
1. Introduction
In the digital age, the explosion of mobile banking, e-commerce, and online payment methods has brought unprecedented convenience to users. However, the downside of this development is the rapid increase in financial fraud with increasingly sophisticated and complex methods. From credit card information theft and phishing attacks to account takeovers, cybercrime poses a serious challenge to the entire global financial system.
According to the latest data released by the Federal Trade Commission (FTC) in March 2025, consumers suffered record losses of up to $12.5 billion in 2024, a staggering 25% increase in just one year. Even more alarming, the percentage of scams resulting in actual financial losses increased from 27% to 38%, demonstrating that cybercrime is not only growing in scale but also optimizing its effectiveness through techniques such as phishing and account hijacking. Even more concerning, these attacks often occur in a split second – measured in milliseconds – rendering traditional manual verification methods completely ineffective.
Against this backdrop, the application of Machine Learning has become a key "weapon", helping banks identify and prevent unauthorized access even before transactions are completed, maximizing the security of customers' assets.

2. What Is Fraud Detection in Banking?
In the banking sector, fraud detection is understood as a system of processes and technologies aimed at identifying, analyzing, and preventing unusual or suspicious transactions. The core objective of this process is to protect customer assets and minimize financial losses and damage to the bank's reputation.
Nowadays, forms of fraud are becoming increasingly sophisticated, including common types such as:
- Credit card fraud: Unauthorized use of credit card information to make payments or withdraw money.
- Identity theft: Stealing personal information (ID card number, phone number) to open accounts or obtain fraudulent loans.
- Account takeover (ATO): Fraudsters gain control of a customer's online banking account through malware or phishing.
- Money laundering: Complex transactions designed to legitimize illicit funds.
- Phishing & Social Engineering: Scams involving text messages and calls impersonating bank employees to trick users into providing OTP codes or passwords.
- APP Fraud (Authorized Push Payment): Scammers trick victims into voluntarily transferring money to a fake account (often seen in lottery scams or financial investment scams).
3. Why Traditional Fraud Detection Methods Are No Longer Effective?
Before machine learning became widely adopted, most banks relied on rule-based systems to detect suspicious transactions. These systems operate by applying a predefined set of rules created by analysts.
Whenever a transaction violates one of these rules, it is flagged for further review.
Some common rules used in traditional systems include:
- Transactions exceeding a certain threshold (e.g., above $5,000)
- Payments made from a country different from the cardholder’s usual location
- Multiple transactions occurring within a very short period
At first glance, this approach appears reasonable. However, in practice, it struggles to keep up with rapidly evolving fraud tactics.
The biggest limitation lies in the fact that fraud patterns are constantly changing. Fraudsters quickly adapt their strategies to bypass existing rules. For example, if transactions above $5,000 are flagged as suspicious, they may split a large transaction into multiple smaller ones to avoid detection. Since these rules must be manually designed and updated by experts, the system often reacts only after new fraud patterns have already emerged.
Another critical issue is the high rate of false positives, where legitimate transactions are mistakenly flagged as fraudulent. This creates inconvenience for both banks and customers. For instance, when a customer travels abroad and makes a payment in a new country, the system may interpret it as unusual activity and temporarily block the card. While the intention is to protect the account, such situations can significantly impact the user experience.
Research in financial fraud detection also indicates that rule-based systems often struggle to handle large volumes of transaction data and complex fraud patterns, where fraudulent behavior can be subtle and difficult to define using fixed thresholds.
Due to these limitations, many financial institutions are shifting toward machine learning, which enables systems to learn directly from transaction data, identify complex behavioral patterns, and better adapt to emerging fraud strategies.
To better illustrate the differences between rule-based systems and machine learning approaches, consider the comparison below:
| Aspect | Rule-Based Fraud Detection Systems | Machine Learning-Based Fraud Detection Systems |
|---|---|---|
| Decision-Making | Based on fixed logic (“If X, then Y”); clear but often rigid | Evaluates multiple factors to make flexible, data-driven decisions in real time |
| Adaptability | Rules must be manually updated when new fraud tactics emerge | Continuously learns from data and adapts as fraud patterns evolve |
| Explainability | Easy to explain since decisions are tied to specific rules | Less intuitive, but many systems provide tools to interpret model decisions |
| Accuracy & Performance | Effective for known fraud patterns but prone to high false positives | Higher accuracy, reducing both false positives and missed fraud cases |
| Scalability | Becomes difficult to manage as transactions and rules increase | Scales efficiently to handle large volumes of data without added rule complexity |
| Customer Experience | Strict rules may block legitimate transactions, causing frustration | Balances security with a smoother experience for trusted customers |
| Fraud Readiness | Reactive: responds after threats appear | Proactive: capable of adapting to new fraud strategies |
Table 3.1. Comparison between traditional rule-based fraud detection systems and machine learning-based systems
;
Source: Channing Lovett
4. Machine Learning Algorithms and Pipeline in Fraud Detection
4.1. Machine Learning Algorithms in Fraud Detection
4.1.2. Supervised Learning
Supervised Learning is a method in Machine Learning where the model is trained using labeled datasets. The algorithm learns to recognize patterns and relationships between input and output data, enabling it to accurately predict outcomes when encountering new real-world data.
In the banking domain, input data can be transaction data (date, time, transaction location), while the output data is labeled and divided into two main categories: normal transactions and abnormal transactions. After training, the model can predict which transactions are fraudulent and which are legitimate.
Some common supervised learning algorithms include:
Random Forest. Random Forest is a supervised machine learning algorithm commonly used for classification and regression problems. It consists of multiple decision trees. Each tree acts as an independent predictive model and produces its own prediction. For classification tasks, Random Forest aggregates the predictions of all trees and selects the most frequent result (majority vote). For regression tasks, the final result is the average of predictions from all trees.
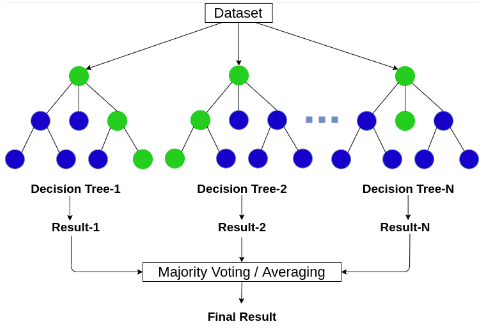
Figure 4.1. Random Forest algorithm; source: AICandy
Gradient Boosting. Gradient Boosting is a machine learning technique that combines multiple weak prediction models into a strong ensemble system. These models are typically decision trees, trained sequentially to minimize errors and improve accuracy. By combining multiple regression trees or classification trees, Gradient Boosting effectively captures complex relationships between features.
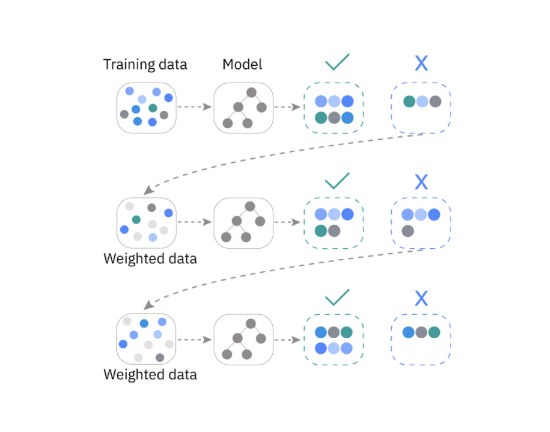
Figure 4.2. Gradient Boosting algorithm; source: VinBigData
Application: Detecting anomalous transaction behavior
The banking sector stores large volumes of transaction data. With this rich data resource, it is feasible to build models for predicting anomalous transactions. The labels in this domain are typically binary (normal vs. abnormal), making them well-suited for classification models. Additionally, due to the high-dimensional nature of the dataset, algorithms such as Random Forest and Gradient Boosting perform effectively.
4.1.2. Unsupervised Learning
Unlike Supervised Learning, Unsupervised Learning works with unlabeled data, where the model automatically discovers patterns and structures within the dataset. Instead of relying on predefined labels, the algorithm analyzes and groups data points based on similarities and differences in the input data. Some common unsupervised learning algorithms include:
Clustering. Clustering algorithms group unlabeled data into clusters based on shared characteristics and features. Data points in different clusters exhibit clear differences. This method helps uncover hidden structures within the dataset.
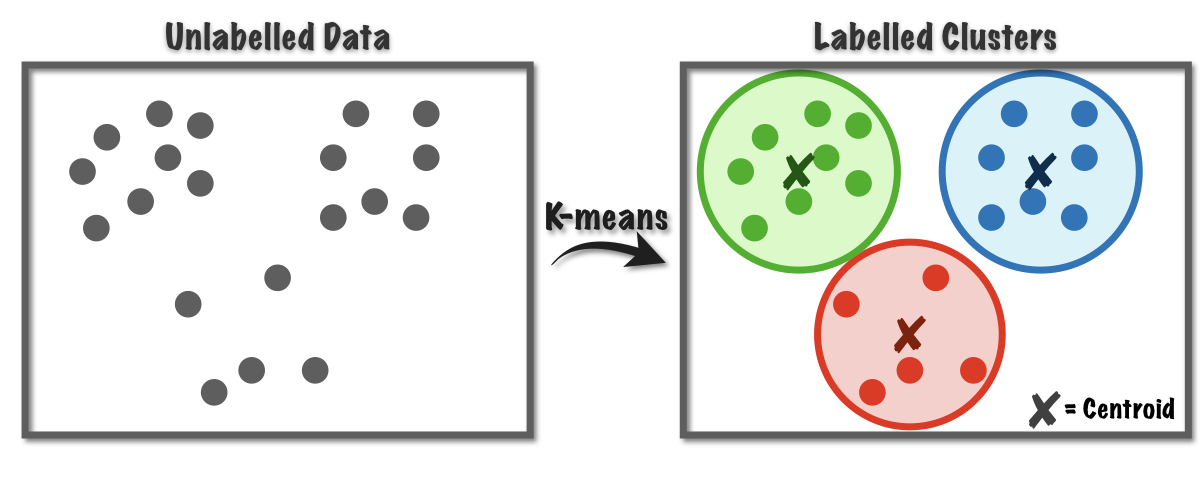
Figure 4.3. Clustering algorithm; source: Medium
Isolation forest. This algorithm is based on decision trees. In Isolation Forest, anomalies or outliers are gradually isolated through tree branches. Data points that require many conditions (more splits) to be isolated are likely normal points. In contrast, data points that require fewer conditions (fewer splits) are more likely to be anomalies, as they can be easily distinguished from the rest of the data.
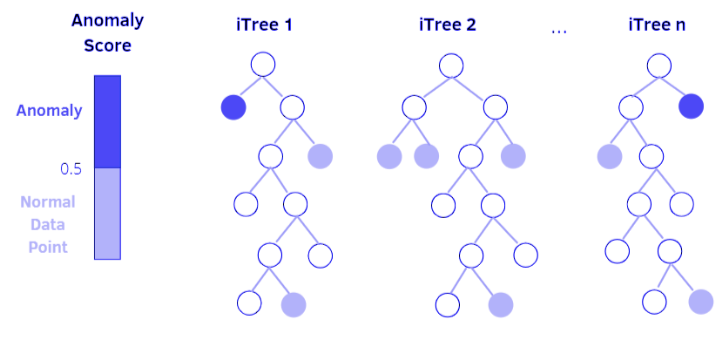
Figure 4.4. Isolation Forest algorithm; source: PyImageSearch
Application: Detecting anomalous transaction behavior
In practice, anomalous transaction data is difficult to label due to its randomness and constantly changing nature. Combined with the large volume of transaction data, labeling requires significant time and may introduce labeling errors. Therefore, clustering algorithms can be more effective in grouping and detecting anomalies within transaction datasets.
4.2. Fraud Detection Pipeline
The basic process for building an anomalous transaction detection model includes:
Step 1: Data collection. This step gathers banking data from multiple sources, such as:
- Transaction history: time, location, transaction amount
- User information: age
- Device data: IP address used during transactions
Step 2: Data processing. Transaction datasets are often large and complex, so preprocessing is necessary before model building:
- Filtering input data
- Handling missing values
- Data normalization
Step 3: Feature engineering. In addition to data preprocessing, feature engineering plays a crucial role in building an effective model. At this stage, features are extracted and selected from the dataset to determine which ones are most relevant for training. Proper feature preparation directly impacts model performance. Example features include:
- Number of transactions within one hour
- Distance between two transaction locations
- Average transaction value
Step 4: Model training. At this stage, an appropriate model is selected for training. For anomaly detection in transactions, if the data is labeled (normal vs. suspicious), supervised learning algorithms can be used, if labeling is not feasible or difficult, unsupervised learning algorithms may be more suitable.
Common algorithms for this problem include:
- Logistic Regression
- Random Forest
- Gradient Boosting
- Neural Networks
Step 5: Real-time detection. After training, the model is deployed for real-time operation when new data arrives:
- Data is fed into the model
- The model computes the fraud probability (likelihood that the transaction is normal or suspicious)
- If the output exceeds a predefined threshold, the system may trigger an alert or block the transaction
5. Real-World Implementation in Banking and Finance
The application of Machine Learning (ML) in transaction monitoring has evolved from isolated experiments into a core component of modern financial security infrastructure.
- Visa’s Advanced Authorization (VAA): This is one of the world's largest AI-driven application networks. Every Visa transaction is evaluated against over 500 unique attributes within just 1 millisecond. The system analyzes merchant risk profiles, cardholder behavior history, and geographic anomalies. According to a Visa report (2023), this tool helps prevent an estimated $27 billion in financial losses annually.
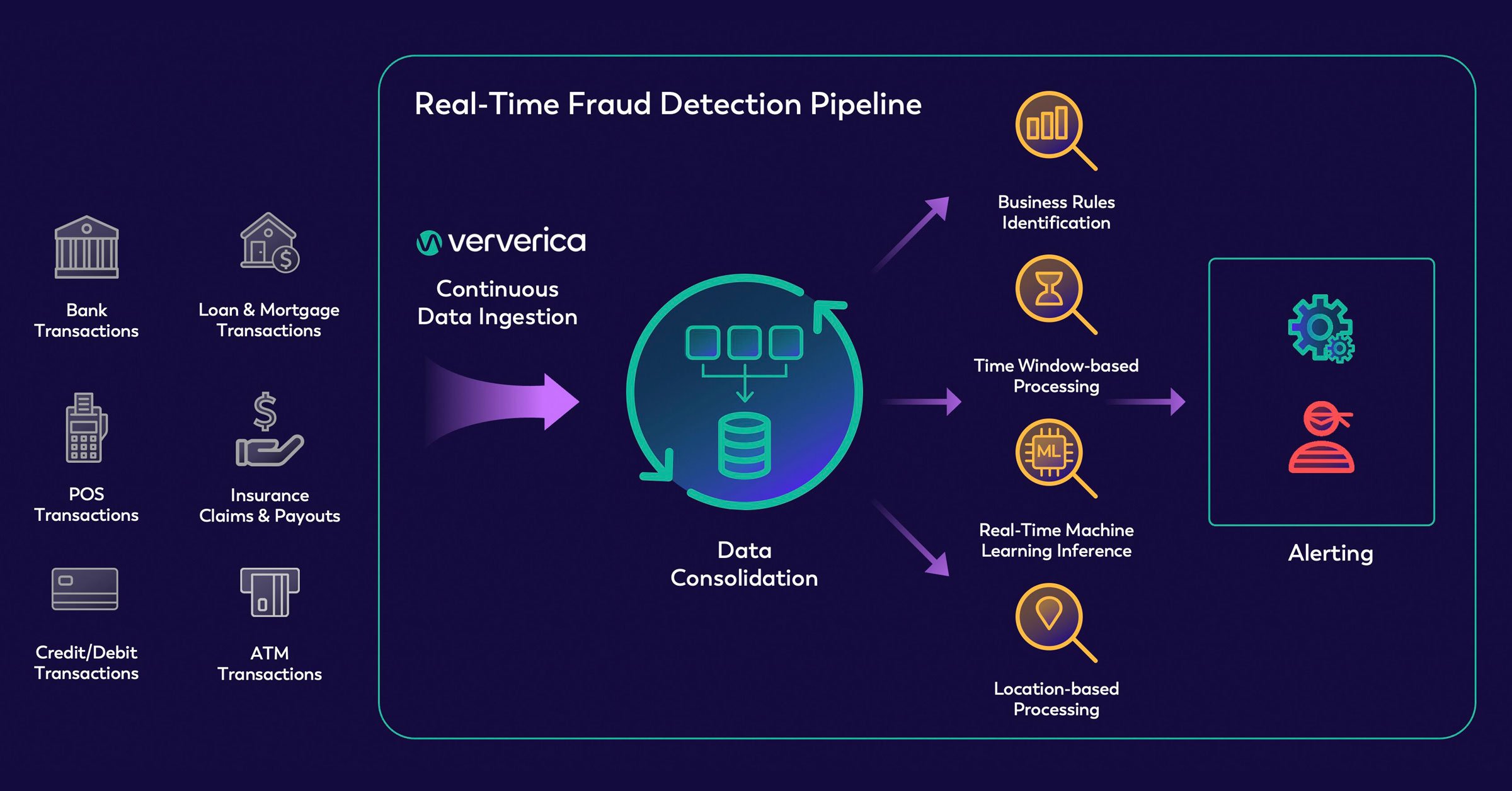
Figure 5.1. Real-time transaction processing and fraud detection workflow; source: ververica
-
PayPal’s Multi-layered Analysis Model: PayPal utilizes a hybrid approach that combines Deep Learning algorithms with human oversight. By identifying micro-behavioral patterns within massive transaction volumes, PayPal maintains a fraud rate of approximately 0.3% of total transaction value, significantly lower than the industry average (PayPal, 2021).
-
Application in the Vietnamese Market: Amidst the explosion of cashless payments, financial institutions in Vietnam are integrating Behavioral Biometrics. ML systems go beyond simple OTP authentication to analyze how users interact with their devices—such as keystroke dynamics, device handling habits, and frequent access locations—to detect early signs of account takeover (ATO).
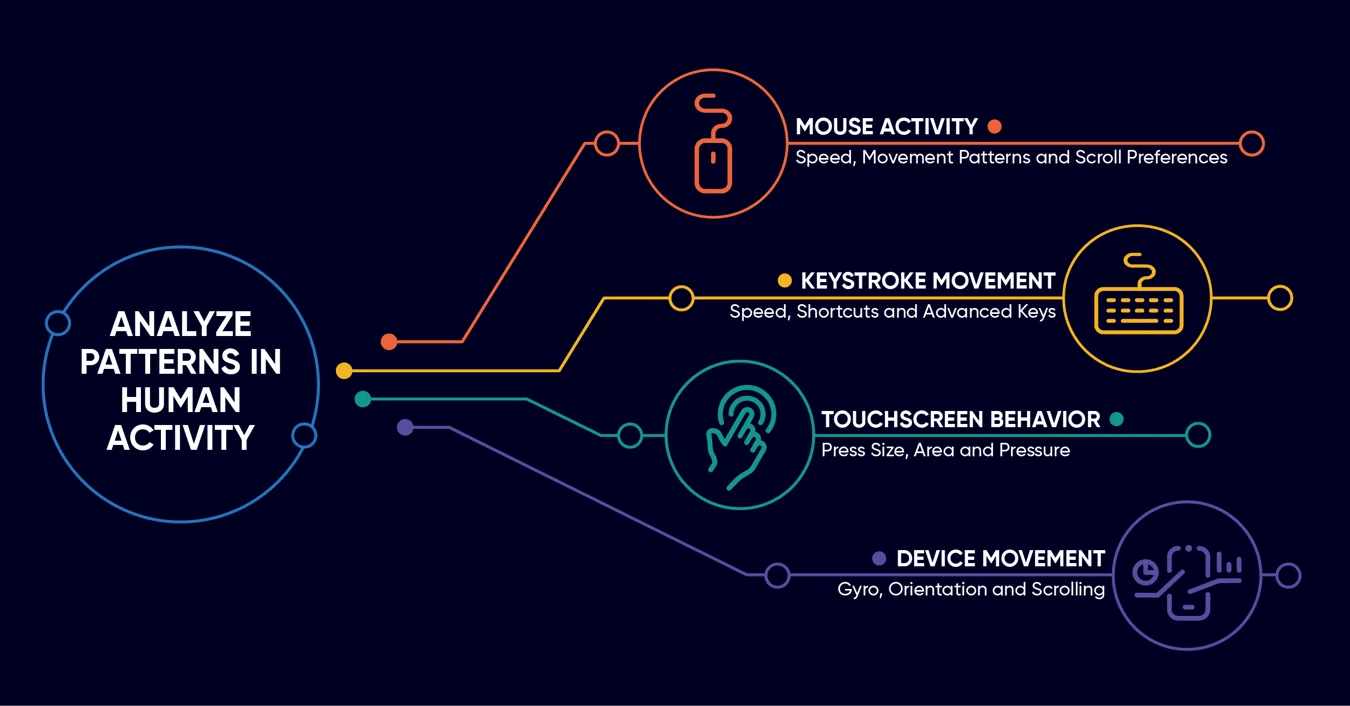
Figure 5.2. Behavioral biometric indicators used in identity authentication; source: BioCatch
6. Challenges in Real-World Implementation and Operation
Despite providing exceptional efficiency, operating ML models in a banking environment still faces stringent technical and legal hurdles.
6.1. Severe Data Imbalance
In practice, fraudulent transactions typically account for a tiny fraction of the data, often less than 0.1% of the total dataset. According to research by Dal Pozzolo et al. (2015), this imbalance makes it easy for algorithms to favor the majority class (legitimate transactions), leading to high overall Accuracy but very low actual fraud detection capability (Recall). Data engineers must apply specialized techniques like SMOTE or adjust Loss Functions to optimize the detection of these rare minority patterns.
6.2. Controlling the False Positive Rate
A major operational challenge is balancing security with customer experience. If a model is too sensitive, a high False Positive Rate leads to blocking legitimate transactions. This not only causes significant inconvenience but also directly impacts the bank's reputation and erodes customer trust.
6.3. Evolution of Data Characteristics (Concept Drift)
Attack methods constantly evolve to find new loopholes. This phenomenon is known as Concept Drift (Gama et al., 2014), where the statistical properties of fraudulent behavior change over time, causing trained models to decline in performance. Consequently, systems require continuous monitoring and retraining to adapt to emerging fraud trends.
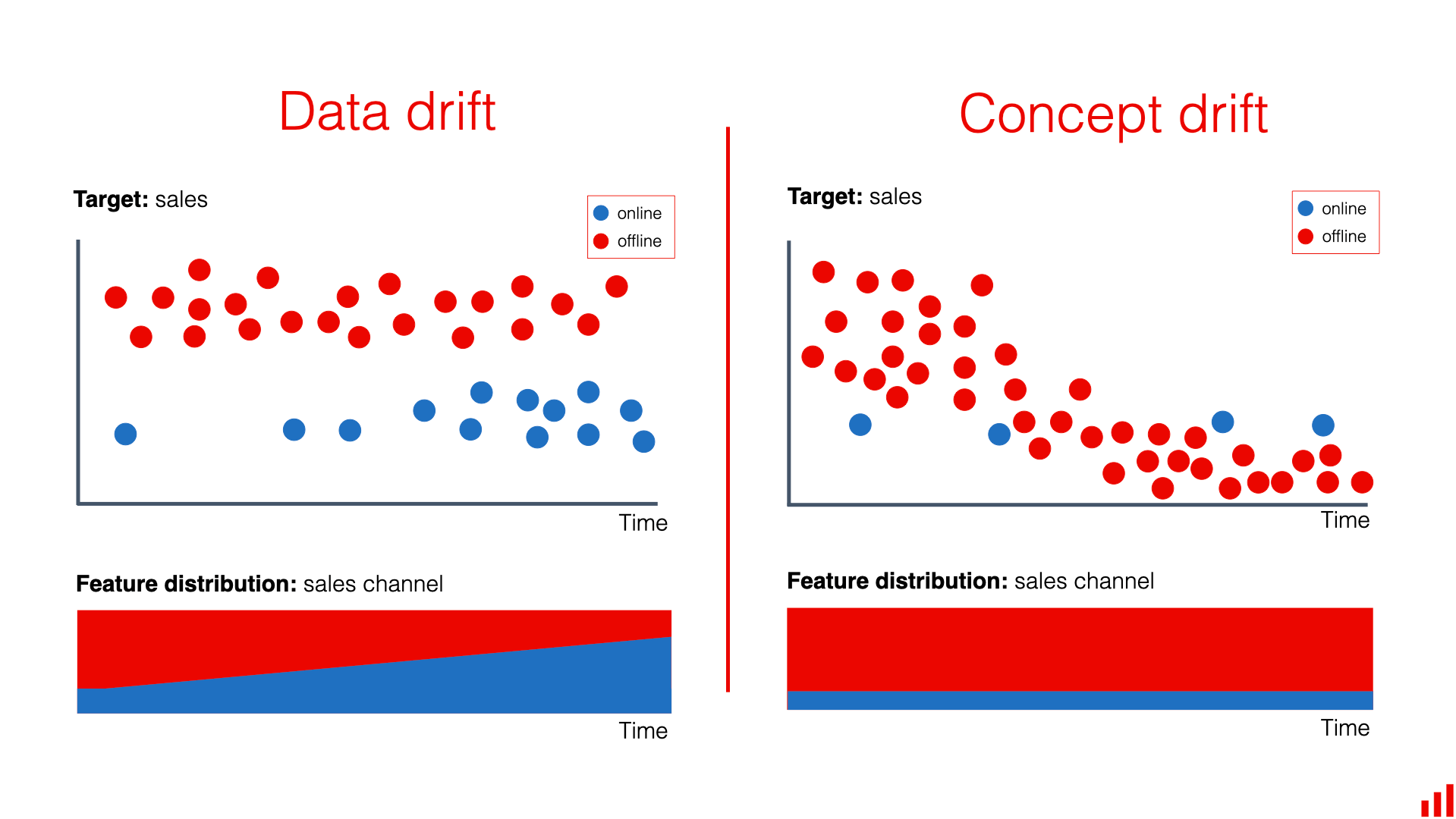
Figure 6.1. Illustration of Concept Drift in data streams; source: Evidently AI
Figure 6.1 illustrates how data patterns shift over time, preventing older models from maintaining their original performance levels.
6.4. Legal Compliance and Transparency Requirements
In Vietnam, personal data processing must strictly comply with Decree No. 13/2023/ND-CP. Although the Decree does not explicitly use the term "algorithmic explanation," the provision for the Right to object to data processing for automated decisions (Article 9, Clause 8) indirectly forces banks to be able to interpret and explain their processing logic.
Furthermore, risk management directives for digital banking from the State Bank of Vietnam (SBV) increasingly emphasize controlling algorithm-based decisions to protect customer interests. This drives the adoption of Explainable AI (XAI) to eliminate algorithmic "black boxes," transforming machine learning outcomes into verifiable, transparent, and fair information.
7. The Future of Fraud Detection
Technology never stands still, and neither do fraudsters. They are no longer relying on simple manual tricks. To stay ahead, banks are investing in smarter and more adaptive defenses. The future is not about constantly chasing criminals, but about building AI systems that can learn on their own, anticipate risks, and understand data at a much deeper level.
7.1. Generative AI and Synthetic Data
One of the biggest challenges in building machine learning models for fraud detection is that real fraud data is extremely rare. In practice, most transactions are legitimate, while fraudulent ones account for only a very small portion. This imbalance makes it difficult for models to fully learn the patterns behind fraudulent behavior.
When there are not enough examples to learn from, AI systems can easily miss new or more sophisticated types of fraud. This is where Generative AI becomes especially valuable. A common approach is to use GANs, short for Generative Adversarial Networks, to create synthetic datasets that closely resemble real fraud cases. Instead of waiting for fraud to occur in the real world, we can proactively generate a wide variety of fraud scenarios to train our models.
With this approach, fraud detection systems can be exposed to a broad range of simulated situations, from common tricks to more complex schemes. Being trained on such diverse scenarios helps models recognize subtle anomalies more effectively, which improves their ability to detect fraud and adapt when deployed in real-world environments.
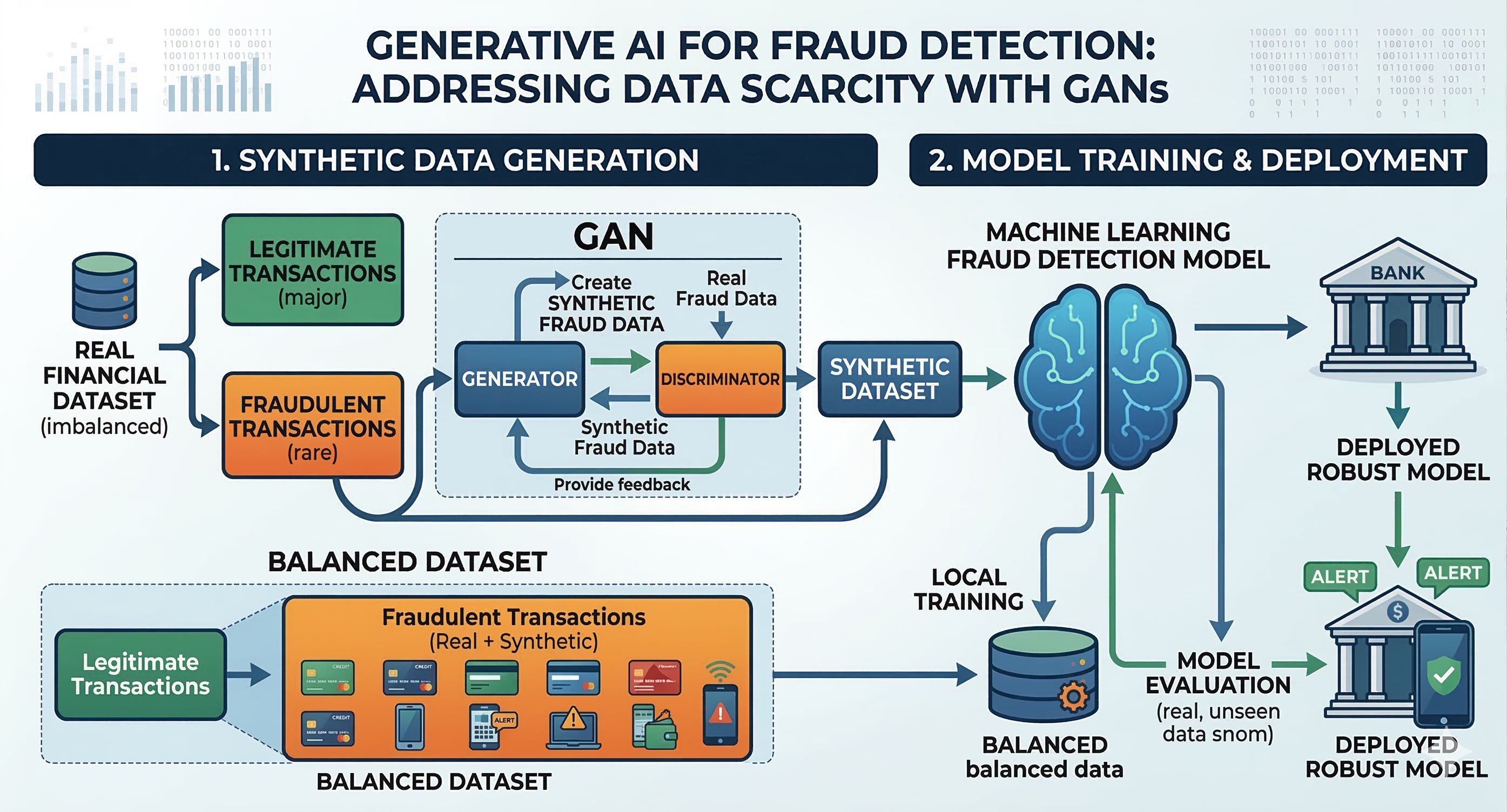
Figure 7.1. Generative AI and Synthetic Data
7.2. Federated Learning
When a fraud scheme succeeds at one bank, it often shows up at others soon after. However, sharing raw customer data between financial institutions is a serious violation of privacy regulations.
Federated Learning offers an elegant solution to this problem. Instead of moving sensitive data around, each bank keeps its data securely within its own system and only shares learned patterns or signals of fraudulent behavior with a shared network.
This way, all participants benefit from collective intelligence while still keeping user data private. Over time, the entire network becomes smarter and more resilient, without ever exposing sensitive customer information.
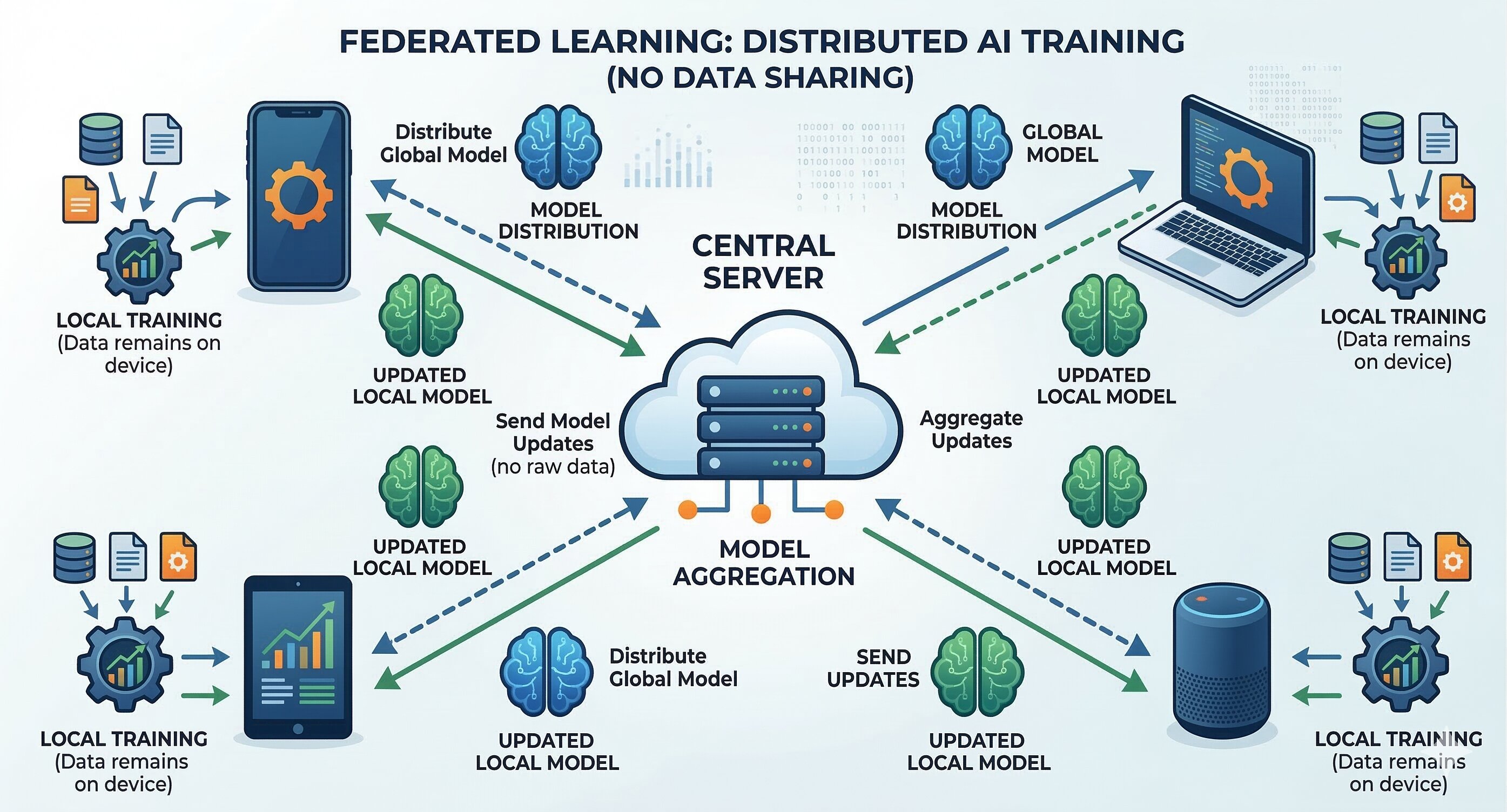
Figure 7.2. Federated Learning
7.3. The Collaboration Between Humans and AI
One of the biggest misconceptions about AI is that it exists to replace humans. In fraud detection, the reality is quite the opposite. The future lies in teams where humans and AI work side by side.
Fraud detection is rarely black and white. AI can quickly flag suspicious behavior in a matter of seconds, but determining whether something is truly fraudulent still requires human judgment. Factors such as cultural differences, a customer’s history, or unique edge cases are often too nuanced for any algorithm to fully understand on its own.
Here is how these roles complement each other:
- AI operates at scale by scanning millions of events and instantly highlighting cases worth investigating.
- Humans provide context by going beyond the data to understand intent, relationships, and exceptional situations that machines may not fully grasp.
- Together, they enable faster action as AI reduces false positives, allowing analysts to focus on complex cases instead of repeatedly reviewing routine alerts.
You can think of AI as a highly efficient assistant for fraud teams. It quickly filters and prioritizes risks, so experts can concentrate their efforts where it matters most.
This collaborative approach also creates a continuous feedback loop. Every confirmed fraud case helps the AI model learn and improve, while every false alarm teaches it what to avoid in the future. Over time, both humans and machines become more accurate and effective.
8. Conclusion
The fight against financial fraud has always been an endless chase. As fraudsters grow more sophisticated, banks can no longer rely on rigid and outdated rule-based systems. The shift toward machine learning is not just a technological upgrade, but a critical advantage that allows financial institutions to move from reactive defense to proactive risk prediction. Of course, deploying AI in the real world still comes with challenges, such as handling imbalanced data and controlling false positives. However, with the rise of Generative AI for data simulation and Federated Learning for secure collaboration, the outlook for fraud prevention is more promising than ever. Most importantly, technology is not here to replace us. In the future, AI will serve as a powerful assistant, while humans remain the final decision-makers, working together to build a payment ecosystem that is secure, seamless, and trustworthy.
References
- Dal Pozzolo, A., Caelen, O., Waterschoot, R. A., & Bontempi, G. (2015). Learned lessons in credit card fraud detection from a practitioner perspective. Expert Systems with Applications, 42(10), 4928-4941.
- Federal Trade Commission (2025). New FTC data show a big jump in reported losses to fraud to $12.5 billion in 2024. www.ftc.gov
- Gama, J., Žliobaitė, I., Bifet, A., Pechenizkiy, M., & Bouchachia, A. (2014). A survey on concept drift adaptation. ACM Computing Surveys (CSUR), 46(4), 1-37.
- PayPal. (2021). PayPal Holdings, Inc. 2021 Annual Report. Retrieved from PayPal Investor Relations.
- Visa. (2023). Visa Advanced Authorization: Real-time fraud risk scoring. Retrieved from Visa Newsroom.
- Bolton, R. J., & Hand, D. J. (2002). Statistical fraud detection: A review. Statistical Science, 17(3), 235–255.
- Ngai, E. W. T., Hu, Y., Wong, Y. H., Chen, Y., & Sun, X. (2011). The application of data mining techniques in financial fraud detection. Decision Support Systems, 50(3), 559–569.
- Phua, C., Lee, V., Smith, K., & Gayler, R. (2010). A comprehensive survey of data mining-based fraud detection research. arXiv preprint arXiv:1009.6119.
- Okafor, G., Akhuemonkhan, E., Njoku, C., Gachui, E., Naibe, I., & Diala, A. K. (2025). The future of generative artificial intelligence (AI) in fraud detection analysis. International Journal of Management & Entrepreneurship Research, 7(4), 294–298. https://doi.org/10.51594/ijmer.v7i4.1875
- Fraud Detection Software. (2026, January 6). The future of AI in fraud detection: Trends & risks. https://frauddetectionsoftware.co/blog/future-ai-fraud-detection
Chưa có bình luận nào. Hãy là người đầu tiên!