
1. Bối cảnh dữ liệu bán lẻ và khái niệm GIGO
1.1. Bối cảnh
Ngành bán lẻ hiện đại đang bước vào kỷ nguyên số, nơi dữ liệu trở thành tài sản cốt lõi giúp doanh nghiệp ra quyết định nhanh hơn, chính xác hơn và tạo lợi thế cạnh tranh bền vững. Sự phát triển của mô hình bán lẻ hợp kênh (Omnichannel) khiến dữ liệu được tạo ra liên tục từ nhiều nguồn như hệ thống điểm bán hàng (POS), nền tảng thương mại điện tử, chương trình khách hàng thân thiết và hệ thống quản lý tồn kho. Tuy nhiên, khi khối lượng, tốc độ và mức độ đa dạng của dữ liệu tăng lên, rủi ro về sai lệch, thiếu hụt và không nhất quán cũng tăng theo.
Tại Việt Nam, quá trình chuyển đổi sang bán lẻ hợp kênh đang diễn ra mạnh mẽ. Nhiều doanh nghiệp đã bắt đầu tích hợp dữ liệu từ cửa hàng vật lý và nền tảng trực tuyến để xây dựng chân dung khách hàng toàn diện, tối ưu tồn kho và cải thiện trải nghiệm mua sắm. Dù vậy, dữ liệu giữa các kênh vẫn thường bị phân mảnh, dẫn đến khó khăn trong việc đồng bộ thông tin, dự báo nhu cầu và hoạch định chiến lược kinh doanh.
Trong bối cảnh đó, chất lượng dữ liệu trở thành điều kiện tiên quyết. Một hệ thống phân tích hiện đại sẽ không thể tạo ra kết quả đáng tin cậy nếu dữ liệu đầu vào chứa quá nhiều lỗi. Đây cũng là lý do khái niệm GIGO có ý nghĩa đặc biệt quan trọng trong phân tích dữ liệu.
1.2. Khái niệm GIGO
GIGO là viết tắt của cụm từ Garbage In, Garbage Out, nghĩa là “đầu vào rác thì đầu ra cũng sẽ là rác”. Đây là một nguyên lý nền tảng trong khoa học máy tính và phân tích dữ liệu, nhấn mạnh rằng chất lượng kết quả của hệ thống phụ thuộc trực tiếp vào chất lượng dữ liệu đầu vào. Dù thuật toán có tiên tiến đến đâu, nếu dữ liệu đầu vào sai, thiếu hoặc nhiễu, kết quả đầu ra vẫn có thể vô nghĩa hoặc gây ra quyết định sai lầm.
Về mặt lịch sử, tư tưởng của GIGO đã xuất hiện từ rất sớm trong quá trình phát triển ngành điện toán. Charles Babbage từng đặt ra vấn đề rằng một cỗ máy không thể tạo ra câu trả lời đúng nếu dữ liệu đầu vào vốn đã sai. Sau này, vào năm 1957, William D. Mellin tiếp tục nhấn mạnh rằng máy tính không thể “tự suy nghĩ” để sửa lỗi cho con người. Đến thập niên 1960, George Fuechsel của IBM đã phổ biến rộng rãi thuật ngữ GIGO nhằm giáo dục người dùng về tầm quan trọng của nhập liệu chính xác.
Nói cách khác, GIGO không chỉ là một khẩu hiệu kỹ thuật mà còn là nguyên tắc cốt lõi của mọi hệ thống phân tích hiện đại. Muốn có báo cáo đúng, mô hình tốt và quyết định đáng tin cậy, doanh nghiệp phải bắt đầu từ việc làm sạch dữ liệu đầu vào.
2. Vai trò của Data Cleaning
2.1. Khái niệm của Data Cleaning
Data cleaning là quá trình làm sạch dữ liệu thô nhằm nâng cao chất lượng, tính nhất quán và khả năng sử dụng của dữ liệu. Trong thực tế, dữ liệu thu thập từ nhiều hệ thống thường tồn tại nhiều vấn đề như giá trị bị thiếu, dữ liệu trùng lặp, sai định dạng, dữ liệu không hợp lệ hoặc chứa nhiễu không liên quan. Nếu không được xử lý, các lỗi này sẽ ảnh hưởng trực tiếp đến độ chính xác của phân tích và độ tin cậy của quyết định.
Quá trình làm sạch dữ liệu giúp biến một tập dữ liệu thô thành tập dữ liệu có thể sử dụng một cách đáng tin cậy trong phân tích, báo cáo và mô hình hóa. Đây là bước không thể thiếu trong hầu hết các dự án phân tích dữ liệu, khoa học dữ liệu và học máy.
Tầm quan trọng của làm sạch dữ liệu
Trong phân tích dữ liệu, làm sạch dữ liệu giúp đảm bảo rằng các kết luận được rút ra phản ánh đúng thực tế. Dữ liệu càng sạch thì sai lệch trong báo cáo và quá trình ra quyết định càng giảm.
Trong khoa học dữ liệu, làm sạch dữ liệu thường chiếm phần lớn thời gian và công sức của dự án. Một bộ dữ liệu chất lượng cao giúp nhà phân tích tiết kiệm thời gian xử lý lỗi, đồng thời cải thiện hiệu quả của toàn bộ quy trình.
Trong học máy, dữ liệu sạch là nền tảng để xây dựng mô hình có độ tin cậy cao. Dữ liệu tốt giúp mô hình học đúng quy luật, cải thiện khả năng dự đoán trên dữ liệu mới và giảm rủi ro quá khớp (overfitting).
Năm tiêu chuẩn đánh giá chất lượng dữ liệu sau khi làm sạch
-
Accuracy (Tính chính xác): Dữ liệu phải phản ánh đúng thực tế.
Ví dụ: đơn giá trong bộ dữ liệu Online Retail phải khớp với giá bán thực tế. -
Completeness (Tính đầy đủ): Dữ liệu cần có đủ thông tin phục vụ mục tiêu phân tích.
Ví dụ: thiếu CustomerID sẽ làm gián đoạn phân tích hành vi khách hàng. -
Consistency (Tính nhất quán): Dữ liệu phải đồng nhất giữa các bảng và các nguồn.
Ví dụ: định dạng ngày tháng hoặc tên quốc gia không được mâu thuẫn giữa các tệp. -
Validity (Tính hợp lệ): Dữ liệu phải tuân thủ quy tắc nghiệp vụ.
Ví dụ: cột Quantity phải có giá trị hợp lệ theo mục tiêu phân tích. -
Timeliness (Tính kịp thời): Dữ liệu phải được cập nhật đúng thời điểm cần sử dụng.
Dữ liệu quá cũ có thể không còn phản ánh đúng tình hình hiện tại.
2.2. Phân biệt Cleaning và Transformation
Mặc dù thường đi cùng nhau trong một pipeline xử lý dữ liệu, cleaning và transformation là hai khái niệm khác nhau.
| Đặc điểm | Cleaning | Transformation |
|---|---|---|
| Mục tiêu | Làm dữ liệu sạch, chính xác, ít lỗi | Chuyển dữ liệu sang cấu trúc phù hợp hơn cho phân tích |
| Hoạt động chính | Xử lý thiếu dữ liệu, trùng lặp, lỗi định dạng, giá trị không hợp lệ | Chuẩn hóa đơn vị, tạo biến mới, đổi cấu trúc bảng, gộp hoặc tách cột |
| Kết quả | Dữ liệu giảm “rác”, tăng độ tin cậy | Dữ liệu sẵn sàng cho báo cáo, trực quan hóa hoặc mô hình hóa |
| Ví dụ | Trim, Remove Duplicates, Replace Null | Unpivot, Group By, Split Column, Merge |
Nói ngắn gọn, cleaning tập trung vào việc sửa lỗi và loại bỏ vấn đề trong dữ liệu, còn transformation tập trung vào việc tổ chức lại dữ liệu để phục vụ mục tiêu phân tích tốt hơn.
2.3. Tư duy xử lý dữ liệu giữa GUI và Code
Trong thực tế, xử lý dữ liệu có thể được thực hiện theo hai hướng chính: dùng giao diện trực quan (GUI) hoặc dùng ngôn ngữ lập trình (Code).
Tư duy GUI (Power Query)
Với Power Query, người dùng thao tác trực tiếp qua giao diện và hệ thống sẽ ghi lại toàn bộ quy trình dưới dạng Applied Steps. Cách tiếp cận này có ưu điểm là trực quan, dễ học, phù hợp với người dùng không chuyên lập trình và rất hiệu quả trong các bài toán dữ liệu vừa và nhỏ. Khi có dữ liệu mới, chỉ cần bấm Refresh để chạy lại toàn bộ quy trình đã lưu.
Tư duy Code (SQL/Pandas)
Khác với GUI, tư duy code tập trung vào việc xây dựng logic xử lý dữ liệu bằng câu lệnh và hàm. Cách tiếp cận này linh hoạt hơn, phù hợp với dữ liệu lớn, yêu cầu logic phức tạp hoặc cần tự động hóa sâu. Với SQL hay Pandas, người dùng có thể xử lý dữ liệu từ nhiều nguồn, tích hợp API, kết nối cloud và mở rộng pipeline ở mức cao hơn.
So sánh GUI và Code
| Đặc điểm | GUI (Power Query) | Code (SQL/Pandas) |
|---|---|---|
| Cách tiếp cận | Tương tác trực quan trên giao diện | Xây dựng logic bằng mã lệnh |
| Lịch sử xử lý | Tự động lưu dưới dạng Applied Steps | Lưu trong file code như .sql, .py |
| Quy mô phù hợp | Dữ liệu vừa và nhỏ | Dữ liệu lớn, logic phức tạp |
| Độ linh hoạt | Phụ thuộc tính năng có sẵn | Tùy biến rất cao |
| Tự động hóa | Dễ dùng, nhanh triển khai | Mạnh hơn trong hệ thống lớn |
2.4. Bảng thuật ngữ Anh – Việt
| Thuật ngữ Anh | Thuật ngữ Việt | Ý nghĩa kỹ thuật |
|---|---|---|
| Raw Data | Dữ liệu thô | Dữ liệu chưa qua xử lý, còn nhiều sai sót |
| Missing Data | Dữ liệu thiếu | Các ô trống hoặc giá trị null |
| Duplicates | Dữ liệu trùng lặp | Các bản ghi lặp lại không mong muốn |
| Outliers | Giá trị ngoại lai | Các giá trị bất thường so với phần còn lại |
| Invalid Values | Giá trị không hợp lệ | Dữ liệu sai định dạng hoặc sai quy tắc |
| Data Profiling | Phân tích hồ sơ dữ liệu | Kiểm tra đặc điểm và chất lượng dữ liệu trước khi làm sạch |
| Applied Steps | Các bước đã thực hiện | Lịch sử thao tác trong Power Query |
| Unpivot | Hủy xoay cột | Chuyển dữ liệu từ dạng ngang sang dạng dọc |
| Data Transformation | Biến đổi dữ liệu | Thay đổi cấu trúc hoặc định dạng dữ liệu |
| Data Pipeline | Luồng xử lý dữ liệu | Chuỗi các bước xử lý từ thu thập đến phân tích |
| Data Quality | Chất lượng dữ liệu | Mức độ đáng tin cậy và sử dụng được của dữ liệu |
| Accuracy | Tính chính xác | Dữ liệu phản ánh đúng thực tế |
| Completeness | Tính đầy đủ | Dữ liệu có đủ thông tin cần thiết |
| Consistency | Tính nhất quán | Dữ liệu đồng nhất giữa các nguồn |
| Validity | Tính hợp lệ | Dữ liệu đúng định dạng và quy tắc |
| Timeliness | Tính kịp thời | Dữ liệu được cập nhật đúng thời điểm |
| Data Analysis | Phân tích dữ liệu | Quá trình khai thác dữ liệu để rút ra thông tin |
| Machine Learning | Học máy | Thuật toán giúp máy tính học từ dữ liệu |
Từ những cơ sở trên có thể thấy rằng làm sạch dữ liệu không chỉ là bước kỹ thuật ban đầu mà còn là nền tảng cho toàn bộ quá trình phân tích. Sau khi hiểu rõ bản chất của dữ liệu bẩn, vai trò của data cleaning và các cách tiếp cận xử lý, phần tiếp theo sẽ trình bày các công cụ phổ biến dùng để làm sạch dữ liệu trong thực tế.
3. Các công cụ làm sạch dữ liệu
Một số công cụ phổ biến và hiệu quả:
1. Power Query (ETL)
2. Excal Data Analysis ToolPak (Thống kê)
3. Lập trình Python (Validation)
Blog đưa ra dự án chuẩn hóa bộ dữ liệu Oneline Retail chứa các giao dịch xuyên biên giới. Đặc thù dữ liệu thô có độ nhiễu cao do lỗi nhập liệu, đơn hàng hủy và khách hàng vãng lai.
Mục tiêu dự án hướng đến xây dựng Pipeline dữ liệu sạch sẽ và hệ thống báo cáo với quy mô 541.999 dòng dữ liệu gốc.
Link csv: Download dữ liệu CSV
3.1. Power Query Engineering - Pipeline ETL
Áp dụng quy trình 8 bước nghiêm ngặt trên Power Query
Bước 1: Chấn đoán sức khỏe dữ liệu
- Import file csv:
Data -> Get Data -> From File -> From Workbook.
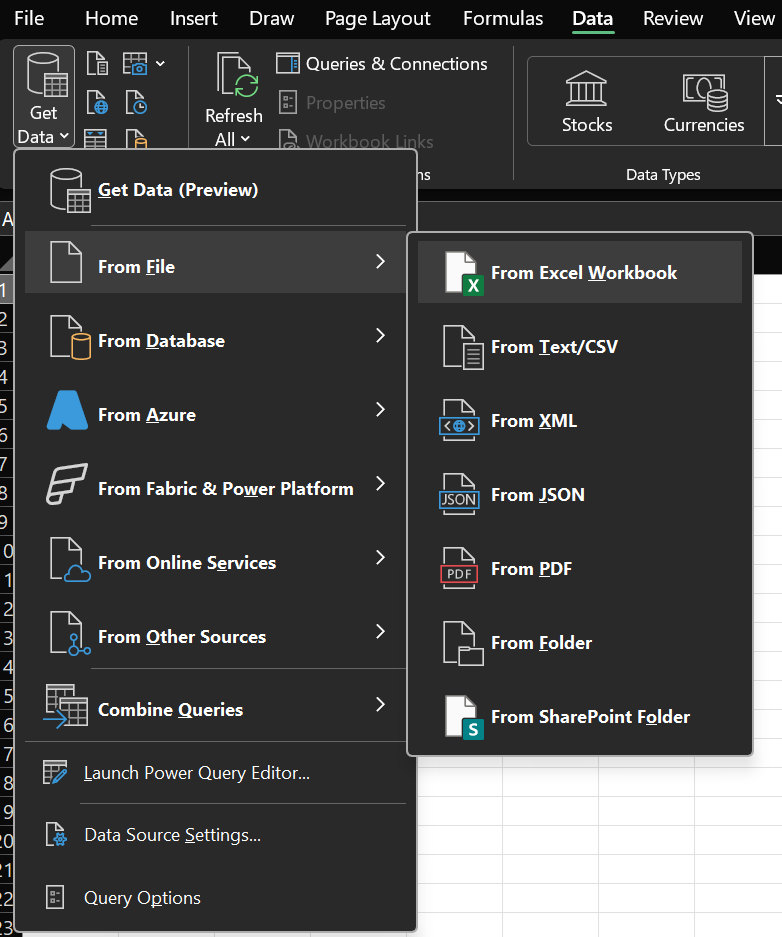 Hình 1a. Tìm mục Excel Workbook để nạp dữ liệu. |
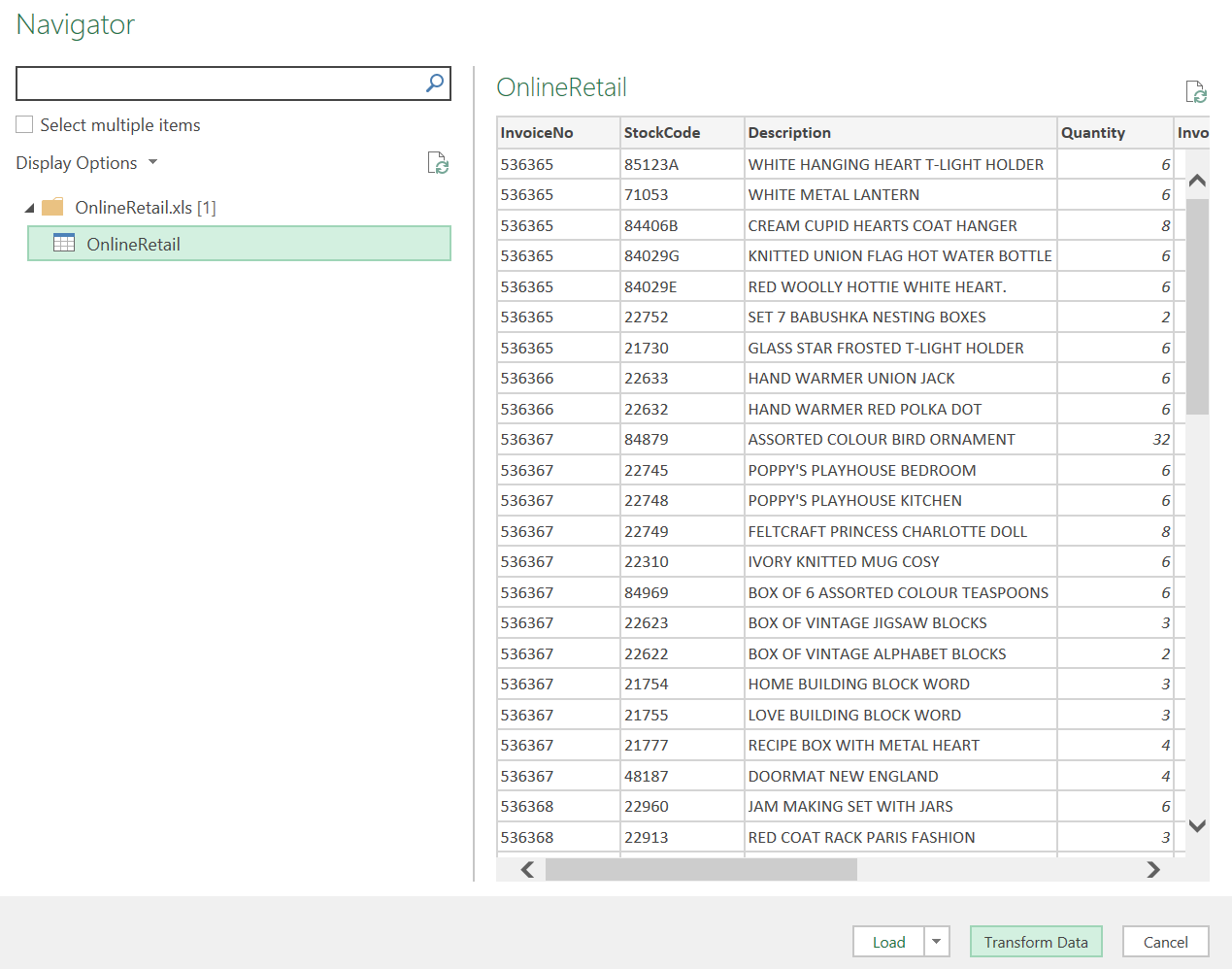 Hình 1b. Chuyển bảng dữ liệu sang Power Query để xử lý. |
Ngay khi nạp, kích hoạt Column Quality và Column Distribution trong tab View
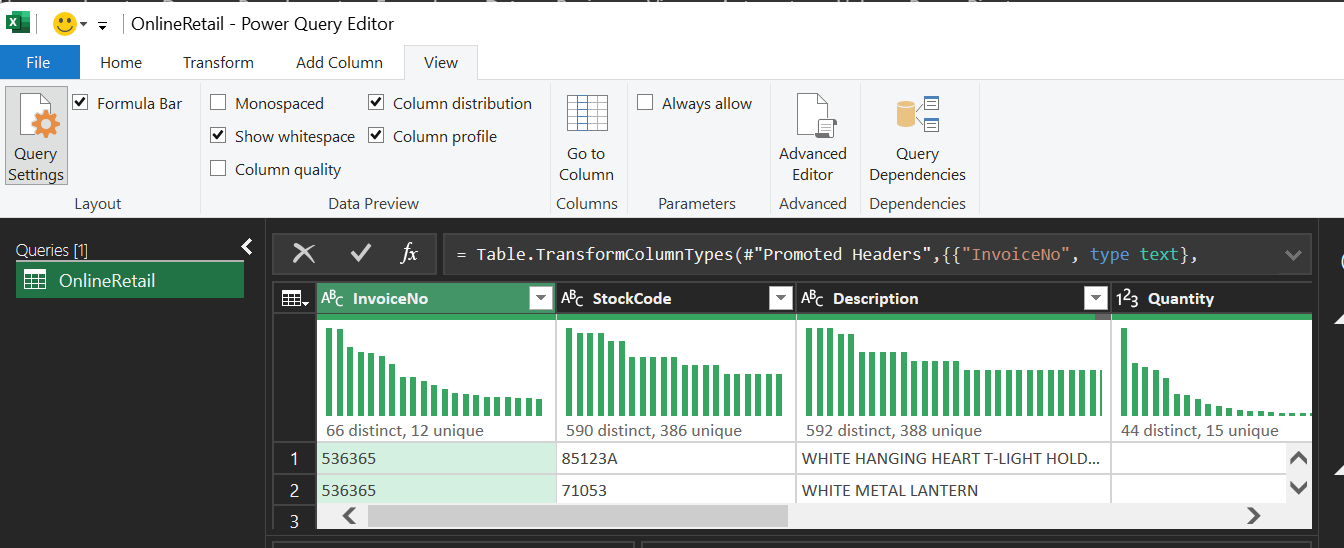
Hình 2. Mở tab View và bật các công cụ profiling (Column Quality/Distribution/Profile).
Kích hoạt các công cụ định lượng ngay tại nguồn:
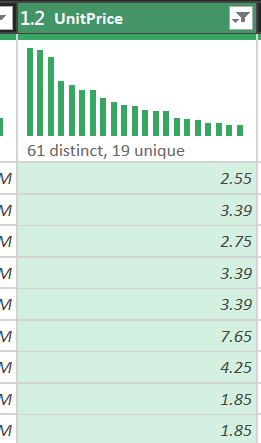
- Column Quality: Kiểm tra tỷ lệ "Valid", "Error" và "Empty". Kết quả cho thấy, cột CustomerID chỉ có 75.1% dữ liệu hợp lệ.
- Column Distribution: Nhận diện sự phân bổ của các mã hàng. Biểu đồ cho thấy sự hiện diện của các mã không phải sản phẩm như POST (phí bưu điện), D (giảm giá), M (thao tác tay).
- Column Profile: Cung cấp thống kê chi tiết cho từng cột (Min, Max, Mean). Phát hiện Quantity âm (-80,995). Đây là các giao dịch trả hàng cần xử lý.
Biểu đồ Column Profile hiển thị giá trị Min/Max của Quantity
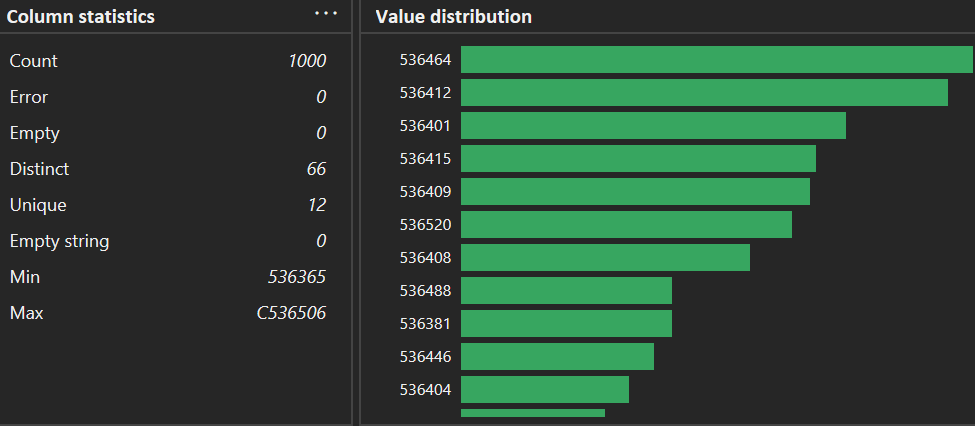
Hình 3. Quan sát 2 dòng cuối của Column statistics (Min/Max) để phát hiện giá trị bất thường.
Bước 2: Xử lý dữ liệu bị thiếu
Phân tích cho thấy có 135,080 dòng thiếu định danh khách hàng.
- Thao tác: Nhấp chuột phải vào cột CustomerID > Remove Empty.
- Giải trình kỹ thuật: Tại sao chọn lọc bỏ thay vì thay thế (Imputation)?
- Tính định danh: CustomerID là "khóa ngoại" duy nhất để liên kết với hành vi khách hàng. Nếu điền mã giả (ví dụ: 0), hệ thống sẽ hiểu 135,080 giao dịch này thuộc về cùng một người, làm hỏng hoàn toàn phân tích lòng trung thành (Retention Rate).
- Mục tiêu RFM: Để tính toán Recency (Ngày mua gần nhất) và Frequency (Tần suất), ta bắt buộc phải có thông tin định danh chính xác từ hệ thống CRM.
Kết quả:
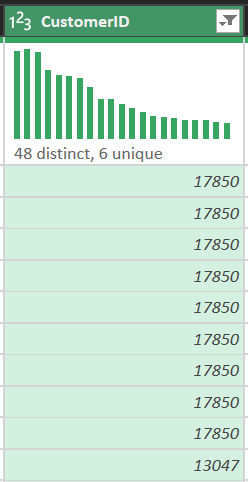
Hình 4. Loại bỏ ô trống trong CustomerID để đảm bảo tính định danh.
Bước 3: Lọc nhiễu giao dịch
Dữ liệu thô chứa các giao dịch hủy (mã hóa bằng tiền tố 'C' trong InvoiceNo) và các dòng thử nghiệm.
- Thao tác: Thiết lập bộ lọc kép
Number Filter > Greater Than 0
cho đồng thời hai cột số lượng và đơn giá. - Ý nghĩa nghiệp vụ: Loại bỏ đơn hàng bị hủy, quà tặng tặng kèm (giá 0) và nợ xấu. Điều này giúp tính toán Doanh thu thực tế (Net Revenue) thay vì doanh thu ảo.
Hình 5. Bấm biểu tượng “phễu” để thiết lập bộ lọc loại bỏ giao dịch không hợp lệ.
Bước 4: Định dạng dữ liệu
Ép kiểu dữ liệu để tối ưu hóa hiệu năng tính toán trong Excel Data Model:
- InvoiceDate: Chuyển sang Date/Time (Cho phép phân tích xu hướng mua hàng theo giờ/tháng).
- UnitPrice: Chuyển sang Decimal Number (Bảo toàn độ chính xác tiền tệ).
- Quantity: Chuyển sang Whole Number (Số lượng đơn vị sản phẩm).
- CustomerID: Chuyển sang Whole Number (Dùng làm định danh thay vì văn bản).
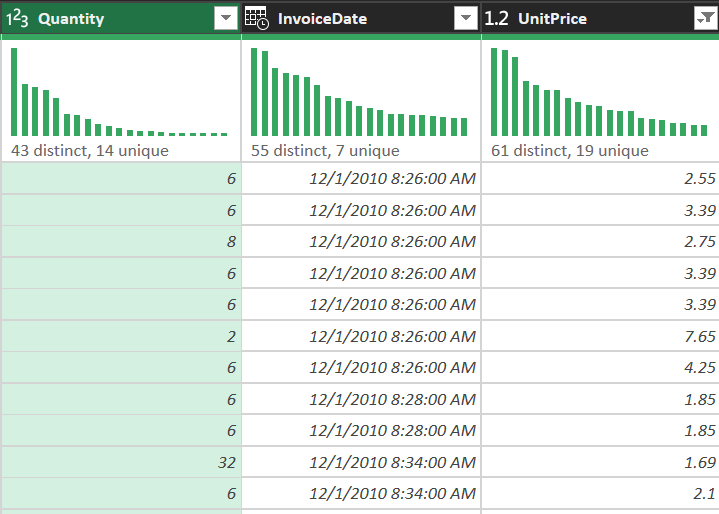
Hình 6. Ép kiểu dữ liệu (Quantity/InvoiceDate/UnitPrice) để tối ưu phân tích và tránh lỗi định dạng.
Bước 5: Text Cleaning – Chuẩn hóa SKUs
Cột Description chứa nhiều lỗi nhập liệu thủ công:
- Trim: Loại bỏ khoảng trắng thừa đầu và cuối chuỗi.
- Clean: Loại bỏ các ký tự ẩn gây lỗi định dạng.
- Capitalize Each Word: Đồng nhất cách viết
(ví dụ: " red mug" -> "Red Mug").
--> Kết quả: Đảm bảo khi chạy Pivot Table, các sản phẩm không bị tách rời vô lý.
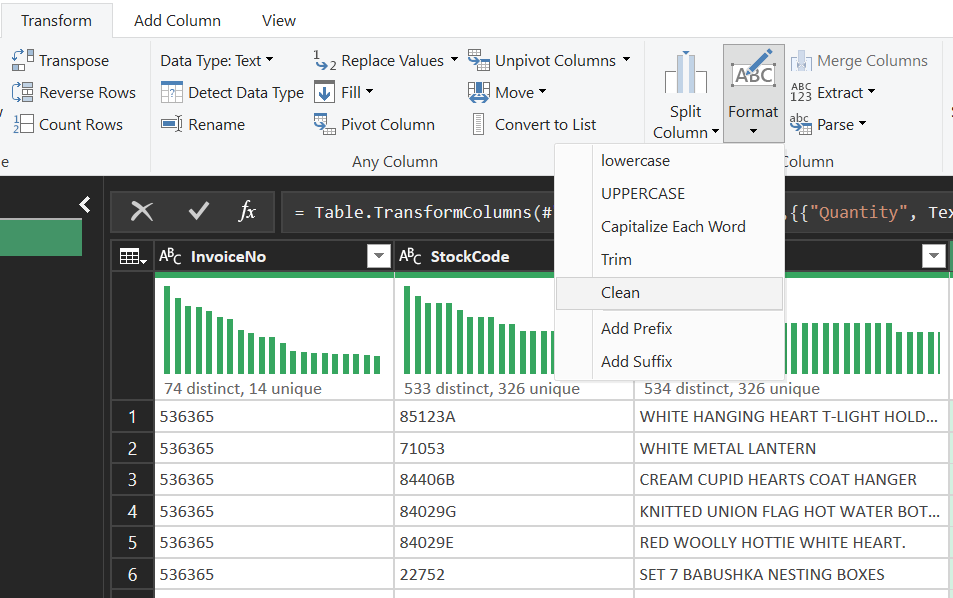
Hình 7. Tìm nút Format để chuẩn hoá văn bản (Trim/Clean/Capitalize Each Word).
Bước 6: Tạo cột trạng thái đơn hàng
Xây dựng cột logic để phân loại quy mô giao dịch:
- Thao tác: Add Column > Conditional Column.
- Logic: if [Quantity] > 100 then "Wholesale" else "Retail".
- Mục đích: Hỗ trợ Designer tạo Slicer trên Dashboard để so sánh hành vi giữa nhóm khách mua sỉ và mua lẻ.
Hình 8. Nhập điều kiện và tạo cột phân loại Wholesale/Retail.
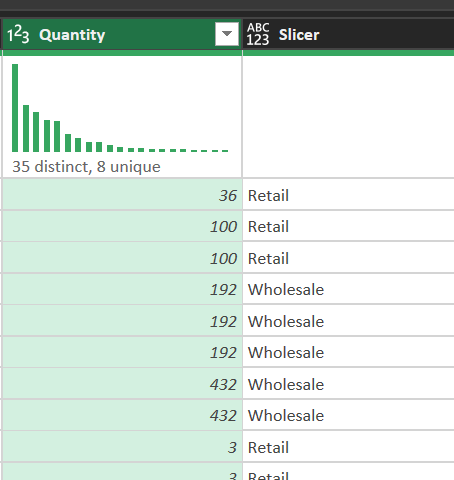
Hình 9. Kiểm tra kết quả cột trạng thái đơn hàng sau khi tạo.
Bước 7: Chi lại lịch sử thao tác
Mọi bước trên được ghi lại trong bảng Applied Steps.
- Ý nghĩa: Đây là "kịch bản" tự động hóa. Khi có tệp dữ liệu tháng tiếp theo, chúng ta chỉ cần nhấn Refresh, Power Query sẽ tự động lặp lại 8 bước này, loại bỏ 100% sai sót thủ công và đảm bảo tính nhất quán (Reproducibility).
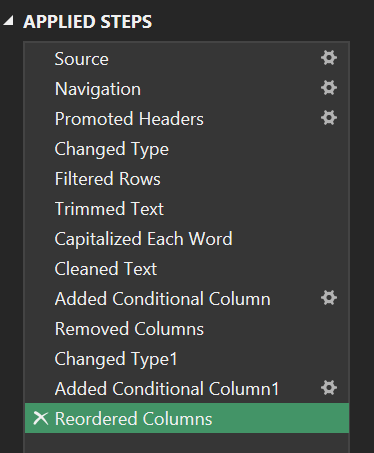
Hình 10. Tìm cột Applied Steps để xem lịch sử thao tác và tái chạy pipeline bằng Refresh.
Bước 8: Advanced Editor & Ngôn ngữ M-Code
Đối với bước phức tạp nhất, khuyến khích sử dụng Advanced Editor để kiểm soát trực tiếp mã nguồn.
Mã M-code chi tiết xử lý pipeline:
let
Source = Excel.Workbook(File.Contents("C:\Data\OnlineRetail.xlsx"), null, true),
Data = Source{[Item="Sheet1",Kind="Sheet"]}[Data],
#"Promoted Headers" = Table.PromoteHeaders(Data, [PromoteAllScalars=true]),
// Lọc bỏ rác và null trong một bước duy nhất để tối ưu Query Folding
#"CleanedData" = Table.SelectRows(#"Promoted Headers", each [CustomerID] <> null and [Quantity] > 0 and [UnitPrice] > 0),
#"ChangedTypes" = Table.TransformColumnTypes(#"CleanedData",{
{"Quantity", Int64.Type}, {"UnitPrice", type number}, {"CustomerID", Int64.Type}, {"InvoiceDate", type datetime}
}),
#"FormattedText" = Table.TransformColumns(#"ChangedTypes", {{"Description", each Text.Proper(Text.Trim(_)), type text}}),
#"AddedStatus" = Table.AddColumn(#"FormattedText", "OrderType", each if [Quantity] > 100 then "Wholesale" else "Retail")
in
#"AddedStatus"
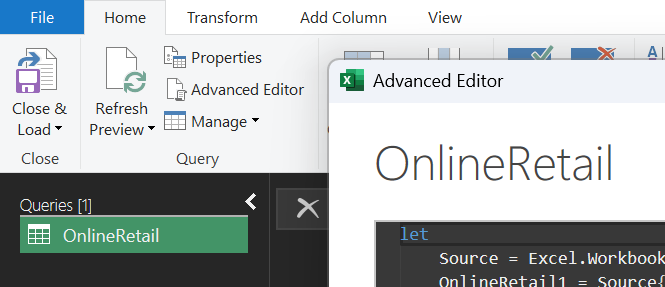
Hình 11. Về tab Home và mở Advanced Editor để xem/toàn quyền chỉnh M-code.
3.2. Phân tích thống kê, vai trò của Analyst
Sử dụng bộ công cụ Descriptive Statistics trong Excel để giải mã các con số đằng sau tập dữ liệu đã sạch.
Chỉ số mô tả chuyên sâu
| Chỉ số | Giá trị | Phân tích chuyên sâu |
|---|---|---|
| MEAN | $22.39$ | Giá trị doanh thu trung bình trên mỗi dòng sản phẩm |
| MEDIAN | $12.30$ | Điểm trung tâm thực sự của dữ liệu, phản ánh khách lẻ bình thường |
| Std Dev $\sigma$ | $165.05$ | Độ lệch chuẩn phản ánh mức độ dao động mạnh giữa các mã hàng |
| Skewness | $3.2$ | Hệ số lệch dương, cho thấy phân phối lệch phải và tồn tại một số giao dịch có giá trị rất lớn |
Công thức độ lệch chuẩn:
$$ \sigma = \sqrt{\frac{1}{N} \sum_{i=1}^{N} (x_i - \mu)^2} $$
Tại sao Median lại là "vị cứu tinh"?
- Trong bộ dữ liệu này, các khách bán sỉ (Wholesalers) mua hàng nghìn món tạo ra các Outliers cực lớn kéo chỉ số MEAN lên cao giả tạo. Chỉ số MEDIAN = 12.30 không bị ảnh hưởng bởi giá trị ngoại lai, giúp nhà quản lý nhận diện đúng hành vi tiêu dùng của 90% khách hàng lẻ (Retailers).
3.3. Python
Sử dụng Python để kiểm chứng lại toàn bộ Pipeline của Power Query, đảm bảo tính khách quan
- Chuẩn bị
Các thư viện
from pathlib import Path
import matplotlib.pyplot as plt
import pandas as pd
from google.colab import files
from IPython.display import display
Phần format pandas
pd.set_option("display.max_columns", None)
pd.set_option("display.float_format", lambda value: f"{value:,.2f}")
Tải file lên Colab và đọc bằng pandas
input_path = Path(next(iter(files.upload())))
raw_data = pd.read_excel(input_path, engine = "xlrd")
Link csv: Download dữ liệu CSV
- Cách đặt tên cột
Đặt tên cột không có khoảng trắng:
- NameName
- Name_Name
TEXT_COLUMNS = ["InvoiceNo", "StockCode", "Description", "Country"]
# Đưa vào giá trị mỗi cột --> Hợp lệ
REQUIRED_COLUMNS = [
"InvoiceNo",
"StockCode",
"Description",
"Quantity",
"InvoiceDate",
"UnitPrice",
"Country",
]
- Chuẩn hóa chữ và giá trị rỗng
def normalize_text(text_series: pd.Series) -> pd.Series:
return (
# Chuyển về string
text_series.astype("string")
# Xóa khoảng trắng thừa
.str.replace(r"\s+", " ", regex=True)
.str.strip()
# Đưa ra giá trị rỗng về NaN
.replace({"": pd.NA, "<NA>": pd.NA})
)
- Báo cáo dữ liệu
Tạo bảng chỉ số để so sánh dữ liệu trước & sau khi làm sạch.
def build_report(data_frame: pd.DataFrame) -> pd.DataFrame:
summary_values = {
"total_rows": len(data_frame),
"missing_customer_id": data_frame["CustomerID"].isna().sum(),
"cancelled_invoices": data_frame["InvoiceNo"].str.startswith("C", na=False).sum(),
"non_positive_quantity": data_frame["Quantity"].le(0).sum(),
"non_positive_unit_price": data_frame["UnitPrice"].le(0).sum(),
"duplicate_rows": data_frame.duplicated().sum(),
"gross_sales": round(data_frame["SaleAmount"].fillna(0).sum(), 2),
"mean_quantity": round(data_frame["Quantity"].dropna().mean(), 2),
"median_quantity": round(data_frame["Quantity"].dropna().median(), 2),
"mean_unit_price": round(data_frame["UnitPrice"].dropna().mean(), 2),
"median_unit_price": round(data_frame["UnitPrice"].dropna().median(), 2),
"mean_sale_amount": round(data_frame["SaleAmount"].dropna().mean(), 2),
"median_sale_amount": round(data_frame["SaleAmount"].dropna().median(), 2),
}
return pd.DataFrame(summary_values.items(), columns=["metric", "value"])
Kết quả trả về:
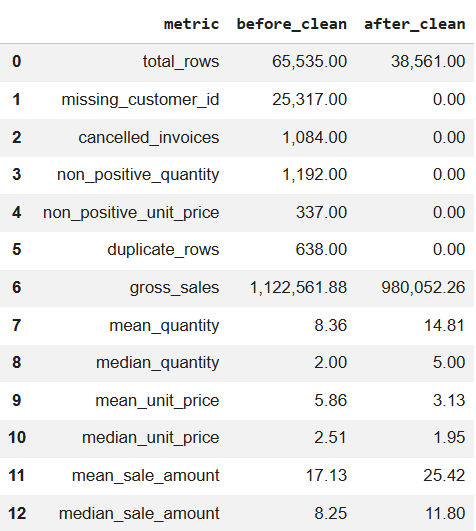 Hình 12a. Báo cáo chỉ số trước khi làm sạch. |
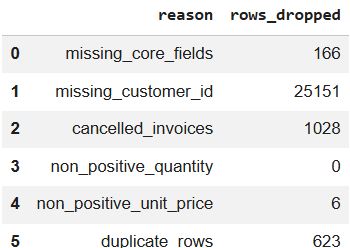 Hình 12b. Báo cáo chỉ số sau khi làm sạch. |
- Làm sạch dữ liệu
def clean_online_retail(raw_data: pd.DataFrame):
# Sao chép dữ liệu gốc: Tránh sửa trực tiếp
cleaned_data = raw_data.copy()
# Làm sạch cột: Tránh sự trùng lặp + khoảng trắng
for column_name in TEXT_COLUMNS:
cleaned_data[column_name] = normalize_text(cleaned_data[column_name])
# Chuẩn hóa mã khách hàng - Ví dụ: 123.0 --> 123
cleaned_data["CustomerID"] = normalize_text(cleaned_data["CustomerID"]).str.replace(
r"\.0$", "", regex=True
)
# Đưa cột ngày/tháng về đúng kiểu dữ liệu: integer, NaN
cleaned_data["Quantity"] = pd.to_numeric(
cleaned_data["Quantity"], errors="coerce"
).astype("Int64")
cleaned_data["UnitPrice"] = pd.to_numeric(cleaned_data["UnitPrice"], errors="coerce")
cleaned_data["InvoiceDate"] = pd.to_datetime(
cleaned_data["InvoiceDate"], errors="coerce"
)
# Tính giá trị dòng hàng để thống kê doanh nghiệp: nhân số lượng đơn giá với dạng float
cleaned_data["SaleAmount"] = (
cleaned_data["Quantity"].astype("float") * cleaned_data["UnitPrice"]
).round(2)
# Tạo bảng thống kê trước khi làm sạch --> Sẽ in ra
before_table = build_report(cleaned_data).rename(columns={"value": "before_clean"})
# Tạo quy tắc để loại bỏ dữ liệu không hợp lý.
invalid_rules = [
("missing_core_fields", cleaned_data[REQUIRED_COLUMNS].isna().any(axis=1)),
("missing_customer_id", cleaned_data["CustomerID"].isna()),
("cancelled_invoices", cleaned_data["InvoiceNo"].str.startswith("C", na=False)),
("non_positive_quantity", cleaned_data["Quantity"].le(0)),
("non_positive_unit_price", cleaned_data["UnitPrice"].le(0)),
]
# Giả sử tất cả các dòng đều hợp lý
keep_row = pd.Series(True, index=cleaned_data.index)
# Tạo hàm loại bỏ
removed_rows = []
# Áp dụng từng quy tắc theo thứ tự
for rule_name, invalid_row in invalid_rules:
current_removed_row = keep_row & invalid_row
removed_rows.append((rule_name, int(current_removed_row.sum())))
keep_row &= ~invalid_row
# Loại bỏ trùng lặp sau khi lọc các dòng
final_data = cleaned_data.loc[keep_row].drop_duplicates().copy()
duplicate_rows = int(cleaned_data.loc[keep_row].duplicated().sum())
# Sắp xếp dữ liệu
final_data = final_data.sort_values(
["InvoiceDate", "InvoiceNo", "StockCode"]
).reset_index(drop=True)
# Tạo bảng thống kê sau khi làm sạch --> Sẽ in ra
after_table = build_report(final_data).rename(columns={"value": "after_clean"})
comparison_table = before_table.merge(after_table, on="metric")
# Bảng index bị loại + lý do đi kèm
removed_table = pd.DataFrame(
removed_rows + [("duplicate_rows", duplicate_rows)],
columns=["reason", "rows_dropped"],
)
return final_data, comparison_table, removed_table
- Biểu diễn biểu đồ giá trị MEAN và MEDIAN
# Nhóm lại chỉ số đếm lượng bản ghi + lỗi dữ liệu
count_metrics = [
"total_rows",
"missing_customer_id",
"cancelled_invoices",
"duplicate_rows",
]
# Nhóm lại chỉ số giá trị xem xu hướng MEAN và MEDIAN
value_metrics = [
"mean_quantity",
"median_quantity",
"mean_unit_price",
"median_unit_price",
"mean_sale_amount",
"median_sale_amount",
]
figure, axes = plt.subplots(1, 2, figsize=(14, 5))
# Biểu đồ 1: So sánh các chỉ đố đếm trước & sau khi làm sạch
comparison_table[comparison_table["metric"].isin(count_metrics)].set_index("metric")[
["before_clean", "after_clean"]
].plot(kind="bar", ax=axes[0], color=["#d97706", "#15803d"])
axes[0].set_title("Count Metrics")
axes[0].set_xlabel("")
axes[0].set_ylabel("Count")
axes[0].tick_params(axis="x", rotation=0)
# Biểu đồ 2: So sánh MEAN (average) và MEDIAN trước & sau khi làm sạch
comparison_table[comparison_table["metric"].isin(value_metrics)].set_index("metric")[
["before_clean", "after_clean"]
].plot(kind="bar", ax=axes[1], color=["#2563eb", "#16a34a"])
axes[1].set_title("Mean and Median")
axes[1].set_xlabel("")
axes[1].set_ylabel("Value")
axes[1].tick_params(axis="x", rotation=45)
plt.tight_layout()
plt.show()
Kết quả trả về:
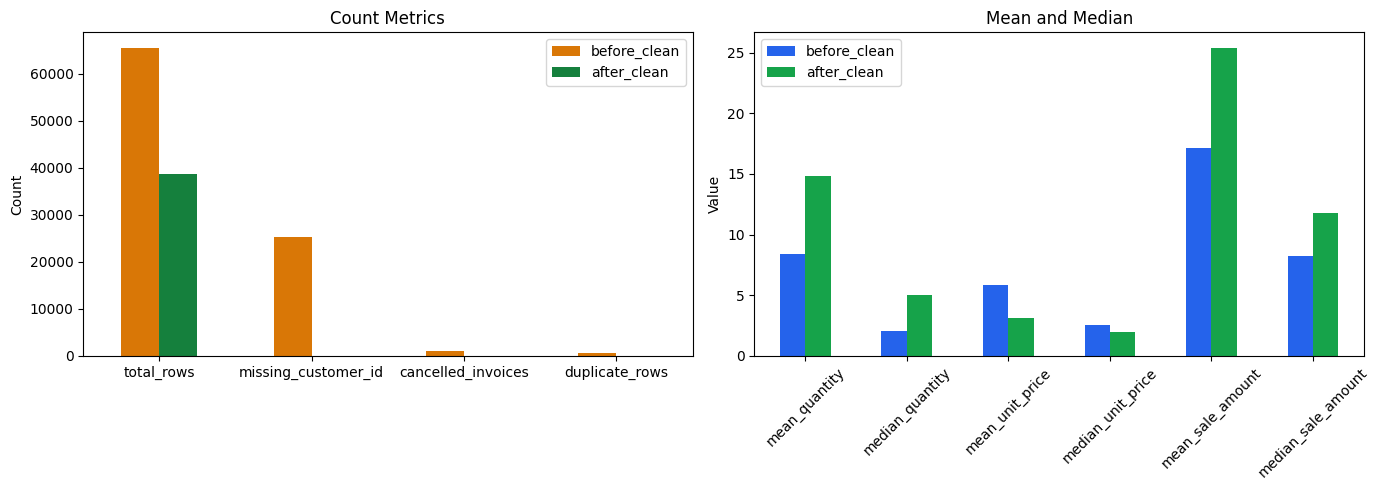
Hình 13. Trực quan hoá so sánh các chỉ số trước và sau khi làm sạch (count metrics và mean/median).
- Đặt tên và định dạng file
output_folder = Path("/content/output")
output_folder.mkdir(parents=True, exist_ok=True)
# Đật tên cột ngày/giờ theo đúng định dạng
export_data = clean_data.copy()
export_data["InvoiceDate"] = export_data["InvoiceDate"].dt.strftime("%Y-%m-%d %H:%M:%S")
# Đặt tên file csv
export_data.to_csv(
output_folder / "online_retail_clean.csv",
index=False,
encoding="utf-8-sig",
)
comparison_table.to_csv(
output_folder / "before_after_summary.csv",
index=False,
encoding="utf-8-sig",
)
removed_table.to_csv(
output_folder / "dropped_reason_summary.csv",
index=False,
encoding="utf-8-sig",
)
list(output_folder.iterdir())
4. Kết luận
Chất lượng dữ liệu quyết định trực tiếp độ tin cậy của phân tích (GIGO). Với bài toán bán lẻ đa kênh, việc thiết kế một pipeline làm sạch rõ ràng và có thể tái chạy là điều kiện bắt buộc để các chỉ số như doanh thu, hành vi mua hàng và phân khúc khách hàng phản ánh đúng thực tế.
Trong bài viết này, Power Query đóng vai trò “ETL trực quan” giúp chuẩn hoá dữ liệu theo quy trình 8 bước; còn Python được dùng như một lớp kiểm chứng (validation) để đối chiếu kết quả, tạo báo cáo so sánh trước/sau làm sạch và tăng tính khách quan. Khi dữ liệu đầu vào đã sạch và nhất quán, các bước phân tích thống kê và xây dựng dashboard sẽ ổn định hơn, giảm rủi ro ra quyết định sai.
5. Nguồn tài liệu tham khảo
[1] Kaggle, Online Retail Dataset. https://www.kaggle.com/datasets/lakshmi25npathi/online-retail-dataset
[2] OnlineRetail.csv, file dữ liệu dùng để thực hành trong dự án (tải từ Kaggle và chuyển đổi sang CSV).
[3] Microsoft Learn, Power Query. https://learn.microsoft.com/power-query/
[4] Microsoft Learn, Power Query M formula language. https://learn.microsoft.com/powerquery-m/
[5] pandas Documentation. https://pandas.pydata.org/docs/
[6] Matplotlib Documentation. https://matplotlib.org/stable/
[7] Wikipedia, Garbage in, garbage out. https://en.wikipedia.org/wiki/Garbage_in,_garbage_out
Chưa có bình luận nào. Hãy là người đầu tiên!