
(Note: All illustrations and diagrams in this article are AI-generated by Gemini.)
Giới thiệu
Trong các khóa học Machine Learning hiện đại, Logistic Regression (Hồi quy Logistic) thường bị xem nhẹ như một mô hình "cơ bản", thậm chí là "nhàm chán". Nhiều người học vội vàng lướt qua nó để nhảy thẳng vào Deep Learning với những kiến trúc phức tạp hơn. Tuy nhiên, điều mà ít người nhận ra là phần toán học phía sau Gradient (đạo hàm) của Logistic Regression lại chính là nền tảng vững chắc cho hầu hết các mô hình học sâu ngày nay. Nếu bạn không thực sự hiểu cách gradient được tính trong Logistic Regression, bạn sẽ gặp khó khăn khi cố gắng debug hoặc tối ưu các mô hình phức tạp hơn.
Trong project này, tôi quyết định xây dựng Logistic Regression hoàn toàn từ đầu, chỉ sử dụng NumPy — không PyTorch, không TensorFlow, không bất kỳ Autodiff Engine (công cụ tính đạo hàm tự động) nào. Mục tiêu không phải là tối ưu hiệu năng hay đạt accuracy cao nhất, mà là để hiểu rõ vì sao gradient có dạng $X^T(p - y)$, quan sát trực tiếp Chain Rule (quy tắc chuỗi) dưới dạng ma trận, và đảm bảo không có bước nào bị "ẩn" đi. Đây là hành trình quay về cội nguồn để thực sự làm chủ Machine Learning từ gốc rễ.
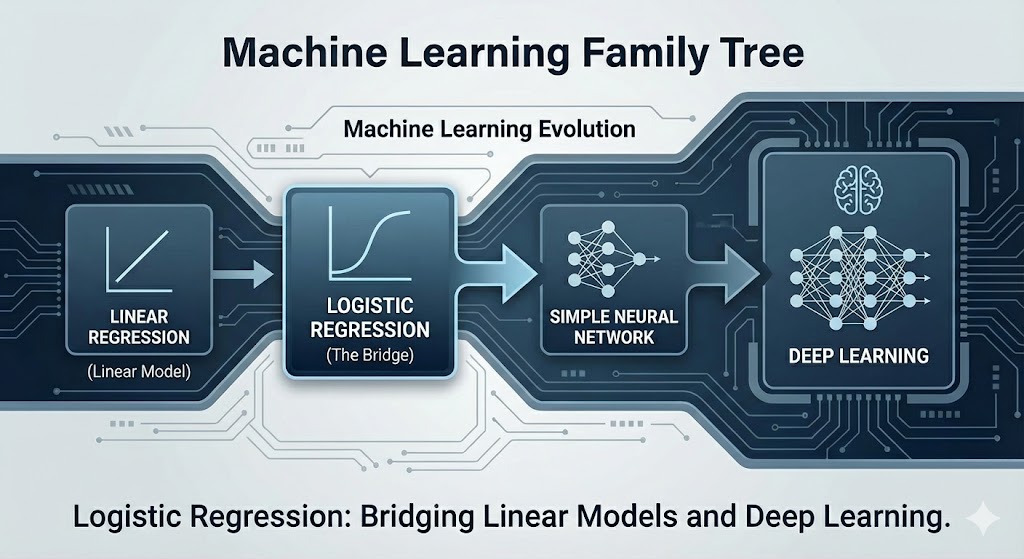
Hình 1. Logistic Regression là cầu nối giữa Linear Model và Neural Network
I. Dataset và Chuẩn Bị Dữ Liệu
1.1 Dataset sử dụng
Project sử dụng Breast Cancer Wisconsin Dataset — một dataset kinh điển trong bài toán Binary Classification (phân loại nhị phân). Dataset này chứa các thông số đo lường từ hình ảnh tế bào ung thư vú, và nhiệm vụ của mô hình là dự đoán xem khối u là lành tính (benign) hay ác tính (malignant). Đây là bài toán y tế thực tế, nơi mà mỗi dự đoán sai đều có thể ảnh hưởng đến cuộc sống của bệnh nhân.
Về mặt toán học, chúng ta biểu diễn dataset như sau: $X \in \mathbb{R}^{n \times d}$ là ma trận dữ liệu với $n$ mẫu và $d$ đặc trưng, còn $y \in \mathbb{R}^n$ là vector nhãn nhị phân (0 hoặc 1). Lý do dataset này phù hợp cho project là vì nhãn nhị phân đúng với bài toán Logistic Regression, các đặc trưng đều là số thực liên tục nên phù hợp với mô hình tuyến tính, và quy mô vừa phải (khoảng 569 mẫu) giúp dễ phân tích và debug khi có lỗi.
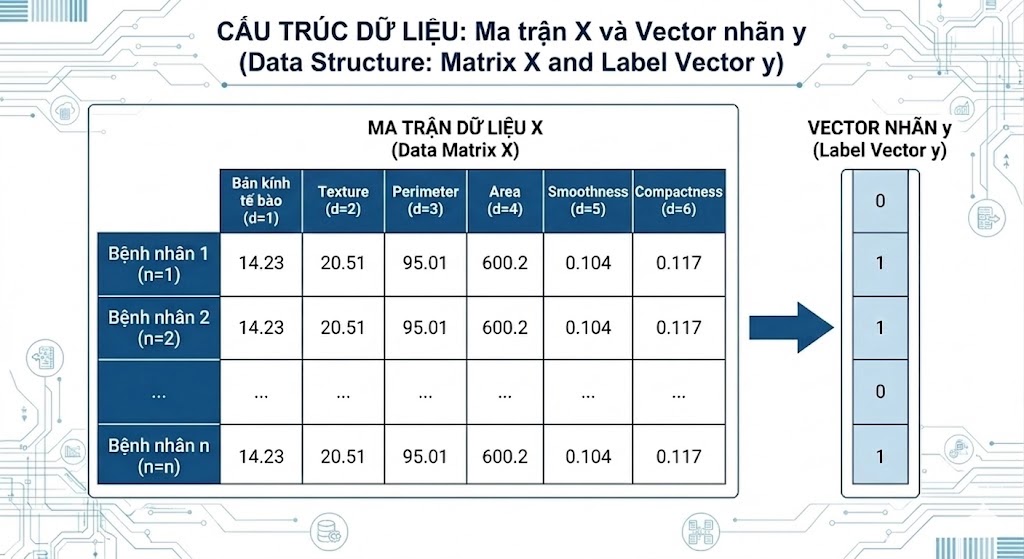
HÌnh 2. Minh họa cấu trúc ma trận dữ liệu X và vector nhãn y
1.2 Chia tập Train / Test
Một nguyên tắc vàng trong Machine Learning là: Không bao giờ đánh giá mô hình trên dữ liệu mà nó đã được huấn luyện. Điều này giống như việc bạn không thể tự chấm bài thi của chính mình — kết quả sẽ thiên vị và không phản ánh đúng năng lực thực sự. Vì vậy, dataset được chia thành 80% dữ liệu huấn luyện (Training Set) và 20% dữ liệu kiểm tra (Test Set).
Training Set được sử dụng để tính gradient và cập nhật Parameters (tham số) của mô hình. Trong suốt quá trình huấn luyện, mô hình sẽ "nhìn" vào Training Set hàng nghìn lần để học các pattern. Ngược lại, Test Set được giữ nguyên như một "phòng thi kín" — mô hình chỉ được đánh giá trên Test Set đúng một lần duy nhất vào cuối quá trình, để đảm bảo kết quả khách quan và tránh Overfitting (quá khớp).
1.3 Chuẩn hóa đặc trưng (Feature Scaling)
Hãy tưởng tượng bạn đang so sánh hai đặc trưng: "diện tích tế bào" (đơn vị: micromet vuông, giá trị từ 100 đến 2500) và "độ đồng nhất" (không đơn vị, giá trị từ 0 đến 1). Nếu để nguyên, Gradient Descent (giảm gradient) sẽ bị chi phối bởi đặc trưng có giá trị lớn, khiến quá trình học trở nên lệch lạc và chậm hội tụ. Điều này giống như việc bạn cố gắng đi bộ trên một mặt phẳng nghiêng — bước chân sẽ bị kéo về phía dốc thay vì đi thẳng đến đích.
Để giải quyết vấn đề này, mỗi đặc trưng được chuẩn hóa theo công thức Standardization (chuẩn hóa): $x \leftarrow \frac{x - \mu}{\sigma}$, trong đó $\mu$ là giá trị trung bình và $\sigma$ là độ lệch chuẩn. Sau khi chuẩn hóa, tất cả đặc trưng đều có mean = 0 và std = 1, giúp Gradient Descent hội tụ nhanh hơn và ổn định hơn. Điều quan trọng cần nhớ là: chuẩn hóa không làm thay đổi dạng toán học của gradient, nó chỉ cải thiện tính ổn định số học.
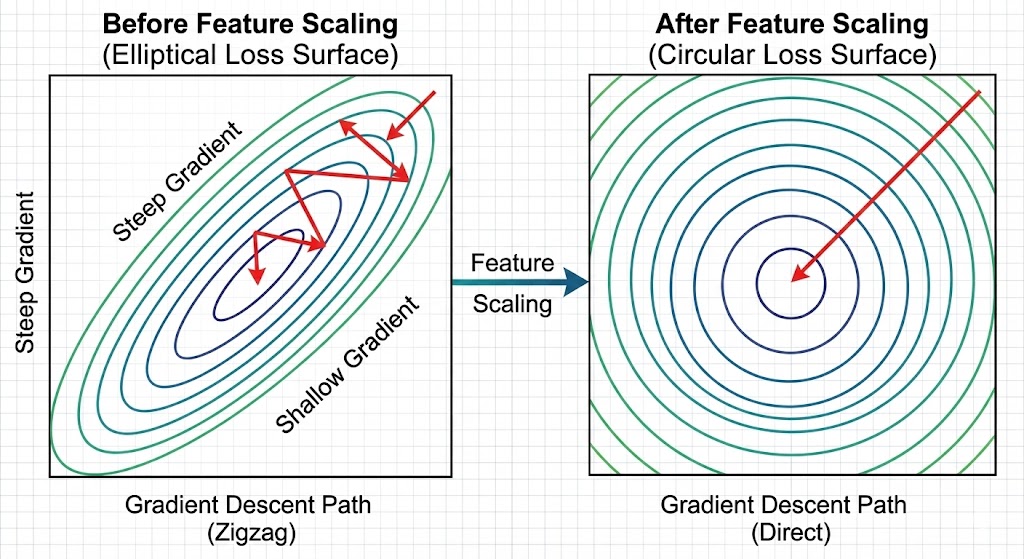
Hình 3. So sánh Loss Surface trước và sau khi Feature Scaling
II. Kiến Trúc Mô Hình
2.1 Forward Pass
Logistic Regression hoạt động theo hai bước tuần tự trong Forward Pass (lan truyền xuôi). Đầu tiên, ta tính Linear Combination (tổ hợp tuyến tính): $z = Xw + b$, trong đó $w \in \mathbb{R}^d$ là vector trọng số và $b \in \mathbb{R}$ là Bias (độ lệch). Giá trị $z$ này có thể là bất kỳ số thực nào từ âm vô cùng đến dương vô cùng, nhưng chúng ta cần xác suất nằm trong khoảng [0, 1].
Đây là lúc Sigmoid Function (hàm Sigmoid) xuất hiện: $p = \sigma(z) = \frac{1}{1 + e^{-z}}$. Hàm này "nén" mọi giá trị thực vào khoảng (0, 1), biến đầu ra thành xác suất hợp lệ. Khi $z$ rất lớn (dương), $\sigma(z)$ tiến về 1; khi $z$ rất nhỏ (âm), $\sigma(z)$ tiến về 0. Điểm uốn tại $z = 0$ cho ra $\sigma(0) = 0.5$ — ngưỡng quyết định tự nhiên cho bài toán phân loại nhị phân.
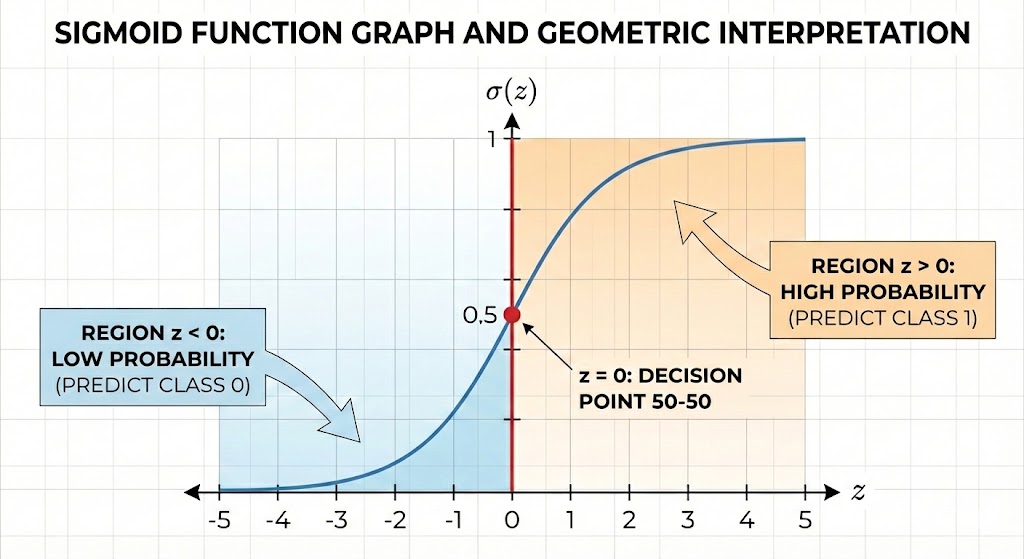
Hình 4. Đồ thị hàm Sigmoid và ý nghĩa hình học
2.2 Bản chất của Logistic Regression
Một insight quan trọng mà nhiều người bỏ qua: Logistic Regression chính là một Neural Network đơn giản nhất — một mạng chỉ có 1 layer, không có Hidden Layer (lớp ẩn). Input đi thẳng qua một phép biến đổi tuyến tính, rồi qua activation function (Sigmoid), và ra output. Nếu bạn hiểu rõ cách gradient chảy qua Logistic Regression, bạn đã hiểu được 80% cơ chế Backpropagation (lan truyền ngược) trong Deep Learning.
Sự khác biệt duy nhất giữa Logistic Regression và một Neural Network phức tạp là số lượng layer và loại activation function. Khi bạn xếp chồng nhiều layer lên nhau và thay Sigmoid bằng ReLU, bạn có một Deep Neural Network. Nhưng nguyên lý tính gradient — Chain Rule trong không gian ma trận — vẫn giữ nguyên. Đây là lý do việc master Logistic Regression có giá trị lâu dài.
III. Hàm Mất Mát (Loss Function)
3.1 Binary Cross-Entropy Loss
Làm sao để đo lường "mức độ sai" của mô hình? Chúng ta cần một Loss Function (hàm mất mát) — một công thức biến đầu ra của mô hình và nhãn thực tế thành một con số duy nhất đại diện cho "sự sai lệch". Với bài toán phân loại nhị phân, hàm mất mát được sử dụng phổ biến nhất là Binary Cross-Entropy (BCE):
$$L = -\frac{1}{n} \sum_{i=1}^{n} \left[ y_i \log(p_i) + (1 - y_i) \log(1 - p_i) \right]$$
Hãy phân tích công thức này theo trực giác. Khi nhãn thực tế $y = 1$ (ung thư ác tính), ta muốn $p$ càng gần 1 càng tốt — lúc này $\log(p)$ sẽ gần 0 (loss thấp). Ngược lại, nếu mô hình dự đoán $p$ gần 0 trong khi $y = 1$, $\log(p)$ sẽ tiến về âm vô cùng (loss cực cao) — đây là hình phạt cho dự đoán sai. Tương tự cho trường hợp $y = 0$. Cross-Entropy Loss "phạt nặng" những dự đoán tự tin nhưng sai, đây chính là đặc tính mong muốn.
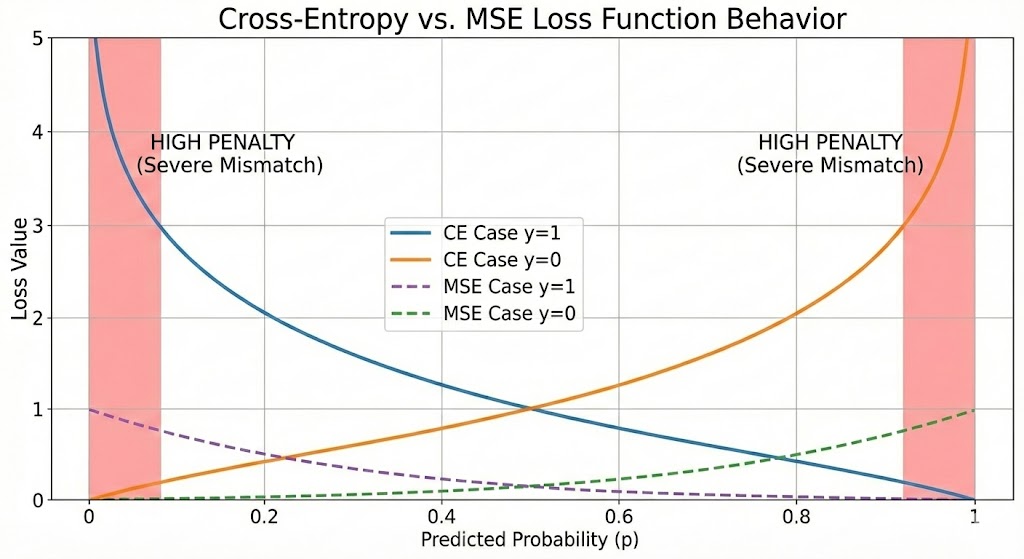
Hình 5. Đồ thị Cross-Entropy Loss theo xác suất dự đoán p
3.2 Tại sao Loss luôn là Scalar?
Một điểm then chốt cần ghi nhớ: Loss luôn là một số vô hướng (Scalar), trong khi tham số có thể là vector hoặc ma trận. Điều này rất quan trọng khi suy luận gradient vì nó định hình cách chúng ta áp dụng Chain Rule. Gradient của Loss theo một tham số sẽ có cùng shape với tham số đó — đây là quy tắc vàng giúp bạn kiểm tra tính đúng đắn của công thức gradient.
Cụ thể: $w \in \mathbb{R}^d$ (vector d chiều) → $\frac{\partial L}{\partial w} \in \mathbb{R}^d$ (cũng là vector d chiều). Tương tự, $b \in \mathbb{R}$ (scalar) → $\frac{\partial L}{\partial b} \in \mathbb{R}$ (cũng là scalar). Nếu gradient bạn tính ra có shape khác với tham số, chắc chắn có lỗi ở đâu đó trong phép tính.
IV. Khởi Tạo Tham Số
4.1 Khởi tạo bằng 0
Trong Deep Learning, việc khởi tạo tham số bằng 0 là một taboo (điều cấm kỵ) vì nó gây ra hiện tượng Symmetry Problem (vấn đề đối xứng) — tất cả các neuron trong cùng một layer sẽ học giống hệt nhau, khiến mạng mất đi khả năng biểu diễn. Tuy nhiên, Logistic Regression là ngoại lệ. Vì chỉ có một layer duy nhất và bài toán là Convex (lồi), khởi tạo $w = 0$ và $b = 0$ là hoàn toàn an toàn.
Bài toán lồi có đặc tính quan trọng: chỉ tồn tại một điểm cực tiểu toàn cục (global minimum), và Gradient Descent sẽ luôn hội tụ về điểm này bất kể xuất phát từ đâu. Không có Local Minima (cực tiểu địa phương) hay Saddle Points (điểm yên ngựa) để mắc kẹt. Đây là một trong những lý do Logistic Regression được ưa chuộng trong các ứng dụng cần sự ổn định và khả năng giải thích cao.
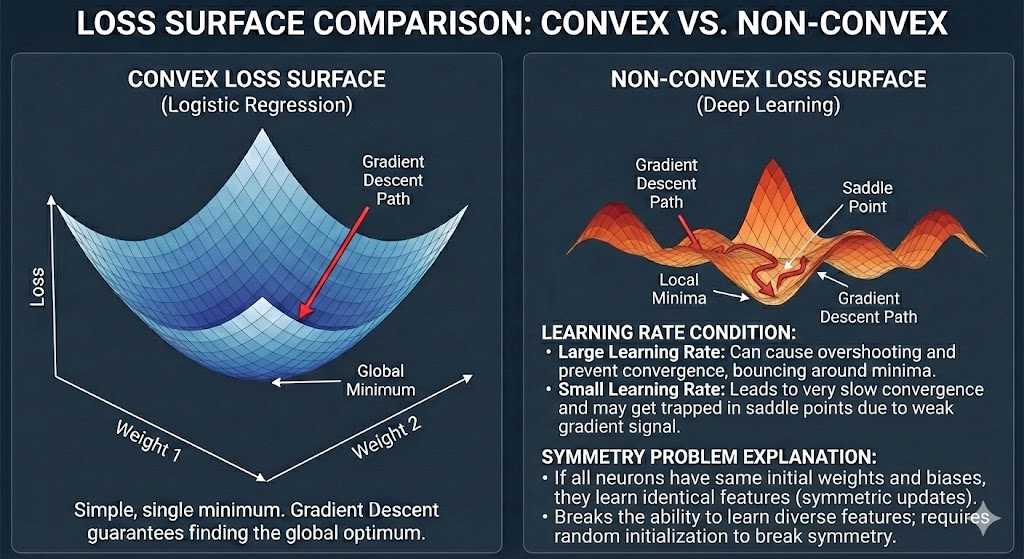
Hình 6. So sánh Loss Surface: Convex (Logistic Regression) vs Non-Convex (Deep Learning)
V. Gradient Dưới Góc Nhìn Giải Tích Ma Trận
5.1 Công thức Gradient
Đây là phần quan trọng nhất của toàn bộ project — nơi Chain Rule được áp dụng trong không gian ma trận để derive (suy diễn) công thức gradient. Sau khi áp dụng cẩn thận từng bước (chi tiết sẽ được trình bày trong phần code), ta thu được hai công thức gradient đẹp đẽ:
$$\frac{\partial L}{\partial w} = \frac{1}{n} X^T (p - y)$$
$$\frac{\partial L}{\partial b} = \frac{1}{n} \sum_{i=1}^{n} (p_i - y_i)$$
Hãy dừng lại và chiêm ngưỡng vẻ đẹp của công thức này. $(p - y)$ là Error Vector (vector sai số) — hiệu giữa xác suất dự đoán và nhãn thực tế. $X^T(p - y)$ là phép nhân ma trận chuyển vị $X$ với error vector, kết quả là một vector có cùng shape với $w$. Đây không phải ngẫu nhiên — đây là kết quả tất yếu của Chain Rule khi được áp dụng đúng cách.
5.2 Ý nghĩa sâu xa của $X^T(p - y)$
Biểu thức $X^T(p - y)$ không chỉ là một công thức toán học khô khan — nó là cấu trúc trung tâm xuất hiện xuyên suốt Machine Learning. Trong Logistic Regression, đây là gradient của Cross-Entropy Loss. Trong Softmax Classifier (phân loại đa lớp), công thức tương tự xuất hiện với $p$ là vector xác suất softmax. Trong Neural Networks nhiều tầng, $X^T(p - y)$ là gradient tại layer cuối cùng, và các layer trước đó chỉ là Chain Rule được áp dụng đệ quy.
Nếu bạn gặp khó khăn khi đọc paper hoặc debug model, hãy quay lại công thức này. Hiểu rõ tại sao gradient có dạng này — từ định nghĩa Loss, qua Sigmoid, đến phép nhân ma trận — sẽ giúp bạn không bao giờ bị "mất phương hướng" trong rừng công thức của Deep Learning.
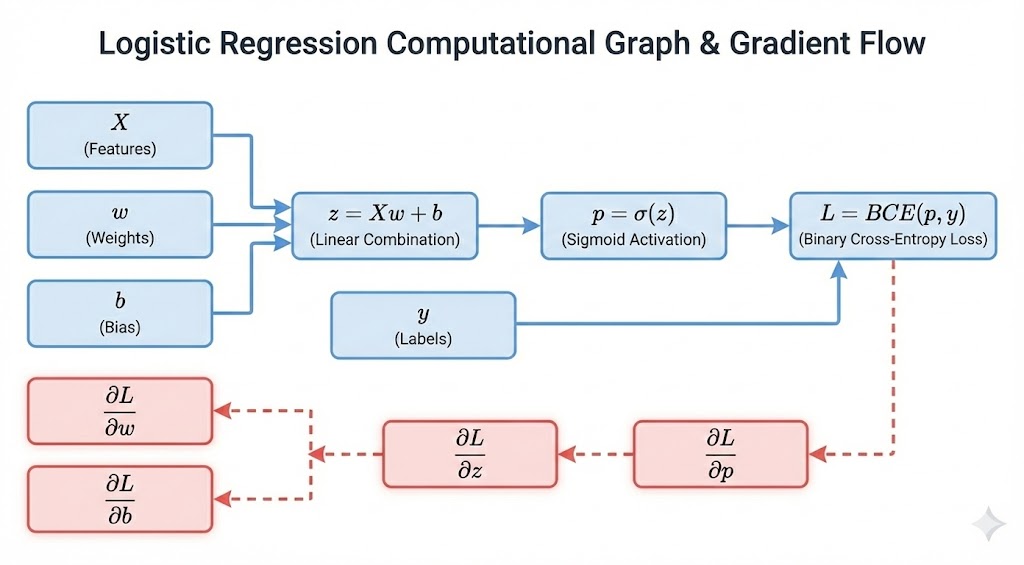
Hình 7. Sơ đồ Computational Graph của Logistic Regression
VI. Vòng Lặp Huấn Luyện (Manual Backpropagation)
6.1 Bốn bước trong mỗi Epoch
Mỗi Epoch (vòng lặp huấn luyện) bao gồm 4 bước tuần tự được thực hiện hoàn toàn thủ công. Bước đầu tiên là Forward Pass: tính $z = Xw + b$, sau đó $p = \sigma(z)$. Bước thứ hai là Compute Loss: tính giá trị scalar $L$ bằng công thức Binary Cross-Entropy. Bước thứ ba là Compute Gradient: áp dụng công thức $\frac{\partial L}{\partial w} = \frac{1}{n} X^T(p - y)$ và $\frac{\partial L}{\partial b} = \frac{1}{n} \sum(p - y)$. Bước cuối cùng là Update Parameters: $w \leftarrow w - \alpha \cdot \frac{\partial L}{\partial w}$ và $b \leftarrow b - \alpha \cdot \frac{\partial L}{\partial b}$, trong đó $\alpha$ là Learning Rate (tốc độ học).
Điều đặc biệt của project này là toàn bộ 4 bước được code bằng tay, không sử dụng loss.backward() của PyTorch hay tape.gradient() của TensorFlow. Mỗi dòng code đều tương ứng với một phép toán ma trận cụ thể, và bạn có thể trace (theo dõi) chính xác gradient chảy như thế nào qua từng biến.
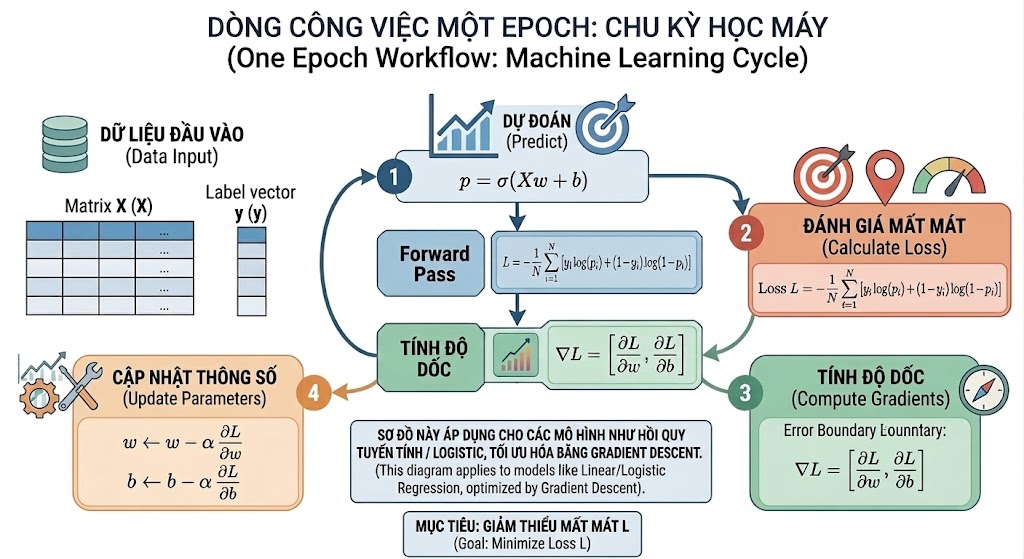
Hình 8. Flowchart 4 bước trong một Epoch
6.2 Đường cong Loss
Sau khi chạy vài trăm epochs, ta vẽ đồ thị Loss theo số epoch để kiểm tra xem thuật toán có hoạt động đúng không. Nếu Loss giảm đều và mượt theo epoch, đó là dấu hiệu cho thấy: công thức gradient là chính xác, learning rate được chọn phù hợp, và thuật toán tối ưu đang hoạt động đúng. Đây là cách kiểm chứng gradient quan trọng nhất khi làm mọi thứ từ scratch.
Ngược lại, nếu Loss dao động mạnh (learning rate quá cao), Loss không giảm (gradient sai hoặc learning rate quá thấp), hoặc Loss tăng vọt rồi thành NaN (numerical instability), bạn biết ngay có lỗi cần debug. Đường cong Loss là "nhịp tim" của quá trình huấn luyện — hãy luôn theo dõi nó.
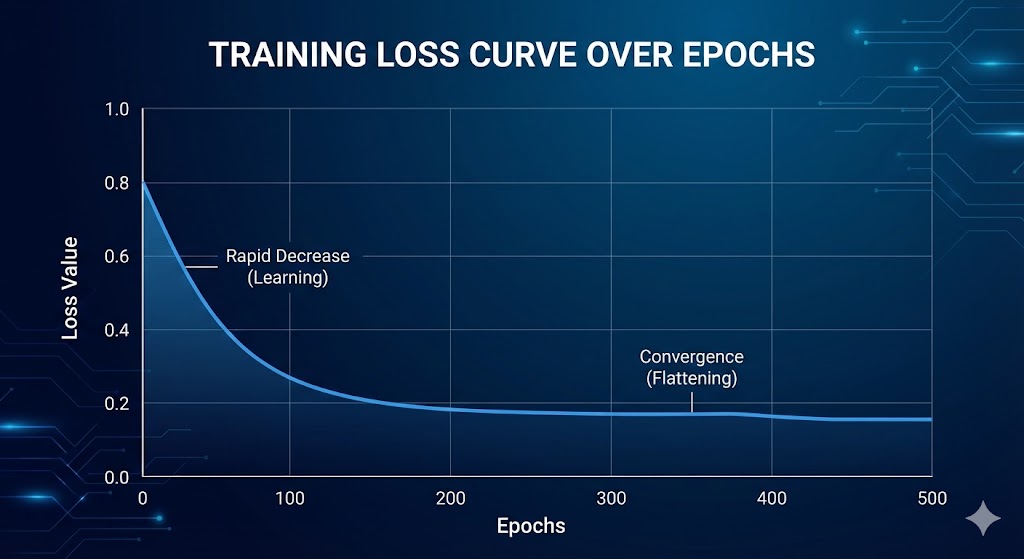
Hình 9. Đường cong Loss giảm theo Epoch
VII. Đánh Giá Mô Hình
7.1 Đánh giá trên tập Test
Sau khi huấn luyện xong, mô hình được đánh giá trên dữ liệu Test — những mẫu mà nó chưa từng "nhìn thấy" trong quá trình học. Quy tắc dự đoán rất đơn giản: nếu $p \geq 0.5$, dự đoán lớp 1 (ung thư ác tính); nếu $p < 0.5$, dự đoán lớp 0 (lành tính). Ngưỡng 0.5 là lựa chọn tự nhiên vì nó tương ứng với điểm $z = 0$ trên hàm Sigmoid.
Accuracy (độ chính xác) được tính bằng tỷ lệ số mẫu dự đoán đúng trên tổng số mẫu. Với Breast Cancer Dataset, mô hình Logistic Regression triển khai thủ công đạt accuracy khoảng 95-97% — tương đương với các implementation sử dụng scikit-learn hay PyTorch. Điều này chứng tỏ rằng việc triển khai thủ công không làm giảm chất lượng mô hình, đồng thời cho thấy Logistic Regression đủ mạnh cho bài toán này.
7.2 So sánh dự đoán và Ground Truth
Ngoài accuracy tổng thể, việc kiểm tra trực tiếp từng mẫu cũng rất quan trọng. Với mỗi mẫu trong Test Set, ta so sánh: xác suất dự đoán $p$, nhãn dự đoán (0 hoặc 1), và nhãn thực tế (Ground Truth). Điều này giúp phát hiện các trường hợp dự đoán "lưng chừng" — những mẫu có $p$ gần 0.5, nơi mô hình không tự tin và dễ mắc lỗi nhất.
Việc phân tích chi tiết này tránh được sự đánh giá mù quáng chỉ dựa vào một con số accuracy. Trong bài toán y tế, một mô hình có accuracy 95% nhưng hay nhầm lẫn ung thư ác tính thành lành tính (False Negative) sẽ nguy hiểm hơn nhiều so với mô hình có accuracy 93% nhưng sai lệch đều hai phía. Đây là lý do Confusion Matrix, Precision, Recall quan trọng không kém Accuracy.
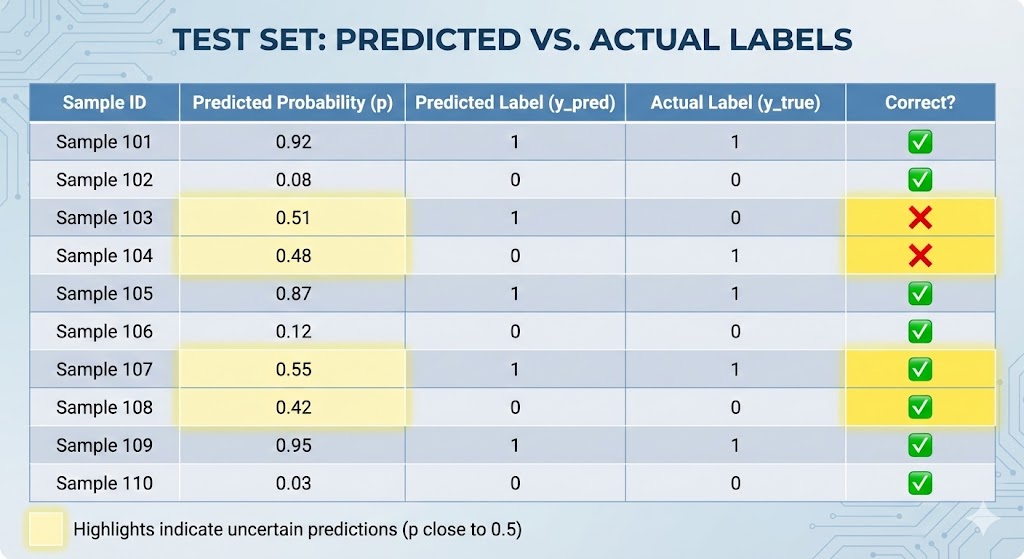
Hinh 10. Bảng so sánh Predicted vs Actual trên một số mẫu Test
VIII. Triển Khai Demo Trực Tuyến
8.1 Gradio Web App trên Hugging Face Spaces
Để project không chỉ đúng về mặt học thuật mà còn hoàn chỉnh về mặt ứng dụng, mô hình được triển khai dưới dạng Gradio Web App và host trên Hugging Face Spaces. Người dùng có thể nhập trực tiếp các thông số đặc trưng của tế bào, sau đó nhận được xác suất dự đoán và nhãn (lành tính/ác tính) trong vài giây. Giao diện trực quan giúp những người không biết code cũng có thể trải nghiệm mô hình.
Việc deploy model lên production là kỹ năng quan trọng mà nhiều khóa học Machine Learning bỏ qua. Một mô hình dù chính xác đến đâu nhưng chỉ nằm trong Jupyter Notebook thì vẫn vô dụng với người dùng cuối. Hugging Face Spaces cung cấp hosting miễn phí với Gradio, giúp bạn biến model thành sản phẩm thực tế chỉ trong vài phút.
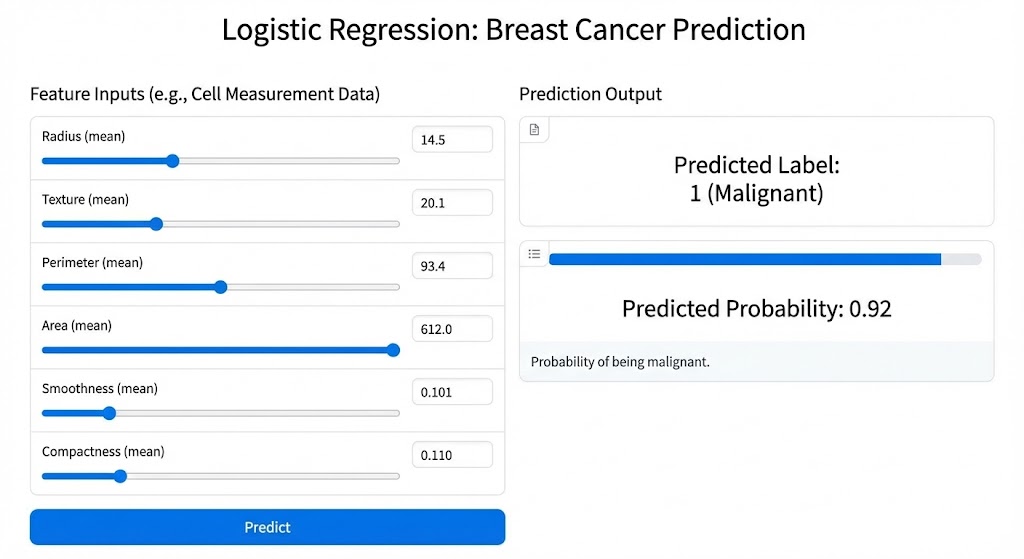
Hình 11. Giao diện Gradio Web App cho Logistic Regression
IX. Kết Luận và Bài Học Rút Ra
9.1 Những điểm then chốt
Từ project này, có thể rút ra các bài học quan trọng sau. Thứ nhất, Loss luôn là scalar, tham số là vector — quy tắc này giúp bạn kiểm tra tính đúng đắn của gradient. Thứ hai, Gradient đến từ Chain Rule trong không gian ma trận — không cần viết Jacobian tường minh, chỉ cần nắm vững quy tắc shape. Thứ ba, $X^T(p - y)$ là cấu trúc trung tâm của Machine Learning — biểu thức này xuất hiện trong Logistic Regression, Softmax, và Neural Networks.
Thứ tư, Logistic Regression là Neural Network đơn giản nhất — hiểu rõ nó nghĩa là bạn đã nắm được foundation của Deep Learning. Và cuối cùng, toán học của mô hình "cơ bản" chính là nền tảng của Deep Learning — đừng vội vàng nhảy qua các kiến trúc phức tạp khi chưa thực sự master những thứ căn bản.
9.2 Hướng phát triển tiếp theo
Project này mở ra nhiều hướng mở rộng tự nhiên. Bạn có thể implement Softmax Classifier cho bài toán đa lớp, nơi công thức gradient tương tự nhưng với vector xác suất softmax thay vì sigmoid scalar. Bạn cũng có thể thực hành Numerical Gradient Checking — kỹ thuật kiểm tra gradient bằng cách so sánh với finite difference, rất hữu ích khi debug các công thức phức tạp.
Một hướng khác là thêm L2 Regularization và derive gradient của regularization term — điều này giúp mô hình tránh overfitting. Cuối cùng, bạn có thể mở rộng lên Neural Network 2-3 layers, nơi Chain Rule được áp dụng đệ quy qua nhiều layer, và bạn sẽ thấy rõ pattern gradient giống nhau ở mọi tầng.
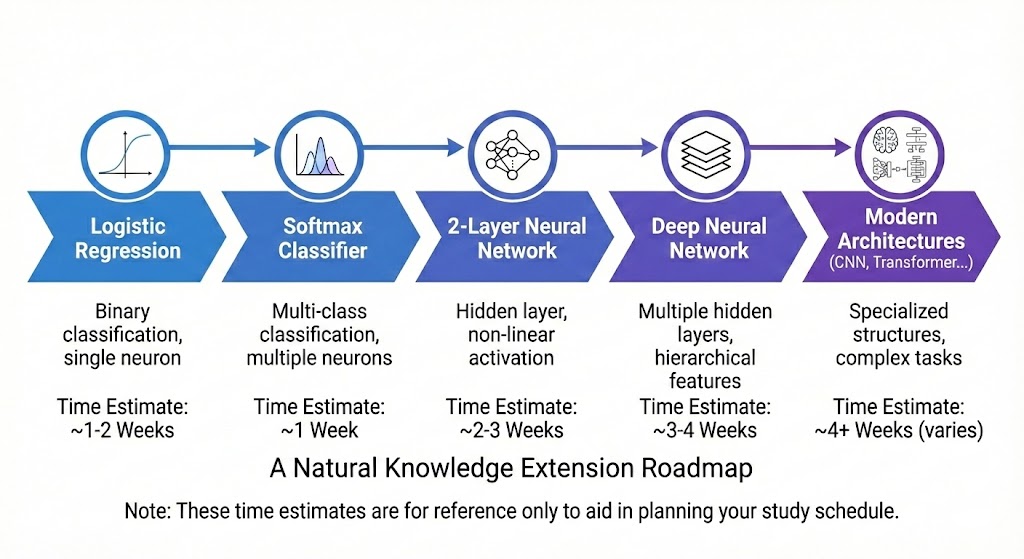
Hinh 12. Roadmap từ Logistic Regression đến Deep Learning
Kết
Hành trình xây dựng Logistic Regression từ scratch không chỉ là một bài tập coding — đây là quá trình làm cho toán học trở nên trong suốt. Khi bạn tự tay viết từng dòng code tính gradient, bạn không còn phải "tin" vào autodiff như một hộp đen nữa. Bạn hiểu tại sao gradient có dạng như vậy, và sự hiểu biết này sẽ theo bạn suốt hành trình Machine Learning, dù bạn làm việc với mô hình đơn giản hay phức tạp đến đâu.
Chưa có bình luận nào. Hãy là người đầu tiên!