
1. Anomaly Detection là gì? – Khi những "kẻ lạc loài" lên tiếng
Trong thế giới Data Science, chúng ta thường dành phần lớn thời gian để đi tìm những quy luật chung (patterns) – thứ giúp mô hình hiểu được số đông. Thế nhưng, đôi khi những giá trị "lệch chuẩn", những điểm dữ liệu "đi lạc" khỏi đám đông lại chính là nơi chứa đựng những thông tin đắt giá nhất. Đó chính là lãnh địa của Anomaly Detection (Phát hiện bất thường).
Nói một cách kỹ thuật, Anomaly Detection là quá trình xác định các điểm dữ liệu có đặc tính phân phối khác biệt đáng kể so với phần còn lại của tập dữ liệu. Trong thống kê, chúng ta gọi chúng là các Outliers (những mẫu ngoại lệ).
Tuy nhiên, cần phân biệt rõ: Anomaly không hoàn toàn là Nhiễu (Noise). Nếu nhiễu là những sai số ngẫu nhiên cần được loại bỏ trong quá trình tiền xử lý (Data Cleaning), thì Anomaly lại là những tín hiệu thực sự, báo hiệu một sự thay đổi đột ngột hoặc một hành vi đặc biệt trong hệ thống.
 Hình 1.1. Minh họa về Anomoly Detection; nguồn: Gemini
Hình 1.1. Minh họa về Anomoly Detection; nguồn: Gemini
Để thấy rõ tầm quan trọng của những "kẻ lạc loài" này, hãy nhìn vào các bài toán thực tế:
- Giao dịch tài chính (Financial Transactions): Giả sử lịch sử chi tiêu của bạn chỉ quẩn quanh các quán cà phê và siêu thị tại Việt Nam với hạn mức dưới 2 triệu đồng. Đột nhiên, một giao dịch 100 triệu đồng mua trang sức tại London xuất hiện. Thuật toán sẽ ngay lập tức gắn cờ (flag) điểm bất thường này để ngăn chặn hành vi chiếm đoạt tài khoản.
- An ninh mạng (Cybersecurity): Một server đang hoạt động ổn định bỗng dưng nhận được lượng request tăng vọt theo cấp số nhân trong vài giây (Spike). Đây không đơn giản là sự tăng trưởng người dùng, mà là dấu hiệu của một cuộc tấn công DDoS đang trực chờ đánh sập hệ thống.
- Giám sát công nghiệp (Industrial IoT): Trong một dây chuyền sản xuất, các cảm biến rung động (Vibration Sensors) gửi về tín hiệu đều đặn. Một sự thay đổi nhỏ trong biên độ sóng có thể là "lời cầu cứu" của vòng bi sắp hỏng trước khi máy móc thực sự đổ vỡ.
2. Sự quan trọng của Anomaly Detection và ứng dụng
2.1. Tại sao Anomaly Detection quan trọng?
Hiện nay với sự phát triển không ngừng của xã hội, dữ liệu đóng vai trò lớn, biểu thị sự phát triển hay vận hành của nhiều lĩnh vực, sự gia tăng về dữ liệu cũng dẫn theo nguy cơ về sai sót và bất thường ngày càng tăng cao. Việc phát hiện sớm các điểm bất thường này có thể giúp các tổ chức, doanh nghiệp xử lí kịp thời vấn đề về sai sót dữ liệu, từ đó đưa ra giải pháp nâng cấp, bảo trì phù hợp, tối ưu hóa chi phí vận hành. Thông qua anomaly detection, một số lợi ích ta có thể đạt được như:
- Phát hiện gian lận
- Phát hiện lỗi hệ thống
- Phát hiện tấn công mạng
2.2. Những ứng dụng của Anomaly Detection
2.2.1. Phát hiện gian lận tài chính
Trong lĩnh vực tài chính, việc phát hiện các điểm bất thường trong giao dịch có thể giúp doanh nghiệp phát hiện kịp thời các giao dịch mang tính gian lận, từ đó doanh nghiệp có thể bảo vệ khách hàng cũng như giảm thiểu rủi ro về tổn thất tài chính. Ứng dụng cụ thể có thể kể đến:
Transaction fraud: Hành vi cố tình sử dụng thông tin tài chính bị đánh cắp để thực hiện các giao dịch mua sắm, chuyển tiền trái phép. Thông qua việc phân tích các điểm bất thường trong dữ liệu giao dịch, ngân hàng có thể can thiệp kịp thời và ngăn chặn các giao dịch trái phép, khả nghi cho khách hàng.
Credit card fraud: Thông tin tín dụng cá nhân rất dễ bị đánh cắp, vì vậy anomaly detection có thể được ứng dụng để truy vết các giao dịch tín dụng từ IP lạ hay các giao dịch lớn bất thường so với thường lệ. Từ đó ngân hàng có thể ngăn chặn các giao dịch này, đảm bảo quyền lợi và thiệt hại tài chính của chủ thẻ.
2.2.2. An ninh mạng
Trong lĩnh vực an ninh mạng, việc phát hiện các truy cập khả nghi hay request bất thường có thể giúp tìm ra lỗ hổng bảo mật hiện có, từ đó có ngăn chặn kịp thời các cuộc tấn công mạng, nâng cao bảo mật của hệ thống mạng máy tính.
Network intrusion: Thông qua giám sát lưu lượng truy cập mạng bất thường của một truy cập, hệ thống có thể đưa ra cảnh báo đến người quản trị, ngăn chặn việc xâm nhập mạng bất thường.
Abnormal login activity: Đề cập đến các truy cập không rõ nguồn gốc, không được cấp phép hay từ các thiết bị mới. Thông qua nhận diện các truy cập này, hệ thống có thể gửi cảnh báo để người dùng về một rủi ro về bảo mật tài khoản hiện tại.
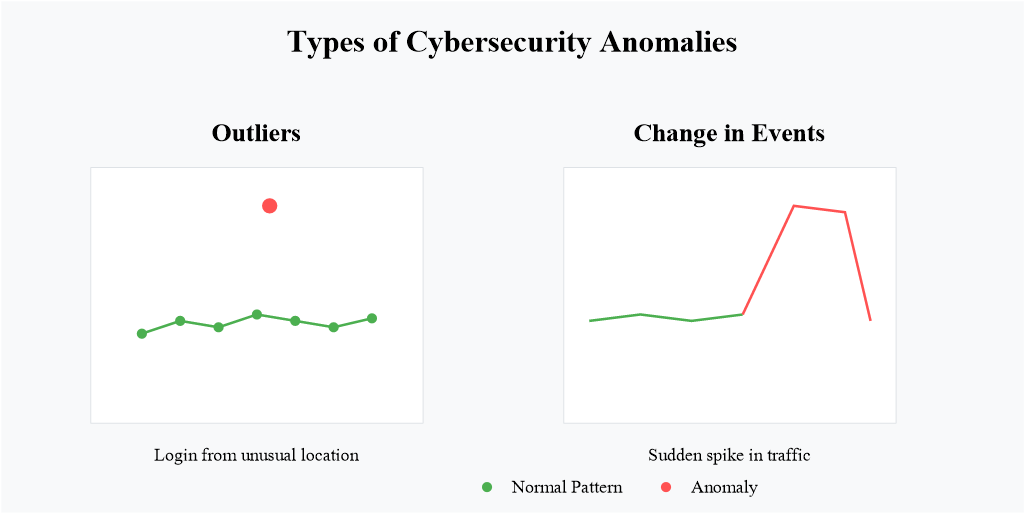 Hình 2.1. Anomaly trong an ninh mạng; nguồn: Wiz
Hình 2.1. Anomaly trong an ninh mạng; nguồn: Wiz
2.2.3. Industrial monitoring:
Trong hệ thống máy công nghiệp, các thiết bị có thể đọc ghi các kết quả sai theo thời gian. Việc phát hiện sớm các sai sót về dữ liệu như sensor có thể giúp doanh nghiệp tìm nguyên nhân và sửa chữa kịp thời, đảm bảo tính ổn định của hệ thống.
Lỗi máy móc: Một hư hỏng về bộ phận bất kì trong máy sản xuất cũng có thể ảnh hưởng đến các thiết bị khác. Ví dụ như hệ thống laser của một máy cắt laser khi bị lỗi có thể cấp nhiệt quá mức cho phép, từ đó gây ra sai số dữ liệu cho sensor nhiệt. Việc phát hiện bất thường trong dữ liệu đọc ghi từ các thiết bị này có thể giúp doanh nghiệp truy vết được các vấn đề khác, từ đó bảo trì máy được tốt hơn.
Sai số điều khiển: Trong lĩnh vực điều khiển, các dữ liệu về motor có thể phản ánh tính chính xác của bộ điều khiển, việc phân tích các dữ liệu có thể giúp tìm ra hạn chế về thiết kế hiện tại và tối ưu hệ thống.
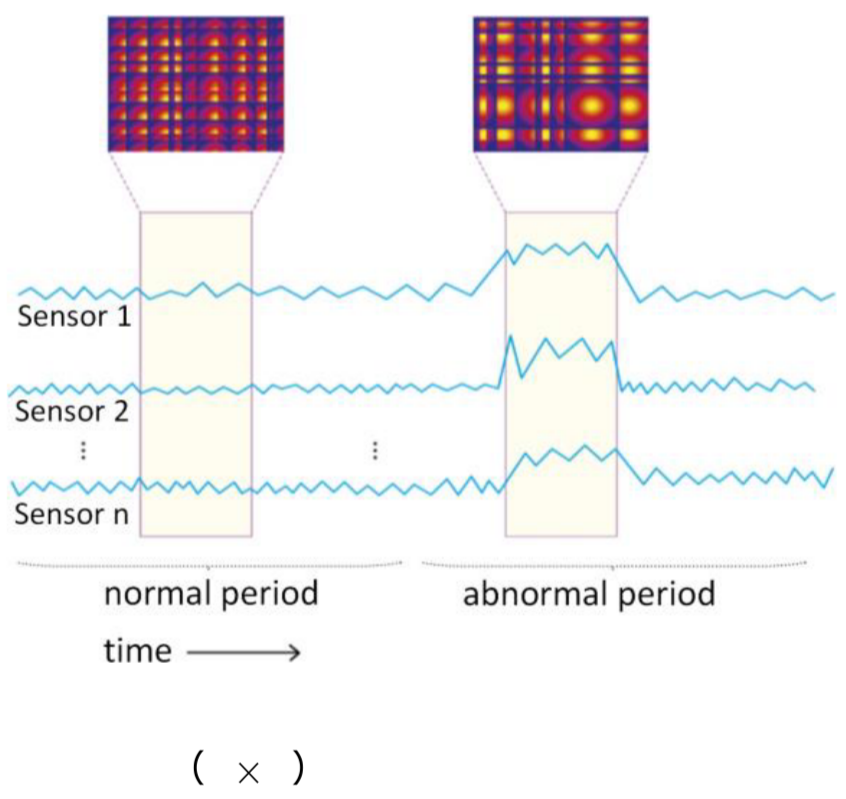 Hình 2.2. Anomaly trong dữ liệu sensor; nguồn: TheMoonlight
Hình 2.2. Anomaly trong dữ liệu sensor; nguồn: TheMoonlight
2.2.4. Healthcare:
Trong lĩnh vực y tế, các dữ liệu về bệnh nhân rất quan trọng cho việc theo dõi sức khỏe bệnh nhân. Thông qua các dữ liệu này, bác sĩ có thể theo dõi các chuyển biến về sức khỏe và cung cấp các giải pháp y tế kịp thời.
Dữ liệu y tế: Các dữ liệu như mỡ máu, huyết áp bất thường giúp bác sĩ tầm soát các bệnh lí có thể xảy ra ở bệnh nhân, qua đó hỗ trợ chuẩn đoán bệnh và phòng ngừa.
 Hình 2.3. Anomaly trong dữ liệu y tế; nguồn: Unit8
Hình 2.3. Anomaly trong dữ liệu y tế; nguồn: Unit8
3. Phân loại Anomaly
Trong Data Science, để chọn đúng phương pháp xử lý, chúng ta cần nhận biết các điểm bất thường (anomalies) dưới hai góc độ: Nguyên nhân sinh ra chúng và cách biểu hiện trong tập dữ liệu.
3.1. Phân loại theo nguyên nhân
Hệ thống phát hiện bất thường có thể phát hiện hai loại bất thường chính: bất thường không chủ đích và bất thường có chủ đích.
3.1.1. Bất thường không chủ đích (Unintentional anomalies)
Những bất thường không cố ý là các điểm dữ liệu lệch khỏi mức bình thường do lỗi hoặc nhiễu trong quá trình thu thập dữ liệu. Những lỗi này có thể là có hệ thống hoặc ngẫu nhiên, thường xuất phát từ các vấn đề như cảm biến bị lỗi hoặc sai sót của con người khi nhập dữ liệu. Các bất thường không cố ý này có thể làm méo mó bộ dữ liệu, khiến việc rút ra kết luận chính xác từ dữ liệu trở nên khó khăn hơn.
Ví dụ:
-
Lỗi thu thập dữ liệu: Một nhân viên nhập liệu vô tình gõ dư một số "0", biến giao dịch 1.000.000 VNĐ thành 10.000.000 VNĐ.
-
Lỗi phần cứng: Một cảm biến nhiệt độ bị chập mạch do trời mưa, gửi về hệ thống mức nhiệt 100°C.
-
Sự kiện ngẫu nhiên: Một bài đăng trên mạng xã hội đột nhiên "viral" khiến lưu lượng truy cập tăng gấp nhiều lần bình thường.
 Hình 3.1. Bài hát đột nhiên lan truyền mạnh khiến lượt nhắc đến tăng vọt; nguồn: Talkwalker Social Listening
Hình 3.1. Bài hát đột nhiên lan truyền mạnh khiến lượt nhắc đến tăng vọt; nguồn: Talkwalker Social Listening
3.1.2. Bất thường có chủ đích (Intentional anomalies)
Bất thường có chủ đích là những điểm dữ liệu khác biệt do một sự kiện hoặc hành động cụ thể, thường mang ý nghĩa quan trọng. Những bất thường này đôi khi lại rất có giá trị, vì chúng có thể cho thấy những hiện tượng đặc biệt hoặc xu hướng đáng chú ý trong bộ dữ liệu.
Ví dụ doanh số bán hàng tăng vọt vào các đợt sale có thể được xem là một intentional anomaly. Mặc dù nó khác với dữ liệu doanh số thông thường, nhưng sự tăng đột biến này là điều có thể dự đoán được vì nó gắn với một sự kiện thực tế và thường được chuẩn bị trước.
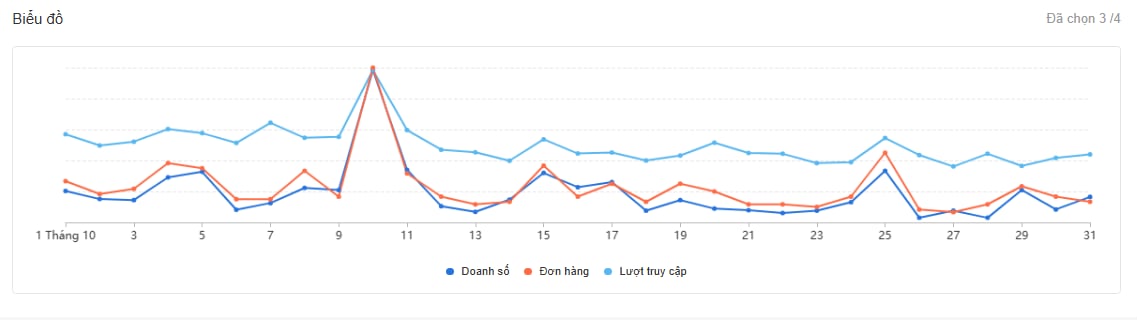 Hình 3.2. Doanh số tăng vọt trong đợt sale, một dạng bất thường có chủ đích trong dữ liệu.
Hình 3.2. Doanh số tăng vọt trong đợt sale, một dạng bất thường có chủ đích trong dữ liệu.
3.2 Phân loại theo Biểu hiện dữ liệu
Một khía cạnh quan trọng của việc phát hiện bất thường là bản chất của bất thường cần phát hiện, có thể được phân loại thành ba loại sau:
3.2.1. Point Anomalies – Bất thường tại một điểm dữ liệu
Point anomaly xảy ra khi một điểm dữ liệu riêng lẻ khác biệt rõ rệt so với phần còn lại của tập dữ liệu. Nói đơn giản hơn, nếu chỉ cần nhìn vào một điểm dữ liệu mà chúng ta đã có thể nhận ra nó “không giống ai”, thì đó chính là point anomaly.
Đây là loại bất thường đơn giản nhất, và cũng là chủ đề được nghiên cứu nhiều nhất trong lĩnh vực anomaly detection. Lý do là vì loại bất thường này khá trực quan: chúng ta chỉ cần so sánh một điểm dữ liệu với phần còn lại để xem nó có nằm ngoài “vùng bình thường” hay không.
Trong hình minh họa dưới đây, các điểm như $o_1$, $o_2$ hoặc những điểm nằm trong vùng $O_3$ thường được xem là bất thường vì chúng nằm ngoài ranh giới của vùng dữ liệu bình thường. Chính vì vậy, chúng được phân loại là point anomalies.
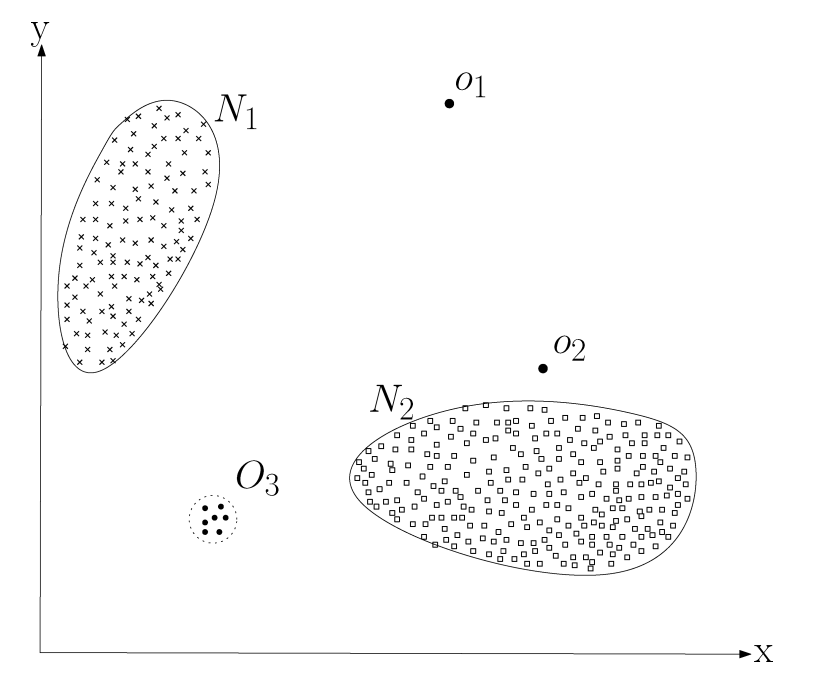 Hình 3.3. Ví dụ đơn giản về các điểm bất thường trong tập dữ liệu hai chiều; nguồn: Chandola, Banerjee, and Kumar (2009) – Anomaly Detection: A Survey
Hình 3.3. Ví dụ đơn giản về các điểm bất thường trong tập dữ liệu hai chiều; nguồn: Chandola, Banerjee, and Kumar (2009) – Anomaly Detection: A Survey
Một ví dụ quen thuộc của point anomaly là trong hệ thống phát hiện gian lận thẻ tín dụng. Giả sử một người thường chi tiêu mỗi lần khoảng 200.000 đến 1.000.000 VND. Nhưng bỗng nhiên xuất hiện một giao dịch 30.000.000 VND. So với lịch sử chi tiêu trước đó, giao dịch này lớn bất thường và có thể được hệ thống đánh dấu là point anomaly để kiểm tra thêm.
3.2.2. Contextual Anomalies – Bất thường theo ngữ cảnh
Một điểm dữ liệu được gọi là bất thường theo ngữ cảnh khi nó chỉ bất thường trong một bối cảnh cụ thể, nhưng không bất thường trong các bối cảnh khác. Loại bất thường này còn được gọi là bất thường có điều kiện (conditional anomaly) [Song et al., 2007].
Khái niệm ngữ cảnh (context) được hình thành từ cấu trúc của tập dữ liệu, và cần được xác định ngay từ giai đoạn xây dựng bài toán. Mỗi điểm dữ liệu thường được mô tả bởi hai nhóm thuộc tính sau:
(1) Thuộc tính ngữ cảnh (Contextual attributes)
Thuộc tính ngữ cảnh được dùng để xác định bối cảnh hoặc vùng lân cận của một điểm dữ liệu.
Ví dụ:
-
Trong dữ liệu không gian (spatial data), kinh độ và vĩ độ của một địa điểm chính là các thuộc tính ngữ cảnh.
-
Trong dữ liệu chuỗi thời gian (time-series), thời gian đóng vai trò là thuộc tính ngữ cảnh vì nó xác định vị trí của một quan sát trong toàn bộ chuỗi dữ liệu.
(2) Thuộc tính hành vi (Behavioral attributes)
Thuộc tính hành vi mô tả đặc trưng thực tế của điểm dữ liệu, độc lập với ngữ cảnh.
Ví dụ:
- Trong một tập dữ liệu không gian mô tả lượng mưa trung bình trên toàn thế giới, thì lượng mưa tại từng địa điểm chính là một thuộc tính hành vi.
Việc xác định một điểm dữ liệu có bất thường hay không sẽ dựa trên giá trị của các thuộc tính hành vi trong một ngữ cảnh cụ thể. Một điểm dữ liệu có thể được xem là bất thường trong một ngữ cảnh, nhưng lại hoàn toàn bình thường trong một ngữ cảnh khác, ngay cả khi giá trị hành vi của nó giống hệt nhau. Đây chính là đặc điểm quan trọng giúp phân biệt thuộc tính ngữ cảnh và thuộc tính hành vi trong các phương pháp phát hiện bất thường theo ngữ cảnh.
Hình sau cho thấy một ví dụ như vậy đối với chuỗi thời gian nhiệt độ thể hiện nhiệt độ hàng tháng của một khu vực trong vài năm qua. Nhiệt độ 35°F có thể là bình thường trong mùa đông (tại thời điểm $t_1$) ở nơi đó, nhưng cùng giá trị đó trong mùa hè (tại thời điểm $t_2$) sẽ là bất thường.
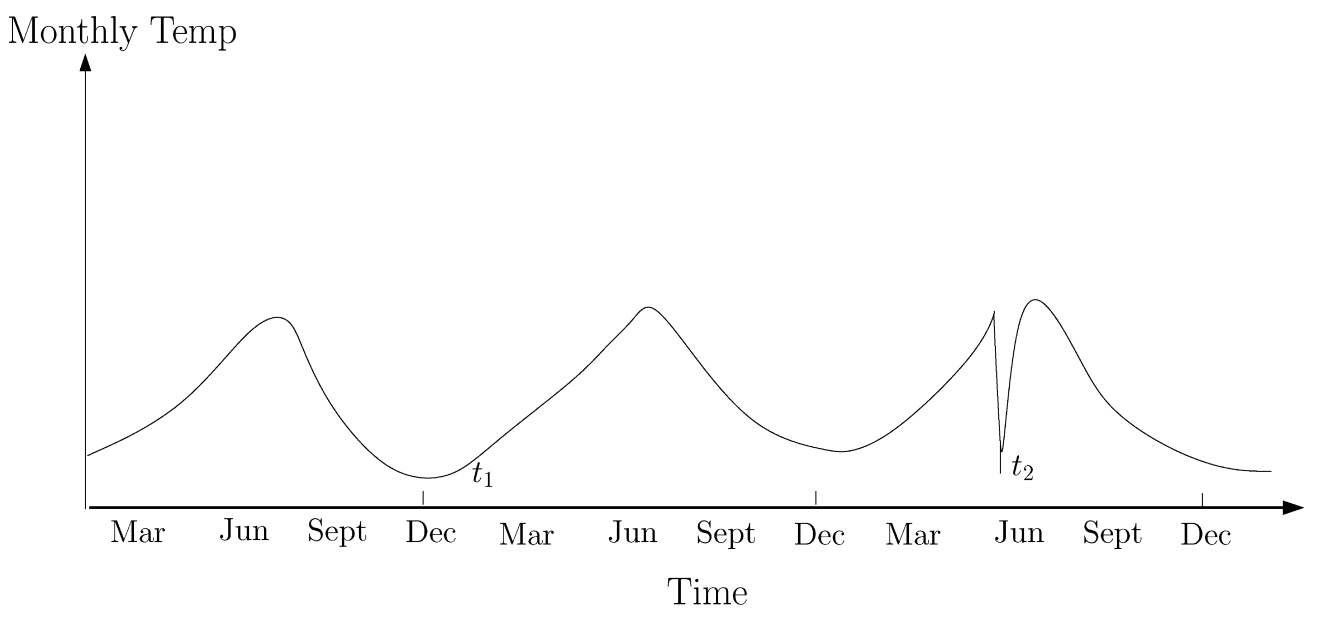 Hình 3.4. Ví dụ về bất thường theo ngữ cảnh trong chuỗi thời gian nhiệt độ; nguồn: Chandola, Banerjee, and Kumar (2009) – Anomaly Detection: A Survey
Hình 3.4. Ví dụ về bất thường theo ngữ cảnh trong chuỗi thời gian nhiệt độ; nguồn: Chandola, Banerjee, and Kumar (2009) – Anomaly Detection: A Survey
3.2.3. Collective Anomalies - Bất thường tập thể
Bất thường tập thể xảy ra khi một nhóm các điểm dữ liệu có liên quan với nhau được xem là bất thường so với toàn bộ tập dữ liệu. Trong trường hợp này, từng điểm dữ liệu riêng lẻ có thể không bất thường, nhưng sự xuất hiện của chúng cùng nhau dưới dạng một tập hợp lại tạo thành bất thường.
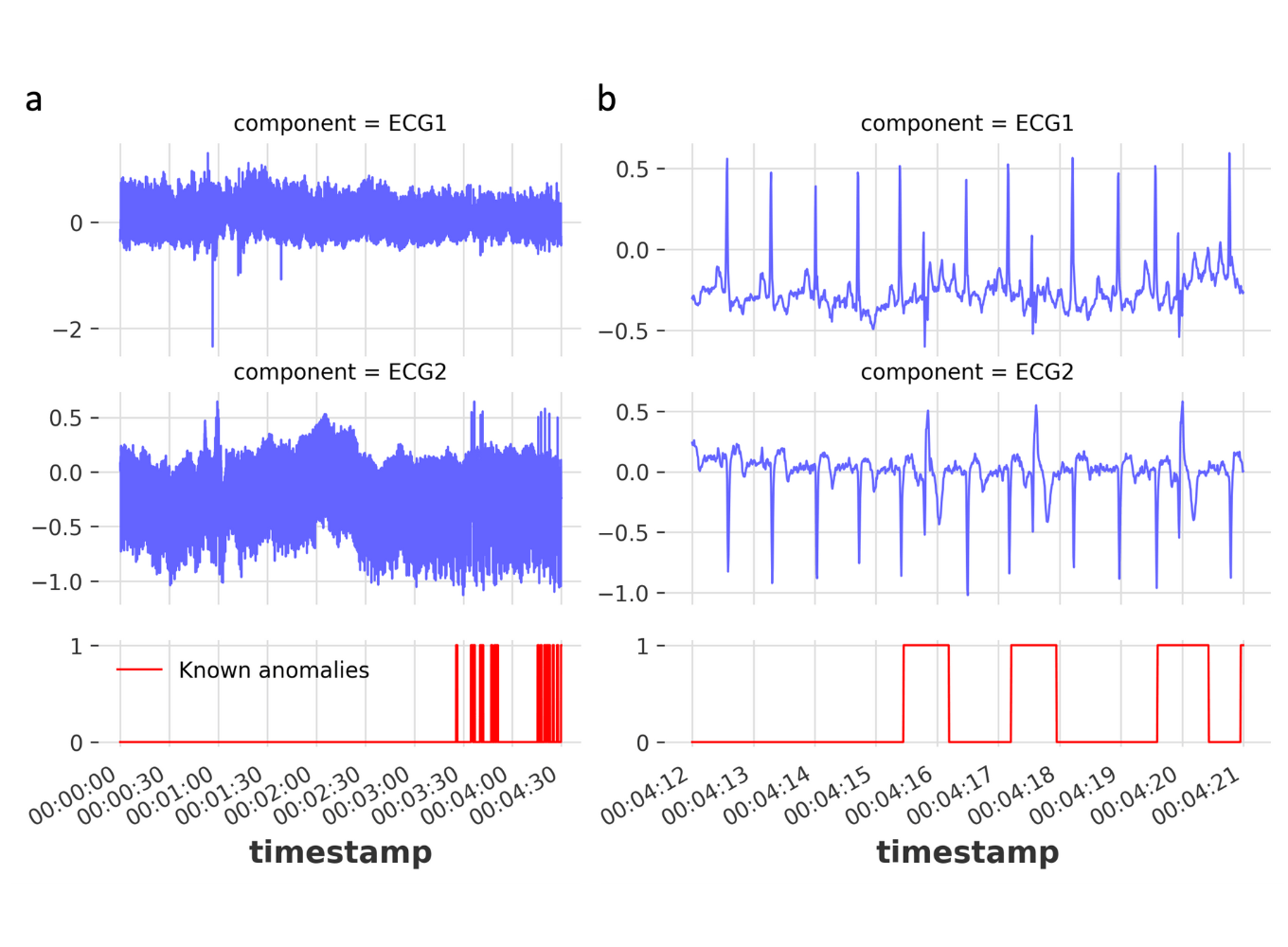
Hình dưới đây minh họa một ví dụ về tín hiệu điện tâm đồ (ECG) của con người [Goldberger et al., 2000]. Vùng được đánh dấu được xem là bất thường vì giá trị thấp kéo dài trong một khoảng thời gian bất thường (tương ứng với hiện tượng Atrial Premature Contraction). Lưu ý rằng bản thân giá trị thấp đó không phải là bất thường, nhưng việc nó kéo dài trong một khoảng thời gian dài mới tạo ra bất thường.
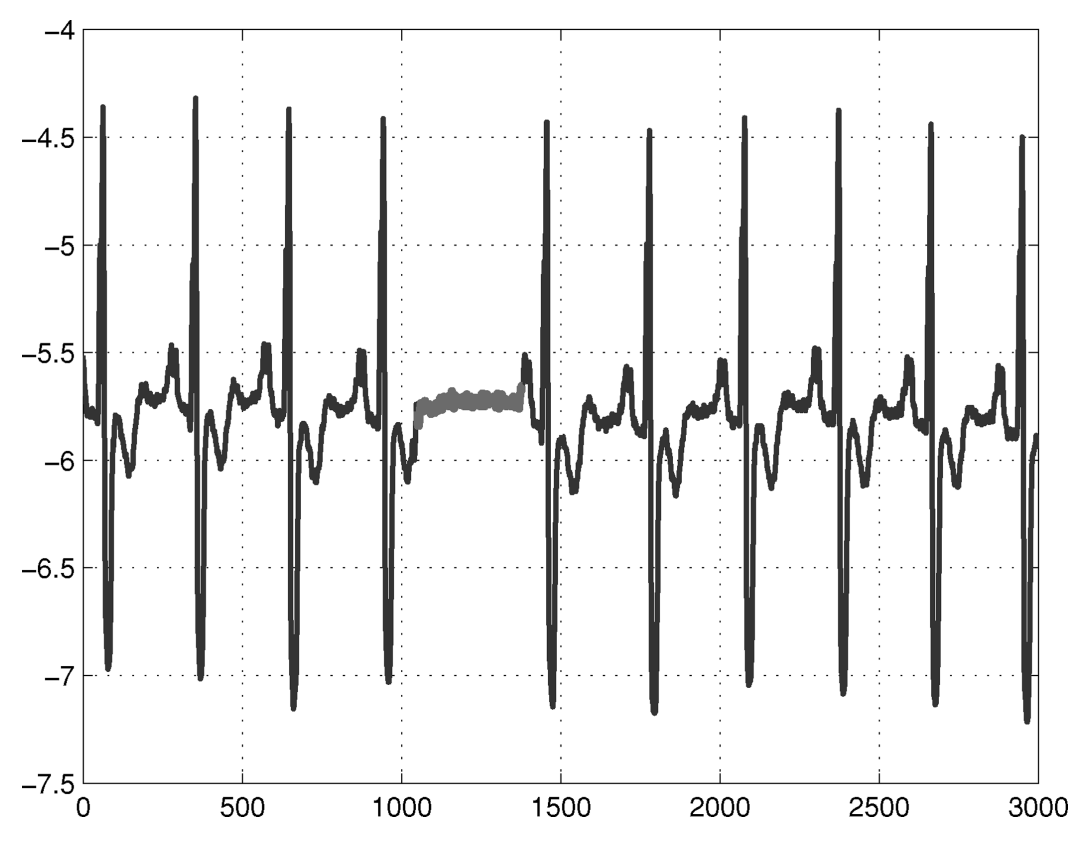 Hình 3.5. Ví dụ về bất thường tập thể trong tín hiệu điện tâm đồ (ECG).; nguồn: Chandola, Banerjee, and Kumar (2009) – Anomaly Detection: A Survey
Hình 3.5. Ví dụ về bất thường tập thể trong tín hiệu điện tâm đồ (ECG).; nguồn: Chandola, Banerjee, and Kumar (2009) – Anomaly Detection: A Survey
4. Các phương pháp phát hiện bất thường phổ biến
Sự gia tăng nhanh chóng của dữ liệu từ nhiều nguồn khác nhau đã khiến việc phát hiện bất thường ngày càng trở nên thiết yếu để xác định những quan sát bất thường có thể báo hiệu lỗi hệ thống, vi phạm an ninh hoặc gian lận. Hiện nay có rất nhiều phương pháp phát hiện bất thường từ đơn giản đến phức tạp, từ truyền thống đến hiện đại. Mỗi phương pháp đều có những ưu và nhược điểm riêng. Tuỳ vào loại dữ liệu và mục đích, mà các doanh nghiệp hay các tổ chức sẽ lựa chọn những phương pháp phù hợp.
Các tiểu mục tiếp theo sẽ lần lượt giới thiệu qua các phương pháp như Trực quan hoá dữ liệu, Kiểm định thống kê, Học máy truyền thống, Học sâu hiện đại và phương pháp kết hợp cả các thuật toán học máy truyền thống lẫn Học sâu.
4.1. Trực quan hóa dữ liệu (Visualization)
Sử dụng hình ảnh trực quan cho việc phát hiện bất thường là phương pháp then chốt khi cần nhận diện nhanh các mẫu dữ liệu lạ, giải thích lí do tại sao một điểm dữ liệu bị coi là bất thường, hoặc giám sát các hệ thống phức tạp trong thời gian thực.
Sau đây là những thời điểm và tình huống cụ thể bạn nên sử dụng hình ảnh trực quan.
4.1.1. Giai đoạn Phân tích Khám phá Dữ liệu (EDA)
Trước khi áp dụng các thuật toán học máy, hình ảnh trực quan giúp bạn hiểu hơn về trạng thái của dữ liệu.
- Xác định ngoại lệ (Outliers): Sử dụng Box Plots để thấy các điểm nằm ngoài dải giá trị tiêu chuẩn hoặc Scatter Plots để phát hiện các điểm dữ liệu tách biệt hẳn so với các cụm dữ liệu chính.
- Nhận diện xu hướng và tính chu kì: Biểu đồ đường (Line charts) cực kì hữu ích để phát hiện các thay đổi đột ngột hoặc sự gián đoạn trong dữ liệu chuỗi thời gian (time-series).
4.1.2. Xác thực và Giải thích Mô hình
Khi một thuật toán (như Isolation Forest) gắn nhãn một điểm là bất thường, hình ảnh trực quan giúp con người kiểm chứng kết quả đó.
- Giải thích "Tại sao": Các công cụ như Power BI Anomaly Detection không chỉ chỉ ra điểm bất thường mà còn cung cấp các giải thích trực quan về các yếu tố ảnh hưởng.
- Phân biệt Bất thường thật và Nhiễu: Hình ảnh giúp chuyên gia phân biệt giữa lỗi hệ thống thực sự và các sự cố ngẫu nhiên không gây hại.
4.1.3. Giám sát Hệ thống trong Thời gian thực
Trong các lĩnh vực an ninh mạng hoặc sản xuất, hình ảnh trực quan là tuyến phòng thủ đầu tiên.
- Phát hiện Xâm nhập & Gian lận: Dashboard hiển thị lưu lượng mạng dưới dạng đồ thị (graph-based) giúp các kỹ sư bảo mật thấy các kết nối đáng ngờ được đánh dấu màu đỏ ngay lập tức.
- Theo dõi thiết bị công nghiệp: Trong sản xuất, các biểu đồ hiển thị sai lệch giữa giá trị thực tế và giá trị dự báo giúp ngăn ngừa hỏng hóc máy móc trước khi chúng xảy ra.
4.1.4. Truyền thông cho các đối tượng không chuyên kĩ thuật
Hình ảnh trực quan là cách tốt nhất để trình bày các phát hiện phức tạp cho các bên liên quan (stakeholders).
- Báo cáo kinh doanh: Biểu đồ giúp người quản lí thấy rõ sự sụt giảm doanh số bất thường mà không cần đọc qua hàng nghìn dòng bảng tính.
- Đưa ra quyết định chiến lược: Việc trực quan hóa các mối đe dọa tiềm tàng giúp tổ chức xây dựng các phản ứng chiến lược hiệu quả hơn.
4.2. Kiểm định thống kê (Statistical Tests)
Khi cần một cơ sở toán học vững chắc để xác định các bất thường và khi các phương pháp học máy trở nên quá phức tạp hoặc không cần thiết, bạn có thể cân nhắc sử dụng phương pháp kiểm định thống kê.
Dưới đây là những thời điểm cụ thể nên ưu tiên kiểm định thống kê.
4.2.1. Dữ liệu tuân theo một phân phối xác định
Nếu bạn biết dữ liệu của mình tuân theo một quy luật phân phối cụ thể (như phân phối Chuẩn/Gaussian), kiểm định thống kê là công cụ mạnh mẽ và chính xác nhất.
- Dữ liệu đơn biến: Sử dụng Z-Score để xác định các điểm nằm cách xa giá trị trung bình (thường là > 3 độ lệch chuẩn).
- Tìm điểm ngoại lệ trong dữ liệu phân phối chuẩn: Z-test hoặc T-test
- So sánh sự khác biệt giữa hai tập dữ liệu (trước và sau): Mann-Whitney U Test hoặc Kolmogorov-Smirnov Test
- Kiểm tra độ phân tán/biến động dữ liệu: F-test
- Phát hiện ngoại lệ (Outliers): Sử dụng các kiểm định chuyên biệt như Grubbs\' Test hoặc Dixon\'s Q-test để tìm một điểm ngoại lệ duy nhất trong tập dữ liệu nhỏ.
4.2.2. Yêu cầu tính minh bạch và giải thích được (Explainability)
Khác với các mô hình "hộp đen" của AI, kiểm định thống kê cung cấp lí do rõ ràng.
- Giải thích logic: Bạn có thể dễ dàng giải thích cho các bên liên quan rằng "Điểm này là bất thường vì nó nằm ngoài khoảng tin cậy 99% của phân phối lịch sử".
- Tuân thủ quy định: Trong kiểm toán hoặc bảo mật, việc có một công thức toán học minh bạch để chứng minh sự bất thường thường được ưu tiên hơn các thuật toán phức tạp.
4.3. Học máy truyền thống (Traditional Machine Learning)
Khi dữ liệu của bạn bắt đầu trở nên phức tạp hơn các phân phối thống kê đơn giản, nhưng vẫn chưa đạt đến mức độ khổng lồ hoặc phi cấu trúc (như video/âm thanh) để cần đến Học sâu, thì bạn sẽ cần đến các thuật toán Học máy truyền thống.
Dưới đây là các tình huống cụ thể để áp dụng.
4.3.1. Dữ liệu có nhiều chiều (High-Dimensional Data)
Khi bạn có hàng chục hoặc hàng trăm đặc trưng (features) tác động lẫn nhau, các kiểm định thống kê đơn biến sẽ thất bại. Các thuật toán như Isolation Forest hoặc One-Class SVM cực kì hiệu quả trong việc tìm ra các điểm bất thường ẩn sâu trong sự kết hợp của nhiều biến số mà mắt thường không thấy được trên biểu đồ.
4.3.2. Không có dữ liệu được dán nhãn (Unsupervised Learning)
Một trong những tình huống phổ biến nhất trong thực tế hiện nay là bạn có rất nhiều dữ liệu nhưng không biết cái nào là "lỗi" cái nào là "sạch". Các thuật toán học không giám sát như Local Outlier Factor (LOF) sẽ tự động học mật độ của dữ liệu và gắn cờ những điểm nằm ở vùng thưa thớt là bất thường.
4.3.3. Cần sự cân bằng giữa hiệu suất và tài nguyên
Các phương pháp Học sâu rất mạnh nhưng cực kì ngốn phần cứng và dữ liệu.
Học máy truyền thống chạy nhanh hơn, tốn ít RAM/CPU hơn và cần ít dữ liệu huấn luyện hơn để đạt được độ chính xác chấp nhận được trong các bài toán như phát hiện gian lận thẻ tín dụng hoặc lỗi thiết bị IoT.
4.3.4. Dữ liệu không tuân theo phân phối chuẩn
Nếu dữ liệu của bạn có hình dạng kì quái, đa phương thức (multimodal) hoặc không có quy luật thống kê rõ ràng. Thuật toán dựa trên khoảng cách/mật độ như K-Nearest Neighbors (KNN) hoặc DBSCAN sẽ dựa vào khoảng cách vật lí giữa các điểm để xác định sự bất thường thay vì dựa vào các giả định toán học khắt khe.
4.4. Học sâu (Deep Learning)
Các phương pháp kể trên đều đã và đang được sử dụng rộng rãi. Tuy nhiên, khi gặp những bộ dữ liệu có số chiều lớn (high dimension) hoặc có những mối liên hệ rắc rối, các phương pháp truyền thống đều tỏ ra kém hiệu quả. Các mô hình học sâu với khả năng học được các quy luật phức tạp, đang dần trở thành các công cụ đắc lực để khắc phục những điểm yếu đó.
Sau đây là ba cách tiếp cận mô hình học sâu.
4.4.1. Cách tiếp cận dựa trên khả năng tái tạo của mô hình (Reconstruction-based Approach)
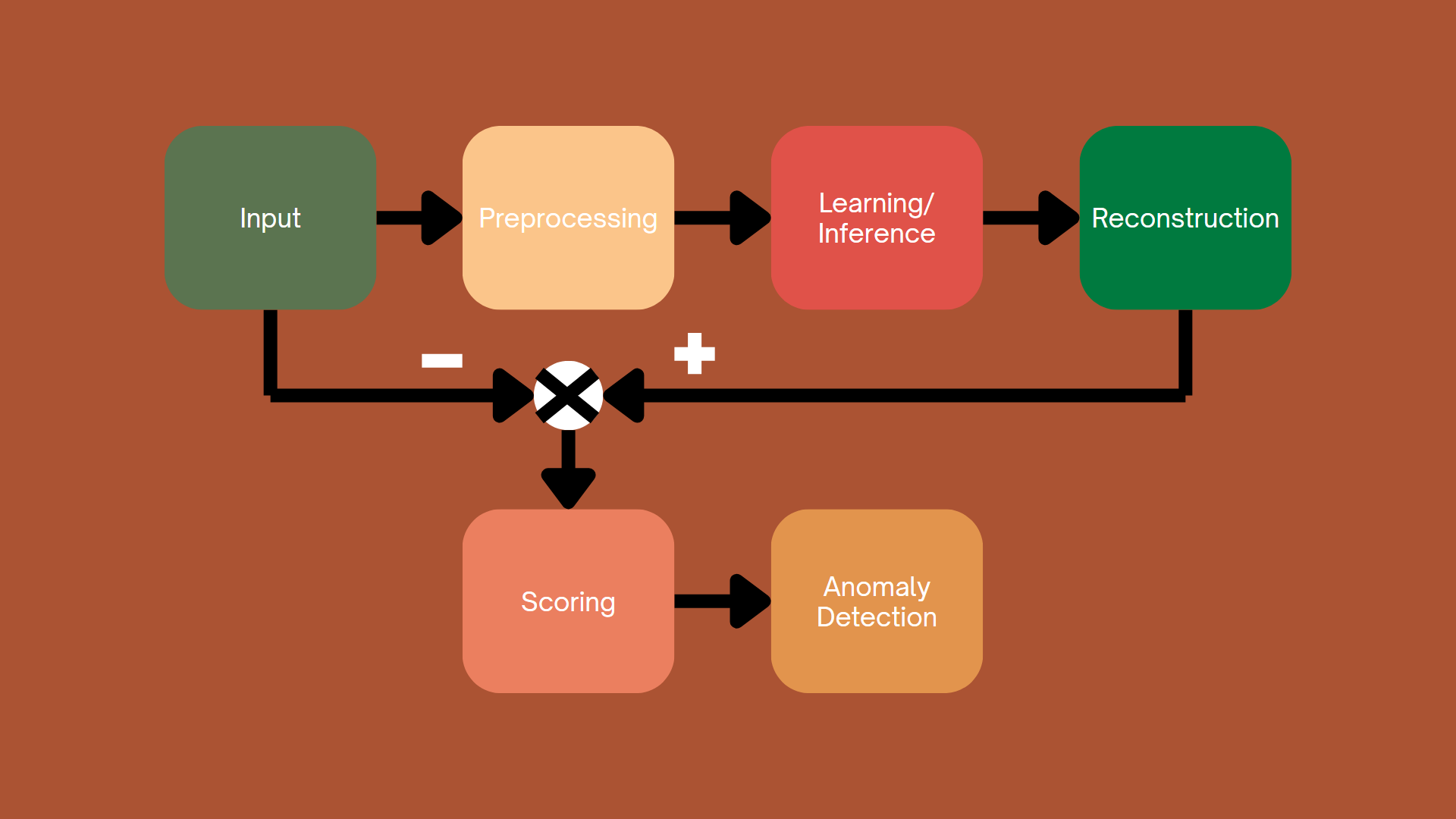 Hình 4.1. Cách tiếp cận dựa trên khả năng tái tạo của mô hình
Hình 4.1. Cách tiếp cận dựa trên khả năng tái tạo của mô hình
Cách tiếp cận này thực hành bằng cách huấn luyện một mô hình có khả năng học được phân phối của dữ liệu bình thường (không có bất thường). Sau khi huấn luyện, mô hình có khả năng tái tạo lại dữ liệu đầu vào. Sự khác biệt giữa dữ liệu gốc và dữ liệu được tái tạo được gọi là sai số tái tạo (reconstruction error). Sai số cao là một dấu hiệu để nhận biết dữ liệu là bất thường.
Trong những năm gần đây, các mô hình tiếp cận theo kiểu ngày thường là các mô hình đối nghịch tạo sinh (GAN), mã hoá tự động (Autoencoder) và khuếch tán (Diffusion).
4.4.2. Cách tiếp cận dựa trên khả năng dự đoán của mô hình (Prediction-based Approach)
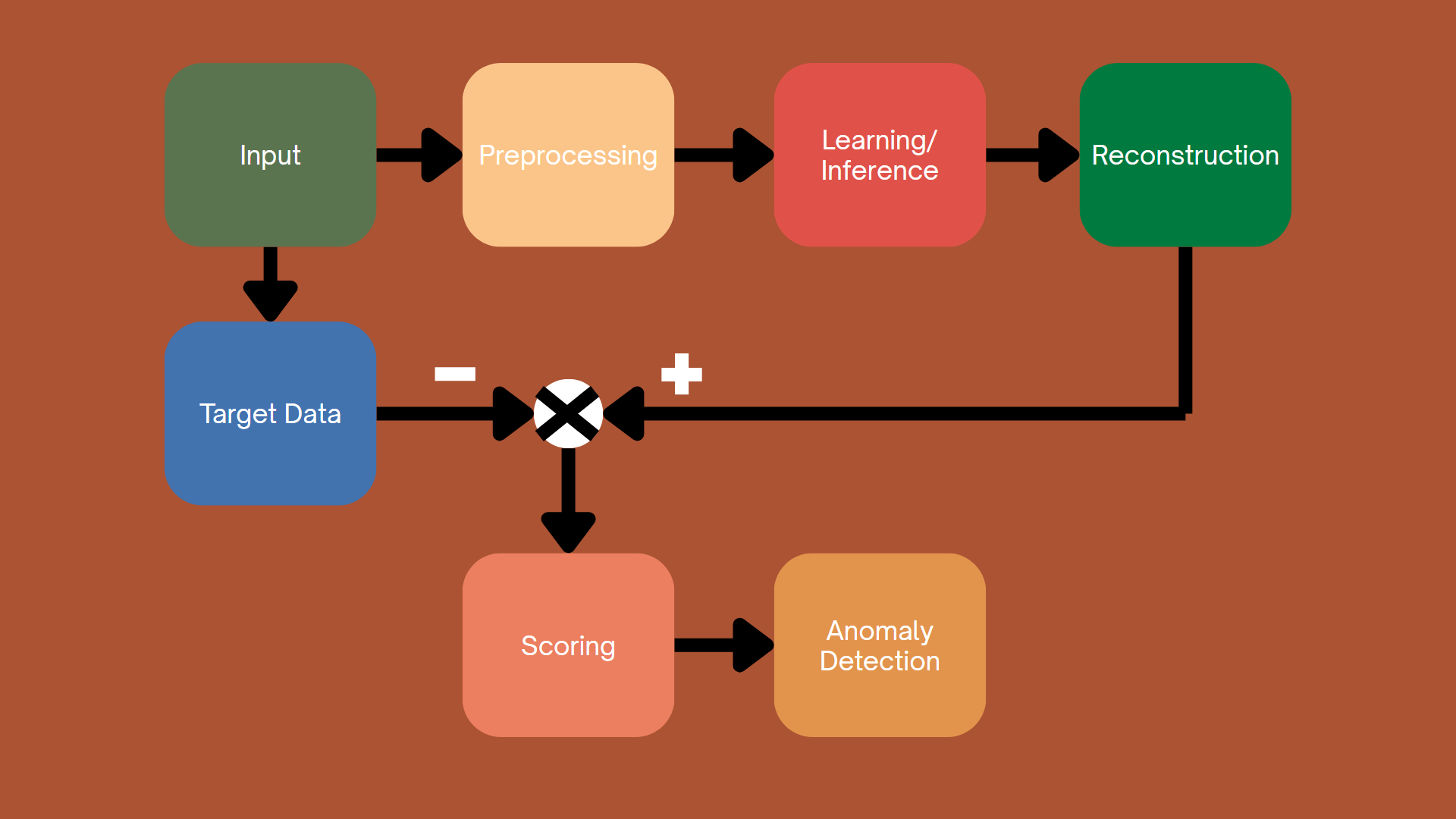 Hình 4.2. Cách tiếp cận dựa trên khả năng dự đoán của mô hình
Hình 4.2. Cách tiếp cận dựa trên khả năng dự đoán của mô hình
Các phương pháp phát hiện bất thường dựa trên dự đoán hoạt động bằng cách dự báo các giá trị trong tương lai hoặc ước tính các thuộc tính bị khuyết, sau đó so sánh các dự đoán này với các giá trị thực tế được quan sát. Khi xảy ra sự sai lệch đáng kể, điều đó cho thấy các bất thường, vì dữ liệu lệch khỏi các mẫu chuẩn đã học.
Các phương pháp này rất linh hoạt và có thể được áp dụng trên nhiều loại dữ liệu khác nhau, tận dụng mối quan hệ giữa các biến hoặc tương quan theo thời gian để phát hiện các bất thường. Bằng cách học các cấu trúc trong dữ liệu, cho dù dựa trên sự phụ thuộc vào thời gian hay các tương tác tổng quát hơn giữa các biến, các phương pháp này có thể dự đoán hiệu quả các kết quả mong đợi. Điều này làm cho các phương pháp dựa trên dự đoán có khả năng thích ứng cao, có thể hoạt động trong các ngữ cảnh khác nhau, bao gồm nhiều loại dữ liệu khác nhau.
Trong phần này, chúng ta sẽ khám phá ba phương pháp chính cho xác định bất thường dựa trên dự đoán: Mạng nơ-ron truy hồi (RNN), cơ chế chú ý (Attention) và mạng nơ-ron đồ thị (GNN).
4.4.3. Cách tiếp cận dựa vào cả khả năng tái tạo và dự đoán của mô hình (Hybrid Method)
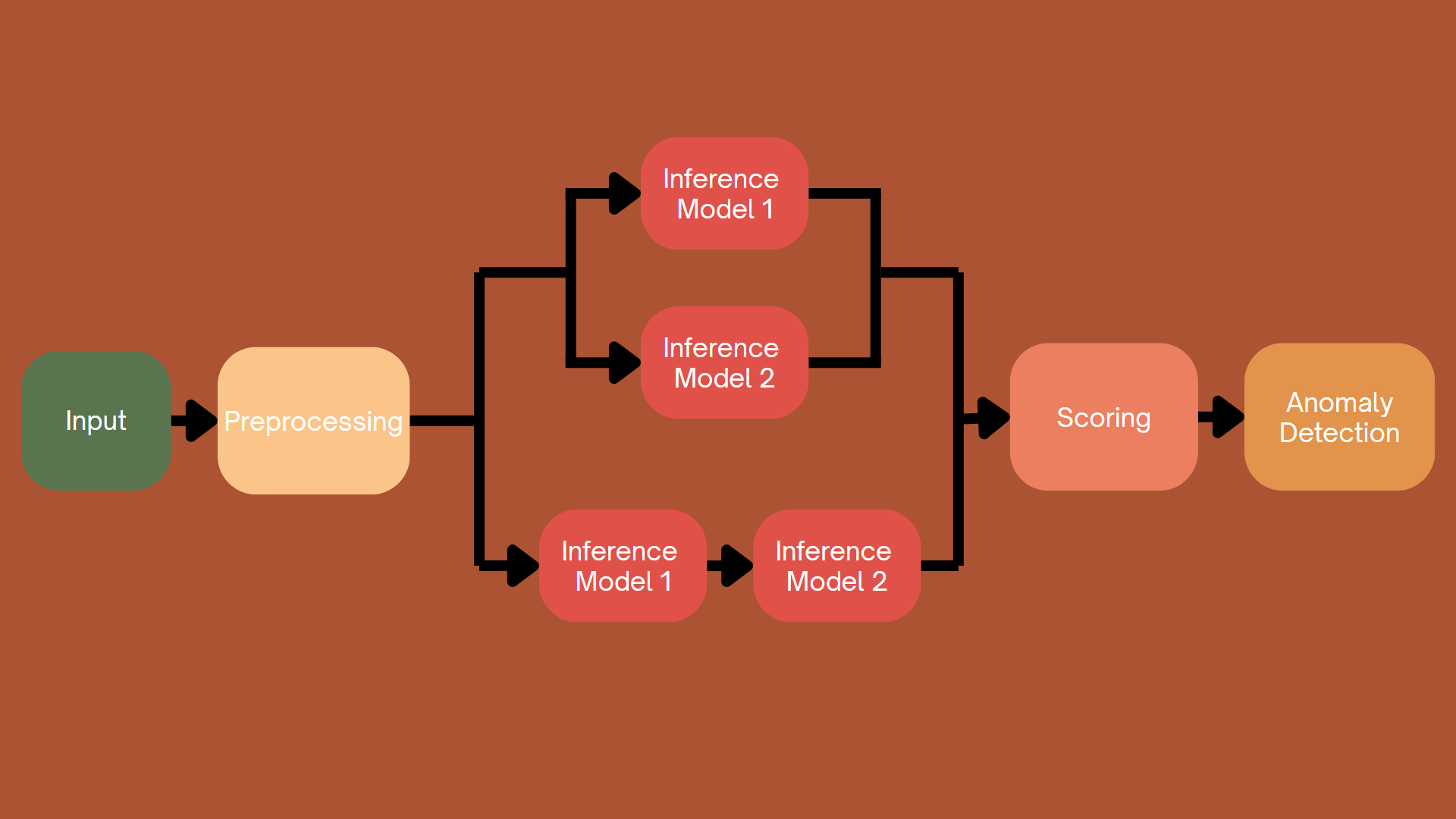 Hình 4.3. Cách tiếp cận dựa vào cả khả năng tái tạo và dự đoán của mô hình
Hình 4.3. Cách tiếp cận dựa vào cả khả năng tái tạo và dự đoán của mô hình
Các phương pháp dựa trên khả năng tái tạo và dựa trên khả năng dự đoán của mô hình cung cấp các cách tiếp cận riêng biệt nhưng bổ sung cho nhau để xác định các bất thường.
Các phương pháp dựa trên khả năng tái tạo của mô hình tập trung vào việc học phân bố cơ bản của dữ liệu bình thường. Sau khi được huấn luyện, mô hình cố gắng tái tạo dữ liệu đầu vào. Cách tiếp cận này đặc biệt hiệu quả trong các trường hợp cần hiểu đầy đủ cấu trúc hoặc phân bố của dữ liệu, chẳng hạn như trong phát hiện bất thường dựa trên hình ảnh hoặc các tập dữ liệu đa chiều khác.
Ngược lại, các phương pháp dựa trên khả năng dự đoán của mô hình tập trung vào việc dự báo các thuộc tính cụ thể hoặc các giá trị bị thiếu từ dữ liệu, thay vì tái tạo toàn bộ đầu vào. Các phương pháp dựa trên dự đoán thường phù hợp hơn với các tập dữ liệu giàu đặc trưng, nơi việc dự đoán các biến cụ thể có thể giúp xác định các mẫu bất thường.
Mặc dù cả hai phương pháp đều khác nhau về cách tiếp cận xử lí dữ liệu, nhưng chúng có thể bổ sung cho nhau rất tốt. Trong nhiều trường hợp, việc kết hợp cả hai cho phép phát hiện bất thường tốt hơn. Các mô hình tái tạo nắm bắt cấu trúc và thông tin tổng thể của dữ liệu, trong khi các mô hình dự đoán tập trung vào việc phát hiện sự sai lệch trong các biến hoặc đặc trưng cụ thể. Sự kết hợp này có thể cung cấp một giải pháp toàn diện hơn để xác định các bất thường trong các tập dữ liệu phức tạp trên nhiều lĩnh vực khác nhau.
Cụ thể, để phát hiện bất thường bạn có thể vừa sử dụng kết quả từ các mô hình tái tạo; vừa sử dụng kết quả từ mô hình dự đoán; và vừa sử dụng kết quả khi cho cho dữ liệu chạy lần lượt qua mô hình dự đoán, rồi tới mô hình tái tạo để tăng cường cho kết quả từ mô hình dự đoán trước đó.
4.5. Kết hợp giữa Học máy truyền thống và Học sâu
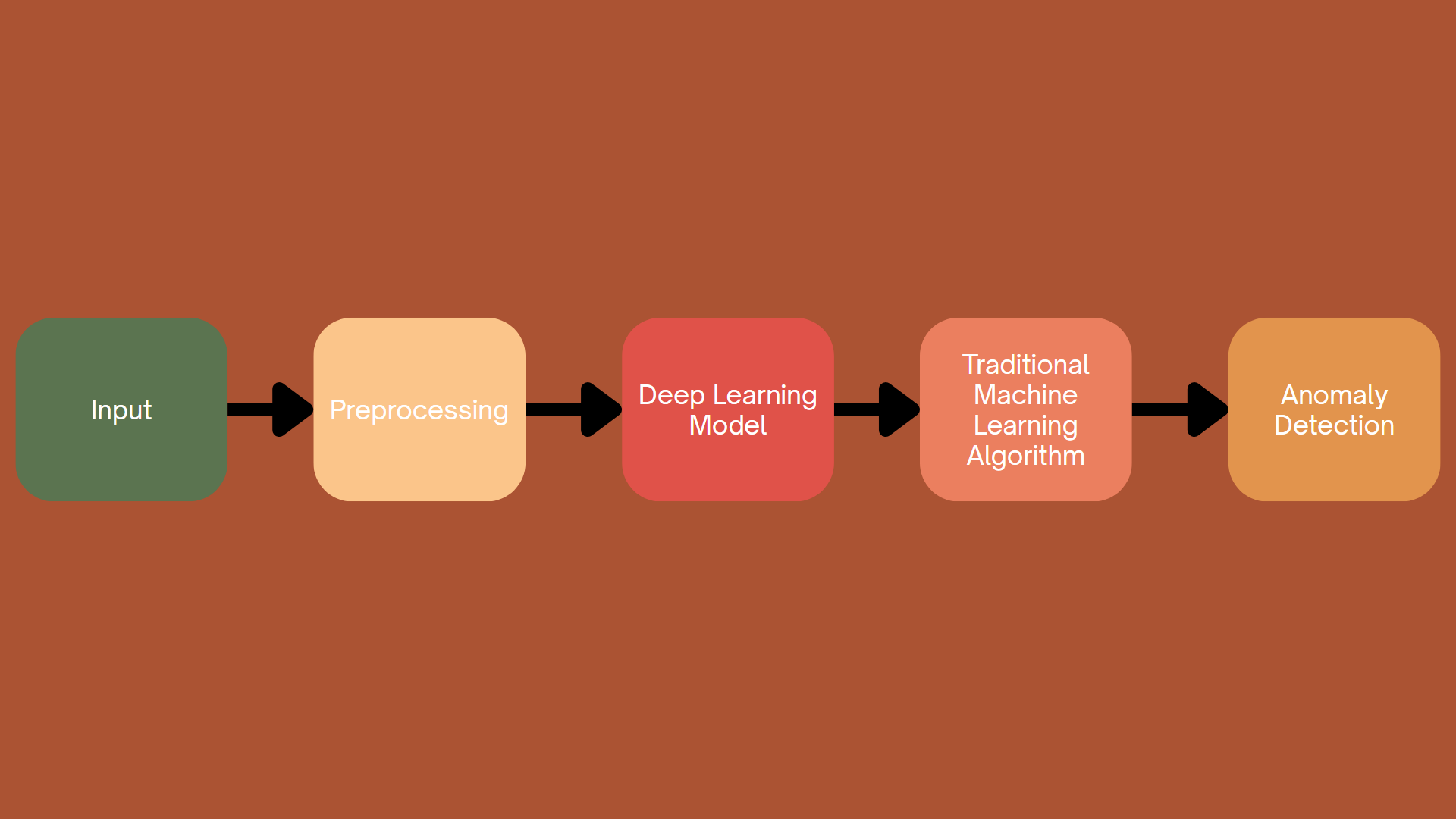 Hình 4.4. Kết hợp giữa Học máy truyền thống và Học sâu
Hình 4.4. Kết hợp giữa Học máy truyền thống và Học sâu
Các phương pháp truyền thống và các phương pháp học sâu đều mang lại những lợi thế riêng biệt. Các phương pháp truyền thống, chẳng hạn như phân cụm (clustering) và máy vectơ hỗ trợ (SVM), thường đơn giản hơn, dễ hiểu hơn và hiệu quả về mặt tính toán. Những phương pháp này vượt trội trong việc cung cấp các quy trình ra quyết định minh bạch, khiến chúng phù hợp với các ứng dụng mà khả năng giải thích mô hình là rất quan trọng. Mặt khác, các phương pháp học sâu, với khả năng mô hình hóa các phân bố dữ liệu phức tạp, đa chiều, cung cấp độ chính xác và khả năng thích ứng phát hiện được nâng cao, đặc biệt là đối với các tập dữ liệu lớn và dữ liệu phi cấu trúc như hình ảnh và chuỗi.
Việc tích hợp các phương pháp truyền thống và học sâu nhằm mục đích tận dụng khả năng giải thích và tính đơn giản của các phương pháp truyền thống với tính mạnh mẽ và linh hoạt của các kĩ thuật học sâu. Bằng cách kết hợp các phương pháp này, các nhà nghiên cứu tìm cách tạo ra các mô hình lai duy trì độ chính xác đồng thời cung cấp những hiểu biết sâu sắc về quy trình ra quyết định cơ bản, cải thiện cả khả năng phát hiện và tính minh bạch của mô hình.
Với cách này, ta thường sử dụng mô hình học sâu để trích xuất các đặc trưng nhiều chiều, phức tạp; rồi sau đó sử dụng các thuật toán như gom cụm hay máy vectơ hỗ trợ để có thể phân loại, phát hiện bất thường.
5. Những hạn chế thực tế trong việc phát hiện bất thường (Anomaly Detection)
Mặc dù anomaly detection là một kỹ thuật rất quan trọng trong data science, việc phát hiện các mẫu dữ liệu bất thường trong dữ liệu thực tế thường gặp nhiều khó khăn. Trong nhiều hệ thống, anomaly xảy ra rất hiếm, dữ liệu có thể thay đổi theo thời gian, và tập dữ liệu có thể chứa rất nhiều đặc trưng khác nhau. Những yếu tố này khiến các thuật toán khó phân biệt chính xác giữa hành vi bình thường và hành vi bất thường.
5.1. Dữ liệu mất cân bằng (Imbalanced Data)
Một trong những thách thức phổ biến nhất của anomaly detection là dữ liệu bị mất cân bằng.
Trong nhiều bài toán thực tế, dữ liệu bất thường chiếm tỷ lệ rất nhỏ so với dữ liệu bình thường. Ví dụ, trong dữ liệu giao dịch tài chính, các giao dịch gian lận thường chỉ chiếm một phần rất nhỏ trong tổng số giao dịch.
Ví dụ:
Normal transactions: 99,9%
Fraudulent transactions: 0,1%
Sự mất cân bằng này có thể khiến các mô hình machine learning truyền thống tập trung quá nhiều vào lớp dữ liệu chiếm đa số (dữ liệu bình thường). Kết quả là mô hình có thể đạt độ chính xác rất cao nhưng lại không phát hiện được anomaly.
Ví dụ, nếu một mô hình dự đoán tất cả giao dịch đều là normal, nó vẫn có thể đạt độ chính xác 99,9% trong ví dụ trên, mặc dù hoàn toàn không phát hiện được bất kỳ giao dịch gian lận nào.
Để giải quyết vấn đề này, các nhà khoa học dữ liệu thường áp dụng những kỹ thuật như sampling methods (ví dụ: oversampling dữ liệu hiếm) hoặc sử dụng các thuật toán chuyên biệt cho anomaly detection nhằm cải thiện khả năng phát hiện các sự kiện hiếm.
 Hình 5.1. Dữ liệu mất cân bằng; nguồn: Train In Data
Hình 5.1. Dữ liệu mất cân bằng; nguồn: Train In Data
5.2. Sự thay đổi của dữ liệu theo thời gian (Evolving Patterns)
Một thách thức khác là các hành vi bất thường không cố định mà có thể thay đổi theo thời gian.
Trong machine learning, hiện tượng này thường được gọi là concept drift, khi đặc tính thống kê của dữ liệu thay đổi theo thời gian. Khi điều này xảy ra, các mô hình được huấn luyện trên dữ liệu cũ có thể trở nên kém hiệu quả khi áp dụng cho dữ liệu mới.
Ví dụ điển hình là trong hệ thống phát hiện gian lận tài chính. Những kẻ gian lận liên tục thay đổi chiến thuật để vượt qua các hệ thống bảo mật. Khi một kiểu gian lận đã bị phát hiện và ngăn chặn, họ thường nhanh chóng tìm ra phương thức mới để thực hiện hành vi đó.
Vì vậy, các hệ thống anomaly detection trong thực tế thường cần:
- theo dõi hiệu suất mô hình liên tục
- cập nhật dữ liệu mới
- huấn luyện lại mô hình định kỳ
để đảm bảo hệ thống vẫn có thể phát hiện anomaly trong môi trường dữ liệu luôn thay đổi.
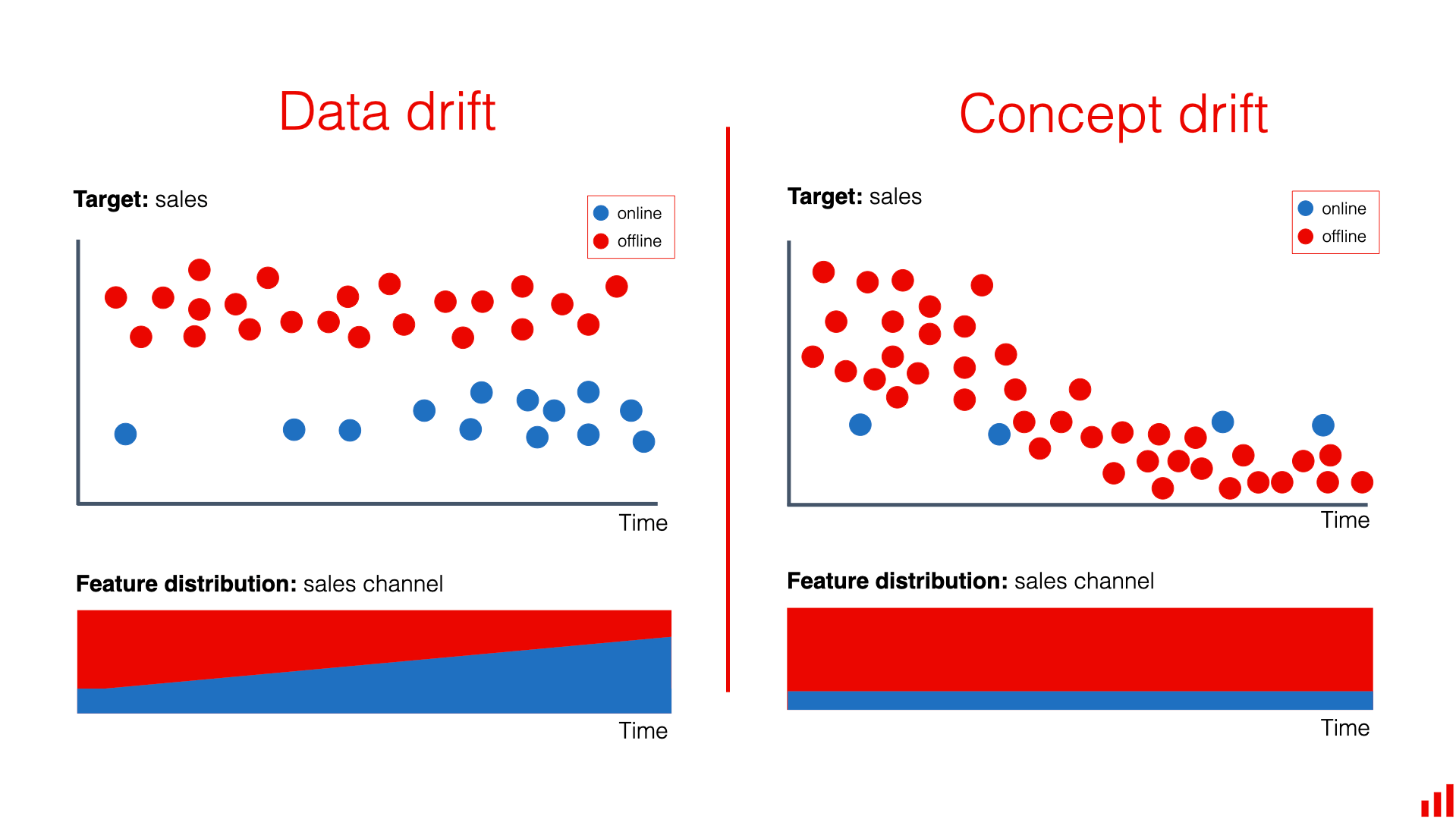 Hình 5.2. Sự thay đổi của dữ liệu theo thời gian; nguồn: EVIDENTLY AI
Hình 5.2. Sự thay đổi của dữ liệu theo thời gian; nguồn: EVIDENTLY AI
5.3. Dữ liệu có nhiều chiều (High-Dimensional Data)
Một khó khăn khác xuất hiện khi dữ liệu có rất nhiều đặc trưng.
Ví dụ, một bản ghi giao dịch có thể bao gồm nhiều thuộc tính như:
- số tiền giao dịch
- thời gian giao dịch
- vị trí địa lý
- loại thiết bị sử dụng
- lịch sử hành vi của người dùng
- phương thức thanh toán
Khi số lượng đặc trưng tăng lên, việc phát hiện anomaly trở nên khó khăn hơn do hiện tượng được gọi là “curse of dimensionality”.
Trong không gian dữ liệu nhiều chiều, khoảng cách giữa các điểm dữ liệu trở nên ít ý nghĩa hơn. Các điểm dữ liệu có thể trông gần như cách xa nhau tương tự nhau, khiến các thuật toán khó phân biệt đâu là dữ liệu bình thường và đâu là anomaly.
Ngoài ra, dữ liệu nhiều chiều cũng làm tăng độ phức tạp tính toán và có thể chứa các đặc trưng không liên quan hoặc nhiễu, làm giảm hiệu quả của mô hình.
Để khắc phục vấn đề này, các nhà khoa học dữ liệu thường sử dụng các kỹ thuật như feature selection (chọn đặc trưng quan trọng) hoặc dimensionality reduction như Principal Component Analysis (PCA).
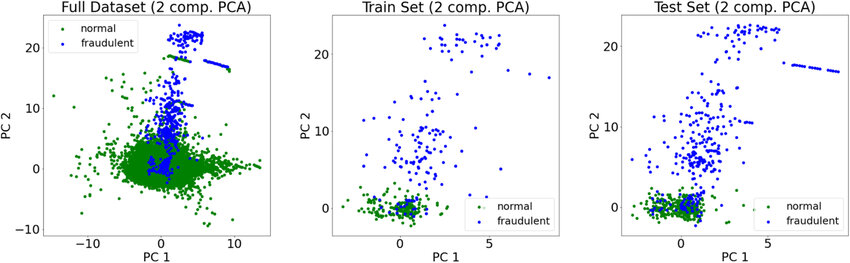 Hình 5.3. Dữ liệu có nhiều chiều; nguồn: ResearchGate
Hình 5.3. Dữ liệu có nhiều chiều; nguồn: ResearchGate
5.4. Yêu cầu phát hiện theo thời gian thực (Real-Time Detection)
Trong nhiều ứng dụng thực tế, hệ thống anomaly detection cần phải hoạt động theo thời gian thực.
Ví dụ, trong các hệ thống phát hiện gian lận thẻ tín dụng hoặc hệ thống an ninh mạng, anomaly cần được phát hiện ngay lập tức để tránh thiệt hại. Nếu việc phát hiện diễn ra quá muộn, hậu quả có thể rất lớn.
Hãy tưởng tượng một trường hợp thẻ tín dụng được sử dụng ở hai địa điểm cách xa nhau trong một khoảng thời gian rất ngắn. Hành vi bất thường này có thể là dấu hiệu của gian lận, và hệ thống cần nhanh chóng gắn cờ giao dịch đó để kiểm tra thêm.
Do đó, các hệ thống anomaly detection phải cân bằng giữa độ chính xác, tốc độ xử lý và chi phí tính toán, đặc biệt khi làm việc với dữ liệu lớn hoặc dữ liệu dạng streaming.
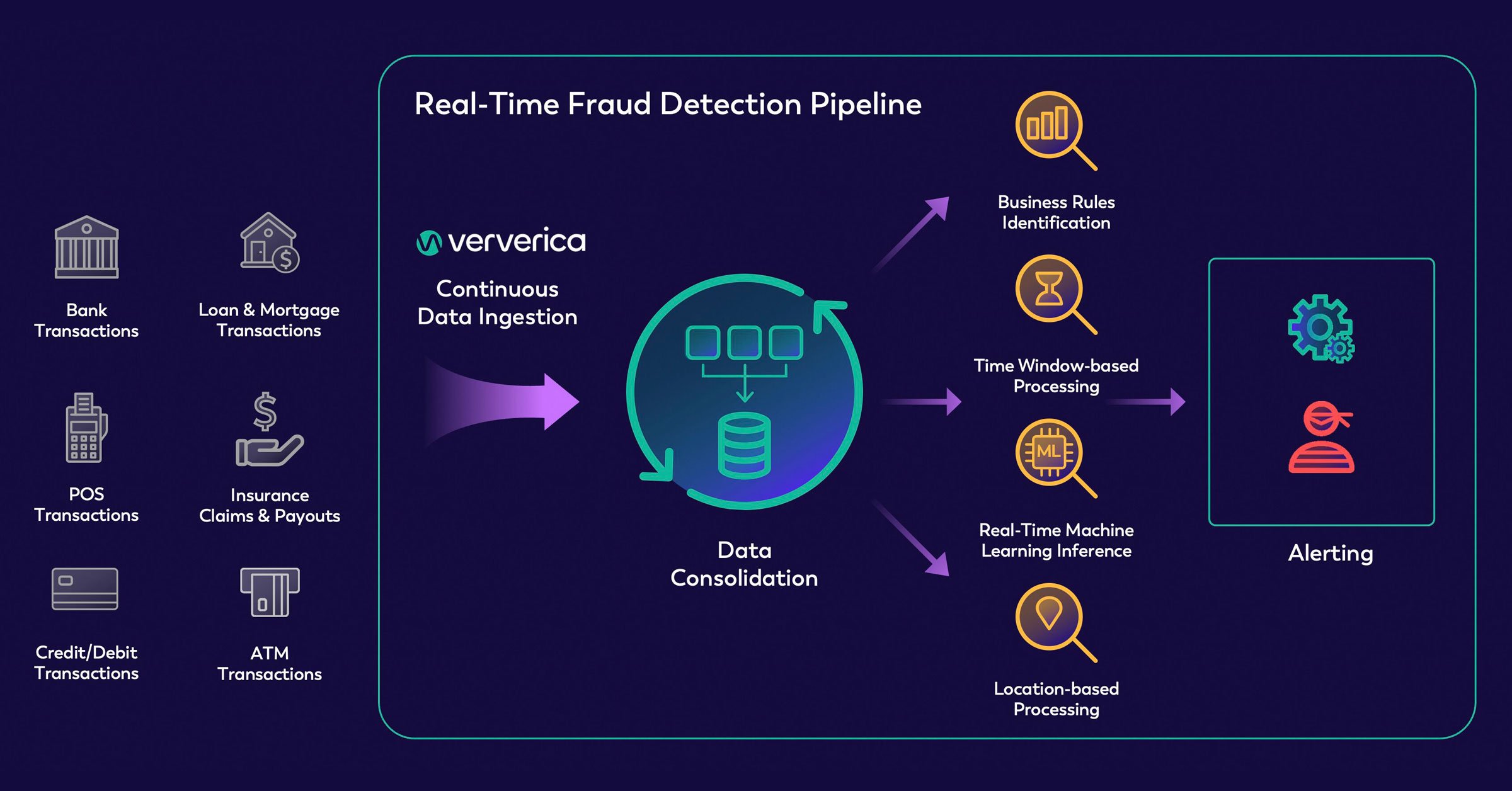 Hình 5.4. Quy trình xử lý giao dịch và phát hiện gian lận trong thời gian thực; nguồn: ververica
Hình 5.4. Quy trình xử lý giao dịch và phát hiện gian lận trong thời gian thực; nguồn: ververica
6. Kết luận
Hành trình giải mã dữ liệu không chỉ là đi tìm sự tương đồng, mà còn là học cách lắng nghe những tín hiệu khác biệt. Anomaly Detection chính là "đôi mắt tinh tường" giúp các hệ thống Data Science không bỏ lỡ những khoảnh khắc quan trọng, từ việc ngăn chặn một cú lừa đảo tài chính tinh vi đến việc bảo vệ hạ tầng mạng trước các cuộc tấn công ẩn mình.
Dù bạn sử dụng các phương pháp thống kê truyền thống hay các kiến trúc máy học hiện đại, mục tiêu cuối cùng vẫn là biến những "điểm đen" bất thường thành những quyết định chính xác. Nhưng làm thế nào để mang những lý thuyết này vào thế giới thực đầy biến động của ngành tài chính? Ở bài viết tiếp theo (Blog 2), chúng ta sẽ cùng "thực chiến" với các kỹ thuật máy học chuyên biệt để xây dựng hệ thống phát hiện gian lận (Fraud Detection) cho ngân hàng. Đừng bỏ lỡ nhé!
Tài liệu tham khảo
Aggarwal, C. C. (2017). Outlier analysis (2nd ed.). Springer.
Chandola, V., Banerjee, A., & Kumar, V. (2009). Anomaly detection: A survey. ACM Computing Surveys, 41(3), 1–58. https://doi.org/10.1145/1541880.1541882
Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep learning. MIT Press.
Chandola, Banerjee, and Kumar (2009). Anomaly Detection: A Survey
Huang, H., Wang, P., et. al. (2025). Deep Learning Advancements in Anomaly Detection: A Comprehensive Survey. arXiv. https://arxiv.org/html/2503.13195v1
IBM. (n.d.). What is anomaly detection? IBM. https://www.ibm.com/think/topics/anomaly-detection
Nguyễn Minh Hải. (2025). Anomaly Detection là gì? Xu hướng phát triển của phát hiện bất thường. VNPT AI. https://vnptai.io/vi/blog/detail/anomaly-detection-la-gi
Song, X., Wu, M., Jermaine, C., & Ranka, S. (2007). Conditional anomaly detection. IEEE Transactions on Knowledge and Data Engineering, 19(5), 631–645. https://doi.org/10.1109/TKDE.2007.1018
Goldberger, A. L., Amaral, L. A. N., Glass, L., Hausdorff, J. M., Ivanov, P. C., Mark, R. G., Mietus, J. E., Moody, G. B., Peng, C.-K., & Stanley, H. E. (2000). PhysioBank, PhysioToolkit, and PhysioNet: Components of a new research resource for complex physiologic signals. Circulation, 101(23), e215–e220. https://doi.org/10.1161/01.CIR.101.23.e215
Chưa có bình luận nào. Hãy là người đầu tiên!