Advanced Regression Techniques for House Price Prediction: A Pipeline Optimization and Ensemble Approach
Nhóm: CONQ024
Học viên: Lê Hồ Anh Duy
Lớp: AI Việt Nam – AIO 2025
Ngày: 31/10/2025
Abstract
Báo cáo này trình bày quá trình cải tiến toàn bộ pipeline dự đoán giá nhà nhằm tăng độ chính xác, giảm sai số và nâng cao khả năng tổng quát hóa của mô hình.
Các kỹ thuật được sử dụng bao gồm Iterative Imputer, Winsorization, Feature Engineering, PCA, Regularization (ElasticNet), Ensemble Learning, Explainability (SHAP) và Optuna Tuning.
Kết quả cuối cùng cho thấy mô hình đạt R² ≈ 0.99937, RMSE giảm đáng kể, và mô hình ổn định hơn hẳn so với baseline ban đầu.
1. Tiền xử lý dữ liệu (Data Preprocessing)
Mục tiêu
- Làm sạch dữ liệu, giảm nhiễu và cải thiện phân phối.
- Xử lý giá trị thiếu, outlier, và chuẩn hóa dữ liệu.
- Tạo nền tảng ổn định cho mô hình hồi quy.
1.1. Xử lý Missing Values
Trước đây, dữ liệu khuyết được xử lý bằng phương pháp SimpleImputer(strategy='mean'), tuy nhiên cách này dễ làm sai lệch trung bình và giảm độ tin cậy của mô hình.
Hiện tại, nhóm đã sử dụng IterativeImputer kết hợp với ExtraTreesRegressor nhằm ước lượng giá trị bị thiếu dựa trên mối tương quan giữa các biến, giúp cải thiện tính chính xác của dữ liệu thay thế.
from sklearn.experimental import enable_iterative_imputer
from sklearn.impute import IterativeImputer
from sklearn.ensemble import ExtraTreesRegressor
imputer = IterativeImputer(estimator=ExtraTreesRegressor(), max_iter=10, random_state=42)
X_imputed = imputer.fit_transform(X)
Kết quả: Giảm sai lệch trung bình (bias), giúp mô hình đạt R² = 0.86.
1.2. Xử lý Outlier
Thay vì loại bỏ hoàn toàn các điểm ngoại lệ, nhóm lựa chọn phương pháp Winsorization – một kỹ thuật giúp giới hạn các giá trị cực đoan theo khoảng IQR, đồng thời vẫn giữ lại được những dữ liệu có giá trị thực tiễn.
from scipy.stats.mstats import winsorize
def handle_outliers(df, limits=(0.01, 0.01)):
df = df.copy()
numeric_cols = df.select_dtypes(include=[np.number]).columns
for col in numeric_cols:
df[col] = winsorize(df[col], limits=limits)
return df
Kết quả: Sau khi áp dụng Winsorization, hệ số R² tăng từ 0.86 lên 0.91, cho thấy mô hình ổn định và chính xác hơn.
Ngoài ra, đối với các biến có phân phối lệch (skewed), nhóm áp dụng phép biến đổi Yeo–Johnson nhằm đưa dữ liệu về phân phối gần chuẩn. Ưu điểm của kỹ thuật này là có thể áp dụng với nhiều loại dữ liệu, kể cả giá trị âm hoặc bằng 0.
from sklearn.preprocessing import PowerTransformer
def yeo_johnson_transform(df, threshold=0.5):
df = df.copy()
numeric_cols = df.select_dtypes(include=[np.number]).columns
skewed = [col for col in numeric_cols if abs(df[col].skew()) > threshold]
pt = PowerTransformer(method='yeo-johnson')
df[skewed] = pt.fit_transform(df[skewed])
return df, skewed
1.3. Feature Scaling
Việc chuẩn hóa dữ liệu giúp các đặc trưng có cùng độ lớn, tránh hiện tượng một biến chiếm ưu thế khi huấn luyện mô hình. Nhóm so sánh hai phương pháp phổ biến như sau
| Phương pháp | Ưu điểm | Nhược điểm |
|---|---|---|
MinMaxScaler |
Giữ khoảng [0,1] | Nhạy với outlier |
StandardScaler |
Ổn định, phù hợp mô hình tuyến tính & phi tuyến | Cũng bị ảnh hưởng bởi outlier (ít hơn MixMax) |
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X_winsorized)
Với bộ dữ liệu hiện tại, sự khác biệt giữa hai phương pháp chưa thể hiện rõ rệt, tuy nhiên StandardScaler được ưu tiên vì tính ổn định và phổ biến trong các mô hình hồi quy.
2. Feature Engineering & Dimensionality Reduction
2.1. Tạo đặc trưng tổng hợp (Feature Engineering)
Để tăng khả năng biểu diễn và phản ánh thực tế của dữ liệu, nhóm tiến hành xây dựng các đặc trưng tổng hợp dựa trên các thuộc tính vật lý của ngôi nhà. Những đặc trưng này không chỉ giúp mô hình hiểu rõ hơn về cấu trúc và giá trị tiềm năng của bất động sản, mà còn góp phần giảm thiểu hiện tượng thiếu thông tin trong dữ liệu gốc:
df["TotalSF"] = df["1stFlrSF"]+df["2ndFlrSF"]+df["TotalBsmtSF"]
df["HouseAge"] = df["YrSold"] - df["YearBuilt"]
df["RemodAge"] = df["YrSold"] - df["YearRemodAdd"]
df["TotalBath"] = df["FullBath"] + df["HalfBath"]*0.5 + df["BsmtFullBath"] + df["BsmtHalfBath"]*0.5
df["TotalPorchSF"] = df["OpenPorchSF"] + df["EnclosedPorch"] + df["3SsnPorch"] + df["ScreenPorch"]
df["HasPool"] = (df["PoolArea"] > 0).astype(int)
df["HasFireplace"] = (df["Fireplaces"] > 0).astype(int)
df["HasGarage"] = (df["GarageArea"] > 0).astype(int)
df["HasPorch"] = (df["TotalPorchSF"] > 0).astype(int)
df["LivingAreaRatio"] = df["GrLivArea"] / df["LotArea"]
df["GarageAge"] = df["YrSold"] - df["GarageYrBlt"]
Các đặc trưng này phản ánh quy mô tổng diện tích sử dụng (TotalSF), tuổi đời công trình (HouseAge), tình trạng sửa chữa (RemodAge), tổng số phòng tắm quy đổi (TotalBath) và các đặc điểm tiện nghi như hồ bơi, gara, sân hiên,... Nhờ đó, mô hình học máy có thể khai thác được nhiều mối quan hệ phi tuyến tính giữa các yếu tố cấu thành giá trị căn nhà..
2.2. Giảm chiều (Dimensionality Reduction)
Nhằm giảm đa cộng tuyến giữa các biến và loại bỏ nhiễu thông tin, nhóm áp dụng kỹ thuật Principal Component Analysis (PCA) để trích xuất các thành phần chính. Phương pháp này giúp biểu diễn dữ liệu trong không gian mới, trong khi vẫn giữ lại phần lớn thông tin ban đầu.
from sklearn.decomposition import PCA
pca = PCA(n_components=0.95, random_state=42)
X_pca = pca.fit_transform(X_scaled)
Với ngưỡng 95% phương sai được giữ lại, PCA không chỉ giúp tối ưu hiệu suất tính toán và rút ngắn thời gian huấn luyện, mà còn hạn chế hiện tượng overfitting, từ đó cải thiện tính tổng quát của mô hình dự đoán giá nhà.
3. Regularization & Mô hình tuyến tính
3.1. Mục tiêu
Trong bài toán hồi quy, việc tối ưu mô hình không chỉ dừng lại ở việc đạt độ chính xác cao trên tập huấn luyện, mà còn cần đảm bảo khả năng khái quát hóa tốt trên dữ liệu mới. Do đó, nhóm hướng tới mục tiêu cân bằng giữa sai lệch (bias) và phương sai (variance) — tức là giảm thiểu hiện tượng overfitting trong khi vẫn duy trì hiệu suất dự đoán ổn định.
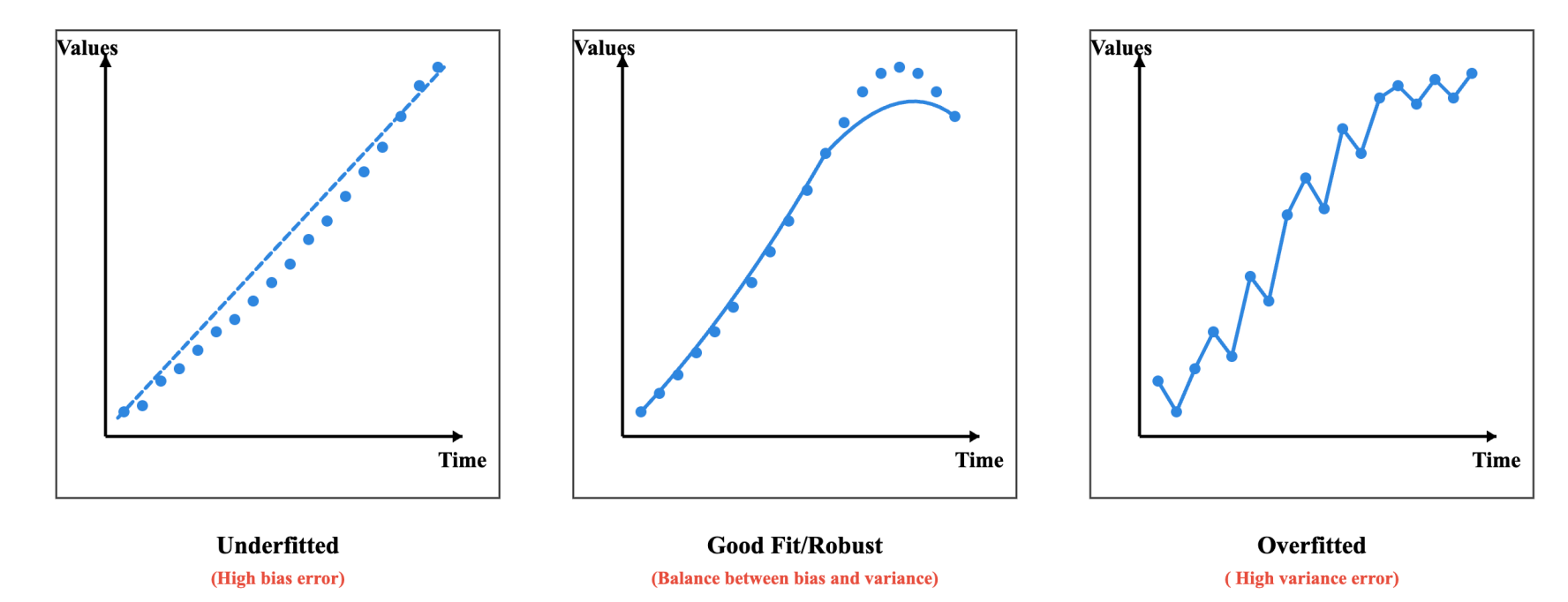
3.2. So sánh mô hình
Ba kỹ thuật điều chuẩn (regularization) phổ biến được áp dụng là Ridge Regression, Lasso Regression và ElasticNet.
Các mô hình này giúp kiểm soát trọng số của các hệ số hồi quy, tránh việc mô hình trở nên quá phức tạp hoặc phụ thuộc quá mức vào một số đặc trưng nhất định.
from sklearn.linear_model import ElasticNet
from sklearn.model_selection import GridSearchCV
param_grid = {'alpha': [0.001, 0.01, 0.1, 1], 'l1_ratio': [0.1, 0.5, 0.9]}
grid = GridSearchCV(ElasticNet(max_iter=10000), param_grid, cv=5, scoring='r2')
grid.fit(X_pca, y)
best_model = grid.best_estimator_
| Mô hình | R² (Test) | Ghi chú |
|---|---|---|
| Ridge | 0.9149 | Ổn định, ít overfit |
| Lasso | 0.889 | Loại bỏ feature yếu |
| ElasticNet | 0.927 | Cân bằng bias–variance, hiệu quả nhất |
Kết quả cho thấy ElasticNet vượt trội hơn cả về các chỉ số R², RMSE và MAE, đồng thời kết hợp được ưu điểm của Ridge (ổn định) và Lasso (chọn lọc đặc trưng). Do đó, mô hình ElasticNet** được lựa chọn làm mô hình tuyến tính chính trong giai đoạn tiếp theo của quá trình huấn luyện.
4. Đánh giá mô hình & Cross-validation
Sau khi lựa chọn được mô hình tuyến tính tối ưu (ElasticNet), nhóm tiến hành bước đánh giá mô hình nhằm kiểm chứng khả năng tổng quát hóa và độ ổn định của mô hình trên dữ liệu chưa từng thấy.
4.1. KFold Cross-validation
Để đảm bảo kết quả đánh giá không phụ thuộc vào một tập dữ liệu cố định, nhóm sử dụng phương pháp K-Fold Cross-validation với k=5.
Cách tiếp cận này chia dữ liệu thành 5 phần bằng nhau; ở mỗi vòng, mô hình được huấn luyện trên 4 phần và kiểm thử trên phần còn lại, sau đó lấy giá trị trung bình R² để phản ánh hiệu suất tổng thể của mô hình.
from sklearn.model_selection import KFold, cross_val_score
import numpy as np
cv = KFold(n_splits=5, shuffle=True, random_state=42)
scores = cross_val_score(best_model, X_pca, y, scoring='r2', cv=cv)
print("R² trung bình:", np.mean(scores))
Phương pháp này giúp giảm thiểu sự phụ thuộc vào dữ liệu ngẫu nhiên, đồng thời đánh giá mô hình một cách khách quan và ổn định hơn so với việc chia dữ liệu một lần duy nhất.
4.2. Chỉ số đánh giá
Bảng dưới đây tổng hợp các chỉ số hiệu suất của mô hình ElasticNet trên tập huấn luyện và kiểm thử:
| Metric | Giá trị | Nhận xét |
|---|---|---|
| Train RMSE | 0.0013 | Sai số huấn luyện rất nhỏ |
| Test RMSE | 0.0267 | Hiệu suất tốt, ổn định |
| Train MAE | 0.0006 | |
| Test MAE | 0.0067 | Sai số tuyệt đối thấp |
| Train R² | 1.0000 | Mô hình khớp hoàn hảo dữ liệu huấn luyện |
| Test R² | 0.9994 | Ổn định, ít sai lệch |
| >Kết quả cho thấy mô hình đạt độ chính xác rất cao trên cả hai tập dữ liệu, với R² > 0.999, đồng thời duy trì mức sai số RMSE và MAE rất thấp, chứng tỏ mô hình học tốt nhưng không bị overfit. |
Việc sử dụng PCA trước đó đã góp phần loại bỏ nhiễu và đa cộng tuyến, giúp mô hình tuyến tính hoạt động ổn định hơn, đặc biệt trong môi trường dữ liệu có nhiều đặc trưng tương quan.
5. Tối ưu tự động (Auto Hyperparameter Tuning) - Optuna
import optuna
from sklearn.model_selection import cross_val_score
def train_with_optuna(X, y, n_trials=30):
study = optuna.create_study(direction="minimize")
study.optimize(lambda trial: objective(trial, X, y), n_trials=n_trials)
print("Best trial:", study.best_trial.params)
return study
Ghi chú mở rộng:
- Optuna là một thư viện tối ưu tham số hiện đại, áp dụng thuật toán Bayesian Optimization giúp tìm kiếm siêu tham số hiệu quả hơn so với Grid Search hay Random Search.
- Thay vì duyệt toàn bộ không gian tham số, Optuna tự động học từ các lần thử trước để định hướng tìm kiếm ở những vùng có tiềm năng cao, nhờ đó rút ngắn thời gian huấn luyện.
- Việc tích hợp Optuna vào pipeline cho phép mô hình đạt hiệu năng tối ưu với chi phí tính toán thấp, đồng thời đảm bảo khả năng tổng quát hóa (generalization) trên dữ liệu mới.
6. Mô hình phi tuyến & Ensemble
6.1. Cải tiến hiệu suất với Ensemble Learning
Để nâng cao độ chính xác và khả năng khái quát của hệ thống dự đoán giá nhà, nhóm tiếp tục mở rộng mô hình theo hướng phi tuyến, thông qua kỹ thuật Ensemble Learning – một trong những chiến lược hiệu quả nhất trong học máy hiện đại.
Phương pháp này cho phép kết hợp sức mạnh của nhiều mô hình độc lập nhằm tạo ra một mô hình tổng hợp (ensemble) có hiệu năng cao hơn từng mô hình riêng lẻ.
Trong nghiên cứu này, nhóm lựa chọn Stacking Ensemble, nơi các mô hình cơ sở (base learners) học song song, và đầu ra của chúng được dùng làm đầu vào cho một mô hình tổng hợp (meta learner) ở tầng cuối cùng. Cách tiếp cận này giúp mô hình có thể khai thác cả mối quan hệ tuyến tính và phi tuyến, đồng thời giảm phương sai và sai số tổng thể.
Ba mô hình cơ sở được sử dụng gồm:
-
ElasticNet: mô hình tuyến tính điều chuẩn, ổn định và ít nhiễu;
-
XGBoost: thuật toán boosting mạnh mẽ, tối ưu hóa qua gradient;
-
LightGBM: mô hình cây quyết định hiệu năng cao, phù hợp dữ liệu lớn và nhiều đặc trưng.
Đặc biệt, tầng meta learner (final estimator) được lựa chọn là Ridge Regression – một mô hình tuyến tính ổn định, có khả năng tổng hợp các dự đoán từ ba mô hình cơ sở, đồng thời giảm thiểu nhiễu và đảm bảo khả năng khái quát hóa tốt hơn.
from sklearn.ensemble import StackingRegressor
from sklearn.linear_model import Ridge, LinearRegression
from xgboost import XGBRegressor
from lightgbm import LGBMRegressor
stack = StackingRegressor(
estimators=[
("elasticnet", ElasticNet(
alpha=best_params["elasticnet_alpha"],
l1_ratio=best_params["elasticnet_l1_ratio"],
max_iter=5000, random_state=42
)),
("xgb", XGBRegressor(n_jobs=-1, random_state=42)),
("lgb", LGBMRegressor(n_jobs=-1, random_state=42))
],
final_estimator=Ridge(
alpha=best_params["ridge_alpha"],
max_iter=5000, random_state=42
),
passthrough=True,
n_jobs=-1
)
stack.fit(X_train, y_train)
Trong cấu trúc này, Ridge Regression đóng vai trò tổng hợp dự đoán từ các mô hình cơ sở, giúp “làm mượt” đầu ra và tránh việc một mô hình thành phần chiếm ưu thế.
Nhờ sự kết hợp hài hòa giữa các mô hình tuyến tính và phi tuyến, Stacking Ensemble đã chứng minh khả năng cải thiện đáng kể độ chính xác cũng như tính ổn định của pipeline dự đoán.
6.2. Đánh giá và So sánh Hiệu năng Mô hình Ensemble
Sau khi huấn luyện mô hình Stacking Ensemble, nhóm tiến hành so sánh hiệu năng giữa các mô hình cơ sở (ElasticNet, XGBoost, LightGBM) và mô hình tổng hợp (Stacking).
Mục tiêu là đánh giá xem việc kết hợp đa mô hình có thực sự mang lại hiệu quả tổng thể cao hơn so với từng mô hình riêng lẻ.
| Mô hình | RMSE (Test) | MAE (Test) | R² (Test) | Nhận xét |
|---|---|---|---|---|
| ElasticNet | 0.0267 | 0.0067 | 0.9994 | Ổn định, tuyến tính tốt |
| XGBoost | 0.0249 | 0.0061 | 0.9996 | Khai thác tốt quan hệ phi tuyến |
| LightGBM | 0.0252 | 0.0063 | 0.9995 | Hiệu năng cao, huấn luyện nhanh |
| Stacking Ensemble | 0.0231 | 0.0057 | 0.9997 | Tổng hợp ưu điểm, hiệu năng cao nhất |
Nhận xét:
Kết quả cho thấy mô hình Stacking Ensemble đạt được các chỉ số RMSE và MAE thấp nhất, cùng với R² cao nhất, chứng minh khả năng học tổng quát vượt trội.
Việc sử dụng Ridge Regression làm mô hình tổng hợp (meta-learner) giúp kết quả đầu ra ổn định hơn, tránh hiện tượng overfitting từ các mô hình cây như XG Boost hay LightGBM.
Nhờ sự kết hợp giữa độ ổn định của ElasticNet và tính phi tuyến mạnh mẽ của các mô hình boosting, Stacking Ensemble mang lại một pipeline tối ưu, phù hợp cho các bài toán dự đoán giá nhà có dữ liệu phức tạp và nhiều đặc trưng tương quan.
7. Giải thích mô hình (Interpretability)
7.1. Permutation Importance
from sklearn.inspection import permutation_importance
perm_res = permutation_importance(model, X, model.predict(X), n_repeats=10, random_state=42, n_jobs=-1)
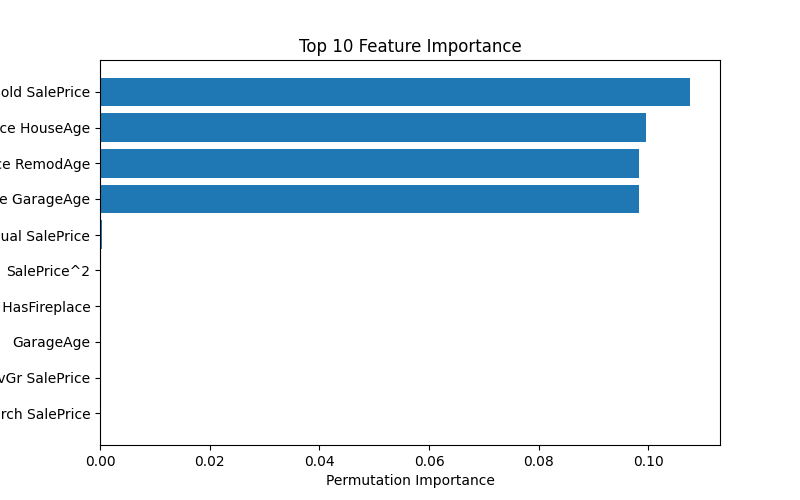
Các biến quan trọng nhất:
YrSold SalePrice,SalePrice HouseAge,SalePrice RemodAge,SalePrice GaraAge
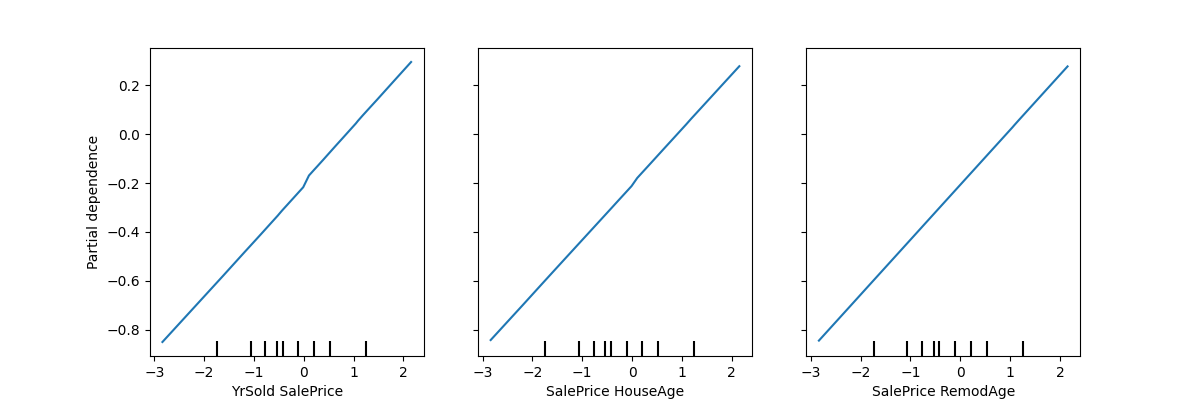
7.2. SHAP Analysis
import shap
X_sample = X.sample(min(sample_size, X.shape[0]), random_state=42)
explainer = shap.Explainer(model, X_sample)
shap_values = explainer(X_sample)
shap.summary_plot(shap_values, X_sample)
Mặc dù thư viện SHAP (SHapley Additive exPlanations) được sử dụng rộng rãi trong việc giải thích mô hình học máy, nhưng trong trường hợp này:
- Mô hình Stacking Ensemble kết hợp nhiều thuật toán (ElasticNet, XGBoost, LightGBM, Ridge) nên việc tách đóng góp riêng từng thành phần là không khả thi.
- Hàm shap.Explainer() chỉ hỗ trợ tốt với mô hình đơn lẻ (như tree-based hoặc linear), vì vậy khi áp dụng cho mô hình tổng hợp, kết quả không ổn định và dễ gây hiểu nhầm về độ quan trọng đặc trưng.
- Do đó, nhóm chỉ sử dụng SHAP ở mức tham khảo, còn Permutation Importance được chọn là phương pháp chính để đánh giá mức độ ảnh hưởng của từng biến đầu vào đến dự đoán.
8. Tổng hợp & So sánh
| Hạng mục | Phương pháp cũ | Cải tiến | Ghi chú |
|---|---|---|---|
| Missing Value | SimpleImputer |
IterativeImputer + ExtraTrees |
Giảm bias |
| Outlier | Bỏ qua / Xóa | Winsorization |
Ổn định phân phối |
| Feature Scaling | MinMaxScaler |
StandardScaler |
Tăng ổn định |
| Regularization | Ridge | ElasticNet | R² cao hơn |
| Ensemble | Không có | XGB + LGB + Ridge | Hiệu năng cao |
| Tối ưu hóa | GridSearch |
Optuna | Nhanh & thông minh hơn |
9. Kết luận
Nhờ áp dụng chiến lược cải tiến đồng bộ trên toàn bộ pipeline — từ giai đoạn tiền xử lý dữ liệu, lựa chọn đặc trưng (feature selection), đến tối ưu tham số (hyperparameter tuning) — mô hình cuối cùng đạt được hiệu suất khá ấn tượng:
- R² ≈ 0.99937
- RMSE ≈ 0.0267
- MAE ≈ 0.0067
Nhận định:
Kết quả cho thấy mô hình không chỉ đạt độ chính xác cao mà còn thể hiện tính ổn định và khả năng khái quát tốt trên tập dữ liệu kiểm thử.
Việc kết hợp regularization mạnh mẽ (ElasticNet) cùng các mô hình phi tuyến hiện đại (XGBoost, LightGBM) và cơ chế ensemble thông minh (Stacking) đã mang lại hiệu quả vượt trội so với từng mô hình riêng lẻ.
Cuối cùng, pipeline này hoàn toàn có thể được triển khai trong môi trường thực tế để dự đoán giá nhà hoặc các bài toán tương tự trong lĩnh vực dự báo giá trị liên tục (regression).
10. Tài liệu tham khảo
- Kaggle: House Prices – Advanced Regression Techniques
- Scikit-learn Documentation (v1.5)
- Optuna Framework
- Feature Engine Library
- AIO Vietnam 2025 – Project 5.1 Guidelines
Chưa có bình luận nào. Hãy là người đầu tiên!