
Linear Regression
1. Linear Regression
1.1. Introduction
Linear regression là một thuật toán học có giám sát trong machine learning, nơi thể hiện mối quan hệ giữa các biến độc lập và biến phụ thuộc. Nó giả định rằng mối quan hệ của biến độc lập và biến phụ thuộc là tuyến tính. Cụ thể, phương pháp này sẽ học từ tập dữ liệu đã được gắn nhãn và ánh xạ các điểm dữ liệu thành một hàm tuyến tính được tối ưu hóa có thể sử dụng để dự đoán trên tập dữ liệu mới.
Phương trình tổng quát của linear regression:$y \approx \hat{y} = w_0 + w_1x_1 + w_2x_2 + \dots + w_nx_n$
Trong đó:
- $y$: giá trị thực của đầu ra (ground truth)
- $\hat y$: biến phụ thuộc (giá trị đầu ra dự đoán - predict output)
- $x_1, x_2, \dots, x_n$: các biến độc lập
- $w_0, w_1, \dots, w_n$: các hệ số cần tìm
Mục tiêu của Linear regression là ước tính các hệ số $w$ để giảm thiểu sai số dự đoán cho biến phụ thuộc - $\hat y$ dựa trên tập hợp các biến độc lập - $x$. Để thực hiện điều này, một cách hiểu đơn giản là cố gắng tìm một phương trình tuyến tính để cho $\hat y$ xấp xỉ với giá trị $y$. Mặc dù, $y$ và $\hat y$ là hai giá trị khác nhau do sai số của mô hình; tuy nhiên chúng ta mong muốn sự khác nhau giữa hai giá trị là nhỏ nhất.
Dưới đây là hình ảnh của Linear Regression với 1 feature.
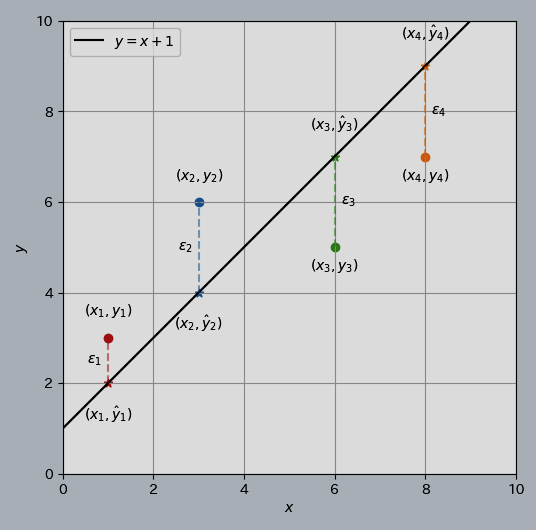
1.2. Hàm mất mát cho linear regression
Như đã thảo luận trước đó, việc tìm ra một phương trình tuyến tính cho các trường hợp thực tế là không dễ dàng vì quá trình tính toán sẽ phát sinh lỗi. Những lỗi này cần được tính toán để giảm thiểu chúng. Sự khác biệt giữa giá trị dự đoán $\hat y$ và giá trị thực $y$ được gọi là hàm mất mát.
Hàm mất mát được hình thành từ việc lấy giá trị dự đoán $\hat y$ và so sánh nó với giá trị mục tiêu (target) $y$ bằng phép tính $(\hat y - y)$ để đo lường khoảng cách giữa giá trị dự đoán và giá trị mục tiêu.
➡️-> Chúng ta muốn tìm các giá trị $w$ để sai số $(\hat y-y)$ là nhỏ nhất.
Ở đây, phép tính $(\hat y-y)$ đôi khi là số âm nên ta có thể tính toán bằng cách lấy giá trị tuyệt đối $|\hat y-y|$ hoặc lấy bình phương $(\hat y-y)^2$. Trong linear regression, cách lấy giá trị tuyệt đối ít được sử dụng hơn vì hàm này không khả vi tại mọi điểm, sẽ không thuận tiện cho việc tối ưu sau này.
Chính vì vậy, MSE - Mean Squared Error được sử dụng để tính toán giá trị trung bình của các sai số bình phương giữa giá trị dự đoán và giá trị thực.
Hàm MSE có thể được tính như sau:
$$J = \frac{1}{n}\sum_{i=1}^{n}(\hat y_i - y_i)^2$$
Bài toán lúc này chuyển thành tìm các giá trị $w$ để giá trị hàm mất mát $J$ là nhỏ nhất.
1.3. Tóm tắt
- Linear regression mong muốn có một đường thẳng phù hợp cho bộ dữ liệu huấn luyện với phương trình: $y = w_0 + w_ix_i$
- Tham số: $w$
- Tùy vào cách chọn các tham số $w$ ta sẽ có được các đường thẳng khác nhau.
- Mục tiêu: Cần tìm $w$ sao cho đường thẳng phù hợp nhất với bộ dữ liệu huấn luyện.
- Để đo mức độ lựa chọn $w$ phù hợp, ta có hàm mất mát (Loss Function).
- Hàm mất mát: Hàm này đo lường sai số giữa các dự đoán của mô hình và giá trị thực tế.
$$J = \frac{1}{n}\sum_{i=1}^{n}(\hat y_i - y_i)^2$$
- Mục tiêu cuối cùng: Tìm các giá trị $w$ để hàm mất mát $J$ là nhỏ nhất.
$$w = \text{minimize}_w J(w)$$
2. Gradient Descent
2.1. Gradient descent là gì?
Gradient descent (GD) là một kỹ thuật tối ưu phổ biến, thường được dùng để huấn luyện các mô hình học máy và mạng nơ-ron. Nó giúp huấn luyện các mô hình bằng cách giảm thiểu sai số giữa kết quả dự đoán và kết quả thực tế.
Trong linear regression, kỹ thuật này giúp chúng ta đi tìm điểm tối ưu trên hàm mất mát, nơi mà sai số dự đoán được giảm thiểu tối đa. Như vậy, có thể nói hàm mất mát đóng vai trò như một thước đo; còn Gradient descent là công cụ để tìm ra tham số tối ưu nhất cho hàm mất mát.
2.2. Cách hoạt động
Gradient descent hoạt động bằng cách bắt đầu với các tham số mô hình ngẫu nhiên và liên tục điều chỉnh chúng để làm giảm sự khác biệt giữa giá trị dự đoán và giá trị thực tế.
Với GD, việc cần làm là tiếp tục thay đổi các tham số $w$ mỗi lần một chút để cố gắng giảm giá trị hàm mất mát $J(w)$ cho đến khi $J$ ổn định hoặc gần mức tối thiểu.
Công thức cập nhật:
$$w = w - \alpha \cdot \nabla J(w)$$
Trong đó:
$w$: là trọng số tối ưu cần tìm
$\alpha$ (alpha): learning rate - là tốc độ học, xác định độ lớn của mỗi bước cập nhật.
$\nabla J(w)$: đạo hàm riêng của hàm mất mát theo từng tham số.
Learning rate thường là số nhỏ giữa 0 và 1, về cơ bản $\alpha$ kiểm soát độ lớn bước di chuyển của trọng số. Đạo hàm giúp xác định được hướng di chuyển của trọng số; các trọng số sẽ di chuyển ngược với hướng của đạo hàm để tìm điểm tối ưu.
GD sẽ lặp lại cho đến khi hội tụ - đạt đến điểm local minimum (nơi các tham số $w$ không còn thay đổi nhiều với mỗi bước di chuyển).
Ở đây điểm local minimum có thể là global minimum, tuy nhiên việc tìm ra điểm global minimum của các hàm mất mát là rất phức tạp thậm chí là bất khả thi. Thay vào đó, người ta thường cố gắng tìm ra các điểm local minimum và coi đó là nghiệm của bài toán. Do vậy, tùy vào điểm khởi tạo tham số $w$ ở đâu sẽ có thể có local minimum khác nhau.
2.3. Các loại Gradient descent
- Batch Gradient Descent: Sử dụng toàn bộ tập dữ liệu để cập nhật trọng số trong mỗi bước lặp. Phương pháp này có độ chính xác cao nhất vì các tham số khi cập nhật được xem xét trên toàn bộ dữ liệu huấn luyện. Tuy nhiên nó tốn nhiều chi phí tính toán đối với các bộ dữ liệu lớn.
- Stochastic Gradient Descent (SGD): Chỉ sử dụng một mẫu dữ liệu huấn luyện ngẫu nhiên để cập nhật trọng số. Tốc độ hội tụ nhanh, nhưng độ chính xác thấp hơn so với Batch Gradient Descent.
- Mini-Batch Gradient Descent: Các tham số được cập nhật theo từng nhóm nhỏ (batch). Đây là phương pháp kết hợp sự ổn định của Batch Gradient Descent và tốc độ của SGD. Tuy nhiên, dữ liệu phải cần thời gian để lựa chọn kích thước batch phù hợp; điều này có thể ảnh hưởng khả năng hội tụ và hiệu suất.
Ngoài ra để cải tiến GD, một số biến thể được giới thiệu như Momentum, Nesterov Accelerated Gradient (NAG), Adagrad, RMSProp, Adam.
2.4. Tổng kết
Gradient Descent là thuật toán tối ưu cốt lõi trong học máy và đặc biệt quan trọng trong deep learning hiện nay. Nó giúp mô hình học bằng cách liên tục điều chỉnh tham số để giảm sai số dự đoán.
Ưu điểm:
- Đơn giản, dễ triển khai.
- Hoạt động tốt với dữ liệu lớn.
- Là nền tảng cho các thuật toán tối ưu hiện đại như Adam, RMSProp hay Adagrad.
Nhược điểm:
- Dễ mắc kẹt tại local minimum.
- Phụ thuộc mạnh vào tốc độ học (learning rate).
- Có thể hội tụ chậm.
Trong thực tế, các biến thể như Mini-Batch GD và Adam đang được sử dụng phổ biến nhờ cân bằng tốt giữa tốc độ và độ ổn định.
2.5. Code implementation
import numpy as np
def linear_regression_gradient_descent(X: np.ndarray, y: np.ndarray, alpha: float, iterations: int) -> np.ndarray:
m, n = X.shape
theta = np.zeros(n)
for _ in range(iterations):
predictions = X @ theta
errors = predictions - y
gradient = (1 / m) * (X.T @ errors)
theta -= alpha * gradient
return np.round(theta, 4)
Run Test
Hình đầu tiên (Epoch #200): Mô hình mới bắt đầu học, các tham số $a, b$ (cuối đường trắng bên trái) còn xa điểm tối ưu (tâm đỏ) nên đường thẳng (bên phải) chưa khớp tốt với dữ liệu và Lỗi Trung bình Bình phương (MSE) còn cao (1.98515).
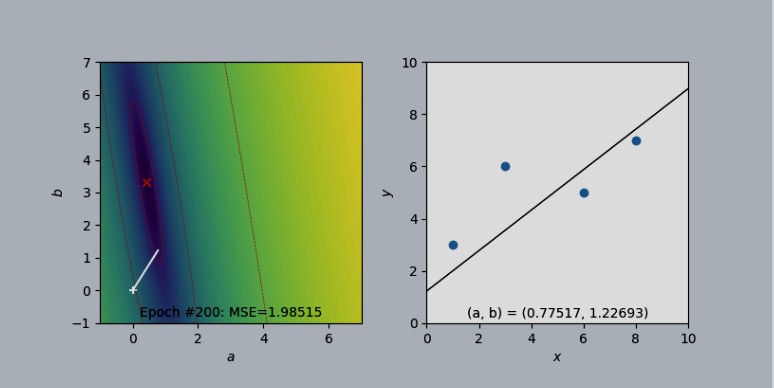
Hình thứ hai (Epoch #4800): Sau khi học 4800 bước, các tham số đã tiến rất gần đến điểm tối ưu (tâm đỏ), giúp đường thẳng (bên phải) khớp tốt hơn nhiều với các điểm dữ liệu và MSE đã giảm xuống rất thấp (0.87884).

3. Vetorizer Linear Regression
Chúng ta sẽ tìm hiểu về việc áp dụng vectorized trong linear regression, việc dùng vectorized sẽ giúp chúng ta tiết kiệm thời gian tính toán dựa vào việc tính toán của ma trận nhanh hơn nhiều lần so với việc tính toán từng lần lặp 1 và cập nhật tham số.
Để có thể hiểu được cách dùng vectorized, bạn sẽ cần có kiến thức cơ bản về ma trận (chiều và cách nhân chia cộng trừ, dot product).
Công thức và các bước trong học máy linear regression:
-
Chọn 1 dữ liệu trong data
-
Tính đầu ra $\hat{Y}$
$\hat{Y} = w_1x_1 + w_2x_2 + \dots + w_ix_i + b$ Trong đó $x_1, x_2, \dots, x_i$ tương ứng với giá trị cột từ 1, 2, ..., i.
$w_1, w_2, \dots, w_i$ và $b$ là các đối số khởi tạo ban đầu ngẫu nhiên.
-
Tính loss
$L = (\hat{Y} - y)^2$
-
Tính đạo hàm theo w và b
$$ \frac{\partial L}{\partial w_1} = 2x_1(\hat{y} - y) $$
$$ \frac{\partial L}{\partial w_2} = 2x_2(\hat{y} - y) $$
$$\frac{\partial L}{\partial w_3} = 2x_3(\hat{y} - y) $$
$$ \frac{\partial L}{\partial b} = 2(\hat{y} - y) $$
- Cập nhật tham số $w_1, w_2, \dots, w_i$ và b
Dữ liệu mẫu để tính toán:
| Features | Label | ||
|---|---|---|---|
| TV | Radio | Newspaper | Sales |
| 230.1 | 37.8 | 69.2 | 22.1 |
| 44.5 | 39.3 | 45.1 | 10.4 |
Từ dữ liệu mẫu, ta có cột TV tương ứng $x_1$, Radio tương ứng $x_2$ và Newspaper tương ứng $x_3$, cột Sales tương ứng $y$ (giá trị thực tế).
Ví dụ tính toán với một dòng dữ liệu:
B1. Khởi tạo tham số $w_1, w_2, w_3, b = 0.01$, n (learning rate) = 0.0001
Chọn dòng dữ liệu đầu tiên ta có $x_1 = 230.1$, $x_2 = 37.8$, $x_3 = 69.2$, và $y = 22.1$.
B2. Tiếp theo, áp dụng công thức ta có:
$$ \hat{Y} = 0.01 * 230.1 + 0.01 * 37.8 + 0.01 * 69.2 + 0.01 = 3.38 $$
B3. Tính Loss = $(\hat{Y}-y)^2 = (3.38-22.1)^2 \approx 350.43$
B4. Tính đạo hàm theo w và b
Ta có $\hat{Y}-y = 3.38 - 22.1 = -18.72$
- Đạo hàm tại $w_1$: $2 * 230.1 * (-18.72) = -8614.944$
- Đạo hàm tại $w_2$: $2 * 37.8 * (-18.72) = -1415.232$
- Đạo hàm tại $w_3$: $2 * 69.2 * (-18.72) = -2590.848$
- Đạo hàm tại $b$: $2 * (-18.72) = -37.44$
B5. Cập nhật $w_1, w_2, w_3$ và b
$w_1 = 0.01 - 0.0001 * (-8614.944) = 0.8714944$
$w_2 = 0.01 - 0.0001 * (-1415.232) = 0.1515232$
$w_3 = 0.01 - 0.0001 * (-2590.848) = 0.2690848$
$b = 0.01 - 0.0001 * (-37.44) = 0.013744$
Ta sẽ tiếp tục dùng dòng thứ 2 của data và tính toán theo 5 bước trên để thu được giá trị tham số $w_1, w_2, w_3, b$ tối ưu nhất.
Đây là kết quả sau khi chạy dòng thứ 2:w1 = 0.46, w2 = -0.21, w3 = -0.15, b = 0.0045
Như các bạn thấy ở trên các tham số sẽ được cập nhật sau mỗi lần huấn luyện 1 dòng data, việc này sẽ đơn giản và ít tốn thời gian so với dữ liệu nhỏ, với dữ liệu lớn việc này sẽ tốn nhiều thời gian để huấn luyện. Do đó việc áp dụng vectorized sẽ giúp tiết kiệm thời gian tính toán.
Với dữ liệu như sau, ta sẽ biến đổi công thức sang dạng vector như sau ở các bước b1, b2, b4, b5:
-
Pick a sample $(\mathbf{x}, y)$ from training data
-
Compute output $\hat{y}$
$$\hat{y} = \boldsymbol{\theta}^T \mathbf{x} = \mathbf{x}^T \boldsymbol{\theta}$$
- Compute loss
$$L = (\hat{y} - y)^2$$
- Compute gradient
$$\nabla_{\boldsymbol{\theta}}L = 2\mathbf{x}(\hat{y} - y)$$
- Update parameters
$$\boldsymbol{\theta} = \boldsymbol{\theta} - \eta \nabla_{\boldsymbol{\theta}}L$$
where $\eta$ is the learning rate.
Khởi tạo tham số $w_1, w_2, w_3, b = 0.01, n = 0.0001$
B1: Ta tạo 1 ma trận X tương đương như sau:
Matrix X:
$$X = \begin{pmatrix} 1 & 1 \\\ 230.1 & 44.5 \\\ 37.8 & 39.3 \\\ 69.2 & 45.1 \end{pmatrix}$$
Tạo ma trận Y tương ứng với cột sales:
$$Y = \begin{pmatrix} 22.1 \\\ 10.4 \end{pmatrix}$$
Tạo ma trận $\theta$:
$$\theta =\begin{pmatrix}0.01 \\\0.01 \\\0.01 \\\0.01\end{pmatrix}$$
B2: Tính $\hat{Y}$, ta có
$$\hat{Y} = X^T \cdot \theta = \begin{pmatrix}1 & 230.1 & 37.8 & 69.2 \\\1 & 44.5 & 39.2 & 45.1\end{pmatrix}\cdot\begin{pmatrix}0.01 \\\0.01 \\\0.01 \\\0.01\end{pmatrix} =\begin{pmatrix}3.38 \\\1.30\end{pmatrix}$$
Ta thu được kết quả $\hat{Y}$ sau:
$$\hat{Y} =\begin{pmatrix}3.381 \\\1.298\end{pmatrix}$$
B3. Tính loss
Công thức MSE dạng ma trận:
$$L = \frac{1}{m} (\hat{Y} - Y)^T (\hat{Y} - Y)$$
Trong đó $m$ là số lượng mẫu dữ liệu (ở đây $m=2$).
- Tính vector sai số ($E = \hat{Y} - Y$):
$$E = \begin{pmatrix} 3.381 \\\ 1.299 \end{pmatrix} - \begin{pmatrix} 22.1 \\\ 10.4 \end{pmatrix} = \begin{pmatrix} -18.719 \\\ -9.101 \end{pmatrix}$$
- Tính Loss (MSE):
$$L = \frac{1}{2} \left( (-18.719)^2 + (-9.101)^2 \right) = \frac{1}{2} (350.40 + 82.83) = 216.615$$
Giá trị loss là 216.615.
B4: Đạo hàm theo w và b:
Công thức tính gradient cho MSE:$$\nabla L = \frac{\partial L}{\partial \theta} = \frac{2}{m} X (\hat{Y} - Y)$$
-
Áp dụng công thức:
Vì $m=2$, hệ số $\frac{2}{m} = 1$. Ta có: $$\nabla L = 1 \cdot X \cdot E = \begin{pmatrix} 1 & 1 \\\ 230.1 & 44.5 \\\ 37.8 & 39.3 \\\ 69.2 & 45.1 \end{pmatrix} \cdot \begin{pmatrix} -18.719 \\\ -9.101 \end{pmatrix}$$
-
Thực hiện phép nhân ma trận:
$$\nabla L =\begin{pmatrix}1(-18.719) + 1(-9.101) \\\ 230.1(-18.719) + 44.5(-9.101) \\\ 37.8(-18.719) + 39.3(-9.101) \\\ 69.2(-18.719) + 45.1(-9.101)\end{pmatrix} = \begin{pmatrix}-27.82 \\\ -4712.24 \\\ -1065.25 \\\ -1705.82\end{pmatrix}$$
B5: Cập nhật tham số
Sử dụng vector gradient vừa tính được để cập nhật $\theta$:
$$\theta_{new} = \theta_{old} - \eta \nabla L$$
$$\begin{pmatrix}0.01 \\\ 0.01 \\\ 0.01 \\\ 0.01\end{pmatrix} - 0.0001 \cdot\begin{pmatrix}-27.82 \\\ -4712.24 \\\ -1065.25 \\\ -1705.82\end{pmatrix} =\begin{pmatrix}0.01 - (-0.00278) \\\ 0.01 - (-0.47122) \\\ 0.01 - (-0.10652) \\\ 0.01 - (-0.17058)\end{pmatrix} =\begin{pmatrix}0.01278 \\\ 0.48122 \\\ 0.11652 \\\ 0.18058\end{pmatrix}$$
$$\begin{pmatrix}w_1 \\\ w_2 \\\ w_3 \\\ b\end{pmatrix} =\begin{pmatrix}0.01278 \\\ 0.48122 \\\ 0.11652 \\\ 0.18058\end{pmatrix}$$
Do ta có 2 data nên sẽ cần phải chạy 2 lần lặp lại b1 và giữ nguyên tham số mới nhất, ta thu được:
$w_1 = 0.01278, w_2 = 0.48122, w_3 = 0.11652, b = 0.18058$
Như vậy việc áp dụng vectorized và sử dụng ma trận sẽ tính toán toàn bộ data trong 1 lần duy nhất mà không cần phải tính toán từng dòng 1. Việc dùng vectorized giúp chúng ta tính toán tất cả data trong cùng 1 lần duy nhất mà không phải đi từng dòng để tính toán, từ đó cải thiện được thời gian tính toán lên rất nhiều.
4. Normal Equation
4.1. Normal Equations là gì?
Normal Equation là một phương pháp giải tích (analytical solution) để tìm ra bộ tham số tối ưu cho mô hình Linear Regression. Thay vì phải huấn luyện mô hình qua nhiều vòng lặp như Gradient Descent, Normal Equation cho phép chúng ta tính toán trực tiếp giá trị tham số tối ưu chỉ bằng một công thức duy nhất.
Ý tưởng cốt lõi: Thay vì "dò dẫm" tìm kiếm nghiệm tối ưu như Gradient Descent, Normal Equation giải trực tiếp phương trình đạo hàm bằng 0 để tìm điểm cực tiểu của hàm mất mát (loss function).
4.2. Công thức của Normal Equation của linear regression:
$$\boldsymbol{\theta} = (\mathbf{X}^T \mathbf{X})^{-1} \mathbf{X}^T \mathbf{y}$$
Trong đó:
-
$\boldsymbol{\theta}$ (theta): Vector chứa các tham số cần tìm của mô hình
-
$\mathbf{X}$: Ma trận dữ liệu đầu vào (mỗi hàng là một mẫu dữ liệu)
-
$\mathbf{X}^T$: Ma trận chuyển vị của X
-
$\mathbf{y}$: Vector chứa giá trị thực tế (target values)
-
$(\mathbf{X}^T \mathbf{X})^{-1}$: Ma trận nghịch đảo của $(\mathbf{X}^T \mathbf{X})$
4.3. Cách hoạt động
Minh họa Linear Regression

Các điểm xanh là dữ liệu, đường đỏ là đường hồi quy tìm được bằng Normal Equation
Bước 1: Chuẩn bị dữ liệu
Giả sử chúng ta có dữ liệu về diện tích nhà và giá nhà:
| Diện tích (m²) | Giá (triệu đồng) |
|---|---|
| 50 | 1500 |
| 80 | 2400 |
| 100 | 3000 |
| 120 | 3600 |
Bước 2: Xây dựng ma trận X và vector y
Ma trận X cần thêm cột 1 ở đầu (để tính hệ số chặn - intercept):
$$\mathbf{X} = \begin{bmatrix}1 & 50 \\\ 1 & 80 \\\ 1 & 100 \\\ 1 & 120\end{bmatrix}$$
Vector y:
$$\mathbf{y} = \begin{bmatrix}1500 \\\ 2400 \\\ 3000 \\\ 3600\end{bmatrix}$$
Bước 3: Áp dụng công thức
Thực hiện các phép tính ma trận theo công thức Normal Equation để tìm $\boldsymbol{\theta}$.
4.4. Code implementation
import numpy as np
# Data
X = np.array([[1, 50], [1, 80], [1, 100], [1, 120]])
y = np.array([[1500], [2400], [3000], [3600]])
# Apply Normal Equation
theta = np.linalg.inv(X.T @ X) @ X.T @ y
# Result: theta[0] = intercept, theta[1] = slope (gradient)
print("Optimal parameters:", theta)
Ưu và nhược điểm
| ✅ Ưu điểm (Advantages) | ❌ Nhược điểm (Disadvantages) |
|---|---|
| Không cần chọn learning rate. | Chậm với dữ liệu lớn (khi số features n > 10,000). |
| Không cần lặp nhiều vòng. | Độ phức tạp tính toán là $O(n^3)$. |
| Tính toán một lần ra kết quả chính xác. | Không hoạt động nếu ma trận $(\mathbf{X}^T \mathbf{X})$ không khả nghịch. |
| Đơn giản, dễ implement. | Tốn bộ nhớ để lưu các ma trận lớn. |
4.5. So sánh với Gradient Descent
Khi nào dùng Normal Equation?
- Khi số lượng features nhỏ (ví dụ: n ≤ 10,000).
- Khi cần kết quả chính xác ngay lập tức.
- Khi không muốn phải tinh chỉnh các siêu tham số (hyperparameters) như learning rate.
Khi nào dùng Gradient Descent?
- Khi số lượng features rất lớn (n > 10,000).
- Khi tập dữ liệu quá lớn, không thể tải hết vào RAM cùng một lúc.
- Khi cần một mô hình có thể học online (cập nhật khi có dữ liệu mới).
4.6. Kết luận
Normal Equation là một công cụ mạnh mẽ và thanh lịch trong Machine Learning, đặc biệt phù hợp với các bài toán Linear Regression có quy mô vừa phải. Việc hiểu rõ cách hoạt động của nó không chỉ giúp bạn giải quyết vấn đề hiệu quả mà còn củng cố nền tảng toán học trong ML.
Điểm quan trọng: Normal Equation là một ví dụ tuyệt vời cho thấy không phải lúc nào cũng cần "học" qua nhiều vòng lặp – đôi khi chúng ta có thể "tính toán" trực tiếp để ra ngay câu trả lời tối ưu!
5. Hàm Mất Mát (Loss Function): "Kim Chỉ Nam" Giúp Mô Hình Học Chính Xác
5.1. Giới Thiệu: Tại Sao Mô Hình Cần Một "Loss Function"?
Hãy tưởng tượng bạn đang dạy một cỗ máy dự đoán giá nhà dựa trên diện tích. Làm sao nó biết dự đoán của mình là "tốt" hay "tệ"? Đó là lúc Hàm Mất Mát (Loss Function) phát huy tác dụng.
Hàm mất mát chính là "kim chỉ nam" cho mô hình máy học. Nó đo lường mức độ sai lệch giữa giá trị dự đoán và giá trị thực tế, từ đó chỉ cho mô hình biết cần phải "sửa sai" theo hướng nào để trở nên chính xác hơn. Toàn bộ quá trình huấn luyện mô hình là một hành trình liên tục điều chỉnh theo sự dẫn dắt của "kim chỉ nam" này để tìm ra điểm có sai số thấp nhất.
5.2. Mô Hình "Học" Như Thế Nào?
Quá trình học của mô hình là một vòng lặp tối ưu hóa gồm 5 bước, được gọi là Gradient Descent:
-
Lấy mẫu: Chọn một cặp dữ liệu (ví dụ: diện tích = 6.7, giá = 9.1).
-
Dự đoán: Dùng các trọng số $w$ và $b$ hiện tại để tính giá dự đoán: $\hat{y} = wx + b$.
-
Tính sai số (Loss): So sánh giá dự đoán và giá thật bằng hàm mất mát, ví dụ:
$$L = (\hat{y} - y)^2$$
-
Tìm hướng sửa sai: Tính đạo hàm của hàm mất mát để biết cần tăng hay giảm $w$ và $b$.
-
Cập nhật: Điều chỉnh $w$ và $b$ một chút theo hướng ngược lại của đạo hàm.
Ví dụ nhanh:
-
Bắt đầu: $w = -0.34$, $b = 0.04$.
-
Dự đoán (Lần 1): $\hat{y} = (-0.34) \times 6.7 + 0.04 = -2.238$ (rất tệ!).
-
Sai số (Lần 1): $L \approx 128.5$ (cực kỳ lớn).
-
Sau khi cập nhật (Lần 2): w và b được điều chỉnh, giả sử thành $w = 1.179$, $b = 0.267$.
-
Dự đoán (Lần 2): $\hat{y} = 1.179 \times 6.7 + 0.267 \approx 8.168$ (gần đúng hơn nhiều!).
-
Sai số (Lần 2): $L \approx 0.868$ (giảm đáng kể!).
Lặp lại quá trình này hàng nghìn lần, mô hình sẽ ngày càng chính xác.
5.3. Các Hàm Mất Mát Phổ Biến
5.3.1. Mean Squared Error (MSE)
-
Công thức: $L = (y - \hat{y})^2$.
-
Đặc điểm: Bình phương sai số, do đó "trừng phạt" các lỗi lớn rất nặng nề. Rất nhạy cảm với các giá trị ngoại lai (outliers).
-
Ưu điểm: Bề mặt hàm mất mát láng mịn, giúp Gradient Descent hội tụ nhanh và ổn định.
5.3.2. Mean Absolute Error (MAE)
-
Công thức: $L = |y - \hat{y}|$.
-
Đặc điểm: Chỉ lấy trị tuyệt đối của sai số, coi mọi lỗi đều có "giá" như nhau. Bền vững và ít bị ảnh hưởng bởi outliers.
-
Nhược điểm: Có một "góc nhọn" tại điểm sai số bằng 0, có thể gây khó khăn cho việc tối ưu hóa và làm mô hình hội tụ chậm.
5.3.3. Huber Loss
-
Đặc điểm: Là sự kết hợp hoàn hảo giữa MSE và MAE. Khi sai số nhỏ (nhỏ hơn ngưỡng $\delta$), nó hoạt động như MSE. Khi sai số lớn, nó chuyển sang hoạt động như MAE.
-
Ưu điểm: Vừa ổn định, vừa bền vững với outliers. Thường là lựa chọn mặc định an toàn.
-
Công thức:
$$L_{\delta}(y, \hat{y}) =\begin{cases}\frac{1}{2}(y - \hat{y})^2 & \text{if } |y - \hat{y}| \le \delta \\\ \delta|y - \hat{y}| - \frac{1}{2}\delta^2 & \text{if } |y - \hat{y}| > \delta\end{cases}$$
5.4. Các Kỹ Thuật Bổ Sung
Để hàm mất mát hoạt động hiệu quả, chúng ta cần:
-
Chuẩn Hóa Dữ Liệu (Data Normalization): Khi các đặc trưng có thang đo quá khác nhau (ví dụ: diện tích nhà và số phòng ngủ), quá trình học sẽ mất cân bằng. Chuẩn hóa sẽ đưa tất cả về cùng một thang đo, giúp mô hình hội tụ nhanh hơn.
-
Regularization: Khi mô hình quá phức tạp và "học thuộc lòng" dữ liệu (overfitting), Regularization sẽ thêm một "thành phần phạt" vào hàm mất mát để kiểm soát độ lớn của các trọng số, giúp mô hình tổng quát hóa tốt hơn.
- L2 (Ridge): Làm các trọng số nhỏ lại.
- L1 (Lasso): Có thể đẩy các trọng số không quan trọng về 0, giúp lựa chọn đặc trưng.
5.5. Lời Khuyên Thực Tiễn: Chọn Gì Bây Giờ?
Bảng so sánh các hàm mất mát
| Tiêu chí | Mean Squared Error (MSE) | Mean Absolute Error (MAE) | Huber Loss |
|---|---|---|---|
| Độ nhạy với Outliers | Cao | Thấp | Thấp |
| Tốc độ hội tụ | Nhanh và ổn định | Có thể chậm và dao động | Nhanh và ổn định |
| Khi nào nên dùng? | Dữ liệu sạch, không có outliers. | Dữ liệu có nhiều outliers cần bỏ qua. | Lựa chọn mặc định an toàn, đặc biệt khi không chắc về chất lượng dữ liệu |
Quy trình đề xuất:
1. Dữ liệu có outliers không?
- Không: Dùng MSE.
- Có: Dùng Huber Loss (hoặc MAE).
2. Các đặc trưng có thang đo khác nhau không?
- Luôn luôn thực hiện Chuẩn hóa dữ liệu.
3. Lo ngại về overfitting?
- Sử dụng Regularization (L1 hoặc L2).
Việc lựa chọn đúng hàm mất mát là một nghệ thuật, đòi hỏi sự am hiểu về dữ liệu và mục tiêu bài toán để xây dựng các mô hình chính xác và đáng tin cậy.
6. XAI(LIME)
6.1. Tóm tắt: Explainable AI (XAI) và LIME
Interpretability (Tính Diễn giải) là gì và Tại sao chúng ta cần nó?
Tính diễn giải (Interpretability) là mức độ mà con người có thể hiểu được nguyên nhân dẫn đến một quyết định do mô hình AI đưa ra. Trong khi các mô hình đơn giản như Cây Quyết định (Decision Trees) vốn dĩ dễ hiểu, các mô hình phức tạp hơn như Mạng Nơ-ron Sâu (Deep Neural Networks) lại hoạt động như những "hộp đen" (black boxes), khiến cho quá trình ra quyết định của chúng trở nên mờ mịt.
Sự thiếu minh bạch này, được gọi là Vấn đề Hộp đen AI (AI Black Box Problem), tạo ra một số thách thức:
- Sự tin cậy và Trách nhiệm giải trình: Rất khó để tin tưởng vào một quyết định nếu bạn không thể hiểu được lý do đằng sau nó.
- Gỡ lỗi (Debugging): Nếu không hiểu được logic của mô hình, việc xác định và sửa lỗi sẽ rất khó khăn.
- Sự công bằng và Tuân thủ: Việc giải thích là rất quan trọng để đảm bảo các hệ thống AI đưa ra quyết định công bằng và tuân thủ các quy định.
AI có thể giải thích (Explainable AI - XAI) nhằm giải quyết những vấn đề này bằng cách cung cấp các kỹ thuật để hiểu và tin tưởng vào kết quả của các mô hình học máy.
6.2. Sự phát triển và Phân loại của XAI 📈
Lĩnh vực XAI đã phát triển đáng kể theo thời gian:
1. Hệ thống Ký hiệu Sơ khai (1950s-1980s): Các hệ thống AI ban đầu như hệ chuyên gia (expert systems) được thiết kế dựa trên luật và có tính minh bạch.
2. Thách thức Hộp đen (1980s-Hiện tại): Sự trỗi dậy của mạng nơ-ron đã giới thiệu các mô hình mạnh mẽ nhưng không minh bạch, tạo ra nhu cầu về các công cụ diễn giải mới.
3. Sự ra đời của các Phương pháp XAI (2016-Hiện tại): Các kỹ thuật như LIME và SHAP đã được phát triển để cung cấp cái nhìn sâu sắc về các mô hình phức tạp.
Các kỹ thuật XAI có thể được phân loại rộng rãi như sau:
- Ante-hoc và Post-hoc: Phương pháp Ante-hoc dành cho các mô hình có bản chất dễ diễn giải (ví dụ: Cây Quyết định). Phương pháp Post-hoc được áp dụng sau khi một mô hình phức tạp đã được huấn luyện để giải thích các dự đoán của nó.
- Phụ thuộc vào Mô hình (Model-Specific) và Bất biến với Mô hình (Model-Agnostic): Các kỹ thuật phụ thuộc vào mô hình chỉ gắn với một kiến trúc mô hình cụ thể (ví dụ: Grad-CAM cho CNN). Các phương pháp bất biến với mô hình có thể được sử dụng trên bất kỳ mô hình nào. LIME là một kỹ thuật post-hoc và bất biến với mô hình.
6.3. LIME: Giải thích Cục bộ Diễn giải được và Bất biến với Mô hình
LIME là một thuật toán XAI phổ biến giúp giải thích dự đoán của bất kỳ mô hình hộp đen phức tạp nào bằng cách xấp xỉ nó với một mô hình đơn giản hơn, có thể diễn giải được (như hồi quy tuyến tính) trong phạm vi cục bộ của dự đoán cần được giải thích.
Ý tưởng cốt lõi là tìm hiểu hành vi của một mô hình phức tạp đối với một dự đoán đơn lẻ bằng cách làm nhiễu đầu vào và xem các dự đoán thay đổi như thế nào.
6.3.1. Cách LIME hoạt động: Ví dụ với Hình ảnh
Giả sử một mô hình phức tạp dự đoán một hình ảnh có chứa "con mèo" được lấy trong tài liệu của AIO. LIME giải thích dự đoán này qua các bước sau:
1. Phân đoạn (Segmentation): Hình ảnh gốc được chia thành các "siêu điểm ảnh" (superpixels), là những mảng liền kề gồm các pixel tương tự nhau. Những siêu điểm ảnh này trở thành các đặc trưng có thể diễn giải được.
import skimage.segmentation
# Tạo các siêu điểm ảnh cho ảnh đầu vào
def generate_superpixels(image):
"""Tạo các siêu điểm ảnh bằng thuật toán quickshift."""
superpixels = skimage.segmentation.quickshift(image, kernel_size=21, max_dist=200, ratio=0.2)
return superpixels
superpixels = generate_superpixels(my_image)

2. Gây nhiễu (Perturbation): Tạo một bộ dữ liệu gồm các hình ảnh mới bằng cách ẩn hoặc hiện ngẫu nhiên các kết hợp khác nhau của các siêu điểm ảnh.

3. Dự đoán (Prediction): Sử dụng mô hình phức tạp ban đầu để dự đoán xác suất có "con mèo" cho mỗi hình ảnh đã bị làm nhiễu.

4. Gán trọng số (Weighting): Gán trọng số cho mỗi ảnh bị nhiễu dựa trên sự gần gũi của nó với ảnh gốc. Các mẫu tương tự hơn (tức là có ít siêu điểm ảnh bị ẩn hơn) sẽ được gán trọng số cao hơn. Điều này thường được thực hiện bằng cách sử dụng một thước đo khoảng cách như khoảng cách cosine và hàm nhân (kernel function) mũ.
import numpy as np
import sklearn.metrics
# Hàm tính toán trọng số dựa trên khoảng cách
def compute_distances_and_weights(perturbations, num_superpixels, kernel_width=8.25):
original_image = np.ones(num_superpixels)[np.newaxis,:]
distances = sklearn.metrics.pairwise_distances(perturbations, original_image, metric='cosine').ravel()
weights = np.sqrt(np.exp(-(distances**2) / kernel_width**2))
return weights
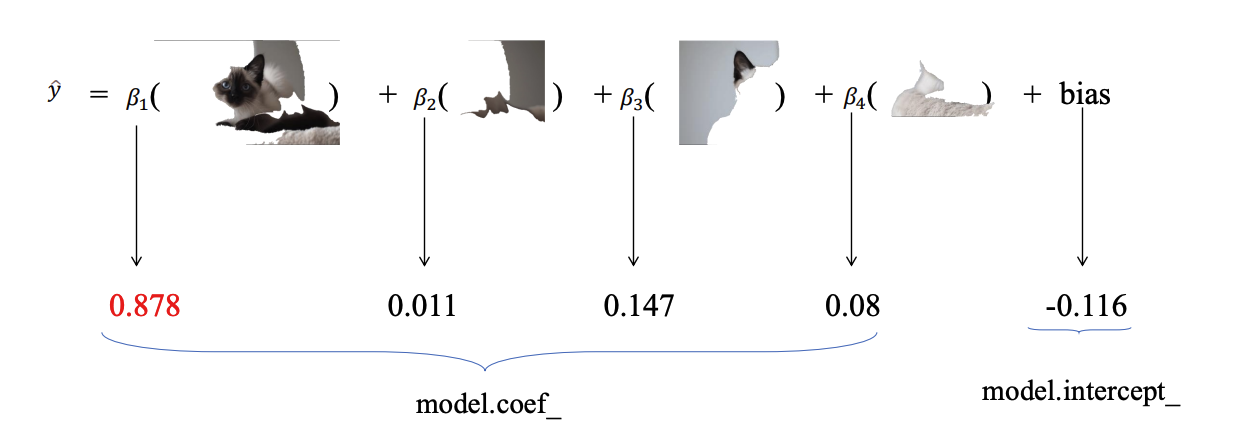
5. Huấn luyện Mô hình Diễn giải được: Huấn luyện một mô hình hồi quy tuyến tính có trọng số đơn giản trên bộ dữ liệu gồm các ảnh bị nhiễu và các dự đoán tương ứng của chúng. Các đặc trưng là biểu diễn nhị phân của các siêu điểm ảnh và mục tiêu là dự đoán từ mô hình phức tạp.
from sklearn.linear_model import LinearRegression
# Huấn luyện một mô hình tuyến tính đơn giản
simpler_model = LinearRegression()
simpler_model.fit(X=perturbations,
y=probabilities[:, 0, class_to_explain],
sample_weight=weights)
6. Giải thích: Các hệ số của mô hình tuyến tính đã huấn luyện cho thấy tầm quan trọng của mỗi siêu điểm ảnh. Một hệ số dương cao có nghĩa là siêu điểm ảnh đó đã đóng góp mạnh mẽ vào dự đoán "con mèo".
6.3.2. LIME cho Văn bản
Quy trình tương tự cũng áp dụng cho dữ liệu văn bản:
1. Mẫu (Instance): Chọn câu cần giải thích (ví dụ: "Bộ phim thật sự tuyệt vời và diễn xuất thật xuất sắc.").
2. Gây nhiễu: Tạo ra các phiên bản mới của câu bằng cách loại bỏ ngẫu nhiên các từ.
3. Dự đoán: Lấy dự đoán về sắc thái (ví dụ: xác suất là "Tích cực") cho mỗi câu đã bị làm nhiễu từ mô hình hộp đen.
4. Gán trọng số: Gán trọng số cao hơn cho các mẫu tương tự hơn với văn bản gốc (càng ít từ bị loại bỏ thì càng tương tự).
5. Huấn luyện Mô hình: Huấn luyện một mô hình tuyến tính có trọng số, trong đó các đặc trưng là các chỉ số nhị phân cho sự hiện diện của mỗi từ.
6. Giải thích: Các hệ số của mô hình cho thấy những từ nào ("tuyệt vời", "xuất sắc") có ảnh hưởng tích cực nhất đến dự đoán.
6.4. Ưu điểm và Nhược điểm của LIME
Ưu điểm: 👍
- Dễ hiểu và dễ triển khai.
- Bất biến với Mô hình (Model-Agnostic): Hoạt động với mọi loại mô hình.
- Cung cấp các giải thích cục bộ trực quan cho các dự đoán riêng lẻ.
Nhược điểm: 👎
- Thiếu ổn định: Các giải thích có thể không ổn định.
- Tốn kém về mặt tính toán: Yêu cầu thực hiện nhiều dự đoán trên các mẫu bị nhiễu.* Định nghĩa về "cục bộ"
7. Reference
[1] Ảnh về Hồi quy Tuyến tính (Linear Regression) được lấy từ lớp học về Học máy (Machine Learning) tại Nhật Bản, truy cập tại: https://chokkan.github.io/mlnote/regression/04sgd.html
[2] Ảnh được lấy từ tài liệu khóa học AIO Module 05 Tuần 01 và 02.
Chưa có bình luận nào. Hãy là người đầu tiên!