Khi Model "Hắt hơi sổ mũi": Xây dựng hệ thống khám bệnh tự động với Prometheus & Grafana cho model

Hình ảnh được tạo bởi Nano Banana Pro
Chào mọi người hôm nay chúng ta sẽ cùng nhau bàn về một chủ đề mà mình tin là bất cứ ai làm về AI/Machine Learning, đặc biệt là khi đưa model ra thực tế (Production), đều sẽ gặp phải. Đó là câu chuyện: Làm sao biết model của mình còn "sống" hay đã "ngắc ngoải"?
1. "Lời nguyền" của môi trường Production
Hãy tưởng tượng kịch bản quen thuộc này:
Bạn train một model phân loại ảnh đạt 99% accuracy ở máy local. Bạn hì hục đóng gói, deploy lên server. Sếp hỏi: "Model chạy ổn không em?". Bạn check log thấy API trả về status 200 OK đều đặn và tự tin trả lời: "Ổn áp lắm anh ơi!".
Nhưng rồi... một tuần sau, team CSKH báo về là khách hàng phàn nàn model dự đoán sai tùm lum. Bạn hoang mang tột độ. Hóa ra, dữ liệu ảnh khách hàng gửi lên khác hoàn toàn với tập train (Data Drift), hoặc server bị quá tải khiến model trả lời chậm như rùa bò (High Latency).
Bài học xương máu: Status 200 là chưa đủ. Nó chỉ cho biết server còn sống, chứ không cho biết model có "khỏe" hay không. Chúng ta cần một hệ thống giám sát sâu hơn thế.
2. Tại sao cần "Khám sức khỏe" cho AI?
Nếu ví hệ thống của bạn là một cơ thể, thì:
- Server Monitoring (Giám sát hạ tầng): Giống như đo nhịp tim, huyết áp (CPU, RAM, Disk). Cái này DevOps lo.
- AI Monitoring (Giám sát mô hình): Giống như xét nghiệm máu, chụp X-quang để tìm bệnh tiềm ẩn. Cái này AI Engineer (là chúng ta) phải lo.
Chúng ta cần theo dõi những chỉ số "sinh tồn" sau:
1. Latency (Độ trễ): Model suy luận mất bao lâu? Chậm quá thì trải nghiệm người dùng sẽ rất tệ.
2. Throughput (Lưu lượng): Có bao nhiêu request mỗi giây? Hệ thống có đang chịu tải cao không?
3. Data Drift (Trôi dạt dữ liệu): Dữ liệu thực tế có còn giống lúc train không? Hay là "hoa hậu" lúc train ra đời thực thành "thị nở"?
4. Prediction Distribution: Model có đang dự đoán thiên lệch về một class nào đó không?
3. Giới thiệu "Bác sĩ" & "Y tá": Prometheus & Grafana
Để xây dựng hệ thống "khám bệnh" tự động này, chúng ta sẽ dùng bộ đôi huyền thoại trong làng monitoring: Prometheus và Grafana. Trước khi đi vào thực chiến, hãy cùng tìm hiểu xem họ là ai và tại sao lại được tin dùng đến vậy.
Prometheus là gì?
Prometheus là một hệ thống giám sát mã nguồn mở (Open Source), hoạt động theo cơ chế Pull (Kéo). Thay vì đợi các service gửi dữ liệu đến, Prometheus sẽ chủ động định kỳ "gõ cửa" từng service để thu thập các chỉ số (metrics) và lưu trữ chúng vào một cơ sở dữ liệu chuỗi thời gian (Time Series Database - TSDB).
Ưu điểm:
- Ngôn ngữ truy vấn mạnh: PromQL hỗ trợ phân tích, lọc, tổng hợp và cảnh báo theo thời gian thực với độ linh hoạt rất cao.
- Hệ sinh thái phong phú: Tích hợp dễ dàng với Kubernetes, Docker, microservices và nhiều exporter/thư viện client (Go, Python, Java…).
- Dễ triển khai: Single-binary, không phụ thuộc hạ tầng phức tạp, cài đặt nhanh và chạy ổn định trên nhiều môi trường.
- Tùy biến linh hoạt: Hỗ trợ tạo custom metrics đơn giản, phù hợp theo dõi ứng dụng hoặc mô hình AI.
- Alerting tích hợp: Kết hợp mượt với Alertmanager để thiết lập cảnh báo từ bất kỳ biểu thức PromQL nào.
Nhược điểm:
- Lưu trữ ngắn hạn: Mặc định chỉ giữ dữ liệu khoảng 15 ngày; muốn lưu dài hạn phải dùng Thanos, Cortex hoặc giải pháp tương tự.
- Khó mở rộng theo chiều ngang: Thiết kế single-node khiến việc scale phải dùng federation, dẫn đến độ phức tạp cao.
- PromQL không dễ học: Sức mạnh cao nhưng cú pháp khá khó đối với người mới.
- Tiêu tốn tài nguyên: Scrape quá nhiều metrics có thể gây tốn CPU/RAM/disk nếu không tối ưu.
- Chỉ tập trung vào metrics: Không hỗ trợ logs/events — muốn full observability cần thêm Grafana Loki hoặc ELK.
- Quản lý thủ công: Cấu hình scrape targets/manual service discovery có thể tốn công nếu không chạy trong môi trường dynamic như Kubernetes.
Grafana là gì?
Nếu Prometheus là "bộ não" lưu trữ và xử lý dữ liệu, thì Grafana chính là "gương mặt" đại diện. Grafana là một nền tảng phân tích và trực quan hóa dữ liệu đa nguồn. Nó có thể kết nối với Prometheus (và nhiều nguồn khác) để biến những con số khô khan thành các biểu đồ (Dashboard) sống động.
Ưu điểm:
- Đẹp & trực quan: Tạo dashboard chuyên nghiệp, rõ ràng và rất mạnh khi phân tích downtime hoặc biến động.
- Kết nối đa nguồn: Hỗ trợ đa số data sources phổ biến (Prometheus, MySQL, PostgreSQL, Elasticsearch, Loki…) và nhiều API/công cụ bên thứ ba.
- Dễ triển khai: Cài đặt nhanh trên cloud hoặc server, chỉ cần vài bước là chạy.
- Plugin phong phú: Sở hữu hệ sinh thái plugin lớn giúp mở rộng khả năng xử lý và trực quan hóa dữ liệu.
- Monitoring & Alerting mạnh: Theo dõi, trực quan hóa và gửi cảnh báo qua Email, Slack, Telegram… rất hiệu quả.
Nhược điểm:
- Phân quyền hạn chế: Tính năng cấp quyền trên dashboard chưa đủ chi tiết cho môi trường yêu cầu bảo mật cao.
- Dashboard mặc định ít: Muốn đẹp và phù hợp use-case thường phải tự thiết kế.
- Giới hạn báo cáo: Loại báo cáo tích hợp sẵn chưa đa dạng, chưa đáp ứng tốt nhu cầu quản trị.
- Cấu hình đôi khi phức tạp: Việc lưu file, tối ưu data source hoặc dựng alert nâng cao có thể rườm rà.
- Tự động hóa báo cáo còn yếu: Chưa mạnh trong việc tạo và gửi báo cáo tự động hằng ngày.
4. Thực chiến: Bắt tay vào làm (Hands-on)
Lý thuyết đủ rồi, giờ chúng ta cùng xắn tay áo lên làm một hệ thống giám sát đơn giản nhé!
Bài toán: Chúng ta sẽ deploy một model phân loại hoa Iris (bài toán kinh điển) và giám sát nó.
Kiến trúc hệ thống
Chúng ta sẽ dùng Docker Compose để dựng 3 container:
1. ML Service: Chạy model bằng FastAPI.
2. Prometheus: Thu thập metrics.
3. Grafana: Hiển thị biểu đồ.
Bước 1: Gắn "cảm biến" vào code (Instrumentation)
Trong code Python (FastAPI), chúng ta dùng thư viện prometheus_client để tạo các metrics.
# server/app.py
from prometheus_client import Counter, Histogram
# Đếm tổng số request
REQUESTS_TOTAL = Counter('inference_requests_total', 'Total requests', ['status'])
# Đo thời gian xử lý (Latency)
DURATION_SECONDS = Histogram('inference_duration_seconds', 'Inference duration')
@app.middleware("http")
async def monitor_requests(request: Request, call_next):
start_time = time.time()
response = await call_next(request)
# Ghi nhận metrics sau khi xử lý xong
process_time = time.time() - start_time
REQUESTS_TOTAL.labels(status=response.status_code).inc()
DURATION_SECONDS.observe(process_time)
return response
Bước 2: Cấu hình Prometheus
Khai báo cho Prometheus biết địa chỉ của ML Service để nó đến lấy dữ liệu.
# monitoring/prometheus.yml
scrape_configs:
- job_name: "ml-inference"
scrape_interval: 5s
static_configs:
- targets: ["ml-service:8000"]
Bước 3: Dựng Dashboard trên Grafana
Sau khi chạy docker-compose up -d, bạn vào Grafana, kết nối với Prometheus và tạo các biểu đồ.
Chúng ta có thể dùng ngôn ngữ truy vấn PromQL để vẽ:
- Tốc độ request (RPS): rate(inference_requests_total[1m])
- Độ trễ trung bình: rate(inference_duration_seconds_sum[1m]) / rate(inference_duration_seconds_count[1m])
Kết quả Demo
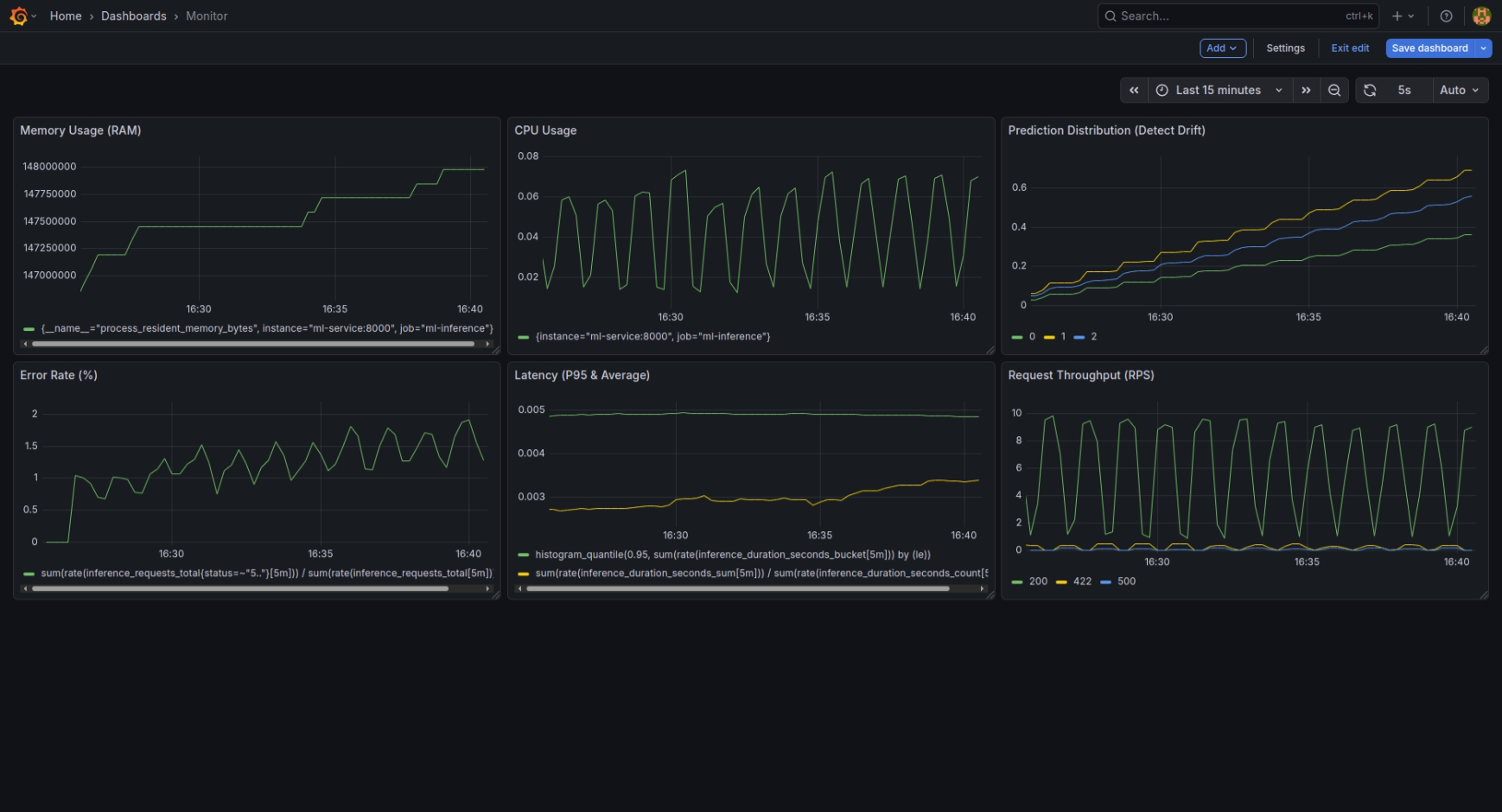
Nhìn vào Dashboard (ảnh trên), chúng ta có thể thấy rõ ràng "bệnh án" của model được phơi bày chi tiết qua từng biểu đồ:
- Request Throughput: Biểu đồ này cho thấy nhịp tim của hệ thống. Lưu lượng request không đều, có những đợt tăng vọt (High Load) thể hiện qua các đỉnh nhọn.
- Latency P95 & Avg: Đây là chỉ số quan trọng nhất về trải nghiệm người dùng. Đường màu xanh (P95) và vàng (Avg) biến động mạnh khi hệ thống chịu tải cao. Khi Latency tăng thì đó là dấu hiệu server đang "khó thở".
- Error Rate: Bình thường đường này nằm im ở mức 0%. Nhưng khi có sự cố (như kịch bản Error Storm), nó dựng đứng lên, báo động cho thấy hệ thống đang trả về lỗi hàng loạt.
- Prediction Distribution: "Máy phát hiện nói dối" của chúng ta. Các cột màu đại diện cho các lớp hoa (Setosa, Versicolor, Virginica). Khi dữ liệu đầu vào bị Drift (hoa đột biến), tỷ lệ các cột này thay đổi bất thường so với phân phối chuẩn, báo hiệu model cần được train lại.
- Resource Usage: CPU và RAM (Memory) cũng "nhảy múa" tương ứng với lượng request, giúp chúng ta biết khi nào cần nâng cấp phần cứng.
5. Kết luận
Việc giám sát hệ thống AI không hề khó như bạn nghĩ, nhưng nó lại là "tấm khiên" bảo vệ bạn khỏi những thảm họa production.
Với bộ đôi Prometheus và Grafana, bạn có thể ngủ ngon hơn mỗi tối vì biết rằng "bác sĩ" và "y tá" đang túc trực 24/7 để canh gác cho model của bạn rồi.
Hy vọng bài viết này giúp ích cho các bạn trên con đường MLOps. Hẹn gặp lại ở các bài viết sau!
Tham khảo
Understanding Data Drift in Machine Learning
Latency in Machine Learning Inference
Prometheus: A Powerful Monitoring Solution (Pros & Cons)
IRIS_Monitoring – GitHub Repository
Tài liệu AIO: Giám sát hệ thống AI với Grafana và Prometheus
Chưa có bình luận nào. Hãy là người đầu tiên!