả có thể thay đổi theo random seed → cần kiểm tra độ ổn định.
- Hiệu quả cao khi kết hợp với Global SHAP + Deep SHAP cho dự đoán toàn cục và mô hình phức tạp.
Tóm lại: Mặc dù tồn tại một số hạn chế, SHAP vẫn là công cụ hiệu quả nhất để con người hiểu, giám sát và tin tưởng mô hình AI, đặc biệt trong các lĩnh vực yêu cầu giải thích và minh bạch cao.
Chưa có bình luận nào. Hãy là người đầu tiên!