
🎯 Câu Chuyện Về DVC: Từ Chaos Đến Control
Câu chuyện: Một ngày nọ, tôi nhận ra rằng quản lý dữ liệu ML không khác gì việc quản lý một thư viện khổng lồ mà không có hệ thống phân loại...
📖 Chương 1: Thảm Họa Quản Lý Dữ Liệu
Khi Mọi Thứ Trở Nên Hỗn Loạn
Hãy tưởng tượng bạn đang làm việc trong một dự án Machine Learning. Một ngày đẹp trời, bạn nhận ra rằng:
- Bạn có 15 file dataset với tên như
data_final.csv,data_final_v2.csv,data_final_v2_really_final.csv - Không biết model nào được train với dataset nào
- Không thể reproduce kết quả của experiment hôm qua
- Team member hỏi: "Anh ơi, model accuracy 95% đó train với data gì vậy?"
Đây chính là lúc DVC xuất hiện như một vị cứu tinh!
📖 Chương 2: MLOps và Vòng Đời Học Máy
MLOps Là Gì?
MLOps (Machine Learning Operations) giống như việc vận hành một nhà máy sản xuất mô hình. Thay vì sản xuất xe hơi, chúng ta sản xuất các mô hình AI.
Vòng Đời MLOps
📊 Thu Thập Dữ Liệu → 🔧 Xử Lý Dữ Liệu → 🏗️ Huấn Luyện Mô Hình
↓ ↓ ↓
[DVC] [DVC + Pipelines] [DVC + Experiments]
↓ ↓ ↓
🚀 Triển Khai Mô Hình → 📈 Giám Sát → 🔄 Huấn Luyện Lại
↓ ↓ ↓
[Công Cụ CI/CD] [Ghi Log] [Tự Động Hóa]
DVC Trong Stack MLOps
| Thành Phần | Công Cụ | Vai Trò DVC |
|---|---|---|
| Quản Lý Phiên Bản | Git, DVC | ✅ Phiên Bản Hóa Dữ Liệu & Mô Hình |
| Xử Lý Dữ Liệu | Airflow, Prefect | ✅ Định Nghĩa Pipeline |
| Huấn Luyện Mô Hình | PyTorch, TensorFlow | ✅ Theo Dõi Thí Nghiệm |
| Đăng Ký Mô Hình | MLflow, Weights & Biases | ✅ Lưu Trữ Mô Hình |
| CI/CD | Jenkins, GitHub Actions | ✅ Kiểm Thử Tự Động |
📖 Chương 3: DVC - Người Hùng Của Chúng Ta
DVC Là Ai?
DVC (Data Version Control) giống như một thủ thư siêu thông minh. Trong khi Git chỉ quản lý sách (code), DVC được thiết kế đặc biệt để quản lý cả thư viện khổng lồ (dữ liệu lớn).
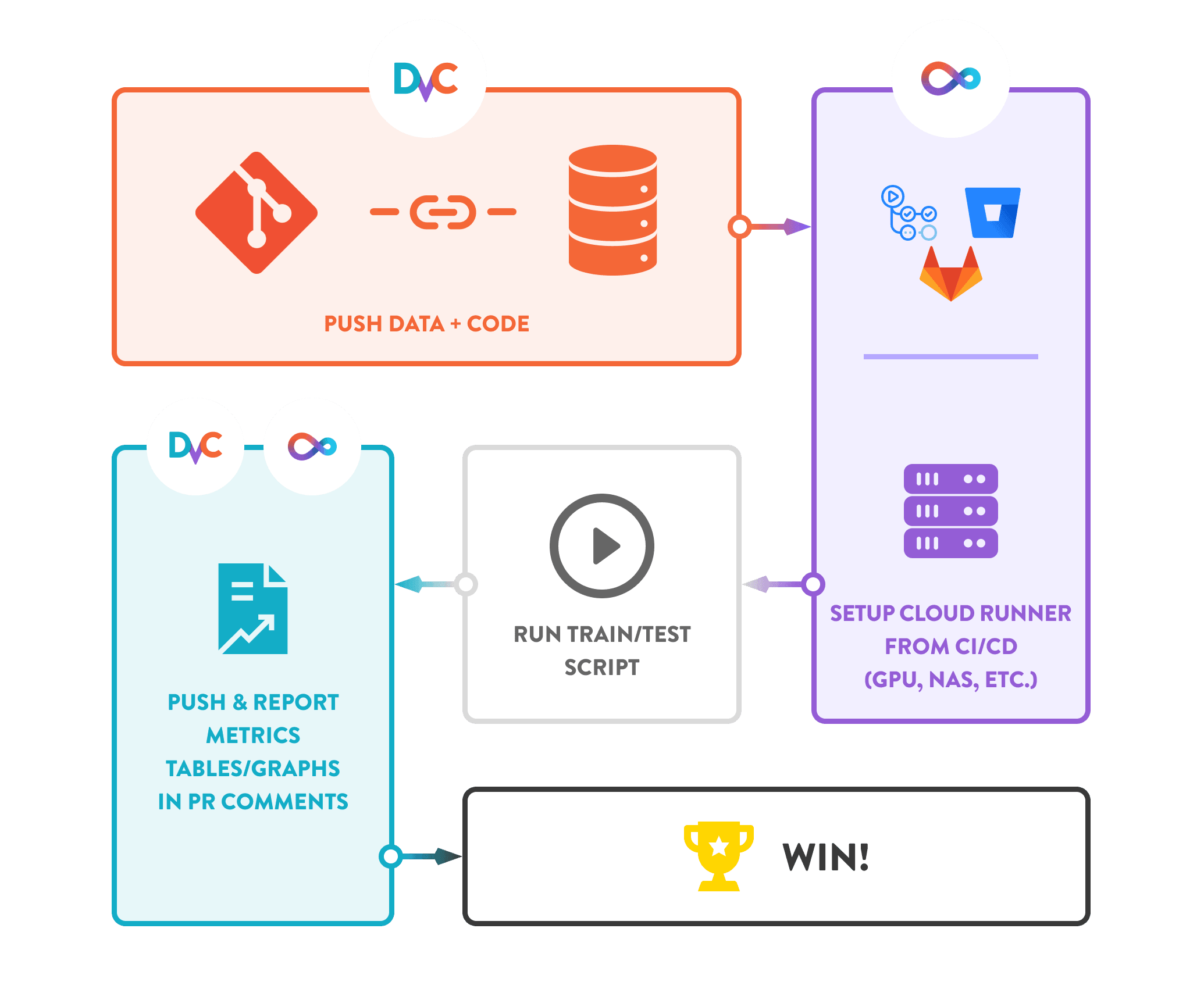
Hình: Quy trình MLOps hoàn chỉnh với DVC - từ push data đến deploy model
Bước 1: PUSH DATA + CODE (Đẩy Dữ Liệu + Code)
- DVC quản lý dữ liệu lớn và mô hình
- Git quản lý code và metadata
- Đẩy lên remote storage (S3, GS, Azure)
Bước 2: SETUP CLOUD RUNNER (Thiết Lập Môi Trường Cloud)
- CI/CD tự động setup môi trường
- Cấu hình GPU, NAS, storage
- Tích hợp với GitLab, GitHub Actions
Bước 3: RUN TRAIN/TEST SCRIPT (Chạy Script Huấn Luyện)
- Thực thi training script trên cloud
- Sử dụng dữ liệu từ DVC
- Tự động hóa toàn bộ quy trình
Bước 4: PUSH & REPORT METRICS (Đẩy & Báo Cáo Metrics)
- DVC tự động báo cáo kết quả
- Hiển thị metrics trong PR comments
- So sánh experiments tự động
Bước 5: WIN! (Thành Công!)
- Quy trình hoàn tất
- Mô hình sẵn sàng deploy
- Có thể reproduce kết quả
Cách DVC Hoạt Động
Hãy tưởng tượng DVC như một hệ thống thư viện thông minh:
- Kệ Sách Cục Bộ - Nơi lưu trữ sách thật trên máy bạn
- Thẻ Mục Lục - File
.dvcchứa thông tin về từng cuốn sách - Kho Lưu Trữ Từ Xa - Thư viện trung tâm (như AWS S3) để backup
- Hệ Thống Quản Lý - Tích hợp với Git để theo dõi mọi thay đổi
Câu Chuyện Về Quy Trình
Bạn có file dữ liệu → DVC tạo thẻ mục lục → Git lưu thông tin → Upload lên cloud
↓ ↓
Team member cần → DVC tải về → Tự động sắp xếp vào đúng chỗ ← ← ← ←┘
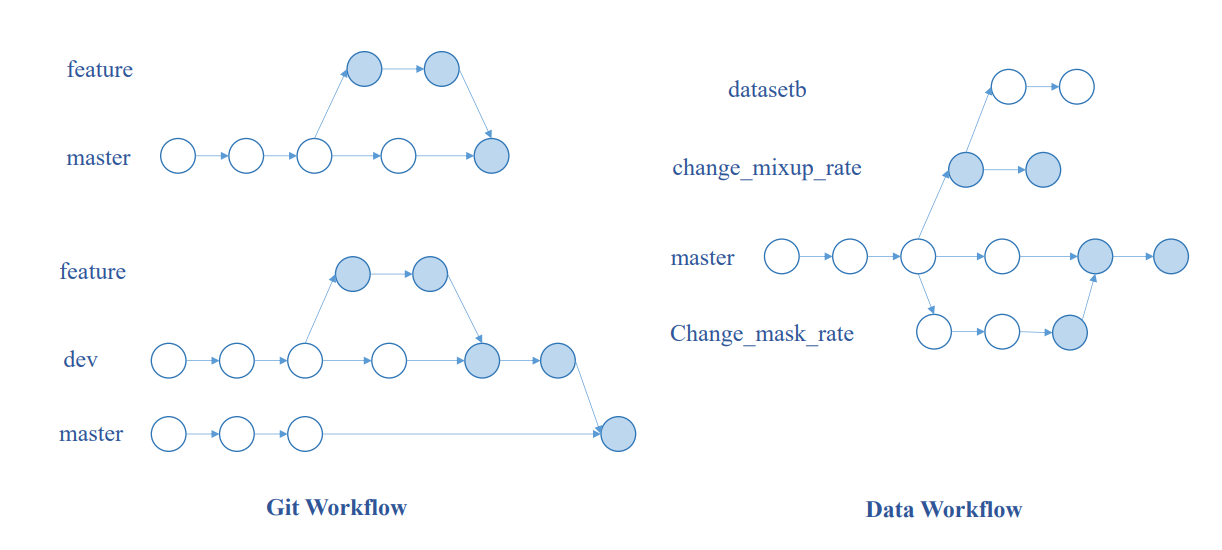
Hình: So sánh quy trình làm việc của Git (cho code) và DVC (cho dữ liệu/mô hình)
🔍 Giải Thích Chi Tiết:
1. Git Workflow (Bên trái):
- Các nhánh: master, dev, feature - quản lý code
- Vòng tròn xanh: Commit quan trọng hoặc merge points
- Vòng tròn rỗng: Commit trung gian
- Mũi tên: Lịch sử phát triển, branching, merging
2. Data Workflow (Bên phải):
- Các nhánh: master, change_mixup_rate, Change_mask_rate - quản lý experiments
- Vòng tròn xanh: Phiên bản dữ liệu/mô hình đã được DVC track
- Vòng tròn rỗng: Trạng thái trung gian chưa track
- datasetb: Tập dữ liệu được tạo từ experiment
🎯 Tại Sao Quan Trọng:
- Git quản lý code như thế nào → DVC quản lý data như vậy
- Branching cho experiments khác nhau
- Merging để kết hợp kết quả tốt nhất
- Version control cho cả code và data
📖 Chương 4: Những Cơn Ác Mộng Thực Tế
Cơn Ác Mộng 1: Thư Mục Hỗn Loạn
Bạn có bao giờ thấy thư mục dự án như thế này chưa?
📂 Project Directory:
├── dataset_final.csv
├── dataset_final_v2.csv
├── dataset_final_v2_really_final.csv
├── data_cleaned_20231215.pkl
├── training_data_augmented_v3_new.npy
└── test_set_updated_fixed.csv
Và rồi bạn tự hỏi:
- "Cái nào là cái cuối cùng nhỉ?"
- "Model accuracy 95% đó train với data gì vậy?"
- "Hôm qua tôi đã làm gì để được kết quả này?"
Cơn Ác Mộng 2: Team Collaboration Hell
Scenario thực tế:
- 👨💻 Developer A: "Mình train được accuracy 95% rồi!"
- 👩💻 Developer B: "Tuyệt! Cho mình code với!"
- 👨💻 Developer A: "Ừm... nhưng mình quên dùng dataset nào rồi 😅"
- 👩💻 Developer B: "Và hyperparameters là gì? Config file đâu?"
- 👨💻 Developer A: "À... mình test nhiều lần quá, không nhớ config nào 😰"
Cơn Ác Mộng 3: Model Performance Drop
Tình huống thực tế:
📊 Hiệu Suất Mô Hình Sản Xuất:
Tuần 1: Độ chính xác 94.2% ✅
Tuần 2: Độ chính xác 92.1% ⚠️
Tuần 3: Độ chính xác 89.3% ❌
Tuần 4: Độ chính xác 85.7% 💥
Và bạn tự hỏi:
- "Tại sao model lại tệ dần vậy?"
- "Data có thay đổi gì không?"
- "Model nào đang chạy trên production vậy?"
Cơn Ác Mộng 4: Multi-Environment Chaos
Tình huống thực tế:
🏢 Công ty có 3 môi trường:
├── Dev: 50GB dữ liệu, 5 mô hình
├── Staging: 200GB dữ liệu, 12 mô hình
└── Production: 2TB dữ liệu, 25 mô hình
❌ Vấn đề:
- Data không sync giữa environments
- Model version mismatch
- Không biết model nào đang chạy ở đâu
- Rollback disaster khi có bug
📖 Chương 5: Cuộc Phiêu Lưu Với MNIST
Bắt Đầu Hành Trình
Hãy cùng tôi kể câu chuyện về một dự án MNIST thực tế. Đây là cách tôi đã áp dụng DVC để giải quyết mọi vấn đề:
Bước 1: Khởi Tạo Dự Án
# Tạo dự án
mkdir mnist-dvc-project
cd mnist-dvc-project
# Khởi tạo Git + DVC
git init
dvc init
# Tạo cấu trúc thư mục
mkdir -p data/{raw,processed} models scripts metrics
# Commit cấu hình
git add .dvc .gitignore
git commit -m "Khởi tạo DVC project"
Lúc này tôi nghĩ: "Okay, bây giờ mình có một dự án sạch sẽ, không còn hỗn loạn nữa!"
Bước 2: Tải Dữ Liệu MNIST
# Tạo script tải dữ liệu MNIST
cat > scripts/download_mnist.py << 'EOF'
import tensorflow as tf
import numpy as np
import argparse
import os
def download_mnist(size='full'):
"""Tải bộ dữ liệu MNIST"""
print(f"Đang tải MNIST dataset ({size})...")
# Tải dữ liệu từ TensorFlow
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
if size == 'subset':
# Chỉ lấy 10k mẫu cho thí nghiệm nhanh
x_train = x_train[:10000]
y_train = y_train[:10000]
print(f"Tạo subset: {len(x_train)} mẫu huấn luyện")
# Tạo thư mục
os.makedirs('data/raw', exist_ok=True)
# Lưu dữ liệu
np.save('data/raw/x_train.npy', x_train)
np.save('data/raw/y_train.npy', y_train)
np.save('data/raw/x_test.npy', x_test)
np.save('data/raw/y_test.npy', y_test)
print(f"✅ Đã lưu dữ liệu vào data/raw/")
print(f" - x_train: {x_train.shape}")
print(f" - y_train: {y_train.shape}")
print(f" - x_test: {x_test.shape}")
print(f" - y_test: {y_test.shape}")
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument('--size', choices=['full', 'subset'], default='full')
args = parser.parse_args()
download_mnist(args.size)
EOF
# Tải bộ dữ liệu MNIST đầy đủ
python scripts/download_mnist.py --size=full
Bước 3: DVC Add - Phiên Bản 1
# Theo dõi với DVC
dvc add data/raw/x_train.npy data/raw/y_train.npy
dvc add data/raw/x_test.npy data/raw/y_test.npy
# Commit vào Git (chỉ metadata!)
git add data/raw/.gitignore data/raw/*.dvc
git commit -m "v1: Bộ dữ liệu MNIST đầy đủ (60k mẫu)"
Bước 4: Huấn Luyện Mô Hình
# Huấn luyện mô hình MNIST
python scripts/train.py
# Kết quả: Độ chính xác 98.5% trên tập kiểm thử
Lúc này tôi nghĩ: "Tuyệt! Mô hình đã được huấn luyện xong. Bây giờ tập trung vào DVC!"
Bước 5: Cấu Hình Remote Storage
🏠 Lựa Chọn 1: Lưu Trữ Local (Đơn Giản)
# Chỉ lưu trên máy local - không cần cloud
dvc add models/mnist_model.h5
dvc add metrics/train_metrics.json
# Commit metadata
git add models/mnist_model.h5.dvc metrics/train_metrics.json.dvc
git commit -m "v1: Mô hình MNIST - Acc: 98.5%"
☁️ Lựa Chọn 2: Lưu Trữ AWS S3 (Chuyên Nghiệp)
# Cấu hình remote S3
dvc remote add -d myremote s3://your-bucket-name/dvc-storage
# Thêm mô hình vào DVC
dvc add models/mnist_model.h5
dvc add metrics/train_metrics.json
# Push lên S3
dvc push
# Commit metadata
git add models/mnist_model.h5.dvc metrics/train_metrics.json.dvc
git commit -m "v1: Mô hình MNIST - Acc: 98.5%"
Lúc này tôi nghĩ: "Tuyệt! Bây giờ có cả local và cloud storage rồi!"
Bước 6: Tạo Phiên Bản 2 (Subset)
# Tạo subset nhỏ hơn
python scripts/download_mnist.py --size=subset
# DVC tự động phát hiện thay đổi
dvc add data/raw/x_train.npy data/raw/y_train.npy
# Huấn luyện với subset
python scripts/train.py
# Thêm mô hình mới
dvc add models/mnist_model.h5
dvc add metrics/train_metrics.json
# Commit phiên bản 2
git add data/raw/x_train.npy.dvc data/raw/y_train.npy.dvc models/mnist_model.h5.dvc metrics/train_metrics.json.dvc
git commit -m "v2: Subset 10k samples - Acc: 96.2%"
Bước 7: So Sánh Phiên Bản
# Xem lịch sử
git log --oneline
# Kiểm tra trạng thái DVC
dvc status
# Xem cache
ls -la .dvc/cache/
Bước 8: Chuyển Đổi Phiên Bản
# Quay lại phiên bản 1
git checkout HEAD~1
dvc checkout # QUAN TRỌNG: Phải chạy sau git checkout!
# Chuyển về phiên bản 2
git checkout HEAD
dvc checkout # QUAN TRỌNG: Phải chạy sau git checkout!
⚠️ Lưu ý quan trọng:
- git checkout chỉ chuyển đổi metadata (file .dvc)
- dvc checkout mới thực sự chuyển đổi dữ liệu thật
- Luôn chạy dvc checkout sau git checkout để đồng bộ dữ liệu!
Câu Chuyện Thực Tế: Bug DVC Checkout
Tình huống: Một ngày đẹp trời, tôi quay lại phiên bản cũ để test:
# Tôi chỉ chạy git checkout
git checkout HEAD~1
# Kiểm tra dữ liệu
python -c "
import numpy as np
x = np.load('data/raw/x_train.npy')
print(f'Training samples: {len(x)}')
"
# Kết quả: Training samples: 10000 (vẫn là subset!)
# Tôi nghĩ: "Sao lại vậy? Mình đã checkout rồi mà?"
Nguyên nhân: Tôi quên chạy dvc checkout!
# Chạy dvc checkout
dvc checkout
# Kiểm tra lại
python -c "
import numpy as np
x = np.load('data/raw/x_train.npy')
print(f'Training samples: {len(x)}')
"
# Kết quả: Training samples: 60000 (đúng rồi!)
Bài học: Git chỉ quản lý metadata, DVC mới quản lý dữ liệu thật!
Các Bug Thường Gặp Với DVC
Bug 1: Quên DVC Checkout
# ❌ Sai - Chỉ chạy git checkout
git checkout HEAD~1
# Dữ liệu không thay đổi!
# ✅ Đúng - Chạy cả hai
git checkout HEAD~1
dvc checkout
# Dữ liệu thay đổi đúng!
Bug 2: Cache Corruption
# Tình huống: Dữ liệu bị lỗi
python -c "import numpy as np; np.load('data/raw/x_train.npy')"
# Lỗi: ValueError: Object arrays cannot be loaded when allow_pickle=False
# Giải pháp: Clean cache và pull lại
dvc cache clean
dvc pull
Bug 3: Remote Connection Issues
# Tình huống: Không push được lên S3
dvc push
# Lỗi: Failed to push to remote storage
# Giải pháp: Kiểm tra credentials
aws s3 ls # Test AWS connection
dvc remote list # Check DVC remotes
Bug 4: File Not Found
# Tình huống: File không tồn tại
python train.py
# Lỗi: FileNotFoundError: data/raw/x_train.npy
# Giải pháp: Pull dữ liệu từ remote
dvc pull
Bug 5: Git Add Quên .dvc Files
# ❌ Sai - Chỉ add file data
git add data/raw/x_train.npy
# ✅ Đúng - Add cả .dvc file
git add data/raw/x_train.npy.dvc
git commit -m "Add training data"
🏠 Cấu Hình Local Storage
Khi Nào Sử Dụng Local Storage?
✅ Phù hợp khi:
- Dự án cá nhân hoặc team nhỏ (< 4 người)
- Dữ liệu < 50GB
- Development và testing
- Môi trường air-gapped (không có internet)
- Budget hạn chế
❌ Không phù hợp khi:
- Team collaboration (4+ người)
- Dữ liệu > 50GB
- Cần backup và disaster recovery
- Production environment
Bước 1: Cấu Hình Local Storage
# Tạo thư mục storage
mkdir -p /path/to/dvc-storage
# Cấu hình DVC remote
dvc remote add -d local_storage /path/to/dvc-storage
# Test cấu hình
dvc push
dvc pull
Bước 2: Cấu Trúc Local Storage
/path/to/dvc-storage/
├── 3a/
│ └── 3a1b2c3d4e5f... # File hash
├── 7f/
│ └── 7f8e9d0c1b2a... # File hash
└── cache/
└── files/
Bước 3: Quản Lý Local Storage
# Xem vị trí cache
dvc cache dir
# Xem dung lượng cache (Linux/Mac)
du -sh .dvc/cache/
# Xem dung lượng cache (Windows)
dir .dvc\cache\ /s
# Dọn dẹp cache không dùng
dvc cache clean --unused
# Xem trạng thái
dvc status
Bước 4: Cấu Hình Network Drive
# Cấu hình network drive
dvc remote add -d network_storage //server/share/dvc-storage
# Hoặc NFS mount
dvc remote add -d nfs_storage /mnt/nfs/dvc-storage
Bước 5: Xử Lý Lỗi Local Storage
Lỗi 1: Quyền Truy Cập
# Kiểm tra quyền
ls -la /path/to/dvc-storage
# Sửa quyền
chmod 755 /path/to/dvc-storage
chown -R $USER:$USER /path/to/dvc-storage
Lỗi 2: Hết Dung Lượng
# Kiểm tra dung lượng (Linux/Mac)
df -h /path/to/dvc-storage
# Kiểm tra dung lượng (Windows)
dir /s /-c /path/to/dvc-storage
# Dọn dẹp cache không dùng
dvc cache clean --unused
# Chuyển sang vị trí khác
dvc remote modify local_storage url /new/path/to/storage
Lỗi 3: Vấn Đề Network Drive
# Test kết nối mạng
ping server-name
# Kiểm tra trạng thái mount
mount | grep network-drive
# Mount lại nếu cần
sudo mount -t cifs //server/share /mnt/dvc-storage
Bước 6: Phân Tích Chi Phí
| Loại Storage | Chi Phí Tháng | Chi Phí Năm | Ghi Chú |
|---|---|---|---|
| Local (1TB SSD) | $0 | $0 | Đầu tư một lần $100 | |
| Network Drive | $0 | $0 | Hạ tầng công ty | |
| External HDD | $0 | $0 | Đầu tư một lần $50 |
☁️ Cấu Hình AWS S3
Bước 1: Tạo AWS Account và IAM User
- Truy cập AWS Console: https://aws.amazon.com/
- Tạo Account và điền thông tin xác thực
- Chọn Free Tier để tiết kiệm chi phí
- Tạo IAM User với quyền S3FullAccess
- Tạo Access Key cho CLI
Bước 2: Cài Đặt AWS CLI
# Cài đặt AWS CLI
pip install awscli
# Cấu hình credentials
aws configure
# Nhập thông tin:
# AWS Access Key ID: [your-access-key]
# AWS Secret Access Key: [your-secret-key]
# Default region name: us-east-1
# Default output format: json
Bước 3: Tạo S3 Bucket
# Tạo S3 bucket
aws s3 mb s3://your-unique-bucket-name
# Kiểm tra bucket
aws s3 ls
Bước 4: Cấu Hình DVC với S3
# Thêm remote storage
dvc remote add -d storage s3://your-bucket-name/dvc-storage
# Cấu hình credentials (tùy chọn)
dvc remote modify storage access_key_id YOUR_ACCESS_KEY
dvc remote modify storage secret_access_key YOUR_SECRET_KEY
# Test kết nối
dvc push
Bước 5: So Sánh Local vs S3
| Tính Năng | Local Storage | AWS S3 |
|---|---|---|
| Chi phí | ✅ Miễn phí | 💰 Trả phí theo usage |
| Tốc độ | ✅ Rất nhanh | ⚠️ Phụ thuộc internet |
| Chia sẻ | ❌ Khó khăn | ✅ Dễ dàng |
| Backup | ❌ Không có | ✅ Tự động |
| Mở rộng | ❌ Giới hạn | ✅ Không giới hạn |
| Phù hợp | Học tập, cá nhân | Team, production |
Bước 6: Hybrid Strategy
# Cấu hình multiple remotes
dvc remote add local /path/to/local/storage
dvc remote add s3 s3://your-bucket/dvc-storage
# Set default remote
dvc remote default s3
# Push to specific remote
dvc push -r local # Push to local
dvc push -r s3 # Push to S3
🛠️ Troubleshooting & Best Practices
Common Issues
Issue 1: DVC Checkout Forgotten
# Problem: Dữ liệu không đồng bộ sau git checkout
# Solution: Luôn chạy dvc checkout sau git checkout
git checkout <version>
dvc checkout # QUAN TRỌNG!
Issue 2: Cache Corruption
# Problem: Dữ liệu bị lỗi trong cache
# Solution: Clean và pull lại
dvc cache clean
dvc pull
Issue 3: Remote Connection Issues
# Problem: Không thể kết nối đến S3
# Solution: Kiểm tra credentials
aws s3 ls # Test AWS connection
dvc remote list # Check DVC remotes
Performance Optimization
# Xem cache usage
dvc cache dir
du -sh .dvc/cache/
# Clean unused cache
dvc cache clean --unused
# Push với parallel jobs
dvc push -j 4
🚀 Advanced Features
DVC Pipeline
# dvc.yaml
stages:
download:
cmd: python scripts/download_mnist.py --size=full
outs:
- data/raw/x_train.npy
- data/raw/y_train.npy
- data/raw/x_test.npy
- data/raw/y_test.npy
train:
cmd: python scripts/train.py
deps:
- scripts/train.py
- data/raw/x_train.npy
- data/raw/y_train.npy
outs:
- models/mnist_model.h5
metrics:
- metrics/train_metrics.json
evaluate:
cmd: python scripts/evaluate.py
deps:
- scripts/evaluate.py
- models/mnist_model.h5
- data/raw/x_test.npy
metrics:
- metrics/eval_metrics.json
Chạy Pipeline
# Chạy toàn bộ pipeline
dvc repro
# Chạy chỉ một stage
dvc repro train
# Xem pipeline
dvc dag
Experiment Tracking
# Chạy experiment
dvc exp run
# So sánh experiments
dvc exp show
# Xem metrics
dvc metrics show
dvc metrics diff
🚀 DVC Pipeline
Tạo DVC Pipeline
# dvc.yaml
stages:
download:
cmd: python scripts/download_mnist.py --size=full
outs:
- data/raw/x_train.npy
- data/raw/y_train.npy
- data/raw/x_test.npy
- data/raw/y_test.npy
train:
cmd: python scripts/train.py --epochs=10
deps:
- scripts/train.py
- data/raw/x_train.npy
- data/raw/y_train.npy
- data/raw/x_test.npy
- data/raw/y_test.npy
outs:
- models/mnist_model.h5
metrics:
- metrics/train_metrics.json:
cache: false
evaluate:
cmd: python scripts/evaluate.py
deps:
- scripts/evaluate.py
- models/mnist_model.h5
- data/raw/x_test.npy
- data/raw/y_test.npy
metrics:
- metrics/eval_metrics.json:
cache: false
Chạy Pipeline
# Chạy toàn bộ pipeline
dvc repro
# Chạy chỉ một stage
dvc repro train
# Xem pipeline
dvc dag
🛠️ Commands Hữu Ích
# Xem trạng thái
dvc status
dvc status --cloud
# Xem cache
dvc cache dir
du -sh .dvc/cache/
# Clean cache
dvc cache clean --unused
# Xem pipeline
dvc dag
# Xem metrics
dvc metrics show
dvc metrics diff
# Xem plots
dvc plots show metrics/train_metrics.json
🎯 Kết Luận
✅ Những gì đã học:
dvc add- Thêm file vào DVCdvc checkout- Chuyển đổi phiên bản dữ liệudvc push/pull- Đồng bộ với remotedvc repro- Chạy pipelinedvc status- Kiểm tra trạng thái
💡 Tips:
- Luôn chạy
dvc checkoutsaugit checkout - DVC chỉ lưu metadata trong Git, dữ liệu thật trong cache
- Sử dụng
dvc reprođể chạy pipeline tự động - Monitor cache size với
du -sh .dvc/cache/
🚀 Next Steps:
- Thử với dữ liệu thật
- Tích hợp S3
- Tạo pipeline phức tạp hơn
- Thử với team
Đây là cách học DVC thực tế nhất - từ lý thuyết đến thực hành với MNIST!
Chưa có bình luận nào. Hãy là người đầu tiên!