Data Version Control (DVC) trong MLOps
I. Theory Perspective (Góc nhìn Lý thuyết)
Phần này tập trung vào việc định nghĩa MLOps, vai trò của AI/ML trong hệ thống phần mềm, và tầm quan trọng của việc quản lý phiên bản dữ liệu (Data Versioning).
1. Recap AI, MLOps
AI trong phần mềm:
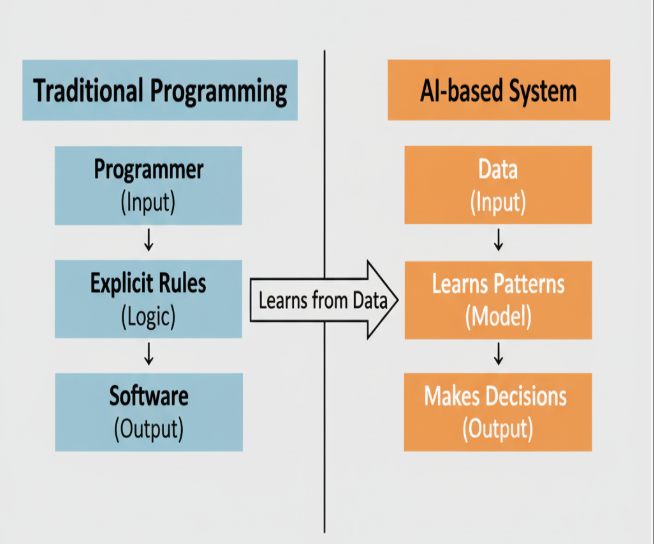
Hình 1: So sánh giữa phương pháp Traditional Programming và AI [1]
Lập trình truyền thống (Traditional Programming): Lập trình viên viết quy tắc rõ ràng → phần mềm chạy theo logic cố định.
Hệ thống dựa trên AI (AI-based): Phần mềm học từ dữ liệu để đưa ra quyết định, không cần quy tắc được viết sẵn.
Ứng dụng AI trong hệ thống thương mại điện tử lớn
- Phân tích cảm xúc (Sentiment Analysis)
- Gợi ý sản phẩm (Recommendation System)
- Phân tích hành vi khách hàng (Customer Behavior Analysis)
- Đảm bảo chất lượng (Quality Ensurement)
AI được coi là một hàm (function) để giải quyết các vấn đề giống như các câu đố (problem-like puzzles).
Chu trình sống của ML (ML Life Cycle)
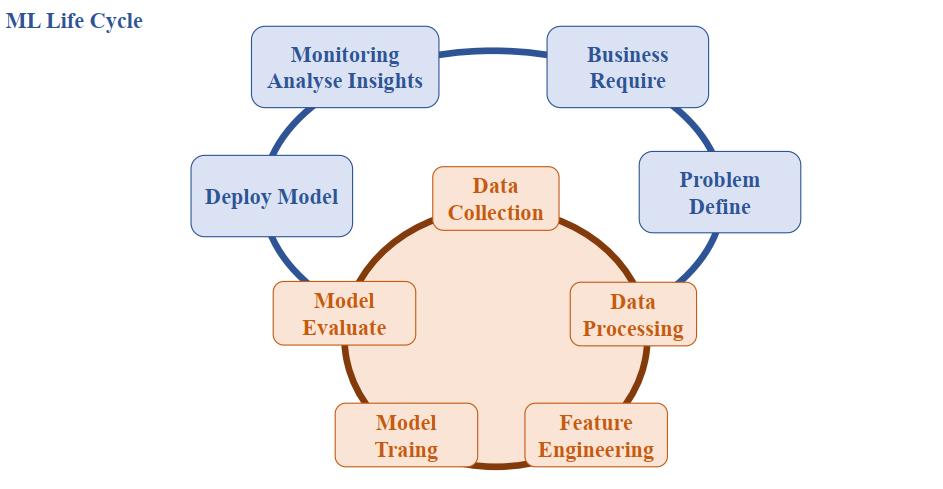
Hình 2: Quy trình xây dựng hệ thống AI [2]
Chu trình này có thể được chia thành hai phần chính:
a) Phần trên (màu xanh dương) - Vòng lặp Kinh doanh/Triển khai:
| Bước | Mô tả | Bước |
|---|---|---|
| 1 | Bắt đầu từ việc xác định Yêu cầu Kinh doanh | Business Require |
| 2 | Tiếp đến là Xác định Vấn đề | Problem Define |
| 3 | Sau khi mô hình được phát triển, nó sẽ được Triển khai | Deploy Model |
| 4 | Cuối cùng là Giám sát & Phân tích Thông tin chi tiết để xem xét hiệu quả và tái lặp lại chu trình | Monitoring Analyse Insights |
b) Phần dưới (màu cam) - Vòng lặp Kỹ thuật Dữ liệu/Phát triển Mô hình:
| Bước | Mô tả | Bước |
|---|---|---|
| 1 | Thu thập Dữ liệu | Data Collection |
| 2 | Xử lý Dữ liệu | Data Processing |
| 3 | Kỹ thuật Tính năng | Feature Engineering |
| 4 | Huấn luyện Mô hình | Model Training |
| 5 | Đánh giá Mô hình | Model Evaluate |
MLOps tập trung vào:
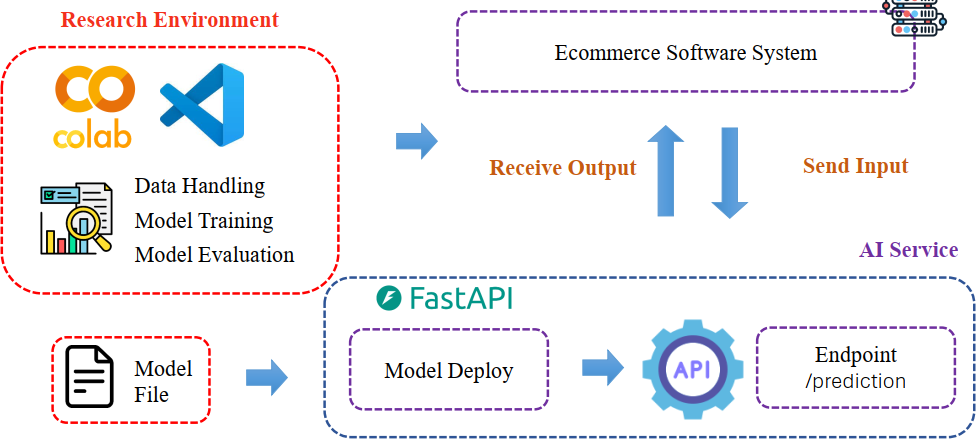
Hình 3: Mô hình Triển khai và Tích hợp Dịch vụ AI (MLOps) [2]
-
Môi trường Nghiên cứu (Research Environment): Đây là nơi các nhà khoa học dữ liệu (Data Scientists) làm việc, thường sử dụng các công cụ như Google Colab hoặc VS Code. Giai đoạn này tập trung vào ba nhiệm vụ chính: Xử lý Dữ liệu (Data Handling), Huấn luyện Mô hình (Model Training), và Đánh giá Mô hình (Model Evaluation).
-
Tạo ra Tệp Mô hình (Model File): Kết quả cuối cùng của quá trình nghiên cứu là một Tệp Mô hình (Model File) đã được tối ưu hóa.
-
Dịch vụ AI (AI Service) & Triển khai: Tệp mô hình sau đó được chuyển sang giai đoạn triển khai (Model Deploy). Mô hình được đóng gói thành một API thông qua các Framework như FastAPI. Dịch vụ AI này cung cấp một Endpoint cụ thể (ví dụ: /prediction) để sẵn sàng nhận yêu cầu từ bên ngoài.
-
Tích hợp với Hệ thống Sản phẩm: Cuối cùng, Hệ thống Phần mềm Thương mại điện tử (Ecommerce Software System) sẽ tương tác với Dịch vụ AI. Hệ thống gửi các yêu cầu đầu vào (Send Input) đến Endpoint /prediction và nhận lại kết quả dự đoán hoặc gợi ý đầu ra (Receive Output), cho phép tính năng AI được nhúng trực tiếp vào trải nghiệm người dùng (ví dụ: gợi ý sản phẩm, phân tích hành vi).
2. Data Versioning
Vấn đề về phiên bản dữ liệu cần quản lý khi có nhiều loại tệp:
- checkpoints
- parameters
- datasets
- augmented data
Ba vấn đề lớn (3 Big Problems)
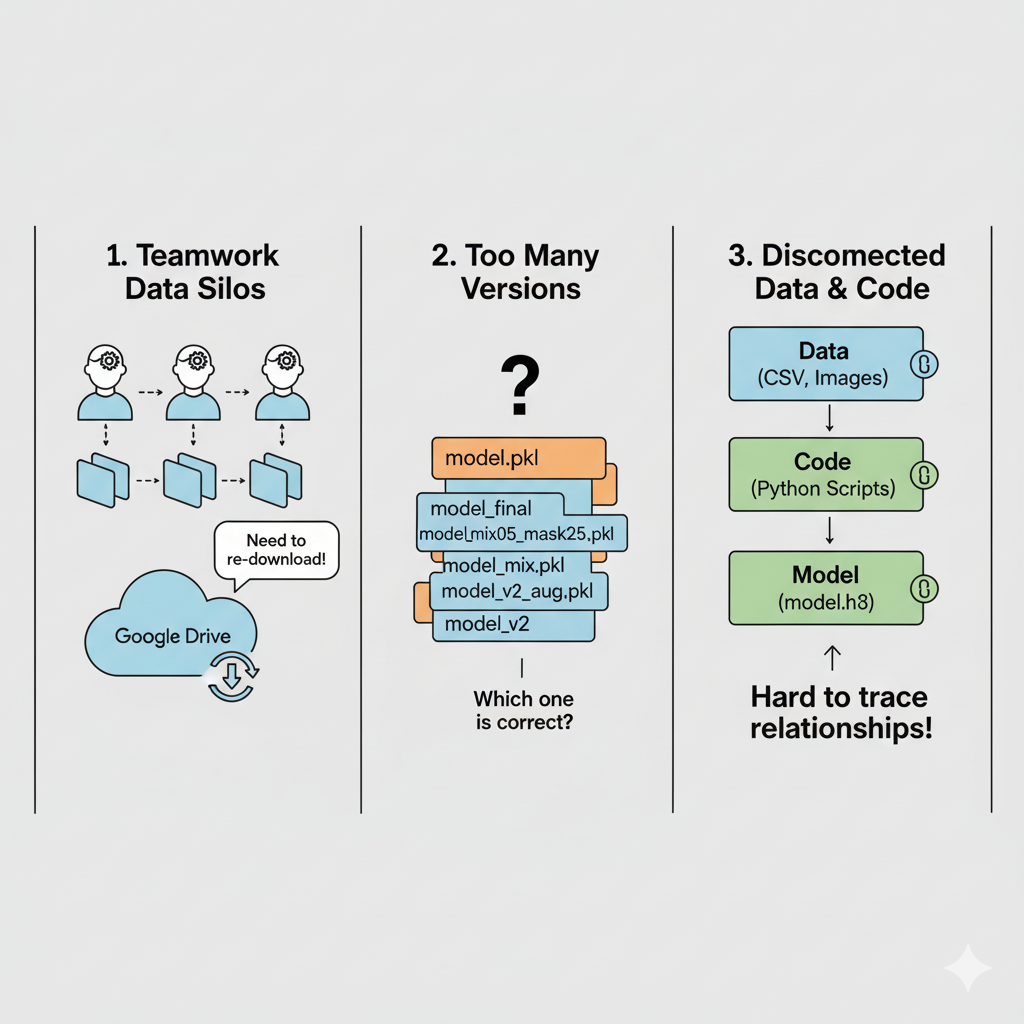
Hình 4: Mô tả 3 vấn đề với data [1]
- Làm việc nhóm: Khó đồng bộ dữ liệu giữa các thành viên (VD: phải tải lại từ Google Drive).
- Quá nhiều phiên bản dữ liệu: Khó xác định tệp nào thuộc mô hình nào (VD:
model.pkl,model_mix05_mask25.pkl). - Dữ liệu và code không kết nối: Gây khó khăn khi truy xuất mối quan hệ giữa dữ liệu, tham số và mô hình.
Giải pháp
| Giai đoạn | Vấn đề gặp phải | Giải pháp quản lý phiên bản với DVC | Lợi ích |
|---|---|---|---|
| Huấn luyện (Training) | - Nhiều dataset khác nhau, khó theo dõi - Không biết dataset nào tương ứng với model nào |
- Theo dõi dữ liệu bằng dvc add- Lưu trữ tham số huấn luyện trong params.yaml- Theo dõi model bằng dvc add models/model.pkl |
- Đảm bảo biết chính xác dataset, tham số, và model tương ứng - Dễ dàng tái lập (reproducibility) |
| Huấn luyện liên tục (Continuous Training) | - Nhiều phiên bản model từ các thử nghiệm khác nhau - Khó so sánh hiệu suất |
- Quản lý thử nghiệm bằng dvc repro, dvc metrics show, dvc params diff- Dữ liệu và model lưu trữ với remote storage (local/S3/GCP) |
- Dễ dàng so sánh các phiên bản model - Theo dõi lịch sử thay đổi tham số và dữ liệu |
| Triển khai (Deployment) | - Khó biết model nào cần deploy - Khó đồng bộ dữ liệu và model trên môi trường production |
- Checkout model và dữ liệu đúng phiên bản bằng dvc checkout- Push dữ liệu lên remote storage trước khi deploy |
- Đảm bảo deploy đúng phiên bản model và dữ liệu - Tăng tính nhất quán giữa môi trường development và production |
3. What is DVC (Data Version Control)?
Định nghĩa
Data Version Control (DVC) là công cụ mã nguồn mở (open-source tool), được thiết kế chuyên biệt để giúp các nhóm khoa học dữ liệu (Data Science) và Machine Learning (ML) quản lý các dự án của họ.
DVC hoạt động như một hệ thống quản lý phiên bản (version control system) cho dữ liệu và mô hình ML, bổ sung cho Git – vốn chỉ được dùng để quản lý mã nguồn (code).
- Mục tiêu chính của DVC là mang lại khả năng tái lập (reproducibility), quản lý lịch sử thay đổi của dữ liệu lớn và tự động hóa pipeline ML một cách hiệu quả.
- DVC sử dụng Git để theo dõi các tệp nhỏ (.dvc file) và metadata, trong khi bản thân các tệp dữ liệu lớn và mô hình được lưu trữ an toàn trên các remote storage (như AWS S3, Google Cloud Storage, hoặc Local Drive).
Thông tin chi tiết có thể được tìm thấy tại website chính thức: https://dvc.org/.
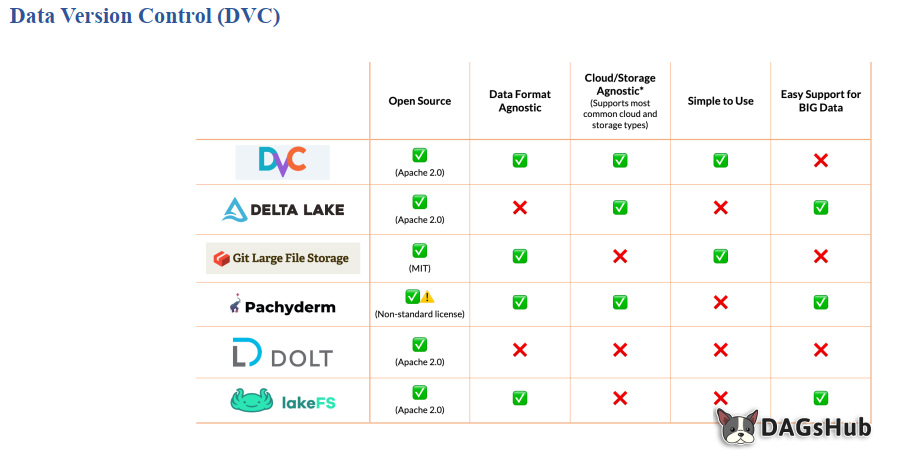
Hình 5: So sánh DVC với các công cụ quản lý dữ liệu và phiên bản khác [2]
Bảng so sánh này đánh giá Data Version Control (DVC) cùng với các công cụ quản lý dữ liệu phổ biến khác như Delta Lake, Git Large File Storage (LFS), Pachyderm, DOLT, và LakeFS dựa trên sáu tiêu chí quan trọng trong bối cảnh MLOps:
1. Open Source (Mã nguồn mở): Hầu hết các công cụ đều là mã nguồn mở (DVC sử dụng giấy phép Apache 2.0, Git LFS sử dụng MIT).
2. Data Format Agnostic (Không phụ thuộc định dạng dữ liệu): DVC, Git LFS, Pachyderm và LakeFS hỗ trợ mọi định dạng dữ liệu, một lợi thế lớn so với Delta Lake và DOLT.
3. Cloud/Storage Agnostic (Không phụ thuộc nền tảng lưu trữ): DVC có ưu điểm vượt trội khi hỗ trợ hầu hết các loại dịch vụ đám mây và lưu trữ phổ biến (như S3, GCP, Azure, v.v.). Delta Lake, Pachyderm cũng hỗ trợ tốt, trong khi Git LFS, DOLT và LakeFS có những hạn chế hơn.
4. Simple to Use (Dễ sử dụng): DVC và Git LFS được đánh giá là dễ sử dụng, trong khi các công cụ như Delta Lake, Pachyderm, DOLT và LakeFS có độ phức tạp cao hơn.
5. Easy Support for BIG Data (Dễ hỗ trợ Dữ liệu lớn): DVC không phải là giải pháp tối ưu cho việc xử lý dữ liệu lớn theo cách truyền thống. Các công cụ như Delta Lake, Pachyderm và LakeFS được xây dựng để hỗ trợ tốt hơn cho việc quản lý các tập dữ liệu cực lớn.
Nền tảng
- Kiến trúc
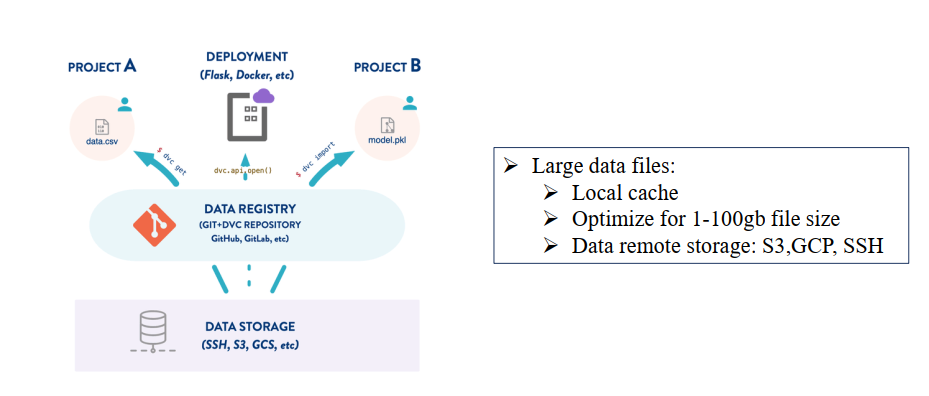
Hình 6: Kiến trúc hoạt động của DVC trong việc quản lý dữ liệu và mô hình [2]
Cách công cụ này đóng vai trò là lớp trung gian mạnh mẽ để kết nối các dự án Machine Learning với hệ thống lưu trữ dữ liệu lớn, qua đó đảm bảo khả năng kiểm soát phiên bản và chia sẻ tài nguyên hiệu quả.
| Thành phần | Vai trò | Tương tác với DVC |
|---|---|---|
| Data Registry | Trung tâm quản lý phiên bản, lưu trữ metadata và mã nguồn. | Dựa trên Git/DVC Repository (GitHub, GitLab). |
| Data Storage | Nơi lưu trữ thực tế các tệp dữ liệu lớn (.csv) và mô hình (.pkl). | Hỗ trợ S3, GCS, SSH, v.v. (Data remote storage). |
| Các Dự án ML | Nơi phát triển và huấn luyện mô hình (Project A, Project B). | Sử dụng lệnh dvc get / dvc import để kéo dữ liệu và mô hình. |
| Deployment | Môi trường triển khai mô hình (Flask, Docker). | Sử dụng dvc.api.open() để truy cập tài nguyên đã phiên bản hóa. |
| Local Cache | Lưu trữ tạm thời cục bộ dữ liệu đã được tải |
- Xây dựng trên bộ công cụ open-source
- Tối ưu cho khoa học dữ liệu
II. Tự động hóa Pipeline và Ý tưởng về Quản lý Phiên bản
Phần này tập trung vào cách DVC sử dụng các tệp cấu hình để tự động hóa pipeline và thực hiện quản lý phiên bản dữ liệu theo quy trình của Git.
Tự động hóa Pipeline với DVC (DVC Reproduction and Workflow)
DVC sử dụng các tệp cấu hình như dvc.yaml và params.yaml để quản lý các bước của pipeline và tự động hóa quy trình làm việc (workflow).
| Lệnh DVC | Chức năng |
|---|---|
dvc repro |
Chạy lại toàn bộ pipeline, chỉ thực hiện lại các bước có đầu vào (input) bị thay đổi. |
dvc dag |
Kiểm tra trạng thái và hiển thị sơ đồ phụ thuộc của pipeline. |
dvc metrics show |
Xem kết quả metrics (chỉ số đánh giá) của các lần chạy. |
dvc params diff |
Hiển thị sự khác biệt giữa các tham số (params.yaml) giữa các phiên bản. |
dvc metrics diff |
Hiển thị sự khác biệt giữa các metrics (chỉ số) giữa các phiên bản. |
Ý tưởng về Quản lý Phiên bản (The Idea of Versioning)
DVC tạo điều kiện cho một Git Workflow + Data Workflow mạnh mẽ, trong đó các thay đổi về dữ liệu và mô hình có thể được quản lý trên các nhánh tính năng (feature branches)
(ví dụ: Change_mask_rate, datasetb) song song với các nhánh code chính (master, dev).
Điều này cho phép quản lý phiên bản đồng thời cả mã nguồn và dữ liệu/mô hình, giúp việc cộng tác và tái tạo kết quả trở nên dễ dàng hơn.
III. Nghiên cứu tình huống và Triển khai DVC (DVC MNIST Project)
Nghiên cứu tình huống này trình bày quy trình từng bước để kiểm soát phiên bản dữ liệu và mô hình cho một dự án MNIST sử dụng DVC.
| Bước | Hoạt động | Lệnh DVC/Git liên quan |
|---|---|---|
| Bước 1: Thiết lập Dự án | Tạo thư mục, cấu trúc dự án (data/raw, models, v.v.), cài đặt môi trường và khởi tạo Git. |
$ git init`, `$ git commit |
| Bước 2 & 3: Dữ liệu V1 & Khởi tạo DVC | Tải dataset phiên bản 1. Khởi tạo DVC và dùng DVC để theo dõi các tệp dữ liệu raw. Commit metadata DVC vào Git. | $ dvc init`, `$ dvc add data/raw/x_train_v1.npy |
| Bước 4: Huấn luyện V1 | Tạo symbolic links trỏ đến dữ liệu V1. Chạy huấn luyện. Dùng DVC để theo dõi mô hình và tệp metrics. Commit kết quả vào Git. | $ dvc add models/model.npy |
| Bước 4.1: Đẩy dữ liệu lên Local Storage | Thiết lập một thư mục cục bộ làm kho lưu trữ từ xa (remote storage). Đẩy dữ liệu đã được theo dõi lên kho này. | $ dvc remote add -d localremote ./dvc_storage`, `$ dvc push |
| Bước 5, 6 & 7: Dữ liệu V2 và Huấn luyện V2 | Tải dataset phiên bản 2 mới. Cập nhật symbolic links. Chạy huấn luyện. Track mô hình/metrics mới và commit kết quả vào Git. | $ git commit -m "Dataset V2"`, `$ git commit -m "Model v2:..." |
| Bước 8: Thiết lập Remote Storage (Đám mây) | Thiết lập kho lưu trữ từ xa trên đám mây (ví dụ: S3). Đẩy dữ liệu lên kho này để chia sẻ. | $ dvc remote add -d mys3 s3://...`, `$ dvc push |
| Bước 9: Kiểm tra Chuyển đổi Phiên bản | Dùng Git để chuyển về một commit ID cũ. Dùng DVC để tự động tải dữ liệu đúng phiên bản tương ứng. | $ git checkout `, `$ dvc checkout |
| Bước 10 & 11: Chia sẻ Dự án | Đẩy code lên GitHub. Người dùng khác có thể clone Git, thêm remote DVC và pull dữ liệu tương ứng. | $ dvc pull |
Tóm tắt các Lệnh DVC Cơ bản
| Lệnh DVC | Chức năng |
|---|---|
pip install dvc |
Cài đặt DVC. |
dvc init |
Khởi tạo DVC trong dự án. |
dvc add data/raw/file.npy |
Bắt đầu theo dõi một tệp dữ liệu lớn bằng DVC. |
dvc remote add |
Thêm cấu hình kho lưu trữ từ xa (S3, GCS, SSH, Local). |
dvc push |
Gửi dữ liệu và mô hình đã được theo dõi lên kho lưu trữ từ xa. |
dvc pull |
Tải dữ liệu và mô hình từ kho lưu trữ từ xa về máy cục bộ. |
dvc checkout |
Chuyển đổi phiên bản dữ liệu/mô hình tương ứng với trạng thái Git hiện tại. |
dvc status |
Kiểm tra trạng thái các tệp được theo dõi có thay đổi hay không. |
dvc run / dvc repro |
Chạy (hoặc chạy lại) các bước pipeline đã được định nghĩa. |
Refernces
[1] DeepMind, "Gemini," Large language model, 2025. [Online]. Available: https://gemini.ai/. [Accessed: Oct. 19, 2025].
[2] Ảnh được lấy từ tài liệu khóa học AIO Module 05 Tuần 01
Chưa có bình luận nào. Hãy là người đầu tiên!